here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(cmdstanr, posterior, bayestestR, brms, emmeans)28 ANOVA ad una via
Panoramica del capitolo
- Fare inferenza sulla media di un campione.
- Trovare le distribuzioni a posteriori usando
brms. - Verificare il modello usando i pp-check plots.
ConsiglioPrerequisiti
- Leggere il capitolo Geocentric models di Statistical rethinking (McElreath, 2020).
AttenzionePreparazione del Notebook
28.1 Codifica del modello con variabili dummy
Supponiamo un esperimento con tre gruppi. Per rappresentare questo fattore all’interno di un modello lineare, usiamo due variabili dummy e consideriamo il terzo gruppo come riferimento implicito. Il modello assume la forma:
\[ Y_i = \alpha + \gamma_1 D_{i1} + \gamma_2 D_{i2} + \varepsilon_i \tag{28.1}\]
dove:
- \(\alpha\) è l’intercetta del modello,
- \(\gamma_1\) e \(\gamma_2\) sono i coefficienti associati alle variabili dummy,
- \(D_{i1}\) e \(D_{i2}\) indicano l’appartenenza dell’osservazione \(i\) ai gruppi 1 e 2, rispettivamente,
- \(\varepsilon_i\) è l’errore aleatorio.
La codifica delle dummy è la seguente:
\[ \begin{array}{c|cc} \text{Gruppo} & D_{1} & D_{2} \\ \hline 1 & 1 & 0 \\ 2 & 0 & 1 \\ 3 & 0 & 0 \end{array} \tag{28.2}\]
28.1.1 Interpretazione dei parametri
Con questa codifica, possiamo esprimere le medie di ciascun gruppo come:
\[ \begin{aligned} \mu_1 &= \alpha + \gamma_1 \\ \mu_2 &= \alpha + \gamma_2 \\ \mu_3 &= \alpha \end{aligned} \]
Da cui otteniamo:
\[ \alpha = \mu_3, \quad \gamma_1 = \mu_1 - \mu_3, \quad \gamma_2 = \mu_2 - \mu_3. \]
Quindi:
- \(\alpha\): media del gruppo 3 (riferimento),
- \(\gamma_1\): quanto il gruppo 1 si discosta da \(\mu_3\),
- \(\gamma_2\): quanto il gruppo 2 si discosta da \(\mu_3\).
In un’ottica bayesiana, questi coefficienti possono essere pensati come distribuzioni: esprimono quanto crediamo che ciascuna differenza sia plausibile, date le osservazioni. Passiamo ora a una simulazione.
28.2 Simulazione
Simuliamo un esperimento con tre condizioni: controllo, psicoterapia1 e psicoterapia2. Ogni gruppo ha una media diversa ma la stessa deviazione standard. Ci interessa modellare la variabilità tra le condizioni e interpretare le differenze in modo probabilistico.
