15 Distribuzione predittiva a posteriori
Panoramica del capitolo
- Previsione bayesiana: incorporare incertezza parametrica e variabilità intrinseca.
- Verifica di coerenza: valutare l’adeguatezza del modello ai dati osservati.
- Caso beta-binomiale: applicazione pratica del framework predittivo.
15.1 La distribuzione predittiva a posteriori
15.1.1 Dall’aggiornamento bayesiano alle previsioni
Dopo aver osservato i dati \(y\) e aggiornato le nostre credenze sui parametri \(\theta\) tramite il teorema di Bayes, otteniamo la distribuzione a posteriori \(p(\theta \mid y)\). Ma spesso il nostro obiettivo non è solo stimare i parametri: vogliamo fare previsioni su nuove osservazioni future.
Date le nostre conoscenze aggiornate sui parametri, cosa possiamo dire su dati futuri \(\tilde{y}\) non ancora osservati?
15.1.2 Definizione e significato
La distribuzione predittiva a posteriori risponde precisamente a questa domanda. Rappresenta la distribuzione probabilistica di una nuova osservazione \(\tilde{y}\), condizionata ai dati già osservati \(y\).
Definizione formale:
\[ p(\tilde{y} \mid y) = \int p(\tilde{y} \mid \theta)\, p(\theta \mid y)\, d\theta. \tag{15.1}\] dove:
- \(\tilde{y}\): osservazione futura che vogliamo prevedere;
- \(p(\tilde{y} \mid \theta)\): modello di verosimiglianza (come i dati dipendono dai parametri);
- \(p(\theta \mid y)\): distribuzione a posteriori (credenze aggiornate sui parametri).
L’Equazione 15.1 calcola una media ponderata: per ogni possibile valore di \(\theta\), genera una previsione per \(\tilde{y}\), poi combina tutte queste previsioni pesandole secondo quanto ciascun valore di \(\theta\) è plausibile dopo aver osservato i dati.
15.1.3 Perché è importante
La distribuzione predittiva a posteriori riveste un’importanza cruciale nell’analisi bayesiana per molteplici ragioni. In primo luogo, essa incorpora sistematicamente l’incertezza parametrica, considerando non un singolo valore stimato di \(\theta\), ma l’intero spettro dei valori plausibili alla luce dei dati osservati. In secondo luogo, essa quantifica l’incertezza predittiva, fornendo non una semplice stima puntuale, ma la distribuzione di probabilità completa per i possibili esiti futuri.
Inoltre, la distribuzione predittiva a posteriori consente le verifiche predittive (posterior predictive checks), ovvero il confronto tra le previsioni del modello e i dati effettivamente osservati, al fine di valutare l’adeguatezza del modello stesso. Infine, dal punto di vista decisionale, la distribuzione predittiva a posteriori costituisce la base per scelte informate, offrendo probabilità complete e calibrate per diversi scenari futuri, aspetto essenziale in contesti applicativi in cui è necessario quantificare non solo gli esiti attesi, ma anche i rischi associati.
Scenario: abbiamo somministrato un test a 100 studenti e vogliamo prevedere il risultato di un nuovo studente.
- Se ignoriamo l’incertezza su \(\theta\) e utilizziamo solo la stima puntuale \(\hat{\theta}\), finiamo per sottostimare l’incertezza reale: trattiamo \(\hat{\theta}\) come se fosse nota con certezza.
- La distribuzione predittiva a posteriori, invece, tiene conto del fatto che il vero valore di \(\theta\) potrebbe trovarsi, ad esempio, tra 0.65 e 0.75. Di conseguenza, le previsioni per il nuovo studente riflettono questa incertezza, producendo un intervallo di risultati plausibili più ampio e realistico.
15.1.4 Intuizione: la distribuzione predittiva come media ponderata di previsioni
Il modo più efficace per comprendere l’Equazione 15.1 è considerarla come un processo in tre fasi, che possiamo illustrare attraverso un esperimento mentale nel contesto del modello beta-binomiale.
Contesto applicativo Supponiamo di voler prevedere il numero di risposte corrette che uno studente fornirà in un test futuro, dopo aver analizzato le prestazioni di un gruppo di studenti precedenti.
Fase 1: esplorazione dello spazio dei parametri. Definiamo una griglia di valori plausibili per \(\theta\): \[ \theta = 0, 0.01, 0.02, \ldots, 0.99, 1 \] in modo da coprire l’intero spettro delle possibili abilità.
Fase 2: generazione delle previsioni condizionate. Per ciascun valore di \(\theta'\) della griglia, calcoliamo la distribuzione binomiale condizionata su \(\theta'\). Essa rappresenta ciò che prevedremmo se fossimo certi che l’abilità dello studente fosse esattamente \(\theta'\):
\[ p(\tilde y \mid \theta') = \binom{n_{\text{new}}}{\tilde y} (\theta')^{\tilde y} (1-\theta')^{n_{\text{new}}-\tilde y}, \]
- con \(\theta' = 0.7\): la previsione si concentra prevalentemente su 6–8 successi;
- con \(\theta' = 0.3\): la previsione si focalizza principalmente su 2–4 successi.
Fase 3: combinazione delle previsioni attraverso i pesi bayesiani. Le diverse previsioni vengono poi pesate in base alla loro plausibilità a posteriori \(p(\theta' \mid y)\):
- se \(p(\theta' = 0.7 \mid y)\) è elevata, la previsione corrispondente riceve un peso sostanziale;
- se \(p(\theta' = 0.2 \mid y)\) è trascurabile, la previsione associata contribuisce solo marginalmente.
Sintesi del processo. La probabilità finale di osservare \(\tilde{y} = k\) successi è una media ponderata di tutte le probabilità condizionate \(p(\tilde y = k \mid \theta')\), dove i pesi sono determinati dalla distribuzione a posteriori \(p(\theta' \mid y)\). Il risultato è la distribuzione predittiva a posteriori, che incorpora contemporaneamente:
- la variabilità dei dati (descritta dal modello binomiale);
- e l’incertezza sui parametri (descritta dalla distribuzione a posteriori di \(\theta\)).
Ciascun valore di \(\theta\) genera una specifica previsione per \(\tilde{y}\); il compito della distribuzione a posteriori è determinare quanto contributo attribuire a ciascuna di queste previsioni alternative.
15.1.5 Confronto: distribuzioni a posteriori concentrate vs. distribuzioni a posteriori disperse
L’incertezza parametrica esercita un’influenza determinante sulla forma della distribuzione predittiva, come mostrato nei due scenari seguenti.
Scenario 1: distribuzione a posteriori concentrata (ad esempio, \(\theta \approx 0.70 \pm 0.03\)).
