4 La dimensione dell’effetto: un laboratorio computazionale
- Calcolare e interpretare il \(d\) di Cohen e il coefficiente di correlazione \(r\).
- Visualizzare concretamente cosa significano effetti “piccoli”, “medi” e “grandi”.
- Comprendere perché \(r^2\) può essere fuorviante rispetto a \(r\).
- Utilizzare benchmark empirici per contestualizzare le dimensioni degli effetti.
- Riconoscere i limiti del “modello a pulsante” nelle scienze sociali.
4.1 Il \(d\) di Cohen: la differenze tra gruppi
4.1.1 Definizione e calcolo
Il \(d\) di Cohen è la misura più utilizzata per quantificare la differenza tra due gruppi. Esprime la differenza tra le medie in unità di deviazione standard:
\[ d = \frac{M_1 - M_2}{S_p}, \] dove \(S_p\) è la deviazione standard combinata (pooled):
\[ S_p = \sqrt{\frac{(n_1 - 1) S_1^2 + (n_2 - 1) S_2^2}{n_1 + n_2 - 2}}. \]
Un \(d = 0.5\) significa che le medie dei due gruppi differiscono di mezza deviazione standard. Ma cosa significa concretamente?
4.1.2 Visualizzare il \(d\) di Cohen
La seguente simulazione mostra come appaiono distribuzioni con diversi valori di \(d\):
palette_groups <- setNames(
palette_qualitative[c(5, 1)],
c("Controllo", "Trattamento")
)
# Funzione per generare dati con un dato Cohen's d
generate_groups <- function(d, n = 1000) {
tibble(
value = c(
rnorm(n, mean = 0, sd = 1),
rnorm(n, mean = d, sd = 1)
),
group = factor(
rep(c("Controllo", "Trattamento"), each = n),
levels = c("Controllo", "Trattamento")
)
)
}
# Valori di d e label
d_values <- c(0.2, 0.5, 0.8, 1.2)
labels <- c(
"Piccolo (d = 0.2)",
"Medio (d = 0.5)",
"Grande (d = 0.8)",
"Molto grande (d = 1.2)"
)
plots <- map2(d_values, labels, function(d, label) {
data <- generate_groups(d)
overlap <- 2 * pnorm(-abs(d) / 2) * 100
ggplot(data, aes(x = value, fill = group)) +
geom_density(alpha = 0.5, color = "white") +
geom_vline(
xintercept = 0,
linetype = "dashed",
color = palette_groups["Controllo"],
alpha = 0.7
) +
geom_vline(
xintercept = d,
linetype = "dashed",
color = palette_groups["Trattamento"],
alpha = 0.7
) +
scale_fill_manual(values = palette_groups) +
labs(
title = label,
subtitle = sprintf("Sovrapposizione: %.0f%%", overlap),
x = "Valore standardizzato",
y = "Densità",
fill = ""
) +
theme(legend.position = "bottom") +
coord_cartesian(xlim = c(-4, 5))
})
(plots[[1]] + plots[[2]]) / (plots[[3]] + plots[[4]])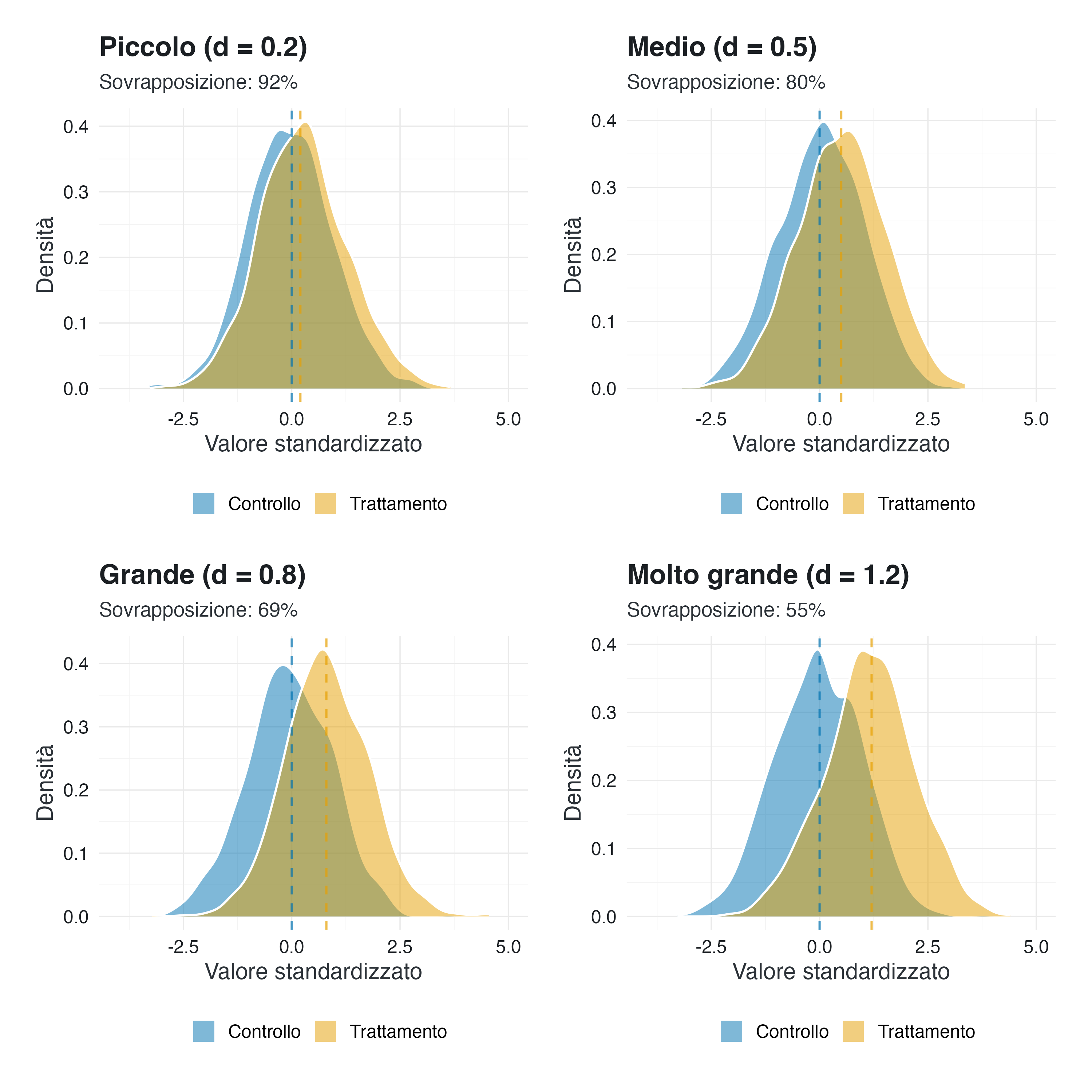
4.1.3 Interpretare il \(d\) di Cohen: dalla scala standardizzata all’intuizione clinica
Un modo particolarmente utile per interpretare il coefficiente \(d\) di Cohen consiste nel tradurlo dalla scala standardizzata a una metrica intuitivamente comprensibile: la probabilità che un individuo estratto casualmente dal gruppo trattamento ottenga un punteggio superiore a un individuo estratto casualmente dal gruppo controllo. Questa metrica, nota come Common Language Effect Size (CLES), trasforma un effetto espresso in unità di deviazione standard in un’indicazione probabilistica immediatamente interpretabile.
La relazione tra \(d\) e la CLES è matematicamente definita: \[ \text{CLES} = \Phi\left(\frac{d}{\sqrt{2}}\right) \] dove \(\Phi\) rappresenta la funzione di distribuzione cumulativa della distribuzione normale standard.
Questa trasformazione offre diversi vantaggi interpretativi:
Intuizione immediata: mentre “d = 0.5” può risultare astratto, affermare che “il 64% degli individui del gruppo trattamento supera il gruppo controllo” fornisce un’immagine concreta della differenza tra i gruppi.
