here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(mice)3 Sintesi a posteriori
Introduzione
Nel manuale didattico abbiamo esaminato come costruire distribuzioni a posteriori integrando la conoscenza preliminare (prior) con i dati osservati mediante la funzione di verosimiglianza. Abbiamo analizzato questo processo in contesti semplici, come la stima di una proporzione attraverso il modello Beta-Binomiale, e ne abbiamo esplorato la generalizzazione grazie al concetto di famiglie coniugate. In questo approfondimento ci dedicheremo a un aspetto solo accennato nel testo principale: una volta ottenuta una distribuzione a posteriori, come possiamo sintetizzarla e comunicarla in modo efficace?
Il posterior non è un singolo numero, ma un’intera distribuzione che rappresenta la nostra incertezza sul parametro. Nella pratica della ricerca psicologica, tuttavia, dobbiamo spesso sintetizzare queste informazioni per presentarle nei risultati di un articolo o per confrontarle con altre stime. Questo capitolo è dedicato proprio a questa esigenza: mostreremo come ricavare quantità riassuntive (media, mediana, moda) e come costruire intervalli credibili che esprimano in modo trasparente i valori più plausibili.
L’obiettivo non è ridurre l’inferenza bayesiana alla ricerca di un punto o di un intervallo, ma imparare a comunicare l’incertezza in modo comprensibile, senza perdere la ricchezza informativa del posterior. Come vedremo, anche nei contesti più complessi, la capacità di sintetizzare correttamente le distribuzioni a posteriori è ciò che distingue un’analisi meramente tecnica da una presentazione scientifica chiara e convincente.
Panoramica del capitolo
- Distribuzione a posteriori = conoscenza aggiornata.
- Stime puntuali: MAP, media, mediana.
- Incertezza: varianza e deviazione standard.
- Intervalli di credibilità: simmetrici e HPD.
- Verifica di ipotesi: probabilità a posteriori.
AttenzionePreparazione del Notebook
3.1 Riepilogo numerico
La distribuzione a posteriori contiene in sé tutte le informazioni disponibili sui potenziali valori del parametro. Nel caso di un parametro unidimensionale o bidimensionale, possiamo rappresentare la distribuzione a posteriori mediante un grafico \(p(\theta \mid y)\). Tuttavia, quando ci troviamo di fronte a vettori di parametri con più di due dimensioni, risulta vantaggioso eseguire una sintesi numerica della distribuzione a posteriori. Possiamo distinguere due forme di sintesi numerica della distribuzione a posteriori: stima puntuale e intervallo di credibilità.
3.2 Stima puntuale
Nel contesto dell’inferenza bayesiana, stimare il valore più credibile di un parametro \(\theta\) a partire dalla distribuzione a posteriori può avvenire attraverso tre statistiche principali: moda, mediana e media. La scelta tra queste dipende dalla forma della distribuzione a posteriori. Queste statistiche forniscono una stima puntuale della tendenza centrale della distribuzione, ossia il valore a cui attribuiamo il massimo grado di fiducia soggettiva, basandoci sia sui dati osservati sia sulle credenze a priori.
Moda (Massimo a Posteriori, MAP)
La moda della distribuzione a posteriori, nota come stima di massimo a posteriori (MAP), corrisponde al valore del parametro \(\theta\) a cui è associata la massima densità di probabilità. Questo concetto rappresenta l’estensione bayesiana della classica stima di massima verosimiglianza (MLE), definita come:
\[ \hat{\theta}_{\text{ML}} = \arg \max_\theta L(\theta \mid y), \] dove \(L(\theta \mid y)\) è la funzione di verosimiglianza. Nell’approccio bayesiano, l’informazione a priori \(p(\theta)\) viene incorporata attraverso il teorema di Bayes, portando alla definizione della stima MAP:
\[ \hat{\theta}_{\text{MAP}} = \arg \max_\theta \, L(\theta \mid y) \, p(\theta). \] In altre parole, \(\hat{\theta}_{\text{MAP}}\) massimizza la densità a posteriori non normalizzata, combinando in modo esplicito l’evidenza empirica con la conoscenza pregressa.
3.2.0.1 Limitazioni della stima MAP
Nonostante l’interpretazione intuitiva, la stima MAP presenta alcune limitazioni di cui è importante essere consapevoli. In primo luogo, la sua determinazione può risultare computazionalmente impegnativa, specialmente quando la distribuzione a posteriori viene campionata mediante metodi MCMC: individuare con precisione il massimo in uno spazio di parametri ad alta dimensionalità o con forme complesse richiede tecniche specifiche e può essere instabile.
In secondo luogo, la bontà della stima MAP dipende fortemente dalla forma della distribuzione a posteriori. In presenza di asimmetrie marcate o di multimodalità, il massimo globale potrebbe non essere rappresentativo della regione di alta probabilità, soprattutto se associato a un picco stretto ma isolato, mentre la maggior parte della massa probabilistica si trova altrove.
Infine, il MAP è intrinsecamente meno robusto di altre statistiche centrali, come la media o la mediana a posteriori, in quanto basato esclusivamente sul valore di massimo densità, ignorando la forma complessiva della distribuzione. Ciò lo rende sensibile a variazioni nella parametrizzazione del modello e poco informativo riguardo all’incertezza complessiva sul parametro.
3.2.1 Media a posteriori
La media a posteriori rappresenta il valore atteso del parametro \(\theta\) rispetto alla sua distribuzione a posteriori. Formalmente, essa è definita come:
\[ \mathbb{E}[\theta \mid y] = \int \theta \, p(\theta \mid y) \, d\theta. \] Questa quantità costituisce una stima di \(\theta\) che tiene conto dell’intera distribuzione a posteriori, integrando su tutti i possibili valori del parametro. Una proprietà notevole della media a posteriori è quella di essere lo stimatore che minimizza l’errore quadratico medio (MSE) nella previsione di \(\theta\), il che ne giustifica l’ampio utilizzo in contesti di ottimizzazione statistica.
