38 Modelli statistici
Panoramica del capitolo
- Cosa significa descrivere i dati rispetto a spiegare i processi che li generano.
- I limiti dei modelli fenomenologici e perché possono indurre in errore.
- Il ruolo delle distribuzioni di probabilità per rappresentare l’incertezza.
- Come confrontare modelli alternativi e scegliere quelli che meglio descrivono i dati e generalizzano a nuovi contesti.
- Leggere il capitolo Common Statistical Models del testo di Chan & Kroese (2025).
38.1 Preparazione del Notebook
38.2 Dalla correlazione alla spiegazione
Un modello che si limita a stimare una correlazione o una regressione lineare può dirci se due variabili sono associate, ma non ci spiega perché. Per esempio, osservare una relazione tra stress e rendimento accademico è informativo, ma non basta per comprendere il processo attraverso il quale lo stress influisce (o non influisce) sulla performance.
Il passo successivo consiste nel cercare di rappresentare i processi psicologici sottostanti che generano i dati osservati. In altre parole, si sposta l’attenzione dalle semplici relazioni statistiche ai meccanismi causali che le producono.
38.2.1 Perché questo cambiamento è cruciale?
Questo cambiamento è fondamentale perché consente di costruire modelli che rispecchiano più fedelmente la complessità dei fenomeni psicologici. In questo modo, le teorie diventano più precise e testabili, mentre i risultati guadagnano in robustezza e potenziale replicabilità, poiché sono radicati in una rappresentazione del processo sottostante e non solo in regolarità osservate in un dato campione.
38.2.2 Anticipazione
Nei prossimi capitoli di questa sezione vedremo come tradurre operativamente questo approccio. Non ci limiteremo a presentare modelli di regressione nelle loro diverse varianti, ma esploreremo anche modelli che tentano di descrivere esplicitamente processi psicologici, come il modello di Rescorla-Wagner per l’apprendimento associativo.
L’obiettivo non è sostituire l’analisi statistica tradizionale, ma integrarla con strumenti che ci permettano di rispondere a una domanda più ambiziosa: quali processi mentali plausibili possono aver generato i dati che osserviamo?
38.3 Campionamento indipendente da una distribuzione fissa
Molti modelli statistici tradizionali si basano su un’assunzione fondamentale: i dati osservati rappresentano un processo di campionamento indipendente da una distribuzione fissa. Si considerino, ad esempio, i punteggi di ansia misurati in un campione di studenti: si assume che seguano una distribuzione normale caratterizzata da una media \(\mu\) e da una deviazione standard \(\sigma\).
In questo quadro concettuale, ogni osservazione viene considerata come un’estrazione indipendente dalla stessa distribuzione di probabilità sottostante. L’obiettivo principale del modello statistico diventa quindi la stima dei parametri che definiscono tale distribuzione, ovvero la media \(\mu\) e la deviazione standard \(\sigma\). Questo approccio presenta indubbi vantaggi per la descrizione sintetica dei dati e l’identificazione delle loro caratteristiche distributive fondamentali.
Tuttavia, è importante riconoscere i suoi limiti concettuali: tale prospettiva rimane essenzialmente muta riguardo ai meccanismi attraverso i quali i livelli di ansia emergono o si modificano effettivamente nel tempo. In altre parole, il modello descrive i dati nella loro manifestazione osservabile (“come sono”), ma non fornisce alcuna informazione sui processi psicologici dinamici che li hanno generati.
38.4 Modelli fenomenologici: descrivere le associazioni
Un passo in avanti è rappresentato dai modelli che analizzano le relazioni tra le variabili, come la regressione lineare o logistica. Questi approcci ci permettono di andare oltre la semplice descrizione di una distribuzione e di studiare sistematicamente come una variabile dipendente varia in funzione di una o più variabili indipendenti.
Per esempio, è possibile modellare la relazione tra stress e rendimento accademico, verificando se un aumento dei livelli di stress corrisponda effettivamente a una diminuzione delle performance scolastiche.
