here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(cmdstanr, HDInterval, lubridate, brms, bayesplot, tidybayes, posterior, tidyr)36 Modello di Poisson
Introduzione
Nelle sezioni precedenti abbiamo visto come i modelli lineari generalizzati possano estendere la logica della regressione a esiti non continui, come variabili dicotomiche o proporzioni. Un altro tipo di dati molto comune nella ricerca psicologica e sociale è costituito dai conteggi: quante volte si verifica un certo evento in un intervallo di tempo o in un contesto definito. Pensiamo, ad esempio, al numero di errori commessi in un compito cognitivo, al numero di episodi di un comportamento clinicamente rilevante, o al numero di interazioni osservate in un gruppo.
Per modellare questi dati ricorriamo alla regressione di Poisson, che assume che la variabile di risposta \(Y\) segua una distribuzione di Poisson e che il logaritmo del suo valore atteso possa essere espresso come una combinazione lineare di parametri sconosciuti. In questo modo, possiamo descrivere il tasso medio di occorrenza di un evento e studiare come esso vari al variare dei predittori.
In questo capitolo utilizzeremo CmdStan per stimare un modello di Poisson in chiave bayesiana. Dopo aver esaminato la media a posteriori e l’incertezza associata al tasso di sparatorie fatali da parte della polizia negli Stati Uniti per ciascun anno, ci chiederemo se vi siano evidenze di una tendenza crescente nel tempo. Questo esempio, oltre a illustrare il funzionamento del modello di Poisson, mostra anche come i GLM possano essere applicati a dati di grande rilevanza sociale.
Per chi volesse approfondire il contesto sostantivo, segnaliamo l’articolo Racial Disparities in Police Use of Deadly Force Against Unarmed Individuals Persist After Appropriately Benchmarking Shooting Data on Violent Crime Rates [Ross et al. (2021)], che offre uno sfondo importante al fenomeno analizzato. La lettura non è obbligatoria per seguire il capitolo, ma aiuta a comprendere meglio il valore applicativo di questo tipo di analisi.
Panoramica del capitolo
- Introduzione alla regressione di Poisson per dati di conteggio.
- Studio dell’andamento temporale delle sparatorie fatali della polizia USA (2015-2024).
- Implementazione del modello in Stan.
- Posterior predictive check e analisi degli Incidence Rate Ratios (IRR).
- Traduzione dei coefficienti in termini di conteggi attesi e trend percentuale annuo.
ConsiglioPrerequisiti
- Leggere Racial Disparities in Police Use of Deadly Force Against Unarmed Individuals Persist After Appropriately Benchmarking Shooting Data on Violent Crime Rates per ottenere una panoramica approfondita su questo fenomeno e sul relativo ambito di ricerca.
AttenzionePreparazione del Notebook
36.1 Regressione di Poisson
La regressione di Poisson è un caso di GLM per variabili di risposta di conteggio (0, 1, 2, …). Denoteremo con \(\lambda_i\) il valore atteso (e, sotto il modello di Poisson, anche la varianza) del conteggio \(Y_i\) alla \(i\)-esima osservazione.
36.1.1 Distribuzione di base
Una variabile casuale di Poisson ha funzione di massa
\[ \Pr(Y=y)=\frac{\lambda^{\,y}e^{-\lambda}}{y!},\qquad y\in\{0,1,2,\dots\}, \] dove \(\lambda>0\) è sia media sia varianza: \(\mathbb{E}[Y]=\lambda,\ \mathrm{Var}(Y)=\lambda\).
Nel contesto del modello di regressione,
\[ Y_i \mid \mathbf{x}_i \sim \text{Poisson}(\lambda_i), \qquad \lambda_i>0 . \]
36.1.2 Forma GLM e funzione di legame
Per garantire \(\lambda_i>0\) si usa il link logaritmico (naturale):
\[ \log \lambda_i = \eta_i \quad\text{con}\quad \eta_i = \alpha + \mathbf{x}_i^\top \boldsymbol{\beta}. \] Equivalente a:
\[ \lambda_i = \exp(\alpha + \mathbf{x}_i^\top \boldsymbol{\beta}). \]
Nota terminologica: il link è \(\log(\cdot)\); l’esponenziale è la sua inversa. Non è corretto chiamare “link esponenziale”.
36.1.3 Conteggi e predittori
Nel modello di regressione di Poisson assumiamo che ciascun conteggio \(Y_i\) segua una distribuzione di Poisson con media \(\lambda_i\). Il legame tra la media \(\lambda_i\) e le variabili esplicative è dato dalla funzione logaritmica:
\[ \log \lambda_i = \alpha + \mathbf{x}_i^\top \boldsymbol{\beta}. \] In questo modo il numero medio di eventi attesi \(\lambda_i\) viene sempre stimato come un valore positivo:
\[ \lambda_i = \exp(\alpha + \mathbf{x}_i^\top \boldsymbol{\beta}). \] Questa formulazione è adatta quando tutti i conteggi si riferiscono a intervalli di osservazione uguali (per esempio, il numero di episodi aggressivi in un anno per ciascuno studente). In tal caso non serve introdurre ulteriori correzioni: il modello lavora direttamente sui conteggi osservati.
