81 Valutare i modelli bayesiani
Introduzione
Nei capitoli precedenti abbiamo visto due concetti fondamentali: l’entropia, che misura l’incertezza insita in una distribuzione, e la divergenza di Kullback–Leibler (\(D_{\text{KL}}\)), che quantifica la distanza tra due distribuzioni di probabilità. Ora possiamo fare un passo ulteriore: usare queste idee per valutare e confrontare modelli statistici nel contesto bayesiano.
Il punto di partenza è una domanda cruciale: quanto bene il modello riesce a prevedere nuovi dati? Un buon modello non deve solo adattarsi ai dati osservati, ma deve anche saper generalizzare a situazioni future. Questa distinzione – adattamento vs. generalizzazione – è il cuore della valutazione predittiva.
Immaginiamo, ad esempio, di sviluppare un test psicologico per stimare l’ansia degli studenti prima di un esame. Non basta sapere che il modello descrive bene il campione usato per costruirlo: vogliamo essere ragionevolmente sicuri che le stesse previsioni funzionino anche per studenti che non hanno partecipato allo studio. In psicologia, scegliere tra due modelli è simile a decidere quale test usare: in entrambi i casi si cerca lo strumento che fornisce previsioni più affidabili.
Panoramica del capitolo
Per rispondere alla domanda fondamentale sulla qualità predittiva, seguiremo un percorso logico che ci condurrà dagli strumenti teorici ai metodi pratici:
- Prima costruiremo la base teorica: vedremo come la distribuzione predittiva posteriore incorpora l’incertezza sui parametri nelle nostre previsioni
- Poi definiremo le misure di accuratezza: il log-score per valutare la bontà delle previsioni punto per punto
- Distingueremo tra valutazione in-sample e out-of-sample: LPPD (sui dati osservati) vs. ELPD (capacità di generalizzazione)
- Collegheremo tutto alla divergenza KL: per capire perché massimizzare l’ELPD equivale a trovare il modello più vicino alla realtà
- Implementeremo metodi pratici: LOO-CV per stimare l’ELPD senza conoscere la vera distribuzione dei dati
- Confronteremo con altri criteri: AIC, BIC, WAIC e i loro ambiti di applicazione
L’obiettivo è fornire strumenti pratici e un quadro concettuale chiaro per guidare la scelta del modello più adatto al problema in esame.
81.1 Il punto di partenza: dalle previsioni deterministiche a quelle probabilistiche
Prima di addentrarci nei dettagli tecnici, facciamo un passo indietro per capire perché la valutazione predittiva bayesiana è diversa da quella frequentista classica.
Nell’approccio classico, una volta stimati i parametri (ad esempio con la massima verosimiglianza), li trattiamo come “veri” e fissi. Se \(\hat{\theta}\) è la nostra stima, la previsione per un nuovo dato \(\tilde{y}\) è semplicemente:
\[ p(\tilde{y} \mid \hat{\theta}). \] Questo approccio ignora completamente l’incertezza sulla stima dei parametri.
Nell’approccio bayesiano, invece, riconosciamo che i parametri sono incerti. Anche dopo aver osservato i dati, la nostra conoscenza di \(\theta\) è descritta da un’intera distribuzione posteriore \(p(\theta \mid y)\), non da un singolo valore. Le previsioni devono quindi riflettere questa incertezza.
81.2 Distribuzione predittiva posteriore: il cuore delle previsioni bayesiane
Nel capitolo sul modello beta–binomiale l’abbiamo già incontrata: è lo strumento che, nell’approccio bayesiano, consente di prevedere nuovi dati incorporando sia la struttura del modello sia l’incertezza sui parametri. La logica è elegante nella sua semplicità: dopo aver osservato i dati \(y\), non otteniamo un singolo “miglior” valore dei parametri, ma una distribuzione posteriore \(p(\theta \mid y)\) che quantifica i valori plausibili di \(\theta\) e la nostra incertezza.
Esempio concreto: Uno psicologo che stima il livello medio di ansia in una popolazione, invece di affermare “la media è 4.7”, dirà: “il valore più plausibile è 4.7, ma è ragionevole che sia tra 4.2 e 5.1”, riflettendo la variabilità della distribuzione a posteriori.
81.2.1 La formula fondamentale
Per prevedere un nuovo dato \(\tilde{y}\), non fissiamo \(\theta\). Mediamo invece tutte le previsioni condizionate \(p(\tilde{y} \mid \theta)\) pesandole con la densità posteriore \(p(\theta\mid y)\):
\[ p(\tilde{y} \mid y) = \int p(\tilde{y} \mid \theta)\, p(\theta \mid y)\, d\theta \tag{81.1}\] Questa è la distribuzione predittiva posteriore, e rappresenta la nostra migliore previsione per dati futuri dato quello che abbiamo osservato.
81.2.2 Decomposizione dell’integrale: cosa significa realmente
L’Equazione 81.1 può sembrare astratta, ma ha un’interpretazione intuitiva molto chiara:
- \(p(\tilde{y} \mid \theta)\): se conoscessimo il vero valore di \(\theta\), questa sarebbe la nostra previsione per \(\tilde{y}\);
- \(p(\theta \mid y)\): questa è la nostra incertezza su quale sia il vero valore di \(\theta\);
- L’integrale: combina le previsioni per tutti i possibili valori di \(\theta\), pesandole secondo quanto crediamo che ciascun valore sia plausibile.
Esaminiamo ora uno script in R che implementa passo per passo l’approssimazione della distribuzione predittiva posteriore binomiale con il metodo su griglia.
