here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(broom)21 La regressione lineare bivariata
Panoramica del capitolo
- Il modello di regressione lineare secondo l’approccio frequentista.
- La stima dei coefficienti del modello utilizzando il metodo dei minimi quadrati.
- L’interpretazione dei coefficienti dei minimi quadrati.
- Il calcolo e l’interpretazione dell’indice di determinazione (\(R^2\)).
- L’inferenza frequentista sui coefficienti dei minimi quadrati.
ConsiglioPrerequisiti
- Leggere il capitolo Basic Regression di Statistical Inference via Data Science: A ModernDive into R and the Tidyverse (Second Edition).
- Consulta l’appendice Appendice Q per un’introduzione alle funzioni lineari.
- Leggere Navigating the Bayes maze: The psychologist’s guide to Bayesian statistics, a hands-on tutorial with R code (Alter et al., 2025).
- Leggere il capitolo Linear Statistical Models (Schervish & DeGroot, 2014).
AttenzionePreparazione del Notebook
21.1 Il modello di regressione lineare bivariato
Il caso più semplice di applicazione è il modello di regressione lineare bivariato, impiegato per descrivere la relazione tra due variabili quantitative. L’idea centrale è che, quando \(X\) e \(Y\) presentano un’associazione di tipo lineare, è possibile sintetizzare tale relazione tramite una retta1. Questa retta mostra come il valore atteso di \(Y\) tenda a variare al variare di \(X\).
Formalmente, il modello si esprime come:
\[ y_i = a + b x_i + e_i, \quad i = 1, \dots, n, \] dove:
- \(a\) rappresenta l’intercetta, cioè il valore atteso di \(Y\) quando \(X = 0\);
- \(b\) rappresenta il coefficiente angolare (o pendenza), ossia la variazione attesa in \(Y\) per ogni incremento di una unità in \(X\);
- \(e_i\) rappresenta l’errore residuo, cioè la differenza tra il valore osservato \(y_i\) e il valore previsto dal modello \((\hat{y}_i = a + b x_i)\).
21.1.1 La rappresentazione grafica: la retta di regressione
Graficamente, l’equazione definisce una retta di regressione. Questa retta rappresenta la migliore approssimazione lineare della nuvola di punti osservati, ottenuta applicando il criterio dei minimi quadrati (descritto nelle prossime sezioni). Poiché i dati raramente seguono una relazione perfetta, è improbabile che tutti i punti giacciano esattamente sulla retta. La distanza verticale tra ciascun punto osservato e la retta di regressione — definita residuo (\(e_i\)) — misura proprio l’errore di previsione del modello per quell’osservazione specifica.
21.1.2 Interpretazione del modello: tendenza media, non legge deterministica
È fondamentale ricordare che la regressione lineare non predice il valore esatto di ogni singola osservazione, ma ne descrive la tendenza media nella popolazione di riferimento. Ad esempio, se \(b = 2\), ciò significa che, in media, a un aumento di 1 unità in \(X\) corrisponde un aumento di 2 unità in \(Y\). Ciò non significa che ogni individuo o caso segua esattamente questa regola, ma che la direzione e l’intensità complessiva della relazione siano coerenti con tale stima.
L’obiettivo principale dell’analisi è stimare i parametri incogniti del modello, ovvero \(a\), \(b\) e la varianza degli errori \(\sigma^2\), a partire dai dati campionari. La stima viene solitamente effettuata tramite il metodo dei minimi quadrati ordinari (OLS) o, in un’ottica più generale, mediante il principio di massima verosimiglianza. Nel paradigma statistico frequentista, i parametri \(a\) e \(b\) sono considerati quantità fisse (sebbene sconosciute) della popolazione, mentre l’incertezza è attribuita interamente all’errore residuo \(e_i\), che riassume la variabilità non spiegata e gli eventuali errori di misura.
21.2 A cosa serve la regressione?
Le applicazioni della regressione lineare, secondo Gelman et al. (2021), rispondono a quattro distinte finalità.
1. Previsione. L’obiettivo è stimare il valore futuro o sconosciuto di una variabile. In questo contesto, l’obiettivo non è spiegare perché le variabili siano associate, ma utilizzare la relazione osservata per fare stime il più accurate possibile.
- Esempi in psicologia: prevedere il rischio di burnout in base al carico di lavoro e allo stile di coping; stimare il punteggio di un test cognitivo conoscendo l’età e il livello di istruzione; classificare pazienti in categorie di rischio (ad esempio, basso/alto) per un certo disturbo in base a indicatori psicometrici.
2. Descrizione e quantificazione delle relazioni. Qui l’obiettivo è misurare e descrivere l’associazione tra le variabili. La regressione risponde a domande del tipo: “Quanto è forte la relazione?” e “In che direzione va?”.
- Esempi in psicologia: quantificare la relazione tra ore di sonno e prestazioni attentive; descrivere l’associazione tra sostegno sociale percepito e sintomi depressivi; esplorare il legame tra diversi tratti di personalità e propensione al rischio.
3. Estrapolazione controllata. In questa applicazione, si cerca di generalizzare i risultati ottenuti in un certo contesto (ad esempio, un campione specifico) ad un altro, procedendo con cautela. Si tratta di un’estensione della previsione a situazioni non direttamente osservate.
- Esempi in psicologia: stimare l’efficacia potenziale di un intervento educativo, testato in una scuola pilota, su tutte le scuole di un distretto o ipotizzare come un programma di riabilitazione sviluppato per adulti potrebbe funzionare su una popolazione anziana.
4. Inferenza causale (in condizioni rigorose). Questa è l’applicazione più ambiziosa e delicata. La regressione può essere utilizzata per stimare l’effetto causale di una variabile (ad esempio, un trattamento) su un esito, solo ed esclusivamente quando il disegno della ricerca lo consente (ad esempio, negli esperimenti randomizzati).
- Esempi in psicologia: valutare l’effetto causale di una terapia cognitivo-comportamentale sui sintomi d’ansia in uno studio randomizzato; stimare l’impatto di un training sulla memoria di lavoro sul rendimento scolastico, tenendo conto dei fattori confondenti.
21.2.1 Una nota di cautela: l’importanza della specificazione del modello
Indipendentemente dall’obiettivo, la validità di qualsiasi applicazione della regressione dipende in modo cruciale dalla corretta specificazione del modello. Ciò significa che il modello statistico deve includere tutte le variabili rilevanti per il fenomeno in questione. L’omissione di variabili chiave, in particolare quelle che agiscono da confondenti (ovvero che influenzano sia il predittore che l’esito), può distorcere le stime, causando un problema noto come errore di specificazione o bias da variabili omesse.
Esempio pratico: in uno studio che valuta l’efficacia di una psicoterapia per la depressione, l’omissione di variabili come la gravità iniziale dei sintomi, l’uso concomitante di farmaci o il livello di supporto sociale potrebbe far attribuire erroneamente alla terapia effetti che in realtà sono dovuti a questi altri fattori, portando a conclusioni fuorvianti.
21.3 Tipologie di regressione
I modelli di regressione possono essere classificati in base al numero di variabili coinvolte, delineando un percorso di crescente complessità analitica che parte da una relazione semplice per arrivare a rappresentazioni più articolate della realtà.
La regressione bivariata rappresenta la forma più elementare, in cui si analizza la relazione tra un unico predittore e una sola variabile esito. La sua semplicità la rende un punto di partenza ideale per comprendere i principi fondamentali della regressione, in quanto consente di apprendere i concetti di base senza dover affrontare complicazioni matematiche eccessive.
Un livello di complessità superiore è dato dalla regressione multipla, nella quale un unico esito viene modellato utilizzando molteplici predittori. Questo approccio consente di esaminare l’effetto simultaneo di diverse variabili indipendenti, ma richiede un’attenta interpretazione dei parametri stimati.
Infine, la regressione multivariata costituisce il caso più generale, in cui più variabili esito vengono analizzate simultaneamente in relazione a uno o più predittori. Questo tipo di modellazione richiede calcoli statistici più complessi e rappresenta lo strumento più potente e complesso tra le tre tipologie.
Il percorso di apprendimento ideale inizia dalla regressione bivariata, che fornisce le basi concettuali e metodologiche su cui è possibile successivamente costruire modelli più sofisticati. La comprensione dei principi fondamentali acquisiti nel caso semplice è infatti un prerequisito essenziale per affrontare le sfide interpretative e computazionali poste dalle regressioni multiple e multivariate.
21.4 La predizione dell’intelligenza
Per illustrare il modello di regressione secondo l’approccio frequentista, utilizzeremo un dataset reale: i dati kidiq tratti dal National Longitudinal Survey of Youth (Gelman et al., 2021). Questi dati riguardano un campione di donne americane e i loro figli, con particolare attenzione a due variabili fondamentali per la nostra analisi: il punteggio cognitivo del bambino (kid_score) e il quoziente intellettivo della madre (mom_iq). L’obiettivo principale è esaminare se e in che misura l’intelligenza materna possa essere considerata un fattore predittivo delle capacità cognitive del bambino.
21.4.1 Esplorazione dei dati
Importiamo i dati in R:
Esaminiamo le prime righe del data frame:
head(kidiq)
#> kid_score mom_hs mom_iq mom_work mom_age
#> 1 65 1 121.1 4 27
#> 2 98 1 89.4 4 25
#> 3 85 1 115.4 4 27
#> 4 83 1 99.4 3 25
#> 5 115 1 92.7 4 27
#> 6 98 0 107.9 1 18Un diagramma a dispersione dei dati di questo campione suggerisce la presenza di un’associazione positiva tra l’intelligenza del bambino (kid_score) e l’intelligenza della madre (mom_iq).