Comunicazione efficace: la CLES rappresenta un linguaggio comune comprensibile a ricercatori, clinici, pazienti e decisori politici, indipendentemente dalla loro familiarità con la statistica inferenziale.
Valutazione contestuale: permette di valutare l’effetto in termini di sovrapposizione tra le distribuzioni dei due gruppi, offrendo una visione più completa della separazione tra le popolazioni.
Questa traduzione probabilistica risulta particolarmente preziosa in contesti applicati, come la psicologia clinica, dove la rilevanza pratica di un intervento si valuta nei termini della sua capacità di produrre differenze clinicamente rilevanti nella vita reale delle persone.
# Funzione per calcolare CLES da Cohen's d
cles <- function(d) {
pnorm(d / sqrt(2))
}
# Funzione per calcolare la percentuale di non-sovrapposizione
non_overlap <- function(d) {
2 * pnorm(abs(d) / 2) - 1
}
tibble(
`Cohen's d` = c(0.0, 0.2, 0.5, 0.8, 1.0, 1.5, 2.0),
`Etichetta Cohen` = c("Nullo", "Piccolo", "Medio", "Grande",
"Grande", "Molto grande", "Enorme"),
`CLES` = sprintf("%.1f%%", cles(`Cohen's d`) * 100),
`Interpretazione CLES` = c(
"50% (come il caso)",
"56% supera il controllo",
"64% supera il controllo",
"71% supera il controllo",
"76% supera il controllo",
"86% supera il controllo",
"92% supera il controllo"
)
) |>
knitr::kable()| Cohen’s d | Etichetta Cohen | CLES | Interpretazione CLES |
|---|---|---|---|
| 0.0 | Nullo | 50.0% | 50% (come il caso) |
| 0.2 | Piccolo | 55.6% | 56% supera il controllo |
| 0.5 | Medio | 63.8% | 64% supera il controllo |
| 0.8 | Grande | 71.4% | 71% supera il controllo |
| 1.0 | Grande | 76.0% | 76% supera il controllo |
| 1.5 | Molto grande | 85.6% | 86% supera il controllo |
| 2.0 | Enorme | 92.1% | 92% supera il controllo |
La traduzione di \(d\) nella probabilità di superiorità offre un’immagine concreta della rilevanza pratica degli effetti standardizzati:
Per un effetto “piccolo” (\(d = 0.2\)):
se selezioniamo casualmente un individuo dal gruppo di trattamento e uno dal gruppo di controllo, l’individuo trattato presenterà un punteggio superiore solo nel 56% dei casi. Questa proporzione supera di soli 6 punti percentuali il puro caso (50%), rappresentando una differenza appena percettibile nella pratica quotidiana.
Per un effetto “grande” (\(d = 0.8\)):
la stessa operazione produce risultati sensibilmente diversi: l’individuo trattato otterrà un punteggio superiore nel 71% dei casi, indicando una separazione più marcata tra le distribuzioni dei due gruppi.
Questa traduzione probabilistica mostra come anche gli effetti classificati come “grandi” secondo le convenzioni di Cohen lascino comunque spazio a una sostanziale sovrapposizione tra i gruppi. Un’interpretazione che considera esclusivamente la grandezza standardizzata dell’effetto rischia di sopravvalutare il suo impatto pratico, mentre la prospettiva della Common Language Effect Size mantiene un ancoraggio realistico alla variabilità individuale e alla sovrapposizione tra le popolazioni.
4.2 Il coefficiente di correlazione \(r\): comprendere le relazioni lineari
Il coefficiente di correlazione \(r\) di Pearson quantifica la forza e la direzione di una relazione lineare tra due variabili continue. La sua scala varia da -1 (correlazione negativa perfetta) a +1 (correlazione positiva perfetta), con lo zero che indica assenza di relazione lineare.
Una proprietà importante è la convertibilità tra \(d\) (differenza standardizzata tra medie) e \(r\) (correlazione):
\[ d = \frac{2r}{\sqrt{1-r^2}} \qquad \text{e} \qquad r = \frac{d}{\sqrt{d^2 + 4}}. \]
Questa relazione permette di tradurre effetti espressi in una metrica nell’altra, facilitando confronti tra diverse tradizioni di ricerca.
4.2.1 Visualizzazione di correlazioni di diversa intensità
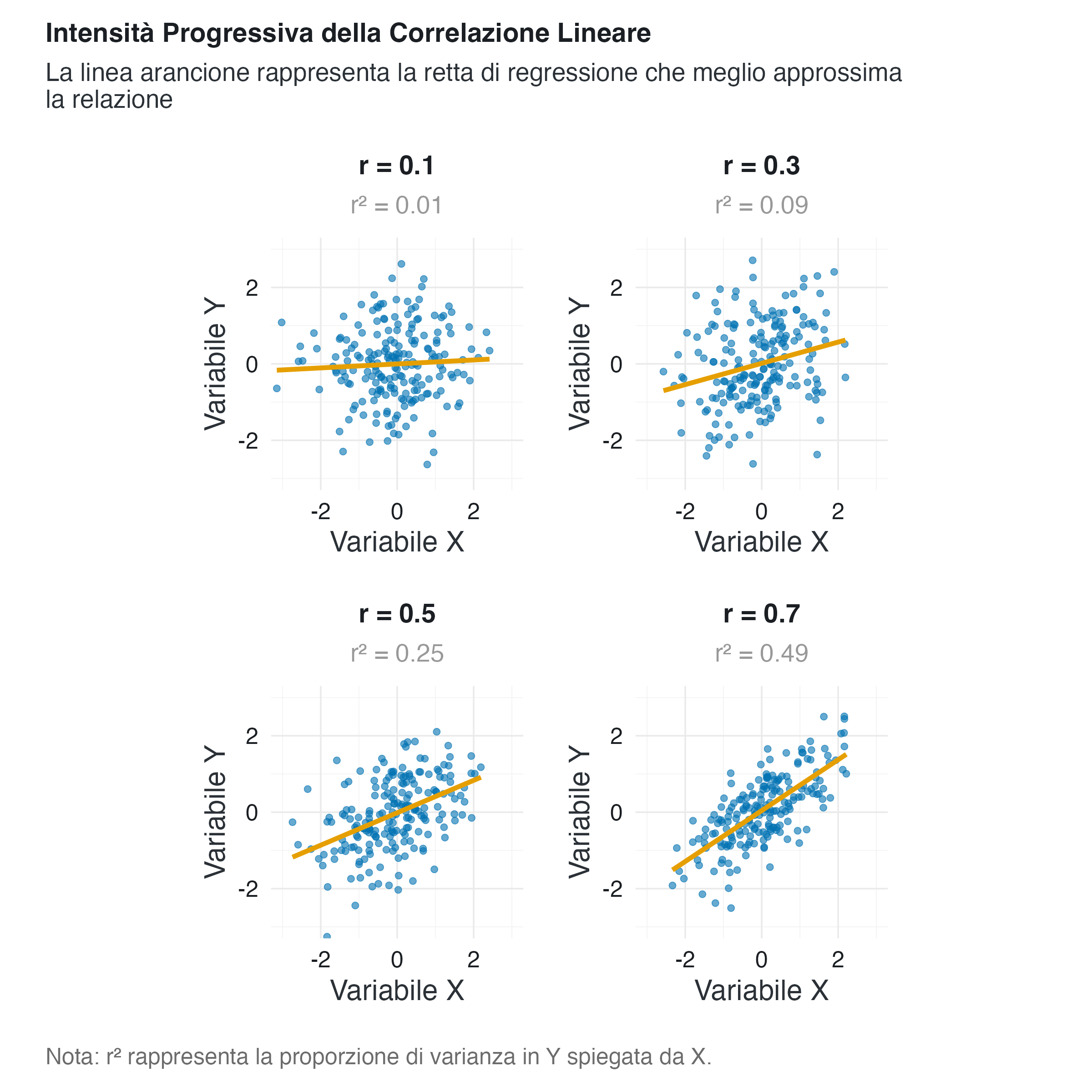
4.3 Il problema di \(r^2\): una simulazione chiarificatrice
4.3.1 La distorsione quadratica nell’interpretazione
Una pratica diffusa nella ricerca applicata consiste nell’elevare al quadrato il coefficiente di correlazione \(r\) per ottenere \(r^2\), tipicamente interpretato come “percentuale di varianza spiegata”. Sebbene matematicamente corretta, questa trasformazione può distorcere gravemente la percezione della grandezza relativa degli effetti, creando interpretazioni fuorvianti.
