here::here("code", "_common.R") |>
source()
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(cmdstanr, posterior, bayesplot, ggplot2, tidyverse, tibble)
conflicts_prefer(posterior::ess_bulk)
conflicts_prefer(posterior::ess_tail)
conflicts_prefer(dplyr::count)57 Modello di Poisson (1)
“Statistical analysis is a dialogue between models and data: we propose a model, confront it with data, and revise our understanding.”
— Andrew Gelman
Introduzione
In questo capitolo affrontiamo un primo esempio di modellazione con Stan, il linguaggio che useremo per costruire modelli statistici e fare inferenza bayesiana. Riprendiamo un caso già risolto con metodi analitici e con il metodo su griglia — il modello Gamma–Poisson — e lo affrontiamo ora con il campionamento MCMC. In questo modo possiamo confrontare i risultati e, soprattutto, imparare un workflow che useremo anche quando non esistono soluzioni chiuse.
Panoramica del capitolo
- Introdurre il modello di Poisson per dati di conteggio.
- Specificare una distribuzione a priori Gamma coniugata.
- Implementare il modello in Stan e stimare i parametri con MCMC.
- Confrontare i risultati con la soluzione analitica Gamma–Poisson.
- Applicare il modello a un dataset reale sulle sparatorie mortali negli Stati Uniti.
57.1 Dal modello teorico al modello computazionale
Quando raccogliamo dati in psicologia, non ci interessa solo descrivere quello che è accaduto nel nostro campione, ma soprattutto stimare il processo che genera i dati nella popolazione.
Immaginiamo di osservare, in otto finestre temporali di pari durata, quante volte si verifica un certo evento psicologico o comportamentale. Per esempio, il numero di compulsioni in otto momenti della giornata, oppure il numero di telefonate ricevute in otto turni orari.
I dati raccolti sono:
y <- c(2, 1, 3, 2, 2, 1, 1, 1)Abbiamo quindi \(N = 8\) osservazioni. Dal campione potremmo calcolare una semplice media (\(\bar y = 1.625\)), ma questo ci dice solo quanto spesso l’evento è avvenuto nei nostri dati. La domanda più interessante è:
qual è il tasso medio di occorrenza nella popolazione?
Chiamiamo questo tasso \(\lambda\): il numero medio di eventi attesi in una finestra temporale.
57.1.1 Perché serve un modello probabilistico?
I dati osservati sono solo un piccolo campione e possono variare da una raccolta all’altra. Un modello probabilistico ci serve per due motivi principali:
- Separare il segnale dal rumore: capire quanto dell’andamento osservato è dovuto al caso e quanto riflette una regolarità della popolazione.
- Quantificare l’incertezza: non ci basta stimare \(\lambda\), vogliamo anche dire quanto siamo sicuri (o incerti) di quella stima.
57.1.2 Il modello di Poisson
Per i fenomeni di conteggio (quante volte un evento si verifica in un intervallo), il modello naturale è la distribuzione di Poisson:
\[ y_i \sim \text{Poisson}(\mu_i), \qquad \mu_i = \lambda \cdot t_i \]
dove:
- \(y_i\) è il numero osservato di eventi nella finestra \(i\),
- \(t_i\) è la durata della finestra,
- \(\lambda\) è il tasso medio.
Nel nostro caso tutte le finestre hanno la stessa durata (\(t_i = 1\)), e quindi:
\[ P(y_i \mid \lambda) = \frac{\lambda^{y_i} e^{-\lambda}}{y_i!}, \qquad \mathbb{E}[y_i]=\lambda, \quad \mathrm{Var}(y_i)=\lambda. \]
In parole semplici: \(\lambda\) rappresenta quanti eventi in media ci aspettiamo per finestra.
57.1.3 La distribuzione a priori
Nell’approccio bayesiano dobbiamo dichiarare che cosa riteniamo plausibile per \(\lambda\) prima di osservare i dati. Per i modelli di Poisson la scelta naturale è la distribuzione Gamma. Ad esempio, una prior Gamma(9, 2) esprime l’idea che, prima di osservare i dati, ci aspettiamo circa 4–5 eventi per finestra, ma lasciamo spazio a una certa variabilità.
57.1.4 Perché usiamo Stan?
Potremmo calcolare la distribuzione a posteriori anche con formule chiuse (qui la posterior è ancora una Gamma). Ma usiamo Stan per due motivi didattici fondamentali:
- Generalizzare: nella pratica incontreremo modelli per cui non esiste una soluzione analitica semplice. Con Stan impariamo un workflow valido in tutti i casi.
- Quantificare l’incertezza: Stan ci fornisce direttamente campioni dalla distribuzione a posteriori, che possiamo usare per costruire intervalli credibili, fare previsioni, confrontare modelli, ecc.
57.1.5 Obiettivi del modello in Stan
Con questo primo esempio vogliamo:
- stimare \(\lambda\), il tasso medio di occorrenza nella popolazione;
- ottenere una misura della nostra incertezza su \(\lambda\);
- verificare che i campioni generati da Stan coincidano con i risultati della formula analitica (dove è disponibile).
In questo modo ci abituiamo a un flusso di lavoro che useremo anche per modelli molto più complessi, in cui solo un approccio computazionale ci permette di fare inferenza bayesiana.
57.2 Scrivere il modello in Stan
Un modello Stan è diviso in blocchi: data (dati), parameters (incognite), model (priori + verosimiglianza). Aggiungiamo anche generated quantities per quantità derivate utili al confronto con la soluzione analitica (e, volendo, per LOO).
