here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(dplyr, tidyr, tibble, purrr, ggplot2, HDInterval)11 Famiglie coniugate
AttenzionePreparazione del Notebook
11.1 Una soluzione in forma chiusa per la distribuzione a posteriori
Una distribuzione a priori è coniugata per una funzione di verosimiglianza quando la distribuzione a posteriori risultante appartiene alla stessa famiglia. Questa proprietà consente un’inferenza bayesiana in forma analitica chiusa, fornendo una soluzione esatta senza l’utilizzo di metodi computazionali complessi.
Per ogni funzione di verosimiglianza appartenente alla famiglia esponenziale (normale, bernoulliana, binomiale, poissoniana, esponenziale, gamma, beta o multinomiale) esiste sempre una distribuzione a priori coniugata. Nei modelli semplici, l’uso di priors coniugati consente di ottenere una soluzione analitica per la distribuzione a posteriori. La combinazione di una verosimiglianza esponenziale e di un prior coniugato costituisce un modello coniugato-esponenziale.
Il meccanismo di aggiornamento si riduce a una modifica algebrica dei parametri della distribuzione a priori. Nel modello Beta-Binomiale, ad esempio, la distribuzione a posteriori si ottiene sommando il numero di successi osservati al parametro \(\alpha\) e il numero di insuccessi al parametro \(\beta\) della distribuzione Beta iniziale. Questa semplicità di calcolo permette di concentrarsi sull’interpretazione dei risultati piuttosto che sugli aspetti tecnici del calcolo stesso.
I parametri delle distribuzioni coniugate hanno un’interpretazione intuitiva: rappresentano una conoscenza a priori sotto forma di “pseudo-osservazioni”. Ad esempio, per la distribuzione Beta, i parametri \(\alpha\) e \(\beta\) corrispondono rispettivamente al numero virtuale di successi e fallimenti pregressi.
Questo meccanismo rende trasparente l’aggiornamento bayesiano, che si riduce alla semplice somma di queste osservazioni virtuali ai dati empirici. La distribuzione a posteriori risulta quindi dalla semplice addizione della conoscenza preesistente all’evidenza nuova.
Il principio si estende anche ad altre famiglie coniugate, in cui i parametri del prior svolgono un ruolo analogo, quantificando sinteticamente l’informazione pregressa. Un ulteriore vantaggio è l’aggiornamento sequenziale: nuovi dati possono essere incorporati iterativamente utilizzando la distribuzione a posteriori come nuovo prior, senza dover rielaborare l’intero dataset. Questo è utile in contesti come il monitoraggio clinico, in cui le valutazioni richiedono un adattamento continuo.
11.2 Panoramica delle principali coppie coniugate
Prima di passare ai dettagli implementativi, presentiamo una sintesi delle principali coppie coniugate utilizzate negli esempi. Ogni riga mostra come una distribuzione dei dati si combini con un prior specifico per produrre una distribuzione a posteriori della stessa famiglia.
| Modello dati | Parametro | Prior coniugata | Posterior |
|---|---|---|---|
| Binomiale\((n,\theta)\) | \(\theta \in [0,1]\) | Beta\((\alpha,\beta)\) | Beta\((\alpha+y, \beta+n-y)\) |
| Poisson\((\theta)\) | \(\theta > 0\) | Gamma\((a,b)\) | Gamma\((a+\sum y_i, b+n)\) |
| Esponenziale\((\theta)\) | \(\theta > 0\) | Gamma\((a,b)\) | Gamma\((a+n, b+\sum y_i)\) |
| Normale\((\mu,\sigma^2)\) | \(\mu \in \mathbb{R}\) | \(\mathcal{N}(\mu_0,\tau_0^2)\) | \(\mathcal{N}(\mu_n,\tau_n^2)\) |
Osserviamo alcuni pattern ricorrenti. Nel modello Beta-Binomiale, i parametri della posterior si ottengono sommando i conteggi osservati ai parametri del prior. Nel modello Gamma-Poisson, la forma della distribuzione aumenta con il totale degli eventi, mentre il parametro di scala aumenta con il numero di osservazioni. Il modello Normale-Normale presenta invece una struttura più complessa, basata su una combinazione ponderata delle precisioni.
11.3 Funzioni per l’aggiornamento bayesiano
Implementiamo ora quattro funzioni che automatizzano il calcolo dell’aggiornamento bayesiano per i modelli coniugati più comuni. Ciascuna funzione accetta come input i parametri del prior e i dati osservati, restituendo i parametri della distribuzione a posteriori.
11.3.1 Beta-Binomiale: proporzioni e percentuali
Il modello Beta-Binomiale è appropriato per l’inferenza su una proporzione incognita. Esempi tipici includono la stima dell’accuratezza in un compito di riconoscimento, la proporzione di pazienti che rispondono a un trattamento o la frequenza di comportamenti osservati in un contesto educativo.
beta_binomiale_aggiorna <- function(successi, prove, alpha_prior, beta_prior) {
alpha_post <- alpha_prior + successi
insuccessi <- prove - successi
beta_post <- beta_prior + insuccessi
list(alpha_post = alpha_post, beta_post = beta_post)
}In questo modello, l’aggiornamento bayesiano è particolarmente intuitivo. I parametri \(\alpha\) e \(\beta\) della distribuzione Beta rappresentano conteggi virtuali di successi e insuccessi derivanti da conoscenze pregresse. L’aggiornamento con i dati osservati si riduce a una semplice somma: ai parametri del prior si aggiungono i successi e gli insuccessi empirici.
Ad esempio, con un prior Beta(\(\alpha = 2, \beta = 2\)) e l’osservazione di 7 successi su 10 prove, la distribuzione a posteriori è Beta(\(\alpha = 2 + 7, \beta = 2 + 3\)) = Beta(9, 5). Il processo mostra in modo trasparente come le convinzioni iniziali si combinino con l’evidenza empirica.
11.3.2 Normale-Normale: medie e misure continue
Il modello Normale-Normale stima la media di una variabile continua assumendo che la varianza sia nota. Questo modello è frequente in psicometria e neuropsicologia, dove molte misure standardizzate hanno una varianza nota per costruzione.
normale_normale_aggiorna <- function(media_campionaria, numerosita,
sigma_noto, mu_prior, tau_prior) {
precisione_prior <- 1 / (tau_prior^2)
precisione_dati <- numerosita / (sigma_noto^2)
precisione_post <- precisione_prior + precisione_dati
varianza_post <- 1 / precisione_post
sd_post <- sqrt(varianza_post)
mu_post <- varianza_post * (mu_prior * precisione_prior + media_campionaria * precisione_dati)
list(mu_post = mu_post, sd_post = sd_post)
}In questo modello, l’incertezza viene quantificata tramite la precisione, definita come il reciproco della varianza: \(\tau = 1/\sigma^2\). Una varianza bassa corrisponde a un’alta precisione e indica una maggiore certezza nella stima.