# ESEMPIO DIDATTICO: predittiva posteriore per Binomiale con metodo su griglia
# Dati e prior
k <- 10 # successi osservati
n <- 50 # prove osservate
a <- 1 # prior Beta(a, b)
b <- 1
m <- 10 # numero di prove future per la predizione (scelta didattica)
J <- 2000 # numero di punti griglia su theta in [0,1]
# -------------------------------------------------------------
# PASSAGGIO 1: Griglia su theta
# -------------------------------------------------------------
theta <- seq(0, 1, length.out = J)
# -------------------------------------------------------------
# PASSAGGIO 2: Densità posteriore non normalizzata su ogni punto di griglia
# -------------------------------------------------------------
# Posteriore ~ Beta(a + k, b + n - k) -> densità proporzionale a theta^(a+k-1) (1-theta)^(b+n-k-1)
post_unnorm <- theta^(a + k - 1) * (1 - theta)^(b + n - k - 1)
# Normalizzazione per ottenere pesi che sommano a 1
w <- post_unnorm / sum(post_unnorm)
# -------------------------------------------------------------
# PASSAGGIO 3: combinare le predittive condizionate p(tilde y | theta)
# -------------------------------------------------------------
# Obiettivo: costruire la pmf predittiva p(tilde y = x | y)
# per ogni x = 0,...,m come media pesata (sulla griglia di θ)
# delle pmf condizionate binomiali.
# 1) Definiamo i valori futuri possibili di tilde y
x_vals <- 0:m
# 2) Inizializziamo una matrice vuota:
# - J righe (una per ciascun θ_j della griglia)
# - (m+1) colonne (una per ogni valore possibile di x)
px_given_theta <- matrix(NA_real_, nrow = J, ncol = m + 1)
# 3) Riempiamo la matrice: per ogni θ_j (riga j) e per ogni x (colonna i)
# calcoliamo P(tilde y = x | θ_j) = Binomiale(x | m, θ_j)
for (j in 1:J) {
for (i in 1:(m + 1)) {
x <- x_vals[i]
px_given_theta[j, i] <- dbinom(x, size = m, prob = theta[j])
}
}
# 4) Combinazione pesata:
# p(tilde y = x | y) ≈ somma_j w_j * P(tilde y = x | θ_j).
# Per ciascun valore di x (colonna i), facciamo la somma pesata.
pred_pmf <- numeric(m + 1)
for (i in 1:(m + 1)) {
pred_pmf[i] <- sum(w * px_given_theta[, i])
}
# Nota didattica:
# - Ogni colonna della matrice px_given_theta contiene le probabilità condizionate
# P(tilde y = x_i | θ_j) per tutti i valori di griglia θ_j.
# - Moltiplicando riga per riga queste probabilità per i pesi posteriori w_j
# e sommando, otteniamo la probabilità predittiva p(tilde y = x_i | y).
# - In questo modo l'integrale viene approssimato da una somma pesata.
# -------------------------------------------------------------
# PASSAGGIO 4: Risultato: una pmf su {0,1,...,m}
# -------------------------------------------------------------
pred_df <- data.frame(x = x_vals, p = pred_pmf)
print(pred_df)
#> x p
#> 1 0 0.11391218
#> 2 1 0.25060680
#> 3 2 0.27617892
#> 4 3 0.19946255
#> 5 4 0.10397516
#> 6 5 0.04068593
#> 7 6 0.01205509
#> 8 7 0.00266151
#> 9 8 0.00041780
#> 10 9 0.00004200
#> 11 10 0.00000205sum(pred_df$p) # dovrebbe essere ~1
#> [1] 1# (Opzionale) campionamento dalla predittiva posteriore approssimata
# Estrae N valori da {0,...,m} con le probabilità 'p'
set.seed(123)
N <- 5000
