here::here("code", "_common.R") |>
source()
conflicts_prefer(ggplot2::theme_void)32 Causalità dai dati osservazionali
Panoramica del capitolo
- Il problema della causalità in assenza di esperimenti.
- I quattro confondenti fondamentali (catena, biforcazione, collider, discendente).
- Le inferenze dai dati osservazionali.
ConsiglioPrerequisiti
- Leggere Statistical Rethinking. Focalizzati sul capitolo 1 The Golem of Prague.
- Leggere Causal inference with observational data and unobserved confounding variables di Byrnes & Dee (2024).
- Leggere Causal design patterns for data analysts (Riederer, 2021). Questo post sul blog fornisce una panoramica di diversi approcci per fare affermazioni causali dai dati osservazionali.
- Leggere The Effect: An Introduction to Research Design and Causality. Focalizzati sul capitolo 10 Treatment Effects.
- Leggere Causal Inference di Scott Cunningham. Focalizzati sul capitolo 3 Directed Acyclic Graphs.
- Leggere Telling Stories with Data (Alexander, 2023). Concentrati sul capitolo 15 Causality from observational data.
ConsiglioPreparazione del Notebook
32.1 Il ruolo dei modelli
Osservare che gli studenti che dormono poco mostrano livelli più elevati di ansia non è sufficiente per stabilire un rapporto di causa ed effetto. La relazione potrebbe essere inversa, bidirezionale o dipendere da una terza variabile, come la pressione legata agli esami. Se ci limitassimo ai dati osservati, dovremmo fermarci al livello delle associazioni, ovvero a una fotografia della realtà priva di indicazioni sul meccanismo che la genera.
La possibilità di formulare inferenze causali dipende invece da un elemento aggiuntivo: la presenza di un modello teorico esplicito. Sono i modelli, intesi come rappresentazioni di ipotesi sul funzionamento psicologico, a permetterci di interpretare i dati come il risultato di processi sottostanti e non solo come covariazioni superficiali.pretare i dati come risultati di processi sottostanti e non soltanto come covariazioni superficiali.
In questo capitolo vedremo come i diversi tipi di modelli svolgono funzioni differenti:
- i modelli descrittivi quantificano le relazioni osservate, senza specificare meccanismi causali;
- i modelli causali integrano invece ipotesi sul modo in cui le variabili interagiscono, permettendo di distinguere spiegazioni alternative.
In altre parole, non considereremo la causalità come una proprietà “che emerge” dai dati, ma come un’ipotesi strutturata che riguarda il processo generativo che sta dietro ai dati stessi.
32.2 Correlazione e causalità: perché i dati non bastano
Il fatto che due variabili varino insieme non implica necessariamente che una sia la causa dell’altra. Questa nozione è familiare anche ai non specialisti, ma nella pratica psicologica rimane fonte di fraintendimenti ricorrenti. Il motivo è che, quando osserviamo covariazioni robuste e replicabili, l’interpretazione causale risulta intuitiva: la mente umana tende a cercare spiegazioni direzionali.
Tuttavia, una stessa correlazione può essere compatibile con più scenari causali. Nel caso dello stress accademico e dei disturbi del sonno, per esempio, si possono avanzare almeno tre spiegazioni plausibili:
- lo stress compromette la qualità del sonno;
- la deprivazione di sonno aumenta lo stress;
- un fattore comune (come gli esami) influenza entrambe le variabili.
Tutte e tre producono un’associazione statistica, ma ciascuna postula un processo causale diverso.
Questa ambiguità non è un dettaglio metodologico: se si inverte la direzione causale, cambiano sia le interpretazioni teoriche sia le implicazioni pratiche (interventi clinici, programmi di prevenzione, politiche educative, ecc.).
La presenza di fattori comuni non osservati, il cosiddetto “confondimento”, è uno dei motivi per cui la correlazione da sola non può supportare conclusioni causali. Anche associazioni molto stabili nel tempo o riscontrate su campioni indipendenti possono essere spiegate da variabili latenti non misurate.
Il messaggio chiave è che il dato associativo è necessario, ma non sufficiente: suggerisce ipotesi causali possibili senza identificarne una come vera.
32.3 Perché i modelli diventano indispensabili
Per affrontare questa ambiguità concettuale, abbiamo bisogno di strumenti che rendano esplicite le ipotesi sul modo in cui le variabili interagiscono. In psicologia sperimentale, clinica e sociale, questa formalizzazione è particolarmente importante: la maggior parte delle variabili rilevanti sono di natura psicologica, non direttamente osservabili e spesso influenzate da strutture latenti, difficili da manipolare.
I modelli causali consentono di:
- rappresentare ipotesi direzionali;
- valutare quali relazioni sono compatibili con i dati e quali no;
- individuare condizioni che permettono di discriminare tra spiegazioni alternative;
- progettare studi che massimizzano l’identificabilità causale.
Senza questa struttura, si rischia di confondere spiegazioni plausibili con spiegazioni dimostrate.
32.4 Rappresentare le ipotesi causali: Una guida visiva al ragionamento scientifico
Per sviluppare e testare ipotesi causali in modo rigoroso è necessario un linguaggio formale. I grafi causali (o diagrammi causali) sono lo strumento moderno più diffuso per questo scopo. Si tratta di strutture composte da nodi (variabili) e archi direzionati (relazioni causali dirette ipotizzate).
32.4.1 La natura operativa dei grafi causali
Queste rappresentazioni non sono semplici illustrazioni, ma modelli operativi con due funzioni fondamentali:
- chiarezza espositiva: rendono immediatamente visibile la struttura causale assunta, esplicitando quali relazioni dirette sono ipotizzate e, altrettanto cruciale, quali sono assenti;
- potere deduttivo: forniscono un calcolo per derivare le conseguenze verificabili del modello. Attraverso regole formali (come le regole di d-separazione), permettono di dedurre quali relazioni di indipendenza condizionale ci si aspetterebbe di osservare nei dati se il modello fosse corretto.
In sintesi, i grafi sono strumenti per il ragionamento. Offrono criteri precisi per stabilire quando un’associazione osservata tra due variabili può essere interpretata come potenzialmente causale e quando, invece, è compatibile con la presenza di fattori confondenti o altri fenomeni.
