here::here("code", "_common.R") |>
source()
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(cmdstanr, posterior, bayesplot, ggplot2, dplyr, tibble, stringr)
conflicts_prefer(posterior::ess_bulk)
conflicts_prefer(posterior::ess_tail)
# Definisci i colori tematici
col_prior <- palette_qualitative[2] # Azzurro per distribuzioni a priori
col_data <- palette_qualitative[6] # Rosso-arancio per dati empirici
col_posterior <- palette_qualitative[5] # Blu per stime a posteriori
col_mean <- palette_qualitative[3] # Verde per medie di popolazione
col_interval <- palette_qualitative[7] # Rosa per intervalli di credibilità
col_shrinkage <- palette_qualitative[8] # Grigio per segmenti di shrinkage
col_highlight <- palette_qualitative[1] # Arancione per elementi evidenziati
color_names <- c(
"#E69F00" = "Arancione",
"#56B4E9" = "Azzurro",
"#009E73" = "Verde",
"#F0E442" = "Giallo",
"#0072B2" = "Blu",
"#D55E00" = "Rosso-arancio",
"#CC79A7" = "Rosa",
"#999999" = "Grigio"
)19 Modello gerarchico beta-binomiale
Panoramica del capitolo
- Specificare un modello beta–binomiale gerarchico.
- Spiegare il ruolo della probabilità media nella popolazione \(\mu\) e concentrazione \(\kappa\).
- Interpretare lo shrinkage e collegarlo al numero di prove per soggetto.
- Leggere le principali diagnostiche MCMC.
- Confrontare la prestazione media con un valore di riferimento (es. 0.5).
AttenzionePreparazione del Notebook
19.1 Meccanismi di regolarizzazione
In questo capitolo, le probabilità di successo individuali sono interpretate come realizzazioni scambiabili estratte da una distribuzione Beta comune. I conteggi di successi per ciascun individuo sono modellati mediante distribuzioni binomiali condizionate a tali probabilità, mentre gli iperparametri della distribuzione Beta — che ne determinano posizione e dispersione — vengono stimati direttamente dai dati.
Nel Capitolo 29, dedicato ai modelli gaussiani a effetti misti, ritroveremo la medesima struttura concettuale in un contesto continuo: i parametri individuali saranno concepiti come estrazioni da una distribuzione normale, la verosimiglianza assumerà una forma gaussiana e il grado di concentrazione della distribuzione degli effetti individuali sarà espresso dalla deviazione standard degli effetti casuali. Il principio unificante resta invariato: gli individui condividono caratteristiche comuni pur mantenendo una propria specificità, e questa condivisione di informazione genera un pooling parziale che bilancia la stabilità delle inferenze di gruppo con la sensibilità alle differenze individuali.
In questa prospettiva, il modello beta-binomiale può essere considerato l’analogo discreto del modello gaussiano a effetti misti. La probabilità individuale \(p_i\) svolge un ruolo concettualmente equivalente a quello del parametro continuo \(\theta_j\) nei modelli gaussiani, la distribuzione Beta rappresenta il corrispettivo discreto della distribuzione Normale e il parametro di concentrazione \(\kappa\) è interpretabile come l’equivalente della deviazione standard degli effetti casuali.
Oltre al suo interesse intrinseco, il modello beta-binomiale offre dunque un caso di studio particolarmente trasparente per osservare all’opera i meccanismi di pooling e di regolarizzazione, prima di estenderli a modelli lineari gerarchici più complessi (si vedano Gelman et al., 2013; McElreath, 2020).
19.2 Perché adottare una struttura gerarchica
L’analisi di dati psicologici raccolti su più individui pone una sfida metodologica importante: come è possibile conciliare il rispetto delle differenze individuali con l’esigenza di formulare conclusioni valide a livello di popolazione? Da un lato, ogni partecipante presenta caratteristiche uniche che meritano di essere rappresentate; dall’altro, l’obiettivo della ricerca è spesso quello di comprendere tendenze generali che vanno oltre il caso singolo. I modelli gerarchici bayesiani offrono una soluzione elegante a questa sfida, integrando entrambe le prospettive in un unico quadro inferenziale coerente.
La logica alla base di questi modelli è insieme semplice e potente. Ogni individuo contribuisce con i propri dati alla stima del proprio parametro specifico, ma al tempo stesso partecipa alla definizione del profilo generale della popolazione. Questo profilo collettivo, a sua volta, esercita un’influenza regolatrice sulle stime individuali. Il risultato è un equilibrio dinamico: quando disponiamo di poche osservazioni per un determinato soggetto, la stima del suo parametro tende ad avvicinarsi alla media del gruppo; quando invece le osservazioni sono numerose, prevale l’evidenza empirica specifica di quel partecipante. Questo fenomeno, noto come shrinkage (letteralmente “restringimento” o “contrazione”), non è un artificio statistico imposto dall’esterno, ma emerge naturalmente dalla struttura probabilistica del modello.
19.2.1 Il principio di scambiabilità
Il fondamento concettuale di questo approccio risiede nel principio di scambiabilità. In assenza di informazioni che permettano di distinguere sistematicamente alcuni individui dagli altri, ad esempio in base a covariate quali l’età, il livello di istruzione o l’appartenenza a gruppi clinici, è metodologicamente appropriato trattare i parametri individuali come realizzazioni indipendenti provenienti da una distribuzione comune. In termini psicologici, ciò equivale a riconoscere che tutti gli individui del campione appartengono alla stessa popolazione di riferimento, pur manifestando una certa variabilità individuale.
Consideriamo un esempio concreto. Supponiamo di analizzare la precisione del riconoscimento delle espressioni facciali. Se non abbiamo ragioni teoriche o empiriche per ritenere che alcuni individui appartengano a sottogruppi sistematicamente diversi (per esempio, in base all’età o alla formazione), possiamo considerare le loro probabilità di successo come scambiabili. Ciò significa che, prima di osservare i dati, non è possibile distinguere a priori le prestazioni dei partecipanti: ciascuno ha la stessa probabilità di mostrare un determinato livello di abilità. Il modello gerarchico cattura questa intuizione, rappresentando tutti i partecipanti come provenienti da una distribuzione comune che descrive il livello medio di abilità della popolazione, pur preservando le differenze individuali attorno a tale valore centrale.
Naturalmente, quando sono disponibili covariate rilevanti o si identificano sottogruppi teoricamente motivati, il modello può essere esteso in modo naturale includendo predittori che spiegano parte della variabilità tra i soggetti. Tuttavia, la logica strutturale di base rimane inalterata: il modello continua a operare una regolarizzazione gerarchica, ora condizionata alle caratteristiche osservate dei partecipanti.
19.3 Struttura del modello e parametrizzazione
Il modello gerarchico adottato si basa su una struttura generativa a due livelli che riflette sia il processo di generazione dei dati osservati sia le ipotesi sulla popolazione di riferimento.
Livello individuale (verosimiglianza). Per ciascun partecipante \(i\), il numero di successi \(y_i\) osservati su \(n_i\) prove è modellato mediante una distribuzione binomiale con probabilità di successo individuale \(p_i\): \[ y_i \sim \text{Binomiale}(n_i, p_i). \] Questo livello del modello descrive il meccanismo stocastico attraverso il quale i dati empirici vengono generati a partire dai parametri individuali.