In questa situazione, tutti i valori plausibili del parametro \(\theta\) si collocano in un intervallo ristretto. Di conseguenza, le previsioni condizionate generate dai diversi valori di \(\theta\) sono sostanzialmente simili tra loro. Il risultato è una distribuzione predittiva concentrata e di forma regolare, che nel caso di \(n_{\text{new}} = 10\) domande assegna la maggior parte della massa probabilistica ai valori compresi tra 6 e 8 successi.
Scenario 2: distribuzione a posteriori dispersa (ad esempio, \(\theta\) plausibilmente compreso tra 0.4 e 0.8).
Quando l’incertezza parametrica è elevata, i valori plausibili di \(\theta\) coprono un’ampia gamma di possibilità. Il processo di media ponderata combina quindi previsioni molto eterogenee: alcuni valori di \(\theta\) (intorno a 0.4) predicono approssimativamente 4 successi, mentre altri (intorno a 0.8) predicono circa 8 successi. Il risultato è una distribuzione predittiva più dispersa e con code più pesanti, la quale riflette adeguatamente la maggiore incertezza sul parametro latente.
Caso con distribuzione a posteriori concentrata: \(\theta \sim \text{Beta}(70, 30)\) dopo 70 successi osservati su 100 prove - Parametri della distribuzione a posteriori: \(\mathbb{E}[\theta] \approx 0.70\), \(\text{SD}[\theta] \approx 0.045\). - Distribuzione della distribuzione predittiva: massa probabilistica concentrata su 6-8 successi. - \(\text{P}(0 \text{ successi}) \approx 0.0001\%\) (evento estremamente improbabile). - \(\text{P}(10 \text{ successi}) \approx 0.03\%\) (evento molto raro).
Caso con distribuzione a posteriori dispersa: \(\theta \sim \text{Beta}(7, 7)\) dopo 7 successi osservati su 14 prove. - Parametri della distribuzione a posteriori: \(\mathbb{E}[\theta] = 0.50\), \(\text{SD}[\theta] \approx 0.13\) (elevata incertezza). - Distribuzione predittiva: massa probabilistica distribuita su 3-7 successi. - \(\text{P}(0 \text{ successi}) \approx 0.1\%\) (raro ma non trascurabile). - \(\text{P}(10 \text{ successi}) \approx 0.1\%\) (analogamente raro). - code della distribuzione marcatamente più pesanti rispetto al caso concentrato.
Questo confronto mostra come l’incertezza sui parametri si propaghi in modo sistematico all’incertezza predittiva, con implicazioni fondamentali per l’interpretazione dei risultati e la pianificazione di studi futuri.
15.1.6 Le due fonti di incertezza predittiva
La maggiore dispersione osservabile nella distribuzione predittiva quando la posterior è ampia deriva dalla combinazione sistematica di due distinte fonti di incertezza:
-
Variabilità intrinseca (aleatory uncertainty):
- Rappresenta la variabilità naturale del processo generativo dei dati
- Anche conoscendo con esattezza il parametro \(\theta\), l’esito \(\tilde{y}\) mantiene una componente stocastica inevitabile
- Esempio: anche supponendo di conoscere con precisione il valore di \(\theta = 0.7\), uno studente potrebbe ottenere 6, 7 o 8 risposte corrette su 10 a causa della variabilità campionaria intrinseca.
-
Incertezza epistemica (epistemic uncertainty):
- Deriva dalla nostra conoscenza imperfetta del parametro latente \(\theta\).
- Rappresenta l’incertezza sulla stima del parametro stesso, che potrebbe assumere valori come 0.65, 0.70, 0.75…
- Questa incertezza parametrica si propaga direttamente alle previsioni attraverso il processo di integrazione bayesiana che considera tutti i valori plausibili di \(\theta\).
La distribuzione predittiva a posteriori NON è la distribuzione di \(\tilde{y}\) per un singolo valore di \(\theta\) (quello più probabile, per esempio). È la media ponderata di tutte le possibili distribuzioni condizionate, dove i pesi riflettono la plausibilità a posteriori di ciascun parametro.
15.1.7 Implicazioni pratiche
La relazione tra l’incertezza parametrica e la dispersione predittiva ha importanti conseguenze operative. Quando le informazioni a disposizione sono limitate, una distribuzione a posteriori ampia genera necessariamente previsioni conservative e poco precise. Questa situazione riflette un’onesta ammissione epistemica: “Non disponiamo di conoscenze sufficienti sul parametro \(\theta\), quindi le nostre previsioni devono rimanere caute”. In questo contesto, le code della distribuzione predittiva risultano più pesanti, assegnando probabilità rilevanti anche agli eventi apparentemente estremi.
Al contrario, quando le informazioni sono abbondanti, una distribuzione a posteriori concentrata produce previsioni più focalizzate e precise. Questo scenario corrisponde all’affermazione: “La nostra conoscenza di \(\theta\) è sufficientemente solida da permetterci di fare previsioni affidabili”. In queste condizioni, gli eventi estremi diventano statisticamente molto improbabili, il che riflette una maggiore certezza sui meccanismi alla base del fenomeno studiato.
Previsioni del tempo a confronto.
Scenario informativo limitato: con un solo giorno di osservazioni storiche (distribuzione a posteriori dispersa), la previsione è cauta: “La temperatura oscillerà probabilmente tra i 10° e i 30° domani”. La distribuzione predittiva è ampia a causa dell’elevata incertezza epistemica.
Scenario informativo ricco: con trent’anni di dati climatici per lo stesso periodo (distribuzione a posteriori concentrata), la previsione diventa più precisa: “La temperatura di domani si attesterà probabilmente tra i 18° e i 22°”. La distribuzione predittiva è più focalizzata grazie alla minore incertezza parametrica.
In entrambi i casi, la variabilità intrinseca del sistema meteorologico rimane invariata, ma nel secondo scenario, la minore incertezza epistemica consente previsioni notevolmente più accurate.
15.1.8 Confronto tra distribuzioni predittive a priori e a posteriori
Per comprendere appieno il valore della distribuzione predittiva a posteriori, è utile metterla a confronto con la sua controparte a priori.
| Caratteristica | Predittiva a priori | Predittiva a posteriori |
|---|---|---|
| Formula | \(p(\tilde{y}) = \int p(\tilde{y} \mid \theta) p(\theta) d\theta\) | \(p(\tilde{y} \mid y) = \int p(\tilde{y} \mid \theta) p(\theta \mid y) d\theta\) |
| Pesi | \(p(\theta)\) (credenze iniziali) | \(p(\theta \mid y)\) (credenze aggiornate) |
| Contesto | Prima di osservare i dati | Dopo aver osservato i dati |
| Finalità | Verificare la coerenza delle assunzioni iniziali | Effettuare previsioni informate dall’evidenza empirica |
| Incertezza | Tipicamente elevata (scarsa informazione) | Ridotta grazie all’apporto dei dati |
Evoluzione dall’a priori all’a posteriori:
Prior vago → Predittiva a priori dispersa
↓ [acquisizione dati osservati]
Posteriori concentrata → Predittiva a posteriori focalizzata- Verifica predittiva a priori: “Le mie assunzioni iniziali generano dati empiricamente plausibili?”
