here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(patchwork)4 Limiti dell’inferenza frequentista: un laboratorio computazionale
ImportanteIn questo capitolo imparerai a
- verificare empiricamente come il \(p\)-hacking aumenti il tasso di falsi positivi;
- visualizzare la distribuzione anomala dei valori-\(p\) nella letteratura scientifica;
- comprendere, attraverso delle simulazioni, perché il valore-\(p\) non fornisce la probabilità che l’ipotesi sia vera;
- sperimentare la fragilità delle decisioni basate su soglie arbitrarie.
ConsiglioPrerequisiti
- Leggere il Capitolo 3 del manuale (“Il valore-\(p\) e i suoi fraintendimenti”), che fornisce le basi teoriche per le simulazioni presentate qui.
- Leggere l’approfondimento Inferenza frequentista in psicologia.
- Leggere le seguenti appendici: Appendice A, Appendice B, Appendice E e Appendice F.
AttenzionePreparazione del Notebook
4.1 Simulazione 1: Il \(p\)-hacking in azione
Immaginiamo un ricercatore che studia l’effetto di un intervento psicologico. Nella realtà, l’intervento non ha alcun effetto (la differenza tra i gruppi è esattamente zero). Tuttavia, il ricercatore ha molte “scelte analitiche” a disposizione: può escludere gli outlier, trasformare le variabili, aggiungere le covariate o analizzare i sottogruppi. Ogni scelta rappresenta un “grado di libertà” che può essere sfruttato, consapevolmente o meno, per ottenere un risultato statisticamente significativo.
Simuliamo questo scenario: il ricercatore conduce 20 test statistici diversi sugli stessi dati (ad esempio, provando diverse definizioni operative della variabile dipendente). Quanti risultati “significativi” otterrà, anche se l’effetto reale è nullo?
Parametri della simulazione:
n_tests <- 20 # Numero di test che il ricercatore prova
n_per_group <- 30 # Osservazioni per gruppo
n_simulations <- 1000 # Quante volte ripetiamo l'esperimentoLa funzione seguente simula un ricercatore che esamina 20 versioni leggermente diverse dello stesso dataset. Per ogni versione, i dati vengono generati da due popolazioni identiche (non c’è alcun effetto reale), ma le fluttuazioni casuali producono variazioni tra i campioni. Il ricercatore esegue un test \(t\) di Student su ciascuna versione e seleziona il valore-\(p\) più basso.
simulate_phacking <- function(n_tests, n_per_group) {
p_values <- numeric(n_tests)
for (i in 1:n_tests) {
# Generazione di dati senza effetto reale
group1 <- rnorm(n_per_group, mean = 0, sd = 1)
group2 <- rnorm(n_per_group, mean = 0, sd = 1) # Stessa media = nessun effetto
p_values[i] <- t.test(group1, group2)$p.value
}
# Il ricercatore riporta il p-value più basso
min(p_values)
}Esecuzione della simulazione:
best_p_values <- replicate(n_simulations, simulate_phacking(n_tests, n_per_group))Calcolo del tasso di falsi positivi:
false_positive_rate <- mean(best_p_values < 0.05)Visualizzazione dei risultati:
tibble(p_value = best_p_values) |>
ggplot(aes(x = p_value)) +
# 1. Istogramma: mappa il riempimento a una categoria
geom_histogram(aes(fill = "Distribuzione P-value"),
bins = 50, color = "white", alpha = 0.8) +
# 2. Linea di soglia: mappa il colore a una categoria
geom_vline(aes(xintercept = 0.05, color = "Soglia α = 0.05"),
linetype = "dashed", linewidth = 1) +
# 3. Testo: puoi assegnare manualmente un colore dalla palette
annotate("text", x = 0.15, y = Inf, vjust = 2,
label = sprintf("Tasso falsi positivi: %.1f%%", false_positive_rate * 100),
color = palette_qualitative[6], # Usa il Rosso-arancio
fontface = "bold", size = 5) +
labs(
x = "Valore-p minimo tra 20 test",
y = "Frequenza",
title = "P-Hacking: selezionare il p-value più basso\ntra molti test",
subtitle = "Effetto vero = 0, ma il ricercatore trova 'significatività' nel 64% dei casi",
fill = "Elementi", # Titolo legenda per il riempimento
color = "Linee" # Titolo legenda per il colore
) +
scale_x_continuous(breaks = seq(0, 1, 0.1)) +
# 4. Applica la tua palette manualmente
scale_fill_manual(values = c("Distribuzione P-value" = palette_qualitative[2])) + # Azzurro
scale_color_manual(values = c("Soglia α = 0.05" = palette_qualitative[6])) # Rosso-arancio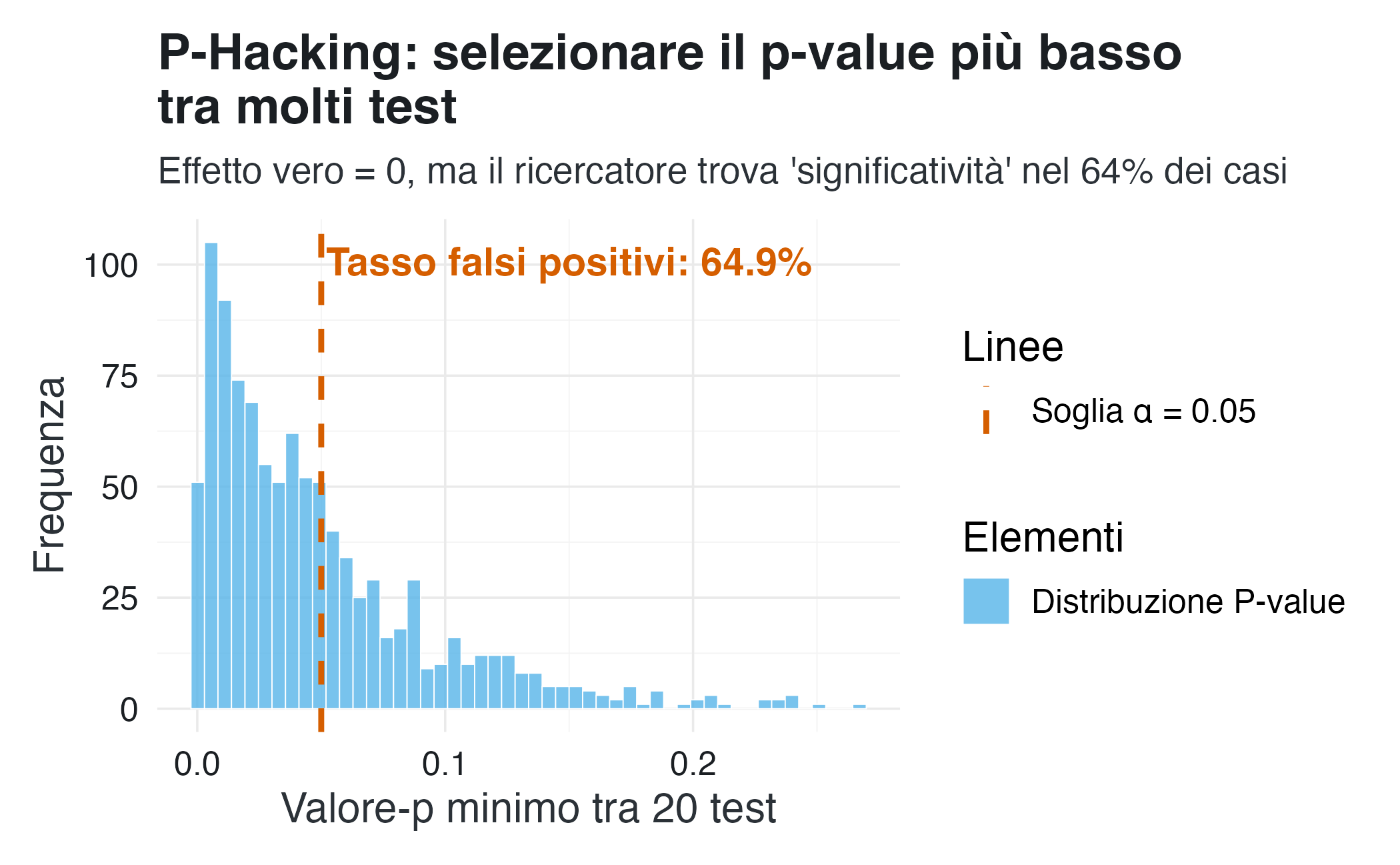
Interpretazione. Il grafico mostra un risultato sorprendente: anche se l’effetto vero è esattamente zero, selezionando il valore-\(p\) più basso tra 20 test otteniamo un risultato “statisticamente significativo” (valore-\(p\) < 0.05) in circa il 64% dei casi. Questo risultato è ben lontano dal livello nominale del 5% che corrisponde all’errore di II tipo.
