here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(tidyr, viridis, vcd)19 Indicatori di tendenza centrale e variabilità
“La tendenza centrale senza una misura di variabilità è spesso di utilità limitata.”
– Jacob Cohen, Statistical Power Analysis for the Behavioral Sciences (1988)
Introduzione
La visualizzazione grafica dei dati rappresenta il pilastro fondamentale di ogni analisi quantitativa. Grazie alle rappresentazioni grafiche adeguate, è possibile individuare importanti caratteristiche di una distribuzione, quali la simmetria o l’asimmetria, nonché la presenza di una o più mode. Successivamente, al fine di descrivere sinteticamente le principali caratteristiche dei dati, si rende necessario l’utilizzo di specifici indici numerici. In questo capitolo, verranno presentati i principali indicatori della statistica descrittiva.
Panoramica del capitolo
- Tendenza centrale: Scelta della misura (media, mediana, moda) in base al tipo di dati e alla presenza di valori anomali.
- Variabilità: Interpretazione di range, varianza, deviazione standard e IQR per quantificare la dispersione dei dati attorno al valore centrale
19.1 Indici di tendenza centrale
Gli indici di tendenza centrale sono misure statistiche che cercano di rappresentare un valore tipico o centrale all’interno di un insieme di dati. Sono utilizzati per ottenere una comprensione immediata della distribuzione dei dati senza dover analizzare l’intero insieme. Gli indici di tendenza centrale sono fondamentali nell’analisi statistica, in quanto forniscono una sintesi semplice e comprensibile delle caratteristiche principali di un insieme di dati. I principali indici di tendenza centrale sono:
- Media: La media è la somma di tutti i valori divisa per il numero totale di valori. È spesso utilizzata come misura generale di tendenza centrale, ma è sensibile agli estremi (valori molto alti o molto bassi).
- Mediana: La mediana è il valore che divide l’insieme di dati in due parti uguali. A differenza della media, non è influenzata da valori estremi ed è quindi più robusta in presenza di outlier.
- Moda: La moda è il valore che appare più frequentemente in un insieme di dati. In alcuni casi, può non essere presente o esserci più di una moda.
La scelta dell’indice di tendenza centrale appropriato dipende dalla natura dei dati e dall’obiettivo dell’analisi. Ad esempio, la mediana potrebbe essere preferita alla media se l’insieme di dati contiene valori anomali che potrebbero distorcere la rappresentazione centrale. La conoscenza e l’applicazione corretta di questi indici possono fornire una preziosa intuizione sulle caratteristiche centrali di una distribuzione di dati.
19.1.1 Moda
La moda (\(\text{Mo}\)) rappresenta il valore della variabile che compare con maggiore frequenza in una distribuzione. In altre parole, è il valore più ricorrente nei dati.
- Nelle distribuzioni unimodali, esiste una sola moda, che coincide con il valore centrale della distribuzione più frequente.
- Tuttavia, in alcune distribuzioni, possono emergere più di una moda, rendendole multimodali. In questi casi, la moda perde il suo significato di indicatore unico di tendenza centrale, poiché la presenza di più valori con frequenze elevate rende difficile individuare un singolo punto di riferimento.
19.1.2 Mediana
La mediana (\(\tilde{x}\)) corrisponde al valore che divide il campione in due metà: il 50% dei dati è inferiore o uguale alla mediana e il restante 50% è superiore o uguale. A differenza della media, la mediana è meno influenzata dai valori estremi, rendendola una misura particolarmente robusta in presenza di dati asimmetrici o outlier.
19.1.3 Media
La media aritmetica di un insieme di valori rappresenta il punto centrale o il baricentro della distribuzione dei dati. È calcolata come la somma di tutti i valori divisa per il numero totale di valori, ed è espressa dalla formula:
\[ \bar{x}=\frac{1}{n}\sum_{i=1}^n x_i, \tag{19.1}\]
dove \(x_i\) rappresenta i valori nell’insieme, \(n\) è il numero totale di valori, e \(\sum\) indica la sommatoria.
19.1.3.1 Calcolo della media con R
Per calcolare la media di un piccolo numero di valori in R, possiamo utilizzare la somma di questi valori e dividerla per il numero totale di elementi. Consideriamo ad esempio i valori 12, 44, 21, 62, 24:
(12 + 44 + 21 + 62 + 24) / 5
#> [1] 32.6ovvero
19.1.3.2 Media spuntata
La media spuntata, indicata come \(\bar{x}_t\) o trimmed mean, è un metodo di calcolo della media che prevede l’eliminazione di una determinata percentuale di dati estremi prima di effettuare la media aritmetica. Solitamente, viene eliminato il 10% dei dati, ovvero il 5% all’inizio e alla fine della distribuzione. Per ottenere la media spuntata, i dati vengono ordinati in modo crescente, \(x_1 \leq x_2 \leq x_3 \leq \dots \leq x_n\), e quindi viene eliminato il primo 5% e l’ultimo 5% dei dati nella sequenza ordinata. Infine, la media spuntata è calcolata come la media aritmetica dei dati rimanenti. Questo approccio è utile quando ci sono valori anomali o quando la distribuzione è asimmetrica e la media aritmetica non rappresenta adeguatamente la tendenza centrale dei dati.
19.1.3.3 Proprietà della media
Una proprietà fondamentale della media è che la somma degli scarti di ciascun valore dalla media è zero:
\[ \sum_{i=1}^n (x_i - \bar{x}) = 0.\notag \tag{19.2}\]
Infatti,
\[ \begin{aligned} \sum_{i=1}^n (x_i - \bar{x}) &= \sum_i x_i - \sum_i \bar{x}\notag\\ &= \sum_i x_i - n \bar{x}\notag\\ &= \sum_i x_i - \sum_i x_i = 0.\notag \end{aligned} \]
Questa proprietà implica che i dati sono equamente distribuiti intorno alla media.
In R abbiamo:
19.1.3.4 La media come centro di gravità dell’istogramma
La media aritmetica può essere interpretata come il centro di gravità o il punto di equilibrio della distribuzione dei dati. In termini fisici, il centro di gravità è il punto in cui la massa di un sistema è equilibrata o concentrata.
In termini statistici, possiamo considerare la media come il punto in cui la distribuzione dei dati è in equilibrio. Ogni valore dell’insieme di dati può essere visto come un punto materiale con una massa proporzionale al suo valore. Se immaginiamo questi punti disposti su una linea, con valori più grandi a destra e più piccoli a sinistra, la media corrisponderà esattamente al punto in cui la distribuzione sarebbe in equilibrio.
Principio dei minimi quadrati
Il metodo dei minimi quadrati afferma che la posizione della media minimizza la somma dei quadrati delle distanze dai dati. Matematicamente, ciò significa che la somma dei quadrati degli scarti tra ciascun valore osservato e la media è minima. Questo principio è alla base dell’analisi statistica della regressione e conferma il ruolo della media come centro di gravità della distribuzione dei dati.
Simulazione. Utilizziamo una simulazione per verificare questo principio, calcolando la somma dei quadrati degli scarti per diversi valori e visualizzando il risultato con ggplot2.
