here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(HistData)63 La regressione verso la media
“The mean filial regression towards mediocrity was directly proportional to the parental deviation from it.”
– Francis Galton, Regression Towards Mediocrity in Hereditary Stature, Journal of the Anthropological Institute 15, 1886, pp. 246–263.
Introduzione
Il concetto di regressione verso la media fu introdotto da Francis Galton alla fine dell’Ottocento, osservando la trasmissione ereditaria dell’altezza. Egli notò che i figli di padri eccezionalmente alti rimanevano in media sopra la statura generale, ma meno dei loro padri; e che lo stesso valeva, in direzione opposta, per i figli di padri molto bassi. Questo “ritorno parziale verso il centro” della distribuzione è il fenomeno che ancora oggi porta il nome di regressione verso la media.
Perché avviene? Un valore estremo, come un’altezza particolarmente alta o bassa, è il risultato della combinazione di fattori genetici, ambientali e casuali. I figli ereditano solo una parte di questi fattori, e nuove influenze si aggiungono al quadro: il risultato è che le loro altezze tendono a essere meno estreme, più vicine alla media della popolazione. Non significa che il figlio di un padre altissimo diventi basso: rimane in media più alto degli altri, ma meno estremo.
Il cuore statistico del fenomeno sta nella correlazione imperfetta tra le due variabili considerate (altezza del padre e del figlio). Se la correlazione fosse pari a 1, gli estremi si replicherebbero perfettamente. Ma quando \(\rho < 1\), i valori attesi dei figli risultano più vicini alla media rispetto a quelli dei padri. Galton stimò, nel suo esempio, una correlazione attorno a 0.5: segno che una parte importante, ma non totale, dell’estremità paterna si trasmette al figlio.
Studiare la regressione verso la media ci permette di capire più a fondo la logica della regressione lineare bivariata. Si tratta infatti di un’applicazione concreta dell’idea di pendenza inferiore a 1 quando la correlazione non è perfetta. Questo fenomeno, apparentemente controintuitivo, è in realtà inevitabile nei dati psicologici e ha implicazioni profonde per l’interpretazione delle osservazioni e dei cambiamenti individuali.
Panoramica del capitolo
- Origine storica e intuizione del fenomeno (Galton).
- Regressione e correlazione: forme standardizzate e non standardizzate.