Questi modelli statistici sono estremamente diffusi e costituiscono il fondamento metodologico di gran parte della ricerca psicologica contemporanea. Tuttavia, è importante riconoscere che rimangono essenzialmente modelli fenomenologici: descrivono efficacemente che cosa accade, documentando, ad esempio, l’esistenza di una correlazione tra stress e rendimento, ma non sono in grado di spiegare perché tale relazione esista.
Un modello di regressione, infatti, non può dirci se lo stress riduce direttamente il rendimento, se entrambe le variabili siano influenzate da un terzo fattore (come il supporto sociale), o se la relazione evolva nel tempo attraverso dinamiche psicologiche complesse. Questa fragilità metodologica ha contribuito direttamente alla crisi di replicazione: i modelli che descrivono soltanto associazioni spesso sembrano solidi in uno studio, ma non riescono a essere replicati in altri contesti, perché non si basano su un processo generativo condiviso.
38.5 Modelli meccanicistici: spiegare i processi
I modelli meccanicistici, detti anche processuali, rappresentano un’ulteriore evoluzione rispetto ai modelli puramente statistici. A differenza dei modelli statistici, che descrivono le associazioni tra variabili, i modelli meccanicistici mirano a formalizzare i meccanismi psicologici che generano i dati osservati.
Questi modelli derivano da ipotesi specifiche su come le persone percepiscono, apprendono, prendono decisioni o reagiscono agli stimoli. Ogni parametro possiede un significato psicologico direttamente interpretabile, come la velocità di apprendimento, la soglia decisionale o la sensibilità alle ricompense e alle punizioni. In questa prospettiva, i dati non sono più considerati come semplici estrazioni indipendenti da una distribuzione fissa, ma come l’esito dinamico di un processo psicologico sottostante.
Un esempio particolarmente illustrativo è il modello di Rescorla-Wagner per l’apprendimento associativo. Questo modello descrive come l’aspettativa di valore di uno stimolo venga aggiornata a ogni prova in base all’errore di previsione commesso dall’individuo. In questo caso, non ci si limita a verificare se “esiste un effetto”, ma si modella esplicitamente il processo di apprendimento che genera le risposte osservate, offrendo una comprensione più profonda e meccanicistica del fenomeno psicologico in esame.
I modelli di questo tipo, radicati in un processo psicologico esplicito, hanno il potenziale di produrre risultati più robusti e replicabili: se il modello coglie effettivamente il meccanismo sottostante, la sua applicazione a nuovi dati dovrebbe confermare le stesse dinamiche di base, anche in presenza di osservazioni specifiche diverse.
38.5.1 Confronto tra i due approcci
I modelli fenomenologici offrono il vantaggio della semplicità e sono spesso sufficienti per una descrizione iniziale dei dati. Questa apparente semplicità nasconde però un limite fondamentale: la tendenza a fornire spiegazioni fragili e poco replicabili, in quanto questi modelli catturano solo relazioni superficiali senza indagare i meccanismi sottostanti.
Al contrario, i modelli meccanicistici richiedono un maggior numero di ipotesi iniziali e presentano una complessità analitica superiore. Questo investimento concettuale viene ricompensato da un fondamentale vantaggio epistemologico: ci avvicinano alla logica metodologica delle scienze naturali, permettendoci di spiegare i dati osservati attraverso la formalizzazione di processi generativi sottostanti. In tal modo, non ci limitiamo a descrivere le relazioni tra variabili, ma miriamo a comprenderne i meccanismi causali.
Un modello fenomenologico si limita a descrivere una relazione osservabile, affermando, per esempio, che “più ore di studio corrispondono a voti più alti”. Al contrario, un modello meccanicistico cerca di spiegare il processo alla base di questa relazione, ad esempio affermando che “ogni sessione di studio aumenta la forza della traccia mnestica con un determinato tasso di apprendimento che, a sua volta, influenza direttamente la probabilità di rispondere correttamente durante l’esame”.
Mentre il primo si concentra sul cosa accade, il secondo cerca di spiegare come e perché accade.