ggplot(kidiq, aes(x = mom_iq, y = kid_score)) +
geom_point(alpha = 0.6, color= palette_qualitative[2]) +
labs(x = "QI della madre", y = "QI del bambino")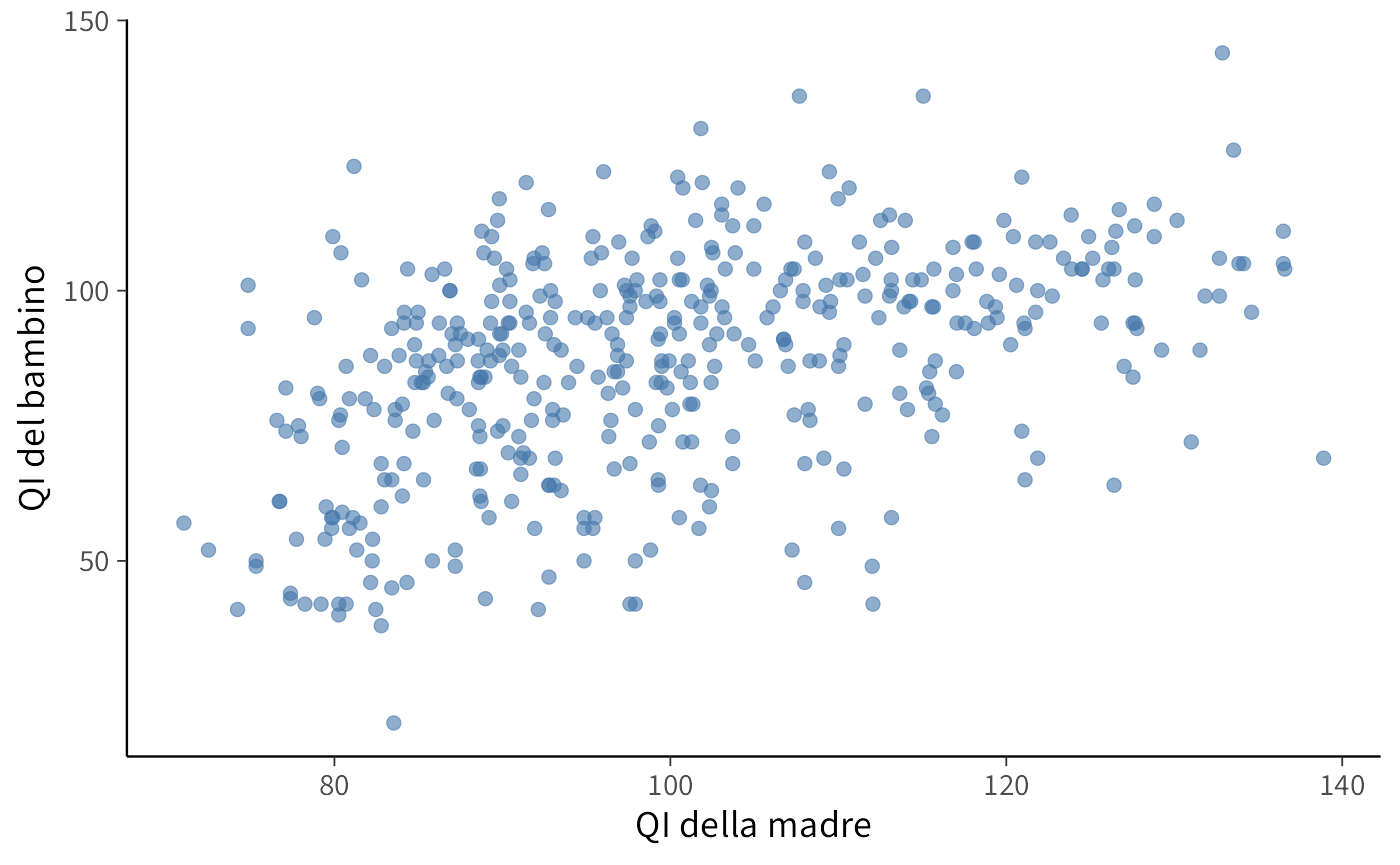
21.4.2 Il modello per i nostri dati
Applichiamo ora il modello di regressione lineare bivariata alla relazione che vogliamo esplorare:
- la variabile di risposta (o outcome) è
kid_score(QI del bambino, \(y\)); - la variabile predittrice (o predictor) è
mom_iq(QI della madre, \(x\)).
La formulazione specifica per il nostro caso è quindi:
\[ \text{kid\_score}_i = a + b \cdot \text{mom\_iq}_i + e_i, \quad i = 1, \dots, n, \] dove:
- \(a\) (intercetta): il valore atteso del QI del bambino quando il QI della madre è 0. Poiché tale scenario è irrealistico (un QI pari a 0 non ha senso), l’intercetta va interpretata principalmente come un parametro tecnico che, insieme alla pendenza, definisce la posizione della retta di regressione nel grafico, piuttosto che come una stima dotata di un significato psicologico sostanziale.
- \(b\) (pendenza): indica di quante unità, in media, ci aspettiamo che cambi il QI del bambino per ogni incremento di un punto nel QI della madre. Questo è il parametro centrale della nostra analisi.
- \(e_i\) (errore residuo): la differenza tra il QI effettivamente osservato per il bambino \(i\) e il QI che il modello prevederebbe per lui (\(\hat{y}_i\)) data l’intelligenza di sua madre. Cattura l’influenza di tutti gli altri fattori non misurati (genetici, ambientali e di misurazione) e la variabilità individuale.
NotaNota sui Dati
Il nostro dataset kidiq contiene le \(n\) coppie di osservazioni necessarie. Per ogni osservazione \(i\) (ogni coppia madre-figlio) abbiamo un valore per mom_iq e uno per kid_score.
Ad esempio, i primi 10 punteggi QI osservati per i bambini sono:
kidiq$kid_score[1:10]
#> [1] 65 98 85 83 115 98 69 106 102 95L’indice \(i\) ci permette di riferirci a ciascuna di queste osservazioni. Per esempio, il punteggio del secondo bambino nella sequenza (\(y_2\)) è:
kidiq$kid_score[2]
#> [1] 98L’obiettivo dell’analisi è stimare i valori dei parametri \(a\) e \(b\) che meglio descrivono, in media, la relazione lineare presente in queste \(n\) coppie di dati, utilizzando il criterio dei minimi quadrati.
21.4.3 Stima del modello di regressione
Calcoliamo i coefficienti della retta di regressione utilizzando la funzione lm.
# Modello di regressione lineare
mod <- lm(kid_score ~ mom_iq, data = kidiq)Esaminiamo i risultati:
# Coefficienti stimati
coef(mod)
#> (Intercept) mom_iq
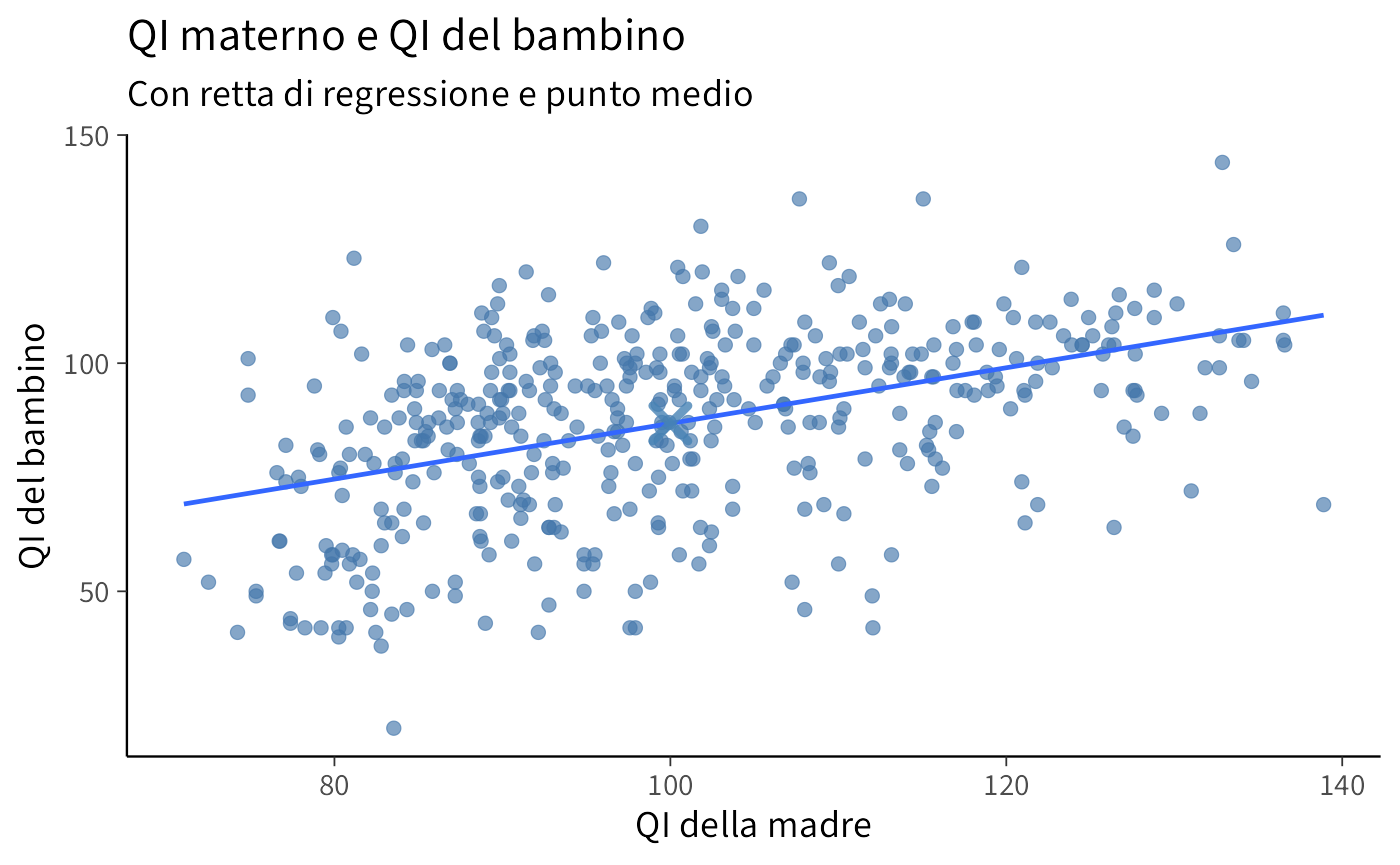
#> 25.80 0.61In generale, molte rette possono approssimare la nube di punti, ma il modello di regressione impone i seguenti vincoli:
- la retta deve passare per il punto medio \((\bar{x}, \bar{y})\);
- la retta deve minimizzare la somma dei quadrati dei residui (SSE).
# Calcola i valori medi
mean_x <- mean(kidiq$mom_iq, na.rm = TRUE)
mean_y <- mean(kidiq$kid_score, na.rm = TRUE)
# Grafico nello stile "manuscript"
ggplot(kidiq, aes(x = mom_iq, y = kid_score)) +
geom_point(alpha = 0.6, color = palette_qualitative[2]) +
geom_smooth(
method = "lm", se = FALSE,
linewidth = 0.8, color = palette_qualitative[1]
) +
annotate(
"point",
x = mean_x, y = mean_y,
color = palette_qualitative[3],
size = 4.5, shape = 4, stroke = 2.2
) +
labs(
x = "QI della madre",
y = "QI del bambino",
title = stringr::str_wrap("QI materno e QI del bambino", width = 50),
subtitle = "Con retta di regressione e punto medio"
) 
21.4.4 Interpretazione
Il coefficiente \(a\) indica l’intercetta della retta di regressione nel diagramma a dispersione. Questo valore rappresenta il punto in cui la retta di regressione interseca l’asse \(y\) del sistema di assi cartesiani. Come abbiamo già detto, in questo caso specifico, il valore di \(a\) non è di particolare interesse psicologico. Successivamente, vedremo come è possibile trasformare i dati per fornire un’interpretazione utile del coefficiente \(a\).
Il coefficiente \(b\) indica invece la pendenza della retta di regressione, ovvero di quanto aumenta (se \(b\) è positivo) o diminuisce (se \(b\) è negativo) la retta di regressione in corrispondenza di un aumento di 1 punto della variabile \(x\). Nel caso specifico del QI delle madri e dei loro figli, il coefficiente \(b\) ci indica che un aumento di 1 punto del QI delle madri è associato, in media, a un aumento di 0.61 punti del QI dei loro figli.
In pratica, il modello di regressione lineare cerca di prevedere le medie dei punteggi del QI dei figli in base al QI delle madri. Ciò significa che non è in grado di prevedere esattamente il punteggio di ciascun bambino in funzione del QI della madre, ma solo una stima della media dei punteggi dei figli quando il QI delle madri aumenta o diminuisce di un punto.
Il coefficiente \(b\) ci dice di quanto aumenta (o diminuisce) in media il QI dei figli per ogni unità di aumento (o diminuzione) del QI della madre. Nel nostro caso, se il QI della madre aumenta di un punto, il QI dei figli aumenta in media di 0.61 punti.
È importante comprendere che il modello statistico di regressione lineare non è in grado di prevedere il valore preciso di ogni singolo bambino, ma solo una stima della media dei punteggi del QI dei figli quando il QI delle madri aumenta o diminuisce. Questa stima è basata su una distribuzione di valori possibili che si chiama distribuzione condizionata \(p(y \mid x_i)\).
Una rappresentazione grafica del valore predetto dal modello di regressione, \(\hat{y}_i = a + bx_i\) è stata fornita in precedenza. Il diagramma presenta ciascun valore \(\hat{y}_i = a + b x_i\) in funzione di \(x_i\). I valori predetti dal modello di regressione sono i punti che si trovano sulla retta di regressione.
