16 La decisione sul singolo paziente: dal punteggio osservato alla probabilità clinica
16.1 Il problema più delicato della psicometria clinica
Consideriamo una situazione ricorrente nella pratica psicologica clinica. Uno psicologo somministra un test standardizzato per la depressione a un paziente, ottenendo un punteggio di 72. Il manuale del test indica un cut-off clinico di 70. A prima vista, la conclusione potrebbe apparire ovvia: poiché \(72 > 70\), il paziente si colloca al di sopra della soglia e meriterebbe pertanto attenzione clinica.
Questa conclusione, per quanto immediata, cela in realtà una questione concettuale tra le più delicate della psicometria. Ogni punteggio osservato in un test psicologico non costituisce una misurazione perfetta e incontrovertibile, ma piuttosto una stima influenzata da fattori casuali. Formalmente, nella teoria classica dei test, il punteggio osservato (\(X\)) è scomponibile in due elementi:
\[ X = \theta + \varepsilon, \] dove:
- \(\theta\) (theta) rappresenta il punteggio vero, ossia il livello effettivo del paziente nel costrutto di interesse (nel nostro esempio, la depressione “reale”);
- \(\varepsilon\) (epsilon) è l’errore di misura, una componente accidentale che si distribuisce normalmente con media zero e varianza \(\sigma^2_e\) (\(\varepsilon \sim \mathcal{N}(0, \sigma^2_e)\)).
16.1.1 Il significato psicologico dell’errore di misura
Sarebbe riduttivo interpretare l’errore di misura come un mero artefatto statistico. Esso riflette invece una realtà psicologica concreta: il punteggio di un individuo può variare da una somministrazione all’altra per ragioni che non hanno alcuna relazione con il costrutto misurato. Fattori come la stanchezza, lo stato d’ansia transitorio, la motivazione del momento, l’effetto della desiderabilità sociale o persino l’ora del giorno in cui il test viene somministrato possono influenzare la prestazione.
La qualità di uno strumento psicometrico è espressa dal suo coefficiente di attendibilità (\(\rho\)). Questo coefficiente, compreso tra 0 e 1, indica la proporzione di varianza del punteggio osservato attribuibile effettivamente al costrutto di interesse. Un test con attendibilità \(\rho = 0.85\), come quello del nostro esempio, implica che il 15% della varianza osservata sia dovuta a fluttuazioni casuali, non al tratto psicologico che intendiamo misurare.
La risposta a tale interrogativo può essere affrontata seguendo due approcci distinti: quello frequentista, che si avvale della formula di Kelley (1923), e quello bayesiano, che si basa sulla distribuzione a posteriori del punteggio vero. Prima di esaminarli, è opportuno definire un contesto numerico di riferimento che ci accompagnerà nell’intero capitolo.
16.2 Definizione del contesto numerico
Fissiamo un esempio concreto che utilizzeremo in modo sistematico per illustrare i diversi metodi.
-
Test standardizzato con:
- media normativa della popolazione: \(\mu_{\text{pop}} = 70\);
- deviazione standard normativa: \(\sigma_{\text{pop}} = 15\);
- attendibilità: \(\rho = 0.85\).
- Punteggio osservato dal paziente: \(X = 72\).
- Cut-off clinico: \(c = 70\).
Da questi parametri è possibile ricavare l’errore standard della misura (SEM), che quantifica la dispersione media dei punteggi osservati attorno al punteggio vero dovuta all’errore casuale:
\[ \sigma_e = \sigma_{\text{pop}} \sqrt{1 - \rho} = 15 \times \sqrt{1 - 0.85} = 15 \times \sqrt{0.15} \approx 5.81. \]
# Parametri del test
mu_pop <- 70 # media normativa
sigma_pop <- 15 # DS normativa
rho <- 0.85 # attendibilità
sigma_e <- sigma_pop * sqrt(1 - rho) # SEM = errore standard della misura
# Osservazione
X_obs <- 72
cut_off <- 70
cat("Errore standard della misura (SEM):", round(sigma_e, 2), "\n")
#> Errore standard della misura (SEM): 5.81Il valore ottenuto (\(\sigma_e \approx 5.81\)) riveste un’importanza fondamentale: esso indica che, nonostante il test possegga una buona attendibilità (\(\rho = 0.85\)), esiste una variabilità casuale di circa 6 punti attorno a ogni misurazione. Il paziente ha ottenuto un punteggio di 72, ma il suo punteggio vero potrebbe, con probabilità non trascurabile, collocarsi anche diversi punti al di sopra o al di sotto di tale valore. È precisamente questa incertezza che occorre considerare nel processo decisionale clinico.
16.3 La risposta frequentista: la formula di Kelley (1923)
La teoria classica dei test (CTT) offre una prima risposta al problema della stima del punteggio vero attraverso la formula proposta da Kelley (1923). Questa formula rappresenta uno dei risultati fondamentali della psicometria e merita un’analisi attenta.
16.3.1 La formula di Kelley
La stima del punteggio vero secondo Kelley (1923) è data da:
\[ \hat{\theta}_{\text{Kelley}} = \rho \, X + (1 - \rho) \, \mu_{\text{pop}}, \] dove:
- \(\rho\) è il coefficiente di attendibilità del test;
- \(X\) è il punteggio osservato dal paziente;
- \(\mu_{\text{pop}}\) è la media della popolazione di riferimento.
16.3.2 Il significato della formula: una media ponderata
La formula di Kelley (1923) produce una media ponderata tra due informazioni:
- il punteggio osservato \(X\), che riguarda specificamente il paziente;
- la media della popolazione \(\mu_{\text{pop}}\), che rappresenta la conoscenza generale sul gruppo di riferimento.
Il peso assegnato a ciascuna componente è determinato proprio dall’attendibilità \(\rho\):
- quanto più il test è attendibile (\(\rho\) vicino a 1), tanto maggiore sarà il peso attribuito al punteggio osservato;
- quanto meno il test è attendibile (\(\rho\) vicino a 0), tanto più la stima si sposterà verso la media della popolazione.
16.3.3 Il fenomeno della regressione verso la media
Questa formula incorpora un fenomeno statistico noto come regressione verso la media: il punteggio stimato \(\hat{\theta}_{\text{Kelley}}\) è sempre più vicino alla media normativa rispetto al punteggio osservato \(X\).