- Verifica predittiva a posteriori: “Il modello aggiornato riproduce adeguatamente i dati osservati e formula previsioni ragionevoli per nuove osservazioni?”
Se combinate, queste due procedure forniscono un framework integrato per la validazione metodologica del modello, coprendo l’intero processo inferenziale bayesiano.
15.1.9 Messaggio conclusivo
La distribuzione predittiva a posteriori rappresenta lo strumento bayesiano per eccellenza per la previsione. A differenza degli approcci che si basano esclusivamente su stime puntuali di \(\theta\), questa distribuzione:
- integra sistematicamente l’intera gamma di incertezza parametrica;
- quantifica in modo esaustivo l’incertezza predittiva attraverso distribuzioni complete;
- riflette fedelmente l’apprendimento ottenuto dai dati osservati;
- guadagna progressivamente in precisione con l’aumentare delle informazioni disponibili.
Possiamo immaginare la distribuzione predittiva a posteriori come un processo di deliberazione collettiva:
- ogni membro della comunità scientifica (valore specifico di \(\theta\)) avanza una previsione;
- i ricercatori più credibili (elevata densità a posteriori) esercitano una maggiore influenza;
- la previsione finale emerge come sintesi ponderata di tutte le prospettive;
- quando il consenso è ampio (posteriori concentrata), le previsioni risultano nette e definite;
- in presenza di opinioni divergenti (posteriori dispersa), le previsioni mantengono un appropriato grado di cautela.
Questa caratteristica di sintesi dell’incertezza rende la distribuzione predittiva a posteriori particolarmente preziosa per la ricerca psicologica, dove la complessità dei fenomeni studiati richiede strumenti in grado di rappresentare adeguatamente i margini di incertezza insiti nei processi inferenziali.
15.2 Il modello Beta-Binomiale
Poniamoci ora l’obiettivo di costruire in pratica la distribuzione predittiva a posteriori nel caso del modello beta-binomiale, il quale ci consente di illustrare il meccanismo quantitativo di questo processo in una situazione particolarmente semplice. Consideriamo un esperimento binomiale consistente in \(n\) prove indipendenti, dove osserviamo il numero di successi \(y\) (ad esempio, il numero di teste nel lancio di una moneta). Per costruire la distribuzione predittiva a posteriori seguiamo un percorso costituito da tre fasi.
-
Specificazione della distribuzione a priori La conoscenza iniziale riguardante la probabilità di successo \(p\) viene formalizzata attraverso una distribuzione Beta(\(\alpha, \beta\)), laddove:
- il parametro \(\alpha\) rappresenta un numero pseudo-osservato di successi;
- il parametro \(\beta\) rappresenta un numero pseudo-osservato di insuccessi.
Questa parametrizzazione consente di incorporare conoscenze pregresse nella forma di un’“evidenza virtuale”.
-
Aggiornamento bayesiano alla distribuzione a posteriori Dopo l’osservazione di \(y\) successi in \(n\) prove, la distribuzione a posteriori si ottiene mediante aggiornamento coniugato:
\[ p \mid y \sim \text{Beta}(\alpha + y, \beta + n - y). \]
La distribuzione a posteriori caratterizza completamente l’incertezza residua sul parametro \(p\) condizionatamente ai dati osservati.
3. Costruzione della distribuzione predittiva a posteriori
Per prevedere il numero di successi \(y_{\text{new}}\) in \(n_{\text{new}}\) prove future, è necessario integrare l’incertezza sul parametro \(p\) - rappresentata dalla distribuzione a posteriori - con la variabilità intrinseca del processo di campionamento, formalizzata dalla distribuzione binomiale. Questo obiettivo si ottiene mediante un procedimento di simulazione iterativa.
Si estrae casualmente un valore del parametro \(p\) dalla distribuzione a posteriori, ottenendo \(p^{(s)} \sim \text{Beta}(\alpha + y, \beta + n - y)\). Utilizzando questo valore campionato, si genera una realizzazione \(y_{\text{new}}^{(s)}\) dalla corrispondente distribuzione binomiale condizionata, secondo \(y_{\text{new}}^{(s)} \sim \text{Binomial}(n_{\text{new}}, p^{(s)})\). Ripetendo questo processo per un numero elevato di iterazioni, si ottiene una sequenza di valori predetti.
La distribuzione empirica dei valori \(y_{\text{new}}^{(s)}\) così generati approssima la distribuzione predittiva a posteriori teorica, sintetizzando in modo completo sia l’incertezza epistemica sul parametro \(p\) sia la variabilità aleatoria del processo binomiale sottostante.
15.2.1 Un esempio numerico
15.2.1.1 I dati e le nostre conoscenze iniziali
- Dati osservati: supponiamo di avere osservato 70 successi su 100 prove (ad esempio, 70 teste su 100 lanci di moneta).
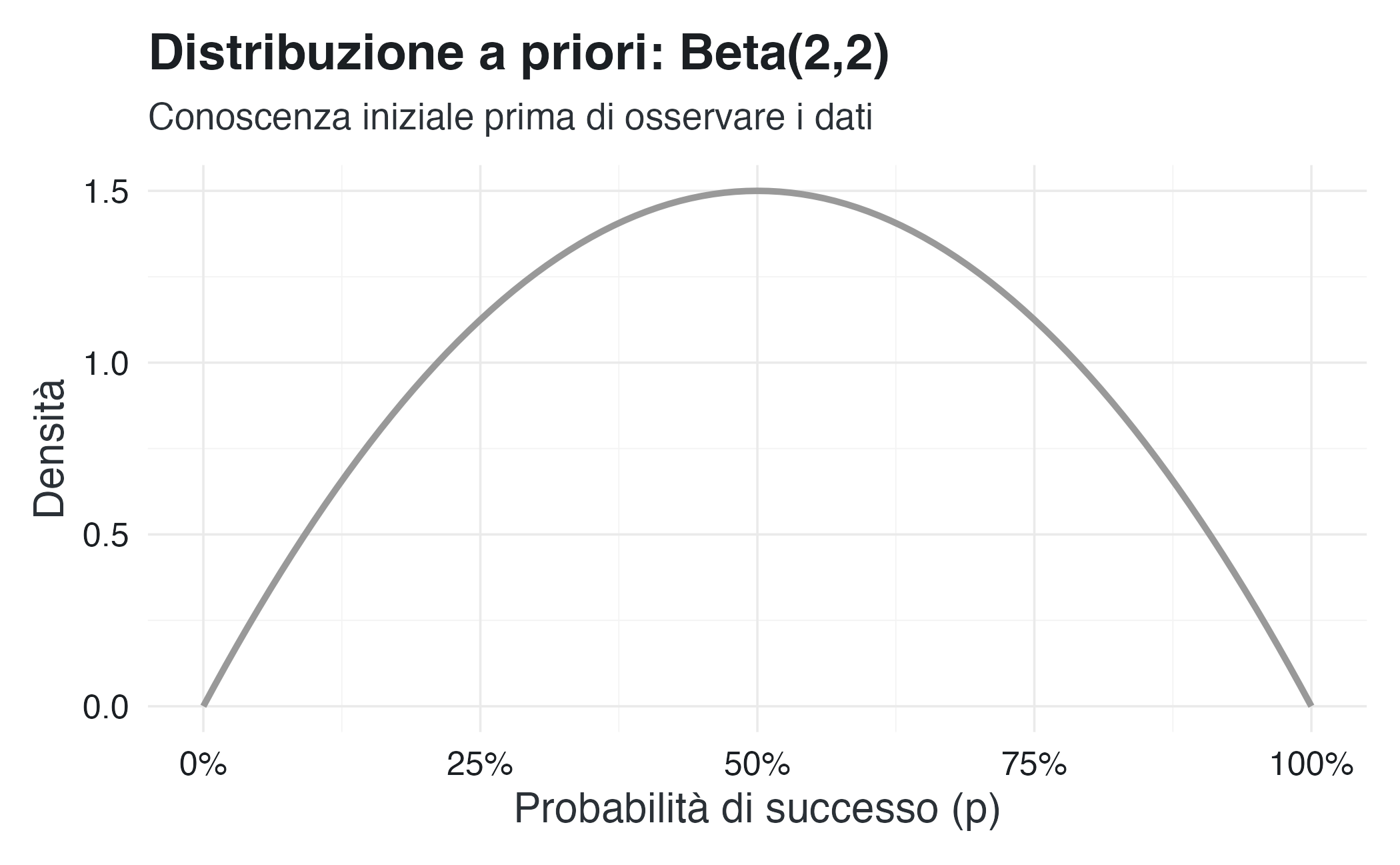
- Conoscenza iniziale (prior): usiamo una distribuzione \(Beta(2, 2)\). Questa prior è “debolmente informativa”, ovvero suggerisce che pensiamo che la moneta sia probabilmente equilibrata (p ≈ 0.5), ma siamo aperti ad altre possibilità.
15.2.1.2 Aggiornamento delle nostre conoscenze
Dopo aver visto i dati, aggiorniamo le nostre convinzioni sulla probabilità di successo \(p\):
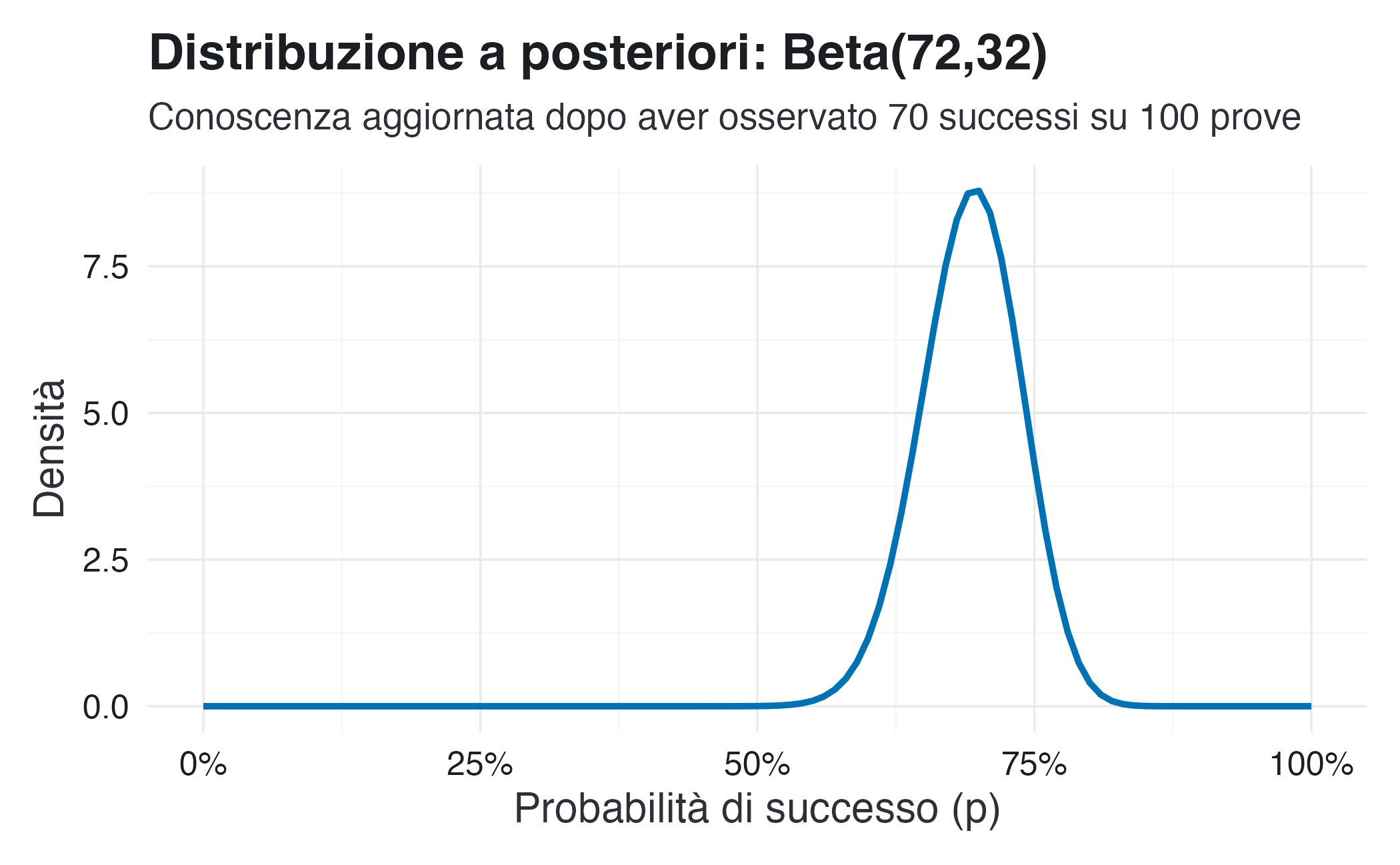
alpha_posterior = 2 + 70 = 72
beta_posterior = 2 + (100 - 70) = 32Ora crediamo che \(p\) segua una distribuzione \(Beta(72, 32)\), che è centrata attorno a 0.7.
15.2.1.3 Simulazione delle previsioni
Vogliamo prevedere cosa succederà in 10 lanci futuri.