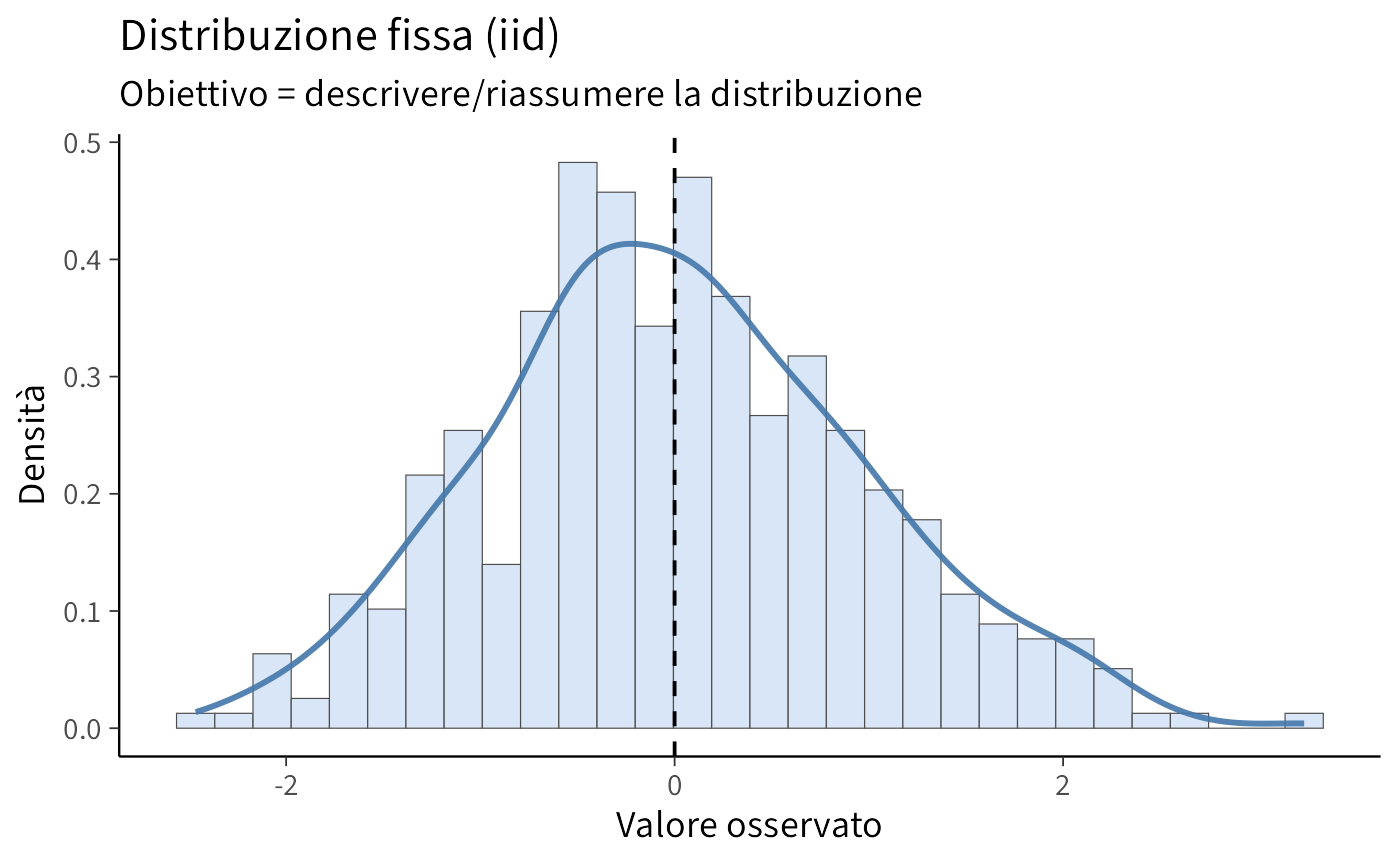
Modello fenomenologico: il focus è sulla forma della distribuzione e sui suoi parametri riassuntivi (media, varianza).