L’esempio classico di Darlington (1990) illustra in modo illuminante questa distorsione. Consideriamo un semplice gioco d’azzardo con due monete:
- Un nickel (5¢): se esce testa, vinci 5 centesimi;
- Un dime (10¢): se esce testa, vinci 10 centesimi.
Entrambe le monete sono eque, ma differiscono nel valore del premio. Calcoliamo le correlazioni tra la probabilità di successo (abilità del giocatore) e la vincita monetaria:
set.seed(123)
n_players <- 1000
# Simulazione del gioco delle monete
darlington_simulation <- tibble(
player = 1:n_players,
# Abilità del giocatore (variabile latente che influenza entrambe le monete)
player_skill = rnorm(n_players, mean = 0, sd = 0.5),
# Probabilità di successo influenzata dall'abilità
nickel_success_prob = 0.4 + 0.2 * pnorm(player_skill),
dime_success_prob = 0.4 + 0.2 * pnorm(player_skill),
# Simulazione degli esiti dei lanci
nickel_outcome = rbinom(n_players, 1, nickel_success_prob),
dime_outcome = rbinom(n_players, 1, dime_success_prob),
# Vincite monetarie
nickel_payout = nickel_outcome * 5, # 0 o 5 centesimi
dime_payout = dime_outcome * 10 # 0 o 10 centesimi
)
# Calcolo delle correlazioni
correlation_results <- tibble(
Statistica = c("Correlazione (r)", "Coefficiente di determinazione (r²)", "Vincita attesa per lancio"),
Nickel = c(
sprintf("%.3f", cor(darlington_simulation$player_skill, darlington_simulation$nickel_payout)),
sprintf("%.3f", cor(darlington_simulation$player_skill, darlington_simulation$nickel_payout)^2),
sprintf("%.2f¢", mean(darlington_simulation$nickel_payout))
),
Dime = c(
sprintf("%.3f", cor(darlington_simulation$player_skill, darlington_simulation$dime_payout)),
sprintf("%.3f", cor(darlington_simulation$player_skill, darlington_simulation$dime_payout)^2),
sprintf("%.2f¢", mean(darlington_simulation$dime_payout))
),
`Rapporto Dime/Nickel` = c(
sprintf("%.2f volte",
cor(darlington_simulation$player_skill, darlington_simulation$dime_payout) /
cor(darlington_simulation$player_skill, darlington_simulation$nickel_payout)),
sprintf("%.2f volte",
(cor(darlington_simulation$player_skill, darlington_simulation$dime_payout)^2) /
(cor(darlington_simulation$player_skill, darlington_simulation$nickel_payout)^2)),
sprintf("%.2f volte",
mean(darlington_simulation$dime_payout) / mean(darlington_simulation$nickel_payout))
)
)
# Visualizzazione della tabella
correlation_results |>
knitr::kable(
align = c("l", "c", "c", "c"),
caption = "Confronto tra nickel e dime: la distorsione introdotta da r²"
) |>
kableExtra::kable_styling(
bootstrap_options = c("striped", "hover"),
full_width = FALSE,
position = "center"
)| Statistica | Nickel | Dime | Rapporto Dime/Nickel |
|---|---|---|---|
| Correlazione (r) | 0.032 | 0.099 | 3.05 volte |
| Coefficiente di determinazione (r²) | 0.001 | 0.010 | 9.31 volte |
| Vincita attesa per lancio | 2.35¢ | 5.06¢ | 2.15 volte |
4.3.2 L’Insight critico: la distorsione quadratica
L’esempio rivela l’illusione creata da \(r^2\):
La realtà lineare: il dime paga esattamente il doppio del nickel (10¢ vs 5¢). Se misuriamo l’effetto dell’abilità del giocatore attraverso \(r\), troviamo che il dime ha una correlazione approssimativamente doppia rispetto al nickel.
La distorsione quadratica: quando eleviamo al quadrato per ottenere \(r^2\), la relazione raddoppiata (×2) diventa quadruplicata (×4). Se interpretassimo \(r^2\) come misura dell’“importanza relativa”, concluderemmo erroneamente che il dime “spiega quattro volte più varianza” del nickel, suggerendo un’importanza relativa quadrupla anziché doppia.
4.3.3 Visualizzazione della relazione non lineare tra \(r\) e \(r^2\)
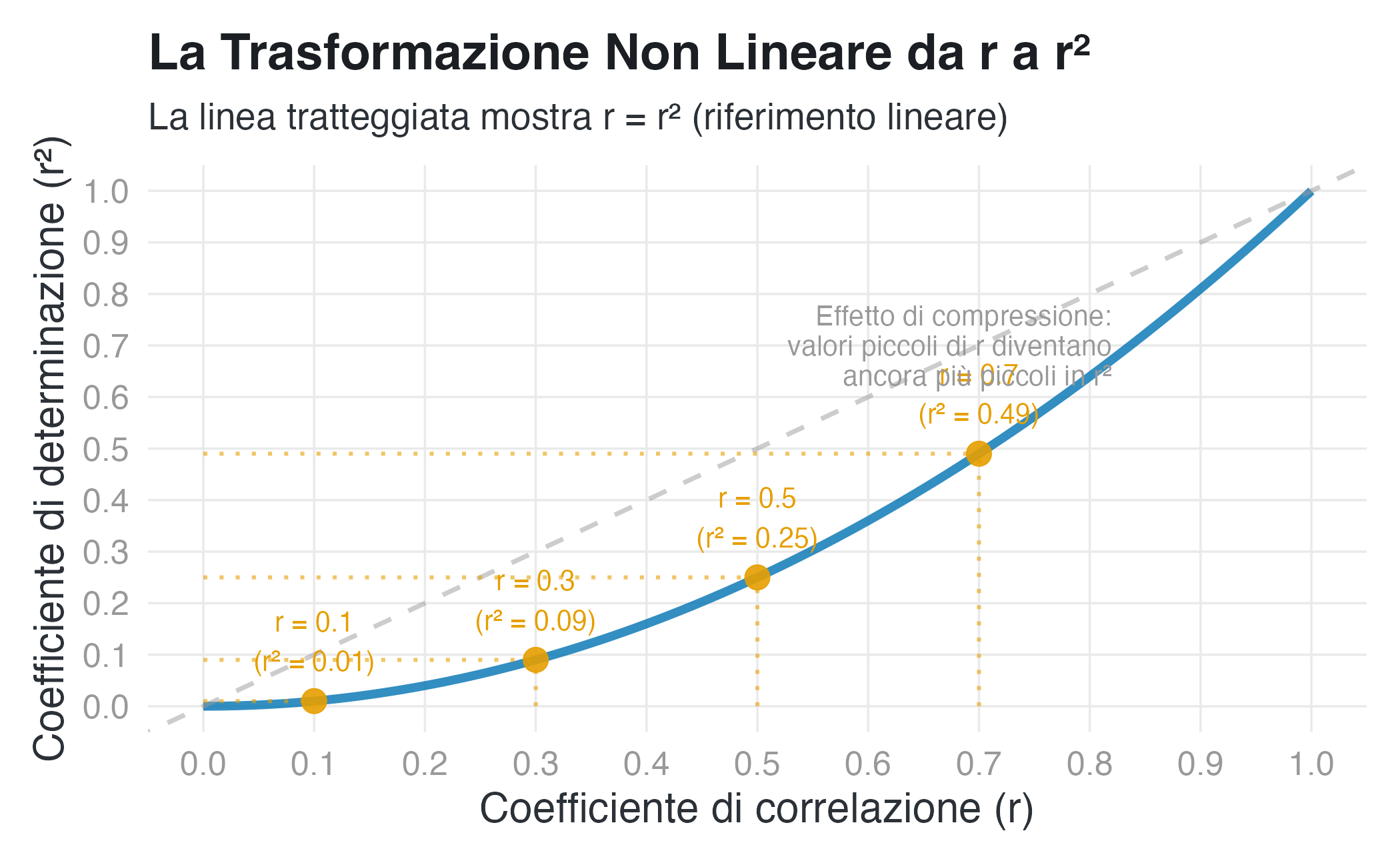
4.3.4 Implicazioni per la ricerca applicata
Questa distorsione sistematica ha conseguenze pratiche rilevanti in diversi contesti di ricerca:
1. Confronto di predittori in modelli di regressione. Quando si confronta l’importanza relativa di diverse variabili predittive, l’uso di \(r^2\) può sovrastimare drasticamente il contributo delle variabili con effetti più forti, distorcendo le conclusioni sui fattori più rilevanti.