21.4.5 Centrare le variabili
In generale, per le variabili a livello di scala a intervalli, l’intercetta del modello di regressione lineare non ha un’interpretazione utile. Questo perché l’intercetta indica il valore atteso di \(y\) quando \(x = 0\), ma nel caso di variabili a scala di intervalli, il valore “0” è arbitrario e non corrisponde a un “intensità nulla” della variabile \(x\). Ad esempio, un QI della madre pari a 0 non indica l’assenza di intelligenza, ma solo un valore arbitrario del test utilizzato per misurare il QI. Pertanto, conoscere il valore medio del QI dei figli quando il QI della madre è pari a 0 non è di alcuna utilità.
Centrando \(x\) attorno alla sua media si ottiene un’intercetta interpretabile: il valore medio di kid_score quando la variabile mom_iq assume il valore corrispondente alla media del campione.
kidiq <- kidiq %>%
mutate(xd = mom_iq - mean(mom_iq))Se ora usiamo le coppie di osservazioni \((xd_i, y_i)\), il diagramma a dispersione assume la forma seguente.
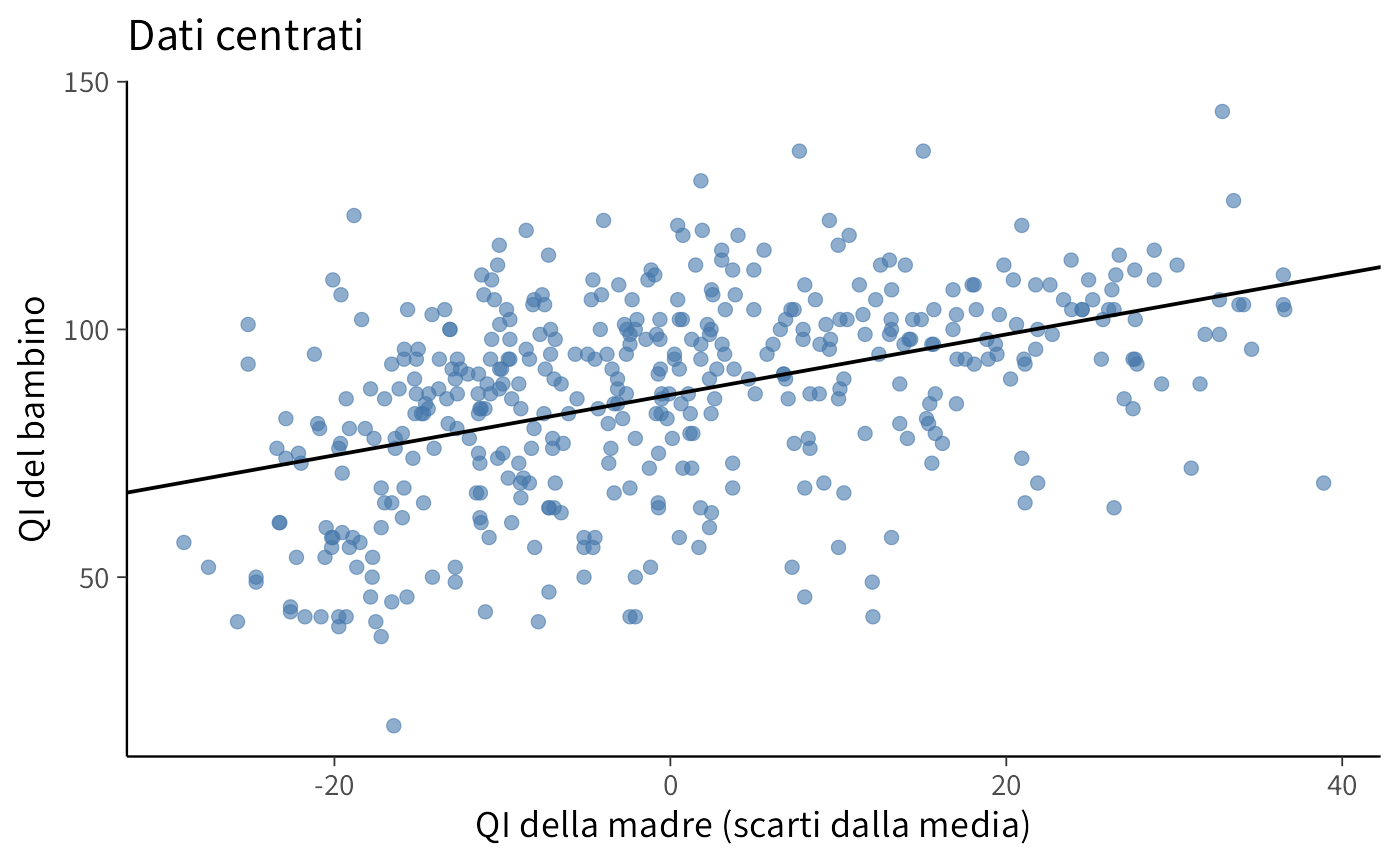
In pratica, abbiamo applicato una trasformazione ai dati, spostando tutti i punti del grafico lungo l’asse delle ascisse in modo che la media dei valori \(x\) risulti pari a zero. Questa operazione non ha alterato la distribuzione o la forma complessiva della nuvola di punti, ma ha semplicemente modificato l’origine del sistema di riferimento sull’asse \(x\).
La pendenza della retta di regressione che mette in relazione \(x\) e \(y\) rimane invariata, sia per i dati originali sia per quelli trasformati. L’unico parametro che subisce una modifica è il valore dell’intercetta della retta di regressione che, in questo modo, acquisisce un’interpretazione più intuitiva e un significato sostanziale.
Nell’output del modello, l’intercetta rappresenta il valore predetto della variabile dipendente \(y\) quando la variabile indipendente \(x\) assume esattamente il suo valore medio campionario. Nel caso specifico dell’esempio, l’intercetta corrisponde al punteggio atteso del QI del bambino (kid_score) quando il quoziente intellettivo della madre (mom_iq) è pari alla media osservata nel campione di riferimento.
21.5 Il metodo dei minimi quadrati
Per adattare il modello di regressione bivariata ai dati osservati è necessario stimare i parametri incogniti \(a\) e \(b\). Il metodo standard per questa stima è il metodo dei minimi quadrati ordinari (OLS, Ordinary Least Squares).
Il criterio fondamentale è scegliere la retta che rende minima la somma dei quadrati degli errori di previsione, detti residui. Formalmente, definito il residuo per l’\(i\)-esima osservazione come
\[ e_i = y_i - (a + b x_i), \]
l’obiettivo è trovare i valori di \(a\) e \(b\) che minimizzano
\[ SSE = \sum_{i=1}^n e_i^2, \]
dove SSE sta per Sum of Squared Errors. Sotto le ipotesi classiche di errori indipendenti, con media zero e varianza costante, questa soluzione coincide con quella fornita dal principio di massima verosimiglianza.
Minimizzando \(SSE\) si ottengono le equazioni normali, che ammettono una soluzione in forma chiusa, espressa dalle seguenti formule:
\[ b = \frac{\mathrm{Cov}(x, y)}{\mathrm{Var}(x)}, \qquad a = \bar{y} - b \,\bar{x}. \]
In queste formule:
- \(\bar{x}\) e \(\bar{y}\) sono rispettivamente le medie campionarie delle variabili \(x\) e \(y\);
- \(\mathrm{Cov}(x,y)\) è la covarianza campionaria tra \(x\) e \(y\);
- \(\mathrm{Var}(x)\) è la varianza campionaria di \(x\).
Dalla formula dell’intercetta \(a = \bar{y} - b\bar{x}\) deriva direttamente una proprietà fondamentale della retta stimata: essa passa sempre per il punto medio \((\bar{x}, \bar{y})\), il baricentro della distribuzione dei dati.
NotaEsempio in R
Coefficienti del modello. Calcoliamo i coefficienti della retta di regressione con le formule dei minimi quadrati:
I risultati replicano quelli ottenuti in precedenza con lm().
Residui. Il residuo, ovvero la componente di ciascuna osservazione \(y_i\) che non viene predetta dal modello di regressione, corrisponde alla distanza verticale tra il valore \(y_i\) osservato e il valore \(\hat{y}_i\) predetto dal modello di regressione:
\[ e_i = y_i - (a + b x_i). \]
Per fare un esempio numerico, consideriamo il punteggio osservato del QI del primo bambino.
kidiq$kid_score[1]
#> [1] 65Il QI della madre è
kidiq$mom_iq[1]
#> [1] 121Per questo bambino, il valore predetto dal modello di regressione è
a + b * kidiq$mom_iq[1]
#> [1] 161L’errore che compiamo per predire il QI del bambino utilizzando il modello di regressione (ovvero, il residuo) è
kidiq$kid_score[1] - (a + b * kidiq$mom_iq[1])
#> [1] -95.7Per tutte le osservazioni abbiamo
res <- kidiq$kid_score - (a + b * kidiq$mom_iq)È una proprietà del modello di regressione (calcolato con il metodo dei minimi quadrati) che la somma dei residui sia uguale a zero.
sum(res)
#> [1] -26473Questo significa che ogni valore osservato \(y_i\) viene scomposto dal modello di regressione in due componenti distinte. La componente deterministica \(\hat{y}_i\), che è predicibile da \(x_i\), è data da \(\hat{y}_i = a + b x_i\). Il residuo, invece, è dato da \(e_i = y_i - \hat{y}_i\). La somma di queste due componenti, ovviamente, riproduce il valore osservato.
# Creazione di un data frame con i valori calcolati
df <- data.frame(
kid_score = kidiq$kid_score,
mom_iq = kidiq$mom_iq,
y_hat = a + b * kidiq$mom_iq,
e = kidiq$kid_score - (a + b * kidiq$mom_iq),
y_hat_plus_e = (a + b * kidiq$mom_iq) + (kidiq$kid_score - (a + b * kidiq$mom_iq))
)
# Visualizzazione dei primi 6 valori
head(df)
#> kid_score mom_iq y_hat e y_hat_plus_e
#> 1 65 121.1 161 -95.7 65
#> 2 98 89.4 141 -43.3 98
#> 3 85 115.4 157 -72.2 85
#> 4 83 99.4 147 -64.5 83
#> 5 115 92.7 143 -28.4 115
#> 6 98 107.9 153 -54.6 98Illustrazione del metodo dei minimi quadrati. Per stimare i coefficienti \(a\) e \(b\), possiamo minimizzare la somma dei quadrati dei residui tra i valori osservati \(y_i\) e quelli previsti \(a + b x_i\).
Iniziamo con il creare una griglia per i valori di \(b\). Supponiamo che il valore di \(a\) sia noto (\(a = 25.79978\)). Usiamo R per creare una griglia di valori possibili per \(b\).
# Griglia di valori per b
b_grid <- seq(0, 1, length.out = 1001)
a <- 25.79978 # Intercetta notaDefiniamo ora una funzione che calcola la somma dei quadrati dei residui (\(SSE\)) per ciascun valore di \(b\).
# Funzione per la somma dei quadrati dei residui
sse <- function(a, b, x, y) {
sum((y - (a + b * x))^2)
}Applichiamo la funzione sse alla griglia di valori \(b\) per calcolare la somma dei quadrati dei residui per ogni valore di \(b\).
# Calcolo di SSE per ciascun valore di b
sse_vals <- sapply(
b_grid,
function(b) sse(a, b, kidiq$mom_iq, kidiq$kid_score)
)-
sapply:- È una funzione di R che applica una funzione ad ogni elemento di un vettore (o lista) e restituisce i risultati in un vettore.
