In psicologia, spesso operiamo in condizioni che rendono complessa l’inferenza statistica, come campioni di piccole dimensioni, misure soggette a rumore e effetti reali ma di lieve entità. In questo contesto, l’approccio bayesiano offre un vantaggio sostanziale, in quanto rende esplicito il modo in cui le conoscenze pregresse si integrano con l’evidenza empirica. Non si tratta di una “correzione” arbitraria dei risultati, ma di una stabilizzazione dell’inferenza che riduce le sovrastime tipiche degli studi condotti su piccoli campioni e gli errori di tipo M.1
Questa dinamica riflette un principio epistemologico fondamentale: quando le nuove informazioni sono poche, è ragionevole affidarsi maggiormente alle conoscenze consolidate; quando le nuove informazioni sono molte, è opportuno lasciar parlare i dati. L’approccio bayesiano non sostituisce i dati con la teoria, ma ne modula la combinazione in base all’informazione disponibile.
12.1 L’aggiornamento bayesiano: un esempio illustrativo
Il meccanismo dell’inferenza bayesiana è più facile da comprendere osservando direttamente come la distribuzione a priori trasforma le credenze iniziali alla luce dei dati. Il modello Beta-Binomiale, grazie alla sua trasparenza analitica, costituisce un contesto ideale per questa analisi.
Consideriamo il problema della stima del parametro \(\theta\), che rappresenta la probabilità che un soggetto fornisca una risposta corretta in un compito cognitivo. In uno scenario sperimentale con 9 prove di memoria, si osservano 6 risposte corrette. L’obiettivo è aggiornare le convinzioni iniziali su \(\theta\) alla luce di questa evidenza.
12.1.1 Il framework coniugato
La distribuzione Beta gode della proprietà di coniugazione rispetto alla Binomiale, il che rende particolarmente agevole il processo di aggiornamento:
\[
\begin{aligned}
\text{Prior: } & \theta \sim \text{Beta}(\alpha, \beta), \\
\text{Dati: } & y \sim \text{Binomiale}(n, \theta), \\
\text{Posterior: } & \theta \mid y \sim \text{Beta}(\alpha + y, \beta + n - y).
\end{aligned}
\]
La distribuzione a posteriori mantiene la forma Beta, modificandone esclusivamente i parametri. La seguente funzione consente di visualizzare questo processo.
# Definisci i colori tematicicol_prior<-palette_qualitative[8]# Grigio per priorcol_likelihood<-palette_qualitative[1]# Arancione per verosimiglianzacol_posterior<-palette_qualitative[5]# Blu per posteriorcol_scenarios<-palette_qualitative[c(2, 3, 6)]# Azzurro, Verde, Rosso-arancio per scenari# Funzione aggiornata con la paletteplot_beta_binomial<-function(alpha, beta, y, n){theta<-seq(0, 1, length.out =100)prior<-dbeta(theta, alpha, beta)likelihood<-dbinom(y, n, theta)posterior<-dbeta(theta, alpha+y, beta+n-y)tibble(theta, Prior =prior/max(prior), Likelihood =likelihood/max(likelihood), Posterior =posterior/max(posterior))|>pivot_longer(-theta, names_to ="Distribuzione", values_to ="Densità")|>ggplot(aes(x =theta, y =Densità, color =Distribuzione))+geom_line(size =1.2)+scale_color_manual( values =c("Prior"=col_prior,"Likelihood"=col_likelihood,"Posterior"=col_posterior))+labs( title ="Aggiornamento Beta–Binomiale\n(6 successi su 9)", x =expression(theta), y ="Densità (scala normalizzata)")+theme(legend.position ="right")}
12.1.2 Tre scenari a confronto
12.1.2.1 Scenario A: Prior non informativa
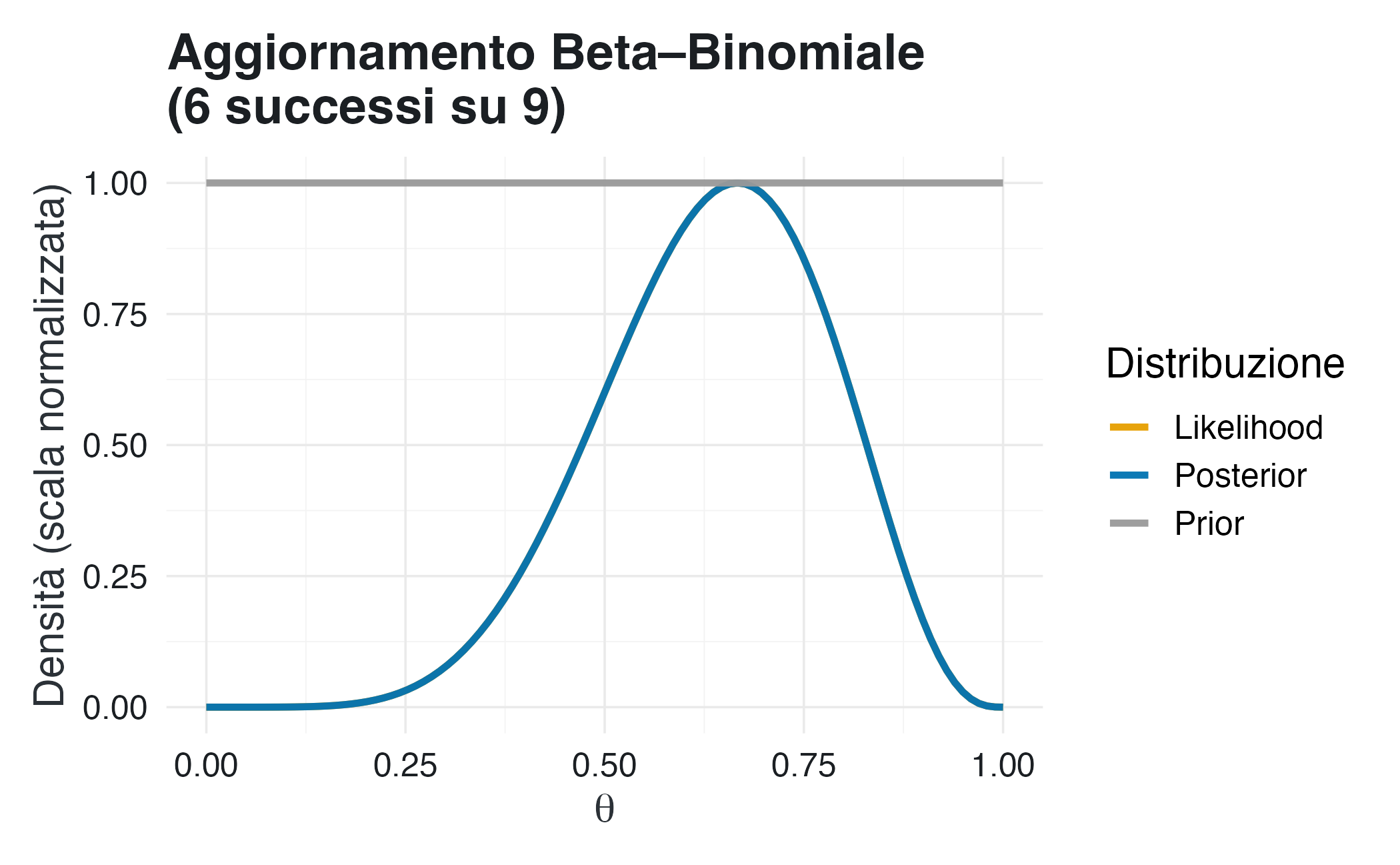
plot_beta_binomial(alpha =1, beta =1, y =6, n =9)
La distribuzione a priori uniforme assegna la stessa probabilità a tutti i valori di \(\theta\), riflettendo incertezza totale. La distribuzione a posteriori coincide sostanzialmente con la verosimiglianza: l’inferenza è interamente dominata dall’evidenza empirica.
