here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(patchwork)31 Causalità: intuizioni, controfattuali e perché l’associazione non basta
ConsiglioTake‑home (in 3 righe)
- Effetto causale medio (ACE) = differenza tra due mondi: se tutti ricevessero il trattamento vs se nessuno lo ricevesse.
- Associazione = differenza tra trattati e non trattati nel mondo osservato: può essere fuorviante per via del confondimento.
- La randomizzazione rende i gruppi comparabili “in media” → associazione ≈ causalità (se SUTVA regge).
AttenzionePreparazione del Notebook
31.1 Dalla regressione alla causalità: perché serve un nuovo framework
Nel modello di regressione standard, esprimiamo una relazione nella forma \(y = \alpha + \beta x + \varepsilon\) e spesso interpretiamo \(\beta\) come “l’effetto di \(x\) su \(y\)”. Tuttavia, questa interpretazione è valida solo in condizioni molto restrittive, che si verificano raramente nella ricerca osservazionale. Per comprenderne il motivo, consideriamo un esempio classico della psicologia.
Immaginiamo di osservare che gli studenti che dormono meno ore a notte tendono a riportare livelli più elevati di ansia. Una regressione lineare potrebbe restituire un coefficiente \(\beta > 0\), suggerendo un’associazione positiva tra privazione di sonno e ansia. Cosa possiamo concludere? Almeno tre spiegazioni causali sono compatibili con questo stesso dato osservativo:
- Il sonno causa l’ansia: la carenza di sonno altera i meccanismi neurofisiologici che regolano la risposta emotiva e lo stress.
- L’ansia causa il sonno: gli stati ansiosi ostacolano l’addormentamento, frammentano il riposo e riducono la durata complessiva del sonno.
- Una terza variabile causa entrambe: periodi di elevato carico accademico, ad esempio, aumentano contemporaneamente l’ansia e riducono il tempo dedicato al sonno.
Il coefficiente di regressione, da solo, non permette di discriminare tra queste possibilità. Ci informa soltanto della covariazione tra \(x\) e \(y\), ma rimane muto riguardo ai meccanismi che la generano. Per rispondere alla domanda “Perché?” dobbiamo quindi abbandonare il linguaggio puramente associativo della regressione e adottare un framework causale.
31.1.1 Cosa cambia con il pensiero causale
Il pensiero causale impone un cambiamento di prospettiva: invece di limitarci a descrivere relazioni osservate, ci chiediamo cosa accadrebbe in scenari non osservati. La domanda centrale diventa: “Se intervenissimo modificando \(x\), come cambierebbe \(y\)?”. Questa non è una domanda descrittiva, ma ipotetica e interventista.
La formalizzazione di questa intuizione si basa sul concetto di esito controfattuale, ovvero il valore che \(y\) assumerebbe in una situazione alternativa a quella effettivamente verificatasi. Si tratta di un’idea che utilizziamo quotidianamente nel ragionamento comune (“Se avessi preso quel treno, sarei arrivato in orario”), ma che richiede una notazione precisa e assunzioni identificabili per poter essere tradotta in inferenza statistica.
Nei prossimi paragrafi introdurremo gli strumenti fondamentali di questo approccio: la notazione dei potenziali esiti, la definizione formale dell’effetto causale individuale e medio e le condizioni (tra cui l’assegnazione casuale del trattamento) sotto le quali l’associazione osservata può essere interpretata come effetto causale.
31.2 Fondamenti dell’inferenza causale: controfattuali, effetto medio e SUTVA
Tutti noi, nella vita di tutti i giorni, formuliamo continuamente domande causali. Uno studente, per esempio, potrebbe chiedersi: “Se applicassi una tecnica di ristrutturazione cognitiva prima dell’esame, riuscirei a gestire meglio l’ansia?” Questa semplice domanda racchiude già l’essenza del problema: esiste un’azione possibile, il trattamento, il cui effetto su un esito desideriamo comprendere.
La statistica formalizza questa intuizione attraverso il concetto di esito potenziale (o controfattuale). Per ogni individuo, possiamo immaginare due scenari alternativi e ben definiti:
- uno scenario in cui l’individuo riceve il trattamento (ad esempio, applica la tecnica di reappraisal); in questo caso l’esito è indicato con \(Y^{(1)}\);
- uno scenario in cui lo stesso individuo non riceve il trattamento e l’esito corrispondente è indicato con \(Y^{(0)}\).
Nella realtà, osserviamo solo uno dei due scenari: se lo studente decide di applicare la tecnica di reappraisal, misureremo \(Y^{(1)}\); l’altro esito, \(Y^{(0)}\), rimane non osservato: è l’esito potenziale. Il legame tra ciò che osserviamo e ciò che ipotizziamo è sancito dall’assunzione di consistenza: se il trattamento effettivamente ricevuto è \(A = a\), allora l’esito osservato \(Y\) coincide con l’esito potenziale corrispondente, ovvero \(Y = Y^{(a)}\).
Da questa struttura logica deriva la definizione dell’effetto causale. A livello individuale, l’effetto è la differenza tra i due esiti potenziali: \[ \tau_i = Y_i^{(1)} - Y_i^{(0)}. \] Tuttavia, poiché per ciascun individuo osserviamo solo uno dei due valori, \(\tau_i\) non è mai direttamente misurabile.
Possiamo però spostare l’attenzione a livello di popolazione, definendo l’effetto causale medio (Average Causal Effect, ACE): \[ \text{ACE} = \mathbb{E}[Y^{(1)}] - \mathbb{E}[Y^{(0)}]. \] In altre parole, l’ACE corrisponde alla differenza attesa negli esiti tra uno scenario in cui tutti ricevono il trattamento e uno in cui nessuno lo riceve. Si tratta della risposta formale alla domanda: “Se intervenissimo sull’intera popolazione, quale sarebbe, in media, la differenza nell’esito?”.
Per poter definire l’ACE in modo corretto e interpretabile, è necessario introdurre un’assunzione fondamentale: la SUTVA (Stable Unit Treatment Value Assumption). Nonostante il nome tecnico, il suo significato concettuale è intuitivo e si articola in due parti:
Assenza di interferenza: il trattamento assegnato a un individuo non influenza gli esiti degli altri individui. Nel nostro esempio, il fatto che uno studente applichi la tecnica del reappraisal non dovrebbe alterare il livello di ansia dei suoi compagni. Questa ipotesi è plausibile in molti contesti psicologici individuali, ma può non essere valida in contesti di gruppo, come classi o comunità.
