93 Limiti dell’inferenza frequentista
Prerequisiti
- Leggere Bayesian statistics for clinical research di Goligher et al. (2024).
Concetti e Competenze Chiave
- Comprensione e limiti della NHST.
- Origine e utilizzo del valore-\(p\).
- Critiche all’uso del valore-\(p\).
- Concetto di \(P\)-hacking.
- L’importanza di valutare la dimensione dell’effetto piuttosto che limitarsi alla significatività statistica.
- Crisi della riproducibilità.
Introduzione
In questa sezione della dispensa, abbiamo approfondito il metodo “tradizionale” per il test di significatività dell’ipotesi nulla (NHST). Comprendere la logica sottostante all’approccio NHST è fondamentale, poiché esso ha rappresentato il principale strumento della statistica inferenziale sin dalla sua introduzione all’inizio del XX secolo, e la maggior parte dei ricercatori continua a basarsi su questa procedura per l’analisi dei dati. Tuttavia, negli ultimi anni, l’NHST è stato oggetto di crescenti critiche, con molti studiosi che sostengono che questo approccio possa generare più problemi di quanti ne risolva. Per questo motivo, è cruciale esaminare le critiche avanzate dalla comunità scientifica nei confronti della procedura inferenziale NHST. In questa sezione, analizzeremo alcuni dei principali dubbi e limiti emersi riguardo a tale metodologia.
93.1 L’uso del valore-\(p\) nel mondo della ricerca
Nel suo articolo “Statistical Errors” (2014), Nuzzo mette in luce i limiti dell’approccio NHST nella pratica scientifica Nuzzo (2014). Sebbene il valore-\(p\) sia stato introdotto da Ronald Fisher negli anni ’20, egli non lo concepì mai come un test formale. Fisher lo considerava piuttosto uno strumento informale per valutare se l’evidenza empirica fosse “significativa” in senso colloquiale, ovvero meritevole di ulteriore attenzione. Nella pratica, Fisher suggeriva di assumere un’ipotesi nulla e di calcolare la probabilità di osservare un risultato altrettanto estremo o più estremo di quello ottenuto, presupponendo che il risultato fosse interamente dovuto alla variabilità campionaria. Tuttavia, per Fisher, il valore-\(p\) non era una conclusione definitiva, ma uno strumento da integrare in un processo decisionale più ampio, che tenesse conto sia delle evidenze empiriche sia delle conoscenze pregresse del ricercatore. In altre parole, il valore-\(p\) era parte di un ragionamento scientifico, non il punto finale di tale ragionamento.
Verso la fine degli anni ’20, Jerzy Neyman e Egon Pearson, rivali di Fisher, formalizzarono le procedure di decisione statistica con l’obiettivo di renderle più rigorose e oggettive. Introdussero concetti come il potere statistico e il tasso di falsi positivi, ma si distanziarono dall’uso del valore-\(p\) proposto da Fisher. Le divergenze tra Fisher, Neyman e Pearson diedero vita a un acceso dibattito: Neyman definì il lavoro di Fisher “matematicamente peggiore dell’inutilità”, mentre Fisher bollò l’approccio di Neyman come “infantile” e “dannoso per la libertà intellettuale dell’Occidente”.
Nel frattempo, altri autori iniziarono a scrivere manuali di statistica per guidare i ricercatori. Tuttavia, molti di questi autori non erano statistici e avevano una comprensione superficiale delle differenze tra i vari approcci. Il risultato fu un sistema ibrido che combinava il valore-\(p\) di Fisher con il framework rigoroso di Neyman e Pearson. Fu in questo contesto che la soglia di un valore-\(p\) pari a 0.05 venne arbitrariamente definita come “statisticamente significativa”.