- Qui, applica la funzione
ssea ciascun valore di \(b\) contenuto inb_grid.
-
function(b):- È una funzione anonima definita al volo per specificare come calcolare \(SSE\) per ciascun valore di \(b\).
- All’interno, viene chiamata la funzione
sse(a, b, x, y)con i seguenti parametri:-
a: il valore dell’intercetta (fissato in precedenza o noto). -
b: il valore corrente nella grigliab_grid. -
x: la variabile indipendente del dataset (kidiq$mom_iq). -
y: la variabile dipendente del dataset (kidiq$kid_score).
-
- Il risultato è un vettore,
sse_vals, che contiene i valori di \(SSE\) corrispondenti a ciascun valore di \(b\) inb_grid.
Tracciamo un grafico che mostra la somma dei quadrati dei residui (\(SSE\)) in funzione dei valori di \(b\), evidenziando il minimo.
# Identificazione del valore di b che minimizza SSE
b_min <- b_grid[which.min(sse_vals)]
# Creazione del dataframe per ggplot
dat <- data.frame(b_grid = b_grid, sse_vals = sse_vals)
# Genera il grafico
ggplot(dat, aes(x = b_grid, y = sse_vals)) +
geom_line(linewidth = 1, color = palette_qualitative[5]) +
annotate(
"point", x = b_min, y = min(sse_vals),
color = palette_qualitative[6], size = 3
) +
labs(
x = expression(paste("Possibili valori di ", hat(beta))),
y = "Somma dei quadrati\ndei residui",
title = "Residui quadratici"
)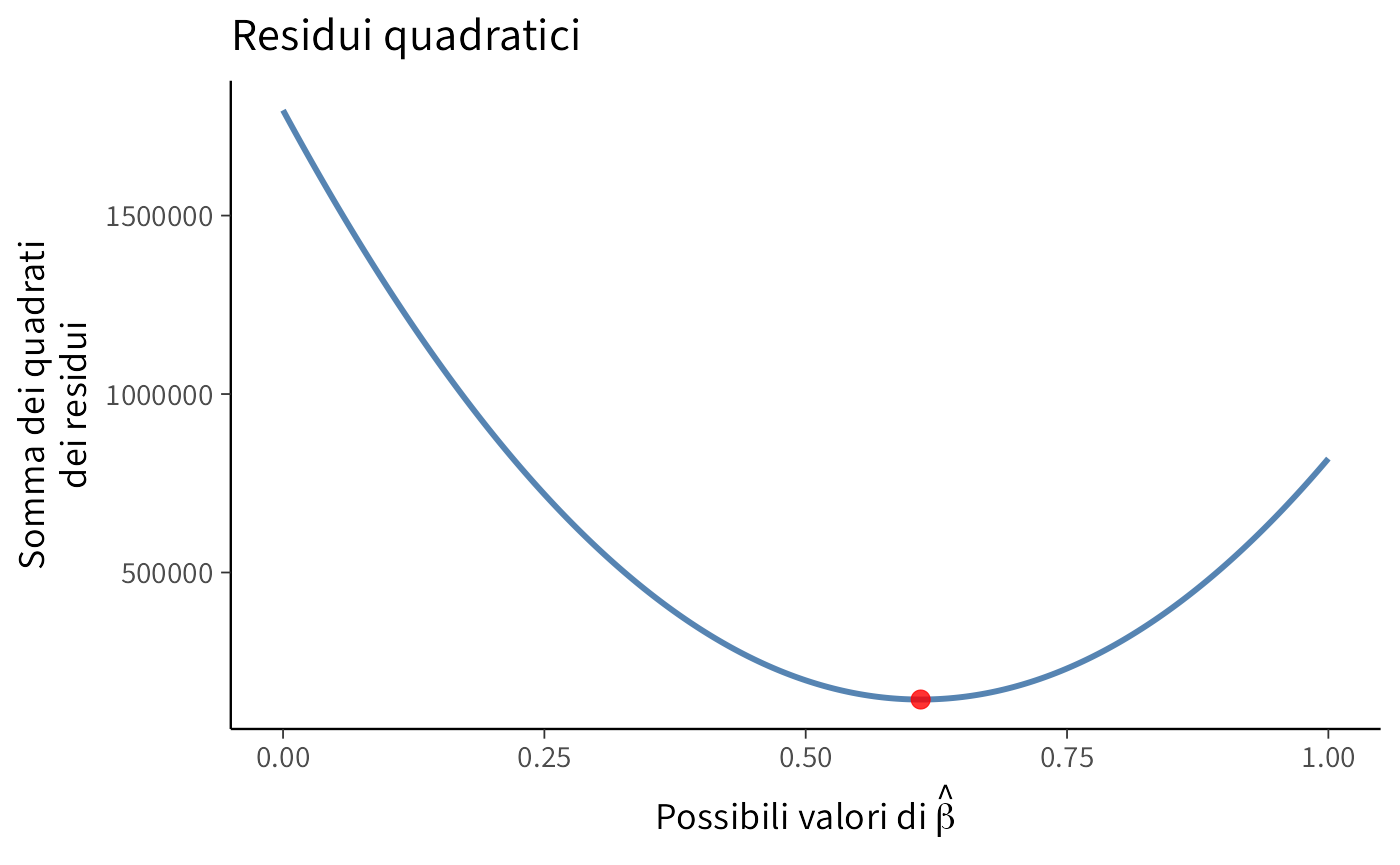
Infine, identifichiamo il valore di \(b\) che minimizza la somma dei quadrati dei residui.
b_min
#> [1] 0.61Con questa simulazione abbiamo stimato il coefficiente \(b\) minimizzando la somma dei quadrati dei residui. Questo approccio può essere esteso per stimare simultaneamente entrambi i coefficienti (\(a\) e \(b\)) utilizzando metodi di ottimizzazione più avanzati, come optim in R.
Questa simulazione illustra come, tramite il metodo dei minimi quadrati, sia possibile stimare i parametri di un modello bivariato di regressione.
21.6 L’errore standard della regressione
L’errore standard della stima \(s_e\) misura la deviazione media dei dati dalla retta:
\[ \sqrt{\frac{1}{n-2} \sum_{i=1}^n \big(y_i - (\hat{a} + \hat{b}x_i)\big)^2}, \tag{21.1}\]
L’indice \(s_e\) possiede la stessa unità di misura di \(y\) ed è una stima della deviazione standard dei residui nella popolazione.
NotaEsempio in R
# Calcolo dei residui
e <- kidiq$kid_score - (a + b * kidiq$mom_iq)
# Mostriamo i primi 10 residui
head(e, 10)
#> [1] -34.68 17.69 -11.22 -3.46 32.63 6.38 -41.52 3.86 26.41 11.21Calcoliamo il valore medio assoluto dei residui per avere un’indicazione della deviazione media rispetto alla retta di regressione.
L’errore standard della stima \(s_e\) si calcola come la radice quadrata della somma dei quadrati dei residui divisa per \(n-2\):
Notiamo che il valore medio assoluto dei residui e l’errore standard \(s_e\) non sono identici, ma hanno lo stesso ordine di grandezza. \(s_e\) è una misura più rigorosa della deviazione standard dei residui.
Questa analisi dimostra come \(s_e\) consenta di valutare quanto le previsioni del modello si discostino (in media) dai dati osservati.
21.7 L’indice di determinazione
Nell’approccio frequentista, la qualità dell’adattamento si apprezza osservando l’indice di determinazione \(R^2\), che indica quanta parte della varianza di \(y\) viene spiegata dal modello, e analizzando i residui: eventuali pattern sistematici nei residui possono segnalare che la struttura scelta non coglie tutte le caratteristiche dei dati o che esistono violazioni delle ipotesi (linearità, omoscedasticità, normalità degli errori). Un esame congiunto di \(R^2\) e residui aiuta a diagnosticare e, se necessario, migliorare il modello.
L’indice di determinazione viene calcolato utilizzando un’importante proprietà del modello di regressione, ovvero la scomposizione della varianza della variabile dipendente \(y\) in due componenti: la varianza spiegata dal modello e la varianza residua.
Per una generica osservazione \(x_i, y_i\), la deviazione di \(y_i\) rispetto alla media \(\bar{y}\) può essere espressa come la somma di due componenti: il residuo \(e_i=y_i- \hat{y}_i\) e lo scarto di \(\hat{y}_i\) rispetto alla media \(\bar{y}\): \[ y_i - \bar{y} = (y_i- \hat{y}_i) + (\hat{y}_i - \bar{y}) = e_i + (\hat{y}_i - \bar{y}). \]
La varianza totale di \(y\) può quindi essere scritta come:
\[ \sum_{i=1}^{n}(y_i - \bar{y})^2 = \sum_{i=1}^{n}(e_i + (\hat{y}_i - \bar{y}))^2. \]
Sviluppando il quadrato e sommando, si ottiene:
\[ \sum_{i=1}^{n}(y_i - \bar{y})^2 = \sum_{i=1}^{n}(y_i - \hat{y}_i)^2 + \sum_{i=1}^{n}(\hat{y}_i - \bar{y})^2. \tag{21.2}\]
Il primo termine rappresenta la varianza residua, mentre il secondo termine rappresenta la varianza spiegata dal modello. Questa scomposizione della devianza va sotto il nome di teorema della scomposizione della devianza.
Questa scomposizione viene utilizzata per calcolare l’indice di determinazione \(R^2\), che fornisce una misura della bontà di adattamento del modello ai dati del campione. L’indice di determinazione \(R^2\) è definito come il rapporto tra la varianza spiegata e la varianza totale: \[ R^2 = \frac{\sum_{i=1}^{n}(\hat{y}_i - \bar{y})^2}{\sum_{i=1}^{n}(y_i - \bar{y})^2}. \tag{21.3}\]
Questo indice varia tra 0 e 1 e indica la frazione di varianza totale di \(y\) spiegata dal modello di regressione lineare. Un valore alto di \(R^2\) indica che il modello di regressione lineare si adatta bene ai dati, in quanto una grande parte della varianza di \(y\) è spiegata dalla variabile indipendente \(x\).
NotaEsempio in R
Per l’esempio in discussione, possiamo calcolare la devianza totale, la devianza spiegata e l’indice di determinazione \(R^2\) come segue:
La devianza totale misura la variabilità complessiva dei punteggi osservati \(y\) rispetto alla loro media:
La devianza spiegata misura la variabilità che il modello è in grado di spiegare, considerando i valori predetti \(a + b x\):
L’indice \(R^2\) è il rapporto tra la devianza spiegata e la devianza totale, e indica la frazione della variabilità totale che è spiegata dal modello di regressione:
# Indice di determinazione
R2 <- dev_r / dev_t
round(R2, 3)
#> [1] 0.201Per verificare i calcoli, utilizziamo il modello di regressione lineare in R e leggiamo \(R^2\) direttamente dal sommario del modello:
Il risultato mostra che circa il 20% della variabilità nei punteggi del QI dei bambini è spiegabile conoscendo il QI delle madri. Questo significa che il modello cattura una porzione rilevante della relazione, ma lascia anche spazio a fattori non inclusi nel modello che influenzano il QI dei bambini.
21.8 Diagnostica dei residui
L’adeguatezza di un modello di regressione non può essere valutata unicamente attraverso l’indice \(R^2\), poiché questo misura solo la bontà di adattamento globale, ma non verifica il rispetto delle ipotesi sottostanti. È quindi fondamentale esaminare i residui per verificare che le assunzioni del modello siano soddisfatte in modo ragionevole. Eventuali pattern sistematici nei residui possono indicare la violazione delle ipotesi fondamentali (linearità, omoschedasticità, indipendenza e normalità) o la presenza di osservazioni influenti e outlier.