32.4.2 Anatomia di un grafo causale
Un grafo causale è un diagramma costituito da:
- nodi (vertici): rappresentano le variabili misurabili o latenti di interesse (es.: livello di stress, sintomi d’ansia, qualità del sonno).
- archi diretti (frecce →): indicano un’influenza causale diretta ipotizzata dalla variabile di origine verso quella di destinazione.
L’assenza di un arco diretto tra due nodi implica che non esiste un effetto causale diretto tra le due variabili.
32.4.3 Un esempio nel contesto psicologico
Consideriamo uno studio sul legame tra Stress percepito e Rendimento accademico. Un’ipotesi plausibile può essere rappresentata dal seguente grafo:
Stress Percepito → Qualità del Sonno → Rendimento Accademico
In questo modello:
- Lo Stress influenza direttamente (e negativamente) la Qualità del Sonno.
- La Qualità del Sonno influenza direttamente il Rendimento Accademico.
- Lo Stress influisce sul Rendimento solo indirettamente, attraverso la mediazione del Sonno.
- Assunzione cruciale: non esiste un effetto causale diretto dello Stress sul Rendimento (nessuna freccia diretta). Questa ipotesi può essere messa verificata empiricamente.
32.4.4 Valore pratico nell’indagine scientifica
Esplicitare visivamente le ipotesi consente di:
- identificare le vie causali: distinguere chiaramente effetti diretti, indiretti e totali tra le variabili;
- Identificare confonditori: visualizzare variabili comuni che, se non misurate o controllate, creano associazioni spurie (es.: un fattore ambientale che causa sia stress che peggiora il sonno).
- Guidare la progettazione dello studio: definire quali variabili misurare, controllare o randomizzare per testare una relazione specifica. Ad esempio, per testare l’effetto diretto del sonno sul rendimento, bisognerebbe controllare statisticamente lo stress.
- Prevenire errori analitici: il grafo chiarisce se e quando è lecito “controllare per” una certa variabile. Controllare inappropriatamente una variabile mediatrice o una collider può introdurre bias invece che rimuoverlo.
32.4.5 Un chiaro avvertimento epistemologico
Un grafo causale è un’ipotesi strutturata, non una verità rivelata. Non determina automaticamente la causalità, ma formalizza ciò che riteniamo plausibile in base alla teoria e alla conoscenza pregressa. Il suo valore risiede nella sua capacità di generare predizioni verificabili (sulle indipendenze condizionali) che i dati possono confermare o falsificare. In questo senso, il grafo rappresenta il punto di partenza per un dialogo rigoroso tra teoria ed evidenza empirica.
32.5 Confondimento, mediazione e moderazione: i ruoli delle variabili nei modelli causali
Nei modelli causali, non tutte le variabili svolgono la stessa funzione. È fondamentale distinguere i diversi ruoli causali, in quanto ciascuno richiede approcci analitici differenti e porta a interpretazioni sostanzialmente diverse dei risultati osservati.
32.5.1 Variabili di confondimento: la fonte delle associazioni spurie
Una variabile di confondimento è un fattore che influenza in modo causale sia la presunta causa che l’effetto. Se non viene misurata e controllata adeguatamente, crea un’associazione statistica tra le due variabili, anche in assenza di una relazione causale diretta tra di esse.
Esempio: si osserva una correlazione tra l’uso intensivo dei social media e i sintomi depressivi in un campione di studenti. Un’interpretazione ingenua suggerirebbe che i social media causano la depressione.
Tuttavia, un potenziale confonditore è la solitudine percepita:
- gli studenti che si sentono più soli tendono a usare i social media più frequentemente (come tentativo di connessione);
- la solitudine è essa stessa un fattore di rischio per sintomi depressivi.
In questo grafo: Solitudine → Uso Social Media e Solitudine → Sintomi Depressivi. Non c’è una freccia diretta dai social media alla depressione. Se non si controlla la variabile “solitudine”, si osserva un’associazione spuria tra “social media” e “depressione” che può portare a conclusioni errate dal punto di vista causale.
32.5.2 Variabili mediatrici: il meccanismo della causalità
Una variabile mediatrice trasmette l’effetto di una variabile indipendente su una variabile dipendente. Non è una fonte di distorsione, ma il meccanismo attraverso il quale opera la relazione causale.
Esempio Stress → Qualità del sonno → Sintomi d’ansia.
- Lo stress cronico compromette la regolarità e la profondità del sonno.
- La privazione o la scarsa qualità del sonno alterano la regolazione emotiva e aumentano i sintomi ansiosi.
In questo caso, la qualità del sonno è il mediatore che spiega come lo stress porti all’ansia. L’effetto causale dello stress sui sintomi d’ansia può essere scomposto in: - effetto indiretto (tramite il Sonno); - effetto diretto (se esiste una freccia residua Stress → Ansia); - effetto totale (somma di diretto e indiretto).
32.5.3 Variabili moderatrici: il “dipende da…”
Una variabile moderatrice modifica la forza, la direzione o l’esistenza stessa della relazione causale tra due altre variabili. Risponde alla domanda: “Per chi o in quali condizioni l’effetto è più forte o più debole?”
Esempio: supponiamo che lo stress accademico influenzi i sintomi d’ansia. Questa relazione potrebbe essere moderata dal supporto sociale percepito.
Nel grafo, la variabile moderatrice si rappresenta con una freccia che punta alla relazione stessa: Stress → Ansia con una freccia da Supporto Sociale che punta alla freccia tra Stress e Ansia.
Interpretazione:
- per gli studenti con un basso supporto sociale, l’effetto dello Stress sull’Ansia è forte;
- per gli studenti con un alto supporto sociale, l’effetto dello Stress sull’Ansia è attenuato o persino assente.
32.5.4 Una distinzione cruciale per la ricerca
Comprendere se una variabile è un confonditore, un mediatore o un moderatore è essenziale per:
progettare lo studio: un confonditore va misurato e controllato per ottenere stime non distorte dal punto di vista causale. Un mediatore va misurato per testare il meccanismo. Un moderatore viene incluso per esplorare le differenze tra i sottogruppi.
scegliere l’analisi statistica: il controllo per un confonditore (per esempio, mediante la regressione multipla) è diverso dalla verifica di mediazione (per esempio, mediante un analisi di percorso) o moderazione (per esempio, mediante un’analisi di regressione che include termini di interazione).
interpretare i risultati in modo corretto: scambiare un confonditore per un mediatore porta a conclusioni completamente errate sulla direzione e sulla natura della causalità.