La caratteristica notevole di questo modello è che le precisioni si combinano linearmente: la precisione a posteriori è la somma della precisione a priori e della precisione dei dati osservati. Questa relazione semplifica l’aggiornamento delle credenze quando si combinano informazioni provenienti da fonti multiple.
11.3.3 Gamma-Poisson: conteggi di eventi
Il modello Gamma-Poisson è adatto per l’analisi del conteggio di eventi in intervalli di tempo o spazio fissi. Alcuni esempi sono: il numero di episodi sintomatici per settimana, gli errori in un compito cognitivo o la frequenza di comportamenti target in sessioni di osservazione.
I parametri del modello hanno un’interpretazione intuitiva: una distribuzione a priori Gamma(\(\alpha\)=2, \(\beta\)=4) equivale all’osservazione virtuale di \(\alpha\)=2 eventi in un periodo totale di \(\beta\)=4 unità temporali, suggerendo un tasso a priori di 0.5 eventi per unità.
L’aggiornamento bayesiano avviene mediante una semplice somma. Con l’osservazione di 4 eventi in 4 unità temporali, la distribuzione a posteriori risulta Gamma(\(\alpha\)=2+4, \(\beta\)=4+4) = Gamma(6, 8). Ciò corrisponde a un’esperienza complessiva di 6 eventi in 8 unità temporali, mostrando come il prior si aggiorni attraverso l’accumulo di evidenza empirica.
11.3.4 Gamma-Esponenziale: tempi tra eventi
Il modello Gamma-Esponenziale analizza i tempi di attesa tra eventi consecutivi. È complementare al modello Gamma-Poisson: quest’ultimo conta gli eventi in un tempo fisso, mentre il modello Gamma-Esponenziale misura l’intervallo tra un evento e il successivo.
In questo modello, la distribuzione a priori Gamma modella l’incertezza sul tasso \(\lambda\) di un processo di eventi rari, mentre la verosimiglianza Esponenziale descrive la distribuzione dei tempi di attesa tra eventi consecutivi.
L’aggiornamento bayesiano è diretto: il parametro di forma \(\alpha\) della Gamma aumenta di un numero pari al numero di eventi osservati, mentre il parametro di velocità \(\beta\) aumenta della somma dei tempi di attesa osservati.
La distinzione tra i modelli Gamma-Poisson e Gamma-Esponenziale è fondamentale. Entrambi utilizzano una distribuzione a priori Gamma per il parametro di tasso \(\lambda\), ma modellano fenomeni diversi.
Il modello Gamma-Poisson descrive il numero di eventi che si verificano in un intervallo di tempo fisso, mentre il modello Gamma-Esponenziale descrive il tempo di attesa tra un evento e l’altro. Il suo processo di aggiornamento bayesiano aumenta il parametro \(\alpha\) della distribuzione Gamma con il conteggio degli eventi osservati e il parametro \(\beta\) con il numero di intervalli temporali presi in considerazione.
Al contrario, il modello Gamma-Esponenziale si concentra sulla lunghezza degli intervalli tra gli eventi consecutivi. In questo caso, il parametro \(\alpha\) viene aggiornato con il numero di eventi osservati, mentre il parametro \(\beta\) viene aggiornato con la somma effettiva dei tempi di attesa misurati.
Questa differenza riflette la natura distinta dei dati analizzati: da un lato i conteggi degli eventi e dall’altro le misure di tempo. Essa illustra inoltre come le distribuzioni a priori coniugate si adattino coerentemente a diverse strutture probabilistiche.
11.4 Il modello beta-binomiale: lo studio sull’obbedienza di Milgram
Consideriamo un esempio applicativo del modello Beta-Binomiale (Johnson et al., 2022) basato sull’esperimento di Milgram (1963). Questo studio rappresenta una pietra miliare nella psicologia sociale per l’analisi dei meccanismi di obbedienza all’autorità. Nell’esperimento, i partecipanti somministravano a un’altra persona quelle che credevano essere scosse elettriche di intensità crescente. I risultati mostrarono che 26 partecipanti su 40 (il 65%) proseguirono fino al livello massimo dello strumento, contrassegnato dalla dicitura “Pericolo: scossa grave”.
Da un punto di vista statistico, ci si può chiedere quale sia la proporzione della popolazione generale che, in condizioni sperimentali simili, mostrerebbe un livello analogo di obbedienza. L’inferenza bayesiana consente di quantificare l’incertezza associata a questa stima e di valutare esplicitamente come i dati modifichino le credenze iniziali.
11.4.1 Specificazione del prior: formalizzare lo scetticismo iniziale
Prima di esaminare i dati, specifichiamo una distribuzione a priori che esprima scetticismo riguardo alla diffusione dell’obbedienza estrema. Adottiamo una distribuzione Beta(1,10).
# Definiamo i parametri della distribuzione a priori
alpha_prior <- 1
beta_prior <- 10
# La media di una distribuzione Beta(alpha, beta) è alpha/(alpha + beta)
media_prior <- alpha_prior / (alpha_prior + beta_prior)
# Creiamo una sequenza di possibili valori del parametro theta
# che rappresenta la proporzione di obbedienza nella popolazione
theta_valori <- seq(from = 0, to = 1, length.out = 500)
# Calcoliamo la densità di probabilità per ciascun valore di theta
# usando la funzione dbeta() che implementa la distribuzione Beta
densita_prior <- dbeta(theta_valori, shape1 = alpha_prior, shape2 = beta_prior)
# Organizziamo i dati in un dataframe per facilitare la visualizzazione
dati_prior <- data.frame(
theta = theta_valori,
densita = densita_prior
)La distribuzione Beta(1,10) ha una media pari a 0.091, riflettendo l’aspettativa che solo una piccola frazione della popolazione manifesti un’obbedienza estrema. I parametri possono essere interpretati come il risultato di un esperimento virtuale in cui un partecipante su undici mostra il comportamento target.