set.seed(123)
n <- 30 # numero di osservazioni per gruppo
# Medie di ciascun gruppo
mean_control <- 30
mean_psico1 <- 25
mean_psico2 <- 20
# Deviazione standard comune
sd_value <- 5
# Generazione dei dati
controllo <- rnorm(n, mean_control, sd_value)
psicoterapia1 <- rnorm(n, mean_psico1, sd_value)
psicoterapia2 <- rnorm(n, mean_psico2, sd_value)
# Creazione del data frame
df <- data.frame(
condizione = rep(c("controllo", "psicoterapia1", "psicoterapia2"), each = n),
punteggio = c(controllo, psicoterapia1, psicoterapia2)
)
df |> head()
#> condizione punteggio
#> 1 controllo 27.2
#> 2 controllo 28.8
#> 3 controllo 37.8
#> 4 controllo 30.4
#> 5 controllo 30.6
#> 6 controllo 38.628.2.1 Esplorazione iniziale
Visualizziamo le distribuzioni dei punteggi:
ggplot(df, aes(x = condizione, y = punteggio, fill = condizione)) +
geom_violin(trim = FALSE) +
geom_boxplot(width = 0.22, outlier.shape = NA,
fill = scales::alpha("white", 0.55)) +
labs(x = "Condizione sperimentale", y = "Punteggio di depressione") +
theme(legend.position = "none")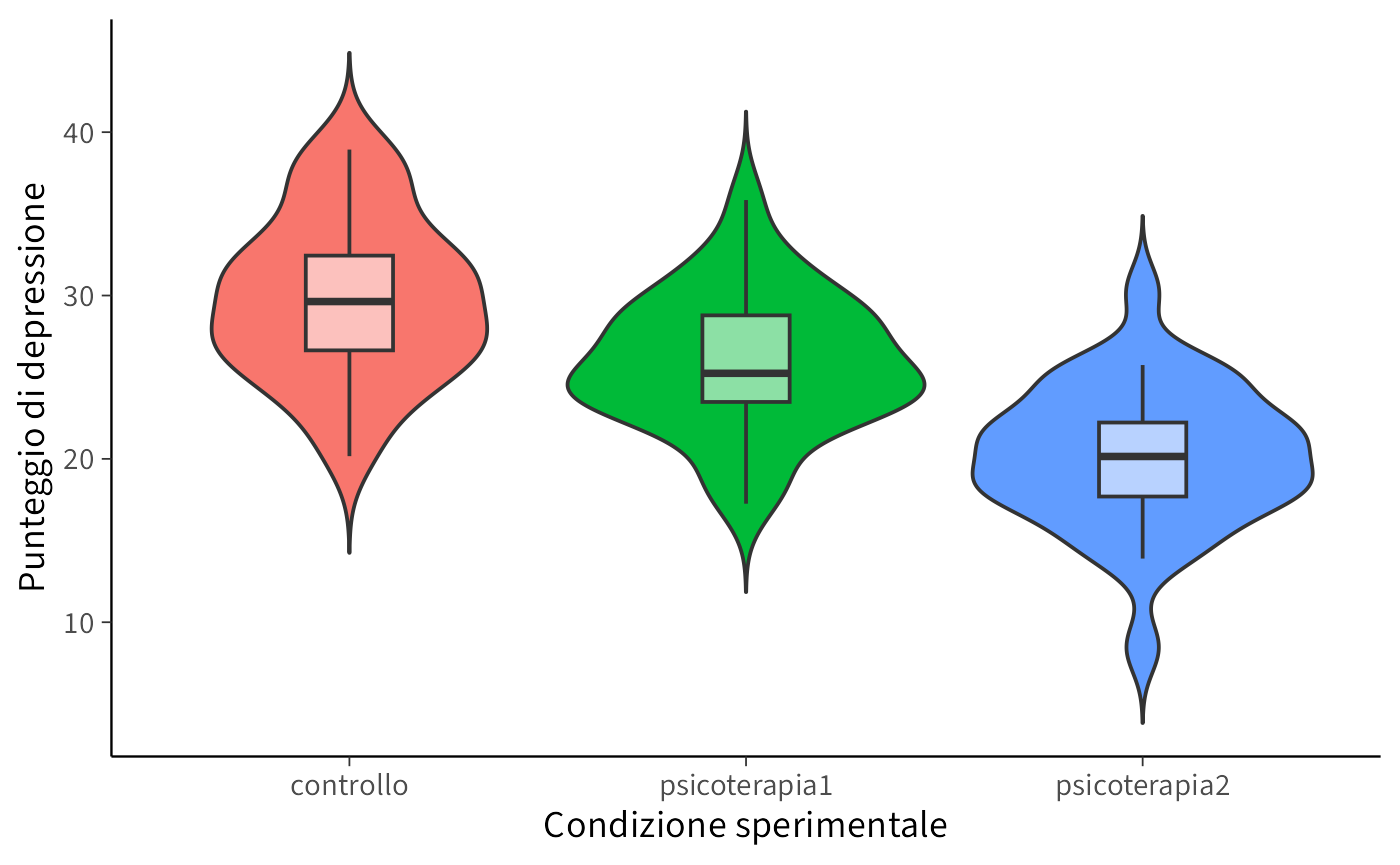
Calcoliamo media e deviazione standard per ogni gruppo:
28.3 Modello lineare con variabili dummy
Convertiamo condizione in fattore e definiamo controllo come categoria di riferimento:
Il modello di regressione con le variabili dummy sarà:
\[ Y_i = \beta_0 + \beta_1 \cdot \text{psicoterapia1}_i + \beta_2 \cdot \text{psicoterapia2}_i + \varepsilon_i, \]
dove:
- \(\beta_0\) è la media del gruppo di controllo;
- \(\beta_1\) e \(\beta_2\) sono le differenze tra le rispettive psicoterapie e il gruppo di controllo.
