here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(cmdstanr, posterior, bayesplot, brms)23 Modello bayesiano di regressione lineare bivariata
Panoramica del capitolo
- Comprendere il modello di regressione bayesiano e come si differenzia dall’approccio frequentista.
- Interpretare i parametri stimati in un contesto bayesiano e confrontarli con quelli frequentisti.
- Familiarizzare con l’uso di brms nella regressione.
- Interpretare le previsioni del modello bayesiano e le verifiche predittive a priori e a posteriori.
ConsiglioPrerequisiti
- Leggere l’Appendice K.
- Leggere il capitolo Simple Normal Regression di Johnson et al. (2022).
- Consultare Regression and Other Stories (Gelman et al., 2021).
- Il pdf del libro è consultabile gratuitamente su questo sito.
- Prestare particolare attenzione ai capitoli 1 “Overview”, 6 “Background on Regression Modeling”, 7 “Linear Regression with a Single Predictor” e 8 “Fitting regression models”, che offrono una guida dettagliata al modello di regressione bivariato da una prospettiva bayesiana.
- Per utilizzare il pacchetto R brms, è necessario installare preliminarmente Stan o CmdStan sul proprio computer. Si consiglia di optare per CmdStan. Il metodo più semplice per installare CmdStan consiste nell’installare il pacchetto R cmdstanr e seguire le istruzioni fornite nella documentazione.
AttenzionePreparazione del Notebook
23.1 L’approccio bayesiano
Nella statistica frequentista i parametri di un modello sono concepiti come quantità fisse ma sconosciute: l’incertezza nasce dalla variabilità campionaria e viene comunicata attraverso strumenti come gli intervalli di confidenza o i valori-\(p\).
L’inferenza bayesiana adotta una prospettiva differente: l’incertezza riguarda direttamente i parametri, che vengono modellati come variabili aleatorie. Non si assume che essi fluttuino nella realtà; si descrive invece il grado di credenza che attribuiamo ai loro possibili valori. L’inferenza consiste nell’aggiornare in modo coerente questa conoscenza quando osserviamo nuovi dati.
Il processo inferenziale si articola in tre passaggi fondamentali.
1. Specificazione delle distribuzioni a priori. Prima di osservare i dati assegniamo a ogni parametro una distribuzione a priori, che formalizza ciò che riteniamo plausibile alla luce della letteratura, dell’esperienza o di vincoli teorici.
- Prior informativo: quando esiste evidenza accumulata, possiamo esprimere aspettative mirate. Ad esempio, se studi precedenti suggeriscono una relazione negativa tra sonno e ansia, potremmo specificare: \[ \beta_1 \sim \mathcal N(-0.7, 0.3). \]
- Prior debole o poco informativo: quando non abbiamo indicazioni precise, scegliamo distribuzioni ampie che consentono ai dati di guidare l’inferenza: \[ \beta_1 \sim \mathcal N(0, 10). \]
2. Aggiornamento alla luce dei dati osservati. Le credenze iniziali vengono combinate con la verosimiglianza tramite il teorema di Bayes, ottenendo la distribuzione a posteriori:
\[ P(\beta_0, \beta_1, \sigma \mid \text{dati}) \propto P(\text{dati} \mid \beta_0, \beta_1, \sigma) \cdot P(\beta_0, \beta_1, \sigma). \]
La distribuzione a posteriori esprime la plausibilità di ciascun valore dei parametri dopo aver assimilato sia la conoscenza pregressa sia l’informazione fornita dai dati.
3. Interpretazione della distribuzione a posteriori. L’esito dell’analisi non è una singola retta di regressione, ma un’intera famiglia di rette compatibili con ciò che sappiamo, pesate dalla loro credibilità.
L’incertezza è descritta in modo diretto tramite intervalli di credibilità, che ammettono un’interpretazione immediata: dato il modello e i dati osservati, c’è una probabilità specificata (per esempio il 95%) che il valore del parametro si trovi in quell’intervallo.
23.1.1 Perché adottare l’approccio bayesiano?
L’inferenza bayesiana presenta notevoli vantaggi per la ricerca psicologica. Consente di integrare in modo coerente le conoscenze pregresse, come i risultati di studi precedenti o di meta-analisi, favorendo così l’accumulo della conoscenza scientifica. Inoltre, l’uso dei prior svolge un effetto di regolarizzazione, stabilizzando le stime e riducendo il rischio di overfitting, un aspetto particolarmente rilevante quando i dati disponibili sono limitati. Un altro punto di forza è rappresentato dall’interpretazione intuitiva dell’incertezza: le distribuzioni a posteriori e gli intervalli di credibilità forniscono risposte probabilistiche dirette alle domande di ricerca, rispecchiando il modo naturale con cui gli scienziati formulano ipotesi e valutano gli effetti.
Per queste ragioni, l’approccio bayesiano si dimostra particolarmente adatto alla complessità dei dati psicologici, dove i campioni sono spesso ridotti e i nuovi risultati devono essere integrati in un corpus di conoscenze in continua evoluzione.
23.2 Il modello di regressione lineare semplice
Per introdurre la regressione lineare semplice in chiave bayesiana, consideriamo un esempio classico in psicologia: prevedere il livello di ansia di una persona (\(y\)) a partire dal numero di ore di sonno dichiarate (\(x\)). L’ipotesi di fondo è che, in media, un maggiore numero di ore di sonno sia associato a livelli di ansia più bassi.
Questo legame si formalizza attraverso il modello:
\[ y_i = \beta_0 + \beta_1 x_i + \varepsilon_i, \]
dove \(\beta_0\) rappresenta l’intercetta, ossia il valore medio atteso di ansia quando le ore di sonno sono pari a zero, \(\beta_1\) è il coefficiente di regressione che indica quanto ci si aspetta che cambi l’ansia per ogni ora aggiuntiva di sonno, e \(\varepsilon_i\) è il termine di errore che cattura gli scostamenti imprevedibili del punteggio osservato rispetto alla media descritta dalla retta.
23.2.1 Assunzioni sul termine di errore
Per rendere il modello operativo, si assume che gli errori siano indipendenti tra gli individui, normalmente distribuiti con media zero e caratterizzati da una varianza costante \(\sigma^2\). In altre parole, dato un valore di \(x_i\), i possibili punteggi di ansia si distribuiscono probabilisticamente attorno a una media condizionata:
\[ y_i \mid x_i \sim \mathcal{N}(\mu_i, \sigma^2), \qquad \text{dove} \qquad \mu_i = \beta_0 + \beta_1 x_i. \]
23.2.2 Interpretazione sostanziale
Il modello non implica che le ore di sonno determinino in modo preciso il livello di ansia né che individui con lo stesso numero di ore di sonno abbiano lo stesso livello di ansia. Piuttosto, il modello descrive come varia in media il livello atteso di ansia in funzione del sonno, riconoscendo la presenza di una variabilità residua dovuta a differenze individuali, errori di misurazione e fattori non controllati.
La retta \(\beta_0 + \beta_1 x\) rappresenta quindi la media teorica della relazione psicologica studiata, mentre \(\sigma^2\) quantifica quanto i dati reali si discostano da essa. Insieme, l’intercetta, la pendenza e la variabilità residua definiscono la struttura completa del modello di regressione lineare semplice.
23.2.3 Confronti descrittivi, non effetti causali
Va sottolineato fin dall’inizio che i coefficienti di regressione rappresentano confronti descrittivi e non implicano automaticamente relazioni causali (Gelman et al., 2021). Nonostante nel linguaggio comune si parli spesso di “effetti”, tale terminologia può essere fuorviante, in quanto lascia intendere l’esistenza di un meccanismo causale sottostante. In realtà, il coefficiente \(\beta_1\) indica semplicemente come varia la media attesa di \(Y\) al variare di una singola unità di \(X\), ovvero la differenza attesa tra due gruppi che differiscono di una sola unità nel predittore.