# Definisci i colori tematici
col_prior <- palette_qualitative[8] # Grigio per prior
col_likelihood <- palette_qualitative[1] # Arancione per verosimiglianza
col_posterior <- palette_qualitative[5] # Blu per posterior
col_mean <- palette_qualitative[6] # Rosso-arancio per linee verticali/medie
col_interval <- palette_qualitative[7] # Rosa per intervalli
col_prediction <- palette_qualitative[2] # Azzurro per distribuzioni predittive
# Creiamo la visualizzazione della distribuzione a priori
ggplot(dati_prior, aes(x = theta, y = densita)) +
geom_line(color = col_prior, size = 1.2) +
geom_area(fill = col_prior, alpha = 0.3) +
geom_vline(xintercept = media_prior, linetype = "dashed",
color = col_mean, size = 0.8) +
annotate("text", x = 0.2, y = max(densita_prior) * 0.8,
label = paste("Media =", round(media_prior, 3)),
color = col_mean, size = 4) +
labs(
title = "Distribuzione a priori Beta(1, 10)",
subtitle = "Rappresenta lo scetticismo iniziale sulla diffusione dell'obbedienza estrema",
x = expression(theta ~ "(proporzione che obbedisce)"),
y = "Densità di probabilità"
)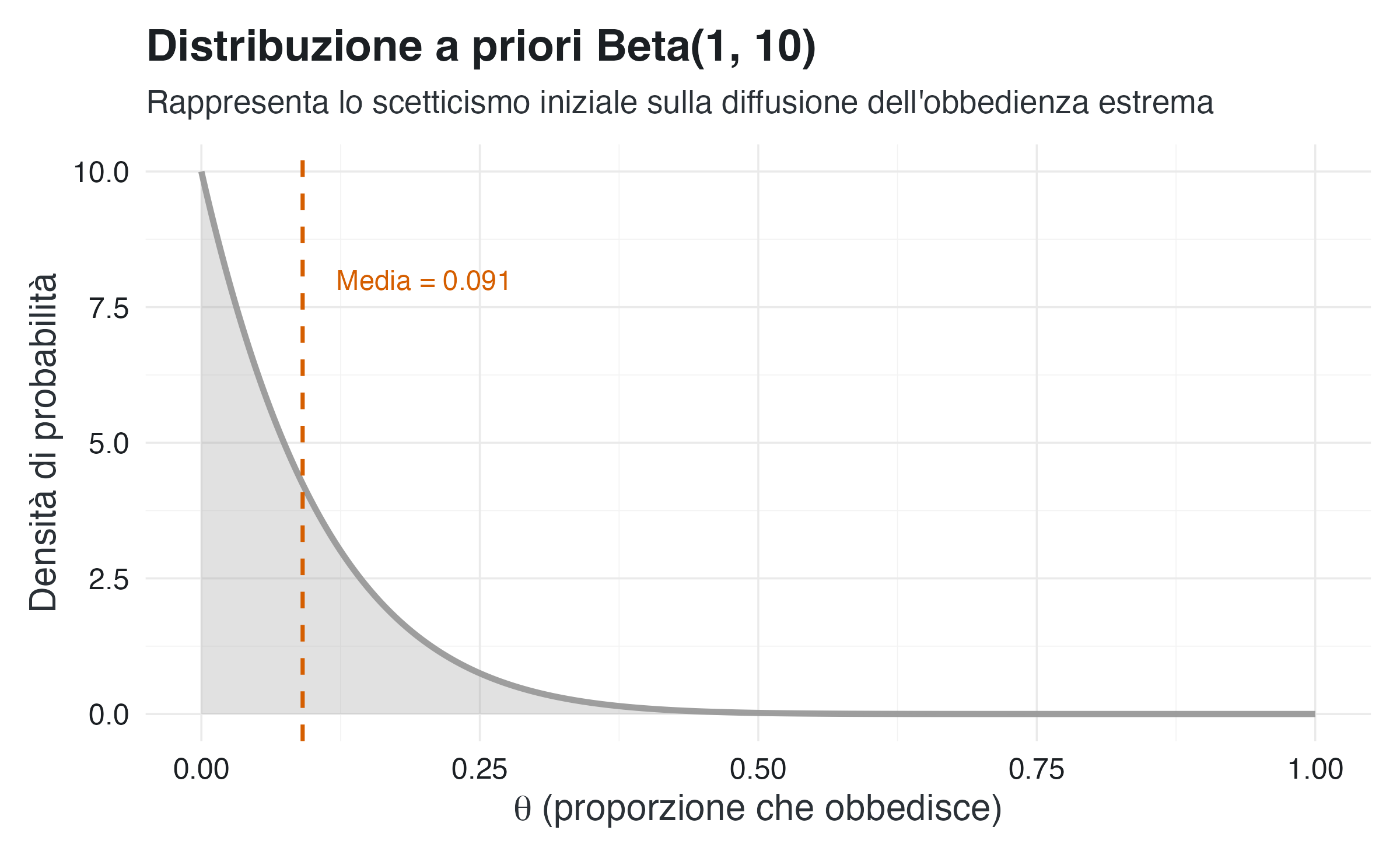
Il grafico mostra che la distribuzione a priori concentra la maggior parte della massa di probabilità su valori bassi di \(\theta\). La forma decrescente della curva indica che, a priori, sono considerate poco plausibili proporzioni più elevate di obbedienza.
11.4.2 L’aggiornamento bayesiano: integrare evidenza e credenze
Aggiorniamo le credenze iniziali incorporando i dati osservati mediante la regola di aggiornamento coniugato:
# Dati osservati nell'esperimento di Milgram
successi_osservati <- 26 # partecipanti che hanno obbedito completamente
prove_totali <- 40 # numero totale di partecipanti
# Applichiamo la funzione di aggiornamento bayesiano
parametri_posteriori <- beta_binomiale_aggiorna(
successi = successi_osservati,
prove = prove_totali,
alpha_prior = alpha_prior,
beta_prior = beta_prior
)
# Estraiamo i parametri aggiornati dalla lista restituita
alpha_post <- parametri_posteriori$alpha_post
beta_post <- parametri_posteriori$beta_post
# Calcoliamo la media della distribuzione a posteriori
media_post <- alpha_post / (alpha_post + beta_post)I parametri della distribuzione a posteriori sono \(\alpha\) = 27 e \(\beta\) = 24. Questi valori riflettono l’accumulo di esperienza: i 26 successi osservati si sommano al singolo successo virtuale del prior (1 + 26 = 27), mentre i 14 insuccessi osservati si sommano ai 10 insuccessi virtuali (10 + 14 = 24). La media a posteriori è pari a 0.529, un valore considerevolmente più alto della media a priori del 9%. Questo spostamento evidenzia l’impatto dell’evidenza empirica nel moderare lo scetticismo iniziale.
11.4.3 Visualizzazione dell’aggiornamento: dalle credenze iniziali alla sintesi finale
Per comprendere il meccanismo dell’aggiornamento bayesiano, visualizziamo simultaneamente tre componenti: la distribuzione a priori, la funzione di verosimiglianza e la distribuzione a posteriori.
