here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(cmdstanr, posterior, brms, bayestestR, insight)67 La grandezza dell’effetto: valutare la rilevanza pratica
“Il valore di P non misura l’importanza di un risultato. Per l’importanza, guardate all’entità dell’effetto.”
– Jacob Cohen, Statistician and psychologist
Introduzione
Nel capitolo precedente abbiamo esaminato la differenza nei punteggi di QI tra bambini nati da madri con e senza diploma di scuola superiore. L’analisi bayesiana ci ha permesso di ottenere una distribuzione a posteriori per questa differenza, da cui derivano inferenze probabilistiche ricche e sfumate. Ma un interrogativo cruciale rimane aperto: questa differenza è importante?
In psicologia, come in molte scienze applicate, non è sufficiente stabilire che un effetto esiste: bisogna valutare se l’effetto ha una magnitudine sufficiente da avere rilevanza teorica, clinica o sociale. È in questa prospettiva che si introduce il concetto di grandezza dell’effetto (effect size), una misura quantitativa dell’intensità di un risultato.
Panoramica del capitolo
- Che cosa misuriamo quando parliamo di “grandezza dell’effetto”.
- Come stimarlo con modelli bayesiani in
brms. - Come comunicarlo con intervalli e predizioni.
67.1 Perché stimare la grandezza dell’effetto
La grandezza dell’effetto fornisce un ponte tra analisi statistica e interpretazione sostanziale dei dati. Essa consente di rispondere a domande come:
- Quanto è marcata la differenza osservata?
- L’effetto ha un impatto concreto nella vita reale o nelle applicazioni cliniche?
- La variazione osservata è sufficiente a giustificare interventi, cambiamenti o nuove ipotesi teoriche?
L’American Psychological Association (APA) raccomanda di riportare sempre una misura di grandezza dell’effetto, in quanto essa fornisce un’informazione critica che va oltre la mera dicotomia “effetto presente / effetto assente”.
67.2 Standardizzare le differenze: il Cohen’s d
Nel confronto tra due gruppi, una delle misure più comuni di grandezza dell’effetto è il Cohen’s d**, che esprime la differenza tra due medie in unità di deviazione standard:
\[ d = \frac{\mu_1 - \mu_2}{\sigma}, \]
dove:
- \(\mu_1\) e \(\mu_2\) sono le medie dei due gruppi,
- \(\sigma\) è una stima comune della deviazione standard.
L’interpretazione di d è indipendente dalle unità di misura originali, il che la rende particolarmente utile per confrontare risultati provenienti da diversi studi o contesti.
67.3 Il Cohen’s d in ottica bayesiana
Nell’approccio bayesiano, non calcoliamo un unico valore di d, ma una distribuzione a posteriori di valori plausibili per d, ottenuta combinando:
- i campioni posteriori della differenza tra gruppi,
- i campioni posteriori della deviazione standard residua.
67.3.1 Esempio pratico con brms
A partire dal modello stimato nel capitolo precedente:
Otteniamo i campioni posteriori:
post <- as_draws_df(fit_1)
d_samples <- post$b_mom_hs / post$sigma67.3.1.1 Visualizzazione della distribuzione di d
mcmc_areas(as_draws_df(tibble(d = d_samples)), pars = "d", prob = 0.89) +
labs(
title = "Distribuzione a posteriori di Cohen's d",
subtitle = "Stima bayesiana della grandezza dell’effetto"
)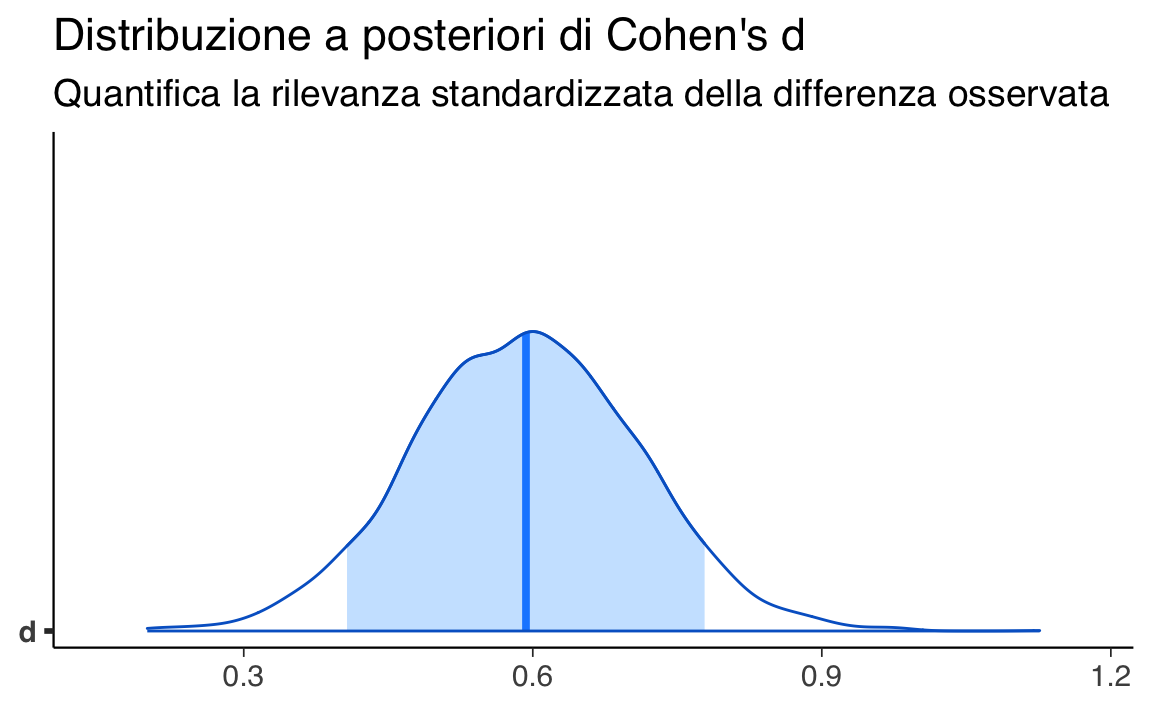
Questa distribuzione esprime l’incertezza residua sulla grandezza dell’effetto, dopo aver osservato i dati, ed è il punto di partenza per una valutazione più completa.