La regressione lineare deve essere interpretata principalmente come uno strumento per descrivere le associazioni tra le variabili e per migliorare le previsioni. I coefficienti sintetizzano confronti medi basati esclusivamente sui dati osservati. Per attribuire a tali confronti un significato causale, il disegno dello studio deve fornire prove adeguate, ad esempio mediante manipolazioni sperimentali controllate o strategie volte a gestire possibili fattori confondenti.
23.3 La verosimiglianza
Nell’inferenza bayesiana, la verosimiglianza misura quanto i dati osservati siano compatibili con un insieme specifico di valori dei parametri. Non valuta la plausibilità intrinseca dei parametri, ma indica quanto bene quei parametri spiegano i dati raccolti.
Nel modello di regressione lineare con errore normalmente distribuito, la plausibilità di ciascuna osservazione \(y_i\) è data dalla densità della distribuzione normale centrata sulla media condizionata \(\mu_i = \beta_0 + \beta_1 x_i\). Assumendo l’indipendenza tra le osservazioni, la verosimiglianza complessiva è
\[ \mathcal{L}(\beta_0, \beta_1, \sigma \mid \mathbf{y}, \mathbf{x}) = \prod_{i=1}^n \mathcal{N}\bigl(y_i \mid \beta_0 + \beta_1 x_i,\ \sigma^2\bigr), \]
che, esplicitata, diventa
\[ \mathcal{L}(\beta_0, \beta_1, \sigma \mid \mathbf{y}, \mathbf{x}) = \prod_{i=1}^n \frac{1}{\sqrt{2\pi \sigma^2}} \exp\Biggl(-\frac{(y_i - \beta_0 - \beta_1 x_i)^2}{2\sigma^2}\Biggr). \tag{23.1}\]
Per semplificare i calcoli, si ricorre spesso alla log-verosimiglianza1, che trasforma il prodotto in una somma:
\[ \log \mathcal{L}(\beta_0, \beta_1, \sigma \mid \mathbf{y}, \mathbf{x}) = -\frac{n}{2}\log(2\pi) - n\log\sigma - \frac{1}{2\sigma^2} \sum_{i=1}^n (y_i - \beta_0 - \beta_1 x_i)^2. \tag{23.2}\]
23.3.1 Il ruolo della verosimiglianza nell’inferenza bayesiana
Nell’approccio bayesiano, la verosimiglianza costituisce uno dei due pilastri fondamentali del teorema di Bayes, insieme alla distribuzione a priori. A differenza della stima di massima verosimiglianza frequentista, il suo scopo non è produrre valori puntuali dei parametri, ma fornire l’evidenza empirica che sarà combinata con le informazioni preesistenti. La formula bayesiana sintetizza questo aggiornamento:
\[ \text{Posterior} ;\propto; \text{Likelihood} \times \text{Prior}. \]
In altre parole, la verosimiglianza rappresenta ciò che i dati ci indicano, mentre il prior codifica ciò che già ritenevamo plausibile. La distribuzione a posteriori nasce dall’integrazione di queste due fonti e rappresenta lo stato aggiornato della conoscenza. È proprio questa combinazione sistematica tra evidenza empirica e conoscenza pregressa che distingue l’inferenza bayesiana e le conferisce la sua capacità di fornire stime probabilistiche direttamente interpretabili.
23.4 Le distribuzioni a priori
Nella regressione lineare bayesiana, è necessario specificare una distribuzione a priori per ciascun parametro del modello: l’intercetta \(\beta_0\), la pendenza \(\beta_1\) e la deviazione standard residua \(\sigma\). La scelta dei prior non riguarda solo il “grado di informazione” da introdurre, ma anche la loro coerenza con l’interpretazione psicologica dei parametri.
23.4.1 Prior per l’intercetta
Se il predittore viene centrato intorno alla media (pratica consigliata nell’analisi bayesiana), l’intercetta \(\beta_0\) non rappresenta più il livello di ansia previsto a zero ore di sonno, ma il livello atteso per una persona con una quantità di sonno nella media. In questo caso, diventa ragionevole assegnare a \(\beta_0\) un prior moderato, ad esempio una distribuzione normale centrata sulla media attesa del costrutto psicologico:
\[ \beta_0 \sim \mathcal{N}(50, 15), \]
considerando, ad esempio, una scala dell’ansia compresa tra 0 e 100. Un prior di questo tipo contribuisce a rendere il modello più stabile e coerente con i dati plausibili.
23.4.2 Prior per la pendenza
La pendenza \(\beta_1\), che misura l’associazione tra ore di sonno e ansia, può essere informata dalla teoria o dalla letteratura: ad esempio, si può ipotizzare che un maggior numero di ore di sonno sia associato a livelli più bassi di ansia. In questo caso, è sensato adottare un prior che concentri la probabilità su valori negativi, pur consentendo la possibilità di valori positivi limitati:
\[ \beta_1 \sim \mathcal{N}(-2, 2). \]
Oppure, si può adottare un prior leggermente asimmetrico che attribuisca minore plausibilità ai grandi valori positivi, incompatibili con le ipotesi teoriche.
23.4.3 Prior per la deviazione standard
Per la deviazione standard residua \(\sigma\), che deve essere positiva, si utilizzano distribuzioni definite solo su valori positivi, come la half-Cauchy o la half-Normal:
\[ \sigma \sim \text{Half-Cauchy}(0, 5). \]
Queste distribuzioni consentono un’ampia variabilità, ma prevengono valori estremamente vicini a zero, poco realistici in un contesto psicologico.
In sintesi, i prior non forniscono solo informazioni aggiuntive al modello, ma ne guidano le stime verso valori plausibili e interpretabili, garantendo al contempo stabilità numerica e coerenza psicologica.
23.5 Le distribuzioni a posteriori
Nel modello di regressione lineare bayesiana, la distribuzione a posteriori sintetizza simultaneamente l’incertezza sui tre parametri fondamentali (\(\beta_0\), \(\beta_1\) e \(\sigma\)), combinando l’evidenza dei dati con le conoscenze iniziali codificate nei prior.
Il comportamento della distribuzione a posteriori dipende in modo cruciale dalla quantità di informazione contenuta nei dati rispetto alla forza dei prior. In presenza di dati poco informativi, come ad esempio campioni piccoli o una variabilità ridotta della \(X\), la distribuzione a posteriori rimane vicina alla forma dei prior, poiché i dati forniscono poche indicazioni in grado di modificarla. Al contrario, quando i dati sono molto informativi, come nel caso di campioni grandi, buona variabilità e chiare associazioni tra predittore e risposta, la componente di verosimiglianza domina e la distribuzione a posteriori riflette principalmente l’evidenza empirica, assumendo una forma coerente con i dati a prescindere dai prior utilizzati, a condizione che non siano eccessivamente restrittivi.
Questo meccanismo mostra come l’inferenza bayesiana realizzi automaticamente un equilibrio tra conoscenza pregressa ed evidenza empirica, evitando conclusioni estreme quando le osservazioni sono scarse e consentendo ai dati di “parlare con forza” quando l’informazione è abbondante.
Un aspetto fondamentale è che la distribuzione a posteriori cattura le interdipendenze tra i parametri. La pendenza \(\beta_1\) e la deviazione residua \(\sigma\) non sono indipendenti nella distribuzione congiunta: se i dati indicano una relazione debole tra sonno e ansia (con \(\beta_1\) vicino a zero), gran parte della variabilità osservata viene attribuita all’errore residuo (valore elevato di \(\sigma\)). Al contrario, una pendenza marcata riduce la necessità di una grande varianza residua per spiegare la dispersione dei dati. L’approccio bayesiano non fornisce quindi solo stime separate per ciascun parametro, ma anche una distribuzione congiunta che incorpora automaticamente queste compensazioni, riflettendo in modo realistico l’incertezza condivisa tra i parametri.
23.5.1 Affermazioni probabilistiche sostantive
La vera forza della distribuzione a posteriori risiede nella possibilità di formulare affermazioni probabilistiche chiare e direttamente interpretabili sul fenomeno psicologico. Ad esempio:
\[ \Pr(\beta_1 < 0 \mid \text{dati}) = 0.97 \] indica che, alla luce dei dati osservati, vi è una probabilità del 97% che un aumento delle ore di sonno sia associato a una diminuzione del livello di ansia. A differenza dei test di ipotesi frequentisti, qui non si confronta il parametro con uno zero teorico, ma si quantifica direttamente la credibilità di un’associazione nella popolazione di riferimento.
