here::here("code", "_common.R") |>
source()
# Funzione per il calcolo dei termini della divergenza KL
kl_terms <- function(p, q) {
stopifnot(length(p) == length(q))
non_zero <- p > 0 & q > 0
p <- p[non_zero]
q <- q[non_zero]
term <- p * log2(p / q)
data.frame(x = seq_along(p), p = p, q = q, term = term)
}
# Funzione compatta per il valore totale
kl_divergence <- function(p, q) {
sum(kl_terms(p, q)$term)
}
# Entropia vera (in bit)
entropy <- function(p) {
p <- p[p > 0]
-sum(p * log2(p))
}
# Entropia incrociata (in bit)
cross_entropy <- function(p, q) {
non_zero <- p > 0 & q > 0
p <- p[non_zero]
q <- q[non_zero]
-sum(p * log2(q))
}44 La divergenza di Kullback-Leibler
Panoramica del capitolo
- L’entropia incrociata come ponte tra entropia e \(D_{\text{KL}}\).
- La definizione e l’interpretazione della \(D_{\text{KL}}\).
- Perché la \(D_{\text{KL}}\) non è simmetrica e cosa significa.
- Come usare la \(D_{\text{KL}}\) per confrontare modelli statistici.
- Il collegamento con gli strumenti pratici (LOO, ELPD) che vedremo nel prossimo capitolo.
ConsiglioPrerequisiti
- Per comprendere appieno questo capitolo, dovresti aver già appreso i concetti di entropia e informazione di Shannon (Capitolo 43).
AttenzionePreparazione del Notebook
44.1 Il problema della generalizzabilità
Prima di introdurre formalmente la divergenza di Kullback–Leibler, è utile chiarire la motivazione epistemologica che ne giustifica l’uso. Uno degli obiettivi centrali della scienza non è soltanto descrivere i dati già osservati, ma formulare modelli che siano generalizzabili, cioè capaci di produrre previsioni affidabili su fenomeni non ancora osservati.
Questa esigenza introduce una tensione strutturale nella modellizzazione statistica:
- se un modello è troppo semplice, sottostima la struttura del fenomeno (underfitting): ignora relazioni sistematiche e pattern rilevanti presenti nei dati, fallendo sia nella spiegazione sia nella previsione;
- se un modello è troppo complesso, sovrastima ciò che ha osservato (overfitting): aderisce così strettamente ai dati disponibili da incorporare non solo le regolarità autentiche, ma anche il rumore statistico e le idiosincrasie del campione, compromettendo la capacità di generalizzare a nuovi dati.
La questione decisiva diventa quindi: come stabilire se un modello stia catturando la struttura genuina del fenomeno, piuttosto che adattarsi alle fluttuazioni accidentali del campione osservato?
Una risposta naturale consiste nello spostare l’attenzione dal criterio “quanto bene il modello descrive i dati osservati” a un criterio più fondamentale: “quanto il modello si avvicina alla distribuzione che ha generato quei dati”. In questo senso, il problema della generalizzabilità può essere riformulato come un problema di distanza informativa tra il modello e la realtà.
È precisamente questa distanza che la divergenza di Kullback–Leibler consente di quantificare. Essa fornisce uno strumento per valutare se un modello stia rappresentando le regolarità informative del processo generatore dei dati oppure se stia codificando informazione spurie, destinate a non ripresentarsi nei dati futuri.
44.2 Dall’entropia all’entropia incrociata
Per arrivare alla divergenza di Kullback–Leibler è utile introdurre un passaggio intermedio fondamentale: l’entropia incrociata (cross-entropy).
44.2.1 Ripasso: entropia come limite di codifica
Abbiamo visto che l’entropia \(H(P)\) di una distribuzione \(P\) rappresenta la lunghezza media minima, espressa in bit, necessaria per codificare in modo efficiente messaggi generati da \(P\). In altre parole, se la distribuzione vera è nota, è possibile costruire un codice ottimale (ad esempio tramite la codifica di Huffman) che si avvicina asintoticamente a questo limite teorico.
Formalmente, per una variabile discreta:
\[ H(P) = -\sum_x p(x),\log_2 p(x). \] Questa quantità stabilisce un limite inferiore: nessun codice privo di perdite può ottenere, in media, una lunghezza inferiore a \(H(P)\) bit per simbolo.
44.2.2 Quando il modello è sbagliato
Nella pratica scientifica, tuttavia, la distribuzione vera \(P\) che genera i dati è sconosciuta. Disponiamo soltanto di un modello approssimato \(Q\), che riteniamo una rappresentazione plausibile del processo sottostante. Se costruiamo un codice ottimale per \(Q\) e lo utilizziamo per codificare dati che in realtà provengono da \(P\), la codifica non sarà più ottimale: spenderemo più bit del necessario.
Un esempio chiarisce l’idea. Supponiamo che la distribuzione vera \(P\) assegni probabilità:
- evento A: \(p(A)=0.9\) (molto frequente);
- evento B: \(p(B)=0.1\) (raro).
Un codice ottimale per \(P\) assegnerebbe a A un codice molto breve, dato che compare quasi sempre. Se invece credessimo erroneamente che A e B siano equiprobabili (\(Q\): \(0.5\)–\(0.5\)), assegneremmo codici di lunghezza simile a entrambi. Il risultato è uno spreco sistematico di bit, poiché l’evento più frequente viene codificato in modo inefficiente.
44.2.3 Definizione dell’entropia incrociata
L’entropia incrociata quantifica esattamente questa inefficienza. Essa è definita come la lunghezza media del codice quando i dati seguono la distribuzione \(P\), ma il codice è costruito assumendo che la distribuzione sia \(Q\):
\[ H(P,Q) = -\sum_x p(x), \log_2 q(x). \]
La struttura della formula rende esplicito il meccanismo sottostante: le probabilità \(p(x)\) pesano gli eventi secondo la loro frequenza reale, mentre i logaritmi di \(q(x)\) riflettono le lunghezze dei codici progettati sulla base del modello \(Q\).
44.2.4 Proprietà essenziale
L’entropia incrociata soddisfa sempre la disuguaglianza
\[ H(P,Q) \ge H(P), \] dove l’uguaglianza vale se e solo se \(P = Q\).
Interpretazione operativa:
- quando \(Q = P\), utilizziamo il codice ottimale e non sprechiamo alcun bit: \(H(P, P) = H(P)\);
- quando \(Q \neq P\), utilizziamo un codice subottimale che assegna lunghezze non ideali agli eventi: \(H(P, Q) > H(P)\);
- la differenza \(H(P, Q) - H(P)\) quantifica quindi lo spreco informativo medio dovuto all’uso di un modello imperfetto.
44.2.5 Significato concettuale
Questa proprietà stabilisce un limite prestazionale fondamentale: nessuna strategia di codifica basata su un modello approssimato può essere più efficiente di quella costruita conoscendo esattamente la distribuzione vera. In questo senso, l’entropia incrociata misura il costo della nostra ignoranza: il prezzo, in bit aggiuntivi, che paghiamo quando utilizziamo un modello \(Q\) al posto della distribuzione reale \(P\).
Nel prossimo passo vedremo che questo costo può essere isolato in modo preciso, portando alla definizione della divergenza di Kullback–Leibler come differenza tra entropia incrociata ed entropia vera.
44.3 La divergenza di Kullback-Leibler
44.3.1 Definizione formale
La divergenza di Kullback–Leibler (\(D_{\text{KL}}\)) quantifica lo spreco informativo introdotto quando utilizziamo un modello approssimato \(Q\) al posto della distribuzione vera \(P\). Come anticipato nella sezione precedente, essa emerge naturalmente come la differenza tra l’entropia incrociata e l’entropia vera:
\[ D_{\text{KL}}(P \parallel Q) = H(P, Q) - H(P). \tag{44.1}\]
Sostituendo le definizioni di entropia incrociata ed entropia, otteniamo:
\[ D_{\text{KL}}(P \parallel Q) = -\sum_x p(x)\,\log_2 q(x) + \sum_x p(x)\,\log_2 p(x), \] che può essere riscritta nella forma canonica:
\[ D_{\text{KL}}(P \parallel Q) = \sum_x p(x)\,\log_2 \frac{p(x)}{q(x)}. \tag{44.2}\]
Questa espressione rende esplicito il confronto punto per punto tra la distribuzione reale \(P\) e il modello \(Q\): per ciascun evento \(x\), si valuta quanto la probabilità assegnata da \(Q\) si discosti da quella assegnata da \(P\), pesando tale scarto in base alla frequenza reale dell’evento.
44.3.2 Tre prospettive interpretative
La divergenza di Kullback–Leibler può essere interpretata in tre modi complementari, che ne chiariscono il significato operativo.
1. Inefficienza di codifica. La \(D_{\text{KL}}(P \parallel Q)\) rappresenta il numero medio di bit aggiuntivi necessari per codificare messaggi generati da \(P\) utilizzando un codice ottimizzato per \(Q\) invece che per \(P\). Essa misura quindi l’inefficienza introdotta da un modello di codifica non ottimale.
2. Eccesso di sorpresa. La \(D_{\text{KL}}\) può essere vista come il valore atteso della differenza tra la sorpresa effettiva degli eventi (secondo \(P\)) e la sorpresa prevista dal modello \(Q\). Quando \(Q\) è impreciso, gli eventi osservati risultano sistematicamente più (o meno) sorprendenti di quanto previsto; la divergenza quantifica precisamente questo eccesso medio di sorpresa.
3. Perdita informativa. Dal punto di vista statistico, la \(D_{\text{KL}}\) misura quanta informazione viene persa quando la realtà descritta da \(P\) viene approssimata mediante il modello \(Q\). In questo senso, essa fornisce una misura diretta dell’inadeguatezza informazionale di un modello rispetto al processo generatore dei dati.
44.3.3 Proprietà fondamentali
La divergenza di Kullback–Leibler possiede alcune proprietà matematiche essenziali che ne definiscono il comportamento.
Non-negatività. Per ogni coppia di distribuzioni \(P\) e \(Q\) vale
\[ D_{\text{KL}}(P \parallel Q) \ge 0, \]
con uguaglianza se e solo se \(P = Q\). Questa proprietà implica che nessun modello approssimato può essere, in media, più efficiente del modello vero: qualsiasi deviazione da \(P\) introduce inevitabilmente un costo informativo.
44.3.4 Asimmetria
\[ D_{\text{KL}}(P \parallel Q) \neq D_{\text{KL}}(Q \parallel P). \]
Questa asimmetria non è un dettaglio tecnico, ma riflette una distinzione concettuale cruciale nel confronto tra modelli:
- la divergenza “in avanti” \(D_{\text{KL}}(P \parallel Q)\) penalizza fortemente i casi in cui il modello \(Q\) assegna probabilità molto basse (o nulle) a eventi che, secondo \(P\), sono invece probabili. È quindi particolarmente sensibile alla sottostima di eventi rilevanti;
- la divergenza “inversa” \(D_{\text{KL}}(Q \parallel P)\) penalizza invece il fatto che \(Q\) assegni probabilità positiva a eventi che, secondo \(P\), non dovrebbero verificarsi. In questo caso, la misura è più sensibile alla sovrastima di eventi impossibili o estremamente improbabili.
Questa differenza rende la direzione della divergenza una scelta concettuale, non puramente formale, e riflette il ruolo asimmetrico tra realtà (\(P\)) e modello (\(Q\)).