21.8.1 Concetti fondamentali sui residui
I residui ordinari sono definiti come la differenza tra il valore osservato e il valore predetto dal modello: \(e_i = y_i - \hat{y}_i\). Per scopi diagnostici, è spesso preferibile utilizzare i residui standardizzati o quelli studentizzati, che sono normalizzati tenendo conto della loro variabilità. I residui studentizzati, in particolare, incorporano anche una correzione per la leva statistica di ciascuna osservazione, rendendoli più adatti all’identificazione degli outlier.2
21.8.2 Panoramica dei grafici diagnostici essenziali
Un primo strumento fondamentale è il diagramma dei residui contro i valori predetti, che permette di valutare simultaneamente le assunzioni di linearità e omoschedasticità. In un modello adeguato, i residui dovrebbero distribuirsi in modo casuale e senza struttura attorno alla linea orizzontale dello zero. Una forma ricurva suggerisce che la relazione non sia ben catturata da un modello lineare, mentre una dispersione a forma di imbuto indica variazioni della varianza degli errori e segnala eteroschedasticità.
Per verificare la normalità degli errori, il Q-Q plot (Quantile-Quantile) dei residui è lo strumento grafico standard. Confrontando i quantili dei residui con i quantili teorici di una distribuzione normale standard, è possibile ottenere una diagnosi visiva immediata: un allineamento dei punti lungo la bisettrice indica compatibilità con la normalità, mentre deviazioni sistematiche, soprattutto nelle code, rivelano discrepanze importanti rispetto a questa assunzione.
Un ulteriore strumento utile è il grafico Scale–Location (o Spread–Location), più sensibile nella diagnosi dell’omoschedasticità rispetto al semplice grafico dei residui. Sull’asse verticale sono riportati i valori della radice quadrata dei residui standardizzati in valore assoluto, che stabilizzano la variabilità, mentre sull’asse orizzontale sono riportati i valori predetti. Una banda piatta e orizzontale è coerente con l’omoschedasticità, mentre un andamento crescente o decrescente evidenzia una varianza non costante.
Infine, il grafico residui–leva è pensato per individuare le osservazioni potenzialmente influenti. Combina la grandezza del residuo con la leva statistica, che misura quanto un’osservazione sia isolata nello spazio dei predittori. I punti con leva elevata e residui ampi (in valore assoluto) hanno la capacità di alterare sensibilmente le stime dei coefficienti. Per questo motivo il grafico include spesso curve di livello della distanza di Cook, che sintetizzano l’influenza complessiva di ogni osservazione sul modello.
NotaEsempio in R
R mette a disposizione un insieme di grafici diagnostici standard per i modelli di regressione:
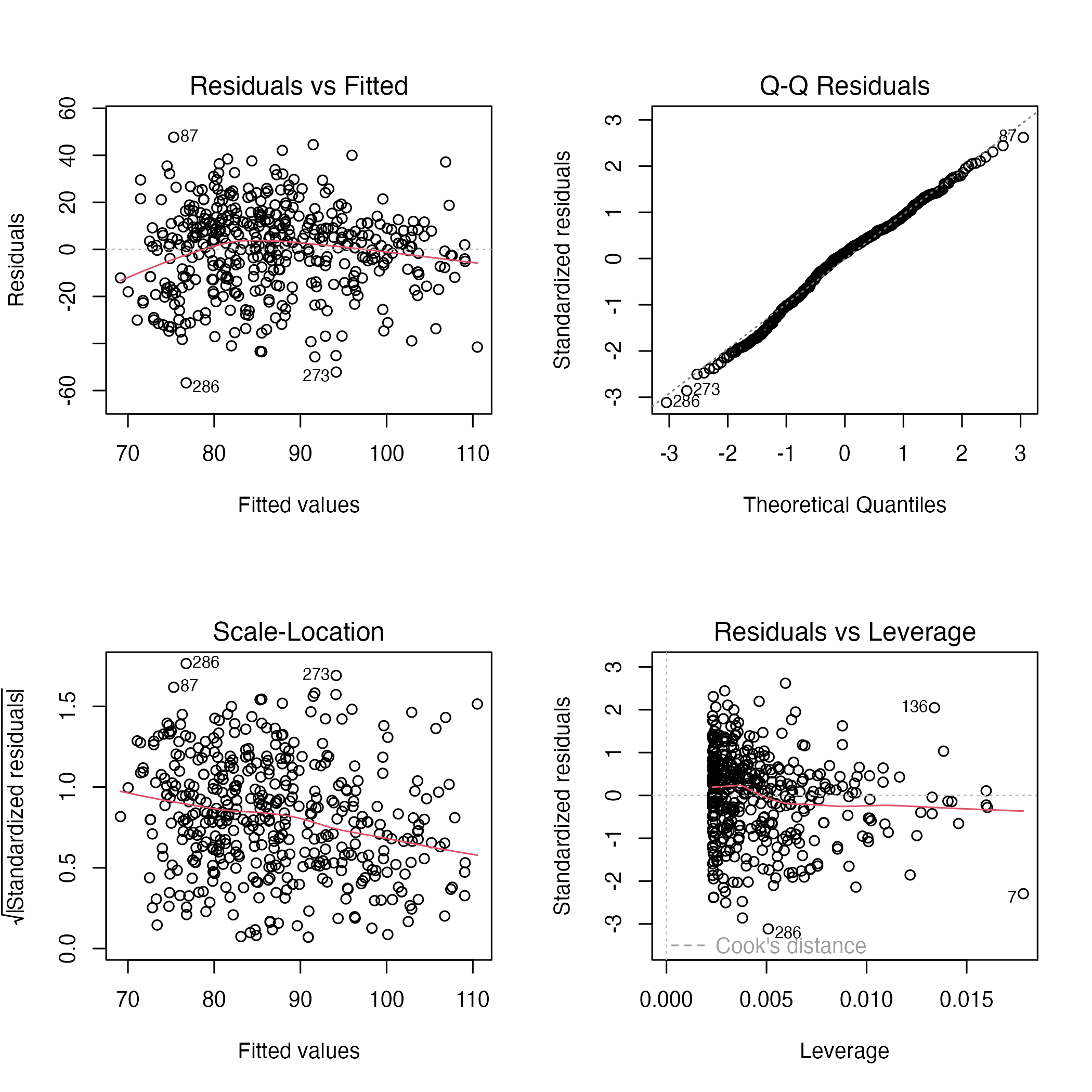
Interpretazione dei grafici:
Residuals vs Fitted: nel nostro esempio i residui si distribuiscono senza pattern evidenti attorno alla linea dello zero, suggerendo che la relazione lineare fornisce una rappresentazione adeguata della struttura dei dati.
Normal Q-Q: i punti seguono abbastanza da vicino la retta di riferimento. Le deviazioni nelle code sono contenute, indicando che l’ipotesi di normalità degli errori è ragionevolmente compatibile con i dati.
Scale-Location: la variabilità dei residui standardizzati rimane relativamente stabile lungo l’asse dei valori predetti. Ciò è coerente con l’assunzione di omoschedasticità.
Residuals vs Leverage: non emergono osservazioni caratterizzate simultaneamente da leva elevata e residui ampi. In altre parole, non ci sono indizi di punti chiaramente influenti sulle stime del modello.
Per approfondire, esaminiamo la distribuzione dei residui:
# Distribuzione dei residui
ggplot(data.frame(residui = residuals(mod)), aes(x = residui)) +
geom_histogram(aes(y = after_stat(density)), bins = 30,
fill = palette_qualitative[2], alpha = 0.7) +
geom_density(linewidth = 1, color = palette_qualitative[1]) +
labs(
x = "Residui",
y = "Densità",
title = "Distribuzione dei residui"
)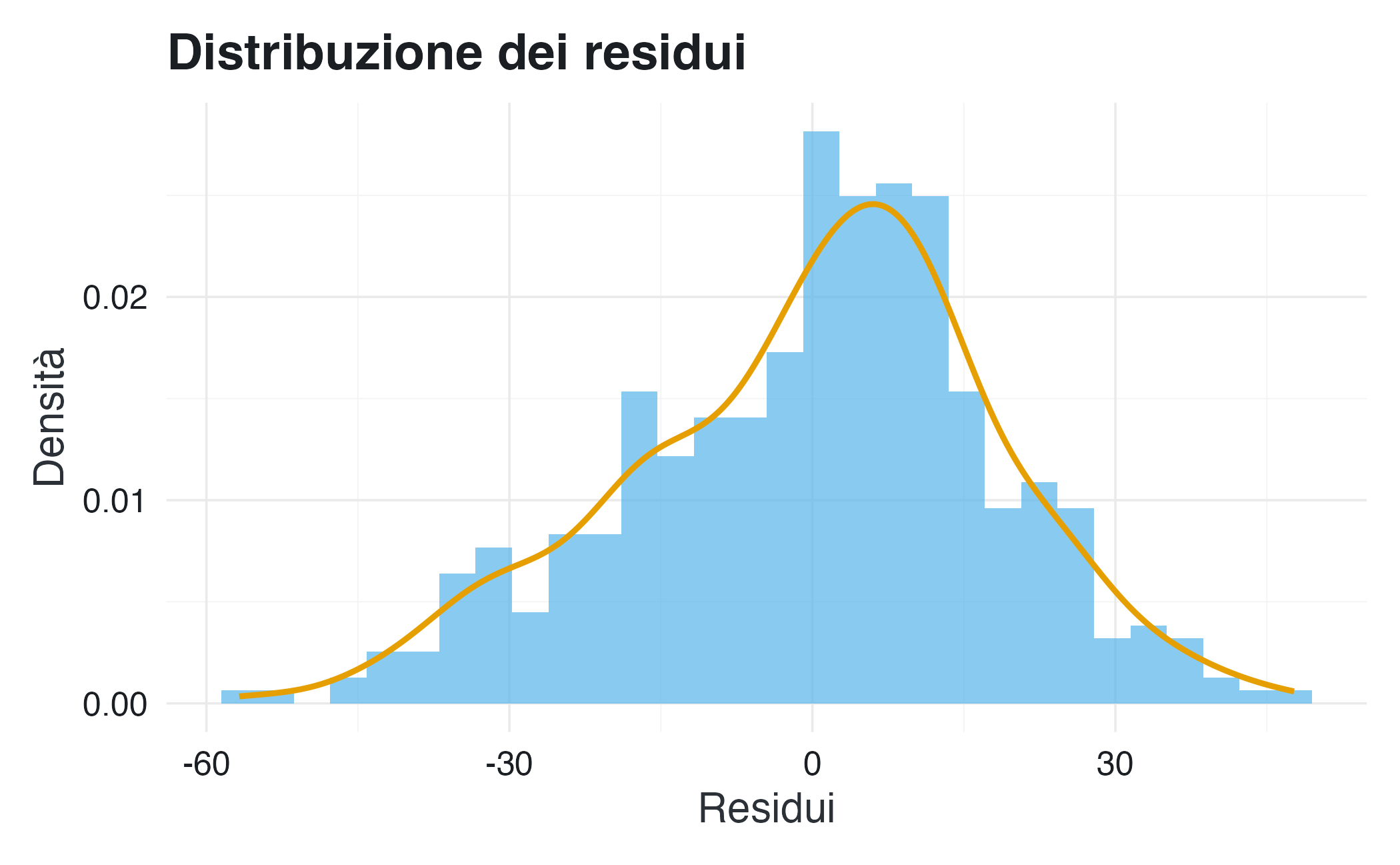
Il test di Shapiro-Wilk tende a respingere l’ipotesi di normalità anche in presenza di deviazioni minime, con campioni ampi. In questo caso, l’analisi grafica suggerisce che eventuali deviazioni dalla normalità sono contenute e non compromettono la validità del modello nelle analisi standard basate sui minimi quadrati.