Questa capacità di tradurre i risultati in affermazioni probabilistiche intuitive trasforma la regressione da un semplice strumento numerico a uno strumento potente per inferenze scientificamente coerenti sul comportamento umano.
23.6 Implementazione con brms
Il pacchetto brms implementa l’inferenza bayesiana utilizzando una sintassi simile a quella di lm() in R. La specifica del modello avviene tramite la formula di Wilkinson:
brm(y ~ x, data = dati)Questa singola istruzione è sufficiente per adattare un modello di regressione lineare bivariato. brms assume automaticamente una verosimiglianza normale e, se non specificati, utilizza prior debolmente informativi per tutti i parametri (intercetta, pendenza, deviazione standard).
23.6.1 Come vengono stimate le distribuzioni a posteriori?
Poiché le distribuzioni a posteriori sono generalmente intrattabili analiticamente, brms le stima tramite tecniche di campionamento MCMC (Markov Chain Monte Carlo). In particolare, utilizza l’algoritmo NUTS (No-U-Turn Sampler), una variante sofisticata dell’Hamiltonian Monte Carlo.
NUTS esplora lo spazio dei parametri adattando automaticamente la lunghezza e la direzione dei passi in base alla geometria della distribuzione a posteriori. In questo modo, si evitano sia passi troppo brevi, che rallenterebbero l’esplorazione, sia passi troppo lunghi, che porterebbero a regioni di bassa probabilità. Grazie a questa strategia, l’algoritmo è in grado di campionare in modo efficiente anche in spazi parametrici ad alta dimensionalità.
A partire dai campioni generati, è possibile calcolare stime puntuali, intervalli di credibilità e previsioni, ottenendo così un quadro completo e quantitativo dell’incertezza sui parametri e delle relazioni tra le variabili.
23.6.2 Un esempio concreto
Definiamo i parametri e simuliamo i dati.
set.seed(123)
# Definizione delle variabili
x <- 1:100
n <- length(x)
alpha <- 1.5
beta <- 0.5
sigma <- 10
# Generazione di y
y <- alpha + beta * x + rnorm(n, 0, sigma)
# Creazione del dataframe
fake <- tibble(x = x, y = y)
head(fake)
#> # A tibble: 6 × 2
#> x y
#> <int> <dbl>
#> 1 1 -3.60
#> 2 2 0.198
#> 3 3 18.6
#> 4 4 4.21
#> 5 5 5.29
#> 6 6 21.7Iniziamo adattando ai dati un modello frequentista:
fm1 <- lm(y ~ x, data = fake)summary(fm1)
#>
#> Call:
#> lm(formula = y ~ x, data = fake)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -24.536 -5.524 -0.346 6.485 20.949
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 1.1360 1.8429 0.62 0.54
#> x 0.5251 0.0317 16.57 <2e-16
#>
#> Residual standard error: 9.15 on 98 degrees of freedom
#> Multiple R-squared: 0.737, Adjusted R-squared: 0.734
#> F-statistic: 275 on 1 and 98 DF, p-value: <2e-16Per ottenere l’intervallo di confidenza (nel senso frequentista) della stima dei parametri usiamo:
confint(fm1, level = 0.95)
#> 2.5 % 97.5 %
#> (Intercept) -2.521 4.793
#> x 0.462 0.588Adattiamo ora ai dati un modello di regressione bayesiano utilizzando brms. Si noti che, anche in questo caso, usiamo la sintassi di Wilkinson y ~ x, come per lm(). Specifichiamo esplicitamente i prior ed eseguiamo il campionamento:
# Prior debolmente informativi
my_priors <- c(
prior(normal(0, 50), class = "Intercept"),
prior(normal(0, 10), class = "b"),
prior(exponential(0.1), class = "sigma")
)
fm2 <- brm(
y ~ x,
data = fake,
prior = my_priors,
backend = "cmdstanr"
)23.6.3 Verifica delle distribuzioni a priori
Prima di esaminare i risultati, è buona pratica verificare quali prior sono stati utilizzati dal modello:
prior_summary(fm2)
#> prior class coef group resp dpar nlpar lb ub tag source
#> normal(0, 10) b user
#> normal(0, 10) b x (vectorized)
#> normal(0, 50) Intercept user
#> exponential(0.1) sigma 0 user23.6.3.1 Prior predictive check
È possibile visualizzare le previsioni generate esclusivamente dai prior del modello, prima di osservare qualsiasi dato. Questo controllo, detto prior predictive check, serve a verificare che i prior producano valori plausibili per il fenomeno studiato e non conducano a risultati irrealistici.
Per eseguire il prior predictive check, è necessario specificare prior informativi (non piatti) per tutti i parametri. Possiamo utilizzare gli stessi prior definiti in precedenza:
fm2_prior <- brm(
y ~ x,
data = fake,
prior = my_priors,
sample_prior = "only",
backend = "cmdstanr"
)pp_check(fm2_prior, ndraws = 50) +
labs(title = "Prior Predictive Check")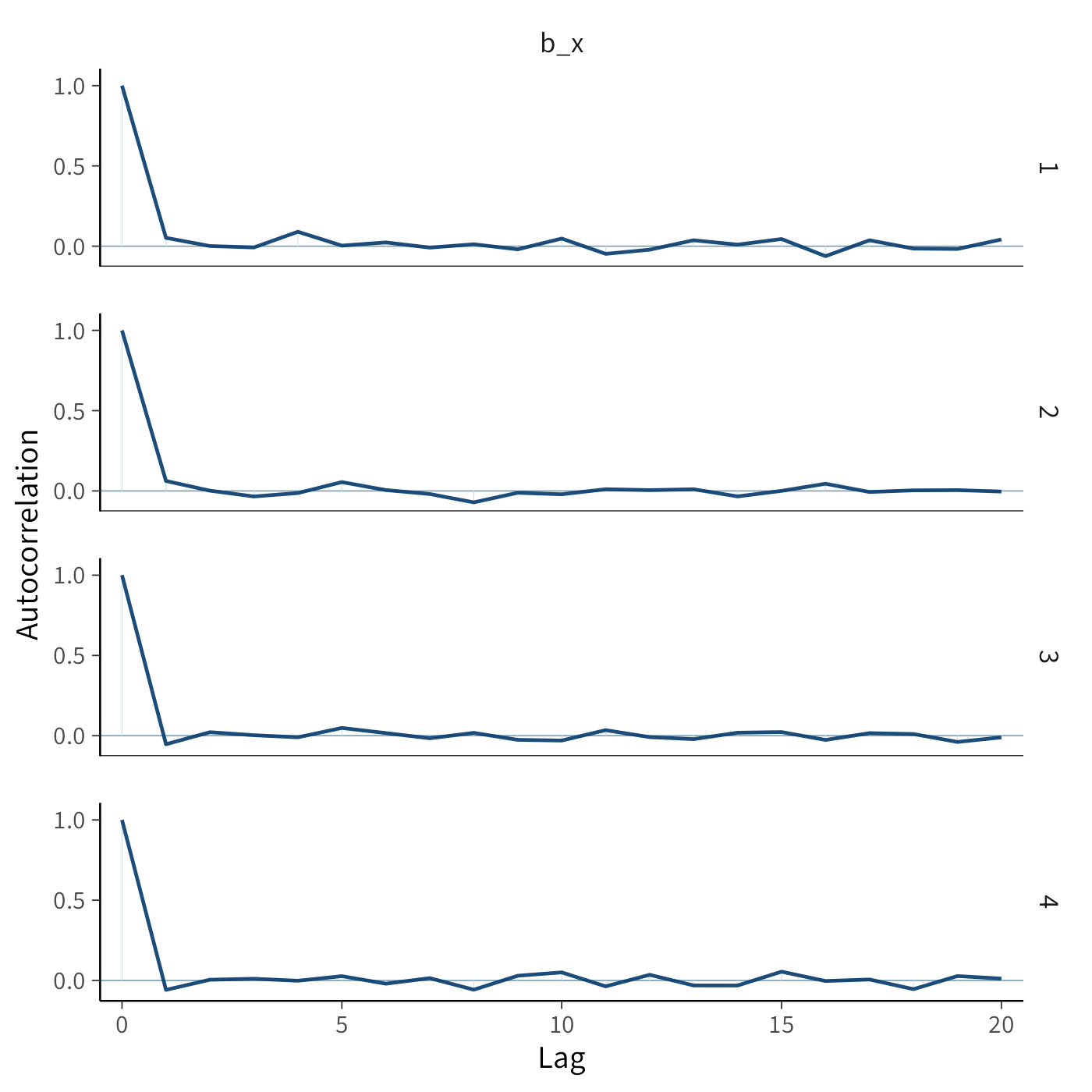
Nel grafico, le linee rappresentano le distribuzioni di \(y\) considerate plausibili dal modello prima di osservare i dati. Se le previsioni fossero completamente fuori scala rispetto ai dati realistici, sarebbe necessario rivedere i prior. Con prior debolmente informativi come quelli specificati, ci aspettiamo una gamma ampia di valori possibili, coerente con l’assenza di conoscenze pregresse forti e consentendo al modello di apprendere efficacemente dai dati.