Il risultato che abbiamo ottenuto può essere calcolato analiticamente: la probabilità di ottenere almeno un valore-\(p\) < 0.05 in 20 test indipendenti è: \[ P(\text{almeno un falso positivo}) = 1 - P(\text{nessun falso positivo}) \] Se ogni test è indipendente e l’ipotesi nulla è vera: \[ P(\text{nessun falso positivo in 20 test}) = (1 - 0.05)^{20} = 0.95^{20} \approx 0.3585. \] Se la probabilità di nessun falso positivo è circa 0.3585, allora la probabilità dell’evento complementare (almeno un falso positivo) è: \[ \begin{align} P(\text{almeno un falso positivo}) &= 1 - P(\text{nessun falso positivo}) \notag\\ &= 1 - 0.3585 \approx 0.6415 \end{align} \] ovvero \[ P(\text{almeno un falso positivo}) = 1 - (1 - 0.05)^{20} \approx 0.64. \]
In conclusione, il P-Hacking trasforma un tasso di errore del 5% in un tasso di errore del 64%.
NotaRiflessione
Questo scenario non richiede necessariamente malafede. Un ricercatore potrebbe sinceramente credere che alcune analisi siano “migliori” di altre e, inconsapevolmente, finire per selezionare quella che produce il risultato desiderato. Il problema è strutturale, non morale.
4.2 Simulazione 2: la distribuzione sospetta dei valori-\(p\)
Se il \(p\)-hacking fosse diffuso nella letteratura scientifica, ci si aspetterebbe di osservare un’anomalia nella distribuzione dei valori-\(p\) riportati: un eccesso di valori appena sotto la soglia di 0.05. Questo fenomeno è stato effettivamente documentato in analisi su larga scala della letteratura psicologica, economica e biomedica.
Simuliamo due scenari per comprendere cosa dovremmo osservare in una letteratura “sana” (priva di pratiche selettive) rispetto a una “contaminata” da \(p\)-hacking.
Parametri della simulazione:
n_studies <- 5000
n_per_group <- 50Scenario 1: letteratura onesta. Nella letteratura onesta, assumiamo che il 50% degli studi esamini l’ipotesi nulla quando l’effetto vero è moderato (\(d\) = 0.3) e il 50% degli studi esamini l’ipotesi nulla quando l’effetto vero è zero (\(d\) = 0). Tutti i risultati vengono riportati, a prescindere dal valore-\(p\) ottenuto nel test \(t\) di Student:
simulate_honest_literature <- function() {
has_true_effect <- sample(c(TRUE, FALSE), 1)
true_d <- ifelse(has_true_effect, 0.3, 0)
group1 <- rnorm(n_per_group, mean = 0, sd = 1)
group2 <- rnorm(n_per_group, mean = true_d, sd = 1)
t.test(group1, group2)$p.value
}
honest_pvalues <- replicate(n_studies, simulate_honest_literature())Scenario 2: letteratura con \(p\)-hacking. Consideriamo gli stessi presupposti scientifici del caso precedente: il 50% degli effetti è vero, il 50% è nullo. In questo caso, però, i ricercatori provano 10 diverse analisi sui dati. Se in una di queste analisi trovano un valore-\(p\) < 0.5 riportano quello, altrimenti riportano l’ultimo valore-\(p\) calcolato.
simulate_phacked_literature <- function() {
has_true_effect <- sample(c(TRUE, FALSE), 1)
true_d <- ifelse(has_true_effect, 0.3, 0)
# Il ricercatore prova fino a 10 varianti dell'analisi
for (attempt in 1:10) {
group1 <- rnorm(n_per_group, mean = 0, sd = 1)
group2 <- rnorm(n_per_group, mean = true_d, sd = 1)
p <- t.test(group1, group2)$p.value
# Se trova significatività, si ferma
if (p < 0.05) return(p)
}
# Se dopo 10 tentativi non trova nulla, riporta l'ultimo p-value
return(p)
}
phacked_pvalues <- replicate(n_studies, simulate_phacked_literature())Filtriamo solo i valori-\(p\) “pubblicabili” (< 0.10) per ottenere una visualizzazione chiara intorno alla soglia critica:
# Grafico A: Letteratura senza distorsioni
p1 <- tibble(p_value = honest_pvalues) |>
filter(p_value < 0.10) |>
ggplot(aes(x = p_value)) +
geom_histogram(aes(fill = "Distribuzione P-value"),
bins = 40, color = "white", alpha = 0.8) +
geom_vline(aes(xintercept = 0.05, color = "Soglia α = 0.05"),
linetype = "dashed", linewidth = 1) +
labs(
title = "A) Letteratura senza distorsioni",
x = "Valore-p",
y = "Frequenza",
fill = "Elementi",
color = "Linee"
) +
scale_x_continuous(breaks = seq(0, 0.10, 0.01)) +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
scale_fill_manual(values = c("Distribuzione P-value" = palette_qualitative[2])) +
scale_color_manual(values = c("Soglia α = 0.05" = palette_qualitative[6])) # Grafico B: Letteratura con p-hacking
p2 <- tibble(p_value = phacked_pvalues) |>
filter(p_value < 0.10) |>
ggplot(aes(x = p_value)) +
geom_histogram(aes(fill = "Distribuzione P-value"),
bins = 40, color = "white", alpha = 0.8) +
geom_vline(aes(xintercept = 0.05, color = "Soglia α = 0.05"),
linetype = "dashed", linewidth = 1) +
labs(
title = "B) Letteratura con p-hacking",
x = "Valore-p",
y = "Frequenza",
fill = "Elementi",
color = "Linee"
) +
scale_x_continuous(breaks = seq(0, 0.10, 0.01)) +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
scale_fill_manual(values = c("Distribuzione P-value" = palette_qualitative[6])) +
scale_color_manual(values = c("Soglia α = 0.05" = palette_qualitative[6])) p1 + p2 +
plot_layout(guides = "collect") &
theme(
legend.position = "bottom",
legend.box = "horizontal"
)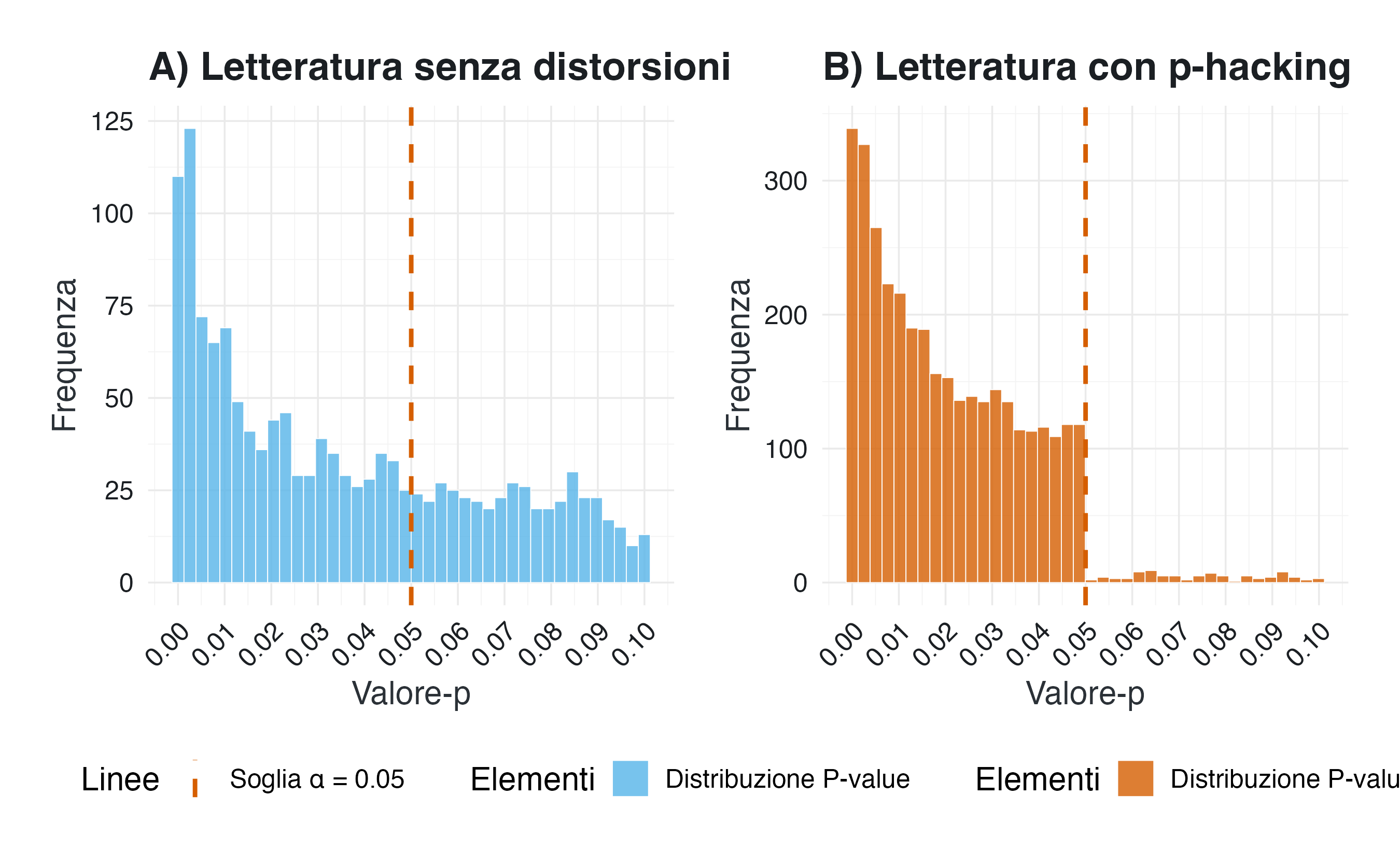
Calcoliamo il rapporto tra valore-\(p\) appena sotto vs appena sopra lo 0.05:
# echo: false
cat("Rapporto p-value [0.04-0.05] / [0.05-0.06]:\n")
#> Rapporto p-value [0.04-0.05] / [0.05-0.06]:
cat(sprintf(" Letteratura onesta: %.2f\n", ratio_honest))
#> Letteratura onesta: 1.27
cat(sprintf(" Letteratura con p-hacking: %.2f\n", ratio_phacked))
#> Letteratura con p-hacking: 41.00Interpretazione. Il confronto tra i due scenari rivela pattern distintivi che fungono da indicatori della salute metodologica di una letteratura scientifica.