Sintesi visiva:
-
confonditore:
Z → XeZ → Y(crea un falso legame traXeY); -
mediatore:
X → M → Y(spiega il legame traXeY); -
moderatore:
Wmodifica la forza diX → Y.
Questa chiarezza concettuale è fondamentale per costruire modelli causali realistici e testabili nelle scienze psicologiche.
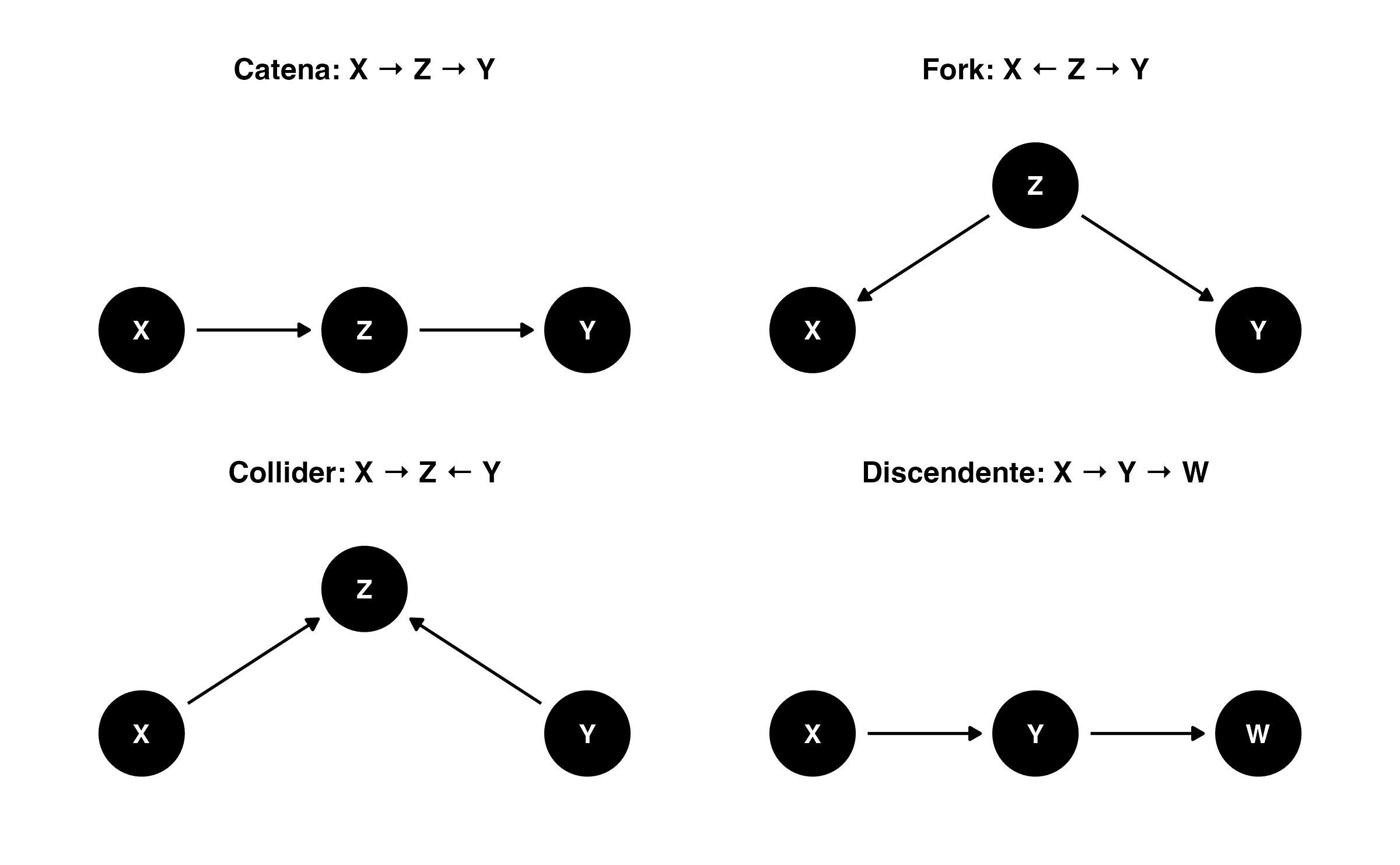
32.5.5 Le quattro configurazioni fondamentali nei DAG
Per comprendere appieno il funzionamento dei grafi causali, è utile conoscere le quattro strutture di base con cui due variabili possono essere collegate attraverso una terza.
-
Catena (o percorso mediato)
\[X \rightarrow Z \rightarrow Y\]
In questa configurazione, \(Z\) funge da mediatore, trasmettendo l’effetto causale da \(X\) a \(Y\).- Se non si controlla per \(Z\), \(X\) e \(Y\) appaiono associati.
- Controllando per \(Z\), l’associazione tra \(X\) e \(Y\) si interrompe, poiché si blocca il percorso causale.
-
Biforcazione (confondimento)
\[X \leftarrow Z \rightarrow Y\]
Qui \(Z\) è un confondente: causa comune sia di \(X\) che di \(Y\).- Senza controllo per \(Z\): si osserva una correlazione spuria tra \(X\) e \(Y\).
- Controllando per \(Z\): l’associazione spuria viene eliminata.
- Senza controllo per \(Z\): si osserva una correlazione spuria tra \(X\) e \(Y\).
-
Collider
\[X \rightarrow Z \leftarrow Y\]
In questa struttura, \(Z\) è un collider, ovvero un effetto comune di \(X\) e \(Y\).- Senza controllo per \(Z\): \(X\) e \(Y\) sono d-separati e quindi indipendenti.
- Controllando per \(Z\) (o un suo discendente): si introduce un bias di collider, creando un’associazione condizionale spuria tra \(X\) e \(Y\).
-
Discendente
\[X \rightarrow Y \rightarrow Z\]
In questo caso, \(Z\) è un discendente di \(Y\).- Ruolo nell’analisi: un discendente fornisce informazioni indirette su un suo antenato, ma non è un confondente. Controllare statisticamente per un discendente equivale a condizionare, almeno parzialmente, la variabile genitore. Questo può aprire percorsi collider a monte, introducendo potenzialmente un bias di selezione e alterando la stima causale d’interesse.