23.7 Diagnostica della convergenza
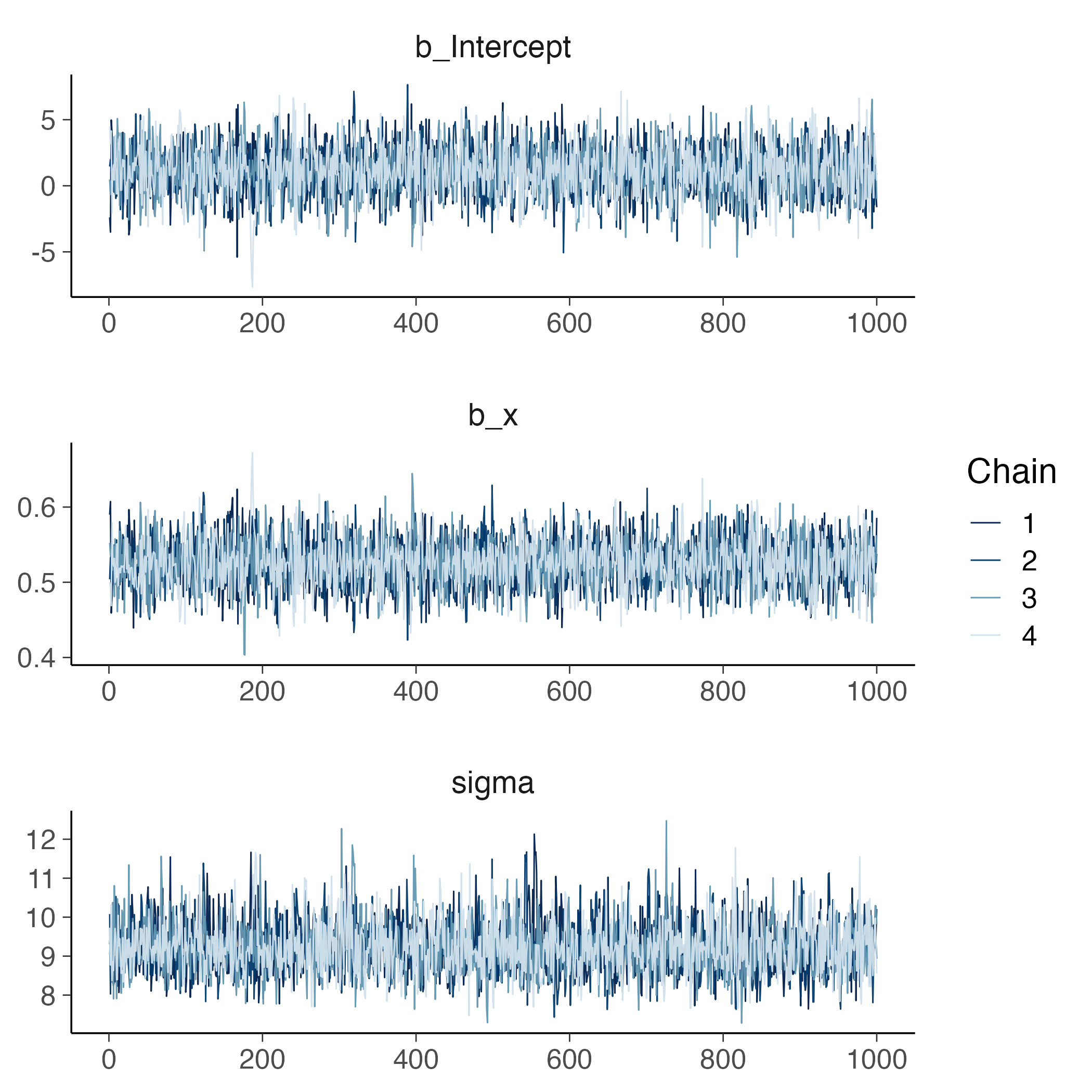
Dopo il campionamento, il primo passo consiste nel verificare la convergenza delle catene MCMC. L’obiettivo è assicurarsi che l’algoritmo abbia esplorato in modo appropriato lo spazio dei parametri e che i campioni siano rappresentativi della distribuzione a posteriori. Nel caso di brm, per impostazione predefinita vengono eseguite quattro catene indipendenti.
La convergenza può essere considerata raggiunta se le catene sono ben miscelate e non presentano trend o pattern sistematici. Nei trace plot, questo si traduce in campioni che fluttuano in maniera casuale attorno a un valore stabile, indicando che le catene stanno esplorando correttamente la regione ad alta probabilità della distribuzione a posteriori.