# Definizione dell'intervallo di valori da testare
nrep <- 10000
M <- seq(20, 40, length.out = nrep)
res <- rep(NA, nrep)
# Calcolo della somma dei quadrati degli scarti per ciascun valore di M
for (i in 1:nrep) {
res[i] = sum((x - M[i])^2)
}
# Identificazione del valore minimo
min_index <- which.min(res)
min_M <- M[min_index]
# Creazione del dataframe per ggplot
df <- data.frame(M, res)
df |>
ggplot(aes(x = M, y = res)) +
geom_line(color = "blue") +
geom_vline(xintercept = min_M, linetype = "dashed", color = "red") +
labs(
title = "Minimizzazione della somma dei quadrati",
x = "Valore di M",
y = "Somma dei quadrati degli scarti"
) 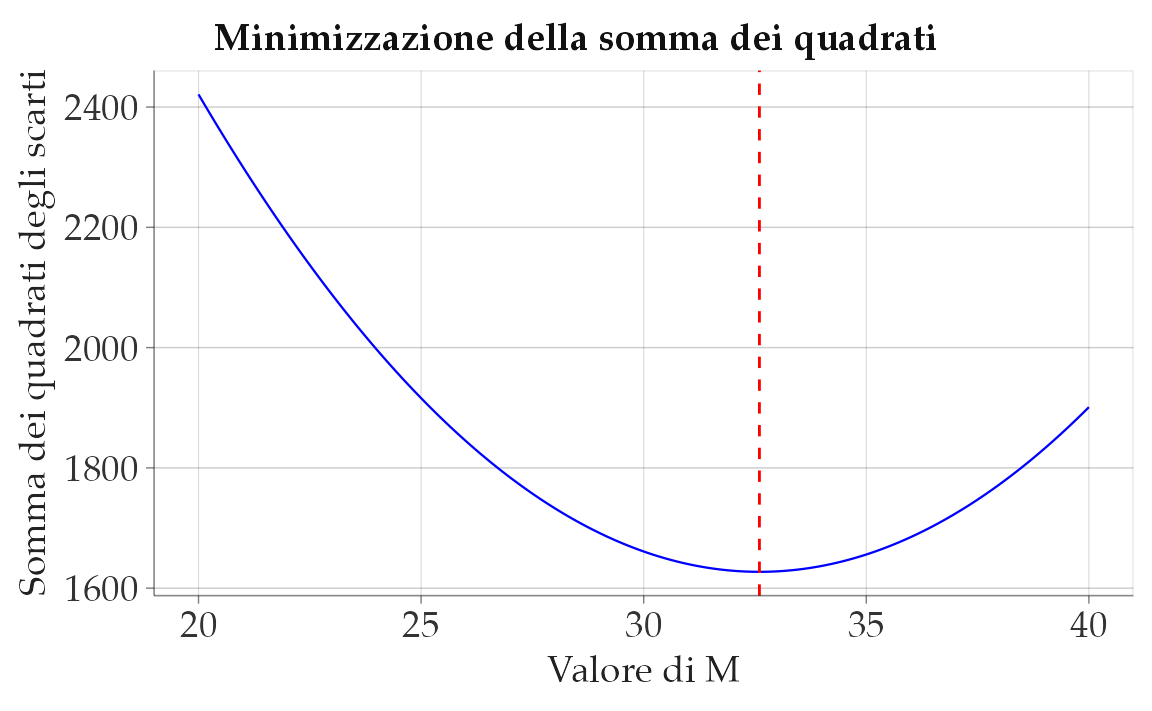
Stampiamo il minimo:
min_M
#> [1] 32.6Confronto con la media:
mean(x)
#> [1] 32.6Osserviamo che il valore di M che minimizza la somma dei quadrati degli scarti coincide con la media dei dati, confermando il principio dei minimi quadrati.
19.1.3.5 Le proporzioni sono medie
Se una collezione consiste solo di uni e zeri, allora la somma della collezione è il numero di uni in essa, e la media della collezione è la proporzione di uni.
È possibile sostituire 1 con il valore booleano True e 0 con False:
19.1.3.6 Limiti della media aritmetica
La media aritmetica, tuttavia, ha alcune limitazioni: non sempre è l’indice più adeguato per descrivere accuratamente la tendenza centrale della distribuzione, specialmente quando si verificano asimmetrie o valori anomali (outlier). In queste situazioni, è più indicato utilizzare la mediana o la media spuntata (come spiegheremo successivamente).
Come descrivere la tendenza centrale in distribuzioni asimmetriche
Gli indici di tendenza centrale – moda, mediana e media – assumono significati molto diversi quando la distribuzione dei dati è asimmetrica. Per esempio, consideriamo i dati del Progetto Natsal (sexual-partners.csv), che riportano il numero di partner sessuali di sesso opposto dichiarati da uomini e donne (35–44 anni).
- Esplorazione dei dati.
Estraggo dieci righe a caso:
Il dataset contiene due colonne principali:
-
Gender: genere del rispondente, -
NumPartners: numero di partner sessuali dichiarati.
Vediamo quanti soggetti ci sono in ciascun gruppo:
sexual_partners |>
group_by(Gender) |>
summarise(count = n())
#> # A tibble: 2 × 2
#> Gender count
#> <chr> <int>
#> 1 Man 796
#> 2 Woman 1193Il numero massimo riportato è molto alto (oltre 500), ma per chiarezza limitiamo l’analisi a valori ≤ 50:
sexual_partners |>
group_by(Gender) |>
summarise(maximum = max(NumPartners))
#> # A tibble: 2 × 2
#> Gender maximum
#> <chr> <int>
#> 1 Man 501
#> 2 Woman 550- Visualizzazione.