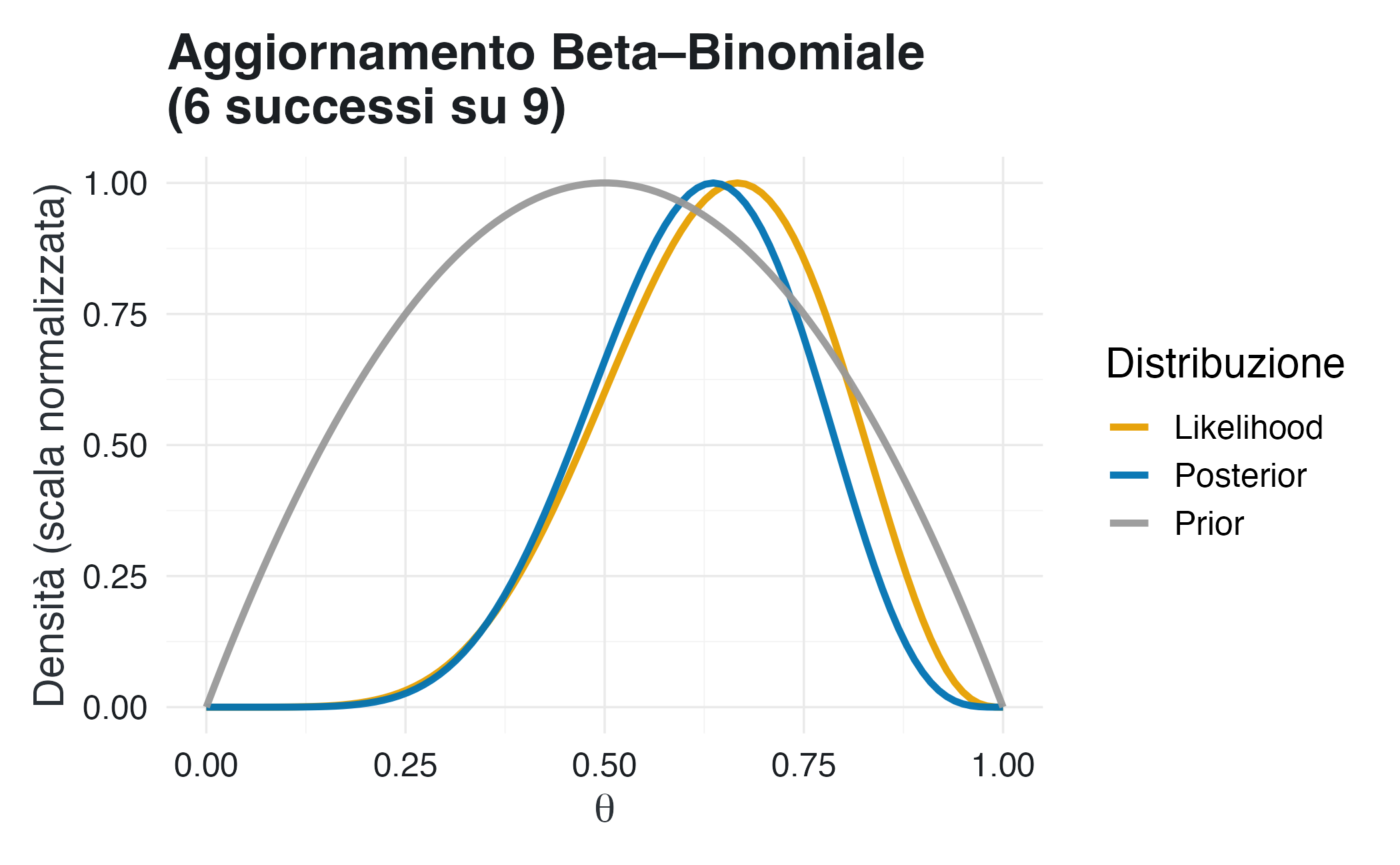
La prior esprime una moderata credenza che \(\theta\) si collochi intorno a 0.5, mantenendo notevole variabilità. Dopo l’aggiornamento, la posteriori si sposta verso i valori suggeriti dai dati (0.67), ma conserva una forma più conservativa, con media attorno a 0.62. La prior esercita un effetto stabilizzante.