Livello di popolazione (distribuzione dei parametri individuali). Le probabilità di successo individuali \(p_i\) non sono considerate come parametri indipendenti, ma come realizzazioni scambiabili estratte da una distribuzione Beta comune, caratterizzata dagli iperparametri \(\alpha\) e \(\beta\): \[ p_i \sim \text{Beta}(\alpha, \beta). \] Questa distribuzione cattura la variabilità interindividuale nella popolazione. Gli iperparametri \(\alpha\) e \(\beta\) ne determinano la forma complessiva e, di conseguenza, il modo in cui le probabilità individuali si distribuiscono attorno a un valore tipico.
Distribuzioni a priori sugli iperparametri. Per completare la descrizione del modello, agli iperparametri \(\alpha\) e \(\beta\) vengono assegnate distribuzioni a priori debolmente informative, che riflettono una conoscenza preliminare limitata e lasciano ai dati un ruolo predominante nell’inferenza.
19.3.1 Una parametrizzazione più interpretabile
Sebbene la parametrizzazione tradizionale in termini di \(\alpha\) e \(\beta\) sia matematicamente conveniente, essa risulta spesso poco immediata dal punto di vista interpretativo. Una riformulazione alternativa, basata sui concetti di media e concentrazione, permette di interpretare i parametri del modello in modo più diretto:
La media di popolazione \[ \mu = \frac{\alpha}{\alpha + \beta} \] rappresenta la probabilità media di successo nella popolazione, ovvero il livello tipico di performance atteso.
La concentrazione \[ \kappa = \alpha + \beta \] quantifica il grado di omogeneità tra i partecipanti. Valori elevati di \(\kappa\) indicano che le probabilità individuali sono fortemente concentrate attorno alla media \(\mu\), suggerendo una popolazione relativamente omogenea, mentre valori ridotti di \(\kappa\), al contrario, consentono una maggiore dispersione delle \(p_i\) e riflettono una popolazione più eterogenea.
Questa parametrizzazione rende più agevole sia la specificazione di distribuzioni a priori sostantivamente motivate sia l’interpretazione dei risultati, facilitando il collegamento tra i parametri statistici del modello e le caratteristiche psicologiche della popolazione studiata.
19.4 Il meccanismo di shrinkage bayesiano
Uno degli aspetti più istruttivi del modello gerarchico emerge dall’analisi della distribuzione a posteriori dei parametri individuali. Quando gli iperparametri \(\alpha\) e \(\beta\) sono noti — o, più realisticamente, stimati dai dati — la coniugazione tra la distribuzione Beta e la verosimiglianza binomiale conduce a una distribuzione a posteriori la cui forma rende particolarmente trasparente il meccanismo di regolarizzazione bayesiana.
La stima bayesiana per l’individuo \(i\)-esimo combina in modo bilanciato la sua evidenza empirica con l’informazione di popolazione: \[ \mathbb{E}[p_i \mid y_i, \alpha, \beta] = w_i \,\hat{p}_i + (1 - w_i)\,\mu, \] dove:
- \(\hat{p}_i = y_i / n_i\) è la proporzione osservata per l’individuo.
- \(\mu = \alpha / (\alpha + \beta)\) è la probabilità media a priori nella popolazione.
- \(w_i = \frac{n_i}{n_i + \kappa}\) è il peso di fiducia nei dati individuali, con \(\kappa = \alpha + \beta\) che ne determina l’intensità.
Questa media ponderata realizza il meccanismo di shrinkage (o regolarizzazione): la stima finale “restringe” l’osservazione grezza \(\hat{p}_i\) verso la media della popolazione \(\mu\). Il peso \(w_i\) determina quanto.
1. Il ruolo della dimensione campionaria individuale (\(n_i\)).
Il peso \(w_i = n_i / (n_i + \kappa)\) regola l’equilibrio tra dato individuale e informazione di gruppo:
- dati scarsi (\(n_i\) piccolo): \(w_i \approx 0\). La stima è attratta verso \(\mu\). Il modello, in mancanza di evidenza solida, preserva per l’individuo l’informazione del gruppo.
- dati abbondanti (\(n_i\) grande): \(w_i \approx 1\). La stima coincide con \(\hat{p}_i\). Il modello affida la stima all’evidenza individuale, ormai affidabile.
2. Il ruolo dell’eterogeneità di popolazione (\(\kappa\)).
Il parametro \(\kappa = \alpha + \beta\), noto come concentrazione, modula globalmente l’intensità dello shrinkage:
- \(\kappa\) grande (popolazione omogenea): il denominatore \(n_i + \kappa\) cresce, riducendo \(w_i\). Il modello promuove una forte regolarizzazione verso una media comune ritenuta molto informativa per tutti.
- \(\kappa\) piccolo (popolazione eterogenea): \(w_i\) rimane vicino a 1 anche per \(n_i\) modesti. Il modello permette maggiore differenziazione, ritenendo la media di popolazione meno rappresentativa per i singoli.
Questo bilanciamento adattivo tra informazione individuale e informazione di gruppo costituisce il nucleo dello shrinkage bayesiano e rappresenta uno dei principali vantaggi dei modelli gerarchici. Il modello non impone a priori un grado fisso di regolarizzazione, ma lo apprende dai dati, producendo stime che risultano al tempo stesso sensibili alle specificità individuali e ancorate alla struttura della popolazione di riferimento.
19.5 Un’applicazione pratica: lo studio sulla terapia tattile
19.5.1 Il contesto sperimentale
Per illustrare concretamente il funzionamento del modello gerarchico beta-binomiale, esaminiamo uno studio sperimentale di Rosa et al. (1998), che ha indagato l’efficacia della cosiddetta “terapia tattile”. Questo controverso approccio terapeutico si basa sull’assunto che alcuni operatori sanitari, specificamente addestrati, siano in grado di percepire e manipolare il cosiddetto “campo energetico umano” che circonda il corpo.
Per verificare questa affermazione, i ricercatori hanno progettato un esperimento in condizioni controllate. Ventotto praticanti del Therapeutic Touch dovevano identificare, senza alcun contatto visivo o fisico, quale delle due mani di un partecipante era stata avvicinata dallo sperimentatore. Il disegno prevedeva che ciascun operatore completasse dieci prove indipendenti, ottenendo in ciascuna un risultato binario: identificazione corretta o errore.
Dal punto di vista statistico, l’obiettivo inferenziale si articola su due livelli complementari:
livello individuale: stimare la probabilità di successo specifica di ciascun operatore, riconoscendo che potrebbero esistere differenze individuali nell’abilità (ammesso che tale abilità esista).
livello di popolazione: stimare la probabilità media di successo dell’intero gruppo di operatori, per valutare se complessivamente la performance si discosti dalla pura casualità.
Entrambi i parametri possono essere interpretati in base al confronto con il valore di riferimento di 0.5, che rappresenta la performance attesa per puro caso in un compito a due alternative forzate. Se gli operatori possiedono effettivamente la capacità dichiarata, si dovrebbero osservare probabilità di successo sistematicamente superiori a tale valore.