Storicamente, tuttavia, il valore-\(p\) proposto da Fisher aveva un significato molto diverso rispetto a quello che gli viene attribuito oggi. Come abbiamo visto, per Fisher era uno strumento informale, da utilizzare all’interno di un processo decisionale più ampio e non come un criterio meccanico per stabilire la verità scientifica. L’uso del valore-\(p\) nel sistema ibrido adottato dai manuali di statistica è quindi privo di una solida giustificazione teorica.
Nel 2016, l’American Statistical Association (ASA) ha espresso forti preoccupazioni riguardo all’uso inappropriato del valore-\(p\) nella pratica scientifica contemporanea Wasserstein & Lazar (2016):
\(P\)-values do not measure the probability that the studied hypothesis is true, or the probability that the data were produced by random chance alone. Researchers often wish to turn a \(p\)-value into a statement about the truth of a null hypothesis, or about the probability that random chance produced the observed data. The \(p\)-value is neither. It is a statement about data in relation to a specified hypothetical explanation, and is not a statement about the explanation itself.
L’articolo prosegue sottolineando che:
Scientific conclusions and business or policy decisions should not be based only on whether a \(p\)-value passes a specific threshold. Practices that reduce data analysis or scientific inference to mechanical “bright-line” rules (such as “\(p < 0.05\)”) for justifying scientific claims or conclusions can lead to erroneous beliefs and poor decision making. A conclusion does not immediately become ‘true’ on one side of the divide and ‘false’ on the other. Researchers should bring many contextual factors into play to derive scientific inferences, including the design of a study, the quality of the measurements, the external evidence for the phenomenon under study, and the validity of assumptions that underlie the data analysis. Pragmatic considerations often require binary, ‘yes-no’ decisions, but this does not mean that \(p\)-values alone can ensure that a decision is correct or incorrect. The widespread use of “statistical significance” (generally interpreted as \(p \leq 0.05\)) as a license for making a claim of a scientific finding (or implied truth) leads to considerable distortion of the scientific process.
93.2 \(P\)-hacking
La pratica del \(P\)-hacking rappresenta una delle principali criticità associate all’uso del valore-\(p\) ed è conosciuta anche con termini come data-dredging, snooping, fishing, significance-chasing o double-dipping. Secondo Uri Simonsohn, professore all’Università della Pennsylvania, il \(P\)-hacking consiste nel manipolare i dati o le analisi fino a ottenere un risultato statisticamente significativo, tipicamente con un valore-\(p\) inferiore a 0.05. Ad esempio, si potrebbe dire: “Quel risultato sembra frutto di \(P\)-hacking; gli autori hanno escluso una condizione per far diminuire il valore-\(p\) sotto la soglia di 0.05” oppure “Lei è un \(P\)-hacker, controlla continuamente i dati durante la raccolta per trovare un risultato significativo”.
Questa pratica trasforma uno studio esplorativo, che dovrebbe essere interpretato con estrema cautela, in uno studio confermativo (apparentemente robusto), i cui risultati, tuttavia, hanno una probabilità molto bassa di essere replicati in ricerche successive. Secondo le simulazioni condotte da Simonsohn, piccole modifiche nelle scelte analitiche possono aumentare il tasso di falsi positivi fino al 60% in un singolo studio.