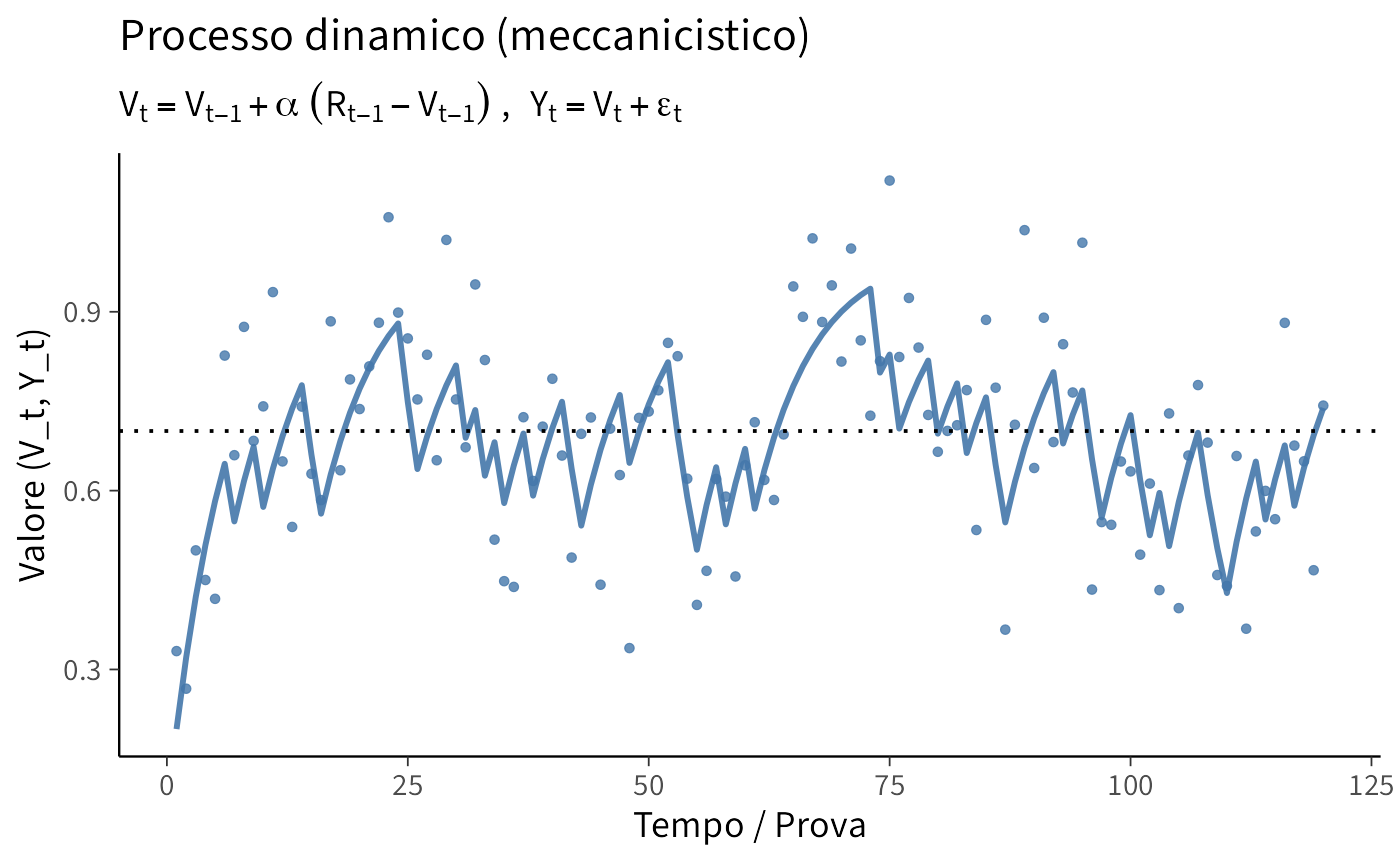
Modello meccanicistico: il focus è sul meccanismo nel tempo (apprendimento): \(V_t\) evolve in base all’errore di previsione e le osservazioni \(Y_t\) sono rumore attorno a \(V_t\).
**Messaggio chiave:* descrivere associazioni vs spiegare processi generativi.
38.6 Valutazione e confronto dei modelli
Ogni modello psicologico, sia esso descrittivo o meccanicistico, costituisce una rappresentazione semplificata della realtà. Nessun modello può catturare interamente la complessità dei fenomeni psicologici; il suo valore scientifico risiede piuttosto nella capacità di aiutarci a comprendere e prevedere i fenomeni osservati.
