Appendice L — Implementazione di modelli bayesiani con Stan tramite cmdstanr
Obiettivo
Questa appendice fornisce un template operativo per eseguire un’analisi bayesiana in R utilizzando Stan attraverso l’interfaccia cmdstanr. L’obiettivo è mostrare, passo dopo passo, il flusso di lavoro completo: dalla preparazione dei dati fino all’interpretazione dei risultati.
Il flusso di lavoro si articola in cinque fasi:
- preparazione dei dati: organizzare le informazioni nel formato richiesto da Stan;
- scrittura del modello: definire prior, verosimiglianza e quantità derivate;
- compilazione: trasformare il codice Stan in un programma eseguibile;
- campionamento MCMC: generare campioni dalla distribuzione a posteriori;
- analisi dei risultati: estrarre, riassumere e visualizzare i campioni.
Questo schema è valido per qualunque modello bayesiano: una volta compreso, può essere adattato a problemi di complessità crescente.
L.1 Perché usare cmdstanr
cmdstanr è l’interfaccia R raccomandata dagli sviluppatori di Stan. A differenza della precedente interfaccia rstan, cmdstanr si appoggia direttamente a CmdStan (la versione “a riga di comando” di Stan), offrendo diversi vantaggi pratici:
- stabilità: la compilazione dei modelli è più affidabile e veloce;
- aggiornamenti semplici: CmdStan può essere aggiornato indipendentemente da R;
- diagnostica avanzata: accesso diretto a tutte le informazioni sul campionamento;
- portabilità: funziona in modo coerente su Windows, macOS e Linux.
L.2 Installazione
Prima di procedere, è necessario installare CmdStan seguendo le istruzioni riportate nell’Appendice K.
L.3 Pacchetti necessari
Carichiamo i pacchetti che utilizzeremo:
L.4 Esempio: il modello beta-binomiale
Per illustrare il flusso di lavoro, consideriamo un problema elementare. Supponiamo di aver condotto un esperimento con 9 prove indipendenti, ciascuna con esito “successo” o “insuccesso”, e di aver osservato 6 successi. Vogliamo stimare la probabilità di successo \(\theta\), che assume valori nell’intervallo \([0, 1]\).
L.4.1 Il modello statistico
Il modello che adottiamo è il seguente:
verosimiglianza: il numero di successi \(y\) segue una distribuzione binomiale: \[ y \sim \text{Binomiale}(N, \theta) \]
prior: per \(\theta\) scegliamo una distribuzione Beta(2, 2), che esprime una credenza iniziale moderata verso valori centrali, senza escludere valori estremi: \[ \theta \sim \text{Beta}(2, 2) \]
La distribuzione a posteriori, combinando prior e verosimiglianza, ci dirà quali valori di \(\theta\) sono plausibili alla luce dei dati osservati.
L.4.2 Passo 1: scrivere il modello Stan
Un programma Stan è suddiviso in blocchi, ciascuno con una funzione specifica. Ecco il codice completo, commentato:
stancode <- "
data {
// Questo blocco dichiara i dati che passeremo a Stan.
// I vincoli (lower, upper) aiutano Stan a verificare la correttezza dei dati.
int<lower=1> N; // numero totale di prove (almeno 1)
int<lower=0, upper=N> y; // successi osservati (tra 0 e N)
real<lower=0> alpha_prior; // parametro alpha del prior Beta
real<lower=0> beta_prior; // parametro beta del prior Beta
}
parameters {
// Questo blocco dichiara i parametri da stimare.
// Stan esplorerà i valori possibili di theta.
real<lower=0, upper=1> theta; // probabilità di successo
}
model {
// Questo blocco definisce il modello statistico:
// prima la distribuzione a priori, poi la verosimiglianza.
theta ~ beta(alpha_prior, beta_prior); // prior
y ~ binomial(N, theta); // verosimiglianza
}
generated quantities {
// Questo blocco calcola quantità aggiuntive dopo il campionamento.