tilde_y_samples <- sample(pred_df$x, size = N, replace = TRUE, prob = pred_df$p)
# Controllo: istogramma delle simulazioni vs pmf teorica approssimata
ggplot() +
geom_histogram(
data = data.frame(x = tilde_y_samples), aes(x = x, y = after_stat(density)),
binwidth = 1, breaks = seq(-0.5, m + 0.5, by = 1), fill = "skyblue",
color = "black") +
geom_point(data = pred_df, aes(x = x, y = p), pch = 19, cex = 3) +
geom_line(data = pred_df, aes(x = x, y = p), lwd = 1.5) +
ylim(0, max(pred_df$p) * 1.1) +
labs(
title = "Posterior Predictive (grid) – m=10",
x = expression(tilde(y)),
y = "Density")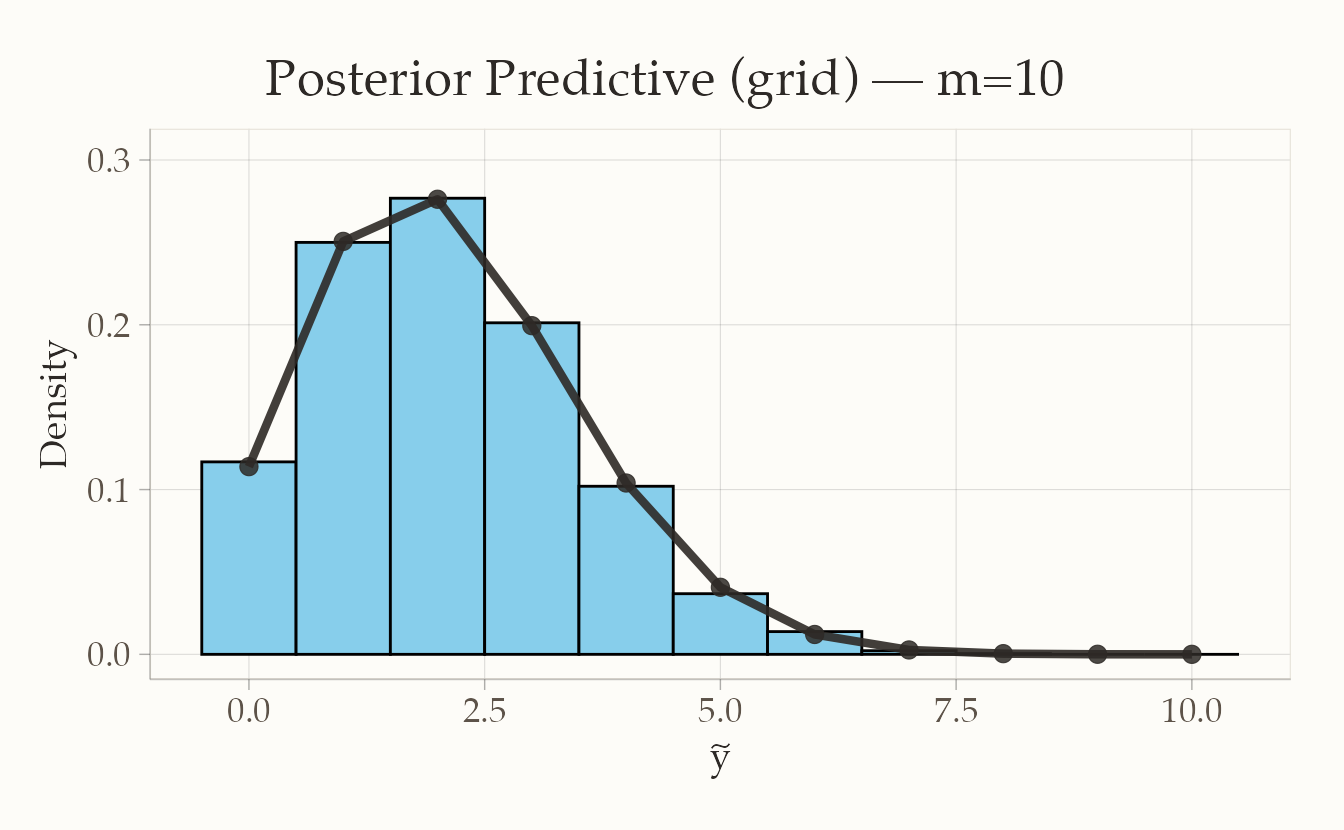
Nota: il vettore
pred_df$pè la pmf della predittiva posteriore approssimata; da qui si leggono probabilità, si calcolano quantità riassuntive e si può estrarre \(\tilde y\).
Verifica quando esiste la formula chiusa: Quando prior e likelihood sono coniugate (Beta + Binomiale), la predittiva è Beta–Binomiale. Possiamo usarla solo come verifica didattica:
# Confronto con Beta-Binomiale (se applicabile)
a_post <- a + k
b_post <- b + n - k
# pmf beta-binomial (con funzione base: dbetabinom in VGAM, altrimenti la implementiamo)
dbetabinom <- function(x, m, a, b) {
# Beta-Binomiale: choose(m, x) * Beta(x+a, m-x+b) / Beta(a, b)
choose(m, x) * beta(x + a, m - x + b) / beta(a, b)
}
bb_pmf <- sapply(0:m, function(x) dbetabinom(x, m, a_post, b_post))
cbind(grid = pred_df$p, beta_binom = bb_pmf)[1:6, ] # prime 6 righe a confronto
#> grid beta_binom
#> [1,] 0.1139 0.1139
#> [2,] 0.2506 0.2506
#> [3,] 0.2762 0.2762
#> [4,] 0.1995 0.1995
#> [5,] 0.1040 0.1040
#> [6,] 0.0407 0.040781.2.3 Notazione e terminologia
Notazione: Useremo talvolta la forma compatta \(p(\cdot \mid y)\) per indicare la predittiva posteriore del modello. Quando ci servirà evidenziare la previsione marginale per una singola osservazione \(y_i\), scriveremo:
\[ p(y_i \mid y) = \int p(y_i \mid \theta)\, p(\theta \mid y)\, d\theta, \] cioè la verosimiglianza \(p(y_i\mid\theta)\) integrata rispetto alla posteriore \(p(\theta\mid y)\).
Idea chiave: La predittiva posteriore propaga l’incertezza sui parametri alle previsioni. È questo passaggio a rendere le valutazioni predittive coerenti con il principio bayesiano, e quindi utilizzabili nel confronto tra modelli e nella stima di quantità legate alla “distanza” dal generatore dei dati.
81.3 Il problema fondamentale della valutazione predittiva
Ora che sappiamo come costruire previsioni bayesiane, affrontiamo la domanda centrale: come valutiamo la qualità di queste previsioni?
81.3.1 Il dilemma teorico
Quando costruiamo un modello, vogliamo sapere quanto bene riesce a predire dati futuri. In altre parole: se ripetessimo l’esperimento o raccogliessimo nuovi dati, quanto sarebbero vicine le predizioni del modello a quei dati?
Per formalizzare questa idea, distinguiamo tra due distribuzioni:
- la distribuzione vera dei dati futuri \(p(\tilde{y})\), che purtroppo non conosciamo,
- la distribuzione predittiva del modello \(p(\tilde{y} \mid y)\), cioè le predizioni basate sui dati osservati \(y\).
L’obiettivo è misurare quanto \(p(\tilde{y} \mid y)\) si avvicina a \(p(\tilde{y})\).