Tuttavia, in presenza di distribuzioni a posteriori marcatamente asimmetriche o con code pesanti, la media potrebbe non rappresentare adeguatamente la regione di massima densità di probabilità. In tali casi, valori estremi possono influenzare eccessivamente la stima, allontanando la media dalla zona in cui è concentrata la maggior parte della massa probabilistica. Per questo motivo, in situazioni di asimmetria pronunciata, altre statistiche come la mediana o la moda a posteriori possono offrire una rappresentazione più appropriata della tendenza centrale.
3.2.2 Mediana a posteriori
La mediana a posteriori è definita come il valore del parametro \(\theta\) che divide la distribuzione a posteriori in due parti di uguale probabilità: il 50% della massa probabilistica si trova al di sotto di tale valore e il restante 50% al di sopra. Formalmente, essa soddisfa la condizione:
\[ P(\theta \leq \hat{\theta}_{\text{med}} \mid y) = 0.5. \]
Rispetto alla media e alla moda a posteriori, la mediana offre una misura di tendenza centrale particolarmente robusta, in quanto poco sensibile alla presenza di valori estremi o code distributive pesanti. Questa proprietà la rende preferibile in contesti in cui la distribuzione a posteriori presenta marcate asimmetrie o è multimodale, situazioni in cui la media può essere distortta da valori anomali e la moda può risultare instabile o non unica. Grazie alla sua stabilità, la mediana a posteriori fornisce una rappresentazione più affidabile della posizione centrale del parametro quando la forma della distribuzione è irregolare, garantendo una sintesi inferenziale solida anche in condizioni di elevata variabilità o non normalità.
3.3 Misurare l’incertezza: varianza a posteriori
Oltre a individuare il valore più plausibile del parametro \(\theta\), è fondamentale quantificare l’incertezza residua associata alla nostra stima. A questo scopo, la varianza a posteriori fornisce una misura della dispersione dei valori di \(\theta\) attorno alla sua media, condizionatamente ai dati osservati \(y\). Formalmente, essa è definita come:
\[ \mathbb{V}(\theta \mid y) = \mathbb{E}\left[(\theta - \mathbb{E}[\theta \mid y])^2 \mid y \right] = \int (\theta - \mathbb{E}[\theta \mid y])^2 \, p(\theta \mid y) \, d\theta. \]
Un modo equivalente per calcolarla è attraverso l’identità:
\[ \mathbb{V}(\theta \mid y) = \mathbb{E}[\theta^2 \mid y] - \left(\mathbb{E}[\theta \mid y]\right)^2. \]
Per interpretare più facilmente l’incertezza nella stessa unità di misura del parametro \(\theta\), è utile considerare la deviazione standard a posteriori, data semplicemente dalla radice quadrata della varianza.
In conclusione, mentre la moda (MAP), la media e la mediana a posteriori forniscono diverse misure di tendenza centrale per la stima puntuale di \(\theta\), la varianza (e la deviazione standard) a posteriori ne quantificano l’affidabilità. La scelta tra le diverse statistiche dipende dalla forma della distribuzione a posteriori e dagli obiettivi dell’analisi. Nel loro insieme, questi indicatori consentono di comunicare in modo sintetico non solo la migliore stima del parametro, ma anche il grado di confidenza ad essa associato, elemento cruciale in qualsiasi processo inferenziale.
3.4 Intervallo di credibilità
Nell’inferenza bayesiana, l’intervallo di credibilità è uno strumento utilizzato per definire un intervallo che contiene una determinata percentuale della massa della distribuzione a posteriori del parametro \(\theta\). Questo intervallo riflette l’incertezza associata alla stima del parametro: un intervallo più ampio suggerisce una maggiore incertezza. Lo scopo principale dell’intervallo di credibilità è fornire una misura quantitativa dell’incertezza riguardante \(\theta\).
A differenza degli intervalli di confidenza frequentisti, non esiste un unico intervallo di credibilità per un dato livello di confidenza \((1 - \alpha) \cdot 100\%\). In effetti, è possibile costruire un numero infinito di tali intervalli. Per questo motivo, è necessario stabilire criteri aggiuntivi per selezionare l’intervallo di credibilità più appropriato. Tra le opzioni più comuni ci sono l’intervallo di credibilità simmetrico e l’intervallo di massima densità posteriore (HPD).
3.4.1 Intervallo di credibilità simmetrico
Questo tipo di intervallo è centrato rispetto al punto di stima puntuale. Se \(\hat{\theta}\) rappresenta la stima del parametro, l’intervallo simmetrico avrà la forma \((\hat{\theta} - a, \hat{\theta} + a)\), dove \(a\) è un valore positivo scelto in modo tale che la massa totale inclusa sia pari a \((1 - \alpha)\). Più formalmente, un intervallo di credibilità simmetrico al livello \(\alpha\) può essere espresso come:
\[ I_{\alpha} = [q_{\alpha/2}, q_{1 - \alpha/2}], \] dove \(q_z\) rappresenta il quantile \(z\) della distribuzione a posteriori. Ad esempio, un intervallo di credibilità simmetrico al 94% sarà:
\[ I_{0.06} = [q_{0.03}, q_{0.97}], \] dove il 3% della massa a posteriori si trova in ciascuna delle due code della distribuzione.