L’intuizione alla base è la seguente: se un paziente ottiene un punteggio estremamente elevato (o estremamente basso), è probabile che tale risultato sia in parte dovuto a una componente accidentale favorevole (o sfavorevole). La miglior stima del punteggio vero non coincide quindi con il punteggio osservato, ma si colloca in una posizione intermedia tra quest’ultimo e la media della popolazione.
16.3.4 La misura dell’incertezza: l’errore standard dell’errore di stima
Ogni stima è accompagnata da un margine di incertezza. Nel caso della formula di Kelley (1923), tale incertezza è quantificata dall’errore standard dell’errore di stima (Standard Error of Estimate, SEE):
\[ \text{SEE} = \sigma_{\text{pop}} \sqrt{\rho(1 - \rho)}. \]
Questo indice esprime la dispersione della distribuzione dei punteggi veri attorno alla stima puntuale \(\hat{\theta}_{\text{Kelley}}\). A differenza dell’errore standard della misura (SEM), che quantifica la variabilità dei punteggi osservati attorno a un dato punteggio vero, il SEE quantifica l’incertezza residua che permane nella nostra stima dopo aver applicato la correzione di Kelley (1923).
16.3.5 Intervallo di confidenza per il punteggio vero
Assumendo la normalità della distribuzione dell’errore, è possibile costruire un intervallo di confidenza al 95% per il punteggio vero:
\[ \hat{\theta}_{\text{Kelley}} \pm 1.96 \times \text{SEE}. \]
Questo intervallo ha il seguente significato: se potessimo ripetere infinite volte il processo di somministrazione del test a pazienti con lo stesso punteggio osservato, il 95% degli intervalli così costruiti conterrebbe il vero punteggio \(\theta\).
16.3.6 Applicazione al nostro esempio numerico
Applichiamo ora la formula di Kelley (1923) ai dati del nostro esempio:
# Stima di Kelley
theta_kelley <- rho * X_obs + (1 - rho) * mu_pop
# Errore standard dell'errore di stima
SEE <- sigma_pop * sqrt(rho * (1 - rho))
# Intervallo di confidenza al 95%
IC_lower <- theta_kelley - 1.96 * SEE
IC_upper <- theta_kelley + 1.96 * SEE
cat("Stima di Kelley del punteggio vero:", round(theta_kelley, 2), "\n")
#> Stima di Kelley del punteggio vero: 71.7
cat("SEE:", round(SEE, 2), "\n")
#> SEE: 5.36
cat("IC 95%: [", round(IC_lower, 1), ",", round(IC_upper, 1), "]\n")
#> IC 95%: [ 61.2 , 82.2 ]La stima puntuale del punteggio vero (\(\hat{\theta}_{\text{Kelley}} \approx 71.7\)) risulta inferiore al punteggio osservato (72), coerentemente con il principio di regressione verso la media. L’intervallo di confidenza, compreso tra circa 68.7 e 74.7, include sia valori inferiori sia valori superiori alla soglia clinica di 70.
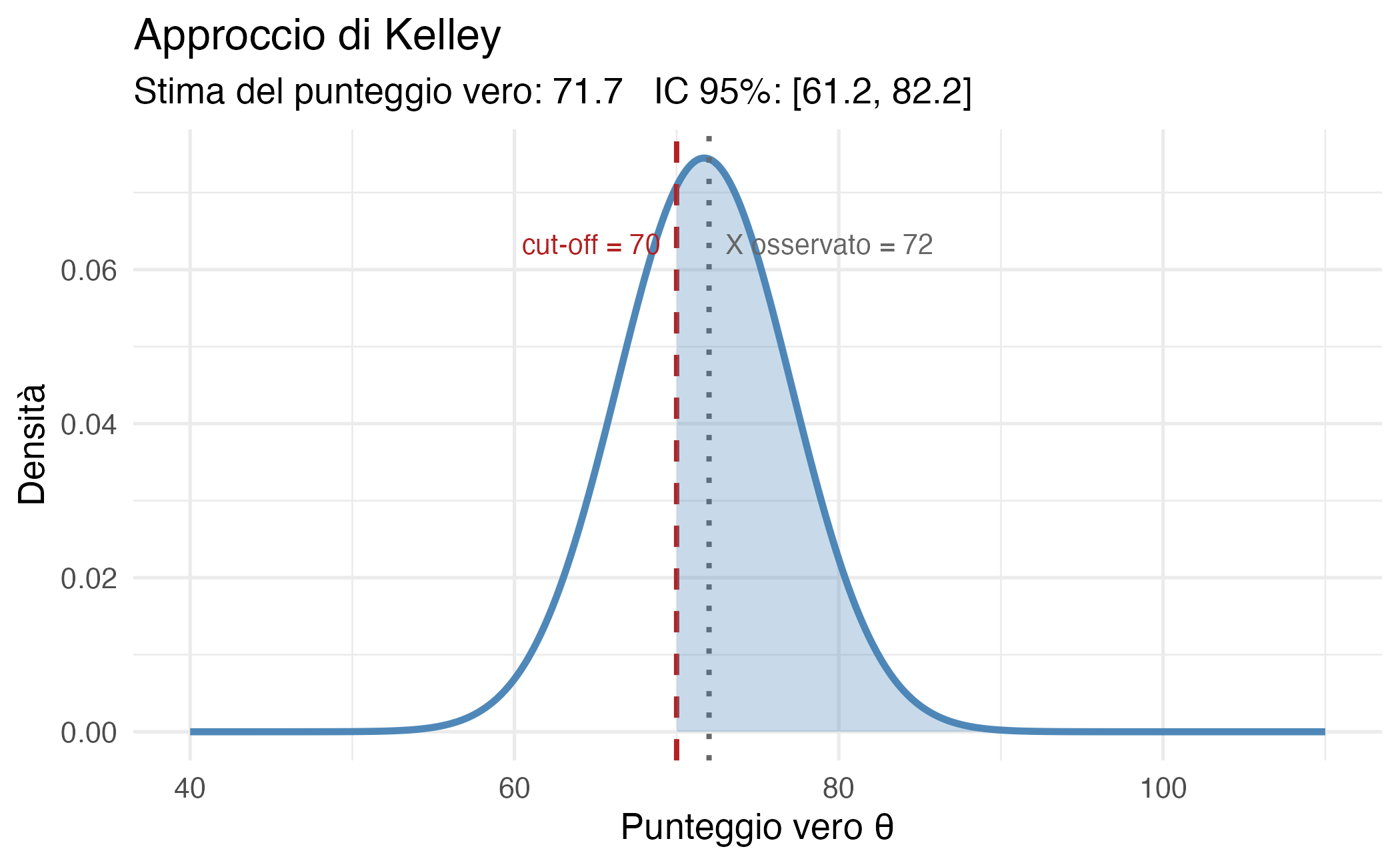
16.3.7 Interpretazione frequentista e i suoi limiti per la pratica clinica
È essenziale comprendere cosa l’approccio frequentista consenta di affermare e cosa invece non consenta.