2. Meta-analisi e sintesi di evidenze. L’aggregazione di effetti attraverso \(r^2\) può produrre stime distorte della grandezza relativa degli effetti tra studi differenti, compromettendo la validità delle sintesi quantitative.
3. Comunicazione Scientifica. Presentare \(r^2\) senza il corrispondente \(r\) può indurre lettori non esperti a conclusioni errate sull’importanza pratica dei risultati. Ad esempio, un \(r = 0.3\) (effetto moderato) diventa \(r^2 = 0.09\), che può essere erroneamente interpretato come “solo il 9% di varianza spiegata” suggerendo un effetto trascurabile.
In sintesi, l’esempio di Darlington serve come monito metodologico: mentre \(r^2\) possiede un’interpretazione matematica precisa come proporzione di varianza spiegata, la sua natura quadratica lo rende uno strumento problematico per confronti relativi. La correlazione \(r\), nonostante i suoi limiti, preserva meglio le proporzioni lineari tra effetti.
La scelta tra \(r\) e \(r^2\) dovrebbe essere guidata dallo scopo analitico specifico:
- per comprendere relazioni lineari e confronti relativi: preferire \(r\);
- per quantificare la capacità predittiva in termini di riduzione dell’errore: considerare \(r^2\) insieme a \(r\);
- per comunicazioni con pubblico non specialistico: presentare entrambi gli indicatori con spiegazioni chiare.
4.4 Gli standard di Cohen: utili ma arbitrari
Jacob Cohen (1988) propose soglie convenzionali per classificare gli effetti:
| Misura | Piccolo | Medio | Grande |
|---|---|---|---|
| \(d\) | 0.20 | 0.50 | 0.80 |
| \(r\) | 0.10 | 0.30 | 0.50 |
Tuttavia, in seguito, lo stesso Cohen espresse rammarico per queste etichette, precisando che dovrebbero essere usate solo in assenza di criteri migliori. Il problema è che “piccolo”, “medio” e “grande” sono privi di significato senza contestualizzazione.
4.4.1 Simulazione: lo stesso \(d\) in contesti diversi
# Scenario 1: Intervento educativo sul QI (SD ≈ 15 punti)
# d = 0.3 → differenza di 4.5 punti QI
# Scenario 2: Farmaco per la pressione (SD ≈ 10 mmHg)
# d = 0.3 → differenza di 3 mmHg
# Scenario 3: Terapia per la depressione (BDI, SD ≈ 10 punti)
# d = 0.3 → differenza di 3 punti BDI
contexts <- tibble(
Contesto = c("QI (SD = 15)", "Pressione arteriosa (SD = 10 mmHg)",
"Depressione BDI (SD = 10)"),
`Cohen's d` = c(0.3, 0.3, 0.3),
`Differenza grezza` = c("4.5 punti QI", "3 mmHg", "3 punti BDI"),
`Interpretazione clinica` = c(
"Modesta ma rilevante per politiche educative",
"Clinicamente rilevante (riduce il rischio cardiovascolare)",
"Sotto la soglia di cambiamento clinicamente rilevante (5 punti)"
)
)
contexts |>
knitr::kable()| Contesto | Cohen’s d | Differenza grezza | Interpretazione clinica |
|---|---|---|---|
| QI (SD = 15) | 0.3 | 4.5 punti QI | Modesta ma rilevante per politiche educative |
| Pressione arteriosa (SD = 10 mmHg) | 0.3 | 3 mmHg | Clinicamente rilevante (riduce il rischio cardiovascolare) |
| Depressione BDI (SD = 10) | 0.3 | 3 punti BDI | Sotto la soglia di cambiamento clinicamente rilevante (5 punti) |
Lo stesso \(d = 0.3\) può essere irrilevante in un contesto e clinicamente importante in un altro. Per questo è cruciale andare oltre le etichette di Cohen.
4.5 Benchmark empirici: un approccio contestualizzato per interpretare le dimensioni degli effetti
Funder & Ozer (2019) propongono due strategie pragmatiche per interpretare le dimensioni degli effetti in termini di rilevanza pratica, superando i limiti delle classificazioni arbitrarie.
1. Confronto con effetti noti.
Piuttosto che ricorrere a etichette arbitrarie (“piccolo”, “medio”, “grande”), si confronta il risultato con effetti ben stabiliti nella letteratura scientifica. Questo approccio fornisce un sistema di riferimento empirico anziché normativo.
# Benchmark da Funder & Ozer (2019) e altre fonti
benchmarks <- tibble(
Effetto = c(
"Ibuprofene sul dolore",
"Antistaminici sul raffreddore",
"Media psicologia sociale (meta-analisi 708 studi)",
"Genere → altezza",
"Psicoterapia → miglioramento sintomi",
"Aspirina → prevenzione infarto",
"Fumo → cancro ai polmoni"
),
r = c(0.14, 0.11, 0.19, 0.67, 0.32, 0.02, 0.40),
Fonte = c("Meyer et al., 2001", "Meyer et al., 2001",
"Richard et al., 2003", "Conoscenza comune",