3.4.2 Intervallo di credibilità più stretto (intervallo di massima densità posteriore, HPD)
L’intervallo di massima densità posteriore (HPD) è l’intervallo più stretto possibile che contiene il \((1 - \alpha) \cdot 100\%\) della massa a posteriori. A differenza dell’intervallo simmetrico, l’HPD include tutti i valori di \(\theta\) che hanno la maggiore densità a posteriori. Per costruirlo, si disegna una linea orizzontale sulla distribuzione a posteriori e si regola l’altezza della linea in modo che l’area sotto la curva corrisponda a \((1 - \alpha)\). L’HPD risulta essere il più stretto tra tutti gli intervalli possibili per lo stesso livello di confidenza. Nel caso di una distribuzione a posteriori unimodale e simmetrica, l’HPD coincide con l’intervallo di credibilità simmetrico.
3.4.2.1 Interpretazione
Il calcolo degli intervalli di credibilità—in particolare dell’intervallo di massima densità posteriore (HPD)—richiede quasi sempre l’utilizzo di software statistici specializzati. Questo perché, nei modelli bayesiani con distribuzioni posteriori articolate o che richiedono simulazioni numeriche (ad esempio tramite Markov Chain Monte Carlo), ricavare a mano i confini dell’intervallo può risultare molto laborioso.
3.4.2.2 Incertezza nel paradigma frequentista
-
Parametro fisso: nel contesto frequentista, il parametro di interesse (ad esempio la media di popolazione \(\mu\)) è un valore costante ma sconosciuto.
-
Ripetizione ipotetica: immaginiamo di ripetere all’infinito il prelievo di campioni dalla popolazione. Per ciascun campione otteniamo una media \(\bar{x}\) e costruendo un intervallo di confidenza al \(100(1-\alpha)\%\) avremo che, nel lungo periodo, il \(100(1-\alpha)\%\) di questi intervalli conterrà il vero \(\mu\).
- Interpretazione del singolo intervallo: per un singolo intervallo calcolato, la probabilità che contenga effettivamente \(\mu\) è formalmente 0 o 1, perché \(\mu\) non è soggetto a variabilità stocastica—siamo semplicemente ignari del suo valore reale.
3.4.2.3 Incertezza nel paradigma bayesiano
-
Parametro come variabile aleatoria: qui \(\mu\) non è più un valore fisso, ma possiede una distribuzione di probabilità che riflette sia l’informazione a priori sia quella fornita dai dati osservati.
-
Campionamento dalla distribuzione a posteriori: grazie a tecniche di simulazione (ad es. MCMC), otteniamo un insieme di possibili valori di \(\mu\) che segue la distribuzione posteriore.
- Costruzione diretta dell’intervallo: scegliendo i quantili al \(2.5\%\) e al \(97.5\%\) di questa distribuzione, otteniamo un intervallo di credibilità al 95%. In termini intuitivi, possiamo affermare che «c’è una probabilità del 95% che \(\mu\) cada all’interno di questo intervallo, dati i dati e le ipotesi a priori».
3.4.2.4 Confronto e considerazioni
-
Frequentista: l’intervallo di confidenza è un costrutto legato alla frequenza di lungo periodo di un procedimento ipotetico di campionamento.
-
Bayesiano: l’intervallo di credibilità fornisce una misura puntuale dell’incertezza sul parametro, direttamente comprensibile come probabilità condizionata sui dati osservati.
- Intuizione: per molti, l’interpretazione bayesiana risulta più aderente al senso comune, perché traduce immediatamente il grado di fiducia che possiamo riporre nei valori ipotizzati per il parametro.
In sintesi, mentre la teoria frequentista quantifica l’affidabilità del metodo di stima nel lungo periodo, l’approccio bayesiano esprime senza ambiguità la probabilità attuale che il parametro si trovi in un certo intervallo, alla luce delle evidenze e delle conoscenze pregresse.
3.5 Verifica di ipotesi bayesiana
L’inferenza bayesiana può essere applicata anche nel contesto della verifica di ipotesi, in un approccio noto come verifica di ipotesi bayesiana. In questo tipo di inferenza, l’obiettivo è valutare la plausibilità che un parametro \(\theta\) assuma valori all’interno di un determinato intervallo. Ad esempio, possiamo voler sapere quanto è probabile che \(\theta\) sia maggiore di 0.5 o che rientri in un intervallo specifico, come [0.5, 1.0].
In questo approccio, si calcola la probabilità a posteriori che \(\theta\) si trovi all’interno dell’intervallo di interesse. Questa probabilità viene ottenuta integrando la distribuzione a posteriori su tale intervallo. Quindi, invece di rifiutare o accettare un’ipotesi come nel test di ipotesi frequentista, la verifica di ipotesi bayesiana fornisce una misura diretta della probabilità che un parametro rientri in un intervallo specifico, dato l’evidenza osservata e le informazioni a priori.
In altre parole, questo approccio consente di quantificare la nostra incertezza rispetto all’affermazione che \(\theta\) rientri in un certo intervallo, fornendo una probabilità che rappresenta direttamente la plausibilità di quell’ipotesi.
Esempio 3.1 Per illustrare l’approccio bayesiano, consideriamo i dati relativi ai punteggi del BDI-II (Beck Depression Inventory - Second Edition) di 30 soggetti clinici, come riportato nello studio condotto da Zetsche et al. (2019). Il BDI-II è uno strumento per valutare la gravità dei sintomi depressivi.
I punteggi del BDI-II per i 30 soggetti sono:
# Dati del BDI-II
bdi <- c(
26, 35, 30, 25, 44, 30, 33, 43, 22, 43,
24, 19, 39, 31, 25, 28, 35, 30, 26, 31,
41, 36, 26, 35, 33, 28, 27, 34, 27, 22
)
bdi
#> [1] 26 35 30 25 44 30 33 43 22 43 24 19 39 31 25 28 35 30 26 31 41 36 26 35 33
#> [26] 28 27 34 27 22Un punteggio BDI-II \(\geq 30\) indica un livello grave di depressione. Nel nostro campione, 17 pazienti su 30 manifestano un livello grave:
# Conteggio di depressione grave
sum(bdi >= 30)
#> [1] 17Stima della distribuzione a posteriori.