Questo contesto sperimentale si presta idealmente all’applicazione di un modello gerarchico, poiché combina l’interesse per le specificità individuali con la necessità di trarre conclusioni sulla popolazione generale, in un dominio dove la performance casuale costituisce un punto di riferimento cruciale.
19.5.2 Preparazione e ispezione dei dati
Procediamo innanzitutto all’importazione dei dati e alla loro organizzazione. Il dataset contiene le risposte di ciascun operatore per ogni singola prova.
# Importazione dei dati
url <- "https://raw.githubusercontent.com/boboppie/kruschke-doing_bayesian_data_analysis/master/2e/TherapeuticTouchData.csv"
tt_dat <- read.csv(url)
tt_dat %>% glimpse()
#> Rows: 280
#> Columns: 2
#> $ y <int> 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0,…
#> $ s <chr> "S01", "S01", "S01", "S01", "S01", "S01", "S01", "S01", "S01", "S01"…Aggreghiamo quindi i dati per operatore, calcolando le statistiche sufficienti necessarie per il modello: il numero totale di successi e il numero di prove completate. Includiamo anche la proporzione empirica di successi come riferimento descrittivo iniziale.
by_subject <- tt_dat |>
group_by(s) |>
summarise(
y = sum(y),
n_trials = n(),
prop_emp = y / n_trials,
.groups = "drop"
) |>
arrange(s)
by_subject |>
head()
#> # A tibble: 6 × 4
#> s y n_trials prop_emp
#> <chr> <int> <int> <dbl>
#> 1 S01 1 10 0.1
#> 2 S02 2 10 0.2
#> 3 S03 3 10 0.3
#> 4 S04 3 10 0.3
#> 5 S05 3 10 0.3
#> 6 S06 3 10 0.319.5.3 Verifica predittiva a priori
Prima di adattare il modello ai dati, è buona pratica verificare che le distribuzioni a priori scelte generino previsioni ragionevoli. In altre parole, vogliamo assicurarci che le nostre prior non escludano a priori scenari plausibili né favoriscano eccessivamente valori estremi.
Per gli iperparametri \(\alpha\) e \(\beta\) adottiamo distribuzioni Gamma debolmente informative, specificate nella parametrizzazione shape-rate: \(\alpha \sim \text{Gamma}(2, 2)\) e \(\beta \sim \text{Gamma}(2, 2)\). Queste prior consentono una vasta di configurazioni possibili per la distribuzione Beta della popolazione, senza imporre vincoli troppo restrittivi.
Generiamo campioni dalla distribuzione predittiva a priori per visualizzare le implicazioni di queste scelte:
set.seed(1)
a_draw <- rgamma(2000, shape = 2, rate = 2)
b_draw <- rgamma(2000, shape = 2, rate = 2)
mu_draw <- a_draw / (a_draw + b_draw)
kappa_draw <- a_draw + b_draw
tibble(mu = mu_draw) |>
ggplot(aes(x = mu)) +
geom_density(linewidth = 0.6, fill = col_prior, alpha = 0.5) +
labs(x = "Media della popolazione (μ)",
y = "Densità",
title = "Distribuzione predittiva a priori\nper la media della popolazione",
subtitle = "Prior Gamma(2,2) su α e β")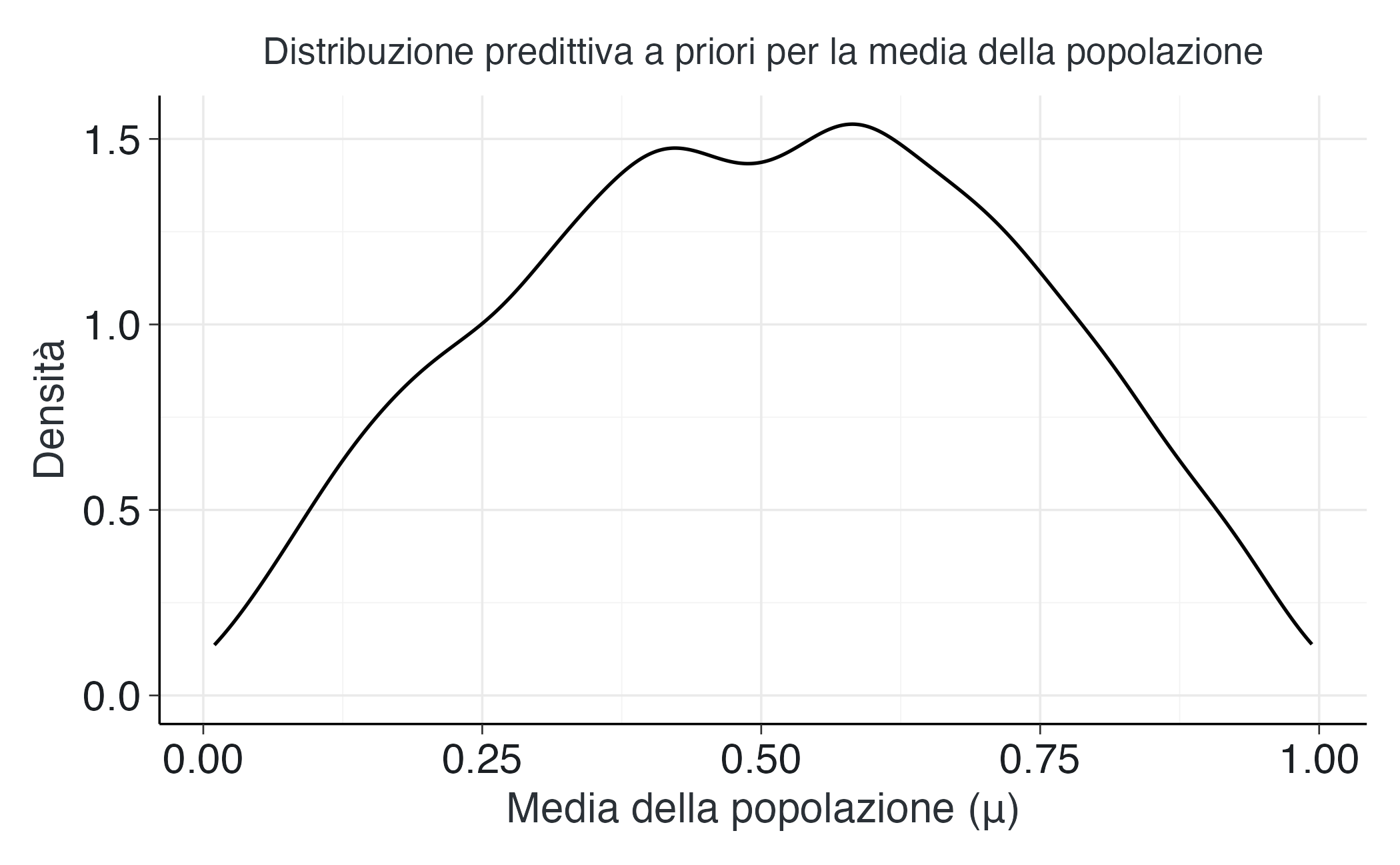
Come possiamo osservare, la distribuzione a priori per la media della popolazione \(\mu\) si distribuisce su un ampio intervallo di valori, senza concentrarsi in modo inappropriato su alcuna regione particolare. Questo comportamento riflette un atteggiamento epistemico prudente: prima di osservare i dati, non imponiamo forti vincoli sulla performance media degli operatori.