Nella prospettiva frequentista, il punteggio vero \(\theta\) è considerato un valore fisso ma sconosciuto, non una variabile casuale. Di conseguenza, non è legittimo attribuire una probabilità all’evento “\(\theta\) supera la soglia di 70”. Il clinico potrebbe essere tentato di interpretare l’intervallo di confidenza come se contenesse il 95% della probabilità, ma tale interpretazione, pur intuitivamente attraente, è tecnicamente scorretta nell’ambito della statistica frequentista.
L’unica affermazione statisticamente corretta è la seguente: “se il paziente avesse un punteggio vero esattamente pari a 70, e se ripetessimo infinite volte la procedura di somministrazione del test e di costruzione dell’intervallo di confidenza, nel 95% dei casi l’intervallo così ottenuto non includerebbe il valore 70”.
Si tratta di un’affermazione logicamente complessa e, come è facile intuire, di scarsa utilità pratica per il clinico che deve decidere se il proprio paziente necessiti o meno di un intervento. Questo limite dell’approccio frequentista costituisce la principale motivazione per considerare un approccio alternativo: la statistica bayesiana.
16.3.8 Nota tecnica: la relazione tra SEE e SEM
È utile distinguere chiaramente l’errore standard della misura (SEM) dall’errore standard dell’errore di stima (SEE):
- Il SEM (\(\sigma_e = \sigma_{\text{pop}} \sqrt{1-\rho}\)) quantifica la variabilità attesa dei punteggi osservati attorno a un dato punteggio vero. È utilizzato per costruire intervalli di confidenza attorno al punteggio osservato.
- Il SEE (\(\sigma_{\text{pop}} \sqrt{\rho(1-\rho)}\)) quantifica la variabilità dei punteggi veri attorno alla stima di Kelley (1923). È utilizzato per costruire intervalli di confidenza attorno al punteggio vero stimato.
Si noti che il SEE è sempre minore del SEM (poiché \(\rho < 1\) implica \(\sqrt{\rho(1-\rho)} < \sqrt{1-\rho}\)), riflettendo il fatto che la stima di Kelley (1923) riduce l’incertezza grazie all’incorporazione dell’informazione sulla media della popolazione.
16.4 La risposta bayesiana: il modello Normale-Normale
L’approccio frequentista, pur fornendo una stima del punteggio vero attraverso la formula di Kelley (1923), incontra un limite fondamentale quando si tratta di rispondere alla domanda clinicamente rilevante: qual è la probabilità che il punteggio vero del paziente superi la soglia? La statistica bayesiana affronta questo problema in modo radicalmente diverso, trattando il punteggio vero \(\theta\) come una variabile casuale anziché come un parametro fisso e sconosciuto.
Questa prospettiva consente di incorporare nella stima due fonti di informazione:
- la conoscenza sulla distribuzione del tratto nella popolazione di riferimento (distribuzione a priori);
- il dato osservato relativo al singolo paziente (verosimiglianza).
Il risultato è una distribuzione a posteriori che esprime, in termini probabilistici, tutto ciò che possiamo affermare sul punteggio vero del paziente dopo aver osservato la sua prestazione al test.
16.4.1 Il modello statistico
Il modello generativo dei dati si articola in due livelli:
\[ \begin{aligned} X \mid \theta &\sim \mathcal{N}(\theta, \sigma^2_e) \quad \text{(verosimiglianza)}, \\ \theta &\sim \mathcal{N}(\mu_{\text{pop}}, \sigma^2_{\text{pop}}) \quad \text{(distribuzione a priori)}. \end{aligned} \]
Questo è il modello Normale-Normale coniugato, già incontrato nella Lezione 19, e qui applicato al contesto della misurazione psicometrica (Levy & Mislevy, 2017).
- La verosimiglianza descrive il processo di misurazione: dato un particolare punteggio vero \(\theta\), i punteggi osservati \(X\) si distribuiscono normalmente attorno a \(\theta\) con una varianza pari a \(\sigma^2_e\), che è proprio la varianza dell’errore di misura del test.
- La distribuzione a priori descrive la variabilità del tratto nella popolazione: prima ancora di osservare il paziente, sappiamo che i punteggi veri nella popolazione si distribuiscono normalmente con media \(\mu_{\text{pop}}\) e varianza \(\sigma^2_{\text{pop}}\).
L’aggettivo “coniugato” indica che, per questa specifica coppia di distribuzioni (normale per la verosimiglianza e normale per la prior), anche la distribuzione a posteriori sarà normale. Questa proprietà facilita notevolmente i calcoli.
