6 La fragilità del valore-\(p\)
- osservare empiricamente la variabilità del valore-\(p\) da campione a campione;
- confrontare la distribuzione dei valori-\(p\) sotto l’ipotesi \(H_0\) vera vs. l’ipotesi \(H_0\) falsa;
- comprendere perché la differenza tra “significativo” e “non significativo” non è significativa;
- confrontare la stabilità delle inferenze frequentiste vs bayesiane.
- Leggere il Capitolo 3 del manuale (“Il valore-\(p\) e i suoi fraintendimenti”).
- Leggere il post di Gelman & Stern (2006): The Difference Between “Significant” and “Not Significant” is not Itself Statistically Significant.
6.1 Simulazione 1: la variabilità del valore-\(p\)
Supponiamo di voler studiare un effetto di modesta entità. Nella popolazione di riferimento, la variabile di interesse ha una media \(\mu = 0.05\) e una deviazione standard \(\sigma = 0.1\). Ciò corrisponde a una dimensione dell’effetto di Cohen \(d\) = 0.5, convenzionalmente considerata di intensità “media”.
Per illustrare l’elevata volatilità del valore-\(p\) in piccoli campioni, simuliamo uno scenario di ricerca tipico: la raccolta ripetuta di nuovi dati. In particolare, dalla popolazione descritta estraiamo 100 campioni casuali indipendenti, ciascuno di dimensioni ridotte (\(n\) = 10). Per ogni campione, eseguiamo un test \(t\) di Student per verificare l’ipotesi nulla \(H_0: \mu = 0\).
L’obiettivo della simulazione è mostrare come, nonostante l’effetto reale nella popolazione sia costante (\(\mu\) = 0.05), il valore-\(p\) oscilli in modo drastico da un campione all’altro. Questa marcata variabilità rivela la natura intrinsecamente instabile del valore-\(p\) quale statistica campionaria. Ne consegue che le sue fluttuazioni potrebbero essere interpretate in modo fuorviante come cambiamenti sostanziali del fenomeno studiato, mentre in realtà riflettono esclusivamente la variabilità casuale insita nel processo di campionamento.
# Parametri della simulazione
n_samples <- 100 # Numero di campioni indipendenti
n_obs <- 10 # Osservazioni per campione
true_mean <- 0.05 # Media vera (effetto piccolo)
true_sd <- 0.1 # Deviazione standard
# Simula i campioni e calcola i p-value
simulation <- tibble(sample_id = 1:n_samples) |>
rowwise() |>
mutate(
data = list(rnorm(n_obs, mean = true_mean, sd = true_sd)),
sample_mean = mean(data),
sample_sd = sd(data),
t_stat = sample_mean / (sample_sd / sqrt(n_obs)),
p_value = 2 * pt(-abs(t_stat), df = n_obs - 1),
significant = p_value < 0.05
) |>
ungroup()#> Effetto vero: μ = 0.05, σ = 0.10 (d = 0.5)
#> Dimensione del campione: n = 10
#> Campo di variazione: [0.0013, 0.9923]
#> Mediana dei valori-p: 0.127
#> Valori-p significativi: 30/100 (30%)Visualizzazione:
# Ordina per p-value per una visualizzazione più chiara
simulation_ordered <- simulation |>
arrange(p_value) |>
mutate(rank = row_number())
col_sig <- palette_qualitative[3] # Verde
col_nons <- palette_qualitative[8] # Grigio
col_thr <- palette_qualitative[8] # Grigio (soglia neutra)
simulation_ordered |>
mutate(significant = factor(significant, levels = c(TRUE, FALSE))) |>
ggplot(aes(x = rank, y = p_value, color = significant)) +
geom_point(size = 2, alpha = 0.8) +
geom_hline(
yintercept = 0.05,
linetype = "dashed",
color = col_thr,
linewidth = 1
) +
scale_color_manual(
values = setNames(c(col_sig, col_nons), c("TRUE", "FALSE")),
labels = c(
"TRUE" = "Significativo (p < 0.05)",
"FALSE" = "Non significativo"
)
) +
scale_y_continuous(
trans = "log10",
breaks = c(0.001, 0.01, 0.05, 0.1, 0.5, 1),
labels = c("0.001", "0.01", "0.05", "0.1", "0.5", "1")
) +
labs(
x = "Campioni (ordinati per valore-p)",
y = "Valore-p (scala logaritmica)",
color = "",
title = "100 studi identici, conclusioni diverse",
subtitle = sprintf(
"Stesso effetto (d = %.1f), stesso n = %d, ma valori-p da %.4f a %.2f",
true_mean/true_sd, n_obs,
min(simulation$p_value), max(simulation$p_value)
)
)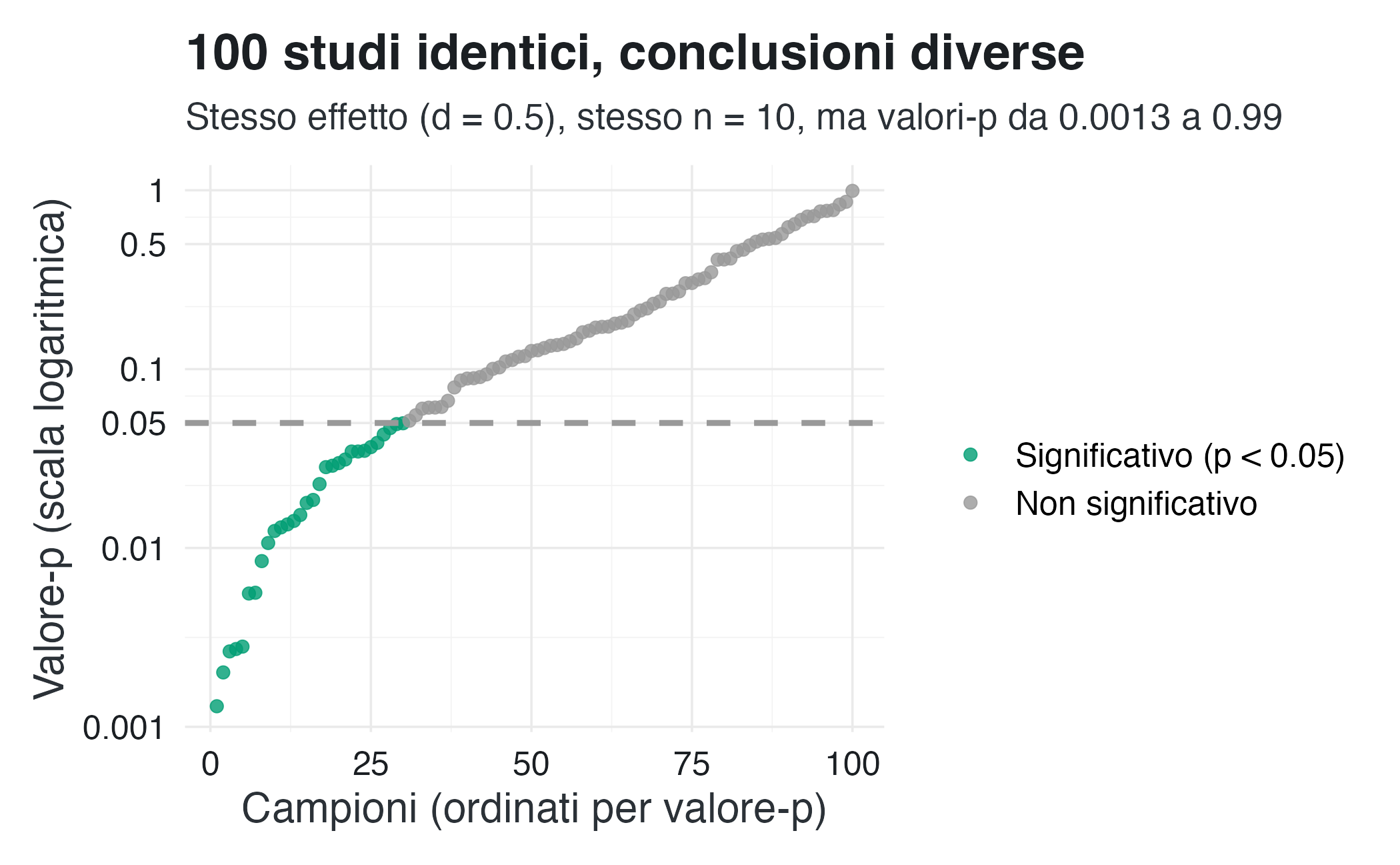
Il grafico mette in evidenza un risultato particolarmente incisivo: lo stesso effetto reale, valutato con la medesima procedura statistica (test \(t\) di Student), può generare valori-\(p\) che coprono pressoché l’intera gamma possibile, da valori prossimi a 0 fino a valori prossimi a 1. In pratica, estraendo campioni diversi dalla stessa popolazione, si giungerebbe a conclusioni diametralmente opposte: con alcuni si dichiarerebbe l’effetto “altamente significativo” (\(p\) < 0.01), mentre con altri non si rileverebbe alcuna evidenza statistica (\(p\) > 0.05). Tale variabilità non riflette differenze nel fenomeno sottostante, ma è esclusivamente un riflesso della fluttuazione casuale intrinseca al processo di campionamento.
6.2 Simulazione 2: la distribuzione dei valori-\(p\) e ciò che ci insegna
Questa simulazione mira a chiarire il seguente principio: il comportamento del valore-\(p\) dipende in modo critico dal fatto che l’ipotesi nulla sia vera o falsa. Comprendere questa differenza è essenziale per interpretare correttamente i risultati.
6.2.1 Sotto l’ipotesi nulla vera
Quando l’ipotesi nulla è vera, il valore-\(p\) è progettato per comportarsi in un modo molto specifico: la sua distribuzione deve essere uniforme tra 0 e 1. In pratica, ciò significa che il 5% dei valori-\(p\) sarà inferiore a 0.05 per puro caso: questo è esattamente il tasso di falsi positivi che il livello di significatività \(\alpha\) intende controllare.
# Colori (Okabe–Ito)
col_hist <- palette_qualitative[5] # Blu
col_ref <- palette_qualitative[8] # Grigio
col_thr <- palette_qualitative[1] # Arancione
# Simulazione sotto H0 vera
n_sims_h0 <- 10000
p_values_h0 <- numeric(n_sims_h0)
for (i in seq_len(n_sims_h0)) {
x <- rnorm(n_obs, mean = 0, sd = true_sd)
p_values_h0[i] <- t.test(x, mu = 0)$p.value
}
tibble(p_value = p_values_h0) |>
ggplot(aes(x = p_value)) +
geom_histogram(
bins = 50,
fill = col_hist,
color = "white",
aes(y = after_stat(density)),
alpha = 0.8
) +
geom_hline(
yintercept = 1,
linetype = "dashed",
color = col_ref,
linewidth = 1
) +
geom_vline(
xintercept = 0.05,
linetype = "dashed",
color = col_thr,
linewidth = 1
) +
annotate(
"text",
x = 0.10, y = 1.3,
label = "5% falsi positivi",
color = col_thr,
hjust = 0
) +
labs(
x = "Valore-p",
y = "Densità",
title = "Distribuzione dei valori-p sotto H₀ vera",
subtitle = sprintf(
"Distribuzione uniforme attesa: %.1f%% dei valori-p < 0.05 (atteso: 5%%)",
100 * mean(p_values_h0 < 0.05)
)
) +
coord_cartesian(ylim = c(0, 1.5))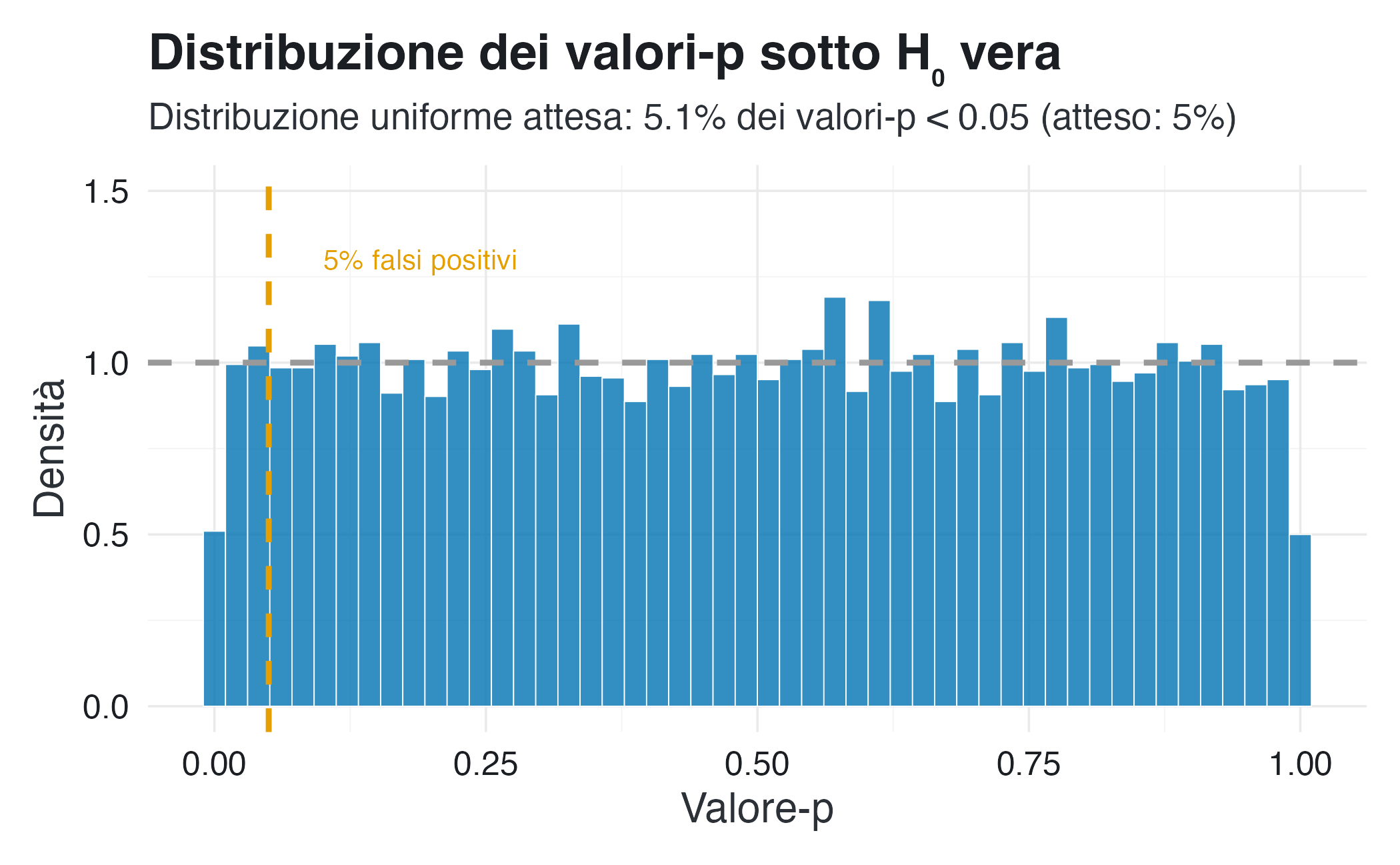
6.2.2 Sotto l’ipotesi nulla falsa (\(H_1: \mu > 0\))
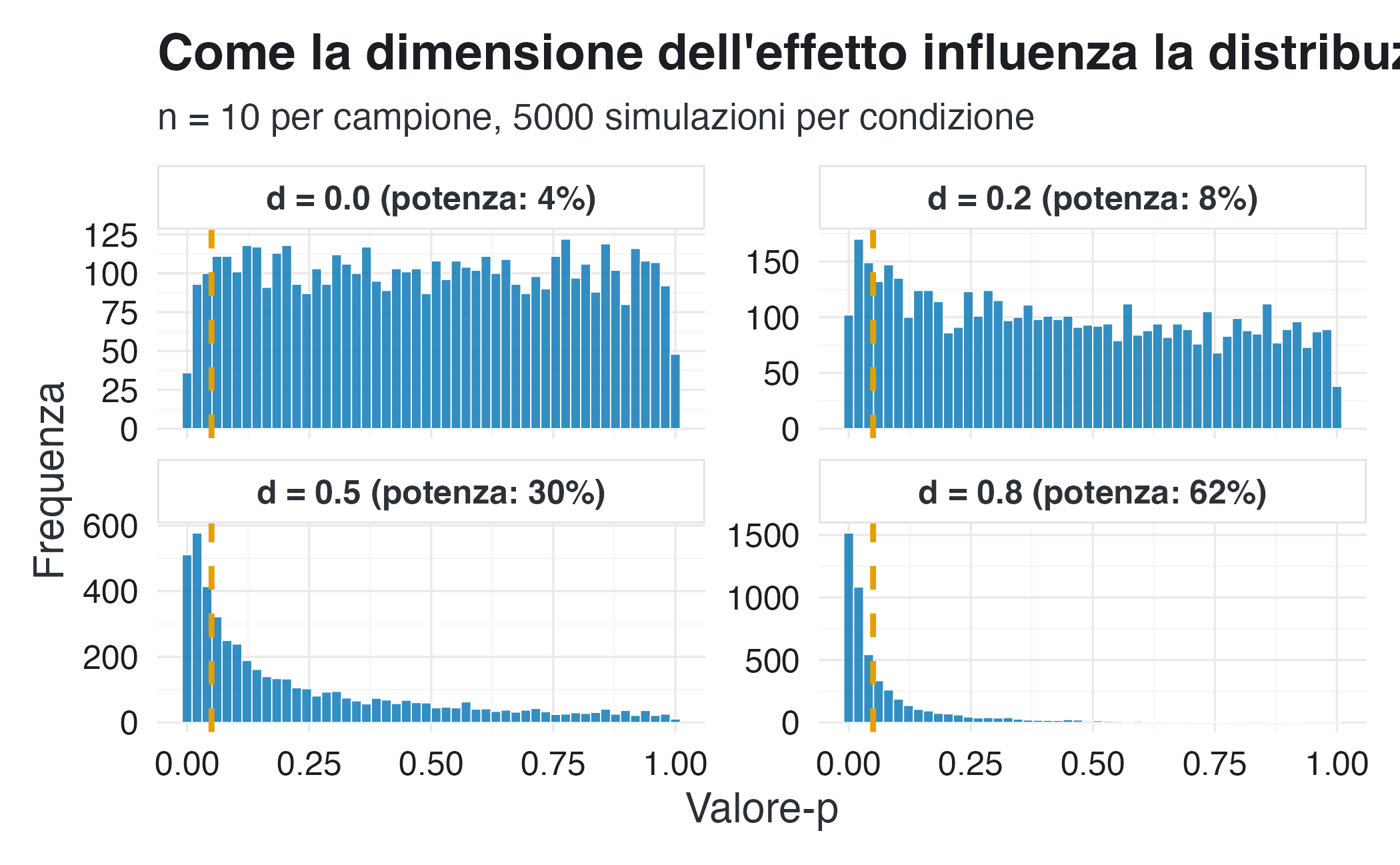
La situazione cambia radicalmente quando esiste un effetto reale nella popolazione. In questo caso, la distribuzione dei valori-\(p\) si “sposta” verso lo zero. Tuttavia, questa distribuzione rimane estremamente dispersa per effetti piccoli o moderati e per campioni di piccole dimensioni. La percentuale di valori-\(p\) che cadono sotto la soglia di significatività (ad esempio, 0.05) corrisponde alla potenza statistica dello studio.