Le tracce dei parametri si ottengono nel modo seguente:
Gli istogrammi delle distribuzioni a posteriori dei parametri si generano nel modo seguente:
23.7.1 Diagnostica dell’autocorrelazione
Per valutare l’autocorrelazione tra i campioni a posteriori del parametro b_x, utilizziamo il seguente comando:
mcmc_acf(fm2, pars = "b_x")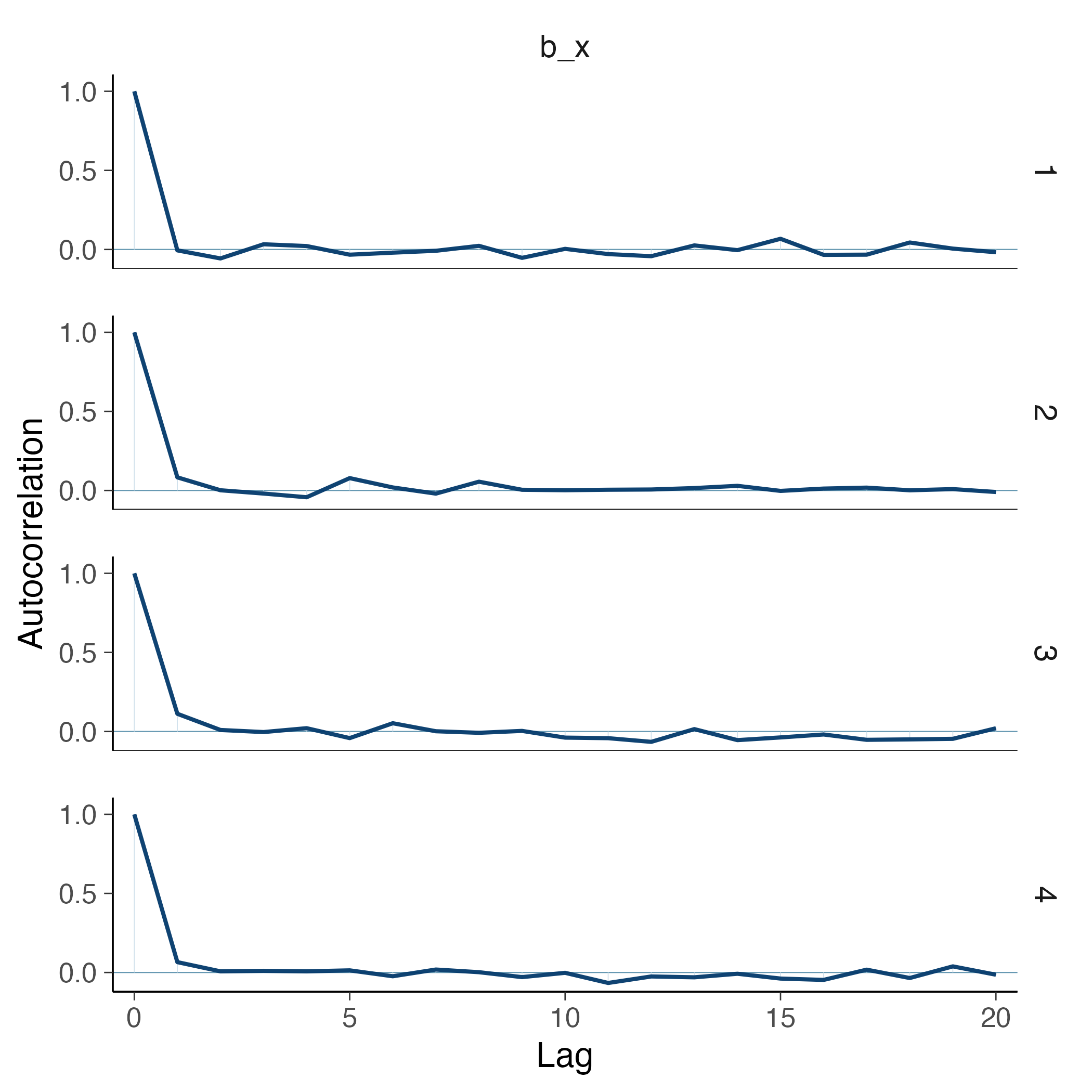
L’autocorrelazione misura la dipendenza tra campioni successivi nella catena di Markov. Poiché gli algoritmi MCMC generano campioni correlati per costruzione, è normale osservare una certa autocorrelazione tra campioni vicini. Tuttavia, una catena ben mescolata dovrebbe mostrare una rapida diminuzione dell’autocorrelazione man mano che aumenta il lag, indicando che i campioni si comportano approssimativamente come indipendenti per lag sufficientemente grandi.
Nel nostro caso, l’autocorrelazione diminuisce rapidamente fino a raggiungere lo zero, il che suggerisce che la catena ha raggiunto la convergenza e che i campioni sono adeguatamente mescolati.
23.7.2 Sintesi numerica del modello
summary(fm2)
#> Family: gaussian
#> Links: mu = identity
#> Formula: y ~ x
#> Data: fake (Number of observations: 100)
#> Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
#> total post-warmup draws = 4000
#>
#> Regression Coefficients:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
#> Intercept 1.10 1.90 -2.61 4.83 1.00 3554 2646
#> x 0.53 0.03 0.46 0.59 1.00 3565 2836
#>
#> Further Distributional Parameters:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
#> sigma 9.23 0.68 8.06 10.66 1.00 3811 2849
#>
#> Draws were sampled using sample(hmc). For each parameter, Bulk_ESS
#> and Tail_ESS are effective sample size measures, and Rhat is the potential
#> scale reduction factor on split chains (at convergence, Rhat = 1).Il sommario mostra le stime a posteriori dei parametri. Confrontandole con i valori veri utilizzati nella simulazione (\(\alpha = 1.5\), \(\beta = 0.5\), \(\sigma = 10\)), si può notare che gli intervalli di credibilità al 95% includono i parametri generativi: l’intervallo per l’intercetta contiene il valore reale, così come quello per la pendenza. Questo risultato indica che il modello non solo recupera con precisione i parametri sottostanti, ma quantifica in modo appropriato l’incertezza delle stime.
23.8 Verifica predittiva a posteriori
Oltre alla diagnostica delle catene, è fondamentale verificare se il modello cattura adeguatamente le caratteristiche dei dati osservati. Il posterior predictive check confronta i dati osservati con dati simulati dal modello stimato:
pp_check(fm2, ndraws = 50)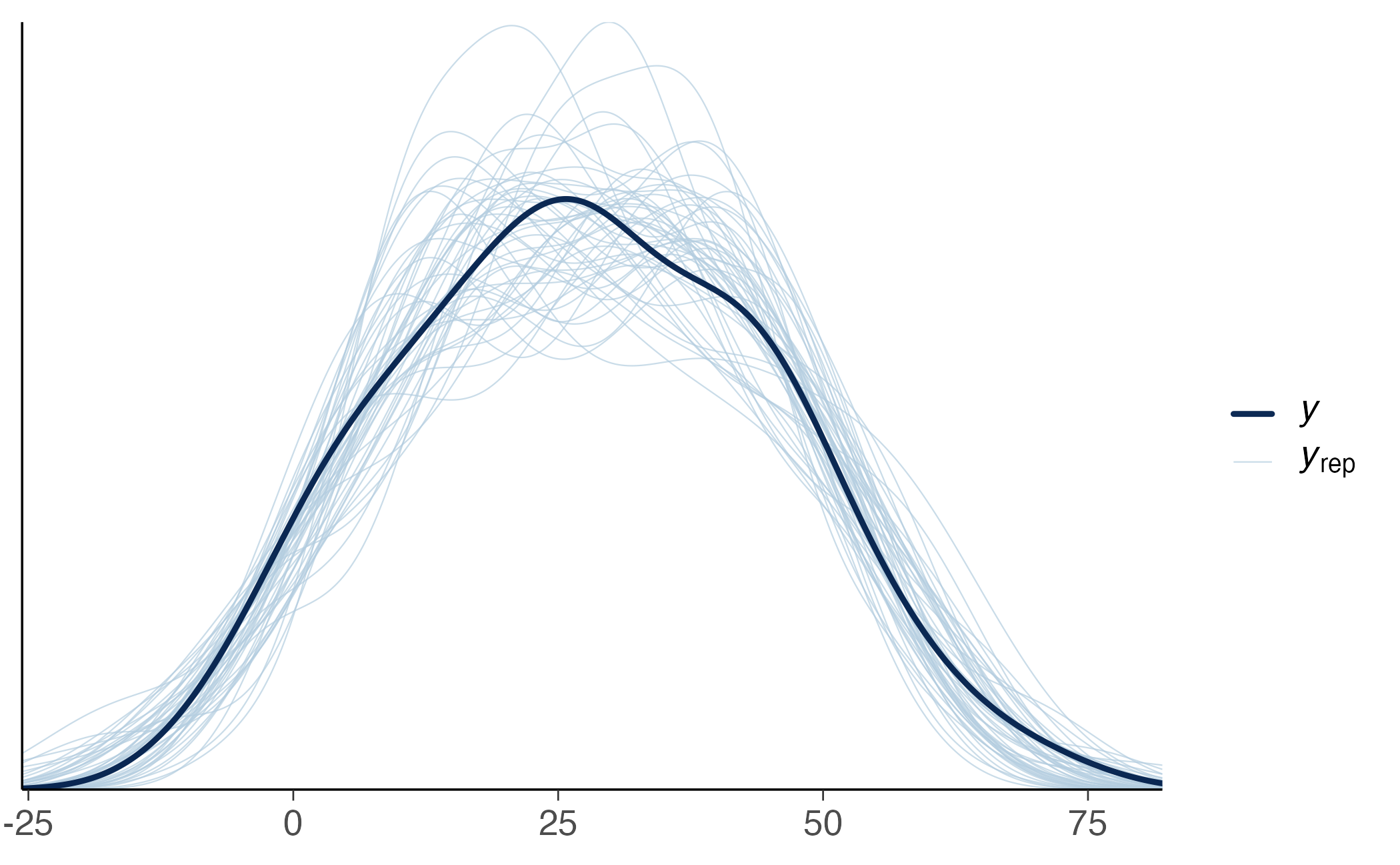
Nel grafico risultante, la linea scura rappresenta la distribuzione dei dati osservati, mentre le linee più chiare mostrano le distribuzioni dei dati simulati dal modello. Un buon modello dovrebbe produrre simulazioni che si sovrappongono ragionevolmente ai dati osservati. Discrepanze sistematiche possono indicare problemi nella specificazione, come non-linearità non catturate o errori che deviano dalla normalità.