// Utili per la verifica del modello e il confronto tra modelli.
int y_rep = binomial_rng(N, theta); // dato replicato (per posterior predictive check)
real log_lik = binomial_lpmf(y | N, theta); // log-verosimiglianza (per LOO-CV)
}
"Nota sulla sintassi: in Stan, l’operatore ~ si legge “è distribuito come”. L’istruzione theta ~ beta(2, 2) significa che \(\theta\) ha distribuzione a priori Beta(2, 2).
L.4.3 Passo 2: preparare i dati
Stan richiede che i dati siano organizzati in una lista di R. I nomi degli elementi della lista devono corrispondere esattamente ai nomi dichiarati nel blocco data del modello:
data_list <- list(
N = 9,
y = 6,
alpha_prior = 2,
beta_prior = 2
)L.4.4 Passo 3: compilare il modello
La compilazione trasforma il codice Stan in un programma eseguibile ottimizzato. Questa operazione richiede alcuni secondi e viene eseguita una sola volta per ogni modello:
mod <- cmdstan_model(
write_stan_file(stancode),
compile = TRUE
)L’oggetto mod contiene il modello compilato. Possiamo visualizzarne il contenuto:
mod$print()
#>
#> data {
#> // Questo blocco dichiara i dati che passeremo a Stan.
#> // I vincoli (lower, upper) aiutano Stan a verificare la correttezza dei dati.
#>
#> int<lower=1> N; // numero totale di prove (almeno 1)
#> int<lower=0, upper=N> y; // successi osservati (tra 0 e N)
#> real<lower=0> alpha_prior; // parametro alpha del prior Beta
#> real<lower=0> beta_prior; // parametro beta del prior Beta
#> }
#>
#> parameters {
#> // Questo blocco dichiara i parametri da stimare.
#> // Stan esplorerà i valori possibili di theta.
#>
#> real<lower=0, upper=1> theta; // probabilità di successo
#> }
#>
#> model {
#> // Questo blocco definisce il modello statistico:
#> // prima la distribuzione a priori, poi la verosimiglianza.
#>
#> theta ~ beta(alpha_prior, beta_prior); // prior
#> y ~ binomial(N, theta); // verosimiglianza
#> }
#>
#> generated quantities {
#> // Questo blocco calcola quantità aggiuntive dopo il campionamento.
#> // Utili per la verifica del modello e il confronto tra modelli.
#>
#> int y_rep = binomial_rng(N, theta); // dato replicato (per posterior predictive check)
#> real log_lik = binomial_lpmf(y | N, theta); // log-verosimiglianza (per LOO-CV)
#> }L.4.5 Passo 4: eseguire il campionamento MCMC
Il metodo $sample() avvia l’algoritmo MCMC, che genera campioni dalla distribuzione a posteriori:
fit <- mod$sample(
data = data_list,
seed = 123,
chains = 4,
parallel_chains = 4
)Cosa significano questi argomenti?
| Argomento | Significato |
|---|---|
data |
La lista con i dati osservati |
seed |
Seme per il generatore casuale (per riproducibilità) |
chains |
Numero di catene MCMC indipendenti |
parallel_chains |
Quante catene eseguire simultaneamente |
Per default, ogni catena produce 1000 campioni dopo la fase di warmup. Con 4 catene, otteniamo quindi 4000 campioni dalla distribuzione a posteriori.
L.4.6 Passo 5: analizzare i risultati
L.4.6.1 Verifica della convergenza
Prima di analizzare i risultati, è necessario verificare che il campionamento sia andato a buon fine:
fit$diagnostic_summary()
#> $num_divergent
#> [1] 0 0 0 0
#>
#> $num_max_treedepth
#> [1] 0 0 0 0
#>
#> $ebfmi
#> [1] 1.150 0.882 1.223 1.165Cosa controllare:
-
num_divergent: deve essere 0 (o molto basso). Le divergenze indicano problemi nell’esplorazione della distribuzione; -
num_max_treedepth: valori alti suggeriscono che il campionatore ha difficoltà; -
ebfmi(energy Bayesian fraction of missing information): valori sotto 0.2 indicano problemi.
