here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(tidyr, purrr, forcats)5 Errori di segno e errori di grandezza
ImportanteIn questo capitolo imparerai a
- Relazione tra crisi della replicabilità e approccio frequentista.
- Limiti della significatività statistica.
- Errori di grandezza e errori di segno.
- Utilizzo dell’approccio bayesiano per ottenere stime più precise e affidabili.
ConsiglioPrerequisiti
- Leggere il Capitolo 4 del manuale (“Distorsioni nelle stime: il problema della significatività statistica”), che introduce i concetti teorici di errore di tipo \(M\) e \(S\).
- Leggere Horoscopes di McElreath (2020).
AttenzionePreparazione del Notebook
ConsiglioDomande Iniziali
Prima di esplorare le simulazioni, prova a formulare delle ipotesi:
- Se l’effetto vero è \(d = 0.2\) e la potenza dello studio è solo 8%, di quanto saranno sovrastimate le stime “significative”?
- Quale percentuale di risultati significativi mostrerà un effetto nella direzione sbagliata?
- Come cambieranno questi errori aumentando la dimensione del campione?
Tieni a mente le tue risposte mentre esplori le simulazioni.
5.1 Il filtro ingannevole della significatività statistica
L’idea che la significatività statistica, convenzionalmente definita dal superamento della soglia \(p < 0.05\), possa fungere da filtro affidabile per distinguere i risultati reali dagli artefatti metodologici è un errore concettuale fondamentale nell’interpretazione dell’evidenza scientifica. Come documentato da Loken & Gelman (2017), questa soglia non solo si è rivelata porosa e inefficace, ma ha anche introdotto distorsioni sistematiche che, paradossalmente, hanno amplificato il rumore statistico anziché eliminarlo.
Il problema si acuisce in presenza di tre condizioni che, paradossalmente, caratterizzano molti ambiti della ricerca psicologica. In primo luogo, quando gli effetti reali sono intrinsecamente piccoli, come spesso accade nello studio di fenomeni complessi, difficilmente riconducibili a cause uniche e potenti. In secondo luogo, quando le dimensioni del campione sono limitate, una circostanza comune negli studi sperimentali che devono bilanciare costi logistici e praticabilità metodologica. Infine, quando la potenza statistica è insufficiente, situazione inevitabile quando le prime due condizioni coesistono, compromettendo la capacità di rilevare effetti genuini.
In questo contesto metodologicamente fragile, i risultati che superano la soglia di significatività non rappresentano un campione fedele degli effetti reali. Al contrario, costituiscono una selezione distorta in cui sono le fluttuazioni casuali e non l’entità effettiva degli effetti a determinare il superamento della soglia statistica. Questo meccanismo produce stime sistematicamente sovrastimate rispetto ai valori reali, offrendo un’immagine distorta dell’evidenza scientifica accumulata. Invece di isolare il segnale dal rumore, il filtro della significatività finisce per concentrare e amplificare il rumore stesso, compromettendo l’integrità della conoscenza scientifica.
5.2 Errori di tipo M e S
Per illustrare le implicazioni del processo decisionale basato sulla significatività statistica, Loken & Gelman (2017) hanno condotto una simulazione in uno scenario ipotetico con un effetto reale, seppur molto debole e difficilmente rilevabile senza un campione di dati molto ampio. Applicando l’approccio frequentista, hanno valutato la capacità di identificare l’effetto tramite la significatività statistica.
I risultati hanno evidenziato che, anche in presenza di un effetto reale, l’approccio frequentista rilevava un risultato significativo solo in una frazione limitata dei casi. Quando un effetto risultava significativo, la stima della sua entità era spesso sovrastimata e instabile, generando una percezione distorta della sua forza reale.
Questa simulazione mette in luce un meccanismo di inflazione selettiva degli effetti: il filtro della significatività non separa efficacemente il segnale dal rumore, ma tende a privilegiare quelle fluttuazioni casuali che superano la soglia statistica. Il risultato è una letteratura in cui gli effetti pubblicati appaiono più grandi e più affidabili di quanto non siano in realtà, compromettendo la replicabilità e la solidità della conoscenza scientifica, soprattutto nei campi della psicologia e delle scienze sociali, caratterizzati da effetti modesti e campioni relativamente piccoli.
5.2.1 Simulazione
Riproduciamo qui, in forma semplificata, la simulazione condotta da Loken & Gelman (2017).
5.2.1.1 Setup della simulazione
Consideriamo due campioni casuali indipendenti di dimensioni \(n_1 = 20\) e \(n_2 = 25\), estratti rispettivamente dalle distribuzioni normali \(\mathcal{N}(102, 10)\) e \(\mathcal{N}(100, 10)\). La dimensione dell’effetto (\(d\)) relativa alla differenza tra le medie dei due campioni viene calcolata come:
\[ d = \frac{\bar{y}_1 - \bar{y}_2}{s_p}, \] dove \(\bar{y}_1\) e \(\bar{y}_2\) sono le medie campionarie dei due gruppi e \(s_p\) è la deviazione standard combinata, definita da:
\[ s_p = \sqrt{\frac{(n_1-1)s_1^2 + (n_2-1)s_2^2}{n_1 + n_2 - 2}}. \]
In questo scenario, la dimensione dell’effetto risulta molto piccola, indicando che la differenza osservata tra i due gruppi ha una rilevanza pratica minima. Ciò implica che, anche quando un’analisi statistica rileva una differenza “significativa”, l’impatto reale tra i gruppi resta trascurabile in termini pratici.
# Parametri della simulazione
true_d <- 0.2 # Effetto vero (Cohen's d)
mu_1 <- 102 # Media gruppo 1
mu_2 <- 100 # Media gruppo 2 (differenza = 2)
sigma <- 10 # Deviazione standard comune
n1 <- 20 # Dimensione gruppo 1
n2 <- 25 # Dimensione gruppo 2
n_simulations <- 50000 # Numero di repliche
# Verifica del Cohen's d teorico
pooled_sd_true <- sigma # Con varianze uguali
d_true <- (mu_1 - mu_2) / pooled_sd_true
cat(sprintf("Effetto vero (d di Cohen): %.2f\n", d_true))
#> Effetto vero (d di Cohen): 0.20
cat(sprintf("Dimensioni campionarie: n1 = %d, n2 = %d\n", n1, n2))
#> Dimensioni campionarie: n1 = 20, n2 = 255.2.1.2 Calcolo della potenza statistica
Prima di procedere con la simulazione, stimiamo la potenza dello studio, cioè la probabilità di ottenere \(p < 0.05\) quando l’effetto esiste realmente:
# Potenza approssimata per test t a due campioni
# Formula: potenza ≈ Φ(|d|√(n1*n2/(n1+n2)) - z_{1-α/2})
n_harmonic <- 2 * n1 * n2 / (n1 + n2) # Media armonica * 2
ncp <- true_d * sqrt(n_harmonic / 2) # Parametro di non centralità
power <- pnorm(ncp - qnorm(0.975)) # Potenza approssimata
cat(sprintf("Potenza statistica: %.1f%%\n", power * 100))
#> Potenza statistica: 9.8%
cat(sprintf("Questo significa che ~%.0f%% degli studi troverà p < 0.05\n", power * 100))
#> Questo significa che ~10% degli studi troverà p < 0.05Con una potenza di appena ~10%, la maggior parte degli studi non rileverà un risultato significativo, anche quando l’effetto esiste davvero. Ma cosa succede ai pochi studi che riescono a ottenere la significatività statistica?
5.2.1.3 Esecuzione della simulazione
Per esplorare le conseguenze dell’approccio frequentista in questo scenario, conduciamo una simulazione in cui vengono estratti due campioni: il primo è composto da 20 osservazioni della prima popolazione, mentre il secondo è composto da 25 osservazioni della seconda popolazione. Per ciascuna iterazione applichiamo il test \(t\) di Student per confrontare le medie dei due gruppi.
Nell’approccio frequentista, il valore-\(p\) guida la decisione statistica: se \(p \ge 0.05\), il risultato è considerato non significativo e generalmente scartato; se \(p < 0.05\), il risultato è considerato “significativo” e ritenuto meritevole di attenzione e di pubblicazione.
Per analizzare in modo esaustivo le implicazioni di questa procedura, ripetiamo l’estrazione dei campioni e il calcolo del test \(t\) di Student per un gran numero di iterazioni, ad esempio 50,000. Questo ci permette di ottenere una distribuzione completa dei risultati e di valutare la frequenza con cui emergono risultati significativi e la stabilità delle stime prodotte dall’approccio frequentista.
