31 Proprietà delle variabili casuali
“If I expect a or b, and have an equal chance of gaining either of them, my Expectation is worth \((a+b)/2\).”
— Christiaan Huygens, De ratiociniis in ludo aleae (1657).
Introduzione
È spesso molto utile sintetizzare la distribuzione di una variabile casuale attraverso indicatori caratteristici. Questi indicatori consentono di cogliere le principali proprietà della distribuzione, come la posizione centrale (ovvero il “baricentro”) e la variabilità (ossia la dispersione attorno al centro). In questo modo, è possibile ottenere una descrizione sintetica e significativa della distribuzione di probabilità della variabile casuale.
In questo capitolo, introdurremo i concetti fondamentali di valore atteso e varianza di una variabile casuale, che sono strumenti essenziali per comprendere e riassumere le proprietà di una distribuzione probabilistica.
Panoramica del capitolo
- Concetti di valore atteso e varianza per variabili casuali discrete.
- Proprietà del valore atteso e della varianza.
- Valore atteso e varianza per variabili casuali continue.
- Utilizzare R per calcolare valore atteso e varianza.
31.1 Tendenza centrale
Quando vogliamo comprendere il comportamento tipico di una variabile casuale, ci interessa spesso determinare il suo “valore tipico”. Tuttavia, questa nozione può essere interpretata in diversi modi:
- Media: La somma dei valori divisa per il numero dei valori.
- Mediana: Il valore centrale della distribuzione, quando i dati sono ordinati in senso crescente o decrescente.
- Moda: Il valore che si verifica con maggiore frequenza.
Ad esempio, per il set di valori \(\{3, 1, 4, 1, 5\}\), la media è \(\frac{3+1+4+1+5}{5} = 2.8\), la mediana è 3, e la moda è 1. Tuttavia, quando ci occupiamo di variabili casuali, anziché di semplici sequenze di numeri, diventa necessario chiarire cosa intendiamo per “valore tipico” in questo contesto. Questo ci porta alla definizione formale del valore atteso.
31.2 Valore atteso
Definizione 31.1 Sia \(X\) una variabile casuale discreta che assume i valori \(x_1, \dots, x_n\) con probabilità \(P(X = x_i) = p(x_i)\). Il valore atteso di \(X\), denotato con \(\mathbb{E}(X)\), è definito come:
\[ \mathbb{E}(X) = \sum_{i=1}^n x_i \cdot p(x_i). \]
In altre parole, il valore atteso (noto anche come speranza matematica o aspettazione) di una variabile casuale è la somma di tutti i valori che la variabile può assumere, ciascuno ponderato dalla probabilità con cui esso si verifica.
