here::here("code", "_common.R") |>
source()
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(cmdstanr, posterior, loo, bayesplot, brms, ggplot2, dplyr, tibble, forcats, MASS, tidyr, bridgesampling)
conflicts_prefer(posterior::ess_bulk)
conflicts_prefer(posterior::ess_tail)
conflicts_prefer(loo::loo)
conflicts_prefer(brms::ar)
conflicts_prefer(MASS::area)
conflicts_prefer(bridgesampling::bf)
conflicts_prefer(dplyr::count)
conflicts_prefer(dplyr::dim_desc)
conflicts_prefer(brms::dstudent_t)
conflicts_prefer(tidyr::extract)
conflicts_prefer(stats::fisher.test)
conflicts_prefer(stats::lag)
conflicts_prefer(posterior::match)
conflicts_prefer(brms::pstudent_t)
conflicts_prefer(brms::qstudent_t)
conflicts_prefer(brms::rstudent_t)
conflicts_prefer(bayesplot::theme_default)46 Valutare e confrontare i modelli bayesiani: dal Bayes Factor alla LOO/ELPD
Introduzione
Confrontare modelli è un passaggio cruciale di ogni analisi scientifica: significa chiedersi quale, tra ipotesi concorrenti, descriva meglio i dati disponibili e, soprattutto, quale offra previsioni più accurate per nuove osservazioni. Nei capitoli precedenti abbiamo introdotto la procedura del ΔELPD come strumento per quantificare la differenza di accuratezza predittiva tra modelli. Questo approccio, basato sulla Leave-One-Out Cross Validation (LOO-CV) e sull’Expected Log Predictive Density (ELPD), ci ha permesso di valutare i modelli in termini di capacità predittiva fuori campione, ponendo l’accento su un criterio pragmatico e interpretabile.
In questo capitolo mettiamo a confronto il ΔELPD con un metodo alternativo e tradizionalmente molto diffuso nella statistica bayesiana: il Bayes Factor (BF). Il BF si basa sul confronto delle marginal likelihoods dei modelli, ossia sulla probabilità complessiva che ciascun modello assegna ai dati osservati, integrata rispetto alla distribuzione a priori dei parametri.
Attraverso due esempi simulati illustreremo i punti di forza e i limiti di questi due approcci. Nel primo scenario mostreremo come LOO/ΔELPD identifichi correttamente il modello più complesso quando l’effetto da stimare è effettivamente presente. Nel secondo scenario, in cui l’effetto è nullo, vedremo invece come LOO/ΔELPD restituisca un verdetto stabile, mentre il Bayes Factor risenta in misura considerevole della scelta delle prior, arrivando a produrre conclusioni opposte a seconda della loro specificazione.
L’obiettivo del capitolo è dunque duplice: da un lato chiarire le differenze concettuali tra Bayes Factor e ΔELPD, dall’altro motivare, dal punto di vista metodologico, perché nella pratica della ricerca psicologica sia preferibile adottare criteri predittivi come LOO/ΔELPD per il confronto tra modelli.
Panoramica del capitolo
- Introdurre il Bayes Factor come criterio alternativo di confronto tra modelli.
- Valutare gli effetti della scelta delle prior sul Bayes Factor.
- Confrontare i risultati del BF con quelli ottenuti tramite ΔELPD/LOO.
ConsiglioPrerequisiti
- Nozioni di base su \(\Delta\) ELPD e LOO.
AttenzionePreparazione del Notebook
46.1 Interpretare la metrica del Bayes Factor
Il Bayes Factor (BF) esprime il rapporto tra le evidenze marginali di due modelli:
\[ BF_{10} = \frac{p(\text{dati} \mid M_1)}{p(\text{dati} \mid M_0)}. \] In altre parole, indica quante volte i dati sono più probabili sotto il modello (\(M_1\)) rispetto al modello (\(M_0\)).
46.1.1 Significato dei valori
- BF = 1 → Nessuna preferenza: i dati supportano in egual misura entrambi i modelli.
- BF > 1 → Evidenza a favore di (\(M_1\)).
- BF < 1 → Evidenza a favore di (\(M_0\)).