# Prepariamo i dati per la visualizzazione di tutte e tre le curve
# Distribuzione a priori (già calcolata)
prior_densita <- dbeta(theta_valori, alpha_prior, beta_prior)
# Funzione di verosimiglianza
# Indica quanto i dati sono compatibili con ciascun valore di theta
likelihood_raw <- dbinom(
x = successi_osservati,
size = prove_totali,
prob = theta_valori
)
# Distribuzione a posteriori
posterior_densita <- dbeta(theta_valori, alpha_post, beta_post)
# La verosimiglianza non è una densità di probabilità, quindi la scaliamo
# per renderla visivamente confrontabile con prior e posterior
likelihood_scaled <- likelihood_raw / max(likelihood_raw) * max(posterior_densita)
# Creiamo un dataframe "lungo" per ggplot2 con tutte e tre le distribuzioni
dati_complete <- data.frame(
theta = rep(theta_valori, 3),
densita = c(prior_densita, likelihood_scaled, posterior_densita),
tipo = rep(
c("Prior", "Verosimiglianza", "Posterior"),
each = length(theta_valori)
)
)
# Convertiamo 'tipo' in un fattore ordinato per controllare la legenda
dati_complete$tipo <- factor(
dati_complete$tipo,
levels = c("Prior", "Verosimiglianza", "Posterior")
)# Creiamo il grafico che mostra l'intero processo di aggiornamento
ggplot(dati_complete, aes(x = theta, y = densita, color = tipo)) +
geom_line(size = 1.3) +
scale_color_manual(
values = c(
"Prior" = col_prior,
"Verosimiglianza" = col_likelihood,
"Posterior" = col_posterior
)
) +
labs(
title = "Aggiornamento Bayesiano: Studio Milgram",
subtitle = paste0(
"Dati: ", successi_osservati, " obbedienti su ",
prove_totali, " partecipanti"
),
x = expression(theta ~ "(proporzione che obbedisce)"),
y = "Densità (scala relativa)",
color = NULL
)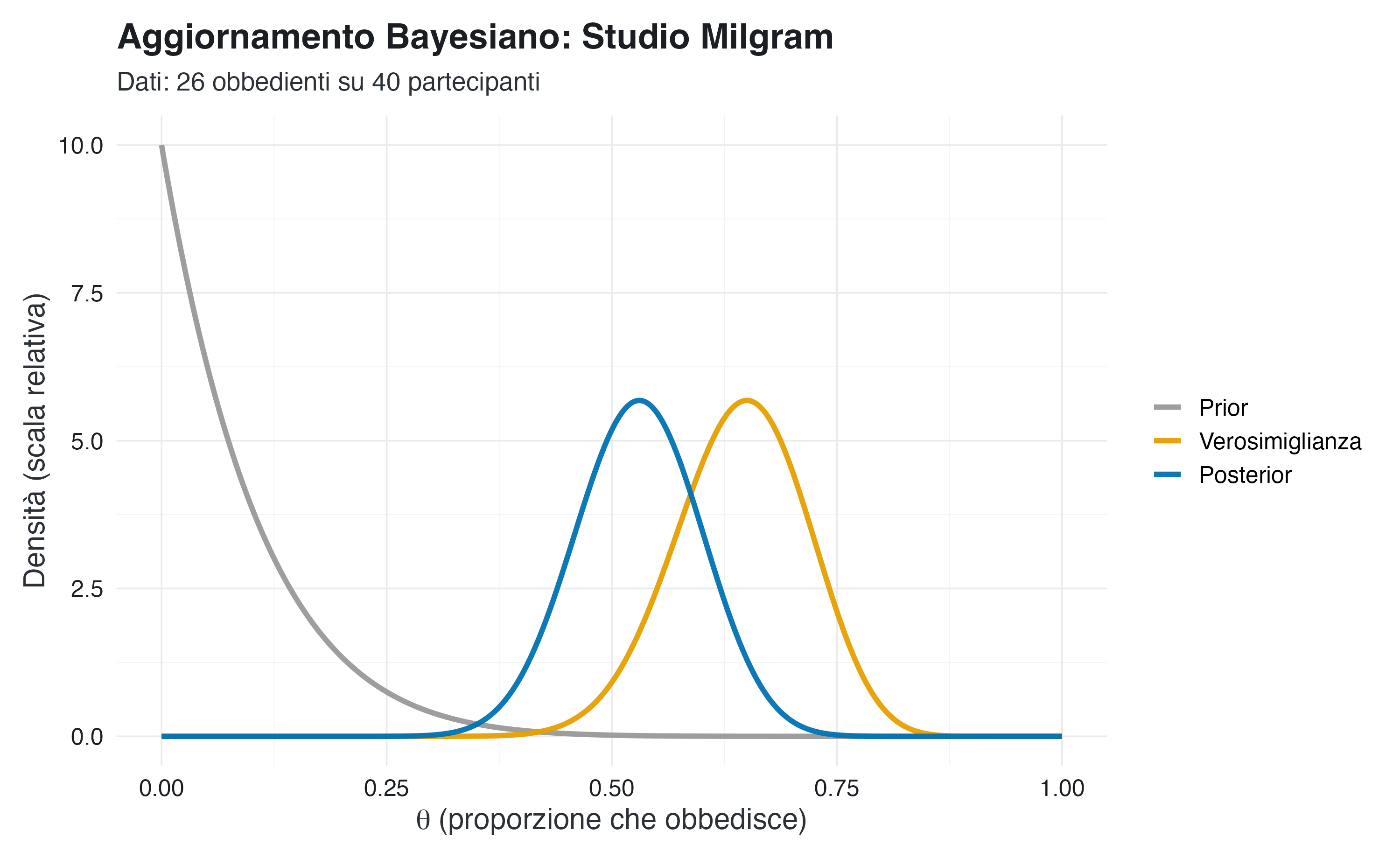
Il grafico illustra il meccanismo dell’inferenza bayesiana. La curva grigia rappresenta le credenze a priori, concentrate sui valori più bassi di \(\theta\). La verosimiglianza (curva arancione) riflette l’informazione campionaria e presenta un picco in corrispondenza della proporzione osservata (26/40 = 0.65).
La distribuzione a posteriori (curva blu) sintetizza queste due fonti di informazione posizionandosi in un punto di equilibrio tra il prior e i dati. La sua posizione, spostata verso la verosimiglianza ma non sovrapposta a essa, evidenzia l’effetto di regolarizzazione del prior: questo modera la stima puramente empirica incorporando nel risultato finale lo scetticismo iniziale.
11.4.4 Quantificazione dell’incertezza e inferenza probabilistica
L’approccio bayesiano consente affermazioni probabilistiche direttamente interpretabili:
# Statistiche descrittive della posterior
media_posteriori <- alpha_post / (alpha_post + beta_post)
moda_posteriori <- (alpha_post - 1) / (alpha_post + beta_post - 2)
varianza_posteriori <- (alpha_post * beta_post) / ((alpha_post + beta_post)^2 * (alpha_post + beta_post + 1))
sd_posteriori <- sqrt(varianza_posteriori)
# Probabilità che θ > 0.5
prob_maggioranza <- pbeta(0.5, shape1 = alpha_post, shape2 = beta_post, lower.tail = FALSE)
# Intervallo di credibilità al 95%
hdi_95 <- HDInterval::hdi(qbeta, credMass = 0.95, shape1 = alpha_post, shape2 = beta_post)La media della distribuzione a posteriori è 0.529, che rappresenta la nostra migliore stima puntuale della proporzione \(\theta\). La moda, pari a 0.531, indica il valore singolo più plausibile secondo la distribuzione a posteriori. La deviazione standard di 0.069 quantifica l’incertezza residua sulla stima, corrispondente a circa 6.9 punti percentuali.
Un risultato di particolare interesse concerne la probabilità che più della metà della popolazione manifesti un’obbedienza estrema in condizioni analoghe. Tale probabilità è pari a 0.664 (circa il 66.4%). Questo valore fornisce una misura diretta dell’evidenza a favore dell’ipotesi che l’obbedienza estrema sia un fenomeno maggioritario nella popolazione.