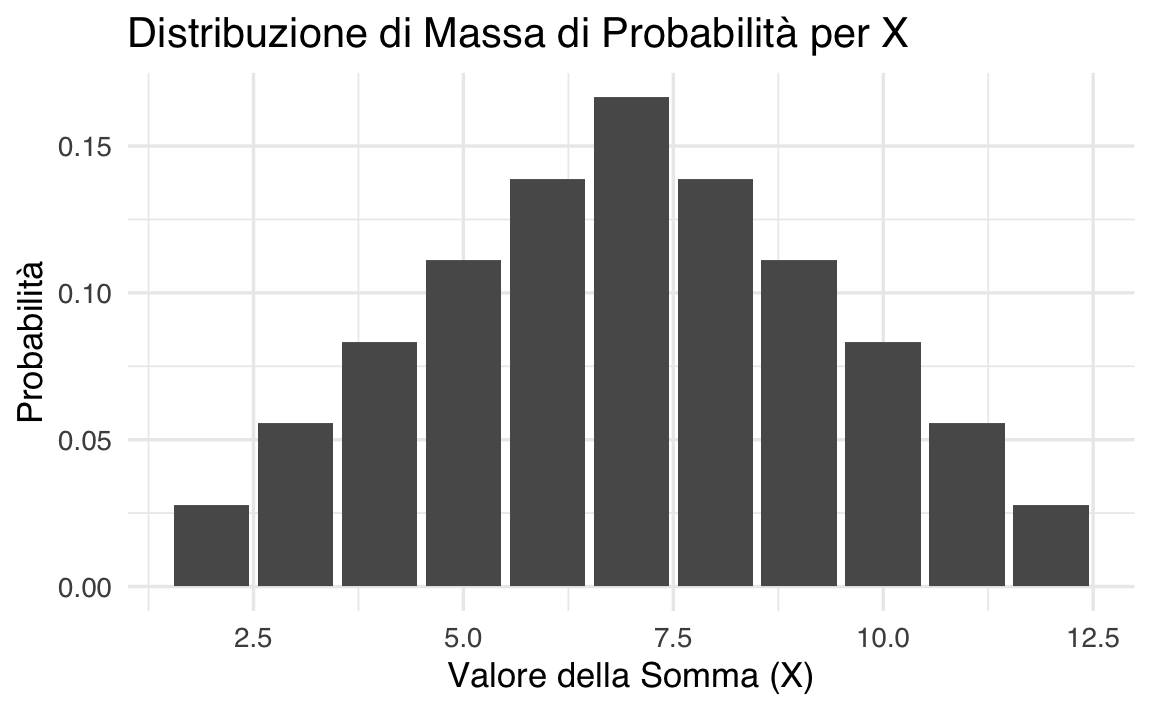
Calcoliamo il valore atteso della variabile casuale \(X\) che rappresenta la somma dei punti ottenuti dal lancio di due dadi equilibrati a sei facce.
La variabile casuale \(X\) può assumere i seguenti valori:
\[ \{2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12\}. \]
La probabilità associata a ciascun valore è data dalla distribuzione di massa di probabilità. Ad esempio, il valore \(X = 2\) si ottiene solo se entrambi i dadi mostrano 1, quindi ha probabilità:
\[ P(X = 2) = \frac{1}{36}. \]
Analogamente, \(X = 7\) può essere ottenuto con sei combinazioni diverse: (1,6), (2,5), (3,4), (4,3), (5,2), (6,1), quindi:
\[ P(X = 7) = \frac{6}{36}. \]
La distribuzione di massa di probabilità completa è:
\[ P(X) = \left\{\frac{1}{36}, \frac{2}{36}, \frac{3}{36}, \frac{4}{36}, \frac{5}{36}, \frac{6}{36}, \frac{5}{36}, \frac{4}{36}, \frac{3}{36}, \frac{2}{36}, \frac{1}{36}\right\}. \]
Il valore atteso \(\mathbb{E}[X]\) è definito come:
\[ \mathbb{E}[X] = \sum_{x} x \cdot P(X = x). \]
Applicando questa formula:
\[ \mathbb{E}[X] = 2 \cdot \frac{1}{36} + 3 \cdot \frac{2}{36} + 4 \cdot \frac{3}{36} + \cdots + 12 \cdot \frac{1}{36} = 7. \]
Ecco come calcolarlo utilizzando R:
Il risultato sarà: \[ \mathbb{E}[X] = 7. \]
Per rappresentare graficamente la distribuzione di massa di probabilità:
# Creazione di un data frame
dati <- data.frame(Valore = valori, Probabilità = prob)
# Plot
ggplot(dati, aes(x = Valore, y = Probabilità)) +
geom_col(fill = "lightblue") +
labs(
title = "Distribuzione di Massa di Probabilità per X",
x = "Valore della Somma (X)",
y = "Probabilità"
) 
Nel suo Ars conjectandi, Bernoulli introduce la nozione di valore atteso con le seguenti parole:
il termine “aspettativa” non deve essere inteso nel suo significato comune […], bensì come la speranza di ottenere il meglio diminuita dalla paura di ottenere il peggio. Pertanto, il valore della nostra aspettativa rappresenta sempre qualcosa di intermedio tra il meglio che possiamo sperare e il peggio che possiamo temere (Hacking, 2006).
In termini moderni, questa intuizione può essere rappresentata in modo più chiaro attraverso una simulazione. Possiamo affermare, infatti, che il valore atteso di una variabile casuale corrisponde alla media aritmetica di un gran numero di realizzazioni indipendenti della variabile stessa.