28.3.1 Stima del modello
Eseguiamo una prima analisi usando il metodo di massima verosimiglianza:
fm1 <- lm(punteggio ~ condizione, data = df)summary(fm1)
#>
#> Call:
#> lm(formula = punteggio ~ condizione, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -11.668 -2.620 -0.183 2.681 10.128
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 29.764 0.819 36.33 < 2e-16
#> condizionepsicoterapia1 -3.873 1.159 -3.34 0.0012
#> condizionepsicoterapia2 -9.642 1.159 -8.32 1.1e-12
#>
#> Residual standard error: 4.49 on 87 degrees of freedom
#> Multiple R-squared: 0.446, Adjusted R-squared: 0.434
#> F-statistic: 35.1 on 2 and 87 DF, p-value: 6.75e-12Verifica delle medie e differenze tra i gruppi:
out <- tapply(df$punteggio, df$condizione, mean)
out[2] - out[1] # psicoterapia1 - controllo
#> psicoterapia1
#> -3.87
out[3] - out[1] # psicoterapia2 - controllo
#> psicoterapia2
#> -9.6428.4 Contrasti personalizzati
I contrasti ci permettono di andare oltre il test globale e formulare ipotesi teoriche mirate. Ad esempio:
- la media del gruppo controllo è diversa dalla media delle due psicoterapie?
- le due psicoterapie differiscono tra loro?
A questo fine, specifichiamo la seguente matrice dei contrasti:
my_contrasts <- matrix(c(
0.6667, 0, # controllo
-0.3333, 0.5, # psicoterapia1
-0.3333, -0.5 # psicoterapia2
), ncol = 2, byrow = TRUE)
colnames(my_contrasts) <- c("Ctrl_vs_PsicoMean", "P1_vs_P2")
rownames(my_contrasts) <- c("controllo", "psicoterapia1", "psicoterapia2")
contrasts(df$condizione) <- my_contrastsAdattiamo il modello:
mod_custom <- lm(punteggio ~ condizione, data = df)Esaminiamo i coefficienti:
summary(mod_custom)
#>
#> Call:
#> lm(formula = punteggio ~ condizione, data = df)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -11.668 -2.620 -0.183 2.681 10.128
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 25.259 0.473 53.40 < 2e-16
#> condizioneCtrl_vs_PsicoMean 6.758 1.003 6.73 1.7e-09
#> condizioneP1_vs_P2 5.770 1.159 4.98 3.2e-06
#>
#> Residual standard error: 4.49 on 87 degrees of freedom
#> Multiple R-squared: 0.446, Adjusted R-squared: 0.434
#> F-statistic: 35.1 on 2 and 87 DF, p-value: 6.75e-12Interpretazione dei coefficienti:
- Intercetta: non rappresenta più una singola media, ma una combinazione lineare dei gruppi.
-
Ctrl_vs_PsicoMean: confronta la media di
controllocon la media combinata delle due psicoterapie. - P1_vs_P2: differenza tra le due psicoterapie.
