suppressPackageStartupMessages({
library(cmdstanr)
library(posterior)
library(bayesplot)
library(ggplot2)
library(dplyr)
library(tidyr)
library(purrr)
})
theme_set(theme_minimal(base_size = 12))
color_scheme_set("brightblue")
# Seed per riproducibilità
set.seed(42)
S <- 10000 # numero di simulazioniAppendice O — Controlli predittivi a priori
I controlli predittivi a priori (Prior Predictive Checks) permettono di valutare le implicazioni delle nostre scelte sui prior prima di osservare i dati. Il principio è il seguente: se le nostre distribuzioni a priori catturano in modo adeguato la conoscenza sul fenomeno in studio (prima di avere osservato i dati), allora i dati simulati generati da tali prior dovrebbero essere plausibili alla luce di tale conoscenza contestuale.
ConsiglioDomanda chiave
Le nostre prior generano dati che hanno senso nel contesto del problema? O producono scenari assurdi che sappiamo non poter accadere?
Questo controllo è essenziale perché prior mal calibrati possono:
- escludere regioni plausibili dello spazio dei parametri;
- assegnare probabilità elevata a scenari impossibili;
- influenzare indebitamente l’inferenza, soprattutto con pochi dati.
AttenzionePreparazione del Notebook
O.1 Logica dei controlli predittivi a priori
La procedura si articola in tre passi sequenziali:
- Campionamento dai prior: si estraggono \(S\) campioni dei parametri \(\theta^{(s)}\) dalle rispettive distribuzioni a priori \(p(\theta)\).
- Generazione di dati predetti: per ciascun set di parametri campionato \(\theta^{(s)}\), si generano dati simulati \(y^{(s)}\) secondo il modello probabilistico specificato \(p(y \mid \theta^{(s)})\).
- Valutazione di plausibilità: l’intera distribuzione dei dati simulati \(\{y^{(1)}, \dots, y^{(S)}\}\) viene confrontata con la conoscenza pre-esperimento del fenomeno, inclusi vincoli teorici o empirici (ad esempio, range possibili, ordine di grandezza atteso).
Se la distribuzione dei dati generati a priori include frequentemente valori che, sulla base della conoscenza del dominio, sono ritenuti manifestamente implausibili o impossibili, il problema risiede nella specificazione dei prior. Questo feedback è particolarmente prezioso perché avviene prima di osservare i dati reali, prevenendo così l’influenza inconsapevole dei dati stessi sulla scelta delle prior.
O.2 Caso 1: modello con distribuzione normale
Assumiamo che la variabile risposta segua una distribuzione normale: \(y_i \sim \mathcal{N}(\mu, \sigma)\).
O.2.1 Scenario A: prior eccessivamente diffusi
# Specificazione di prior con varianza molto ampia
set.seed(123)
S <- 10000 # Numero di simulazioni
mu_A <- rnorm(S, mean = 50, sd = 50) # Media con deviazione standard enorme (50)
sigma_A <- rexp(S, rate = 1/20) # Deviazione standard con media 20
y_A <- rnorm(S, mean = mu_A, sd = sigma_A) # Dati generatiO.2.2 Scenario B: prior debolmente informativi e ragionevoli
O.2.3 Confronto visivo dei due scenari