Invarianza rispetto a trasformazioni invertibili. La \(D_{\text{KL}}\) rimane invariata sotto trasformazioni reversibili dei dati. Ad esempio, una conversione di unità di misura (da centimetri a pollici) non altera il valore della divergenza. Ciò garantisce che la misura catturi una differenza intrinseca tra le distribuzioni, indipendente dalla loro rappresentazione.
Dipendenza dalla base logaritmica. Il valore numerico della \(D_{\text{KL}}\) dipende dalla base del logaritmo utilizzato. Con il logaritmo in base 2 la divergenza è misurata in bit; con il logaritmo naturale è misurata in nat. Questa scelta influisce solo su una costante di scala e non altera i confronti qualitativi tra modelli.
Non è una metrica. Nonostante il nome, la \(D_{\text{KL}}\) non è una distanza matematica. Essa non è simmetrica e non soddisfa la disuguaglianza triangolare. Va quindi interpretata non come una distanza geometrica, ma come una misura direzionale di disaccordo informazionale, che quantifica il costo di utilizzare \(Q\) come approssimazione di \(P\).
NotaPerché la KL non è simmetrica
L’asimmetria della \(D_{\text{KL}}\) è una delle sue caratteristiche più profonde e, inizialmente, può risultare sorprendente. Tuttavia, non si tratta di una stranezza matematica, ma di un principio fondamentale della modellazione statistica. Confrontare un modello con la realtà non è come misurare la distanza tra due punti su una mappa; è un’operazione intrinsecamente direzionale, poiché il costo degli errori dipende dalla direzione in cui li commettiamo.
Due domande fondamentali, due risposte diverse.
La scelta dell’ordine degli argomenti in \(D_{\text{KL}}(P \parallel Q)\) corrisponde a porre due domande concettualmente diverse:
- \(D_{\text{KL}}(P \parallel Q)\): “Qual è il costo di agire nel mondo governato da \(P\) credendo che valga \(Q\)?”;
- \(D_{\text{KL}}(Q \parallel P)\): “Qual è il costo di agire nel mondo governato da \(Q\) credendo che valga \(P\)?”.
Nella ricerca scientifica, solo la prima domanda è rilevante: il nostro universo è regolato dalla distribuzione vera \(P\) (anche se ignota), e disponiamo solo di un modello approssimato \(Q\). L’obiettivo è quantificare il prezzo della nostra conoscenza imperfetta.
Esempio pratico: modello troppo semplice.
Consideriamo un esempio discreto e binario per semplicità:
- \(P = [0.9, 0.1]\) — La realtà: un evento comune e uno raro.
- \(Q = [0.5, 0.5]\) — Il nostro modello: un’approssimazione ingenua di equiprobabilità.
Interpretazione:
\(D_{\text{KL}}(P \parallel Q) \approx 0.531\) bit: rappresenta il costo reale dell’errore. Il modello \(Q\) assegna una probabilità troppo bassa all’evento più frequente, costringendoci a un codice inefficiente. Questo è il costo della sottostima.
\(D_{\text{KL}}(Q \parallel P) \approx 0.368\) bit: descrive uno scenario controfattuale. Se la realtà fosse \(Q\) ma noi usassimo \(P\), l’inefficienza sarebbe minore. Questo è il costo della sovrastima, inferiore perché il modello non penalizza così severamente la previsione di eventi frequenti.
La regola generale: sottostimare è più costoso che sovrastimare.
La discrepanza numerica evidenzia un principio generale della modellazione probabilistica: sottostimare la probabilità di un evento frequente ha conseguenze più gravi che sovrastimarla. Questo perché l’errore viene “pagato” ogni volta che l’evento si verifica, amplificando l’impatto dello sbaglio. Questo principio spiega perché, nella valutazione dei modelli, penalizziamo severamente quelli che non assegnano sufficiente probabilità agli eventi che accadono spesso.
44.4 Calcolo dettagliato della divergenza KL
Per consolidare la comprensione della \(D_{\text{KL}}\), esaminiamo due esempi numerici che mostrano passo passo come i singoli eventi contribuiscono al costo complessivo di un modello imperfetto.
NotaEsempio 1: scomposizione dei contributi evento-specifici
Consideriamo una variabile categoriale con tre possibili esiti:
| Esito | \(P\) (distribuzione vera) | \(Q\) (modello) |
|---|---|---|
| A | 0.5 | 0.4 |
| B | 0.3 | 0.4 |
| C | 0.2 | 0.2 |
Passo 1: Rapporto tra probabilità
Per ogni esito calcoliamo \(\frac{p(x)}{q(x)}\):
- A: (0.5 / 0.4 = 1.25) → il modello sottostima la probabilità dell’evento;
- B: (0.3 / 0.4 = 0.75) → il modello sovrastima;
- C: (0.2 / 0.2 = 1.00) → perfetta calibrazione.
Passo 2: Trasformazione logaritmica
Applichiamo \(\log_2\) per ottenere il contributo in bit:
- A: \(\log_2(1.25) \approx 0.322\) bit;
- B: \(\log_2(0.75) \approx -0.415\) bit;
- C: \(\log_2(1.00) = 0\) bit.
Passo 3: Ponderazione per la frequenza reale
Moltiplichiamo per la probabilità reale (P) per ottenere il contributo medio:
- A: \(0.5 \times 0.322 = 0.161\) bit;
- B: \(0.3 \times (-0.415) = -0.125\) bit;
- C: \(0.2 \times 0 = 0\) bit.
Passo 4: Somma totale
\[ D_{\text{KL}}(P \parallel Q) = 0.161 - 0.125 + 0 = 0.036 \text{ bit}. \]
Interpretazione:
- l’evento A contribuisce maggiormente al costo informativo perché è frequente e sottostimato;
- l’evento B produce un “risparmio” limitato perché meno frequente;
- l’evento C non contribuisce, essendo perfettamente previsto.