# Funzione per simulare un singolo studio
simulate_study <- function(mu_1, mu_2, sigma, n1, n2) {
y1 <- rnorm(n1, mean = mu_1, sd = sigma)
y2 <- rnorm(n2, mean = mu_2, sd = sigma)
pooled_sd <- sqrt(((n1 - 1) * var(y1) + (n2 - 1) * var(y2)) / (n1 + n2 - 2))
d_observed <- (mean(y1) - mean(y2)) / pooled_sd
t_result <- t.test(y1, y2, var.equal = TRUE)
tibble(
d_observed = d_observed,
p_value = t_result$p.value,
significant = p_value < 0.05
)
}
# Esecuzione delle simulazioni
results <- map_dfr(1:n_simulations, ~simulate_study(mu_1, mu_2, sigma, n1, n2))
# Separazione dei risultati significativi e non
significant_results <- results |> dplyr::filter(significant)
nonsignificant_results <- results |> dplyr::filter(!significant)
cat(sprintf("Studi totali: %d\n", nrow(results)))
#> Studi totali: 50000
cat(sprintf("Studi con p < 0.05: %d (%.1f%%)\n",
nrow(significant_results),
100 * nrow(significant_results) / nrow(results)))
#> Studi con p < 0.05: 4969 (9.9%)5.2.1.4 Quantificazione degli Errori M e S
Per comprendere meglio le distorsioni prodotte dall’approccio frequentista, calcoliamo due metriche chiave:
- Errore di tipo M (Magnitude): misura quanto le stime degli effetti significativi tendano a sovrastimare l’effetto reale.
- Errore di tipo S (Sign): misura la probabilità che l’effetto significativo abbia il segno opposto rispetto a quello reale.
#> Effetto vero: d = 0.20
#> Media effetti significativi: |d| = 0.76
#> TYPE M (exaggeration ratio): 3.8x
#> TYPE S (wrong sign rate): 4.4%5.2.1.5 Interpretazione
I risultati della simulazione mostrano chiaramente il meccanismo di inflazione selettiva degli effetti tipico dell’approccio frequentista basato sulla significatività statistica. Solo una piccola frazione di studi raggiunge la soglia \(p < 0.05\), e sono proprio questi studi “fortunati” a entrare nella letteratura, mentre la maggior parte dei risultati, pur basati sullo stesso effetto reale, viene ignorata. Questo processo genera due distorsioni principali:
- sovrastima sistematica dell’effetto (Type M): le stime degli effetti statisticamente significativi risultano mediamente molto più grandi dell’effetto reale;
- errore di segno (Type S): una piccola ma non trascurabile percentuale di effetti statisticamente significativi presenta il segno opposto rispetto all’effetto reale.
In pratica, la soglia di significatività (ad esempio, \(p\) < 0.05) non non filtra il segnale dal rumore, ma seleziona invece quegli studi in cui il caso ha prodotto un effetto apparentemente più forte rispetto alla realtà sottostante. Ne consegue una letteratura in cui gli effetti pubblicati appaiono più forti e coerenti di quanto non siano in realtà, compromettendo la replicabilità e la solidità della conoscenza scientifica.
Questa dinamica spiega perché, in ambiti caratterizzati da effetti modesti e campioni piccoli, come la psicologia e le scienze sociali, gli studi “significativi” tendano a fornire un’immagine ingannevole della realtà, enfatizzando risultati che sono in larga parte il prodotto del caso piuttosto che della forza effettiva dell’effetto.
5.2.1.6 Visualizzazione e interpretazione dei risultati
Le figure seguenti mostrano come la selezione dei risultati basata sulla significatività statistica (\(p < 0.05\)) introduca una distorsione sistematica nella letteratura scientifica. Quando l’effetto reale è modesto, questo filtro opera una doppia distorsione: non solo sovrastima sistematicamente l’entità degli effetti, ma può anche invertirne la direzione percepita, producendo conclusioni che sembrano indicare un effetto opposto a quello realmente esistente.
La prima figura include soltanto gli studi che superano la soglia di significatività. In questo sottoinsieme, la distribuzione delle stime dell’indice d di Cohen risulta nettamente spostata verso valori più elevati rispetto all’effetto reale:
col_hist <- palette_qualitative[5] # Blu
col_true <- palette_qualitative[1] # Arancione
col_zero <- palette_qualitative[8] # Grigio
col_emph <- palette_qualitative[5] # Blu (annotazione)
ggplot(significant_results, aes(x = d_observed)) +
geom_histogram(
bins = 30,
fill = col_hist,
color = "white",
alpha = 0.8
) +
geom_vline(
xintercept = true_d,
color = col_true,
linetype = "dashed",
linewidth = 1.2
) +
geom_vline(
xintercept = 0,
color = col_zero,
linetype = "dotted"
) +
annotate(
"text",
x = true_d + 0.05,
y = Inf,
vjust = 2,
hjust = 0,
label = sprintf("Effetto vero\nd = %.2f", true_d),
color = col_true
) +
annotate(
"text",
x = mean(abs(significant_results$d_observed)),
y = Inf,
vjust = 4,
hjust = 0.5,
label = sprintf(
"Media |d| significativi\n= %.2f (%.1fx il vero)",
mean(abs(significant_results$d_observed)),
type_m_ratio
),
color = col_emph
) +
labs(
x = "Stima d di Cohen",
y = "Frequenza",
title = "Errore di Tipo M:\nsovrastima sistematica degli effetti 'significativi'",
subtitle = sprintf(
"Solo %d/%d studi (%.1f%%) raggiungono p < 0.05",
nrow(significant_results),
n_simulations,
100 * nrow(significant_results) / n_simulations
)
)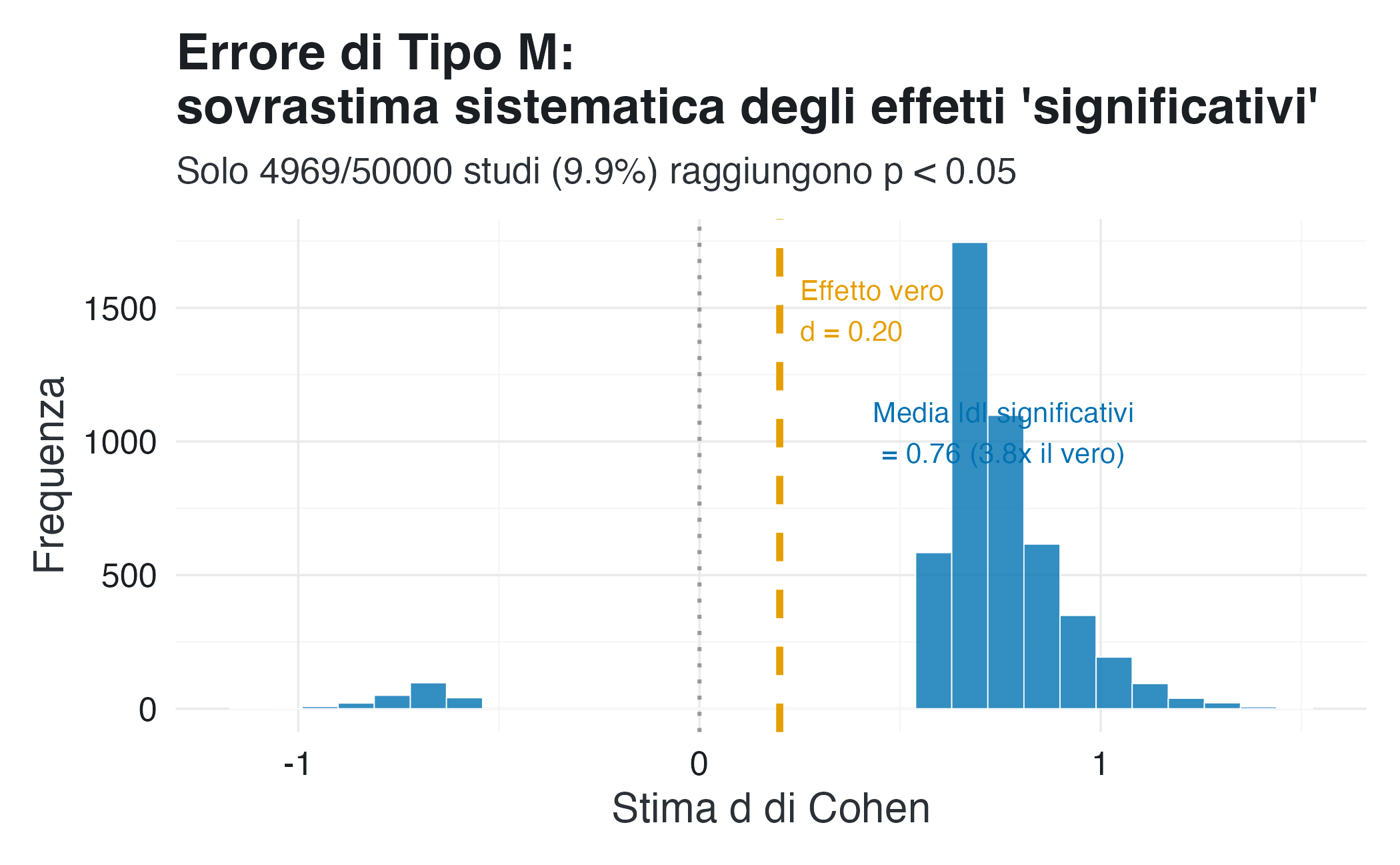
La distribuzione asimmetrica delle stime, con una coda lunga verso valori elevati, non riflette la vera entità del fenomeno, ma è un artefatto della selezione. Solo quegli studi in cui la fluttuazione campionaria casuale ha prodotto una differenza eccezionalmente ampia riescono a superare la soglia della significatività statistica. Il risultato è che la letteratura scientifica finisce per rappresentare, in media, una sovrastima sistematica dell’effetto, quantificabile in circa quattro volte il suo valore reale. In sintesi, il problema non risiede nella misurazione dell’effetto, ma nella selezione sistematica dei risultati che tendono a esagerare il fenomeno.
La seconda figura approfondisce un aspetto diverso: tra gli studi che superano la soglia di significatività, alcuni stimano un effetto nella direzione opposta rispetto a quella reale.
palette_sign_error <- setNames(
palette_qualitative[c(5, 1)], # blu + arancione
c("FALSE", "TRUE")
)
col_zero <- palette_qualitative[8] # grigio
col_true <- palette_qualitative[1] # arancione
significant_results |>
mutate(sign_error = factor(d_observed < 0, levels = c(FALSE, TRUE))) |>
ggplot(aes(x = d_observed, fill = sign_error)) +
geom_histogram(bins = 30, color = "white", alpha = 0.8) +
geom_vline(
xintercept = 0,
color = col_zero,
linewidth = 1
) +
geom_vline(
xintercept = true_d,
color = col_true,
linetype = "dashed",
linewidth = 1
) +
scale_fill_manual(
values = palette_sign_error,
labels = c(
"FALSE" = "Segno corretto",
"TRUE" = "Segno sbagliato"
)
) +
labs(
x = "Stima d di Cohen",
y = "Frequenza",
fill = "",
title = "Errore di Tipo S:\nrisultati significativi con direzione errata",
subtitle = sprintf(
"%.1f%% dei risultati 'significativi' ha il segno sbagliato",
type_s_rate * 100
)
)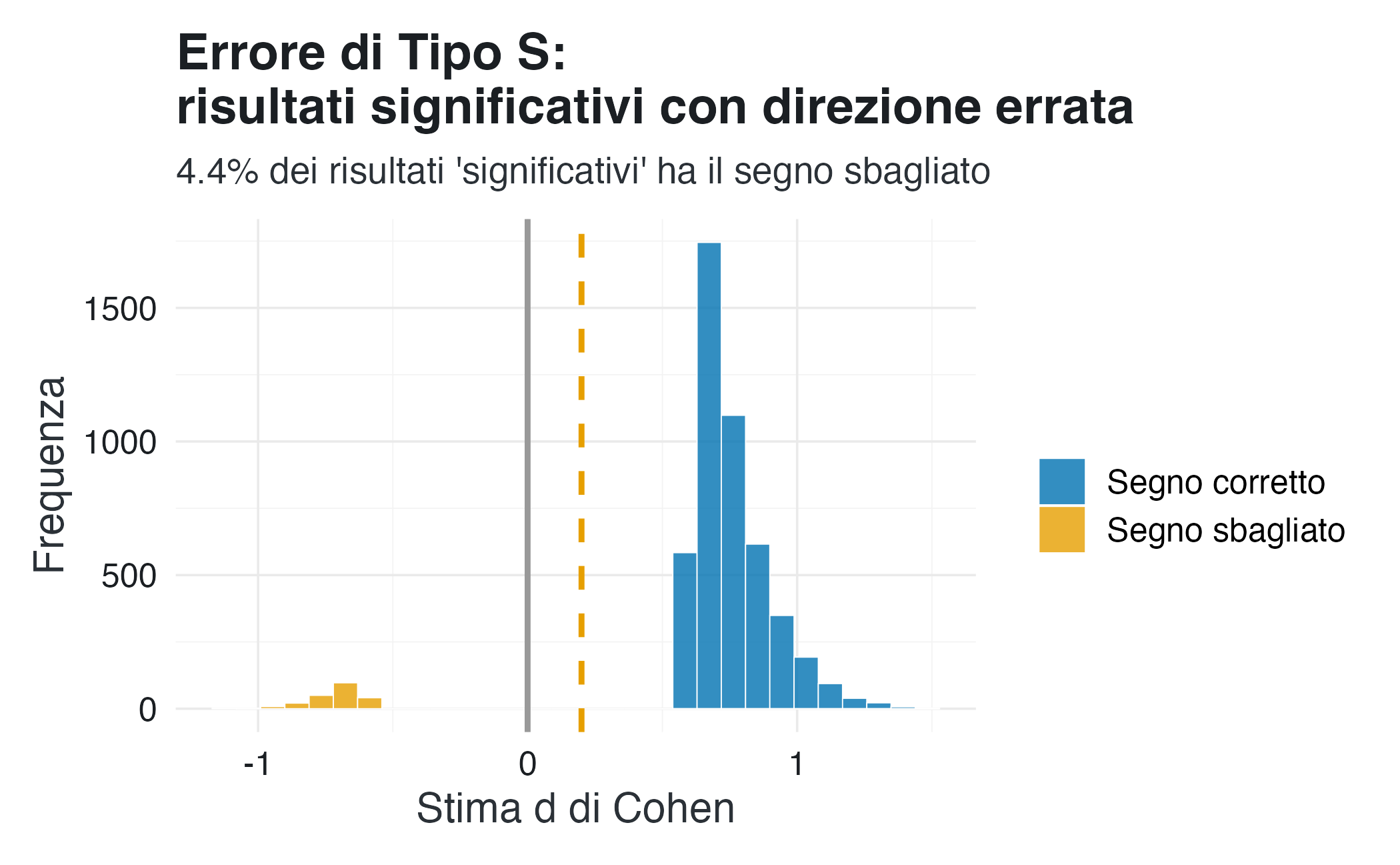
Questo fenomeno si verifica in condizioni di bassa potenza statistica. In tali contesti, non solo è improbabile rilevare un piccolo effetto, ma aumenta anche il rischio che il rumore campionario generi una stima significativa nella direzione opposta. L’inclusione di questi risultati nella letteratura scientifica contribuisce a creare incoerenze empiriche, a ridurre la replicabilità degli studi e a generare dispute teoriche basate su dati non attendibili.
La terza figura permette di confrontare questo scenario con la distribuzione delle stime ottenute considerando tutti i 50,000 studi simulati, indipendentemente dal valore-\(p\):
col_hist <- palette_qualitative[8] # Grigio
col_true <- palette_qualitative[1] # Arancione
col_mean <- palette_qualitative[5] # Blu
p3 <- ggplot(results, aes(x = d_observed)) +
geom_histogram(
bins = 50,
fill = col_hist,
color = "white",
alpha = 0.8
) +
geom_vline(
xintercept = true_d,
color = col_true,
linetype = "dashed",
linewidth = 1
) +
geom_vline(
xintercept = mean(results$d_observed),
color = col_mean,
linewidth = 1
) +
labs(
title = "Tutti gli studi (N = 50.000)",
subtitle = sprintf(
"Media = %.3f (≈ effetto vero)",
mean(results$d_observed)
),
x = "Stima d di Cohen",
y = "Frequenza"
)
p3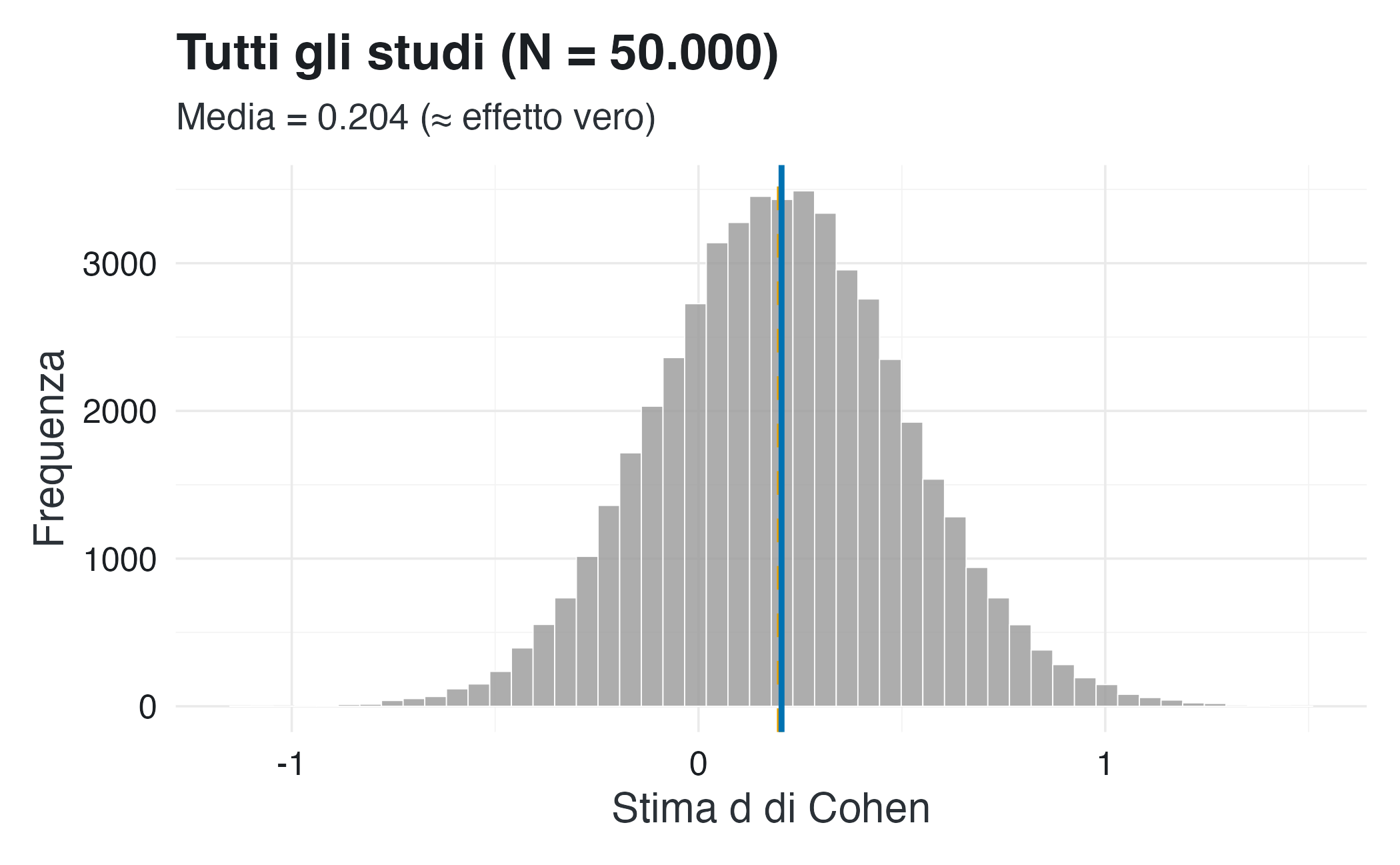
Quando tutti gli studi sono inclusi, le fluttuazioni casuali si compensano a vicenda e la media delle stime converge verso l’effetto reale. Pertanto, gli errori di Tipo M (sovrastima) e di Tipo S (segno invertito) non sono una caratteristica delle stime stesse, ma emergono unicamente come artefatto del processo di selezione basato sulla soglia di significatività.