Per tradizione si usa la scala di Jeffreys (1998), sebbene vada intesa solo come guida qualitativa (si veda anche Lee & Wagenmakers, 2014):
| BF (o 1/BF) | Interpretazione |
|---|---|
| 1 – 3 | Evidenza debole |
| 3 – 10 | Evidenza moderata |
| 10 – 30 | Evidenza forte |
| > 30 | Evidenza molto forte |
In forma reciproca (ad esempio 1/BF), la stessa logica vale per l’altro modello.
46.1.2 Buone pratiche
- Analisi di sensibilità: il BF dipende fortemente dalle prior, quindi è essenziale mostrare come le conclusioni cambiano variando le specificazioni ragionevoli.
- Evitare soglie rigide: le categorie “debole/moderata/forte” sono euristiche, non regole assolute.
- Contestualizzare: l’interpretazione del BF deve sempre tener conto del disegno sperimentale, della qualità dei dati e delle ipotesi in gioco.
46.1.3 Perché usare il logaritmo
Il Bayes Factor può assumere valori estremamente grandi o molto vicini a zero. Per rendere le differenze più leggibili e stabili numericamente, si utilizza spesso il logaritmo:
- log(BF) in base naturale: interpretabile come differenza di log marginal likelihood.
- log10(BF) in base 10: indica gli “ordini di grandezza” a favore di un modello (es. log10(BF) = 2 significa 100 a 1).
Il logaritmo consente anche di rappresentare graficamente le evidenze in maniera più intuitiva, evitando scale distorte.
46.2 Scenario A — L’interazione tra ansia di tratto e periodo d’esame
Immaginiamo di voler studiare il livello di affetto negativo (NA) di un gruppo di studenti. Ogni studente viene misurato più volte prima e dopo un esame, e per ciascuno di essi conosciamo anche il punteggio di ansia di tratto (trait_z, standardizzato). L’ipotesi è che gli studenti con un’elevata ansia di tratto mostrino un aumento maggiore di NA durante il periodo dell’esame: in altre parole, ci si aspetta un’interazione tra post (pre/post esame) e trait_z.
46.2.1 Simulazione dei dati
set.seed(42)
# Parametri simulazione
N_id <- 120
n_pre <- 3
n_post <- 3
trait_by_id <- rnorm(N_id, mean = 0, sd = 1.2)
# Effetti veri
beta_0 <- 0.0
beta_1 <- 0.2 # effetto medio di post
beta_2 <- 0.5 # effetto trait
beta_3 <- 1.0 # interazione forte
sigma_e <- 0.5 # rumore residuo
# Random effects con correlazione
sd_u0 <- 0.6; sd_u1 <- 0.7; rho_u <- 0.5
Sigma_u <- matrix(c(sd_u0^2, rho_u*sd_u0*sd_u1,
rho_u*sd_u0*sd_u1, sd_u1^2), 2, 2)
U <- MASS::mvrnorm(N_id, mu = c(0,0), Sigma = Sigma_u)
u0 <- U[,1]; u1 <- U[,2]
# Dataset lungo
dat <- tidyr::expand_grid(
id = 1:N_id,
time = 1:(n_pre + n_post)
) %>%
mutate(
post = as.integer(time > n_pre),
trait_z = trait_by_id[id],
u0_id = u0[id],
u1_id = u1[id],
mu = beta_0 + beta_1*post + beta_2*trait_z + beta_3*post*trait_z +
u0_id + u1_id*post,
NA_score = rnorm(n(), mu, sigma_e)
)Abbiamo quindi un dataset con più osservazioni per ciascuno studente, dove l’interazione Post × Trait è davvero presente.