Calcoliamo e rappresentiamo la distribuzione dei partner (≤50) separatamente per genere:
sexual_partners_truncated <- sexual_partners |>
filter(NumPartners <= 50)
percentage_data <- sexual_partners_truncated %>%
group_by(Gender, NumPartners) %>%
summarise(Count = n(), .groups = "drop") %>%
group_by(Gender) %>%
mutate(Percentage = Count / sum(Count) * 100)
y_max <- max(percentage_data$Percentage)
gender_labels <- c("Man" = "Uomini 35–44", "Woman" = "Donne 35–44")
percentage_data |>
ggplot(aes(NumPartners, Percentage, fill = Gender)) +
geom_col(position = "dodge", color = "black") +
facet_wrap(~Gender, labeller = labeller(Gender = gender_labels)) +
scale_y_continuous(limits = c(0, y_max)) +
labs(x = "Numero di partner sessuali dichiarati", y = "Percentuale") +
theme(legend.position = "none")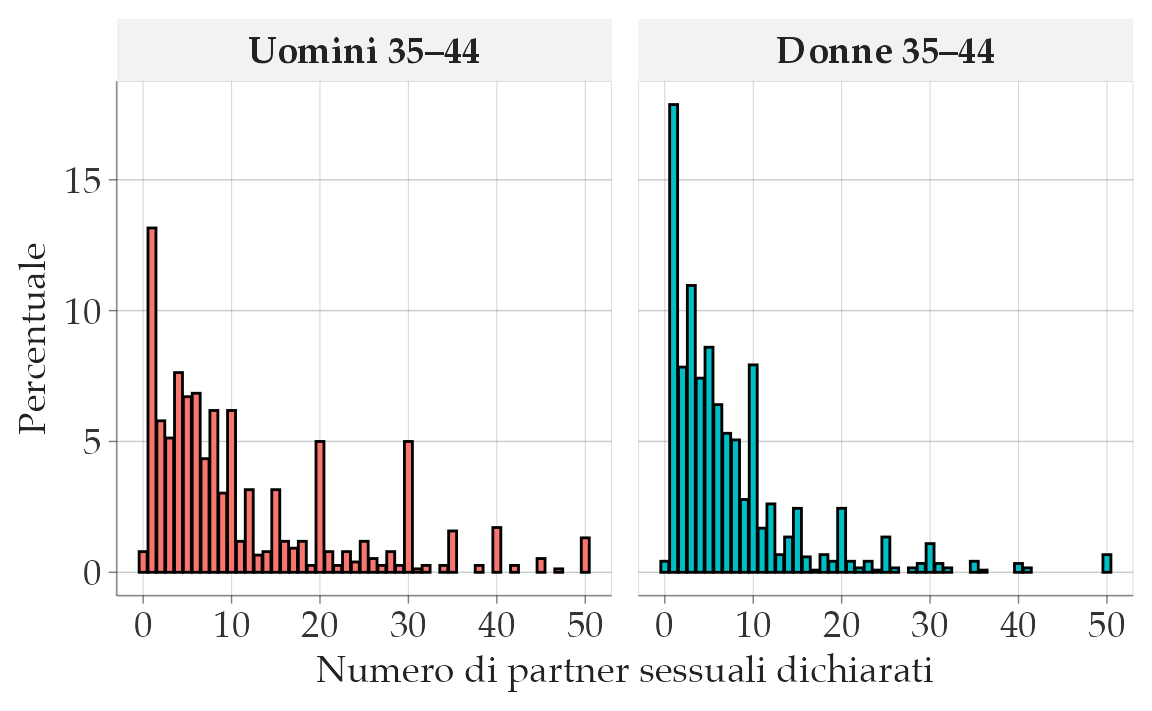
La distribuzione risulta altamente asimmetrica positiva: molti soggetti dichiarano pochi partner, pochi soggetti valori molto alti.
- Indici di tendenza centrale.
Calcoliamo media, mediana e moda per ciascun genere:
get_mode <- function(x) {
tbl <- table(x)
as.numeric(names(tbl)[which.max(tbl)])
}
sexual_partners_truncated |>
group_by(Gender) |>
summarise(
media = mean(NumPartners, na.rm = TRUE),
mediana = median(NumPartners, na.rm = TRUE),
moda = get_mode(NumPartners)
)
#> # A tibble: 2 × 4
#> Gender media mediana moda
#> <chr> <dbl> <dbl> <dbl>
#> 1 Man 11.4 7 1
#> 2 Woman 7.51 5 1- Interpretazione.
- Media: più alta di mediana e moda → influenzata dalla coda lunga a destra.
- Mediana: valore centrale, meno influenzata da estremi → misura più robusta.
- Moda: valore più frequente (1 partner), ma spesso poco rappresentativa in distribuzioni molto sparse.
- Conclusioni pratiche.
- In distribuzioni asimmetriche, la mediana è in genere l’indice di tendenza centrale più affidabile.
- È utile riportare anche media e moda per evidenziare le differenze.
- La descrizione numerica va sempre accompagnata da una visualizzazione grafica (istogrammi, boxplot) per cogliere l’asimmetria e i valori estremi.
- Una descrizione completa richiede anche misure di dispersione, che vedremo nella sezione successiva.
19.1.3.7 La media come rappresentazione della psicologia umana: un’arma a doppio taglio?
La media è uno degli strumenti statistici più semplici e intuitivi che i ricercatori utilizzano per sintetizzare i dati. È un indice di tendenza centrale familiare e intuitivo: se chiediamo a un gruppo di persone la loro età e calcoliamo la media, otteniamo un valore che sintetizza in un’unica cifra l’informazione disponibile. Ma cosa significa, in realtà, “riassumere” i dati con la media? E soprattutto, questa operazione ha senso quando si studiano i processi psicologici e il comportamento umano?
In molte discipline scientifiche, il concetto di media è utile perché descrive fenomeni che tendono a essere stabili e uniformi. Per esempio, se misuriamo l’altezza di un gruppo di persone, possiamo aspettarci che la distribuzione sia approssimativamente normale e che la media offra una stima ragionevole di un valore tipico. Tuttavia, la mente umana e i processi psicologici non funzionano come il sistema cardiovascolare o i muscoli. Ogni persona ha esperienze uniche che plasmano le sue risposte, i suoi pensieri e le sue emozioni.
Un problema centrale, sollevato da Speelman & McGann (2013), riguarda l’implicita assunzione che ci sia un vero valore sottostante ai processi psicologici che possiamo stimare attraverso la media, come se il comportamento umano fosse determinato da meccanismi identici in ogni individuo, con le differenze attribuibili solo a “rumore” sperimentale. Questo approccio, tipico della psicologia sperimentale tradizionale, assume che testare un gruppo di persone e mediare i loro risultati ci permetta di rivelare la struttura comune della mente umana. Ma questa assunzione è davvero giustificata?
19.1.3.8 La fallacia ergodica e l’illusione dell’universalità
Un errore metodologico frequente nella psicologia è la cosiddetta fallacia ergodica, ovvero l’errata convinzione che le caratteristiche medie di un gruppo possano essere automaticamente applicate ai singoli individui che lo compongono (Speelman et al., 2024). Questo equivoco nasce dall’idea che la media descriva un valore “tipico” valido per tutti, senza considerare le differenze individuali o le variazioni nel tempo.
Immaginiamo di studiare la felicità di un gruppo di persone nel corso di una settimana e di calcolare la media dei loro punteggi di benessere giornalieri. Se lunedì una persona ha un punteggio di 2 (molto infelice), mercoledì 5 (moderatamente felice) e sabato 8 (molto felice), il suo punteggio medio sarà 5. Tuttavia, questo valore intermedio non rappresenta in alcun modo la realtà soggettiva vissuta da quella persona nei singoli giorni. Lo stesso problema si pone quando si usano le medie per descrivere abilità cognitive, tratti di personalità o stati emotivi: la media può nascondere fluttuazioni e differenze individuali fondamentali per comprendere la psicologia umana.
Il rischio, come sottolineato da Molden & Dweck (2006), è che il nostro desiderio di trovare universalità nei processi cognitivi ci porti a enfatizzare somiglianze tra le persone, ignorando le variazioni individuali che possono essere altrettanto, se non più, informative. Per esempio, due studenti con lo stesso punteggio medio in un test di memoria potrebbero aver ottenuto quel risultato in modi completamente diversi: uno potrebbe aver avuto prestazioni costantemente nella media, mentre l’altro potrebbe aver avuto picchi di eccellenza alternati a difficoltà estreme.
19.1.3.9 La media: uno strumento da usare con cautela
Questi problemi non significano che la media sia inutile in psicologia. È un indicatore potente e spesso informativo, ma deve essere interpretato con cautela. In particolare, non può essere usata per fare inferenze sui singoli individui senza considerare altre misure, come la varianza e la deviazione standard, che ci dicono quanto i dati siano dispersi intorno alla media.
In psicologia, comprendere la variabilità è tanto importante quanto individuare una tendenza centrale. Se vogliamo davvero capire il comportamento umano, dobbiamo chiederci non solo qual è il valore medio? ma anche quanto variano i dati? e cosa ci dice questa variabilità sulle differenze individuali? Nella prossima sezione, esamineremo questi concetti e vedremo come la varianza e la deviazione standard ci aiutano a catturare le differenze che la media, da sola, non può rivelare.
19.2 La variabilità nei dati psicologici
Nei fenomeni psicologici e comportamentali, la variabilità è una caratteristica intrinseca. Ad esempio, se misuriamo il livello di stress percepito da una persona più volte nella stessa giornata, è raro osservare lo stesso valore anche utilizzando strumenti identici. Allo stesso modo, un questionario standardizzato sull’autostima somministrato a un gruppo di studenti universitari restituirà punteggi differenti per ciascun partecipante. Anche registrando i tempi di reazione in un compito cognitivo, noteremo fluttuazioni sia tra individui diversi sia nelle prestazioni dello stesso individuo in prove ripetute.
Questa dispersione sistematica non è un “rumore” da ignorare, ma un elemento informativo cruciale. L’analisi statistica in psicologia ha infatti uno scopo duplice: da un lato, quantificare la variabilità; dall’altro, identificarne le origini. Differenze individuali, contesto ambientale, errori di misurazione o interazioni tra fattori sono solo alcune delle possibili fonti che contribuiscono alla variazione osservata.
In questa sezione esploreremo:
-
La scomposizione della variabilità in componenti spiegate (attribuibili a fattori noti, come un intervento sperimentale) e non spiegate (legate a elementi casuali o non controllati).
- Strumenti per descriverla, sia attraverso rappresentazioni grafiche (boxplot, istogrammi) sia mediante indici numerici (differenza interquartile, varianza, deviazione standard).
Comprendere la variabilità non è un esercizio tecnico, ma un passo fondamentale per interpretare fenomeni complessi come le differenze di personalità, le oscillazioni emotive o l’efficacia di una terapia. Ogni modello psicologico, infatti, deve fare i conti con questa dimensione dinamica e multideterminata dei dati.
19.2.1 Quantili
Accanto alle misure di tendenza centrale, i quantili descrivono la posizione relativa di un’osservazione in una distribuzione. Se media, mediana e moda individuano un valore “tipico”, i quantili rispondono invece a una domanda diversa: qual è il valore al di sotto del quale si colloca una determinata proporzione dei dati?
19.2.1.1 Definizione
Il quantile di ordine \(p\) (\(0 < p < 1\)) è il valore \(q_p = x_{(k)}\), dove \(x_{(k)}\) rappresenta il \(k\)-esimo elemento dei dati ordinati in senso crescente e \(k = \lceil p \cdot n \rceil\), con \(n\) numero totale di osservazioni e \(\lceil \cdot \rceil\) funzione di arrotondamento per eccesso. Questo è il cosiddetto quantile non interpolato. Quando \(p \cdot n\) non è intero, si ricorre di norma all’interpolazione lineare tra due osservazioni consecutive: è il metodo implementato nei principali software statistici.
Per chiarire, consideriamo i dati ordinati \({15, 20, 23, 25, 28, 30, 35, 40, 45, 50}\). Il 30° percentile (\(p=0.3\)) si calcola come \(k = \lceil 0.3 \cdot 10 \rceil = 3\), dunque \(q_{0.3} = 23\).
19.2.1.2 Percentili e quartili
Un caso particolare sono i percentili, che suddividono la distribuzione in cento parti uguali. Il 25° percentile (o primo quartile \(Q_1\)) lascia al di sotto di sé un quarto dei dati, il 50° percentile corrisponde alla mediana e il 75° percentile (terzo quartile \(Q_3\)) delimita i tre quarti inferiori della distribuzione.
19.2.1.3 Esempio applicativo
Per illustrare l’uso dei quantili, consideriamo la variabile NumPartners, distinta per genere. Calcoliamo il 10° e il 90° percentile.
I risultati mostrano che, tra gli uomini, il 10% ha dichiarato al massimo un partner, mentre il 10% con i valori più elevati supera i 34 partner. Tra le donne, il 10° percentile coincide ancora con un partner, ma il 90° percentile non va oltre 18.
Questa differenza indica che le distribuzioni dei due gruppi condividono una base simile (molti individui con pochi partner) ma divergono nella coda superiore: negli uomini, pochi soggetti con valori estremi spingono la distribuzione verso destra, generando una maggiore asimmetria positiva.
19.2.1.4 Misure di dispersione basate sui quantili
I quantili possono essere utilizzati anche per costruire indici di variabilità che non fanno ipotesi sulla forma della distribuzione. La misura più semplice è l’intervallo di variazione, pari alla differenza tra valore massimo e minimo. Questo indice è immediato da calcolare, ma dipende esclusivamente dagli estremi e risulta quindi molto sensibile agli outlier.
Nell’esempio l’intervallo è 23, valore che descrive l’ampiezza complessiva dei dati ma non la loro distribuzione interna.
Un indicatore più robusto è la differenza interquartile (IQR), che misura la distanza fra il terzo e il primo quartile, racchiudendo così il 50% centrale dei dati.
IQR(x)
#> [1] 9Se in un gruppo di studenti i quartili sono \(Q_1 = 25\) e \(Q_3 = 40\), l’IQR è pari a 15: significa che metà dei punteggi si colloca in un intervallo di 15 unità. Questo indice riduce l’influenza dei valori estremi, anche se non rappresenta l’intera dispersione della distribuzione.
In sintesi, l’intervallo di variazione e l’IQR offrono due prospettive complementari: il primo fornisce un’idea immediata dell’ampiezza totale dei dati, il secondo descrive la variabilità tipica della parte centrale della distribuzione. Entrambi hanno limiti che rendono necessario affiancarli a misure più complete, come la varianza e la deviazione standard, di cui parleremo nella sezione successiva.
19.2.2 La varianza
La varianza è una delle misure di dispersione più utilizzate in statistica perché tiene conto di tutte le osservazioni e descrive quanto i valori si discostano dalla loro media. Formalmente, se abbiamo \(n\) osservazioni \(x_1, x_2, \dots, x_n\) e indichiamo con \(\bar{x} = \frac{1}{n} \sum_{i=1}^n x_i\) la loro media, la varianza (in versione descrittiva) si calcola così:
\[ S^2 = \frac{1}{n} \sum_{i=1}^n (x_i - \bar{x})^2. \tag{19.3}\]
In altre parole, per trovare la varianza:
- calcoliamo la media di tutti i valori (\(\bar{x}\)),
- sottraiamo la media a ciascun valore, ottenendo così lo scarto \((x_i - \bar{x})\),
- eleviamo ogni scarto al quadrato, per rendere positivi i valori ed enfatizzare gli scostamenti più grandi,
- infine, facciamo la media di questi quadrati.
Maggiore è la varianza, maggiore è la variabilità (o dispersione) dei dati rispetto alla media. Al contrario, una varianza prossima allo zero indica che le osservazioni sono molto vicine tra loro e quasi coincidenti con la media.
Nota su popolazione e campione. Spesso, nell’analisi di dati campionari, la varianza viene calcolata usando \(\frac{1}{n-1}\) al denominatore al posto di \(\frac{1}{n}\). In questo modo otteniamo una stima corretta (non distorta) della varianza della popolazione. Nel contesto della formula sopra riportata, invece, stiamo calcolando la varianza descrittiva (o popolazione completa).
19.2.2.1 Interpretazione
Nel caso dell’esempio precedente relativo alle ore di studio giornaliere, una varianza pari a 1.25 indica che le ore di studio giornaliere si discostano, in media, di 1.25 unità quadrate dalla media di 2.5 ore. Per comprendere meglio l’ordine di grandezza di questa dispersione, solitamente si fa riferimento alla deviazione standard, che è la radice quadrata della varianza. In questo caso, \(\sqrt{1.25} \approx 1.12\) ore.
- Se la varianza (o la deviazione standard) fosse stata molto più grande, avremmo dedotto che gli studenti del campione presentano abitudini di studio molto diverse.
- Al contrario, se la varianza fosse prossima a 0, significherebbe che quasi tutti studiano un numero di ore molto simile a 2.5.
19.2.2.2 Calcolo in R
Se volessimo effettuare in R i calcoli relativi all’esempio sulle ore di studio, potremmo fare così:
# Dati
x <- c(3, 1, 4, 2)
# Calcolo manuale della media
media_x <- mean(x)
# Calcolo manuale della varianza secondo la formula descrittiva
varianza_descr <- mean((x - media_x)^2)
varianza_descr
#> [1] 1.25
# [1] 1.25
# Calcolo della varianza con la funzione var() di R
# (Attenzione: per default var() usa n-1 al denominatore)
varianza_campionaria <- var(x)
varianza_campionaria
#> [1] 1.667
# [1] 1.666667Osserviamo che var(x) dà un valore di circa 1.67 perché R, di default, calcola la varianza campionaria (con \(n-1\) al denominatore). Se vogliamo la varianza descrittiva (come nella formula con \(n\) al denominatore), usiamo la nostra varianza_descr.
In sintesi, la varianza fornisce un modo per quantificare quanto siano diverse tra loro le osservazioni. Nel caso dell’esempio sulle ore di studio, abbiamo visto che i valori, pur non essendo tutti identici, non mostrano una dispersione eccessiva (la varianza è 1.25). Se i comportamenti di studio fossero estremamente diversificati (per esempio, se qualcuno studiasse 0 ore al giorno e qualcun altro 10), la varianza sarebbe molto più elevata, indicando una marcata eterogeneità nel campione.
19.2.2.3 Stima della varianza della popolazione
Si noti il denominatore della formula della varianza. Nell’Equazione 19.3, ho utilizzato \(n\) come denominatore (l’ampiezza campionaria, ovvero il numero di osservazioni nel campione). In questo modo, otteniamo la varianza come statistica descrittiva del campione. Tuttavia, è possibile utilizzare \(n-1\) come denominatore alternativo:
\[ s^2 = \frac{1}{n-1} \sum_{i=1}^n (x_i - \bar{x})^2 . \tag{19.4}\]
In questo secondo caso, otteniamo la varianza come stimatore della varianza della popolazione. Si può dimostrare che l’Equazione 19.4 fornisce una stima corretta (ovvero, non distorta) della varianza della popolazione da cui abbiamo ottenuto il campione, mentre l’Equazione 19.3 fornisce (in media) una stima troppo piccola della varianza della popolazione. Si presti attenzione alla notazione: \(S^2\) rappresenta la varianza come statistica descrittiva, mentre \(s^2\) rappresenta la varianza come stimatore.
Simulazione
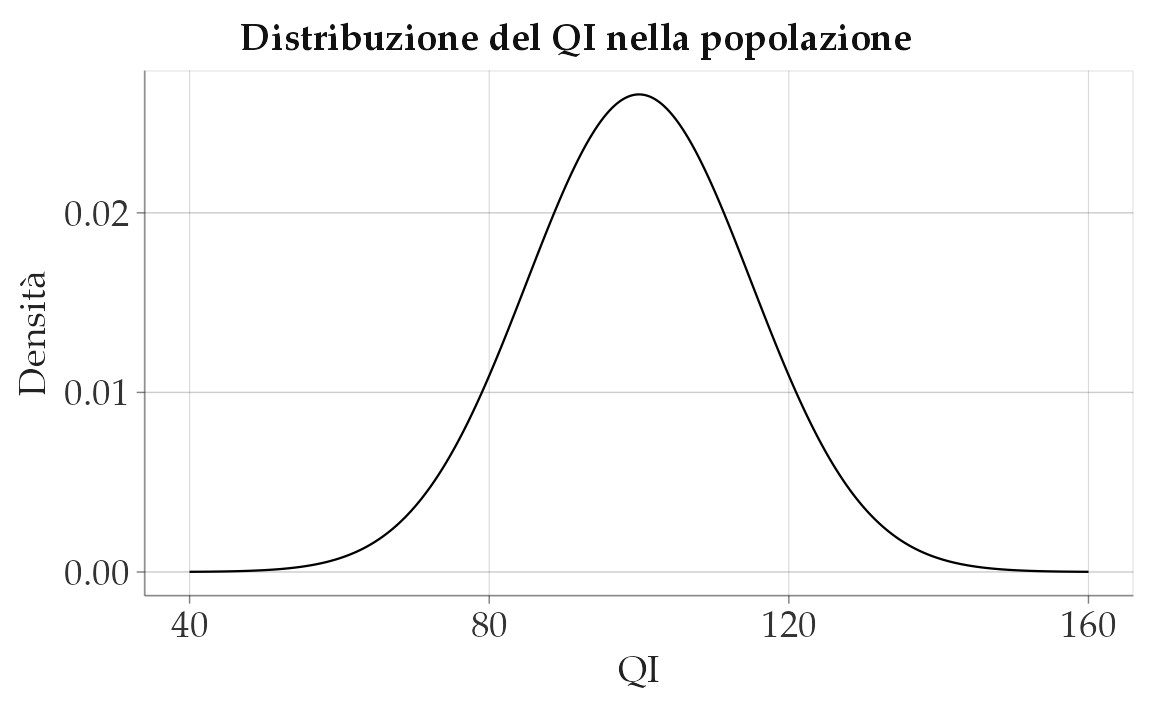
Per illustrare questo punto, svolgiamo una simulazione. Consideriamo la distribuzione dei punteggi del quoziente di intelligenza (QI). I valori del QI seguono una particolare distribuzione chiamata distribuzione normale (v. Capitolo 20), con media 100 e deviazione standard 15. La forma di questa distribuzione è illustrata nella figura seguente.
# Define parameters
x <- seq(100 - 4 * 15, 100 + 4 * 15, by = 0.001)
mu <- 100
sigma <- 15
# Compute the PDF
pdf <- dnorm(x, mean = mu, sd = sigma)
# Plot using ggplot2
data <- tibble(x = x, pdf = pdf)
ggplot(data, aes(x = x, y = pdf)) +
geom_line() +
labs(
x = "QI",
y = "Densità",
title = "Distribuzione del QI nella popolazione"
) 
Supponiamo di estrarre un campione casuale di 4 osservazioni dalla popolazione del quoziente di intelligenza – in altre parole, supponiamo di misurare il quoziente di intelligenza di 4 persone prese a caso dalla popolazione.
Calcoliamo la varianza usando \(n\) al denominatore. Si noti che la vera varianza del quoziente di intelligenza è \(15^2\) = 225.
var(x)
#> [1] 196.9Consideriamo ora 10 campioni casuali del QI, ciascuno di ampiezza 4.
Il primo campione è
random_samples[1]
#> [[1]]
#> [1] 91.59 96.55 123.38 101.06Il decimo campione è
random_samples[10]
#> [[1]]
#> [1] 108.31 99.07 95.41 94.29Stampiamo i valori di tutti i 10 campioni.
rs <- do.call(rbind, random_samples)
rs
#> [,1] [,2] [,3] [,4]
#> [1,] 91.59 96.55 123.38 101.06
#> [2,] 101.94 125.73 106.91 81.02
#> [3,] 89.70 93.32 118.36 105.40
#> [4,] 106.01 101.66 91.66 126.80
#> [5,] 107.47 70.50 110.52 92.91
#> [6,] 83.98 96.73 84.61 89.07
#> [7,] 90.62 74.70 112.57 102.30
#> [8,] 82.93 118.81 106.40 95.57
#> [9,] 113.43 113.17 112.32 110.33
#> [10,] 108.31 99.07 95.41 94.29Per ciascun campione (ovvero, per ciascuna riga della matrice precedente), calcoliamo la varianza usando la formula con \(n\) al denominatore. Otteniamo così 10 stime della varianza della popolazione del QI.
Notiamo due cose:
- le stime sono molto diverse tra loro; questo fenomeno è noto con il nome di variabilità campionaria;
- in media le stime sono troppo piccole.
Per aumentare la sicurezza riguardo al secondo punto menzionato in precedenza, ripeteremo la simulazione utilizzando un numero di iterazioni maggiore.
mu <- 100
sigma <- 15
size <- 4
niter <- 10000
random_samples <- list()
set.seed(123) # Replace 123 with your desired seed for reproducibility
for (i in 1:niter) {
one_sample <- rnorm(size, mean = mu, sd = sigma)
random_samples[[i]] <- one_sample
}
rs <- do.call(rbind, random_samples)
x_var <- apply(rs, 1, var) * (size - 1) / size # Adjust for population variance (ddof = 0)Esaminiamo la distribuzione dei valori ottenuti.
# Create a data frame for plotting
data <- data.frame(x_var = x_var)
# Plot the histogram using ggplot2
ggplot(data, aes(x = x_var)) +
geom_histogram(fill = "lightblue", bins = 30, color = "black") +
scale_x_continuous(limits = c(0, 1500)) +
scale_y_continuous(limits = c(0, 2250)) +
labs(
x = "Varianza",
y = "Frequenza",
title = "Varianza del QI in campioni di n = 4"
)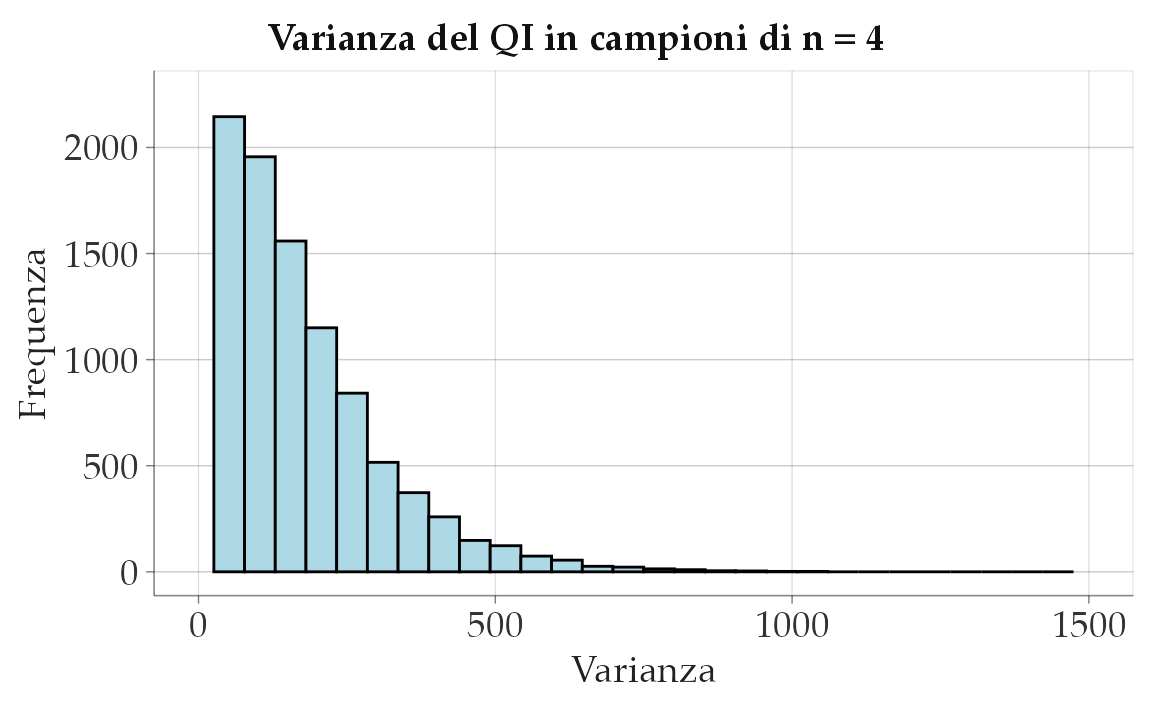
La stima più verosimile della varianza del QI è dato dalla media di questa distribuzione.
mean(x_var)
#> [1] 168.9Si noti che il nostro spospetto è stato confermato: il valore medio della stima della varianza ottenuta con l’Equazione 19.3 è troppo piccolo rispetto al valore corretto di \(15^2 = 225\).
Ripetiamo ora la simulazione usando la formula della varianza con \(n-1\) al denominatore.
Esaminiamo la distribuzione dei valori ottenuti.