Allo stesso modo, le distribuzioni implicite per il parametro di concentrazione \(\kappa\) non impongono né un’omogeneità estrema (che costringerebbe tutti gli operatori a essere quasi identici) né una variabilità eccessiva (che impedirebbe al modello di condividere informazioni tra gli individui). Qualora si desideri un controllo ancora più esplicito su questi aspetti, è possibile specificare prior direttamente sulla parametrizzazione \((\mu, \kappa)\).
19.5.4 Implementazione del modello in Stan
Traduciamo ora la struttura generativa del modello in codice Stan. L’architettura del programma riflette direttamente la struttura gerarchica descritta in precedenza.
Blocco data: specifica i dati osservati che forniamo al modello: il numero di operatori, i successi ottenuti da ciascuno e il numero di prove completate.
Blocco parameters: dichiara i parametri da stimare – gli iperparametri \(\alpha\) e \(\beta\) che caratterizzano la distribuzione Beta di popolazione e le probabilità individuali \(p_i\) per ciascun operatore, vincolate all’intervallo \([0,1]\).
Blocco model: specifica le distribuzioni a priori per gli iperparametri e la struttura gerarchica del modello. Qui definiamo esplicitamente che le probabilità individuali sono estratte da una distribuzione Beta comune e che i dati osservati seguono una distribuzione binomiale condizionata a tali probabilità.
Blocco generated quantities: calcola quantità derivate di interesse, in particolare la media della popolazione \(\mu = \alpha/(\alpha + \beta)\), che utilizzeremo per confrontare la performance media con la soglia casuale di 0.5.
stan_code <- "
data {
int<lower=1> N; // numero di operatori
array[N] int<lower=0> y; // successi per operatore
array[N] int<lower=1> n_trials; // prove per operatore
}
parameters {
real<lower=0> alpha; // parametro shape della Beta
real<lower=0> beta; // parametro shape della Beta
array[N] real<lower=0, upper=1> p; // probabilità individuali
}
model {
alpha ~ gamma(2, 2); // prior su alpha
beta ~ gamma(2, 2); // prior su beta
// Livello di popolazione: le probabilità individuali seguono una Beta comune
for (i in 1:N) {
p[i] ~ beta(alpha, beta);
}
// Livello individuale: verosimiglianza binomiale
for (i in 1:N) {
y[i] ~ binomial(n_trials[i], p[i]);
}
}
generated quantities {
real overall_p = alpha / (alpha + beta); // media di popolazione
}
"Procediamo alla compilazione del modello:
mod <- cmdstanr::cmdstan_model(write_stan_file(stan_code))Prepariamo i dati nel formato richiesto da Stan:
stan_data <- list(
N = nrow(by_subject),
y = as.integer(by_subject$y),
n_trials = as.integer(by_subject$n_trials)
)E infine avviamo il campionamento MCMC utilizzando l’algoritmo di default (No-U-Turn Sampler):
set.seed(84735)
fit <- mod$sample(
data = stan_data,
chains = 4,
parallel_chains = 4,
iter_warmup = 1000,
iter_sampling = 2000,
adapt_delta = 0.9,
max_treedepth = 12,
refresh = 0
)19.5.5 Diagnostica della convergenza
Al termine del campionamento, è essenziale verificare che l’algoritmo MCMC abbia raggiunto la convergenza. Esaminiamo le principali diagnostiche per gli iperparametri e per un sottoinsieme rappresentativo delle probabilità individuali:
posterior::summarise_draws(
fit$draws(variables = c("alpha", "beta", "overall_p", "p[1]", "p[2]", "p[3]")),
"mean", "sd", "rhat", "ess_bulk", "ess_tail"
)
#> # A tibble: 6 × 6
#> variable mean sd rhat ess_bulk ess_tail
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 alpha 2.30 0.625 1.00 6375. 5674.
#> 2 beta 2.83 0.777 1.00 6916. 5882.
#> 3 overall_p 0.449 0.0453 1.00 9668. 6381.
#> 4 p[1] 0.217 0.105 1.00 13325. 5691.
#> 5 p[2] 0.283 0.116 1.00 14168. 5108.
#> 6 p[3] 0.349 0.120 1.00 13573. 5489.Gli indici \(\hat{R}\) prossimi a 1.00 indicano che le catene hanno raggiunto una distribuzione stazionaria comune, mentre valori di dimensione campionaria effettiva (ESS) dell’ordine delle migliaia confermano che disponiamo di un numero sufficiente di campioni indipendenti per l’inferenza. In presenza di problemi di convergenza, questi indicatori mostrerebbero segnali d’allarme che richiederebbero un intervento correttivo.
19.5.6 Analisi dello shrinkage e interpretazione dei risultati
Uno degli aspetti più illuminanti dell’analisi consiste nell’esaminare visivamente il fenomeno dello shrinkage. Estraiamo le stime a posteriori delle probabilità individuali e confrontiamole graficamente con le proporzioni empiriche osservate.
