suppressPackageStartupMessages({
library(cmdstanr)
library(posterior)
library(bayesplot)
library(ggplot2)
library(dplyr)
})
theme_set(theme_minimal(base_size = 12))
color_scheme_set("brightblue")Appendice P — Controlli predittivi a posteriori
I controlli predittivi a posteriori (Posterior Predictive Checks, PPC) costituiscono un metodo fondamentale per valutare la bontà di adattamento di un modello bayesiano. L’idea è semplice: se un modello rappresenta adeguatamente il processo generativo dei dati osservati, allora dati nuovi, simulati a partire dalla distribuzione a posteriori dei parametri, dovrebbero essere statisticamente simili ai dati osservati.
In termini operativi, la procedura implica la generazione di repliche predittive condizionate ai valori campionati dalla distribuzione a posteriori. Il confronto sistematico tra queste repliche e i dati osservati consente di identificare discrepanze tra il modello e la realtà empirica, guidando così eventuali raffinamenti della specificazione del modello.
Questo capitolo è dedicato specificamente alla distribuzione predittiva a posteriori, cioè alla generazione di dati simulati dopo aver aggiornato le nostre credenze sui parametri attraverso l’evidenza dei dati osservati. Per un’analisi complementare che valuta la plausibilità dei dati prima di osservarli, incentrata sulla scelta delle distribuzioni a priori, si rimanda alla sezione sui controlli predittivi a priori (Appendice O).
ConsiglioDomanda chiave
Il modello, una volta informato dai dati, è in grado di generare osservazioni che assomigliano a quelle reali?
AttenzionePreparazione del Notebook
P.1 La distribuzione predittiva a posteriori
La distribuzione predittiva a posteriori formalizza l’incertezza riguardo a future osservazioni, integrando le informazioni apprese dai dati già osservati. La sua definizione formale è:
\[ p(\tilde{y} \mid y) = \int_{\Theta} p(\tilde{y} \mid \theta)\, p(\theta \mid y)\, d\theta, \]
dove i simboli rappresentano:
- \(\tilde{y}\): i dati replicati (nuove osservazioni predette);
- \(y\): il vettore dei dati osservati;
- \(\theta\): i parametri del modello;
- \(p(\theta \mid y)\): la distribuzione a posteriori dei parametri, data l’evidenza osservata;
- \(\Theta\): lo spazio dei parametri.
L’interpretazione operativa di questa formula è chiara: per ottenere la previsione su nuovi dati, si media la verosimiglianza condizionata \(p(\tilde{y} \mid \theta)\) su tutti i possibili valori del parametro \(\theta\), utilizzando come pesi la loro plausibilità a posteriori \(p(\theta \mid y)\). In altre parole, non si sceglie un singolo “migliore” valore dei parametri (come una stima puntuale), ma si considera l’intera distribuzione a posteriori, riconoscendo l’incertezza residua sul loro vero valore dopo aver osservato i dati.
Questa media integrale equivale a generare previsioni in due fasi, che riflettono il processo inferenziale bayesiano:
- campionare un valore \(\theta^{(s)}\) dalla distribuzione a posteriori \(p(\theta \mid y)\);
- campionare una nuova osservazione \(\tilde{y}^{(s)}\) dalla distribuzione dei dati condizionata a quel parametro, \(p(\tilde{y} \mid \theta^{(s)})\).
La collezione \(\{\tilde{y}^{(1)}, \tilde{y}^{(2)}, \dots\}\) così ottenuta approssima la distribuzione predittiva a posteriori \(p(\tilde{y} \mid y)\), che incorpora sia l’incertezza sui parametri (tramite il campionamento a posteriori) sia la variabilità intrinseca del processo generativo dei dati (tramite la verosimiglianza).
In Stan, le repliche si generano nel blocco generated quantities usando le funzioni _rng().