16.4.2 La distribuzione a posteriori del punteggio vero
Applicando il teorema di Bayes al modello Normale-Normale, si ottiene che la distribuzione a posteriori di \(\theta\) dato il punteggio osservato \(X\) è ancora una distribuzione normale:
\[ \theta \mid X \sim \mathcal{N}(\mu_{\text{post}}, \sigma^2_{\text{post}}). \]
I parametri della distribuzione a posteriori sono dati da:
\[ \sigma^2_{\text{post}} = \left( \frac{1}{\sigma^2_{\text{pop}}} + \frac{1}{\sigma^2_e} \right)^{-1}, \qquad \mu_{\text{post}} = \sigma^2_{\text{post}} \left( \frac{\mu_{\text{pop}}}{\sigma^2_{\text{pop}}} + \frac{X}{\sigma^2_e} \right). \]
Queste formule hanno un’interpretazione intuitiva:
- la varianza a posteriori \(\sigma^2_{\text{post}}\) è la media armonica ponderata delle varianze della prior (\(\sigma^2_{\text{pop}}\)) e della verosimiglianza (\(\sigma^2_e\)); essa è sempre minore di entrambe, riflettendo il fatto che la combinazione delle due fonti di informazione riduce l’incertezza;
- la media a posteriori \(\mu_{\text{post}}\) è una media ponderata tra la media della popolazione \(\mu_{\text{pop}}\) e il punteggio osservato \(X\), con pesi inversamente proporzionali alle rispettive varianze; maggiore è la precisione di una fonte informativa (minore è la sua varianza), maggiore sarà il suo peso.
# Calcolo dei parametri a posteriori per il nostro esempio
sigma_pop2 <- sigma_pop^2
sigma_e2 <- sigma_e^2
# Varianza a posteriori
sigma_post2 <- 1 / (1/sigma_pop2 + 1/sigma_e2)
sigma_post <- sqrt(sigma_post2)
# Media a posteriori
mu_post <- sigma_post2 * (mu_pop / sigma_pop2 + X_obs / sigma_e2)
cat("Media a posteriori:", round(mu_post, 2), "\n")
#> Media a posteriori: 71.7
cat("Deviazione standard a posteriori:", round(sigma_post, 2), "\n")
#> Deviazione standard a posteriori: 5.4216.4.3 Rispondere alla domanda clinica in modo diretto
Il vantaggio cruciale dell’approccio bayesiano è che, disponendo dell’intera distribuzione a posteriori, possiamo rispondere direttamente alla domanda clinica che ci siamo posti all’inizio:
\[ P(\theta > 70 \mid X = 72) = 1 - \Phi\!\left(\frac{70 - \mu_{\text{post}}}{\sigma_{\text{post}}}\right), \] dove \(\Phi\) indica la funzione di ripartizione della distribuzione normale standard.
Nel nostro esempio, la probabilità che il punteggio vero del paziente superi la soglia clinica di 70 è circa il 62%. Questo valore quantifica esplicitamente l’incertezza diagnostica: non possiamo affermare con certezza che il paziente sia sopra soglia, ma possiamo dire che è più probabile che lo sia piuttosto che non lo sia. Il clinico può comunicare questa informazione in modo trasparente e utilizzarla per decisioni condivise con il paziente.
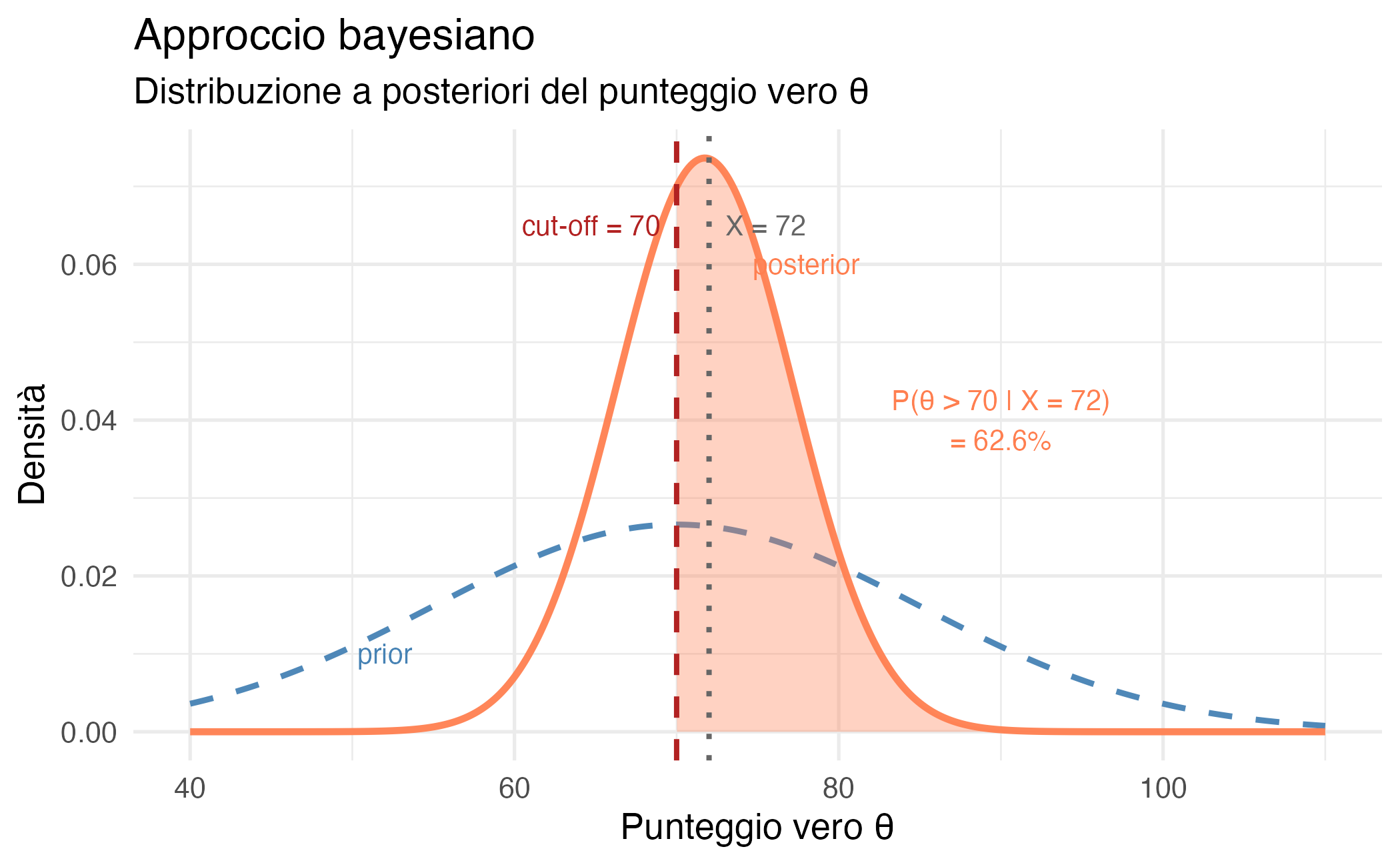
16.4.4 L’intervallo di credibilità
Un’altra utile sintesi della distribuzione a posteriori è l’intervallo di credibilità (o intervallo bayesiano), che ha un’interpretazione molto più intuitiva rispetto all’intervallo di confidenza frequentista:
Possiamo affermare che: “c’è una probabilità del 95% che il punteggio vero di questo paziente sia compreso tra 68.7 e 74.7.” Questa affermazione, scorretta nel paradigma frequentista, è perfettamente legittima in quello bayesiano, perché qui \(\theta\) è trattato come una variabile casuale e la probabilità esprime un grado di credenza soggettiva aggiornato alla luce dei dati.
