Questo capitolo apre la sezione dedicata alla crisi metodologica in psicologia. Nel manuale (Parti I e II) sono già stati presentati i fondamenti teorici del problema: la nozione di replicabilità, i limiti del paradigma frequentista e le pratiche di ricerca discutibili. In questo capitolo non verranno ripresi questi concetti, ma si darà per scontato che siano già noti. Ci sposteremo invece sul piano delle storie. Ci concentreremo sulle vicende che hanno reso questa crisi concreta e visibile a tutta la comunità scientifica: i ricercatori coinvolti in prima persona, gli scandali e le indagini che hanno scosso il campo, gli eventi che hanno catalizzato il cambiamento. Attraverso questi casi emblematici, esploreremo le lezioni più pratiche e urgenti che se ne possono trarre per la pratica scientifica.
ConsiglioLetture preparatorie
Prima di procedere, ti consiglio tre letture che offrono prospettive complementari:
La crisi della replicabilità non è scoppiata all’improvviso. Si è sviluppata lentamente, ignorando o minimizzando segnali che si sono accumulati per anni, finché una serie di eventi ravvicinati ha reso impossibile distogliere lo sguardo. Riflettere su questa vicenda non è un esercizio di archeologia accademica, ma un modo per comprendere come siamo arrivati a questo punto e, soprattutto, come evitare di ritrovarci nella stessa situazione.
3.1.1 Atto primo: i profeti inascoltati (2005)
Nel 2005, John Ioannidis pubblicò un articolo dal titolo provocatorio: “Why Most Published Research Findings Are False”(Ioannidis, 2005). La tesi, semplice ma inquietante, era la seguente: in un sistema accademico caratterizzato da campioni di piccole dimensioni, flessibilità analitica, pressione a ottenere risultati “interessanti” e un forte bias di pubblicazione, la maggior parte dei risultati scientifici pubblicati ha un’alta probabilità di essere falsa.
L’articolo è diventato uno dei più citati nella storia della psicologia. Tuttavia, per anni è rimasto una voce isolata e inascoltata: tutti lo citavano, ma quasi nessuno ne traeva le dovute conseguenze. La psicologia, nel suo complesso, proseguì imperterrita con le sue pratiche consolidate. I laboratori producevano dati, le riviste pubblicavano articoli e le carriere avanzavano. In un sistema che sembrava funzionare, quale incentivo c’era a cambiare?
La risposta arrivò sei anni dopo, nel modo più improbabile.
3.1.2 Atto secondo: l’anno che cambiò tutto (2011)
Il 2011 fu l’annus horribilis per la psicologia sociale. Due eventi apparentemente scollegati tra loro, ma che in realtà si intrecciarono, portarono alla luce le fragilità della disciplina.
3.1.2.1 Daryl Bem e la precognizione
Daryl Bem, uno stimato psicologo della Cornell University, noto per i suoi contributi alla teoria dell’autopercezione, divenne protagonista di uno scandalo metodologico con la pubblicazione del suo articolo Feeling the Future nel Journal of Personality and Social Psychology, una delle riviste più prestigiose del settore. Nel lavoro, Bem presentava nove esperimenti che, utilizzando metodologie standard, sembravano offrire prove “statisticamente significative” a favore della precognizione, ovvero la capacità di percepire eventi futuri prima che accadano.
L’esperimento più provocatorio era una variante temporale del classico paradigma di priming. Nella sua forma tradizionale, il priming mostra come uno stimolo precedente (per esempio, la parola “felice”) influenzi la successiva valutazione di un’immagine. Bem ne invertì la sequenza: i partecipanti valutavano prima un’immagine, e solo dopo veniva loro presentato uno stimolo di priming. Sorprendentemente, l’effetto di congruenza persisteva: i soggetti erano più rapidi nel giudicare come piacevoli quelle immagini che, in seguito, sarebbero state associate a parole positive.
I risultati erano formalmente inattaccabili: valori-\(p\) inferiori a 0.05, metodi canonici, un processo di peer review superato, la pubblicazione su una rivista di prestigio. Eppure, la comunità si trovò di fronte a un dilemma epistemologico imbarazzante: accettare la possibilità della precognizione o ammettere che le pratiche di ricerca standard, che includono esperimenti con piccoli campioni e una grande flessibilità analitica, possono generare “evidenze” convincenti anche per i fenomeni paranormali, contraddicendo così tutte le nostre conoscenze scientifiche consolidate.
Il vero scandalo, quindi, non era che Bem credesse ai fenomeni paranormali, ma che l’intero sistema metodologico della psicologia fosse strutturalmente fragile. Se quelle stesse procedure potevano validare la precognizione, quale certezza rimaneva per tutti gli altri fenomeni pubblicati con gli stessi criteri? L’esperimento di Bem non metteva in discussione un singolo risultato, ma l’affidabilità della produzione scientifica dell’intera disciplina.
3.1.2.2 Diederik Stapel e la fabbrica dei dati
Pochi mesi dopo, la comunità psicologica olandese fu scossa da uno scandalo senza precedenti. Diederik Stapel, professore presso l’Università di Tilburg e figura di spicco della psicologia sociale europea, fu accusato di aver falsificato i dati di decine di studi pubblicati nell’arco di oltre un decennio.
I suoi studi erano affascinanti e controintuitivi: l’ambiente disordinato aumenta il razzismo, mangiare carne rende più antisociali e la discriminazione danneggia le prestazioni cognitive delle minoranze. Studi eleganti, risultati chiari e pubblicazioni su riviste prestigiose. C’era solo un problema: i dati non esistevano. Stapel li aveva inventati di sana pianta, spesso senza nemmeno reclutare i partecipanti che dichiarava di avere testato.
La commissione d’inchiesta scoprì che la frode era iniziata fin dai tempi del dottorato e si era protratta per quasi vent’anni. Cinquantotto articoli furono ritirati. Ma la domanda più inquietante era un’altra: come aveva potuto andare avanti così a lungo? Come era possibile che nessuno, collaboratori, revisori o editori, si fosse accorto di nulla?
La risposta era semplice e terribile: nessuno controllava. Il sistema si basava sulla fiducia e la fiducia era stata tradita.
3.1.3 Atto terzo: il verdetto (2015)
Dopo gli shock del 2011, la comunità psicologica reagì in modi diversi. Alcuni minimizzarono il problema, parlando di “casi isolati”, altri difesero le pratiche esistenti, mentre un gruppo minoritario ma determinato colse l’occasione per avviare una riflessione metodologica radicale.
Brian Nosek, psicologo dell’Università della Virginia, guidò quest’ultimo fronte. Nel 2012 fondò l’Open Science Collaboration (OSC), un progetto senza precedenti che prevedeva la replicazione sistematica di 100 studi pubblicati sulle tre riviste di psicologia più prestigiose. L’obiettivo non era quello di selezionare lavori deboli, ma di campionare la produzione scientifica ordinaria della disciplina, considerata la più solida (Nosek et al., 2012).
Il progetto coinvolse oltre 270 ricercatori in tutto il mondo. La metodologia adottata fu rigorosa: gli autori originali furono consultati per garantire che le repliche fossero fedeli; le dimensioni campionarie furono aumentate per assicurare una potenza statistica adeguata e tutti i protocolli furono preregistrati per evitare aggiustamenti post hoc.
I risultati, pubblicati su Science nel 2015, furono un terremoto epistemologico: solo il 36% degli studi replicati produsse risultati statisticamente significativi. In psicologia sociale la percentuale crollava addirittura al 25%. Anche laddove gli effetti venivano replicati, le loro dimensioni medie risultavano dimezzate rispetto agli originali. Se gli effetti originari fossero stati reali, il tasso di replicabilità atteso (cioè la percentuale di studi che si sarebbero replicati) sarebbe stato dell’89%. Il divario tra aspettativa e realtà tra aspettativa teorica e realtà empirica costituiva un atto d’accusa devastante contro decenni di pratiche di ricerca consolidate (Collaboration, 2015).
3.2 Le storie dietro i numeri
Le statistiche aggregate raccontano solo una parte della storia. Per comprendere le radici profonde della crisi, è necessario passare dalle meta-analisi ai casi individuali, alle storie concrete dei ricercatori, alle pressioni istituzionali e agli incentivi distorti. Qui esaminiamo due esempi paradigmatici.
3.2.1 Il crollo dell’ego depletion
Per oltre un decennio, la teoria dell’“esaurimento dell’ego” è stata un pilastro della psicologia sociale. La metafora, introdotta da Roy Baumeister negli anni Novanta, era potente e intuitiva: l’autocontrollo funzionerebbe come un muscolo, che dopo uno sforzo si affatica, compromettendo la nostra capacità di resistere a tentazioni successive.
Centinaia di studi sembravano confermare questa teoria e le meta-analisi più autorevoli riportavano un effetto medio robusto. Il concetto varcò i confini accademici, diventando un luogo comune in manuali, TED Talk e saggi divulgativi.
Poi, con l’avvento della crisi della replicabilità, il castello ha cominciato a scricchiolare. I progetti “Many Labs”, progettati per garantire la massima potenza statistica e la massima trasparenza metodologica, fallirono sistematicamente nel replicare l’effetto, ottenendo risultati prossimi allo zero.
Come ha potuto un fenomeno così “solido” dissolversi? La spiegazione risiede in una combinazione sistematica di distorsioni: gli studi originali utilizzavano spesso campioni di piccole dimensioni e un’elevata flessibilità analitica, esplorando i dati finché non emergeva un risultato significativo. A ciò si aggiungeva un potente bias di pubblicazione che selezionava per le riviste solo gli esperimenti riusciti. Le meta-analisi, aggregando una letteratura già contaminata, non fecero altro che cristallizzare e amplificare un’illusione statistica. L’ego depletion non era forse un fenomeno inesistente, ma la sua reale entità era stata ingigantita ben oltre l’evidenza empirica, rivelando le crepe di un sistema scientifico che per anni aveva premiato il risultato sorprendente più della rigorosa verificabilità.
3.2.2 Il food lab della Cornell University: quando l’incentivo distorce il metodo
Brian Wansink ha diretto il Food and Brand Lab della Cornell University, un centro di ricerca all’avanguardia nello studio dei fattori ambientali che influenzano il comportamento alimentare. Le sue scoperte sono diventate paradigmi diffusi: un piatto più grande incoraggia a mangiare di più, le ciotole a riempimento automatico aggirano il senso di sazietà e attribuire un nome “esotico” a un piatto ne esalta il sapore percepito.
Nel 2017, tuttavia, un gruppo di ricercatori indipendenti passò al setaccio i suoi dataset pubblicati, scoprendo un quadro scioccante: più di 150 anomalie statistiche in un numero ristretto di articoli. Sono emersi numeri incongruenti, errori metodologici ricorrenti e pattern di dati atipici, indizi di una possibile manipolazione sistematica dei risultati. La Cornell University ha avviato un’indagine interna che ha portato all’accertamento di “cattiva condotta scientifica” da parte di Wansink, con il ritiro di diciotto suoi articoli e le sue dimissioni nel 2018.
Questa vicenda svela una verità fondamentale: il confine tra “flessibilità analitica” e frode scientifica è spesso sfumato e permeabile. A differenza di Diederik Stapel, che fabbricava dati inesistenti, Wansink operava in una zona grigia metodologica, testando ipotesi multiple a posteriori, eliminando selettivamente i dati anomali e affinando i criteri analitici fino a ottenere un risultato pubblicabile. Un sistema accademico ossessionato dalle pubblicazioni e dalla visibilità mediatica lo aveva acclamato per anni, prima che l’intera impalcatura crollasse sotto il peso della trasparenza e del rigore metodologico.
3.3 Perché è successo
Nel manuale abbiamo già esaminato le cause strutturali: la pressione del “publish or perish”, il bias di pubblicazione, le pratiche di ricerca discutibili e i limiti intrinseci del test di significatività statistica. Qui, invece, esamineremo una riflessione più personale che, partendo dal livello istituzionale, scende fino all’esperienza del singolo ricercatore.
La crisi di replicabilità non è il risultato di “cattivi scienziati”. La stragrande maggioranza dei ricercatori coinvolti in studi poi non replicabili erano persone in buona fede che cercavano di fare buona scienza all’interno di un sistema dagli incentivi distorti. Il problema non era, o non era principalmente, una questione di etica individuale. Era un problema sistemico.
Immagina di essere un ricercatore precario. Il tuo contratto scade tra due anni. Per ottenere una posizione stabile, devi pubblicare su riviste prestigiose. Per riuscirci, sono necessari risultati statisticamente “significativi”. Come sai, i risultati nulli hanno scarse possibilità. Hai un dataset che, analizzato in modo standard, produce un valore-\(p\) = 0.06, appena sopra la fatidica soglia di “significatività statistica”. Sai anche che, con qualche scelta analitica giustificabile, ovvero escludendo un outlier “sospetto”, controllando per una covariata aggiuntiva o cambiando lievemente il modello, quel valore-\(p\) potrebbe scendere a 0.04. Non stai falsificando i dati. Stiamo parlando di scelte metodologiche plausibili. Scelte che, però, convergono sistematicamente verso l’unico esito che il sistema premia: la significatività statistica.
Questa è l’essenza della “zona grigia” delle QRPs. Non si tratta di frode dichiarata, ma neanche di scienza rigorosa e trasparente. Quando centinaia di ricercatori, sotto le stesse pressioni, adottano le stesse flessibilità, l’effetto aggregato è una letteratura scientifica satura di falsi positivi e di effetti la cui entità viene sistematicamente sovrastimata.
3.3.1 Il paradosso di Meehl: quando tutto è “significativo”, nulla lo è
Già negli anni ’70, lo psicologo Paul Meehl aveva individuato con lucidità le profonde contraddizioni del paradigma dominante. In un esperimento concettuale illuminante, analizzò un dataset enorme, relativo a oltre 57000 studenti delle scuole superiori del Minnesota, incrociando una moltitudine di variabili (religione, hobby, ordine di nascita, aspirazioni future, ecc.). Considerò 990 coppie di variabili. Il risultato fu sorprendente: il 92% delle correlazioni risultò statisticamente significativo (Meehl, 2012).
L’intuizione di Meehl, però, andava ben oltre l’aneddoto. Il suo vero punto era metodologico: con campioni molto grandi e un numero elevato di confronti, qualcosa di “significativo” si trova quasi sempre per puro caso. La significatività statistica, svincolata da una forte teoria predittiva e da un contesto interpretativo, diventa una metrica vuota. La significatività statistica, dunque, non garantisce la rilevanza sostanziale o la robustezza di un risultato scientifico.
Tuttavia, l’intero ecosistema della ricerca, costituito da riviste, finanziatori e università, aveva ormai ancorato la propria autorevolezza a quella stessa metrica. Il paradosso denunciato da Meehl era tragico e sistemico: si stava abusando di uno strumento che, nell’uso comune, funzionava da macchina perfetta per produrre rumore statistico e scoperte spurie. Il fallimento collettivo nell’ascoltare questo monito avrebbe, qualche decennio dopo, costretto la psicologia a pagare un prezzo altissimo in termini di credibilità.
3.4 Vedere la crisi in azione
Le discussioni teoriche sono importanti, ma niente può sostituire l’esperienza diretta. Ora, con una simulazione, vediamo come le pratiche problematiche possano generare falsi positivi.
3.4.1 Il valore-\(p\) ballerino
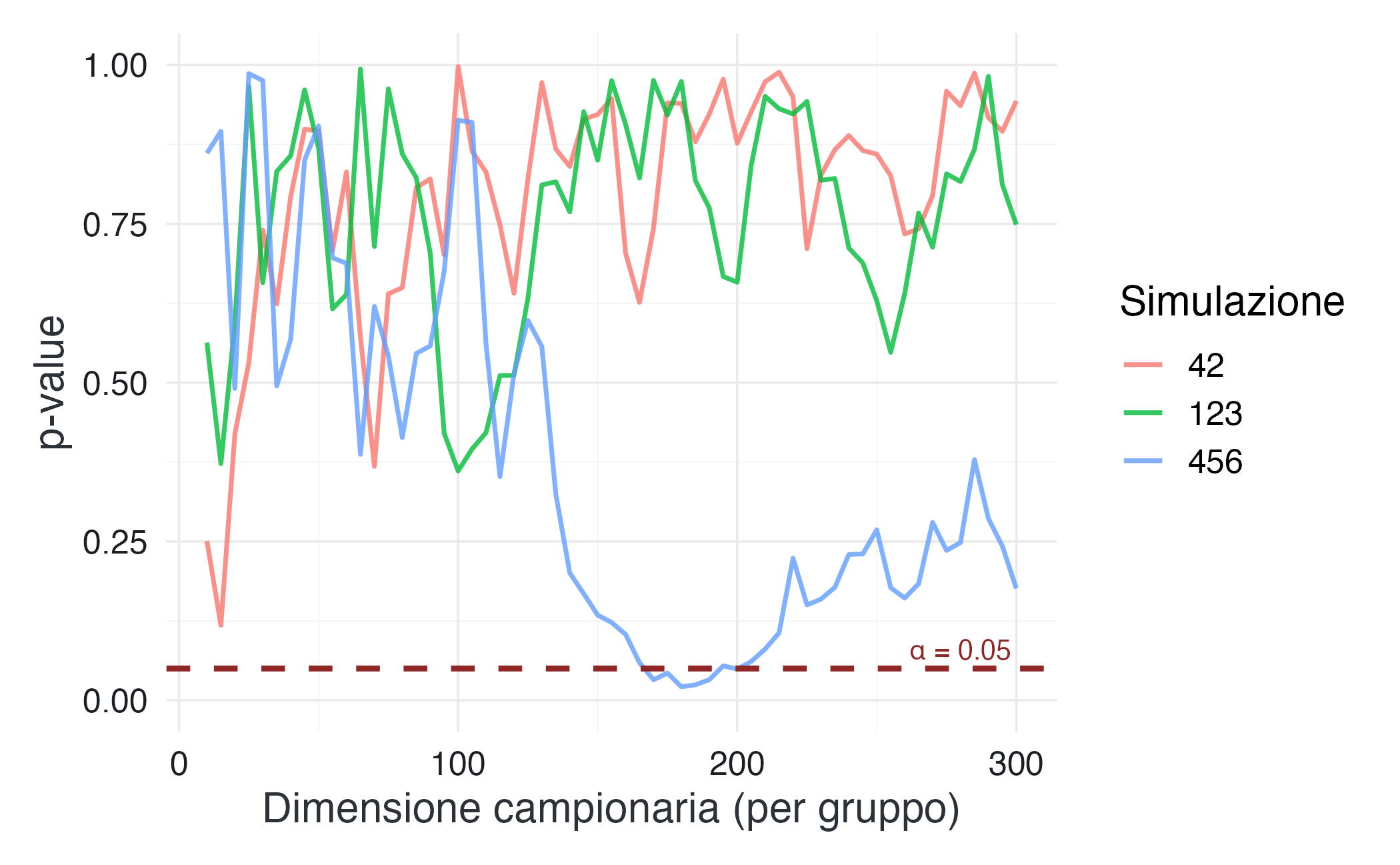
Immagina di confrontare due gruppi estratti dalla stessa popolazione (quindi, per definizione, non ci sono differenze reali). Cosa succede al valore-\(p\) mentre aumenti progressivamente la dimensione del campione?
simulate_p_trajectory<-function(seed, max_n=300){set.seed(seed)# Due campioni dalla STESSA distribuzionefull_sample1<-rnorm(max_n, mean =0, sd =2)full_sample2<-rnorm(max_n, mean =0, sd =2)# Calcola p-value per dimensioni campionarie crescentisample_sizes<-seq(10, max_n, by =5)p_values<-sapply(sample_sizes, function(n){t.test(full_sample1[1:n], full_sample2[1:n], var.equal =TRUE)$p.value})data.frame(n =sample_sizes, p =p_values, seed =factor(seed))}# Genera tre traiettorie diversetrajectories<-do.call(rbind, lapply(c(42, 123, 456), simulate_p_trajectory))ggplot(trajectories, aes(x =n, y =p, color =seed))+geom_line(linewidth =0.8, alpha =0.8)+geom_hline(yintercept =0.05, linetype ="dashed", color ="#8f2727", linewidth =1)+annotate("text", x =280, y =0.08, label ="α = 0.05", color ="#8f2727", size =3.5)+scale_y_continuous(limits =c(0, 1))+labs( x ="Dimensione campionaria (per gruppo)", y ="p-value", color ="Simulazione")
Figura 3.1: L’andamento del valore-\(p\) aumentando la dimensione campionaria. I dati provengono dalla stessa popolazione, quindi non esiste alcuna differenza reale. Eppure il valore-\(p\) oscilla, e occasionalmente scende sotto la soglia di 0.05.
Osserva la Figura 3.1: il valore-\(p\) non converge ordinatamente verso 1, come ci si aspetterebbe in assenza di un effetto reale. Al contrario, fluttua in modo erratico. In alcune esecuzioni della simulazione, attraversa ripetutamente la soglia di 0.05, talvolta per pochi dati, altre volte più a lungo.
Ora immagina un ricercatore che adotta l’optional stopping: raccoglie i dati in modo sequenziale, calcola ripetutamente il valore-\(p\) e decide di interrompere la raccolta proprio nel momento in cui il risultato diventa “statisticamente significativo”. Con questa strategia, prima o poi il successo è garantito, anche quando si parte da un’ipotesi completamente falsa. Il valore-\(p\) non diventa mai una misura affidabile dell’evidenza, ma piuttosto il bersaglio mobile di una caccia in cui il momento dell’arresto determina l’esito.
3.4.2 Cosa ci dice l’approccio bayesiano
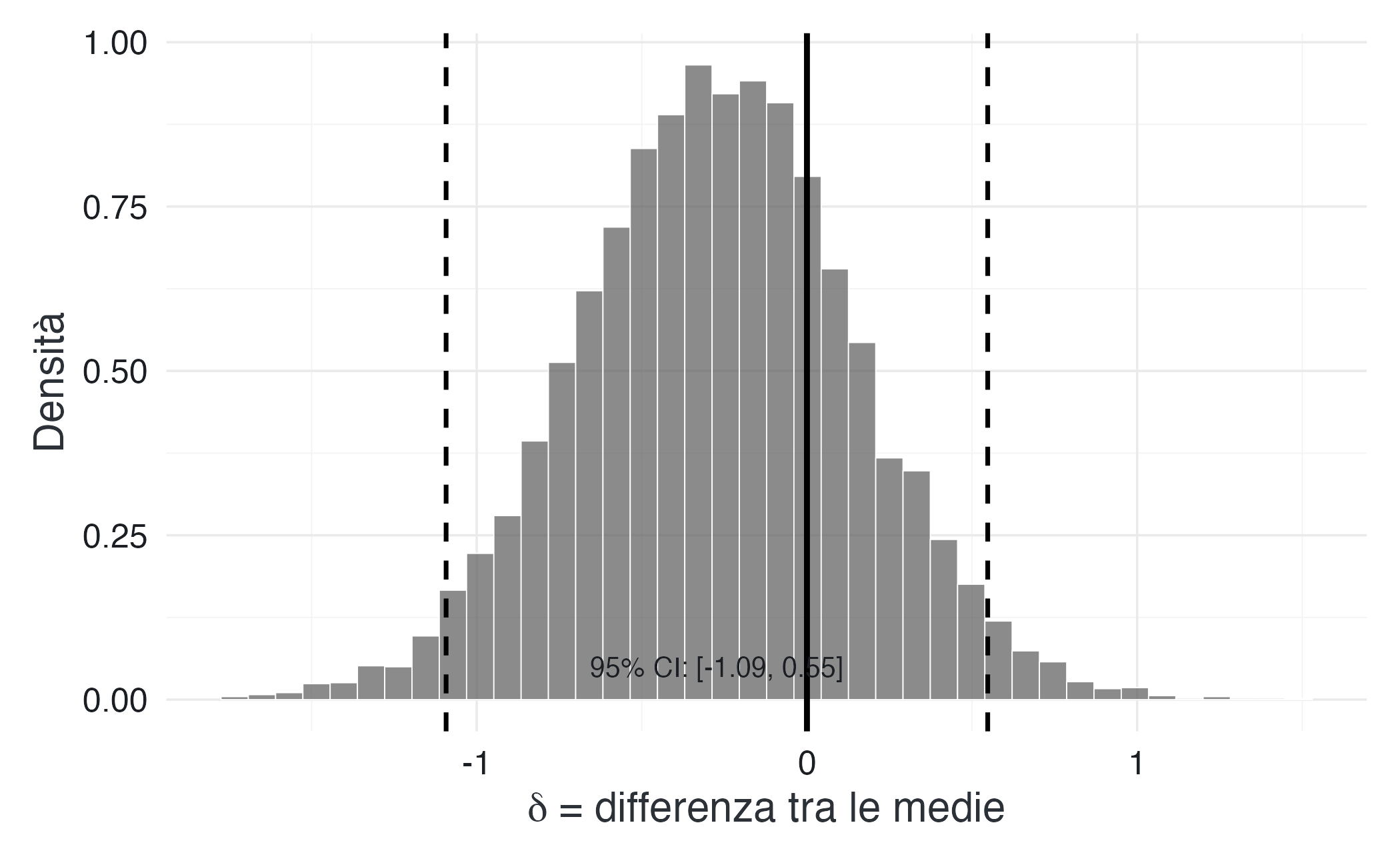
Analizziamo gli stessi dati con un modello bayesiano. La domanda è: qual è la distribuzione plausibile della differenza tra le medie dei due gruppi?
delta_draws<-fit$draws(variables ="delta", format ="df")$deltaci_95<-quantile(delta_draws, probs =c(0.025, 0.975))ggplot(data.frame(delta =delta_draws), aes(x =delta))+geom_histogram(aes(y =after_stat(density)), bins =40, alpha =0.7, color ="white")+geom_vline(xintercept =0, linetype ="solid", linewidth =1)+geom_vline(xintercept =ci_95, linetype ="dashed", linewidth =0.8)+annotate("text", x =mean(ci_95), y =0.05, label =sprintf("95%% CI: [%.2f, %.2f]", ci_95[1], ci_95[2]), size =3.5)+scale_color_qualitative()+labs( x =expression(delta~"= differenza tra le medie"), y ="Densità")
Figura 3.2: Distribuzione a posteriori della differenza tra le medie (δ). L’intervallo di credibilità al 95% include comodamente lo zero, suggerendo che non c’è evidenza di una differenza sostanziale.
L’intervallo di credibilità al 95% per δ va da -1.09 a 0.55. Poiché tale intervallo comprende lo zero, possiamo affermare che, alla luce dei dati e delle assunzioni a priori, non c’è evidenza di una differenza rilevante tra i due gruppi.
Questo risultato è coerente con il modo in cui i dati sono stati generati (stessa distribuzione di origine). Tuttavia, osserva come cambia la comunicazione statistica rispetto al paradigma tradizionale:
Frequentista: “Il valore-\(p\) è 0.03 → rifiuto l’ipotesi nulla” (decisione binaria, sensibile al campionamento e alle soglie arbitrarie).
Bayesiano: “La distribuzione a posteriori di δ è concentrata attorno a zero, con ampia incertezza” (descrizione continua dell’evidenza e della sua incertezza).
L’inferenza bayesiana non rende la ricerca immune da errori o interpretazioni scorrette. Ciò che cambia è il linguaggio dell’incertezza: invece di costringerci a fornire una risposta sì/no basata su un valore di soglia, ci permette di esprimere il nostro livello di incertezza, la direzione e l’intensità di quest’ultima. Un modello non prende decisioni al posto nostro, ma ci offre una rappresentazione più fedele della conoscenza che i dati ci permettono di ottenere e dei suoi limiti.