library(ggplot2)
library(dplyr)
dati_confronto <- bind_rows(
tibble(y = y_A, scenario = "A: Prior eccessivamente diffusi"),
tibble(y = y_B, scenario = "B: Prior debolmente informativi")
)
ggplot(dati_confronto, aes(x = y, fill = scenario)) +
geom_density(alpha = 0.5, adjust = 1.5) +
geom_vline(xintercept = c(0, 100), linetype = "dashed", color = "gray50", alpha = 0.7) +
annotate("rect", xmin = 0, xmax = 100, ymin = 0, ymax = Inf,
alpha = 0.05, fill = "gray") +
labs(
title = "Distribuzione predittiva a priori per un modello normale",
subtitle = "Confronto tra specificazioni di prior diverse",
x = "y (es. punteggio su scala 0-100)",
y = "Densità",
fill = "Scenario"
) +
theme_minimal() +
theme(legend.position = "bottom")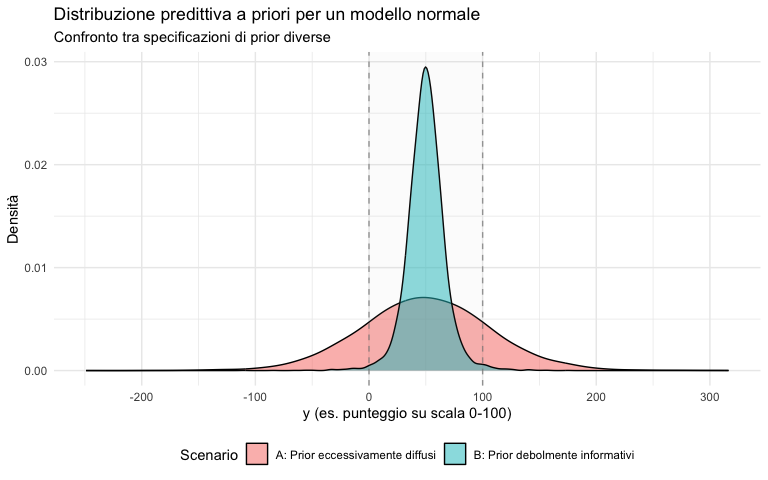
O.2.4 Interpretazione del confronto
Supponendo che la variabile \(y\) rappresenti un punteggio su una scala da 0 a 100:
Scenario A (prior diffusi): genera una proporzione sostanziale di valori al di fuori dell’intervallo [0, 100] (molti negativi e molti sopra 100). Questo indica che i prior, nella loro estrema diffusione, assegnano una probabilità non trascurabile a scenari che sappiamo essere impossibili (punteggi fuori scala).
Scenario B (prior debolmente informativi): la massa della distribuzione predittiva si concentra all’interno dell’intervallo plausibile. I prior permettono un’ampia variabilità (ad esempio, punteggi tra circa 20 e 80 sono tutti plausibili) ma escludono in modo efficace i valori impossibili.
L’obiettivo dei prior non è forzare meccanicamente i dati entro un campo di variazione predefinito, ma esprimere una conoscenza pregressa che, per coerenza logica, non dovrebbe rendere probabili scenari che il ricercatore sa essere impossibili. I controlli predittivi a priori rivelano quando questa coerenza viene violata.
O.2.5 Implementazione in Stan
Per i prior predictive checks, possiamo usare un modello Stan senza verosimiglianza:
gauss_prior_stan <- "
data {
int<lower=1> N;
}
parameters {
real mu;
real<lower=0> sigma;
}
model {
// Solo prior, nessuna verosimiglianza
mu ~ normal(50, 10);
sigma ~ exponential(0.1); // media = 10
}
generated quantities {
vector[N] y_rep;
for (i in 1:N) {
y_rep[i] = normal_rng(mu, sigma);
}
}
"mod_gauss <- cmdstanr::cmdstan_model(
cmdstanr::write_stan_file(gauss_prior_stan),
compile = TRUE
)
fit_gauss <- mod_gauss$sample(
data = list(N = 200),
chains = 4,
iter_warmup = 500,
iter_sampling = 1000,
seed = 123,
refresh = 0
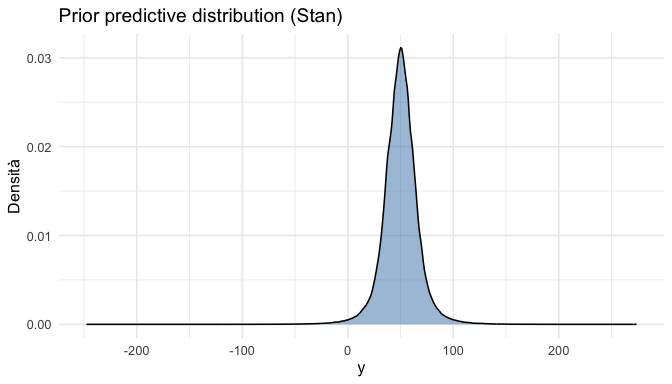
)y_rep_gauss <- as_draws_matrix(fit_gauss$draws("y_rep"))
as_tibble(y_rep_gauss) |>
pivot_longer(everything(), values_to = "y") |>
ggplot(aes(x = y)) +
geom_density(fill = "steelblue", alpha = 0.5) +
labs(
title = "Prior predictive distribution (Stan)",
x = "y",
y = "Densità"
)
O.3 Caso 2: Regressione lineare
Consideriamo il modello: \(y = \alpha + \beta x + \varepsilon\), con \(\varepsilon \sim \mathcal{N}(0, \sigma)\).
O.3.1 Importanza della scala
L’interpretazione dei prior dipende criticamente dalla scala delle variabili:
- se \(x\) è standardizzato (media 0, SD 1), allora \(\beta\) rappresenta la variazione in \(y\) per una SD di \(x\);
- un prior \(\beta \sim \mathcal{N}(0, 1)\) implica che effetti “moderati” sono più probabili, mentre effetti > 3 SD sono rari.
O.3.2 Scenario C: prior troppo larghi
O.3.3 Scenario D: prior debolmente informativi
O.3.4 Confronto
bind_rows(
tibble(y = y_C, scenario = "C: Prior molto larghi"),
tibble(y = y_D, scenario = "D: Prior debolmente informativi")
) |>
ggplot(aes(x = y, fill = scenario)) +
geom_density(alpha = 0.4) +
labs(
title = "Prior predictive: regressione lineare",
x = "Valori simulati di y",
y = "Densità"
) +
theme(legend.position = "bottom")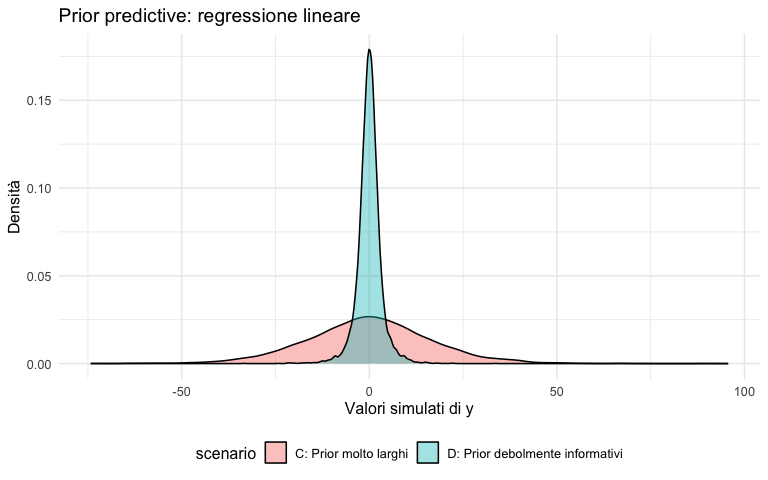
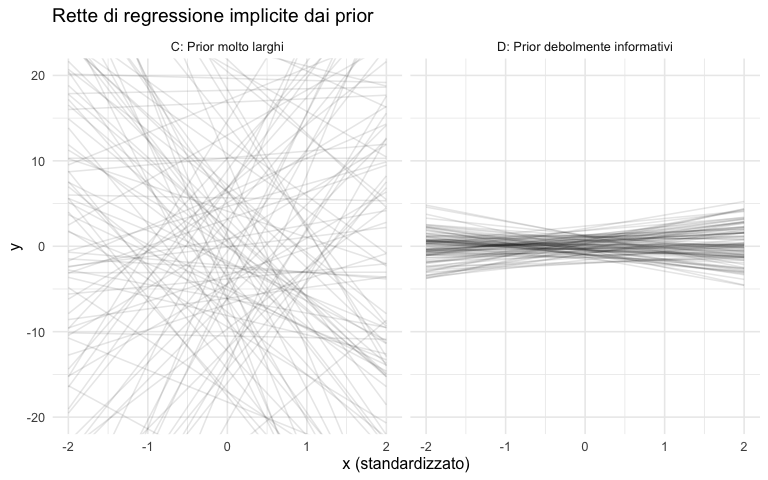
O.3.5 Visualizzare le rette di regressione
Un modo efficace per valutare i prior nella regressione è visualizzare le rette implicite:
x_grid <- seq(-2, 2, length.out = 100)
# Selezioniamo 100 linee per ciascuno scenario
n_lines <- 100
df_lines <- bind_rows(
# Scenario C
map_dfr(1:n_lines, function(i) {
tibble(
x = x_grid,
y = alpha_C[i] + beta_C[i] * x_grid,
line_id = i,
scenario = "C: Prior molto larghi"
)
}),
# Scenario D
map_dfr(1:n_lines, function(i) {
tibble(
x = x_grid,
y = alpha_D[i] + beta_D[i] * x_grid,
line_id = i,
scenario = "D: Prior debolmente informativi"
)
})
)
ggplot(df_lines, aes(x = x, y = y, group = line_id)) +
geom_line(alpha = 0.1) +
facet_wrap(~scenario) +
coord_cartesian(ylim = c(-20, 20)) +
labs(
title = "Rette di regressione implicite dai prior",
x = "x (standardizzato)",
y = "y"
)
O.3.6 Implementazione in Stan
linear_prior_stan <- "
data {
int<lower=1> N;
vector[N] x;
}
parameters {
real alpha;
real beta;
real<lower=0> sigma;
}
model {
alpha ~ normal(0, 1);
beta ~ normal(0, 1);
sigma ~ exponential(0.5);
}
generated quantities {
vector[N] y_rep;
for (i in 1:N) {
y_rep[i] = normal_rng(alpha + beta * x[i], sigma);
}
}
"mod_lin <- cmdstanr::cmdstan_model(
cmdstanr::write_stan_file(linear_prior_stan),
compile = TRUE
)
x_new <- runif(200, -2, 2)
fit_lin <- mod_lin$sample(
data = list(N = length(x_new), x = x_new),
chains = 4,
iter_warmup = 500,
iter_sampling = 1000,
seed = 123,
refresh = 0
)y_rep_lin <- as_draws_matrix(fit_lin$draws("y_rep"))
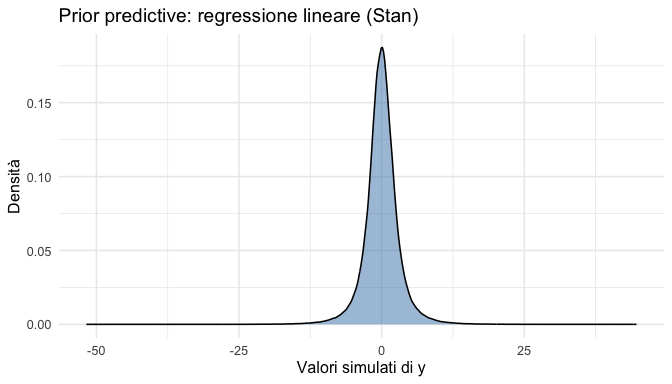
as_tibble(y_rep_lin) |>
pivot_longer(everything(), values_to = "y") |>
ggplot(aes(x = y)) +
geom_density(fill = "steelblue", alpha = 0.5) +
labs(
title = "Prior predictive: regressione lineare (Stan)",
x = "Valori simulati di y",
y = "Densità"
)
O.4 Caso 3: Regressione logistica
Nella regressione logistica, i parametri operano sulla scala logit:
\[ \text{logit}\, P(y=1 \mid x) = \alpha + \beta x. \]
La funzione logit ha una pendenza accentuata: differenze di 2-3 unità sulla scala logit corrispondono a variazioni da ~0.1 a ~0.9 nelle probabilità.
O.4.1 L’importanza critica dei prior
Con predittori standardizzati:
- \(\beta \sim \mathcal{N}(0, 1)\): effetti moderati, probabilità lontane dagli estremi;
- \(\beta \sim \mathcal{N}(0, 2.5)\): permette valori logit fino a ±5, cioè probabilità praticamente 0 o 1.
O.4.2 Scenario E: prior larghi
O.4.3 Scenario F: prior debolmente informativi
O.4.4 Confronto delle probabilità implicite
bind_rows(
tibble(p = p_E, scenario = "E: Prior larghi (SD = 2.5)"),
tibble(p = p_F, scenario = "F: Prior moderati (SD = 1)")
) |>
ggplot(aes(x = p, fill = scenario)) +
geom_density(alpha = 0.4) +
labs(
title = "Prior predictive: probabilità nella regressione logistica",
subtitle = "Distribuzione implicita di P(y=1|x)",
x = "Probabilità",
y = "Densità"
) +
theme(legend.position = "bottom")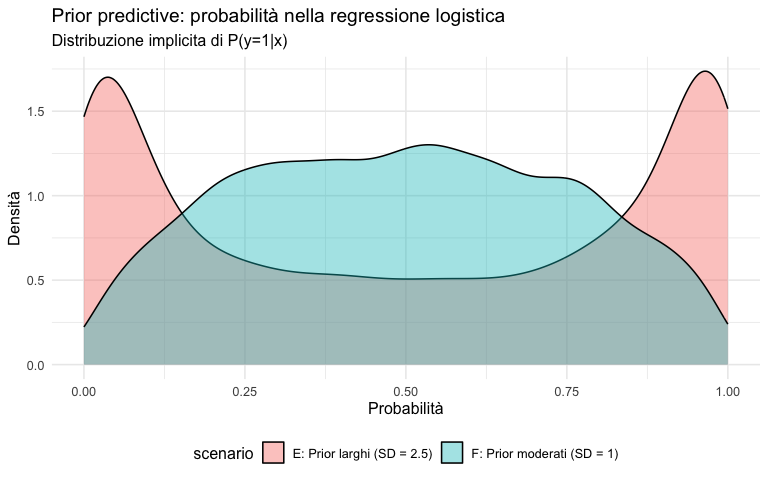
O.4.5 Interpretazione
- Scenario E: le probabilità sono frequentemente vicine a 0 o 1, implicando quasi-certezza;
- Scenario F: le probabilità si distribuiscono in un range più realistico (0.05-0.95).
AvvisoAttenzione
Prior troppo larghi nella regressione logistica equivalgono ad assumere, prima di vedere i dati, che siano probabili risposte quasi deterministiche. Questo è spesso incoerente con la variabilità tipica dei fenomeni psicologici.
O.4.6 Implementazione in Stan
logistic_prior_stan <- "
data {
int<lower=1> N;
vector[N] x;
}
parameters {
real alpha;
real beta;
}
model {
alpha ~ normal(0, 1);
beta ~ normal(0, 1);
}
generated quantities {
vector[N] p;
array[N] int y_rep;
for (i in 1:N) {
p[i] = inv_logit(alpha + beta * x[i]);
y_rep[i] = bernoulli_rng(p[i]);
}
}
"mod_log <- cmdstanr::cmdstan_model(
cmdstanr::write_stan_file(logistic_prior_stan),
compile = TRUE
)
x_new_log <- rnorm(300)
fit_log <- mod_log$sample(
data = list(N = length(x_new_log), x = x_new_log),
chains = 4,
iter_warmup = 500,
iter_sampling = 1000,
seed = 123,
refresh = 0
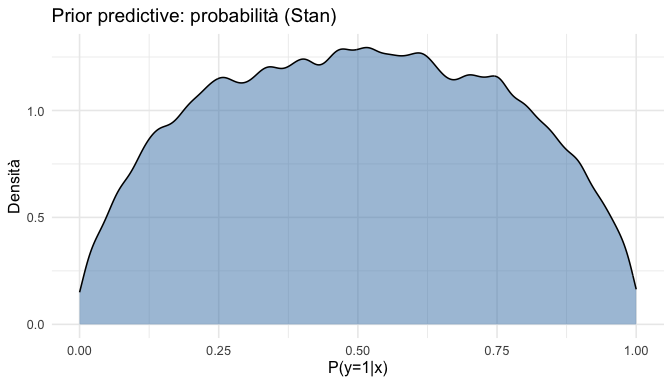
)p_draws <- as_draws_matrix(fit_log$draws("p"))
as_tibble(p_draws) |>
pivot_longer(everything(), values_to = "p") |>
ggplot(aes(x = p)) +
geom_density(fill = "steelblue", alpha = 0.5) +
labs(
title = "Prior predictive: probabilità (Stan)",
x = "P(y=1|x)",
y = "Densità"
)
O.5 Linee guida pratiche
O.5.1 1. Lavorare sulla scala appropriata
- Standardizzare i predittori quando possibile.
- Un prior \(\mathcal{N}(0, 1)\) su \(\beta\) ha un’interpretazione chiara con predittori standardizzati.
O.5.2 2. Prior per i coefficienti (\(\beta\))
| Prior | Interpretazione |
|---|---|
| \(\mathcal{N}(0, 0.5)\) | Effetti piccoli molto probabili |
| \(\mathcal{N}(0, 1)\) | Effetti moderati probabili |
| \(\mathcal{N}(0, 2)\) | Effetti grandi possibili |
O.5.3 3. Prior per l’intercetta (\(\alpha\))
- Outcome continui: centrare \(y\) rende \(\alpha\) più interpretabile.
- Outcome binari: \(\mathcal{N}(0, 1.5)\) implica probabilità base tra ~0.05 e ~0.95.
O.5.4 4. Prior per la dispersione (\(\sigma\))
- Usare distribuzioni positive (Half-Normal, Exponential, Gamma).
- Calibrare il parametro di scala sulla variabilità attesa del fenomeno.
O.5.5 5. Scale non lineari (logit, log)
- Non interpretare solo sulla scala trasformata: convertire sempre nelle scale naturali.
- Tradurre coefficienti logit in probabilità, coefficienti log in tassi.
O.5.6 6. Documentare il processo
Tenere traccia di:
- quali prior sono stati considerati;
- perché sono stati modificati;
- quali prior predictive checks sono stati eseguiti.
NotaWorkflow per i prior predictive checks
- Definire i prior basandosi sulla conoscenza del dominio.
-
Simulare dati usando solo i prior (in R o in Stan con
fixed_param = TRUE). -
Valutare la plausibilità:
- i valori sono nell’ordine di grandezza corretto?
- scenari assurdi (valori negativi per scale positive, probabilità estreme) sono esclusi?
- Iterare se necessario, modificando i prior.
- Documentare le scelte e le motivazioni.
Riflessioni conclusive
I controlli predittivi a priori rappresentano un esercizio di coerenza logica che permette di valutare se le assunzioni iniziali incorporate nel modello siano ragionevoli, in totale indipendenza dai dati che verranno successivamente osservati. Questa pratica è fondamentale per le seguenti ragioni:
- Ottimizzazione delle risorse: identificare specificazioni a priori problematiche in una fase preliminare previene l’investimento di tempo e risorse computazionali in analisi basate su presupposti incoerenti.
- Trasparenza metodologica: documentare esplicitamente la scelta e la validazione dei prior attraverso simulazioni predittive aumenta la riproducibilità dell’analisi e consente una revisione critica del processo di modellazione.
- Efficienza inferenziale: prior calibrati in modo appropriato migliorano la stabilità numerica dell’algoritmo di campionamento, favoriscono la convergenza delle catene MCMC e riducono l’autocorrelazione.
L’obiettivo non è imporre vincoli arbitrariamente stretti o “costringere” i dati a rientrare in un intervallo predefinito. Piuttosto, si tratta di garantire che la distribuzione a priori non assegni una massa di probabilità significativa a regioni dello spazio dei parametri o dei dati predetti che, in base alla conoscenza del dominio, sono ritenute impossibili o estremamente implausibili.
Un insieme di distribuzioni a priori può essere considerato ben specificato quando:
- non esclude a priori valori del parametro che sono teoricamente plausibili;
- non assegna una probabilità eccessiva a scenari che contraddicono la conoscenza consolidata sul fenomeno;
- esprime, con un’appropriata misura di incertezza, la migliore comprensione disponibile prima della raccolta dei dati.
I controlli predittivi a priori costituiscono quindi il primo passo fondamentale nel flusso di lavoro dell’inferenza bayesiana, precedendo persino la raccolta dei dati. Questi controlli forniscono un feedback critico sulla coerenza logica del modello stesso. Questo processo viene completato, dopo aver osservato i dati, dai controlli predittivi a posteriori (descritti in Appendice P), che valutano l’adeguatezza del modello alla luce dell’evidenza empirica.
NotaInformazioni sull’ambiente di sviluppo
R version 4.5.2 (2025-10-31)
Platform: aarch64-apple-darwin20
Running under: macOS Tahoe 26.2
Matrix products: default
BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
locale:
[1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
time zone: Europe/Rome
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] purrr_1.2.0 tidyr_1.3.1 dplyr_1.1.4 ggplot2_4.0.1
[5] bayesplot_1.14.0 posterior_1.6.1 cmdstanr_0.8.0
loaded via a namespace (and not attached):
[1] gtable_0.3.6 jsonlite_2.0.0 compiler_4.5.2
[4] tidyselect_1.2.1 scales_1.4.0 yaml_2.3.12
[7] fastmap_1.2.0 R6_2.6.1 labeling_0.4.3
[10] generics_0.1.4 distributional_0.5.0 knitr_1.50
[13] htmlwidgets_1.6.4 backports_1.5.0 checkmate_2.3.3
[16] tibble_3.3.0 pillar_1.11.1 RColorBrewer_1.1-3
[19] rlang_1.1.6 xfun_0.54 S7_0.2.1
[22] cli_3.6.5 withr_3.0.2 magrittr_2.0.4
[25] ps_1.9.1 digest_0.6.39 grid_4.5.2
[28] processx_3.8.6 lifecycle_1.0.4 vctrs_0.6.5
[31] data.table_1.17.8 evaluate_1.0.5 glue_1.8.0
[34] tensorA_0.36.2.1 farver_2.1.2 abind_1.4-8
[37] rmarkdown_2.30 tools_4.5.2 pkgconfig_2.0.3
[40] htmltools_0.5.9