È possibile approfondire l’analisi concentrandosi su caratteristiche specifiche dei dati, come la media o la deviazione standard dei valori osservati:
pp_check(fm2, type = "stat", stat = "mean")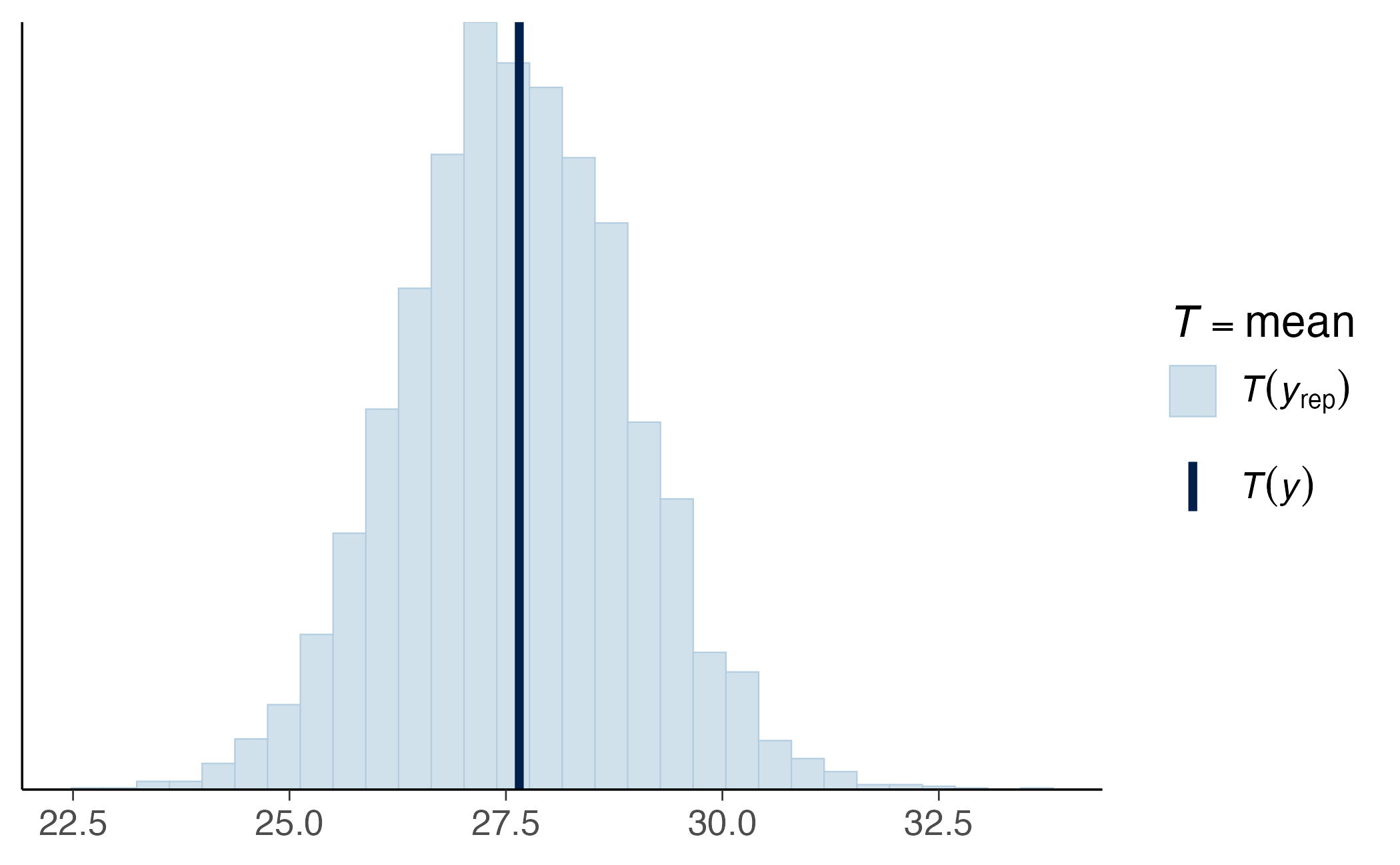
pp_check(fm2, type = "stat", stat = "sd")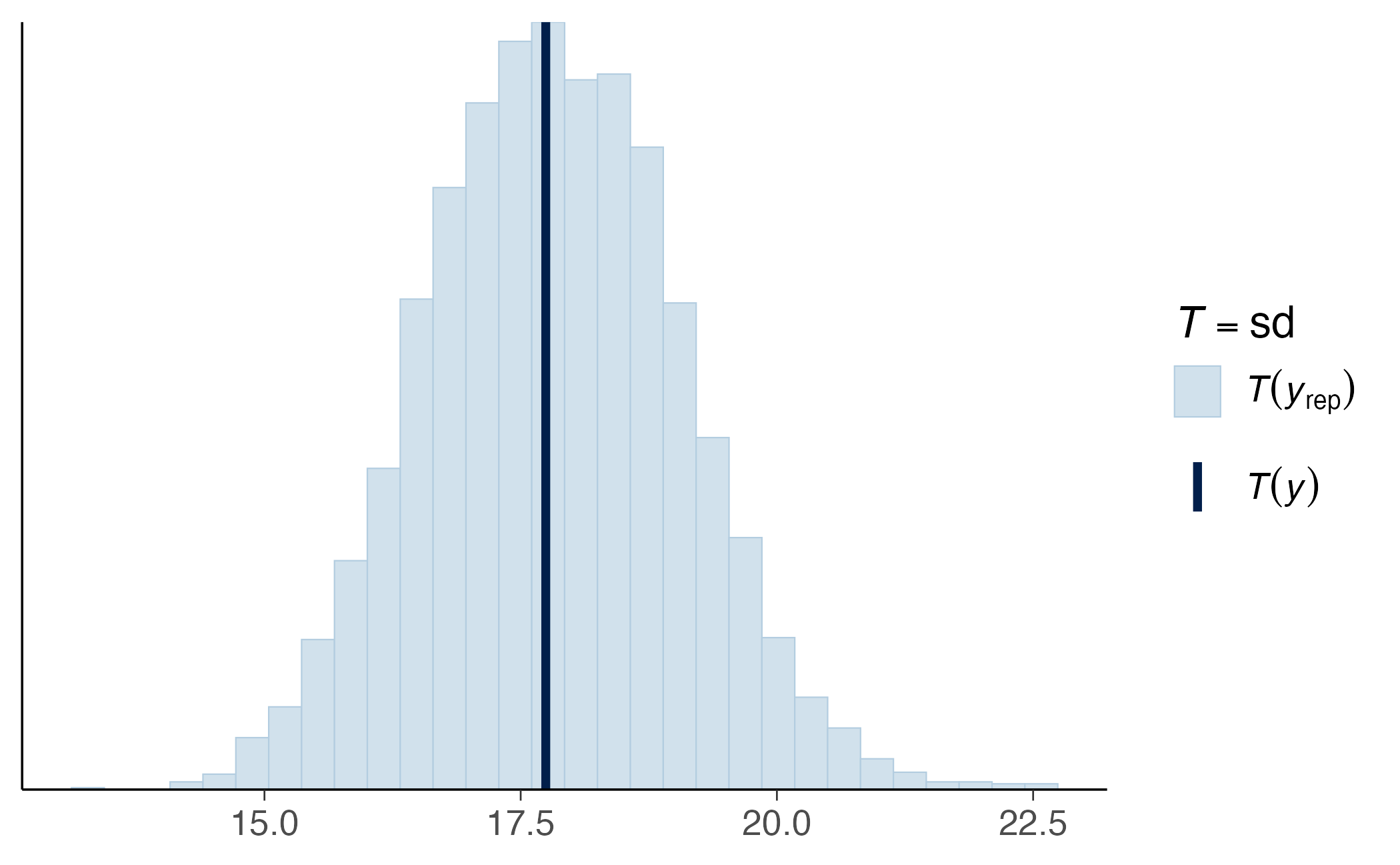
23.8.1 Visualizzazione della relazione stimata
conditional_effects(fm2) |>
plot(points = TRUE)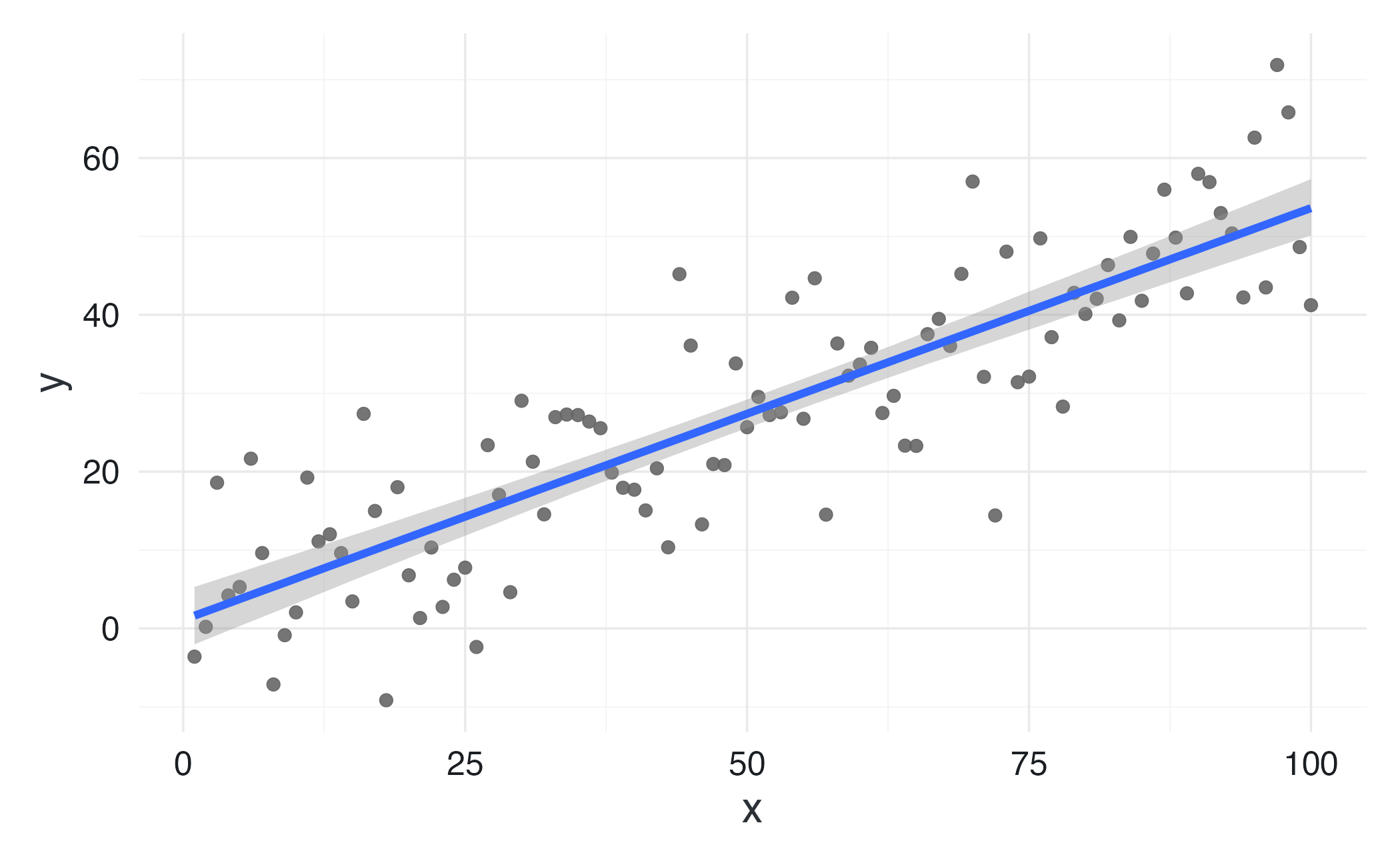
Il grafico prodotto da conditional_effects() mostra tre componenti principali. La relazione media stimata è rappresentata dalla linea centrale, che mostra il valore atteso di \(y\) per ciascun valore di \(x\), calcolato utilizzando le medie a posteriori di \(\beta_0\) e \(\beta_1\). L’incertezza delle previsioni è visualizzata attraverso le bande colorate attorno alla linea, che rappresentano intervalli di credibilità (tipicamente al 95%) e quantificano l’incertezza nelle previsioni del modello per ciascun valore di \(x\). Bande più strette indicano maggiore certezza. I dati osservati appaiono come punti che mostrano i valori effettivi di \(y\), permettendo un confronto visivo tra dati reali e previsioni del modello.
Questa visualizzazione consente una verifica visiva della direzione e della forza della relazione stimata, dell’adeguatezza del modello attraverso il confronto tra dati osservati e previsioni, e della comprensione del grado di incertezza associato alle stime in diverse regioni dello spazio dei predittori.
Riflessioni conclusive
In questo capitolo, abbiamo ridefinito la regressione lineare bivariata secondo una prospettiva bayesiana, mostrando come la stima di un modello corrisponda all’aggiornamento delle conoscenze a priori sui parametri alla luce dei dati osservati. L’introduzione di distribuzioni a priori per l’intercetta, la pendenza e la varianza residua ha permesso di combinare informazioni pregresse, di natura teorica, empirica o anche euristica, con l’evidenza empirica, generando distribuzioni a posteriori che quantificano esplicitamente l’incertezza associata alle grandezze di interesse.