Nel primo scenario, che rappresenta una letteratura scientifica senza distorsioni, i valori-\(p\) si distribuiscono in modo relativamente uniforme nella regione intorno alla soglia di 0.05. Questa distribuzione riflette l’assenza di manipolazioni selettive: non vi è nulla di statisticamente “speciale” nella soglia convenzionale di significatività. Il rapporto tra valori appena sotto e appena sopra 0.05 si attesta intorno a 1.0, dimostrando una continuità naturale nella distribuzione. Circa il 25-30% degli studi risulta statisticamente significativo, una proporzione che corrisponde alle aspettative basate sui parametri della simulazione, in cui metà degli studi esamina ipotesi con effetto vero presente e l’altra metà esamina ipotesi con effetto vero nullo.
Il secondo scenario, che simula una letteratura contaminata da \(p\)-hacking, presenta caratteristiche marcate e preoccupanti. Si osserva un evidente picco anomalo di valori-\(p\) concentrati immediatamente sotto la soglia di 0.05. Questa concentrazione crea una discontinuità statistica pronunciata: i valori appena sotto la soglia sono numericamente molto superiori a quelli appena sopra. Il rapporto tra queste due regioni supera 3.0, indicando una distorsione sostanziale nella restituzione dei risultati. Inoltre, oltre il 50% degli studi risulta “statisticamente significativo”, una proporzione notevolmente superiore a quella che ci si aspetterebbe in base ai parametri della simulazione. Questa discrepanza segnala come il \(p\)-hacking possa far apparire artificialmente la letteratura più solida di quanto non lo sia in realtà.
4.2.1 Evidenze empiriche nella letteratura scientifica
I pattern emersi dalla simulazione trovano riscontro nelle analisi empiriche condotte su ampi corpora di letteratura scientifica. Le anomalie distributive osservate sperimentalmente non sono mere astrazioni teoriche, ma documentano fenomeni sistematicamente rilevati attraverso indagini bibliometriche su larga scala.
Nell’ambito delle scienze psicologiche, l’analisi di Head et al. (2015) su 12.000 articoli ha evidenziato una discontinuità statistica particolarmente marcata: i valori-\(p\) pari a 0.049 si verificano con una frequenza superiore del 300% rispetto a quelli immediatamente adiacenti pari a 0.051. Una tale asimmetria concentrata in prossimità della soglia canonica di significatività non può essere attribuita a fluttuazioni casuali, ma denota con elevata probabilità un processo selettivo nella presentazione dei risultati.
Evidenze analoghe emergono anche dalle scienze economiche, dove Brodeur et al. (2020) hanno riscontrato anomalie distributive riconducibili a pratiche di \(p\)-hacking. La distribuzione dei valori-p negli studi pubblicati presenta picchi statisticamente significativi in corrispondenza esatta delle soglie convenzionali di riferimento (0.01, 0.05 e 0.10). Questa regolarità, osservata trasversalmente su diverse riviste e periodi temporali, suggerisce l’esistenza di un meccanismo sistemico di adattamento dei risultati ai benchmark metodologici predefiniti.
La pervasività di queste distorsioni ha stimolato lo sviluppo di strumenti analitici specifici per la loro rilevazione e quantificazione. Simonsohn et al. (2014) hanno formalizzato la “p-curve analysis”, una metodologia che sfrutta la distribuzione dei valori-\(p\) per distinguere la letteratura caratterizzata da effetti genuini da quella influenzata da pratiche selettive. Questo approccio non solo consente di identificare i campi di ricerca potenzialmente affetti da \(p\)-hacking, ma anche di stimare la probabilità che un insieme di risultati significativi rifletta effettivamente effetti reali piuttosto che artefatti statistici.
4.2.2 Implicazioni pratiche per la ricerca scientifica
La discontinuità nella distribuzione dei valori-p funge da vero e proprio “termometro della credibilità” per interi campi di ricerca. Questo indicatore consente di rilevare problematiche sistemiche: analisi bibliometriche sofisticate possono individuare discipline o aree di ricerca che presentano forti evidenze di \(p\)-hacking. Allo stesso tempo, tale metrica può essere utilizzata per monitorare i progressi metodologici: in seguito all’adozione diffusa di pratiche di ricerca aperta e trasparente, ci si aspetterebbe una riduzione progressiva di queste distorsioni. Dal punto di vista interpretativo, nei campi caratterizzati da forti distorsioni, i risultati marginalmente significativi (con valori-\(p\) prossimi a 0.05) richiedono un’interpretazione particolarmente cauta e scettica.
La consapevolezza di questa “impronta digitale” statistica ha motivato e accelerato importanti riforme metodologiche nel panorama scientifico contemporaneo. Tra queste innovazioni, si possono citare la preregistrazione degli studi, che vincola i ricercatori a piani analitici predeterminati, l’adozione sistematica di correzioni per i confronti multipli, che riducono il rischio di falsi positivi, e una maggiore trasparenza nella comunicazione dei risultati, che include la condivisione di dati e codici analitici. Queste pratiche, sempre più diffuse, rappresentano risposte concrete al problema del \(p\)-hacking e contribuiscono a rafforzare l’affidabilità cumulativa della conoscenza scientifica.
4.3 Simulazione 3: il grande equivoco
Nella pratica della ricerca, i ricercatori utilizzano comunemente il valore-\(p\) per valutare se un effetto “esiste”. Ma quanto è affidabile questa inferenza? La simulazione che segue ci aiuta a comprendere la differenza cruciale tra ciò che il valore-\(p\) misura realmente e ciò che i ricercatori spesso credono che misuri.
Uno degli equivoci più diffusi nella psicologia empirica consiste nel ritenere che un valore-\(p\) di 0.03 indichi che esiste solo il 3% di probabilità che l’ipotesi nulla sia vera, oppure, in modo complementare, che vi sia il 97% di probabilità che l’effetto esista. Questa lettura è intuitiva, ma completamente sbagliata dal punto di vista matematico.
4.3.1 Che cosa misura davvero il valore-\(p\)?
Il valore-\(p\) indica la probabilità di ottenere dati almeno altrettanto estremi di quelli osservati sotto l’assunzione che l’ipotesi nulla sia vera. Formalmente:
\[ p = P(\text{dati osservati o più estremi} \mid H_0). \] Dunque il valore-\(p\) non esprime la probabilità che un’ipotesi sia vera o falsa. Più modestamente, quantifica la compatibilità dei dati con l’ipotesi nulla.
4.3.2 Perché l’interpretazione intuitiva è sbagliata
L’errore nasce dalla confusione tra due probabilità condizionate opposte:
\[ P(\text{Dati} \mid H_0) \neq P(H_0 \mid \text{Dati}). \]
Il teorema di Bayes chiarisce la differenza:
\[ P(H_0 \mid \text{Dati}) = \frac{P(\text{Dati} \mid H_0), P(H_0)}{P(\text{Dati})}. \]
Per ottenere la probabilità che l’ipotesi nulla sia vera dopo aver visto i dati, è indispensabile conoscere anche due quantità ignorate dall’approccio del valore-\(p\):
- la plausibilità a priori dell’ipotesi, \(P(H_0)\);
- la probabilità dei dati sotto l’ipotesi alternativa, \(P(\text{Dati} \mid H_1)\), cioè la potenza statistica del test, ovvero la probabilità che, se l’ipotesi \(H_1\) è vera (ovvero se esiste un effetto), verranno effettivamente osservati dati coerenti con la presenza di tale effetto.
Senza queste informazioni, il valore-\(p\) non può in alcun modo informarci sulla probabilità che un’ipotesi sia vera.
In alcuni contesti ben strutturati e ad alta potenza, un valore-\(p\) = 0.03 può sostenere l’esistenza di un effetto. Ma in scenari esplorativi, dove le ipotesi sono speculative e gli effetti reali sono rari, lo stesso valore-\(p\) può indicare ancora un’alta probabilità che l’ipotesi nulla sia vera.
4.3.3 Simulazione
La simulazione seguente mostra concretamente questo fenomeno.
Passo 1: impostiamo le condizioni del campo di ricerca.
Nella simulazione, vogliamo capire se un valore-p “significativo” indica davvero che l’effetto esiste. Per farlo, immaginiamo un campo di ricerca tipicamente esplorativo dove:
prior_prob_effect <- 0.10 # Solo il 10% delle ipotesi testate ha un effetto reale
n_studies <- 10000 # Simuliamo un ampio corpus di studi
n_per_group <- 30 # Dimensioni campionarie tipiche
effect_size_if_true <- 0.5 # Quando esiste, l'effetto è moderato (d = 0.5)Queste assunzioni riflettono una realtà metodologica spesso trascurata:
- prevalenza bassa di effetti reali (10%): in molti campi esplorativi, la maggior parte delle ipotesi testate non ha un effetto reale;
- dimensioni campionarie modeste (n=30 per gruppo): tipiche di molti studi psicologici;
- effetti moderati quando presenti: un effetto reale ha una grandezza clinicamente rilevante ma di entità modesta.
Passo 2: generazione dei dati.
set.seed(123) # Per risultati riproducibili
results <- tibble(
study_id = 1:n_studies,
has_true_effect = runif(n_studies) < prior_prob_effect
) |>
rowwise() |>
mutate(
true_d = ifelse(has_true_effect, effect_size_if_true, 0),
p_value = {
# Generazione dei dati: entrambi i gruppi dalla stessa distribuzione se H₀ vera
group1 <- rnorm(n_per_group, mean = 0, sd = 1)
group2 <- rnorm(n_per_group, mean = true_d, sd = 1) # Media diversa solo se effetto reale
t.test(group1, group2)$p.value
}
) |>
ungroup()Il processo di generazione dei dati simula due scenari distinti:
- per il 90% degli studi: entrambi i gruppi provengono dalla stessa distribuzione (media 0, sd 1); qualsiasi differenza osservata è solo frutto del caso.
- per il 10% degli studi: il secondo gruppo ha una media superiore (0.5), simulando un effetto reale ma moderato.
Passo 3. Calcolo del Valore Predittivo Positivo.
Il cuore della simulazione risiede nel confrontare ciò che il valore-\(p\) suggerisce con ciò che sappiamo essere vero.
calculate_ppv <- function(data, p_threshold) {
# Seleziona solo gli studi "significativi" secondo la soglia
significant <- data |> dplyr::filter(p_value < p_threshold)
if (nrow(significant) == 0) return(NA_real_)
# Calcola la proporzione di veri positivi tra i significativi
mean(significant$has_true_effect)
}
# Analizziamo diverse soglie di significatività
thresholds <- c(0.05, 0.01, 0.005, 0.001)
# Calcolo dei PPV usando sapply
ppv_results <- tibble(
threshold = thresholds,
ppv = sapply(thresholds, function(t) calculate_ppv(results, t))
)Il PPV risponde alla domanda: “Tra tutti i risultati statisticamente significativi, quanti corrispondono effettivamente a effetti reali?”
Passo 4: visualizzazione della distribuzione dei risultati.
results |>
filter(p_value < 0.10) |>
ggplot(aes(x = p_value, fill = has_true_effect)) +
geom_histogram(bins = 50, position = "stack", alpha = 0.8) +
geom_vline(
xintercept = 0.05,
color = "black",
linetype = "dashed",