36.1.4 Interpretazione dei coefficienti
Nel modello di regressione di Poisson ogni osservazione \(Y_i\) segue
\[ Y_i \sim \text{Poisson}(\lambda_i), \qquad \log \lambda_i = \alpha + \mathbf{x}_i^\top \boldsymbol{\beta}. \] Qui \(\lambda_i\) è il numero medio di eventi attesi per l’osservazione \(i\).
Per il j-esimo predittore \(x_{ij}\), il rapporto tra i valori attesi quando \(x_{ij}\) aumenta di 1 unità è
\[ \frac{\lambda_i(x_{ij}+1)}{\lambda_i(x_{ij})} = \exp(\beta_j). \] Questo significa che \(\exp(\beta_j)\) è il fattore moltiplicativo atteso sul numero medio di eventi per un incremento unitario di \(x_{ij}\).
- Se \(\beta_j = 0\), non c’è effetto (\(\exp(\beta_j)=1\)).
- Se \(\beta_j > 0\), i conteggi attesi crescono moltiplicati per \(\exp(\beta_j)\).
- Se \(\beta_j < 0\), i conteggi attesi diminuiscono, divisi per \(\exp(|\beta_j|)\).
Per variabili binarie, \(\exp(\beta_j)\) confronta direttamente i due gruppi (1 contro 0).
Esempio. Se studiamo il numero di episodi aggressivi in un anno per ciascuno studente, il modello può essere scritto come
\[ \log \lambda_i = \beta_0 + \beta_1 \,\text{Stress}_i + \beta_2 \,\text{Supporto}_i + \beta_3 \,\text{Depressione}_i. \] Qui \(\exp(\beta_1)\) indica di quanto si moltiplica il numero medio di episodi aggressivi attesi quando lo stress aumenta di 1 unità, a parità delle altre variabili.
36.1.5 Assunzioni di base
Per usare la regressione di Poisson facciamo alcune ipotesi semplici:
- Risposta a conteggio: la variabile dipendente è un numero intero non negativo (0, 1, 2, …).
- Indipendenza: le osservazioni sono considerate indipendenti tra loro.
- Media = varianza: nella distribuzione di Poisson la media e la varianza coincidono. Se nei dati la varianza è molto più grande della media, il modello di Poisson può non essere adatto.
- Relazione log-lineare: il logaritmo del numero medio di eventi è una combinazione lineare dei predittori.
36.1.6 Come il modello rappresenta lambda
Nella regressione di Poisson non stimiamo direttamente il valore medio \(\lambda_i\), ma il suo logaritmo:
\[ \eta_i = \log \lambda_i = \alpha + \mathbf{x}_i^\top \boldsymbol{\beta}. \]
-
Caso senza predittori: il modello stima solo l’intercetta \(\alpha\). In questo caso
\[ \lambda = \exp(\alpha). \]
-
Caso con predittori: dati i valori delle variabili esplicative \(\mathbf{x}_i\), il numero medio di eventi per l’osservazione \(i\) è
\[ \lambda_i = \exp\big(\alpha + \mathbf{x}_i^\top \boldsymbol{\beta}\big). \] In altre parole, il modello lavora sempre sulla scala logaritmica (più semplice da trattare matematicamente), e poi si passa alla scala naturale dei conteggi applicando l’esponenziale.
36.2 La domanda di ricerca
Grazie all’archivio pubblico del Washington Post disponiamo di tutti i casi di sparatorie fatali accadute negli Stati Uniti dal 2015 in poi. L’interesse è stimare quante se vi siano evidenze di una tendenza all’aumento di tale tasso nel corso del tempo.
Importiamo e prepariamo i dati:
url <- "https://raw.githubusercontent.com/washingtonpost/data-police-shootings/master/v2/fatal-police-shootings-data.csv"
raw <- read.csv(url, stringsAsFactors = FALSE)
raw$date <- as.Date(raw$date)
raw$year <- lubridate::year(raw$date)
# Escludiamo il 2025 perché l’anno è ancora in corso e i dati sarebbero incompleti
shootings <- subset(raw, year < 2025)
df <- shootings %>%
dplyr::count(year, name = "events")
df
#> year events
#> 1 2015 995
#> 2 2016 959
#> 3 2017 984
#> 4 2018 992
#> 5 2019 993
#> 6 2020 1021
#> 7 2021 1050
#> 8 2022 1097
#> 9 2023 1164
#> 10 2024 1175Per facilitare l’interpretazione, centriamo la colonna year. In questo modo, l’intercetta si riferità all’anno 2019.
df <- df |>
mutate(year = year - 2019)
df
#> year events
#> 1 -4 995
#> 2 -3 959
#> 3 -2 984
#> 4 -1 992
#> 5 0 993
#> 6 1 1021
#> 7 2 1050
#> 8 3 1097
#> 9 4 1164
#> 10 5 1175A questo punto abbiamo una tabella df con due colonne: year (centrato), che va dal -4 (2015) a 5 (2024), ed events, che contiene il numero di sparatorie fatali registrate in ciascun anno.