# Estrazione delle distribuzioni a posteriori
draws_p <- fit$draws("p")
draws_mu <- fit$draws("overall_p")
mu_hat <- posterior::summarise_draws(draws_mu, "mean")$mean
# Calcolo delle statistiche riassuntive per le probabilità individuali
sum_p <- posterior::summarise_draws(draws_p, "mean", "median", "sd") %>%
mutate(s = as.integer(stringr::str_extract(variable, "\\d+"))) %>%
arrange(s)
# Calcolo degli intervalli di credibilità al 90%
qs <- posterior::summarise_draws(draws_p, ~ quantile2(.x, probs = c(0.05, 0.95))) %>%
mutate(s = as.integer(stringr::str_extract(variable, "\\d+"))) %>%
arrange(s)
sum_p <- sum_p %>%
left_join(qs %>% select(s, q5 = `q5`, q95 = `q95`), by = "s")
# Integrazione con i dati osservati
df_shrink <- by_subject %>%
mutate(s_idx = as.integer(stringr::str_extract(s, "\\d+"))) %>%
arrange(s_idx) %>%
select(s, s_idx, prop_emp, n_trials) %>%
inner_join(
sum_p %>% select(s, post_mean = mean, post_med = median,
post_q05 = q5, post_q95 = q95),
by = join_by(s_idx == s)
) %>%
arrange(prop_emp) %>%
mutate(s_ord = factor(s, levels = s))Creiamo ora una visualizzazione che mostra simultaneamente le proporzioni empiriche, le stime a posteriori e l’entità della contrazione verso la media di popolazione:
ggplot(df_shrink, aes(x = s_ord)) +
# Segmenti per lo shrinkage
geom_segment(aes(xend = s_ord, y = prop_emp, yend = post_mean),
linewidth = 0.8, alpha = 0.7, color = col_shrinkage,
arrow = arrow(length = unit(0.1, "cm"), ends = "both", type = "closed")) +
# Punti per le stime empiriche
geom_point(aes(y = prop_emp), size = 3, alpha = 0.9, color = col_data,
shape = 16) +
# Punti per le stime a posteriori
geom_point(aes(y = post_mean), size = 3, color = col_posterior, shape = 17) +
# Intervalli di credibilità
geom_errorbar(aes(ymin = post_q05, ymax = post_q95),
width = 0.2, alpha = 0.8, linewidth = 0.6, color = col_interval) +
# Media di popolazione
geom_hline(yintercept = mu_hat, linetype = "dashed", alpha = 0.8,
color = col_mean, linewidth = 0.7) +
labs(x = "Operatore",
y = "Probabilità di successo",
title = "Effetto di shrinkage\nnel modello gerarchico beta-binomiale",
subtitle = sprintf("Shrinkage verso la media di popolazione: %.3f", mu_hat),
caption = paste0(
"Punti ", color_names[col_data], ": proporzioni empiriche | ",
"Punti ", color_names[col_posterior], ": stime a posteriori | ",
"Segmenti ", color_names[col_shrinkage], ": entità dello shrinkage"
)) +
theme(
panel.grid.minor = element_blank(),
panel.grid.major.x = element_blank(),
axis.text.x = element_text(angle = 45, hjust = 1, vjust = 1, size = 9),
axis.text.y = element_text(size = 9),
plot.caption = element_text(size = 8, color = "gray40", hjust = 0),
plot.subtitle = element_text(face = "bold", color = col_mean)
) +
scale_x_discrete(labels = function(x) gsub("s", "Op. ", x)) +
# Evidenzia i segmenti di shrinkage più ampi
geom_segment(data = df_shrink %>%
mutate(shrinkage_magnitude = abs(prop_emp - post_mean)) %>%
filter(shrinkage_magnitude > quantile(abs(prop_emp - post_mean), 0.7)),
aes(xend = s_ord, y = prop_emp, yend = post_mean),
linewidth = 1.2, alpha = 1, color = col_highlight)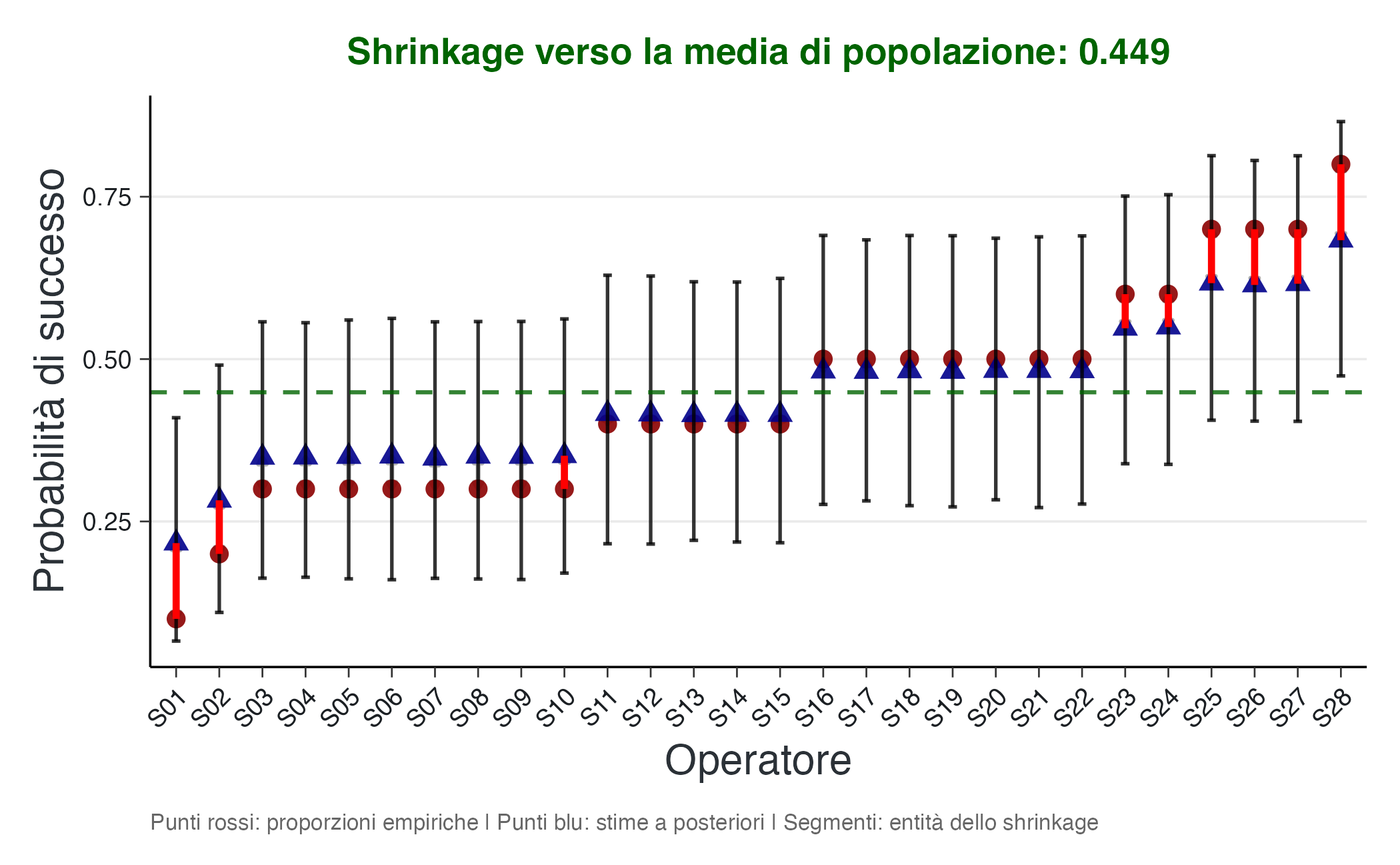
In questa visualizzazione, i punti rossi rappresentano le proporzioni empiriche (i dati grezzi), mentre i triangoli blu mostrano le stime a posteriori prodotte dal modello gerarchico. I segmenti verticali collegano ciascuna coppia di stime, rendendo visibile l’entità dello shrinkage. Gli intervalli di credibilità al 90% (barre verticali) quantificano l’incertezza associata a ciascuna stima a posteriori.
Si nota chiaramente un effetto di regolarizzazione: le stime a posteriori sono sistematicamente “attratte” verso la media della popolazione (linea tratteggiata), con un effetto più marcato per gli operatori con proporzioni empiriche più estreme. Questo comportamento è particolarmente pronunciato per gli operatori che hanno ottenuto solo successi o solo insuccessi nelle dieci prove: in questi casi, la proporzione empirica suggerirebbe probabilità pari a 0 o 1, ma il modello gerarchico, riconoscendo la limitatezza del campione (solo dieci prove), produce stime più moderate e realistiche.