Unicità della versione del trattamento: esiste una sola modalità ben definita di “ricevere il trattamento”. Se la tecnica di ristrutturazione cognitiva venisse applicata in modi sostanzialmente diversi tra i partecipanti, queste diverse modalità dovrebbero essere considerate come trattamenti distinti.
Queste nozioni, ovvero esiti potenziali, consistenza, effetto causale medio e SUTVA, costituiscono i fondamenti del ragionamento causale moderno. Pur richiedendo un linguaggio più formale, queste nozioni non fanno altro che esplicitare e rendere più precise le intuizioni causali che guidano il nostro pensiero quotidiano.
31.3 Causale vs associativo: perché differiscono?
Quando parliamo di effetto causale, ci riferiamo a un confronto ipotetico tra due mondi alternativi. Nel primo mondo immaginiamo che tutti ricevano il trattamento, nel secondo che nessuno lo riceva. La domanda è: quanto cambia, in media, l’esito se passiamo da un mondo all’altro? Questo è l’effetto causale medio (ACE), espresso come la differenza tra \(\mathbb{E}[Y^{(1)}]\) e \(\mathbb{E}[Y^{(0)}]\).
Il ragionamento associativo, invece, si concentra su ciò che osserviamo direttamente nei dati: confronta due gruppi reali, ovvero chi ha ricevuto il trattamento e chi non lo ha ricevuto, e guarda la differenza tra \(\mathbb{E}[Y \,|\, A=1]\) e \(\mathbb{E}[Y \,|\, A=0]\).
La differenza tra i due approcci è sostanziale. Il confronto causale presuppone che la stessa popolazione viva due scenari alternativi e paralleli. Il confronto associativo, al contrario, mette a confronto due gruppi distinti, che potrebbero differire per molteplici caratteristiche già prima dell’assegnazione del trattamento.
Questa distinzione è cruciale. Consideriamo l’esempio dello studente ansioso: se solo gli studenti con un livello alto di ansia di tratto decidono di applicare una tecnica di rilassamento, i gruppi “trattati” e “non trattati” non saranno confrontabili sin dall’inizio. La differenza osservata \(\mathbb{E}[Y \,|\, A=1] - \mathbb{E}[Y \,|\, A=0]\) rifletterà quindi non solo l’eventuale efficacia della tecnica, ma anche il divario preesistente nei livelli di ansia tra i due gruppi.
Questa discrepanza tra associazione e causalità prende il nome di confondimento: si verifica quando esiste una variabile (o un insieme di variabili) che influenza sia la probabilità di ricevere il trattamento sia l’esito stesso. In presenza di confondimento, la differenza osservata può essere:
- ingannevolmente ampia (se, ad esempio, chi riceve il trattamento parte già svantaggiato),
- ingannevolmente attenuata (se il trattamento viene assegnato a chi è già avvantaggiato),
- aersino di segno opposto rispetto all’effetto causale vero.
Il confondimento rappresenta dunque il principale ostacolo all’inferenza causale nei dati osservazionali, in quanto ci impedisce di interpretare la semplice differenza tra i gruppi come una stima dell’effetto del trattamento. Nei prossimi paragrafi esploreremo come il disegno sperimentale, e in particolare la randomizzazione, possano risolvere questo problema, rendendo il confronto associativo un’approssimazione valida del confronto causale.
31.3.1 La regressione non risolve automaticamente il problema
A questo punto potremmo chiederci: “Ma la regressione multipla non serve proprio a questo? Se includo le variabili confondenti nel modello, posso stimare l’effetto ‘al netto’ di queste variabili”. Questa intuizione coglie un aspetto importante, ma è incompleta e in alcuni casi pericolosamente fuorviante.
Il problema fondamentale è che il controllo statistico non è neutrale: includere una variabile nel modello non sempre migliora la stima causale. Come vedremo nel Capitolo 32, esistono configurazioni di relazioni tra variabili — in particolare i collider — in cui controllare per una variabile introduce distorsione anziché eliminarla. Più in generale, ogni decisione su cosa includere o escludere da un modello richiede una comprensione della struttura causale sottostante, e non può essere automatizzata mediante criteri puramente statistici come la correlazione osservata o algoritmi di selezione delle variabili.
Il pericolo sta proprio qui: il controllo mal posto può produrre distorsioni più gravi dell’omissione stessa. Una regressione che include variabili inappropriate può darci l’illusione del rigore (“ho controllato per tutto”) mentre in realtà stima una quantità che non corrisponde a nessun effetto causale ben definito.
Per questo motivo, è essenziale distinguere tra due obiettivi distinti:
- stimare associazioni, cioè descrivere le relazioni presenti nei dati osservati;
- stimare effetti causali, cioè rispondere a domande del tipo “cosa accadrebbe se intervenissimo?”.
È proprio il divario tra questi due obiettivi che rende necessario adottare un framework causale esplicito e affiancare all’analisi statistica un’attenta riflessione sul disegno dello studio e sulla struttura delle relazioni tra le variabili. Le strategie che esploreremo nei prossimi capitoli, dal disegno sperimentale randomizzato ai metodi per dati osservazionali, nascono tutte dalla necessità di colmare questo divario in modo rigoroso e trasparente.
31.4 Quale misura di effetto? Additiva o moltiplicativa
Una volta chiarito il concetto di effetto causale medio, resta da definire come quantificarlo. Non esiste una misura universalmente migliore: la scelta deve essere guidata dalla domanda di ricerca e dal modo in cui intendiamo comunicare l’impatto dell’intervento.
Se l’esito è dicotomico, come ad esempio “aver avuto un attacco di panico (sì/no)”, possiamo calcolare la differenza di rischi: \[ \text{RD} = P(Y^{(1)} = 1) - P(Y^{(0)} = 1). \] Questa misura additiva risponde a una domanda di salute pubblica: “Quanti casi in più o in meno possiamo attenderci se tutti ricevessero il trattamento?”. Il risultato è immediatamente interpretabile in termini di impatto concreto sul numero di persone affette.
Un’alternativa è il rapporto di rischi (risk ratio): \[ \text{RR} = \frac{P(Y^{(1)} = 1)}{P(Y^{(0)} = 1)}. \] Questo approccio moltiplicativo è utile quando vogliamo esprimere il rischio relativo: “Chi non applica il reappraisal ha un rischio doppio di avere un attacco di panico”. In ambito psicologico clinico, l’odds ratio viene spesso utilizzato per i modelli logistici e per descrivere le associazioni negli studi caso-controllo, anche se la sua interpretazione diretta come moltiplicatore del rischio è meno intuitiva.