"Smith et al., 1980", "ISIS-2, 1988", "Doll & Hill, 1950")
) |>
mutate(
d = 2 * r / sqrt(1 - r^2),
Cohen_label = case_when(
abs(r) < 0.1 ~ "< Piccolo",
abs(r) < 0.3 ~ "Piccolo",
abs(r) < 0.5 ~ "Medio",
TRUE ~ "Grande"
)
) |>
arrange(r)
palette_cohen <- setNames(
palette_qualitative[c(8, 2, 5, 1)],
c("< Piccolo", "Piccolo", "Medio", "Grande")
)
ggplot(
benchmarks,
aes(x = r, y = reorder(Effetto, r), fill = Cohen_label)
) +
geom_col(alpha = 0.8) +
geom_vline(
xintercept = c(0.1, 0.3, 0.5),
linetype = "dashed",
color = palette_qualitative[8], # grigio
alpha = 0.5
) +
scale_fill_manual(values = palette_cohen) +
labs(
x = "Correlazione (r)",
y = "",
fill = "Etichetta Cohen",
title = "Benchmark empirici per le dimensioni degli effetti",
subtitle = "Le linee tratteggiate indicano le soglie di Cohen (0.1, 0.3, 0.5)"
) +
theme(legend.position = "bottom")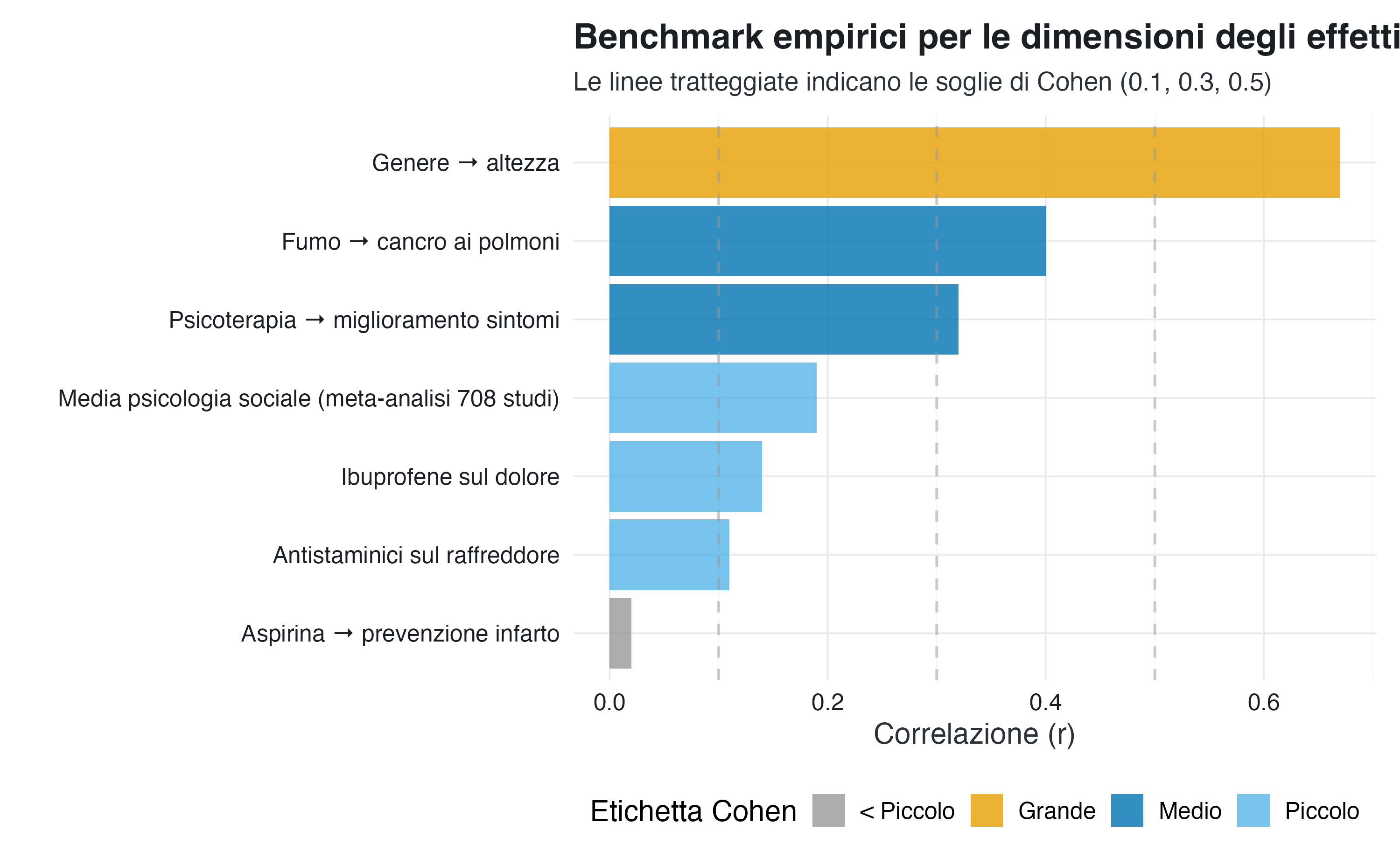
Questi benchmark offrono una prospettiva chiarificatrice. L’effetto dell’aspirina nella prevenzione dell’infarto (\(r = 0.02\)) è classificato come “trascurabile” secondo le categorie di Cohen, eppure l’ISIS-2 trial ha dimostrato che salva circa 25 vite ogni 1000 pazienti trattati. Al contrario, molti effetti “medi” in psicologia sociale potrebbero non avere alcuna rilevanza pratica.
2. L’importanza degli effetti cumulativi.
Un effetto statisticamente modesto può generare conseguenze sostanziali quando applicato su larga scala o quando si accumula nel tempo. Questa prospettiva è particolarmente rilevante per le politiche pubbliche e gli interventi a livello di popolazione.
# Simulazione: effetto di un intervento educativo su larga scala
n_students <- c(100, 1000, 10000, 100000, 1000000)
effect_r <- 0.10
effect_d <- 2 * effect_r / sqrt(1 - effect_r^2)
# Assumiamo che "successo" significhi superare una soglia (es. promozione)
# Baseline: 50% di successo
# Con l'intervento: la distribuzione si sposta di d
baseline_success <- 0.50
intervention_success <- pnorm(qnorm(baseline_success) + effect_d)
cumulative <- tibble(
`Studenti totali` = scales::comma(n_students),
`Successi baseline` = scales::comma(round(n_students * baseline_success)),
`Successi con intervento` = scales::comma(round(n_students * intervention_success)),
`Studenti in più che hanno successo` = scales::comma(
round(n_students * (intervention_success - baseline_success))
)
)
cumulative |>
knitr::kable()| Studenti totali | Successi baseline | Successi con intervento | Studenti in più che hanno successo |
|---|---|---|---|
| 100 | 50 | 58 | 8 |
| 1,000 | 500 | 580 | 80 |
| 10,000 | 5,000 | 5,797 | 797 |
| 100,000 | 50,000 | 57,965 | 7,965 |
| 1,000,000 | 500,000 | 579,654 | 79,654 |
La tabella illustra un principio fondamentale: la rilevanza pratica di un effetto non dipende solo dalla sua grandezza standardizzata, ma anche dalla scala della sua applicazione.
Con un effetto piccolo (\(r = 0.10\), classificato come “piccolo” secondo Cohen), applicato a una scuola di 1000 studenti, si ottengono 40 studenti in più che raggiungono il successo accademico. Estendendo lo stesso intervento a livello regionale (100,000 studenti), si generano circa 4,000 successi aggiuntivi. A livello nazionale (1,000,000 di studenti), l’effetto produce circa 40,000 successi in più.
Questo approccio contestuale sfida tre presupposti comuni.
- Il mito della soglia minima: effetti classificati come “piccoli” o “trascurabili” secondo Cohen possono avere importanza pratica sostanziale quando valutati nel loro contesto applicativo.
- La necessità del confronto: l’interpretazione di una dimensione dell’effetto è intrinsecamente relativa. Un \(r = 0.20\) è modesto se paragonato al fumo come fattore di rischio per il cancro (\(r = 0.40\)), ma rilevante se confrontato con l’efficacia di farmaci comunemente prescritti.
- L’importanza della scala: la valutazione della rilevanza pratica deve considerare non solo la grandezza standardizzata dell’effetto, ma anche la popolazione a cui si applica e le conseguenze cumulative nel tempo.
Questa prospettiva riconcilia la precisione statistica con la rilevanza pratica, promuovendo una ricerca che non si limita a dimostrare effetti statisticamente significativi, ma che valuta la loro importanza nel mondo reale.