col_hist <- palette_qualitative[5] # Blu
col_thr <- palette_qualitative[1] # Arancione
# Simulazione sotto H0 falsa (effetti di diversa ampiezza)
effect_sizes <- c(0, 0.2, 0.5, 0.8)
n_sims <- 5000
pvalue_distributions <- tibble()
for (d in effect_sizes) {
p_vals <- numeric(n_sims)
for (i in seq_len(n_sims)) {
x <- rnorm(n_obs, mean = d * true_sd, sd = true_sd)
p_vals[i] <- t.test(x, mu = 0)$p.value
}
pvalue_distributions <- bind_rows(
pvalue_distributions,
tibble(
effect_size = d,
p_value = p_vals,
label = sprintf(
"d = %.1f (potenza: %.0f%%)",
d, 100 * mean(p_vals < 0.05)
)
)
)
}
ggplot(pvalue_distributions, aes(x = p_value)) +
geom_histogram(
bins = 50,
fill = col_hist,
color = "white",
alpha = 0.8
) +
geom_vline(
xintercept = 0.05,
linetype = "dashed",
color = col_thr,
linewidth = 1
) +
facet_wrap(~label, ncol = 2, scales = "free_y") +
labs(
x = "Valore-p",
y = "Frequenza",
title = "Come la dimensione dell'effetto influenza la distribuzione dei valori-p",
subtitle = sprintf(
"n = %d per campione, %d simulazioni per condizione",
n_obs, n_sims
)
)
6.2.3 Interpretazione dei risultati
Il comportamento del valore-\(p\) sotto l’ipotesi nulla. Il primo grafico illustra una proprietà fondamentale dell’inferenza frequentista: quando l’ipotesi nulla (\(H_0\)) è vera, la distribuzione del valore-\(p\) è uniforme nell’intervallo [0,1]. In tale scenario, esattamente il 5% dei valori simulati risulta inferiore a 0.05 per puro effetto del caso. Questo conferma che il livello di significatività \(\alpha\) = 0.05 corrisponde al tasso nominale di errori di tipo I (falsi positivi) controllato dal test.
-
La criticità della potenza statistica con campioni ridotti. La seconda figura mostra chiaramente l’impatto della dimensione del campione (\(n\) = 10) sulla potenza del test. Nonostante l’uso della stessa procedura (test t per un campione), la probabilità di rifiutare correttamente \(H_0\) varia drasticamente in base alla dimensione dell’effetto reale (\(d\) di Cohen):
- per un effetto trascurabile (d = 0.2), la potenza empirica è solo del 9%, rendendo il test pressoché incapace di distinguere l’effetto dal rumore casuale;
- per un effetto di entità media (d = 0.5), la potenza raggiunge appena il 30%. In termini pratici, ciò implica che 7 studi replicati su 10 non riuscirebbero a raggiungere la significatività statistica, generando così un errore di tipo II (falso negativo);
- solo per un effetto di ampia entità (d = 0.8) la potenza supera il 60%, anche se una quota sostanziale (circa il 38%) dei campioni non raggiunge comunque il criterio di rifiuto.
L’elevata variabilità campionaria del valore-\(p\). Per dimensioni dell’effetto piccole o moderate, la distribuzione del valore-\(p\) rimane dispersa, riflettendo un’elevata volatilità campionaria. Di conseguenza, un singolo valore-\(p\) costituisce una stima estremamente imprecisa della forza dell’evidenza contro \(H_0\). È perfettamente plausibile che due studi identici, condotti sulla stessa popolazione, producano conclusioni statisticamente opposte (ad esempio, \(p\) < 0.01 in uno, \(p\) > 0.50 nell’altro) unicamente a causa della variabilità intrinseca del campionamento.
In sintesi, la simulazione mette in guardia da un’interpretazione semplicistica del valore-\(p\), ricordandone la natura probabilistica. Il valore-\(p\) non fornisce un verdetto binario sulla presenza o sull’entità di un effetto: un risultato non significativo non implica l’assenza di un effetto, così come un risultato significativo non garantisce che l’effetto sia di ampia portata. Con campioni di dimensioni ridotte – una condizione frequente nella ricerca psicologica – il valore-\(p\) si rivela una statistica fortemente instabile, la cui interpretazione dipende in modo critico dalla potenza statistica dello studio. Questi risultati sottolineano pertanto la necessità di integrare il valore-\(p\) con stime puntuali e intervalli di confidenza, di progettare la ricerca mediante un’analisi di potenza a priori e, soprattutto, di fondare le inferenze non sul singolo esperimento, ma su una replicabilità sistematica e su una sintesi cumulativa delle evidenze.
6.3 Simulazione 3: due studi “contraddittori”
Nella pratica dell’inferenza statistica, una delle osservazioni più controintuitive riguarda il confronto dei risultati di studi empirici. Nella letteratura scientifica è comune incontrare affermazioni del tipo:
- Studio A: \(p = 0.04\) → “L’effetto è statisticamente significativo”
- Studio B: \(p = 0.06\) → “Non vi è evidenza di un effetto”
Questa contrapposizione suggerisce che i due studi giungano a conclusioni opposte. Tuttavia, come mostrato da Gelman & Stern (2006), tale interpretazione è fuorviante: la differenza tra un risultato “significativo” e uno “non significativo” non implica necessariamente una differenza sostanziale tra gli effetti osservati. Spesso, tale differenza può essere spiegata dalla sola variabilità campionaria.
Per capire quanto questo fenomeno sia frequente, possiamo simulare coppie di studi che esaminano lo stesso effetto reale utilizzando lo stesso disegno sperimentale e la stessa numerosità campionaria. Questa simulazione permette di valutare con quanta frequenza differenze minime nei dati portino a conclusioni apparentemente opposte a causa della soglia arbitraria di \(p\) < 0.05.