Se l’esito è continuo — come un punteggio su una scala di ansia — l’effetto più naturale è la differenza tra le medie dei potenziali esiti: \[ \text{ACE} = \mathbb{E}[Y^{(1)}] - \mathbb{E}[Y^{(0)}], \] che ci dice di quanto, in media, il punteggio cambierebbe se tutti ricevessero il trattamento.
La scelta della misura non è dunque neutra: ognuna racconta una parte diversa della stessa storia. La differenza di rischi enfatizza l’impatto assoluto e la rilevanza pratica in termini di numero di casi, mentre il rapporto di rischi mette in luce la forza relativa dell’associazione e può essere più adatto per confrontare gli effetti tra sottogruppi con rischi di base diversi. È importante evitare gli automatismi e selezionare consapevolmente la scala che meglio si adatta alla domanda di ricerca e al pubblico a cui ci rivolgiamo.
31.4.1 Due fonti di variabilità
Quando stimiamo un effetto causale, dobbiamo riconoscere che i valori ottenuti sono sempre accompagnati da un margine di incertezza. Tale incertezza può avere almeno due origini distinte, che spesso vengono confuse ma che è importante distinguere concettualmente.
La prima è la variabilità da campionamento. Nella ricerca empirica non osserviamo mai l’intera popolazione, ma solo un sottoinsieme di individui, il campione, estratto da essa. Se ripetessimo lo studio con campioni diversi provenienti dalla stessa popolazione, otterremmo stime leggermente diverse. Questa oscillazione riflette il fatto che ogni campione rappresenta una possibile “fotografia” della realtà e che la nostra stima attuale è solo una di queste. È la variabilità che la statistica inferenziale tradizionale cattura attraverso l’errore standard e gli intervalli di confidenza.
La seconda fonte di variabilità riguarda la eterogeneità degli effetti stessi. Anche se potessimo osservare l’intera popolazione, l’effetto del trattamento non sarebbe identico per tutti gli individui. Le differenze nelle caratteristiche di base (età, genere, tratti della personalità, contesto sociale) interagiscono con l’intervento, producendo risposte diverse. Questo fenomeno, noto come effetto causale individuale, implica che, anche a parità di trattamento, gli esiti possono variare considerevolmente da persona a persona.
Per quantificare e comunicare entrambi i tipi di incertezza, in questo manuale ci affideremo agli strumenti della statistica bayesiana. In particolare, faremo ampio uso degli intervalli di credibilità che ci permettono di rappresentare in modo intuitivo e probabilistico il grado di fiducia nelle nostre stime. Ad esempio, affermeremo che c’è il 95% di probabilità che l’effetto causale reale si collochi all’interno di un determinato intervallo. Questo approccio non solo integra naturalmente l’incertezza derivante dal campionamento, ma può anche essere esteso per modellare esplicitamente l’eterogeneità degli effetti tra individui o sottogruppi.
31.5 Mini-simulazioni: confondimento e randomizzazione
Per chiarire meglio i concetti, è utile ricorrere a una simulazione che mostri cosa succede in presenza di confondimento e cosa, invece, quando il trattamento viene assegnato in modo casuale. Le simulazioni proposte di seguito sono volutamente semplificate: non hanno lo scopo di produrre risultati realistici, ma di rendere evidente la logica alla base delle nozioni che stiamo esaminando.