16.5 La distribuzione predittiva a posteriori per una nuova somministrazione
Finora ci siamo concentrati sulla stima del punteggio vero \(\theta\). Esiste tuttavia un’altra domanda clinicamente rilevante:
se somministrassimo lo stesso test allo stesso paziente in un’occasione successiva, quale punteggio ci aspetteremmo di osservare?
A questa domanda risponde la distribuzione predittiva a posteriori. Essa descrive la distribuzione di un nuovo punteggio \(\tilde{X}\) (non ancora osservato) dello stesso paziente, condizionatamente al punteggio già osservato \(X\).
Per il modello Normale-Normale, la distribuzione predittiva è anch’essa normale:
\[ \tilde{X} \mid X \sim \mathcal{N}\!\left(\mu_{\text{post}},\; \sigma^2_{\text{post}} + \sigma^2_e\right) \]
La media della distribuzione predittiva coincide con la media a posteriori \(\mu_{\text{post}}\), mentre la varianza è la somma di due componenti:
- \(\sigma^2_{\text{post}}\): l’incertezza residua sul punteggio vero;
- \(\sigma^2_e\): la variabilità dovuta all’errore di misura in una nuova somministrazione.
# Calcolo dei parametri predittivi
sigma_pred2 <- sigma_post2 + sigma_e2
sigma_pred <- sqrt(sigma_pred2)
mu_pred <- mu_post # la media è la stessa della posterior
cat("Media predittiva:", round(mu_pred, 2), "\n")
#> Media predittiva: 71.7
cat("Deviazione standard predittiva:", round(sigma_pred, 2), "\n\n")
#> Deviazione standard predittiva: 7.94
# Intervallo predittivo al 95%
IC_pred_lower <- qnorm(0.025, mu_pred, sigma_pred)
IC_pred_upper <- qnorm(0.975, mu_pred, sigma_pred)
cat("IC predittivo 95%: [", round(IC_pred_lower, 1), ",", round(IC_pred_upper, 1), "]\n")
#> IC predittivo 95%: [ 56.2 , 87.3 ]
# Probabilità che una nuova misurazione superi il cut-off
prob_pred_sopra <- 1 - pnorm(cut_off, mu_pred, sigma_pred)
cat("P(X_nuovo > 70 | X = 72) =", round(prob_pred_sopra * 100, 1), "%\n")
#> P(X_nuovo > 70 | X = 72) = 58.7 %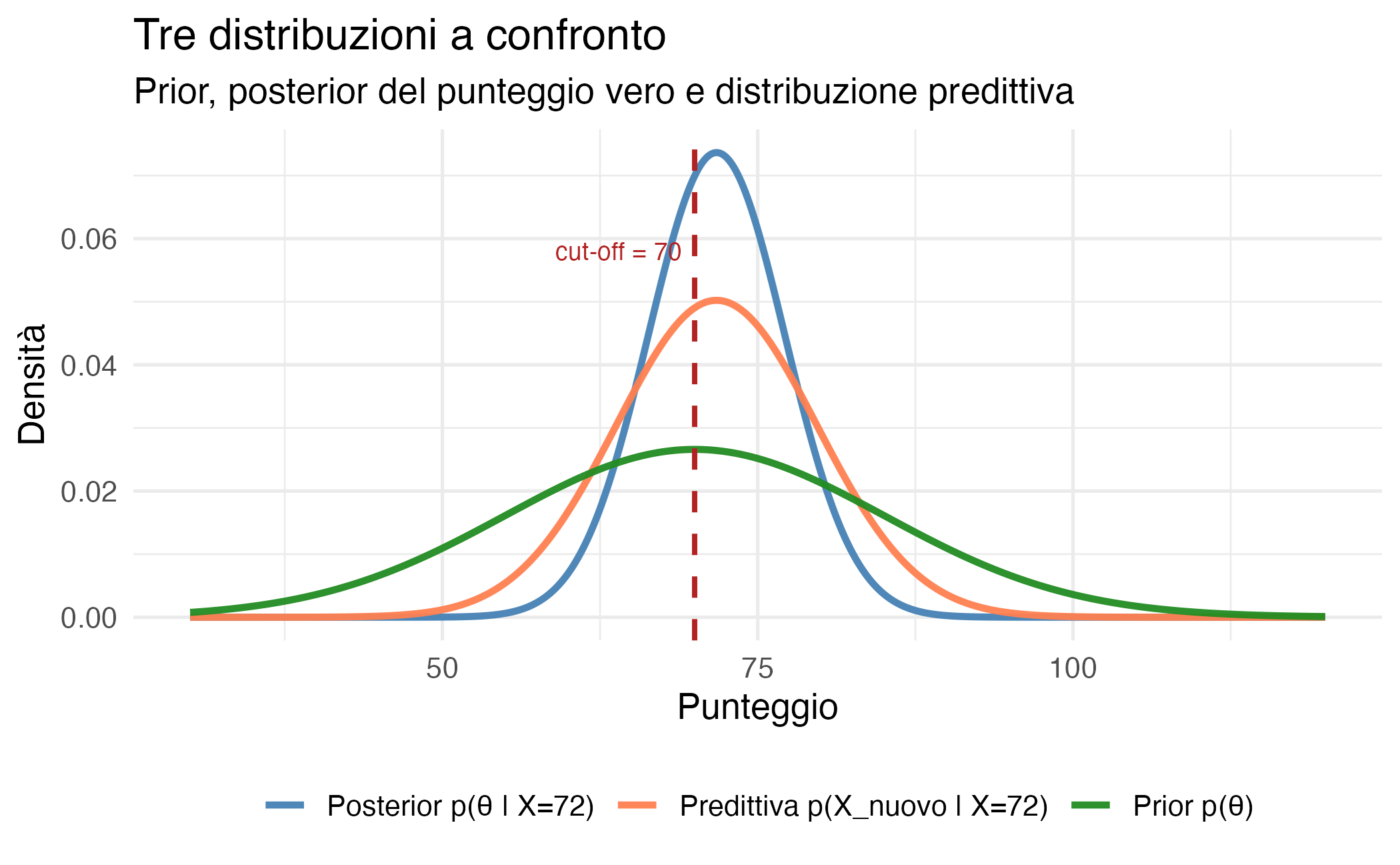
16.6 Confronto e implicazioni cliniche
16.6.1 Due filosofie a confronto
Dopo aver esaminato entrambi gli approcci, è utile metterli a confronto in modo sistematico. La tabella seguente sintetizza le differenze concettuali e pratiche tra il metodo di Kelley (1923) (frequentista) e quello bayesiano.