P.2 Esempio: modello normale
P.2.1 Il modello Stan
Consideriamo un modello per la stima della media di una distribuzione normale con varianza nota.
stan_code <- "
data {
int<lower=0> N;
vector[N] y;
real mu0; // media del prior
real<lower=0> tau0; // SD del prior
real<lower=0> sigma; // SD nota dei dati
int<lower=0, upper=1> prior_only; // flag per prior predictive
}
parameters {
real mu;
}
model {
mu ~ normal(mu0, tau0);
if (prior_only == 0)
y ~ normal(mu, sigma);
}
generated quantities {
vector[N] y_rep;
for (n in 1:N)
y_rep[n] = normal_rng(mu, sigma);
}
"
NotaIl parametro prior_only
Impostando prior_only = 1, il modello ignora la verosimiglianza e campiona solo dal prior. Questo permette di usare lo stesso file Stan sia per i controlli a priori che per quelli a posteriori.
P.2.2 Compilazione e adattamento
mod <- cmdstanr::cmdstan_model(
cmdstanr::write_stan_file(stan_code),
compile = TRUE
)fit <- mod$sample(
data = stan_data,
chains = 4,
iter_sampling = 1000,
iter_warmup = 500,
refresh = 0,
seed = 123
)P.2.3 Estrazione delle repliche
Per i controlli predittivi con bayesplot, le repliche devono essere organizzate in una matrice con:
-
righe: draw posteriori (
Sdraw totali); -
colonne: osservazioni (
Nosservazioni).
y_rep <- fit$draws("y_rep", format = "matrix")
dim(y_rep)[1] 4000 100P.2.4 Sovrapposizione delle densità
Il confronto visivo più immediato consiste nel sovrapporre la distribuzione empirica dei dati osservati alla distribuzione di un campione di repliche predittive generate dal modello. In questo tipo di grafico:
- i dati osservati (\(y\)) sono rappresentati da una singola linea scura (tipicamente nera o blu scuro);
- le repliche predittive (\(\tilde{y}^{(s)}\)) sono rappresentate da più linee chiare (tipicamente grigie o trasparenti), ciascuna corrispondente a un diverso set di parametri campionato dalla posterior.
ppc_dens_overlay(y_obs, y_rep[1:50, ]) +
labs(
title = "Posterior predictive check: sovrapposizione densità",
subtitle = "Linea scura = dati osservati, linee chiare = repliche",
x = "y",
y = "Densità"
)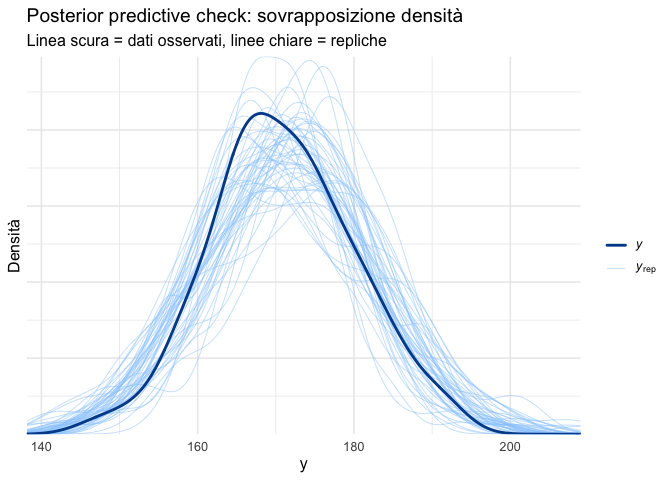
P.2.5 Interpretazione
Se il modello è adeguato, la densità dei dati osservati dovrebbe essere sostanzialmente sovrapponibile al “nube” delle densità delle repliche. Un dato osservato che cade sistematicamente fuori dall’insieme delle repliche suggerisce una discrepanza tra modello e realtà.
Discrepanze sistematiche indicano problemi:
- repliche troppo strette: il modello sottostima la variabilità;
- repliche troppo larghe: il modello sovrastima la variabilità;
- repliche sistematicamente spostate: bias nella stima della posizione.
P.2.6 Controlli su statistiche riassuntive
Possiamo verificare se specifiche statistiche dei dati simulati sono compatibili con quelle osservate.