# Dati osservati
successi_osservati <- 70
lanci_totali <- 100
# Prior (conoscenza iniziale)
alpha_prior <- 2
beta_prior <- 2
# Posterior (conoscenza aggiornata)
alpha_post <- alpha_prior + successi_osservati
beta_post <- beta_prior + (lanci_totali - successi_osservati)
# Simuliamo 1000 valori plausibili per p
valori_p <- rbeta(1000, alpha_post, beta_post)
# Per ogni valore di p, simuliamo 10 lanci futuri
successi_futuri <- rbinom(1000, size = 10, prob = valori_p)
# Calcoliamo le proporzioni di successo
proporzioni_future <- successi_futuri / 1015.2.1.4 Spiegazione passo per passo
Abbiamo osservato 70 successi su 100 prove. Con un prior \(Beta(2,2)\), la distribuzione a posteriori risulta una \(Beta(72,32)\). Questo significa che, sebbene non possiamo determinare il valore esatto della probabilità di successo \(p\), possiamo quantificarne l’incertezza in modo probabilistico: è molto plausibile che \(p\) si collochi attorno a 0.7, con una dispersione attorno a questo valore centrale definita dalla distribuzione \(Beta(72,32)\).
Per rappresentare questa incertezza, estraiamo 1000 valori da una distribuzione \(Beta(72,32)\): valori_p <- rbeta(1000, 72, 32). Ciascun valore estratto è un candidato possibile per \(p\), compatibile con i dati osservati e con la nostra conoscenza iniziale. Si noti che i valori estratti nell’intervallo [0, 1] non hanno tutti la stessa probabilità di essere campionati; la probabilità di essere campionati dipende dalla densità \(Beta(72,32)\).
A questo punto, ci chiediamo: quali risultati potremmo realisticamente aspettarci in una sequenza futura di 10 lanci? Per rispondere, procediamo nel modo seguente: per ciascuno dei valori di \(p\) campionati in precedenza, generiamo una distribuzione binomiale con parametro \(n = 10\). Da ciascuna di queste distribuzioni campioniamo quindi un singolo valore \(y\), che rappresenta il numero di successi attesi in 10 prove future. È importante notare che i possibili valori \(y\) nell’intervallo \([0, 10]\) non sono tutti equiprobabili, ma ciascuno ha una probabilità di realizzazione determinata dalla specifica distribuzione binomiale condizionata al valore di \(p'\) preso in considerazione. Ripetendo questo processo 1000 volte con l’istruzione successi_futuri <- rbinom(1000, size = 10, prob = valori_p), otteniamo un campione rappresentativo della distribuzione predittiva a posteriori.
Infine, per ottenere risultati immediatamente interpretabili come probabilità di successo nei lanci futuri, trasformiamo il numero di successi in proporzioni dividendo per 10: proporzioni_future <- successi_futuri / 10. In altre parole, otteniamo un quadro di ciò che possiamo aspettarci, tenendo insieme due fonti di incertezza: da un lato non conosciamo il valore esatto di \(p\); dall’altro, anche conoscendo \(p\), i risultati dei lanci rimarrebbero comunque soggetti al caso.
Il vettore proporzioni_future riassume queste possibilità: non una singola previsione puntuale, ma un’intera distribuzione di esiti futuri, coerente con i dati raccolti e con il modello bayesiano adottato.
15.2.1.5 Visualizziamo i risultati
Distribuzione iniziale (prima di osservare i dati):
# Definisci i colori tematici
col_prior <- palette_qualitative[8] # Grigio per prior
col_posterior <- palette_qualitative[5] # Blu per posterior
col_pred_dist <- palette_qualitative[2] # Azzurro per distribuzioni predittive
col_line <- palette_qualitative[6] # Rosso-arancio per linee verticali
# Distribuzione iniziale (prima di osservare i dati) — PRIOR
ggplot(data.frame(x = c(0, 1)), aes(x = x)) +
stat_function(
fun = dbeta,
args = list(shape1 = alpha_prior, shape2 = beta_prior),
linewidth = 1.1,
color = col_prior
) +
scale_x_continuous(labels = scales::label_percent(accuracy = 1)) +
labs(
x = "Probabilità di successo (p)",
y = "Densità",
title = "Distribuzione a priori: Beta(2,2)",
subtitle = "Conoscenza iniziale prima di osservare i dati"
)
Conoscenza aggiornata (dopo aver osservato i dati):
# Conoscenza aggiornata (dopo aver osservato i dati) — POSTERIOR
ggplot(data.frame(x = c(0, 1)), aes(x = x)) +
stat_function(
fun = dbeta,
args = list(shape1 = alpha_post, shape2 = beta_post),
linewidth = 1.1,
color = col_posterior
) +
scale_x_continuous(labels = scales::label_percent(accuracy = 1)) +
labs(
x = "Probabilità di successo (p)",
y = "Densità",
title = "Distribuzione a posteriori: Beta(72,32)",
subtitle = "Conoscenza aggiornata dopo aver osservato 70 successi su 100 prove"
) 
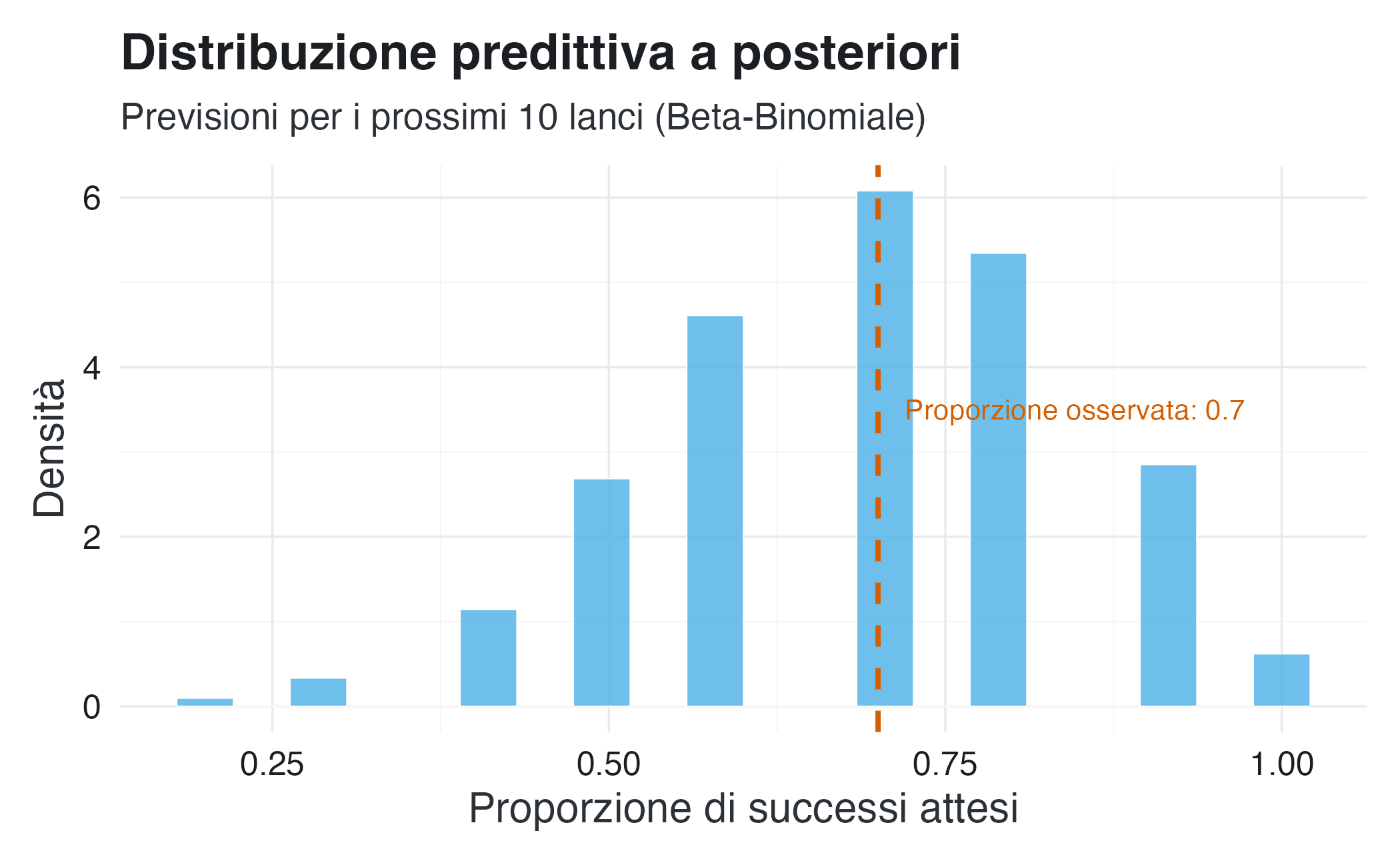
Previsioni per i prossimi 10 lanci:
# Previsioni per i prossimi 10 lanci — Posterior predictive
ggplot(data.frame(proporzioni = proporzioni_future), aes(x = proporzioni)) +