# Simula coppie di studi
n_pairs <- 1000
# Verifica che n_obs e true_mean siano definiti (se necessario, aggiungi:)
# n_obs <- 50 # esempio
# true_mean <- 0.2 # esempio
# true_sd <- 1 # esempio
p_a <- numeric(n_pairs)
p_b <- numeric(n_pairs)
for (i in seq_len(n_pairs)) {
x_a <- rnorm(n_obs, mean = true_mean, sd = true_sd)
x_b <- rnorm(n_obs, mean = true_mean, sd = true_sd)
p_a[i] <- t.test(x_a, mu = 0)$p.value
p_b[i] <- t.test(x_b, mu = 0)$p.value
}
study_pairs <- tibble(pair_id = 1:n_pairs) |>
mutate(
p_a = p_a,
p_b = p_b,
sig_a = p_a < 0.05,
sig_b = p_b < 0.05,
concordance = case_when(
sig_a & sig_b ~ "Entrambi significativi",
!sig_a & !sig_b ~ "Entrambi non significativi",
TRUE ~ "Risultati discordanti"
)
)
# Statistiche
concordance_stats <- study_pairs |>
dplyr::count(concordance) |>
mutate(pct = n / sum(n) * 100)
# Colori
col_ref <- palette_qualitative[8] # grigio
col_line <- palette_qualitative[8] # grigio
palette_concordance <- setNames(
palette_qualitative[c(3, 8, 6)], # verde, grigio, rosso-arancio (anziché 1)
c("Entrambi significativi", "Entrambi non significativi", "Risultati discordanti")
)
# Visualizzazione
ggplot(study_pairs, aes(x = p_a, y = p_b, color = concordance)) +
geom_point(alpha = 0.5, size = 2) +
geom_hline(yintercept = 0.05, linetype = "dashed", color = col_ref) +
geom_vline(xintercept = 0.05, linetype = "dashed", color = col_ref) +
geom_abline(slope = 1, intercept = 0, color = col_line, linetype = "dotted") +
scale_color_manual(values = palette_concordance) +
labs(
x = "P-value Studio A",
y = "P-value Studio B",
color = "",
title = "Coppie di studi sullo stesso effetto",
subtitle = sprintf(
"Circa %.0f%% delle coppie produce risultati discordanti",
concordance_stats |>
filter(concordance == "Risultati discordanti") |>
pull(pct)
)
) +
coord_fixed()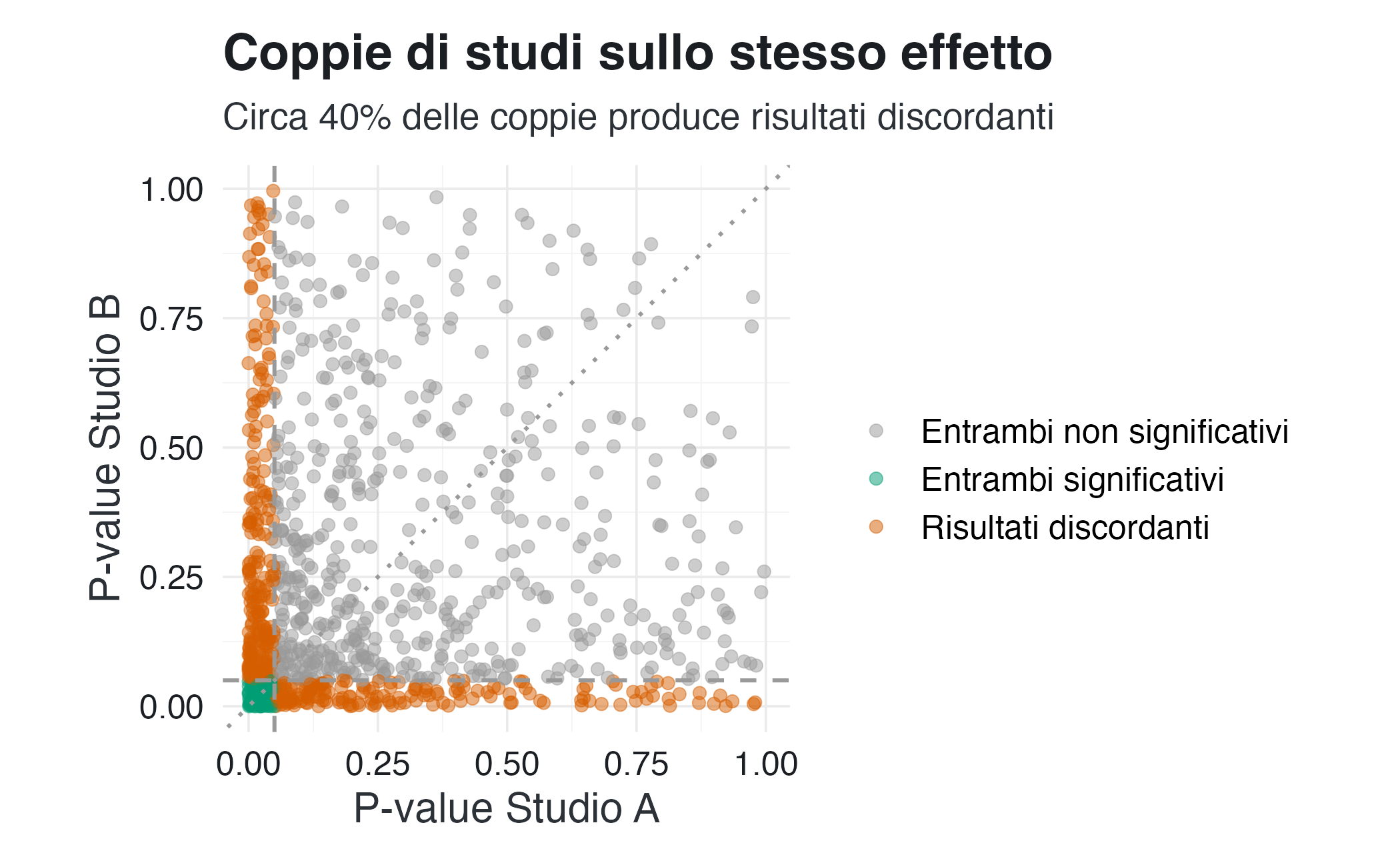
6.3.1 Interpretazione
La simulazione evidenzia un punto cruciale: conclusioni apparentemente discordanti possono emergere anche quando due studi indagano lo stesso effetto reale con il medesimo protocollo sperimentale. In assenza di differenze sostanziali tra i fenomeni esaminati, la sola variabilità campionaria può generare stime che, a seconda che il valore-\(p\) superi o meno una soglia convenzionale, portano a interpretazioni diametralmente opposte.
Come osservano Gelman & Stern (2006), il problema non risiede nel valore-\(p\) in sé, ma nell’uso della soglia di significatività come criterio di confronto inferenziale tra studi. Dal punto di vista statistico, confrontare un risultato “significativo” con uno “non significativo” non fornisce alcuna informazione sulla differenza tra gli effetti sottostanti. L’elemento appropriato da valutare non è il superamento della soglia dello 0.05, ma la differenza stimata tra gli effetti e la relativa incertezza inferenziale.
In termini sintetici:
La differenza tra significativo e non significativo non è statisticamente significativa.
Questa considerazione ha importanti implicazioni per la metodologia della ricerca empirica. La dicotomizzazione dei risultati sulla base di una soglia di significatività si rivela un criterio debole e potenzialmente fuorviante per valutare la coerenza tra gli studi. Una pratica inferenziale adeguata richiede invece di focalizzarsi sulle stime degli effetti, sui loro intervalli di incertezza e sulla quantificazione comparativa delle differenze, abbandonando l’uso di soglie arbitrarie come strumento decisionale primario.
6.4 Simulazione 4: confronto con l’approccio bayesiano
L’approccio frequentista tradizionale richiede spesso l’adozione di soglie decisionali rigide (ad esempio, \(p\) < 0.05). Al contrario, l’inferenza bayesiana non impone dicotomie: essa fornisce una distribuzione a posteriori dei parametri e consente di esprimere in modo diretto la probabilità che un effetto sia positivo, tenendo conto sia dei dati sia dell’incertezza pre-esistente.
Di seguito, confrontiamo l’instabilità dei valori-\(p\) con la stabilità della probabilità a posteriori che l’effetto sia positivo, calcolata assumendo come prior una distribuzione normale centrata sullo zero.
# Funzione per calcolo bayesiano approssimato
# Prior: mu ~ N(0, prior_sd)
# Likelihood: x_bar | mu ~ N(mu, sigma/sqrt(n))
bayesian_posterior_prob <- function(data, prior_sd = 0.2) {
x_bar <- mean(data)
se <- sd(data) / sqrt(length(data))
# Posterior (coniugazione normale)
prior_precision <- 1 / prior_sd^2
data_precision <- 1 / se^2
post_precision <- prior_precision + data_precision
post_mean <- (data_precision * x_bar) / post_precision
post_sd <- sqrt(1 / post_precision)
# P(mu > 0 | data)
pnorm(0, mean = post_mean, sd = post_sd, lower.tail = FALSE)
}
# Calcola entrambe le misure per i campioni simulati
comparison <- simulation |>
rowwise() |>
mutate(prob_positive = bayesian_posterior_prob(data)) |>
ungroup()Statistiche descrittive:
pv_min <- min(comparison$p_value); pv_max <- max(comparison$p_value)
pv_mean <- mean(comparison$p_value); pv_sd <- sd(comparison$p_value); pv_cv <- pv_sd / pv_mean
post_min <- min(comparison$prob_positive); post_max <- max(comparison$prob_positive)
post_mean <- mean(comparison$prob_positive); post_sd <- sd(comparison$prob_positive); post_cv <- post_sd / post_mean
pct_p_below05 <- mean(comparison$p_value < 0.05) * 100
pct_post_above095 <- mean(comparison$prob_positive > 0.95) * 100Grafici comparativi:
col_pvalue <- palette_qualitative[6]
col_postprob <- palette_qualitative[5]
col_line <- palette_qualitative[8]
# (A) histogram p-value con rug e annotazioni
pA <- ggplot(comparison, aes(x = p_value)) +
geom_histogram(bins = 30, fill = col_pvalue, color = "white", alpha = 0.9) +
geom_rug(sides = "b", alpha = 0.3, color = col_pvalue) +
geom_vline(xintercept = 0.05, linetype = "dashed", color = col_line, linewidth = 0.8) +
annotate("text",
x = 0.65, y = Inf,
label = sprintf("Range: [%.3f, %.3f]\nMedia: %.3f\nCV: %.2f\n%% p<0.05: %.1f%%",
pv_min, pv_max, pv_mean, pv_cv, pct_p_below05),
hjust = 1, vjust = 1.2, size = 3.5, lineheight = 0.9,
color = col_pvalue, fontface = "bold") +
labs(title = "A) Distribuzione dei p-value",
x = "p-value", y = "Frequenza")
# (B) histogram posterior probabilities con rug e annotazioni
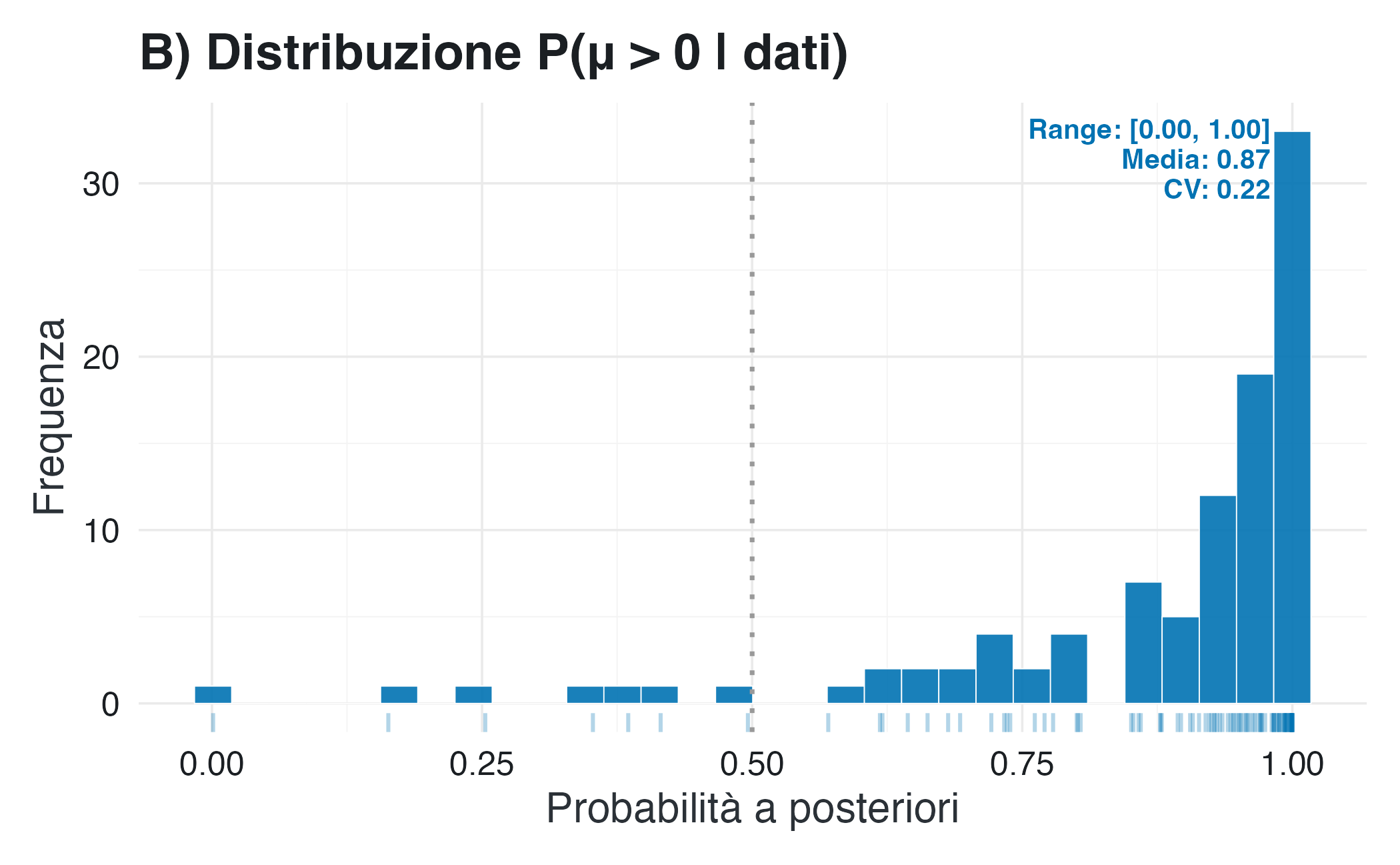
pB <- ggplot(comparison, aes(x = prob_positive)) +
geom_histogram(bins = 30, fill = col_postprob, color = "white", alpha = 0.9) +
geom_rug(sides = "b", alpha = 0.3, color = col_postprob) +
geom_vline(xintercept = 0.5, linetype = "dotted", color = col_line, linewidth = 0.8) +
annotate("text",
x = 0.98, y = Inf,
label = sprintf("Range: [%.2f, %.2f]\nMedia: %.2f\nCV: %.2f",
post_min, post_max, post_mean, post_cv),
hjust = 1, vjust = 1.2, size = 3.5, lineheight = 0.9,
color = col_postprob, fontface = "bold") +
labs(title = "B) Distribuzione P(μ > 0 | dati)",
x = "Probabilità a posteriori", y = "Frequenza")
# (C) scatter p-value vs posterior probability + 2D density contours
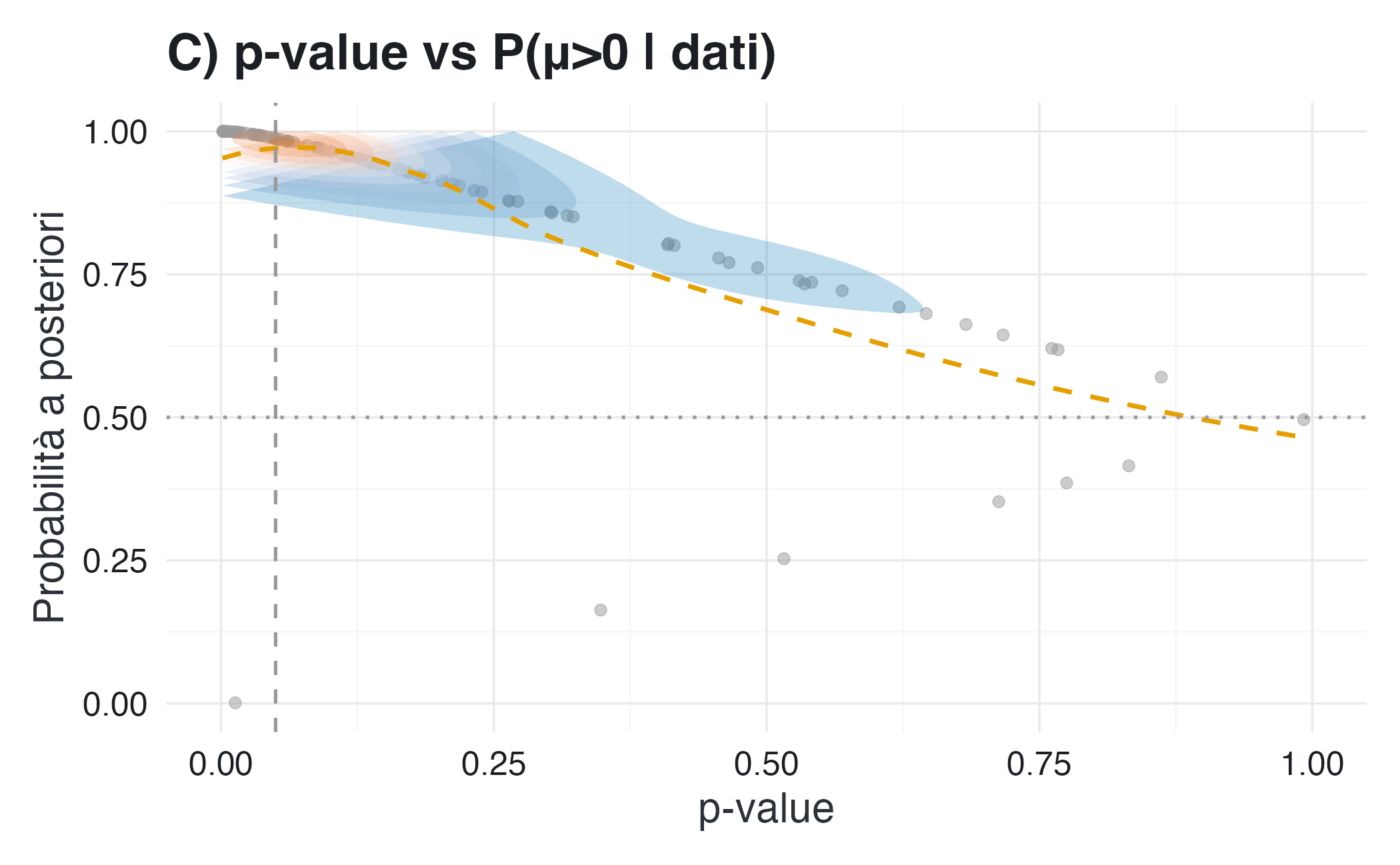
pC <- ggplot(comparison, aes(x = p_value, y = prob_positive)) +
geom_point(alpha = 0.5, size = 1.8, color = palette_qualitative[8]) + # Grigio per i punti
stat_density_2d(aes(fill = ..level..), geom = "polygon",
alpha = 0.25, color = NA) +
# Usa gradient con colori dalla tua palette
scale_fill_gradientn(colors = c(col_postprob, "#FFFFFF", col_pvalue)) +
geom_smooth(method = "loess", se = FALSE,
color = palette_qualitative[1], # Arancione
linetype = "dashed", linewidth = 0.8) +