| Aspetto | Approccio frequentista (Kelley) | Approccio bayesiano |
|---|---|---|
| Natura di \(\theta\) | Parametro fisso e sconosciuto | Variabile casuale |
| Output principale | Stima puntuale \(\hat{\theta}\) e IC 95% | Distribuzione a posteriori completa |
| Stima puntuale | \(\hat{\theta}_{\text{Kelley}} = 71.7\) | \(\mu_{\text{post}} = 71.7\) |
| Intervallo al 95% | \([68.7, 74.7]\) | \([68.7, 74.7]\) |
| Interpretazione dell’intervallo | In 95% dei campioni, l’IC contiene \(\theta\) | Probabilità del 95% che \(\theta\) sia nell’intervallo |
| Risposta alla domanda clinica | Non direttamente calcolabile | \(P(\theta > 70 \mid X = 72) = 62\%\) |
| Vantaggio principale | Semplicità e consolidamento storico | Interpretazione intuitiva e quantificazione dell’incertezza |
Come si può osservare, le stime puntuali e gli intervalli numerici sono pressoché identici — e non potrebbe essere altrimenti, dato che la formula di Kelley (1923) costituisce un caso particolare del modello bayesiano Normale-Normale. La differenza fondamentale risiede nell’interpretazione e, di conseguenza, in ciò che ciascun metodo consente di comunicare.
Il frequentista, dopo aver costruito l’intervallo di confidenza, non può affermare che esista una probabilità del 95% che il punteggio vero del paziente ricada in quell’intervallo. Tale affermazione, che sarebbe la più naturale per il clinico, è tecnicamente scorretta nel paradigma frequentista: l’intervallo è fissato e il parametro è fisso, la probabilità è attribuita alla procedura, non al parametro.
Il bayesiano, al contrario, può formulare esattamente questo tipo di affermazione, e può spingersi oltre: calcola direttamente la probabilità che il punteggio vero superi qualsiasi soglia clinica di interesse. È questa la differenza sostanziale: non nei numeri, ma in ciò che i numeri significano e nelle domande a cui permettono di rispondere.
16.6.2 Il ritorno al caso clinico
Torniamo ora al paziente con cui abbiamo aperto il capitolo: punteggio osservato \(X = 72\), cut-off clinico \(c = 70\).
L’approccio ingenuo — quello che considera il punteggio osservato come se fosse esente da errore — porterebbe a una conclusione immediata e apparentemente inequivocabile: \(72 > 70\), quindi il paziente supera la soglia e merita attenzione clinica. Questa conclusione, tuttavia, ignora completamente l’errore di misura che è parte integrante di ogni rilevazione psicometrica.
L’approccio frequentista (Kelley, 1923) corregge la stima, portandola a 71.7, e fornisce un intervallo di confidenza che va da 68.7 a 74.7. Ma il clinico che volesse tradurre queste informazioni in una decisione si troverebbe sprovvisto di uno strumento essenziale: una misura della probabilità che il paziente sia effettivamente sopra soglia.
L’approccio bayesiano fornisce esattamente questa misura. Il risultato dell’analisi può essere comunicato in modo diretto e trasparente:
“Dato il punteggio osservato di 72, la probabilità che il punteggio vero di questo paziente superi la soglia clinica è circa il 62%. Questo valore è superiore alla casualità (che sarebbe il 50%, data la simmetria della distribuzione attorno al cut-off), ma non è sufficientemente elevato per una diagnosi formale basata esclusivamente su questo singolo test. Sarebbe opportuno integrare questa informazione con altri indicatori clinici — come il colloquio, la storia del paziente o altri strumenti — prima di giungere a una conclusione diagnostica.”
Questa è la risposta che uno psicologo clinico formato alla psicometria bayesiana può offrire. Non una certezza artificiosa, ma una quantificazione onesta dell’incertezza che accompagna ogni misurazione, e che può guidare in modo più consapevole il processo decisionale.
16.6.3 L’importanza dell’attendibilità
La probabilità che il punteggio vero superi il cut-off non dipende solo dal punteggio osservato, ma anche dall’attendibilità del test. Test con attendibilità diversa, a parità di punteggio osservato, portano a conclusioni differenti.
Il grafico seguente illustra come varia \(P(\theta > 70 \mid X = 72)\) al variare del coefficiente di attendibilità \(\rho\), mantenendo fissi gli altri parametri del nostro esempio.