geom_histogram(
aes(y = after_stat(density)),
bins = 20,
fill = col_pred_dist,
color = "white",
alpha = 0.85,
linewidth = 0.2
) +
geom_vline(
aes(xintercept = successi_osservati / lanci_totali),
linewidth = 0.9,
linetype = "dashed",
color = col_line
) +
annotate(
"text",
x = successi_osservati / lanci_totali + 0.02,
y = 3.5,
label = paste0("Proporzione osservata: ",
round(successi_osservati / lanci_totali, 2)),
color = col_line,
hjust = 0
) +
labs(
x = "Proporzione di successi attesi",
y = "Densità",
title = "Distribuzione predittiva a posteriori",
subtitle = "Previsioni per i prossimi 10 lanci (Beta-Binomiale)"
)
15.2.1.6 Interpretazione dei risultati
La nostra conoscenza del parametro \(p\) risulta ora concentrata attorno al valore 0.7, come evidenziato dal grafico in rosso. Le previsioni per i prossimi 10 lanci mostrano una maggiore variabilità, dovuta alla combinazione di due fattori: persiste un certo grado di incertezza sul valore esatto di \(p\), e anche ammettendo di conoscerlo perfettamente, i risultati di 10 lanci presentano comunque una fluttuazione intrinseca. Il fatto che il risultato osservato del 70% di successi cada nella regione più probabile delle nostre previsioni indica che il modello adottato è ragionevole e può essere utilizzato per le previsioni future.
In termini pratici, se si dovesse formulare una previsione per i prossimi 10 lanci, l’intervallo più plausibile si collocherebbe tra 6 e 8 successi, anche se non si possono escludere esiti di 5 o 9 successi, a causa della variabilità casuale.
Potrebbe sembrare ovvio che la distribuzione predittiva a posteriori riproduca fedelmente i dati osservati nel nostro esempio. In realtà, questo risultato positivo non è affatto scontato ed è importante dal punto di vista metodologico: attesta la buona calibrazione del nostro modello.
Nel caso che abbiamo discusso, abbiamo scelto un modello binomiale con un prior Beta perché ci permette di illustrare chiaramente la logica alla base della distribuzione predittiva a posteriori in un caso particolarmente semplice. È tuttavia cruciale riconoscere che la ricerca psicologica opera tipicamente con modelli di complessità ben superiore. In questi contesti applicativi, la corrispondenza tra i dati osservati e quelli generati tramite la distribuzione predittiva non può mai essere data per scontata, ma deve sempre essere oggetto di verifica empirica.
15.3 Validazione del modello: controlli predittivi a posteriori
15.3.1 Oltre il confronto relativo: validazione assoluta del modello
Mentre i metodi di valutazione relativa tra modelli—quali criteri informativi, fattori di Bayes o cross-validation—sono essenziali per confrontare modelli rivali e saranno approfonditi in un capitolo successivo, è altrettanto cruciale saper valutare la bontà di un singolo modello in termini assoluti. I Posterior Predictive Checks (PPC) rispondono proprio a questa esigenza, permettendo di quantificare quanto bene un modello si adatti ai dati osservati, indipendentemente dall’esistenza di alternative.
La logica sottostante è potente e intuitiva: se un modello rappresenta un’accurata approssimazione del processo che ha realmente generato i dati, allora i parametri stimati (la distribuzione a posteriori) dovrebbero essere in grado di generare—se simuliamo un nuovo esperimento—dati replicati con caratteristiche simili a quelle che abbiamo effettivamente osservato.
Un modello adeguato non deve solo adattarsi ai dati osservati, ma deve anche essere in grado di generare dati con proprietà statistiche simili. Se i dati osservati risultano atipici o “estremi” rispetto all’universo di dati che il modello può generare, abbiamo un segnale d’allarme sulla sua adeguatezza.
15.3.2 La distribuzione predittiva a posteriori per la verifica
Consideriamo un modello parametrico con parametro \(\theta \in \Theta\), densità a priori \(p(\theta)\) e funzione di verosimiglianza \(p(x \mid \theta)\) per i dati osservati \(x\). Sia \(\pi(\theta) = p(\theta \mid x)\) la densità a posteriori.
La distribuzione predittiva a posteriori per dati replicati è la distribuzione marginale di un nuovo campione \(x_{\text{rep}}\), generato dallo stesso modello di verosimiglianza, integrata rispetto alla distribuzione a posteriori del parametro:
\[ \pi(x_{\text{rep}}) := \int_{\Theta} p(x_{\text{rep}} \mid \theta)\, \pi(\theta)\, d\theta. \tag{15.2}\]
Sebbene formalmente identica alla distribuzione predittiva per dati futuri, qui l’utilizzo è concettualmente diverso. Non siamo interessati a prevedere il futuro, ma a simulare un esperimento replicato per verificare la plausibilità che il nostro modello abbia generato i dati già in nostro possesso.