Per fare un esempio concreto, consideriamo nuovamente il caso del lancio di due dadi bilanciati a sei facce, dove la variabile casuale \(X\) rappresenta la “somma dei due dadi”. Simuliamo un numero elevato di realizzazioni indipendenti di \(X\).
L’istruzione sample(x, size = 1e6, replace = TRUE, prob = px)) utilizza R per generare un array di 1.000.000 di elementi (specificato dal parametro size), selezionati casualmente dall’array x secondo le probabilità specificate nell’array px.
Quando il numero di realizzazioni indipendenti è sufficientemente grande, la media aritmetica dei campioni generati si avvicina al valore atteso della variabile casuale:
mean(x_samples)
#> [1] 6.998Questo risultato conferma che il valore atteso \(\mathbb{E}[X] = 7\) rappresenta la somma media dei punti ottenuti nel lancio di due dadi equilibrati su un numero elevato di prove. Anche se ogni singola somma può variare tra 2 e 12, in media ci aspettiamo una somma di 7.
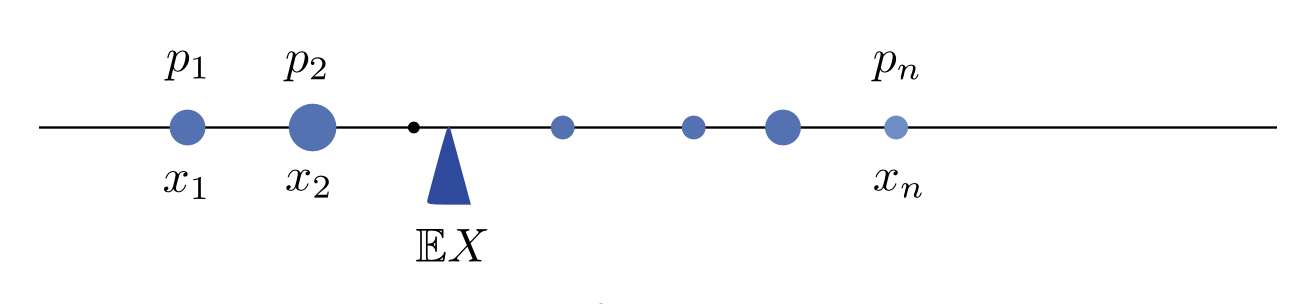
L’aspettativa può anche essere interpretata come un centro di massa. Immagina che delle masse puntiformi con pesi \(p_1, p_2, \dots, p_n\) siano posizionate alle posizioni \(x_1, x_2, \dots, x_n\) sulla retta reale. Il centro di massa—il punto in cui i pesi sono bilanciati—è dato da:
\[ \text{centro di massa} = x_1 p_1 + x_2 p_2 + \dots + x_n p_n, \]
che corrisponde esattamente all’aspettativa della variabile discreta \(X\), che assume valori \(x_1, \dots, x_n\) con probabilità \(p_1, \dots, p_n\). Una conseguenza ovvia di questa interpretazione è che, per una funzione di densità di probabilità (pdf) simmetrica, l’aspettativa coincide con il punto di simmetria (a patto che l’aspettativa esista).
31.2.1 Proprietà del valore atteso
Una delle proprietà più importanti del valore atteso è la sua linearità: il valore atteso della somma di due variabili casuali è uguale alla somma dei loro rispettivi valori attesi:
\[ \mathbb{E}(X + Y) = \mathbb{E}(X) + \mathbb{E}(Y). \tag{31.1}\]
Questa proprietà, espressa dalla formula sopra, è intuitiva quando \(X\) e \(Y\) sono variabili casuali indipendenti, ma è valida anche nel caso in cui \(X\) e \(Y\) siano correlate.
Inoltre, se moltiplichiamo una variabile casuale per una costante \(c\), il valore atteso del prodotto è uguale alla costante moltiplicata per il valore atteso della variabile casuale:
\[ \mathbb{E}(cY) = c \mathbb{E}(Y). \tag{31.2}\]
Questa proprietà ci dice che una costante può essere “estratta” dall’operatore di valore atteso, e si applica a qualunque numero di variabili casuali.
Un’altra proprietà significativa riguarda il prodotto di variabili casuali indipendenti. Se \(X\) e \(Y\) sono indipendenti, allora il valore atteso del loro prodotto è uguale al prodotto dei loro valori attesi:
\[ \mathbb{E}(XY) = \mathbb{E}(X) \mathbb{E}(Y). \tag{31.3}\]
Infine, consideriamo la media aritmetica \(\bar{X} = \frac{X_1 + \ldots + X_n}{n}\) di \(n\) variabili casuali indipendenti con la stessa distribuzione e con valore atteso \(\mu\). Il valore atteso della media aritmetica è:
\[ \mathbb{E}(\bar{X}) = \frac{1}{n} \left(\mathbb{E}(X_1) + \dots + \mathbb{E}(X_n)\right) = \frac{1}{n} \cdot n \cdot \mathbb{E}(X) = \mu. \]
Questo risultato conferma che la media aritmetica di un campione di variabili casuali indipendenti ha lo stesso valore atteso della distribuzione originaria, rendendo il valore atteso uno strumento cruciale per l’analisi statistica e probabilistica.
31.2.2 Valore atteso di una variabile casuale continua
Nel caso di una variabile casuale continua \(X\), il valore atteso è definito come:
\[ \mathbb{E}(X) = \int_{-\infty}^{+\infty} x \cdot p(x) \, \mathrm{d}x. \]
Anche in questo contesto, il valore atteso rappresenta una media ponderata dei valori di \(x\), dove ogni possibile valore di \(x\) è ponderato in base alla densità di probabilità \(p(x)\).
L’integrale può essere interpretato analogamente a una somma continua, in cui \(x\) rappresenta la posizione delle barre infinitamente strette di un istogramma, e \(p(x)\) rappresenta l’altezza di tali barre. La notazione \(\int_{-\infty}^{+\infty}\) indica che si sta sommando il contributo di ogni valore possibile di \(x\) lungo l’intero asse reale.
Questa interpretazione rende chiaro come l’integrale calcoli una somma ponderata che si estende su tutti i possibili valori di \(x\), fornendo una misura centrale della distribuzione della variabile casuale continua. Per ulteriori dettagli sulla notazione dell’integrale, si veda l’?sec-calculus.
31.2.2.1 Moda
Un’altra misura di tendenza centrale delle variabili casuali continue è la moda. La moda di \(Y\) individua il valore \(y\) più plausibile, ovvero il valore \(y\) che massimizza la funzione di densità \(p(y)\):
\[ Mo(Y) = \text{argmax}_y p(y). \tag{31.4}\]
31.3 Varianza
Dopo il valore atteso, la seconda proprietà più importante di una variabile casuale è la varianza.
Definizione 31.2 Se \(X\) è una variabile casuale discreta con distribuzione \(p(x)\), la varianza di \(X\), denotata con \(\mathbb{V}(X)\), è definita come:
\[ \mathbb{V}(X) = \mathbb{E}\Big[\big(X - \mathbb{E}(X)\big)^2\Big]. \tag{31.5}\]
In altre parole, la varianza misura la deviazione media quadratica dei valori della variabile rispetto alla sua media. Se denotiamo il valore atteso di \(X\) con \(\mu = \mathbb{E}(X)\), la varianza \(\mathbb{V}(X)\) diventa il valore atteso di \((X - \mu)^2\).
La varianza rappresenta una misura della “dispersione” dei valori di \(X\) intorno al suo valore atteso. Quando calcoliamo la varianza, stiamo effettivamente misurando quanto i valori di \(X\) tendono a differire dalla media \(\mu\).
Per capire meglio, consideriamo la variabile casuale \(X - \mathbb{E}(X)\), detta scarto o deviazione dalla media. Questa variabile rappresenta le “distanze” tra i valori di \(X\) e il valore atteso \(\mathbb{E}(X)\). Tuttavia, poiché lo scarto può essere positivo o negativo, la media dello scarto è sempre zero, il che lo rende inadatto a quantificare la dispersione.
Per risolvere questo problema, eleviamo al quadrato gli scarti, ottenendo \((X - \mathbb{E}(X))^2\), che rende tutte le deviazioni positive. La varianza è quindi la media di questi scarti al quadrato, fornendo una misura efficace della dispersione complessiva dei valori di \(X\) rispetto alla sua media.
Questo concetto è fondamentale per comprendere la variabilità di una distribuzione e per applicare strumenti statistici che richiedono una conoscenza approfondita della distribuzione dei dati.
31.3.1 Formula alternativa per la varianza
La varianza di una variabile casuale \(X\), indicata come \(\mathbb{V}(X)\), misura la dispersione dei valori attorno alla media. La definizione classica è:
\[ \mathbb{V}(X) = \mathbb{E}\Big[\big(X - \mathbb{E}(X)\big)^2\Big]. \]
Esiste però una formula alternativa che semplifica il calcolo.
Dimostrazione.
Espansione del quadrato
Consideriamo la varianza, definita come \(\mathbb{V}(X) = \mathbb{E}\big[(X - \mathbb{E}(X))^2\big]\).
Espandiamo il quadrato \((X - \mathbb{E}(X))^2\) utilizzando la regola \((a - b)^2 = a^2 - 2ab + b^2\): \[ (X - \mathbb{E}(X))^2 = X^2 - 2\,X\,\mathbb{E}(X) + \big(\mathbb{E}(X)\big)^2. \]Applicazione dell’aspettativa
Applichiamo \(\mathbb{E}[\cdot]\) a ciascun termine, ricordando che l’aspettativa è un operatore lineare: \[ \mathbb{E}\big[(X - \mathbb{E}(X))^2\big] = \mathbb{E}\big[X^2\big] \;-\; 2 \,\mathbb{E}\big[X\,\mathbb{E}(X)\big] \;+\; \mathbb{E}\big[\big(\mathbb{E}(X)\big)^2\big]. \]-
Gestione dei termini costanti
L’aspettativa \(\mathbb{E}(X)\) è una costante (indipendente da \(X\)). Indichiamola con \(\mu\). Quindi:- \(\mathbb{E}(X^2)\) resta com’è.
- \(\mathbb{E}[X \cdot \mu] = \mu \, \mathbb{E}[X] = \mu \cdot \mu = \mu^2\).
- \(\mathbb{E}\big(\mu^2\big) = \mu^2\).
-
Sostituzione e semplificazione
Rimpiazzando i risultati nel secondo passaggio si ottiene: \[ \mathbb{E}(X^2) \;-\; 2\,\mu^2 \;+\; \mu^2 \;=\; \mathbb{E}(X^2) - \mu^2. \]
Poiché \(\mu = \mathbb{E}(X)\), la varianza può quindi essere scritta come:\[ \boxed{ \mathbb{V}(X) = \mathbb{E}(X^2) \;-\; \bigl(\mathbb{E}(X)\bigr)^2. } \tag{31.6}\]
Questa forma risulta molto utile per ragioni di efficienza computazionale: invece di calcolare gli scarti \((X - \mu)\) per ogni osservazione, è sufficiente trovare \(\mathbb{E}(X^2)\) e poi sottrarre \(\mu^2\). In tal modo si riducono i passaggi intermedi e, di conseguenza, si minimizzano gli errori pratici. Inoltre, nelle dimostrazioni che richiedono manipolazioni algebriche – come quelle tipiche della Teoria Classica dei Test – questa espressione semplifica notevolmente le trasformazioni.
31.3.2 Proprietà
Segno della varianza. La varianza di una variabile aleatoria non è mai negativa, ed è zero solamente quando la variabile assume un solo valore.
Invarianza per traslazione. La varianza è invariante per traslazione, che lascia fisse le distanze dalla media, e cambia quadraticamente per riscalamento:
\[ \mathbb{V}(a + bX) = b^2\mathbb{V}(X). \]
Dimostrazione. Iniziamo a scrivere
\[ (aX+b)-{\mathbb{E}}[aX+b]=aX+b-a{\mathbb{E}}[X]-b=a(X-{\mathbb {E}}[X]). \]
Quindi
\[ \sigma _{{aX+b}}^{2}={\mathbb{E}}[a^{2}(X-{\mathbb {E}}[X])^{2}]=a^{2}\sigma _{X}^{2}. \]
Esaminiamo una dimostrazione numerica.