38.6.1 Due prospettive complementari
La valutazione dei modelli si articola su due dimensioni distinte ma complementari: 1. l’adeguatezza esplicativa, che misura quanto bene un modello descriva i dati già osservati; 2. la capacità predittiva, che valuta invece la sua abilità di generalizzare a nuovi dati non ancora raccolti.
È importante notare come queste due dimensioni non sempre coincidono: un modello eccessivamente complesso può adattarsi perfettamente ai dati esistenti, mostrando un’eccellente adeguatezza esplicativa, ma può rivelarsi al contempo incapace di fare previsioni accurate su dati nuovi, manifestando così una scarsa capacità predittiva.
38.6.2 Confrontare i modelli
La crisi di replicazione ci ricorda che non basta adattare un modello ai dati disponibili, ma ciò che conta è la sua capacità di prevedere dati nuovi. È proprio qui che la valutazione e il confronto dei modelli diventano strumenti centrali per una psicologia più solida e cumulativa.
Il confronto tra i modelli rappresenta un aspetto cruciale della ricerca scientifica, in quanto riconosce che per uno stesso fenomeno possono esistere molteplici spiegazioni plausibili. Il compito del ricercatore è quello di identificare il modello che produce rappresentazioni più utili e coerenti con la realtà osservata.
Tale confronto può avvenire sia tra approcci diversi, sia all’interno dello stesso paradigma. Ad esempio, i modelli fenomenologici e meccanicistici possono essere messi a confronto. Allo stesso modo, due modelli meccanicistici alternativi possono essere messi a confronto per determinare quale dei due spieghi meglio il comportamento osservato.
38.6.3 Anticipazione
Nella prossima sezione del manuale esploreremo le metodologie concrete per condurre questi confronti, introducendo strumenti statistici che permettono di quantificare oggettivamente la bontà predittiva dei modelli. In particolare:
approfondiremo criteri statistici come la log-verosimiglianza, il WAIC e il LOO-CV, che permettono un confronto formale delle capacità predittive dei modelli;
esamineremo casi di studio psicologici in cui modelli alternativi – come diversi modelli di apprendimento o processi decisionali – vengono sottoposti a verifica empirica sugli stessi dati.
Questo approccio ci permetterà di passare da valutazioni qualitative a giudizi quantitativi e rigorosi sulla validità dei modelli teorici.
Un modello non è mai “vero” in senso assoluto: è più o meno utile. La valutazione e il confronto dei modelli sono strumenti fondamentali per rendere la psicologia una scienza cumulativa, in cui teorie diverse possono essere messe a confronto sulla base dei dati.
I modelli possono essere valutati secondo due prospettive fondamentali: quella esplicativa e quella predittiva.
La valutazione esplicativa (o fit del modello) misura quanto bene un modello riesce a descrivere i dati già osservati, ovvero quanto sia in grado di adattarsi alle informazioni in nostro possesso.
La valutazione predittiva (o validazione del modello) misura invece la capacità del modello di generalizzare, ovvero di fare previsioni accurate su dati nuovi, non ancora osservati e provenienti da outside del campione originario.
Il messaggio chiave è che un modello statisticamente valido non è solo quello che spiega bene il passato, ma soprattutto quello che dimostra di saper prevedere in modo affidabile il futuro. La vera prova della bontà di un modello risiede nella sua capacità predittiva, non solo in quella descrittiva.
38.6.4 Un esempio psicologico: scelte alimentari negli adolescenti
Immaginiamo di voler studiare le scelte alimentari di un gruppo di adolescenti, osservando se scelgono uno snack salutare o non salutare in una serie di decisioni.
Approccio fenomenologico Possiamo costruire una regressione logistica che predice la probabilità di scegliere lo snack salutare in funzione di alcune variabili, ad esempio il livello di stress e la disponibilità economica. Questo modello ci direbbe se lo stress è associato a una minore probabilità di fare scelte salutari, senza però chiarire perché avvenga.