P.2.6.1 Media
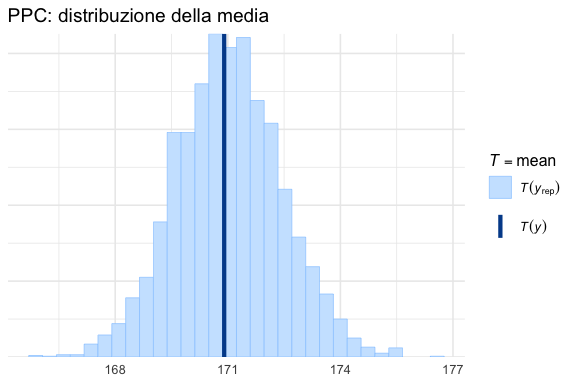
P.2.6.2 Deviazione standard
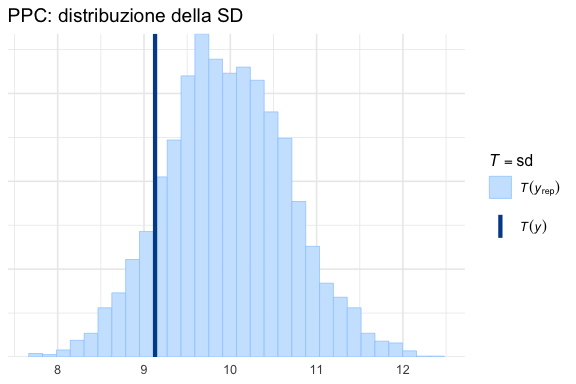
P.2.6.3 Quantili estremi
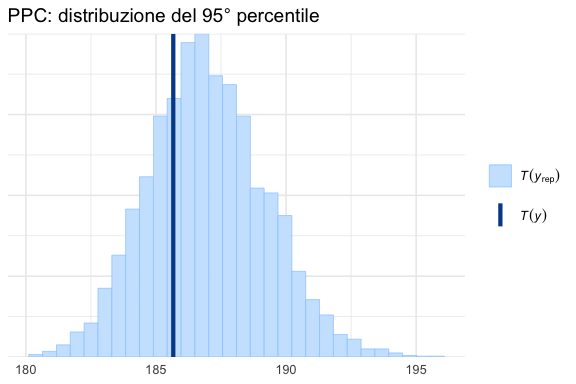
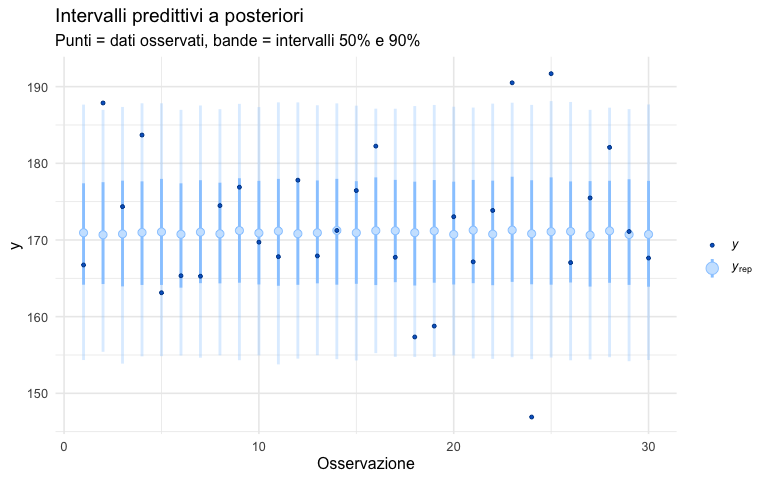
P.2.7 Intervalli predittivi
Gli intervalli predittivi mostrano se la dispersione generata dal modello è compatibile con i dati.