36.2.1 Modello Stan
Definiamo il seguente modello
stan_code <- '
data {
int<lower=1> N;
array[N] int<lower=0> y; // conteggi
vector[N] year; // -4, -3, ..., 5 (non standardizzato)
}
parameters {
real alpha; // log media per anno 0
real beta; // effetto per 1 anno (log-IRR per anno)
}
model {
// Priors coerenti con: lambda ~ 600 circa, 400–900 plausibile
alpha ~ normal(6.4, 0.25); // oppure 0.30 se preferisci più ampia
beta ~ normal(0, 0.05); // oppure 0.10 se vuoi più permissiva
// Poisson con link log
y ~ poisson_log(alpha + beta * year);
}
generated quantities {
vector[N] eta = alpha + beta * year;
vector[N] lambda = exp(eta);
array[N] int<lower=0> y_rep;
for (n in 1:N) y_rep[n] = poisson_log_rng(eta[n]);
}
'Specificare la distribuzione a priori:
- Intercetta: \(\alpha=\log\lambda\). Poiché riteniamo plausibile, prima dei dati, una media annua \(\lambda\) centrata attorno a 600, con intervallo ~400–900, imponiamo \(\alpha \sim \mathcal N(6.40,\ 0.25)\) (oppure \(0.30\) per un intervallo un po’ più ampio).
- Pendenza: \(\beta\) è il log-IRR per anno. Attese variazioni annue piccole ⇒ \(\beta \sim \mathcal N(0,\ 0.05)\) (più prudente) oppure \(\mathcal N(0,\ 0.10)\) (più ampia).
Dati:
dat <- data.frame(
year = -4:5,
events = c(995, 959, 984, 992, 993, 1021, 1050, 1097, 1164, 1175)
)
stan_data <- list(
N = nrow(dat),
y = dat$events,
year = dat$year
)
glimpse(stan_data)
#> List of 3
#> $ N : int 10
#> $ y : num [1:10] 995 959 984 992 993 ...
#> $ year: int [1:10] -4 -3 -2 -1 0 1 2 3 4 5Compiliamo il modello e avviamo il campionamento MCMC.
mod <- cmdstan_model(write_stan_file(stan_code))fit <- mod$sample(
data = stan_data, seed = 1234,
chains = 4, parallel_chains = 4
)Estraiamo le quantità derivate di maggiore interesse:
fit$summary(variables = c("alpha", "beta", "lambda"))
#> # A tibble: 12 × 10
#> variable mean median sd mad q5 q95 rhat
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 alpha 6.94 6.94 0.0101 0.00993 6.92 6.95 1.00
#> 2 beta 0.0222 0.0222 0.00342 0.00345 0.0166 0.0279 1.00
#> 3 lambda[1] 941. 942. 17.7 17.0 912. 971. 1.00
#> 4 lambda[2] 963. 963. 15.3 15.0 938. 988. 1.00
#> 5 lambda[3] 984. 984. 13.2 13.0 963. 1006. 1.00
#> 6 lambda[4] 1006. 1006. 11.4 11.4 988. 1025. 1.00
#> 7 lambda[5] 1029. 1029. 10.4 10.2 1012. 1046. 1.00
#> 8 lambda[6] 1052. 1052. 10.4 10.3 1035. 1069. 1.00
#> 9 lambda[7] 1075. 1075. 11.7 11.8 1056. 1095. 1.00
#> 10 lambda[8] 1100. 1100. 13.9 14.3 1077. 1123. 1.00
#> 11 lambda[9] 1124. 1124. 17.0 17.4 1097. 1152. 1.00
#> 12 lambda[10] 1150. 1149. 20.5 20.9 1116. 1184. 1.00
#> ess_bulk ess_tail
#> <dbl> <dbl>
#> 1 2205. 2352.
#> 2 3921. 3016.
#> 3 2680. 2640.
#> 4 2529. 2551.
#> 5 2360. 2548.
#> 6 2225. 2343.
#> 7 2205. 2352.
#> 8 2432. 2512.
#> 9 2907. 2834.
#> 10 3450. 2973.
#> 11 3874. 2998.
#> 12 4105. 3054.36.2.2 Interpretazione
Il parametro alpha rappresenta il logaritmo del numero medio atteso di eventi nell’anno di riferimento \(x=0\). Nel nostro modello l’anno 0 è semplicemente il punto centrale della sequenza di anni osservata (−4,…,5).
Il valore stimato è \(\alpha \approx 6.94\), con un intervallo di credibilità al 95% compreso tra 6.92 e 6.95. Trasformando sulla scala naturale, otteniamo:
\[ \exp(\alpha) \approx 1\,030 \] cioè circa 1030 eventi attesi nell’anno di riferimento.
Il parametro beta misura la variazione logaritmica attesa per ogni anno aggiuntivo. La stima \(\beta \approx 0.022\) (ICr 95%: 0.017–0.028) indica una crescita positiva.
Per interpretare questo effetto sulla scala dei conteggi:
\[ \exp(\beta) \approx 1.022 , \] ossia ogni anno in più corrisponde a un aumento atteso di circa +2.2% degli eventi rispetto all’anno precedente.
Se traduciamo questa percentuale in termini assoluti, partendo dal valore base \(\exp(\alpha)\approx 1.030\), otteniamo:
\[ \exp(\alpha)\times(\exp(\beta)-1) \;\approx\; 23 \] quindi in media circa 23 eventi in più per ogni anno successivo.