# Create a data frame for plotting
data <- data.frame(x_var = x_var)
# Plot the histogram using ggplot2
ggplot(data, aes(x = x_var)) +
geom_histogram(fill = "lightblue", bins = 30, color = "black") +
scale_x_continuous(limits = c(0, 1500)) +
scale_y_continuous(limits = c(0, 2250)) +
labs(
x = "Varianza Corretta",
y = "Frequenza",
title = "Varianza corretta del QI in campioni di n = 4"
)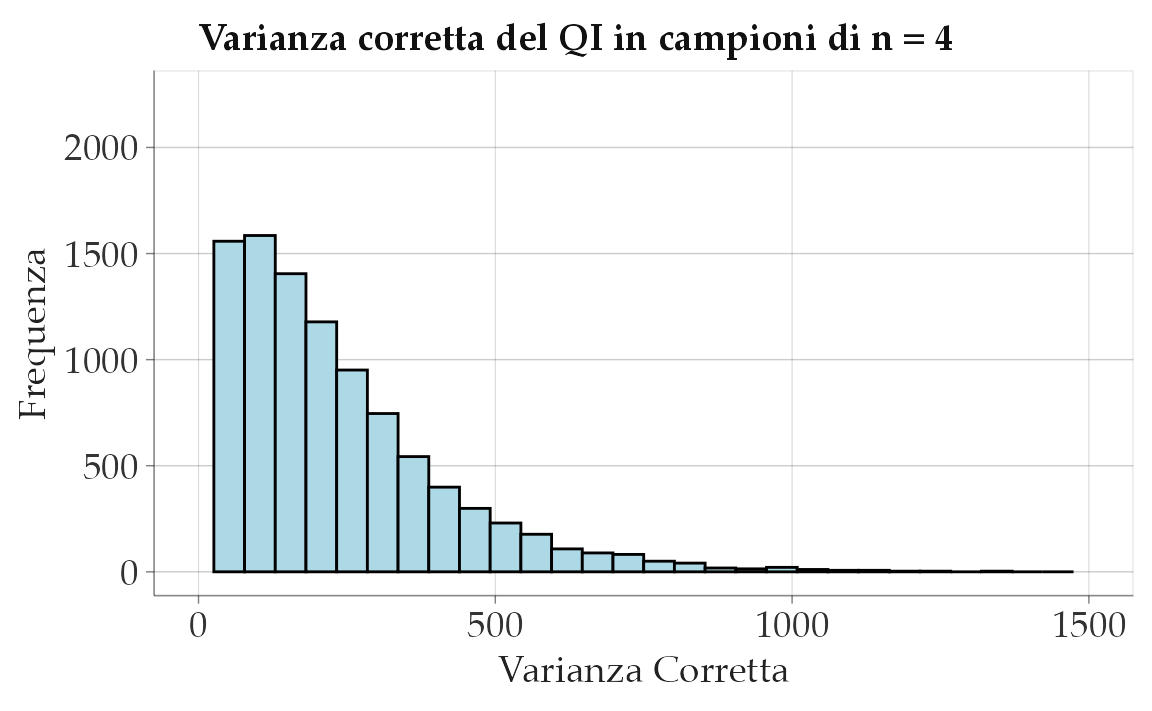
Nel secondo caso, se utilizziamo \(n-1\) come denominatore per calcolare la stima della varianza, il valore atteso di questa stima è molto vicino al valore corretto di 225. Se il numero di campioni fosse infinito, i due valori sarebbero identici.
mean(x_var)
#> [1] 225.2In conclusione, le due formule della varianza hanno scopi diversi.
- La formula della varianza con \(n\) al denominatore viene utilizzata come statistica descrittiva per descrivere la variabilità di un particolare campione di osservazioni.
- D’altro canto, la formula della varianza con \(n-1\) al denominatore viene utilizzata come stimatore per ottenere la migliore stima della varianza della popolazione da cui quel campione è stato estratto.
19.2.3 Deviazione standard
Per interpretare la varianza in modo più intuitivo, si può calcolare la deviazione standard (o scarto quadratico medio o scarto tipo) prendendo la radice quadrata della varianza. La deviazione standard è espressa nell’unità di misura originaria dei dati, a differenza della varianza che è espressa nel quadrato dell’unità di misura dei dati. La deviazione standard fornisce una misura della dispersione dei dati attorno alla media, rendendo più facile la comprensione della variabilità dei dati.
La deviazione standard (o scarto quadratico medio, o scarto tipo) è definita come:
\[ s^2 = \sqrt{(n-1)^{-1} \sum_{i=1}^n (x_i - \bar{x})^2}. \tag{19.5}\]
Quando tutte le osservazioni sono uguali, \(s = 0\), altrimenti \(s > 0\).
La deviazione standard \(s\) dovrebbe essere utilizzata solo quando la media è una misura appropriata per descrivere il centro della distribuzione, ad esempio nel caso di distribuzioni simmetriche. Tuttavia, è importante tener conto che, come la media \(\bar{x}\), anche la deviazione standard è fortemente influenzata dalla presenza di dati anomali, ovvero pochi valori che si discostano notevolmente dalla media rispetto agli altri dati della distribuzione. In presenza di dati anomali, la deviazione standard può risultare ingannevole e non rappresentare accuratamente la variabilità complessiva della distribuzione. Pertanto, è fondamentale considerare attentamente il contesto e le caratteristiche dei dati prima di utilizzare la deviazione standard come misura di dispersione. In alcune situazioni, potrebbe essere più appropriato ricorrere a misure di dispersione robuste o ad altre statistiche descrittive per caratterizzare la variabilità dei dati in modo più accurato e affidabile.
19.2.3.1 Interpretazione
La deviazione standard misura la dispersione dei dati rispetto alla media aritmetica. In termini semplici, indica quanto, in media, ciascun valore osservato si discosta dalla media del campione. Anche se è simile allo scarto semplice medio campionario (la media dei valori assoluti degli scarti rispetto alla media), la deviazione standard utilizza lo scarto quadratico medio e produce un valore leggermente diverso.
Esempio 19.1 Per verificare l’interpretazione della deviazione standard, utilizziamo i punteggi relativi alle ore di studio di un piccolo numero di studenti.
La deviazione standard calcolata è 1.12. Questo valore ci dice che, in media, ciascun punteggio si discosta di circa 1.12 ore dalla media aritmetica delle ore di studio di questo gruppo di studenti.
- Valore più alto: indica maggiore dispersione dei dati intorno alla media.
- Valore più basso: i dati sono più concentrati vicino alla media.
Se calcoliamo anche lo scarto semplice medio campionario per confronto, otteniamo:
I due valori (deviazione standard e scarto semplice medio) sono simili ma non identici, a causa delle diverse definizioni matematiche.
19.2.4 Varianza spiegata e non spiegata
La varianza, come abbiamo visto, misura quanto i dati si disperdono attorno alla media. Un concetto fondamentale nei modelli statistici lineari è la distinzione tra varianza spiegata e varianza non spiegata, che ci permette di valutare quanto bene un modello teorico riesca a chiarire la variabilità osservata nei dati.
19.2.4.1 Decomposizione della varianza
Quando osserviamo un fenomeno (ad esempio i risultati di un test), troviamo inevitabilmente differenze tra individui. Queste differenze possono essere suddivise in due componenti principali:
- varianza spiegata: la parte di variabilità che può essere attribuita a fattori identificati e misurabili;
- varianza non spiegata: la parte rimanente di variabilità che non è chiarita dai fattori considerati.
Formalmente, questa decomposizione può essere espressa come:
\[ \sum_{i=1}^{n}(Y_i - \bar{Y})^2 = \sum_{i=1}^{n}(\hat{Y}_i - \bar{Y})^2 + \sum_{i=1}^{n}(Y_i - \hat{Y}_i)^2 , \]
dove:
- \(Y_i\) sono i dati osservati,
- \(\bar{Y}\) è la media dei dati osservati,
- \(\hat{Y}_i\) sono i valori attesi (previsti) dal modello teorico.
Intuitivamente:
- la varianza totale (lato sinistro della formula) rappresenta la dispersione complessiva dei dati attorno alla loro media;
- la varianza spiegata (primo termine a destra) indica quanto bene i valori previsti dal modello descrivono il comportamento dei dati;
- la varianza non spiegata (secondo termine a destra) riflette ciò che il modello non riesce a prevedere.
19.2.5 Deviazione mediana assoluta
La deviazione mediana assoluta (MAD) è una misura robusta di dispersione basata sulla mediana. È definita come la mediana dei valori assoluti delle deviazioni dei dati rispetto alla mediana:
\[ \text{MAD} = \text{median} \left( |X_i - \text{median}(X)| \right) \tag{19.6}\]
La MAD è particolarmente utile per analizzare dati contenenti outlier o distribuzioni asimmetriche, poiché è meno influenzata dai valori estremi rispetto alla deviazione standard.
19.2.5.1 Relazione tra MAD e deviazione standard in una distribuzione normale
Quando i dati seguono una distribuzione normale (gaussiana), esiste una relazione approssimativa tra MAD e deviazione standard. La MAD può essere convertita in una stima della deviazione standard moltiplicandola per una costante di 1.4826:
\[ \sigma \approx k \times \text{MAD}, \]
dove:
- \(\sigma\) è la deviazione standard,
- MAD è la Mediana della Deviazione Assoluta,
- \(k\) è una costante che, per una distribuzione normale, è tipicamente presa come circa 1.4826.
Questa costante deriva dalla proprietà della distribuzione normale, in cui circa il 50% dei valori si trova entro 0.6745 deviazioni standard dalla media.
La formula completa per convertire la MAD in una stima della deviazione standard in una distribuzione normale è:
\[ \sigma \approx 1.4826 \times \text{MAD} \]
Questa relazione è utile per stimare la deviazione standard in modo più robusto, specialmente quando si sospetta la presenza di outlier o si ha a che fare con campioni piccoli. Di conseguenza, molti software restituiscono il valore MAD moltiplicato per questa costante per fornire un’indicazione più intuitiva della variabilità dei dati. Tuttavia, è importante notare che questa relazione si mantiene accurata solo per le distribuzioni che sono effettivamente normali. In presenza di distribuzioni fortemente asimmetriche o con elevati outlier, la deviazione standard e la MAD possono fornire indicazioni molto diverse sulla variabilità dei dati.
19.2.5.2 Quando usare deviazione standard e MAD
Deviazione standard: È la misura più appropriata per dati normalmente distribuiti e situazioni in cui l’obiettivo è descrivere la dispersione dei dati rispetto alla media. Tuttavia, è sensibile ai valori anomali (outlier).
Deviazione mediana assoluta: È ideale quando i dati sono non normali, asimmetrici o contengono outlier. La MAD è più robusta poiché utilizza la mediana anziché la media e non è influenzata da valori estremi.
19.2.6 Indici di variabilità relativi
A volte può essere necessario confrontare la variabilità di grandezze incommensurabili, ovvero di caratteri misurati con differenti unità di misura. In queste situazioni, le misure di variabilità descritte in precedenza diventano inadeguate poiché dipendono dall’unità di misura utilizzata. Per superare questo problema, si ricorre a specifici numeri adimensionali chiamati indici relativi di variabilità.
Il più importante di questi indici è il coefficiente di variazione (\(C_v\)), definito come il rapporto tra la deviazione standard (\(\sigma\)) e la media dei dati (\(\bar{x}\)):
\[ C_v = \frac{\sigma}{\bar{x}}. \tag{19.7}\]
Il coefficiente di variazione è un numero puro e permette di confrontare la variabilità di distribuzioni con unità di misura diverse.
Un altro indice relativo di variabilità è la differenza interquartile rapportata a uno dei tre quartili (primo quartile, terzo quartile o mediana). Questo indice è definito come:
\[ \frac{x_{0.75} - x_{0.25}}{x_{0.25}}, \qquad \frac{x_{0.75} - x_{0.25}}{x_{0.75}}, \qquad \frac{x_{0.75} - x_{0.25}}{x_{0.50}}. \]
Questi indici relativi di variabilità forniscono una misura adimensionale della dispersione dei dati, rendendo possibile il confronto tra grandezze con diverse unità di misura e facilitando l’analisi delle differenze di variabilità tra i dati.
Riflessioni conclusive
Le statistiche descrittive forniscono strumenti essenziali per sintetizzare e comprendere i dati raccolti in psicologia e nelle scienze sociali. Le misure di tendenza centrale, come la media, la mediana e la moda, ci permettono di individuare un valore tipico o rappresentativo di una distribuzione, facilitando la sintesi e l’interpretazione generale dei dati raccolti. Parallelamente, gli indici di dispersione, come la deviazione standard, la varianza e l’intervallo interquartile, offrono informazioni cruciali sulla variabilità, mostrandoci quanto i singoli dati siano vicini o distanti da questa tendenza centrale.
Tuttavia, è fondamentale riflettere attentamente sulle implicazioni teoriche e metodologiche che accompagnano l’uso di queste misure. In particolare, è importante considerare il rischio della fallacia ergodica, ovvero l’errata convinzione che i risultati ottenuti da medie e statistiche aggregate possano automaticamente applicarsi ai singoli individui. Nella pratica psicologica, infatti, ogni persona è caratterizzata da una notevole variabilità intra- e inter-individuale, che spesso non può essere adeguatamente rappresentata da semplici indicatori aggregati.
Le statistiche descrittive rappresentano quindi un primo e fondamentale passo nella comprensione dei dati psicologici, ma devono essere integrate da analisi più approfondite e attente alle differenze individuali. L’uso critico e consapevole di questi strumenti statistici ci consente di evitare generalizzazioni eccessive, fornendo una visione più accurata e realistica dei fenomeni psicologici e comportamentali che studiamo.
Esercizi
Bibliografia
Barroso, C., Ganley, C. M., McGraw, A. L., Geer, E. A., Hart, S. A., & Daucourt, M. C. (2021). A meta-analysis of the relation between math anxiety and math achievement. Psychological Bulletin, 147(2), 134–168.
Molden, D. C., & Dweck, C. S. (2006). Finding" meaning" in psychology: a lay theories approach to self-regulation, social perception, and social development. American Psychologist, 61(3), 192–203.
Speelman, C. P., & McGann, M. (2013). How mean is the mean? Frontiers in Psychology, 4, 451.
Speelman, C. P., Parker, L., Rapley, B. J., & McGann, M. (2024). Most Psychological Researchers Assume Their Samples Are Ergodic: Evidence From a Year of Articles in Three Major Journals. Collabra: Psychology, 10(1).