# Selezioniamo un sottoinsieme di osservazioni per chiarezza
idx <- sample(1:N, 30)
ppc_intervals(y_obs[idx], y_rep[, idx], prob = 0.5, prob_outer = 0.9) +
labs(
title = "Intervalli predittivi a posteriori",
subtitle = "Punti = dati osservati, bande = intervalli 50% e 90%",
x = "Osservazione",
y = "y"
)
P.3 Confronto tramite istogrammi
Un’alternativa efficace al grafico di sovrapposizione delle densità è il confronto diretto tra l’istogramma dei dati osservati e quelli delle repliche predittive. Questo approccio è particolarmente utile quando si desidera visualizzare la distribuzione dei dati in termini di frequenze assolute piuttosto che di densità.
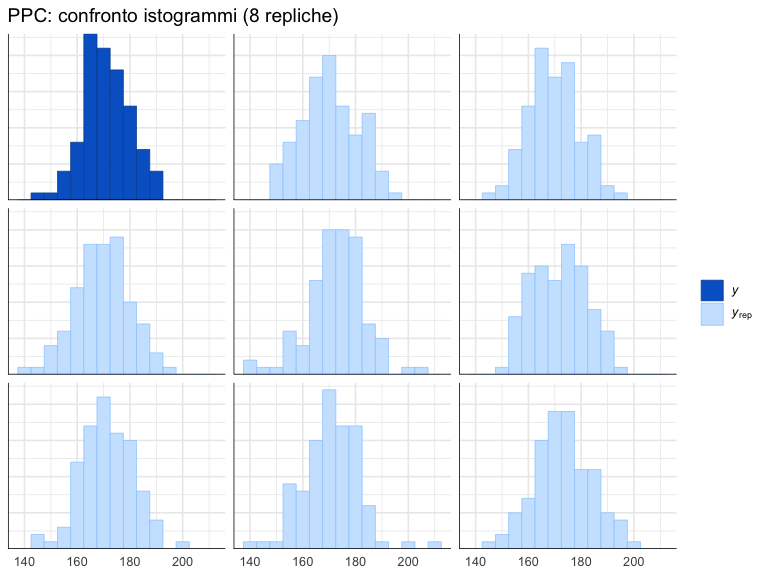
Se il modello è appropriato, l’istogramma dei dati osservati dovrebbe apparire simile nella forma e nella dispersione agli istogrammi delle repliche. Differenze sistematiche (ad esempio, un picco più alto, code più lunghe o una diversa asimmetria nei dati osservati) segnalano potenziali inadeguatezze del modello.
P.4 Diagnosticare i problemi tramite i PPC
Quando i controlli predittivi a posteriori rivelano discrepanze sistematiche tra i dati osservati e le repliche generate dal modello, è necessario indagare le possibili cause. Queste possono essere ricondotte a quattro categorie principali, ciascuna delle quali suggerisce specifiche azioni correttive.
P.4.1 1. Distribuzioni a priori inadeguate
Anche dopo aver osservato i dati, distribuzioni a priori eccessivamente informative o mal collocate possono “trascinare” la distribuzione a posteriori e quindi le predizioni verso regioni inadeguate. Allo stesso modo, prior eccessivamente diffuse possono causare problemi di identificazione.
Strategia di intervento: riesaminare la scelta delle prior, ricorrendo ai prior predictive checks (Appendice O) per valutarne la plausibilità indipendentemente dai dati. Spesso si rivela utile passare a prior debolmente informativi che escludono valori assolutamente impossibili senza imporre vincoli troppo forti.
P.4.2 2. Specificazione impropria della verosimiglianza
La famiglia distributiva scelta per il modello potrebbe non essere in grado di catturare le caratteristiche salienti dei dati osservati:
- Code troppo leggere: se i dati mostrano outliers o code più pesanti del previsto, una distribuzione normale è inadeguata. Una distribuzione \(t\) di Student, con parametro di gradi di libertà stimato, offre maggiore robustezza.
- Asimmetria: distribuzioni simmetriche (come la normale) falliscono nel modellare dati asimmetrici. Occorre considerare famiglie asimmetriche come la Gamma, la Log-normale o la Beta.
- Eteroschedasticità: modelli che assumono varianza costante (\(\sigma^2\) fissa) falliscono quando la variabilità cambia sistematicamente con la media o con una covariata. È necessario modellare esplicitamente la varianza.
Strategia di intervento: condurre un confronto formale (ad esempio, tramite LOO-CV) tra modelli basati su diverse famiglie distributive, dando priorità a quelle che incorporano flessibilità per le caratteristiche osservate nei PPC.
P.4.3 3. Struttura del modello incompleta
Il modello potrebbe essere specificato correttamente a livello distributivo ma non includere componenti strutturali necessarie per catturare i pattern presenti nei dati:
- trend o effetti temporali non modellati;
- variazione tra gruppi (ad esempio, tra soggetti o scuole) non catturata, che richiederebbe una struttura gerarchica;
- dipendenze spaziali, temporali o di altro tipo tra le osservazioni, che violano l’assunzione di indipendenza.
Strategia di intervento: espandere la specificazione del modello per includere i termini strutturali rilevanti (effetti fissi per covariate, effetti casuali per gruppi, termini di correlazione spaziale/temporale).
P.4.4 4. Parametri di dispersione fissati in modo errato
Nell’esempio discusso, si è assunta la deviazione standard \(\sigma\) nota. Se il valore fissato è troppo grande o troppo piccolo rispetto alla variabilità reale dei dati, le predizioni avranno sistematicamente una dispersione errata.
Strategia di intervento: in una modellazione realistica, il parametro di dispersione (come \(\sigma\) in un modello normale) dovrebbe essere stimato dai dati, non fissato a priori, a meno che non esista una ragione teorica solida per farlo.
L’identificazione della causa più probabile attraverso i PPC guida uno sviluppo del modello iterativo e informato, spostando l’attenzione dalla semplice stima dei parametri alla costruzione di un modello statisticamente adeguato.
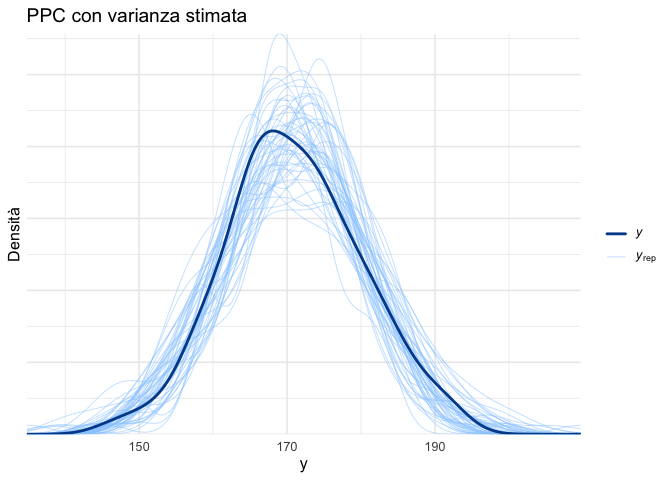
P.5 Esempio con varianza stimata
Estendiamo il modello per stimare anche \(\sigma\):
stan_code_sigma <- "
data {
int<lower=0> N;
vector[N] y;
}
parameters {
real mu;
real<lower=0> sigma;
}
model {
mu ~ normal(170, 20); // prior debolmente informativo
sigma ~ exponential(0.1); // prior su sigma
y ~ normal(mu, sigma);
}
generated quantities {
vector[N] y_rep;
for (n in 1:N)
y_rep[n] = normal_rng(mu, sigma);
}
"mod_sigma <- cmdstanr::cmdstan_model(
cmdstanr::write_stan_file(stan_code_sigma),
compile = TRUE
)
fit_sigma <- mod_sigma$sample(
data = list(N = N, y = y_obs),
chains = 4,
iter_sampling = 1000,
refresh = 0,
seed = 123
)y_rep_sigma <- fit_sigma$draws("y_rep", format = "matrix")
ppc_dens_overlay(y_obs, y_rep_sigma[1:50, ]) +
labs(
title = "PPC con varianza stimata",
x = "y",
y = "Densità"
)
NotaWorkflow per i PPC
-
Definire
y_repnel bloccogenerated quantitiesdel modello Stan -
Estrarre le repliche come matrice:
fit$draws("y_rep", format = "matrix") - Verificare le dimensioni: deve essere [S × N]
-
Applicare i controlli:
-
ppc_dens_overlay(): confronto densità globale -
ppc_stat(): verifiche su statistiche specifiche -
ppc_intervals(): copertura degli intervalli
-
- Interpretare le discrepanze e iterare sul modello
Riflessioni conclusive
I controlli predittivi a posteriori rappresentano un cambio di paradigma fondamentale nell’analisi statistica, spostando il focus dalla mera stima dei parametri alla valutazione della capacità generativa del modello. È perfettamente possibile che un modello produca stime parametriche ragionevoli e inferenze statisticamente significative, ma fallisca comunque nel riprodurre aspetti essenziali della struttura osservata nei dati. I PPC rivelano proprio queste discrepanze tra il modello e la realtà empirica.
I PPC non vanno interpretati come un test formale di ipotesi che produce un valore-\(p\) per rigettare un modello. Piuttosto, costituiscono uno strumento diagnostico esplorativo che risponde a una domanda più pratica e profonda: le predizioni del modello sono plausibili alla luce dei dati che abbiamo effettivamente osservato? Questo approccio è perfettamente in linea con la filosofia bayesiana, che considera il modello non come una “verità” da verificare, ma come uno strumento di ragionamento la cui utilità va giudicata in base alla sua capacità di aiutarci a comprendere e prevedere il fenomeno in studio.
Nella pratica di ricerca, i PPC sono particolarmente preziosi nelle fasi esplorative iniziali della modellazione, quando si stanno prendendo in considerazione diverse specifiche alternative. Forniscono un riscontro rapido e intuitivo per affinare il modello. Una volta individuata una famiglia di modelli con proprietà predittive soddisfacenti, è possibile ricorrere a metodi di confronto più formali e quantitativi, come la Leave-One-Out Cross-Validation (LOO-CV) o il Watanabe-Akaike Information Criterion (WAIC), per effettuare una scelta finale tra le alternative più promettenti.
NotaInformazioni sull’ambiente di sviluppo
R version 4.5.2 (2025-10-31)
Platform: aarch64-apple-darwin20
Running under: macOS Tahoe 26.2
Matrix products: default
BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
locale:
[1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
time zone: Europe/Rome
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] dplyr_1.1.4 ggplot2_4.0.1 bayesplot_1.14.0 posterior_1.6.1
[5] cmdstanr_0.8.0
loaded via a namespace (and not attached):
[1] gtable_0.3.6 jsonlite_2.0.0 compiler_4.5.2
[4] Rcpp_1.1.0 tidyselect_1.2.1 stringr_1.6.0
[7] scales_1.4.0 yaml_2.3.12 fastmap_1.2.0
[10] plyr_1.8.9 R6_2.6.1 labeling_0.4.3
[13] generics_0.1.4 distributional_0.5.0 knitr_1.50
[16] htmlwidgets_1.6.4 backports_1.5.0 checkmate_2.3.3
[19] tibble_3.3.0 pillar_1.11.1 RColorBrewer_1.1-3
[22] rlang_1.1.6 stringi_1.8.7 xfun_0.54
[25] S7_0.2.1 cli_3.6.5 withr_3.0.2
[28] magrittr_2.0.4 ps_1.9.1 digest_0.6.39
[31] grid_4.5.2 processx_3.8.6 lifecycle_1.0.4
[34] vctrs_0.6.5 data.table_1.17.8 evaluate_1.0.5
[37] glue_1.8.0 tensorA_0.36.2.1 farver_2.1.2
[40] abind_1.4-8 reshape2_1.4.5 rmarkdown_2.30
[43] tools_4.5.2 pkgconfig_2.0.3 htmltools_0.5.9