geom_vline(xintercept = 0.05, linetype = "dashed",
color = col_line, linewidth = 0.6) +
geom_hline(yintercept = 0.5, linetype = "dotted",
color = col_line, linewidth = 0.6) +
labs(title = "C) p-value vs P(μ>0 | dati)",
x = "p-value", y = "Probabilità a posteriori") +
coord_cartesian(xlim = c(0, 1), ylim = c(0, 1)) +
theme(legend.position = "none")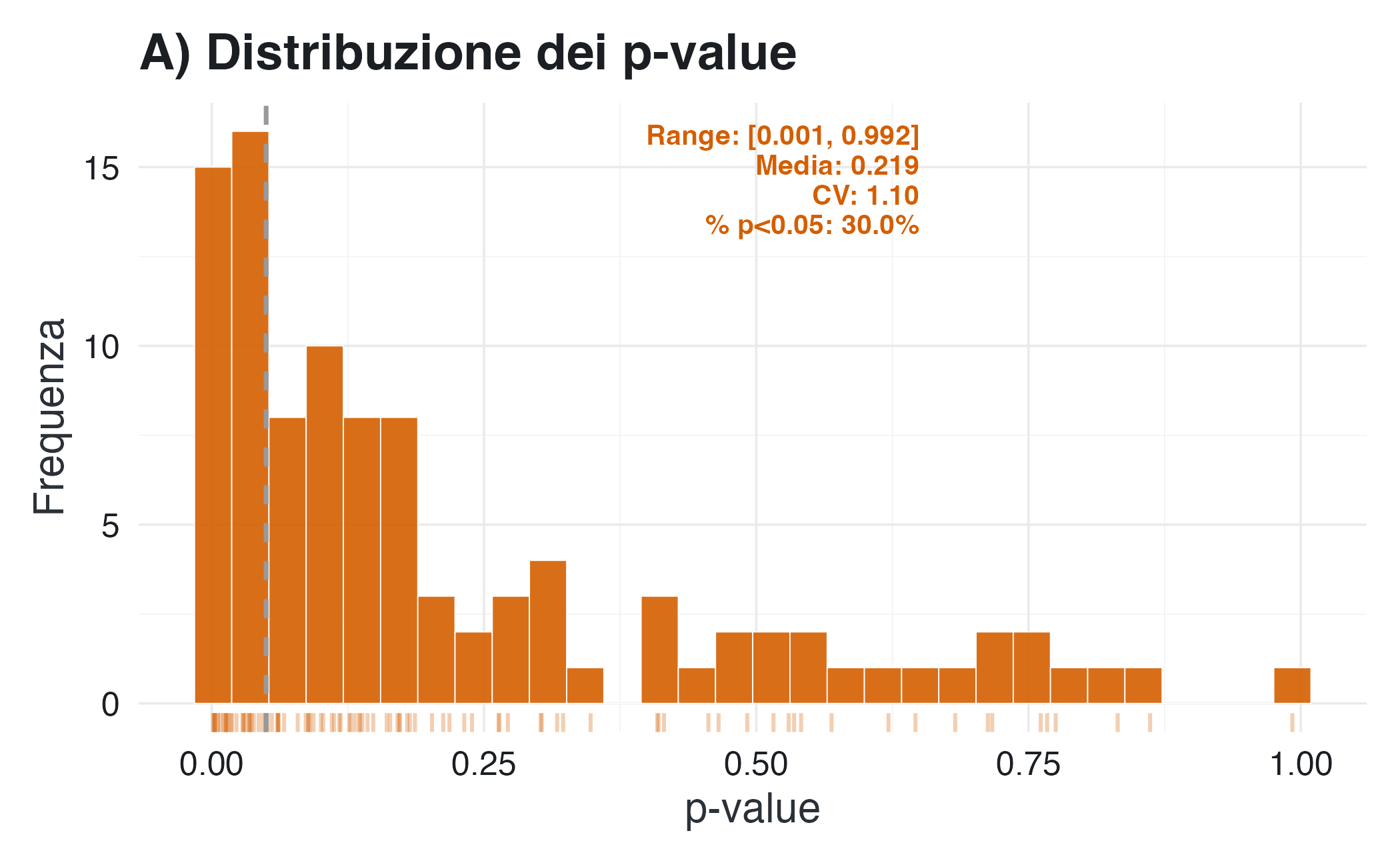
Confronto numerico:
#> Coefficiente di variazione del valore-p: 1.10
#> Coefficiente di variazione P(μ>0|dati): 0.22
#> Campo di variazione del valore-p: [0.001, 0.992]
#> Campo di variazione di P(μ>0|dati): [0.00, 1.00]6.4.1 Interpretazione
I risultati mostrano una differenza cruciale: i valori-\(p\) oscillano considerevolmente da un campione all’altro. Per questo motivo, conclusioni opposte possono dipendere unicamente dal superamento o meno della soglia convenzionale di 0.05. La probabilità a posteriori che l’effetto sia positivo, invece, varia in modo più graduale e raramente porta a decisioni drasticamente opposte tra campioni simili.
La maggiore stabilità è dovuta al fatto che l’approccio bayesiano incorpora l’incertezza preesistente tramite uno shrinkage naturale verso la distribuzione a priori. Inoltre, evita la trasformazione non lineare che porta al valore-\(p\), la quale tende ad amplificare le fluttuazioni campionarie. Infine, l’approccio bayesiano esprime l’evidenza in una scala direttamente interpretabile, ossia come probabilità dell’ipotesi di interesse, piuttosto che come risultato di un test controfattuale.
Anche l’inferenza bayesiana è soggetta alla variabilità campionaria. Introdurre una regola decisionale arbitraria, come ad esempio “concludere che l’effetto esiste se \(P(\mu > 0 \mid \text{dati}) > 0.95\)”, riprodurrebbe esattamente i problemi concettuali legati all’uso dicotomico del valore-\(p\). Il vero vantaggio del metodo bayesiano non risiede nel fornire certezze definitive, ma nell’offrire una rappresentazione continua e trasparente dell’incertezza a posteriori.
In sintesi, l’approccio bayesiano non elimina l’incertezza, ma la quantifica in modo esplicito, mentre la soglia frequentista tende a mascherarla, trasformando la naturale variabilità dei risultati in un conflitto artificiale tra studi apparentemente contraddittori.
6.5 Simulazione 5: l’effetto della dimensione campionaria
Un argomento spesso avanzato a sostegno dell’uso del valore-\(p\) è che, aumentando la dimensione campionaria, le inferenze diventano più stabili. In parte questa affermazione è vera: campioni più ampi, infatti, offrono una maggiore potenza statistica, il che rende più frequenti i risultati “statisticamente significativi” quando esiste un effetto reale. Tuttavia, questa osservazione rischia di nascondere un fatto meno intuitivo, ma altrettanto importante: anche con campioni molto grandi, il valore-\(p\) conserva una sostanziale variabilità e rimane strettamente dipendente dalle caratteristiche specifiche del singolo campione osservato.
Per illustrare questo fenomeno, abbiamo condotto 1000 simulazioni per quattro diverse dimensioni campionarie crescenti (da \(n = 10\) a \(n = 300\)), ipotizzando un effetto reale di piccola entità, \(d = 0.2\). Per ciascuna delle simulazioni, abbiamo calcolato il valore-\(p\) associato a un test \(t\) di Student a una coda.