32.5.5.1 L’importanza delle configurazioni fondamentali
Queste quattro strutture costituiscono le componenti elementari da cui sono costruiti tutti i DAG complessi. La capacità di identificare ciascuna configurazione e di applicare le corrette regole di controllo statistico è fondamentale per un’inferenza causale valida. In sintesi:
- è necessario controllare per le variabili in configurazione di mediatore (catena) se si vuole stimare un effetto diretto, e per i confondenti (biforcazione) per eliminare le associazioni spurie;
- è invece cruciale non controllare per le variabili in posizione di collider (o per i loro discendenti), poiché ciò aprirebbe percorsi di associazione artificiale e introdurrebbe bias;
- analogamente, controllare un discendente può aprire percorsi collider indiretti ed è generalmente da evitare, a meno che non sia esplicitamente giustificato dal disegno dello studio.
Distinguere tra questi casi non è una semplice scelta tecnica, ma rappresenta la differenza tra stimare una relazione causale vera e produrre una stima distorta da associazioni spurie.
ImportanteImplicazioni per la regressione lineare
Questa distinzione ha conseguenze operative dirette sull’applicazione dei modelli di regressione. Nei capitoli precedenti abbiamo visto che aggiungere predittori a un modello aumenta la varianza spiegata \((R^2)\). Tuttavia, la prospettiva causale dimostra che la scelta delle variabili da includere non può essere motivata esclusivamente dal criterio di “aumentare la varianza spiegata”. Includere una variabile errata (ad esempio un collider o un discendente di un collider) può introdurre bias nelle stime degli effetti di interesse, peggiorando la validità inferenziale anziché migliorarla.
Pertanto, la regressione multipla può essere uno strumento affidabile per l’inferenza causale solo se guidata da un DAG che formalizzi le ipotesi teoriche sui meccanismi causali sottostanti. Senza questa guida teorica, il modello di regressione rischia di produrre stime che, seppur “statisticamente significative”, possono essere fuorvianti dal punto di vista causale.
32.6 Dai grafi causali all’inferenza statistica
Finora abbiamo visto che i grafi causali servono a rappresentare le nostre ipotesi. Ma come possiamo collegarli ai dati e verificare se un modello causale è plausibile?
32.6.1 Indipendenze e dipendenze
Un’idea chiave è che un grafo causale non descrive solo “chi influenza chi”, ma implica anche certe relazioni di indipendenza tra le variabili. Queste relazioni sono importanti perché ci permettono di confrontare il grafo con i dati: se le indipendenze predette non si verificano, il grafo non può essere corretto.
32.6.1.1 Esempio 1: Catena (mediazione)
Supponiamo di ipotizzare la seguente relazione causale:
Stress → Sonno → Ansia.
In questa struttura, Sonno è un mediatore, in quanto trasmette parzialmente o totalmente l’effetto dello Stress sull’Ansia. Se non misuriamo il livello di Sonno, Stress e Ansia appariranno associati a causa del percorso causale attivo. Tuttavia, una volta che condizioniamo sul Sonno, l’associazione tra Stress e Ansia si interrompe, poiché blocchiamo il meccanismo di trasmissione. Da un punto di vista inferenziale, conoscendo il livello di Sonno, lo Stress non fornisce ulteriori informazioni sull’Ansia.
Questa relazione è espressa formalmente dalla condizione di indipendenza condizionale:
\[ \text{Ansia} \; \perp\!\!\!\perp \; \text{Stress} \mid \text{Sonno} \]
32.6.1.2 Esempio 2: Fork (causa comune)
Consideriamo ora la seguente struttura causale: Sonno → Stress; Sonno → Ansia.
In questo caso, Sonno agisce da confondente (o causa comune) per Stress e Ansia. Se non controlliamo statisticamente per il Sonno, Stress e Ansia appariranno associati, generando una correlazione spuria. Condizionando sul Sonno, invece, l’associazione tra Stress e Ansia scompare, poiché viene bloccato l’unico percorso (non causale) che le collega.
Formalmente, ciò si esprime tramite la condizione di indipendenza condizionale:
\[ \text{Ansia} \; \perp\!\!\!\perp \; \text{Stress} \mid \text{Sonno} \]
Questa notazione indica che, dato il livello di Sonno, Stress e Ansia sono statisticamente indipendenti.
32.6.1.3 Esempio 3: Collider (effetto comune)
Consideriamo ora la struttura opposta:
Stress → Ansia ← Sonno.
In questo caso, Ansia agisce come un collider: è un effetto comune di due cause potenzialmente indipendenti, Stress e Sonno. Il comportamento statistico di questa configurazione è controintuitivo:
- Senza condizionare su Ansia, le due cause (Stress e Sonno) sono d-separate e quindi statisticamente indipendenti nella popolazione.
- Condizionando su Ansia (o su una qualsiasi sua conseguenza), si apre artificialmente un percorso di associazione tra Stress e Sonno. Questo fenomeno, noto come bias di collider o bias da condizionamento, genera una correlazione spuria tra le due variabili originariamente indipendenti.
Questa proprietà fondamentale è espressa formalmente come:
\[ \text{Stress} \; \perp\!\!\!\perp \; \text{Sonno} \quad \text{ma} \quad \text{Stress} \; \cancel{\perp\!\!\!\perp} \; \text{Sonno} \mid \text{Ansia} \]
Dove il simbolo \(\cancel{\perp\!\!\!\perp}\) indica la violazione dell’indipendenza condizionale.
32.6.2 Tabella riassuntiva delle strutture causali elementari
| Struttura | Forma | Relazione tra \(X\) e \(Y\) (senza controllo) | Relazione tra \(X\) e \(Y\) (dopo controllo su \(Z\)) | Ruolo di \(Z\) |
|---|---|---|---|---|
| Catena (Mediazione) | \(X \to Z \to Y\) | Dipendenti (percorso aperto) | Indipendenti (percorso bloccato) | Mediatore |
| Fork (Causa comune) | \(X \leftarrow Z \to Y\) | Dipendenti (associazione spuria) | Indipendenti (confondimento rimosso) | Confondente |
| Collider (Effetto comune) | \(X \to Z \leftarrow Y\) | Indipendenti (nessun percorso attivo) | Dipendenti (associazione spuria indotta) | Collider |
Legenda:
-
Percorso aperto/bloccato: riferimento al criterio di d-separation nei DAG.