46.2.2 Due modelli a confronto
Il primo modello (M0) include solo gli effetti principali di post e trait_z e un’intercetta casuale per studente. Il secondo modello (M1) aggiunge l’interazione Post × Trait e consente un effetto casuale sulle pendenze per la variabile post.
priors_common <- c(
prior(student_t(3, 0, 2.5), class = "Intercept"),
prior(normal(0, 1), class = "b"),
prior(student_t(3, 0, 2.5), class = "sigma"),
prior(student_t(3, 0, 2.5), class = "sd")
)
# Modello M0
fit_M0 <- brm(
NA_score ~ 1 + post + trait_z + (1 | id),
data = dat, family = gaussian(),
prior = priors_common,
backend = "cmdstanr",
iter = 2000, warmup = 1000, chains = 4, cores = 4
)
# Modello M1
fit_M1 <- brm(
NA_score ~ 1 + post*trait_z + (1 + post | id),
data = dat, family = gaussian(),
prior = priors_common,
backend = "cmdstanr",
iter = 2000, warmup = 1000, chains = 4, cores = 4
)46.2.3 Confronto con LOO/ELPD
loo_M0 <- loo(fit_M0)
loo_M1 <- loo(fit_M1)
loo_compare(loo_M1, loo_M0)
#> elpd_diff se_diff
#> fit_M1 0.0 0.0
#> fit_M0 -340.1 20.0Il risultato mostra che M1 ha un ELPD più alto con una differenza superiore all’incertezza, il che significa che predice meglio i nuovi dati. Ciò è in linea con le nostre aspettative, dato che l’interazione è reale.
46.2.4 Visualizzare le differenze punto per punto
Possiamo guardare dove M1 vince su M0.
elpd_diff <- loo_M1$pointwise[,"elpd_loo"] - loo_M0$pointwise[,"elpd_loo"]
df_elpd <- dat %>%
mutate(
diff = elpd_diff,
postF = factor(post, labels = c("Pre-esame","Post-esame"))
)
ggplot(df_elpd, aes(x = trait_z, y = diff, color = postF)) +
geom_hline(yintercept = 0, linetype = 2) +
geom_point(alpha = 0.45) +
geom_smooth(se = FALSE, method = "loess") +
labs(x = "Ansia di tratto (z)", y = "Differenza ELPD (M1 - M0)",
color = "Periodo",
title = "M1 migliora la predizione") 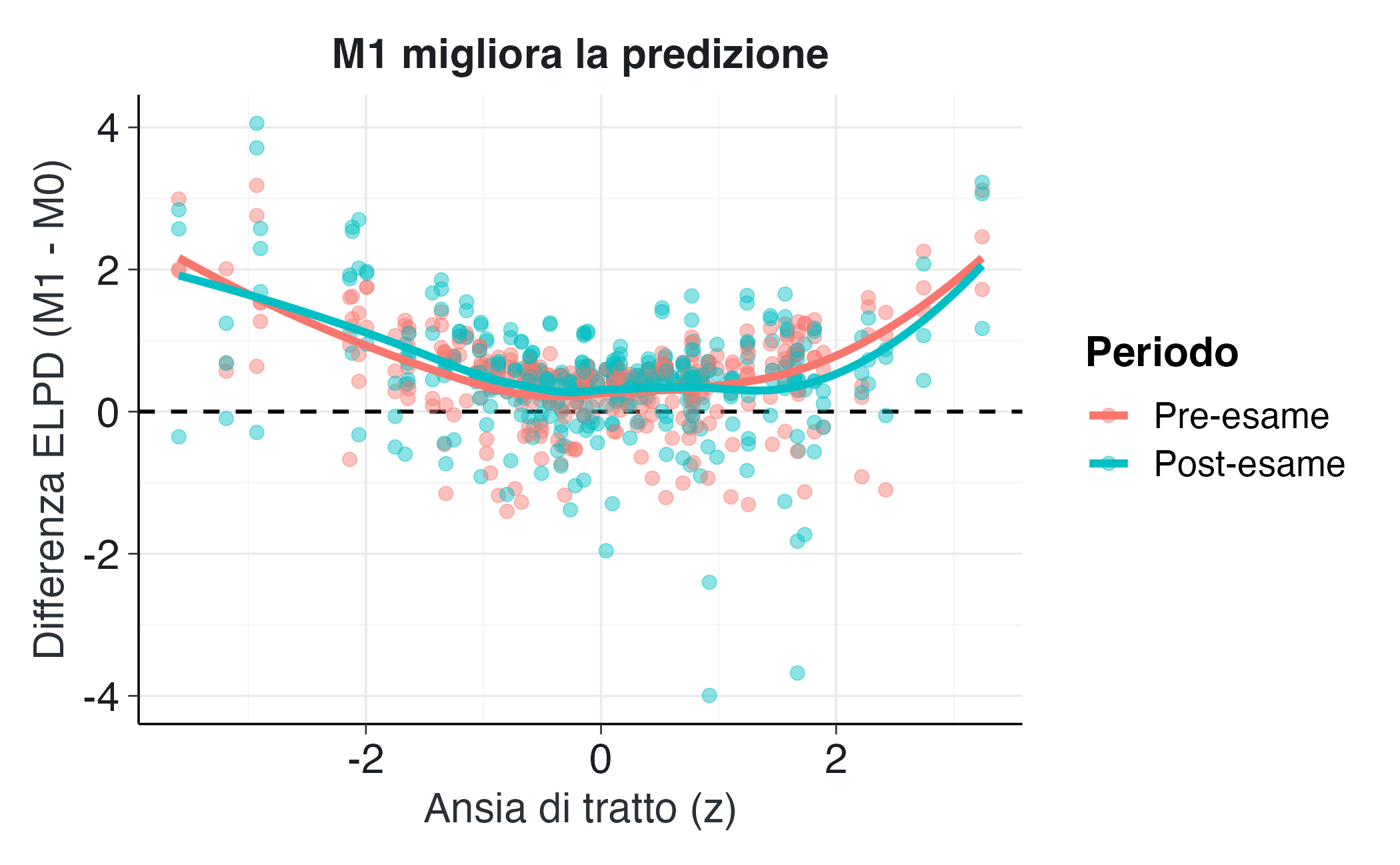
Il grafico mostra chiaramente che M1 ha un vantaggio rispetto a M0: la differenza ELPD (M1 - M0) tende a essere positiva per la maggior parte delle osservazioni.
46.3 Scenario B — Un predittore inutile