Interpretazione: dati l’evidenza osservata e le nostre assunzioni iniziali, possiamo affermare con una probabilità del 0.95 che la vera proporzione di obbedienza estrema nella popolazione è compresa tra 39.4% e ´r round(hdi_95[2] * 100, 1)`%.
11.4.5 Distribuzione predittiva a posteriori: proiezioni per studi futuri
L’approccio bayesiano consente di formulare previsioni probabilistiche per osservazioni future. Supponendo di replicare l’esperimento con un nuovo campione di 40 partecipanti, ci si chiede quanti soggetti mostreranno un’obbedienza estrema. La risposta richiede una distribuzione di probabilità che integri due fonti di incertezza:
- l’incertezza sul parametro \(\theta\), rappresentata dalla distribuzione a posteriori;
- la variabilità campionaria intrinseca al processo binomiale.
Anche conoscendo il valore esatto di \(\theta\), il numero di soggetti con obbedienza estrema in un nuovo campione varierebbe secondo la distribuzione binomiale. Poiché non conosciamo con precisione il valore di \(\theta\), ma disponiamo della sua distribuzione a posteriori, la distribuzione predittiva integra queste due fonti di incertezza.
Nel modello Beta-Binomiale, la distribuzione predittiva assume una forma analitica chiusa nota come distribuzione Beta-Binomiale.
Per un nuovo campione di 40 partecipanti:
dimensione_futura <- 40
possibili_esiti <- 0:dimensione_futura
beta_binomial_prob <- function(k, n, alpha, beta) {
choose(n, k) * beta(alpha + k, beta + n - k) / beta(alpha, beta)
}
prob_predittive <- sapply(possibili_esiti, beta_binomial_prob, n = dimensione_futura,
alpha = alpha_post, beta = beta_post)
valore_atteso_predetto <- sum(possibili_esiti * prob_predittive)
moda_predittiva <- possibili_esiti[which.max(prob_predittive)]# dataframe per il plotting predittivo
pred_df <- data.frame(
numero_obbedienti = possibili_esiti,
probabilita = prob_predittive
)Il valore medio predetto è 21.2 partecipanti, mentre l’esito più probabile (moda) è 21 partecipanti.
# Plot della distribuzione predittiva
ggplot(pred_df, aes(x = numero_obbedienti, y = probabilita)) +
geom_col(fill = col_prediction, alpha = 0.7, width = 0.9) +
geom_vline(xintercept = valore_atteso_predetto,
color = col_mean, linetype = "dashed", size = 1) +
annotate("text",
x = valore_atteso_predetto + 3,
y = max(pred_df$probabilita) * 0.9,
label = paste("Media predetta =", round(valore_atteso_predetto, 1)),
color = col_mean, size = 4.5, hjust = 0) +
labs(
title = "Distribuzione Predittiva: Replica dell'esperimento di Milgram",
subtitle = paste0("Previsione per un nuovo studio con n = ", dimensione_futura, " partecipanti"),
x = "Numero di partecipanti che obbediscono completamente",
y = "Probabilità"
) +
scale_x_continuous(breaks = seq(0, dimensione_futura, by = 5))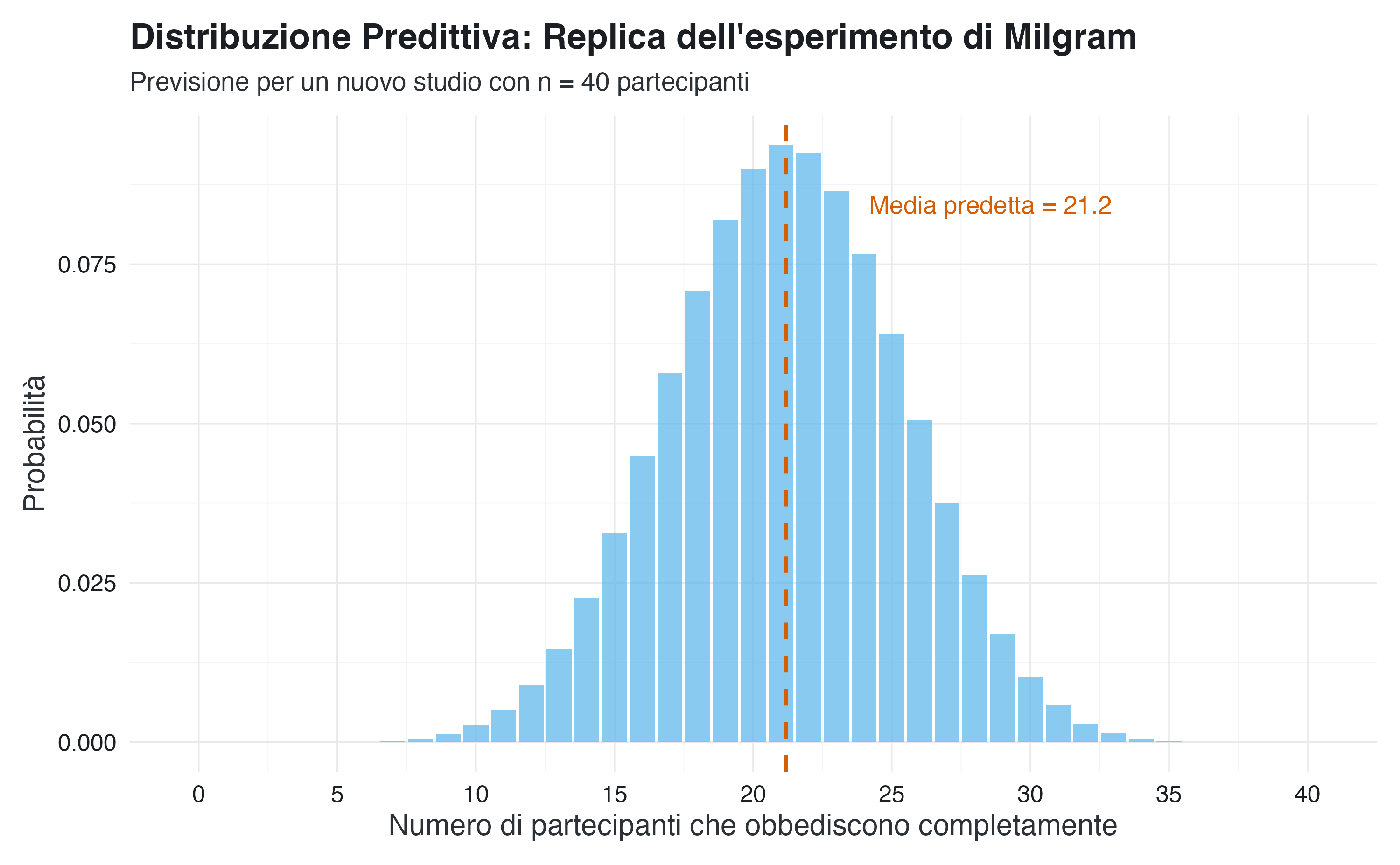
La distribuzione predittiva, approssimativamente normale e centrata attorno a 21 partecipanti, combina l’incertezza sul parametro \(\theta\) e la variabilità campionaria. Presenta una lieve asimmetria, ereditata dalla forma non perfettamente simmetrica della distribuzione a posteriori di \(\theta\).