-
Controllo: include qualsiasi condizionamento statistico (stratificazione, aggiustamento in regressione).
- Dipendenza spuria: associazione statistica non corrispondente a un effetto causale diretto.
32.6.3 Le quattro strutture causali elementari nei DAG
Di seguito sono illustrate le quattro configurazioni minime che definiscono le relazioni causali fondamentali all’interno di un DAG: Catena, Fork, Collider e Discendente. Ciascuna struttura segue regole precise di d-separation che determinano quando due variabili sono condizionatamente indipendenti, guidando così le scelte critiche di controllo statistico nell’inferenza causale.
ConsiglioErrore comune: il condizionamento sui collider
-
Struttura Collider: \(X \to Z \leftarrow Y\)
-
Senza condizionare su \(Z\): \(X\) e \(Y\) sono statisticamente indipendenti.
- Condizionando su \(Z\) (o un suo discendente): si introduce artificialmente una correlazione condizionale spuriosa tra \(X\) e \(Y\) (bias di collider o bias da selezione).
-
Senza condizionare su \(Z\): \(X\) e \(Y\) sono statisticamente indipendenti.
Linea guida pratica:
- Controllare è appropriato per confondenti (fork) e mediatori (catena) per ottenere stime causali non distorte.
- Non controllare mai un collider o un suo discendente se l’obiettivo è stimare l’effetto totale o diretto tra \(X\) e \(Y\): il condizionamento creerebbe un’associazione dove non esiste alcun legame causale diretto.
32.6.4 Significato e rilevanza
Questi esempi dimostrano come il concetto di indipendenza condizionata sia intrinsecamente legato alla struttura causale del grafo. La sua interpretazione, pertanto, non è puramente statistica, ma causale:
- nelle strutture di catena e fork, condizionare sulla variabile intermedia interrompe l’associazione tra le variabili estreme;
- nella struttura di collider, condizionare sulla variabile centrale genera artificialmente un’associazione dove prima non ne esisteva.
La capacità di distinguere tra queste situazioni è fondamentale per evitare errori sistematici e per selezionare il set di controllo appropriato nell’inferenza causale.
32.6.5 Verifica empirica dell’indipendenza condizionata
Dato un modello causale (DAG) e dati osservati, è possibile verificare empiricamente le previsioni di indipendenza condizionata mediante diversi strumenti statistici:
- Correlazioni parziali: si calcola la correlazione tra Stress e Ansia dopo aver rimosso statisticamente l’influenza lineare del Sonno. Una correlazione parziale prossima allo zero supporta l’ipotesi di indipendenza condizionata;
- Regressione multipla: si stima un modello in cui l’Ansia è predetta sia dallo Stress che dal Sonno. Se la struttura a catena è corretta, il coefficiente di Stress dovrebbe diventare statisticamente nullo una volta incluso il Sonno nel modello;
- Test di indipendenza condizionale: metodi statistici formali (come ad esempio i test basati sul rapporto di verosimiglianza o sulle reti bayesiane) permettono di verificare direttamente l’ipotesi \(\text{Ansia} \perp\!\!\!\perp \text{Stress} \mid \text{Sonno}\).
32.6.6 Il legame fondamentale tra teoria e dati
Il ponte tra modelli teorici e verifica empirica costituisce il nucleo dell’inferenza causale moderna:
- i DAG formalizzano le nostre ipotesi causali a priori, derivanti dalla teoria e dalla conoscenza del dominio;
- le indipendenze condizionali osservate (o non osservate) nei dati forniscono un test per la validità di tali ipotesi.
Questo crea un ciclo virtuoso di affinamento della conoscenza: se i dati contraddicono l’indipendenza prevista dal grafo, il modello causale deve essere rivisto o integrato. In questo modo, l’analisi statistica diventa uno strumento non solo per una stima quantitativa, ma anche per testare e perfezionare la teoria causale sottostante.
32.6.7 Punti chiave da ricordare
Quando si afferma che l’inferenza causale richiede metodi statistici appropriati, ci si riferisce proprio a questo insieme di strumenti, ovvero correlazioni parziali, regressioni multiple e modelli strutturali, che permettono di verificare se i dati osservati sono coerenti con le previsioni di indipendenza condizionale derivanti da un DAG. In altre parole, questi metodi traducono in pratica il principio fondamentale secondo cui ogni ipotesi causale implica specifiche restrizioni statistiche sui dati.
Il linguaggio dei DAG, quindi, non è un esercizio puramente teorico, ma costituisce un ponte operativo tra la teoria psicologica e l’evidenza empirica. Per il ricercatore in psicologia, ciò significa integrare nella propria cassetta degli attrezzi metodologici tecniche quali:
- la regressione multipla per il controllo dei confondenti e la verifica di mediazione;
- le correlazioni parziali e semiparziali per testare le indipendenze condizionate;
- i modelli di equazioni strutturali (SEM) per rappresentare e stimare direttamente reti causali complesse.
Tutti questi approcci condividono l’obiettivo di mettere alla prova le implicazioni testabili dei nostri modelli causali, trasformando le ipotesi teoriche in affermazioni empiricamente falsificabili. In questo modo, l’analisi statistica non è solo uno strumento descrittivo, ma diventa un mezzo attivo per costruire e validare la conoscenza causale in psicologia.
32.7 Strategie per lo studio della causalità in psicologia
I DAG forniscono un linguaggio formale per esplicitare le ipotesi causali e derivarne le implicazioni empiriche. Ma come si traduce questo quadro teorico nella pratica della ricerca psicologica?
32.7.1 1. Esperimenti controllati randomizzati (RCT)
Il metodo più diretto e robusto per stabilire una relazione causale è l’esperimento controllato randomizzato. In questo disegno:
- i partecipanti vengono assegnati casualmente a due o più gruppi (ad esempio, trattamento vs. controllo);
- un gruppo riceve una manipolazione sperimentale (ad esempio, un training di mindfulness), mentre l’altro funge da gruppo di controllo;
- si confrontano i risultati tra i gruppi dopo l’intervento.