81.3.2 Una misura di distanza: la divergenza di Kullback–Leibler
La divergenza di Kullback–Leibler (KL) fornisce una misura di questa distanza:
\[ D_{\text{KL}}(p \parallel q) = \mathbb{E}_{p} \left[ \log \frac{p(\tilde{y})}{q(\tilde{y} \mid y)} \right]. \tag{81.2}\] Interpretazione intuitiva:
- se \(q\) (il nostro modello) assegna probabilità alte agli stessi eventi che sono probabili in \(p\) (la realtà), la distanza sarà piccola,
- se invece \(q\) “sbaglia bersaglio”, assegnando probabilità alte a eventi che in realtà sono rari, la distanza sarà grande.
81.3.3 Un ostacolo pratico insormontabile
Il problema è che \(p(\tilde{y})\) non lo conosciamo mai: non abbiamo accesso alla “vera” distribuzione dei dati futuri. Questa è la sfida fondamentale della validazione predittiva: come possiamo valutare la qualità delle nostre previsioni senza conoscere la verità?
Per questo dobbiamo ricorrere a strategie di approssimazione, come la validazione incrociata e criteri predittivi come ELPD, che vedremo nelle prossime sezioni.
81.3.3.1 Mini-esempio intuitivo
Immagina una moneta truccata che dà testa il 70% delle volte.
Vogliamo confrontare due modelli:
- Modello A: ipotizza una moneta equa (\(p = 0.5\)),
- Modello B: ipotizza una probabilità leggermente sbilanciata (\(p = 0.65\)).
Se sapessimo che la probabilità “vera” è \(p = 0.7\), sarebbe chiaro che il Modello B è più vicino alla realtà. La divergenza di Kullback–Leibler serve proprio a quantificare quanta informazione perdiamo quando ci affidiamo a un modello meno accurato (come A) invece che a uno più vicino alla verità (come B).
Il punto cruciale è che nella pratica non conosciamo mai la probabilità vera della moneta. Abbiamo soltanto i dati osservati, cioè gli esiti dei lanci. Per decidere quale modello predice meglio dobbiamo quindi basarci sui dati disponibili: è qui che entrano in gioco i metodi di confronto predittivo che studieremo.
81.4 Il log-score: misurare l’accuratezza predittiva punto per punto
Abbiamo definito la distribuzione predittiva posteriore e il problema teorico della valutazione. Ora introduciamo il primo strumento pratico: il log-score.
81.4.1 La domanda di base
Per ogni osservazione nei nostri dati, vogliamo sapere: quanto il nostro modello considerava plausibile questo specifico risultato? Il log-score risponde proprio a questa domanda.
81.4.2 Definizione formale
Il log-score per un’osservazione \(y_i\) è semplicemente il logaritmo della probabilità che il modello assegnava a quell’osservazione:
\[ \text{Log-score}(y_i) = \log p(y_i \mid y) , \tag{81.3}\] dove \(p(y_i \mid y)\) è la distribuzione predittiva posteriore che abbiamo appena imparato a calcolare:
\[ p(y_i \mid y) = \int p(y_i \mid \theta)\, p(\theta \mid y)\, d\theta . \]
81.4.3 Interpretazione: “scommettere” sui dati
Il log-score può essere interpretato come quanto il modello avrebbe “scommesso” su quel particolare risultato:
- se il modello assegna alta probabilità* a \(y_i\)*: \(p(y_i \mid y) \approx 1\), quindi \(\log p(y_i \mid y) \approx 0\) (buono);
- se il modello assegna bassa probabilità* a \(y_i\)*: \(p(y_i \mid y) \approx 0\), quindi \(\log p(y_i \mid y) \ll 0\) (molto negativo, scarso).
81.4.4 Dal singolo dato al punteggio totale
Per avere una visione complessiva della performance del modello, sommiamo i log-score su tutte le osservazioni:
\[ S = \sum_{i=1}^n \log p(y_i \mid y) . \tag{81.4}\] Più \(S\) è alto (meno negativo), più il modello “scommette” bene sui dati osservati (in-sample).
81.4.5 Due filosofie a confronto: parametri fissi vs. incerti
Il calcolo del log-score può seguire due approcci concettualmente diversi, che riflettono due filosofie statistiche diverse.
81.4.5.1 Approccio classico: parametri fissi
Nell’impostazione frequentista classica, usiamo una stima puntuale dei parametri (ad es. Massima Verosimiglianza o MAP) e ignoriamo l’incertezza:
\[ \text{Log-score classico} = \log p(y_i \mid \hat{\theta}). \]
81.4.5.2 Approccio bayesiano: gestione dell’incertezza sui parametri
Nell’approccio bayesiano non fissiamo i parametri a un singolo valore stimato, ma li trattiamo come incerti. Questo significa che, invece di calcolare la verosimiglianza con un $$, “mescoliamo” tutte le verosimiglianze possibili, pesandole in base alla loro plausibilità a posteriori:
\[ \begin{align} \text{Log-score bayesiano} &= \log p(y_i \mid y) \\ &= \log \int p(y_i \mid \theta)\, p(\theta \mid y)\, d\theta . \end{align} \tag{81.5}\]
In altre parole, la probabilità predittiva di \(y_i\) non dipende da un solo \(\theta\), ma dalla media delle predizioni condizionate su tutti i valori plausibili dei parametri.
81.4.6 Implementazione pratica con il metodo MCMC
L’integrale nell’nell’Equazione 81.5 raramente ha una soluzione analitica (cioè non si può calcolare con una formula esatta). Possiamo però stimarlo in modo pratico ed efficiente utilizzando i campioni generati da un algoritmo MCMC (Markov Chain Monte Carlo).