15.3.3 Implementare i controlli predittivi: valutare l’adeguatezza del modello
I PPC quantificano numericamente se i dati osservati \(x\) appaiano “atipici” rispetto alla distribuzione predittiva \(\pi(x_{\text{rep}})\). La procedura standardizzata prevede:
- Definire una Statistica di Discrepanza \(T(\cdot)\): una quantità (es., media, varianza, skewness) che catturi una caratteristica dei dati che vogliamo verificare.
- Calcolare un Posterior Predictive p-value: la probabilità che la statistica calcolata su dati replicati sia più estrema di quella osservata. Una versione pratica è la proporzione di repliche in cui \(T(x_{\text{rep}}) \ge T(x)\).
Contesto: modelliamo i tempi di reazione in un compito di Stroop con una distribuzione normale.
Problema: i tempi di reazione reali sono tipicamente asimmetrici (distribuzione con coda a destra), mentre la normale è simmetrica.
Controllo PPC:
- Statistica scelta: coefficiente di asimmetria (skewness).
- Procedura: generiamo 5.000 dataset replicati \(x_{\text{rep}}\) dal modello e per ognuno calcoliamo la sua skewness.
- Risultato: se la skewness osservata nei dati reali è maggiore del 98% delle skewness simulate, concludiamo che il modello normale non riesce a catturare l’asimmetria dei dati, suggerendo l’adozione di modelli alternativi (es., log-normale, Gamma).
15.3.4 Interpretazione e limiti
I PPC sono strumenti diagnostici potenti, ma la loro interpretazione richiede attenzione:
- Non sono test di ipotesi classici: il posterior predictive p-value non va interpretato come un p-value frequentista. Non esiste una soglia universale di “significatività”; è un indicatore di discrepanza relativa.
- La scelta della statistica \(T\) è fondamentale: statistiche diverse rivelano inadeguatezze diverse. È buona pratica testare più aspetti (ad esempio, minimo, massimo, correlazioni) per un esame completo.
- Strumento complementare: i PPC non sostituiscono il confronto di modelli. Un modello può superare un PPC ma essere peggiore di un’alternativa più parsimoniosa.
15.3.5 Implementazione pratica
Nei software bayesiani moderni (come Stan, brms, o PyMC), i controlli predittivi a posteriori sono facilmente implementabili:
# Esempio con brms
pp_check(fit, type = "dens_overlay", ndraws = 100) # Confronto densità
pp_check(fit, type = "stat", stat = "mean") # Confronto media
pp_check(fit, type = "stat_2d", stat = c("mean", "sd")) # Confronto bivariatoQueste funzioni generano automaticamente dataset replicati dalla distribuzione predittiva a posteriori e visualizzano il confronto con i dati osservati, facilitando la diagnosi visuale dell’adeguatezza del modello.
La distribuzione predittiva a posteriori non serve solo a fare previsioni su dati futuri, ma costituisce anche lo strumento fondamentale per la validazione critica del modello stesso. Chiedendoci “Questo modello potrebbe plausibilmente aver generato i dati che osservo?”, adottiamo una posizione epistemologica coerente con il framework bayesiano: i modelli sono approssimazioni provvisorie delle nostre credenze, sempre soggette a revisione alla luce dell’esperienza.
Riflessioni conclusive
Le distribuzioni predittive a posteriori rappresentano il naturale completamento del percorso iniziato con i prior. Se i prior predictive checks ci consentono di controllare la plausibilità delle nostre assunzioni iniziali, i posterior predictive checks ci permettono di verificare la plausibilità del modello alla luce dei dati.
Dal punto di vista applicativo, questo approccio rafforza la trasparenza e la robustezza delle nostre inferenze. Non ci limitiamo a riportare valori puntuali o intervalli di credibilità per i parametri, ma mostriamo esplicitamente quali dati il nostro modello ritiene plausibili e li confrontiamo con i dati effettivamente raccolti. Questo rende la comunicazione dei risultati più chiara e intuitiva, anche per chi non ha familiarità con la statistica bayesiana.
In sintesi, le distribuzioni predittive a posteriori ci ricordano che la forza dell’approccio bayesiano non risiede soltanto nella stima dei parametri, ma soprattutto nella capacità di prevedere e spiegare i fenomeni. Nei capitoli successivi, vedremo come questa logica si estenda anche al confronto sistematico tra modelli, aprendo la strada a un approccio più rigoroso e cumulativo alla psicologia.
Consideriamo i dati della SWLS somministrata a un campione di studenti, ottenendo per ciascuno uno score complessivo. Per semplicità, vogliamo “dichiarare positivo” lo studente se il punteggio SWLS supera una determinata soglia (ad esempio, 20 su 35). In questo modo otteniamo una variabile dicotomica (0/1), che useremo come “successo” in un modello binomiale.
-
Dati e conteggio dei successi
- Carica il dataset con le risposte SWLS.
- Costruisci la variabile binaria (ad esempio
SWLS_dich) che vale 1 se lo score ≥ 20, e 0 altrimenti.
- Calcola il numero di successi (numero di persone che superano la soglia) e il numero totale di osservazioni (N).
- Carica il dataset con le risposte SWLS.
-
Modello beta-binomiale (approccio manuale via simulazione)
-
Specifica una distribuzione Beta(a, b) come prior per la probabilità di successo \(p\). Scegli una coppia \((a, b)\) relativamente poco informativa, ad esempio (2,2) o (1,1).
- Osservando \(y\) successi su \(n\) soggetti, aggiorna i parametri a posteriori: \[
a_{\text{post}} = a + y,
\quad
b_{\text{post}} = b + (n - y).
\]
- Simula un gran numero di campioni di \(p\) dalla distribuzione Beta\(\bigl(a_{\text{post}},\, b_{\text{post}}\bigr)\).
- Per ciascun campione di \(p\), genera un valore \(\tilde{y}\) da una Binomiale\(\bigl(n_{\text{new}}, p\bigr)\), dove \(n_{\text{new}}\) è la dimensione di un ipotetico nuovo campione (che puoi scegliere, ad esempio, uguale a \(n\) oppure un valore diverso). Otterrai così una posterior predictive distribution per \(\tilde{y}\).
- Infine, calcola statistiche descrittive (media, varianza, intervalli) e/o disegna un istogramma di \(\tilde{y}\) o della proporzione \(\tilde{y}/n_{\text{new}}\).
-
Specifica una distribuzione Beta(a, b) come prior per la probabilità di successo \(p\). Scegli una coppia \((a, b)\) relativamente poco informativa, ad esempio (2,2) o (1,1).