12.1.2.3 Scenario C: Prior fortemente informativa
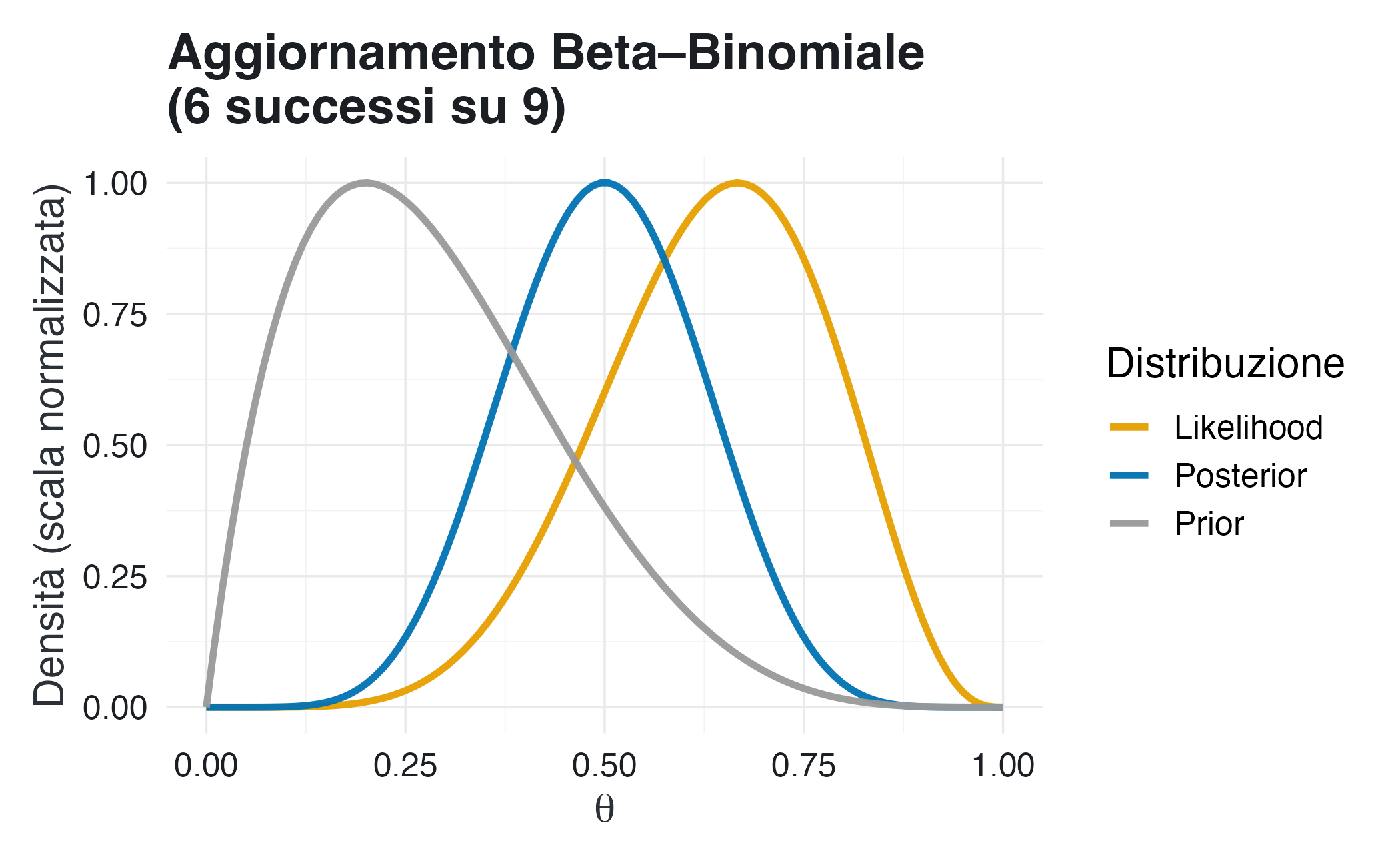
plot_beta_binomial(alpha =2, beta =5, y =6, n =9)
La prior riflette una convinzione forte che \(\theta\) assuma valori modesti (media a priori = 0.29). Nonostante l’evidenza empirica suggerisca 0.67, la posteriori mantiene una posizione intermedia (attorno a 0.45), dimostrando come convinzioni iniziali forti possano resistere parzialmente all’evidenza contraria.
12.1.3 La prior come evidenza fittizia
Il confronto tra i tre scenari rivela un principio fondamentale: la distribuzione a priori può essere concepita come un insieme di “osservazioni fittizie” che precedono la raccolta dei dati. Nel modello Beta-Binomiale, questa interpretazione è particolarmente trasparente: i parametri \((\alpha,\beta)\) si sommano rispettivamente ai successi e agli insuccessi osservati.
La quantità \(\alpha + \beta\), nota come sample size equivalente della prior, quantifica il peso delle convinzioni iniziali. Con \(\alpha + \beta = 2\), la prior possiede un’influenza modesta; con \(\alpha + \beta = 20\), incorpora un peso informativo rilevante e richiede evidenza empirica sostanziale per essere modificata.
L’equilibrio tra prior ed evidenza emerge dalla struttura della media a posteriori:
La stima finale è una media ponderata tra credenza iniziale ed evidenza osservata. In contesti data-rich\((n \gg \alpha+\beta)\), domina l’evidenza empirica; in situazioni data-poor\((n \ll \alpha+\beta)\), la prior esercita un effetto stabilizzante.
12.2 L’influenza della prior in relazione all’informazione disponibile
La conclusione della sezione precedente mette in evidenza come l’influenza della distribuzione a priori non sia costante, ma vari in funzione della quantità e della qualità delle informazioni contenute nei dati. Quando i dati sono numerosi e precisi, è la verosimiglianza a prevalere, rendendo le stime robuste anche in presenza di scelte di prior ragionevolmente diverse. Quando i dati sono limitati o rumorosi, condizione frequente nella ricerca psicologica, la prior acquisisce un peso determinante.
12.2.1 Due scenari empirici
Si consideri uno studio sull’efficacia di un intervento di mindfulness nella riduzione dello stress. Con un campione di 15 partecipanti e elevata variabilità individuale, la stima potrebbe essere \(b = -0.4\) con errore standard \(s = 0.3\). Il segnale risulterebbe debole (\(z = -1.33\)) e i dati fornirebbero evidenza ambigua. Una prior debolmente informativa, come \(\beta \sim \mathrm{Normal}(0, 1)\), eserciterebbe un’importante azione di regolarizzazione, attirando la stima verso lo zero.
Con un campione di 500 partecipanti, a parità di stima puntuale, l’errore standard si ridurrebbe a \(s = 0.04\), portando a \(z = -10\). La verosimiglianza dominerebbe il processo inferenziale, rendendo trascurabile l’impatto della prior.
Il principio è semplice: l’influenza della prior è inversamente proporzionale all’informazione contenuta nei dati.