set.seed(123)
true_mean <- 0.2
true_sd <- 1
sample_sizes <- c(10, 30, 100, 300)
n_sims <- 1000
sample_size_effect <- tibble()
for (n in sample_sizes) {
p_vals <- numeric(n_sims)
for (i in seq_len(n_sims)) {
x <- rnorm(n, mean = true_mean, sd = true_sd)
p_vals[i] <- t.test(x, mu = 0)$p.value
}
sample_size_effect <- bind_rows(
sample_size_effect,
tibble(
n = n,
p_value = p_vals,
label = sprintf("n = %d", n)
)
)
}
ggplot(sample_size_effect, aes(x = p_value)) +
geom_histogram(
aes(fill = "Distribuzione P-value"),
bins = 40,
color = "white",
alpha = 0.8
) +
geom_vline(
aes(xintercept = 0.05, color = "Soglia α = 0.05"),
linetype = "dashed",
linewidth = 1
) +
facet_wrap(~label, ncol = 2) +
labs(
x = "Valore-p",
y = "Frequenza",
title = "Distribuzione dei valori-p\nper diverse dimensioni campionarie",
subtitle = sprintf("Effetto vero: d = %.1f", true_mean/true_sd),
fill = "Elementi",
color = "Linee"
) +
scale_fill_manual(values = c("Distribuzione P-value" = palette_qualitative[2])) +
scale_color_manual(values = c("Soglia α = 0.05" = palette_qualitative[6])) 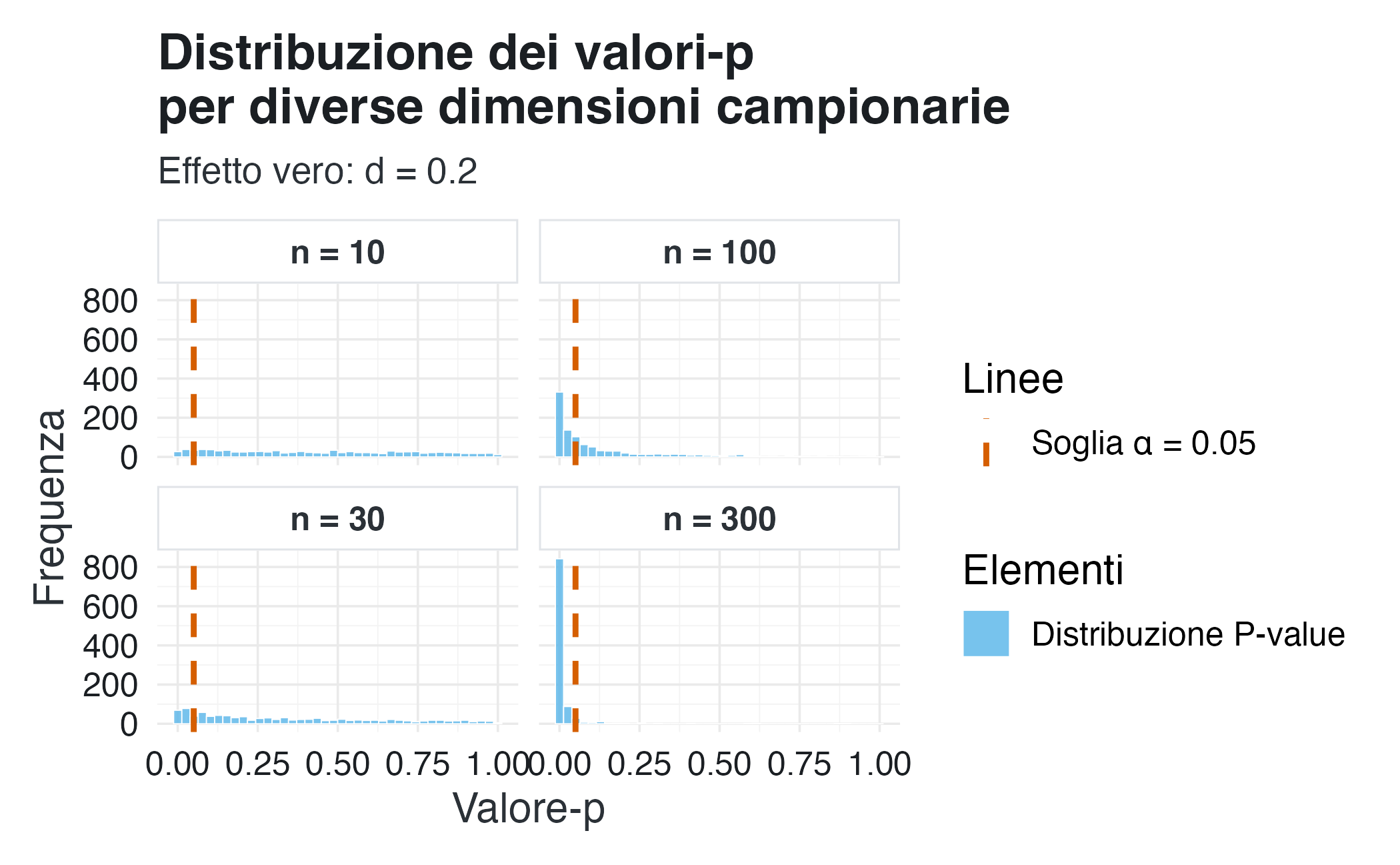
# Statistiche riassuntive
sample_size_effect |>
group_by(n) |>
summarise(
`Mediana p` = sprintf("%.3f", median(p_value)),
`Range p` = sprintf("[%.3f, %.3f]", min(p_value), max(p_value)),
`% significativi` = sprintf("%.0f%%", 100 * mean(p_value < 0.05)),
.groups = "drop"
) |>
knitr::kable(caption = "Variabilità del p-value in funzione di n")| n | Mediana p | Range p | % significativi |
|---|---|---|---|
| 10 | 0.428 | [0.000, 0.999] | 8% |
| 30 | 0.287 | [0.000, 0.999] | 16% |
| 100 | 0.044 | [0.000, 0.993] | 52% |
| 300 | 0.001 | [0.000, 0.895] | 95% |
I risultati mostrano che, anche con \(n\) = 300, i valori-\(p\) oscillano da 0.0 a 0.895. Mentre la potenza statistica aumenta effettivamente (come evidenziato dalla maggiore percentuale di studi che superano la soglia convenzionale), la variabilità intrinseca del valore-\(p\) persiste. Questi risultati confermano che il valore-\(p\) non è una misura stabile dell’evidenza, ma piuttosto una statistica estremamente sensibile alle fluttuazioni campionarie specifiche.
6.6 Riflessioni conclusive
Le simulazioni presentate in questo capitolo illustrano in modo concreto la fragilità del valore-\(p\) come strumento inferenziale. Un primo aspetto riguarda la marcata instabilità dei valori campionari del valore-\(p\). A parità di effetto reale e applicando la medesima procedura statistica, è possibile ottenere risultati radicalmente discordanti: lo stesso fenomeno può generare un valore-\(p\) pari a 0.001 in un campione, interpretato come un’evidenza molto forte a sostegno dell’effetto, e in un altro campione un valore-\(p\) di 0.90, interpretato come totale assenza di supporto. Queste oscillazioni non derivano da differenze metodologiche tra le analisi né da variazioni dell’effetto studiato, ma sono una conseguenza diretta della variabilità intrinseca del processo di campionamento. Il valore-\(p\), quindi, non fornisce un indicatore stabile dell’evidenza empirica, ma rimane altamente sensibile alla fluttuazione casuale insita nei dati osservati.
La seconda evidenza riguarda la discordanza sistematica tra gli studi. Due ricercatori che indagano lo stesso fenomeno, utilizzando protocolli metodologicamente solidi, possono facilmente giungere a conclusioni statisticamente opposte. Questo non rappresenta un caso eccezionale, ma una caratteristica intrinseca dell’inferenza basata sul valore-\(p\), che compromette la coerenza e la cumulatività della conoscenza scientifica.
La terza evidenza riguarda la distribuzione uniforme dei valori-\(p\) sotto l’ipotesi nulla. Quando l’ipotesi nulla è vera, i valori-\(p\) si distribuiscono in modo uniforme tra 0 e 1, il che implica che, per puro caso, circa il 5% dei risultati supererà inevitabilmente la soglia convenzionale del 5%. In altre parole, questa soglia non agisce come un filtro affidabile per distinguere il segnale dal rumore, ma funziona piuttosto come un generatore sistematico di falsi positivi.
La quarta evidenza emerge dal confronto con l’approccio bayesiano. Le probabilità a posteriori presentano una stabilità molto maggiore rispetto ai valori-\(p\), fornendo stime più coerenti dell’evidenza a partire dai dati. Tuttavia, questa maggiore stabilità non implica certezza: l’inferenza bayesiana riduce, ma non elimina, l’incertezza intrinseca derivante dal campionamento, offrendo una quantificazione dell’evidenza più sfumata e trasparente, pur rimanendo soggetta alla variabilità dei dati osservati.
La quinta evidenza riguarda l’effetto della dimensione campionaria. L’aumento del numero di osservazioni aumenta la potenza statistica e riduce la probabilità di falsi negativi, ma non elimina la variabilità intrinseca delle stime. Anche gli studi che coinvolgono migliaia di partecipanti producono risultati che oscillano attorno al vero valore del parametro, sebbene tali fluttuazioni siano più contenute rispetto a campioni più piccoli.
La lezione principale che emerge da queste simulazioni è che la distinzione binaria tra “significativo” e “non significativo” è arbitraria nella sua definizione e fragile nella sua applicazione. Come osservato da Gelman & Stern (2006), interpretare questa separazione artificiale come se riflettesse una differenza sostanziale nel fenomeno studiato costituisce un grave errore epistemologico. Considerare valori-\(p\) di 0.049 e 0.051 come portatori di significati scientifici opposti significa confondere un artefatto della procedura statistica con una proprietà effettiva della realtà studiata.
6.7 Esercizi
Un ricercatore trova \(p = 0.048\) nel suo studio. Qual è la probabilità che una replica esatta (stesso \(n\), stessa popolazione) trovi anch’essa \(p < 0.05\)?