11.4.6 Quantificazione dell’incertezza predittiva
Per comprendere le implicazioni pratiche di questa distribuzione, calcoliamo gli intervalli e le probabilità di interesse. Questi valori aiutano a definire aspettative realistiche per gli studi futuri e a identificare i risultati che potrebbero essere considerati sorprendenti.
# statistiche predittive
prob_cumulativa <- cumsum(pred_df$probabilita)
indice_inferiore <- which(prob_cumulativa >= 0.05)[1]
indice_superiore <- which(prob_cumulativa >= 0.95)[1]
limite_inf_90 <- pred_df$numero_obbedienti[indice_inferiore]
limite_sup_90 <- pred_df$numero_obbedienti[indice_superiore]
# probabilità estremi
prob_molto_basso <- sum(pred_df$probabilita[pred_df$numero_obbedienti <= 15]) # 0..15
prob_molto_alto <- sum(pred_df$probabilita[pred_df$numero_obbedienti >= 30]) # 30..40
# deviazione standard predittiva
varianza_predittiva <- sum((pred_df$numero_obbedienti - valore_atteso_predetto)^2 * pred_df$probabilita)
sd_predittiva <- sqrt(varianza_predittiva)L’intervallo di predizione al 90% va da 14 a 28 partecipanti estremamente obbedienti. Ciò significa che, in una replica dell’esperimento, il numero di partecipanti estremamente obbedienti atteso ricadrebbe in questo intervallo con probabilità di 0.90. Valori inferiori a 14 o superiori a 28 risulterebbero insoliti.
La probabilità di osservare un tasso di obbedienza “notevolmente basso” (inferiore a 15 partecipanti) è pari a 0.089 (circa 8.9%), quantificando quanto un simile risultato si discosterebbe dalle evidenze disponibili. Allo stesso modo, la probabilità di un risultato “notevolmente alto” (oltre 30 partecipanti) è 0.021 (circa 2.1%).
La deviazione standard della distribuzione predittiva è pari a 4.18 partecipanti, valore sensibilmente maggiore rispetto a quello della distribuzione a posteriori di \(\theta\) (2.8 partecipanti). Questa differenza evidenzia come la variabilità predittiva incorpori sia l’incertezza sul parametro sia la variabilità campionaria intrinseca.
11.4.7 Implicazioni metodologiche ed etiche
L’intervallo di predizione al 90% va da 14 a 28 partecipanti obbedienti. La probabilità di osservare un tasso insolitamente basso (<15 obbedienti) è 0.089, mentre quella di un tasso insolitamente alto (>30 obbedienti) è 0.021.
Queste previsioni hanno conseguenze pratiche e metodologiche chiare: richiedono protocolli di debriefing e tutela dei partecipanti adeguati, data l’elevata probabilità stimata di obbedienza estrema; permettono di testare la validità del modello, perché le osservazioni che cadono al di fuori dell’intervallo predittivo indicano la probabile presenza di fattori contestuali mancanti; infine, guidano la pianificazione sperimentale, fornendo informazioni utili per scegliere la dimensione campionaria più efficiente per le future repliche.
11.4.8 Aggiornamento sequenziale: apprendimento cumulativo
Il framework bayesiano supporta naturalmente l’aggiornamento sequenziale. Immaginiamo una replica con 19 obbedienti su 40 partecipanti:
# Aggiornamento sequenziale
successi_replica <- 19
prove_replica <- 40
alpha_post2 <- alpha_post + successi_replica
beta_post2 <- beta_post + (prove_replica - successi_replica)
media_post2 <- alpha_post2 / (alpha_post2 + beta_post2)La nuova distribuzione a posteriori avrebbe parametri \(\alpha\) = 46, \(\beta\) = 45 e media 0.505. Questo meccanismo formalizza il processo cumulativo della scoperta scientifica, dove ogni nuovo studio affina le stime precedenti senza invalidarle.
11.5 Il modello Gamma-Poisson: valutazione clinica degli attacchi di panico
Nel trattamento cognitivo-comportamentale del disturbo di panico, il monitoraggio della frequenza degli attacchi costituisce un indicatore cruciale dell’efficacia terapeutica. I pazienti tendono a sovrastimare la frequenza degli episodi nelle fasi acute e a sottovalutare i miglioramenti graduali, rendendo essenziale una registrazione sistematica che fornisca un riferimento oggettivo.
Consideriamo il caso di un paziente monitorato per quattro settimane, con il seguente profilo: 2 attacchi nella prima settimana, 1 nella seconda, 0 nella terza e 1 nella quarta, per un totale di 4 attacchi nel periodo osservato. Questo andamento, sebbene suggerisca un miglioramento, presenta una variabilità che richiede un approccio probabilistico per inferenze robuste.
11.5.1 Fondamenti del modello Gamma-Poisson
Gli attacchi di panico possono essere modellati come eventi rari mediante la distribuzione di Poisson, basata su tre assunzioni fondamentali: l’indipendenza tra gli eventi, un tasso medio costante nell’intervallo temporale considerato e una probabilità trascurabile di eventi simultanei.
Il parametro centrale è \(\theta\), ovvero il tasso medio settimanale di attacchi. L’approccio bayesiano affronta l’incertezza iniziale su \(\theta\) assegnandogli una distribuzione a priori Gamma che, sfruttando la coniugazione con la verosimiglianza di Poisson, permette di ottenere una distribuzione a posteriori in forma chiusa.
11.5.2 Configurazione del modello e scelta del prior
Adottiamo un prior debolmente informativo Gamma(1,1) per rappresentare l’incertezza iniziale tipica delle fasi preliminari del trattamento.
La distribuzione Gamma(1,1) presenta media 1 e deviazione standard 1, riflettendo un’incertezza sostanziale clinicamente appropriata per la fase iniziale del trattamento.
11.5.3 Aggiornamento bayesiano e distribuzione a posteriori
Integriamo le osservazioni cliniche mediante l’aggiornamento coniugato:
# Aggiornamento bayesiano
a_post <- a_prior + sum(attacchi_settimanali)
b_post <- b_prior + length(attacchi_settimanali)
# Statistiche della posterior
tasso_medio_post <- a_post / b_post
sd_post <- sqrt(a_post) / b_post
# Intervallo di credibilità al 95%
hdi_95 <- qgamma(c(0.025, 0.975), shape = a_post, rate = b_post)La distribuzione a posteriori risultante è Gamma(5, 5), con:
- tasso medio stimato: 1 attacchi/settimana;
- deviazione standard: 0.447;
- intervallo di credibilità al 95%: [0.325, 2.048].
Interpretazione: dati l’evidenza osservata e le nostre assunzioni iniziali, possiamo affermare con probabilità 0.95 che il vero tasso medio di attacchi del paziente è compreso tra 0.325 e 2.048 episodi per settimana.