# Anni da predire (quelli del dataset)
years <- -4:5
# Estrai i draw posteriori di alpha e beta da cmdstanr
# (se vuoi in formato data frame "largo")
draws <- as_draws_df(fit$draws(variables = c("alpha", "beta")))
# Costruisci predizioni posteriori di lambda per ogni anno
pred <- lapply(years, function(y) {
tibble(
year = y,
lambda = exp(draws$alpha + draws$beta * y)
)
}) |>
bind_rows()
# Riassumi: media e intervallo di credibilità 95%
pred_sum <- pred |>
group_by(year) |>
summarise(
lambda_mean = mean(lambda),
lambda_q05 = quantile(lambda, 0.05),
lambda_q95 = quantile(lambda, 0.95),
.groups = "drop"
)
# (opzionale) unisci i dati osservati
dat <- tibble(
year = -4:5,
events = c(995, 959, 984, 992, 993, 1021, 1050, 1097, 1164, 1175)
)
# Grafico: banda 90% (5%-95%), linea media e punti osservati
ggplot(pred_sum, aes(x = year)) +
geom_ribbon(aes(ymin = lambda_q05, ymax = lambda_q95), alpha = 0.2) +
geom_line(aes(y = lambda_mean), linewidth = 1) +
geom_point(data = dat, aes(y = events), size = 2) +
labs(
x = "Anno (codifica -4 … 5)",
y = "Numero atteso di eventi"
) 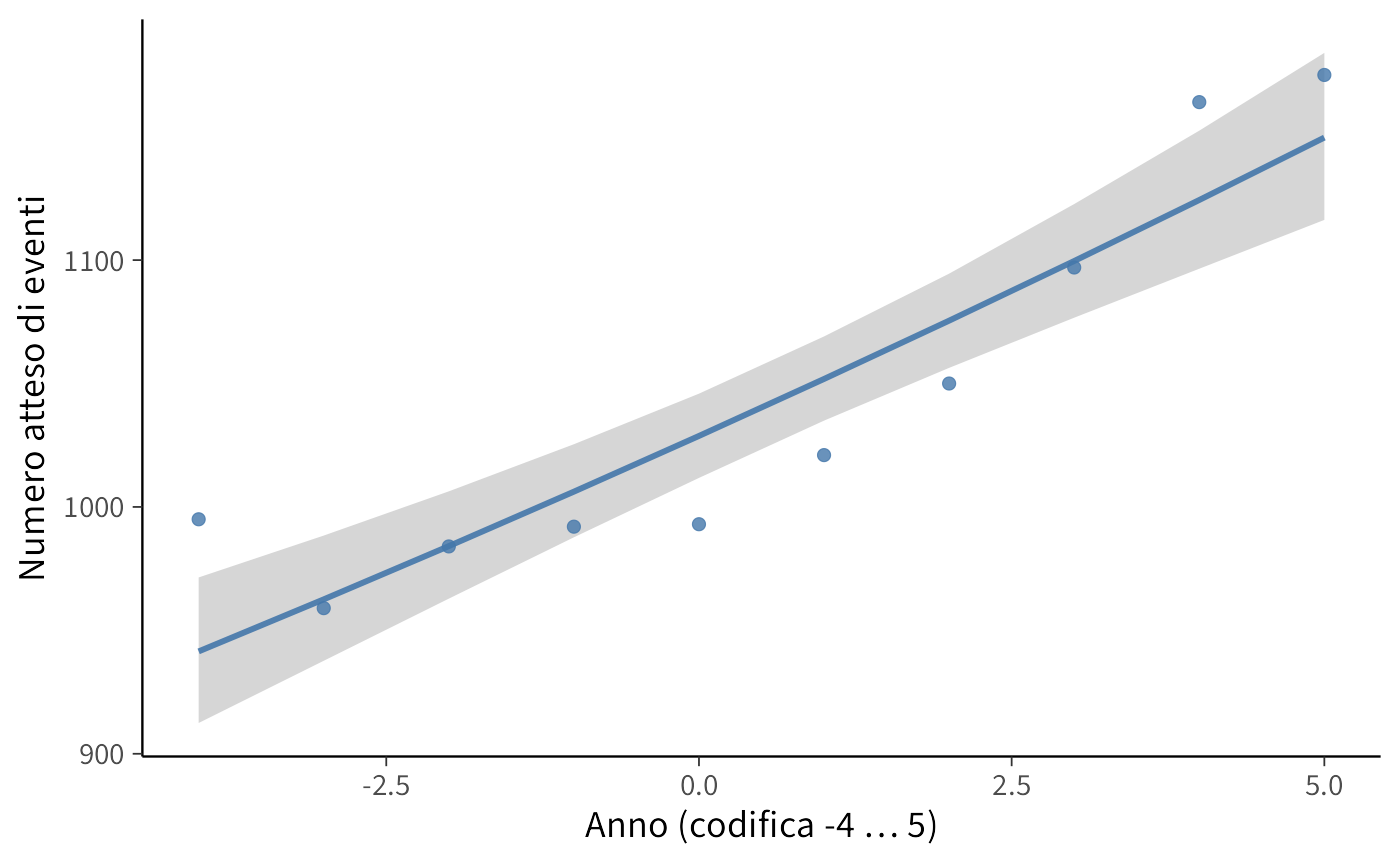
Il modello di regressione di Poisson mostra che il numero medio di eventi segue una crescita regolare nel tempo. L’intercetta indica che nell’anno di riferimento (\(x=0\)) ci si attendono circa 1030 eventi, mentre la pendenza suggerisce un incremento annuo di circa +2%, pari a una ventina di eventi in più ogni anno.