La randomizzazione garantisce, in media, l’equivalenza pre-trattamento tra i gruppi rispetto a tutti i possibili fattori confondenti, noti e ignoti. Qualsiasi differenza sistematica osservata nell’esito può quindi essere attribuita con un alto grado di fiducia alla manipolazione sperimentale.
32.7.2 2. Quasi-esperimenti
In molti contesti psicologici, la randomizzazione è impraticabile o non etica (ad esempio, quando si studiano gli effetti di un trauma, di un evento di vita o di fattori demografici). In questi casi si ricorre a disegni quasi-sperimentali, che cercano di emulare la logica causale dell’esperimento attraverso:
- il confronto tra gruppi pre-selezionati ma comparabili (ad esempio, scuole con programmi diversi);
- misure longitudinali pre- e post-evento (disegni interrotti a serie temporali);
- tecniche statistiche come l’abbinamento (matching) o l’uso di variabili strumentali per ridurre il bias da confondimento.
Sebbene non siano così robusti come gli RCT, i quasi-esperimenti possono fornire prove causali convincenti, a condizione che il disegno sia ben strutturato e che i limiti interpretativi siano chiaramente riconosciuti.
32.7.3 3. Studi osservazionali e modelli di controllo statistico
La maggior parte dei dati in psicologia proviene da studi osservazionali, in cui i ricercatori misurano le variabili senza manipolarle. In questi contesti, il rischio di confondimento è massimo. Per avvicinarsi a un’interpretazione causale, è essenziale:
- specificare un DAG a priori, basato sulla teoria, per identificare i confondenti chiave;
- utilizzare modelli statistici (come la regressione multipla o i modelli strutturali) per controllare per i confondenti identificati;
- valutare la robustezza dei risultati attraverso analisi di sensibilità che quantifica quanto un confondente non misurato dovrebbe essere forte per invalidare le conclusioni.
32.7.4 Sintesi: una gerarchia di evidenza causale
In psicologia, la forza dell’inferenza causale può essere concepita come un continuum:
- evidenza più forte: esperimenti randomizzati, in cui la manipolazione e la randomizzazione garantiscono la validità interna;
- evidenza intermedia: quasi-esperimenti ben progettati, che approssimano la logica sperimentale in contesti naturali;
- evidenza più debole ma informativa: studi osservazionali supportati da DAG espliciti e metodi statistici avanzati (ad esempio, modelli di regressione con controllo dei fattori confondenti e analisi di mediazione), la cui interpretazione causale è condizionata alle assunzioni non testabili del modello.
La scelta del disegno dipende dalla domanda di ricerca, dal contesto etico e dalla fattibilità. In ogni caso, l’uso esplicito di grafi causali e di metodi statistici appropriati rimane cruciale per strutturare il ragionamento, comunicare le assunzioni e trarre conclusioni che vadano oltre la mera descrizione delle associazioni.
32.8 Strategie statistiche per il controllo del confondimento
Quando non è possibile ricorrere alla randomizzazione sperimentale, è necessario utilizzare approcci statistici che, se applicati correttamente, permettono di stimare l’effetto causale mimando le condizioni di un esperimento controllato. Queste tecniche non garantiscono la certezza causale come un RCT, ma, sulla base di ipotesi esplicite, permettono di ridurre sistematicamente il bias dovuto ai confondenti osservati.
32.8.1 1. Regressione multipla con aggiustamento
La strategia più comune è l’uso della regressione multipla per il controllo statistico. Inserendo nel modello le variabili che si presume agiscano da confondenti, è possibile stimare l’effetto della variabile d’interesse condizionatamente ai livelli degli altri predittori, ovvero a parità di valori delle variabili di controllo.
Esempio applicativo. Per stimare l’effetto dell’uso dei social media sul benessere psicologico, si può includere la solitudine come variabile di controllo nel modello. Il coefficiente associato all’uso dei social media rappresenterà quindi l’effetto stimato al netto delle differenze individuali nella solitudine, a condizione che la solitudine sia misurata in modo adeguato, che il modello lineare sia specificato in modo appropriato e che non esistano altri fattori confondenti rilevanti non inclusi nel modello.
Limitazione fondamentale: la regressione controlla solo per i confondenti osservati e inclusi nel modello. Se un confondente rilevante viene omesso (confondimento residuo), la stima risulterà distorta. Questo rende cruciale la fase di specificazione del modello, che dovrebbe essere guidata idealmente da un DAG.
AvvisoAttenzione: la regressione non è una bacchetta magica
La regressione multipla consente un’inferenza causale valida solo sotto specifiche e forti assunzioni, spesso non testabili direttamente dai dati. La correttezza della stima dipende criticamente da:
- identificazione corretta dei confondenti: il set di variabili incluso nel modello deve bloccare tutti i percorsi di confondimento tra il trattamento e l’esito, come indicato da un DAG formalizzato. L’omissione di un confondente rilevante (bias da variabile omessa) compromette la stima.
- misurazione accurata dei confondenti: le variabili di controllo devono essere misurate senza errore sistematico. Un errore di misurazione dei confondenti può lasciare residui di confondimento non controllato, vanificando parzialmente l’aggiustamento.
- assenza di condizionamento su collider: il modello non deve includere variabili che sono effetti comuni (collider) del trattamento e dell’esito o di altri percorsi. Condizionare su un collider apre percorsi di backdoor artificiali, introducendo un bias di collider.
- corretta specificazione funzionale: la forma del modello (ad esempio, linearità, additività) deve riflettere fedelmente le vere relazioni funzionali nella popolazione. Specificazioni errate (come l’omissione di interazioni o forme non lineari rilevanti) portano a un bias da modello mal specificato.
Queste condizioni costituiscono problemi di specificazione del modello la cui violazione può invalidare le conclusioni causali. La regressione è quindi uno strumento potente ma il suo impiego a fini causali non è meccanico: richiede una giustificazione teorica esplicita per ogni scelta di specificazione, tipicamente basata sulla conoscenza sostanziale e rappresentata in un DAG.
32.8.2 Matching
Un’alternativa è la tecnica del matching, che mira a costruire un gruppo di controllo comparabile al gruppo di trattamento rendendoli simili per tutte le caratteristiche osservate. In pratica, per ogni individuo esposto alla condizione di interesse (per esempio, l’uso intensivo dei social media), se ne identifica uno o più non esposti con caratteristiche simili (per esempio, età, genere, rendimento scolastico e livello di solitudine). Confrontando gli esiti di questi gruppi appaiati, si riduce il bias da confondimento osservato, imitando la comparabilità garantita dalla randomizzazione.