Supponiamo di voler stimare la probabilità \(\theta\) di depressione grave nei pazienti clinici utilizzando una distribuzione a priori \(Beta(8, 2)\). I dati possono essere visti come una sequenza di prove Bernoulliane indipendenti, dove la presenza di depressione grave è un “successo”. La verosimiglianza è quindi binomiale con parametri \(n = 30\) e \(y = 17\).
Con una distribuzione a priori \(Beta(8, 2)\), la distribuzione a posteriori di \(\theta\) sarà:
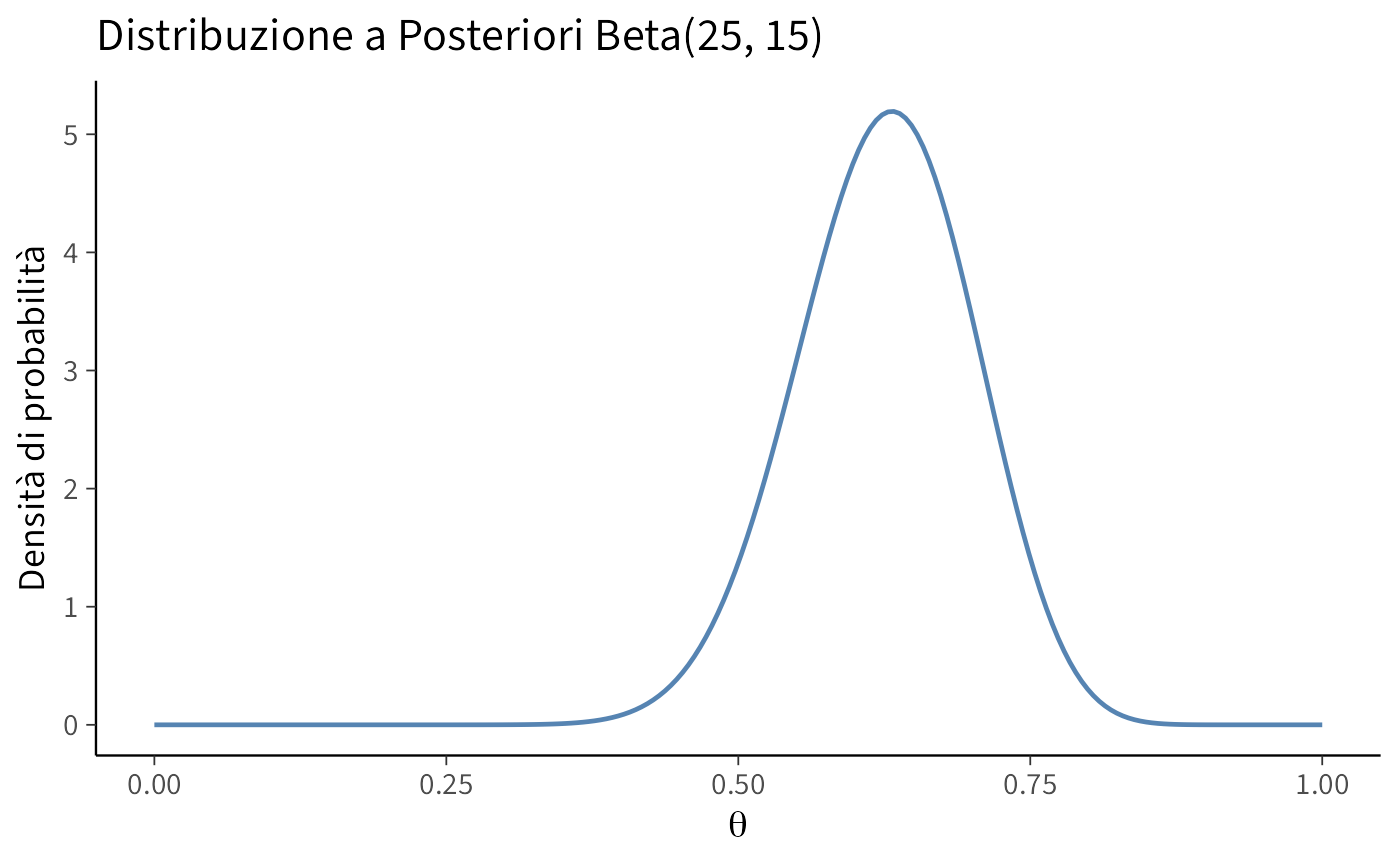
\[ \text{Beta}(\alpha = 8 + 17, \beta = 2 + 30 - 17) = \text{Beta}(25, 15). \] Tracciamo la distribuzione a posteriori.
# Parametri della distribuzione Beta
alpha <- 25
beta <- 15
# Calcolo della densità per valori di theta
theta <- seq(0, 1, length.out = 200)
posterior_density <- dbeta(theta, alpha, beta)
# Grafico della distribuzione a posteriori
ggplot(data = data.frame(theta, posterior_density), aes(x = theta, y = posterior_density)) +
geom_line() +
labs(
title = "Distribuzione a Posteriori Beta(25, 15)",
x = expression(theta),
y = "Densità di probabilità"
) 
Stime puntuali.