L.4.6.2 Statistiche riassuntive
Il metodo $summary() calcola le principali statistiche descrittive della distribuzione a posteriori:
fit$summary(variables = "theta")
#> # A tibble: 1 × 10
#> variable mean median sd mad q5 q95 rhat ess_bulk ess_tail
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 theta 0.620 0.628 0.129 0.132 0.394 0.820 1.00 1247. 1842.Interpretazione delle colonne:
| Colonna | Significato |
|---|---|
mean |
Media a posteriori di \(\theta\) |
median |
Mediana a posteriori |
sd |
Deviazione standard a posteriori |
q5, q95
|
Intervallo di credibilità al 90% |
rhat |
Indice di convergenza (deve essere < 1.01) |
ess_bulk, ess_tail
|
Dimensione effettiva del campione |
Un valore di rhat vicino a 1 indica che le catene hanno raggiunto la stessa distribuzione stazionaria. Valori di ess (effective sample size) elevati indicano campioni poco autocorrelati.
L.4.6.3 Statistiche personalizzate
Possiamo calcolare qualunque statistica sui campioni. Ad esempio, la probabilità che \(\theta\) sia minore o uguale a 0.5:
fit$summary("theta", pr_less_05 = ~ mean(. <= 0.5))
#> # A tibble: 1 × 2
#> variable pr_less_05
#> <chr> <dbl>
#> 1 theta 0.180Questo calcolo sfrutta il fatto che, con i campioni MCMC, le probabilità si stimano come proporzioni: contiamo quanti campioni soddisfano la condizione e dividiamo per il totale.
L.4.6.4 Estrarre i campioni
I campioni possono essere estratti in diversi formati. Il formato data frame è spesso il più comodo per analisi successive:
draws_df <- as_draws_df(fit)
head(draws_df)
#> # A draws_df: 6 iterations, 1 chains, and 4 variables
#> lp__ theta y_rep log_lik
#> 1 -8.7 0.60 8 -1.4
#> 2 -8.8 0.67 9 -1.3
#> 3 -8.7 0.59 6 -1.4
#> 4 -11.8 0.89 9 -2.8
#> 5 -8.7 0.57 7 -1.5
#> 6 -8.7 0.61 8 -1.4