32.8.3 Variabili strumentali
Quando un confondente rilevante non è osservabile o non può essere misurato adeguatamente, gli approcci di regressione standard falliscono. In tali situazioni, la metodologia delle variabili strumentali offre una possibile soluzione.
32.8.3.1 Concetto di variabile strumentale
Una variabile \(Z\) è uno strumento valido per stimare l’effetto causale di \(X\) su \(Y\) se soddisfa due condizioni critiche. In primo luogo, la rilevanza: \(Z\) deve essere correlata alla variabile di trattamento \(X\). In secondo luogo, deve soddisfare la condizione di esogeneità: \(Z\) deve influenzare $Y solo attraverso \(X\); non deve avere, cioè, un effetto diretto su \(Y\) né deve essere associata a fattori confondenti non misurati di \(X\) e \(Y\). In pratica, lo strumento agisce come una fonte esogena di variazione per \(X\), che può essere sfruttata per isolare la componente puramente causale dell’effetto di \(X\) su \(Y\).
32.8.3.2 Esempio applicativo
Si consideri il problema di stimare l’effetto delle ore di sonno (\(X\)) sul rendimento accademico (\(Y\)). La motivazione (\(U\)) è un potente confondente non osservato: gli studenti più motivati tendono sia a dormire di più sia a ottenere voti migliori. Senza una misura di \(U\), la regressione standard produce stime distorte.
32.8.3.3 Il ruolo dello strumento
Si supponga che il rumore notturno vicino alla residenza universitaria (\(Z\)) influenzi la durata del sonno degli studenti, ma non abbia alcun effetto diretto sul loro rendimento (ad esempio, non causando stress diurno) e non sia correlato alla loro motivazione. In questo scenario, Z è un candidato plausibile per lo strumento. La variazione di \(Z\) (rumore) causa una variazione di \(X\) (sonno). L’unico percorso attraverso cui Z influenza Y (rendimento) è quello mediato da X.
L’approccio alle variabili strumentali utilizza quindi la variazione “indotta dal rumore” delle ore di sonno per stimare l’effetto causale del sonno sul rendimento, aggirando il problema del confondimento dovuto alla motivazione non misurata.
32.8.3.4 Da ricordare
Le variabili strumentali sono molto potenti, ma difficili da trovare: è necessaria una variabile che influenzi solo la causa e non l’effetto. Quando si riesce a trovarle, però, ci permettono di “simulare” un esperimento naturale, isolando una fonte di variazione quasi casuale nella variabile di interesse.
Nella pratica psicologica strumenti così puliti sono rari, ma l’idea è utile per capire il principio piuttosto che per trovare uno strumento perfetto. Queste tecniche non sostituiscono l’esperimento, ma rappresentano strumenti preziosi per trarre conclusioni causali quando i dati osservazionali sono l’unica fonte a nostra disposizione.
32.9 Un esempio numerico di confondimento
Supponiamo di voler stimare se lo studio pomeridiano (\(X\)) migliori il rendimento a un test (\(Y\)). Supponiamo però che esista una variabile di confondimento: la motivazione (\(U\)).
- Gli studenti molto motivati tendono sia a studiare più spesso nel pomeriggio (\(X\)) e ad avere voti più alti (\(Y\)).
- Se non teniamo conto della motivazione, potremmo erroneamente concludere che lo studio pomeridiano causi voti migliori.
Ecco dei dati simulati:
set.seed(123)
n <- 200
motivazione <- rbinom(n, 1, 0.5) # 0 = bassa, 1 = alta
studio <- rbinom(n, 1, 0.3 + 0.4*motivazione) # più motivati studiano più spesso
rendimento <- rbinom(n, 1, 0.2 + 0.5*motivazione) # motivazione influenza il voto
table(studio, rendimento)
#> rendimento
#> studio 0 1
#> 0 52 43
#> 1 45 60Se confrontiamo il rendimento senza considerare la motivazione, otteniamo:
prop.table(table(studio, rendimento), 1)
#> rendimento
#> studio 0 1
#> 0 0.547 0.453
#> 1 0.429 0.571Sembra che chi studia nel pomeriggio ottenga risultati migliori. In realtà, però, l’effetto non dipende dallo studio, ma dalla motivazione, che è il vero fattore causale. Per separare l’effetto reale da quello spurio, è necessario controllare per \(U\) (ad esempio, con una regressione).
32.9.1 Cosa impariamo
Questo esempio numerico chiarisce in modo concreto ciò che i DAG permettono di rendere visibile: quando è presente una variabile di confondimento, come la motivazione, si apre un percorso indiretto tra la causa ipotizzata (\(X\), lo studio) e l’esito (\(Y\), il rendimento). Tale percorso può generare l’apparenza di un effetto causale anche in assenza di un legame diretto tra \(X\) e \(Y\).
In letteratura, questi collegamenti indesiderati sono noti come percorsi back-door: percorsi che partono a monte della variabile di interesse e raggiungono l’esito passando attraverso un’altra variabile. Se non vengono adeguatamente considerati, questi percorsi compromettono l’interpretazione causale dei dati.
Per ottenere una stima corretta dell’effetto causale, è quindi necessario bloccare i percorsi backdoor, ossia tenere conto delle variabili che li generano nell’analisi empirica. Ciò può avvenire, ad esempio, includendo il confondente in una regressione, costruendo gruppi di confronto comparabili tramite tecniche di matching o, nel caso ideale, ricorrendo alla randomizzazione sperimentale che rende i gruppi equivalenti anche rispetto a fattori non osservabili.
In definitiva, se la motivazione non viene controllata, i dati possono risultare fuorvianti; includendola nell’analisi, invece, diventa possibile distinguere una correlazione spuria da una relazione causale autentica.
Riflessioni conclusive
Lo studio della causalità non è un esercizio puramente teorico. Ogni volta che uno psicologo legge un articolo scientifico, progetta un esperimento o valuta l’efficacia di un trattamento, è chiamato a porsi una domanda fondamentale: la relazione osservata riflette un vero legame causale o è il risultato di un confondimento non riconosciuto? Saper operare questa distinzione è una competenza fondamentale per produrre una scienza psicologica più rigorosa, affidabile e realmente utile.