Il confronto con l’approccio frequentista mette in luce un cambiamento di prospettiva più che di tecnica. Non si tratta solo di ottenere intervalli anziché stime puntuali, ma di adottare una logica inferenziale in cui le domande che realmente ci poniamo — “quanto è plausibile questa pendenza?”, “quanto è probabile che l’associazione tra sonno e ansia sia negativa?” — trovano una risposta diretta e quantitativa. La possibilità di formulare affermazioni probabilistiche sui parametri non è un semplice raffinamento formale, ma rappresenta la condizione per un’inferenza coerente con il ragionamento sotto incertezza.
Questa maggiore ricchezza interpretativa comporta però un costo computazionale. Le soluzioni analitiche per le distribuzioni a posteriori sono disponibili solo per modelli semplici come quello qui discusso; già con pochi predittori aggiuntivi o con strutture gerarchiche, le distribuzioni diventano intrattabili analiticamente. Per affrontare problemi reali nella ricerca psicologica è quindi necessario ricorrere ad algoritmi di approssimazione e a tecniche di campionamento avanzate, in grado di esplorare spazi parametrici complessi. Nei capitoli successivi verrà introdotto Stan, un linguaggio di programmazione progettato per rendere operativa questa prospettiva: Stan non calcola soluzioni analitiche, ma consente di affrontare problemi che, in assenza di tale strumento, risulterebbero computazionalmente intrattabili.
In definitiva, la regressione bivariata non è un modello elementare di limitata utilità. Essa costituisce piuttosto la base concettuale per comprendere come l’inferenza bayesiana possa essere applicata a modelli sempre più complessi e strutturati, in grado di rappresentare in modo realistico la natura multidimensionale dei fenomeni psicologici.
ImportanteProblemi
Verosimiglianza Definire la funzione di verosimiglianza per il modello bayesiano di regressione lineare bivariata, esplicitando i parametri e la loro interpretazione.
Scelta dei prior Proporre un set di prior debolmente informativi differenti da quelli riportati, motivando la scelta delle distribuzioni.
Simulazione dati Scrivere un blocco di codice in R/Quarto per simulare un dataset con \(n=50\), parametri \(\alpha=2\), \(\beta=0.5\), \(\sigma=1\) e visualizzare un grafico di dispersione con la retta di regressione vera.