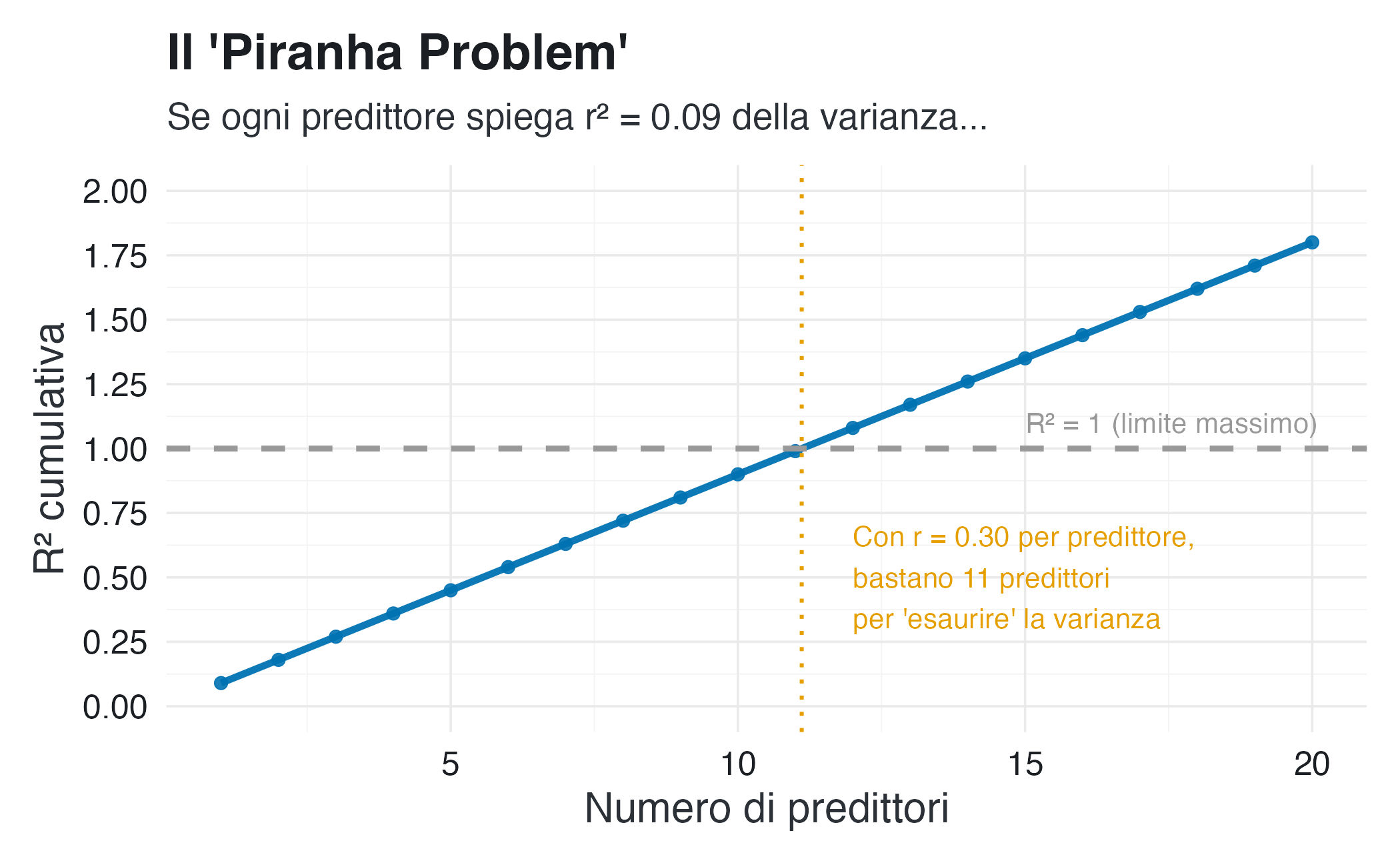
4.6 Il problema del “piranha”: effetti troppo grandi per essere veri
Andrew Gelman ha coniato il termine piranha problem per descrivere una contraddizione sistemica nella letteratura psicologica: se esistessero realmente tutti gli effetti grandi e robusti riportati negli studi, questi piranha statistici si “mangerebbero a vicenda” poiché non esisterebbe sufficiente varianza da spiegare (Tosh et al., 2021).
Il concetto è fondamentalmente aritmetico: il comportamento umano emerge dall’interazione di innumerevoli fattori genetici, ambientali, culturali e situazionali. Se ciascuno di questi fattori producesse indipendentemente un effetto di dimensione media (\(r = 0.30\), secondo le convenzioni di Cohen), rapidamente supereremmo il 100% della varianza spiegabile. La matematica di base dell’analisi della varianza rende questa situazione impossibile.
# Simulazione: quanta varianza "consumano" predittori multipli?
n_predictors <- 1:20
r_each <- 0.30
# Se i predittori fossero indipendenti, R² ≈ n * r²
# (semplificazione per illustrare il concetto)
cumulative_r2 <- n_predictors * r_each^2
col_main <- palette_qualitative[5] # Blu
col_limit <- palette_qualitative[8] # Grigio
col_marker <- palette_qualitative[1] # Arancione
tibble(
`Numero di predittori` = n_predictors,
`R² cumulativa (se indipendenti)` = cumulative_r2
) |>
ggplot(aes(x = `Numero di predittori`, y = `R² cumulativa (se indipendenti)`)) +
geom_line(color = col_main, linewidth = 1.2) +
geom_point(color = col_main, size = 2) +
geom_hline(
yintercept = 1,
color = col_limit,
linetype = "dashed",
linewidth = 1
) +
annotate(
"text",
x = 15, y = 1.1,
label = "R² = 1 (limite massimo)",
color = col_limit,
hjust = 0
) +
geom_vline(
xintercept = 1 / r_each^2,
color = col_marker,
linetype = "dotted"
) +
annotate(
"text",
x = 12, y = 0.5,
label = sprintf(
"Con r = %.2f per predittore,\nbastano %.0f predittori\nper 'esaurire' la varianza",
r_each, 1 / r_each^2
),
color = col_marker,
hjust = 0
) +
scale_y_continuous(limits = c(0, 2), breaks = seq(0, 2, 0.25)) +
labs(
title = "Il 'Piranha Problem'",
subtitle = "Se ogni predittore spiega r² = 0.09 della varianza...",
y = "R² cumulativa"
)
Riflessioni conclusive
La discussione sulla dimensione dell’effetto ha rivelato una verità semplice ma profonda: non esistono scorciatoie interpretative. Gli indici statistici standardizzati, come il \(d\) di Cohen e il coefficiente \(r\), sono strumenti potenti ma ambigui. Questi strumenti non sono utili quando pretendono di fornire risposte definitive, ma quando ci aiutano a porre le giuste domande sulla rilevanza pratica e teorica dei risultati della ricerca.
La standardizzazione, sebbene formalmente elegante, crea un’illusione di comparabilità che può rivelarsi ingannevole. Un valore identico di \(d\) in due studi diversi non garantisce un effetto equivalente, poiché il denominatore, ovvero la deviazione standard, è una proprietà contingente del campione, della misura e del contesto. Quando una metrica astratta sostituisce un valore concretamente interpretabile, come i punti di scala o le unità biologiche, si perde il legame essenziale tra statistica e fenomeno, favorendo una comunicazione opaca e confronti privi di fondamento sostanziale.
Questa astrattezza si combina con problemi tecnici insidiosi. Nei campioni di piccole dimensioni, frequenti in psicologia, la deviazione standard e, di conseguenza, la stima dell’effetto standardizzato diventano estremamente instabili. Tale instabilità si intreccia in modo perverso con il bias di pubblicazione: in un ecosistema che premia la significatività statistica (\(p\) < 0.05), gli studi pubblicati sono spesso quelli in cui una fluttuazione casuale favorevole (un effetto osservato grande, associato a una stima della variabilità insolitamente bassa) ha prodotto un risultato “significativo”. La standardizzazione cristallizza proprio queste anomalie, producendo una sovrastima sistematica degli effetti reali nella letteratura (bias di tipo M). Il piranha problem di Gelman descrive l’assurdità logica di questo processo: se tutti gli effetti grandi riportati fossero reali e indipendenti, non ci sarebbe più varianza da spiegare.
Anche la scelta della metrica di presentazione è cruciale. L’uso prevalente di \(r^2\) (“varianza spiegata”), sebbene matematicamente corretto, esercita un effetto di compressione psicologica che minimizza la percezione degli effetti più modesti. La correlazione \(r\), unita a traduzioni intuitive come la Common Language Effect Size (CLES), preserva molto meglio le proporzioni lineari e comunica la forza di una relazione in modo più fedele e immediato.
Alla luce di queste criticità, l’applicazione acritica delle etichette convenzionali di Cohen (“piccolo”, “medio”, “grande”) non solo appare inadeguata, ma rischia anche di essere fuorviante. Queste soglie arbitrarie sostituiscono il necessario giudizio scientifico, radicato nella teoria, nel contesto applicativo e nella conoscenza del dominio, con un automatismo privo di significato. Ciò che è considerato un effetto “piccolo” in un contesto (come un aumento minimo di un farmaco salvavita) può essere di importanza cruciale, mentre un effetto “grande” in un altro ambito può essere praticamente irrilevante.