Verifica manuale:
# Controllo - media delle psicoterapie
out[1] - (out[2] + out[3]) / 2
#> controllo
#> 6.76# Psicoterapia1 - Psicoterapia2
out[2] - out[3]
#> psicoterapia1
#> 5.77
28.5 Estensione bayesiana con brms e emmeans
Usiamo ora il modello bayesiano:
mod <- brm(punteggio ~ condizione, data = df, backend = "cmdstanr")summary(mod)
#> Family: gaussian
#> Links: mu = identity
#> Formula: punteggio ~ condizione
#> Data: df (Number of observations: 90)
#> Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
#> total post-warmup draws = 4000
#>
#> Regression Coefficients:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS
#> Intercept 25.26 0.48 24.33 26.15 1.00 4321
#> condizioneCtrl_vs_PsicoMean 6.78 1.04 4.73 8.85 1.00 4260
#> condizioneP1_vs_P2 5.76 1.16 3.49 8.08 1.00 4598
#> Tail_ESS
#> Intercept 2937
#> condizioneCtrl_vs_PsicoMean 2964
#> condizioneP1_vs_P2 2785
#>
#> Further Distributional Parameters:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
#> sigma 4.54 0.34 3.93 5.26 1.00 4287 3279
#>
#> Draws were sampled using sample(hmc). For each parameter, Bulk_ESS
#> and Tail_ESS are effective sample size measures, and Rhat is the potential
#> scale reduction factor on split chains (at convergence, Rhat = 1).Le medie marginali e i confronti possono essere ottenuti con il pacchetto emmeans:
em <- emmeans(mod, specs = "condizione")
em
#> condizione emmean lower.HPD upper.HPD
#> controllo 29.8 28.1 31.4
#> psicoterapia1 25.9 24.3 27.5
#> psicoterapia2 20.1 18.4 21.7
#>
#> Point estimate displayed: median
#> HPD interval probability: 0.95Confronti tra gruppi:
pairs(em) # confronti a coppie
#> contrast estimate lower.HPD upper.HPD