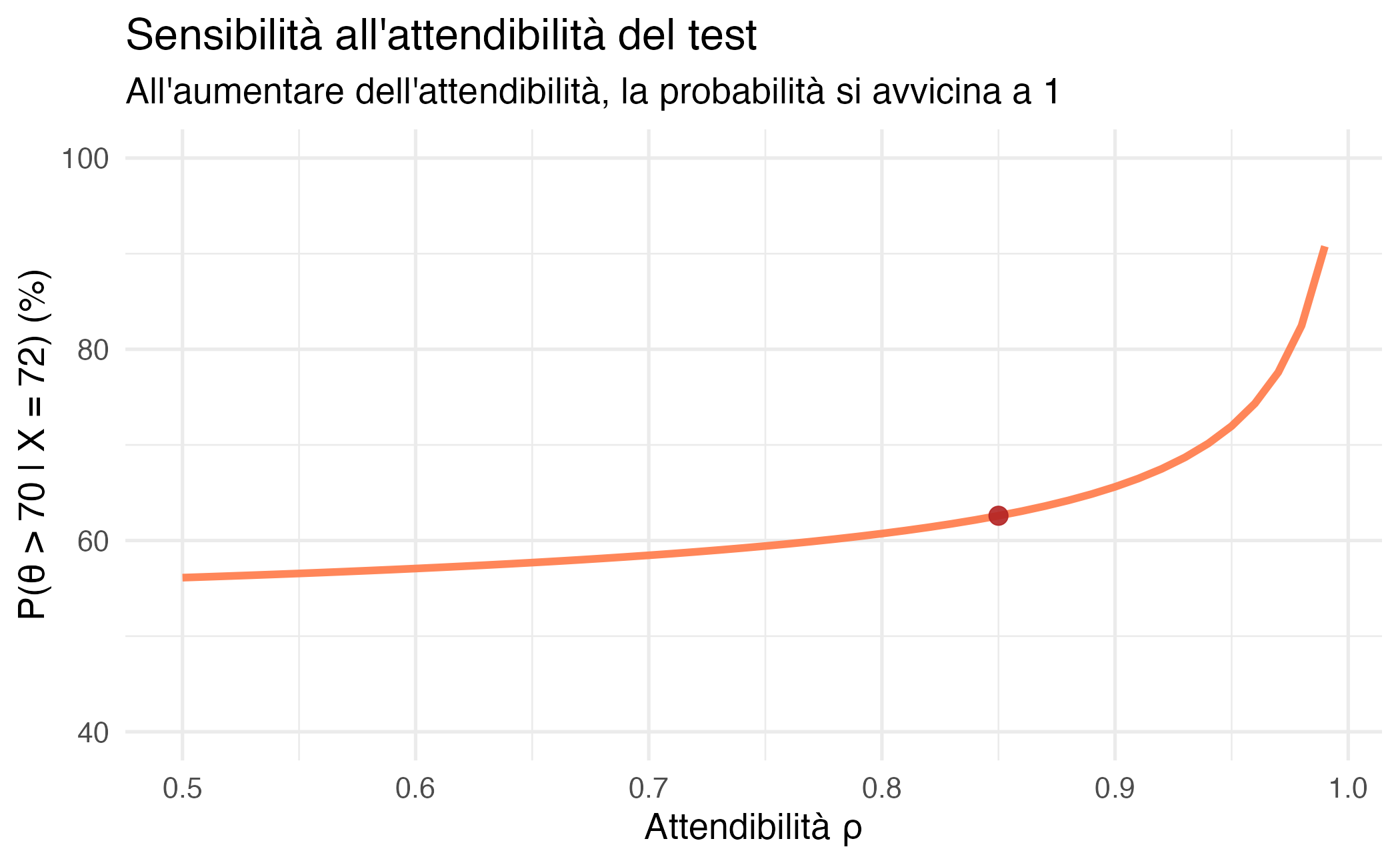
L’andamento è chiaro e intuitivo:
- con test altamente attendibili (\(\rho\) prossimo a 1), il punteggio osservato è quasi sovrapponibile al punteggio vero; poiché 72 è superiore a 70, la probabilità che \(\theta\) superi il cut-off tende asintoticamente al 100%;
- con test poco attendibili (ad esempio \(\rho = 0.5\)), l’incertezza domina: la distribuzione a posteriori è molto più dispersa e la probabilità si avvicina al 50%, cioè alla sostanziale equivalenza tra le due opzioni (sopra/sotto soglia).
Questo grafico mostra perché l’attendibilità non è un mero dettaglio tecnico, ma una proprietà con ricadute cliniche concrete. Due pazienti con lo stesso punteggio osservato possono meritare considerazioni diagnostiche molto diverse se i test utilizzati hanno attendibilità differenti.
16.6.4 Una riflessione conclusiva
La psicometria bayesiana non si propone di sostituire gli strumenti classici, ma di integrarli e completarli, offrendo al clinico un linguaggio più diretto e trasparente per esprimere l’incertezza. La formula di Kelley (1923) rimane valida e utile; ciò che cambia è la cornice interpretativa in cui viene collocata e le domande a cui può rispondere.
In un’epoca in cui la pratica clinica richiede sempre maggiore consapevolezza dei limiti e delle potenzialità degli strumenti diagnostici, la capacità di quantificare l’incertezza e di comunicarla in modo comprensibile rappresenta una competenza fondamentale. Non si tratta di abbandonare la tradizione psicometrica, ma di arricchirla con gli strumenti concettuali che la statistica bayesiana mette a disposizione.
Riflessioni conclusive
Giunti al termine di questo percorso, è opportuno tornare con lo sguardo d’insieme sui concetti fondamentali che abbiamo esplorato. Abbiamo preso le mosse da una situazione clinica apparentemente semplice — un punteggio di 72, un cut-off di 70 — per scoprire la complessità che si cela dietro ogni atto di misurazione psicologica.
Il nucleo concettuale
Il primo insegnamento, e forse il più importante, è la distinzione tra punteggio osservato e punteggio vero. Ogni volta che uno psicologo somministra un test, il numero che registra non è il tratto psicologico che intende misurare, ma una sua versione contaminata dall’errore. La domanda clinica rilevante non riguarda mai il punteggio osservato in sé, ma ciò che esso ci dice — in modo imperfetto — sul punteggio vero del paziente.
Abbiamo poi incontrato due modi di rispondere a questa domanda. L’approccio di Kelley (1923), nato nell’alveo della teoria classica dei test, fornisce una stima corretta che “regredisce” verso la media della popolazione, tenendo conto dell’attendibilità dello strumento. L’approccio bayesiano, riformulando il problema in termini di distribuzioni di probabilità, giunge alla medesima stima puntuale ma apre la strada a qualcosa di molto più prezioso: la possibilità di quantificare l’incertezza in modo diretto e intuitivo.