Verso un’interpretazione contestuale e responsabile
La via d’uscita da questa impasse non è l’abbandono delle misure di grandezza dell’effetto, ma la loro implementazione consapevole e contestuale. Questo richiede:
- preferire la metrica originale: comunicare i risultati nelle unità di misura della ricerca, affiancando le misure standardizzate come complemento e non come sostituto. Questo preserva il significato pratico e facilita il dialogo con gli stakeholders.
- utilizzare benchmark empirici: ancorare l’interpretazione confrontando l’effetto ottenuto con quello di fenomeni noti e ben documentati nella letteratura (ad esempio, confrontare l’effetto di un nuovo intervento con l’efficacia consolidata della psicoterapia). Questo fornisce un sistema di riferimento molto più informativo delle soglie arbitrarie.
- valutare la rilevanza pratica: considerare sistematicamente le implicazioni dell’effetto nella sua scala di applicazione. Un piccolo effetto applicato a una vasta popolazione, o che si accumula nel tempo, può avere un impatto sostanziale.
- applicare il “piranha test”: mantenere un sano scetticismo di fronte a effetti molto grandi, specialmente se multipli e dichiarati indipendenti, e chiedere verifiche di robustezza e replicazione.
- andare oltre il singolo numero: ricordare che un indice di grandezza dell’effetto è una sintesi estrema e inevitabilmente riduttiva della complessità osservata. Bisogna indagare la forma della relazione (lineare, non lineare), l’eterogeneità tra sottogruppi e i meccanismi causali sottostanti.
La statistica bayesiana, che esploreremo in seguito, offre un quadro concettuale naturale per questo approccio integrato. Essa incoraggia a esplicitare le conoscenze pregresse (i benchmark), quantifica l’incertezza in modo intuitivo attraverso gli intervalli di credibilità e sposta il focus dal test di ipotesi dicotomico alla stima quantitativa e contestualizzata. L’obiettivo finale non è produrre un numero standardizzato, ma costruire un modello interpretabile che arricchisca la nostra comprensione della complessità del comportamento umano, guidando al contempo decisioni informate nella ricerca e nella pratica.
4.7 Esercizi
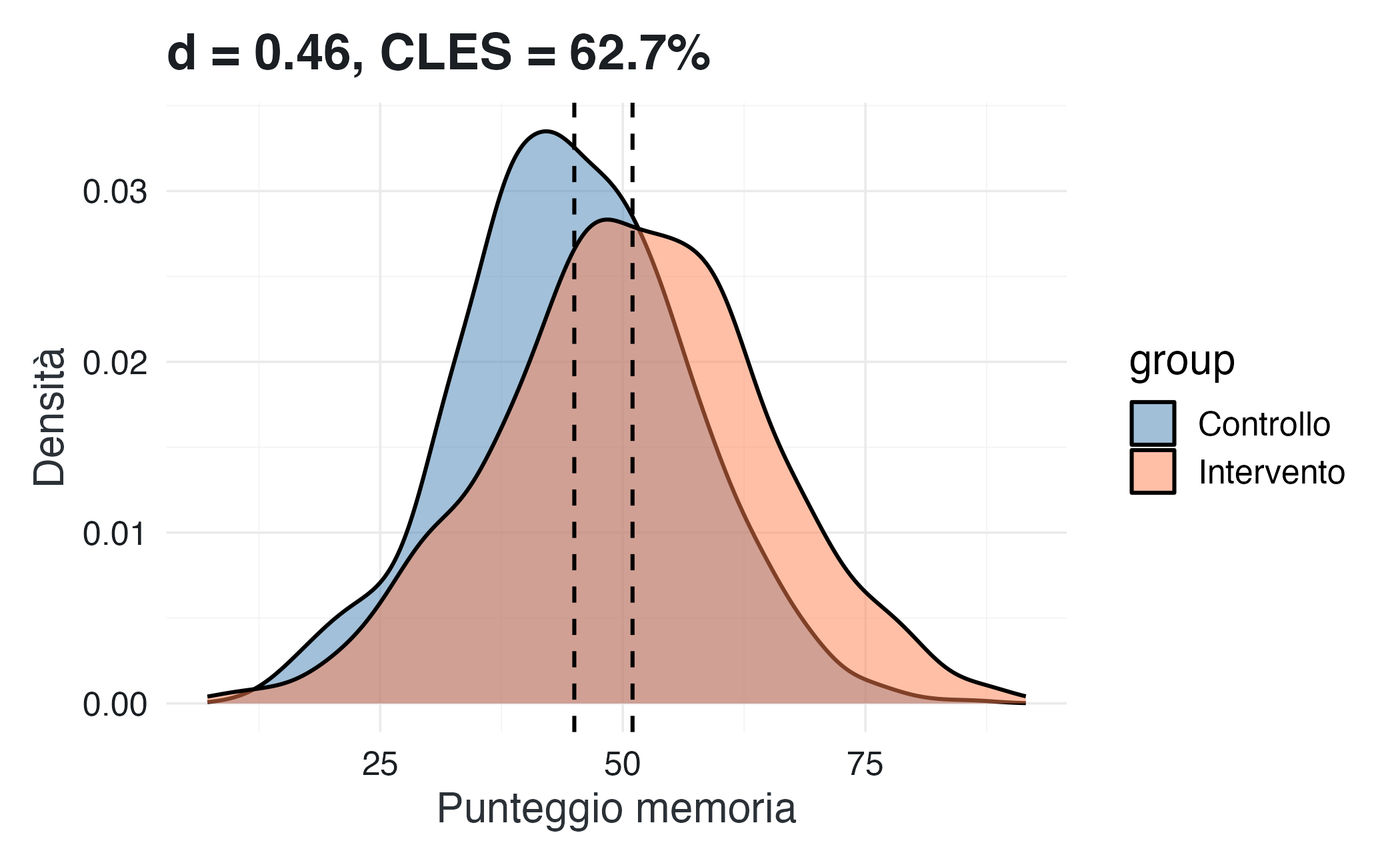
Hai condotto uno studio su un intervento per migliorare la memoria. I risultati sono:
- Gruppo controllo: \(M = 45\), \(SD = 12\), \(n = 30\)
- Gruppo intervento: \(M = 51\), \(SD = 14\), \(n = 32\)
- Calcola il \(d\) di Cohen con la formula della pooled SD.
- Calcola il CLES (probabilità che un partecipante del gruppo intervento superi uno del controllo).
- Visualizza le due distribuzioni sovrapposte.
# Dati
m1 <- 45; sd1 <- 12; n1 <- 30
m2 <- 51; sd2 <- 14; n2 <- 32
# 1. Calcolo Cohen's d
pooled_sd <- sqrt(((n1 - 1) * sd1^2 + (n2 - 1) * sd2^2) / (n1 + n2 - 2))
cohens_d <- (m2 - m1) / pooled_sd
cat(sprintf("Pooled SD: %.2f\n", pooled_sd))
#> Pooled SD: 13.07
cat(sprintf("Cohen's d: %.2f\n", cohens_d))
#> Cohen's d: 0.46
# 2. CLES
cles_value <- pnorm(cohens_d / sqrt(2))
cat(sprintf("CLES: %.1f%% (probabilità che intervento > controllo)\n", cles_value * 100))
#> CLES: 62.7% (probabilità che intervento > controllo)
# 3. Visualizzazione
tibble(
value = c(rnorm(1000, m1, sd1), rnorm(1000, m2, sd2)),
group = rep(c("Controllo", "Intervento"), each = 1000)
) |>
ggplot(aes(x = value, fill = group)) +
geom_density(alpha = 0.5) +
geom_vline(xintercept = c(m1, m2), linetype = "dashed") +
scale_fill_manual(values = c("steelblue", "coral")) +
labs(
title = sprintf("d = %.2f, CLES = %.1f%%", cohens_d, cles_value * 100),
x = "Punteggio memoria",
y = "Densità"
)
Un ricercatore afferma: “La correlazione tra ore di studio e voto è r = 0.40, ma questo spiega solo il 16% della varianza, quindi studiare conta poco.”