Supponiamo di avere una serie di campioni di parametri, \(\theta^{(1)},\dots,\theta^{(S)}\), estratti dalla distribuzione a posteriori \(p(\theta\mid y)\). Il procedimento per approssimare la probabilità predittiva si articola in due semplici passi:
81.4.6.1 Passo 1: calcolare la verosimiglianza per ogni campione
Per ogni set di parametri \(\theta^{(s)}\) che abbiamo campionato, calcoliamo la probabilità (verosimiglianza) di osservare il dato \(y_i\) sotto quei parametri:
\[ p\bigl(y\_i \mid \theta^{(s)}\bigr). \]
Fare questo per tutti i campioni \(S\) ci fornisce un insieme di valori:
\[ \bigl\{\, p(y\_i \mid \theta^{(1)}),\; p(y\_i \mid \theta^{(2)}),\; \dots,\; p(y\_i \mid \theta^{(S)}) \,\bigr\} \] Questa collezione rappresenta come la plausibilità del dato \(y_i\) cambi al variare dei parametri, ponderata per la loro probabilità a posteriori.
81.4.6.2 Passo 2: calcolare la media dei valori ottenuti
La probabilità predittiva per \(y_i\) (che tiene conto di tutta l’incertezza sui parametri) è approssimata semplicemente calcolando la media aritmetica dell’insieme di valori ottenuti nel passo precedente:
\[ p(y_i \mid y) \;\approx\; \frac{1}{S}\sum_{s=1}^S p\bigl(y_i \mid \theta^{(s)}\bigr). \tag{81.6}\]
Il risultato è un singolo valore numerico (uno scalare) che sintetizza in una previsione probabilistica tutto ciò che abbiamo appreso sull’incertezza dei parametri del modello.
81.4.7 La LPPD: una misura bayesiana di bontà della previsione
Per valutare la capacità predittiva dell’intero modello su tutti i dati, ripetiamo il procedimento per ogni osservazione \(y_i\) e procediamo così:
- per ogni osservazione \(y_i\), calcoliamo la sua probabilità predittiva media \(p(y_i \mid y)\);
- prendiamo il logaritmo naturale di questa probabilità. (Usiamo il logaritmo per motivi computazionali e perché trasforma prodotti in somme);
- sommiamo i logaritmi di tutte le \(n\) osservazioni.
Il risultato di questo processo è la Log Pointwise Predictive Density (LPPD):
\[ \text{LPPD} = \sum_{i=1}^n \log \left[ \frac{1}{S} \sum_{s=1}^S p\bigl(y_i \mid \theta^{(s)}\bigr) \right]. \tag{81.7}\]
Confronto e Sintesi:
- Il log-score classico (usato nella statistica frequentista) valuta la previsione utilizzando un unico valore stimato dei parametri (ad esempio, la stima di massima verosimiglianza \(\hat{\theta}\)). Questo ignora completamente l’incertezza esistente sulla stima dei parametri.
- La LPPD bayesiana compie la stessa operazione fondamentale, ma in modo più robusto: invece di usare un singolo valore dei parametri, media le previsioni su tutte le migliaia di valori plausibili dei parametri campionati dalla distribuzione a posteriori. In questo modo, la misura di bontà predittiva incorpora in modo naturale tutta l’incertezza del modello.
81.4.8 Il problema nascosto: overfitting in-sample
La LPPD è calcolata sugli stessi dati usati per stimare il modello: modelli molto flessibili possono “scommettere bene” anche sul rumore, gonfiando la LPPD in-sample.
Analogia: È come valutare uno studente facendogli ripetere gli stessi esercizi che ha già risolto durante lo studio. Otterrà un punteggio alto, ma non sappiamo se sarebbe altrettanto bravo con problemi nuovi.
Per valutare la capacità di generalizzazione, serve una stima out-of-sample. Nelle prossime sezioni introdurremo la validazione incrociata leave-one-out (LOO-CV) e l’ELPD (Expected Log Pointwise Predictive Density), che forniscono una versione “fuori campione” della LPPD per il confronto predittivo tra modelli.
81.5 La svolta: dall’adattamento alla generalizzazione
81.5.1 Il problema dell’overfitting spiegato
Immagina di voler valutare la capacità di uno studente di riconoscere emozioni nei volti.
- Scenario A: lo testi sempre con le stesse fotografie che ha già visto molte volte durante l’allenamento.
- Scenario B: lo testi con nuove fotografie di persone mai viste prima.
Nel primo caso, lo studente probabilmente avrà un punteggio molto alto, ma non sapremo se ha davvero imparato a riconoscere le emozioni o se si limita a ricordare quelle immagini specifiche. Il secondo scenario, invece, è più onesto: misura la capacità di generalizzare la competenza a stimoli nuovi.
Lo stesso accade con i modelli statistici.
- La LPPD corrisponde allo Scenario A: valuta il modello sugli stessi dati usati per adattarlo, rischiando di dare un’illusione di performance eccellente.
- Per sapere se il modello sa davvero “generalizzare”, serve testarlo come nello Scenario B: con dati nuovi o tramite tecniche di validazione incrociata.
81.5.2 Guardare oltre i dati osservati
Quando valutiamo un modello, non ci basta sapere quanto bene spiega i dati che ha già visto. La vera domanda è: quanto bene predirebbe dati nuovi, mai osservati?
La Expected Log Predictive Density (ELPD) risponde a questa domanda. La logica è la stessa della LPPD, ma con una differenza cruciale: la previsione di ogni osservazione \(y_i\) viene fatta senza usare \(y_i\) per stimare il modello. Questa tecnica si chiama Leave-One-Out (LOO):
\[ \text{ELPD} = \sum_{i=1}^n \log p(y_i \mid y_{-i}), \tag{81.8}\] dove \(y_{-i}\) indica il dataset a cui è stata tolta l’osservazione \(i\).
81.5.2.1 Un esempio concreto per chiarire la differenza
Immagina di voler costruire un modello che predice i punteggi di memoria a breve termine degli studenti a partire dal loro livello di concentrazione.
- Con la LPPD, il modello viene valutato sugli stessi studenti che sono serviti per stimarlo. È come dire: “quanto bene il modello spiega questi dati noti?”.
- Con la ELPD, invece, ogni volta togliamo uno studente dal campione, stimiamo il modello sugli altri e proviamo a predire il punteggio di quello escluso. È come chiedere: “quanto bene il modello predirebbe un nuovo studente, mai visto prima?”.
81.5.2.2 Procedura passo per passo
- Prendiamo il primo studente ed escludiamolo dal dataset.
- Adattiamo il modello usando i dati dei rimanenti studenti.
- Prediciamo il punteggio di memoria dello studente escluso.
- Ripetiamo lo stesso procedimento per ogni studente, uno alla volta.
- Sommiamo tutti i log-score ottenuti: questo è l’ELPD.
81.6 Il collegamento con la divergenza KL
81.6.1 La teoria che unifica tutto
Abbiamo visto che l’ELPD fornisce una misura empirica della capacità predittiva di un modello. Esiste, tuttavia, una giustificazione teorica profonda e unificante che spiega il motivo per cui massimizzare l’ELPD è il principio corretto per la selezione dei modelli. Questa giustificazione poggia sul concetto di divergenza di Kullback-Leibler (KL).
81.6.1.1 Cosa misura la divergenza KL?
La divergenza KL, indicata come \(D_{\text{KL}}\), misura la “distanza” informazionale tra la distribuzione vera dei dati, \(p(\tilde{y})\) (la realtà che vogliamo catturare), e la distribuzione predittiva del nostro modello, \(q(\tilde{y} \mid y)\) (la nostra approssimazione). È definita come:
\[ D_{\text{KL}}(p \parallel q) = \mathbb{E}_p \left[ \log \frac{p(\tilde{y})}{q(\tilde{y} \mid y)} \right], \] dove l’aspettativa \(\mathbb{E}_p\) è calcolata rispetto alla distribuzione vera \(p(\tilde{y})\).
81.6.1.2 Scomponiamo la divergenza KL
Per comprendere a fondo, espandiamo la definizione:
\[ D_{\text{KL}}(p \parallel q) = \underbrace{\mathbb{E}_p[\log p(\tilde{y})]}_{\text{(1) Entropia}} - \underbrace{\mathbb{E}_p[\log q(\tilde{y} \mid y)]}_{\text{(2) Accuratezza predittiva}}. \tag{81.9}\]
Analizziamo i due termini:
- \(\mathbb{E}_p[\log p(\tilde{y})]\) (Entropia): Rappresenta il contenuto informativo intrinseco della distribuzione vera. È una quantità fissa, immutabile e, soprattutto, indipendente dal modello che stiamo considerando. È una costante.
- \(-\mathbb{E}_p[\log q(\tilde{y} \mid y)]\) (Log-verosimiglianza attesa): Questo è il termine cruciale. Misura quanto è buona la nostra distribuzione predittiva \(q\) nel prevedere nuovi dati provenienti dalla vera distribuzione \(p\). Nota: questo è esattamente l’opposto della quantità che stimiamo con l’ELPD \((\sum \log q(\tilde{y} \mid y))\).
81.6.1.3 Il collegamento fondamentale
Poiché il primo termine dell’Equazione 81.9 è una costante, minimizzare la divergenza KL \(D_{\text{KL}}(p \parallel q)\) equivale esattamente a massimizzare il secondo termine, ovvero l’accuratezza predittiva attesa. Questo risultato si traduce in una regola pratica potentissima per il confronto tra modelli. Date due distribuzioni predittive, \(q_A\) e \(q_B\), la differenza nelle loro divergenze KL è:
\[ \begin{aligned} D_{\text{KL}}(p \parallel q_A) - D_{\text{KL}}(p \parallel q_B) &= \left( \cancel{\mathbb{E}_p[\log p(\tilde{y})]} - \mathbb{E}_p[\log q_A(\tilde{y} \mid y)] \right) \notag\\ &\qquad - \left( \cancel{\mathbb{E}_p[\log p(\tilde{y})]} - \mathbb{E}_p[\log q_B(\tilde{y} \mid y)] \right) \\ &= \mathbb{E}_p[\log q_B(\tilde{y} \mid y)] - \mathbb{E}_p[\log q_A(\tilde{y} \mid y)] \\ &= \text{ELPD}(q_B) - \text{ELPD}(q_A) \end{aligned} \] dove abbiamo cancellato il termine entropia costante.
81.6.1.4 Conclusione teorica fondamentale
Il risultato precedente ci porta alla conclusione chiave di tutta la teoria:
\[ \text{Massimizzare l'ELPD} \;\; \equiv \;\; \text{Minimizzare la divergenza KL dalla verità}. \] In altre parole, quando preferiamo il modello con l’ELPD più alto, non stiamo solo seguendo un criterio empirico. Stiamo scegliendo consapevolmente il modello la cui distribuzione predittiva è, in media, più vicina alla realtà sottostante in senso informazionale. Questo principio unifica la teoria dell’informazione con la pratica della valutazione e selezione dei modelli predittivi.
81.7 Stimare l’ELPD nella pratica: la Leave-One-Out Cross-Validation
Abbiamo chiarito che l’ELPD è la misura ideale della bontà predittiva di un modello, perché è direttamente collegata alla divergenza KL. Il problema è che, per definizione, richiede un’aspettativa rispetto alla vera distribuzione dei dati futuri \(p(\tilde{y})\), che non conosciamo mai.