- Visualizzazione della RTM tramite retta di regressione.
- RTM ≠ causalità: errori di misura e artefatti di selezione.
63.0.1 I dati di Galton
Esaminiamo il fenomeno della regressione verso la media usando i dati di Galton. Nel pacchetto HistData di R sono disponibili i dati originali raccolti da Galton, che includono informazioni sull’altezza di padri, madri, figli maschi e femmine. Per semplificare l’analisi, possiamo creare un dataset che include solo l’altezza del padre e l’altezza di un figlio maschio scelto casualmente da ogni famiglia:
Questo dataset contiene due colonne: father (altezza del padre) e son (altezza del figlio maschio). Calcolando la media e la deviazione standard delle altezze dei padri e dei figli, otteniamo:
I risultati mostrano che, in media, i padri e i figli hanno altezze simili, anche se le distribuzioni non sono identiche. Un grafico di dispersione (scatterplot) evidenzia una chiara tendenza: padri più alti tendono ad avere figli più alti:
galton_heights |>
ggplot(aes(father, son)) +
geom_point(alpha = 0.5)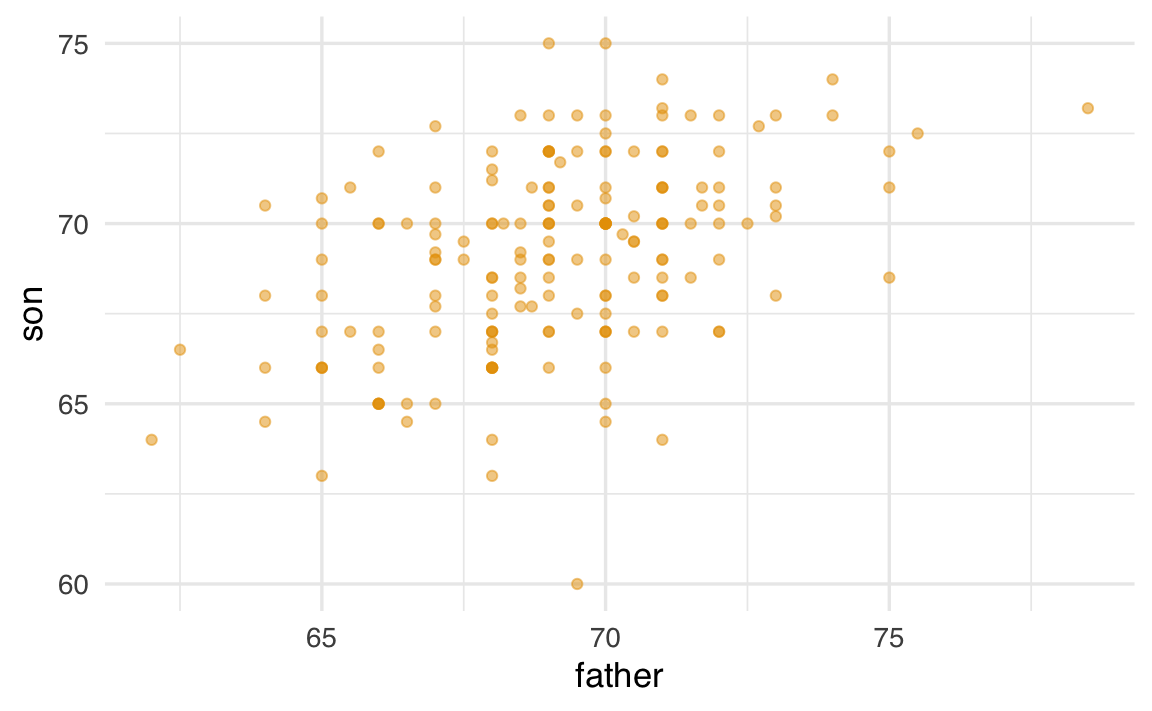
63.0.2 Il coefficiente di correlazione
La forza e la direzione dell’associazione lineare tra le due variabili sono misurate dal coefficiente di correlazione di Pearson, definito come:
\[ \rho = \frac{1}{n}\sum_{i=1}^n \left(\frac{x_i - \mu_x}{\sigma_x}\right) \left(\frac{y_i - \mu_y}{\sigma_y}\right). \]
dove \(\mu_X, \mu_Y\) sono le medie e \(\sigma_X, \sigma_Y\) le deviazioni standard delle rispettive popolazioni. La sua stima campionaria, \(r\), è calcolata in R come:
galton_heights |>
summarize(r = cor(father, son)) |>
pull(r)
#> [1] 0.443Un coefficiente di 0.5 indica un’associazione lineare positiva di moderata intensità, implicando che l’altezza paterna spiega solo parzialmente la variabilità dell’altezza dei figli.
63.0.3 L’aspettativa condizionata e l’emergenza del fenomeno di regressione
Un obiettivo inferenziale comune è la stima del valore atteso dell’altezza del figlio (\(Y\)), condizionata a un specifico valore dell’altezza del padre (\(X = x_0\)), formalmente \(\mathbb{E}(Y \mid X = x_0)\).
Un approccio intuitivo è stratificare i dati e calcolare la media campionaria del sottogruppo. Ad esempio, per \(X = 72\) pollici:
Tale stima risulta sistematicamente più vicina alla media generale di \(Y\) di quanto \(x_0\) non lo sia alla media di \(X\). Questo fenomeno è noto come regressione verso la media.