12.2.2 Visualizzazione mediante simulazione
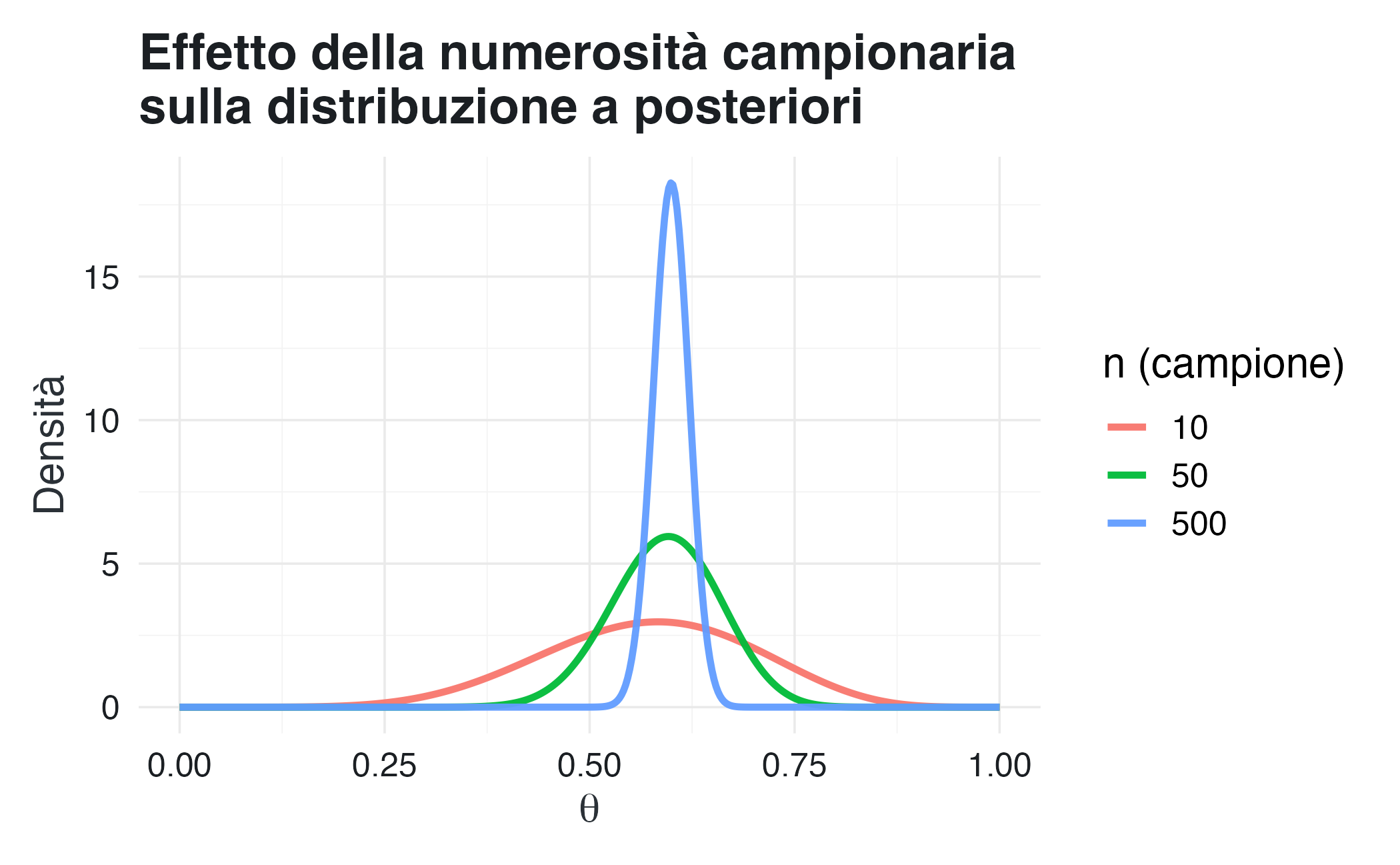
Come mostrato nel grafico seguente, con \(n = 10\), la posteriori è ampia e la prior esercita un’influenza visibile. Con \(n = 50\), la posteriori si restringe. Con \(n = 500\), la posteriori risulta stretta e centrata sul valore vero e l’influenza della prior diventa trascurabile.
theta_true<-0.6alpha<-2; beta<-2n_values<-c(10, 50, 500)posterior_list<-list()for(iinseq_along(n_values)){n<-n_values[i]k<-round(theta_true*n)theta<-seq(0, 1, length.out =400)dens<-dbeta(theta, alpha+k, beta+n-k)posterior_list[[i]]<-data.frame(theta =theta, dens =dens, n =n)}posterior_densities<-do.call(rbind, posterior_list)ggplot(posterior_densities, aes(x =theta, y =dens, color =factor(n)))+geom_line(size =1.2)+labs( title ="Effetto della numerosità campionaria\nsulla distribuzione a posteriori", x =expression(theta), y ="Densità", color ="n (campione)")
Situazione
Influenza della prior
Effetto pratico
Campione piccolo, dati rumorosi
Alta
Stabilizza, evita sovrastime
Campione medio
Moderata
Compromesso equilibrato
Campione grande
Bassa
I dati dominano
Questo meccanismo, formalmente noto come “shrinkage”, implementa una regola epistemologicamente sensata: in presenza di informazioni deboli, si evitano stime estreme; in presenza di informazioni robuste, prevale il segnale dei dati.
12.3 La scala del parametro: perché è decisiva
Un aspetto fondamentale ma spesso trascurato è che le distribuzioni a priori non sono invarianti rispetto ai cambiamenti di scala. Dichiarare di aver scelto “una prior uniforme” non equivale automaticamente ad adottare un atteggiamento neutrale: la stessa distribuzione a priori può assumere un significato completamente diverso quando si modifica l’unità di misura del parametro.
Immaginiamo uno studio sulla soddisfazione lavorativa misurata su una scala 1–10. Un ricercatore assegna una prior uniforme all’effetto \(\beta\), ritenendo equiprobabili tutti i valori tra –10 e +10. Se successivamente ricodifica la variabile su una scala 0–100 senza modificare la prior, l’intervallo originario si dilata di un ordine di grandezza: ciò che prima rappresentava una gamma moderata di variazioni diventa ora un insieme estremamente ampio di possibilità. La credenza “uniforme” iniziale non è più la stessa.
La conclusione è semplice: una prior non può essere piatta su qualunque scala allo stesso tempo. La sua apparente “neutralità” vale soltanto rispetto alla scala in cui è stata formulata.