In questo capitolo è emerso che l’analisi causale in psicologia è intrinsecamente complessa, ma non irraggiungibile. Abbiamo chiarito la differenza tra correlazione e causalità, mostrato come i grafi causali consentano di esplicitare e comunicare le ipotesi teoriche e approfondito il ruolo di concetti chiave quali confondimento, mediazione e moderazione nel determinare il significato delle relazioni empiriche osservate.
Sono stati inoltre discussi i principali approcci empirici per valutare le ipotesi causali, evidenziando che gli esperimenti controllati rappresentano lo standard di riferimento, che i quasi-esperimenti offrono soluzioni pragmatiche quando la randomizzazione non è possibile e che gli studi osservazionali richiedono un uso particolarmente attento di modelli e tecniche statistiche per evitare interpretazioni fuorvianti.
Il messaggio conclusivo è che i dati, da soli, non “parlano”. Essi acquistano significato solo all’interno di un modello teorico esplicito che guidi l’analisi e l’interpretazione. Anche le procedure statistiche più sofisticate non possono produrre inferenze causali valide se non sono guidate da ipotesi chiare sui meccanismi sottostanti che si intendono studiare.
NotaIl messaggio per chi usa la regressione
Il modello di regressione che abbiamo studiato nei capitoli precedenti è uno strumento descrittivo potente. Tuttavia, i suoi coefficienti non hanno automaticamente un’interpretazione causale. Per passare dall’associazione alla causalità sono necessari:
- un DAG che espliciti le nostre assunzioni sul processo generativo dei dati;
- la verifica che le variabili controllate siano quelle giuste (confondenti sì, collider no);
- un’attenzione all’errore di misurazione, che può distorcere le stime;
- la consapevolezza che, con dati osservazionali, le conclusioni causali rimangono sempre condizionate dalle assunzioni del modello.
Questo è il senso profondo dell’insalata causale di cui parla McElreath: aggiungere variabili a una regressione senza un ragionamento causale esplicito può causare più danni che benefici (McElreath, 2020).
ConsiglioInformazioni sull’ambiente di sviluppo
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] grid stats graphics grDevices utils datasets methods
#> [8] base
#>
#> other attached packages:
#> [1] ggdag_0.2.13 ragg_1.5.0 tinytable_0.15.1
#> [4] withr_3.0.2 systemfonts_1.3.1 patchwork_1.3.2
#> [7] ggdist_3.3.3 tidybayes_3.0.7 bayesplot_1.14.0
#> [10] ggplot2_4.0.1 reliabilitydiag_0.2.1 priorsense_1.2.0
#> [13] posterior_1.6.1 loo_2.8.0 rstan_2.32.7
#> [16] StanHeaders_2.32.10 brms_2.23.0 Rcpp_1.1.0
#> [19] sessioninfo_1.2.3 conflicted_1.2.0 janitor_2.2.1
#> [22] matrixStats_1.5.0 modelr_0.1.11 tibble_3.3.0
#> [25] dplyr_1.1.4 tidyr_1.3.1 rio_1.2.4
#> [28] here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] gridExtra_2.3 inline_0.3.21 sandwich_3.1-1
#> [4] rlang_1.1.6 magrittr_2.0.4 multcomp_1.4-29
#> [7] snakecase_0.11.1 compiler_4.5.2 vctrs_0.6.5
#> [10] stringr_1.6.0 pkgconfig_2.0.3 arrayhelpers_1.1-0
#> [13] fastmap_1.2.0 backports_1.5.0 labeling_0.4.3
#> [16] ggraph_2.2.2 rmarkdown_2.30 purrr_1.2.0
#> [19] xfun_0.54 cachem_1.1.0 jsonlite_2.0.0
#> [22] tweenr_2.0.3 broom_1.0.11 parallel_4.5.2
#> [25] R6_2.6.1 stringi_1.8.7 RColorBrewer_1.1-3
#> [28] boot_1.3-32 lubridate_1.9.4 estimability_1.5.1
#> [31] knitr_1.50 zoo_1.8-14 igraph_2.2.1
#> [34] Matrix_1.7-4 splines_4.5.2 timechange_0.3.0
#> [37] tidyselect_1.2.1 viridis_0.6.5 abind_1.4-8
#> [40] yaml_2.3.12 codetools_0.2-20 curl_7.0.0
#> [43] dagitty_0.3-4 pkgbuild_1.4.8 lattice_0.22-7
#> [46] bridgesampling_1.2-1 S7_0.2.1 coda_0.19-4.1
#> [49] evaluate_1.0.5 survival_3.8-3 polyclip_1.10-7
#> [52] RcppParallel_5.1.11-1 pillar_1.11.1 tensorA_0.36.2.1
#> [55] checkmate_2.3.3 stats4_4.5.2 distributional_0.5.0
#> [58] generics_0.1.4 rprojroot_2.1.1 rstantools_2.5.0
#> [61] scales_1.4.0 xtable_1.8-4 glue_1.8.0
#> [64] emmeans_2.0.0 tools_4.5.2 graphlayouts_1.2.2
#> [67] mvtnorm_1.3-3 tidygraph_1.3.1 QuickJSR_1.8.1
#> [70] colorspace_2.1-2 nlme_3.1-168 ggforce_0.5.0
#> [73] cli_3.6.5 textshaping_1.0.4 svUnit_1.0.8
#> [76] viridisLite_0.4.2 Brobdingnag_1.2-9 V8_8.0.1
#> [79] gtable_0.3.6 digest_0.6.39 ggrepel_0.9.6
#> [82] TH.data_1.1-5 htmlwidgets_1.6.4 farver_2.1.2
#> [85] memoise_2.0.1 htmltools_0.5.9 lifecycle_1.0.4
#> [88] MASS_7.3-65Bibliografia
Alexander, R. (2023). Telling Stories with Data: With Applications in R. Chapman; Hall/CRC.
Byrnes, J. E., & Dee, L. E. (2024). Causal inference with observational data and unobserved confounding variables. bioRxiv, 2024–2002.
McElreath, R. (2020). Statistical rethinking: A Bayesian course with examples in R and Stan (2nd Edition). CRC Press.
Riederer, E. (2021). Causal design patterns for data analysts. https://emilyriederer.netlify.app/post/causal-design-patterns/