Approccio meccanicistico Possiamo invece ipotizzare un modello di apprendimento associativo (ad esempio il modello di Rescorla–Wagner): ad ogni prova, l’adolescente aggiorna le proprie aspettative di ricompensa per ciascuna opzione sulla base dell’esperienza precedente. In questo quadro, i dati delle scelte non sono solo correlati a variabili esterne, ma sono l’esito di un processo dinamico di apprendimento governato da parametri interpretabili (tasso di apprendimento, sensibilità alla ricompensa, variabilità decisionale).
38.6.4.1 Confronto dei due modelli
Entrambi i modelli possono adattarsi agli stessi dati, ma offrono spiegazioni molto diverse: la regressione descrive un’associazione “statica” tra stress e scelta, mentre il modello di apprendimento descrive un meccanismo dinamico, cioè come gli adolescenti aggiornano le loro preferenze. Valutare e confrontare i modelli significa allora chiedersi quale delle due rappresentazioni sia più utile: quella che ci dice solo quali variabili sono correlate, o quella che propone un processo psicologico plausibile alla base delle decisioni?
Gli stessi dati possono essere interpretati con modelli diversi. Il confronto tra modelli non è un lusso, ma una necessità: ci permette di capire quale rappresentazione dei dati sia più informativa e più vicina ai processi psicologici reali.
Riflessioni conclusive
In questo capitolo abbiamo distinto tra due modi di intendere i modelli in psicologia:
- i modelli fenomenologici, che descrivono le relazioni osservabili tra variabili;
- i modelli meccanicistici, che cercano invece di rappresentare i processi psicologici che generano i dati.
I primi hanno il vantaggio della semplicità e forniscono un punto di partenza utile per descrivere i fenomeni. I secondi, più complessi, ci permettono però di avvicinarci a una spiegazione: ci dicono non solo che cosa accade, ma anche come e perché accade.
Abbiamo visto che la psicologia, per rafforzare la propria solidità scientifica, non può limitarsi all’analisi delle associazioni. È necessario un salto verso modelli che mettano al centro i meccanismi generativi. Solo così possiamo rendere le nostre teorie più precise, più testabili e più replicabili.
Un altro punto fondamentale riguarda la valutazione dei modelli: non esiste un modello “vero” in senso assoluto, ma modelli più o meno utili. Per questo dobbiamo sempre confrontare alternative, verificare la loro capacità di spiegare i dati raccolti e soprattutto la loro forza nel prevedere dati nuovi.
Nei prossimi capitoli passeremo dal livello concettuale a quello operativo, vedendo come l’approccio bayesiano ci consenta di costruire e confrontare concretamente modelli fenomenologici e meccanicistici.
L’uso dei modelli meccanicistici, insieme a strumenti di confronto basati sulla capacità predittiva, rappresenta una via promettente per affrontare la crisi di replicabilità in psicologia. Nei capitoli successivi vedremo come tradurre questi principi in pratiche concrete di analisi statistica e di modellazione.
Qual è il processo concettuale alla base della modellizzazione e dell’analisi statistica?
Cosa significa che un campione è indipendente e identicamente distribuito (iid) e perché questa assunzione è importante nei modelli statistici?
Come si differenziano i modelli di campionamento da una singola distribuzione rispetto ai modelli di campioni multipli indipendenti?
Qual è la differenza tra regressione lineare semplice e regressione lineare multipla?
In che modo i modelli computazionali, come il modello di apprendimento associativo e il modello drift-diffusion, si differenziano dai modelli statistici tradizionali?
Consegna: Rispondi con parole tue e carica il file .qmd, convertito in PDF su Moodle.
Il processo concettuale della modellizzazione e analisi statistica inizia con un problema reale e i dati raccolti su tale problema. Si costruisce quindi un modello probabilistico che rappresenta le conoscenze disponibili e il modo in cui i dati sono stati ottenuti. L’analisi viene condotta all’interno del modello, producendo conclusioni sui suoi parametri. Infine, i risultati vengono tradotti in inferenze sulla realtà, con lo scopo di migliorare la comprensione del fenomeno studiato.
Un campione è detto indipendente e identicamente distribuito (iid) se le osservazioni sono indipendenti tra loro e seguono la stessa distribuzione di probabilità. Questa assunzione è fondamentale perché semplifica le analisi statistiche e permette di applicare risultati teorici importanti, come la legge dei grandi numeri e il teorema del limite centrale.