La regolarizzazione operata dal modello gerarchico sembra sostanziale, ma con sole dieci prove per partecipante, è metodologicamente appropriata. In pratica, il modello ci sta dicendo: “Attenzione, dieci prove sono poche per poter affermare con certezza che questa performance estrema rifletta la vera abilità dell’operatore; dobbiamo tenere conto anche di ciò che sappiamo sugli altri partecipanti”. Questo bilanciamento automatico tra l’evidenza individuale e l’informazione di gruppo rappresenta uno dei principali vantaggi dell’approccio gerarchico.
19.5.7 Verifica predittiva a posteriori
Un ulteriore passo essenziale consiste nel valutare l’adeguatezza complessiva del modello mediante una verifica predittiva a posteriori. L’idea di fondo è semplice: se il modello è adeguato, dovrebbe essere in grado di generare dati simulati simili ai dati realmente osservati.
Procediamo campionando dalla distribuzione predittiva a posteriori: per ciascuna iterazione MCMC, si genera un dataset replicato completo utilizzando i valori degli iperparametri campionati in quell’iterazione. Quindi, confrontiamo le statistiche sintetiche dei dati osservati con la distribuzione di queste stesse statistiche calcolate sui dati replicati.
In particolare, ci concentriamo sulla media complessiva delle proporzioni individuali, una statistica naturale per valutare la tendenza centrale della performance.
set.seed(123)
draws <- posterior::as_draws_df(fit$draws(c("alpha", "beta")))
S <- 1000
idx <- sample(seq_len(nrow(draws)), S, replace = TRUE)
yrep_mean <- numeric(S)
yobs_mean <- mean(by_subject$y / by_subject$n_trials)
for (s in seq_len(S)) {
# Estrai i valori degli iperparametri per questa iterazione
a <- draws$alpha[idx[s]]
b <- draws$beta[idx[s]]
# Genera probabilità individuali dalla distribuzione Beta di popolazione
p_ <- rbeta(nrow(by_subject), a, b)
# Genera dati replicati dalla verosimiglianza binomiale
y_ <- rbinom(nrow(by_subject), size = by_subject$n_trials, prob = p_)
# Calcola la statistica di interesse per questo dataset replicato
yrep_mean[s] <- mean(y_ / by_subject$n_trials)
}
# Visualizzazione
tibble(yrep_mean = yrep_mean) %>%
ggplot(aes(x = yrep_mean)) +
geom_density(linewidth = 0.6, fill = col_prior, alpha = 0.5) +
geom_vline(xintercept = yobs_mean, linetype = "dashed",
color = col_data, linewidth = 1) +
annotate("text", x = yobs_mean + 0.02, y = 10,
label = sprintf("Media osservata = %.3f", yobs_mean),
color = col_data, hjust = 0) +
labs(x = "Media delle proporzioni (dati replicati)",
y = "Densità",
title = "Verifica predittiva a posteriori",
subtitle = "Distribuzione delle medie replicate vs. valore osservato")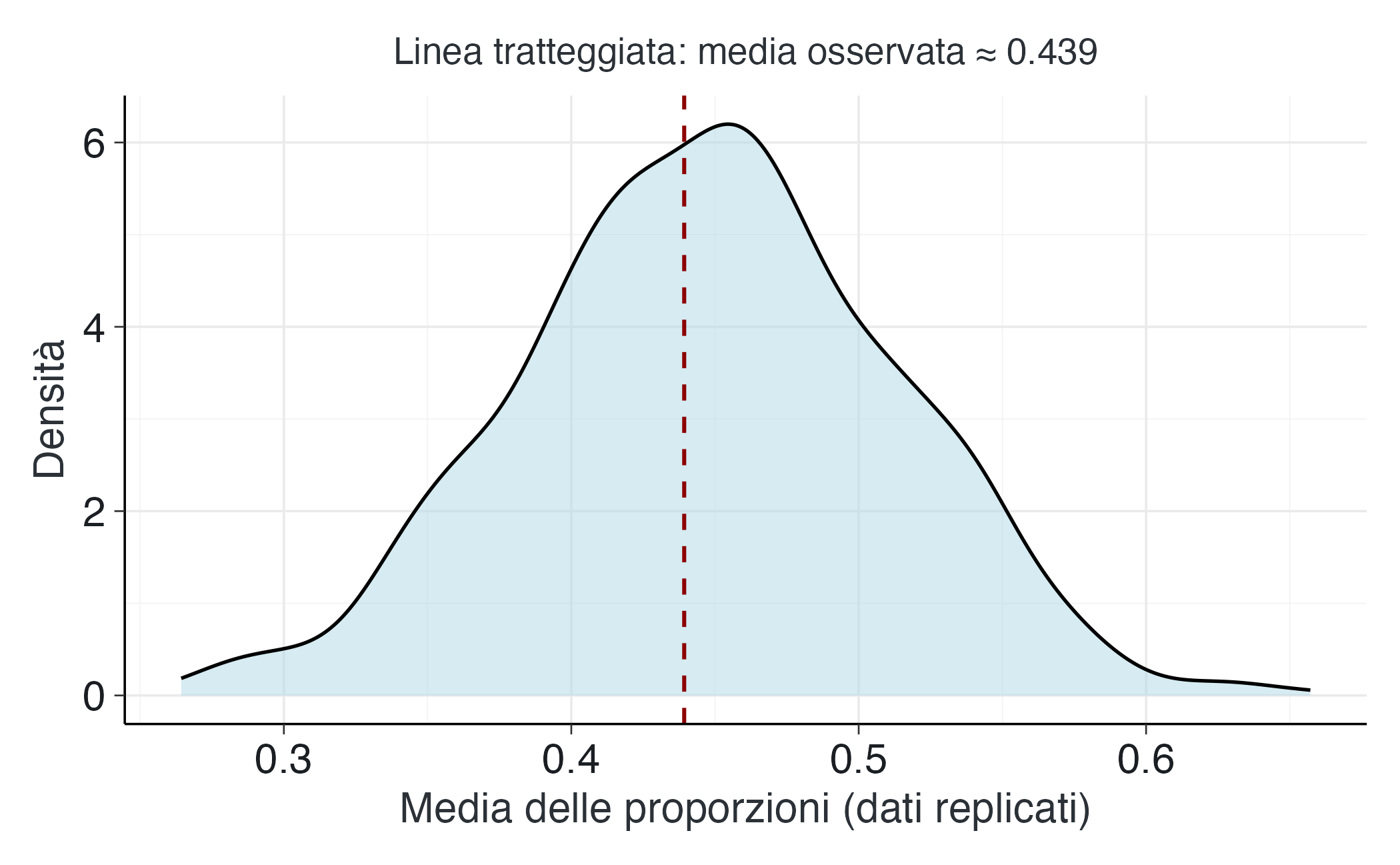
La distribuzione delle medie replicate (in blu) rappresenta la variabilità che ci aspetteremmo di osservare in campioni futuri generati dallo stesso processo, secondo quanto stimato dal modello. La linea tratteggiata rossa indica il valore effettivamente osservato nei dati reali.
Se il valore osservato cade in una regione di alta densità della distribuzione predittiva, come accade in questo caso, possiamo concludere che il modello è adeguato nel riprodurre questa caratteristica dei dati. Se invece il valore osservato cadesse in una coda estrema della distribuzione predittiva, ciò costituirebbe un segnale d’allarme, suggerendo che il modello potrebbe non catturare adeguatamente alcuni aspetti importanti del processo generativo dei dati.
Eventuali discrepanze sistematiche potrebbero indicare la necessità di rivedere le assunzioni del modello, per esempio, riconsiderando le distribuzioni a priori sulla concentrazione, o valutando se l’ipotesi di scambiabilità semplice sia appropriata, oppure esplorando l’inclusione di covariate per modellare fonti di eterogeneità non catturate dalla struttura gerarchica di base.
19.5.8 Valutazione dell’efficacia della terapia tattile
L’obiettivo principale dello studio è determinare se i praticanti del Therapeutic Touch sono in grado di identificare il campo energetico umano con un’accuratezza superiore a quella attesa per puro caso (0.5). Per rispondere a questa domanda, possiamo esaminare direttamente la distribuzione a posteriori della probabilità media di successo nella popolazione \(\mu\), ovvero overall_p.
Calcoliamo gli intervalli di credibilità (IC) per questo parametro chiave:
# Calcolo dell'intervallo di credibilità per l'accuratezza media
draws_mu <- fit$draws("overall_p")
mu_summary <- posterior::summarise_draws(
draws_mu,
mean = ~mean(.x),
sd = ~sd(.x),
~quantile2(.x, probs = c(0.025, 0.05, 0.25, 0.5, 0.75, 0.95, 0.975))
)
print(mu_summary)
#> # A tibble: 1 × 10
#> variable mean sd q2.5 q5 q25 q50 q75 q95 q97.5
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 overall_p 0.449 0.0453 0.361 0.375 0.418 0.449 0.479 0.523 0.537Possiamo anche calcolare la probabilità a posteriori che l’accuratezza media sia maggiore di 0.5:
prob_above_chance <- posterior::summarise_draws(
draws_mu,
prob_above_0.5 = ~mean(.x > 0.5)
)
print(prob_above_chance)
#> # A tibble: 1 × 2
#> variable prob_above_0.5
#> <chr> <dbl>
#> 1 overall_p 0.134Interpretazione: l’intervallo di credibilità al 95% per l’accuratezza media della popolazione (\(\mu\)) è [0.361, 0.537]. Questo intervallo contiene il valore di riferimento 0.5 (anche se la maggior parte della massa della distribuzione, ovvero, il 79% dell’IC, si trova al di sotto di esso). La probabilità a posteriori che l’accuratezza media sia maggiore di 0.5 è solo del %.
Conclusione sull’efficacia: i dati non forniscono prove convincenti a sostegno dell’efficacia del Therapeutic Touch. La performance media del gruppo di operatori non è statisticamente distinguibile dal caso, con una lieve tendenza verso performance peggiori rispetto al valore atteso di 0.5. Questo risultato, ottenuto da un modello che tiene conto della variabilità individuale, fornisce una risposta robusta alla domanda di ricerca originale, in linea con le conclusioni dello studio di Rosa et al. (1998).
19.5.9 Vantaggi del modello gerarchico in questo contesto
L’adozione di un modello gerarchico beta-binomiale in questo contesto sperimentale offre diversi vantaggi metodologici rispetto agli approcci non gerarchici:
Stime robuste per soggetti con dati limitati: con solo 10 prove per operatore, le proporzioni empiriche grezze sono stime molto instabili delle reali abilità individuali. Il modello gerarchico, attraverso il meccanismo di shrinkage, produce stime più conservative e realistiche, in particolare per quegli operatori con proporzioni empiriche estreme (0 o 1), evitando così conclusioni fuorvianti sulle abilità individuali basate su evidenze aneddotiche.
Inferenza simultanea a più livelli: il modello ci permette di trarre conclusioni sia a livello individuale (le abilità specifiche \(p_i\)) che a livello di popolazione (l’accuratezza media \(\mu\) e l’eterogeneità \(\kappa\)), il tutto all’interno di un unico quadro coerente. Al contrario, un’analisi separata per ciascun operatore non solo fallirebbe nel fornire una stima affidabile della tendenza centrale, ma perderebbe del tutto l’informazione sull’eterogeneità sistematica del gruppo, limitando la generalizzabilità dei risultati.
Quantificazione dell’eterogeneità: il parametro di concentrazione \(\kappa\) (o la sua varianza equivalente nella distribuzione Beta) misura direttamente la dispersione delle abilità individuali nella popolazione. Questo valore non è solo un iperparametro tecnico, ma fornisce una risposta sostanziale a una domanda di ricerca fondamentale: quanto sono simili gli operatori? Un valore elevato di \(\kappa\) indica una popolazione omogenea, con abilità degli operatori concentrate attorno alla media comune. Un valore ridotto di \(\kappa\) indica invece una popolazione marcatamente eterogenea, caratterizzata da una grande variabilità delle abilità tra gli individui.
Gestione automatica dell’incertezza: il modello propaga l’incertezza in modo appropriato a tutti i livelli della gerarchia. Gli intervalli di credibilità delle probabilità individuali incorporano l’incertezza sia sulla stima del singolo operatore che sugli iperparametri della popolazione, producendo intervalli più calibrati e realistici.
Pooling parziale delle informazioni: a differenza di un approccio che aggrega tutti i dati (ignorando le differenze individuali) o che analizza ogni soggetto separatamente (ignorando le similarità), il modello gerarchico trova un equilibrio ottimale tra questi due estremi. Il grado di pooling è determinato dai dati stessi: maggiore è il numero di prove per soggetto, minore è lo shrinkage verso la media.
In sintesi, la struttura gerarchica rappresenta una scelta metodologica ottimale per l’analisi di dati sperimentali in psicologia, caratterizzati da un tipico disegno “multi-livello”: molti partecipanti, ciascuno con un numero limitato di osservazioni ripetute. A differenza di altri modelli che trattano le osservazioni come indipendenti o che considerano i soggetti in modo isolato, questo modello sfrutta l’informazione di gruppo per produrre stime individuali regolarizzate e stabili, anche quando i dati grezzi sarebbero troppo scarsi. Contemporaneamente, esso fornisce una valutazione integrata e quantitativa dell’eterogeneità della popolazione, preservando una calibrazione rigorosa dell’incertezza statistica a tutti i livelli.