31.5.1 Il caso del confondimento: quando i trattati sono già diversi all’inizio
Immaginiamo una situazione in cui il trattamento — per esempio, l’uso di una strategia di reappraisal per ridurre l’ansia — viene scelto soprattutto da chi è già più ansioso per natura. In questo caso, stiamo assumendo che il trattamento, di per sé, non abbia alcun effetto causale sull’esito; tuttavia, poiché le persone con un’elevata ansia tendono a sottoporsi a più trattamenti, il confronto tra i trattati e i non trattati sarà inevitabilmente distorto. Si noterà infatti una differenza nei livelli di ansia osservati, ma questa differenza non sarà dovuta al trattamento, bensì al confondimento.
Il codice seguente genera questo scenario. Inizialmente, creiamo una variabile che rappresenta l’ansia di tratto a livello di base. Poi, costruiamo una probabilità di ricevere il trattamento che aumenta con l’aumentare dell’ansia di partenza. Infine, si simula l’esito che dipende solo dall’ansia di tratto e dal caso, ma non dal trattamento.
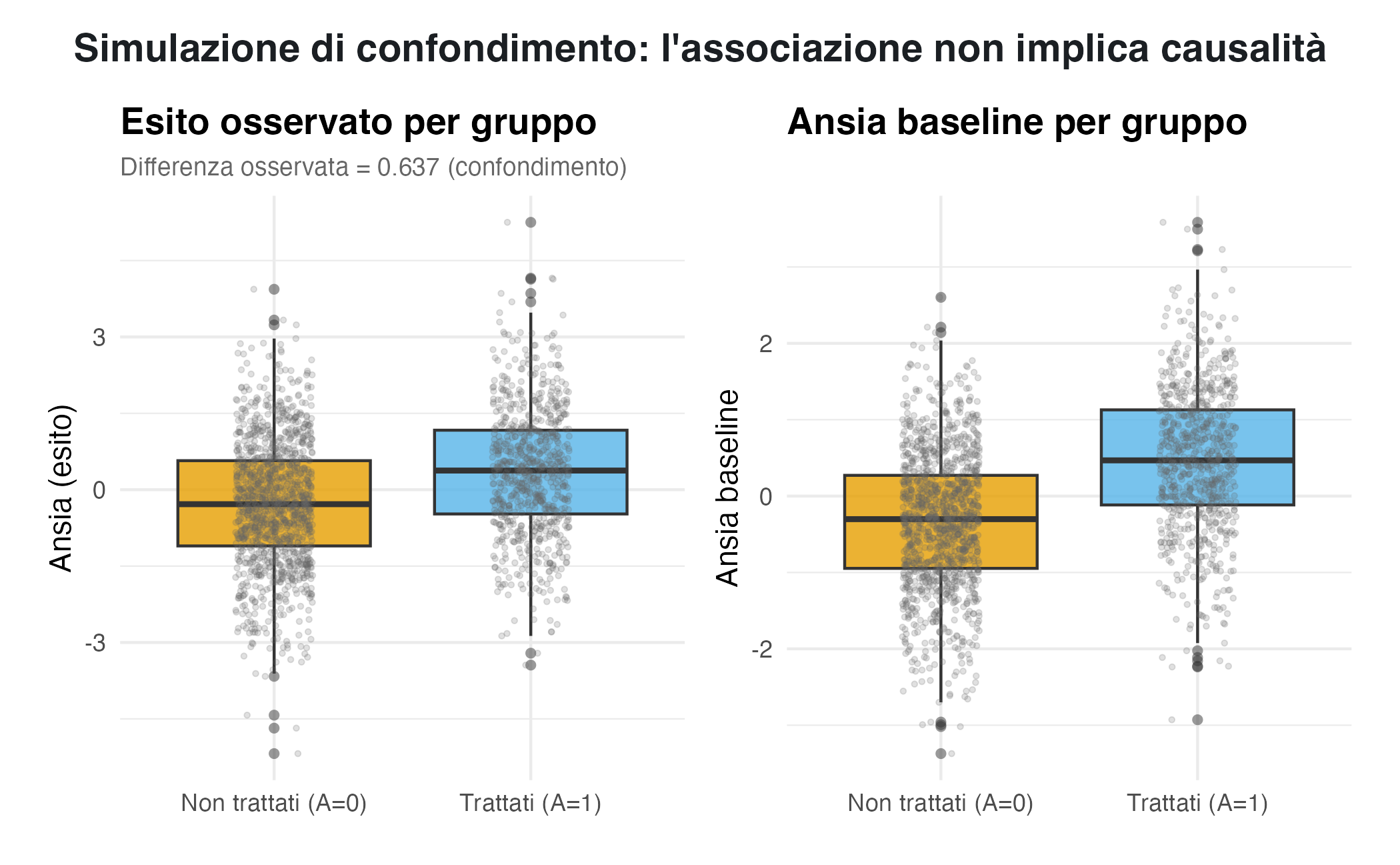
I grafici illustrano chiaramente il fenomeno. Il primo mostra che il gruppo trattato presenta in media livelli di ansia più elevati, quasi come se il trattamento avesse sortito un effetto negativo. Tuttavia, ed è questo il punto cruciale, in questa simulazione il trattamento non ha alcun effetto causale reale. Il secondo grafico rivela il motivo: i soggetti assegnati al gruppo di trattamento presentavano già livelli di ansia basale significativamente più alti.
Questa simulazione dimostra chiaramente come l’associazione osservata tra trattamento ed esito possa divergere radicalmente dal suo effetto causale. In questo caso, la differenza apparente è interamente attribuibile al confondimento: una variabile non controllata (l’ansia di base) influenza sia la probabilità di ricevere il trattamento sia l’esito finale, creando un’illusione di causalità laddove non esiste.
31.5.2 Randomizzazione: quando associazione e causalità coincidono (se ACE = 0)
Riprendiamo lo stesso scenario della simulazione precedente, ma con una modifica decisiva: invece di consentire che il trattamento venga scelto in base al livello di ansia di base, lo assegniamo in modo casuale. Questo equivale a lanciare una moneta bilanciata: ogni individuo ha la stessa probabilità (50%) di ricevere l’intervento.
In questo nuovo contesto, l’effetto causale del trattamento rimane nullo, in quanto non abbiamo alterato il meccanismo che lega l’ansia di tratto all’esito. La differenza cruciale sta nel fatto che, grazie alla randomizzazione, i gruppi dei trattati e dei non trattati risultano statisticamente equivalenti in media per tutte le caratteristiche osservabili e non osservabili, comprese le variabili di confondimento.
Ecco il codice R che implementa questa simulazione:
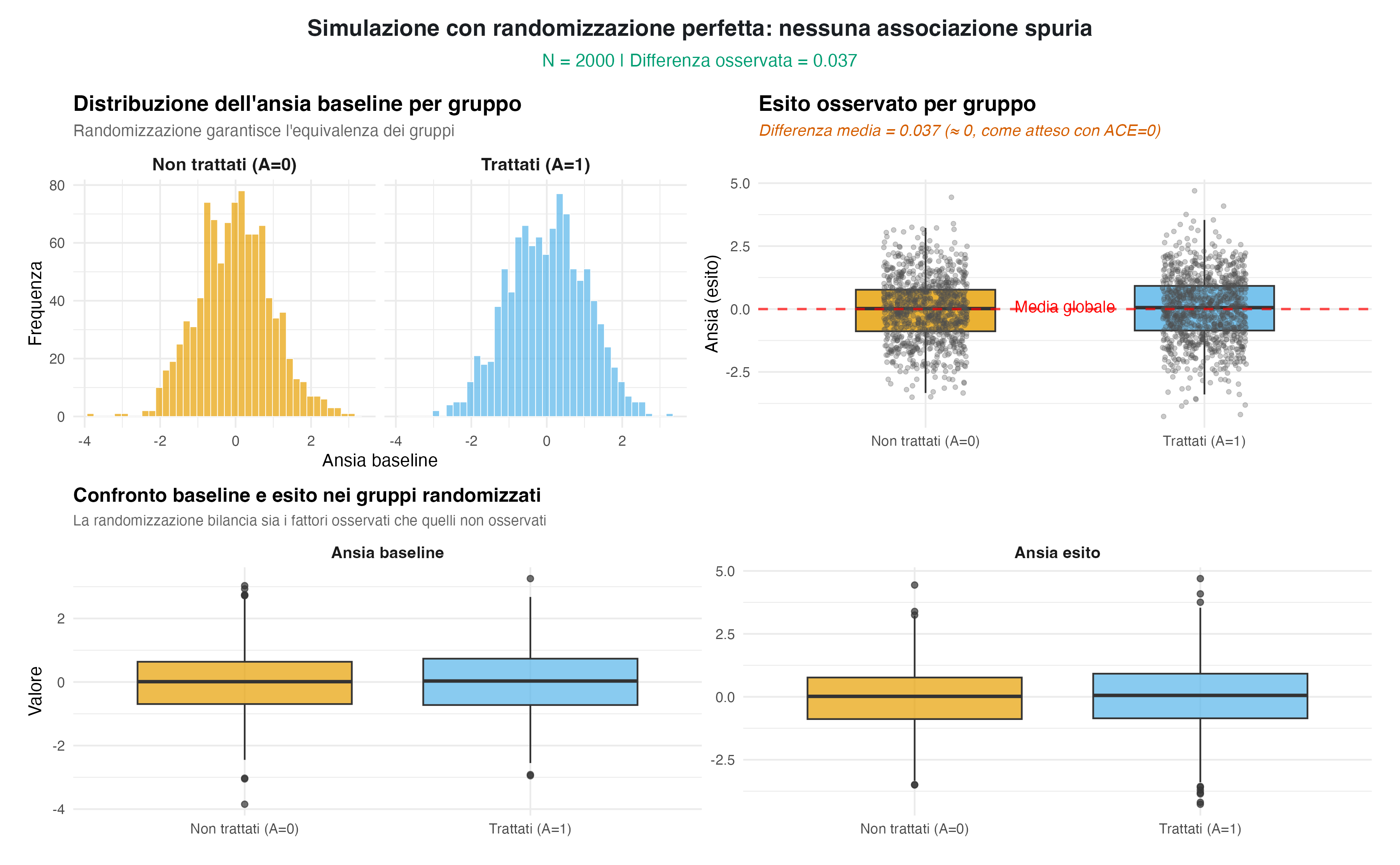
#> Differenza media osservata (randomized) = 0.037Questa volta, confrontando i due gruppi, notiamo che le distribuzioni dell’ansia di tratto sono simili. Infatti, la differenza media osservata negli esiti si avvicina a zero, proprio come il vero effetto causale. In questo esempio, associazione e causalità coincidono, perché l’assegnazione casuale ha eliminato il legame spurio con i confondenti.