In sintesi, il valore \(p\) non è un semplice criterio di rilevanza, ma agisce da filtro altamente selettivo e distorsivo. Isolando sistematicamente le stime più estreme, spesso aberranti, nelle code della distribuzione campionaria, questo meccanismo produce una sovrastima sistematica degli effetti nella letteratura pubblicata, rappresentando i fenomeni come più ampi di quanto non siano nella realtà. In casi estremi, può addirittura generare inversioni di segno statisticamente significative, dando credito a conclusioni fuorvianti. Il risultato è l’accumulo di un corpus di conoscenze affetto da una distorsione sistematica che erode il progresso cumulativo della scienza. Da ciò derivano, in larga parte, sia la crisi di replicabilità sia l’instabilità dei risultati nella psicologia empirica e in altre discipline (Gelman & Stern, 2006).
5.3 Confronto con l’approccio bayesiano
A differenza dei test d’ipotesi frequentisti, l’inferenza bayesiana non opera con soglie dicotomiche. Invece di giudicare un risultato in base al superamento di un limite arbitrario, fornisce una distribuzione a posteriori che quantifica la plausibilità relativa di ogni possibile valore dell’effetto, aggiornando una credenza iniziale esplicita (prior) con i dati osservati. Questo approccio permette di rappresentare l’incertezza in modo continuo e naturale, evitando le distorsioni di selezione e sovrastima indotte dalla soglia del \(p < 0.05\).
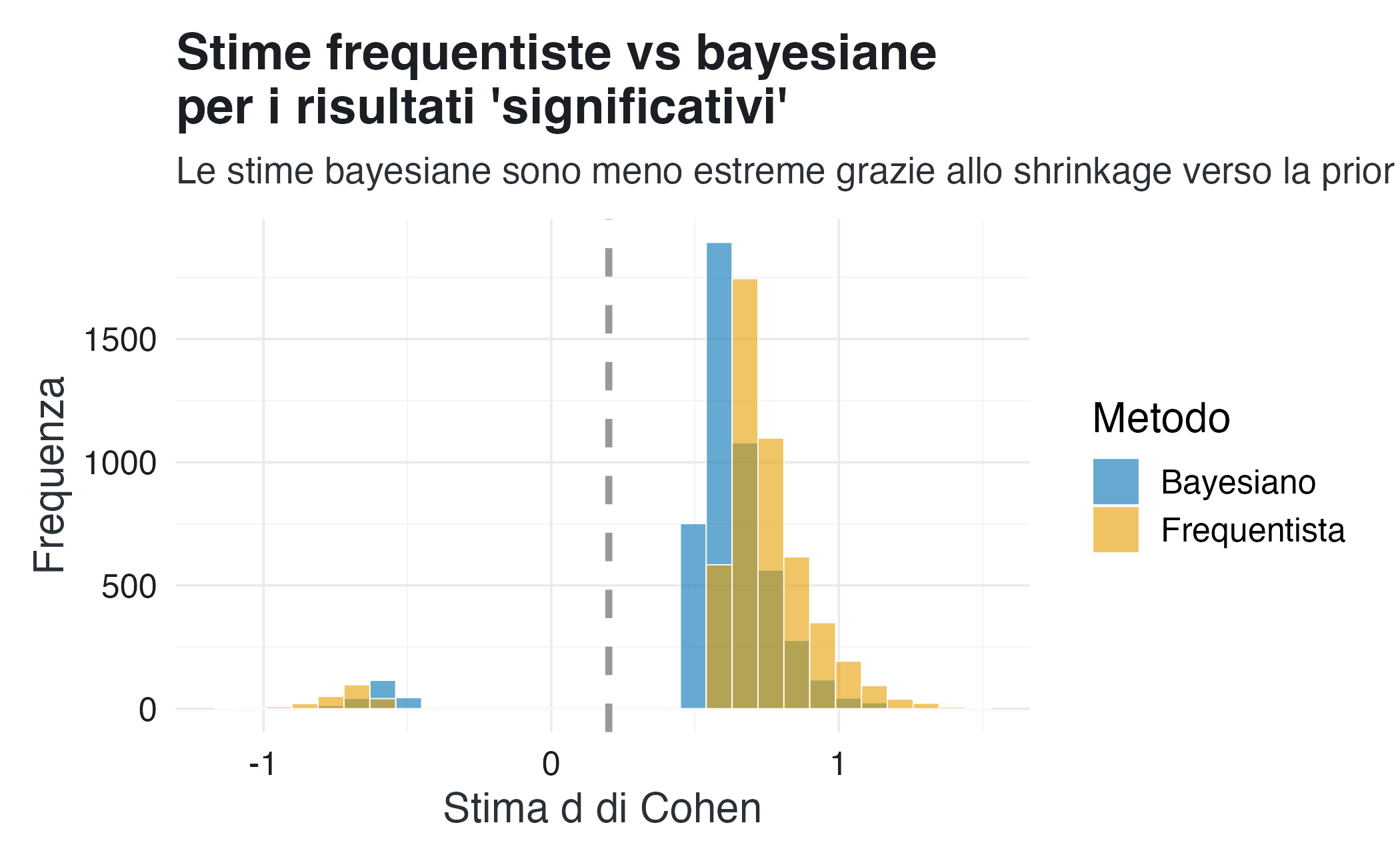
Tuttavia, per un confronto equo con il paradigma frequentista, applicheremo lo stesso filtro della “significatività statistica” anche alle stime bayesiane, sebbene questo filtro sia estraneo alla filosofia bayesiana. Il confronto mostra che le stime bayesiane sono più robuste: anche quando selezionate arbitrariamente, presentano una distorsione sistematica (errori di tipo M e S) notevolmente inferiore rispetto a quelle frequentiste.
5.3.1 Un’analisi bayesiana
Per la distribuzione a posteriori, utilizziamo un’approssimazione normale (valida per campioni non troppo piccoli). Definiamo un risultato bayesiano “significativo” quando la probabilità a posteriori che l’effetto sia positivo supera il 95% (equivalente approssimativo del \(p < 0.05\) in un test a una coda).