La banda di credibilità attorno alla curva stimata conferma che l’incertezza sulle previsioni è contenuta e che l’andamento crescente è chiaramente supportato dai dati. In termini sostantivi, il modello descrive bene una tendenza di crescita graduale ma costante negli anni osservati.
36.2.3 Posterior predictive check
# Dati osservati
dat <- tibble::tibble(
year = -4:5,
events = c(995, 959, 984, 992, 993, 1021, 1050, 1097, 1164, 1175)
)
# Estrai i draw di y_rep in matrice (draws x N)
yrep_mat <- fit$draws(variables = "y_rep") |>
as_draws_matrix()
# Seleziona solo le colonne y_rep[...] mantenendo l'ordine
cols <- grep("^y_rep\\[", colnames(yrep_mat))
yrep_mat <- yrep_mat[, cols, drop = FALSE]
# Calcola quantili per colonna (per ogni anno)
qs <- colQuantiles(yrep_mat, probs = c(0.05, 0.50, 0.95))
pred_sum <- tibble::tibble(
year = dat$year,
q05 = qs[, 1],
q50 = qs[, 2],
q95 = qs[, 3]
)
# Grafico PPC: banda 90% + mediana + punti osservati
ggplot(pred_sum, aes(x = year)) +
geom_ribbon(aes(ymin = q05, ymax = q95), alpha = 0.2) +
geom_line(aes(y = q50), linewidth = 1) +
geom_point(data = dat, aes(y = events), size = 2) +
labs(
x = "Anno (codifica -4 … 5)",
y = "Conteggio"
) 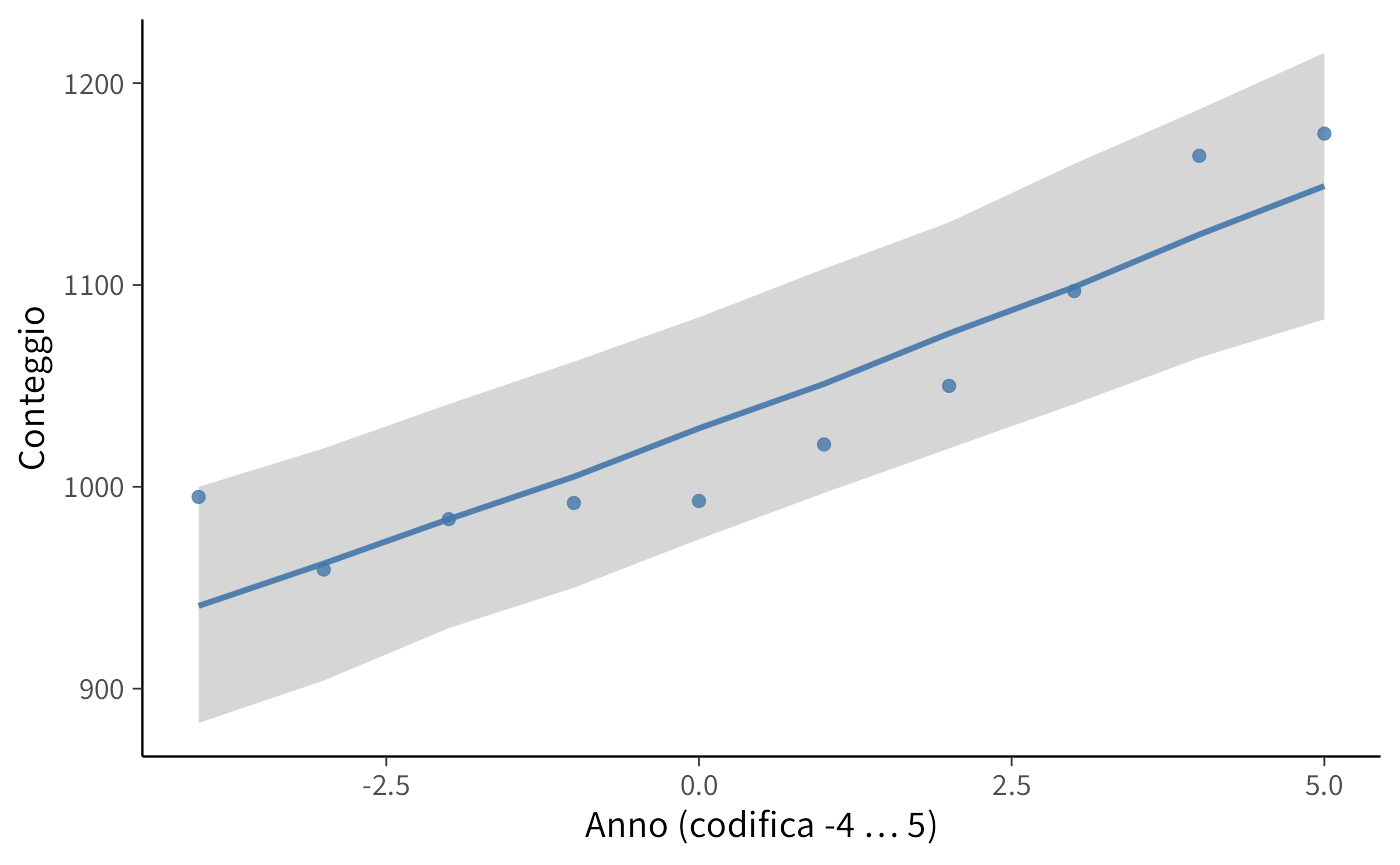
- La banda ombreggiata rappresenta il 90% della distribuzione predittiva del conteggio per ciascun anno (5%–95%).