12.3.1 La soluzione: lavorare con un parametro adimensionale
Per ottenere inferenze coerenti e confrontabili, conviene definire le prior su quantità prive di unità di misura. Quando stimiamo un coefficiente \(\beta\) con errore standard \(s\), l’informazione rilevante non sta in \(\beta\) in sé, ma nel rapporto adimensionale
\[
\xi = \frac{\beta}{s},
\] che quantifica l’intensità del segnale rispetto al rumore.
L’uso di \(\xi\) presenta tre vantaggi: l’inferenza diventa invariante ai cambi di unità, permette confronti consistenti tra studi diversi e rende più trasparente il ruolo effettivo della prior nei risultati finali.
Per esempio, se osserviamo un effetto \(b = 4\) con errore standard \(s = 2\) su una scala 0–10, il valore z è pari a 2. Se ricodifichiamo la variabile su una scala 0–100, otteniamo (b’ = 40) e \(s' = 20\), ma il rapporto resta invariato: \(z = z' = 2\). Una prior definita su \(\beta/s\) produce dunque la stessa inferenza in entrambe le scale. Una prior definita direttamente su \(\beta\), invece, porterebbe a conclusioni diverse semplicemente perché la scala è cambiata.
12.3.2 Verifica mediante simulazione
b<-4; s<-2a<-10# fattore di riscalamentob2<-a*b; s2<-a*sgrid1<-seq(-20, 20, length.out =1001)grid2<-seq(-200, 200, length.out =1001)like1<-dnorm(grid1, mean =b, sd =s)like2<-dnorm(grid2, mean =b2, sd =s2)# Prior uniforme su β (non invariante)prior_unif1<-rep(1/length(grid1), length(grid1))prior_unif2<-rep(1/length(grid2), length(grid2))post_unif1<-like1*prior_unif1; post_unif1<-post_unif1/sum(post_unif1)post_unif2<-like2*prior_unif2; post_unif2<-post_unif2/sum(post_unif2)# Prior Cauchy su β/s (invariante)prior_cauchy1<-dcauchy(grid1/s)/sprior_cauchy2<-dcauchy(grid2/s2)/s2post_cauchy1<-like1*prior_cauchy1; post_cauchy1<-post_cauchy1/sum(post_cauchy1)post_cauchy2<-like2*prior_cauchy2; post_cauchy2<-post_cauchy2/sum(post_cauchy2)# Medie posteriori (riportate alla scala originale)m_unif1<-sum(grid1*post_unif1)m_unif2<-sum(grid2*post_unif2)/am_cauchy1<-sum(grid1*post_cauchy1)m_cauchy2<-sum(grid2*post_cauchy2)/atibble( Prior =c("Uniforme su β", "Cauchy su β/s"), Media_orig =c(m_unif1, m_cauchy1), Media_rescaled =c(m_unif2, m_cauchy2))#> # A tibble: 2 × 3#> Prior Media_orig Media_rescaled#> <chr> <dbl> <dbl>#> 1 Uniforme su β 4.00 4.00#> 2 Cauchy su β/s 2.56 2.56
La prior uniforme produce risultati diversi dopo il cambio di scala, mentre la prior su \(\beta/s\) produce risultati identici. In pratica, definire la prior sul rapporto segnale-rumore garantisce coerenza, confrontabilità e indipendenza da convenzioni arbitrarie.
Tipo di trasformazione
Esempio
Prior uniforme su \(\beta\)
Prior su \(\beta/s\)
Cambio unità
0-10 → 0-100
Cambia forma e densità
Nessuna differenza
Inversione segno
A-B → B-A
Cambia il centro
Solo inversione segno
Standardizzazione
Grezzi → z
Cambia la scala
Nessuna differenza
12.4 Tipologie di distribuzioni a priori
12.4.1 Prior non informative
Scopo: minimizzare l’influenza delle convinzioni preesistenti.
Esempio: per indagare la relazione tra l’arousal fisiologico e i pensieri intrusivi in assenza di letteratura pregressa, si potrebbe adottare la seguente distribuzione a priori: \[
\rho \sim \text{Uniform}(-1, 1).
\]
Avvertenza: il termine “non informativa” è fuorviante. Una prior uniforme su una scala non lo è su un’altra (ad esempio, dopo una trasformazione non lineare). Inoltre, questo approccio attribuisce probabilità non trascurabili a valori estremi che si manifestano raramente nei fenomeni psicologici.
12.4.2 Prior debolmente informative
Scopo: imporre vincoli di plausibilità senza precludere ai dati di esprimersi.
Esempio: per uno studio sull’efficacia di un intervento di mindfulness: \[
\beta \sim \text{Normal}(0, 1).
\] Questa scelta comunica: “riteniamo più probabile un effetto nullo o modesto, ma non escludiamo effetti più sostanziali se i dati li supporteranno”.
Vantaggio: funge da stabilizzatore, soprattutto in campioni piccoli, prevenendo la sovrastima di effetti spurii.
12.4.3 Prior informative
Scopo: incorporare evidenze consolidate da studi precedenti o meta-analisi.
Esempio: se una meta-analisi indica che la CBT produce una riduzione media dei sintomi depressivi pari a \(d = 0.5\): \[
\beta \sim \text{Normal}(0.5, 0.2).
\] Questa distribuzione esprime una convinzione ragionevolmente forte, pur ammettendo un margine di incertezza.
12.4.4 Prior empiriche (da corpus)
Scopo: calibrare la prior sui dati quantitativi di un insieme di studi affini.
Esempio: analizzando la distribuzione degli z-score riportati in studi che utilizzano l’Experience Sampling Method, si può stimare una distribuzione empirica che rappresenti il tipico rapporto segnale-rumore in questo ambito.