Per comprendere i limiti del Bayes Factor, consideriamo ora uno scenario in cui non esiste alcun effetto reale. Supponiamo di misurare l’effetto negativo NA_score come variabile casuale standard normale, e di registrare un predittore X (per esempio “ore di studio ieri”) che in realtà non ha alcuna relazione con NA_score.
set.seed(2025)
N <- 80
X <- scale(rnorm(N))
y <- rnorm(N, mean = 0, sd = 1)
dat_b <- tibble(NA_score = as.numeric(y), X = as.numeric(X))46.3.1 Due modelli
- M0: solo intercetta.
- M1: aggiunge X come predittore.
Stimiamo M1 con tre prior diverse su β_X: stretta (Normal(0,0.1)), media (Normal(0,1)), e larghissima (Normal(0,30)).
priors_base <- c(
prior(student_t(3, 0, 2.5), class = "Intercept"),
prior(student_t(3, 0, 2.5), class = "sigma")
)
fit_M0 <- brm(NA_score ~ 1, data = dat_b, family = gaussian(),
prior = priors_base,
backend = "cmdstanr",
iter = 3000, warmup = 1500, chains = 4, cores = 4)
fit_M1_tight <- brm(NA_score ~ 1 + X, data = dat_b, family = gaussian(),
prior = c(priors_base,
prior(normal(0, 0.1), class = "b", coef = "X")),
backend = "cmdstanr",
iter = 3000, warmup = 1500, chains = 4, cores = 4)
fit_M1_medium <- brm(NA_score ~ 1 + X, data = dat_b, family = gaussian(),
prior = c(priors_base,
prior(normal(0, 1), class = "b", coef = "X")),
backend = "cmdstanr",
iter = 3000, warmup = 1500, chains = 4, cores = 4)
fit_M1_wide <- brm(NA_score ~ 1 + X, data = dat_b, family = gaussian(),
prior = c(priors_base,
prior(normal(0, 30), class = "b", coef = "X")),
backend = "cmdstanr",
iter = 3000, warmup = 1500, chains = 4, cores = 4)46.3.2 Confronto con LOO
loo_M0 <- loo(fit_M0)
loo_M1_tight <- loo(fit_M1_tight)
loo_M1_medium <- loo(fit_M1_medium)
loo_M1_wide <- loo(fit_M1_wide)
loo_compare(loo_M0, loo_M1_tight, loo_M1_medium, loo_M1_wide)
#> elpd_diff se_diff
#> fit_M1_tight 0.0 0.0
#> fit_M0 0.0 0.4
#> fit_M1_wide -0.2 0.5
#> fit_M1_medium -0.2 0.4I risultati mostrano differenze minime e non robuste: nessun modello offre un vantaggio predittivo. In altre parole, includere X non migliora la previsione, a prescindere dalla prior.