-
Replicare con brms
-
Usa il pacchetto brms per costruire un modello binomiale. Per esempio:
library(brms) # Crea un data frame con la variabile dicotomica df_binom <- data.frame( successes = y, # conteggio dei successi failures = n - y ) # Modello binomiale con prior Beta(a,b) approssimato tramite logit fit_brms <- brm( bf(successes | trials(n) ~ 1), data = df_binom, family = binomial(link = "logit"), prior = c( prior(beta(2, 2), class = "Intercept", dpar = "mu") # NOTA: la specifica di una "beta(2,2)" diretta sull'intercetta # è un'approssimazione, tipicamente serve passare a una scala logit. # In brms, di solito si usa prior su scale normali dell'intercetta. ), seed = 123 )(Le specifiche del
priorpotrebbero richiedere una formulazione differente se vuoi rispettare esattamente la corrispondenza con Beta(a,b). In ogni caso, l’idea è mostrare come definire un prior e costruire un modello binomiale conbrms.) -
Verifica la convergenza e poi estrai la posterior predictive distribution con le funzioni di brms:
pp_check(fit_brms, nsamples = 100)Questo ti mostrerà come i dati predetti dal modello (in termini di binomiale) si confrontano con i dati osservati.
-
-
Confronto e interpretazione
- Metti a confronto i risultati della simulazione “manuale” (Beta-Binomial) e quelli ottenuti con brms. Noterai che le distribuzioni predittive dovrebbero essere coerenti, se hai impostato un prior per brms simile a quello del modello Beta-Binomiale.
- Discuti brevemente se la distribuzione predittiva a posteriori acquisita è plausibile rispetto ai dati osservati. Ad esempio, la probabilità di osservare \(\tilde{y}\) simile a \(y\) dovrebbe essere relativamente alta se il modello è appropriato.
- Se vuoi, puoi cambiare \(n_{\text{new}}\) (es. previsione su 200 soggetti futuri) per vedere come la variabilità della previsione si “ridimensiona” o cresce a seconda della taglia del campione.
- Metti a confronto i risultati della simulazione “manuale” (Beta-Binomial) e quelli ottenuti con brms. Noterai che le distribuzioni predittive dovrebbero essere coerenti, se hai impostato un prior per brms simile a quello del modello Beta-Binomiale.
-
Costruzione del dataset
-
Se la SWLS varia tra 5 e 35, e la soglia è 20, puoi fare:
-
-
Approccio Beta-Binomial manuale
Prior: \((a, b) = (2, 2)\)
Posterior: \((a_{\text{post}}, b_{\text{post}}) = (2 + y,\, 2 + n - y)\).
-
Generazione dei campioni:
-
Statistiche:
-
Grafici (istogramma e densità):
hist(prop_pred, freq=FALSE, col='lightblue', main='Posterior Predictive Distribution: prop. di successi')
-
Modello con brms
Usa la sintassi di una binomiale con offset o con
trials(n).-
Specifica un prior che approssimi Beta(2,2) sullo scale logit, ad esempio:
# Beta(2,2) ha media ~ 0.5, varianza relativamente ampia. # Approssimandola su scala logit ~ normal(0, 2.2) # (valore indicativo: la normal(0, 2) su logit copre un intervallo ampio). prior_approx <- prior(normal(0, 2), class = "Intercept") Esegui
pp_check(fit_brms)e interpreta.
-
Interpretazione
- Se la soglia scelta per la SWLS cattura un “buon livello di soddisfazione”, potresti aspettarti una certa % di successi.
- Se i dati futuri simulati sono coerenti con i dati reali — ad esempio, la media di \(\tilde{y}\) è vicina a \(y\) — allora il modello sembra descrivere bene la realtà. Altrimenti, potresti rivedere la soglia o la specifica del prior.
- Se la soglia scelta per la SWLS cattura un “buon livello di soddisfazione”, potresti aspettarti una certa % di successi.
L’elemento chiave è che la distribuzione predittiva a posteriori (posterior predictive distribution) non si limita a considerare un solo valore di \(p\), bensì campiona molteplici valori plausibili (dalla posterior), e per ciascuno simula un potenziale outcome. Così facendo, si riflette pienamente l’incertezza residua sul parametro e l’aleatorietà del processo binomiale.
sessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] ragg_1.5.0 tinytable_0.15.2 withr_3.0.2
#> [4] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [7] tidybayes_3.0.7 bayesplot_1.15.0 ggplot2_4.0.1
#> [10] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [13] loo_2.9.0 rstan_2.32.7 StanHeaders_2.32.10
#> [16] brms_2.23.0 Rcpp_1.1.0 sessioninfo_1.2.3
#> [19] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [22] modelr_0.1.11 tibble_3.3.0 dplyr_1.1.4
#> [25] tidyr_1.3.2 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] svUnit_1.0.8 tidyselect_1.2.1 farver_2.1.2
#> [4] S7_0.2.1 fastmap_1.2.0 TH.data_1.1-5
#> [7] tensorA_0.36.2.1 digest_0.6.39 timechange_0.3.0
#> [10] estimability_1.5.1 lifecycle_1.0.4 survival_3.8-3
#> [13] magrittr_2.0.4 compiler_4.5.2 rlang_1.1.6
#> [16] tools_4.5.2 knitr_1.51 labeling_0.4.3
#> [19] bridgesampling_1.2-1 htmlwidgets_1.6.4 curl_7.0.0
#> [22] pkgbuild_1.4.8 RColorBrewer_1.1-3 abind_1.4-8
#> [25] multcomp_1.4-29 purrr_1.2.0 grid_4.5.2
#> [28] stats4_4.5.2 colorspace_2.1-2 xtable_1.8-4
#> [31] inline_0.3.21 emmeans_2.0.1 scales_1.4.0
#> [34] MASS_7.3-65 cli_3.6.5 mvtnorm_1.3-3
#> [37] rmarkdown_2.30 generics_0.1.4 otel_0.2.0
#> [40] RcppParallel_5.1.11-1 cachem_1.1.0 stringr_1.6.0
#> [43] splines_4.5.2 parallel_4.5.2 vctrs_0.6.5
#> [46] V8_8.0.1 Matrix_1.7-4 sandwich_3.1-1
#> [49] jsonlite_2.0.0 arrayhelpers_1.1-0 glue_1.8.0
#> [52] codetools_0.2-20 distributional_0.5.0 lubridate_1.9.4
#> [55] stringi_1.8.7 gtable_0.3.6 QuickJSR_1.8.1
#> [58] pillar_1.11.1 htmltools_0.5.9 Brobdingnag_1.2-9
#> [61] R6_2.6.1 textshaping_1.0.4 rprojroot_2.1.1
#> [64] evaluate_1.0.5 lattice_0.22-7 backports_1.5.0
#> [67] memoise_2.0.1 broom_1.0.11 snakecase_0.11.1
#> [70] rstantools_2.5.0 gridExtra_2.3 coda_0.19-4.1
#> [73] nlme_3.1-168 checkmate_2.3.3 xfun_0.55
#> [76] zoo_1.8-15 pkgconfig_2.0.3