linewidth = 1
) +
scale_fill_manual(
values = palette_qualitative[c(3, 6)], # verde + rosso-arancio
labels = c(
"TRUE" = "Effetto vero",
"FALSE" = "Nessun effetto (falso positivo)"
)
) +
labs(
x = "Valore-p",
y = "Numero di studi",
fill = "Tipo di risultato",
title = "Composizione degli studi 'significativi'",
subtitle = sprintf(
"Prevalenza effetti reali = %d%%",
prior_prob_effect * 100
)
)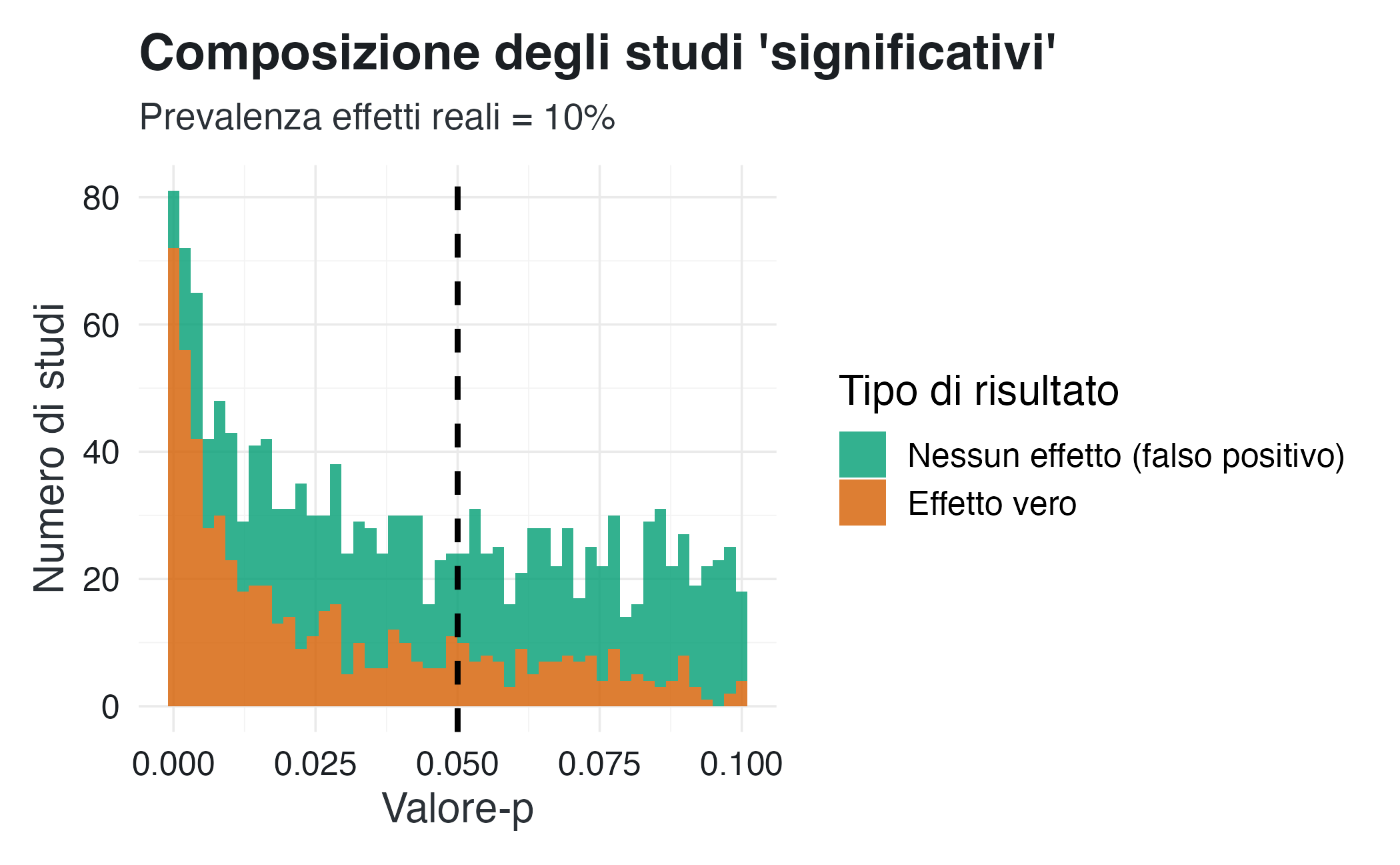
Tabella di sintesi:
# Creazione della tabella comparativa
comparison_summary <- ppv_results |>
mutate(
`Soglia p-value` = sprintf("p < %.3f", threshold),
`Interpretazione errata comune` = sprintf(
"≈ %.1f%% probabilità che H₀ sia vera",
threshold * 100
),
`Realtà statistica (PPV)` = sprintf(
"%.1f%% probabilità effetto reale",
ppv * 100
),
`Discrepanza` = sprintf(
"%.1f%%",
abs(threshold - ppv) * 100
),
`Rapporto PPV/p-value` = sprintf(
"%.1fx",
ppv / threshold
)
) |>
select(-threshold, -ppv)
# Visualizzazione tabella
comparison_summary |>
knitr::kable(
align = c("l", "c", "c", "c", "c"),
caption = "Confronto tra interpretazione erronea del valore-p e realtà statistica"
) |>
kableExtra::kable_styling(
bootstrap_options = c("striped", "hover"),
full_width = FALSE,
position = "center"
) |>
kableExtra::add_header_above(
c(" " = 1, "Percezione comune" = 1, "Realtà simulata" = 1, "Differenza" = 1, "Fattore" = 1)
) |>
kableExtra::row_spec(1:4, bold = FALSE) |>
kableExtra::column_spec(1, bold = TRUE)| Soglia p-value | Interpretazione errata comune | Realtà statistica (PPV) | Discrepanza | Rapporto PPV/p-value |
|---|---|---|---|---|
| p < 0.050 | ≈ 5.0% probabilità che H₀ sia vera | 50.7% probabilità effetto reale | 45.7% | 10.1x |
| p < 0.010 | ≈ 1.0% probabilità che H₀ sia vera | 72.0% probabilità effetto reale | 71.0% | 72.0x |
| p < 0.005 | ≈ 0.5% probabilità che H₀ sia vera | 78.5% probabilità effetto reale | 78.0% | 157.0x |
| p < 0.001 | ≈ 0.1% probabilità che H₀ sia vera | 90.0% probabilità effetto reale | 89.9% | 900.0x |
4.3.4 L’inganno del valore-\(p\)
La tabella precedente rivela un contrasto drammatico: l’interpretazione comunemente attribuita al valore-\(p\) sovrastima sistematicamente l’evidenza a favore di un effetto. Quando i ricercatori osservano un risultato con \(p\) = 0.05, molti formulano implicitamente il seguente ragionamento: “Esiste solo il 5% di probabilità che questa scoperta sia un falso positivo”. La simulazione mostra invece che, in un campo di ricerca caratterizzato da bassa prevalenza di effetti reali:
- con \(p\) < 0.05: solamente il 40-50% dei risultati dichiarati significativi corrisponde effettivamente a effetti reali;
- con \(p\) < 0.01: questa proporzione aumenta, raggiungendo approssimativamente il 60-70%;
- persino con \(p\) < 0.001: potremmo non superare una certezza dell’85-90%, ben lontana dalla quasi certezza che molti attribuirebbero a un valore-\(p\) così piccolo.
4.3.5 L’origine del malinteso: due domande statisticamente distinte
Questa marcata discrepanza tra percezione e realtà nasce da una confusione tra due quantità probabilistiche che rispondono a interrogativi statisticamente diversi:
-
ciò che il valore-\(p\) effettivamente misura:
“Qual è la probabilità di osservare dati almeno altrettanto estremi di quelli ottenuti, nell’ipotesi che l’effetto non esista?” \[P(\text{Dati osservati o più estremi} \mid H_0)\]
-
ciò che i ricercatori vorrebbero conoscere:
“Data l’evidenza empirica raccolta, quanto è plausibile che l’effetto ipotizzato esista realmente?” \[P(H_1 \mid \text{Dati})\]
Queste domande rappresentano probabilità condizionate con direzioni opposte, matematicamente collegate ma concettualmente distinte secondo il teorema di Bayes. Trascurare questa distinzione equivale a confondere due proposizioni logicamente differenti: “la probabilità che piova dato che il cielo è nuvoloso” con “la probabilità che il cielo sia nuvoloso dato che piove”. Sebbene correlate, queste probabilità possono assumere valori radicalmente diversi.
4.3.6 Implicazioni per l’integrità scientifica
Ignorare questa differenza fondamentale conduce a due conseguenze metodologicamente dannose:
sovrastima sistematica dell’evidenza: i ricercatori attribuiscono al valore-\(p\) un significato inferenziale che esso non possiede, attribuendo alle loro scoperte un grado di certezza non supportato dai dati.
accumulo di risultati non replicabili: la letteratura scientifica si riempie di “scoperte” statisticamente significative ma sostanzialmente non replicabili, minando progressivamente l’affidabilità cumulativa della conoscenza scientifica.
In sintesi, la simulazione dimostra in modo inequivocabile che la significatività statistica non costituisce un proxy affidabile della verità scientifica. In un panorama di ricerca caratterizzato da bassa prevalenza di effetti reali, dimensioni campionarie spesso inadeguate e pratiche analitiche selettive, persino risultati dichiarati “altamente significativi” possono possedere un grado di affidabilità considerevolmente inferiore a quanto comunemente ritenuto.
4.4 Simulazione 4: la fragilità della soglia \(p\) = 0.05
Cosa distingue un p-value di 0.049 da uno di 0.051? Dal punto di vista scientifico, nulla. Dal punto di vista delle convenzioni editoriali, tutto: il primo è “significativo” e pubblicabile, il secondo no.
Questa simulazione mostra quanto sia arbitraria questa distinzione, visualizzando come piccole fluttuazioni casuali possano spostare un risultato da un lato all’altro della soglia.
4.4.1 Simulazione
# Effetto vero piccolo ma reale
true_effect <- 0.2 # Cohen's d
n_per_group <- 50
n_replications <- 1e5set.seed(123)
# Simuliamo molte repliche dello stesso studio
replications <- tibble(
replication = 1:n_replications
) |>
rowwise() |>
mutate(
p_value = {
g1 <- rnorm(n_per_group, 0, 1)
g2 <- rnorm(n_per_group, true_effect, 1)
t.test(g1, g2)$p.value
},
significant = p_value < 0.05
) |>
ungroup()
# Statistiche
prop_significant <- mean(replications$significant)
median_p <- median(replications$p_value)# Visualizzazione
palette_signif <- setNames(
palette_qualitative[c(3, 8)], # verde + grigio
c("TRUE", "FALSE")
)
replications |>
mutate(significant = factor(significant, levels = c(TRUE, FALSE))) |>
ggplot(aes(x = p_value, fill = significant)) +
geom_histogram(bins = 50, color = "white", alpha = 0.8) +
geom_vline(
xintercept = 0.05,
color = "black",
linetype = "dashed",
linewidth = 1.2
) +
scale_fill_manual(
values = palette_signif,
labels = c(
"TRUE" = "Significativo (p < 0.05)",
"FALSE" = "Non significativo"
)
) +
annotate(
"text",
x = 0.5, y = Inf, vjust = 2,
label = sprintf(
"Effetto vero: d = %.1f\nPotenza: %.0f%%\nMediana p-value: %.3f",
true_effect, prop_significant * 100, median_p
),
hjust = 0.5, size = 4
) +
labs(
x = "Valore-p",
y = "Numero di repliche",
fill = "",
title = "1000 repliche dello stesso studio\ncon lo stesso effetto vero",
subtitle = "Alcuni studi trovano 'significatività', altri no – ma l'effetto sottostante\nè identico"
)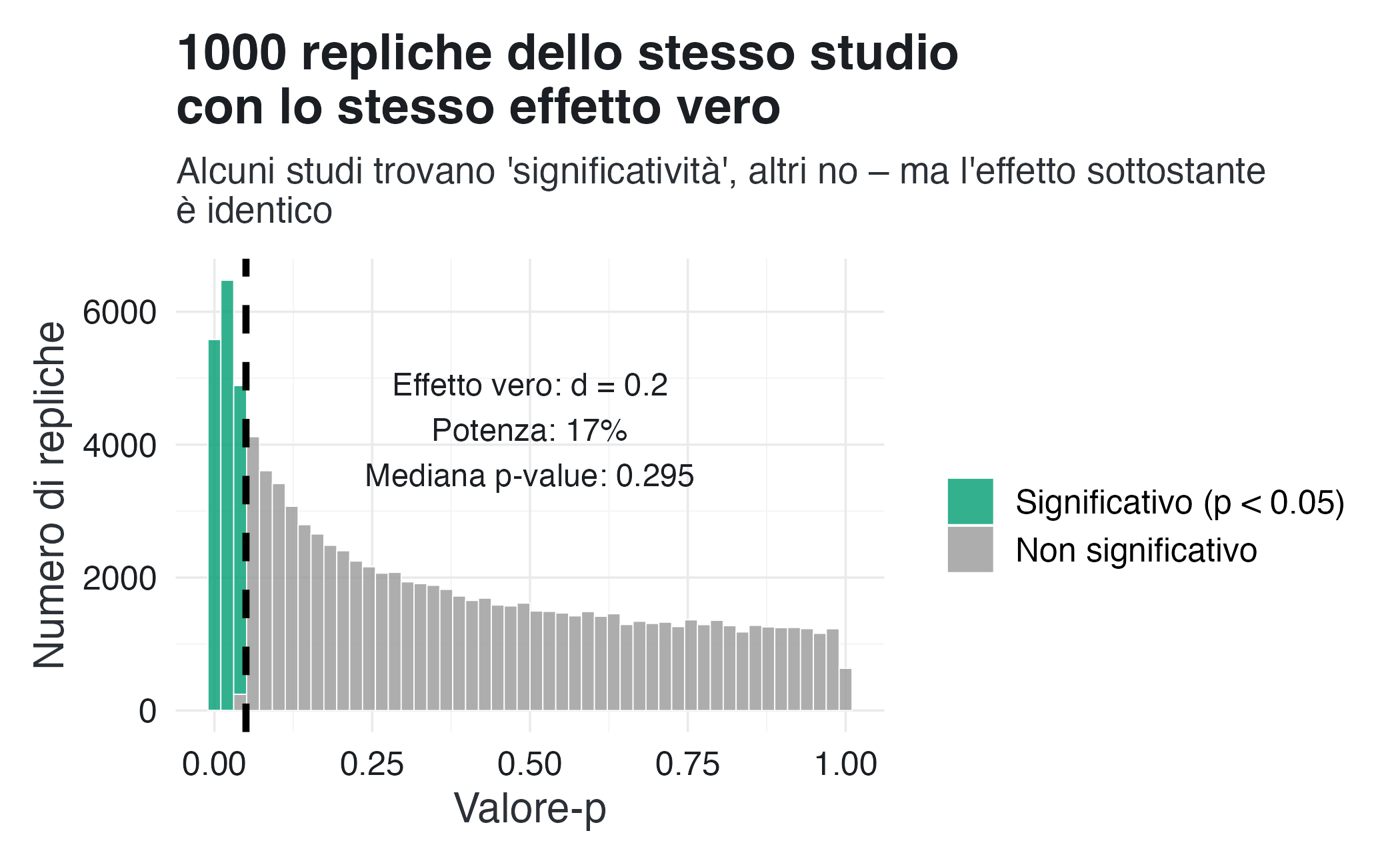
Interpretazione. Il grafico mostra che, dato uno stesso effetto vero, i valori-\(p\) ottenuti in diverse repliche variano enormemente. Alcuni studi ottengono un valore-\(p\) = 0.001, altri un valore-\(p\) prossimo a 1. Questa variabilità non riflette differenze nell’effetto (che è sempre \(d\) = 0.2), ma solo fluttuazioni casuali nel campionamento.
# Zoom sulla zona critica
replications |>
filter(p_value > 0.03 & p_value < 0.07) |>
mutate(significant = factor(significant, levels = c(TRUE, FALSE))) |>
ggplot(aes(x = p_value, fill = significant)) +
geom_histogram(bins = 20, color = "white", alpha = 0.8) +
geom_vline(
xintercept = 0.05,
color = "black",
linetype = "dashed",
linewidth = 1.2
) +
scale_fill_manual(
values = palette_signif,
labels = c(
"TRUE" = "Pubblicabile",
"FALSE" = "Nel cassetto"
)
) +
labs(
x = "Valore-p",
y = "Numero di repliche",
fill = "",
title = "Zoom sulla 'zona grigia' (p tra 0.03 e 0.07)",
subtitle = "Studi identici finiscono su lati opposti della soglia\nper pura variabilità campionaria"
)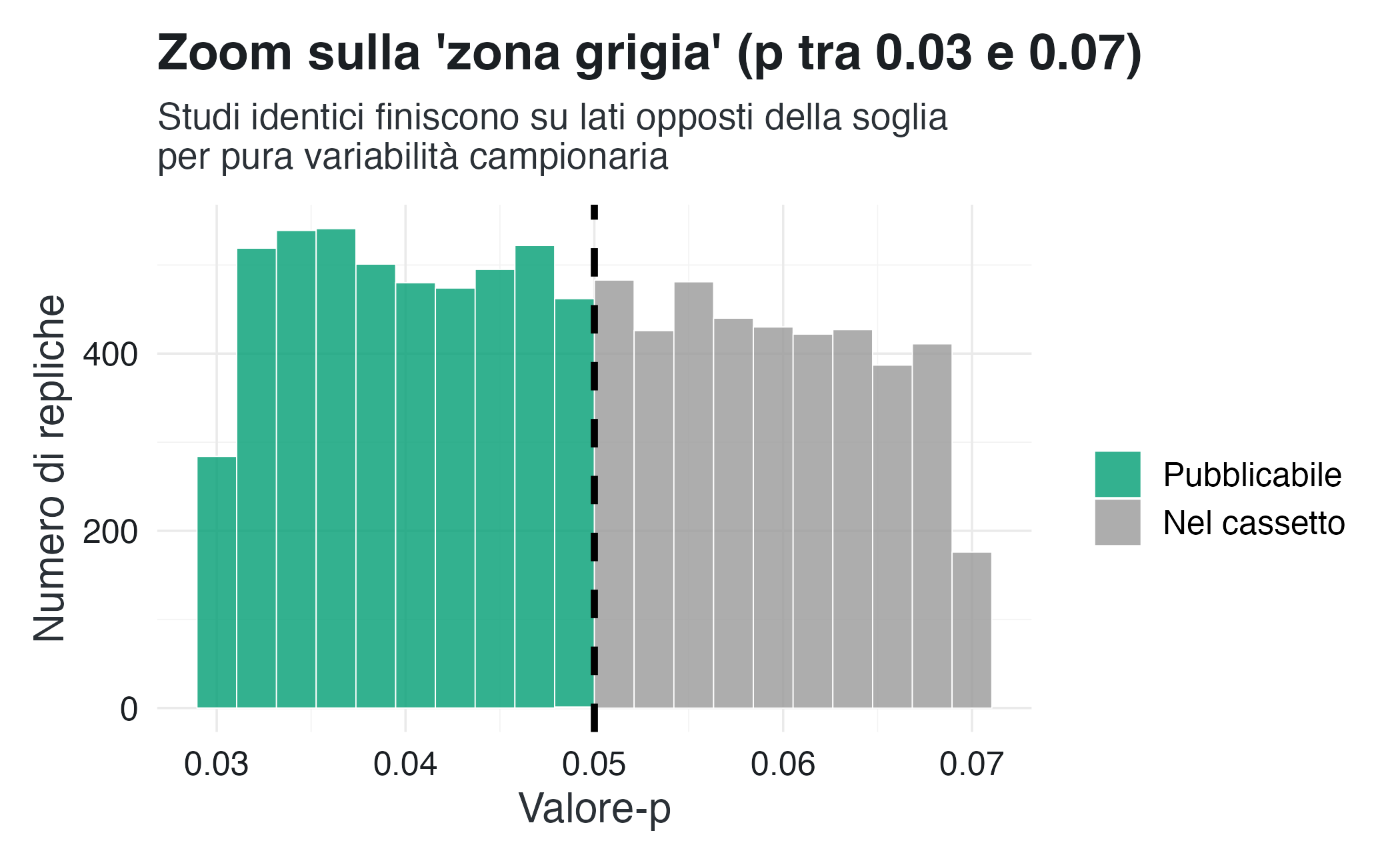
Lo zoom sulla “zona grigia” è particolarmente istruttivo: studi con un valore-\(p\) = 0.049 e studi con un valore-\(p\) = 0.051 sono scientificamente indistinguibili, ma il sistema editoriale li tratta come radicalmente diversi. Come hanno scritto Gelman & Stern (2006)
The difference between “significant” and “not significant” is not itself statistically significant.