#> # ... hidden reserved variables {'.chain', '.iteration', '.draw'}Ogni riga rappresenta un campione; le colonne .chain, .iteration e .draw identificano la provenienza di ciascun campione.
L.4.6.5 Visualizzazione grafica
Il pacchetto bayesplot offre funzioni specializzate per visualizzare i risultati. Un istogramma della distribuzione a posteriori:
mcmc_hist(fit$draws("theta"), binwidth = 0.02) +
labs(
x = expression(theta),
y = "Frequenza",
title = "Distribuzione a posteriori di θ"
) +
theme_minimal()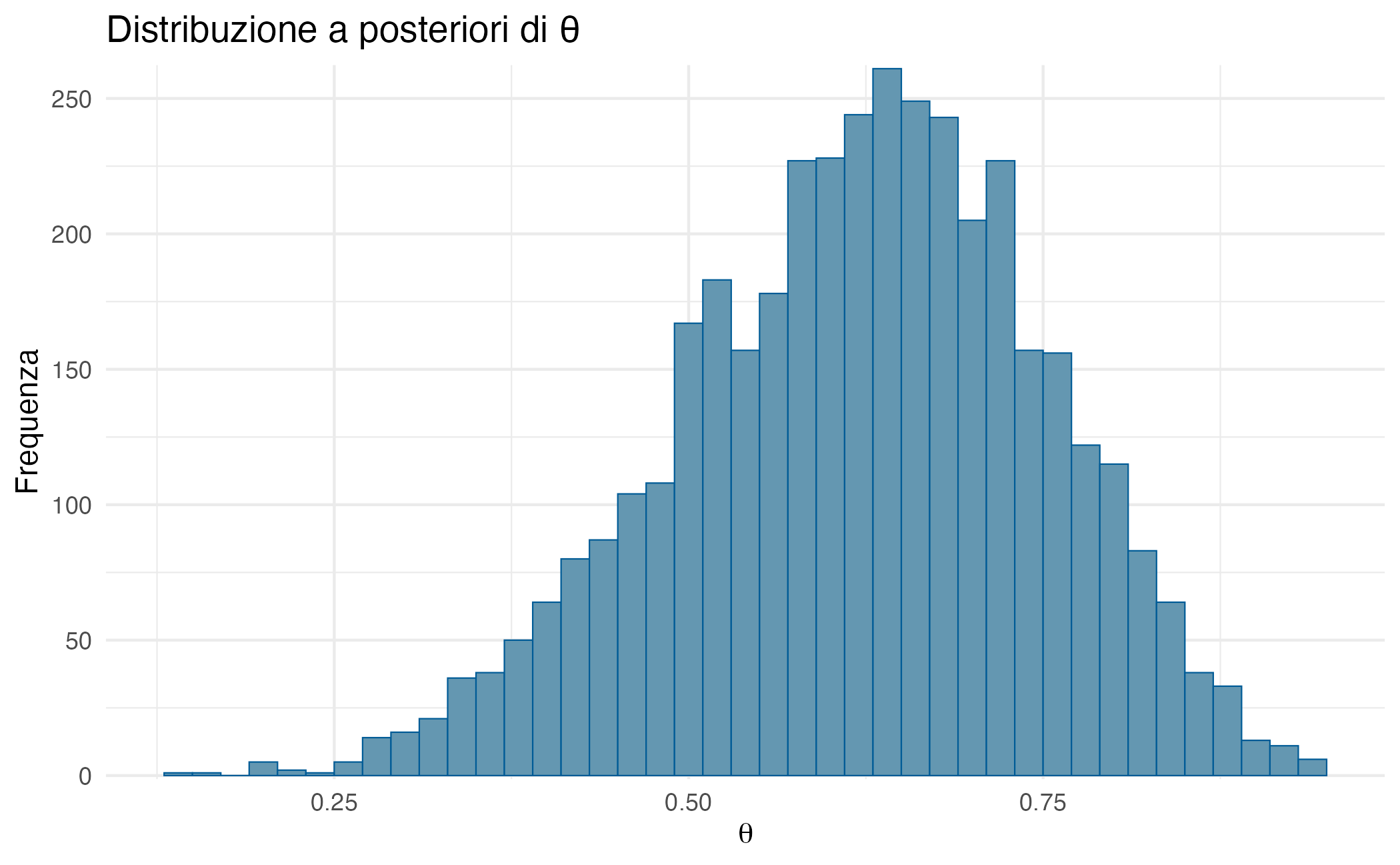
Per verificare visivamente la convergenza, possiamo esaminare i trace plot (tracciati delle catene):
mcmc_trace(fit$draws("theta")) +
labs(
x = "Iterazione",
y = expression(theta),
title = "Trace plot delle 4 catene"
) +
theme_minimal()
Le catene dovrebbero apparire come “rumore” sovrapposto, senza trend o differenze sistematiche tra loro.
L.5 Riepilogo del flusso di lavoro
Il diagramma seguente riassume le fasi dell’analisi:
┌─────────────────────┐
│ 1. DATI │ Organizzare i dati in una lista R
│ data_list <- ... │ con nomi corrispondenti al modello
└─────────┬───────────┘
│
▼
┌─────────────────────┐
│ 2. MODELLO │ Scrivere il codice Stan:
│ stancode <- "..." │ data, parameters, model
└─────────┬───────────┘
│
▼
┌─────────────────────┐
│ 3. COMPILAZIONE │ Trasformare Stan in eseguibile
│ cmdstan_model() │
└─────────┬───────────┘
│
▼
┌─────────────────────┐
│ 4. CAMPIONAMENTO │ Generare campioni MCMC
│ mod$sample() │ dalla distribuzione a posteriori
└─────────┬───────────┘
│
▼
┌─────────────────────┐
│ 5. ANALISI │ Diagnostica, statistiche,
│ fit$summary() │ visualizzazioni
└─────────────────────┘Questo schema rimane invariato indipendentemente dalla complessità del modello. Una volta padroneggiato su un esempio semplice, può essere applicato a regressioni, modelli gerarchici e qualunque altra analisi bayesiana.