# Funzione per analisi bayesiana approssimata
# Prior: d ~ N(0, 1) (prior debolmente informativa)
# Likelihood: d_obs | d ~ N(d, SE²)
# Posterior: d | d_obs ~ N(mu_post, sigma_post²)
bayesian_estimate <- function(d_observed, se, prior_mean = 0, prior_sd = 1) {
prior_precision <- 1 / prior_sd^2
data_precision <- 1 / se^2
posterior_precision <- prior_precision + data_precision
posterior_sd <- sqrt(1 / posterior_precision)
posterior_mean <- (prior_precision * prior_mean + data_precision * d_observed) / posterior_precision
tibble(
posterior_mean = posterior_mean,
posterior_sd = posterior_sd,
prob_positive = pnorm(0, posterior_mean, posterior_sd, lower.tail = FALSE)
)
}
# Applica l'analisi bayesiana a tutti gli studi
se_d <- sqrt(2 / ((n1 * n2) / (n1 + n2))) # SE approssimato per Cohen's d
bayesian_results <- results |>
rowwise() |>
mutate(
bayes = list(bayesian_estimate(d_observed, se_d))
) |>
unnest(bayes) |>
ungroup()5.3.2 Confronto delle stime
# Confronto per i risultati significativi
comparison <- bayesian_results |>
dplyr::filter(significant) |>
dplyr::select(d_observed, posterior_mean) |>
pivot_longer(everything(), names_to = "method", values_to = "estimate") |>
mutate(method = ifelse(method == "d_observed", "Frequentista", "Bayesiano"))
palette_methods <- setNames(
palette_qualitative[c(1, 5)], # arancione + blu
c("Frequentista", "Bayesiano")
)
col_true <- palette_qualitative[8] # grigio
ggplot(comparison, aes(x = estimate, fill = method)) +
geom_histogram(
bins = 30,
alpha = 0.6,
position = "identity",
color = "white"
) +
geom_vline(
xintercept = true_d,
color = col_true,
linetype = "dashed",
linewidth = 1.2
) +
scale_fill_manual(values = palette_methods) +
labs(
x = "Stima d di Cohen",
y = "Frequenza",
fill = "Metodo",
title = "Stime frequentiste vs bayesiane\nper i risultati 'significativi'",
subtitle = "Le stime bayesiane sono meno estreme grazie allo shrinkage verso la prior"
)
#> Effetto vero: d = 0.20
#> Media |d| frequentista: 0.76 (3.8x il vero)
#> Media |d| bayesiana: 0.64 (3.2x il vero)
#> Riduzione dell'errore: 21%Interpretazione: anche quando è costretta a subire lo stesso filtro di selezione arbitrario del paradigma frequentista, l’analisi bayesiana riduce sia la sovrastima dell’effetto sia gli errori di segno. Questo avviene perché l’inferenza bayesiana incorpora in modo naturale lo “shrinkage”: le stime estreme vengono “contratte” verso la distribuzione a priori, che in questo caso è centrata sullo zero. Il risultato non è l’eliminazione dell’errore, ma la sua sostanziale attenuazione, il che dimostra come la struttura stessa dell’inferenza bayesiana produca stime più robuste e meno sensibili alle distorsioni introdotte dalla selezione dei soli risultati pubblicabili.
5.4 Come cambiano gli errori con la dimensione del campione?
# Simulazione con diverse dimensioni campionarie
sample_sizes <- c(20, 50, 100, 200, 500)