12.4.5 Visualizzazione comparativa
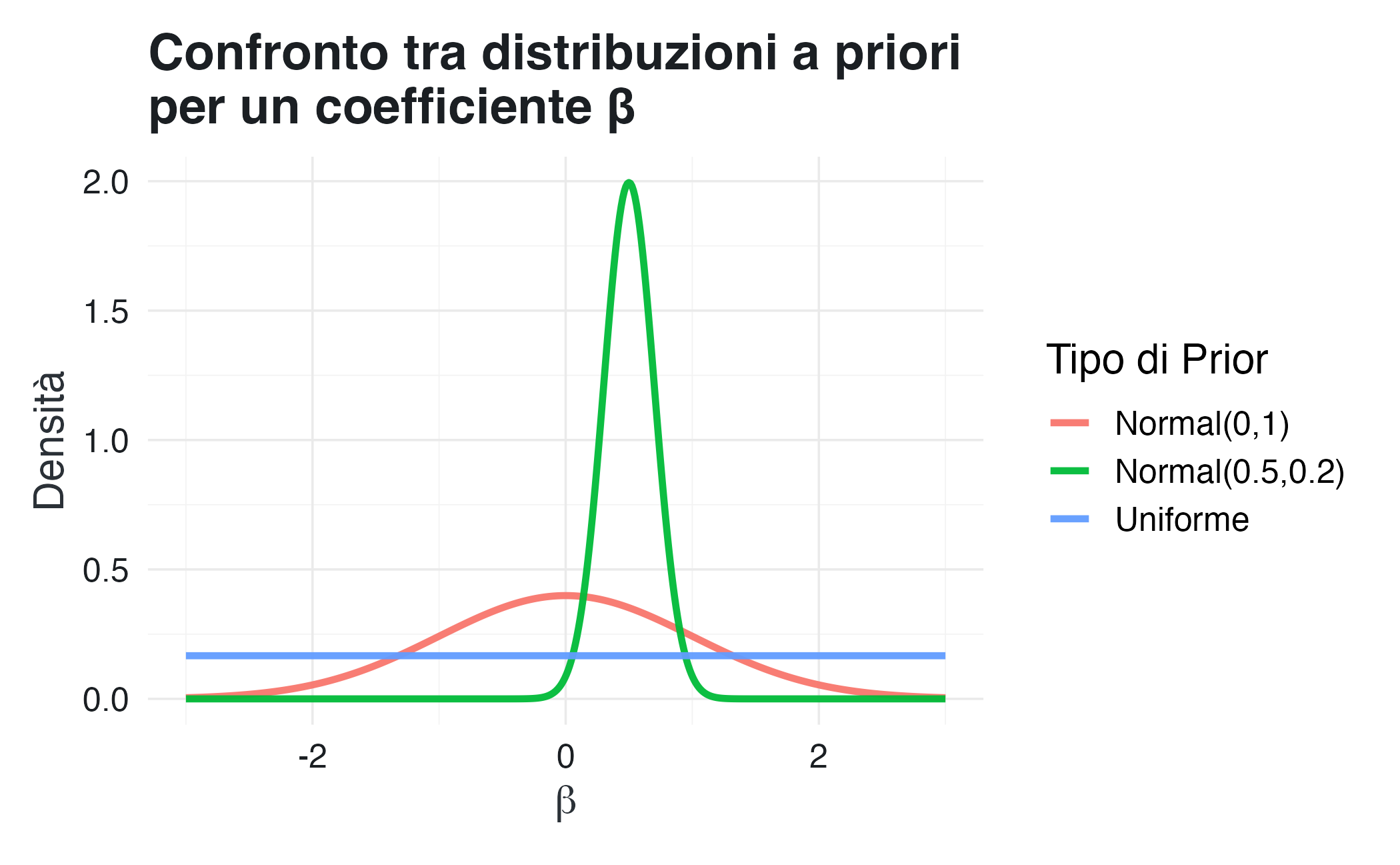
beta_grid<-seq(-3, 3, length.out =500)priors<-tibble( beta =rep(beta_grid, 3), tipo =rep(c("Uniforme", "Normal(0,1)", "Normal(0.5,0.2)"), each =length(beta_grid)), dens =c(dunif(beta_grid, -3, 3),dnorm(beta_grid, 0, 1),dnorm(beta_grid, 0.5, 0.2)))ggplot(priors, aes(x =beta, y =dens, color =tipo))+geom_line(linewidth =1.2)+labs( title ="Confronto tra distribuzioni a priori\nper un coefficiente β", x =expression(beta), y ="Densità", color ="Tipo di Prior")
La prior uniforme assegna una densità costante senza preferenze. La Normal(0,1) esprime un moderato scetticismo nei confronti dell’ipotesi nulla. La Normal(0.5, 0.2) incorpora un’aspettativa precisa.
Tipo
Quando usarla
Vantaggi
Rischi
Non informativa
Nessuna conoscenza pregressa
Lascia parlare i dati
Instabile con campioni piccoli
Debolmente informativa
Effetti plausibili ma incerti
Regolarizza, evita outlier
Può sembrare arbitraria
Informativa
Evidenze forti da studi precedenti
Integra conoscenza teorica
Può dominare se i dati sono pochi
12.5 Prior su scala SNR: strategie in presenza o assenza di corpus empirici
Zwet & Gelman (2022) propongono l’utilizzo di prior informative basate su corpora di studi di riferimento, implementate mediante miscele di distribuzioni. Consideriamo una prior costituita da una miscela simmetrica di due componenti normali centrate sullo zero:
i pesi (\(\pi_1, \pi_2\)) rappresentano la proporzione relativa di effetti “piccoli” rispetto a quelli “più sostanziali”;
le scale (\(\tau_1, \tau_2\)) catturano l’ampiezza tipica degli effetti in ciascuna categoria.
I valori specifici si ottengono calibrando la miscela su un corpus di studi metodologicamente affini, consentendo uno shrinkage differenziato: effetti plausibilmente piccoli vengono regolarizzati più fortemente, mentre effetti sostanziali subiscono un’interferenza minima.
12.5.1 Strategie in assenza di corpus consolidato
Quando non si dispone di un corpus di riferimento o mancano informazioni preliminari affidabili, è consigliabile adottare distribuzioni a code più pesanti. La proposta standard è la distribuzione di Cauchy:
\[
\frac{\beta}{s} \sim \mathrm{Cauchy}(0, 1).
\]
La scelta della Cauchy non è casuale ma riflette un preciso profilo statistico:
code più marcate rispetto alla normale, riducendo la penalizzazione eccessiva per effetti moderatamente grandi;
comportamento ottimale: forte regolarizzazione per effetti modesti (\(|z| < 2\)), interferenza minima per effetti sostanziali (\(|z| > 3\));
proprietà di calibrazione: pari probabilità di effetti sopra/sotto una determinata soglia (es. \(P(|\xi|>2.5) \approx 0.1\)).