11.5.4 Distribuzione predittiva a posteriori
La distribuzione predittiva integra l’incertezza sul parametro \(\theta\) con la variabilità intrinseca del processo Poissoniano. Per una settimana futura:
# Distribuzione predittiva Poisson-Gamma
calc_negbin_prob <- function(k, r, beta) {
# r = alpha_post, beta = beta_post
(gamma(r + k) / (gamma(r) * factorial(k))) *
(beta / (beta + 1))^r * (1 / (beta + 1))^k
}
k_values <- 0:10
pred_probs <- calc_negbin_prob(k_values, a_post, b_post)
# Statistiche predittive
expected_attacks <- sum(k_values * pred_probs)
mode_pred <- k_values[which.max(pred_probs)]- numero atteso di attacchi: 1;
- esito più probabile: 0 attacchi.
11.5.5 Implicazioni cliniche e terapeutiche
L’analisi bayesiana fornisce diversi spunti di riflessione clinicamente rilevanti:
- monitoraggio dell’efficacia: il tasso medio post-terapia di 1 attacchi/settimana rappresenta un benchmark quantitativo per valutare i progressi;
- pianificazione terapeutica: l’intervallo di predizione fornisce informazioni sulle aspettative realistiche per le settimane successive, supportando la regolazione degli interventi;
- comunicazione col paziente: le stesse probabilità facilitano la psicoeducazione, mostrando l’andamento atteso in termini accessibili;
- decisioni cliniche: la probabilità di riacutizzazione può essere quantificata direttamente dalla distribuzione predittiva.
11.5.6 Aggiornamento sequenziale nel follow-up
Il framework supporta naturalmente l’aggiornamento continuo man mano che nuovi dati divengono disponibili. Supponiamo che nelle due settimane successive si osservino 0 e 1 attacchi:
La nuova distribuzione a posteriori Gamma(6, 7) avrebbe media 0.857, mostrando un ulteriore affinamento della stima che riflette il processo cumulativo di apprendimento clinico.
11.5.7 Valutazione dell’efficacia terapeutica mediante soglie probabilistiche
Per tradurre l’analisi statistica in giudizi clinicamente operativi, definiamo una soglia di efficacia terapeutica di 0.5 attacchi settimanali, corrispondente a non più di due episodi mensili. Questo livello è comunemente associato a un buon controllo dei sintomi nel disturbo di panico.
# Soglia di efficacia clinica
soglia_efficacia <- 0.5
# Probabilità a posteriori di efficacia
probabilita_efficacia <- pgamma(soglia_efficacia, shape = a_post, rate = b_post)La probabilità che il tasso effettivo di attacchi sia inferiore alla soglia di 0.5 episodi/settimana è 0.109 (10.9%). Questo valore indica un’evidenza limitata a sostegno del raggiungimento dell’obiettivo terapeutico, con circa 11 scenari plausibili su 100 che soddisfano il criterio di efficacia.
11.5.8 Raccomandazioni cliniche basate su evidenza probabilistica
La bassa probabilità di efficacia (10.9%) suggerisce la necessità di un aggiustamento terapeutico. La raccomandazione clinica è quindi quella di modificare il protocollo terapeutico, in quanto l’evidenza attuale non supporta l’efficacia del trattamento in corso.
Raccomandazioni utili potrebbero riguardare un’intensificazione mirata delle strategie per gestire l’ansia acuta, insieme a un controllo sistematico dell’aderenza agli esercizi di esposizione. In alcuni casi può essere opportuno valutare l’integrazione di un supporto farmacologico, mentre un’attenzione particolare andrebbe dedicata all’eventuale presenza di fattori di mantenimento finora non identificati.
11.5.9 Previsioni a breve termine mediante distribuzione predittiva
La distribuzione predittiva a posteriori, che segue una Binomiale Negativa con parametri r = 5 e p = 0.833, fornisce previsioni probabilistiche per la settimana successiva:
# Calcoli predittivi
attacchi_attesi <- a_post / b_post
prob_zero_attacchi <- dnbinom(0, size = a_post, prob = b_post/(b_post+1))
prob_almeno_uno <- 1 - prob_zero_attacchi- Numero atteso di attacchi: 1.
- Probabilità di zero attacchi: 0.402 (40.2%).
- Probabilità di almeno un attacco: 0.598 (59.8%).
11.5.10 Implicazioni per il monitoraggio clinico
La distribuzione predittiva fornisce un benchmark quantitativo per valutare l’evoluzione sintomatologica.
- Un risultato di 0 attacchi ricade nel 40.2% degli esiti più probabili.
- Tre o più attacchi costituirebbero un’osservazione atipica (<5% di probabilità) che indicherebbe un peggioramento clinico.
11.5.11 Aggiornamento sequenziale e apprendimento continuo
Il framework bayesiano supporta un aggiornamento iterativo delle stime. Con l’osservazione di nuove settimane:
# Simulazione aggiornamento con dati aggiuntivi
nuovi_dati <- 0 # Zero attacchi nella settimana successiva
a_post2 <- a_post + nuovi_dati
b_post2 <- b_post + 1
prob_efficacia_aggiornata <- pgamma(soglia_efficacia, shape = a_post2, rate = b_post2)L’osservazione di zero attacchi incrementerebbe la probabilità di efficacia a 0.185 (18.5%), dimostrando come l’accumulo di evidenza favorisca un affinamento progressivo delle valutazioni cliniche.
11.6 Modello Gamma-Esponenziale: analisi dei tempi tra episodi comportamentali
Nel monitoraggio educativo dei comportamenti dirompenti, l’analisi degli intervalli temporali tra episodi fornisce una prospettiva complementare al semplice conteggio degli eventi. Questo approccio è particolarmente rilevante quando l’obiettivo è estendere la durata dei periodi di comportamento adeguato.
Consideriamo un bambino in età scolare che manifesta comportamenti dirompenti. Dopo l’implementazione di un intervento educativo, sono stati registrati i seguenti intervalli tra episodi consecutivi: 0.5, 1.2, 0.8 e 2.4 ore. Questi dati costituiscono la base per valutare l’efficacia dell’intervento.
11.6.1 Fondamenti del modello Gamma-Esponenziale
La distribuzione esponenziale modella i tempi di attesa tra eventi che seguono un processo di Poisson. Se gli episodi si verificano con tasso costante \(\theta\) (eventi/ora), il tempo \(T\) tra eventi consecutivi segue una distribuzione esponenziale con parametro \(\theta\). Il tempo medio atteso è 1/\(\theta\).
La distribuzione Gamma funge da prior coniugato per \(\theta\), consentendo un aggiornamento bayesiano in forma chiusa. A differenza del modello Gamma-Poisson che utilizza conteggi in intervalli fissi, questo modello lavora direttamente con le durate temporali osservate.
11.6.2 Configurazione del modello e prior iniziale
Adottiamo un prior debolmente informativo Gamma(1,1) per rappresentare l’incertezza iniziale tipica della fase preliminare dell’intervento.