- Media a posteriori. La media della distribuzione a posteriori è calcolata come:
\[ \mathbb{E}(\theta | y = 17) = \frac{\alpha}{\alpha + \beta} = \frac{25}{25 + 15} = 0.625. \] In R:
# Calcolo della media a posteriori
posterior_mean <- alpha / (alpha + beta)
posterior_mean
#> [1] 0.625- Moda a posteriori (MAP). La moda della distribuzione a posteriori è:
\[ Mo(\theta | y = 17) = \frac{\alpha - 1}{\alpha + \beta - 2} = \frac{25 - 1}{25 + 15 - 2} = 0.6316. \] In R:
# Calcolo della moda a posteriori
posterior_mode <- (alpha - 1) / (alpha + beta - 2)
posterior_mode
#> [1] 0.632- Mediana a posteriori. La mediana si ottiene utilizzando la funzione di distribuzione cumulativa inversa:
# Calcolo della mediana a posteriori
posterior_median <- qbeta(0.5, alpha, beta)
posterior_median
#> [1] 0.627Intervallo di credibilità.
- Intervallo di credibilità simmetrico. L’intervallo di credibilità simmetrico al 94% è dato dai percentili 3% e 97%:
Possiamo interpretare questo intervallo come segue: c’è una certezza soggettiva del 94% che \(\theta\) sia compreso tra 0.478 e 0.761.
Verifica di ipotesi bayesiana. Infine, calcoliamo la probabilità che \(\theta > 0.5\):
\[ P(\theta > 0.5 | y = 17) = \int_{0.5}^1 f(\theta | y = 17) d\theta. \] In R:
# Probabilità P(theta > 0.5)
prob_theta_greater_0_5 <- pbeta(0.5, alpha, beta, lower.tail = FALSE)
prob_theta_greater_0_5
#> [1] 0.946In conclusione, utilizzando un approccio bayesiano, abbiamo stimato la distribuzione a posteriori di \(\theta\), ottenuto stime puntuali e costruito intervalli di credibilità. Abbiamo inoltre calcolato la probabilità che \(\theta\) superi una soglia specifica, mostrando la flessibilità e l’interpretabilità delle analisi bayesiane.
3.6 Sintesi della distribuzione a posteriori in contesti multivariati
L’estensione dell’analisi bayesiana a modelli con più parametri introduce complessità legate alle interdipendenze tra i parametri stessi. Tali relazioni, se non adeguatamente considerate, possono condurre a sintesi incomplete o fuorvianti della distribuzione a posteriori, con possibili errori interpretativi.
3.6.1 La sfida delle correlazioni tra parametri
Uno degli aspetti critici riguarda la presenza di correlazioni tra i parametri. Le distribuzioni marginali a posteriori — spesso utilizzate nei riassunti statistici — possono risultare ingannevoli se esaminate isolatamente. Parametri fortemente correlati possono dar luogo a marginali apparentemente piatte o poco informative, benché la loro struttura congiunta restringa significativamente lo spazio delle combinazioni plausibili. Ciò implica che, nonostante l’incertezza marginale possa sembrare elevata, l’incertezza congiunta su specifiche relazioni parametriche può essere molto ridotta.
Un’ulteriore complicazione sorge quando le relazioni tra parametri sono non lineari. In tali casi, il massimo della distribuzione congiunta può non coincidere con i massimi delle distribuzioni marginali. Ad esempio, in presenza di strutture a “banana” o altre forme complesse, gli usuali indicatori di tendenza centrale (come la moda o la media) calcolati sui singoli parametri possono non riflettere la regione di massima densità di probabilità nello spazio multivariato.
3.6.2 Approcci per una sintesi efficace
Per una rappresentazione fedele dell’incertezza in contesti multivariati, è essenziale adottare una prospettiva che vada oltre l’analisi delle marginali:
Visualizzazione delle relazioni congiunte: grafici di dispersione a coppie (pair plots) o contour plot bidimensionali consentono di esplorare visivamente le dipendenze tra parametri, rivelando strutture non catturate dalle marginali.
Utilizzo di distribuzioni predittive: il confronto tra distribuzioni predittive a priori e a posteriori fornisce una visione complessiva dell’incertezza ridotta dall’evidenza dei dati, tenendo conto di tutte le interazioni parametriche.
Misure di dipendenza avanzate: in casi di relazioni non lineari, misure come la correlazione di Spearman o l’informazione mutua possono integrare la correlazione lineare, offrendo una descrizione più completa delle dipendenze.
Analisi di sensibilità: valutare come variano le inferenze al variare di gruppi di parametri aiuta a identificare le relazioni più influenti e a comprendere la stabilità delle conclusioni.
In conclusione, una sintesi appropriata della distribuzione a posteriori in presenza di più parametri richiede un esame congiunto delle relazioni tra di essi. La sola inspezione delle distribuzioni marginali rischia di occultare importanti fonti di informazione circa la struttura parametrica, con possibili conseguenze sulle inferenze tratte. Un approccio integrato — che unisca visualizzazione, misure di dipendenza e analisi di sensibilità — è fondamentale per una comprensione robusta dei risultati bayesiani in contesti multivariati.
Riflessioni conclusive
Questo approfondimento ha mostrato come sintetizzare la distribuzione a posteriori in modo informativo. Abbiamo analizzato diverse misure di tendenza centrale (media, mediana e moda) e vari tipi di intervalli di credibilità, mettendo in luce come ciascuna di queste misure fornisca una prospettiva complementare sull’incertezza dei nostri parametri.
Queste sintesi non intendono sostituire la distribuzione completa, ma renderla più comunicabile. In particolare, l’intervallo di credibilità permette di identificare con precisione quali valori del parametro hanno una determinata probabilità di essere veri, in base al modello e ai dati osservati. Questa caratteristica segna una differenza fondamentale rispetto all’approccio frequentista, in cui l’interpretazione degli intervalli di confidenza rimane indiretta e potenzialmente ambigua.
Nella ricerca psicologica, la capacità di sintetizzare efficacemente le distribuzioni a posteriori è particolarmente preziosa. Molti disegni sperimentali prevedono la stima di proporzioni, medie o differenze tra gruppi e la scelta del modo in cui rappresentare l’incertezza può influire sulla chiarezza delle conclusioni. Una sintesi ben calibrata non solo migliora la comunicazione dei risultati, ma ne aumenta anche la robustezza, rendendo espliciti i margini di incertezza.