31.6 Quando l’effetto causale c’è davvero
Finora abbiamo simulato scenari in cui il trattamento non produceva alcun effetto reale. Ma cosa accadrebbe se introducessimo un vero effetto causale? Supponiamo, ad esempio, che l’applicazione della tecnica di reappraisal riduca il livello di ansia di 0.4 punti in media sulla scala di misurazione.
In questo caso, grazie alla randomizzazione, la differenza media osservata tra i soggetti trattati e quelli non trattati riflette fedelmente, almeno in media, questo effetto causale. La randomizzazione garantisce che i gruppi siano comparabili all’inizio, quindi qualsiasi differenza sistematica osservata nell’esito può essere plausibilmente attribuita al trattamento.
La simulazione che segue implementa proprio questo scenario:
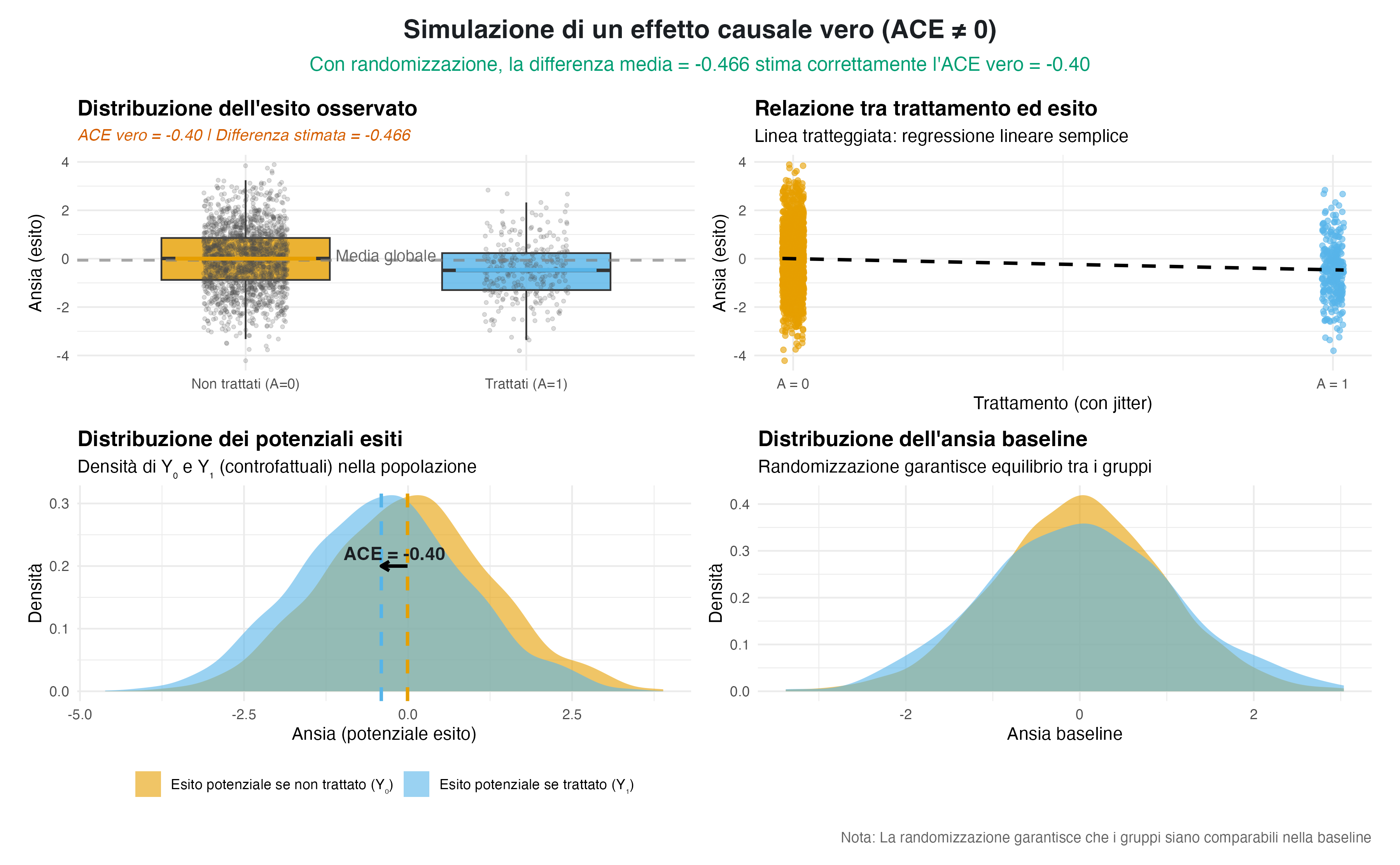
#> Differenza media osservata = -0.466 (vero effetto = -0.400)Il risultato è chiaro: quando esiste un vero effetto causale e i gruppi sono stati resi comparabili mediante la randomizzazione, la differenza media osservata diventa una buona stima dell’ACE. In altre parole, l’esperimento controllato ci permette di trasformare un’associazione in un’inferenza causale credibile.
31.6.1 Domande guida per l’inferenza causale
Lavorare con dati osservazionali in psicologia richiede un cambio di prospettiva: da un approccio meramente associativo a uno che, con metodo e cautela, si avvicini al “cosa sarebbe successo se”. Il seguente kit di domande guida fornisce una bussola metodologica per navigare questa complessità in modo rigoroso (questi argomenti saranno sviluppati nel Capitolo 32).
