here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(readr, VennDiagram)24 Modelli probabilistici
“La probabilità è il calcolo più importante nella vita civile. Tuttavia, è il più soggetto a errori e paradossi; anche le menti più brillanti possono ingannarsi su questioni che, dopo essere state spiegate, appaiono così ovvie da far vergognare di non averle capite prima.”
– Pierre-Simon Laplace, Saggio filosofico sulle probabilità (1814)
Introduzione
Dopo aver esaminato il significato filosofico della probabilità nel Capitolo 23, questo capitolo ne sviluppa una trattazione più formale, creando un collegamento tra la riflessione teorica e gli strumenti operativi. Partendo dalla definizione di esperimento casuale – come il lancio di una moneta o la somministrazione di un test psicologico – costruiremo un framework matematico per analizzare e quantificare le proprietà di tali esperimenti. In particolare, approfondiremo i concetti di spazio campionario, eventi e proprietà della probabilità, fornendo le basi per un’interpretazione rigorosa dei fenomeni complessi in psicologia e nelle scienze sociali.
Panoramica del capitolo
- Nozioni di spazio campionario, eventi e operazioni su eventi.
- Definizione di probabilità.
- Spazi discreti o continui.
- Teorema della somma.
24.1 Esperimenti casuali
Il concetto fondamentale della probabilità è l’esperimento casuale, ovvero un procedimento il cui esito non può essere previsto con certezza, ma che può essere analizzato quantitativamente. Alcuni esempi di esperimenti casuali includono: lanciare un dado e osservare il numero ottenuto sulla faccia superiore; estrarre una carta a caso da un mazzo e registrarne il seme e il valore; misurare il livello di stress percepito da un gruppo di individui in un determinato contesto, come durante un esame o un evento stressante; contare il numero di risposte corrette fornite dai partecipanti a un test di memoria entro un tempo prestabilito; eccetera.
L’analisi probabilistica ha lo scopo di comprendere il comportamento di tali esperimenti attraverso la costruzione di modelli matematici. Una volta formalizzato matematicamente un esperimento casuale, è possibile calcolare grandezze di interesse, come probabilità ed aspettative. Questi modelli possono essere implementati al computer per simulare l’esperimento e analizzarne i risultati. Inoltre, la modellizzazione matematica degli esperimenti casuali costituisce la base della statistica, disciplina che permette di confrontare diversi modelli e identificare quello più adeguato ai dati osservati.
24.1.1 Il lancio di una moneta
Uno degli esperimenti casuali più semplici e fondamentali è il lancio ripetuto di una moneta. Molti concetti chiave della teoria della probabilità possono essere illustrati partendo da questo esperimento elementare. Per studiarne il comportamento, possiamo simularlo al computer utilizzando il linguaggio R.
Di seguito, un semplice script in R simula 100 lanci di una moneta equa (cioè con probabilità uguali di ottenere Testa o Croce) e rappresenta graficamente la distribuzione dei risultati mediante un diagramma a barre.
set.seed(123) # Imposta il seed per garantire la riproducibilità
x <- runif(100) < 0.5 # Genera 100 numeri casuali e verifica se sono minori di 0.5
x
#> [1] TRUE FALSE TRUE FALSE FALSE TRUE FALSE FALSE FALSE TRUE FALSE TRUE
#> [13] FALSE FALSE TRUE FALSE TRUE TRUE TRUE FALSE FALSE FALSE FALSE FALSE
#> [25] FALSE FALSE FALSE FALSE TRUE TRUE FALSE FALSE FALSE FALSE TRUE TRUE
#> [37] FALSE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
#> [49] TRUE FALSE TRUE TRUE FALSE TRUE FALSE TRUE TRUE FALSE FALSE TRUE
#> [61] FALSE TRUE TRUE TRUE FALSE TRUE FALSE FALSE FALSE TRUE FALSE FALSE
#> [73] FALSE TRUE TRUE TRUE TRUE FALSE TRUE TRUE TRUE FALSE TRUE FALSE
#> [85] TRUE TRUE FALSE FALSE FALSE TRUE TRUE FALSE TRUE FALSE TRUE TRUE
#> [97] FALSE TRUE TRUE FALSENel codice, la funzione runif genera 100 numeri casuali distribuiti uniformemente nell’intervallo [0, 1]. Confrontando ciascun numero con 0.5, otteniamo un vettore logico che rappresenta il risultato di ogni lancio: Testa (TRUE) o Croce (FALSE).