Con questo capitolo si conclude il primo ciclo del nostro percorso: abbiamo imparato a costruire distribuzioni a posteriori e a sintetizzarne il contenuto informativo. Nei prossimi approfondimenti esploreremo come estendere questi strumenti oltre la stima dei parametri, utilizzando la distribuzione a posteriori per prevedere dati futuri e per confrontare modelli alternativi. È in questa direzione che il pensiero bayesiano rivelerà appieno il suo potenziale: non solo per descrivere ciò che conosciamo, ma anche per orientare ciò che possiamo legittimamente aspettarci.
ImportanteProblemi
1. Quali sono le principali statistiche utilizzate per la stima puntuale di un parametro nella distribuzione a posteriori?
- Spiega le differenze tra moda (MAP), media a posteriori e mediana.
- In quali contesti è preferibile utilizzare una di queste statistiche rispetto alle altre?
2. Qual è la differenza tra un intervallo di credibilità bayesiano e un intervallo di confidenza frequentista?
- Spiega le differenze concettuali tra i due approcci.
- Quale dei due è più intuitivo in termini di incertezza sui parametri?
3. Cos’è un intervallo di massima densità posteriore (HPD) e in cosa si differenzia dall’intervallo di credibilità simmetrico?
- Spiega il concetto di HPD e perché è più informativo in alcuni casi.
- In quali situazioni l’HPD è preferibile rispetto all’intervallo di credibilità simmetrico?
4. Quali sono le problematiche associate alla moda (MAP) come stima puntuale?
- Perché il MAP può essere meno affidabile rispetto ad altre statistiche?
- Quali problemi si possono incontrare nei modelli bayesiani complessi?
5. In che modo la sintesi della distribuzione a posteriori cambia nel caso di più parametri incogniti?
- Quali sono le principali difficoltà nell’interpretare la distribuzione congiunta di più parametri?
- Come si possono visualizzare e sintetizzare distribuzioni posteriori multivariate?
Domande applicative in R
Per queste domande, usa il dataset basato sulla Satisfaction with Life Scale (SWLS), supponendo che i dati seguano una distribuzione normale.
1. Calcola la media, la mediana e la moda a posteriori della distribuzione della media SWLS, assumendo una distribuzione a priori gaussiana molto diffusa. - Usa il metodo delle distribuzioni coniugate per ottenere la distribuzione a posteriori.
2. Costruisci un intervallo di credibilità simmetrico al 94% per la media SWLS.
- Usa la distribuzione normale a posteriori per calcolare l’intervallo.
3. Visualizza la distribuzione a posteriori della media SWLS con un grafico di densità.
- Genera un campione dalla distribuzione a posteriori e rappresentalo con ggplot2.
4. Confronta l’intervallo di credibilità simmetrico con l’intervallo di massima densità posteriore (HPD).
- Usa la funzione hdi() del pacchetto bayestestR per calcolare l’HPD.
5. Calcola la probabilità a posteriori che la media SWLS sia minore di 23.
- Usa la distribuzione a posteriori per calcolare questa probabilità.
ConsiglioSoluzioni
1. Quali sono le principali statistiche utilizzate per la stima puntuale di un parametro nella distribuzione a posteriori?
Le tre principali statistiche usate per ottenere una stima puntuale del parametro \(\theta\) nella distribuzione a posteriori sono:
-
Moda (Massimo a Posteriori, MAP)
- È il valore di \(\theta\) che massimizza la distribuzione a posteriori \(p(\theta \mid y)\).
- Se la distribuzione è unimodale e simmetrica, il MAP coincide con la media a posteriori.
- Il MAP è spesso simile alla stima di massima verosimiglianza (MLE) quando il prior è uniforme.
- È il valore di \(\theta\) che massimizza la distribuzione a posteriori \(p(\theta \mid y)\).
-
Media a Posteriori
- È il valore atteso della distribuzione a posteriori:
\[ E(\theta \mid y) = \int \theta \, p(\theta \mid y) \, d\theta \] - È la stima più utile quando si vuole minimizzare l’errore quadratico medio (MSE).
- Risente dell’eventuale asimmetria della distribuzione, spostandosi verso le code.
- È il valore atteso della distribuzione a posteriori:
-
Mediana a Posteriori
- È il valore che divide la distribuzione a posteriori in due parti uguali:
\[ P(\theta \leq \theta_{\text{mediana}} \mid y) = 0.5 \] - È più robusta agli outlier rispetto alla media ed è utile quando la distribuzione è fortemente asimmetrica.
- È il valore che divide la distribuzione a posteriori in due parti uguali:
💡 Quando usarle? - Se la distribuzione è simmetrica, tutte e tre le statistiche coincidono. - Se la distribuzione è asimmetrica, la mediana è più robusta, la media può essere influenzata dalle code e il MAP è utile se si vuole un valore più probabile.
2. Qual è la differenza tra un intervallo di credibilità bayesiano e un intervallo di confidenza frequentista?
| Caratteristica | Intervallo di Credibilità (Bayesiano) | Intervallo di Confidenza (Frequentista) |
|---|---|---|
| Significato | Esprime la probabilità che il parametro sia nell’intervallo, dati i dati osservati. | È una proprietà di un metodo di campionamento: se si ripetesse l’esperimento infinite volte, il \((1 - \alpha)100\%\) degli intervalli conterrebbe il vero valore del parametro. |
| Approccio | Assume che il parametro sia una variabile casuale con una distribuzione di probabilità. | Assume che il parametro sia fisso e sconosciuto, mentre i dati sono casuali. |
| Interpretazione | “C’è il 95% di probabilità che il parametro sia tra questi valori.” | “Se ripetessimo l’esperimento molte volte, il 95% degli intervalli conterrebbe il vero parametro.” |
💡 Differenza fondamentale:
- L’intervallo di credibilità è probabilistico e più intuitivo: si può direttamente dire che il parametro ha il 95% di probabilità di trovarsi nell’intervallo.