1. La domanda causale è definita con precisione? L’inferenza causale inizia con una domanda ben definita. Questo richiede di specificare con esattezza quattro elementi: - Trattamento: che cosa costituisce l’esposizione o l’intervento (ad esempio, “applicare la tecnica di reappraisal secondo il protocollo X per almeno 15 minuti al giorno”)? - Esito: qual è la variabile di risultato e come viene operazionalizzata e misurata (ad esempio, “punteggio totale alla scala di ansia di stato Y, misurato subito dopo la sessione”)? - Popolazione: a quale gruppo specifico di individui ci si riferisce (ad esempio, “studenti universitari di corsi umanistici, di età compresa tra 20 e 25 anni”)? - Contesto temporale: in quale finestra temporale ci si aspetta che l’effetto si manifesti (ad esempio, “effetto immediato post-intervento”)? Un problema definito in modo vago porta inevitabilmente a conclusioni altrettanto vaghe.
2. Quali sono le possibili variabili di confondimento? Il confondimento rappresenta la minaccia principale alla validità causale. Una variabile di confondimento influenza sia la probabilità di ricevere il trattamento che l’esito stesso, creando un’associazione spuria tra i due. Identificarla richiede un esercizio di teoria e conoscenza del dominio. Ad esempio, studiando l’effetto dell’uso dei social media (Trattamento) sul benessere psicologico (Esito), la solitudine è un forte candidato confondente: può spingere sia a un uso maggiore dei social sia a un minore benessere.
3. Le assunzioni SUTVA sono plausibili nel mio contesto? L’assunzione SUTVA (Stable Unit Treatment Value Assumption) è spesso data per scontata, ma deve essere esplicitamente verificata. Comprende due parti: (1) assenza di interferenza – il trattamento assegnato a un individuo influenza solo il suo esito, non quello di altri (un’ipotesi che può essere violata in contesti di gruppo o comunitari); e (2) unicità del trattamento – esiste una sola versione ben definita del trattamento (in psicologia, gli “interventi” spesso variano nella loro implementazione pratica). Valutare la plausibilità di SUTVA guida la scelta del disegno di ricerca e l’interpretazione dei risultati.
4. Su quale scala è più significativo misurare l’effetto? La scelta della misura d’effetto deve rispondere alla domanda di ricerca e agli scopi pratici dello studio, non seguire una regola universale. - La differenza di rischi (o di medie per esiti continui) risponde a una domanda di impatto assoluto: “Quanti casi in più/meno possiamo attenderci?”. - Il rapporto di rischi (o odds ratio) risponde a una domanda di rischio relativo: “Quante volte è più (o meno) probabile l’esito?”. La scelta influenza l’interpretazione pratica e la comunicazione dei risultati verso clinici, pazienti o decisori pubblici.
5. Come posso avvicinarmi al controfattuale con i dati che ho? In assenza di randomizzazione, il ricercatore deve “ricreare” le condizioni di comparabilità tramite l’analisi, affidandosi a strumenti specifici. I Grafici Causali (DAG) rappresentano visivamente le ipotesi sulle relazioni tra variabili e sono fondamentali per distinguere confonditori, mediatori e collider (configurazioni che, se controllate, introducono distorsione invece di rimuoverla). Una volta definito il DAG, il criterio backdoor indica formalmente quale insieme minimo di variabili è necessario controllare (ad esempio, tramite regressione o stratificazione) per bloccare i percorsi di confondimento. Infine, si applicano i metodi statistici appropriati (come la regressione multivariata o il propensity score matching) per stimare l’effetto una volta isolate le variabili chiave.
ConsiglioTake-home (riepilogo)
In sintesi, l’effetto causale è un confronto controfattuale su tutta la popolazione, in cui si considerano due mondi: uno con il trattamento e uno senza. L’associazione, invece, è un confronto osservazionale tra gruppi reali che può essere distorto dai fattori confondenti. La randomizzazione rende i gruppi comparabili e, in media, elimina il confondimento. Con i dati osservazionali, invece, dobbiamo affidarci a ipotesi e metodi appropriati per avvicinarci il più possibile a uno scenario controfattuale.
31.7 Micro-esercizi
Per consolidare le idee fin qui introdotte, proponiamo due semplici esercizi. Non hanno la pretesa di esaurire la complessità dell’argomento, ma vogliono offrire l’opportunità di “toccare con mano” alcuni concetti che ritroveremo più avanti nel manuale.
31.7.1 Il paradosso di Simpson
Il paradosso di Simpson rappresenta un esempio paradigmatico di come le associazioni aggregate possano condurre a conclusioni fuorvianti sull’effetto di un trattamento. Si verifica quando una tendenza osservata in un’intera popolazione scompare o si inverte quando si esaminano i sottogruppi che la compongono.
Consideriamo due sottogruppi di individui: uno con bassa ansia di tratto e uno con alta ansia di tratto. Supponiamo che all’interno di ciascun sottogruppo l’effetto causale del trattamento sia identico e negativo, ovvero riduca l’ansia di una quantità fissa. Il paradosso emerge quando la probabilità di ricevere il trattamento non è omogenea tra i gruppi. Ad esempio, se gli individui con un’alta ansia di tratto cercano attivamente il trattamento con maggiore frequenza, il gruppo dei trattati sarà composto in modo sproporzionato da persone già più ansiose.
Di conseguenza, quando si confrontano semplicemente le medie dell’intero gruppo trattato con quelle dell’intero gruppo di controllo (confronto marginale), la differenza osservata sarà una miscela confusa di due elementi: il vero effetto del trattamento e il divario preesistente nei livelli di ansia tra i sottogruppi. Questo può produrre una stima aggregata che è nulla, attenuata o, in casi estremi, di segno opposto rispetto all’effetto reale presente in ogni sottogruppo.
La simulazione seguente illustra questo meccanismo in azione, mostrando come un trattamento che si è rivelato efficace in ogni sottogruppo possa apparire inefficace o addirittura dannoso quando i dati vengono analizzati senza considerare la struttura dei sottogruppi.