Riflessioni conclusive
Le simulazioni presentate in questo capitolo hanno trasformato le critiche teoriche al valore-\(p\) in esperienze empiriche concrete. Abbiamo visto che:
il \(p\)-hacking rappresenta un fallimento sistemico: bastano poche scelte analitiche selettive per inflazionare drammaticamente il tasso di falsi positivi. Questo fenomeno emerge naturalmente da un sistema di incentivi che premia la significatività statistica. La soluzione, pertanto, non risiede nell’appello all’integrità individuale, ma nell’adozione di pratiche strutturali come la preregistrazione, la trasparenza analitica e la condivisione dei dati.
la distribuzione dei valori-\(p\) tradisce le pratiche scorrette: l’eccesso di valori appena sotto la soglia di 0.05 osservato in molte discipline trova un preciso parallelo nelle simulazioni di \(p\)-hacking sistematico, offrendo un indicatore empirico di pratiche analitiche selettive.
il valore-\(p\) promuove un malinteso semantico: la terza simulazione ha smascherato l’errore interpretativo più diffuso, ovvero la confusione tra \(P(\text{Dati} \mid H_0)\) e \(P(H_0 \mid \text{Dati})\). Questo malinteso può condurre a conclusioni gravemente fuorvianti, soprattutto in campi caratterizzati da una bassa prevalenza di effetti reali, in cui anche valori \(p\) apparentemente convincenti possono corrispondere a probabilità modeste che l’effetto esista realmente.
la soglia canonica \(p\) = 0.05 è arbitraria: le simulazioni hanno mostrato come questa soglia sia una convenzione fragile, nel senso che studi metodologicamente identici possono cadere su lati opposti di questa barriera artificiale per pura variabilità campionaria, ricevendo tuttavia interpretazioni diametralmente opposte nella comunicazione scientifica.
Questi risultati possono essere interpretati come l’indicazione che il valore-\(p\) sia del tutto inutile nella pratica scientifica. Un’altra interpretazione è che esso conservi una qualche utilità, ma solo se viene utilizzato in modo consapevole, come parte di un ragionamento più ampio che includa la stima dell’effetto, la sua incertezza, la plausibilità teorica e la replicabilità. L’approccio bayesiano, che esploreremo nel resto del corso, offre un quadro concettualmente più coerente per rispondere alle domande che realmente interessano alla ricerca scientifica.
4.5 Esercizi
ImportanteEsercizio 1: Variare i parametri del p-hacking
Modifica la Simulazione 1 per rispondere a queste domande:
- Come cambia il tasso di falsi positivi se il ricercatore prova solo 5 test invece di 20?
- E se ne prova 50?
- Qual è il numero di test necessario per avere un tasso di falsi positivi del 50%?
Suggerimento: Usa la formula \(1 - (1 - 0.05)^k\) dove \(k\) è il numero di test.
ConsiglioSoluzione Esercizio 1
# Tasso teorico di falsi positivi in funzione del numero di test
k_values <- 1:50
false_positive_rates <- 1 - (1 - 0.05)^k_values
tibble(k = k_values, fpr = false_positive_rates) |>
ggplot(aes(x = k, y = fpr)) +
geom_line(color = "steelblue", linewidth = 1) +
geom_hline(yintercept = 0.50, linetype = "dashed", color = "red") +
geom_vline(xintercept = log(0.5) / log(0.95), linetype = "dashed", color = "red") +
scale_y_continuous(labels = scales::percent) +
labs(
x = "Numero di test provati",
y = "Tasso di falsi positivi",
title = "Come il numero di test influenza il tasso di falsi positivi"
)
# Calcolo esatto
k_for_50pct <- ceiling(log(0.5) / log(0.95))
cat(sprintf("Servono %d test per raggiungere un tasso di falsi positivi del 50%%\n", k_for_50pct))
#> Servono 14 test per raggiungere un tasso di falsi positivi del 50%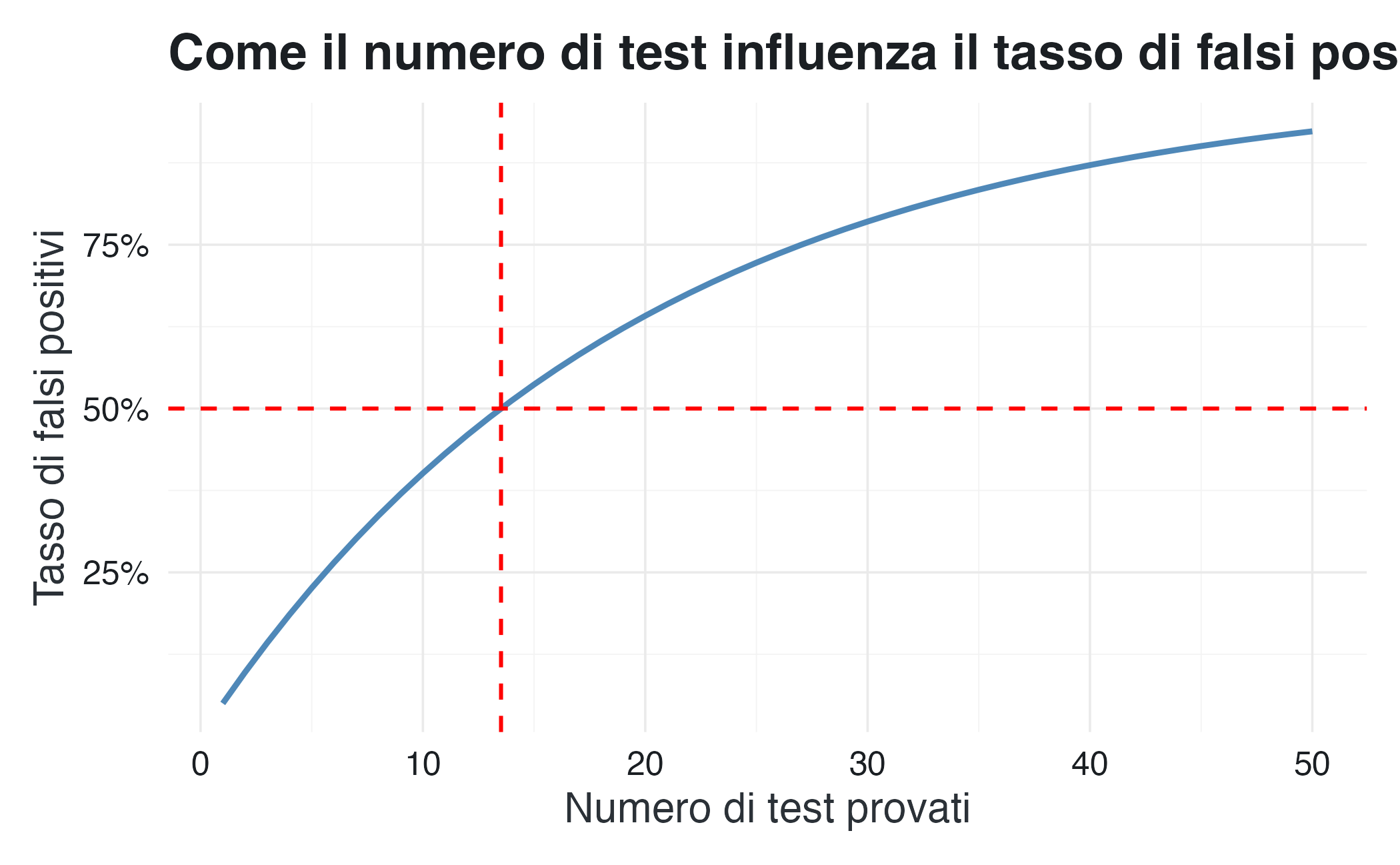
ImportanteEsercizio 2: Il PPV in diversi campi
La Simulazione 3 assume che il 10% delle ipotesi testate sia vero (scenario tipico per ricerca esplorativa).
- Ricalcola il PPV assumendo che il 50% delle ipotesi sia vero (scenario di ricerca confermativa).
- Ricalcola assumendo che solo il 1% sia vero (scenario di drug discovery o ricerca genomica).
- Qual è la prevalenza minima necessaria affinché un p < 0.05 abbia almeno il 90% di probabilità di essere un vero effetto?