Il risultato complessivo indica una discrepanza informativa minima, coerente con la somiglianza tra \(P\) e \(Q\).
P <- c(0.5, 0.3, 0.2)
Q <- c(0.4, 0.4, 0.2)
df <- data.frame(
esito = c("A", "B", "C"),
p = P,
q = Q,
rapporto = P / Q,
log_rapporto = log2(P / Q),
contributo = P * log2(P / Q)
)
print(df)
#> esito p q rapporto log_rapporto contributo
#> 1 A 0.5 0.4 1.25 0.322 0.161
#> 2 B 0.3 0.4 0.75 -0.415 -0.125
#> 3 C 0.2 0.2 1.00 0.000 0.000
cat("\nDivergenza KL totale:", round(sum(df$contributo), 4), "bit\n")
#>
#> Divergenza KL totale: 0.0365 bit
NotaEsempio 2: verifica della coerenza matematica
Consideriamo ora \(P = [0.1, 0.6, 0.3]\) e \(Q = [0.2, 0.5, 0.3]\). Vogliamo verificare la coerenza della definizione \(D_{\text{KL}} = H(P,Q) - H(P)\).
P <- c(0.1, 0.6, 0.3)
Q <- c(0.2, 0.5, 0.3)
df_kl <- data.frame(
esito = c("A", "B", "C"),
p = P,
q = Q,
rapporto = P / Q,
log_rapporto = log2(P / Q),
contributo = P * log2(P / Q)
)
print(df_kl)
#> esito p q rapporto log_rapporto contributo
#> 1 A 0.1 0.2 0.5 -1.000 -0.100
#> 2 B 0.6 0.5 1.2 0.263 0.158
#> 3 C 0.3 0.3 1.0 0.000 0.000
# Divergenza totale
kl_total <- sum(df_kl$contributo)
cat("\nDivergenza KL calcolata direttamente:", round(kl_total, 4), "bit\n")
#>
#> Divergenza KL calcolata direttamente: 0.0578 bit
# Verifica con entropia incrociata
H_cross <- -sum(P * log2(Q))
H_P <- -sum(P * log2(P))
cat("Verifica (H(P,Q) - H(P)):", round(H_cross - H_P, 4), "bit\n")
#> Verifica (H(P,Q) - H(P)): 0.0578 bitL’uguaglianza conferma che la \(D_{\text{KL}}\) può essere interpretata sia come somma dei contributi evento-specifici sia come differenza tra entropia incrociata ed entropia reale.
Osservazione: anche se singoli eventi possono avere contributi negativi (quando il modello sovrastima la probabilità), la somma totale è sempre non negativa. Nessun modello imperfetto può essere più efficiente della conoscenza perfetta della distribuzione reale; i “risparmi” locali sono sempre compensati dai costi globali.
44.5 La divergenza KL nella selezione dei modelli
44.5.1 Principio fondamentale: scegliere l’approssimazione più fedele
In statistica, un principio fondamentale per la selezione dei modelli afferma che, in linea di principio, tra tutti i modelli candidati è preferibile quello che minimizza la divergenza di Kullback–Leibler rispetto alla distribuzione vera dei dati.
Formalmente, se \(P\) rappresenta il processo generatore reale dei dati e \(Q\) una distribuzione approssimante (il modello), il modello ottimale è definito come:
\[ Q_{\text{ottimale}} = \arg\min_{Q} D_{\text{KL}}(P \parallel Q). \]
Questo criterio ha un’interpretazione profonda: il modello ottimale è quello che, in media, introduce la minore perdita informativa quando viene utilizzato al posto di \(P\). Equivalentemente, è il modello che spreca meno bit nella codifica degli eventi reali, genera meno sorpresa inattesa rispetto alle aspettative corrette e cattura più fedelmente la struttura informazionale del fenomeno osservato. Minimizzare la \(D_{\text{KL}}\) equivale quindi a scegliere la rappresentazione informativamente più economica della realtà sottostante.
44.5.2 Il paradosso: minimizzare l’ignoto
Sorge però immediatamente una difficoltà concettuale: come possiamo minimizzare la divergenza rispetto a \(P\) se \(P\) è ignota? La distribuzione vera che ha generato i dati è proprio l’oggetto dell’inferenza statistica. A prima vista, il criterio sembra circolare: per scegliere il miglior modello dovremmo conoscere la realtà, ma per conoscere la realtà abbiamo bisogno di un modello.
44.5.3 La soluzione: confrontare i modelli senza conoscere \(P\)
La soluzione a questo apparente paradosso emerge da una semplice ma cruciale scomposizione della divergenza di Kullback–Leibler:
\[ D_{\text{KL}}(P \parallel Q) = H(P, Q) - H(P), \]
dove \(H(P, Q)\) è l’entropia incrociata e \(H(P)\) è l’entropia della distribuzione vera.
Il termine \(H(P)\) rappresenta l’incertezza intrinseca e irriducibile del processo generatore dei dati ed è indipendente dalla scelta del modello. Di conseguenza, quando confrontiamo due modelli candidati \(Q_1\) e \(Q_2\), otteniamo:
\[ D_{\text{KL}}(P \parallel Q_1) - D_{\text{KL}}(P \parallel Q_2) = \big[H(P, Q_1) - H(P)\big] - \big[H(P, Q_2) - H(P)\big] = H(P, Q_1) - H(P, Q_2). \]
Il termine \(H(P)\) si elide completamente. Questo risultato è fondamentale: per confrontare due modelli in termini di aderenza informazionale alla realtà, non è necessario conoscere \(P\). È sufficiente confrontare le rispettive entropie incrociate, quantità che possono essere stimate empiricamente dai dati osservati, sebbene con un’incertezza dovuta al campionamento finito.
44.5.4 Stima empirica della divergenza KL
L’entropia incrociata \(H(P, Q)\) può essere stimata a partire dai dati osservati come la media del logaritmo della verosimiglianza del modello \(Q\) sui dati:
\[ H(P, Q) \approx -\frac{1}{n} \sum_{i=1}^n \log_2 q(x_i), \] dove \(x_1, \dots, x_n\) rappresentano il campione osservato e \(q(x_i)\) è la densità (o massa) di probabilità assegnata dal modello \(Q\) all’osservazione \(x_i\).
Questa quantità è, a segno cambiato, la log-verosimiglianza media del modello. Essa costituisce il fondamento di numerosi criteri pratici per la selezione e la validazione dei modelli:
- il log-score (o log-verosimiglianza campionaria), che misura quanto bene il modello descrive i dati osservati;
- l’Expected Log Predictive Density (ELPD), che estende questo concetto alla previsione out-of-sample;
- la Leave-One-Out Cross-Validation (LOO-CV), che fornisce una stima robusta dell’ELPD utilizzando esclusivamente i dati disponibili.
In questo modo, il criterio teorico di minimizzazione della divergenza di Kullback–Leibler si traduce in strumenti operativi che permettono di confrontare modelli senza accesso diretto alla distribuzione vera, mantenendo come obiettivo ultimo la massima capacità di generalizzazione.
44.5.5 Visualizzazione: confronto tra modelli candidati
(Nel grafico seguente la distribuzione \(P\) è nota solo a scopo illustrativo.)
# Distribuzione vera (nota solo a scopo illustrativo)
P <- c(0.1, 0.3, 0.4, 0.2)
# Modelli candidati
Q1 <- c(0.15, 0.25, 0.40, 0.20) # buona approssimazione
Q2 <- c(0.25, 0.25, 0.25, 0.25) # modello uniforme
# Calcolo delle divergenze KL
kl_1 <- kl_divergence(P, Q1)
kl_2 <- kl_divergence(P, Q2)
# Preparazione dati per il grafico
df <- data.frame(
esito = rep(c("A", "B", "C", "D"), 3),
distribuzione = rep(c("P (vera)", "Q1 (buona)", "Q2 (uniforme)"), each = 4),
probabilità = c(P, Q1, Q2)
)
ggplot(df, aes(x = esito, y = probabilità, fill = distribuzione)) +
geom_col(position = "dodge", width = 0.7) +
labs(
title = "Selezione del modello basata sulla divergenza KL",
subtitle = sprintf("D_KL(P||Q1) = %.3f bit | D_KL(P||Q2) = %.3f bit", kl_1, kl_2),
x = "Esito",
y = "Probabilità",
fill = "Distribuzione",
caption = "Q1 cattura meglio la struttura di P, Q2 paga un costo informativo maggiore"
) +
scale_fill_manual(values = c("P (vera)" = "#2c7bb6",
"Q1 (buona)" = "#1a9641",
"Q2 (uniforme)" = "#d7191c")) +
theme_minimal() 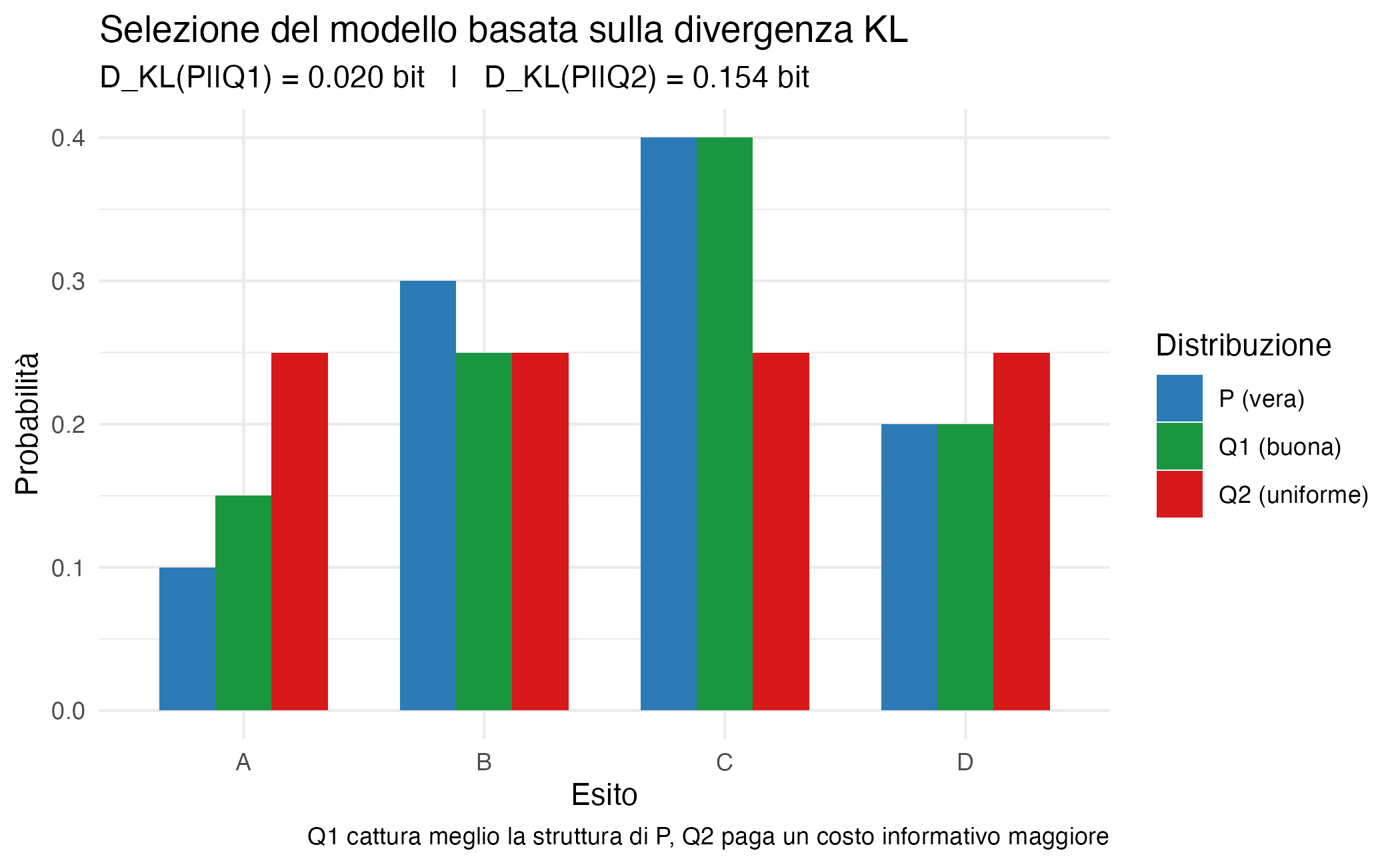
Interpretazione. Il modello \(Q_1\), con divergenza KL minore, cattura le principali regolarità di \(P\), mentre \(Q_2\) non riconosce le asimmetrie della distribuzione reale e paga un costo informativo maggiore. Questo esempio rende visibile il principio secondo cui la selezione del modello è, in ultima analisi, una questione di perdita informativa.
NotaEsempio psicologico: modelli per l’ansia
Per ancorare i concetti astratti della teoria dell’informazione alla pratica della ricerca psicologica, consideriamo uno scenario tipico di modellazione in psicologia clinica.
Il contesto di ricerca.
Immaginiamo che uno psicologo clinico voglia sviluppare un modello per descrivere e prevedere la distribuzione dei livelli di ansia — categorizzati in bassa, media e alta — tra studenti universitari durante il periodo degli esami. Sulla base di dati osservativi, intende confrontare due modelli concorrenti.
Il Modello A è parsimonioso e utilizza come unico predittore il punteggio individuale nelle strategie di coping. Il Modello B è più complesso e integra, oltre al coping, una misura del supporto sociale percepito.
Distribuzioni predittive (scenario illustrativo).
A scopo puramente illustrativo, supponiamo che la distribuzione vera dei livelli di ansia nella popolazione sia:
\[ P = [0.30, 0.45, 0.25]. \]
Il Modello A produce la distribuzione predittiva:
\[ Q_A = [0.35, 0.40, 0.25]. \]
mentre il Modello B genera: \[ Q_B = [0.32, 0.43, 0.25]. \] (In una situazione reale, la distribuzione \(P\) non sarebbe osservabile; qui è nota solo per chiarire il significato della divergenza KL.)
#> Divergenza KL - Modello A (solo coping): 0.0097 bit
#> Divergenza KL - Modello B (coping + supporto): 0.0016 bit
#>
#> Differenza: 0.0082 bit a favore del Modello B44.5.6 Interpretazione dei risultati
Confronto informazionale.
Il calcolo della divergenza di Kullback–Leibler mostra che:
- il Modello B presenta una \(D_{\text{KL}}\) leggermente inferiore;
- il vantaggio informazionale è reale ma modesto (circa 0.003 bit).
Dal punto di vista teorico, ciò indica che il Modello B approssima meglio la distribuzione generatrice dei dati. Tuttavia, l’entità del miglioramento è minima.
Visualizzazione del confronto.
df <- data.frame(
livello_ansia = rep(c("Bassa", "Media", "Alta"), 3),
modello = rep(c("Distribuzione Vera P", "Modello A (coping)", "Modello B (coping + supporto)"), each = 3),
probabilita = c(P, QA, QB)
)
ggplot(df, aes(x = livello_ansia, y = probabilita, fill = modello)) +
geom_col(position = "dodge", width = 0.7) +
labs(
title = "Confronto di modelli predittivi per l'ansia",
subtitle = sprintf("D_KL(P||A) = %.4f bit vs D_KL(P||B) = %.4f bit", kl_A, kl_B),
x = "Livello di Ansia",
y = "Probabilità",
caption = "Il Modello B mostra un leggero vantaggio predittivo, ma il guadagno è modesto"
) +
scale_fill_manual(values = c("Distribuzione Vera P" = "#2c7bb6",
"Modello A (coping)" = "#fdae61",
"Modello B (coping + supporto)" = "#1a9641")) +
theme_minimal() +
theme(legend.position = "bottom")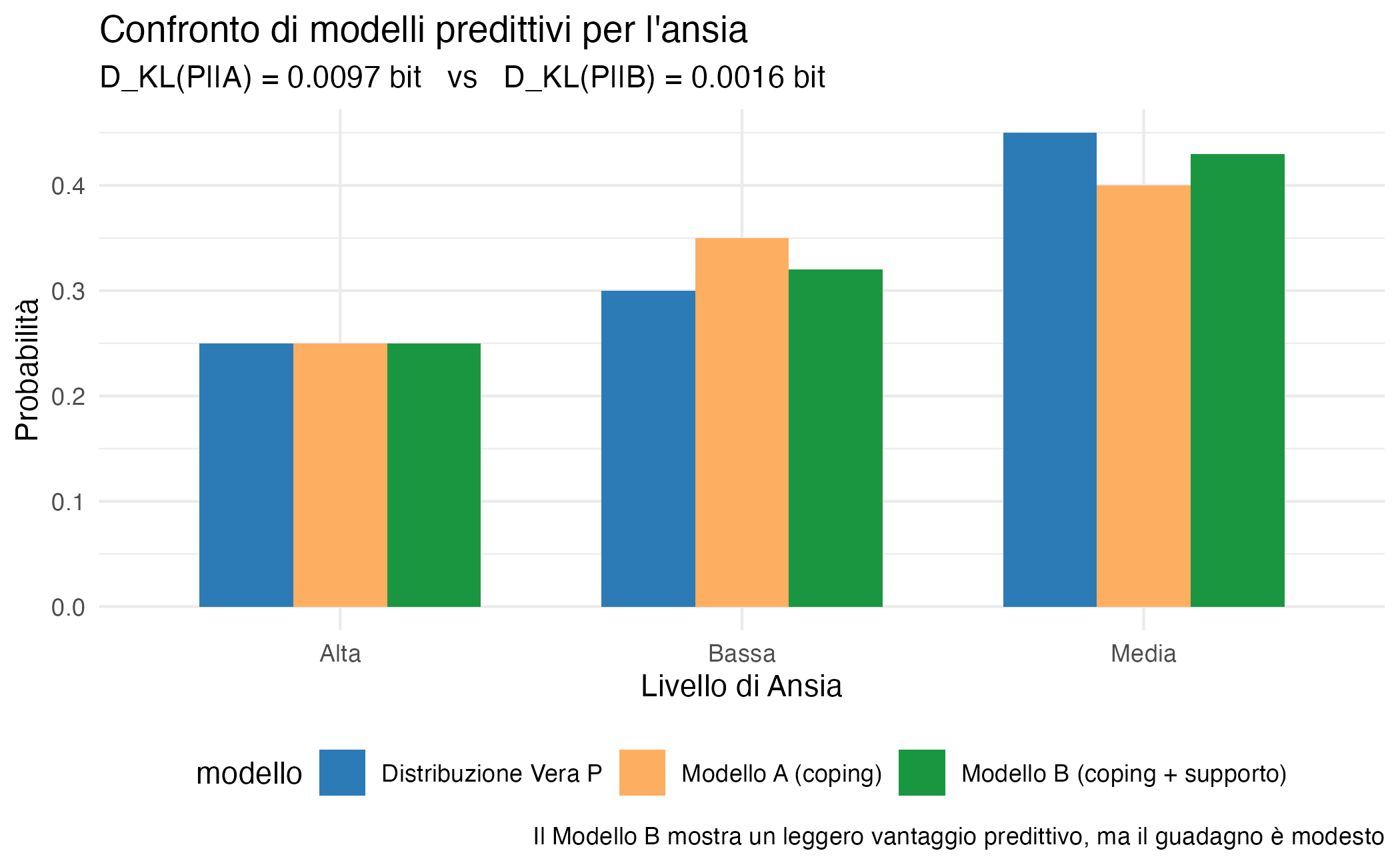
Interpretazione metodologica.
Questo risultato mette in luce un dilemma centrale della modellazione statistica:
un guadagno predittivo marginale giustifica un aumento della complessità del modello?