- Commenta criticamente questa affermazione.
- Calcola quante ore di studio in più servono per aumentare il voto di 1 punto (assumendo voto medio = 25, SD = 4, ore studio medie = 20, SD = 10).
- Confronta questo effetto con i benchmark della letteratura.
# 1. Critica
cat("L'affermazione è fuorviante per tre ragioni:\n\n")
#> L'affermazione è fuorviante per tre ragioni:
cat("a) r = 0.40 è un effetto 'medio-grande' secondo Cohen\n")
#> a) r = 0.40 è un effetto 'medio-grande' secondo Cohen
cat("b) r² minimizza sistematicamente l'interpretabilità\n")
#> b) r² minimizza sistematicamente l'interpretabilità
cat("c) Il 16% di varianza può tradursi in differenze pratiche significative\n\n")
#> c) Il 16% di varianza può tradursi in differenze pratiche significative
# 2. Calcolo pratico
r <- 0.40
sd_voto <- 4
sd_ore <- 10
mean_voto <- 25
mean_ore <- 20
# La pendenza della regressione standardizzata è r
# In unità originali: b = r * (SD_y / SD_x)
b <- r * (sd_voto / sd_ore)
ore_per_punto <- 1 / b
cat(sprintf("Per ogni ora di studio in più, il voto aumenta di %.2f punti\n", b))
#> Per ogni ora di studio in più, il voto aumenta di 0.16 punti
cat(sprintf("Per aumentare il voto di 1 punto, servono %.1f ore in più\n\n", ore_per_punto))
#> Per aumentare il voto di 1 punto, servono 6.2 ore in più
# 3. Confronto con benchmark
cat("Confronto con benchmark:\n")
#> Confronto con benchmark:
cat("- r = 0.40 è più forte dell'effetto medio in psicologia sociale (r = 0.19)\n")
#> - r = 0.40 è più forte dell'effetto medio in psicologia sociale (r = 0.19)
cat("- È comparabile all'effetto fumo → cancro (r ≈ 0.40)\n")
#> - È comparabile all'effetto fumo → cancro (r ≈ 0.40)
cat("- È molto più forte dell'effetto aspirina → prevenzione infarto (r = 0.02)\n")
#> - È molto più forte dell'effetto aspirina → prevenzione infarto (r = 0.02)Un articolo afferma di aver trovato 5 predittori indipendenti del benessere psicologico, ciascuno con \(r = 0.35\):
- Supporto sociale
- Esercizio fisico
- Qualità del sonno
- Reddito
- Ottimismo
Usa il “piranha test” per valutare la plausibilità di questi risultati.
# Piranha test
r <- 0.35
n_predictors <- 5
# R² cumulativa se i predittori fossero indipendenti
r2_each <- r^2
r2_cumulative <- n_predictors * r2_each
cat(sprintf("Ogni predittore 'spiega' r² = %.2f della varianza\n", r2_each))
#> Ogni predittore 'spiega' r² = 0.12 della varianza
cat(sprintf("5 predittori indipendenti spiegherebbero R² = %.2f\n\n", r2_cumulative))
#> 5 predittori indipendenti spiegherebbero R² = 0.61
if (r2_cumulative > 1) {
cat("IMPOSSIBILE: R² > 1!\n")
} else if (r2_cumulative > 0.5) {
cat("SOSPETTO: R² > 0.50 per il benessere psicologico è implausibile\n")
cat("Il benessere è influenzato da centinaia di fattori, non solo 5\n")
}
#> SOSPETTO: R² > 0.50 per il benessere psicologico è implausibile
#> Il benessere è influenzato da centinaia di fattori, non solo 5
cat("\nPossibili spiegazioni:\n")
#>
#> Possibili spiegazioni:
cat("1. Gli effetti sono sovrastimati (errore di tipo M)\n")
#> 1. Gli effetti sono sovrastimati (errore di tipo M)
cat("2. I predittori sono correlati tra loro (multicollinearità)\n")
#> 2. I predittori sono correlati tra loro (multicollinearità)
cat("3. Le misure condividono varianza di metodo\n")
#> 3. Le misure condividono varianza di metodo
cat("4. P-hacking o selezione dei predittori post-hoc\n")
#> 4. P-hacking o selezione dei predittori post-hocsessionInfo()
#> R version 4.5.2 (2025-10-31)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.2
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] lubridate_1.9.4 forcats_1.0.1 stringr_1.6.0
#> [4] purrr_1.2.0 readr_2.1.6 tidyverse_2.0.0
#> [7] ragg_1.5.0 tinytable_0.15.2 withr_3.0.2
#> [10] systemfonts_1.3.1 patchwork_1.3.2 ggdist_3.3.3
#> [13] tidybayes_3.0.7 bayesplot_1.15.0 ggplot2_4.0.1
#> [16] reliabilitydiag_0.2.1 priorsense_1.2.0 posterior_1.6.1
#> [19] loo_2.9.0 rstan_2.32.7 StanHeaders_2.32.10
#> [22] brms_2.23.0 Rcpp_1.1.0 sessioninfo_1.2.3
#> [25] conflicted_1.2.0 janitor_2.2.1 matrixStats_1.5.0
#> [28] modelr_0.1.11 tibble_3.3.0 dplyr_1.1.4
#> [31] tidyr_1.3.2 rio_1.2.4 here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] gridExtra_2.3 inline_0.3.21 sandwich_3.1-1
#> [4] rlang_1.1.6 magrittr_2.0.4 multcomp_1.4-29
#> [7] snakecase_0.11.1 otel_0.2.0 compiler_4.5.2
#> [10] mgcv_1.9-4 vctrs_0.6.5 pkgconfig_2.0.3
#> [13] arrayhelpers_1.1-0 fastmap_1.2.0 backports_1.5.0
#> [16] labeling_0.4.3 rmarkdown_2.30 tzdb_0.5.0
#> [19] xfun_0.55 cachem_1.1.0 jsonlite_2.0.0
#> [22] broom_1.0.11 parallel_4.5.2 R6_2.6.1
#> [25] stringi_1.8.7 RColorBrewer_1.1-3 estimability_1.5.1
#> [28] knitr_1.51 zoo_1.8-15 Matrix_1.7-4
#> [31] splines_4.5.2 timechange_0.3.0 tidyselect_1.2.1
#> [34] rstudioapi_0.17.1 abind_1.4-8 yaml_2.3.12
#> [37] codetools_0.2-20 curl_7.0.0 pkgbuild_1.4.8
#> [40] lattice_0.22-7 bridgesampling_1.2-1 S7_0.2.1
#> [43] coda_0.19-4.1 evaluate_1.0.5 survival_3.8-3
#> [46] RcppParallel_5.1.11-1 xml2_1.5.1 pillar_1.11.1
#> [49] tensorA_0.36.2.1 checkmate_2.3.3 stats4_4.5.2
#> [52] distributional_0.5.0 generics_0.1.4 rprojroot_2.1.1
#> [55] hms_1.1.4 rstantools_2.5.0 scales_1.4.0
#> [58] xtable_1.8-4 glue_1.8.0 emmeans_2.0.1
#> [61] tools_4.5.2 mvtnorm_1.3-3 grid_4.5.2
#> [64] QuickJSR_1.8.1 colorspace_2.1-2 nlme_3.1-168
#> [67] cli_3.6.5 kableExtra_1.4.0 textshaping_1.0.4
#> [70] svUnit_1.0.8 viridisLite_0.4.2 svglite_2.2.2
#> [73] Brobdingnag_1.2-9 V8_8.0.1 gtable_0.3.6
#> [76] digest_0.6.39 TH.data_1.1-5 htmlwidgets_1.6.4
#> [79] farver_2.1.2 memoise_2.0.1 htmltools_0.5.9
#> [82] lifecycle_1.0.4 MASS_7.3-65