63.1 Visualizzare del fenomeno attraverso la stratificazione
Il fenomeno è generalizzabile visualizzando la media condizionata \(\mathbb{E}(Y \mid X = x)\) per diversi valori di \(x\), ottenuti tramite stratificazione:
galton_heights |>
mutate(father_strata = factor(round(father))) |>
group_by(father_strata) |>
summarize(avg_son = mean(son)) |>
ggplot(aes(x = father_strata, y = avg_son)) +
geom_point()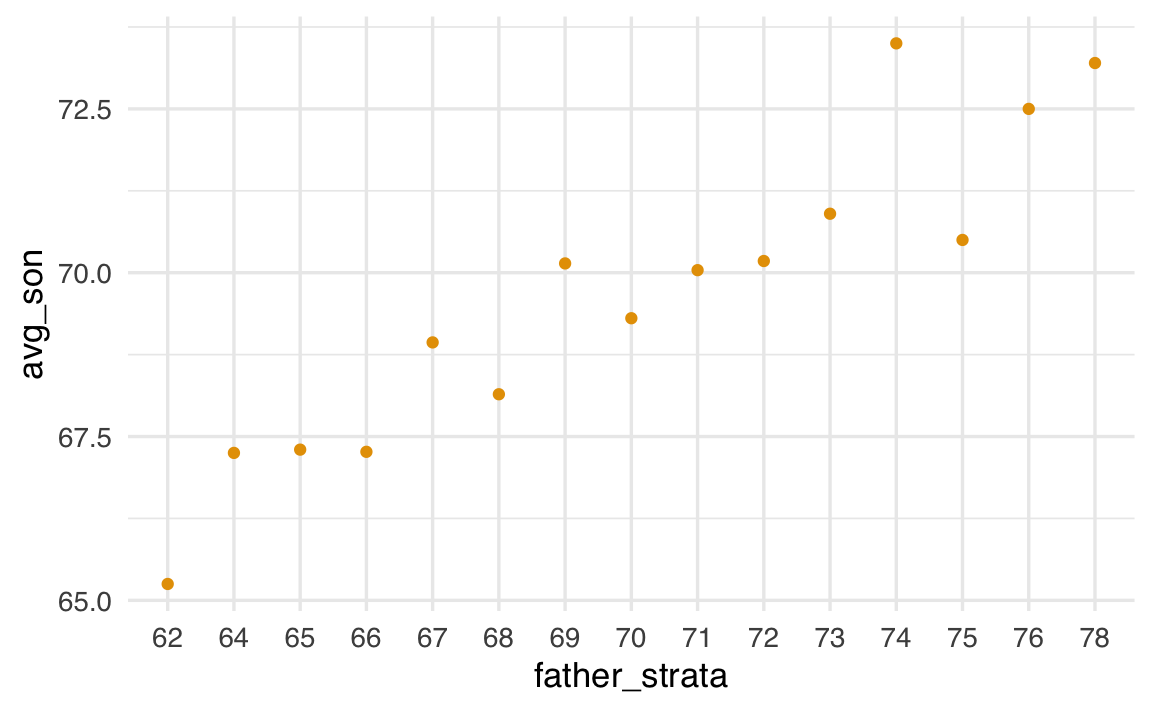
La nube di punti delle medie condizionate presenta una pendenza positiva ma inferiore a 45°, dimostrando visivamente la regressione verso la media.
63.2 Modello di regressione lineare e interpretazione dei parametri
Il modello statistico che formalizza questa relazione è la regressione lineare semplice:
\[ Y = \beta_0 + \beta_1 X + \varepsilon , \]
dove \(\epsilon\) è un termine di errore stocastico con media zero.
Gli stimatori dei minimi quadrati ordinari (OLS) per i parametri \(\beta_0\) (intercetta) e \(\beta_1\) (pendenza) sono:
\[ \hat{\beta}_1 = r \frac{s_Y}{s_X}, \quad \hat{\beta}_0 = \bar{Y} - \hat{\beta}_1\bar{X} \]
dove \(s_X\), \(s_Y\) sono le deviazioni standard campionarie e \(\bar{X}\), \(\bar{Y}\) le medie campionarie.
L’applicazione del modello ai dati di Galton fornisce:
La pendenza stimata \(\hat{\beta}_1 = 0.454\) conferma che per ogni pollice in più del padre, l’altezza attesa del figlio aumenta di circa 0.454 pollici, un valore inferiore a 1 che è consistente con la regressione verso la media.