Il Modello B può essere preferito per la sua maggiore aderenza informazionale e per il suo allineamento con una teoria psicosociale più ricca. Potrebbe inoltre catturare effetti specifici in sottogruppi o interazioni che il modello più semplice non rileva.
D’altro canto, il Modello A offre maggiore parsimonia, interpretabilità e robustezza, soprattutto in contesti con campioni ridotti, dove il rischio di overfitting diventa rilevante. La sua semplicità lo rende anche più facilmente applicabile in contesti clinici e operativi.
Il ponte verso la valutazione predittiva.
Questo esempio mostra perché la sola differenza di divergenza KL, pur concettualmente fondamentale, non è sufficiente per guidare la selezione dei modelli nella pratica. È necessario valutare anche:
- l’incertezza associata alla stima della performance;
- la stabilità predittiva out-of-sample;
- il rischio di sovradattamento.
Nel capitolo successivo vedremo come strumenti come la Leave-One-Out Cross-Validation (LOO-CV) e l’Expected Log Predictive Density (ELPD) forniscano un quadro formale per quantificare sistematicamente questo compromesso, consentendo decisioni di selezione dei modelli che siano al tempo stesso predittive, parsimoniose e metodologicamente rigorose.
Riflessioni conclusive
In questo capitolo abbiamo sviluppato la divergenza di Kullback–Leibler come strumento fondamentale per misurare la distanza informazionale tra una rappresentazione teorica e la realtà empirica nella modellazione statistica.
Abbiamo visto che l’entropia incrociata \(H(P,Q)\) quantifica la lunghezza media del codice richiesta quando si utilizza un modello \(Q\) per rappresentare dati generati dalla distribuzione vera \(P\). Il fatto che \(H(P,Q)\) sia sempre maggiore o uguale all’entropia \(H(P)\) stabilisce un limite fondamentale: nessuna strategia di codifica basata su un modello approssimato può superare l’efficienza del codice ottimale costruito sulla piena conoscenza di \(P\).
La divergenza di Kullback–Leibler isola precisamente la differenza \(H(P,Q) - H(P)\), fornendo una misura dello spreco informativo introdotto dall’adozione di una rappresentazione imperfetta. Le sue diverse interpretazioni, come inefficienza di codifica, eccesso di sorpresa e perdita informativa, convergono verso un principio comune: ogni approssimazione della realtà comporta un costo, e la \(D_{\text{KL}}\) fornisce la metrica per quantificarlo.
L’asimmetria della \(D_{\text{KL}}\) non è un difetto matematico, ma riflette la natura intrinsecamente direzionale del processo di modellazione scientifica. Il nostro interesse non è misurare una distanza simmetrica tra due oggetti astratti, ma valutare quanto un modello \(Q\) riesca ad approssimare il processo generatore reale \(P\), e quale sia il prezzo informazionale della discrepanza residua.