Varianza della somma di due variabili indipendenti. La varianza della somma di due variabili indipendenti o anche solo incorrelate è pari alla somma delle loro varianze:
\[ \mathbb{V}(X+Y) = \mathbb{V}(X) + \mathbb{V}(Y). \]
Dimostrazione. Se \(\mathbb{E}(X) = \mathbb{E}(Y) = 0\), allora \(\mathbb{E}(X+Y) = 0\) e
\[\mathbb{V}(X+Y) = \mathbb{E}((X+Y)^2) = \mathbb{E}(X^2) + 2 \mathbb{E}(XY) + \mathbb{E}(Y^2).\]
Siccome le variabili sono indipendenti risulta \(\mathbb{E}(XY) = \mathbb{E}(X)\mathbb{E}(Y) = 0\).
Varianza della differenza di due variabili indipendenti. La varianza della differenza di due variabili indipendenti è pari alla somma delle loro varianze:
\[ \mathbb{V}(X-Y) = \mathbb{V}(X) + \mathbb{V}(Y). \]
Dimostrazione.
\[ \mathbb{V}(X-Y) = \mathbb{V}(X +(-Y)) = \mathbb{V}(X) + \mathbb{V}(-Y) = \mathbb{V}(X) + \mathbb{V}(Y). \]
Varianza della somma di due variabili non indipendenti. Se \(X\) e \(Y\) non sono indipendenti, la formula viene corretta dalla loro covarianza:
\[ \mathbb{V}(X+Y) = \mathbb{V}(X) + \mathbb{V}(Y) + 2 Cov(X,Y), \]
dove \(Cov(X,Y) = \mathbb{E}(XY) - \mathbb{E}(X)\mathbb{E}(Y)\).
Una dimostrazione numerica di questo principio è fornita sotto.
Varianza della media di variabili indipendenti. La media aritmetica \(\textstyle {\bar {X}}={\frac {X_{1}+\ldots +X_{n}}{n}}\) di \(n\) variabili casuali indipendenti aventi la medesima distribuzione, ha varianza
\[ \mathbb{V}(\bar{X}) = \frac{1}{n^2} \mathbb{V}(X_1)+ \dots \mathbb{V}(X_n) = \frac{1}{n^2} n \mathbb{V}(X) = \frac{1}{n} \mathbb{V}(X). \]
31.3.3 Varianza di una variabile casuale continua
Per una variabile casuale continua \(X\), la varianza è definita come:
\[ \mathbb{V}(X) = \int_{-\infty}^{+\infty} \large[x - \mathbb{E}(X)\large]^2 p(x) \,\operatorname {d}\!x. \tag{31.7}\]
Analogamente al caso discreto, la varianza di una variabile casuale continua \(X\) una misura della dispersione, ovvero la “distanza” media quadratica attesa dei valori \(x\) rispetto alla loro media \(\mathbb{E}(X)\). In altre parole, la varianza quantifica quanto i valori della variabile casuale si discostano tipicamente dal loro valore medio.
31.3.4 Deviazione standard
Quando si lavora con le varianze, i valori sono elevati al quadrato, il che può rendere i numeri significativamente più grandi (o più piccoli) rispetto ai dati originali. Per riportare questi valori all’unità di misura della scala originale, si prende la radice quadrata della varianza. Il risultato ottenuto è chiamato deviazione standard ed è comunemente indicato con la lettera greca \(\sigma\).
Definizione 31.3 La deviazione standard, o scarto quadratico medio, è definita come la radice quadrata della varianza:
\[ \sigma_X = \sqrt{\mathbb{V}(X)}. \tag{31.8}\]
Come nella statistica descrittiva, la deviazione standard di una variabile casuale fornisce una misura della dispersione, ossia la “distanza” tipica o prevista dei valori \(x\) rispetto alla loro media.
31.4 Standardizzazione
Definizione 31.4 Data una variabile casuale \(X\), si dice variabile standardizzata di \(X\) l’espressione
\[ Z = \frac{X - \mathbb{E}(X)}{\sigma_X}. \tag{31.9}\]
Solitamente, una variabile standardizzata viene denotata con la lettera \(Z\).
31.5 Il teorema di Chebyshev
Il Teorema di Chebyshev ci permette di stimare la probabilità che una variabile aleatoria si discosti dal suo valore atteso (media) di una certa quantità. In altre parole, ci fornisce un limite superiore alla probabilità che una variabile aleatoria assuma valori “estremi”.
Il teorema di Chebyshev afferma che, per qualsiasi variabile aleatoria X con media E(X) e varianza Var(X), e per qualsiasi numero reale k > 0, si ha:
\[ P(\mid X - E(X)\mid \geq k \sigma) \leq 1/k^2, \tag{31.10}\]
dove:
- \(P(\mid X - E(X)\mid \geq k \sigma)\) è la probabilità che lo scarto assoluto tra X e la sua media sia maggiore o uguale a k volte la deviazione standard (σ).
- σ è la radice quadrata della varianza, ovvero la deviazione standard.
Cosa ci dice questo teorema?
- Limite superiore: Il teorema ci fornisce un limite superiore alla probabilità che una variabile aleatoria si discosti dalla sua media di più di k deviazioni standard.
- Qualsiasi distribuzione: La bellezza di questo teorema è che vale per qualsiasi distribuzione di probabilità, a patto che la media e la varianza esistano.
- Utilizzo: Il teorema di Chebyshev è molto utile quando non conosciamo la distribuzione esatta di una variabile aleatoria, ma conosciamo la sua media e la sua varianza.
In sintesi, il teorema di Chebyshev ci fornisce un limite superiore alla probabilità che una variabile aleatoria si discosti dalla sua media di una certa quantità, in base alla sua varianza. Il teorema di Chebyshev ci permette quindi di fare inferenze sulla distribuzione di una variabile aleatoria anche quando abbiamo informazioni limitate.
31.6 Momenti di variabili casuali
Definizione 31.5 Si chiama momento di ordine \(q\) di una v.c. \(X\), dotata di densità \(p(x)\), la quantità
\[ \mathbb{E}(X^q) = \int_{-\infty}^{+\infty} x^q p(x) \; dx. \tag{31.11}\]
Se \(X\) è una v.c. discreta, i suoi momenti valgono:
\[ \mathbb{E}(X^q) = \sum_i x_i^q P(x_i), \tag{31.12}\]
dove:
- \(E(X^q)\) rappresenta il valore atteso di \(X\) elevato alla \(q\)-esima potenza.
- \(x_i\) sono i possibili valori della variabile discreta.
- \(P(x_i)\) è la probabilità associata a ciascun valore discreto.
I momenti sono parametri statistici che forniscono informazioni importanti sulle caratteristiche di una variabile casuale. Tra questi, i più noti e utilizzati sono:
- Il momento del primo ordine (\(q\) = 1): corrisponde al valore atteso (o media) della variabile casuale \(X\).
- Il momento del secondo ordine (\(q\) = 2): quando calcolato rispetto alla media, corrisponde alla varianza.
Per i momenti di ordine superiore al primo, è comune calcolarli rispetto al valore medio di \(X\). Questo si ottiene applicando una traslazione: \(x_0 = x − \mathbb{E}(X)\), dove \(x_0\) rappresenta lo scarto dalla media. In particolare, il momento centrale del secondo ordine, calcolato con questa traslazione, corrisponde alla definizione di varianza.
In R, possiamo calcolare il valore atteso e la varianza di variabili casuali discrete utilizzando vettori di valori e probabilità.
Consideriamo una variabile casuale \(X\) che rappresenta i valori ottenuti dal lancio di un dado non equilibrato, con valori possibili da 0 a 6, e con la seguente distribuzione di massa di probabilità: 0.1, 0.2, 0.3, 0.1, 0.1, 0.0, 0.2.
Iniziamo a definire un vettore che contiene i valori della v.c.:
x <- 0:6
print(x)
#> [1] 0 1 2 3 4 5 6Il vettore px conterrà le probabilità associate ai valori x:
Controlliamo che la somma sia 1:
sum(px)
#> [1] 1Calcoliamo il valore atteso di \(X\) implementando la formula del valore atteso utilizzando i vettori x e px:
x_ev <- sum(x * px)
x_ev
#> [1] 2.7Calcoliamo la varianza di \(X\) usando i vettori x e px:
x_var <- sum((x - x_ev)^2 * px)
x_var
#> [1] 3.81Calcoliamo la deviazione standard di \(X\) prendendo la radice quadrata della varianza:
x_sd <- sqrt(x_var)
x_sd
#> [1] 1.952Per rappresentare graficamente la distribuzione di massa, possiamo usare ggplot2:
df <- data.frame(x = x, pmf = px)
ggplot(df, aes(x = x, y = pmf)) +
geom_point(color = "#832F2B", size = 3) +
geom_segment(aes(xend = x, yend = 0), linewidth = 1) +
labs(title = "Distribuzione di massa di probabilità",
x = "Valori", y = "Probabilità")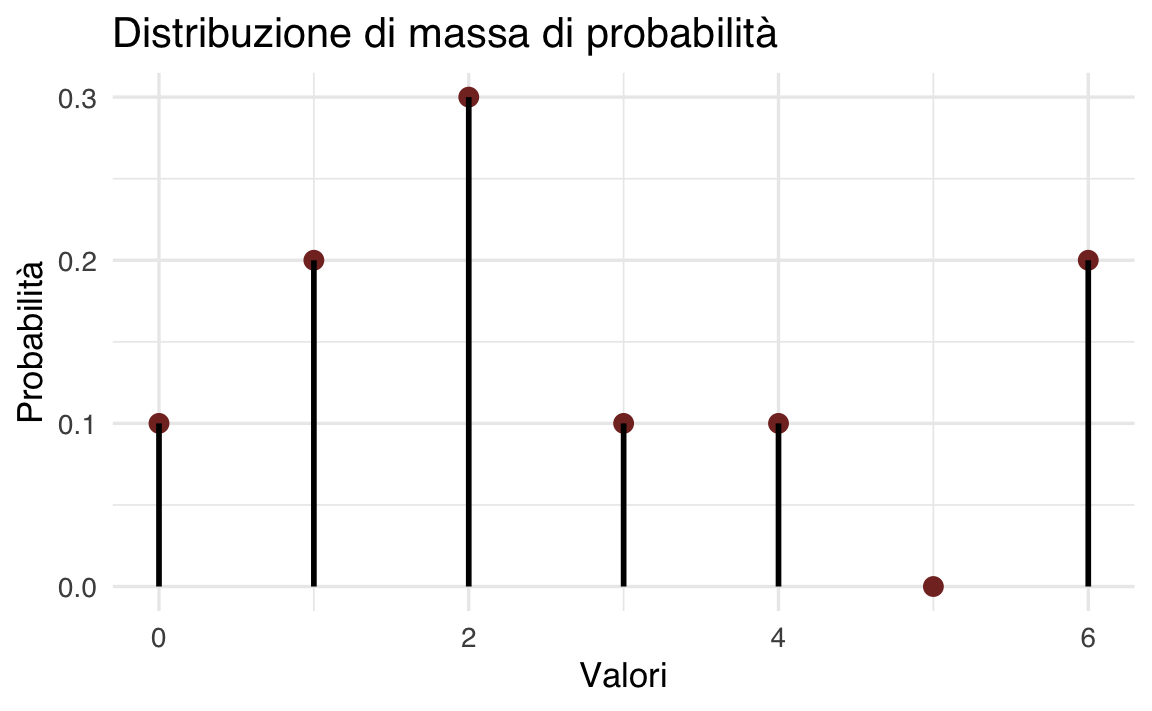
Questo codice calcola il valore atteso, la varianza e la deviazione standard di una variabile casuale discreta e rappresenta graficamente la distribuzione di massa, tutto in R.
Riflessioni conclusive
In conclusione, i concetti di valore atteso e varianza sono fondamentali per comprendere il comportamento delle variabili casuali. Il valore atteso fornisce una misura centrale, rappresentando il “valore tipico” che ci si aspetta di osservare, mentre la varianza quantifica la dispersione dei valori attorno a questa media, offrendo una visione più completa della distribuzione. Questi strumenti sono essenziali per l’analisi e la modellizzazione statistica, fornendo le basi per valutare e interpretare la variabilità nei fenomeni aleatori.