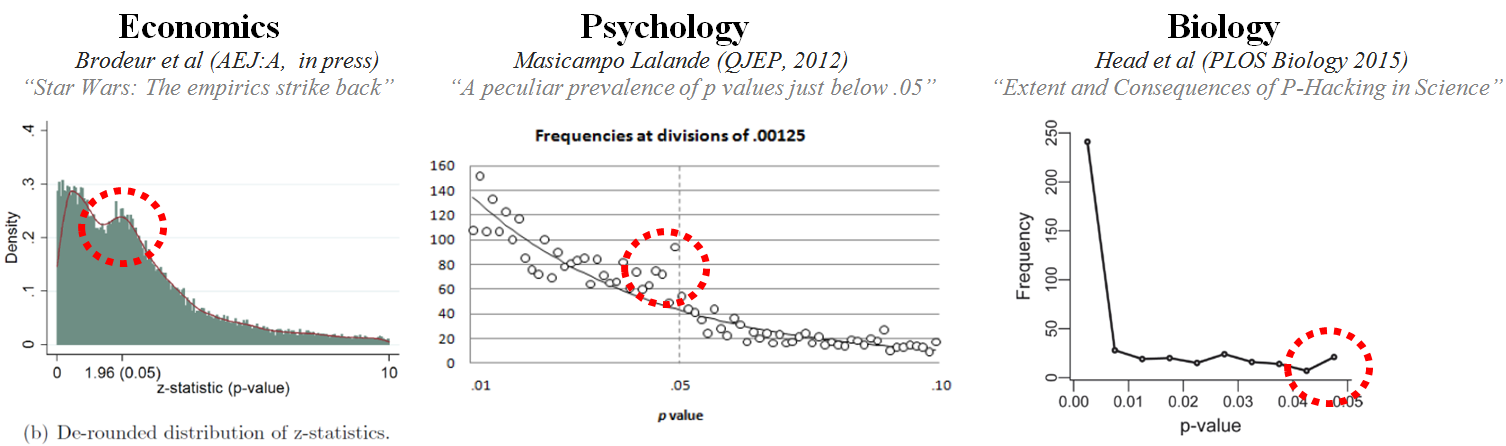
Il \(P\)-hacking è particolarmente diffuso negli studi che cercano di dimostrare effetti di piccola entità utilizzando dati molto rumorosi. Un’analisi della letteratura psicologica ha rivelato che i valori-\(p\) riportati tendono a concentrarsi appena al di sotto della soglia di 0.05, un fenomeno che può essere interpretato come un segnale di \(P\)-hacking: i ricercatori eseguono molteplici test statistici fino a trovarne uno che raggiunge la “significatività statistica” e poi riportano solo quello. Come evidenziato in figura, questa pratica non è limitata alla psicologia, ma è ampiamente diffusa in tutti i campi della ricerca scientifica, contribuendo a minare l’affidabilità dei risultati pubblicati.
93.3 Critiche al valore-\(p\)
Il valore-\(p\) è stato spesso paragonato a creature fastidiose e persistenti come le zanzare, oppure ai “vestiti nuovi dell’imperatore”, metafora che rappresenta la tendenza a ignorare problemi evidenti preferendo fingere che tutto vada bene. È stato anche definito un intellectual rake sterile, un termine che sottolinea la sua incapacità di produrre risultati utili. Non manca nemmeno l’ironia sul fatto che la procedura di statistical hypothesis inference testing venga chiamata così principalmente per l’acronimo che genera.
Il valore-\(p\) promuove un modo di pensare distorto, spostando l’attenzione dal cuore della ricerca, ovvero la forza della manipolazione sperimentale, verso la dimostrazione di un’ipotesi nulla che si sa già essere falsa. Ad esempio, uno studio condotto su oltre 19,000 individui ha mostrato che le coppie che si incontrano online hanno una probabilità inferiore di divorziare (\(p < 0.002\)) e riportano una maggiore soddisfazione nella vita matrimoniale (\(p < 0.001\)) rispetto a quelle che si sono conosciute offline. Sebbene questi risultati possano sembrare interessanti, senza considerare la dimensione dell’effetto – come la riduzione del tasso di divorzio dal 7.67% al 5.96% o l’aumento dell’indice di soddisfazione matrimoniale da 5.48 a 5.64 su una scala a sette punti – il loro impatto pratico rischia di essere sopravvalutato. In generale, la domanda chiave non dovrebbe essere “c’è un effetto?”, ma piuttosto “quanto è grande l’effetto?”. Questo approccio permette di valutare meglio l’effettiva rilevanza dei risultati, andando oltre la semplice significatività statistica.