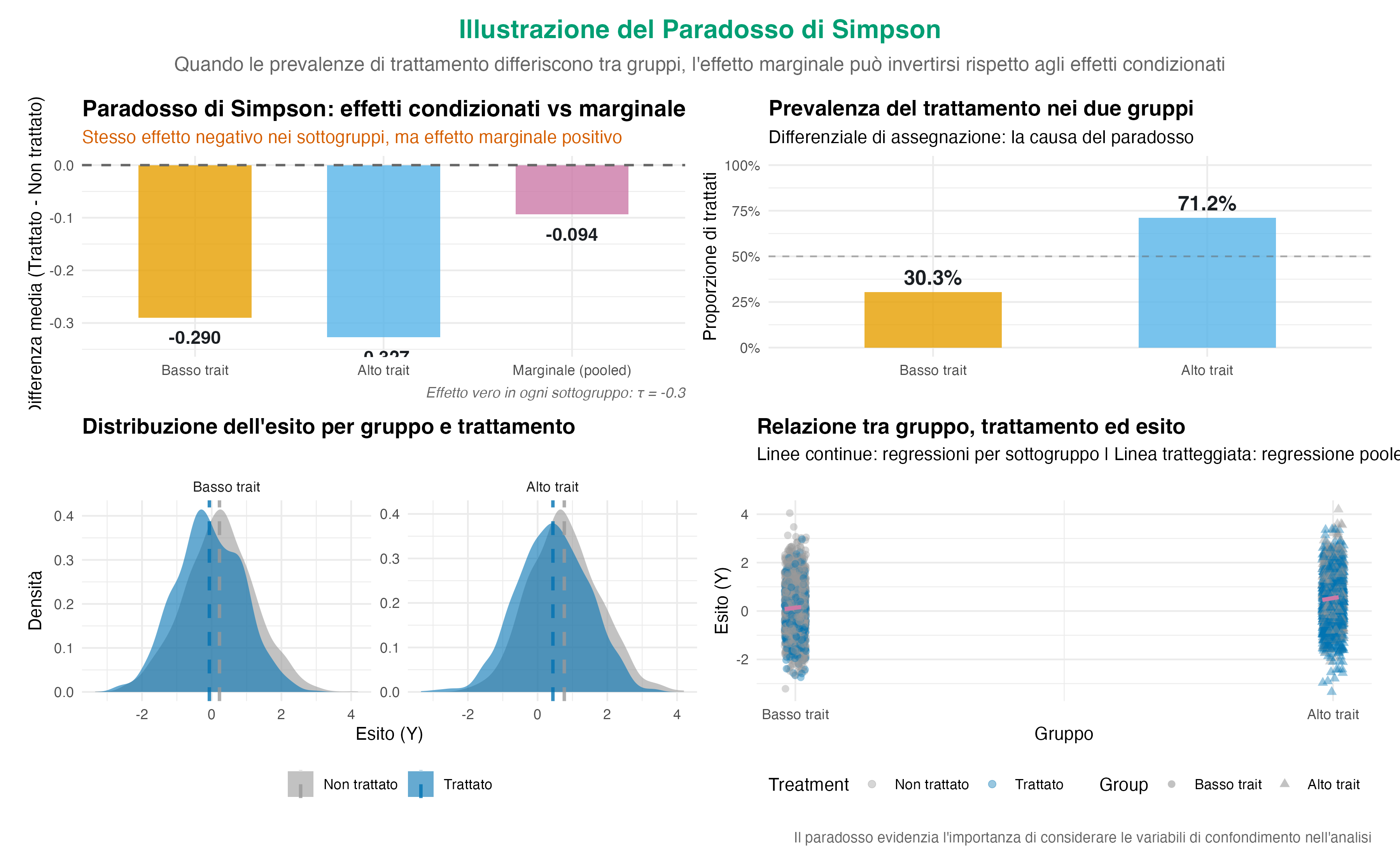
I due grafici a barre relativi ai sottogruppi mostrano un effetto coerente e negativo, come previsto dall’ipotesi di partenza. Tuttavia, il barplot “marginale”, che ignora la distinzione tra alto e basso tratto, racconta un’altra storia, ovvero quella di un effetto prossimo a zero.
Questa discrepanza descrive il Paradosso di Simpson. Dimostra come una conclusione basata su dati aggregati possa essere diametralmente opposta a quella che emerge dall’analisi stratificata. Il meccanismo alla base di questa discrepanza è il confondimento: la variabile “ansia di tratto” distorce l’associazione osservata perché influenza sia la probabilità di ricevere il trattamento sia l’esito stesso.
Pertanto, per risalire all’effetto causale vero, è necessario aggiustare per questo fattore confondente. Non si tratta di includere meccanicamente ogni covariata correlata in una regressione, ma di un’operazione concettuale precisa: dobbiamo condizionare sull’ansia di tratto, in modo da confrontare individui che, a parità di livello di tratto, differiscono solo per lo stato di trattamento.
È proprio questa operazione di ragionamento sui fattori confondenti e sugli aggiustamenti necessari che i DAG (Directed Acyclic Graphs) formalizzano e guidano, e che affronteremo nel Capitolo 32.
31.7.2 Effetto causale espresso su scale diverse: una questione di comunicazione e interpretazione
Un secondo esercizio ci permette di confrontare direttamente le diverse scale su cui è possibile esprimere un effetto causale. Supponiamo che la probabilità di un certo esito (ad esempio, un attacco d’ansia) sia del 20% tra i soggetti trattati e del 10% tra i soggetti non trattati. Da qui è possibile calcolare tre misure diverse: la differenza di rischi (RD), il rapporto di rischi (RR) e l’odds ratio (OR).
#> RD = 0.095; RR = 1.91; OR = 2.13Ciascuna di queste misure racconta la stessa storia con un linguaggio diverso, rispondendo a domande distinte:
| Misura | Formula | Domanda a cui risponde | Interpretazione concreta |
|---|---|---|---|
| Differenza di Rischi (RD) | p1 - p0 |
“Quanti casi in più si osservano?” | Su 100 persone trattate, ci attendiamo 10 casi in più di attacco d’ansia rispetto a 100 non trattate. Risponde a una domanda di impatto assoluto. |
| Rapporto di Rischi (RR) | p1 / p0 |
“Di quante volte è più probabile?” | Il rischio di un attacco d’ansia è 2 volte superiore nel gruppo trattato. Risponde a una domanda di rischio relativo. |
| Odds Ratio (OR) | (p1/(1-p1)) / (p0/(1-p0)) |
“Quanto cambiano le probabilità relative?” | Le odds (probabilità relativa) di un attacco d’ansia sono circa 2.25 volte maggiori nei trattati. È meno intuitiva, ma essenziale per i modelli statistici. |
La scelta della scala non è una questione tecnica neutra, ma una decisione di natura comunicativa e interpretativa. Per uno psicologo che opera nel settore della sanità pubblica e che è interessato all’impatto reale di un intervento, la RD (10% di casi in più) è fondamentale per la pianificazione delle risorse e dei servizi. Per uno psicologo clinico o un ricercatore che valuta la forza di un fattore di rischio, il RR (rischio doppio) potrebbe invece essere più rilevante. L’OR, pur essendo una misura meno intuitiva, è lo strumento statistico di elezione per i modelli logistici e le analisi complesse.