21.9 Inferenza sui coefficienti
La stima dei coefficienti di regressione è solo il primo passo dell’inferenza. L’obiettivo principale dell’inferenza è quantificare l’incertezza associata a queste stime, un’incertezza che deriva dal fatto che i dati provengono da un campione e non dall’intera popolazione. A tale scopo, l’approccio frequentista l’approccio frequentista introduce il concetto di distribuzione campionaria degli stimatori.
Nel modello di regressione bivariata:
\[ Y_i = \beta_0 + \beta_1 X_i + \varepsilon_i, \]
il metodo dei Minimi Quadrati Ordinari (OLS) fornisce gli stimatori \(\hat{\beta}_0\) e \(\hat{\beta}_1\). Applicati ai dati osservati, questi stimatori producono le stime puntuali dei parametri incogniti \(\beta_0\) e \(\beta_1\).
Dal punto di vista frequentista, gli stimatori sono variabili casuali: il loro valore cambia da campione a campione. Se ripetessimo l’indagine tante volte, estraendo ogni volta un nuovo campione dalla stessa popolazione, otterremmo ogni volta valori diversi di \(\hat{\beta}_0\) e \(\hat{\beta}_1\). La stima ricavata con il nostro dataset è dunque solo una tra le molte possibili realizzazioni dello stesso processo.
Immaginare questa sequenza di replicazioni aiuta a visualizzare la variabilità campionaria, cioè la fluttuazione inevitabile delle stime dovuta al fatto che osserviamo solo un sottoinsieme dei dati possibili.
La collezione teorica di tutti i possibili valori di \(b_1\) che otterremmo ripetendo idealmente l’esperimento un numero infinito di volte costituisce la distribuzione campionaria di \(b_1\). È questa distribuzione che descrive la variabilità del coefficiente attorno al suo valore vero e, nell’approccio frequentista, fornisce la base concettuale per costruire intervalli di confidenza e valutare ipotesi sui parametro del modello.
21.9.1 Le assunzioni del modello e la distribuzione dello stimatore
Per poter fare inferenza sul coefficiente di regressione nella popolazione (\(\beta_1\)) a partire dalla stima campionaria (\(\hat{\beta}_1\) o \(b_1\)) è necessario chiarire quali proprietà statistiche abbia lo stimatore. Nel modello di regressione bivariata, la stima dei minimi quadrati della pendenza è
\[ \hat{\beta}_1 = \frac{\sum_{i=1}^n (X_i - \bar{X})(Y_i - \bar{Y})}{\sum_{i=1}^n (X_i - \bar{X})^2}. \]
Poiché questo valore dipende dal particolare campione osservato, \(\hat{\beta}_1\) è una variabile casuale. Comprenderne il comportamento richiede di esplicitare le assunzioni del modello.
1. Le assunzioni di Gauss-Markov.
Le condizioni note come assunzioni di Gauss-Markov garantiscono che lo stimatore dei minimi quadrati sia il migliore stimatore lineare corretto (BLUE, Best Linear Unbiased Estimator):
- linearità (nei parametri): il valore atteso della variabile di risposta \(Y\), dato \(X\), è una funzione lineare: \(\operatorname{E}(Y_i \mid X_i) = \beta_0 + \beta_1 X_i\).
- campionamento casuale e indipendenza: le coppie di osservazioni \((X_i, Y_i)\) sono estratte in modo casuale e sono indipendenti tra loro.
- esogeneità (media condizionata nulla degli errori): dato \(X\), l’errore \(\varepsilon_i\) ha media zero: \(\operatorname{E}(\varepsilon_i \mid X_i) = 0\). La violazione di questa assunzione comporta stime distorte (bias).
- omoschedasticità: la varianza dell’errore è costante per tutti i valori di \(X\): \(\operatorname{Var}(\varepsilon_i \mid X_i) = \sigma^2\).
- variabilità del predittore: la variabile \(X\) non è costante: \(\sum_{i=1}^n (X_i - \bar{X})^2 > 0\).
Per ottenere risultati esatti nei piccoli campioni è inoltre necessaria un’ulteriore condizione:
- normalità degli errori: \(\varepsilon_i \mid X_i \sim N(0, \sigma^2)\).
2. La distribuzione campionaria di \(\hat{\beta}_1\).
Sotto le assunzioni precedenti (e, per l’inferenza esatta, sotto la normalità), la distribuzione campionaria di \(\hat{\beta}_1\) ha le seguenti tre proprietà fondamentali:
- correttezza (non distorsione): il valore atteso dello stimatore coincide con il parametro vero della popolazione: \(\operatorname{E}(\hat{\beta}_1) = \beta_1\). In altre parole, se lo studio fosse replicato un numero molto elevato di volte, la media delle stime ottenute convergerebbe al valore “vero” del parametro.
- varianza: la variabilità dello stimatore attorno al suo valore atteso è data da \[ \operatorname{Var}(\hat{\beta}_1) = \frac{\sigma^2}{\sum_{i=1}^n (X_i - \bar{X})^2}. \] Poiché \(\sigma^2\) è sconosciuta, la si sostituisce con la varianza residua \(s_e^2 = \frac{\sum e_i^2}{n-2}\). L’errore standard di \(\hat{\beta}_1\), che quantifica la precisione della stima, è quindi: \[ \operatorname{SE}(\hat{\beta}_1) = \sqrt{\frac{s_e^2}{\sum (X_i - \bar{X})^2}}. \]
-
forma della distribuzione:
- con errori normali, \(\hat{\beta}_1\) è esattamente normale per qualsiasi dimensione campionaria \(n\).
- con errori non normali, per campioni ampi \(\hat{\beta}_1\) è comunque approssimativamente normale grazie al Teorema del Limite Centrale.
3. L’utilizzo pratico: l’inferenza statistica
La distribuzione campionaria di \(\hat{\beta}_1\) consente di quantificare l’incertezza della stima e quindi di effettuare inferenza.
- Test di ipotesi. Per valutare, ad esempio, \(H_0: \beta_1 = 0\), si utilizza la statistica test \(t = \frac{\hat{\beta}_1}{\operatorname{SE}(\hat{\beta}_1)}\), la cui distribuzione sotto \(H_0\) è nota.
- Intervalli di confidenza. Un intervallo plausibile per \(\beta_1\) si costruisce come \(\hat{\beta}_1 \pm t_{n-2,\,0.975} \times \operatorname{SE}(\hat{\beta}_1)\).
In sintesi, la distribuzione campionaria di \(\hat{\beta}_1\) descrive come la stima del coefficiente angolare varia da un campione all’altro. Conoscerne le proprietà, ovvero correttezza, dispersione e approssimazione normale, è essenziale per interpretare i risultati di una regressione frequentista e per formulare conclusioni attendibili sulla popolazione di riferimento.3
NotaEsempio in R
Calcoliamo la distribuzione campionaria di \(\hat{\beta}_1\). Iniziamo simulando un modello lineare bivariato con variabili standardizzate:
\[ Y_i = \beta X_i + \varepsilon_i, \quad \varepsilon_i \sim N(0, \sigma_\varepsilon = 0.5), \] con \(\beta = 1.5\) e \(n = 30\) osservazioni.
Ripetiamo il campionamento \(100{,}000\) volte per approssimare la distribuzione campionaria di \(\hat{\beta}_1\).
# Parametri
beta <- 1.5 # pendenza vera
sigma_e <- 0.5 # deviazione standard errori
n <- 30 # dimensione campione
nrep <- 1e5 # numero repliche
# X fissata una volta (come nelle assunzioni di Gauss-Markov)
x <- rnorm(n, mean = 0, sd = 1)
# Stime memorizzate
b_hat <- numeric(nrep)
# Simulazione
for (i in 1:nrep) {
e <- rnorm(n, mean = 0, sd = sigma_e) # errori
y <- beta * x + e # risposta
b_hat[i] <- cov(x, y) / var(x) # formula OLS
}Esaminiamo i risultati:
# Statistiche empiriche
mean_b_hat <- mean(b_hat) # media stimata
sd_b_hat <- sd(b_hat) # deviazione standard stimata
# Errore standard teorico
se_theo <- sqrt(sigma_e^2 / sum((x - mean(x))^2))
c(media_empirica = mean_b_hat,
sd_empirica = sd_b_hat,
SE_teorico = se_theo)
#> media_empirica sd_empirica SE_teorico
#> 1.501 0.112 0.112Generiamo un grafico della distribuzione:
ggplot(data.frame(b_hat = b_hat), aes(x = b_hat)) +
geom_histogram(aes(y = after_stat(density)),
bins = 50, fill = palette_qualitative[2], alpha = 0.7) +
stat_function(fun = dnorm,
args = list(mean = mean_b_hat, sd = sd_b_hat),
linewidth = 1, color = palette_qualitative[1]) +
labs(
title = expression("Distribuzione campionaria di" ~ hat(beta)[1]),
x = expression(hat(beta)[1]),
y = "Densità"
)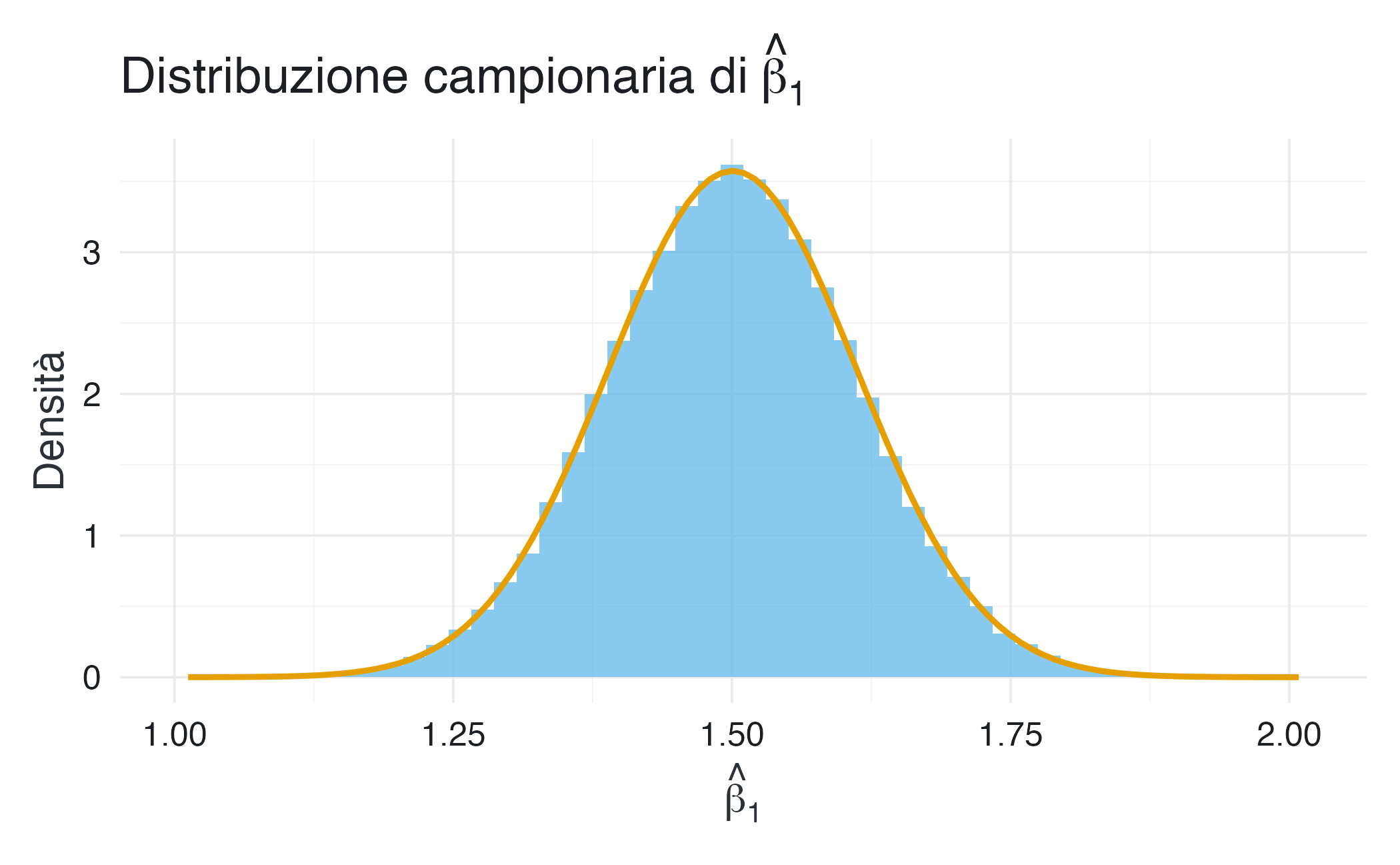
L’analisi della distribuzione campionaria dello stimatore \(\hat{\beta}_1\) conferma tre proprietà statistiche fondamentali. In primo luogo, emerge la non distorsione dello stimatore: la media empirica calcolata si attesta approssimativamente a 1.5, valore che coincide con il parametro teorico \(\beta_1\). Questo risultato fornisce una verifica empirica della proprietà per cui, sotto le assunzioni di Gauss-Markov, vale l’uguaglianza \(E(\hat{\beta}_1) = \beta_1\), indicando che lo stimatore è corretto e non sistematicamente distorto.