3.5 Oltre la crisi: verso una nuova cultura scientifica
La crisi di replicabilità ha avuto almeno un merito innegabile: ha costretto la psicologia a un doloroso, ma necessario, esame di coscienza collettivo. Da questo confronto è nata una rivoluzione della credibilità (credibility revolution) che sta lentamente, ma inesorabilmente, riscrivendo le regole della disciplina.
3.5.1 I progressi tangibili
Rispetto al panorama di un decennio fa, il cambiamento è già evidente:
La condivisione aperta di dati e codice, prerequisito per la riproducibilità analitica, non è più un’opzione ma un requisito. Essa abilita il controllo indipendente e rende la conoscenza veramente cumulativa.
I progetti di ricerca multi-lab (Many Labs, Many Babies, Psychological Science Accelerator) dimostrano che la collaborazione su larga scala può produrre evidenze più solide e generalizzabili, superando i limiti dei singoli laboratori.
La preregistrazione sta diventando una pratica consolidata. Sebbene non sia una soluzione miracolosa, riduce drasticamente il margine per il p-hacking e per costruire narrazioni ad hoc a partire dai risultati ottenuti.
I Registered Reports hanno ribaltato la logica della pubblicazione. Il merito scientifico viene valutato nella fase di progettazione, prima ancora che i dati vengano raccolti. Questo sgancia l’accettazione dal risultato finale, neutralizzando alla radice il bias di pubblicazione.
3.5.2 Le sfide aperte
Tuttavia, la trasformazione è ancora incompleta. I sistemi di incentivi accademici evolvono lentamente, la pressione a pubblicare rimane intatta e l’adozione di queste pratiche virtuose non è ancora uniforme.
La sfida più profonda, però, è concettuale: non basta adottare nuove procedure se non cambia il framework con cui interpretiamo l’evidenza. L’approccio bayesiano, che costituirà la bussola delle prossime sezioni, offre un linguaggio logicamente più coerente per quantificare l’incertezza e aggiornare le nostre credenze alla luce dei dati. Tuttavia, richiede un investimento in formazione, strumenti computazionali e nuove abitudini cognitive.
Questo investimento è necessario. Il criterio ultimo, infatti, non è l’ortodossia di un metodo in astratto, ma la sua utilità concreta: ci aiuta a capire la mente umana? Permette di costruire una conoscenza che si accumula invece di disperdersi? Genera risultati affidabili e verificabili?
La crisi ha messo in luce che, per lungo tempo, le risposte a queste domande sono state deludenti. L’obiettivo di questo companion è fornirti gli strumenti per immaginare e costruire un futuro diverso, un futuro in cui queste risposte possano essere, in modo replicabile e motivato, affermative.
3.6 Per approfondire
NotaRisorse consigliate
Pennington (2023) — Testo di riferimento adottato per questo capitolo.
Collaboration (2015) — Risultati completi del Reproducibility Project.
Simmons et al. (2011) — Articolo seminale sulle pratiche di ricerca flessibili.
Retraction Watch — Database aggiornato delle ritrattazioni scientifiche.
Data Colada — Blog di Uri Simonsohn e collaboratori sulla metodologia della ricerca.
Collaboration, O. S. (2015). Estimating the reproducibility of psychological science. Science, 349(6251), aac4716.
Ioannidis, J. P. (2005). Why most published research findings are false. PLoS medicine, 2(8), e124.
Meehl, P. E. (2012). Why summaries of research on psychological theories are often uninterpretable. In Improving inquiry in social science (pp. 13–59). Routledge.
Nosek, B. A., Spies, J. R., & Motyl, M. (2012). Scientific utopia: II. Restructuring incentives and practices to promote truth over publishability. Perspectives on Psychological Science, 7(6), 615–631.
Pennington, C. (2023). A student’s guide to open science: Using the replication crisis to reform psychology. McGraw-Hill Education (UK).
Simmons, J. P., Nelson, L. D., & Simonsohn, U. (2011). False-positive psychology: Undisclosed flexibility in data collection and analysis allows presenting anything as significant. Psychological science, 22(11), 1359–1366.