sample_size_analysis <- map_dfr(sample_sizes, function(n) {
# Simula studi con n osservazioni per gruppo
sim_results <- map_dfr(1:10000, function(i) {
y1 <- rnorm(n, mean = mu_1, sd = sigma)
y2 <- rnorm(n, mean = mu_2, sd = sigma)
pooled_sd <- sqrt(((n - 1) * var(y1) + (n - 1) * var(y2)) / (2 * n - 2))
d_obs <- (mean(y1) - mean(y2)) / pooled_sd
p_val <- t.test(y1, y2, var.equal = TRUE)$p.value
tibble(d_observed = d_obs, p_value = p_val, significant = p_val < 0.05)
})
sig_results <- sim_results |> filter(significant)
tibble(
n_per_group = n,
power = mean(sim_results$significant),
type_m = mean(abs(sig_results$d_observed)) / true_d,
type_s = mean(sig_results$d_observed < 0)
)
})
col_power <- palette_qualitative[5] # Blu
col_m <- palette_qualitative[1] # Arancione
col_s <- palette_qualitative[7] # Rosa
col_ref <- palette_qualitative[8] # Grigio
# Visualizzazione
p_power <- ggplot(sample_size_analysis, aes(x = n_per_group, y = power)) +
geom_line(color = col_power, linewidth = 1.2) +
geom_point(color = col_power, size = 3) +
geom_hline(
yintercept = 0.80,
linetype = "dashed",
color = col_ref
) +
scale_y_continuous(labels = scales::percent, limits = c(0, 1)) +
labs(
title = "Potenza statistica",
x = "n per gruppo",
y = "Potenza"
)
p_type_m <- ggplot(sample_size_analysis, aes(x = n_per_group, y = type_m)) +
geom_line(color = col_m, linewidth = 1.2) +
geom_point(color = col_m, size = 3) +
geom_hline(
yintercept = 1,
linetype = "dashed",
color = col_ref
) +
labs(
title = "Errore Tipo M (exaggeration)",
x = "n per gruppo",
y = "Fattore di esagerazione"
)
p_type_s <- ggplot(sample_size_analysis, aes(x = n_per_group, y = type_s)) +
geom_line(color = col_s, linewidth = 1.2) +
geom_point(color = col_s, size = 3) +
scale_y_continuous(labels = scales::percent) +
labs(
title = "Errore Tipo S (wrong sign)",
x = "n per gruppo",
y = "Tasso errore di segno"
)p_power 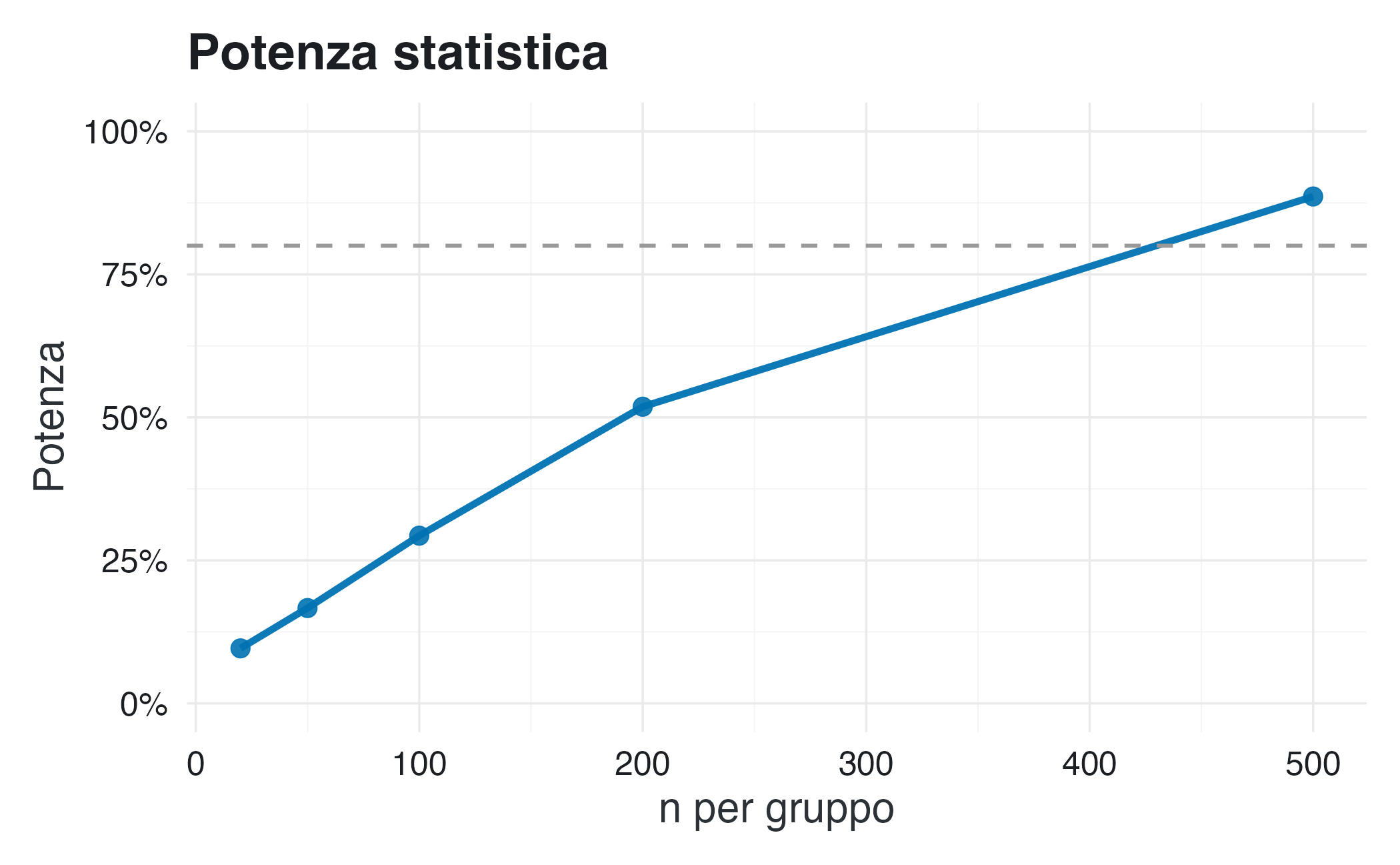
p_type_m 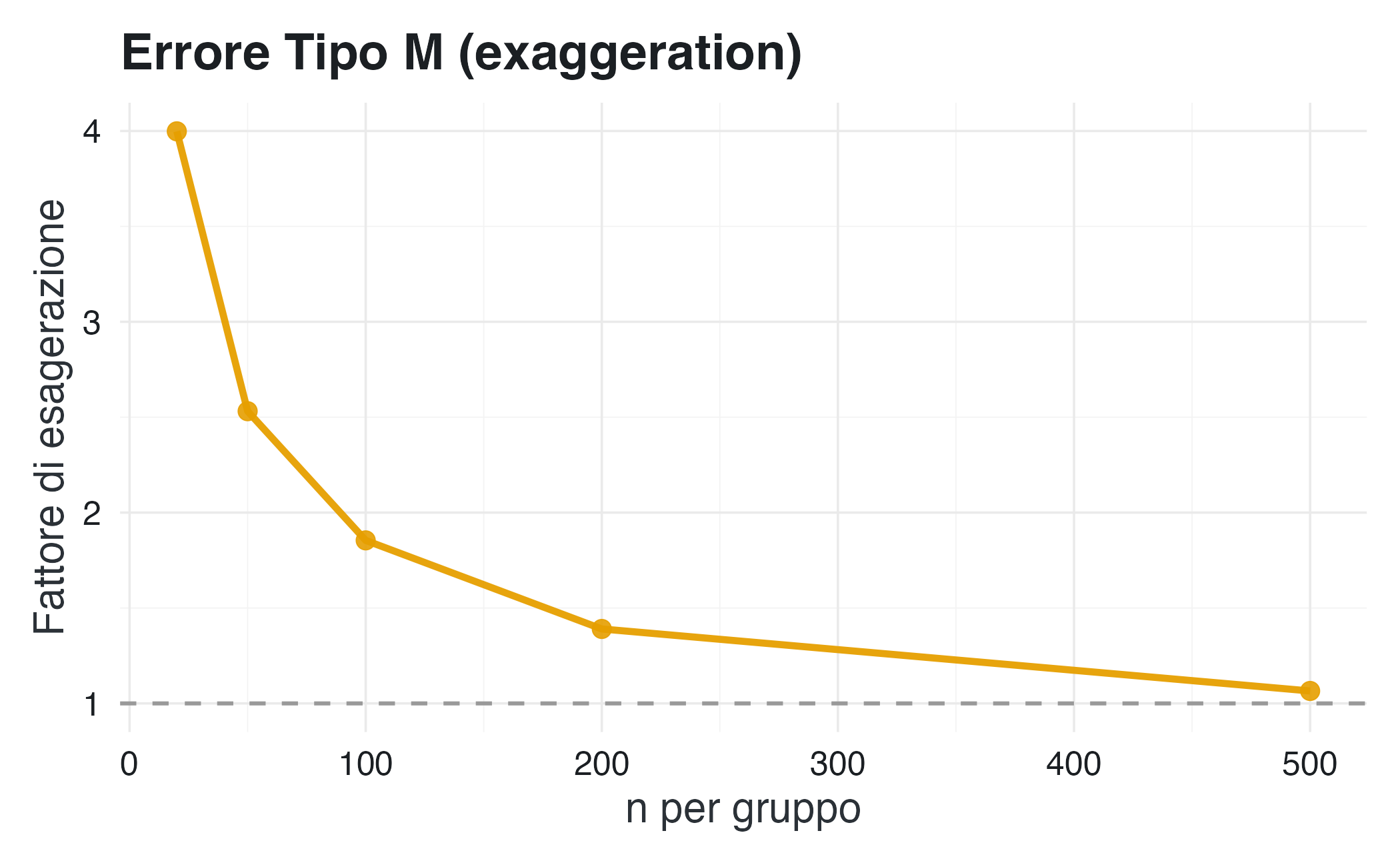
p_type_s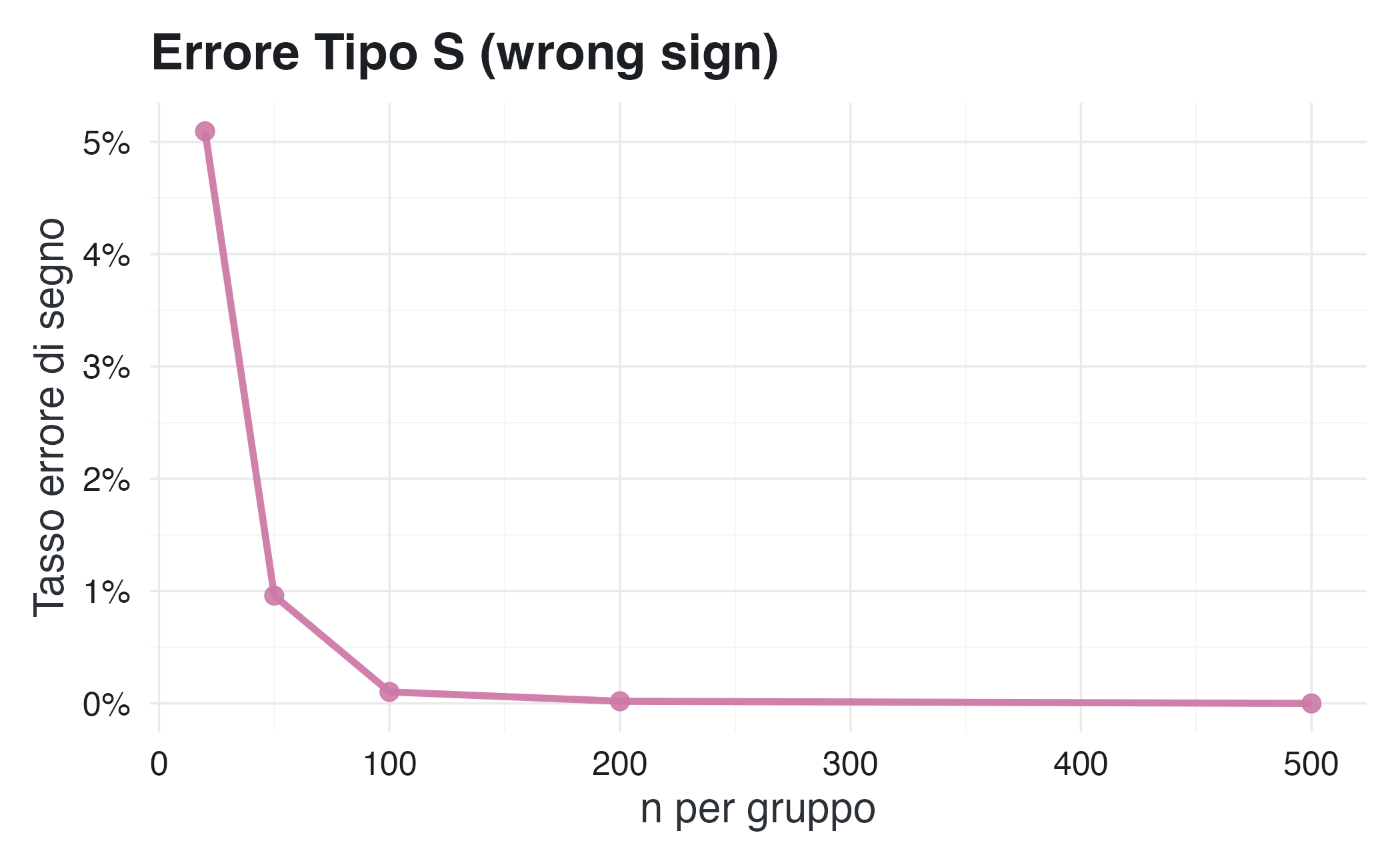
Tabella riassuntiva:
sample_size_analysis |>
mutate(
`n per gruppo` = n_per_group,
`Potenza` = sprintf("%.0f%%", power * 100),
`Type M (×)` = sprintf("%.1f", type_m),
`Type S (%)` = sprintf("%.1f%%", type_s * 100)
) |>
dplyr::select(`n per gruppo`, Potenza, `Type M (×)`, `Type S (%)`) |>
knitr::kable(caption = "Errori M e S in funzione della dimensione del campione (effetto vero d = 0.2)")| n per gruppo | Potenza | Type M (×) | Type S (%) |
|---|---|---|---|
| 20 | 10% | 4.0 | 5.1% |
| 50 | 17% | 2.5 | 1.0% |
| 100 | 29% | 1.9 | 0.1% |
| 200 | 52% | 1.4 | 0.0% |
| 500 | 89% | 1.1 | 0.0% |
La tabella mostra una relazione chiara: con campioni piccoli e bassa potenza, gli errori sono enormi. Solo con \(n \geq 500\) per gruppo (potenza ~90%) gli errori diventano accettabili.