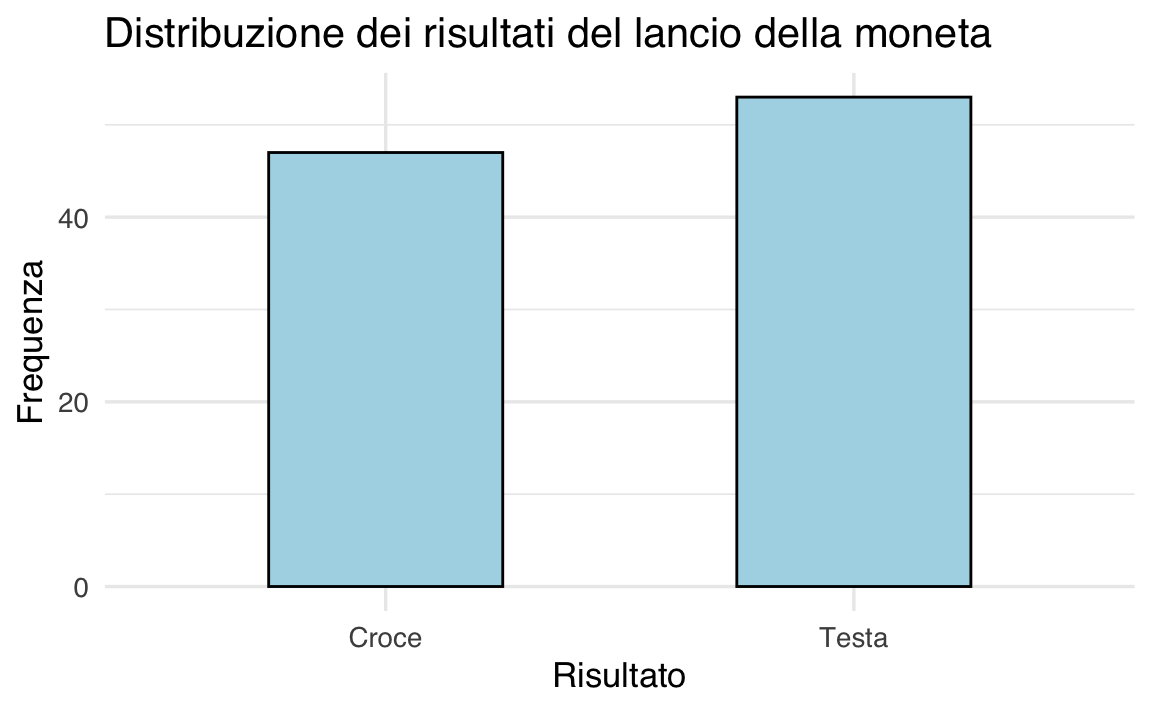
Il grafico a barre mostra la distribuzione osservata degli esiti.
# Creazione del grafico a barre della distribuzione dei risultati
dat |>
ggplot(aes(x = Risultato)) +
geom_bar(aes(y = after_stat(prop), group = 1), width = 0.5) +
labs(
x = "Risultato",
y = "Frequenza relativa"
)
Un aspetto rilevante di questo esperimento è l’andamento della proporzione osservata di esiti “Testa” in funzione del numero di lanci. Il grafico riportato di seguito illustra l’evoluzione della media cumulativa degli esiti “Testa”, che, in accordo con la legge dei grandi numeri, dovrebbe convergere al valore teorico di 0.5.
y <- cumsum(x) / t # Calcola la media cumulativa delle Teste
# Creazione del dataframe per il grafico della media mobile
data_mean <- tibble(
Lancio = t,
Media_Testa = y
)
# Creazione del grafico della media cumulativa
data_mean |>
ggplot(
aes(x = Lancio, y = Media_Testa)
) +
geom_line(linewidth = 1.5) +
geom_hline(yintercept = 0.5, linetype = "dashed", color = "red") +
labs(
x = "Numero di lanci",
y = "Frequenza cumulativa di Teste"
)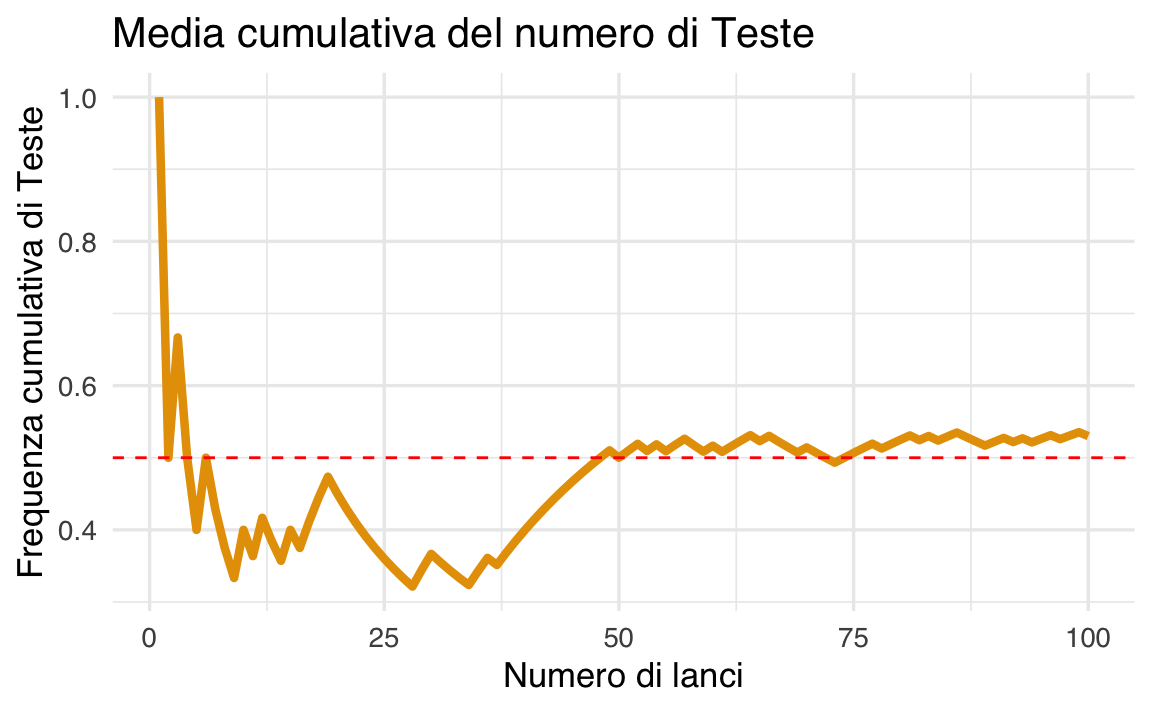
Il grafico mostra come la media delle Teste oscilla inizialmente a causa della variabilità intrinseca dell’esperimento, ma tende progressivamente a stabilizzarsi intorno a 0.5. Questo fenomeno è un esempio della Legge dei Grandi Numeri, secondo cui, ripetendo un esperimento casuale un numero sempre maggiore di volte, la frequenza relativa di un evento si avvicina alla sua probabilità teorica.
24.1.2 Domande di interesse
L’esperimento casuale del lancio di una moneta porta a numerose domande, tra cui:
- Qual è la probabilità di ottenere un certo numero \(x\) di Teste in 100 lanci?
- Qual è il numero atteso di Teste in un esperimento di 100 lanci?
Dal punto di vista statistico, quando osserviamo i risultati di un esperimento reale (ad esempio, 100 lanci di una moneta), possiamo anche porci domande come:
- La moneta è davvero equa o è sbilanciata?
- Qual è il miglior metodo per stimare la probabilità \(p\) di ottenere Testa dalla sequenza osservata di lanci?
- Quanto è precisa la stima ottenuta e con quale livello di incertezza?
Questi interrogativi costituiscono la base della statistica inferenziale, che permette di testare ipotesi sulla probabilità di un evento e stimare parametri sconosciuti sulla base di dati osservati.
24.1.3 Modellizzazione
La descrizione matematica di un esperimento casuale si basa su tre elementi fondamentali:
Lo spazio campionario: rappresenta l’insieme di tutti i possibili esiti dell’esperimento. Nel caso di esperimenti semplici, lo spazio campionario è immediato da individuare, mentre in situazioni più complesse è necessario applicare i principi del calcolo combinatorio.
Gli eventi: sono sottoinsiemi dello spazio campionario e rappresentano gli esiti di interesse. Per analizzare e manipolare gli eventi, utilizziamo gli strumenti della teoria degli insiemi.
La probabilità: assegna un valore numerico a ciascun evento, indicando la sua probabilità di verificarsi. L’assegnazione delle probabilità avviene secondo gli assiomi di Kolmogorov.
Nei paragrafi seguenti, analizzeremo ciascuna di queste componenti in dettaglio.
24.2 Spazio campionario
Anche se non possiamo prevedere con esattezza l’esito di un singolo esperimento casuale, possiamo comunque definire tutti i risultati che potrebbero verificarsi. L’insieme completo di questi esiti possibili si chiama spazio campionario.