- L’intervallo di confidenza è basato sulla ripetizione ipotetica dell’esperimento e non può essere interpretato in termini probabilistici sul singolo intervallo.
3. Cos’è un intervallo di massima densità posteriore (HPD) e in cosa si differenzia dall’intervallo di credibilità simmetrico?
L’intervallo di massima densità posteriore (HPD) è l’intervallo più stretto che contiene una percentuale fissata (es. 94%) della distribuzione a posteriori. Si distingue dall’intervallo di credibilità simmetrico perché:
| Caratteristica | Intervallo HPD | Intervallo di Credibilità Simmetrico |
|---|---|---|
| Definizione | Contiene il \((1 - \alpha)100\%\) della probabilità a posteriori, minimizzando la lunghezza dell’intervallo. | È centrato attorno alla mediana e copre una frazione fissa della distribuzione. |
| Forma | Può essere asimmetrico e discontinuo se la distribuzione è multimodale. | È sempre simmetrico. |
| Vantaggio | È più informativo se la distribuzione è asimmetrica o multimodale. | È più facile da calcolare, specialmente per distribuzioni unimodali. |
💡 Quando usarli?
- Se la distribuzione è simmetrica, entrambi gli intervalli danno risultati simili.
- Se la distribuzione è asimmetrica o multimodale, l’HPD è più informativo.
4. Quali sono le problematiche associate alla moda (MAP) come stima puntuale?
Sebbene il MAP sia un concetto intuitivo (il valore più probabile della distribuzione a posteriori), presenta alcune limitazioni:
-
Difficoltà computazionale con MCMC
- Con metodi di campionamento come Markov Chain Monte Carlo (MCMC), trovare il massimo della distribuzione a posteriori è difficile perché la funzione viene stimata in modo discreto.
- Spesso si preferisce stimare media o mediana, più facili da calcolare con MCMC.
-
Sensibilità ai dati e al prior
- Il MAP dipende fortemente dal prior scelto.
- Se il prior è informativo, il MAP può spostarsi troppo rispetto ai dati.
-
Problemi con distribuzioni multimodali
- Se la distribuzione a posteriori ha più di un massimo (moda), il MAP potrebbe non essere una buona rappresentazione della distribuzione.
💡 Quando evitarlo?
- Se la distribuzione a posteriori è asimmetrica o multimodale. - Se si usa un metodo MCMC, dove la media o la mediana sono più semplici da stimare.
5. In che modo la sintesi della distribuzione a posteriori cambia nel caso di più parametri incogniti?
Quando l’inferenza bayesiana coinvolge più parametri (es. \(\mu\) e \(\sigma\)), l’analisi diventa più complessa per diversi motivi:
-
Interazioni tra parametri
- I parametri spesso non sono indipendenti: la distribuzione a posteriori congiunta può mostrare correlazioni che non emergono dalle distribuzioni marginali.
-
Difficoltà di visualizzazione
- Per un parametro si usa un istogramma o una funzione di densità.
- Per due parametri si usa un contour plot o un grafico 3D.
- Con più di due parametri, si ricorre a pair plots o matrici di correlazione.
-
Stimare margine e congiunta
- La distribuzione marginale di un parametro si ottiene integrando la distribuzione congiunta rispetto agli altri parametri: \[ p(\theta_1) = \int p(\theta_1, \theta_2) d\theta_2 \]
- Se i parametri sono fortemente correlati, le marginali possono nascondere informazioni importanti.
-
Rischio di correlazioni non lineari
- Le correlazioni non lineari tra i parametri possono portare a distribuzioni con forme complesse (es. a banana), rendendo difficile la sintesi con MAP o media.
💡 Strategie per affrontare il problema:
- Visualizzare le correlazioni tra i parametri con scatter plot o heatmap.
- Usare tecniche di riduzione della dimensionalità come PCA (Analisi delle Componenti Principali).
- Utilizzare il MCMC per campionare direttamente dalla distribuzione congiunta.
Esercizio in R con i dati SWLS
Nell’esercizio, usa i dati della SWLS che sono stati raccolti. Qui useremo i dati seguenti:
swls_data <- data.frame(
soddisfazione = c(4.2, 5.1, 4.7, 4.3, 5.5, 4.9, 4.8, 5.0, 4.6, 4.4)
)1. Calcola la media, la mediana e la moda a posteriori della distribuzione della media SWLS, assumendo una distribuzione a priori gaussiana molto diffusa.
- Usa il metodo delle distribuzioni coniugate per ottenere la distribuzione a posteriori.
library(tibble)
# Dati
n <- nrow(swls_data)
mean_x <- mean(swls_data$soddisfazione)
sigma <- 1 # Deviazione standard nota
# Prior diffuso
mu_prior <- 4.5
sigma_prior <- 10
# Media a posteriori
mu_post <- (sigma_prior^2 * mean_x + sigma^2 * n * mu_prior) / (sigma_prior^2 + sigma^2 * n)
# Deviazione standard a posteriori
sigma_post <- sqrt((sigma_prior^2 * sigma^2) / (sigma_prior^2 + sigma^2 * n))
# Moda (MAP)
posterior_mode <- mu_post # Per una distribuzione normale, MAP coincide con la media
# Mediana (simile alla media in una distribuzione normale)
posterior_median <- mu_post
tibble("Media a Posteriori" = mu_post,
"Moda (MAP)" = posterior_mode,
"Mediana" = posterior_median)2. Costruisci un intervallo di credibilità simmetrico al 94% per la media SWLS.