67.3.1.2 Statistiche riassuntive
bayestestR::describe_posterior(d_samples, ci = 0.89)
#> Summary of Posterior Distribution
#>
#> Parameter | Median | 89% CI | pd | ROPE | % in ROPE
#> --------------------------------------------------------------------
#> Posterior | 0.59 | [0.41, 0.78] | 100% | [-0.10, 0.10] | 0%Questa funzione fornisce:
- la stima centrale (media o mediana) di d,
- l’intervallo di credibilità,
- la probabilità che d sia maggiore o minore di soglie rilevanti.
67.3.1.3 Interpretare la grandezza dell’effetto: da soglie fisse a giudizi probabilistici
In ambito frequentista, la seguente classificazione è comunemente usata:
| Valore di d | Interpretazione convenzionale |
|---|---|
| ≈ 0.2 | Effetto piccolo |
| ≈ 0.5 | Effetto medio |
| ≥ 0.8 | Effetto grande |
Queste soglie hanno valore euristico, ma non vanno applicate meccanicamente. Nell’approccio bayesiano possiamo invece porre domande più informative, del tipo:
- Qual è la probabilità che l’effetto superi 0.5 (soglia di effetto medio)?
- Qual è la probabilità che sia minore di 0.2 (effetto trascurabile)?
- Qual è l’intervallo entro cui cade il 89% degli effetti più credibili?
Queste domande trovano risposta diretta nei dati posteriori:
67.3.1.4 La soglia di rilevanza pratica
In contesti applicativi, non basta sapere che l’effetto è diverso da zero: bisogna chiedersi se supera una soglia minima di rilevanza (minimum effect of interest, o region of practical equivalence).
Ad esempio, se uno psicologo clinico ritiene che un effetto inferiore a d = 0.3 sia irrilevante dal punto di vista terapeutico, può valutare:
mean(d_samples > 0.3)
#> [1] 0.9938Questa quantità risponde alla domanda: qual è la probabilità che l’effetto sia rilevante nella pratica clinica?
Riflessioni conclusive
Le linee guida dell’American Psychological Association (APA) sottolineano l’importanza di riportare sistematicamente le stime della dimensione dell’effetto (effect size) nella comunicazione dei risultati della ricerca. Questa raccomandazione nasce dalla consapevolezza che la mera verifica di ipotesi, spesso concentrata su un valore di probabilità, fornisce un’informazione limitata. La stima dell’effect size, al contrario, consente di quantificare la magnitudine di un fenomeno, offrendo una base più solida per valutarne la rilevanza teorica o applicativa. L’identificazione di un effetto statisticamente rilevante rappresenta dunque solo un primo passo; la sua reale interpretazione scientifica richiede una comprensione approfondita della sua entità.
Nell’ambito della statistica frequentista, la dimensione dell’effetto viene tipicamente comunicata attraverso una stima puntuale corredata da un intervallo di confidenza. Quest’ultimo descrive la variabilità attesa della stima in un’ipotetica sequenza di replicazioni dello studio. Sebbene utile, questa rappresentazione può incoraggiare, anche involontariamente, un’interpretazione dicotomica dei risultati, dove l’attenzione si concentra esclusivamente sul superamento di una soglia di significatività.
L’inferenza bayesiana propone una prospettiva alternativa, trattando la dimensione dell’effetto non come un parametro fisso ma come una variabile aleatoria. La sua incertezza viene rappresentata attraverso una distribuzione di probabilità a posteriori, che sintetizza l’evidenza proveniente dai dati osservati e dalle conoscenze preliminari, formalizzate in una distribuzione a priori. Questo quadro concettuale permette di formulare affermazioni probabilistiche dirette sull’effect size, come calcolare la probabilità che esso superi una determinata soglia di rilevanza clinica o teorica. L’incertezza viene così rappresentata in modo continuo e sfumato, evitando categorizzazioni rigide.
Questo approccio si adatta particolarmente bene all’indagine dei processi psicologici, caratterizzati da un’elevata complessità e variabilità. L’obiettivo dell’analisi bayesiana non è quello di giungere a una conclusione definitiva, ma di aggiornare in modo coerente e trasparente il grado di plausibilità associato a diverse ipotesi. In questo contesto, la stima della dimensione dell’effetto assume un ruolo centrale, diventando uno strumento inferenziale per valutare la credibilità e l’importanza pratica dei risultati ottenuti.
Adottare una prospettiva bayesiana significa quindi abbracciare un paradigma inferenziale che privilegia la valutazione probabilistica e contestualizzata rispetto alla decisione dicotomica. Questo passaggio favorisce una comunicazione scientifica più ricca e meno ambigua, contribuendo a una psicologia maggiormente riflessiva, trasparente e focalizzata sul significato sostanziale dei propri risultati.
Bibliografia
Kruschke, J. K. (2013). Bayesian estimation supersedes the t test. Journal of Experimental Psychology: General, 142(2), 573–603.