Come possiamo allora stimarlo? La soluzione più usata è la Leave-One-Out Cross-Validation (LOO-CV), che ci permette di avvicinarci all’ELPD teorico usando soltanto i dati osservati.
81.7.1 L’idea alla base della LOO-CV
Il principio è semplice: trattare ogni osservazione del dataset come se fosse “nuova” e verificare se il modello, addestrato sui dati rimanenti, riesce a prevederla.
Il procedimento è questo:
- Si prende un’osservazione \(y_i\).
- La si rimuove temporaneamente dal dataset.
- Si stima il modello sui dati rimanenti \(y_{-i}\).
- Si calcola la densità predittiva che il modello assegna al dato escluso: \(p(y\_i \mid y_{-i})\).
- Si ripete per tutte le osservazioni e si sommano i logaritmi.
In formula:
\[ \text{ELPD}_{\text{LOO}} = \sum_{i=1}^n \log p(y_i \mid y_{-i}) . \tag{81.10}\]
Così otteniamo una stima out-of-sample: il modello viene valutato su dati che non ha mai visto.
81.7.2 Perché funziona
La LOO-CV funziona perché sostituisce l’aspettativa teorica rispetto a \(p(\tilde{y})\) con una media empirica sulle osservazioni reali. Ogni \(y_i\) viene trattata come un nuovo dato proveniente da \(p\), e la media dei log-score fuori campione fornisce una stima della capacità predittiva attesa:
\[ \text{ELPD}_{\text{LOO}} \approx \mathbb{E}_p[\log q(\tilde{y}\mid y)] . \tag{81.11}\]
81.7.3 Confrontare i modelli con LOO-CV
Una volta stimato l’ELPD-LOO, possiamo confrontare due modelli calcolando la differenza:
\[ \Delta \text{ELPD} = \text{ELPD}_{\text{LOO}}(M_1) - \text{ELPD}_{\text{LOO}}(M_2). \tag{81.12}\]
Se la differenza è positiva, il modello \(M_1\) ha una distribuzione predittiva più vicina alla realtà di quella di \(M_2\).
È utile stimare anche un errore standard della differenza. Come regola empirica, una differenza di almeno due volte l’SE indica un vantaggio credibile di un modello sull’altro.
81.7.4 Overfitting e vantaggio della LOO-CV
Se valutassimo un modello sugli stessi dati usati per addestrarlo, la sua performance apparirebbe gonfiata (overfitting). La LOO-CV aggira questo problema: ogni osservazione viene valutata solo con modelli che non l’hanno vista. Il punteggio ottenuto è quindi una misura più realistica della capacità di generalizzare a nuovi dati.
81.7.5 PSIS-LOO: la scorciatoia pratica
Un limite della LOO tradizionale è che richiederebbe di riadattare il modello \(n\) volte, cosa spesso impraticabile. Per questo oggi si usa il metodo Pareto-Smoothed Importance Sampling (PSIS-LOO), che consente di stimare l’ELPD-LOO a partire da un unico adattamento del modello, sfruttando i campioni MCMC.
In R, tutto ciò è implementato nel pacchetto loo, già integrato in brms e rstanarm, attraverso funzioni come loo() e loo_compare(). Oltre ai valori di ELPD, queste funzioni forniscono anche diagnostiche (le Pareto k) per capire se la stima è affidabile.
81.7.5.1 In sintesi
- L’ELPD misura la capacità predittiva del modello su dati futuri.
- Non conoscendo la distribuzione vera, usiamo la LOO-CV per stimarlo.
- La differenza di ELPD-LOO tra modelli approssima la differenza nelle loro divergenze KL.
- PSIS-LOO rende il calcolo efficiente anche per modelli complessi.
- La regola pratica: preferire il modello con ELPD-LOO più alto, tenendo conto anche della sua semplicità e interpretabilità.
81.8 Criteri di informazione
Oltre alla convalida incrociata Leave-One-Out, la statistica offre altri strumenti per stimare la qualità predittiva di un modello senza conoscere la distribuzione vera dei dati. Molti di questi metodi affondano le loro radici teoriche nel concetto di divergenza di Kullback-Leibler, che misura la distanza tra la distribuzione generatrice dei dati e quella stimata dal nostro modello.
L’obiettivo comune è valutare la capacità di un modello di generalizzare, ovvero di fare buone previsioni su dati non osservati, senza farsi trarre in inganno dall’overfitting. Tutti i criteri seguono una logica simile, bilanciando due componenti: una misura della bontà di adattamento ai dati e una penalità per la complessità del modello stesso. I vari criteri si distinguono proprio per come definiscono queste due componenti e per le assunzioni su cui si basano.
81.8.1 Una panoramica dei criteri principali
L’AIC (Akaike Information Criterion) approssima la distanza di Kullback-Leibler utilizzando la verosimiglianza massimizzata e applica una penalità semplice, proporzionale al numero di parametri. È un criterio veloce e ampiamente utilizzato, particolarmente utile per modelli regolari con campioni non troppo piccoli e privi di struttura gerarchica.
Il BIC (Bayesian Information Criterion) segue una logica simile all’AIC, ma introduce una penalità per la complessità che cresce all’aumentare della dimensione del campione. Questo lo porta tendenzialmente a preferire modelli più parsimoniosi quando il numero di osservazioni è grande e, sotto specifiche ipotesi, può essere collegato alla verosimiglianza marginale.
Il WAIC (Widely Applicable Information Criterion) rappresenta una versione pienamente bayesiana. Utilizza l’intera distribuzione predittiva a posteriori per valutare il fit e stima una penalità per la complessità effettiva del modello, che può differire dal semplice numero di parametri. È particolarmente adatto per modelli complessi o non regolari ed è concettualmente molto vicino alla stima LOO.
