58 Flusso di lavoro bayesiano
“Bayesian data analysis is not a set of methods but a way of thinking: building models, checking them, and learning from the misfits.”
— Andrew Gelman, Bayesian Data Analysis (2013)
Introduzione
Fare analisi bayesiana non significa semplicemente applicare la formula di Bayes e ottenere delle stime. Nella pratica della ricerca, serve un approccio più ampio e strutturato: il workflow bayesiano. Si tratta di un processo ciclico che aiuta i ricercatori a passare dall’idea di partenza (una domanda di ricerca) a un modello utile e convincente, capace di generare previsioni plausibili e di guidare le conclusioni.
Immaginiamo di voler valutare l’efficacia di un nuovo intervento psicologico. Non basta raccogliere i dati e stimare i parametri: bisogna decidere quali variabili considerare, come trattare le differenze tra individui e gruppi, quali assunzioni fare sulle distribuzioni, e come controllare che il modello davvero rifletta la realtà osservata. Tutto questo richiede un percorso iterativo di costruzione, verifica e revisione.
In breve: il workflow bayesiano è un metodo per fare ricerca in modo più consapevole e trasparente.
Panoramica del capitolo
- Cos’è un workflow bayesiano e perché è utile nella ricerca.
- Le principali fasi del processo: formulare, verificare e migliorare un modello.
- Le verifiche predittive, cioè le simulazioni che ci aiutano a capire se il modello funziona.
- L’analisi multiverso, un approccio che esplora più modelli alternativi in modo trasparente.
58.1 Il ciclo di Box
Negli anni ’60, lo statistico George Box descrisse la modellizzazione come un ciclo continuo di costruzione, valutazione e revisione. Questo approccio, noto come Ciclo di Box, è diventato un punto di riferimento anche per il workflow bayesiano.
L’idea chiave è semplice: i modelli non sono mai perfetti, ma strumenti che possono essere continuamente migliorati.
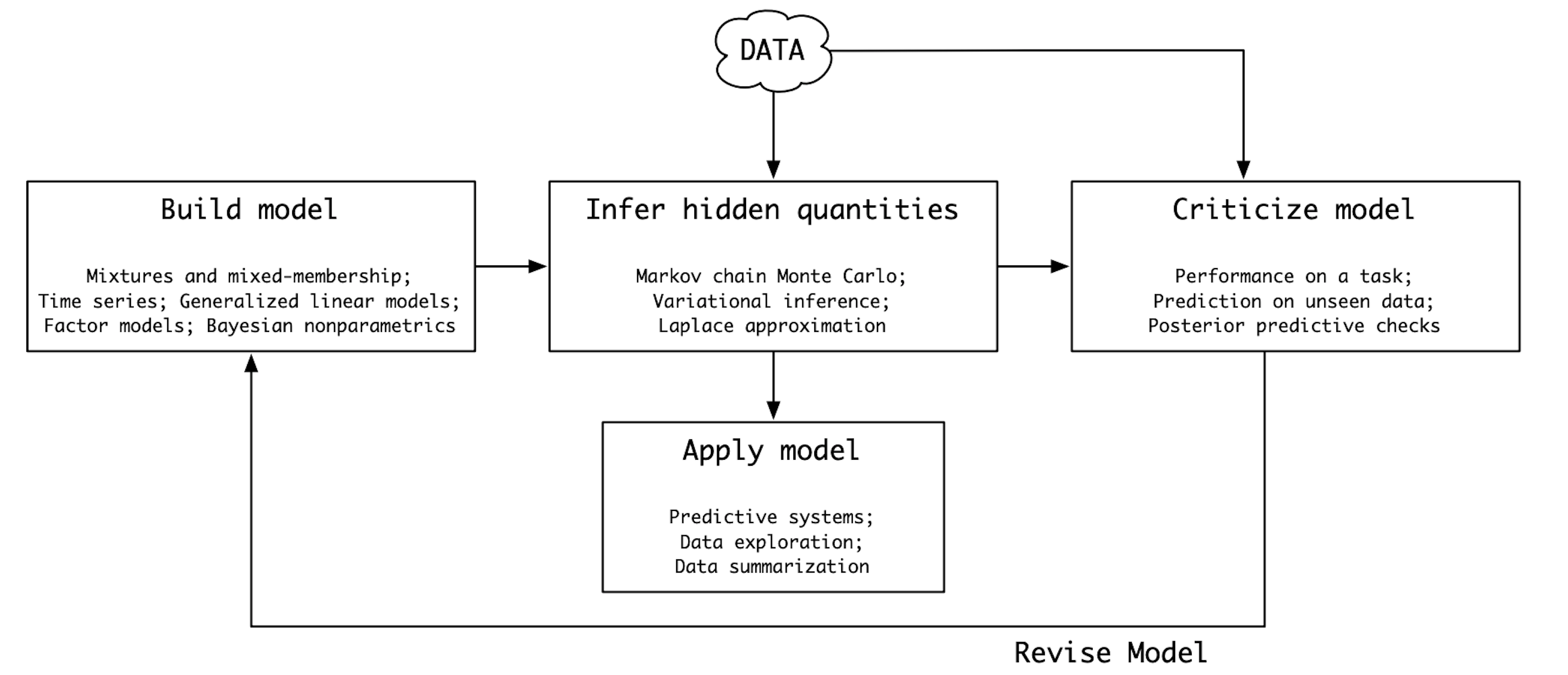
Il ciclo comprende quattro fasi:
- Formulare un modello sulla base delle conoscenze disponibili;
- Fare inferenza, cioè stimare parametri e incertezze;
- Valutare il modello, controllando quanto descrive bene i dati;
- Rivedere il modello, correggendo le discrepanze.