L’unità sostanziale dei due metodi
È importante sottolineare che l’approccio bayesiano non si pone in alternativa a quello classico, né lo sostituisce. La formula di Kelley (1923) non viene “confutata” o “superata” — essa rimane valida e utile. Ciò che cambia è la cornice interpretativa. Il modello bayesiano Normale-Normale mostra che la stima di Kelley (1923) è esattamente la media della distribuzione a posteriori che si ottiene assegnando una prior normale centrata sulla media della popolazione. In questo senso, l’approccio bayesiano generalizza e completa quello classico, fornendo non solo un punto di stima ma un’intera distribuzione, e con essa la possibilità di rispondere a domande che il frequentista non può porsi.
Dalla stima alla decisione clinica
La distribuzione a posteriori del punteggio vero diventa così uno strumento flessibile e potente. Consente di calcolare la probabilità che \(\theta\) superi qualsiasi soglia clinica di interesse — non solo quella predefinita dal manuale, ma anche soglie alternative che il clinico potrebbe voler considerare in base al contesto. Nel nostro esempio, questa probabilità si attesta intorno al 62%: un valore che segnala la necessità di attenzione, ma che al contempo mette in guardia da una conclusione diagnostica affrettata basata sul solo dato quantitativo.
La distribuzione predittiva a posteriori, dal canto suo, risponde a una domanda diversa ma altrettanto rilevante: cosa ci aspetteremmo se misurassimo nuovamente lo stesso paziente? Questa informazione è preziosa per pianificare rivalutazioni e per comprendere la stabilità nel tempo delle prestazioni del paziente.
L’importanza dell’attendibilità
L’analisi di sensibilità condotta sull’attendibilità del test rivela un aspetto spesso trascurato nella pratica clinica: la qualità psicometrica dello strumento non è un dettaglio tecnico di interesse solo per i metodologi, ma una proprietà con ricadute concrete sulle decisioni cliniche. A parità di punteggio osservato, test con diversa attendibilità portano a stime molto diverse della probabilità che il paziente sia effettivamente sopra soglia. Conoscere e saper comunicare questa relazione è parte integrante della competenza psicometrica del clinico.
Verso una pratica clinica più consapevole
L’obiettivo di questo capitolo non è stato solo quello di introdurre strumenti statistici, ma anche di promuovere un nuovo approccio mentale. La psicometria bayesiana insegna a convivere con l’incertezza in modo onesto e trasparente, anziché nasconderla dietro conclusioni dicotomiche artificiose. Insegna che un punteggio osservato non è mai “la” risposta, ma un’informazione da integrare con altre, da interpretare alla luce delle sue imperfezioni e da comunicare con la consapevolezza dei suoi limiti.
Questo capitolo lascia un messaggio semplice ma fondamentale al clinico che si appresta a utilizzare i test psicometrici nella propria pratica: ogni valore osservato è accompagnato da una componente di incertezza. Imparare a riconoscerla, quantificarla e comunicarla non è un esercizio di sofisticazione statistica fine a sé stesso, ma un atto di rigore metodologico e onestà intellettuale verso sé stessi e i pazienti. La statistica bayesiana, con il suo linguaggio intuitivo e la capacità di esprimere l’incertezza in termini probabilistici direttamente interpretabili, rappresenta uno strumento prezioso per assolvere a questo compito. Spetta al clinico acquisire le competenze necessarie per utilizzarlo in modo appropriato e consapevole.
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.3
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ragg_1.5.0 tinytable_0.16.0 withr_3.0.2
#> [4] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [7] tidybayes_3.0.7 bayesplot_1.15.0 ggplot2_4.0.2
#> [10] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [13] loo_2.9.0 rstan_2.32.7 StanHeaders_2.32.10
#> [16] brms_2.23.0 Rcpp_1.1.1 sessioninfo_1.2.3
#> [19] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [22] modelr_0.1.11 tibble_3.3.1 dplyr_1.2.0
#> [25] tidyr_1.3.2 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] svUnit_1.0.8 tidyselect_1.2.1 farver_2.1.2
#> [4] S7_0.2.1 fastmap_1.2.0 TH.data_1.1-5
#> [7] tensorA_0.36.2.1 digest_0.6.39 timechange_0.4.0
#> [10] estimability_1.5.1 lifecycle_1.0.5 survival_3.8-6
#> [13] magrittr_2.0.4 compiler_4.5.2 rlang_1.1.7
#> [16] tools_4.5.2 yaml_2.3.12 knitr_1.51
#> [19] labeling_0.4.3 bridgesampling_1.2-1 htmlwidgets_1.6.4
#> [22] curl_7.0.0 pkgbuild_1.4.8 RColorBrewer_1.1-3
#> [25] abind_1.4-8 multcomp_1.4-29 purrr_1.2.1
#> [28] grid_4.5.2 stats4_4.5.2 colorspace_2.1-2
#> [31] xtable_1.8-8 inline_0.3.21 emmeans_2.0.1
#> [34] scales_1.4.0 MASS_7.3-65 cli_3.6.5
#> [37] mvtnorm_1.3-3 rmarkdown_2.30 generics_0.1.4
#> [40] otel_0.2.0 RcppParallel_5.1.11-1 cachem_1.1.0
#> [43] stringr_1.6.0 splines_4.5.2 parallel_4.5.2
#> [46] vctrs_0.7.1 V8_8.0.1 Matrix_1.7-4
#> [49] sandwich_3.1-1 jsonlite_2.0.0 arrayhelpers_1.1-0
#> [52] glue_1.8.0 codetools_0.2-20 distributional_0.6.0
#> [55] lubridate_1.9.5 stringi_1.8.7 gtable_0.3.6
#> [58] QuickJSR_1.9.0 pillar_1.11.1 htmltools_0.5.9
#> [61] Brobdingnag_1.2-9 R6_2.6.1 textshaping_1.0.4
#> [64] rprojroot_2.1.1 evaluate_1.0.5 lattice_0.22-9
#> [67] backports_1.5.0 memoise_2.0.1 broom_1.0.12
#> [70] snakecase_0.11.1 rstantools_2.6.0 gridExtra_2.3
#> [73] coda_0.19-4.1 nlme_3.1-168 checkmate_2.3.4
#> [76] xfun_0.56 zoo_1.8-15 pkgconfig_2.0.3