- La linea è la mediana predittiva; i punti sono i conteggi osservati.
- Se i punti stanno per lo più dentro le bande, il modello riproduce bene i livelli di conteggio anno per anno.
- Se molti punti cadono fuori (o tutti da un lato), il modello potrebbe essere troppo rigido o mancare di struttura (p.es. overdispersione, forma non lineare nel tempo, effetti non inclusi).
# Media/varianza osservate
mean_obs <- mean(dat$events)
var_obs <- var(dat$events)
# Media/varianza delle repliche (per draw)
mean_rep <- rowMeans(yrep_mat)
var_rep <- apply(yrep_mat, 1, var)
# p-value predittivi (proporzione di repliche >= osservato)
p_mean <- mean(mean_rep >= mean_obs)
p_var <- mean(var_rep >= var_obs)
tibble::tibble(
stat = c("media", "varianza"),
osservato = c(mean_obs, var_obs),
media_rep = c(mean(mean_rep), mean(var_rep)),
p_pred = c(p_mean, p_var)
)
#> # A tibble: 2 × 4
#> stat osservato media_rep p_pred
#> <chr> <dbl> <dbl> <dbl>
#> 1 media 1043 1042. 0.468
#> 2 varianza 5940. 6093. 0.486p1 <- ggplot(data.frame(mean_rep), aes(x = mean_rep)) +
geom_histogram(bins = 30) +
geom_vline(xintercept = mean_obs, linetype = 2) +
labs(title = "PPC media", x = "Media (repliche)", y = "Frequenza")
p2 <- ggplot(data.frame(var_rep), aes(x = var_rep)) +
geom_histogram(bins = 30) +