5.5 Riflessioni conclusive
Le simulazioni sviluppate in questo capitolo confermano empiricamente ciò che l’analisi teorica del Capitolo 4 del manuale illustra concettualmente.
Il primo insegnamento riguarda l’inefficacia del filtro della significatività statistica. Le simulazioni mostrano che il superamento della soglia di \(p < 0.05\) non protegge dal rumore, ma opera come un meccanismo selettivo che favorisce sistematicamente le stime più estreme e spesso fuorvianti. Il risultato è una letteratura scientifica strutturalmente distorta, in cui le dimensioni degli effetti sono sovrastimate in modo sistematico.
Il secondo insegnamento rivela come gli errori di Tipo M (sovrastima) e di Tipo S (segno) siano prevedibili e quantificabili in base alla potenza statistica. Con livelli di potenza tipici di molti studi (intorno all’8%), le simulazioni mostrano un’esagerazione media delle stime di circa quattro volte l’effetto reale, e una probabilità di invertire il segno dell’effetto di circa il 4% tra i risultati dichiarati significativi. Ciò trasforma quello che potrebbe sembrare un errore occasionale in un problema sistemico e prevedibile.
Il terzo insegnamento valuta il ruolo dell’approccio bayesiano nell’attenuare queste distorsioni. L’incorporazione di una distribuzione a priori produce un effetto di shrinkage statistico, riducendo la dispersione e l’ampiezza delle stime verso valori più plausibili e mitigando così gli errori di sovrastima e segno. Tuttavia, le simulazioni chiariscono che si tratta di una riduzione parziale, non di una soluzione radicale al problema di fondo.
Il quarto e decisivo insegnamento identifica l’incremento della potenza statistica come unica contromisura efficace. Solo quando la potenza raggiunge almeno l’80% gli errori diventano trascurabili: la sovrastima si riduce a meno di 1,1 volte il valore reale e la probabilità di errore di segno scende sotto lo 0,1%. Questo livello di potenza, ottenibile tramite campioni adeguati o metodi di aggregazione, è l’unica via per ottenere stime affidabili e robuste.
In conclusione, le simulazioni proposte da Loken & Gelman (2017) fungono da ponte metodologico tra teoria e pratica, trasformando concetti statistici astratti in dimostrazioni concrete. Queste simulazioni dimostrano in modo incontrovertibile che la soglia di significatività introduce distorsioni anziché filtrarle, che la bassa potenza genera sistematicamente sovrastime e inversioni di segno e che solo un aumento sostanziale della potenza può garantire inferenze valide. Queste simulazioni non sono solo un esercizio didattico, ma un vero e proprio laboratorio critico che permette di acquisire consapevolezza dei limiti degli strumenti statistici convenzionali e di comprendere le condizioni necessarie per produrre inferenze affidabili.
ConsiglioRisposte alle domande iniziali
Ora confrontiamo le previsioni con i risultati ottenuti dalle simulazioni:
Sovrastima della grandezza dell’effetto: I risultati pubblicati tendono a essere selezionati sulla base della significatività statistica, il che porta a una sovrastima sistematica della grandezza dell’effetto rispetto alla realtà. Questo fenomeno, noto come errore di tipo M (magnitude), si verifica perché solo gli effetti con valori estremi (per caso) superano la soglia di significatività statistica e vengono pubblicati.
Falsi positivi e loro frequenza: In uno scenario in cui non esiste alcuna differenza tra i due gruppi (cioè la vera differenza è zero), il test t ha fornito risultati statisticamente significativi nel 5% dei casi, come previsto dalla soglia di α = 0.05. Tuttavia, la selezione dei risultati pubblicati amplifica questo problema, rendendo più probabile che i lettori incontrino falsi positivi nella letteratura scientifica.
Bias nella pubblicazione: Gli studi che riportano risultati significativi hanno maggiore probabilità di essere pubblicati rispetto a quelli che non trovano un effetto significativo. Questo porta a un effetto distorsivo nella letteratura scientifica, in cui i risultati pubblicati tendono a sovrastimare l’effetto reale. Il “filtro della significatività statistica” crea una percezione distorta della realtà scientifica, poiché gli effetti nulli o piccoli tendono a essere sottorappresentati nella letteratura.
Replicabilità e significatività statistica: Gli studi con effetti piccoli e campioni ridotti sono particolarmente vulnerabili al fallimento della replicazione. Anche quando un effetto reale esiste, la probabilità di ottenerne una stima precisa è bassa, e la replicazione potrebbe risultare in un valore non significativo, generando confusione nella comunità scientifica.
Considerazioni Finali
Le simulazioni evidenziano come la significatività statistica, utilizzata come criterio per la pubblicazione, contribuisca a un bias nella selezione dei risultati, distorcendo la percezione della realtà scientifica. Questo fenomeno, noto come “filtro della significatività statistica”, è una delle cause principali della crisi della replicabilità, poiché induce i ricercatori e i lettori a sovrastimare la grandezza e la presenza di effetti studiati.
Per affrontare queste problematiche, approcci alternativi, come quelli bayesiani, possono offrire soluzioni più robuste, permettendo una valutazione più affidabile delle ipotesi alla luce dei dati osservati.
Esercizi
ImportanteProblemi 1
- Perché la significatività statistica non è un criterio affidabile per valutare la validità dei risultati scientifici?
- Spiega il concetto di “filtro della significatività statistica” e il suo impatto sulla pubblicazione dei risultati.
- Qual è la differenza tra errore di tipo M e errore di tipo S? Come influenzano l’interpretazione dei risultati?
- Perché i risultati pubblicati tendono a sovrastimare la grandezza dell’effetto rispetto alla realtà?
- Quali sono le conseguenze della pubblicazione selettiva dei risultati per la replicabilità degli studi?
- Perché gli studi con campioni di piccole dimensioni sono più vulnerabili a errori nella stima della grandezza dell’effetto?
- In che modo la selezione dei risultati pubblicati altera la percezione della forza degli effetti studiati?
- Perché un test frequentista può portare a una falsa conclusione sulla direzione di un effetto?
- Quali sono le principali differenze tra l’approccio frequentista e quello bayesiano nella valutazione della significatività di un effetto?
- In che modo l’approccio bayesiano può ridurre il rischio di errori dovuti alla selezione dei risultati basata sulla significatività statistica?
ConsiglioSoluzioni 1
La significatività statistica non garantisce la validità di un risultato perché dipende dalla dimensione del campione e da soglie arbitrarie (come p < 0.05). Inoltre, non misura la rilevanza pratica di un effetto, ma solo la probabilità che i dati osservati siano ottenuti sotto l’ipotesi nulla.
Il “filtro della significatività statistica” si riferisce alla tendenza a pubblicare solo risultati con p < 0.05, tralasciando studi con risultati non significativi. Questo porta a una distorsione nella letteratura scientifica e a una sovrastima della forza degli effetti riportati.
Errore di tipo M (Magnitude) indica la sovrastima della grandezza dell’effetto nei risultati pubblicati, mentre errore di tipo S (Sign) si riferisce all’errata determinazione della direzione dell’effetto. Questi errori si verificano perché solo gli effetti più estremi tendono a superare il filtro della significatività statistica.
I risultati pubblicati tendono a sovrastimare la grandezza dell’effetto perché solo gli effetti più grandi (anche per pura casualità) superano la soglia di significatività statistica e vengono pubblicati, mentre quelli più piccoli restano inediti.
La pubblicazione selettiva riduce la replicabilità perché introduce una distorsione sistematica nei risultati disponibili. Le repliche spesso non trovano effetti altrettanto grandi o significativi, creando instabilità nella conoscenza scientifica.
I campioni piccoli aumentano la variabilità delle stime dell’effetto, rendendo più probabile che un risultato significativo sia solo un’oscillazione casuale dei dati piuttosto che un vero effetto replicabile.
La selezione dei risultati pubblicati altera la percezione della forza degli effetti perché induce i lettori a credere che gli effetti siano più forti e consistenti di quanto non siano realmente.
Un test frequentista può portare a una falsa conclusione sulla direzione dell’effetto perché, in campioni piccoli, le stime dell’effetto possono essere fortemente influenzate dal rumore, portando a interpretazioni errate.
L’approccio frequentista si basa sul valore-p e sulla soglia di significatività, mentre l’approccio bayesiano utilizza la probabilità a posteriori per aggiornare la credibilità delle ipotesi alla luce dei dati osservati. Il metodo bayesiano permette inferenze più flessibili e robuste.
L’approccio bayesiano riduce il rischio di errori dovuti alla selezione dei risultati perché non si basa su una soglia arbitraria di significatività, ma fornisce un quadro probabilistico della forza dell’effetto, evitando distorsioni dovute alla pubblicazione selettiva.