Infine, il LOO-CV (Leave-One-Out Cross-Validation), specialmente nella sua efficiente implementazione PSIS-LOO, stima direttamente l’Expected Log Predictive Density (ELPD) escludendo un dato alla volta. È spesso considerato il gold standard per il confronto predittivo nell’ambito della modellazione bayesiana, grazie alla sua robustezza e alle utili diagnostiche che fornisce.
81.8.1.1 Come orientarsi nella scelta
Una regola pratica è che se l’obiettivo principale è la previsione fuori campione in un contesto bayesiano, il PSIS-LOO o il WAIC sono generalmente da preferire ad AIC e BIC. In un approccio frequentista classico, con modelli regolari e campioni di dimensioni medio-grandi, l’AIC rimane un buon compromesso, mentre il BIC può essere più appropriato quando si desidera enfatizzare la parsimonia.
Per modelli bayesiani con obiettivo predittivo e dati reali (spesso non iid o gerarchici), il PSIS-LOO è la prima scelta, con il WAIC utile come riscontro. Con campioni piccoli, strutture complesse o unità dipendenti, è bene evitare criteri puramente asintotici come AIC e BIC, preferendo invece LOO o definendo con attenzione l’unità di esclusione (ad esempio, per soggetto o per gruppo). Nei modelli gerarchici o multilivello, LOO e WAIC possono essere applicati in modo coerente, prestando attenzione a non escludere singole osservazioni se queste non sono indipendenti, ma piuttosto interi cluster.
81.8.1.2 Errori comuni e best practice
Un errore frequente è utilizzare il Mean Squared Error (MSE) sul campione di addestramento come metro di giudizio, poiché questo valore non penalizza la complessità e tende quindi a favorire modelli eccessivamente flessibili e soggetti a overfitting. Allo stesso modo, è importante ricordare che AIC e BIC si basano su stime puntuali (MLE o MAP) e non catturano l’incertezza completa sui parametri, il che li rende meno ideali in un contesto bayesiano puro. WAIC e LOOCV, al contrario, sono espressamente concepiti per stimare la performance predittiva su dati nuovi.
Quando si riporta un confronto tra modelli, è buona norma includere non solo il modello “vincente”, ma anche la differenza di ELPD con il suo errore standard, le diagnostiche sui parametri di Pareto-k, una stima della complessità effettiva e un commento sostantivo che spieghi il motivo della preferenza, che potrebbe risiedere nella parsimonia, nell’interpretabilità dei parametri o nella robustezza.
81.8.1.3 In sintesi: il workflow essenziale
Un mini-workflow consigliato per un approccio bayesiano prevede di: adattare i modelli; calcolare il LOO per ciascuno di essi e controllare i parametri di Pareto-k; se si riscontrano valori di k elevati, considerare una convalida incrociata K-fold o una LOO per cluster; confrontare i modelli con appositi strumenti e riportare le differenze di ELPD; opzionalmente, calcolare il WAIC come controllo incrociato; argomentare infine la scelta finale anche in base a parsimonia e interpretabilità.
La selezione del modello, in definitiva, ruota attorno a una domanda essenziale: quanto bene il modello predice dati che non ha mai visto? Il riferimento teorico è l’Expected Log Predictive Density (ELPD), che misura quanto la distribuzione predittiva del modello si avvicina alla vera distribuzione dei dati. Poiché quest’ultima è sconosciuta, l’ELPD va stimato con strumenti come LOO-CV e WAIC, che oggi rappresentano gli standard più affidabili per guidare una scelta consapevole, equilibrata e focalizzata sulla capacità di generalizzazione.
Riflessioni conclusive
Il principio fondamentale della modellazione bayesiana risiede nella valutazione della qualità di un modello attraverso la sua capacità di produrre previsioni probabilistiche robuste, rappresentate dalla distribuzione predittiva a posteriori \(p(\tilde{y} \mid y)\).
La misura che guida questa valutazione è l’Expected Log Predictive Density (ELPD), che quantifica la capacità predittiva del modello su dati non osservati. A differenza delle metriche in-sample, soggette a sovradattamento, l’ELPD fornisce una stima imparziale della capacità di generalizzazione. Teoricamente, massimizzare l’ELPD equivale a minimizzare la divergenza di Kullback-Leibler rispetto alla vera distribuzione generatrice dei dati.
Operativamente, l’ELPD viene stimato mediante PSIS-LOO, integrato con i diagnostici Pareto-k. Il WAIC costituisce un’alternativa bayesiana solida, spesso coerente con LOO. Al contrario, criteri come AIC e BIC, sebbene computazionalmente efficienti, si basano su stime puntuali e approssimazioni asintotiche, risultando meno affidabili in contesti di campioni piccoli o modelli gerarchici.
Nel confronto tra modelli, è essenziale riportare non solo l’ELPD-LOO, ma anche le differenze ΔELPD e i relativi errori standard. Tuttavia, la selezione del modello non dovrebbe ridursi a un esercizio meccanico: differenze trascurabili nell’ELPD, specialmente se associate ad alta incertezza, possono essere irrilevanti sul piano sostanziale. Modelli meno performanti ma più parsimoniosi o teoricamente fondati possono rappresentare scelte migliori.
L’obiettivo finale è bilanciare capacità predittiva e coerenza teorica, ricordando che lo scopo della modellazione non è solo prevedere, ma comprendere. La valutazione deve quindi integrare strumenti come il PSIS-LOO con considerazioni sull’incertezza statistica, la struttura dei dati e il contesto teorico di riferimento.