Per evitare dipendenze da percorsi locali, creiamo e compiliamo il modello direttamente dalla stringa:
stan_code <- "
data {
int<lower=0> N;
array[N] int<lower=0> y;
real<lower=0> alpha_prior;
real<lower=0> beta_prior;
}
parameters {
real<lower=0> lambda;
}
model {
lambda ~ gamma(alpha_prior, beta_prior);
y ~ poisson(lambda);
}
generated quantities {
real alpha_post = alpha_prior + sum(y);
real beta_post = beta_prior + N;
array[N] real log_lik;
for (i in 1:N) log_lik[i] = poisson_lpmf(y[i] | lambda);
}
"Compiliamo:
mod <- cmdstan_model(write_stan_file(stan_code))Prepariamo i dati:
Una volta preparati i dati, lanciamo il campionamento:
fit <- mod$sample(
data = stan_data,
seed = 123,
chains = 4,
parallel_chains = 4,
iter_sampling = 3000,
iter_warmup = 2000,
refresh = 0
)57.2.1 Analizzare i risultati
Una volta che Stan ha terminato il campionamento, otteniamo migliaia di valori possibili di \(\lambda\), campionati dalla distribuzione a posteriori. Questi valori ci permettono di “vedere” la distribuzione a posteriori invece di calcolarla solo con una formula.
1. Estraiamo i campioni di \(\lambda\)
Estraiamo i valori campionati di λ dalla posterior. L’oggetto draws restituisce tutti i campioni MCMC, noi qui selezioniamo solo il parametro lambda:
posterior_draws <- fit$draws("lambda", format = "df")Creiamo un vettore con solo i valori di lambda:
lambda_samples <- posterior_draws$lambdaOra lambda_samples contiene migliaia di valori di \(\lambda\): possiamo usarli per calcolare media, intervalli credibili e per costruire grafici.
2. Calcoliamo i parametri della distribuzione posteriore teorica
Dato che in questo caso abbiamo una posterior coniugata, conosciamo la formula esatta della distribuzione a posteriori (Gamma). Ci serve per confrontarla con i campioni generati da Stan:
alpha_post <- alpha_prior + sum(y) # nuovo parametro shape
beta_post <- beta_prior + N # nuovo parametro rate3. Confrontiamo i due risultati (MCMC vs formula)
Creiamo un grafico che mostri l’istogramma dei campioni ottenuti con Stan (in azzurro) e la curva della distribuzione Gamma calcolata analiticamente (in rosso).
ggplot(data.frame(lambda = lambda_samples), aes(x = lambda)) +
# Istogramma dei campioni posteriori
geom_histogram(
aes(y = after_stat(density)),
bins = 50,
fill = okabe_ito["sky"],
alpha = 0.7
) +
# Curva teorica Gamma con parametri aggiornati
stat_function(
fun = function(x) dgamma(x, shape = alpha_post, rate = beta_post),
color = okabe_ito["vermillion"],
linewidth = 1.2
) +
labs(
title = "Distribuzione a posteriori di λ",
x = "λ (tasso medio di occorrenza)",
y = "Densità"
)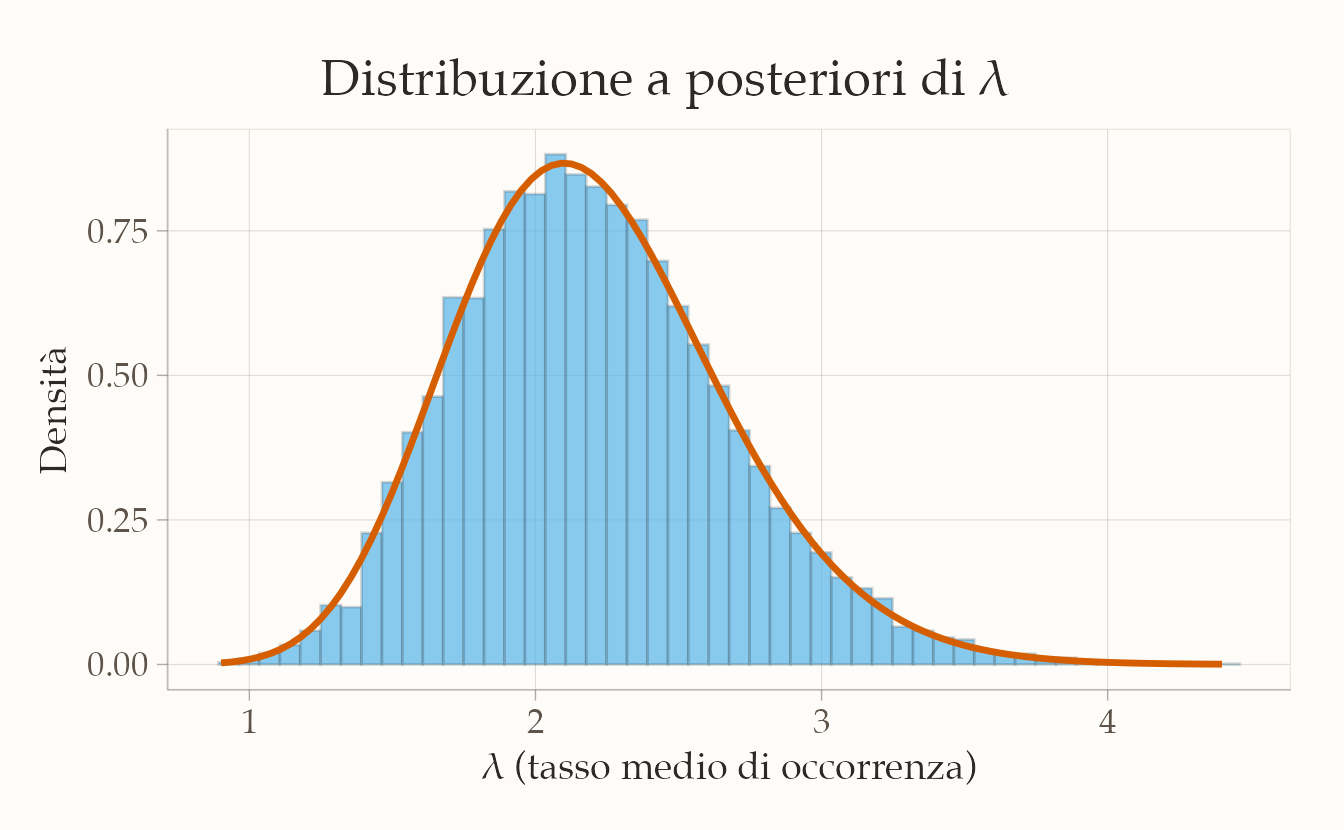
Il confronto visivo è molto utile:
- l’istogramma mostra la distribuzione stimata con Stan tramite campionamento MCMC,
- la curva rossa rappresenta la distribuzione teorica Gamma–Poisson che conosciamo già.
Se le due coincidono (entro piccole fluttuazioni casuali), significa che Stan ha fatto un buon lavoro: il nostro workflow MCMC funziona!
57.2.2 Intervallo di credibilità
Un grande vantaggio dell’approccio bayesiano è che non otteniamo solo una stima puntuale di \(\lambda\), ma una distribuzione completa dei valori plausibili. Da questa distribuzione possiamo ricavare un intervallo di credibilità: un intervallo che contiene, ad esempio, il 94% o il 95% della massa a posteriori.
1. Calcoliamo i quantili della distribuzione
Calcoliamo i quantili al 3%, 50% (mediana) e 97%:
- il valore al 50% è la mediana della distribuzione a posteriori,
- i valori al 3% e 97% delimitano un intervallo centrale che contiene il 94% della distribuzione.
2. Interpretazione dei risultati
I risultati ottenuti indicano che:
- il valore “tipico” di \(\lambda\) (mediana) è circa 2.2 eventi per finestra,
- c’è un 94% di probabilità che \(\lambda\) si trovi tra 1.42 e 3.20.
L’informazione più importante non è tanto la stima puntuale (2.2), ma il fatto che possiamo quantificare la nostra incertezza: la posterior ci dice chiaramente quali valori di \(\lambda\) sono più o meno plausibili.
57.2.3 Diagnostica essenziale
Dopo il campionamento MCMC, è fondamentale verificare che le catene abbiano esplorato bene la distribuzione a posteriori. Per questo guardiamo due tipi di informazioni: indici numerici (come \(\hat{R}\) e ESS) e grafici delle catene (traceplot).
Possiamo ottenere una sintesi numerica della distribuzione a posteriore dei parametri con la funzione summarise_draws del pacchetto posterior:
posterior::summarise_draws(fit$draws("lambda"), rhat, ess_bulk, ess_tail)
#> # A tibble: 1 × 4
#> variable rhat ess_bulk ess_tail
#> <chr> <dbl> <dbl> <dbl>
#> 1 lambda 1.00 4666.65 6265.97\(\hat{R}\) (R-hat): misura la convergenza delle catene. Valori vicini a 1.00 indicano che le catene si sono mescolate bene; valori maggiori di 1.01 segnalano possibili problemi.
-
ESS (Effective Sample Size): indica quanti campioni “indipendenti” equivalenti abbiamo ottenuto.
-
ess_bulkvaluta la precisione delle stime centrali (media, mediana). -
ess_tailvaluta la precisione nelle code della distribuzione (intervalli credibili). Più sono grandi, meglio è: in genere migliaia di campioni equivalenti sono più che sufficienti.
-
Possiamo generare un traceplot con la funzione mcmc_trace di bayesplot:
bayesplot::mcmc_trace(fit$draws("lambda")) +
ggtitle("Traceplot di λ")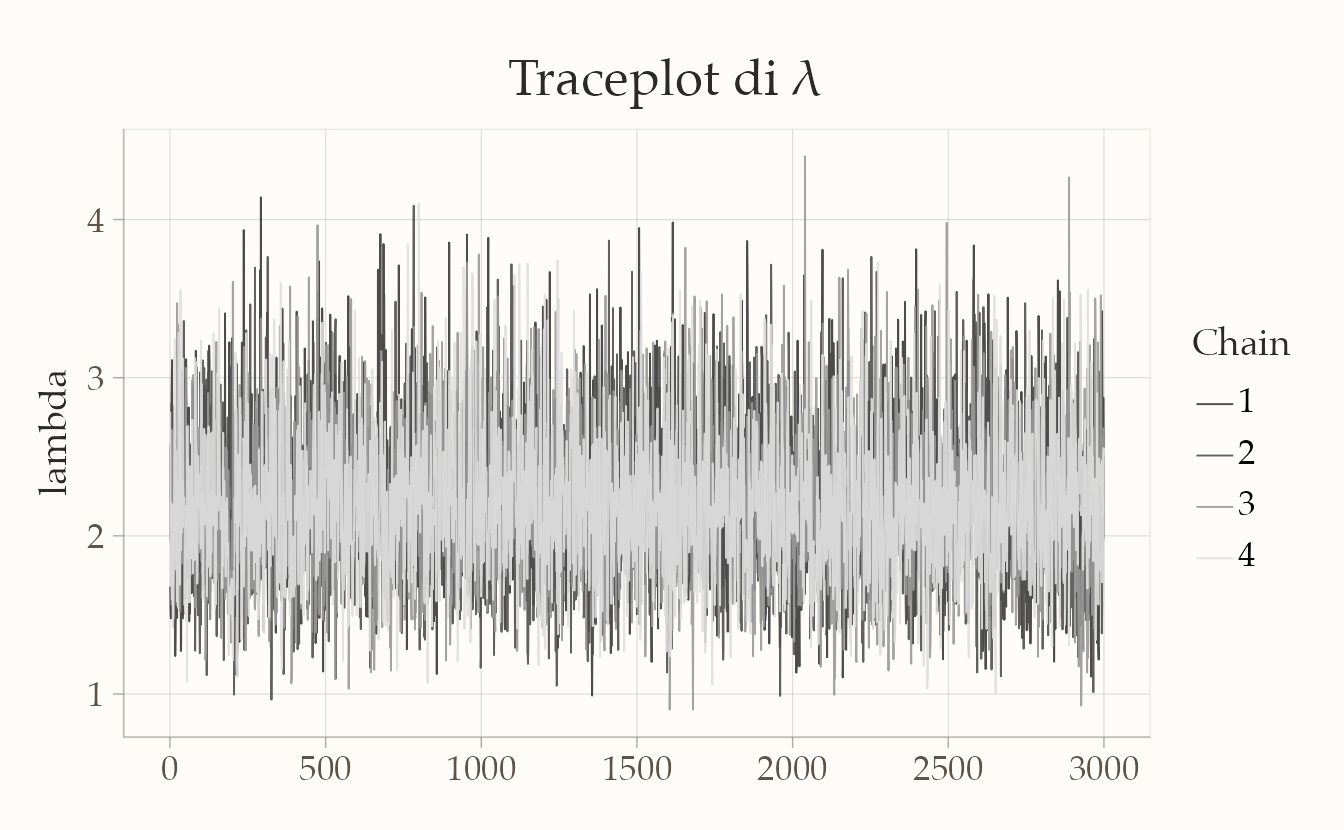
Il traceplot mostra l’andamento dei valori di \(\lambda\) campionati dalle diverse catene. Se le catene:
- oscillano liberamente attorno alla stessa regione,
- senza trend sistematici o salti strani,
allora possiamo concludere che il campionamento è avvenuto correttamente.
In sintesi: se \(\hat{R} \approx 1\), ESS è elevato e i traceplot sono ben mescolati, possiamo fidarci delle stime ottenute.
57.3 Sparatorie mortali
Nella sezione precedente abbiamo esaminato il processo di derivazione della distribuzione a posteriori per i parametri della distribuzione Gamma, la quale viene impiegata quando si adotta un prior Gamma per una verosimiglianza di Poisson. In questo esempio, useremo tale metodo per affrontare una questione relativa all’analisi di un set di dati reali.
57.3.1 Domanda della ricerca
Come spiegato qui, i dati che esamineremo sono raccolti dal Washington Post con lo scopo di registrare ogni sparatoria mortale negli Stati Uniti ad opera di agenti di polizia, a partire dal 1° gennaio 2015. Il Washington Post ha adottato un approccio sistematico e accurato nella raccolta di queste informazioni, fornendo dati che possono essere utili per valutare i problemi legati alla violenza delle forze di polizia negli Stati Uniti.
Obiettivo. Stimare, per il periodo 2015–ultimo anno completo disponibile, il tasso medio annuo e l’incertezza associata. Poiché il 2025 è incompleto, lo escludiamo.
57.3.2 Importazione e pre-processing dei dati
# URL del dataset
url <- "https://raw.githubusercontent.com/washingtonpost/data-police-shootings/master/v2/fatal-police-shootings-data.csv"
# Importa i dati
fps_dat <- read_csv(url, show_col_types = FALSE)
# Conversione colonna date
fps_dat <- fps_dat %>%
mutate(date = ymd(date),
year = year(date))
# Esamina le colonne disponibili
colnames(fps_dat)
#> [1] "id" "date"
#> [3] "threat_type" "flee_status"
#> [5] "armed_with" "city"
#> [7] "county" "state"
#> [9] "latitude" "longitude"
#> [11] "location_precision" "name"
#> [13] "age" "gender"
#> [15] "race" "race_source"
#> [17] "was_mental_illness_related" "body_camera"
#> [19] "agency_ids" "year"
# Filtra eliminando i casi con year == 2025
fps <- fps_dat %>%
filter(year != 2025)
# Conta le occorrenze per anno
year_counts <- fps %>%
count(year, name = "events")
# Mostra i risultati
print(year_counts)
#> # A tibble: 10 × 2
#> year events
#> <dbl> <int>
#> 1 2015 995
#> 2 2016 959
#> 3 2017 984
#> 4 2018 992
#> 5 2019 993
#> 6 2020 1021
#> 7 2021 1050
#> 8 2022 1097
#> 9 2023 1164
#> 10 2024 117557.3.3 Modello di Poisson (pooling completo)
Assumiamo \(y_t \sim \text{Poisson}(\lambda)\) con \(\lambda\) costante sul periodo:
\[ y_t \,\sim\, \text{Poisson}(\lambda), \quad t=1,\dots,n. \]
Il supporto di \(\lambda\) è \([0,\infty)\). Si noti che abbiamo considerato i dati come iid. Guardando la serie temporale, però, è ovvio che le cose non stanno così: i valori aumentano nel tempo.
57.3.4 Prior
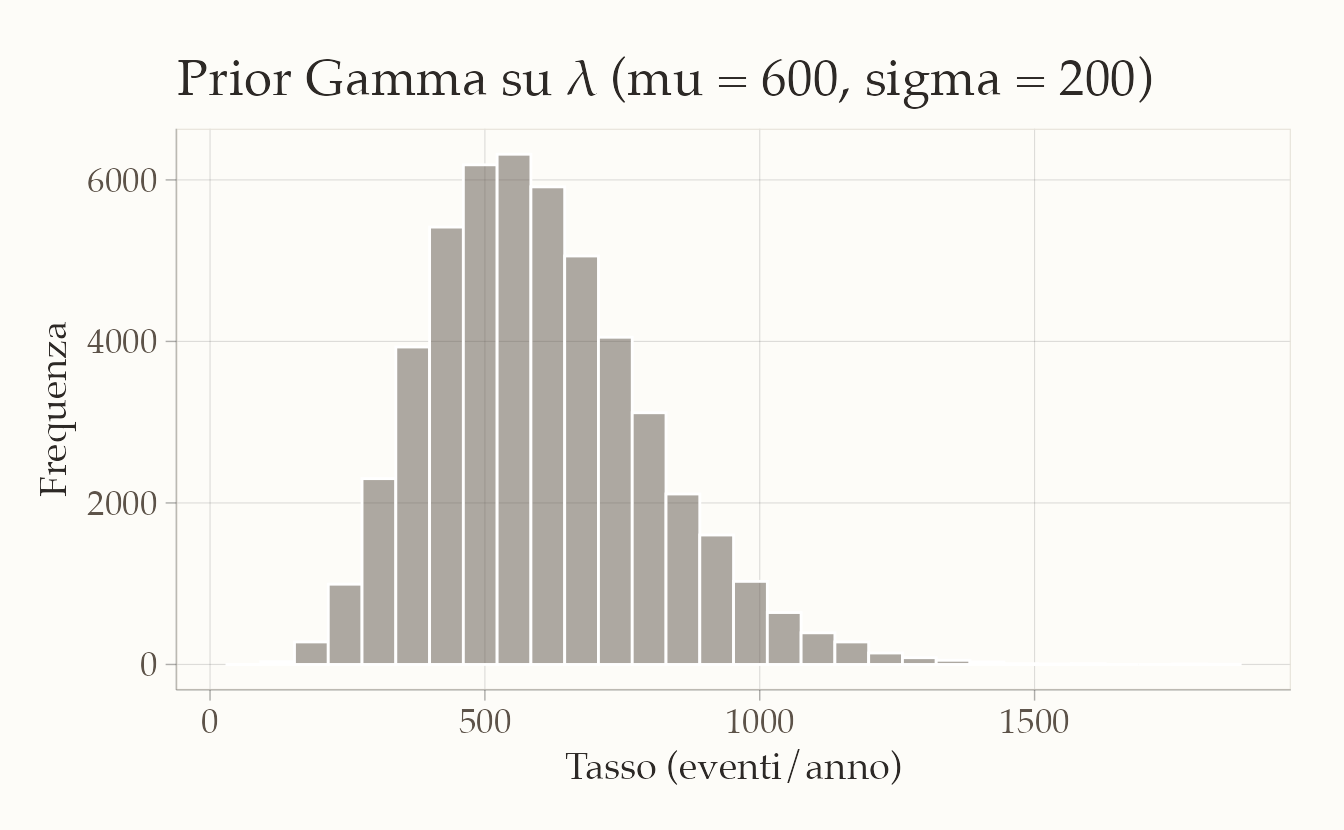
Usiamo una prior coniugata Gamma su \(\lambda\), scelta in modo debolmente informativo. Un’ipotesi ragionevole (da verificare e discutere in aula) è una media a priori di 600 eventi/anno, con deviazione standard 200. In termini Gamma(shape, rate):
\[ \alpha = (\mu/\sigma)^2,\qquad \beta = \mu/\sigma^2. \]
Visualizziamo la prior (campionando in R):
mu <- 600
sigma <- 200
# Parametrizzazione Gamma(shape = k, scale = theta) per la simulazione
theta <- sigma^2 / mu
k <- mu / theta
set.seed(2)
x_draws <- rgamma(50000, shape = k, scale = theta)
ggplot(data.frame(x = x_draws), aes(x = x)) +
geom_histogram(bins = 30, color = "white") +
labs(
x = "Tasso (eventi/anno)",
y = "Frequenza",
title = "Prior Gamma su λ (mu = 600, sigma = 200)"
)
57.3.5 Modello di Poisson con Stan
Qui stimiamo \(\lambda\) assumendo lo stesso tasso per tutti gli anni (pooling completo). Con prior Gamma in parametrizzazione (shape, rate):
stan_code <- "
data {
int<lower=1> N; // numero di anni
array[N] int<lower=0> y; // conteggi annuali
real<lower=0> alpha_prior; // shape
real<lower=0> beta_prior; // rate
}
parameters {
real<lower=0> lambda; // tasso medio annuo
}
model {
lambda ~ gamma(alpha_prior, beta_prior); // prior Gamma(shape, rate)
y ~ poisson(lambda); // verosimiglianza
}
generated quantities {
real log_lik = poisson_lpmf(y | lambda);
}
"# Dati (usa i conteggi 2015...2024 ordinati)
y_vec <- year_counts$events # ordine per anno; per Poisson i.i.d. l'ordine non incide
# Prior: coerente con la sezione precedente
alpha_prior <- (mu / sigma)^2
beta_prior <- mu / sigma^2
stan_data <- list(
N = length(y_vec),
y = as.integer(y_vec),
alpha_prior = alpha_prior,
beta_prior = beta_prior
)
stan_data
#> $N
#> [1] 10
#>
#> $y
#> [1] 995 959 984 992 993 1021 1050 1097 1164 1175
#>
#> $alpha_prior
#> [1] 9
#>
#> $beta_prior
#> [1] 0.015Compilazione ed esecuzione:
mod <- cmdstan_model(write_stan_file(stan_code))fit <- mod$sample(
data = stan_data,
iter_warmup = 1000,
iter_sampling = 4000,
chains = 4,
seed = 123,
refresh = 0
)Riassunto dei parametri:
fit$summary("lambda")
#> # A tibble: 1 × 10
#> variable mean median sd mad q5 q95 rhat ess_bulk
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 lambda 1042.41 1042.35 10.27 10.36 1025.69 1059.53 1.00 6110.78
#> ess_tail
#> <dbl>
#> 1 8233.18posterior::summarise_draws(
fit$draws("lambda"),
mean, sd, ~quantile(.x, c(0.025, 0.5, 0.975))
)
#> # A tibble: 1 × 6
#> variable mean sd `2.5%` `50%` `97.5%`
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 lambda 1042.41 10.27 1022.54 1042.35 1062.58Visualizzazione:
bayesplot::mcmc_hist(fit$draws("lambda")) +
ggtitle("Posterior di λ (tasso annuo)")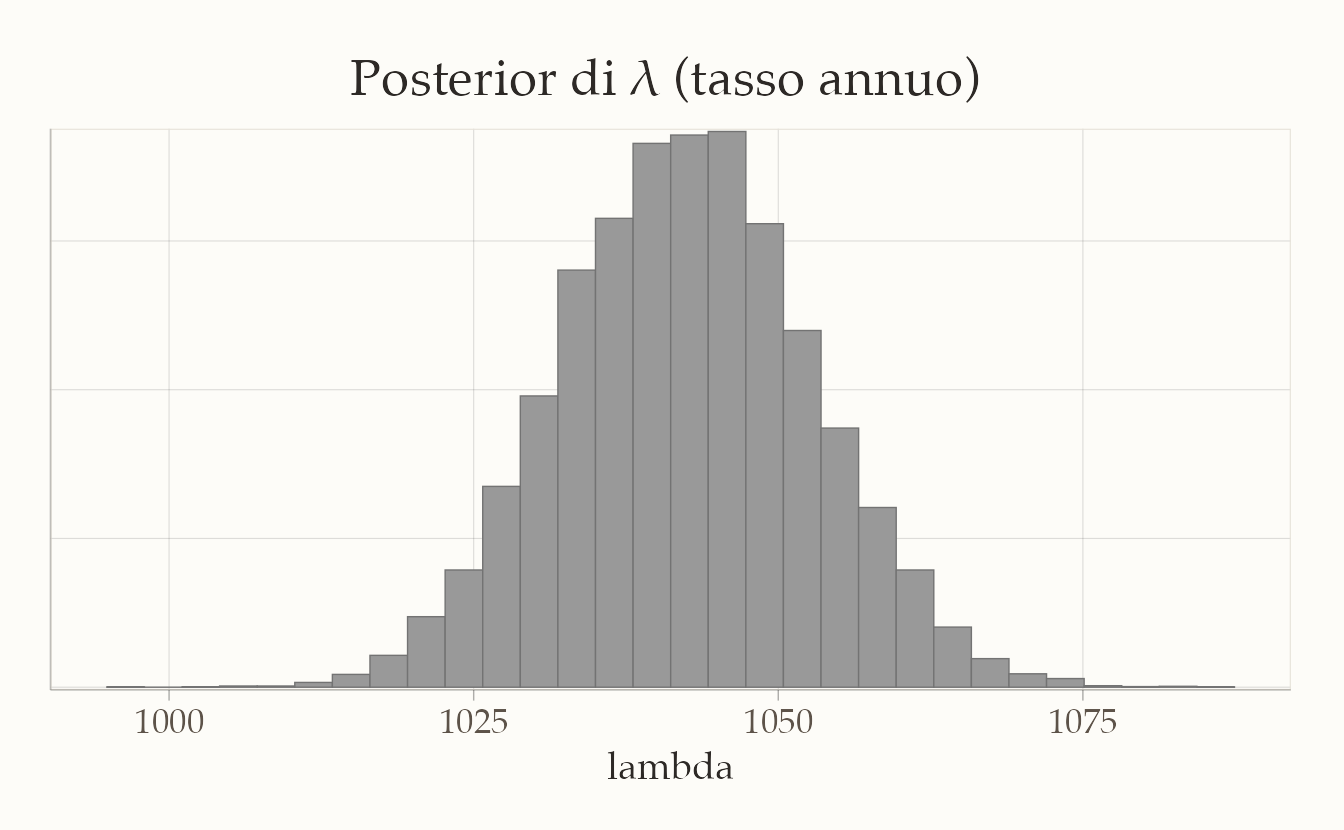
bayesplot::mcmc_areas(fit$draws("lambda"), prob = 0.95) +
ggtitle("Posterior di λ (ICr 95%)")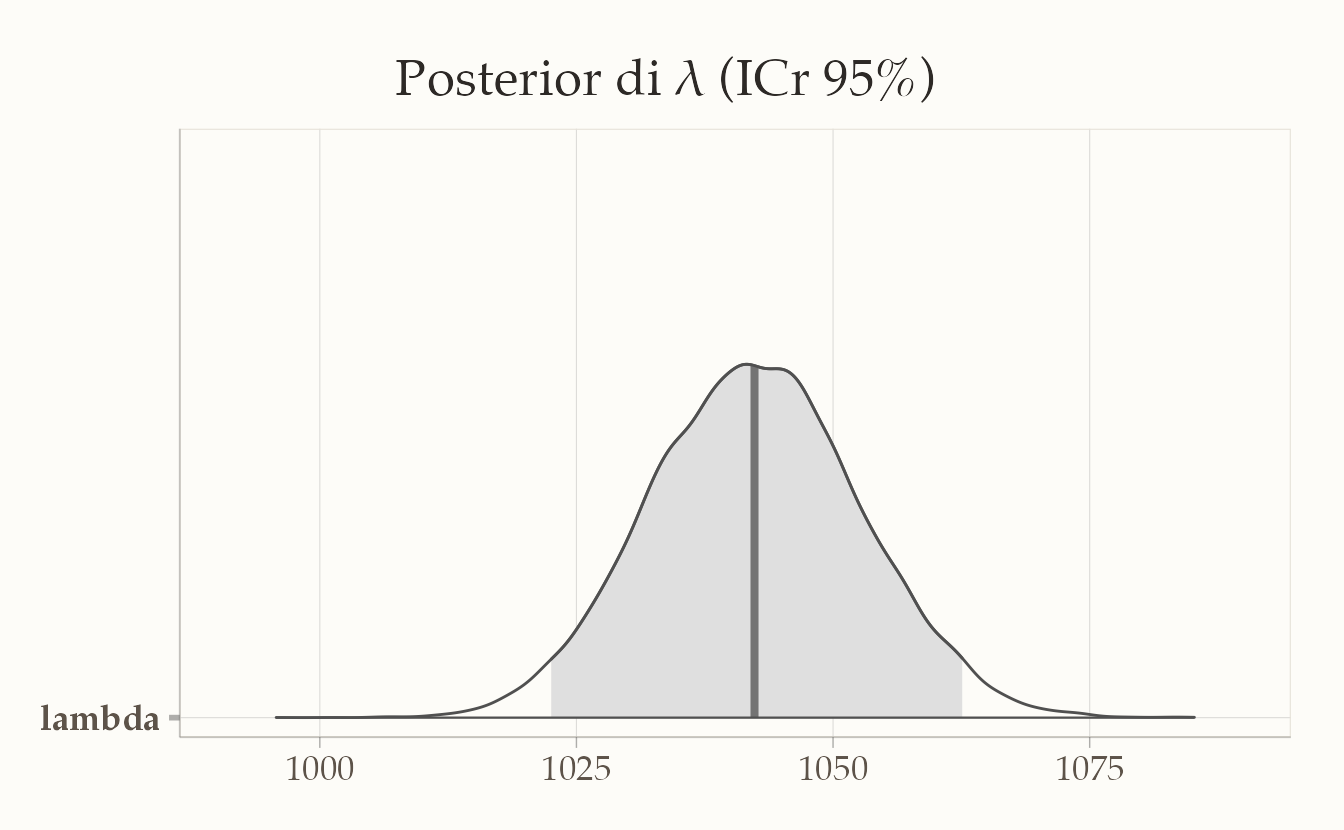
Il grafico mostra che il tasso di sparatorie fatali ha una media annuale di 1042 con CI [1022, 1062].
In sintesi, analizzando i dati compresi tra il 2015 e il 2025 e basandoci su una distribuzione a priori che presuppone una sparatoria mortale al mese per stato, possiamo concludere con un grado di certezza soggettivo del 95% che il tasso stimato di sparatorie fatali da parte della polizia negli Stati Uniti sia di 1028 casi all’anno, con un intervallo di credibilità compreso tra 1022 e 1062.
Diagnostica essenziale:
# Indicatori numerici chiave: Rhat ~ 1, ESS adeguati
posterior::summarize_draws(
fit$draws(c("lambda")), "rhat", "ess_bulk", "ess_tail"
)
#> # A tibble: 1 × 4
#> variable rhat ess_bulk ess_tail
#> <chr> <dbl> <dbl> <dbl>
#> 1 lambda 1.00 6110.78 8233.18# Traceplot di controllo su OR
bayesplot::mcmc_trace(fit$draws("lambda")) +
ggtitle("Traceplot di lambda")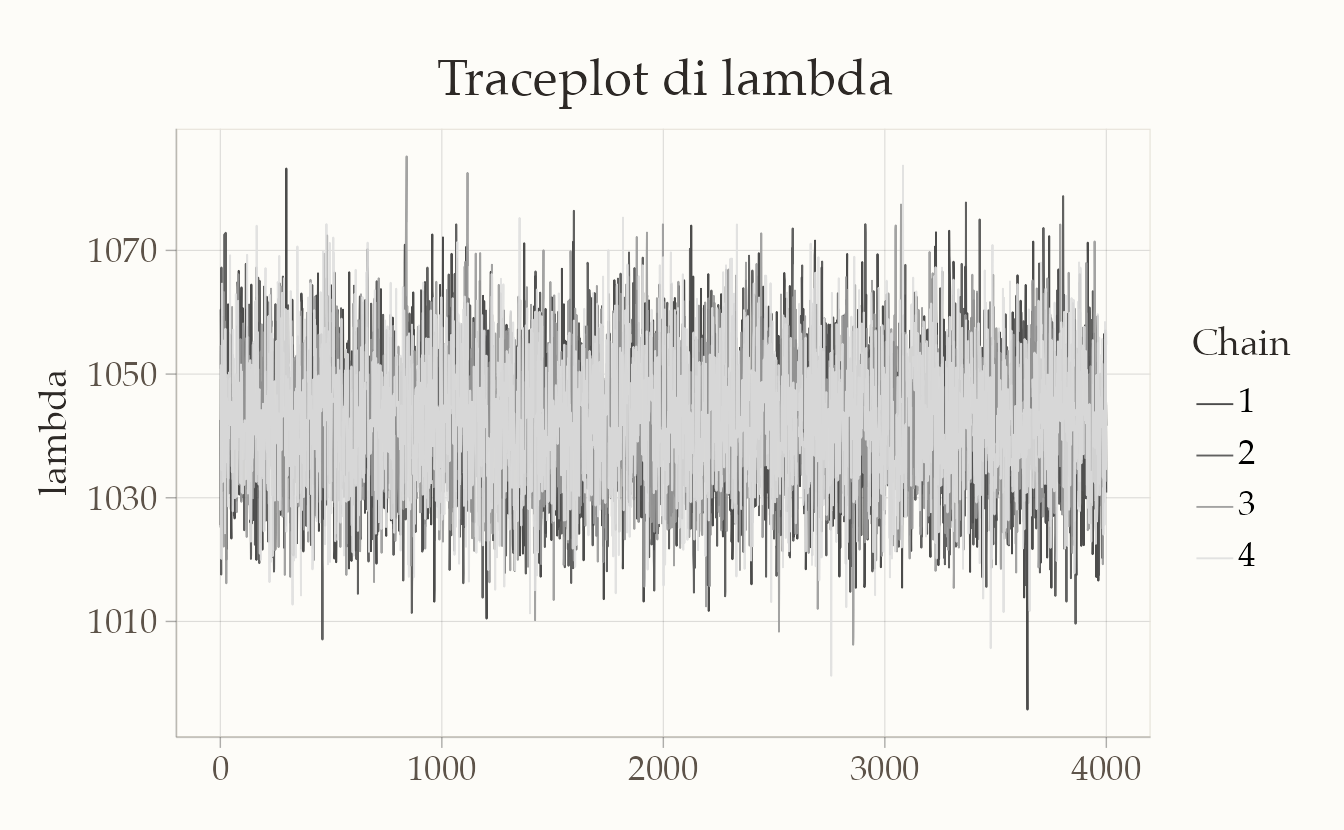
57.3.6 Derivazione analitica (Gamma–Poisson)
Con prior \(\lambda \sim \text{Gamma}(\alpha,\beta)\) e dati \(y_1,\dots,y_n\) i.i.d. Poisson(\(\lambda\)), il posteriore è:
\[ \lambda \mid \mathbf{y} \;\sim\; \text{Gamma}\!\left(\alpha + \sum_{t=1}^n y_t,\;\; \beta + n\right). \]
Quindi:
- media posteriore \(\mathbb{E}[\lambda\mid y] = \dfrac{\alpha + \sum y_t}{\beta + n}\);
- ICr 95% con i quantili Gamma al 2.5% e 97.5%.
# Dati e prior come nella sezione Stan
data_vec <- year_counts$events
n <- length(data_vec)
sum_y <- sum(data_vec)
mu <- 600
sigma <- 200
alpha_prior <- (mu / sigma)^2
beta_prior <- mu / sigma^2
# Posterior coniugato
alpha_post <- alpha_prior + sum_y
beta_post <- beta_prior + n
post_mean <- alpha_post / beta_post
ci95 <- qgamma(c(0.025, 0.975), shape = alpha_post, rate = beta_post)
cat("Posterior mean λ:", round(post_mean, 2), "\n")
#> Posterior mean λ: 1042
cat("95% CrI: [", round(ci95[1], 2), ", ", round(ci95[2], 2), "]\n")
#> 95% CrI: [ 1022 , 1062 ]La derivazione analitica e i risultati MCMC coincidono (entro l’errore Monte Carlo).
57.4 Riflessioni conclusive
In questo capitolo abbiamo fatto un passo importante: abbiamo visto come tradurre un modello probabilistico relativamente semplice in Stan, come eseguire il campionamento MCMC, e come confrontare i risultati con la soluzione analitica. Questo esempio ci ha permesso di verificare che Stan funziona correttamente, perché in questo caso conoscevamo già la distribuzione a posteriori esatta.
L’aspetto davvero interessante, però, è che la stessa procedura può essere usata anche quando la soluzione analitica non esiste. Nei capitoli successivi incontreremo modelli più complessi, in cui la coniugatezza non ci aiuta più e non abbiamo formule chiuse per la distribuzione a posteriori. In quei casi, il campionamento MCMC sarà lo strumento indispensabile per fare inferenza bayesiana.
Qui abbiamo lavorato con un modello coniugato, in cui la posterior è ancora Gamma. Ma nei modelli più complessi che incontreremo (per esempio con predittori, effetti gerarchici o dinamici), non avremo più formule chiuse: sarà Stan, con MCMC, a permetterci di fare inferenza.