Usa la simulazione per rispondere, considerando tre scenari: 1. L’effetto vero è quello stimato nello studio originale 2. L’effetto vero è la metà di quello stimato (Type M error) 3. L’effetto vero è zero (falso positivo originale)
# Parametri dello studio originale
n_original <- 30
d_estimated <- 0.4 # Stima dallo studio con p = 0.048
# Scenari
scenarios <- tibble(
scenario = c("Effetto = stimato", "Effetto = metà", "Effetto = zero"),
true_d = c(d_estimated, d_estimated/2, 0)
)
# Simula repliche
n_reps <- 10000
replication_probs <- tibble()
for (i in seq_len(nrow(scenarios))) {
d <- scenarios$true_d[i]
p_reps <- numeric(n_reps)
for (j in seq_len(n_reps)) {
x <- rnorm(n_original, mean = d, sd = 1)
p_reps[j] <- t.test(x, mu = 0)$p.value
}
replication_probs <- bind_rows(
replication_probs,
tibble(
scenario = scenarios$scenario[i],
prob_replicate = mean(p_reps < 0.05)
)
)
}
replication_probs |>
mutate(`P(replica significativa)` = sprintf("%.0f%%", prob_replicate * 100)) |>
select(scenario, `P(replica significativa)`) |>
knitr::kable()| scenario | P(replica significativa) |
|---|---|
| Effetto = stimato | 56% |
| Effetto = metà | 18% |
| Effetto = zero | 5% |
Interpretazione: Anche assumendo che l’effetto stimato sia corretto, la replica ha solo ~50% di probabilità di essere significativa. Se l’effetto è sovrastimato (Type M error), la probabilità scende drasticamente.
Se un effetto vero è \(d = 0.3\) e \(n = 50\), quale intervallo conterrà il 95% dei p-value ottenibili in studi futuri?
Confronta questo intervallo con quello per la probabilità a posteriori bayesiana.
# Simulazione
d <- 0.3
n <- 50
n_sims <- 10000
future_studies <- tibble(
p_value = numeric(n_sims),
prob_positive = numeric(n_sims)
)
for (i in seq_len(n_sims)) {
x <- rnorm(n, mean = d, sd = 1)
# P-value
future_studies$p_value[i] <- t.test(x, mu = 0)$p.value
# Bayesiano
x_bar <- mean(x)
se <- sd(x) / sqrt(n)
prior_sd <- 0.5
post_precision <- 1 / prior_sd^2 + 1 / se^2
post_mean <- (1 / se^2 * x_bar) / post_precision
post_sd <- sqrt(1 / post_precision)
future_studies$prob_positive[i] <-
pnorm(0, post_mean, post_sd, lower.tail = FALSE)
}
# Intervalli al 95%
cat("Intervallo al 95% per p-value:\n")
#> Intervallo al 95% per p-value:
cat(sprintf(" [%.4f, %.4f]\n",
quantile(future_studies$p_value, 0.025),
quantile(future_studies$p_value, 0.975)))
#> [0.0001, 0.7702]
cat("\nIntervallo al 95% per P(μ > 0 | dati):\n")
#>
#> Intervallo al 95% per P(μ > 0 | dati):
cat(sprintf(" [%.3f, %.3f]\n",
quantile(future_studies$prob_positive, 0.025),
quantile(future_studies$prob_positive, 0.975)))
#> [0.568, 1.000]
cat("\nAmpiezza relativa degli intervalli:\n")
#>
#> Ampiezza relativa degli intervalli:
cat(sprintf(" P-value: %.2f (su scala 0-1)\n",
diff(quantile(future_studies$p_value, c(0.025, 0.975)))))
#> P-value: 0.77 (su scala 0-1)
cat(sprintf(" Bayesiano: %.2f (su scala 0-1)\n",
diff(quantile(future_studies$prob_positive, c(0.025, 0.975)))))
#> Bayesiano: 0.43 (su scala 0-1)Alcuni hanno proposto di abbassare la soglia a \(p < 0.005\) per ridurre i falsi positivi. Simula cosa succederebbe in termini di:
- Tasso di falsi positivi
- Potenza (con \(d = 0.3\), \(n = 50\))
- Concordanza tra studi
thresholds <- c(0.05, 0.01, 0.005, 0.001)
d <- 0.3
n <- 50
n_sims <- 10000
threshold_analysis <- tibble()
for (alpha in thresholds) {
## H0
p_h0 <- numeric(n_sims)
for (i in seq_len(n_sims)) {
p_h0[i] <- t.test(rnorm(n, 0, 1), mu = 0)$p.value
}
fpr <- mean(p_h0 < alpha)
## H1
p_h1 <- numeric(n_sims)
for (i in seq_len(n_sims)) {
p_h1[i] <- t.test(rnorm(n, d, 1), mu = 0)$p.value
}
power <- mean(p_h1 < alpha)
## Coppie
sig1 <- logical(1000)
sig2 <- logical(1000)
for (i in seq_len(1000)) {
sig1[i] <- t.test(rnorm(n, d, 1), mu = 0)$p.value < alpha
sig2[i] <- t.test(rnorm(n, d, 1), mu = 0)$p.value < alpha
}
discord <- mean(sig1 != sig2)
threshold_analysis <- bind_rows(
threshold_analysis,
tibble(
alpha = alpha,
`Falsi positivi` = sprintf("%.2f%%", fpr * 100),
`Potenza` = sprintf("%.0f%%", power * 100),
`Discordanza` = sprintf("%.0f%%", discord * 100)
)
)
}
threshold_analysis |>
mutate(Soglia = sprintf("p < %.3f", alpha)) |>
select(Soglia, `Falsi positivi`, Potenza, Discordanza) |>
knitr::kable(caption = "Effetto di soglie più stringenti")| Soglia | Falsi positivi | Potenza | Discordanza |
|---|---|---|---|
| p < 0.050 | 4.86% | 54% | 49% |
| p < 0.010 | 0.94% | 30% | 41% |
| p < 0.005 | 0.44% | 22% | 33% |
| p < 0.001 | 0.09% | 10% | 17% |
Interpretazione: Abbassare la soglia riduce i falsi positivi ma anche la potenza. La discordanza tra studi rimane alta perché il problema è la variabilità del p-value, non la soglia scelta.
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ragg_1.5.0 tinytable_0.15.2 withr_3.0.2
#> [4] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [7] tidybayes_3.0.7 bayesplot_1.15.0 ggplot2_4.0.1
#> [10] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [13] loo_2.9.0 rstan_2.32.7 StanHeaders_2.32.10
#> [16] brms_2.23.0 Rcpp_1.1.0 sessioninfo_1.2.3
#> [19] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [22] modelr_0.1.11 tibble_3.3.0 dplyr_1.1.4
#> [25] tidyr_1.3.2 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] gridExtra_2.3 inline_0.3.21 sandwich_3.1-1
#> [4] rlang_1.1.6 magrittr_2.0.4 multcomp_1.4-29
#> [7] snakecase_0.11.1 otel_0.2.0 compiler_4.5.2
#> [10] mgcv_1.9-4 vctrs_0.6.5 stringr_1.6.0
#> [13] pkgconfig_2.0.3 arrayhelpers_1.1-0 fastmap_1.2.0
#> [16] backports_1.5.0 labeling_0.4.3 rmarkdown_2.30
#> [19] purrr_1.2.0 xfun_0.55 cachem_1.1.0
#> [22] jsonlite_2.0.0 broom_1.0.11 parallel_4.5.2
#> [25] R6_2.6.1 stringi_1.8.7 RColorBrewer_1.1-3
#> [28] lubridate_1.9.4 estimability_1.5.1 knitr_1.51
#> [31] zoo_1.8-15 Matrix_1.7-4 splines_4.5.2
#> [34] timechange_0.3.0 tidyselect_1.2.1 abind_1.4-8
#> [37] yaml_2.3.12 codetools_0.2-20 curl_7.0.0
#> [40] pkgbuild_1.4.8 lattice_0.22-7 bridgesampling_1.2-1
#> [43] S7_0.2.1 coda_0.19-4.1 evaluate_1.0.5
#> [46] survival_3.8-3 RcppParallel_5.1.11-1 isoband_0.3.0
#> [49] pillar_1.11.1 tensorA_0.36.2.1 checkmate_2.3.3
#> [52] stats4_4.5.2 distributional_0.5.0 generics_0.1.4
#> [55] rprojroot_2.1.1 rstantools_2.5.0 scales_1.4.0
#> [58] xtable_1.8-4 glue_1.8.0 emmeans_2.0.1
#> [61] tools_4.5.2 mvtnorm_1.3-3 grid_4.5.2
#> [64] QuickJSR_1.8.1 colorspace_2.1-2 nlme_3.1-168
#> [67] cli_3.6.5 textshaping_1.0.4 svUnit_1.0.8
#> [70] Brobdingnag_1.2-9 V8_8.0.1 gtable_0.3.6
#> [73] digest_0.6.39 TH.data_1.1-5 htmlwidgets_1.6.4
#> [76] farver_2.1.2 memoise_2.0.1 htmltools_0.5.9
#> [79] lifecycle_1.0.4 MASS_7.3-65