93.4 L’effetto sperimentale è esattamente nullo?
Una delle critiche più ricorrenti alla logica del test di verifica delle ipotesi statistiche riguarda l’assunzione irrealistica che l’effetto della manipolazione sperimentale sia esattamente nullo. Ad esempio, la fisica ci dimostra che persino lo spostamento di un grammo di massa in una stella distante anni luce dalla Terra può influenzare, seppur minimamente, il movimento delle molecole di un gas sul nostro pianeta (Borel, 1914). Questo esempio suggerisce che ogni manipolazione sperimentale, per quanto piccola, produca in qualche modo un effetto. Pertanto, come sottolinea Andrew Gelman, il problema non è tanto dimostrare che l’ipotesi nulla sia falsa – ovvero che la manipolazione sperimentale non abbia alcun effetto – quanto piuttosto valutare se la dimensione dell’effetto sia sufficientemente grande da avere un impatto pratico e se tale effetto sia riproducibile.
In questo contesto, la logica del test dell’ipotesi nulla risulta particolarmente problematica, specialmente quando si lavora con campioni piccoli ed effetti di modesta entità, come accade spesso negli studi psicologici. Questo approccio può portare a una sovrastima della dimensione dell’effetto e a una visione binaria dei risultati (vero/falso), distogliendo l’attenzione dalla stima accurata e non distorta della dimensione effettiva dell’effetto. In altre parole, la ricerca dovrebbe concentrarsi meno sul rifiutare un’ipotesi nulla spesso irrealistica e più sulla comprensione e quantificazione dell’impatto reale delle variabili studiate.
93.5 Attenti al valore-\(p\)!
Consideriamo il seguente problema. Supponiamo di eseguire un \(t\)-test per due campioni indipendenti per verificare l’ipotesi nulla che le medie delle due popolazioni siano uguali. Fissiamo un livello di significatività \(\alpha = 0.05\) e otteniamo un valore-\(p\) pari a \(0.04\). La domanda è: qual è la probabilità che i due campioni provengano da distribuzioni con la stessa media?
Le opzioni sono:
(a) \(19/20\); (b) \(1/19\); (c) \(1/20\); (d) \(95/100\); (e) sconosciuta.
La risposta corretta è: (e) sconosciuta. Questo perché la statistica frequentista calcola le probabilità dei dati condizionatamente alle ipotesi (assunte come vere), ma non permette di determinare la probabilità di un’ipotesi. In altre parole, il valore-\(p\) non fornisce informazioni sulla probabilità che l’ipotesi nulla sia vera o falsa; indica solo la probabilità di osservare i dati (o risultati più estremi) assumendo che l’ipotesi nulla sia vera.
93.6 La crisi della riprodicibilità dei risultati della ricerca
Negli ultimi anni, la mancanza di replicabilità dei risultati della ricerca – inclusa quella psicologica – è emersa come un tema di grande rilevanza nel dibattito scientifico. In questo contesto, è stato evidenziato che alcuni aspetti del metodo scientifico, in particolare l’uso del valore-\(p\) e la pratica del test di significatività dell’ipotesi nulla (NHST, Null Hypothesis Significance Testing), potrebbero contribuire a quella che è stata definita una “crisi della ricerca scientifica”. Un’analisi approfondita di questo problema è stata proposta da Gelman (2016), il quale sostiene che la NHST sia intrinsecamente problematica. Questo approccio, infatti, spinge i ricercatori a cercare di rigettare un’ipotesi “fantoccio” (straw-man), spesso già falsa a priori o di scarso interesse scientifico, a favore di un’ipotesi alternativa che il ricercatore preferisce. In generale, è più ragionevole affermare che la differenza tra due condizioni sia molto piccola piuttosto che esattamente uguale a zero, ma la NHST non è progettata per cogliere questa sfumatura.
