7 I gradi di libertà del ricercatore
- Simulare come diverse scelte analitiche producono risultati diversi sugli stessi dati.
- Costruire una multiverse analysis per mappare lo spazio delle conclusioni possibili.
- Visualizzare una specification curve che mostra la distribuzione degli effetti.
- Comprendere perché la pre-registrazione riduce (ma non elimina) l’arbitrarietà.
- Leggere il Capitolo 3 del manuale sulla crisi della replicabilità.
- Leggere l’articolo di Science: Even faced with the same data, ecologists sometimes come to opposite conclusions.
- Opzionale: Silberzahn et al. (2018) per il progetto many-analysts originale in psicologia.
7.1 Il problema: uno spazio analitico immenso
Condurre l’analisi dei dati raramente consiste nell’applicazione di un’unica procedura predeterminata. Ogni studio richiede una sequenza di scelte metodologiche, spesso tutte legittime ma raramente univoche. Consideriamo, a titolo esemplificativo, alcune delle decisioni più comuni che ogni ricercatore deve prendere:
- Come trattare gli outlier? (escluderli, winsorizzarli, conservarli)
- Quali variabili includere nel modello? (età, genere, SES, tutte, nessuna)
- Quale modello adottare? (regressione lineare, ANOVA, modelli a effetti misti)
- In che forma usare la variabile dipendente? (valori grezzi, trasformazioni, standardizzazione)
- Quali criteri di esclusione applicare? (gestione dei dati mancanti, trial sospetti)
Ciascuna di queste scelte rappresenta un bivio metodologico all’interno del “giardino dei sentieri che si biforcano” (garden of forking paths) del ricercatore (McElreath, 2020). Anche con un numero limitato di opzioni plausibili per ciascuna decisione, lo spazio complessivo delle possibili strategie analitiche cresce in modo esponenziale. Ad esempio con tre opzioni per 5 decisioni: \[ 3^5 = 243 \text{ percorsi analitici distinti. } \] Con tre opzioni per 10 decisioni: \[ 3^{10} = 59.049 \text{ analisi potenzialmente diverse. } \]
Attraversando il “giardino dei sentieri che si biforcano”, il ricercatore potrebbe potenzialmente generare decine di migliaia di risultati diversi a partire da un unico insieme di dati, ognuno giustificato da scelte analitiche formalmente valide. Di conseguenza, ogni articolo scientifico pubblicato rappresenta soltanto una traiettoria selezionata all’interno di uno spazio di possibilità metodologiche vastissimo e che il ricercatore esplora solo in minima parte.
Questo scenario di “iperflessibilità” analitica apre la strada alla possibilità di selezionare, intenzionalmente o inconsapevolmente, solo le combinazioni di scelte che conducono a un risultato statisticamente significativo o in linea con le aspettative. Questa asimmetria tra la vastità dello spazio analitico potenziale e la pubblicazione di un solo percorso, presentato come quello “corretto”, è una delle cause della crisi di replicabilità.
7.2 Simulazione
Creare un dataset “ambiguo”.
Per illustrare come possono emergere i risultati riportati da Gould et al. (2025), eseguiamo una simulazione. Costruiamo un dataset che riproduce le sfide tipiche della ricerca empirica: un effetto reale di piccola entità, unito alla presenza di valori anomali, dati mancanti e covariate correlate.
L’obiettivo non è padroneggiare i dettagli tecnici dello script R utilizzato per la simulazione, ma comprendere come le scelte analitiche di un ricercatore, pur essendo tutte metodologicamente legittime, possano influenzare i risultati e condurre a conclusioni diverse a partire dallo stesso insieme di dati.
set.seed(42)
n <- 200
# Effetto vero: differenza di 3 punti sulla scala dell'outcome
TRUE_EFFECT <- 2
dataset <- tibble(
id = 1:n,
# Età: correlata con la condizione (sbilanciamento)
age = round(rnorm(n, 35, 12)),
gender = sample(c("M", "F", "Other"), n, replace = TRUE, prob = c(0.48, 0.48, 0.04)),
education = sample(c("High school", "Bachelor", "Master", "PhD"), n,
replace = TRUE, prob = c(0.3, 0.4, 0.2, 0.1))
) |>
mutate(
condition = rep(c("control", "treatment"), each = n/2),
# Sbilanciamento età tra gruppi (confounding)
age = age + ifelse(condition == "treatment", 3, -3),
# L'età è un predittore dell'outcome (confounding)
age_effect = 0.15 * (age - 35),
# Outcome base con effetto del trattamento e dell'età
outcome_base = 50 +
ifelse(condition == "treatment", TRUE_EFFECT, 0) +
age_effect +
rnorm(n, 0, 18),
# Outlier ASIMMETRICI: nel gruppo control tendono verso il basso,
# nel gruppo treatment tendono verso l'alto
# Questo crea bias nelle stime quando gli outlier vengono trattati diversamente
is_outlier = runif(n) < 0.10,
outlier_direction = case_when(
is_outlier & condition == "control" ~ sample(c(-1, 1), n, replace = TRUE, prob = c(0.8, 0.2)),
is_outlier & condition == "treatment" ~ sample(c(-1, 1), n, replace = TRUE, prob = c(0.2, 0.8)),
TRUE ~ 0
),
outlier_magnitude = ifelse(is_outlier, abs(rnorm(n, 20, 5)), 0),
outcome_raw = outcome_base + outlier_direction * outlier_magnitude,
# Missing: 8% casuali ma leggermente più frequenti per valori estremi
missing_prob = 0.05 + 0.05 * (abs(outcome_raw - 50) > 15),
outcome = ifelse(runif(n) < missing_prob, NA, outcome_raw)
)#> Dataset simulato
#> ----------------
#> Campioni totali: 200
#> Missing outcome: 14 (7.0%)
#> Outlier simulati: 21 (10.5%)
#> Effetto vero (differenza tra gruppi): 2.0 punti
#>
#> Età media - Control: 32.4, Treatment: 36.9Un’analisi multiverso.
Esaminiamo ora in modo sistematico come diverse scelte analitiche, tutte plausibili, possano modificare le conclusioni di uno studio. Ci concentreremo su quattro scelte metodologiche di base.
- Trattamento degli outlier: conservarli tutti, escludere quelli oltre 3 deviazioni standard, applicare la winsorizzazione.
- Gestione dei dati mancanti: esclusione listwise, imputazione con la media.
- Selezione delle covariate: nessuna covariate, solo età, età e genere, tutte le covariate disponibili.
- Trasformazione della variabile dipendente: valori grezzi, trasformazione logaritmica, standardizzazione.
# Definisci lo spazio delle scelte analitiche
analytical_choices <- list(
# 1. Gestione degli outlier
outlier_handling = c("keep", "remove_2.5sd", "winsorize"),
# 2. Gestione dei dati mancanti
missing_handling = c("listwise", "mean_imputation"),
# 3. Covariate da includere nel modello
covariates = c("none", "age", "age_gender", "all"),
# 4. Trasformazione della variabile dipendente
transformation = c("raw", "log", "standardized")
)Considerando le opzioni per ciascuna delle quattro decisioni da prendere, il numero totale di combinazioni analitiche possibili è:
#> Numero totale di analisi possibili: 72Implementazione delle scelte.
# Funzione per preparare i dati secondo le scelte
prepare_data <- function(data, outlier_method, missing_method, transform_method) {
df <- data
# 1. Gestione missing (prima degli outlier per calcoli corretti)
if (missing_method == "listwise") {
df <- df |> filter(!is.na(outcome))
} else if (missing_method == "mean_imputation") {
m <- mean(df$outcome, na.rm = TRUE)
df <- df |> mutate(outcome = ifelse(is.na(outcome), m, outcome))
}
# 2. Gestione outlier
if (outlier_method == "remove_2.5sd") {
m <- mean(df$outcome, na.rm = TRUE)
s <- sd(df$outcome, na.rm = TRUE)
df <- df |>
filter(outcome > m - 2.5 * s & outcome < m + 2.5 * s)
} else if (outlier_method == "winsorize") {
lower <- quantile(df$outcome, 0.05, na.rm = TRUE)
upper <- quantile(df$outcome, 0.95, na.rm = TRUE)
df <- df |>
mutate(outcome = pmax(pmin(outcome, upper), lower))
}
# 3. Trasformazione
if (transform_method == "log") {
# Shift per evitare log di valori negativi o zero
if (all(is.na(df$outcome))) return(df) # <- AGGIUNTO
min_val <- min(df$outcome, na.rm = TRUE)
shift <- ifelse(min_val <= 0, abs(min_val) + 1, 0)
df <- df |> mutate(outcome = log(outcome + shift))
} else if (transform_method == "standardized") {
if (all(is.na(df$outcome))) return(df) # <- AGGIUNTO
df <- df |> mutate(outcome = as.numeric(scale(outcome)))
}
return(df)
}
# Funzione per eseguire l'analisi
run_analysis <- function(data, covariate_set) {
# Controlla se ci sono abbastanza dati
if (nrow(data) < 20) return(NULL)
# Verifica che ci siano entrambe le condizioni
if (length(unique(data$condition)) < 2) return(NULL)
formula <- switch(covariate_set,
"none" = outcome ~ condition,
"age" = outcome ~ condition + age,
"age_gender" = outcome ~ condition + age + gender,
"all" = outcome ~ condition + age + gender + education
)
tryCatch({
model <- lm(formula, data = data)
# Estrai coefficiente del treatment
tidy_model <- tidy(model, conf.int = TRUE)
treatment_row <- tidy_model |> filter(term == "conditiontreatment")
if (nrow(treatment_row) == 0) return(NULL)
tibble(
estimate = treatment_row$estimate,
std_error = treatment_row$std.error,
p_value = treatment_row$p.value,
conf_low = treatment_row$conf.low,
conf_high = treatment_row$conf.high,
n_used = nrow(data),
r_squared = summary(model)$r.squared
)
}, error = function(e) {
return(NULL)
})
}Esecuzione dell’analisi multiverse.
# Genera tutte le combinazioni
multiverse <- expand_grid(
outlier = analytical_choices$outlier_handling,
missing = analytical_choices$missing_handling,
covariates = analytical_choices$covariates,
transformation = analytical_choices$transformation
)
# Esegui ogni analisi
multiverse_results <- multiverse |>
rowwise() |>
mutate(
prepared_data = list(prepare_data(dataset, outlier, missing, transformation)),
results = list(run_analysis(prepared_data, covariates))
) |>
unnest(results) |>
ungroup() |>
mutate(
analysis_id = row_number(),
significant = p_value < 0.05,
direction = ifelse(estimate > 0, "positive", "negative")
)Per ciascuna delle 72 analisi possibili consideriamo la variabile dipendente, operazionalizzata in vari modi, in un modello di regressione lineare che inclue o no covariati, dopo il pre-processing dei dati che affronta il problema degli outlier e dei dati mancanti.
#> Analisi completate: 72
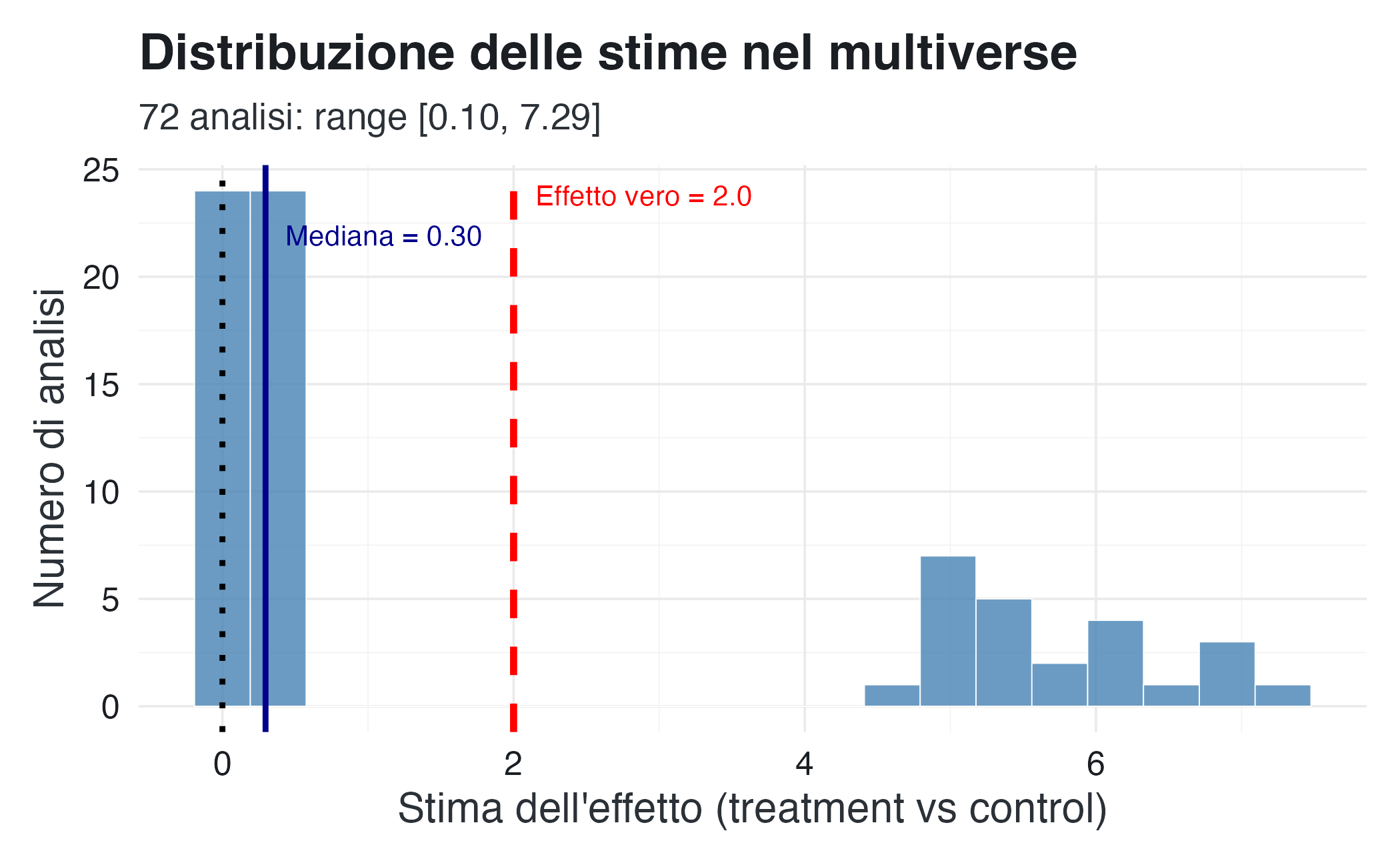
#> Range stime: [0.103, 7.285]
#> Significative (p < 0.05): 37 (51.4%)
#> Sovrastima (stima > 2.0): 24 (33.3%)
#> Sottostima (stima < 2.0): 48 (66.7%)Si noti che solo circa la metà delle analisi (51.4%) produce risultati statisticamente significativi ($ p$ < 0.05). Inoltre, le stime dell’effetto mostrano una notevole variabilità, oscillando tra un minimo di 0.10 e un massimo di 7.29 punti. Questo intervallo include sia sovrastime (33% dei casi) che sottostime (67% dei casi) rispetto all’effetto vero, evidenziando come le scelte analitiche possano distorcere sistematicamente i risultati.
Visualizzazione: curva di specificazione.
La curva di specificazione (specification curve) rappresenta graficamente come le stime di un effetto variano in funzione delle diverse specifiche analitiche applicate agli stessi dati. Ogni punto corrisponde a una combinazione unica di scelte metodologiche.
# Ordina per stima
multiverse_ordered <- multiverse_results |>
arrange(estimate) |>
mutate(rank = row_number())
# Panel superiore: stime con CI
p_estimates <- ggplot(multiverse_ordered, aes(x = rank, y = estimate)) +
geom_hline(yintercept = 0, linetype = "dashed", color = "gray50") +
geom_hline(yintercept = TRUE_EFFECT, linetype = "dotted", color = "red", alpha = 0.5) +
geom_linerange(aes(ymin = conf_low, ymax = conf_high, color = significant),
alpha = 0.4, linewidth = 0.3) +
geom_point(aes(color = significant), size = 1.5) +
scale_color_manual(values = c("TRUE" = "forestgreen", "FALSE" = "gray60")) +
annotate("text", x = max(multiverse_ordered$rank) * 0.95, y = 2.5,
label = "Effetto vero", color = "red", hjust = 1, vjust = -0.5, size = 3) +
labs(
y = "Stima dell'effetto",
title = "Specification Curve: 72 modi di analizzare gli stessi dati"
) +
theme(
axis.text.x = element_blank(),
axis.ticks.x = element_blank(),
axis.title.x = element_blank(),
legend.position = "none"
)
# Panel inferiore: scelte analitiche
choices_long <- multiverse_ordered |>
select(rank, outlier, missing, covariates, transformation) |>
pivot_longer(cols = -rank, names_to = "choice_type", values_to = "choice") |>
mutate(
choice_type = factor(choice_type,
levels = c("outlier", "missing", "covariates", "transformation"),
labels = c("Outlier", "Missing", "Covariate", "Trasformazione"))
)
p_choices <- ggplot(choices_long, aes(x = rank, y = choice_type, fill = choice)) +
geom_tile(color = "white", linewidth = 0.1) +
scale_fill_viridis_d(option = "turbo") +
labs(x = "Analisi (ordinate per stima)", y = "", fill = "Scelta") +
theme(
legend.position = "bottom",
legend.key.size = unit(0.4, "cm"),
axis.text.y = element_text(size = 9)
) +
guides(fill = guide_legend(nrow = 2))
# Combina
p_estimates / p_choices + plot_layout(heights = c(2, 1))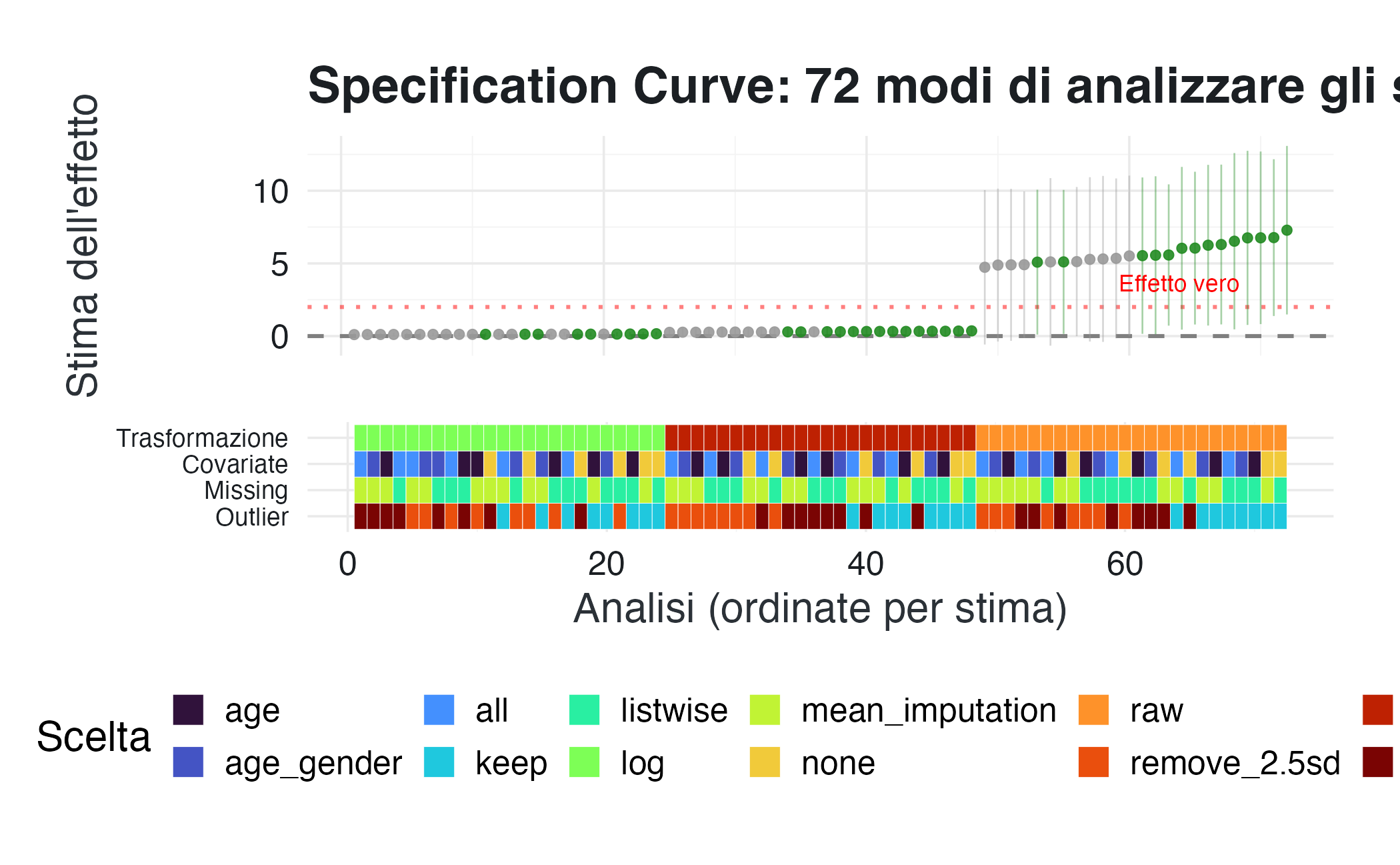
ggplot(multiverse_results, aes(x = estimate)) +
geom_histogram(bins = 20, fill = "steelblue", color = "white", alpha = 0.8) +
geom_vline(xintercept = TRUE_EFFECT, color = "red", linetype = "dashed", linewidth = 1.2) +
geom_vline(xintercept = 0, color = "black", linetype = "dotted", linewidth = 1) +
geom_vline(xintercept = median(multiverse_results$estimate),
color = "darkblue", linewidth = 1) +
annotate("text", x = TRUE_EFFECT, y = Inf, vjust = 2, hjust = -0.1,
label = sprintf("Effetto vero = %.1f", TRUE_EFFECT), color = "red") +
annotate("text", x = median(multiverse_results$estimate), y = Inf, vjust = 4, hjust = -0.1,
label = sprintf("Mediana = %.2f", median(multiverse_results$estimate)),
color = "darkblue") +
labs(
x = "Stima dell'effetto (treatment vs control)",
y = "Numero di analisi",
title = "Distribuzione delle stime nel multiverse",
subtitle = sprintf("72 analisi: range [%.2f, %.2f]",
min(multiverse_results$estimate),
max(multiverse_results$estimate))
)
Quali scelte contano di più?
Alcune decisioni analitiche hanno più impatto di altre. Analizziamo la varianza spiegata da ciascuna scelta:
# Calcola la varianza spiegata da ogni scelta
variance_decomposition <- multiverse_results |>
summarise(
total_var = var(estimate),
var_outlier = var(tapply(estimate, outlier, mean)),
var_missing = var(tapply(estimate, missing, mean)),
var_covariates = var(tapply(estimate, covariates, mean)),
var_transformation = var(tapply(estimate, transformation, mean))
) |>
pivot_longer(everything(), names_to = "source", values_to = "variance") |>
dplyr::filter(source != "total_var") |>
mutate(
source = str_remove(source, "var_"),
source = factor(source,
levels = c("outlier", "missing", "covariates", "transformation"),
labels = c("Gestione outlier", "Gestione missing",
"Scelta covariate", "Trasformazione")),
pct = variance / sum(variance) * 100
)
ggplot(variance_decomposition, aes(x = reorder(source, pct), y = pct)) +
geom_col(fill = "steelblue", alpha = 0.8) +
geom_text(aes(label = sprintf("%.0f%%", pct)), hjust = -0.2) +
coord_flip() +
labs(
x = "",
y = "% varianza nelle stime",
title = "Quale scelta analitica conta di più?",
subtitle = "Decomposizione della variabilità nel multiverse"
) +
scale_y_continuous(limits = c(0, max(variance_decomposition$pct) * 1.2))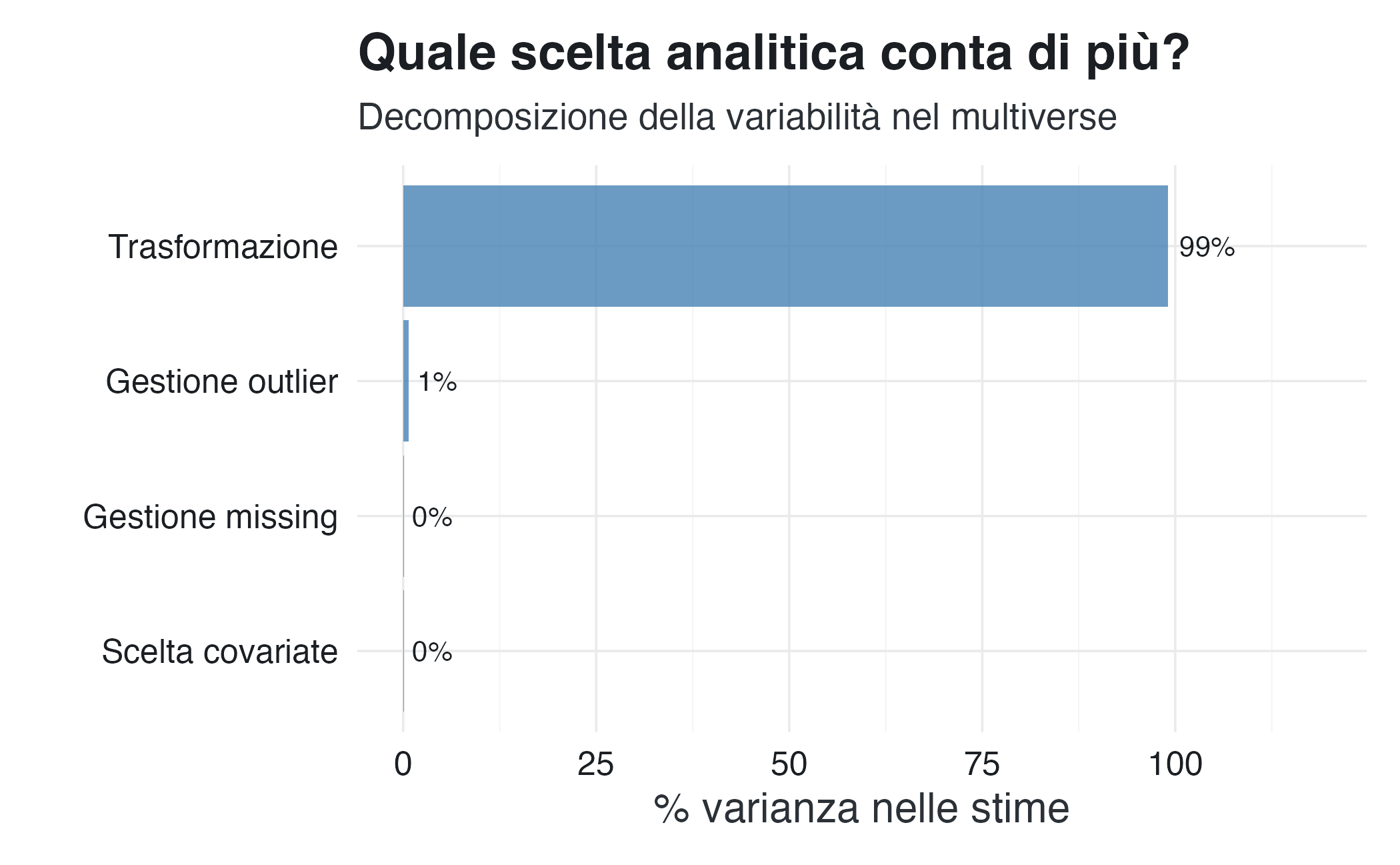
# Tabella dettagliata per scelta
multiverse_results |>
group_by(outlier) |>
summarise(
`Media stima` = sprintf("%.2f", mean(estimate)),
`SD stima` = sprintf("%.2f", sd(estimate)),
`% significativi` = sprintf("%.0f%%", 100 * mean(significant)),
.groups = "drop"
) |>
rename(`Gestione outlier` = outlier) |>
knitr::kable(caption = "Effetto della gestione degli outlier")| Gestione outlier | Media stima | SD stima | % significativi |
|---|---|---|---|
| keep | 2.35 | 3.07 | 88% |
| remove_2.5sd | 1.83 | 2.37 | 8% |
| winsorize | 1.94 | 2.51 | 58% |
Scenario “Molti analisti”.
Simuliamo ora la variabilità che emergerebbe se 50 ricercatori indipendenti analizzassero lo stesso dataset, ciascuno adottando scelte metodologiche diverse ma tutte plausibili e giustificabili.
set.seed(123)
# Simula 50 ricercatori con scelte casuali (ma pesate verso opzioni comuni)
n_researchers <- 50
set.seed(123)
# Simula 50 ricercatori con scelte casuali
n_researchers <- 50
researcher_results <- tibble(researcher_id = 1:n_researchers) |>
rowwise() |>
mutate(
# MODIFICA: probabilità più equilibrate per ottenere più varietà
outlier = sample(c("keep", "remove_2.5sd", "winsorize"), 1,
prob = c(0.4, 0.3, 0.3)),
missing = sample(c("listwise", "mean_imputation"), 1,
prob = c(0.5, 0.5)),
covariates = sample(c("none", "age", "age_gender", "all"), 1,
prob = c(0.25, 0.25, 0.25, 0.25)),
transformation = sample(c("raw", "log", "standardized"), 1,
prob = c(0.34, 0.33, 0.33)),
# Esegui l'analisi
prepared_data = list(prepare_data(dataset, outlier, missing, transformation)),
results = list(run_analysis(prepared_data, covariates))
) |>
unnest(results) |>
ungroup() |>
mutate(
significant = p_value < 0.05,
conclusion = case_when(
p_value < 0.05 & estimate > 0 ~ "Effetto positivo significativo",
p_value < 0.05 & estimate < 0 ~ "Effetto negativo significativo",
TRUE ~ "Non significativo"
)
)
# Visualizzazione stile Gould et al.
ggplot(researcher_results, aes(x = reorder(researcher_id, estimate), y = estimate)) +
geom_hline(yintercept = 0, linetype = "dashed", color = "gray50") +
geom_hline(yintercept = TRUE_EFFECT, linetype = "dashed", color = "red", alpha = 0.7) +
geom_linerange(aes(ymin = conf_low, ymax = conf_high), color = "gray60", alpha = 0.5) +
geom_point(aes(color = conclusion), size = 3) +
scale_color_manual(values = c(
"Effetto positivo significativo" = "forestgreen",
"Non significativo" = "gray50",
"Effetto negativo significativo" = "coral"
)) +
annotate("text", x = n_researchers * 0.9, y = 2.5, label = "Effetto vero",
color = "red", vjust = -1) +
labs(
x = "Ricercatore (ordinato per stima)",
y = "Stima dell'effetto",
color = "Conclusione",
title = "50 ricercatori, 50 risultati diversi",
subtitle = sprintf("Stessi dati, stessa domanda, range stime: [%.2f, %.2f]",
min(researcher_results$estimate), max(researcher_results$estimate))
) +
theme(
axis.text.x = element_blank(),
axis.ticks.x = element_blank(),
legend.position = "bottom"
)
# Statistiche
conclusion_stats <- researcher_results |>
dplyr::count(conclusion) |>
mutate(pct = n / sum(n) * 100)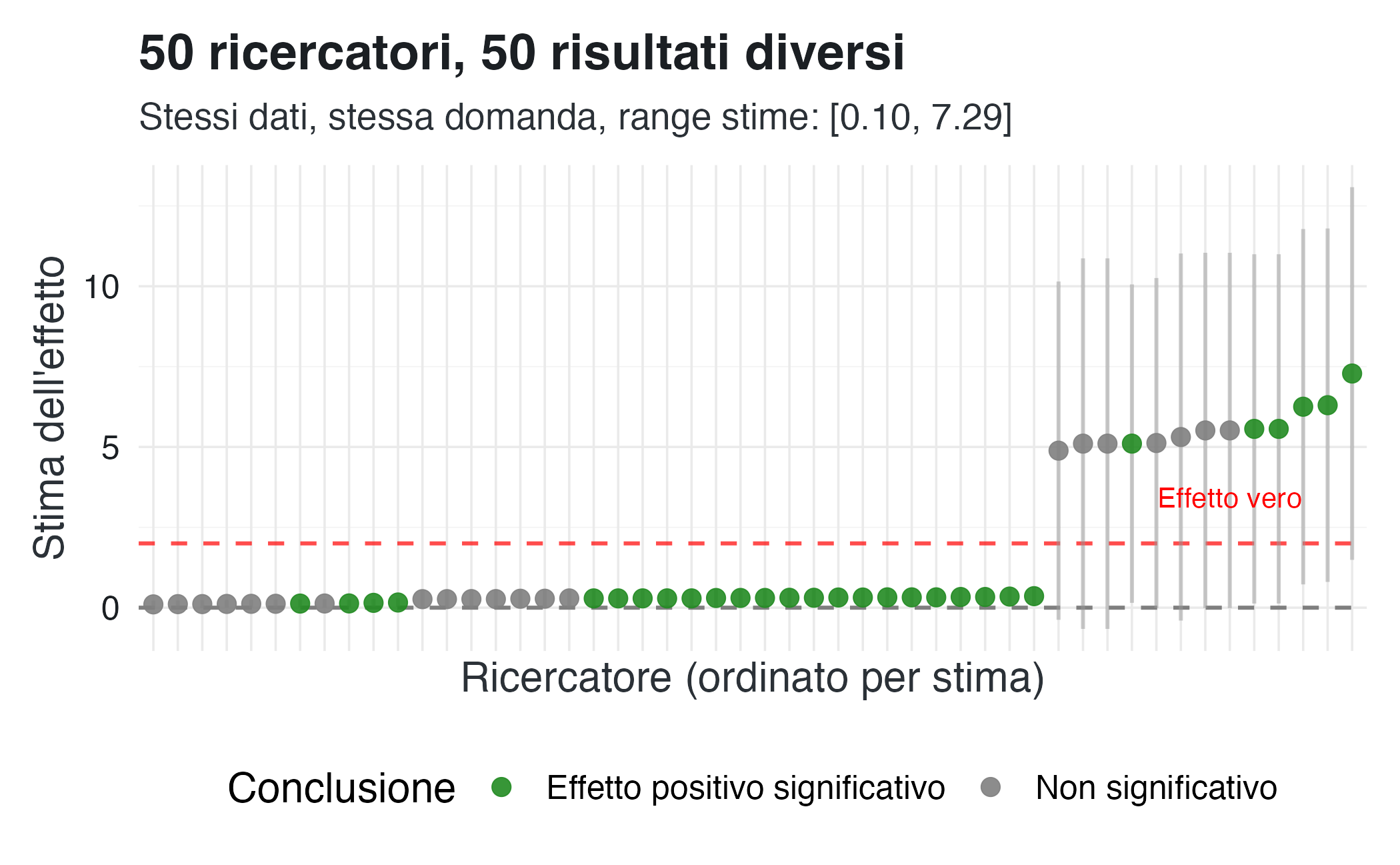
#> Effetto positivo significativo: 29 (58%)
#> Non significativo: 21 (42%)Se consideriamo le scelte analitiche effettuate da 50 “ricercatori virtuali”, ognuno con combinazioni diverse ma plausibili di scelte metodologiche, notiamo che i risultati mostrano una marcata variabilità: solo il 58% di essi ottiene stime statisticamente significative (\(p\) < 0.05).
7.3 Strategie di mitigazione
La simulazione presentata in questo capitolo riproduce, su scala ridotta, quanto documentato da Gould et al. (2025) con dati reali in un ambizioso progetto di analisi collaborativa. Nel loro studio, 174 team di ricerca indipendenti hanno ricevuto gli stessi dataset e la stessa domanda di ricerca. Il risultato è stato sorprendente per la sua eterogeneità: le stime degli effetti variavano da fortemente negative a positive, con conclusioni statistiche diametralmente opposte tra i vari gruppi. Questa variabilità non era dovuta a incompetenza o errori, ma alla naturale conseguenza di scelte analitiche tutte ragionevoli e metodologicamente difendibili.
La nostra simulazione, pur operando su scala molto più ridotta con 72 combinazioni analitiche, cattura la stessa dinamica fondamentale. Partendo da un effetto vero di 2.5 punti, le stime ottenute vanno da valori che sottostimano l’effetto reale a valori che lo sovrastimano. Alcune analisi portano a conclusioni statisticamente significative, altre no, il tutto come conseguenza di decisioni apparentemente tecniche, quali il trattamento dei valori anomali, la gestione dei dati mancanti, l’inclusione di variabili indipendenti e la trasformazione delle variabili.
Di fronte a questa fragilità intrinseca del processo analitico, la comunità scientifica ha sviluppato diverse strategie di mitigazione. La pre-registrazione è forse l’approccio più diffuso: fissando le scelte analitiche prima di osservare i dati, si elimina la possibilità di selezionare, a posteriori, l’analisi che produce i risultati più favorevoli. Tuttavia, la pre-registrazione presenta importanti limiti. Non garantisce che le scelte pre-specificate siano le migliori possibili e la ricerca spesso rivela complessità impreviste che richiedono di deviare dal piano originale. Inoltre, come mostrano i dati di Gould et al. (2025), anche i ricercatori che operano in buona fede e con piani ben definiti possono giungere a conclusioni sostanzialmente diverse.
Un’alternativa complementare è la trasparenza attraverso l’analisi multiverse. Invece di presentare un singolo risultato come se fosse l’unica verità possibile, il ricercatore può esplorare sistematicamente lo spazio delle decisioni analitiche e riportare l’intera distribuzione delle conclusioni possibili. Questo approccio ha il vantaggio di rendere esplicita l’incertezza metodologica, ovvero quella componente di variabilità che non deriva dal campionamento statistico, ma dalle scelte del ricercatore. Quando un lettore vede che il 60% delle analisi ragionevoli produce risultati significativi, mentre il 40% no, acquisisce una comprensione molto più sfumata della robustezza dell’evidenza rispetto a quando legge un singolo valore-\(p\).
Lo studio di Gould et al. (2025) ha rivelato altri aspetti preoccupanti. Né la complessità delle analisi né il processo di revisione tra pari interno ai team hanno mostrato una correlazione con l’accuratezza delle stime. La variabilità osservata tra gli analisti superava quella attribuibile esclusivamente all’errore di campionamento, suggerendo che la componente umana del processo analitico introduce una fonte di incertezza sistematicamente sottovalutata nella pratica scientifica corrente. Ciò non significa che il metodo scientifico sia inaffidabile, ma piuttosto che dovremmo essere più umili riguardo alla precisione delle nostre conclusioni e più trasparenti riguardo alle scelte che le hanno generate.
Le implicazioni pratiche di queste osservazioni sono profonde. Per i ricercatori, suggeriscono l’importanza di esplorare la sensibilità dei risultati derivanti da scelte analitiche alternative, anche quando esiste un piano pre-registrato. Per i lettori della letteratura scientifica, queste implicazioni suggeriscono un atteggiamento critico nei confronti dei risultati presentati come definitivi senza alcuna discussione sulla loro robustezza. Per la comunità scientifica nel suo insieme, indicano la necessità di sviluppare standard di reportistica che includano informazioni sulla variabilità dei risultati derivante dalle scelte metodologiche dei ricercatori, non solo su quella statistica.
7.4 Riflessioni conclusive
Le simulazioni e le evidenze empiriche presentate in questo capitolo convergono su una conclusione importante, ma spesso trascurata: lo spazio delle analisi possibili per qualsiasi dataset è vasto e le scelte metodologiche ragionevoli possono condurre a conclusioni divergenti. Questo non è un difetto del metodo scientifico, ma una sua caratteristica intrinseca che emerge ogni volta che i dati richiedono un’interpretazione e le procedure non sono completamente automatizzate.
La lezione fondamentale non è che la ricerca empirica sia inaffidabile, ma che la sua affidabilità dipende crucialmente dalla trasparenza con cui il processo analitico viene documentato e comunicato. Quando leggiamo uno studio che riporta un valore p appena sotto la soglia di significatività, dovremmo chiederci quante altre analisi ragionevoli avrebbero potuto essere condotte e quante di queste avrebbero potuto condurre a conclusioni diverse. La risposta, come mostrano le nostre simulazioni e lo studio di Gould et al. (2025), è quasi sempre “molte”.
Quando leggete uno studio che riporta \(p = 0.03\), chiedetevi: “Quante altre analisi ragionevoli avrebbero potuto essere fatte? Quante avrebbero dato \(p > 0.05\)?” La risposta è quasi sempre: molte.
Alcune scelte analitiche hanno un impatto maggiore di altre. Nella nostra simulazione, la gestione dei valori anomali e la scelta delle covariate hanno mostrato l’impatto maggiore sulla variabilità delle stime. Ciò suggerisce che è necessario dedicare particolare attenzione alla giustificazione di queste decisioni cruciali e, possibilmente, esplorare alternative.
La pre-registrazione offre una protezione parziale, ma importante, contro l’esplorazione opportunistica dello spazio analitico. Fissare le scelte prima di vedere i dati elimina la tentazione di selezionare, a posteriori, l’analisi che produce i risultati desiderati. Tuttavia, la pre-registrazione non garantisce che la scelta pre-specificata sia quella corretta né elimina la legittima variabilità che emergerebbe se diversi ricercatori pre-registrassero piani diversi.
L’approccio multiverse rappresenta un complemento prezioso, in quanto permette di quantificare esplicitamente l’incertezza metodologica e di comunicare ai lettori non solo i risultati ottenuti, ma anche la robustezza di tali risultati rispetto a scelte alternative. In un’epoca in cui la riproducibilità della ricerca è sotto scrutinio, la trasparenza diventa un valore scientifico fondamentale.
La sfida per la psicologia e per le scienze empiriche in generale non è eliminare i gradi di libertà del ricercatore, cosa impossibile data la complessità intrinseca dei fenomeni studiati, ma piuttosto rendere queste scelte visibili, giustificabili e sottoponibili al controllo della comunità scientifica. Solo in questo modo sarà possibile distinguere i risultati robusti, che resistono a molteplici analisi specifiche, da quelli fragili, che dipendono criticamente da decisioni arbitrarie.
7.5 Esercizi
Uno studio sulla relazione tra uso dei social media e benessere psicologico negli adolescenti riporta i seguenti risultati di un’analisi multiverse con 48 specifiche analitiche diverse:
- Range delle stime: da r = −0.15 a r = +0.08
- Mediana delle stime: r = −0.04
- Percentuale di analisi con p < 0.05: 35%
- Percentuale di analisi con effetto negativo: 73%
Gli autori concludono: “I risultati dimostrano un effetto negativo significativo dei social media sul benessere adolescenziale.”
Rispondete alle seguenti domande:
La conclusione degli autori è giustificata dai dati del multiverse? Argomentate la vostra risposta.
Quali informazioni aggiuntive vorreste avere per valutare meglio la robustezza di questo risultato?
Come riformulereste la conclusione per renderla più coerente con i risultati del multiverse?
La conclusione degli autori non è pienamente giustificata. Sebbene la maggioranza delle analisi (73%) mostri un effetto negativo, solo il 35% raggiunge la significatività statistica. Inoltre, il range delle stime include valori positivi (fino a r = +0.08), indicando che alcune specifiche analitiche ragionevoli portano a conclusioni opposte. La mediana di r = −0.04 suggerisce un effetto molto piccolo, probabilmente di scarsa rilevanza pratica. Affermare un “effetto negativo significativo” è una semplificazione eccessiva che ignora la considerevole incertezza metodologica evidenziata dal multiverse.
Sarebbe utile conoscere: quali scelte analitiche producono gli effetti più estremi (positivi vs negativi); se esiste una giustificazione teorica per preferire alcune specifiche ad altre; la distribuzione completa delle stime, non solo il range e la mediana; quali combinazioni di scelte portano alla significatività e quali no; e se i risultati cambiano per sottogruppi demografici diversi.
Una conclusione più appropriata potrebbe essere: “L’analisi multiverse suggerisce una possibile associazione negativa di piccola entità tra uso dei social media e benessere adolescenziale (mediana r = −0.04), ma questo risultato mostra considerevole sensibilità alle scelte analitiche. Mentre la maggioranza delle specifiche indica un’associazione negativa, solo un terzo raggiunge la significatività statistica, e alcune analisi plausibili suggeriscono effetti nulli o leggermente positivi. Questi risultati evidenziano l’importanza di non sovrastimare la certezza delle conclusioni in questo ambito di ricerca.”
Due gruppi di ricerca studiano indipendentemente l’efficacia di un nuovo intervento di mindfulness sull’ansia. Entrambi i gruppi pre-registrano il loro piano di analisi prima di raccogliere i dati.
Gruppo A pre-registra:
- Misura dell’ansia: State-Trait Anxiety Inventory (STAI)
- Gestione outlier: rimozione valori oltre 3 SD
- Analisi: t-test tra gruppi
Gruppo B pre-registra:
- Misura dell’ansia: Beck Anxiety Inventory (BAI)
- Gestione outlier: winsorizzazione al 95° percentile
- Analisi: ANCOVA controllando per ansia baseline
I risultati sono:
- Gruppo A: differenza significativa (p = 0.03, d = 0.45)
- Gruppo B: differenza non significativa (p = 0.12, d = 0.28)
Rispondete alle seguenti domande:
Entrambi i gruppi hanno seguito rigorosamente la pre-registrazione. Perché i risultati divergono?
Un revisore suggerisce che uno dei due studi “deve essere sbagliato”. Questa affermazione è corretta? Perché?
Cosa ci insegna questo esempio sui limiti della pre-registrazione come soluzione al problema dei gradi di libertà?
I risultati divergono perché i due gruppi hanno pre-registrato scelte analitiche diverse, tutte metodologicamente legittime. Le differenze riguardano lo strumento di misura (STAI vs BAI, che misurano costrutti correlati ma non identici), il trattamento degli outlier (rimozione vs winsorizzazione), e il modello statistico (t-test vs ANCOVA). Queste scelte, pur essendo tutte ragionevoli, possono produrre stime e p-value differenti. La pre-registrazione ha eliminato la flessibilità post-hoc all’interno di ciascuno studio, ma non ha eliminato la variabilità tra studi dovuta a scelte iniziali diverse.
L’affermazione del revisore non è corretta. Entrambi gli studi potrebbero essere condotti correttamente e produrre comunque risultati diversi. Come dimostrato dallo studio di Gould et al. (2025), ricercatori competenti che analizzano gli stessi dati con approcci diversi ma legittimi arrivano regolarmente a conclusioni divergenti. La divergenza non indica necessariamente un errore, ma riflette l’incertezza metodologica intrinseca alla ricerca empirica. Un effetto reale di dimensione intermedia potrebbe essere rilevato da alcune specifiche analitiche e non da altre, specialmente con campioni di dimensione tipica per la ricerca psicologica.
Questo esempio illustra che la pre-registrazione risolve il problema della flessibilità post-hoc (impedisce al singolo ricercatore di esplorare molteplici analisi e riportare solo quella favorevole), ma non elimina il problema della molteplicità a priori. Ricercatori diversi, tutti in buona fede, possono pre-registrare piani diversi che portano a conclusioni diverse. La pre-registrazione garantisce trasparenza e previene il p-hacking, ma non garantisce che le scelte pre-specificate siano quelle “corrette” o che producano stime accurate dell’effetto reale. Per questo motivo, la pre-registrazione dovrebbe essere considerata una condizione necessaria ma non sufficiente per la credibilità scientifica, idealmente complementata da analisi di sensibilità o approcci multiverse.
Uno studente di dottorato sta pianificando uno studio sull’effetto della privazione di sonno sulla memoria di lavoro. Descrive così il suo piano:
“Recluterò partecipanti e li assegnerò casualmente alla condizione di privazione di sonno (4 ore) o controllo (8 ore). Il giorno dopo misurerò la memoria di lavoro. Analizzerò i dati per vedere se c’è un effetto.”
Questa descrizione lascia molte decisioni non specificate che rappresentano potenziali gradi di libertà del ricercatore.
Identificate almeno 5 decisioni metodologiche o analitiche che lo studente dovrà prendere e che non sono specificate nel piano.
Per ciascuna decisione identificata, indicate almeno due alternative ragionevoli che lo studente potrebbe scegliere.
Se ciascuna delle 5 decisioni ha 2-3 alternative, quante analisi diverse potrebbe potenzialmente condurre lo studente? Cosa implica questo per l’interpretazione di un singolo risultato “significativo”?
- e b) Ecco cinque decisioni non specificate con le relative alternative:
Quale test di memoria di lavoro utilizzare? Alternative: N-back task, Operation Span, Digit Span, Corsi Block Task. Questi test misurano aspetti correlati ma distinti della memoria di lavoro.
Come gestire i partecipanti che non rispettano il protocollo? (es. chi dorme più o meno del previsto). Alternative: escluderli dall’analisi, includerli comunque, analizzare per “intention to treat”, analizzare per “protocol completers”.
Quali covariate includere nel modello? Alternative: nessuna (semplice confronto tra gruppi), controllare per età, controllare per qualità abituale del sonno, controllare per livello di caffeina, controllare per ansia da prestazione.
Come definire e gestire gli outlier nelle prestazioni? Alternative: non escludere nessuno, escludere prestazioni oltre 2 o 3 deviazioni standard, escludere tempi di risposta anomali, winsorizzare i valori estremi.
Quale misura della prestazione usare? Alternative: accuratezza (% risposte corrette), tempi di reazione medi, tempi di reazione mediani, punteggio composito accuratezza-velocità.
Altre possibili decisioni: dimensione del campione e regola di stop per il reclutamento; come gestire dati mancanti; quale test statistico usare (t-test, ANOVA, regressione, test non parametrici); se e come trasformare i dati.
- Se ciascuna delle 5 decisioni ha anche solo 2-3 alternative, il numero di combinazioni possibili è almeno \(2^5 = 32\) e potenzialmente \(3^5 = 243\) o più. Questo implica che lo studente potrebbe condurre decine o centinaia di analisi diverse, tutte legittime. Se riporta solo quella che ha prodotto p < 0.05, sta implicitamente selezionando da un vasto spazio di possibilità. Un singolo risultato “significativo” in questo contesto è molto meno informativo di quanto sembri: la probabilità di trovare almeno un risultato significativo per caso (anche senza effetto reale) aumenta considerevolmente con il numero di analisi possibili. Questo esempio illustra perché la trasparenza sulle scelte analitiche e, idealmente, l’esplorazione sistematica delle alternative (multiverse analysis) sono fondamentali per valutare la robustezza dei risultati.
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.1
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] stringr_1.6.0 broom_1.0.11 ragg_1.5.0
#> [4] tinytable_0.15.1 withr_3.0.2 systemfonts_1.3.1
#> [7] patchwork_1.3.2 ggdist_3.3.3 tidybayes_3.0.7
#> [10] bayesplot_1.14.0 ggplot2_4.0.1 reliabilitydiag_0.2.1
#> [13] priorsense_1.2.0 posterior_1.6.1 loo_2.8.0
#> [16] rstan_2.32.7 StanHeaders_2.32.10 brms_2.23.0
#> [19] Rcpp_1.1.0 sessioninfo_1.2.3 conflicted_1.2.0
#> [22] janitor_2.2.1 matrixStats_1.5.0 modelr_0.1.11
#> [25] tibble_3.3.0 dplyr_1.1.4 tidyr_1.3.1
#> [28] rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] gridExtra_2.3 inline_0.3.21 sandwich_3.1-1
#> [4] rlang_1.1.6 magrittr_2.0.4 multcomp_1.4-29
#> [7] snakecase_0.11.1 compiler_4.5.2 vctrs_0.6.5
#> [10] pkgconfig_2.0.3 arrayhelpers_1.1-0 fastmap_1.2.0
#> [13] backports_1.5.0 labeling_0.4.3 rmarkdown_2.30
#> [16] purrr_1.2.0 xfun_0.54 cachem_1.1.0
#> [19] jsonlite_2.0.0 parallel_4.5.2 R6_2.6.1
#> [22] stringi_1.8.7 RColorBrewer_1.1-3 lubridate_1.9.4
#> [25] estimability_1.5.1 knitr_1.50 zoo_1.8-14
#> [28] Matrix_1.7-4 splines_4.5.2 timechange_0.3.0
#> [31] tidyselect_1.2.1 abind_1.4-8 yaml_2.3.12
#> [34] codetools_0.2-20 curl_7.0.0 pkgbuild_1.4.8
#> [37] lattice_0.22-7 bridgesampling_1.2-1 S7_0.2.1
#> [40] coda_0.19-4.1 evaluate_1.0.5 survival_3.8-3
#> [43] RcppParallel_5.1.11-1 pillar_1.11.1 tensorA_0.36.2.1
#> [46] checkmate_2.3.3 stats4_4.5.2 distributional_0.5.0
#> [49] generics_0.1.4 rprojroot_2.1.1 rstantools_2.5.0
#> [52] scales_1.4.0 xtable_1.8-4 glue_1.8.0
#> [55] emmeans_2.0.0 tools_4.5.2 mvtnorm_1.3-3
#> [58] grid_4.5.2 QuickJSR_1.8.1 colorspace_2.1-2
#> [61] nlme_3.1-168 cli_3.6.5 textshaping_1.0.4
#> [64] svUnit_1.0.8 viridisLite_0.4.2 Brobdingnag_1.2-9
#> [67] V8_8.0.1 gtable_0.3.6 digest_0.6.39
#> [70] TH.data_1.1-5 htmlwidgets_1.6.4 farver_2.1.2
#> [73] memoise_2.0.1 htmltools_0.5.9 lifecycle_1.0.4
#> [76] MASS_7.3-65