# Dati osservati (ore tra episodi)
intervalli <- c(0.5, 1.2, 0.8, 2.4)
# Parametri del prior Gamma(1,1)
a_prior <- 1
b_prior <- 1
# Statistiche descrittive del prior
tasso_prior <- a_prior / b_prior
tempo_medio_prior <- 1 / tasso_priorIl prior Gamma(1,1) corrisponde a un tempo medio atteso di 1 ore, con un ampio intervallo di credibilità che riflette l’incertezza iniziale.
11.6.3 Aggiornamento bayesiano e distribuzione a posteriori
Aggiorniamo le credenze iniziali incorporando i dati osservati:
# Aggiornamento bayesiano
a_post <- a_prior + length(intervalli)
b_post <- b_prior + sum(intervalli)
# Statistiche della posterior
tasso_medio_post <- a_post / b_post
tempo_medio_post <- 1 / tasso_medio_post
# Campionamento per inferenza sul tempo medio
set.seed(123)
campioni_tasso <- rgamma(10000, shape = a_post, rate = b_post)
campioni_tempo <- 1 / campioni_tasso
hdi_tempo <- quantile(campioni_tempo, c(0.025, 0.975))La distribuzione a posteriori risultante è Gamma(5, 5.9), con tasso medio stimato: 0.847 episodi/ora, tempo medio stimato: 1.18 ore e intervallo di credibilità 95% per il tempo medio: [0.59, 3.61] ore.
11.6.4 Valutazione rispetto agli obiettivi educativi
Definiamo come obiettivo educativo un tempo medio tra episodi superiore a 2 ore (corrispondente a un tasso inferiore a 0.5 episodi/ora).
# Valutazione dell'efficacia
tempo_target <- 2
tasso_target <- 1 / tempo_target
prob_successo <- pgamma(tasso_target, shape = a_post, rate = b_post)La probabilità che il tempo medio effettivo superi il target di 2 ore è 0.176 (17.6%). Questo valore indica un’evidenza limitata a sostegno del raggiungimento dell’obiettivo educativo.
11.6.5 Distribuzione predittiva per il prossimo intervallo
La distribuzione predittiva integra l’incertezza sul parametro \(\theta\) con la variabilità intrinseca del processo esponenziale:
# Distribuzione predittiva
set.seed(456)
theta_camp <- rgamma(10000, shape = a_post, rate = b_post)
tempi_predetti <- rexp(10000, rate = theta_camp)
# Statistiche predittive
tempo_mediano_predetto <- median(tempi_predetti)
prob_lungo <- mean(tempi_predetti > tempo_target)
prob_breve <- mean(tempi_predetti < 0.5)
hdi_pred <- quantile(tempi_predetti, c(0.05, 0.95))- Mediana predetta: 0.89 ore.
- Probabilità di intervallo lungo (>2h): 0.233 (23.3%).
- Probabilità di intervallo breve (<0.5h): 0.335 (33.5%).
- Intervallo di predizione 90%: [0.06, 4.76] ore.
11.6.6 Implicazioni per la gestione educativa
- Pianificazione delle attività: la probabilità di 33.5% di intervalli brevi suggerisce di mantenere supporto ravvicinato durante le transizioni.
- Valutazione dei progressi: intervalli superiori a 4.8 ore costituirebbero evidenza di miglioramento significativo.
- Comunicazione con stakeholders: il tempo medio di 1.2 ore fornisce un benchmark quantitativo per discutere i progressi.
11.6.7 Aggiornamento sequenziale e monitoraggio longitudinale
Il framework supporta l’aggiornamento iterativo man mano che nuovi dati diventano disponibili:
Con l’aggiunta di tre nuovi intervalli (1.5, 2.8, 1.9 ore), la probabilità di successo aumenterebbe a 0.263 (26.3%), dimostrando come l’accumulo di evidenza affini progressivamente le valutazioni educative.
I vantaggi metodologici sono evidenti: l’analisi dei tempi che intercorrono tra gli eventi risulta più intuitiva rispetto al semplice conteggio, mentre la distribuzione predittiva consente di formulare previsioni probabilistiche immediatamente utilizzabili. L’aggiornamento sequenziale offre inoltre una descrizione formale di come l’esperienza modifichi progressivamente le credenze e lo stesso impianto probabilistico consente di prendere decisioni educative graduali e basate sull’evidenza.
Riflessioni conclusive
I modelli coniugati esaminati (Beta-Binomiale, Normale-Normale, Gamma-Poisson e Gamma-Esponenziale) illustrano i meccanismi fondamentali dell’aggiornamento bayesiano. La proprietà di coniugazione, che preserva la forma funzionale della distribuzione durante l’aggiornamento, rende trasparente il processo di integrazione tra credenze a priori ed evidenza empirica.
Questa trasparenza matematica mette in luce i principi del ragionamento bayesiano. Nel modello Beta-Binomiale, l’aggiornamento avviene mediante la semplice somma dei conteggi osservati. Nel modello Normale-Normale, le precisioni si combinano in modo additivo. I modelli Gamma-Poisson e Gamma-Esponenziale offrono prospettive complementari sullo stesso processo sottostante. Questa semplicità computazionale ha un valore euristico, in quanto consente di concentrarsi sui concetti fondamentali senza la complessità degli algoritmi.
Tuttavia, i modelli coniugati costituiscono un caso particolare nell’analisi dei dati psicologici. La maggior parte dei fenomeni presenta una complessità che supera le loro assunzioni semplificatorie. Le variabili psicologiche presentano spesso asimmetrie e non normalità, richiedendo strutture di dipendenza che i modelli coniugati non riescono a catturare in modo adeguato. La scelta delle distribuzioni a priori dovrebbe essere guidata da considerazioni teoriche e non dalla convenienza computazionale.
I progressi nei metodi computazionali, in particolare le tecniche MCMC, hanno superato questi limiti, consentendo l’inferenza bayesiana per modelli di complessità arbitraria. Questi metodi consentono l’uso di distribuzioni a priori non coniugate, strutture gerarchiche complesse e dipendenze multivariate articolate. I principi appresi dallo studio dei modelli coniugati rimangono validi anche in questi contesti più generali e forniscono l’intuizione necessaria per interpretare i risultati di analisi avanzate.
I modelli coniugati rappresentano quindi un ponte essenziale tra i principi teorici del ragionamento bayesiano e la pratica dell’analisi dei dati. La loro comprensione fornisce le basi concettuali per affrontare modelli più complessi, mantenendo come criterio fondamentale l’adeguatezza delle scelte modellistiche rispetto alle domande di ricerca e alle caratteristiche specifiche dei dati psicologici.
Bibliografia
Johnson, A. A., Ott, M., & Dogucu, M. (2022). Bayes Rules! An Introduction to Bayesian Modeling with R. CRC Press.
Milgram, S. (1963). Behavioral study of obedience. The Journal of Abnormal and Social Psychology, 67(4), 371–378.