Nei modelli di campionamento da una singola distribuzione, si assume che tutte le osservazioni provengano da una stessa popolazione e seguano la stessa distribuzione. Nei modelli di campioni multipli indipendenti, invece, si confrontano più gruppi distinti, ciascuno con la propria distribuzione, per studiare differenze tra le popolazioni. Un esempio è il confronto tra altezze di individui con madri fumatrici e non fumatrici.
La regressione lineare semplice analizza la relazione tra una variabile dipendente e una sola variabile indipendente attraverso una relazione lineare. La regressione lineare multipla, invece, estende questo concetto a più variabili indipendenti, permettendo di modellare fenomeni più complessi e controllare l’effetto di più fattori simultaneamente.
I modelli computazionali, come il modello di apprendimento associativo e il modello drift-diffusion, differiscono dai modelli statistici tradizionali perché mirano a simulare i processi mentali e decisionali sottostanti il comportamento umano. I modelli statistici descrivono principalmente relazioni tra variabili nei dati osservati, mentre i modelli computazionali cercano di rappresentare dinamicamente i meccanismi cognitivi e comportamentali che generano tali dati.
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.1
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] grid stats graphics grDevices utils datasets methods
#> [8] base
#>
#> other attached packages:
#> [1] ragg_1.5.0 tinytable_0.15.1 withr_3.0.2
#> [4] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [7] tidybayes_3.0.7 bayesplot_1.14.0 ggplot2_4.0.1
#> [10] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [13] loo_2.8.0 rstan_2.32.7 StanHeaders_2.32.10
#> [16] brms_2.23.0 Rcpp_1.1.0 sessioninfo_1.2.3
#> [19] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [22] modelr_0.1.11 tibble_3.3.0 dplyr_1.1.4
#> [25] tidyr_1.3.1 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] svUnit_1.0.8 tidyselect_1.2.1 farver_2.1.2
#> [4] S7_0.2.1 fastmap_1.2.0 TH.data_1.1-5
#> [7] tensorA_0.36.2.1 digest_0.6.39 timechange_0.3.0
#> [10] estimability_1.5.1 lifecycle_1.0.4 survival_3.8-3
#> [13] magrittr_2.0.4 compiler_4.5.2 rlang_1.1.6
#> [16] tools_4.5.2 yaml_2.3.12 knitr_1.50
#> [19] labeling_0.4.3 bridgesampling_1.2-1 htmlwidgets_1.6.4
#> [22] curl_7.0.0 pkgbuild_1.4.8 RColorBrewer_1.1-3
#> [25] abind_1.4-8 multcomp_1.4-29 purrr_1.2.0
#> [28] stats4_4.5.2 colorspace_2.1-2 xtable_1.8-4
#> [31] inline_0.3.21 emmeans_2.0.0 scales_1.4.0
#> [34] MASS_7.3-65 cli_3.6.5 mvtnorm_1.3-3
#> [37] rmarkdown_2.30 generics_0.1.4 RcppParallel_5.1.11-1
#> [40] cachem_1.1.0 stringr_1.6.0 splines_4.5.2
#> [43] parallel_4.5.2 vctrs_0.6.5 V8_8.0.1
#> [46] Matrix_1.7-4 sandwich_3.1-1 jsonlite_2.0.0
#> [49] arrayhelpers_1.1-0 glue_1.8.0 codetools_0.2-20
#> [52] distributional_0.5.0 lubridate_1.9.4 stringi_1.8.7
#> [55] gtable_0.3.6 QuickJSR_1.8.1 pillar_1.11.1
#> [58] htmltools_0.5.9 Brobdingnag_1.2-9 R6_2.6.1
#> [61] textshaping_1.0.4 rprojroot_2.1.1 evaluate_1.0.5
#> [64] lattice_0.22-7 backports_1.5.0 memoise_2.0.1
#> [67] broom_1.0.11 snakecase_0.11.1 rstantools_2.5.0
#> [70] gridExtra_2.3 coda_0.19-4.1 nlme_3.1-168
#> [73] checkmate_2.3.3 xfun_0.54 zoo_1.8-14
#> [76] pkgconfig_2.0.3