Per quanto riguarda la precisione dello stimatore, si osserva che la deviazione standard empirica risulta molto vicina all’errore standard teorico, definito come \(SE(\hat{\beta}_1) = \sqrt{\sigma^2 / \sum (X_i - \bar{X})^2}\). Questa corrispondenza suggerisce che la variabilità campionaria osservata è in linea con quanto previsto dal framework teorico, supportando l’affidabilità delle inferenze basate su questo stimatore.
Infine, l’esame della forma della distribuzione rivela che l’istogramma dei valori stimati è ben approssimato da una curva normale. Questo risultato conferma la normalità asintotica dello stimatore anche per un campione di dimensione moderata (\(n = 30\)), giustificando l’utilizzo della distribuzione normale per la costruzione di intervalli di confidenza e test di ipotesi in questo contesto.
Riflessioni conclusive
In questo capitolo abbiamo introdotto la regressione lineare bivariata dal punto di vista frequentista, mostrando come il metodo dei minimi quadrati permetta di stimare i parametri della retta di regressione e di quantificarne l’incertezza. Abbiamo discusso il ruolo dell’intercetta, della pendenza e della varianza residua, sottolineando le condizioni necessarie affinché il modello fornisca una sintesi affidabile dei dati. Abbiamo anche presentato gli strumenti diagnostici fondamentali per valutare la validità delle assunzioni attraverso l’analisi dei residui.
Questa cornice classica, pur ampiamente utilizzata, presenta alcuni limiti strutturali:
- l’inferenza si basa su valori-\(p\) e intervalli di confidenza, strumenti spesso fraintesi. La loro interpretazione corretta fa riferimento a esperimenti ipotetici ripetuti e non fornisce una probabilità diretta sul valore del parametro.
- non consente di integrare formalmente conoscenze pregresse, teoriche o empiriche, fornite dalla letteratura.
- richiede un insieme di assunzioni parametriche stringenti (normalità, omoschedasticità, indipendenza), la cui violazione può compromettere l’affidabilità delle conclusioni.
- non risponde in modo immediato a domande che sono naturalmente formulate in termini probabilistici, come “Qual è la probabilità che l’effetto sia positivo?”.
Per superare questi vincoli, nei capitoli successivi esamineremo la regressione lineare da una prospettiva bayesiana. Questo approccio permette di incorporare in modo esplicito le informazioni a priori, di rappresentare l’incertezza tramite distribuzioni di probabilità e di rispondere direttamente alle domande sui parametri del modello. Mostreremo come l’inferenza bayesiana consenta di fare affermazioni come “c’è il 95% di probabilità che la pendenza sia compresa tra \(a\) e \(b\)”, offrendo un’interpretazione più trasparente e più vicina al modo in cui i ricercatori ragionano in condizioni di incertezza.
ImportanteProblemi
1 – Definizione e scopi della regressione
Secondo Gelman et al. (2021), quali sono i quattro principali utilizzi della regressione? Fornisci una breve descrizione di ciascuno.
2 – Errore di specificazione
Cos’è l’“errore di specificazione” in un modello di regressione? Quali effetti ha sulle stime dei parametri?
3 – Stima del modello con lm()
Usando il data‑set kidiq (variabili kid_score e mom_iq):
Adatta il modello kid_score ~ mom_iq e riporta intercetta e pendenza.
4 – Interpretazione della pendenza
Interpreta in parole la pendenza stimata al punto 3 nel contesto dei QI di madri e figli.
5 – Indice R²
Calcola l’R² del modello di cui al punto 3. Cosa indica il suo valore?
6 – Centratura del predittore
Crea la variabile centrata mom_iq_c = mom_iq - mean(mom_iq) e ri‑adatta il modello kid_score ~ mom_iq_c. Qual è la nuova intercetta e perché adesso è più interpretabile?
7 – Calcolo manuale di \(b\)
Calcola manualmente la pendenza con la formula
\(b = \frac{\text{Cov}(x,y)}{\text{Var}(x)}\)
e confrontala col risultato di lm().
8 – Confronto tra σ̂ (tradizionale) e σ_CV
* (a) Calcola l’errore standard della regressione (σ̂) usando il modello completo.
* (b) Esegui una validazione incrociata leave‑one‑out (LOOCV) e ottieni σ_CV.
* (c) Spiega perché, in genere, σ_CV è ≥ σ̂.
9 – Assunzioni di Gauss‑Markov
Elenca le cinque assunzioni di Gauss‑Markov per la regressione lineare semplice e indica quale, se violata, rende distorto lo stimatore OLS della pendenza.
10 – Simulazione della distribuzione campionaria di \(b\)
Simula 100 000 campioni (n = 30) dal modello
\(Y_i = 1.5\,X_i + \varepsilon_i,\; X_i \sim \mathcal N(0,1),\; \varepsilon_i \sim \mathcal N(0,0.5^2)\).
Per ogni campione calcola \(b̂\). Rappresenta l’istogramma dei 100 000 \(b̂\), riporta media e deviazione standard empiriche e confrontale con l’errore standard teorico.
11 – Diagnostica dei residui
Utilizzando il modello kid_score ~ mom_iq:
(a) Genera i quattro grafici diagnostici standard con plot(mod).
(b) Descrivi cosa verifica ciascun grafico e quali assunzioni del modello permettono di valutare.
(c) Sulla base dei grafici, le assunzioni del modello appaiono ragionevolmente soddisfatte?
ConsiglioSoluzioni
1 – Definizione e scopi
1. Previsione – modellare / predire nuove osservazioni.
2. Esplorazione delle associazioni – quantificare relazioni \(X \rightarrow Y\).
3. Estrapolazione – generalizzare dal campione alla popolazione.
4. Inferenza causale – stimare l’effetto di un intervento quando il design lo consente.
2 – Errore di specificazione
Omettere un predittore rilevante ⇒ i residui assorbono la sua varianza ⇒ stime di \(b\) distorte (bias) e varianze sottostimate → inferenze non valide.
3 – Stima del modello
Esempio di output
(Intercept) mom_iq
25.800 0.610 4 – Interpretazione della pendenza
Un punto in più di QI materno è associato, in media, a 0.61 punti di QI del figlio.
5 – Indice R²
summary(mod)$r.squared
#> [1] 0.201Output ≈ 0.20 ⇒ il 20 % della varianza di kid_score è spiegato da mom_iq.
6 – Centratura
L’intercetta ora ≈ media del QI dei bambini quando il QI materno è medio.
La pendenza resta 0.61.
7 – Calcolo manuale di b
TRUE → concordanza perfetta (salvo arrotondamenti).
8 – σ̂ vs σ_CV
# (a) σ̂
sigma_hat <- summary(mod)$sigma
# (b) LOOCV
n <- nrow(kidiq)
res_cv2 <- numeric(n)
for (i in seq_len(n)){
fit_i <- lm(kid_score ~ mom_iq, data = kidiq[-i,])
res_cv2[i] <- (kidiq$kid_score[i] - predict(fit_i, kidiq[i,]))^2
}
sigma_CV <- sqrt(mean(res_cv2))
c(sigma_hat = sigma_hat, sigma_CV = sigma_CV)
#> sigma_hat sigma_CV
#> 18.3 18.3σ_CV tende a superare σ̂ perché ogni predizione è fatta su dati che non hanno “visto” quell’osservazione → niente sovradimensionamento.
9 – Assunzioni Gauss‑Markov
1. Linearità nei parametri
2. Campionamento casuale IID
3. Esogeneità \(E(\varepsilon_i\!\mid X_i)=0\) ← questa garantisce non‑distorsione
4. Omoschedasticità
5. Assenza di collinearità perfetta
10 – Simulazione
set.seed(123)
beta <- 1.5; sigma_e <- 0.5; n <- 30; nrep <- 1e5
x <- rnorm(n)
b_hat <- replicate(nrep, {
y <- beta * x + rnorm(n, sd = sigma_e)
cov(x,y) / var(x)
})
mean_emp <- mean(b_hat)
sd_emp <- sd(b_hat)
se_theo <- sqrt(sigma_e^2 / sum((x - mean(x))^2))
c(media_empirica = mean_emp, sd_empirica = sd_emp, SE_teorico = se_theo)
#> media_empirica sd_empirica SE_teorico
#> 1.5001 0.0948 0.0946L’istogramma (codice sotto) mostra la forma quasi normale centrata su 1.5.