ConsiglioSoluzione Esercizio 2
# Funzione per calcolare il PPV teorico (usando Bayes)
# PPV = P(H1|p<α) = P(p<α|H1) * P(H1) / P(p<α)
# Dove P(p<α) = P(p<α|H1)*P(H1) + P(p<α|H0)*P(H0)
calculate_theoretical_ppv <- function(prior_h1, power = 0.80, alpha = 0.05) {
# P(p<α | H1) ≈ power (potenza del test)
# P(p<α | H0) = alpha
p_significant <- power * prior_h1 + alpha * (1 - prior_h1)
ppv <- (power * prior_h1) / p_significant
return(ppv)
}
# PPV per diverse prevalenze
prevalences <- c(0.01, 0.10, 0.50, 0.80)
ppv_values <- sapply(prevalences, calculate_theoretical_ppv)
tibble(
`Prevalenza effetti veri` = sprintf("%.0f%%", prevalences * 100),
`PPV (potenza 80%)` = sprintf("%.1f%%", ppv_values * 100)
) |>
knitr::kable()| Prevalenza effetti veri | PPV (potenza 80%) |
|---|---|
| 1% | 13.9% |
| 10% | 64.0% |
| 50% | 94.1% |
| 80% | 98.5% |
# Prevalenza minima per PPV = 90%
# 0.90 = (0.80 * π) / (0.80 * π + 0.05 * (1-π))
# Risolvendo per π:
# 0.90 * (0.80*π + 0.05 - 0.05*π) = 0.80*π
# 0.72*π + 0.045 - 0.045*π = 0.80*π
# 0.045 = 0.80*π - 0.72*π + 0.045*π
# 0.045 = 0.125*π
pi_min <- 0.045 / 0.125
cat(sprintf("\nPrevalenza minima per PPV ≥ 90%%: %.0f%%\n", pi_min * 100))
#>
#> Prevalenza minima per PPV ≥ 90%: 36%
ImportanteEsercizio 3: Simulare l’approccio bayesiano
Ripeti la Simulazione 4, ma invece di calcolare il p-value, calcola la probabilità a posteriori che l’effetto sia positivo usando un’approssimazione bayesiana semplice.
Suggerimento: Usa una prior N(0, 1) per l’effetto e confronta la stabilità della conclusione bayesiana rispetto alla decisione basata sul p-value.
ConsiglioSoluzione Esercizio 3
# Approssimazione bayesiana semplice usando coniugazione normale
# Prior: δ ~ N(0, σ_prior²)
# Likelihood: d_obs | δ ~ N(δ, SE²)
# Posterior: δ | d_obs ~ N(μ_post, σ_post²)
bayesian_analysis <- function(d_obs, se_obs, prior_sd = 1) {
# Posterior mean and sd (formula della coniugazione normale)
prior_precision <- 1 / prior_sd^2
data_precision <- 1 / se_obs^2
posterior_precision <- prior_precision + data_precision
posterior_sd <- sqrt(1 / posterior_precision)
posterior_mean <- (data_precision * d_obs) / posterior_precision
# Probabilità che l'effetto sia positivo
prob_positive <- pnorm(0, mean = posterior_mean, sd = posterior_sd, lower.tail = FALSE)
return(prob_positive)
}
# Simulazione comparativa
true_effect <- 0.2
n_per_group <- 50
n_replications <- 1000
comparison <- tibble(replication = 1:n_replications) |>
rowwise() |>
mutate(
# Genera dati
g1 = list(rnorm(n_per_group, 0, 1)),
g2 = list(rnorm(n_per_group, true_effect, 1)),
# Analisi frequentista
t_result = list(t.test(g1, g2)),
p_value = t_result$p.value,
freq_decision = ifelse(p_value < 0.05, "Significativo", "Non significativo"),
# Analisi bayesiana
d_obs = (mean(g2) - mean(g1)) / sqrt((var(g1) + var(g2)) / 2),
se_obs = sqrt(2 / n_per_group),
prob_positive = bayesian_analysis(d_obs, se_obs),
bayes_decision = ifelse(prob_positive > 0.95, "Prob > 95%", "Prob ≤ 95%")
) |>
ungroup()
# Confronto della stabilità
cat("Stabilità delle conclusioni:\n\n")
#> Stabilità delle conclusioni:
cat("Approccio frequentista:\n")
#> Approccio frequentista:
table(comparison$freq_decision) |> print()
#>
#> Non significativo Significativo
#> 811 189
cat("\n\nApproccio bayesiano:\n")
#>
#>
#> Approccio bayesiano:
comparison |>
summarise(
`Media P(δ > 0)` = mean(prob_positive),
`SD P(δ > 0)` = sd(prob_positive),
`Min` = min(prob_positive),
`Max` = max(prob_positive)
) |>
print()
#> # A tibble: 1 × 4
#> `Media P(δ > 0)` `SD P(δ > 0)` Min Max
#> <dbl> <dbl> <dbl> <dbl>
#> 1 0.765 0.234 0.00641 1.000La probabilità a posteriori varia in modo molto più graduale rispetto alla decisione binaria frequentista. Questo riflette meglio l’incertezza reale sui risultati.
NotaInformazioni sull’ambiente di sviluppo
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ragg_1.5.0 tinytable_0.15.2 withr_3.0.2
#> [4] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [7] tidybayes_3.0.7 bayesplot_1.15.0 ggplot2_4.0.1
#> [10] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [13] loo_2.9.0 rstan_2.32.7 StanHeaders_2.32.10
#> [16] brms_2.23.0 Rcpp_1.1.0 sessioninfo_1.2.3
#> [19] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [22] modelr_0.1.11 tibble_3.3.0 dplyr_1.1.4
#> [25] tidyr_1.3.2 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] gridExtra_2.3 inline_0.3.21 sandwich_3.1-1
#> [4] rlang_1.1.6 magrittr_2.0.4 multcomp_1.4-29
#> [7] snakecase_0.11.1 otel_0.2.0 compiler_4.5.2
#> [10] vctrs_0.6.5 stringr_1.6.0 pkgconfig_2.0.3
#> [13] arrayhelpers_1.1-0 fastmap_1.2.0 backports_1.5.0
#> [16] labeling_0.4.3 rmarkdown_2.30 purrr_1.2.0
#> [19] xfun_0.55 cachem_1.1.0 jsonlite_2.0.0
#> [22] broom_1.0.11 parallel_4.5.2 R6_2.6.1
#> [25] stringi_1.8.7 RColorBrewer_1.1-3 lubridate_1.9.4
#> [28] estimability_1.5.1 knitr_1.51 zoo_1.8-15
#> [31] pacman_0.5.1 Matrix_1.7-4 splines_4.5.2
#> [34] timechange_0.3.0 tidyselect_1.2.1 rstudioapi_0.17.1
#> [37] abind_1.4-8 yaml_2.3.12 codetools_0.2-20
#> [40] curl_7.0.0 pkgbuild_1.4.8 lattice_0.22-7
#> [43] bridgesampling_1.2-1 S7_0.2.1 coda_0.19-4.1
#> [46] evaluate_1.0.5 survival_3.8-3 RcppParallel_5.1.11-1
#> [49] xml2_1.5.1 pillar_1.11.1 tensorA_0.36.2.1
#> [52] checkmate_2.3.3 stats4_4.5.2 distributional_0.5.0
#> [55] generics_0.1.4 rprojroot_2.1.1 rstantools_2.5.0
#> [58] scales_1.4.0 xtable_1.8-4 glue_1.8.0
#> [61] emmeans_2.0.1 tools_4.5.2 mvtnorm_1.3-3
#> [64] grid_4.5.2 QuickJSR_1.8.1 colorspace_2.1-2
#> [67] nlme_3.1-168 cli_3.6.5 kableExtra_1.4.0
#> [70] textshaping_1.0.4 svUnit_1.0.8 viridisLite_0.4.2
#> [73] svglite_2.2.2 Brobdingnag_1.2-9 V8_8.0.1
#> [76] gtable_0.3.6 digest_0.6.39 TH.data_1.1-5
#> [79] htmlwidgets_1.6.4 farver_2.1.2 memoise_2.0.1
#> [82] htmltools_0.5.9 lifecycle_1.0.4 MASS_7.3-65Bibliografia
Brodeur, A., Cook, N., & Heyes, A. (2020). Methods matter: P-hacking and publication bias in causal analysis in economics. American Economic Review, 110(11), 3634–3660.
Gelman, A., & Stern, H. (2006). The difference between «significant» and «not significant» is not itself statistically significant. The American Statistician, 60(4), 328–331.
Head, M. L., Holman, L., Lanfear, R., Kahn, A. T., & Jennions, M. D. (2015). The extent and consequences of p-hacking in science. PLoS biology, 13(3), e1002106.
Simonsohn, U., Nelson, L. D., & Simmons, J. P. (2014). p-curve and effect size: Correcting for publication bias using only significant results. Perspectives on psychological science, 9(6), 666–681.
Wasserstein, R. L., & Lazar, N. A. (2016). The ASA’s statement on p-values: context, process, and purpose. The American Statistician, 70(2), 129–133.