geom_vline(xintercept = var_obs, linetype = 2) +
labs(title = "PPC varianza", x = "Varianza (repliche)", y = "Frequenza")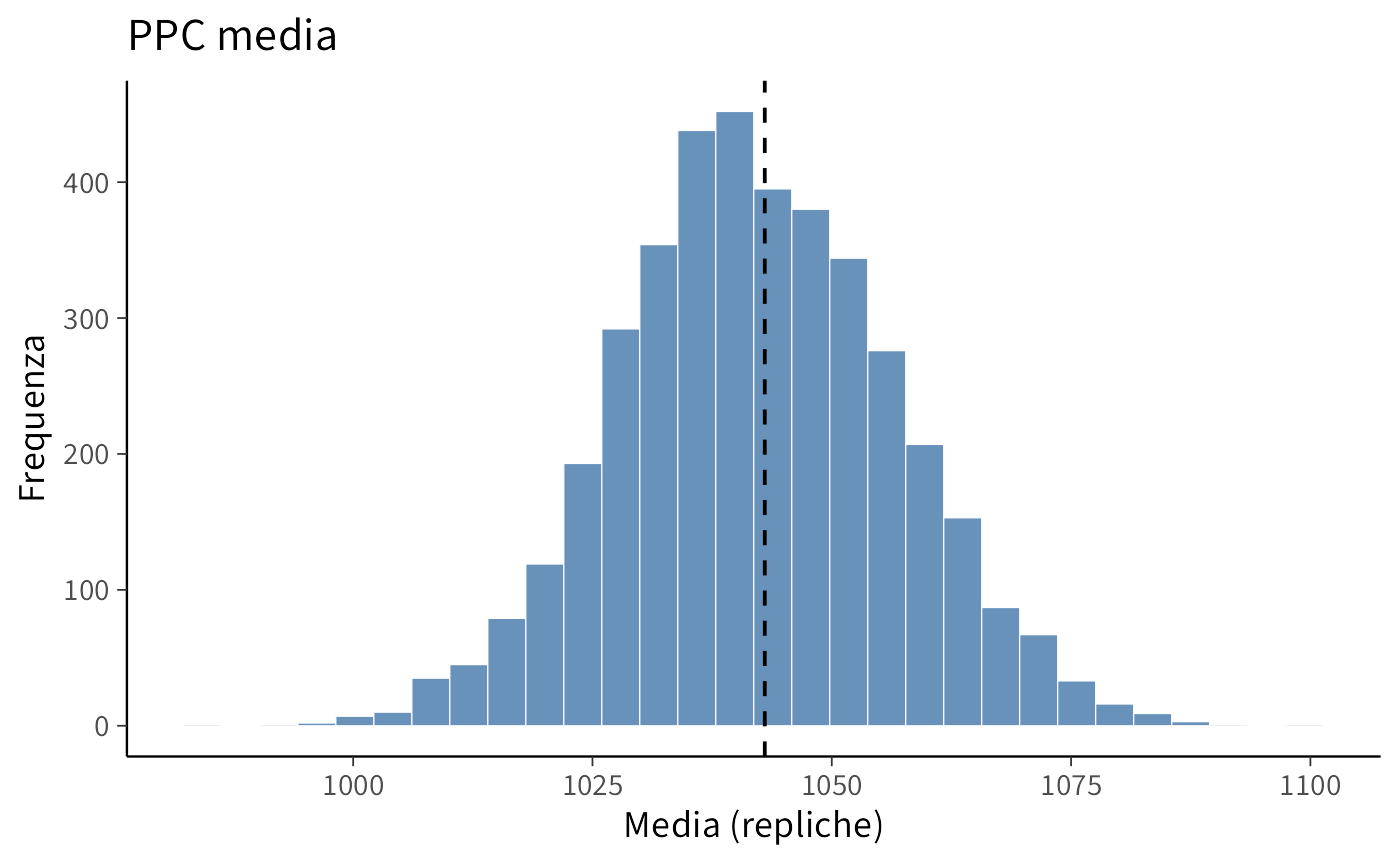
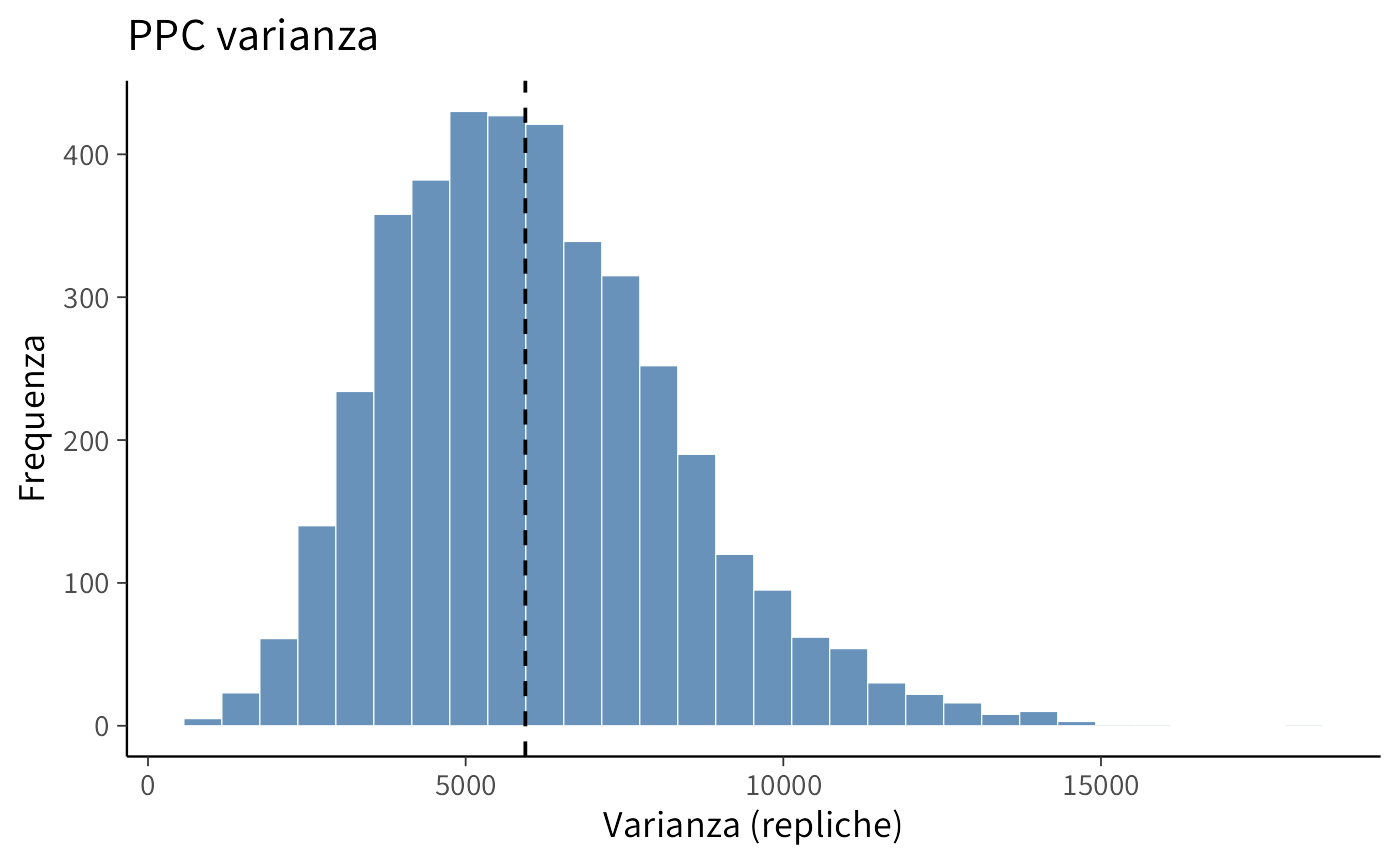
Il controllo predittivo mostra che i conteggi osservati ricadono interamente entro le bande di credibilità del modello. Inoltre, la media e la varianza osservate sono molto vicine a quelle prodotte dalle repliche simulate (p-value predittivi ~0.5), il che indica che il modello non sottostima né sovrastima la variabilità dei dati. Nel complesso, questi risultati suggeriscono che la regressione di Poisson con legame log e trend lineare nel tempo fornisce una rappresentazione adeguata dei dati osservati.
36.2.3.1 Incidence Rate Ratio (IRR)
Il valore medio stimato dell’IRR è 1.022, con un intervallo di credibilità al 90% compreso tra 1.017 e 1.028. Questo significa che, a ogni anno in più, il numero medio di eventi attesi aumenta di circa il 2.2%, con un margine di incertezza che va da circa +1.7% a +2.8%.
Poiché l’intero intervallo si colloca sopra 1, il modello suggerisce con elevata credibilità che la tendenza temporale sia effettivamente crescente: non stiamo osservando fluttuazioni casuali, ma un aumento sistematico anno dopo anno.