#> controllo - psicoterapia1 3.90 1.70 6.21
#> controllo - psicoterapia2 9.65 7.31 12.03
#> psicoterapia1 - psicoterapia2 5.76 3.57 8.14
#>
#> Point estimate displayed: median
#> HPD interval probability: 0.95Contrasti personalizzati:
contrast(em, method = my_list)
#> contrast estimate lower.HPD upper.HPD
#> Ctrl_vs_PsicoMean 6.77 4.77 8.88
#> P1_vs_P2 5.76 3.57 8.14
#>
#> Point estimate displayed: median
#> HPD interval probability: 0.95# Visualizzazione
plot(em)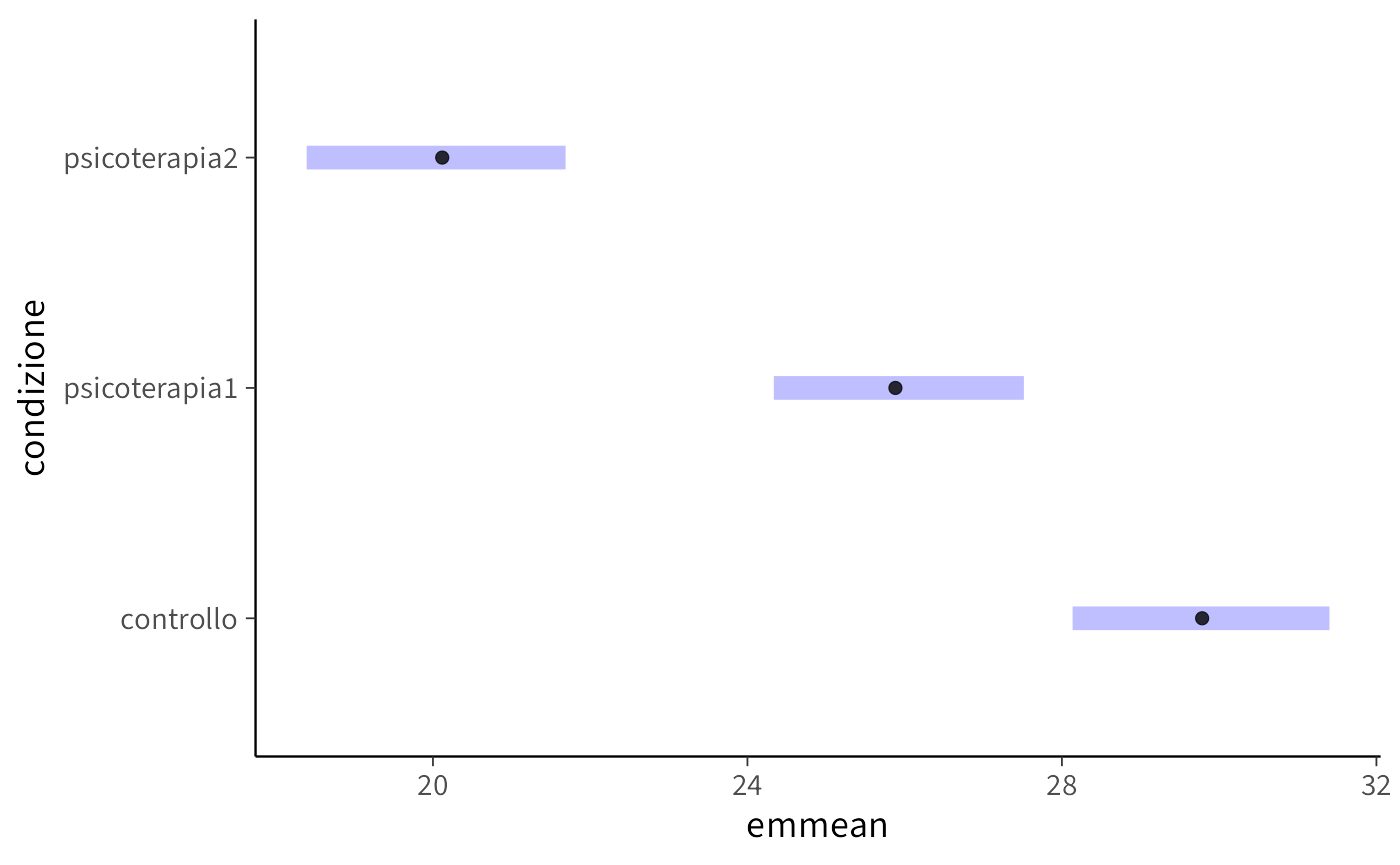
Riflessioni conclusive
In questo capitolo abbiamo visto come l’ANOVA a una via non sia un metodo a sé stante, ma un caso particolare del modello lineare. Attraverso l’uso di variabili indicatrici, infatti, il confronto tra più gruppi può essere formulato come un’estensione naturale della regressione, in cui ciascuna media di gruppo è rappresentata da un parametro del modello.
L’approccio frequentista tradizionale all’ANOVA si concentra sul test dell’ipotesi nulla di uguaglianza tra le medie, producendo un singolo indice sintetico (la statistica \(F\)). L’approccio bayesiano, invece, ci permette di andare oltre: possiamo stimare la distribuzione a posteriori delle differenze tra gruppi, valutare la probabilità che certe medie siano più alte o più basse di altre, e soprattutto ragionare sulla rilevanza pratica delle differenze osservate.
L’insegnamento più importante è che regressione e ANOVA non sono strumenti separati, ma due volti dello stesso impianto metodologico. Il modello lineare costituisce il quadro unificante che ci consente di descrivere, stimare e interpretare relazioni tra variabili, sia quantitative sia categoriali, con la stessa logica di base.