19.6 Dal modello beta-binomiale ai modelli gaussiani gerarchici
Ora che abbiamo sviluppato una comprensione concreta del funzionamento dei modelli gerarchici attraverso il caso beta-binomiale, possiamo anticipare un’importante transizione: l’estensione ai modelli gaussiani a effetti misti per dati continui. Questa transizione, pur comportando un cambiamento nella formalizzazione matematica, mantiene inalterata la struttura concettuale che abbiamo esplorato. La tabella seguente evidenzia le corrispondenze tra i due framework:
| Aspetto | Modello Beta-Binomiale | Modello Gaussiano Gerarchico |
|---|---|---|
| Parametri individuali | \(p_i\) (probabilità di successo) | \(\theta_j\) (effetti casuali) |
| Distribuzione di popolazione | \(\text{Beta}(\alpha, \beta)\) | \(\text{Normale}(\mu, \sigma_\theta)\) |
| Parametro di concentrazione | \(\kappa = \alpha + \beta\) | Deviazione standard \(\sigma_\theta\) |
| Verosimiglianza | \(y_i \sim \text{Binomiale}(n_i, p_i)\) | \(y_{ij} \sim \text{Normale}(\theta_j, \sigma_y)\) |
| Meccanismo di shrinkage | Regolato da \(w_i = n_i/(n_i + \kappa)\) | Regolato da \(\sigma_\theta\) e dall’informazione disponibile |
Il principio fondamentale rimane invariato: il modello stima simultaneamente i parametri individuali e le caratteristiche della distribuzione della popolazione. Il fenomeno dello shrinkage emerge naturalmente come conseguenza della struttura gerarchica e bilancia automaticamente l’evidenza individuale con l’informazione di gruppo.
Nel caso gaussiano:
- le probabilità di successo \(p_i\) vengono sostituite da effetti casuali \(\theta_j\), che rappresentano le deviazioni individuali rispetto alla media di gruppo;
- la distribuzione Beta viene sostituita da una distribuzione Normale per gli effetti casuali;
- il parametro di concentrazione \(\kappa\) trova il suo analogo nella deviazione standard \(\sigma_\theta\): valori piccoli di \(\sigma_\theta\) indicano maggiore omogeneità (shrinkage più forte), mentre valori grandi permettono maggiore eterogeneità.
Sebbene le formule matematiche specifiche siano diverse, la logica inferenziale sottostante rimane la stessa: la condivisione delle informazioni tra le unità, la regolarizzazione delle stime individuali tramite le informazioni di gruppo e l’adattamento automatico del grado di regolarizzazione in base alla quantità di dati disponibili.
Riflessioni conclusive
Il modello gerarchico beta-binomiale si presta in modo ideale come punto di partenza pedagogico per l’inferenza multilivello Questo perché, grazie alla trasparenza derivante dalla coniugazione Beta-binomiale e da una parametrizzazione intuitiva (media \(\mu\) e concentrazione \(\kappa\)), è possibile visualizzare il cuore dell’inferenza gerarchica: il meccanismo dello shrinkage.
La formula esplicita del peso \(w_i = n_i/(n_i + \kappa)\) non è solo un risultato algebrico, ma l’espressione matematica di un importante principio inferenziale: il modello bilancia in modo automatico e ottimale l’informazione individuale e quella di gruppo. In tal modo, la struttura gerarchica non appare come un compromesso arbitrario, ma come la soluzione naturale alla tensione fondamentale tra specificità individuale e generalizzazione di gruppo, una conseguenza diretta dell’assunzione di scambiabilità e del quadro probabilistico.
Padroneggiare questo caso esemplare fornisce quindi un framework concettuale robusto e trasferibile. Una volta consolidata l’intuizione nel dominio discreto e binomiale, il lettore sarà in grado di identificare e generalizzare i principi operativi fondamentali, ovvero la condivisione dell’informazione, la regolarizzazione e la stima simultanea, ai più comuni modelli gaussiani a effetti misti per dati continui. I dettagli matematici possono cambiare, ma la filosofia statistica fondamentale rimane invariata: la condivisione parsimoniosa dell’informazione per migliorare le inferenze a tutti i livelli.
NotaInformazioni sull’ambiente di sviluppo
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] stringr_1.6.0 cmdstanr_0.8.0 ragg_1.5.0
#> [4] tinytable_0.15.2 withr_3.0.2 systemfonts_1.3.1
#> [7] patchwork_1.3.2 ggdist_3.3.3 tidybayes_3.0.7
#> [10] bayesplot_1.15.0 ggplot2_4.0.1 reliabilitydiag_0.2.1
#> [13] priorsense_1.2.0 posterior_1.6.1 loo_2.9.0
#> [16] rstan_2.32.7 StanHeaders_2.32.10 brms_2.23.0
#> [19] Rcpp_1.1.0 sessioninfo_1.2.3 conflicted_1.2.0
#> [22] janitor_2.2.1 matrixStats_1.5.0 modelr_0.1.11
#> [25] tibble_3.3.0 dplyr_1.1.4 tidyr_1.3.2
#> [28] rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] gridExtra_2.3 inline_0.3.21 sandwich_3.1-1
#> [4] rlang_1.1.6 magrittr_2.0.4 multcomp_1.4-29
#> [7] snakecase_0.11.1 otel_0.2.0 compiler_4.5.2
#> [10] vctrs_0.6.5 pkgconfig_2.0.3 arrayhelpers_1.1-0
#> [13] fastmap_1.2.0 backports_1.5.0 labeling_0.4.3
#> [16] utf8_1.2.6 rmarkdown_2.30 ps_1.9.1
#> [19] purrr_1.2.0 xfun_0.55 cachem_1.1.0
#> [22] jsonlite_2.0.0 broom_1.0.11 parallel_4.5.2
#> [25] R6_2.6.1 stringi_1.8.7 RColorBrewer_1.1-3
#> [28] lubridate_1.9.4 estimability_1.5.1 knitr_1.51
#> [31] zoo_1.8-15 pacman_0.5.1 Matrix_1.7-4
#> [34] splines_4.5.2 timechange_0.3.0 tidyselect_1.2.1
#> [37] abind_1.4-8 yaml_2.3.12 codetools_0.2-20
#> [40] processx_3.8.6 curl_7.0.0 pkgbuild_1.4.8
#> [43] lattice_0.22-7 bridgesampling_1.2-1 S7_0.2.1
#> [46] coda_0.19-4.1 evaluate_1.0.5 survival_3.8-3
#> [49] RcppParallel_5.1.11-1 pillar_1.11.1 tensorA_0.36.2.1
#> [52] checkmate_2.3.3 stats4_4.5.2 distributional_0.5.0
#> [55] generics_0.1.4 rprojroot_2.1.1 rstantools_2.5.0
#> [58] scales_1.4.0 xtable_1.8-4 glue_1.8.0
#> [61] emmeans_2.0.1 tools_4.5.2 data.table_1.18.0
#> [64] mvtnorm_1.3-3 grid_4.5.2 QuickJSR_1.8.1
#> [67] colorspace_2.1-2 nlme_3.1-168 cli_3.6.5
#> [70] textshaping_1.0.4 svUnit_1.0.8 Brobdingnag_1.2-9
#> [73] V8_8.0.1 gtable_0.3.6 digest_0.6.39
#> [76] TH.data_1.1-5 htmlwidgets_1.6.4 farver_2.1.2
#> [79] memoise_2.0.1 htmltools_0.5.9 lifecycle_1.0.4
#> [82] MASS_7.3-65Bibliografia
Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., & Rubin, D. B. (2013). Bayesian Data Analysis (3rd ed.). Chapman; Hall/CRC.
McElreath, R. (2020). Statistical rethinking: A Bayesian course with examples in R and Stan (2nd Edition). CRC Press.
Rosa, L., Rosa, E., Sarner, L., & Barrett, S. (1998). A close look at therapeutic touch. Jama, 279(13), 1005–1010.