Il valore medio dell’IRR è 1.022: questo equivale a un incremento di circa +2.2% per anno.
- In termini assoluti, partendo da una media di circa 1030 eventi, un aumento del 2.2% corrisponde a circa +23 eventi all’anno.
- L’intervallo di credibilità (1.017–1.028) implica che l’aumento medio sia compreso tra circa +18 e +29 eventi per anno.
In altre parole, il modello suggerisce che il fenomeno osservato cresce in modo regolare e consistente: ogni anno si verificano in media da una ventina a una trentina di eventi in più rispetto all’anno precedente.
Riflessioni conclusive
In questo capitolo abbiamo visto come il modello di Poisson possa essere usato per descrivere dati che rappresentano conteggi, come il numero di comportamenti osservati in un certo periodo di tempo o la frequenza con cui si manifesta un sintomo. L’idea centrale è semplice: invece di trattare i dati come proporzioni o medie, li consideriamo come eventi che “accadono” con una certa intensità, rappresentata dal parametro \(\lambda\). Questo ci permette di modellare direttamente le frequenze osservate, rispettando la natura discreta e positiva dei dati.
Dal punto di vista psicologico, ciò significa avere uno strumento adatto per studiare fenomeni che non si esprimono in valori continui ma in conteggi (ad esempio, il numero di episodi ansiosi in una settimana, o il numero di errori commessi in un compito). L’approccio bayesiano aggiunge un ulteriore vantaggio: possiamo combinare le informazioni provenienti dai dati con ciò che sappiamo (o ipotizziamo) a priori sul fenomeno, ottenendo una stima che riflette sia l’evidenza empirica sia la nostra conoscenza di base.
Nei prossimi capitoli vedremo come estendere ulteriormente questa logica ad altri tipi di dati e modelli, consolidando l’idea che i GLM rappresentino un quadro flessibile e potente per affrontare molte delle domande classiche della ricerca psicologica.
NotaInformazioni sull’ambiente di sviluppo
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.1
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] lubridate_1.9.4 HDInterval_0.2.4 cmdstanr_0.8.0
#> [4] ragg_1.5.0 tinytable_0.15.1 withr_3.0.2
#> [7] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [10] tidybayes_3.0.7 bayesplot_1.14.0 ggplot2_4.0.1
#> [13] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [16] loo_2.8.0 rstan_2.32.7 StanHeaders_2.32.10
#> [19] brms_2.23.0 Rcpp_1.1.0 sessioninfo_1.2.3
#> [22] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [25] modelr_0.1.11 tibble_3.3.0 dplyr_1.1.4
#> [28] tidyr_1.3.1 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] gridExtra_2.3 inline_0.3.21 sandwich_3.1-1
#> [4] rlang_1.1.6 magrittr_2.0.4 multcomp_1.4-29
#> [7] snakecase_0.11.1 compiler_4.5.2 vctrs_0.6.5
#> [10] stringr_1.6.0 pkgconfig_2.0.3 arrayhelpers_1.1-0
#> [13] fastmap_1.2.0 backports_1.5.0 labeling_0.4.3
#> [16] utf8_1.2.6 rmarkdown_2.30 ps_1.9.1
#> [19] purrr_1.2.0 xfun_0.54 cachem_1.1.0
#> [22] jsonlite_2.0.0 broom_1.0.11 parallel_4.5.2
#> [25] R6_2.6.1 stringi_1.8.7 RColorBrewer_1.1-3
#> [28] estimability_1.5.1 knitr_1.50 zoo_1.8-14
#> [31] pacman_0.5.1 Matrix_1.7-4 splines_4.5.2
#> [34] timechange_0.3.0 tidyselect_1.2.1 abind_1.4-8
#> [37] yaml_2.3.12 codetools_0.2-20 processx_3.8.6
#> [40] curl_7.0.0 pkgbuild_1.4.8 lattice_0.22-7
#> [43] bridgesampling_1.2-1 S7_0.2.1 coda_0.19-4.1
#> [46] evaluate_1.0.5 survival_3.8-3 RcppParallel_5.1.11-1
#> [49] pillar_1.11.1 tensorA_0.36.2.1 checkmate_2.3.3
#> [52] stats4_4.5.2 distributional_0.5.0 generics_0.1.4
#> [55] rprojroot_2.1.1 rstantools_2.5.0 scales_1.4.0
#> [58] xtable_1.8-4 glue_1.8.0 emmeans_2.0.0
#> [61] tools_4.5.2 data.table_1.17.8 mvtnorm_1.3-3
#> [64] grid_4.5.2 QuickJSR_1.8.1 colorspace_2.1-2
#> [67] nlme_3.1-168 cli_3.6.5 textshaping_1.0.4
#> [70] svUnit_1.0.8 Brobdingnag_1.2-9 V8_8.0.1
#> [73] gtable_0.3.6 digest_0.6.39 TH.data_1.1-5
#> [76] htmlwidgets_1.6.4 farver_2.1.2 memoise_2.0.1
#> [79] htmltools_0.5.9 lifecycle_1.0.4 MASS_7.3-65Bibliografia
Ross, C. T., Winterhalder, B., & McElreath, R. (2021). Racial disparities in police use of deadly force against unarmed individuals persist after appropriately benchmarking shooting data on violent crime rates. Social Psychological and Personality Science, 12(3), 323–332.