Nei libri di statistica, la NHST viene spesso presentata come una sorta di “alchimia” che trasforma la casualità in una falsa certezza, utilizzando termini come “confidenza” e “significatività” (Gelman, 2016). Il processo di raccolta dei dati, analisi e inferenza statistica viene sintetizzato in una conclusione espressa in termini di valore-\(p\) e intervalli di confidenza che escludono lo zero. Tuttavia, questo può creare l’impressione errata che il ricercatore abbia una comprensione completa del fenomeno studiato. Il problema principale della NHST è che spesso produce risultati “statisticamente significativi” in contesti in cui le caratteristiche del fenomeno non giustificano le conclusioni tratte. Questo può portare a una bassa replicabilità dei risultati, contribuendo alla crisi di fiducia nella ricerca.
La comunità statistica ha sottolineato come la non replicabilità sia particolarmente evidente quando i ricercatori, utilizzando la NHST, traggono conclusioni errate basate su piccoli campioni ed effetti di dimensioni ridotte. Queste condizioni, insieme ad altre, rendono l’applicazione della NHST estremamente problematica. Purtroppo, queste situazioni descrivono molte delle ricerche recenti in psicologia, un campo in cui gli effetti sono spesso modesti e i campioni limitati.
La statistica è stata definita come un metodo per prendere decisioni razionali in condizioni di incertezza. Gli statistici raccomandano ai ricercatori non solo di padroneggiare le tecniche statistiche, ma anche di imparare a convivere con l’incertezza, nonostante la crescente sofisticazione degli strumenti disponibili. Conviverci significa evitare di pensare che ottenere un valore-\(p\) “statisticamente significativo” equivalga a risolvere un problema scientifico. Ma allora, come possiamo avere fiducia in ciò che apprendiamo dai dati? Una possibile strategia è la replicazione e la convalida esterna dei risultati, sebbene nella ricerca psicologica e nelle scienze sociali questo sia spesso difficile da realizzare a causa degli elevati costi e delle complessità pratiche. Il problema di quali strumenti metodologici e metodi statistici siano più adatti per indagare i fenomeni psicologici, senza cadere in errori di interpretazione, rimane quindi una questione aperta e di cruciale importanza.
93.7 Commenti e considerazioni finali
Non possiamo concludere senza affrontare la controversia che circonda il concetto di valore-\(p\). Nonostante sia ancora ampiamente utilizzato e spesso interpretato in modo errato, il valore-\(p\) conferisce solo una parvenza di legittimità a risultati dubbi, incoraggia cattive pratiche di ricerca e favorisce la produzione di falsi positivi. Inoltre, il suo significato è spesso frainteso, persino dagli esperti: quando chiamati a definire il valore-\(p\), molti forniscono risposte imprecise o sbagliate. Ciò che i ricercatori desiderano sapere è se i risultati di uno studio siano corretti o meno, ma il valore-\(p\) non fornisce questa informazione. Non dice nulla sulla dimensione dell’effetto, sulla forza dell’evidenza o sulla probabilità che il risultato sia frutto del caso. Allora, qual è il suo vero significato? Stuart Buck lo spiega in modo efficace:
Immaginate di avere una moneta che sospettate sia truccata a favore della testa (l’ipotesi nulla è che la moneta sia equa). La lanciate 100 volte e ottenete più teste che croci. Il valore-\(p\) non vi dirà se la moneta è equa, ma vi indicherà la probabilità di ottenere almeno lo stesso numero di teste osservato se la moneta fosse equa. Questo è tutto – niente di più.
In sintesi, il valore-\(p\) risponde a una domanda molto specifica che, tuttavia, non ha alcuna rilevanza diretta per la validità scientifica dei risultati di una ricerca. In un’epoca in cui la crisi della riproducibilità dei risultati è sempre più evidente (Baker, 2016), il test dell’ipotesi nulla e gli intervalli di confidenza frequentisti sono stati identificati come una delle principali cause del problema. Questo ha spinto molti ricercatori a cercare alternative metodologiche più robuste e informative, in grado di superare i limiti intrinseci del valore-\(p\) e di promuovere una scienza più affidabile e trasparente.