46.3.3 Confronto con Bayes Factor
set.seed(123)
bs_M0 <- bridge_sampler(fit_M0, silent = TRUE)
bs_M1_tight <- bridge_sampler(fit_M1_tight, silent = TRUE)
bs_M1_medium <- bridge_sampler(fit_M1_medium, silent = TRUE)
bs_M1_wide <- bridge_sampler(fit_M1_wide, silent = TRUE)
BF_tight <- bayes_factor(bs_M1_tight, bs_M0)$bf
BF_medium <- bayes_factor(bs_M1_medium, bs_M0)$bf
BF_wide <- bayes_factor(bs_M1_wide, bs_M0)$bfc(BF_tight = BF_tight, BF_medium = BF_medium, BF_wide = BF_wide)
#> BF_tight BF_medium BF_wide
#> 0.97371 0.19455 0.0065746.3.4 Confronto con Bayes Factor
set.seed(123)
bs_M0 <- bridge_sampler(fit_M0, silent = TRUE)
bs_M1_tight <- bridge_sampler(fit_M1_tight, silent = TRUE)
bs_M1_medium <- bridge_sampler(fit_M1_medium, silent = TRUE)
bs_M1_wide <- bridge_sampler(fit_M1_wide, silent = TRUE)
BF_tight <- bayes_factor(bs_M1_tight, bs_M0)$bf
BF_medium <- bayes_factor(bs_M1_medium, bs_M0)$bf
BF_wide <- bayes_factor(bs_M1_wide, bs_M0)$bfc(BF_tight = BF_tight, BF_medium = BF_medium, BF_wide = BF_wide)
#> BF_tight BF_medium BF_wide
#> 0.97371 0.19455 0.00657I risultati evidenziano una forte sensibilità del Bayes Factor alla varianza della distribuzione a priori scelta per il coefficiente di X. In particolare:
- ** on prior molto strette (informative)** il BF risulta vicino a 1, il che significa che i dati non forniscono un’evidenza sostanziale a favore di nessuno dei due modelli;
-
Con prior di ampiezza intermedia il BF tende già a favorire M0, suggerendo l’assenza dell’effetto di
X; - con prior larghissime (debolmente informative) il BF diventa estremo a favore di M0, segnalando un supporto “decisivo” per il modello nullo, pur in assenza di un reale miglioramento predittivo.
Questa progressione riflette direttamente il principio del rasoio di Occam, implementato nel Bayes Factor attraverso la cosiddetta Occam penalty. La marginal likelihood infatti penalizza i modelli che, a causa di prior molto ampie, allocano massa di probabilità su regioni dello spazio dei parametri non supportate dai dati. In questi casi il verdetto del BF è influenzato maggiormente dalla scelta della prior che dall’evidenza empirica, anche quando la capacità predittiva dei modelli a confronto rimane sostanzialmente identica.
46.3.5 Visualizzazione
Per prima cosa, esaminiamo i valori di ELPD ottenuti per il modello M1 con tre diverse scelte di prior sul coefficiente della variabile X:
df_plot <- tibble(
prior = c("tight","medium","wide"),
elpd = c(loo_M1_tight$estimates["elpd_loo","Estimate"],
loo_M1_medium$estimates["elpd_loo","Estimate"],
loo_M1_wide$estimates["elpd_loo","Estimate"]),
bf = c(BF_tight, BF_medium, BF_wide)
)
df_plot
#> # A tibble: 3 × 3
#> prior elpd bf
#> <chr> <dbl> <dbl>
#> 1 tight -110. 0.974
#> 2 medium -110. 0.195
#> 3 wide -110. 0.00657Come si può notare, i valori di ELPD rimangono pressoché invariati a prescindere dall’ampiezza della prior. Ciò conferma che la valutazione predittiva tramite LOO/ELPD è robusta rispetto a questa scelta e restituisce un criterio stabile e direttamente interpretabile in termini di accuratezza predittiva fuori campione. Passiamo ora al Bayes Factor.
p2 <- ggplot(df_plot, aes(prior, log10(bf), group = 1)) +
geom_point(size = 3) + geom_line() +
labs(x = "Prior su β_X", y = "log10 BF (M1 vs M0)",
title = "Bayes Factor molto sensibile alla larghezza della prior")
p2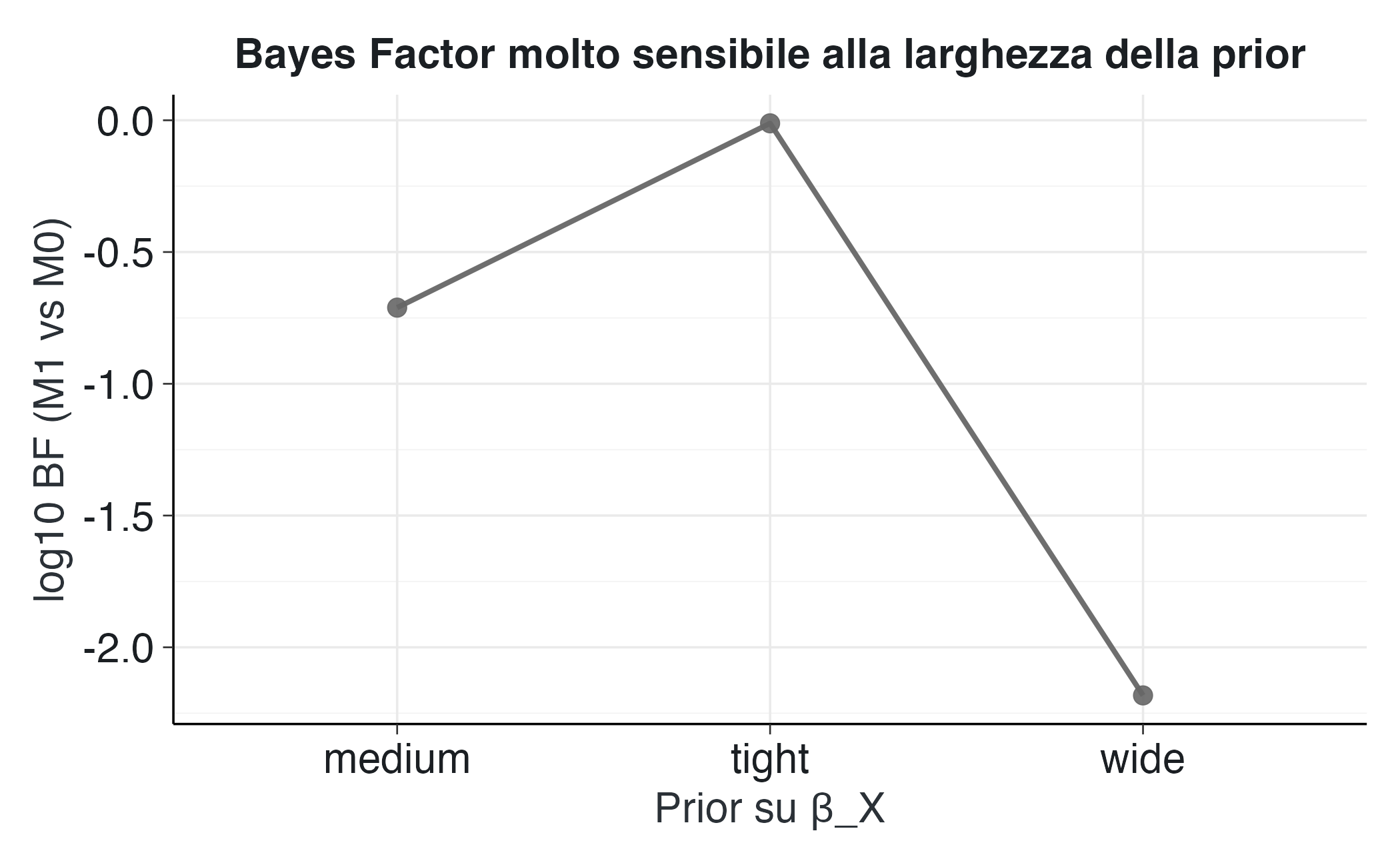
Il grafico mostra invece l’elevata sensibilità del Bayes Factor alla specificazione della distribuzione a priori. Basta modificare l’ampiezza della prior sul coefficiente di X per ottenere conclusioni radicalmente diverse:
Prior informativa (stretta). Con una distribuzione concentrata attorno a valori ridotti, il log10(BF) rimane vicino a zero. Ciò corrisponde a un Bayes Factor ≈ 1, ovvero a un verdetto di indifferenza: i due modelli sono sostanzialmente equivalenti rispetto ai dati.