- Usa la distribuzione normale a posteriori per calcolare l’intervallo.
3. Visualizza la distribuzione a posteriori della media SWLS con un grafico di densità.
- Genera un campione dalla distribuzione a posteriori e rappresentalo con ggplot2.
library(ggplot2)
# Campionamento dalla distribuzione a posteriori
set.seed(123)
samples <- rnorm(1000, mean = mu_post, sd = sigma_post)
# Creazione del dataframe
samples_df <- tibble(media_campionata = samples)
# Grafico della distribuzione a posteriori
ggplot(samples_df, aes(x = media_campionata)) +
geom_density(fill = "blue", alpha = 0.5) +
labs(title = "Distribuzione a Posteriori della Media SWLS",
x = "Media", y = "Densità")4. Confronta l’intervallo di credibilità simmetrico con l’intervallo di massima densità posteriore (HPD).
- Usa la funzione hdi() del pacchetto bayestestR per calcolare l’HPD.
library(bayestestR)
# Calcolo intervallo HPD al 94%
hpd_interval <- hdi(samples, ci = 0.94)
hpd_interval5. Calcola la probabilità a posteriori che la media SWLS sia minore di 23 – per fare un esempio, qui caloleremo per i dati simulati la probabilità a posteriori per la media SWLS maggiore di 4.7.
- Usa la distribuzione a posteriori per calcolare questa probabilità.
prob_greater_4_7 <- 1 - pnorm(4.7, mean = mu_post, sd = sigma_post)
prob_greater_4_7
NotaInformazioni sull’ambiente di sviluppo
sessionInfo()
#> R version 4.5.1 (2025-06-13)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Tahoe 26.0.1
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRblas.0.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C.UTF-8/UTF-8/C.UTF-8/C/C.UTF-8/C.UTF-8
#>
#> time zone: Europe/Zagreb
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] mice_3.18.0 ragg_1.5.0 tinytable_0.13.0
#> [4] withr_3.0.2 systemfonts_1.3.1 patchwork_1.3.2
#> [7] ggdist_3.3.3 tidybayes_3.0.7 bayesplot_1.14.0
#> [10] ggplot2_4.0.0 reliabilitydiag_0.2.1 priorsense_1.1.1
#> [13] posterior_1.6.1 loo_2.8.0 rstan_2.32.7
#> [16] StanHeaders_2.32.10 brms_2.23.0 Rcpp_1.1.0
#> [19] sessioninfo_1.2.3 conflicted_1.2.0 janitor_2.2.1
#> [22] matrixStats_1.5.0 modelr_0.1.11 tibble_3.3.0
#> [25] dplyr_1.1.4 tidyr_1.3.1 rio_1.2.4
#> [28] here_1.0.2
#>
#> loaded via a namespace (and not attached):
#> [1] Rdpack_2.6.4 gridExtra_2.3 inline_0.3.21
#> [4] sandwich_3.1-1 rlang_1.1.6 magrittr_2.0.4
#> [7] multcomp_1.4-28 snakecase_0.11.1 compiler_4.5.1
#> [10] vctrs_0.6.5 stringr_1.5.2 shape_1.4.6.1
#> [13] pkgconfig_2.0.3 arrayhelpers_1.1-0 fastmap_1.2.0
#> [16] backports_1.5.0 labeling_0.4.3 rmarkdown_2.30
#> [19] nloptr_2.2.1 purrr_1.1.0 jomo_2.7-6
#> [22] xfun_0.53 glmnet_4.1-10 cachem_1.1.0
#> [25] jsonlite_2.0.0 pan_1.9 broom_1.0.10
#> [28] parallel_4.5.1 R6_2.6.1 stringi_1.8.7
#> [31] RColorBrewer_1.1-3 rpart_4.1.24 boot_1.3-32
#> [34] lubridate_1.9.4 estimability_1.5.1 iterators_1.0.14
#> [37] knitr_1.50 zoo_1.8-14 pacman_0.5.1
#> [40] nnet_7.3-20 Matrix_1.7-4 splines_4.5.1
#> [43] timechange_0.3.0 tidyselect_1.2.1 abind_1.4-8
#> [46] codetools_0.2-20 curl_7.0.0 pkgbuild_1.4.8
#> [49] lattice_0.22-7 bridgesampling_1.1-2 S7_0.2.0
#> [52] coda_0.19-4.1 evaluate_1.0.5 survival_3.8-3
#> [55] RcppParallel_5.1.11-1 pillar_1.11.1 tensorA_0.36.2.1
#> [58] foreach_1.5.2 checkmate_2.3.3 stats4_4.5.1
#> [61] reformulas_0.4.1 distributional_0.5.0 generics_0.1.4
#> [64] rprojroot_2.1.1 rstantools_2.5.0 scales_1.4.0
#> [67] minqa_1.2.8 xtable_1.8-4 glue_1.8.0
#> [70] emmeans_1.11.2-8 tools_4.5.1 lme4_1.1-37
#> [73] mvtnorm_1.3-3 grid_4.5.1 rbibutils_2.3
#> [76] QuickJSR_1.8.1 colorspace_2.1-2 nlme_3.1-168
#> [79] cli_3.6.5 textshaping_1.0.4 svUnit_1.0.8
#> [82] Brobdingnag_1.2-9 V8_8.0.1 gtable_0.3.6
#> [85] digest_0.6.37 TH.data_1.1-4 htmlwidgets_1.6.4
#> [88] farver_2.1.2 memoise_2.0.1 htmltools_0.5.8.1
#> [91] lifecycle_1.0.4 mitml_0.4-5 MASS_7.3-65Bibliografia
Zetsche, U., Buerkner, P.-C., & Renneberg, B. (2019). Future expectations in clinical depression: biased or realistic? Journal of Abnormal Psychology, 128(7), 678–688.