Il flusso di lavoro bayesiano si integra bene con questo ciclo perché le nostre convinzioni possono essere aggiornate man mano che arrivano nuovi dati.
58.2 Le fasi del workflow bayesiano
Nella pratica, il workflow bayesiano segue alcune tappe principali:
- Definizione della domanda di ricerca: partire da un problema chiaro e da un’ipotesi sul processo che genera i dati.
- Costruzione del modello: tradurre l’ipotesi in un modello probabilistico.
- Simulazioni a priori: generare dati fittizi dai soli priori per capire se le ipotesi iniziali sono ragionevoli.
- Adattamento ai dati: stimare i parametri del modello sui dati osservati.
- Verifiche a posteriori: confrontare i dati osservati con quelli simulati a partire dal modello stimato.
- Diagnostiche: controllare che il procedimento di stima sia andato a buon fine (per esempio, che le catene MCMC abbiano esplorato bene lo spazio dei parametri).
- Iterazione: tornare indietro e migliorare il modello quando necessario.
Questa sequenza non è lineare: spesso bisogna ripetere più volte alcuni passaggi, fino a raggiungere un equilibrio tra semplicità e capacità esplicativa.
58.3 Verifiche predittive
Uno strumento centrale sono le verifiche predittive.
- Le verifiche a priori controllano che i priori scelti non producano scenari irrealistici.
- Le verifiche a posteriori servono per confrontare i dati osservati con i dati che il modello, una volta stimato, sarebbe capace di generare.
Se il modello produce dati molto diversi da quelli reali, vuol dire che qualcosa va rivisto.
Queste verifiche non sono test statistici “passa/non passa”, ma occasioni di apprendimento: ci dicono dove il modello funziona e dove deve essere migliorato.
58.4 Analisi multiverso
Un’estensione recente del workflow bayesiano è l’analisi multiverso [Steegen et al. (2016); Riha et al. (2024)].
L’idea è semplice: invece di puntare su un unico modello, esploriamo più modelli possibili, ognuno basato su scelte diverse (per esempio, variabili incluse, tipo di distribuzione, forma della relazione).
I vantaggi sono:
- maggiore trasparenza sulle scelte fatte;
- confronto diretto tra alternative;
- conclusioni più robuste, perché sappiamo quanto dipendono dalle assunzioni iniziali.
Ovviamente, più modelli significano anche più complessità. Per gestirla, sono stati proposti approcci di “filtraggio iterativo”: si parte da molti modelli e, passo dopo passo, si scartano quelli che non funzionano bene, fino a concentrarsi su un insieme ristretto e più solido.
Un esempio è l’analisi di dati clinici sulle crisi epilettiche (studio di Leppik et al., 1987). In quel caso, decine di modelli sono stati confrontati utilizzando criteri predittivi come l’ELPD (Expected Log Predictive Density). Alcuni modelli si sono rivelati poco plausibili, altri molto più predittivi e stabili. Questo dimostra come l’analisi multiverso possa rendere le conclusioni più affidabili, senza ridursi a una sola scelta arbitraria.
Riflessioni conclusive
Il workflow bayesiano è un approccio pratico e flessibile per fare ricerca. Non si tratta di una serie di regole rigide, ma di una guida che incoraggia cicli di costruzione, verifica e revisione dei modelli.
Con strumenti come le verifiche predittive e l’analisi multiverso, i ricercatori possono:
- evitare modelli troppo semplici o troppo complicati;
- rendere trasparenti le proprie scelte;
- costruire inferenze più solide e replicabili.
In altre parole, il workflow bayesiano aiuta a trasformare la teoria in pratica, accompagnando il ricercatore in tutte le fasi del processo analitico.