Nel confronto tra modelli alternativi emerge un risultato cruciale: non è necessario conoscere esplicitamente la distribuzione vera \(P\). Il termine \(H(P)\), che rappresenta l’incertezza intrinseca e irriducibile del fenomeno, si annulla nei confronti tra modelli, rendendo possibile una valutazione relativa basata esclusivamente sulle entropie incrociate \(H(P,Q)\). In questo modo, la selezione dei modelli può essere formulata come un problema di confronto informazionale, anche in assenza di accesso diretto alla verità sottostante.
La \(D_{\text{KL}}\) fornisce quindi un criterio teorico elegante e solido: il modello migliore è quello che minimizza \(D_{\text{KL}}(P \parallel Q)\). Tuttavia, l’applicazione pratica di questo principio solleva tre sfide fondamentali. In primo luogo, l’entropia incrociata \(H(P,Q)\) deve essere stimata a partire da campioni finiti e potenzialmente rumorosi. In secondo luogo, la valutazione basata sugli stessi dati utilizzati per adattare il modello tende a essere ottimistica, favorendo modelli più complessi. Infine, è necessario quantificare l’incertezza associata alle stime per distinguere miglioramenti predittivi sostanziali da semplici fluttuazioni campionarie.
Nel prossimo capitolo mostreremo come la Leave-One-Out Cross-Validation (LOO-CV) e la Expected Log Predictive Density (ELPD) affrontino sistematicamente queste difficoltà, trasformando il principio astratto della minimizzazione della divergenza di Kullback–Leibler in uno strumento operativo, robusto e direttamente applicabile alla selezione e alla valutazione dei modelli nella ricerca psicologica.
ImportanteEsercizi
- Consideriamo due distribuzioni discrete:
p <- c(0.2, 0.5, 0.3)
q <- c(0.1, 0.2, 0.7)Calcolare: (a) l’entropia di \(p\), (b) l’entropia incrociata \(H(p,q)\), (c) la \(D_{\text{KL}}\) da \(p\) a \(q\).
Ripetere con q = c(0.2, 0.55, 0.25) e confrontare i risultati.
- Sia \(p\) la distribuzione binomiale con \(\theta = 0.2\) e \(n = 5\):
Confrontare due approssimazioni:
-
q1 = c(0.328, 0.410, 0.205, 0.051, 0.006, 0.000)(approssimazione ragionevole) -
q2 = rep(1/6, 6)(distribuzione uniforme)
Quale approssimazione è migliore secondo la \(D_{\text{KL}}\)?
- Dimostrare numericamente l’asimmetria della \(D_{\text{KL}}\) calcolando \(D_{\text{KL}}(P \parallel Q)\) e \(D_{\text{KL}}(Q \parallel P)\) per \(P = [0.7, 0.2, 0.1]\) e \(Q = [0.4, 0.3, 0.3]\).
NotaInformazioni sull’ambiente di sviluppo
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Zagreb
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ragg_1.5.0 tinytable_0.15.2 withr_3.0.2
#> [4] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [7] tidybayes_3.0.7 bayesplot_1.15.0 ggplot2_4.0.1
#> [10] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [13] loo_2.9.0 rstan_2.32.7 StanHeaders_2.32.10
#> [16] brms_2.23.0 Rcpp_1.1.0 sessioninfo_1.2.3
#> [19] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [22] modelr_0.1.11 tibble_3.3.0 dplyr_1.1.4
#> [25] tidyr_1.3.2 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] svUnit_1.0.8 tidyselect_1.2.1 farver_2.1.2
#> [4] S7_0.2.1 fastmap_1.2.0 TH.data_1.1-5
#> [7] tensorA_0.36.2.1 digest_0.6.39 timechange_0.3.0
#> [10] estimability_1.5.1 lifecycle_1.0.4 survival_3.8-3
#> [13] magrittr_2.0.4 compiler_4.5.2 rlang_1.1.6
#> [16] tools_4.5.2 yaml_2.3.12 knitr_1.51
#> [19] labeling_0.4.3 bridgesampling_1.2-1 htmlwidgets_1.6.4
#> [22] curl_7.0.0 pkgbuild_1.4.8 RColorBrewer_1.1-3
#> [25] abind_1.4-8 multcomp_1.4-29 purrr_1.2.0
#> [28] grid_4.5.2 stats4_4.5.2 colorspace_2.1-2
#> [31] xtable_1.8-4 inline_0.3.21 emmeans_2.0.1
#> [34] scales_1.4.0 MASS_7.3-65 cli_3.6.5
#> [37] mvtnorm_1.3-3 rmarkdown_2.30 generics_0.1.4
#> [40] otel_0.2.0 RcppParallel_5.1.11-1 cachem_1.1.0
#> [43] stringr_1.6.0 splines_4.5.2 parallel_4.5.2
#> [46] vctrs_0.6.5 V8_8.0.1 Matrix_1.7-4
#> [49] sandwich_3.1-1 jsonlite_2.0.0 arrayhelpers_1.1-0
#> [52] glue_1.8.0 codetools_0.2-20 distributional_0.5.0
#> [55] lubridate_1.9.4 stringi_1.8.7 gtable_0.3.6
#> [58] QuickJSR_1.8.1 pillar_1.11.1 htmltools_0.5.9
#> [61] Brobdingnag_1.2-9 R6_2.6.1 textshaping_1.0.4
#> [64] rprojroot_2.1.1 evaluate_1.0.5 lattice_0.22-7
#> [67] backports_1.5.0 memoise_2.0.1 broom_1.0.11
#> [70] snakecase_0.11.1 rstantools_2.5.0 gridExtra_2.3
#> [73] coda_0.19-4.1 nlme_3.1-168 checkmate_2.3.3
#> [76] xfun_0.55 zoo_1.8-15 pkgconfig_2.0.3Bibliografia
Kullback, S., & Leibler, R. A. (1951). On information and sufficiency. The Annals of Mathematical Statistics, 22(1), 79–86.