Per modelli complessi o quando si desidera maggiore controllo sulle code, è possibile considerare:
troncamenti ragionevoli della distribuzione (es. \(|\xi| < 10\))
distribuzioni \(t\) di Student con gradi di libertà \(\nu \in [3,7]\), che permettono di modulare il peso delle code
12.5.2 Quadro decisionale per la scelta della prior
Situazione metodologica
Prior consigliata su \(\beta/s\)
Vantaggi e considerazioni
Nessun corpus disponibile
Cauchy(0,1)
Default robusto, adatto a scenari esplorativi; bilancia regolarizzazione e sensibilità
Corpus di studi metodologicamente affini
Miscela di Normali
Shrinkage adattivo: calibra la regolarizzazione in base alla distribuzione empirica degli effetti nel campo
Pregressa evidenza di effetti piccoli
Normal(0,0.5) o Normal(0,1)
Prior più concentrate riducono il rischio di sovrastime per effetti modesti
Potenziali effetti grandi e incertezza elevata
t₃(0,2) o Cauchy(0,2)
Code più ampie preservano la capacità di rilevare segnali sostanziali, anche quando rari
Questa struttura decisionale permette di ancorare la scelta della prior a considerazioni sostantiva e metodologiche, promuovendo inferenze più coerenti e replicabili. L’approccio basato sul parametro adimensionale \(\beta/s\) garantisce che tali scelte rimangano invarianti rispetto alle scale di misurazione utilizzate nello studio.
12.6 Dalla teoria alla pratica
12.6.1 Guida alla scelta della prior
La costruzione di una prior ben calibrata richiede di rispondere a tre domande: Su quale scala è definito il parametro? Quale intervallo è plausibile? Quanto è forte la nostra convinzione iniziale?
Scala: per coefficienti di regressione, la scala adimensionale \(\xi = \beta/s\) è preferibile. Nei GLM, la prior deve essere specificata sulla scala del link (logit, log). La standardizzazione dei predittori conferisce interpretazione immediata.
Plausibilità: per predittori standardizzati, effetti con \(|\beta| > 1-2\) sono generalmente sostanziali. La prior deve delimitare lo spazio dei valori plausibili senza “indovinare” il valore vero.
Informatività: in assenza di evidenze solide, distribuzioni a code pesanti su \(\xi\) realizzano shrinkage adattivo. Con letteratura consolidata, una normale centrata su stime meta-analitiche è appropriata.
ConsiglioProcedura operativa
Identifica la scala e i vincoli. Ci sono limiti naturali (≥0 per varianze, [0,1] per probabilità)? È possibile usare una scala adimensionale?
Stima l’ordine di grandezza plausibile. Quale intervallo ha senso per il fenomeno studiato?
Attingi alla letteratura. Meta-analisi e studi precedenti ancorano la prior a valori empiricamente plausibili.
Calibra l’informatività. Distribuzioni a code pesanti offrono un buon compromesso: regolarizzano senza escludere effetti inattesi.
Regola empirica: in assenza di letteratura solida, una \(t\) o Cauchy sul rapporto \(\beta/s\) rappresenta la scelta più sicura.
12.6.2 Prior predictive check
Prima di analizzare i dati, occorre verificare che le assunzioni siano coerenti con la fenomenologia del dominio: “Quali dati potrei osservare se le mie prior rispecchiassero la realtà?”
set.seed(1)n<-30mu_prior_sd<-1.0S<-2000mu_samp<-rnorm(S, mean =0, sd =mu_prior_sd)ybar_rep<-sapply(mu_samp, function(m)mean(rnorm(n, mean =m, sd =1)))quantile(ybar_rep, c(.025, 0.5, .975))#> 2.5% 50% 97.5% #> -2.1320 -0.0455 2.0263
Con \(n=30\) e \(\sigma=1\), una prior \(\mu \sim \text{Normal}(0,1)\) genera medie campionarie tra -0.7 e 0.7. Se il fenomeno produce tipicamente effetti con medie attorno a \(\pm 1.5\), questa prior potrebbe essere troppo restrittiva.
12.6.3 Errori comuni
L’illusione della neutralità: le distribuzioni uniformi non sono invarianti rispetto alle trasformazioni e tendono a concentrare massa in regioni implausibili.
Incoerenza con la realtà: specificare prior che assegnano probabilità a esiti impossibili (tempi di reazione negativi, probabilità fuori da [0,1]) compromette la credibilità del modello.
Asimmetrie ingiustificate: se l’interpretazione cambia radicalmente ricodificando una variabile, la prior non è stata definita su una scala appropriata.
12.7 Il conflitto tra prior e verosimiglianza: un test di coerenza inferenziale
Cosa accade quando le nostre assunzioni a priori entrano in conflitto con l’evidenza empirica contenuta nei dati? Questo scenario, più che un problema, rappresenta un’opportunità istruttiva: ci permette di valutare quanto il nostro modello sia internamente coerente e quanto i dati siano in grado di opporre resistenza alle nostre aspettative iniziali.
Come sottolinea Richard McElreath, in questi casi non possiamo affidarci all’intuizione: anche combinazioni apparentemente semplici di prior e verosimiglianza possono generare distribuzioni a posteriori sorprendenti e controintuitive. Questa complessità intrinseca richiede un’attenta analisi delle dinamiche in gioco.
12.7.1 Le trappole delle specificazioni improprie
Prior eccessivamente restrittive: una distribuzione a priori troppo concentrata può soffocare il segnale dei dati, producendo stime a posteriori che riflettono più le nostre preconcezioni che l’evidenza osservata. Questo è particolarmente problematico quando la prior viene scelta per convenienza computazionale piuttosto che per plausibilità sostanziale.
Prior eccessivamente vaghe: all’estremo opposto, distribuzioni troppo diffuse producono stime a posteriori dominate dal rumore dei dati, con intervalli di credibilità talmente ampi da risultare praticamente inutili per la ricerca o la decisione.
La soluzione intermedia delle code pesanti: le prior flessibili, come la Cauchy o le distribuzioni \(t\) di Student con pochi gradi di libertà, offrono un compromesso robusto: forniscono una regolarizzazione efficace per gli effetti modesti (evitando sovrastime) senza reprimere eccessivamente segnali sostanziali e inattesi.
12.7.2 Oltre l’impostazione meccanica: verso un approccio critico
L’implementazione di modelli bayesiani richiede un approccio critico che vada oltre l’applicazione meccanica di formule. Non basta semplicemente “avere una prior”: è necessario valutarne sistematicamente la compatibilità con i dati osservati.