Con questo capitolo si chiude la sezione dedicata alla regressione. Abbiamo percorso un itinerario che ci ha portato dalla regressione bivariata alla regressione verso la media, dal confronto tra due gruppi all’ANOVA, passando per l’interpretazione bayesiana dei modelli e per la loro implementazione in Stan. Il filo conduttore è stato duplice: da un lato, la consapevolezza che i modelli lineari sono strumenti fenomenologici, utili per descrivere le associazioni ma non per spiegare i meccanismi sottostanti; dall’altro, la convinzione che l’approccio bayesiano renda queste descrizioni più trasparenti, interpretabili e coerenti con il modo in cui la psicologia scientifica dovrebbe affrontare l’incertezza.
NotaInformazioni sull’ambiente di sviluppo
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.1
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] emmeans_2.0.0 bayestestR_0.17.0 cmdstanr_0.8.0
#> [4] ragg_1.5.0 tinytable_0.15.1 withr_3.0.2
#> [7] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [10] tidybayes_3.0.7 bayesplot_1.14.0 ggplot2_4.0.1
#> [13] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [16] loo_2.8.0 rstan_2.32.7 StanHeaders_2.32.10
#> [19] brms_2.23.0 Rcpp_1.1.0 sessioninfo_1.2.3
#> [22] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [25] modelr_0.1.11 tibble_3.3.0 dplyr_1.1.4
#> [28] tidyr_1.3.1 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] gridExtra_2.3 inline_0.3.21 sandwich_3.1-1
#> [4] rlang_1.1.6 magrittr_2.0.4 multcomp_1.4-29
#> [7] snakecase_0.11.1 compiler_4.5.2 reshape2_1.4.5
#> [10] vctrs_0.6.5 stringr_1.6.0 pkgconfig_2.0.3
#> [13] arrayhelpers_1.1-0 fastmap_1.2.0 backports_1.5.0
#> [16] labeling_0.4.3 utf8_1.2.6 rmarkdown_2.30
#> [19] ps_1.9.1 purrr_1.2.0 xfun_0.54
#> [22] cachem_1.1.0 jsonlite_2.0.0 broom_1.0.11
#> [25] parallel_4.5.2 R6_2.6.1 stringi_1.8.7
#> [28] RColorBrewer_1.1-3 lubridate_1.9.4 estimability_1.5.1
#> [31] knitr_1.50 zoo_1.8-14 pacman_0.5.1
#> [34] Matrix_1.7-4 splines_4.5.2 timechange_0.3.0
#> [37] tidyselect_1.2.1 abind_1.4-8 yaml_2.3.12
#> [40] codetools_0.2-20 processx_3.8.6 curl_7.0.0
#> [43] pkgbuild_1.4.8 plyr_1.8.9 lattice_0.22-7
#> [46] bridgesampling_1.2-1 S7_0.2.1 coda_0.19-4.1
#> [49] evaluate_1.0.5 survival_3.8-3 RcppParallel_5.1.11-1
#> [52] pillar_1.11.1 tensorA_0.36.2.1 checkmate_2.3.3
#> [55] stats4_4.5.2 insight_1.4.4 distributional_0.5.0
#> [58] generics_0.1.4 rprojroot_2.1.1 rstantools_2.5.0
#> [61] scales_1.4.0 xtable_1.8-4 glue_1.8.0
#> [64] tools_4.5.2 data.table_1.17.8 mvtnorm_1.3-3
#> [67] grid_4.5.2 QuickJSR_1.8.1 colorspace_2.1-2
#> [70] nlme_3.1-168 cli_3.6.5 textshaping_1.0.4
#> [73] svUnit_1.0.8 Brobdingnag_1.2-9 V8_8.0.1
#> [76] gtable_0.3.6 digest_0.6.39 TH.data_1.1-5
#> [79] htmlwidgets_1.6.4 farver_2.1.2 memoise_2.0.1
#> [82] htmltools_0.5.9 lifecycle_1.0.4 MASS_7.3-65Bibliografia
McElreath, R. (2020). Statistical rethinking: A Bayesian course with examples in R and Stan (2nd Edition). CRC Press.