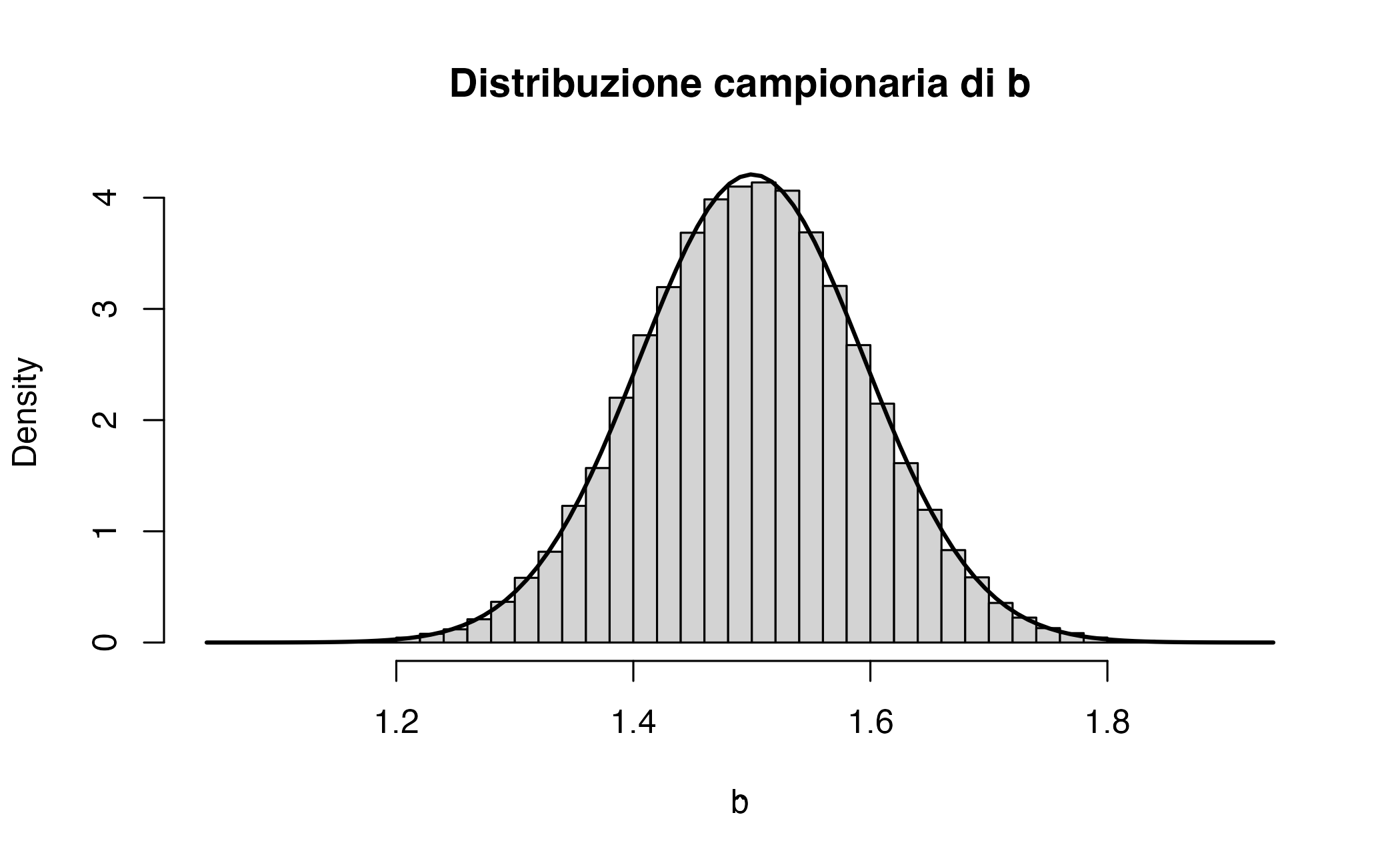
- La media empirica ≈ 1.5 ⇒ unbiased.
- La sd empirica ≈ SE teorico ⇒ formula varianza confermata.
- Distribuzione simmetrica ≈ Normale ⇒ normalità asintotica verificata.
11 – Diagnostica dei residui
- Grafici diagnostici:
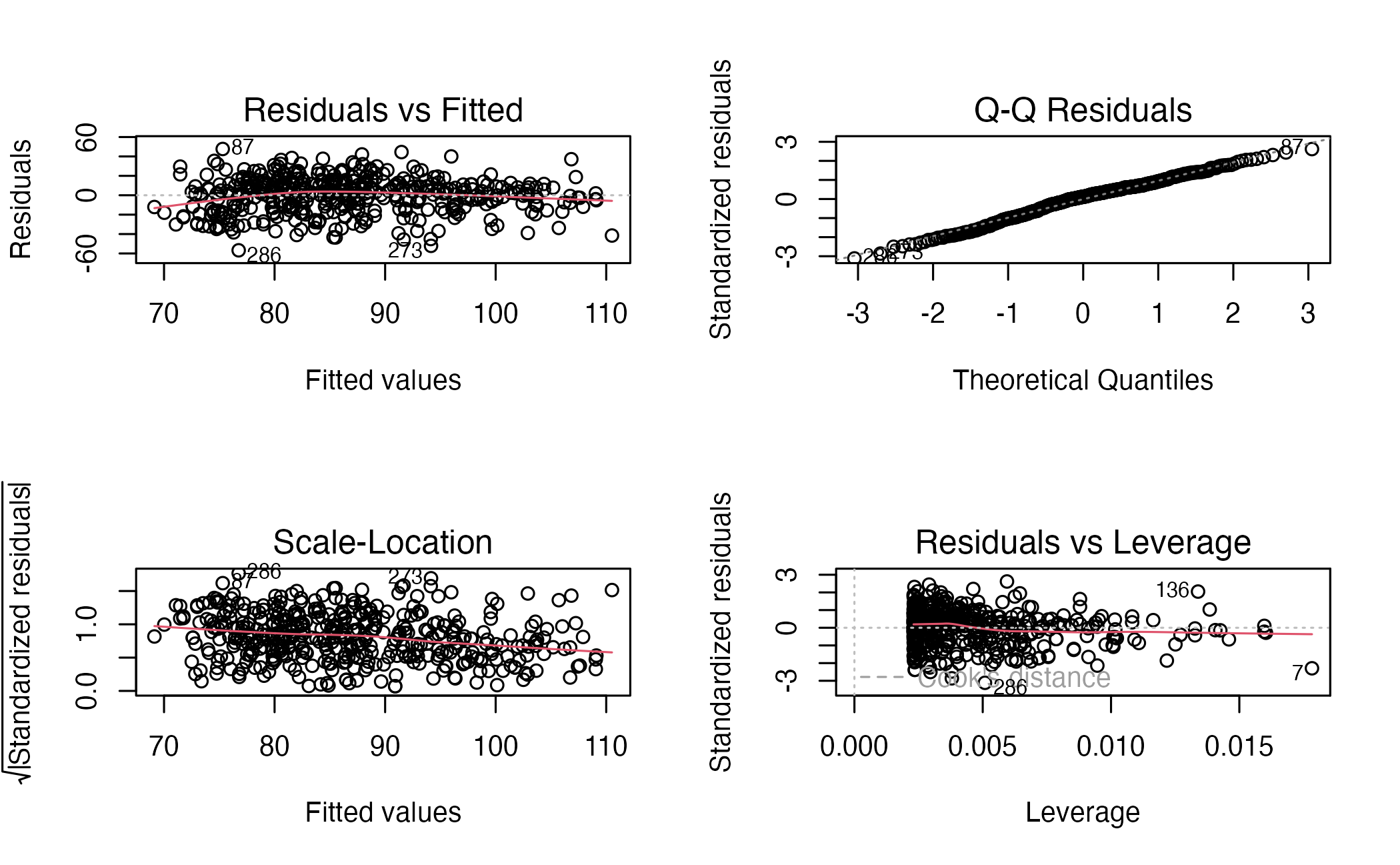
- I quattro grafici verificano:
- Residuals vs Fitted: linearità e omoschedasticità (i residui devono essere distribuiti casualmente attorno allo zero)
- Normal Q-Q: normalità degli errori (i punti devono seguire la diagonale)
- Scale-Location: omoschedasticità (la dispersione deve essere costante)
- Residuals vs Leverage: identificazione di osservazioni influenti
- Nel dataset
kidiq, le assunzioni appaiono ragionevolmente soddisfatte: i residui mostrano una distribuzione casuale, il Q-Q plot è approssimativamente lineare, e non si osservano osservazioni eccessivamente influenti.
NotaInformazioni sull’ambiente di sviluppo
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] broom_1.0.11 ragg_1.5.0 tinytable_0.15.2
#> [4] withr_3.0.2 systemfonts_1.3.1 patchwork_1.3.2
#> [7] ggdist_3.3.3 tidybayes_3.0.7 bayesplot_1.15.0
#> [10] ggplot2_4.0.1 reliabilitydiag_0.2.1 priorsense_1.2.0
#> [13] posterior_1.6.1 loo_2.9.0 rstan_2.32.7
#> [16] StanHeaders_2.32.10 brms_2.23.0 Rcpp_1.1.0
#> [19] sessioninfo_1.2.3 conflicted_1.2.0 janitor_2.2.1
#> [22] matrixStats_1.5.0 modelr_0.1.11 tibble_3.3.0
#> [25] dplyr_1.1.4 tidyr_1.3.2 rio_1.2.4
#> [28] here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] gridExtra_2.3 inline_0.3.21 sandwich_3.1-1
#> [4] rlang_1.1.6 magrittr_2.0.4 multcomp_1.4-29
#> [7] snakecase_0.11.1 otel_0.2.0 compiler_4.5.2
#> [10] mgcv_1.9-4 vctrs_0.6.5 stringr_1.6.0
#> [13] pkgconfig_2.0.3 arrayhelpers_1.1-0 fastmap_1.2.0
#> [16] backports_1.5.0 labeling_0.4.3 rmarkdown_2.30
#> [19] tzdb_0.5.0 haven_2.5.5 purrr_1.2.0
#> [22] xfun_0.55 cachem_1.1.0 jsonlite_2.0.0
#> [25] parallel_4.5.2 R6_2.6.1 stringi_1.8.7
#> [28] RColorBrewer_1.1-3 lubridate_1.9.4 estimability_1.5.1
#> [31] knitr_1.51 zoo_1.8-15 pacman_0.5.1
#> [34] R.utils_2.13.0 readr_2.1.6 Matrix_1.7-4
#> [37] splines_4.5.2 timechange_0.3.0 tidyselect_1.2.1
#> [40] abind_1.4-8 yaml_2.3.12 codetools_0.2-20
#> [43] curl_7.0.0 pkgbuild_1.4.8 lattice_0.22-7
#> [46] bridgesampling_1.2-1 S7_0.2.1 coda_0.19-4.1
#> [49] evaluate_1.0.5 survival_3.8-3 RcppParallel_5.1.11-1
#> [52] pillar_1.11.1 tensorA_0.36.2.1 checkmate_2.3.3
#> [55] stats4_4.5.2 distributional_0.5.0 generics_0.1.4
#> [58] rprojroot_2.1.1 hms_1.1.4 rstantools_2.5.0
#> [61] scales_1.4.0 xtable_1.8-4 glue_1.8.0
#> [64] emmeans_2.0.1 tools_4.5.2 forcats_1.0.1
#> [67] mvtnorm_1.3-3 grid_4.5.2 QuickJSR_1.8.1
#> [70] colorspace_2.1-2 nlme_3.1-168 cli_3.6.5
#> [73] textshaping_1.0.4 svUnit_1.0.8 Brobdingnag_1.2-9
#> [76] V8_8.0.1 gtable_0.3.6 R.methodsS3_1.8.2
#> [79] digest_0.6.39 TH.data_1.1-5 htmlwidgets_1.6.4
#> [82] farver_2.1.2 R.oo_1.27.1 memoise_2.0.1
#> [85] htmltools_0.5.9 lifecycle_1.0.4 MASS_7.3-65Bibliografia
Caudek, C., & Luccio, R. (2001). Statistica per psicologi (III rist. 2023, Vol. 11, p. 320). Laterza.
Gelman, A., Hill, J., & Vehtari, A. (2021). Regression and other stories. Cambridge University Press.
Schervish, M. J., & DeGroot, M. H. (2014). Probability and statistics (Vol. 563). Pearson Education London, UK:
Per un ripasso sulla funzione lineare, si veda l’Appendice Q.↩︎
La leva quantifica quanto il vettore dei predittori di un’osservazione sia distante dalla configurazione tipica dei dati nello spazio delle variabili indipendenti. Un punto con leva elevata occupa una regione periferica o isolata di questo spazio e, per la natura dei minimi quadrati, tende a “tirare” la retta (o il piano) di regressione verso di sé, producendo una stima più interpolante nella sua direzione. Tuttavia, il suo impatto complessivo dipende anche dal residuo: solo quando a un’alta leva si associa uno scostamento marcato tra il valore osservato e il valore predetto, l’osservazione diventa realmente influente, ovvero modifica in modo sostanziale le stime dei coefficienti.↩︎
Per un approfondimento sull’approccio frequentista alla regressione, si veda, per esempio, Caudek & Luccio (2001).↩︎