Analisi di sensibilità prevede che variazioni ragionevoli nella specificazione della prior non alterino drasticamente le conclusioni sostanziali. Se piccole modifiche producono grandi cambiamenti nelle stime a posteriori, ciò indica che i dati sono insufficientemente informativi o che la specificazione del modello è eccessivamente dipendente dalle assunzioni iniziali.
Prior predictive checks: questa tecnica fondamentale passa dalla domanda “che prior ho scelto?” a “che tipo di dati si aspetta la mia prior?”. Simulando i dati dall’assegnazione congiunta della prior e del modello, possiamo valutare se le nostre assunzioni iniziali corrispondono a pattern realistici e plausibili per il fenomeno in studio. Se la prior predice regolarmente valori estremi o pattern implausibili, è necessario riconsiderare la specificazione.
12.7.3 Questo conflitto come strumento diagnostico
Il disaccordo tra la prior e la verosimiglianza non è un fallimento del modello, ma piuttosto un segnale che le nostre ipotesi iniziali non reggono il confronto con la realtà empirica, spingendoci a rivedere o affinare sia la specificazione del modello che la nostra comprensione teorica del fenomeno. In questo senso, il conflitto diventa uno strumento diagnostico centrale nell’inferenza bayesiana responsabile, trasformando quello che potrebbe sembrare un problema tecnico in un’opportunità per un apprendimento scientifico più approfondito.
12.8 Buone pratiche e raccomandazioni
12.8.1 Costruire un corpus onesto
Quando si utilizza un corpus per definire una prior, è essenziale che i dati siano rappresentativi: è necessario includere repliche e registered reports, evitare la selezione dei soli risultati “positivi” e documentare chiaramente i criteri e le fonti utilizzati. Un corpus ben costruito evita di perpetuare stime gonfiate.
12.8.2 Specificare l’ambito
Una prior non è universale, ma vale all’interno di un ambito metodologico ben definito. Una prior per gli studi EMA sulla self-compassion non è adatta agli esperimenti con rinforzo. Indicare sempre il tipo di disegno, la variabile dipendente e la scala di misura aumenta la trasparenza.
12.8.3 Verificare la sensibilità
Dopo l’analisi, è necessario verificare quanto i risultati dipendano dalla prior: è necessario confrontare la prior con prior alternative (più strette, più larghe o centrate altrove), controllare come cambiano la media e gli intervalli di credibilità e discutere le differenze. Se la conclusione cambia drasticamente, i dati da soli non sono ancora convincenti: un’informazione preziosa.
12.8.4 Il prior come ipotesi teorica
Un buon prior non è solo una forma di distribuzione, ma un’ipotesi teorica esplicita. Specificarlo significa dichiarare ciò che riteniamo plausibile e fino a che punto siamo disposti a lasciarci sorprendere. In psicologia, questo rappresenta un vantaggio epistemologico: i modelli diventano luoghi di dialogo tra teoria e dati.
Principio
Implicazione pratica
Corpus onesto
Basi empiriche trasparenti
Ambito definito
Evita l’uso improprio
Analisi di sensibilità
Verifica la robustezza
Prior heavy-tailed
Default prudente quando manca evidenza
Prior = ipotesi teorica
Connessione esplicita tra teoria e dati
Riflessioni conclusive
L’inferenza bayesiana è un dialogo metodologicamente strutturato tra teoria ed esperienza. Ogni distribuzione a priori incorpora un frammento di conoscenza pregressa—esplicita, criticabile, migliorabile attraverso l’evidenza. Questo approccio riconosce che l’analisi dei dati non avviene nel vuoto epistemologico, ma all’interno di un contesto teorico che informa l’interpretazione.
La relazione dinamica tra prior ed evidenza rappresenta un aspetto centrale. In condizioni di scarsità informativa, le prior esercitano un’influenza determinante, incorporando trasparentemente le conoscenze accumulate. Quando l’evidenza diventa abbondante, è la verosimiglianza a dominare. Questa proprietà garantisce che l’approccio bayesiano non imponga rigidamente le convinzioni iniziali, ma specifichi esplicitamente il peso dell’informazione pregressa.
La regolarizzazione verso valori plausibili, particolarmente rilevante quando l’evidenza è debole, riduce sistematicamente gli errori di grandezza e contribuisce alla replicabilità dei risultati. L’approccio bayesiano supera la dicotomia tra “fidarsi dei dati” e “credere nella teoria”, mostrando come questi elementi possano essere combinati in modo coerente, proporzionato e trasparente.
Un punto pratico importante: per rendere le priors confrontabili e indipendenti da scelte arbitrarie di unità è utile specificarle su grandezze adimensionali (p. es. il rapporto \(\beta/s\)) oppure standardizzare le variabili prima di modellare. Questa semplice convenzione (che non sostituisce la necessità di motivare la prior) facilita la scelta di priors interpretabili, mantiene l’invarianza rispetto alla scala di misura e semplifica il confronto fra studi; ricordarsi inoltre di riportare sempre i risultati nella scala originale per favorire l’interpretazione sostantiva.
La vera forza dell’inferenza bayesiana risiede nella sua onestà epistemologica: non presume neutralità, ma esplicita il punto di partenza e mantiene costante disponibilità a rivedere le convinzioni attraverso l’evidenza. Questa trasparenza rappresenta un contributo fondamentale per una pratica di ricerca più consapevole e cumulativa.
Gelman, A., & Carlin, J. (2014). Beyond Power Calculations: Assessing Type S (Sign) and Type M (Magnitude) Errors. Perspectives on Psychological Science, 9(6), 641–651.
Ioannidis, J. P. (2005). Contradicted and initially stronger effects in highly cited clinical research. Journal of the American Medical Association, 294(2), 218–228.
Zwet, E. van, & Gelman, A. (2022). A proposal for informative default priors scaled by the standard error of estimates. The American Statistician, 76(1), 1–9.
Errore di tipo M (Magnitude): scostamento sistematico tra la magnitudine stimata di un effetto e il suo valore reale. Nei piccoli campioni, la selezione dei risultati basata sulla significatività statistica tende a sovrastimare gli effetti. Si distingue dall’errore di tipo S (Sign), che riguarda l’inversione del segno dell’effetto. L’uso di distribuzioni a priori debolmente informative a code pesanti introduce uno shrinkage adattivo che mitiga gli errori di tipo M quando l’evidenza è debole, preservando gli effetti genuini quando l’evidenza è forte (Gelman & Carlin, 2014; Ioannidis, 2005).↩︎