ImportanteProblemi 2
In questo esercizio simuleremo più esperimenti, ognuno con 15 osservazioni, per comprendere come il filtro della significatività statistica possa distorcere le nostre conclusioni sugli effetti osservati.
Obiettivo
- Comprendere come l’approccio frequentista possa portare a stime errate dell’effetto reale.
- Esplorare gli errori di tipo M (magnitude) e S (sign), derivanti dal filtro della significatività statistica.
Struttura dell’esercizio
- Simuliamo esperimenti in cui il vero effetto tra due gruppi è piccolo (Cohen’s d = 0.2). Consideriamo i dati SWLS e due popolazioni che differiscono nel modo indicato. Ipotizziamo che le due popolazioni SWLS siano normali.
- Estraiamo 15 osservazioni per gruppo.
- Usiamo un test t per verificare se la differenza tra i gruppi è significativa.
- Registriamo solo i risultati con p < 0.05, calcolando la distribuzione degli effetti significativi.
- Valutiamo se la stima dell’effetto nei risultati pubblicabili è gonfiata rispetto al vero effetto.
- Contiamo i casi in cui il segno dell’effetto è invertito.
ConsiglioSoluzioni 2
# Librerie necessarie
library(ggplot2)
# Impostazioni della simulazione
set.seed(42) # Per la riproducibilità
n_sims <- 50000 # Numero di simulazioni
n_per_group <- 15 # Numero di osservazioni per gruppo
true_d <- 0.2 # Vero effetto (Cohen's d)
swls_mean <- 25 # Media ipotizzata per il primo gruppo
swls_sd <- 5 # Deviazione standard ipotizzata per la SWLS
# Calcolo della media del secondo gruppo sulla base di Cohen's d
swls_mean_2 <- swls_mean + true_d * swls_sd
# Inizializziamo i vettori per registrare i risultati
effect_sizes <- c()
false_sign_count <- 0
# Simulazioni
for (i in 1:n_sims) {
# Generazione dei due gruppi da distribuzioni normali
group1 <- rnorm(n_per_group, mean = swls_mean, sd = swls_sd)
group2 <- rnorm(n_per_group, mean = swls_mean_2, sd = swls_sd)
# Calcolo della dimensione dell'effetto (Cohen's d)
mean_diff <- mean(group2) - mean(group1)
pooled_sd <- sqrt(((n_per_group - 1) * var(group1) + (n_per_group - 1) * var(group2)) / (2 * n_per_group - 2))
d_estimated <- mean_diff / pooled_sd
# Test t per confrontare le medie
t_test <- t.test(group1, group2, var.equal = TRUE)
# Consideriamo solo i risultati statisticamente significativi
if (t_test$p.value < 0.05) {
effect_sizes <- c(effect_sizes, d_estimated)
# Conta i casi in cui il segno è invertito
if (d_estimated < 0) {
false_sign_count <- false_sign_count + 1
}
}
}
# Creazione di un dataframe per la visualizzazione
res_df <- data.frame(effect_size = effect_sizes)
# Istogramma della dimensione dell'effetto tra i risultati "significativi"
ggplot(res_df, aes(x = effect_size)) +
geom_histogram(bins = 30, fill = "blue", color = "black", alpha = 0.7) +
geom_vline(xintercept = true_d, color = "red", linetype = "dashed", size = 1.2) +
labs(
x = "Dimensione dell'effetto stimata",
y = "Frequenza",
title = "Distribuzione degli effetti significativi (SWLS)"
) +
theme_minimal()
# Output di sintesi
cat("Numero di risultati statisticamente significativi:", length(effect_sizes), "\n")
cat("Media della dimensione dell'effetto tra i risultati pubblicati:", mean(effect_sizes), "\n")
cat("Numero di risultati con segno invertito:", false_sign_count, "\n")
cat("Proporzione di risultati con segno invertito:", false_sign_count / length(effect_sizes), "\n")Interpretazione dei Risultati
- Errore di tipo M (Magnitude): La media degli effetti stimati nei risultati pubblicati sarà molto più grande di 0.2 (il vero effetto), dimostrando come il filtro della significatività tenda a sovrastimare gli effetti reali.
- Errore di tipo S (Sign): Una percentuale dei risultati pubblicabili mostrerà effetti nella direzione sbagliata (d < 0), dimostrando che il processo decisionale basato su p < 0.05 può portare a conclusioni errate.
- Visualizzazione: L’istogramma mostrerà che la distribuzione degli effetti significativi è spostata rispetto al vero effetto (linea rossa tratteggiata).
Domande di discussione:
- Perché la stima dell’effetto è gonfiata nei risultati pubblicabili?
- Come cambia la situazione aumentando il numero di osservazioni per gruppo?
- Quali strategie alternative potrebbero ridurre questi errori?
Approfondimento:
- Ripetere l’esperimento con n_per_group = 50 e osservare se l’errore di tipo M diminuisce.
- Confrontare questo approccio con un’analisi Bayesiana per evidenziare il ruolo dell’inferenza basata su probabilità posteriori.
Conclusione
Questo esercizio mostra chiaramente i problemi dell’approccio frequentista basato su p < 0.05, evidenziando i limiti dell’uso della significatività statistica come filtro decisionale.
NotaInformazioni sull’ambiente di sviluppo
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] forcats_1.0.1 purrr_1.2.0 ragg_1.5.0
#> [4] tinytable_0.15.2 withr_3.0.2 systemfonts_1.3.1
#> [7] patchwork_1.3.2 ggdist_3.3.3 tidybayes_3.0.7
#> [10] bayesplot_1.15.0 ggplot2_4.0.1 reliabilitydiag_0.2.1
#> [13] priorsense_1.2.0 posterior_1.6.1 loo_2.9.0
#> [16] rstan_2.32.7 StanHeaders_2.32.10 brms_2.23.0
#> [19] Rcpp_1.1.0 sessioninfo_1.2.3 conflicted_1.2.0
#> [22] janitor_2.2.1 matrixStats_1.5.0 modelr_0.1.11
#> [25] tibble_3.3.0 dplyr_1.1.4 tidyr_1.3.2
#> [28] rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] gridExtra_2.3 inline_0.3.21 sandwich_3.1-1
#> [4] rlang_1.1.6 magrittr_2.0.4 multcomp_1.4-29
#> [7] snakecase_0.11.1 otel_0.2.0 compiler_4.5.2
#> [10] vctrs_0.6.5 stringr_1.6.0 pkgconfig_2.0.3
#> [13] arrayhelpers_1.1-0 fastmap_1.2.0 backports_1.5.0
#> [16] labeling_0.4.3 rmarkdown_2.30 xfun_0.55
#> [19] cachem_1.1.0 jsonlite_2.0.0 broom_1.0.11
#> [22] parallel_4.5.2 R6_2.6.1 stringi_1.8.7
#> [25] RColorBrewer_1.1-3 lubridate_1.9.4 estimability_1.5.1
#> [28] knitr_1.51 zoo_1.8-15 pacman_0.5.1
#> [31] Matrix_1.7-4 splines_4.5.2 timechange_0.3.0
#> [34] tidyselect_1.2.1 abind_1.4-8 yaml_2.3.12
#> [37] codetools_0.2-20 curl_7.0.0 pkgbuild_1.4.8
#> [40] lattice_0.22-7 bridgesampling_1.2-1 S7_0.2.1
#> [43] coda_0.19-4.1 evaluate_1.0.5 survival_3.8-3
#> [46] RcppParallel_5.1.11-1 pillar_1.11.1 tensorA_0.36.2.1
#> [49] checkmate_2.3.3 stats4_4.5.2 distributional_0.5.0
#> [52] generics_0.1.4 rprojroot_2.1.1 rstantools_2.5.0
#> [55] scales_1.4.0 xtable_1.8-4 glue_1.8.0
#> [58] emmeans_2.0.1 tools_4.5.2 mvtnorm_1.3-3
#> [61] grid_4.5.2 QuickJSR_1.8.1 colorspace_2.1-2
#> [64] nlme_3.1-168 cli_3.6.5 textshaping_1.0.4
#> [67] svUnit_1.0.8 Brobdingnag_1.2-9 V8_8.0.1
#> [70] gtable_0.3.6 digest_0.6.39 TH.data_1.1-5
#> [73] htmlwidgets_1.6.4 farver_2.1.2 memoise_2.0.1
#> [76] htmltools_0.5.9 lifecycle_1.0.4 MASS_7.3-65Bibliografia
Gelman, A., & Stern, H. (2006). The difference between «significant» and «not significant» is not itself statistically significant. The American Statistician, 60(4), 328–331.
Loken, E., & Gelman, A. (2017). Measurement Error and the Replication Crisis. Science, 355(6325), 584–585.
McElreath, R. (2020). Statistical rethinking: A Bayesian course with examples in R and Stan (2nd Edition). CRC Press.