-
Prior intermedia (media). Con una prior di ampiezza moderata, il Bayes Factor stimato è:
bf_medium <- df_plot %>% filter(prior == "medium") %>% pull(bf) bf_medium #> [1] 0.195In questo caso il log10(BF) è negativo, il che indica che l’evidenza si sposta verso M0, ma in misura meno estrema rispetto alla prior larga.
-
Prior vaga (larga). Con una distribuzione molto diffusa, che assegna probabilità non trascurabili anche a effetti di grande entità, il Bayes Factor stimato è:
bf_wide <- df_plot %>% filter(prior == "wide") %>% pull(bf) bf_wide #> [1] 0.00657Per interpretarlo:
- il logaritmo in base 10 (
log10(bf_wide)) fornisce il valore mostrato nel grafico; - il reciproco (
1 / bf_wide) indica quante volte M0 è considerato più plausibile di M1.
In questo caso, il reciproco restituisce 152.3, il che significa che, pur avendo una capacità predittiva sostanzialmente equivalente a M0, il modello M1 viene considerato circa 152.3 volte meno plausibile.
- il logaritmo in base 10 (
Questa analisi evidenzia un aspetto cruciale: il Bayes Factor non è un indicatore oggettivo, ma dipende in modo sostanziale dalle ipotesi a priori. La conclusione non deriva esclusivamente dai dati, ma è co-determinata dalla scelta della prior: una prior stretta porta a un giudizio di equivalenza, mentre una prior larga può generare una forte evidenza a favore del modello nullo.
Ne consegue una raccomandazione metodologica fondamentale: ogni analisi basata sul Bayes Factor dovrebbe essere accompagnata da un’accurata analisi di sensibilità, volta a verificare come le conclusioni cambino al variare di prior ragionevoli. In assenza di questa verifica, si rischia di scambiare un artefatto dovuto alle assunzioni a priori per un’evidenza empirica.
46.4 Riflessioni conclusive
Gli esempi discussi ci hanno permesso di considerare due scenari opposti e complementari.
- Quando l’effetto è reale (Scenario A), il confronto basato su LOO/ELPD premia il modello più complesso, riflettendo la sua superiore capacità predittiva.
- Quando l’effetto è nullo (Scenario B), LOO segnala correttamente l’equivalenza predittiva tra i modelli, mentre il Bayes Factor produce valutazioni fortemente divergenti a seconda della prior scelta, fino a giungere a conclusioni diametralmente opposte.
Da questa analisi emergono alcuni messaggi chiave di natura metodologica:
- Il Bayes Factor rappresenta uno strumento di importanza storica indiscutibile, ma la sua elevata sensibilità alle scelte a priori e l’instabilità nei modelli complessi ne limitano l’affidabilità pratica.
- L’ELPD stimato tramite LOO offre un criterio alternativo, basato sulla capacità predittiva fuori campione. Si tratta di una misura intuitiva, interpretabile e robusta, che negli ultimi anni si è affermata come standard nella pratica bayesiana.
- In ambito psicologico, caratterizzato da dati intrinsecamente rumorosi e da modelli spesso gerarchici o complessi, l’adozione sistematica del LOO/ELPD come strumento principale di confronto tra modelli appare la scelta metodologicamente più solida e raccomandabile (Kruschke & Liddell, 2018).
NotaInformazioni sull’ambiente di sviluppo
sessionInfo()
#> R version 4.5.1 (2025-06-13)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.0
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRblas.0.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] bridgesampling_1.1-2 MASS_7.3-65 forcats_1.0.1
#> [4] cmdstanr_0.9.0 ragg_1.5.0 tinytable_0.13.0
#> [7] withr_3.0.2 systemfonts_1.2.3 patchwork_1.3.2
#> [10] ggdist_3.3.3 tidybayes_3.0.7 bayesplot_1.14.0
#> [13] ggplot2_4.0.0 reliabilitydiag_0.2.1 priorsense_1.1.1
#> [16] posterior_1.6.1 loo_2.8.0 rstan_2.32.7
#> [19] StanHeaders_2.32.10 brms_2.23.0 Rcpp_1.1.0
#> [22] sessioninfo_1.2.3 conflicted_1.2.0 janitor_2.2.1
#> [25] matrixStats_1.5.0 modelr_0.1.11 tibble_3.3.0
#> [28] dplyr_1.1.4 tidyr_1.3.1 rio_1.2.4
#> [31] here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] gridExtra_2.3 inline_0.3.21 sandwich_3.1-1
#> [4] rlang_1.1.6 magrittr_2.0.4 multcomp_1.4-28
#> [7] snakecase_0.11.1 compiler_4.5.1 mgcv_1.9-3
#> [10] callr_3.7.6 vctrs_0.6.5 stringr_1.5.2
#> [13] pkgconfig_2.0.3 arrayhelpers_1.1-0 fastmap_1.2.0
#> [16] backports_1.5.0 labeling_0.4.3 utf8_1.2.6
#> [19] rmarkdown_2.30 ps_1.9.1 purrr_1.1.0
#> [22] xfun_0.53 cachem_1.1.0 jsonlite_2.0.0
#> [25] broom_1.0.10 parallel_4.5.1 R6_2.6.1
#> [28] stringi_1.8.7 RColorBrewer_1.1-3 lubridate_1.9.4
#> [31] estimability_1.5.1 knitr_1.50 zoo_1.8-14
#> [34] pacman_0.5.1 Matrix_1.7-4 splines_4.5.1
#> [37] timechange_0.3.0 tidyselect_1.2.1 abind_1.4-8
#> [40] yaml_2.3.10 codetools_0.2-20 processx_3.8.6
#> [43] curl_7.0.0 pkgbuild_1.4.8 lattice_0.22-7
#> [46] S7_0.2.0 coda_0.19-4.1 evaluate_1.0.5
#> [49] survival_3.8-3 RcppParallel_5.1.11-1 pillar_1.11.1
#> [52] tensorA_0.36.2.1 checkmate_2.3.3 stats4_4.5.1
#> [55] distributional_0.5.0 generics_0.1.4 rprojroot_2.1.1
#> [58] rstantools_2.5.0 scales_1.4.0 xtable_1.8-4
#> [61] glue_1.8.0 emmeans_1.11.2-8 tools_4.5.1
#> [64] data.table_1.17.8 mvtnorm_1.3-3 grid_4.5.1
#> [67] QuickJSR_1.8.1 colorspace_2.1-2 nlme_3.1-168
#> [70] cli_3.6.5 textshaping_1.0.3 svUnit_1.0.8
#> [73] Brobdingnag_1.2-9 V8_8.0.0 gtable_0.3.6
#> [76] digest_0.6.37 TH.data_1.1-4 htmlwidgets_1.6.4
#> [79] farver_2.1.2 memoise_2.0.1 htmltools_0.5.8.1
#> [82] lifecycle_1.0.4Bibliografia
Jeffreys, H. (1998). The theory of probability. OuP Oxford.
Kruschke, J. K., & Liddell, T. M. (2018). The Bayesian New Statistics: Hypothesis testing, estimation, meta-analysis, and power analysis from a Bayesian perspective. Psychonomic Bulletin & Review, 25(1), 178–206.
Lee, M. D., & Wagenmakers, E.-J. (2014). Bayesian cognitive modeling: A practical course. Cambridge university press.