Il messaggio finale è che non esiste una scala “corretta” in assoluto: tutto dipende dalla domanda di ricerca specifica e dal contesto in cui vengono comunicati i risultati. Una discussione completa richiede spesso di considerare più di una misura, evitando di presentare un singolo numero isolato dal suo significato pratico.
31.8 Riflessioni conclusive
Attraverso le simulazioni e gli esercizi presentati, abbiamo illustrato quanto sia facile confondere l’associazione con la causalità e quanto sia invece necessario, nonché fondamentale per il metodo scientifico, separare le due prospettive.
Abbiamo visto come il semplice confronto statistico tra due gruppi (l’associazione) possa essere gravemente distorto da fattori confondenti, arrivando persino a suggerire un effetto opposto a quello reale, come nel paradosso di Simpson. Abbiamo compreso che la randomizzazione sperimentale risolve questo problema creando due gruppi paragonabili e consentendo di attribuire le differenze osservate al trattamento stesso. Abbiamo anche esplorato come un unico effetto causale possa essere comunicato su scale diverse: la differenza assoluta o il rischio relativo, ognuna delle quali risponde a una domanda diversa e serve uno scopo comunicativo diverso.
Questi concetti non sono semplici cavilli teorici, ma costituiscono la premessa per una ricerca quantitativa rigorosa. Tuttavia, nella ricerca psicologica osservazionale, in cui non è possibile assegnare casualmente ansia, tratti di personalità o esperienze di vita, il problema rimane irrisolto. Come possiamo estrarre un segnale causale da dati intrinsecamente confusi?
È a questa domanda pratica che risponderemo nel Capitolo 32. In quel capitolo trasformeremo l’intuizione in una metodologia operativa, imparando a:
- formalizzare le nostre ipotesi causali attraverso i DAG (Directed Acyclic Graphs);
- identificare in modo sistematico, mediante il criterio di backdoor, l’insieme minimo di variabili da controllare per isolare l’effetto del trattamento;
- applicare gli strumenti statistici appropriati, come il matching, la pesatura, la regressione multivariata e l’uso dei propensity score, per implementare tale controllo.
L’obiettivo finale sarà dotarci di un protocollo chiaro per avvicinare il più possibile l’analisi dei dati osservazionali all’ideale dell’esperimento randomizzato, trasformando i limiti dei nostri dati in una riflessione esplicita e rigorosa sulla struttura causale del fenomeno che stiamo studiando.
ConsiglioInformazioni sull’ambiente di sviluppo
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ragg_1.5.0 tinytable_0.15.1 withr_3.0.2
#> [4] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [7] tidybayes_3.0.7 bayesplot_1.14.0 ggplot2_4.0.1
#> [10] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [13] loo_2.8.0 rstan_2.32.7 StanHeaders_2.32.10
#> [16] brms_2.23.0 Rcpp_1.1.0 sessioninfo_1.2.3
#> [19] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [22] modelr_0.1.11 tibble_3.3.0 dplyr_1.1.4
#> [25] tidyr_1.3.1 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] gridExtra_2.3 inline_0.3.21 sandwich_3.1-1
#> [4] rlang_1.1.6 magrittr_2.0.4 multcomp_1.4-29
#> [7] snakecase_0.11.1 compiler_4.5.2 mgcv_1.9-4
#> [10] vctrs_0.6.5 stringr_1.6.0 pkgconfig_2.0.3
#> [13] arrayhelpers_1.1-0 fastmap_1.2.0 backports_1.5.0
#> [16] labeling_0.4.3 rmarkdown_2.30 purrr_1.2.0
#> [19] xfun_0.54 cachem_1.1.0 jsonlite_2.0.0
#> [22] broom_1.0.11 parallel_4.5.2 R6_2.6.1
#> [25] stringi_1.8.7 RColorBrewer_1.1-3 lubridate_1.9.4
#> [28] estimability_1.5.1 knitr_1.50 zoo_1.8-14
#> [31] pacman_0.5.1 Matrix_1.7-4 splines_4.5.2
#> [34] timechange_0.3.0 tidyselect_1.2.1 abind_1.4-8
#> [37] yaml_2.3.12 codetools_0.2-20 curl_7.0.0
#> [40] pkgbuild_1.4.8 lattice_0.22-7 bridgesampling_1.2-1
#> [43] S7_0.2.1 coda_0.19-4.1 evaluate_1.0.5
#> [46] survival_3.8-3 RcppParallel_5.1.11-1 pillar_1.11.1
#> [49] tensorA_0.36.2.1 checkmate_2.3.3 stats4_4.5.2
#> [52] distributional_0.5.0 generics_0.1.4 rprojroot_2.1.1
#> [55] rstantools_2.5.0 scales_1.4.0 xtable_1.8-4
#> [58] glue_1.8.0 emmeans_2.0.0 tools_4.5.2
#> [61] mvtnorm_1.3-3 grid_4.5.2 QuickJSR_1.8.1
#> [64] colorspace_2.1-2 nlme_3.1-168 cli_3.6.5
#> [67] textshaping_1.0.4 svUnit_1.0.8 Brobdingnag_1.2-9
#> [70] V8_8.0.1 gtable_0.3.6 digest_0.6.39
#> [73] TH.data_1.1-5 htmlwidgets_1.6.4 farver_2.1.2
#> [76] memoise_2.0.1 htmltools_0.5.9 lifecycle_1.0.4
#> [79] MASS_7.3-65Bibliografia
Hernán, M. A., & Robins, J. M. (2020). Causal Inference: What If. Chapman & Hall/CRC.
Le correlazioni spurie sono estremamente comuni. Un modello di regressione può descrivere formalmente e accuratamente una relazione spuria, ma ciò non ci fornisce alcuna informazione utile sul funzionamento dei fenomeni psicologici. Il sito Spurious Correlations documenta numerose associazioni statisticamente forti ma del tutto accidentali — mostrando, con ironia, che anche correlazioni bizzarre potrebbero dar vita a pubblicazioni scientifiche prive di significato. Il messaggio fondamentale rimane: una correlazione, di per sé, non ci informa sui meccanismi sottostanti un fenomeno. Comprendere il funzionamento dei processi psicologici non è un problema meramente statistico: non basta descrivere accuratamente le associazioni tra variabili. Si tratta piuttosto di un problema di modellazione teorica: è necessario formulare modelli validi delle relazioni causali che generano i dati osservati.↩︎