Stima frequentista vs bayesiana Utilizzando i dati simulati, adattare un modello con
lm()e uno conbrm()(specificando i prior). Confrontare i risultati prodotti dai due approcci, riportando i valori stimati e gli intervalli di confidenza/credibilità.Diagnosi MCMC Elencare e spiegare almeno tre controlli diagnostici da effettuare sulle catene MCMC per garantire la convergenza e un buon mescolamento.
Interpretazione dei coefficienti In un contesto osservazionale, discutere perché non è appropriato interpretare i coefficienti della regressione come effetti causali. Fare riferimento ai concetti di confondimento e disegno sperimentale.
Prior predictive check Spiegare a cosa serve il prior predictive check e come può guidare la scelta dei prior.
Posterior predictive check Descrivere come il posterior predictive check può essere utilizzato per valutare l’adeguatezza del modello ai dati.
ConsiglioSoluzioni
-
Verosimiglianza
\[ \mathcal{L}(\beta_0, \beta_1, \sigma \mid y, x) = \prod_{i=1}^n \frac{1}{\sqrt{2\pi}\sigma} \exp\left(-\frac{(y_i - (\beta_0 + \beta_1 x_i))^2}{2\sigma^2}\right). \]
-
Scelta dei prior
Ad esempio:
- \(\beta_0 \sim \mathcal{N}(0, 10)\): consente maggiore variabilità iniziale per l’intercetta;
- \(\beta_1 \sim \text{Student-}t(3, 0, 2.5)\): distribuzione con code pesanti, robusta a valori anomali;
-
\(\sigma \sim \text{Half-Student-}t(3, 0, 2.5)\): prior standard di
brmsper le deviazioni standard.
-
Simulazione dati
-
Stima frequentista vs bayesiana
Frequentista (
lm()):Bayesiano (
brm()):fm_b <- brm( y ~ x, data = data.frame(x, y), prior = c( set_prior("normal(0, 10)", class = "Intercept"), set_prior("normal(0, 5)", class = "b"), set_prior("student_t(3, 0, 2.5)", class = "sigma") ), iter = 2000, chains = 4 ) summary(fm_b)Confronto: i valori medi a posteriori e gli intervalli di credibilità dovrebbero essere molto simili a quelli frequentisti, dato l’uso di prior debolmente informativi.
-
Diagnosi MCMC
- Trace plots: verificare che le catene mostrino un buon mescolamento (aspetto “a caterpillar”) senza trend o pattern sistematici;
- R-hat (\(\hat{R}\)): un valore vicino a 1 (tipicamente < 1.01) indica convergenza delle catene a una distribuzione stazionaria comune;
- Effective Sample Size (ESS): indica quanti campioni indipendenti equivalenti sono stati ottenuti; valori > 400 per coda (tail-ESS) e per bulk sono generalmente considerati adeguati.
-
Interpretazione dei coefficienti
La regressione osservazionale non controlla automaticamente i potenziali confondenti. Senza randomizzazione o un disegno sperimentale rigoroso, non è possibile inferire causalità. Ad esempio, l’associazione tra sonno e ansia potrebbe essere confusa da variabili come lo stress lavorativo (che causa sia insonnia sia ansia) o condizioni mediche sottostanti. L’analisi di regressione, di per sé, non distingue tra associazione e causalità.
-
Prior predictive check
Il prior predictive check genera dati simulati utilizzando solo le distribuzioni a priori, prima di osservare i dati reali. Serve a verificare che i prior producano previsioni ragionevoli per il fenomeno studiato. Se le previsioni a priori includono valori impossibili (es. età negative, punteggi fuori scala), i prior dovrebbero essere rivisti. È uno strumento per la “calibrazione” dei prior rispetto alla conoscenza del dominio.
-
Posterior predictive check
Il posterior predictive check confronta i dati osservati con dati simulati dal modello stimato. Se il modello cattura adeguatamente le caratteristiche dei dati, le simulazioni dovrebbero essere simili alle osservazioni reali. Discrepanze sistematiche (es. differenze nelle code della distribuzione, nella variabilità, o nella forma) suggeriscono che il modello non è adeguato e potrebbe richiedere modifiche nella specificazione (es. distribuzione degli errori diversa dalla normale, termini non lineari).
NotaInformazioni sull’ambiente di sviluppo
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.1
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] cmdstanr_0.8.0 ragg_1.5.0 tinytable_0.15.1
#> [4] withr_3.0.2 systemfonts_1.3.1 patchwork_1.3.2
#> [7] ggdist_3.3.3 tidybayes_3.0.7 bayesplot_1.14.0
#> [10] ggplot2_4.0.1 reliabilitydiag_0.2.1 priorsense_1.2.0
#> [13] posterior_1.6.1 loo_2.8.0 rstan_2.32.7
#> [16] StanHeaders_2.32.10 brms_2.23.0 Rcpp_1.1.0
#> [19] sessioninfo_1.2.3 conflicted_1.2.0 janitor_2.2.1
#> [22] matrixStats_1.5.0 modelr_0.1.11 tibble_3.3.0
#> [25] dplyr_1.1.4 tidyr_1.3.1 rio_1.2.4
#> [28] here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] gridExtra_2.3 inline_0.3.21 sandwich_3.1-1
#> [4] rlang_1.1.6 magrittr_2.0.4 multcomp_1.4-29
#> [7] snakecase_0.11.1 compiler_4.5.2 reshape2_1.4.5
#> [10] vctrs_0.6.5 stringr_1.6.0 pkgconfig_2.0.3
#> [13] arrayhelpers_1.1-0 fastmap_1.2.0 backports_1.5.0
#> [16] labeling_0.4.3 rmarkdown_2.30 ps_1.9.1
#> [19] purrr_1.2.0 xfun_0.54 cachem_1.1.0
#> [22] jsonlite_2.0.0 broom_1.0.11 parallel_4.5.2
#> [25] R6_2.6.1 stringi_1.8.7 RColorBrewer_1.1-3
#> [28] lubridate_1.9.4 estimability_1.5.1 knitr_1.50
#> [31] zoo_1.8-14 pacman_0.5.1 Matrix_1.7-4
#> [34] splines_4.5.2 timechange_0.3.0 tidyselect_1.2.1
#> [37] abind_1.4-8 yaml_2.3.12 codetools_0.2-20
#> [40] processx_3.8.6 curl_7.0.0 pkgbuild_1.4.8
#> [43] plyr_1.8.9 lattice_0.22-7 bridgesampling_1.2-1
#> [46] S7_0.2.1 coda_0.19-4.1 evaluate_1.0.5
#> [49] survival_3.8-3 RcppParallel_5.1.11-1 pillar_1.11.1
#> [52] tensorA_0.36.2.1 checkmate_2.3.3 stats4_4.5.2
#> [55] distributional_0.5.0 generics_0.1.4 rprojroot_2.1.1
#> [58] rstantools_2.5.0 scales_1.4.0 xtable_1.8-4
#> [61] glue_1.8.0 emmeans_2.0.0 tools_4.5.2
#> [64] data.table_1.17.8 mvtnorm_1.3-3 grid_4.5.2
#> [67] QuickJSR_1.8.1 colorspace_2.1-2 nlme_3.1-168
#> [70] cli_3.6.5 textshaping_1.0.4 svUnit_1.0.8
#> [73] Brobdingnag_1.2-9 V8_8.0.1 gtable_0.3.6
#> [76] digest_0.6.39 TH.data_1.1-5 htmlwidgets_1.6.4
#> [79] farver_2.1.2 memoise_2.0.1 htmltools_0.5.9
#> [82] lifecycle_1.0.4 MASS_7.3-65Bibliografia
Gelman, A., Hill, J., & Vehtari, A. (2021). Regression and other stories. Cambridge University Press.
Johnson, A. A., Ott, M., & Dogucu, M. (2022). Bayes Rules! An Introduction to Bayesian Modeling with R. CRC Press.
La derivazione completa di questa formula è presentata nell’Appendice R.↩︎