63.2.0.1 Standardizzazione
Standardizzando le variabili (\(Z_X = (X - \bar{X})/s_X\), \(Z_Y = (Y - \bar{Y})/s_Y\)), il modello di regressione assume la forma
\[ Z_Y = \rho\, Z_X + \varepsilon. \]
Vediamo come si arriva a questo risultato. Consideriamo il modello lineare semplice
\[ Y = \beta_0 + \beta_1 X + \varepsilon, \qquad \mathbb{E}[\varepsilon] = 0, \qquad \mathrm{Cov}(X,\varepsilon) = 0. \]
Dalle equazioni normali dei minimi quadrati otteniamo, a livello di popolazione:
\[ \beta_1 = \frac{\mathrm{Cov}(X,Y)}{\mathrm{Var}(X)}, \qquad \beta_0 = \mu_Y - \beta_1 \mu_X. \]
Scrivendo la covarianza come \(\mathrm{Cov}(X,Y) = \rho \sigma_X \sigma_Y\), segue che
\[ \beta_1 = \rho \,\frac{\sigma_Y}{\sigma_X}. \]
Se ora standardizziamo \(X\) e \(Y\), entrambe le deviazioni standard valgono 1, quindi la pendenza diventa
\[ \beta_1^* = \rho. \]
Inoltre, poiché le variabili standardizzate hanno media zero, anche l’intercetta scompare.
In conclusione, la regressione di \(Z_Y\) su \(Z_X\) ha sempre intercetta pari a 0 e coefficiente angolare pari alla correlazione \(\rho\).
Infatti, nei dati campionari:
La pendenza è \(0.4434\), numericamente uguale alla correlazione \(r\) calcolata in precedenza (a meno di errori di arrotondamento). Poiché \(|\rho| < 1\), la previsione per un valore standardizzato \(z_x\) sarà \(\hat{z}_y = \rho z_x\), che è sempre, in valore assoluto, minore di \(z_x\). Questo spiega matematicamente il perché un valore estremo di \(X\) porta a una previsione per \(Y\) che è meno estrema, ossia più vicina alla sua media standardizzata (zero).
In sintesi, la correlazione imperfetta (\(\rho < 1\)) è la ragione principale per cui un valore estremo di \(X\) (ad esempio, un padre molto alto) porta a un valore \(\hat{Y}\) che è sì superiore (o inferiore) alla media, ma meno estremo del padre. Questo “ritorno verso il centro” è ciò che chiamiamo regressione verso la media.
Riflessioni conclusive
La regressione verso la media è un fenomeno statistico inevitabile ogni volta che due misurazioni sono correlate, ma non perfettamente. In termini standardizzati, se \(\rho < 1\), il valore atteso di una variabile condizionata a un valore estremo dell’altra risulta più vicino alla media. Ciò significa che le osservazioni molto alte o molto basse tenderanno, in media, a “rientrare” verso il centro nelle rilevazioni successive.
Questo effetto non è un artefatto, ma la naturale conseguenza della variabilità residua e della presenza di errori di misura. In psicologia, le implicazioni sono notevoli: senza tener conto della regressione verso la media, si rischia di interpretare come cambiamento reale ciò che è in parte dovuto a fluttuazioni statistiche. È il caso, ad esempio, di studi pre–post senza gruppo di controllo, in cui miglioramenti apparenti possono riflettere semplicemente la tendenza dei valori estremi ad avvicinarsi alla media.
Comprendere questo fenomeno significa anche comprendere meglio il funzionamento del modello di regressione lineare bivariata: la regressione verso la media è, in fondo, l’espressione grafica e concettuale del fatto che la pendenza della retta di regressione sia inferiore a 1 quando la correlazione non è perfetta.
Questo ci ricorda che la regressione lineare, pur essendo un modello fenomenologico e descrittivo, può offrire intuizioni preziose sul comportamento dei dati psicologici e sui limiti delle nostre inferenze. Nei prossimi capitoli ci sposteremo dal quadro frequentista a quello bayesiano, per vedere come sia possibile affrontare queste stesse questioni in termini di probabilità sui parametri, incorporando conoscenze pregresse e ottenendo una rappresentazione più trasparente dell’incertezza.
Bibliografia
Schervish, M. J., & DeGroot, M. H. (2014). Probability and statistics (Vol. 563). Pearson Education London, UK: