17 Analisi bayesiana dell’odds ratio
Panoramica del capitolo
- Come si definiscono probabilità, odds e odds ratio.
- Come si interpreta l’odds ratio in contesti psicologici.
- Come stimarlo in ottica bayesiana, implementando un modello in Stan.
- Come presentare i risultati con intervalli di credibilità.
17.1 Il contesto sperimentale
Per introdurre l’analisi bayesiana dell’odds ratio, consideriamo il seguente esperimento. Nella prima metà del Novecento, Karl von Frisch si domandò se le api possedessero la visione dei colori. Per verificarlo, ideò una serie di esperimenti in cui le api potevano associare un colore a una ricompensa. Ispirandoci a una ricostruzione proposta da Hoffmann et al. (2022), possiamo immaginare una versione semplificata del disegno sperimentale:
- gruppo sperimentale: api addestrate ad associare un disco blu a una soluzione zuccherina;
- gruppo di controllo: api che non ricevono alcun addestramento.
Nella fase di test, la soluzione zuccherina viene rimossa e si registra il numero di volte in cui le api si avvicinano al disco blu (evento critico).
I risultati osservati sono riportati nella tabella seguente:
| Gruppo | Successi (scelta blu) | Totale |
|---|---|---|
| Sperimentale | 130 | 200 |
| Controllo | 100 | 200 |
La domanda di ricerca può essere così formulata: le api addestrate mostrano un odds maggiore di scegliere il disco blu rispetto alle api di controllo?
17.1.1 Dalle probabilità agli odds
La probabilità di successo (scelta del disco blu) nel gruppo sperimentale è:
\[ p_1 = \frac{130}{200} = 0.65. \]
I corrispondenti odds si calcolano come:
\[ \text{odds}_1 = \frac{p_1}{1-p_1} = \frac{0.65}{0.35} \approx 1.86. \]
Per il gruppo di controllo abbiamo:
\[ p_2 = \frac{100}{200} = 0.50, \quad \text{odds}_2 = \frac{0.50}{0.50} = 1.00. \]
L’odds ratio (OR) confronta i due odds:
\[ \text{OR} = \frac{\text{odds}_1}{\text{odds}_2} = \frac{1.86}{1.00} = 1.86. \]
Interpretazione. Un odds ratio pari a 1.86 indica che il rapporto tra scelte corrette e scelte errate nelle api addestrate è circa 1.9 volte quello osservato nel gruppo di controllo. È importante distinguere questo concetto dalla probabilità: l’OR confronta due odds (successi/insuccessi), non due probabilità dirette.
Per questo motivo un OR di 1.86 non implica che la probabilità di scegliere il disco blu sia aumentata dell’86% o che sia quasi raddoppiata. Significa invece che, per ogni errore commesso, le api addestrate producono un numero di scelte corrette quasi doppio rispetto alle api non addestrate. Questo chiarisce perché differenze moderate nelle probabilità possano tradursi in differenze più marcate negli odds.
Tuttavia, l’OR calcolato dai dati è pur sempre una stima puntuale, che non esprime da sola l’incertezza associata all’effetto. È in questo passaggio, ovvero nella necessità di quantificare l’incertezza in modo trasparente, che il paradigma bayesiano offre un contributo decisivo.
17.1.2 Approccio bayesiano
Nel frequentismo, l’incertezza sull’odds ratio viene stimata per mezzo di intervalli di confidenza, spesso basati su approssimazioni asintotiche. L’approccio bayesiano, invece, fornisce direttamente la distribuzione a posteriori dell’OR, che descrive in maniera completa il grado di incertezza dopo aver osservato i dati.
Ciò consente di eseguire diverse operazioni inferenziali particolarmente utili:
- calcolare probabilità direttamente interpretabili, ad esempio la probabilità che l’OR sia maggiore di 1 (preferenza effettiva per il blu nel gruppo addestrato);
- valutare la rilevanza pratica dell’effetto, stimando la probabilità che l’OR ricada in un intervallo di equivalenza (ROPE);
- ottenere intervalli di credibilità esatti, come l’ETI o l’HDI, non basati su approssimazioni.
In sintesi, mentre l’approccio frequentista fornisce un valore puntuale e un intervallo costruito in termini di ripetizioni ipotetiche, l’approccio bayesiano permette di rispondere direttamente a domande del tipo: “Qual è la probabilità che l’effetto sia reale?” o “Qual è la probabilità che l’odds ratio superi 1?”. Queste domande corrispondono più direttamente agli interessi scientifici del ricercatore.
17.2 Versione binomiale con prior Beta
Un modo semplice e intuitivo per stimare l’odds ratio consiste nel modellare separatamente le probabilità di successo nei due gruppi, \(\theta_1\) e \(\theta_2\), assumendo per ciascuna una distribuzione binomiale con prior di tipo Beta. Questo approccio è particolarmente naturale quando i dati possono essere organizzati in una tabella \(2\times 2\), e conserva una chiara interpretazione psicologica: ogni parametro \(\theta_g\) rappresenta la propensione del gruppo (g) a fornire la risposta corretta.
L’odds ratio viene poi ottenuto come funzione deterministica delle due probabilità a posteriori:
\[ \text{OR} \;=\; \frac{\theta_1/(1-\theta_1)}{\theta_2/(1-\theta_2)} \;=\; \exp\!\bigl[\operatorname{logit}(\theta_1) - \operatorname{logit}(\theta_2)\bigr]. \]
Questa parametrizzazione ha il vantaggio di rendere immediato il collegamento tra i parametri psicologicamente interpretabili (\(\theta_1\), \(\theta_2\)) e l’effetto comparativo di interesse (OR). In altri termini, il modello non richiede di specificare direttamente una distribuzione per l’odds ratio, ma lo considera come una trasformazione delle probabilità di successo nei due gruppi.
La scelta di prior \(\text{Beta}(2,2)\) per entrambi i parametri è coerente con l’impostazione generale del capitolo, in quanto specifica una distribuzione debolmente informativa simmetrica attorno a 0.5, che assegna bassa densità di probabilità agli estremi (0 e 1). Tale configurazione permette ai dati osservati di dominare l’aggiornamento delle stime, fornendo un punto di partenza equilibrato che favorisce un’inferenza guidata dall’evidenza empirica senza introdurre assunzioni forti a priori.
17.2.1 Implementazione in Stan
stancode_or_beta <- "
data {
int<lower=0> k1; // numero di successi nel gruppo sperimentale
int<lower=1> n1; // numero totale di prove nel gruppo sperimentale
int<lower=0> k2; // numero di successi nel gruppo di controllo
int<lower=1> n2; // numero totale di prove nel gruppo di controllo
}
parameters {
real<lower=0,upper=1> theta1; // probabilità di successo nel gruppo sperimentale
real<lower=0,upper=1> theta2; // probabilità di successo nel gruppo di controllo
}
model {
// Prior distributions (debolmente informativi, riflettono incertezza iniziale)
theta1 ~ beta(2, 2);
theta2 ~ beta(2, 2);
// Likelihood
k1 ~ binomial(n1, theta1);
k2 ~ binomial(n2, theta2);
}
generated quantities {
real logOR = logit(theta1) - logit(theta2); // log-odds ratio
real OR = exp(logOR); // odds ratio
}
"Organizziamo i dati nel formato richiesto da Stan:
# Dati aggregati per il modello binomiale
data_list_beta <- list(
k1 = 130, n1 = 200, # gruppo sperimentale: 130 successi su 200 prove
k2 = 100, n2 = 200 # gruppo di controllo: 100 successi su 200 prove
)Compilazione ed esecuzione del modello:
stanmod_or_beta <- cmdstanr::cmdstan_model(write_stan_file(stancode_or_beta))
fit_or_beta <- stanmod_or_beta$sample(
data = data_list_beta,
iter_warmup = 1000,
iter_sampling = 4000,
chains = 4,
parallel_chains = 4,
seed = 123,
refresh = 0
)Diagnostica essenziale:
# Indicatori numerici chiave: Rhat ~ 1, ESS adeguati
posterior::summarize_draws(
fit_or_beta$draws(c("OR")),
"rhat", "ess_bulk", "ess_tail"
)
#> # A tibble: 1 × 4
#> variable rhat ess_bulk ess_tail
#> <chr> <dbl> <dbl> <dbl>
#> 1 OR 1.00 13793. 10545.# Traceplot di controllo su OR
bayesplot::mcmc_trace(fit_or_beta$draws("OR")) 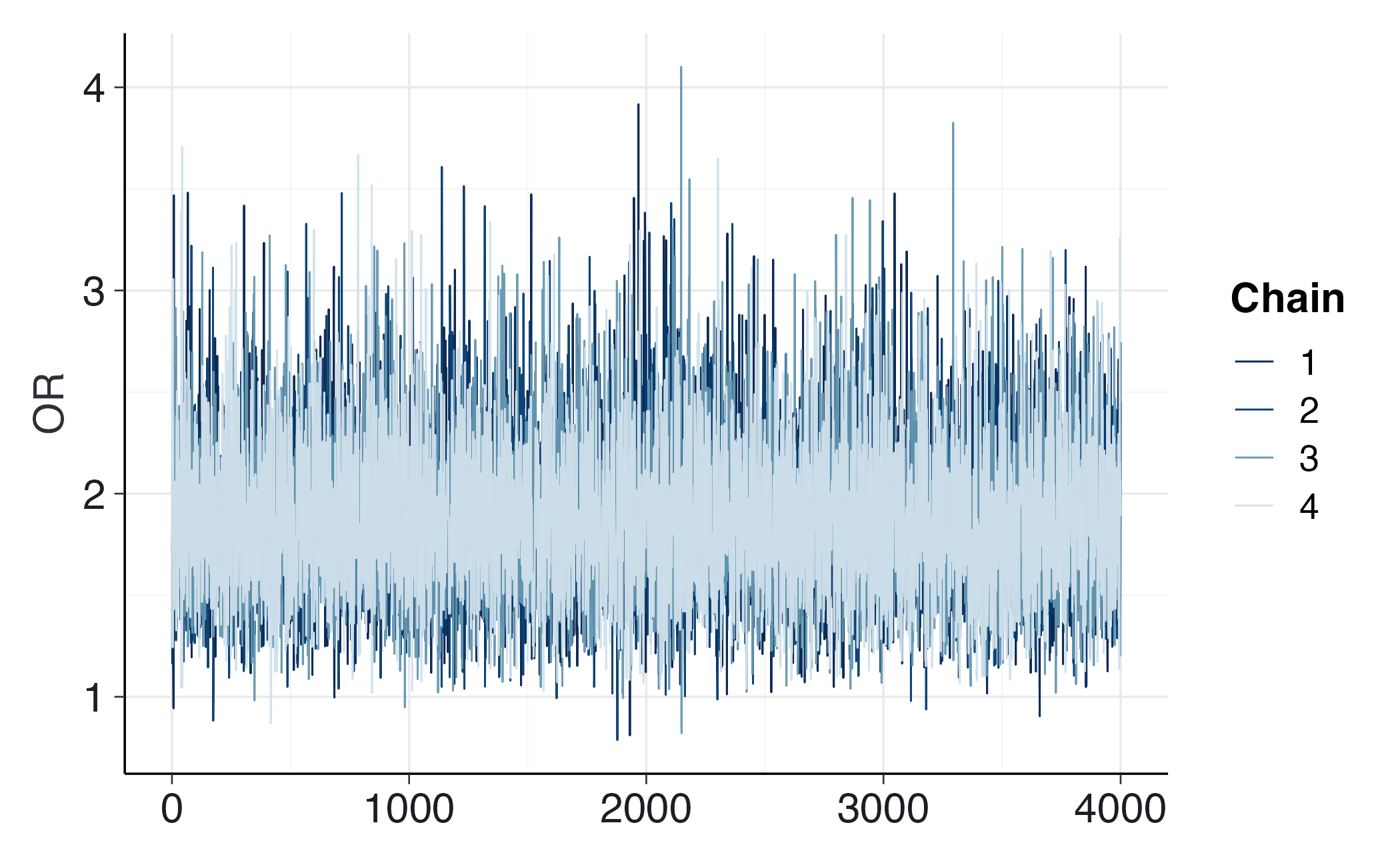
Se emergono problemi (Rhat > 1.01, ESS basso, divergenze riportate in output), conviene aumentare iter_warmup/iter_sampling, alzare adapt_delta o, in ultima istanza, riconsiderare i prior se sono eccessivamente stretti.
17.2.1.1 Analisi dei risultati
Riassunti posteriori per il modello Beta-Binomiale:
posterior::summarise_draws(
fit_or_beta$draws(c("theta1", "theta2", "logOR", "OR")),
mean, sd, ~quantile(.x, c(0.025, 0.5, 0.975))
)
#> # A tibble: 4 × 6
#> variable mean sd `2.5%` `50%` `97.5%`
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 theta1 0.647 0.0336 0.579 0.648 0.712
#> 2 theta2 0.500 0.0350 0.432 0.500 0.569
#> 3 logOR 0.610 0.204 0.207 0.611 1.00
#> 4 OR 1.88 0.387 1.23 1.84 2.73L’output mostra media, deviazione standard, mediana e intervallo di credibilità al 95% per l’odds ratio.
Visualizzazione della distribuzione a posteriori:
bayesplot::mcmc_areas(fit_or_beta$draws("OR"), prob = 0.95) +
xlab("Odds Ratio") + ylab("Densità")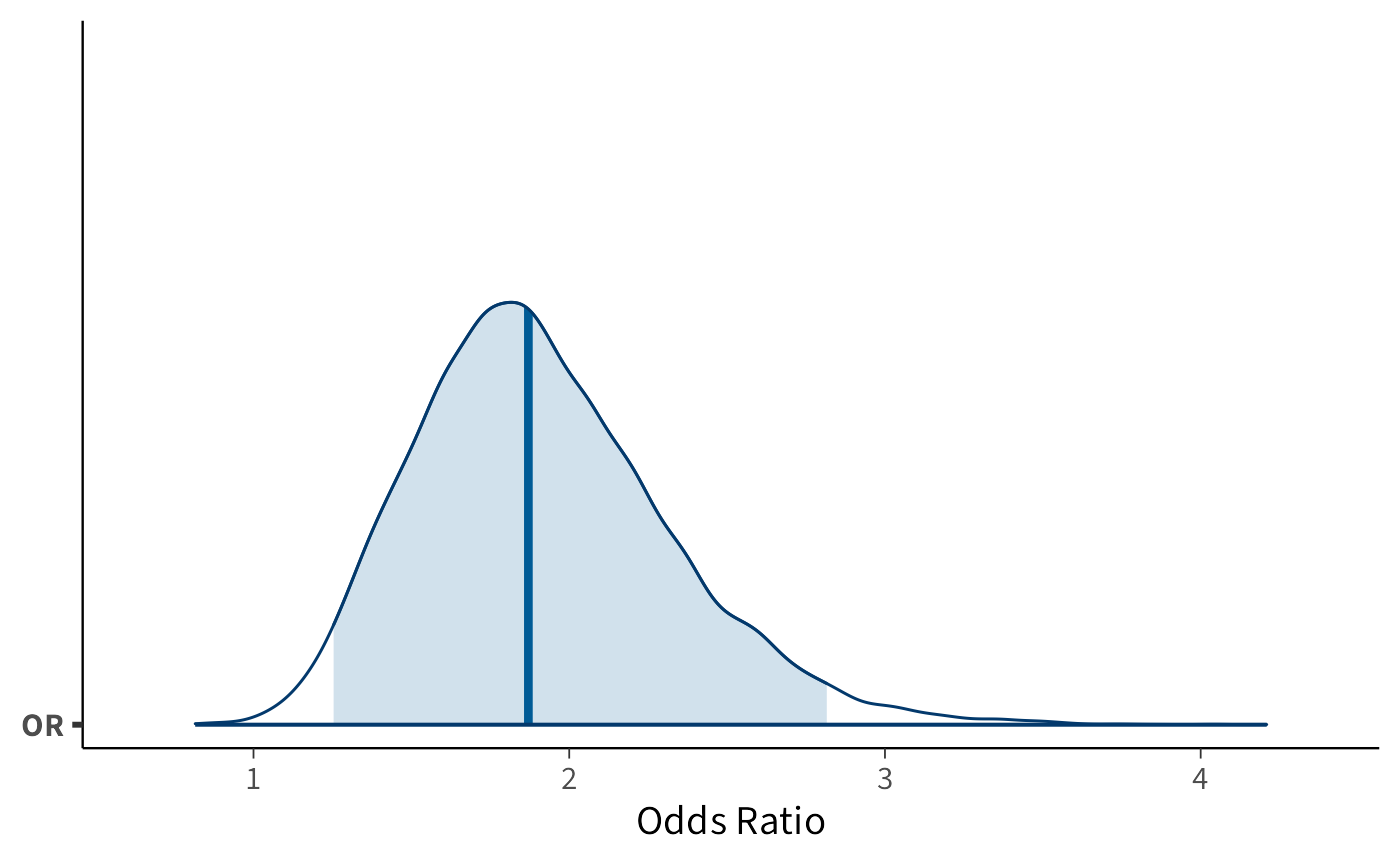
Il grafico mostra chiaramente che la distribuzione dell’odds ratio è concentrata su valori superiori a 1, con alta probabilità.
Interpretazione: i risultati indicano in modo credibile che l’addestramento aumenti la tendenza delle api a scegliere il disco blu rispetto al gruppo di controllo. La distribuzione a posteriori dell’OR è fortemente concentrata su valori superiori a 1, evidenziando che l’effetto è verosimilmente diverso dall’assenza di differenza e che la preferenza osservata non può essere attribuita al solo caso.
17.3 Relazione con la regressione logistica
L’odds ratio può essere stimato in modo del tutto equivalente anche attraverso un modello di regressione logistica. Consideriamo il modello:
\[ \text{logit}(p_i) = \alpha + \beta, x_i, \] dove \(x_i\) è un indicatore del gruppo (0 = controllo, 1 = sperimentale). In questa parametrizzazione, il coefficiente \(\beta\) rappresenta la differenza tra i log-odds dei due gruppi, e la quantità \(\exp(\beta)\) coincide esattamente con l’odds ratio sperimentale rispetto al controllo.
Questo collegamento mostra come la regressione logistica generalizzi il confronto tra due proporzioni: il modello esprime l’effetto in termini di log-odds e consente di incorporare in modo naturale ulteriori predittori, covariate e strutture gerarchiche. La stima dell’OR diventa quindi un caso particolare di un framework più ampio e flessibile, in grado di adattarsi a problemi inferenziali complessi tipici della ricerca psicologica.
17.3.1 Versione con modello logistico
Nel modello logistico, i dati vengono rappresentati a livello individuale: per ciascuna ape registriamo 1 se sceglie il disco blu e 0 in caso contrario.
# Dati individuali
y <- c(rep(1, 130), rep(0, 70), # gruppo sperimentale: 130 successi, 70 insuccessi
rep(1, 100), rep(0, 100)) # gruppo di controllo: 100 successi, 100 insuccessi
x <- c(rep(1, 200), rep(0, 200)) # 1 = sperimentale, 0 = controllo
data_list <- list(N = length(y), y = y, x = x)
glimpse(data_list)
#> List of 3
#> $ N: int 400
#> $ y: num [1:400] 1 1 1 1 1 1 1 1 1 1 ...
#> $ x: num [1:400] 1 1 1 1 1 1 1 1 1 1 ...17.3.2 Specifica del modello in Stan
stancode_or <- "
data {
int<lower=1> N; // numero totale di osservazioni
array[N] int<lower=0,upper=1> y; // esito binario (0/1)
vector[N] x; // variabile indicatrice del gruppo (0 = controllo, 1 = sperimentale)
}
parameters {
real alpha; // intercetta (log-odds nel gruppo di controllo)
real beta; // coefficiente (differenza in log-odds tra gruppo sperimentale e controllo)
}
model {
// Priors
alpha ~ normal(0, 5);
beta ~ normal(0, 5);
// Likelihood
y ~ bernoulli_logit(alpha + beta * x);
}
generated quantities {
real OR = exp(beta); // odds ratio
}
"In questo contesto, il coefficiente \(\beta\) quantifica la variazione nei log-odds di scegliere il disco blu associata all’addestramento: valori positivi indicano che le api addestrate mostrano una maggiore propensione alla risposta corretta rispetto al gruppo di controllo.
17.3.2.1 Compilazione ed esecuzione del modello
stanmod_or <- cmdstanr::cmdstan_model(write_stan_file(stancode_or))
fit_or <- stanmod_or$sample(
data = data_list,
iter_warmup = 1000,
iter_sampling = 4000,
chains = 4,
seed = 123,
refresh = 0
)17.3.2.2 Interpretazione dei risultati
Il riepilogo dei parametri stimati è riportato di seguito:
print(fit_or$summary(c("alpha", "beta", "OR")), n = Inf)
#> # A tibble: 3 × 10
#> variable mean median sd mad q5 q95 rhat ess_bulk ess_tail
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 alpha -0.00366 -0.00355 0.144 0.144 -0.240 0.232 1.00 5153. 6998.
#> 2 beta 0.628 0.626 0.208 0.208 0.288 0.970 1.00 5183. 7043.
#> 3 OR 1.91 1.87 0.403 0.386 1.33 2.64 1.00 5183. 7043.Il parametro alpha rappresenta i log-odds di successo nel gruppo di controllo; beta quantifica la variazione nei log-odds introdotta dall’addestramento; infine, OR = exp(beta) fornisce una misura direttamente interpretabile dell’effetto, indicando di quanto variano gli odds di scegliere il disco blu nel gruppo sperimentale rispetto al controllo.
Per una descrizione più completa dell’incertezza associata all’effetto, consideriamo la distribuzione a posteriori dell’odds ratio:
posterior::summarise_draws(
fit_or$draws("OR"),
mean, sd, ~quantile(.x, c(0.025, 0.5, 0.975))
)
#> # A tibble: 1 × 6
#> variable mean sd `2.5%` `50%` `97.5%`
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 OR 1.91 0.403 1.25 1.87 2.82La distribuzione può essere visualizzata in modo intuitivo tramite:
bayesplot::mcmc_areas(fit_or$draws("OR"), prob = 0.95) +
xlab("Odds Ratio") + ylab("Densità")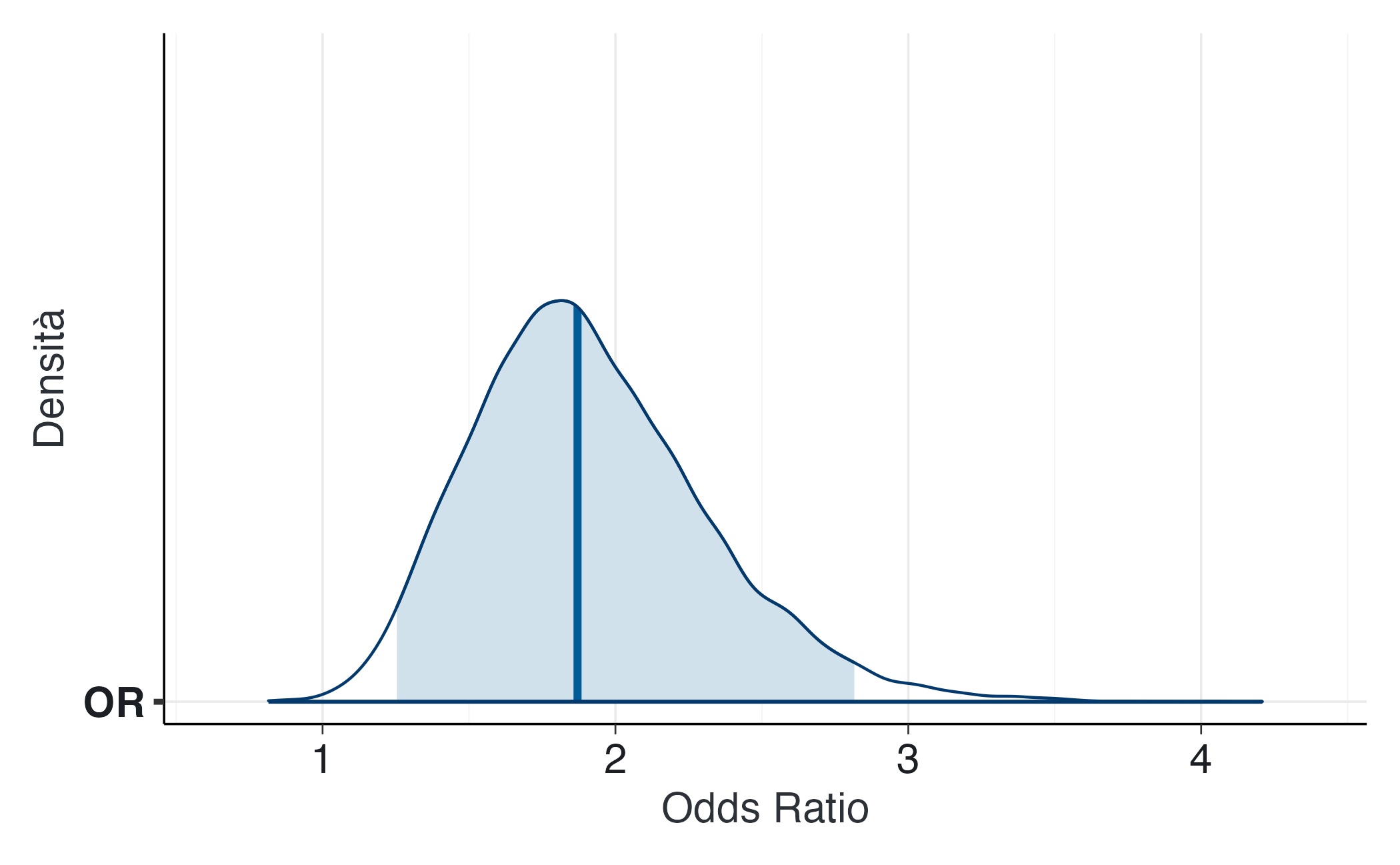
17.3.2.3 Diagnostica del modello
Gli indicatori di convergenza confermano la qualità dell’adattamento:
posterior::summarize_draws(
fit_or$draws(c("alpha","beta","OR")),
"rhat", "ess_bulk", "ess_tail"
)
#> # A tibble: 3 × 4
#> variable rhat ess_bulk ess_tail
#> <chr> <dbl> <dbl> <dbl>
#> 1 alpha 1.00 5153. 6998.
#> 2 beta 1.00 5183. 7043.
#> 3 OR 1.00 5183. 7043.
bayesplot::mcmc_trace(fit_or$draws("OR"))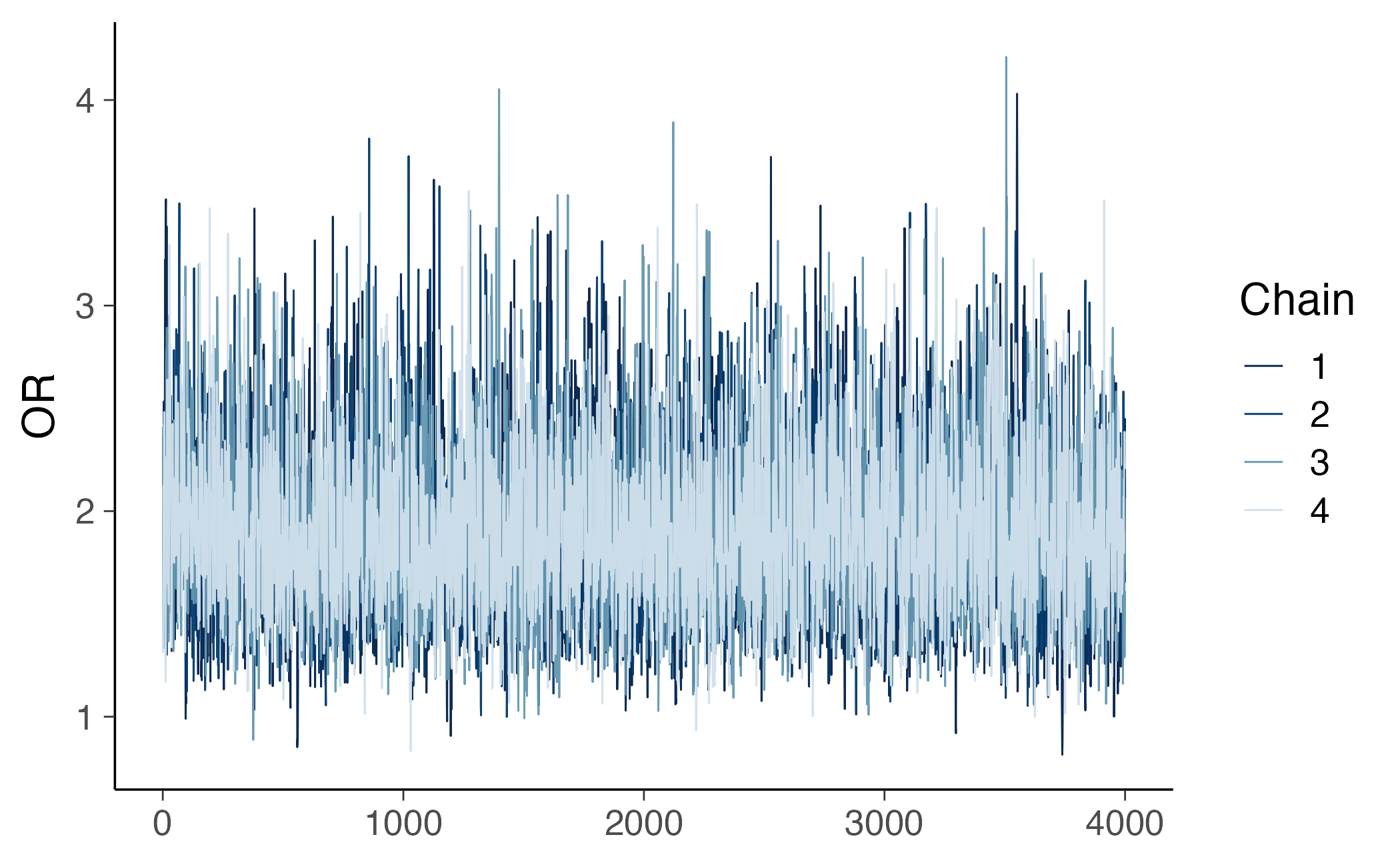
17.3.3 Analisi comparativa dei risultati
Per verificare la coerenza tra i due approcci (modello Beta–Binomiale e regressione logistica), confrontiamo gli intervalli di credibilità:
summ_logit <- posterior::summarise_draws(
fit_or$draws("OR"),
mean, sd, ~quantile(.x, c(0.025, 0.5, 0.975))
)
summ_beta <- posterior::summarise_draws(
fit_or_beta$draws("OR"),
mean, sd, ~quantile(.x, c(0.025, 0.5, 0.975))
)
list(Regressione_Logistica = summ_logit, Beta_Binomiale = summ_beta)
#> $Regressione_Logistica
#> # A tibble: 1 × 6
#> variable mean sd `2.5%` `50%` `97.5%`
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 OR 1.91 0.403 1.25 1.87 2.82
#>
#> $Beta_Binomiale
#> # A tibble: 1 × 6
#> variable mean sd `2.5%` `50%` `97.5%`
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 OR 1.88 0.387 1.23 1.84 2.73Anche la sovrapposizione delle distribuzioni posteriori evidenzia la sostanziale equivalenza dei due modelli:
OR_logit <- as.numeric(fit_or$draws("OR"))
OR_beta <- as.numeric(fit_or_beta$draws("OR"))
tibble(
OR = c(OR_logit, OR_beta),
Modello = rep(c("Regressione Logistica", "Beta-Binomiale"),
c(length(OR_logit), length(OR_beta)))
) |>
ggplot(aes(x = OR, fill = Modello)) +
geom_density(alpha = 0.4) +
labs(x = "Odds Ratio", y = "Densità")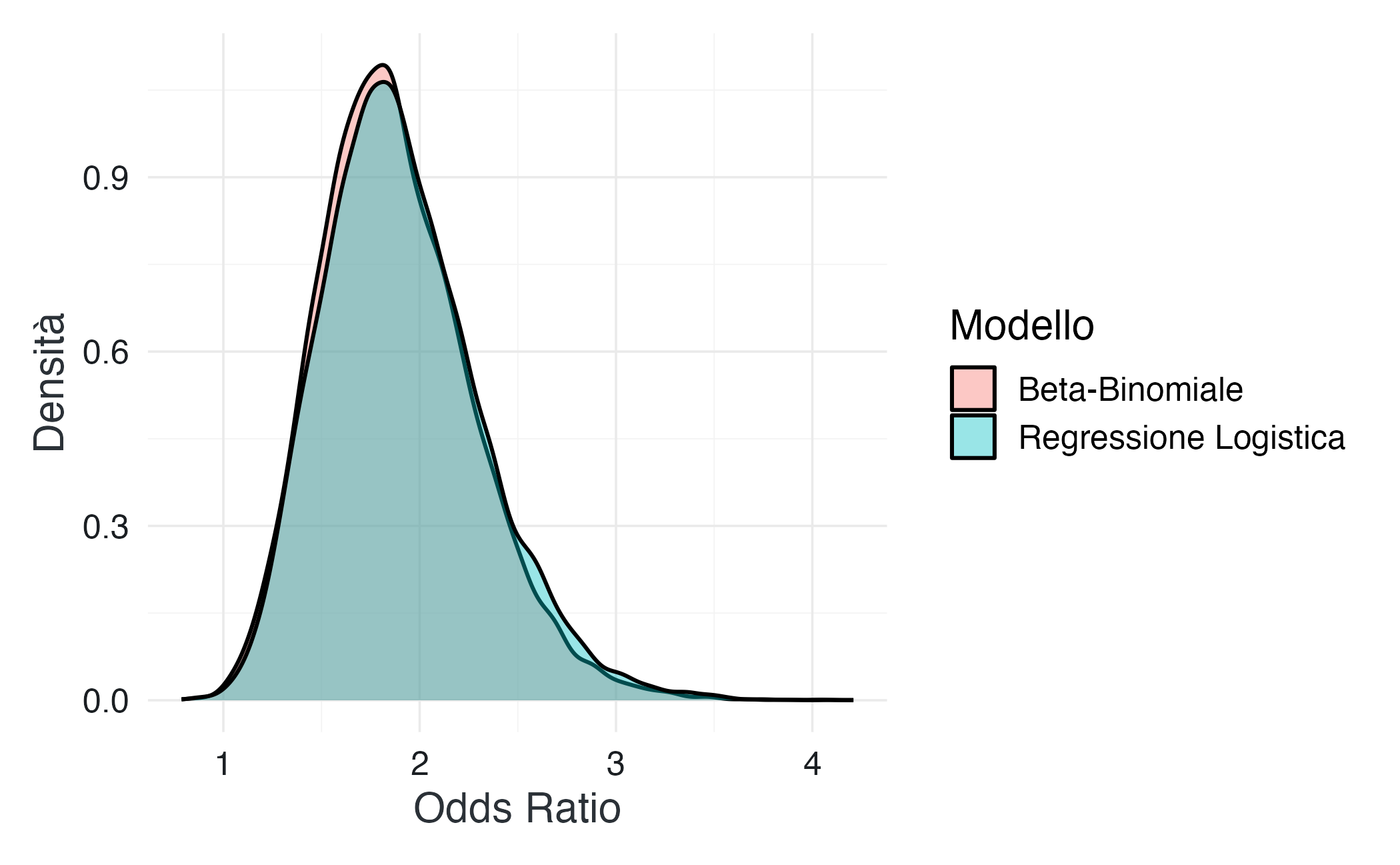
Un confronto diretto della probabilità a posteriori che l’OR sia maggiore di 1 conferma ulteriormente la convergenza dei risultati:
17.4 Considerazioni metodologiche
I due modelli restituiscono inferenze pressoché identiche: in entrambi i casi l’addestramento aumenta in modo credibile la probabilità di scegliere il disco blu. La differenza tra i due approcci riguarda soprattutto la parametrizzazione e la struttura dei dati:
- Regressione logistica: adatta a dati individuali e facilmente estensibile a modelli multivariati o gerarchici; fornisce un quadro generale per analisi più complesse.
- Modello Beta–Binomiale: particolarmente intuitivo quando i dati sono aggregabili in tabelle di contingenza; offre una lettura diretta dei parametri come proporzioni di successo nei gruppi.
In sintesi, entrambi gli approcci modellano lo stesso effetto in maniera coerente. La scelta tra l’uno e l’altro dipende dal livello di granularità dei dati e dagli obiettivi dell’analisi, non dall’effetto inferenziale finale.
Riflessioni conclusive
Questo capitolo ha mostrato come l’inferenza bayesiana sulle proporzioni, inizialmente introdotta tramite soluzioni analitiche e metodi a griglia, possa essere implementata in modo naturale e altamente flessibile in Stan. L’esempio dell’odds ratio ha messo in luce un aspetto fondamentale: l’approccio bayesiano mantiene inalterate le proprie basi concettuali, mentre l’uso di Stan ne amplia notevolmente il campo di applicazione.
Due aspetti meritano particolare attenzione. In primo luogo, la continuità concettuale. Stan non modifica l’architettura dell’inferenza bayesiana, ma al centro rimane sempre il campionamento dalla distribuzione a posteriori che consente di quantificare in modo trasparente l’incertezza sui parametri. Ciò che cambia è la capacità di applicare lo stesso principio a modelli che non hanno soluzioni chiuse o che sarebbero troppo complessi da trattare con metodi manuali o approssimazioni semplicistiche.
In secondo luogo, l’esempio discusso mostra l’importanza pratica di questo ampliamento. La stima dell’odds ratio, un problema metodologico ben noto in psicologia, diventa un’occasione per familiarizzare con Stan in un contesto concettualmente accessibile. Da ciò emerge chiaramente come Stan possa diventare uno strumento di uso quotidiano, dalla modellazione delle proporzioni alle analisi con covariate, fino ai modelli per i conteggi, ai processi dinamici e alle strutture gerarchiche.
In questa prospettiva, il capitolo rappresenta un punto di svolta metodologico. L’inferenza bayesiana non è più confinata a esempi didattici o modelli elementari, ma si configura come un quadro operativo completo, riproducibile e adatto a qualsiasi tipo di dato psicologico. Stan diventa quindi la piattaforma che rende possibile questa transizione, fornendo gli strumenti per affrontare in modo coerente e rigoroso le analisi più avanzate del volume.
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.1
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] cmdstanr_0.8.0 ragg_1.5.0 tinytable_0.15.1
#> [4] withr_3.0.2 systemfonts_1.3.1 patchwork_1.3.2
#> [7] ggdist_3.3.3 tidybayes_3.0.7 bayesplot_1.14.0
#> [10] ggplot2_4.0.1 reliabilitydiag_0.2.1 priorsense_1.2.0
#> [13] posterior_1.6.1 loo_2.8.0 rstan_2.32.7
#> [16] StanHeaders_2.32.10 brms_2.23.0 Rcpp_1.1.0
#> [19] sessioninfo_1.2.3 conflicted_1.2.0 janitor_2.2.1
#> [22] matrixStats_1.5.0 modelr_0.1.11 tibble_3.3.0
#> [25] dplyr_1.1.4 tidyr_1.3.1 rio_1.2.4
#> [28] here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] gridExtra_2.3 inline_0.3.21 sandwich_3.1-1
#> [4] rlang_1.1.6 magrittr_2.0.4 multcomp_1.4-29
#> [7] snakecase_0.11.1 ggridges_0.5.7 compiler_4.5.2
#> [10] reshape2_1.4.5 vctrs_0.6.5 stringr_1.6.0
#> [13] pkgconfig_2.0.3 arrayhelpers_1.1-0 fastmap_1.2.0
#> [16] backports_1.5.0 labeling_0.4.3 utf8_1.2.6
#> [19] rmarkdown_2.30 ps_1.9.1 purrr_1.2.0
#> [22] xfun_0.54 cachem_1.1.0 jsonlite_2.0.0
#> [25] broom_1.0.11 parallel_4.5.2 R6_2.6.1
#> [28] stringi_1.8.7 RColorBrewer_1.1-3 lubridate_1.9.4
#> [31] estimability_1.5.1 knitr_1.50 zoo_1.8-14
#> [34] Matrix_1.7-4 splines_4.5.2 timechange_0.3.0
#> [37] tidyselect_1.2.1 abind_1.4-8 yaml_2.3.12
#> [40] codetools_0.2-20 curl_7.0.0 processx_3.8.6
#> [43] pkgbuild_1.4.8 plyr_1.8.9 lattice_0.22-7
#> [46] bridgesampling_1.2-1 S7_0.2.1 coda_0.19-4.1
#> [49] evaluate_1.0.5 survival_3.8-3 RcppParallel_5.1.11-1
#> [52] pillar_1.11.1 tensorA_0.36.2.1 checkmate_2.3.3
#> [55] stats4_4.5.2 distributional_0.5.0 generics_0.1.4
#> [58] rprojroot_2.1.1 rstantools_2.5.0 scales_1.4.0
#> [61] xtable_1.8-4 glue_1.8.0 emmeans_2.0.0
#> [64] tools_4.5.2 data.table_1.17.8 mvtnorm_1.3-3
#> [67] grid_4.5.2 QuickJSR_1.8.1 colorspace_2.1-2
#> [70] nlme_3.1-168 cli_3.6.5 textshaping_1.0.4
#> [73] svUnit_1.0.8 Brobdingnag_1.2-9 V8_8.0.1
#> [76] gtable_0.3.6 digest_0.6.39 TH.data_1.1-5
#> [79] htmlwidgets_1.6.4 farver_2.1.2 memoise_2.0.1
#> [82] htmltools_0.5.9 lifecycle_1.0.4 MASS_7.3-65