Definizione 24.1 Lo spazio campionario \(\Omega\) di un esperimento casuale è l’insieme di tutti i possibili esiti dell’esperimento.
24.2.1 Esempi di spazi campionari
Consideriamo lo spazio campionario di alcuni esperimenti casuali.
Lancio di due dadi consecutivi: \[ \Omega = \{(1,1), (1,2), \dots, (6,6)\}. \]
Tempo di reazione a uno stimolo visivo: \[\Omega = \mathbb{R}^+,\] ovvero l’insieme dei numeri reali positivi.
Numero di errori in un test di memoria a breve termine: \[\Omega = \{0, 1, 2, \dots\}.\]
Misurazione delle altezze di dieci persone: \[\Omega = \{(x_1, \dots, x_{10}) : x_i \ge 0, \; i=1,\dots,10\} \subset \mathbb{R}^{10}.\]
24.3 Eventi
Solitamente non siamo interessati a un singolo esito, ma a un insieme di essi. Un evento è un sottoinsieme dello spazio campionario a cui possiamo assegnare una probabilità.
Definizione 24.2 Un evento è un sottoinsieme \(A \subseteq \Omega\) al quale viene assegnata una probabilità. Indichiamo gli eventi con lettere maiuscole \(A, B, C, \dots\). Diciamo che l’evento \(A\) si verifica se l’esito dell’esperimento appartiene a \(A\).
24.3.1 Esempi di eventi
Consideriamo alcuni possibili eventi definiti sugli spazi campionari descritti sopra.
Lancio di due dadi consecutivi.
Evento: “La somma dei due dadi è uguale a 7”
\[ A = \{(1,6), (2,5), (3,4), (4,3), (5,2), (6,1)\}. \]Tempo di reazione a uno stimolo visivo.
Evento: “Il tempo di reazione è inferiore a 2 secondi”
\[ A = [0, 2). \]Numero di errori in un test di memoria a breve termine.
Evento: “Il numero di errori è al massimo 3”
\[ A = \{0, 1, 2, 3\}. \]Misurazione delle altezze di dieci persone.
Evento: “Almeno due persone hanno un’altezza superiore a 180 cm”
\[ A = \{(x_1, \dots, x_{10}) : \text{almeno due } x_i > 180\}. \]
Questi esempi mostrano come gli eventi possano essere definiti in modo diverso a seconda della natura dello spazio campionario e del contesto di interesse.
24.4 Operazioni sugli eventi
Poiché gli eventi sono definiti come insiemi, possiamo applicare loro le classiche operazioni insiemistiche.
Unione (\(\cup\)). L’unione di due eventi \(A\) e \(B\) è l’insieme di tutti gli esiti che appartengono almeno a uno dei due:
\[ A \cup B = \{\omega \in \Omega : \omega \in A \text{ oppure } \omega \in B\}. \]
Intersezione (\(\cap\)). L’intersezione di due eventi è l’insieme degli esiti comuni:
\[ A \cap B = \{\omega \in \Omega : \omega \in A \text{ e } \omega \in B\}. \]
Complemento (\(A^c\)). Il complemento di un evento \(A\) è l’insieme di tutti gli esiti che non appartengono ad \(A\):
\[ A^c = \{\omega \in \Omega : \omega \notin A\}. \]
Eventi mutuamente esclusivi. Due eventi sono mutuamente esclusivi se non hanno esiti in comune, ovvero:
\[ A \cap B = \emptyset. \]
Esempio
# Universo
U <- 1:10
# Definizione degli insiemi A e B
A <- c(1, 2, 3, 4, 5)
B <- c(4, 5, 6, 7, 8)
# Calcolare l'unione, l'intersezione e il complemento relativo a un universo U
union_AB <- union(A, B)
intersect_AB <- intersect(A, B)
complement_A <- setdiff(U, A)
complement_B <- setdiff(U, B)
# Visualizzazione testuale
cat("Unione A ∪ B:", union_AB, "\n")
#> Unione A ∪ B: 1 2 3 4 5 6 7 8
cat("Intersezione A ∩ B:", intersect_AB, "\n")
#> Intersezione A ∩ B: 4 5
cat("Complemento di A:", complement_A, "\n")
#> Complemento di A: 6 7 8 9 10
cat("Complemento di B:", complement_B, "\n")
#> Complemento di B: 1 2 3 9 10# Visualizzazione con diagrammi di Venn
venn.plot <- draw.pairwise.venn(
area1 = length(A),
area2 = length(B),
cross.area = length(intersect(A, B)), # Corretto: usa intersect() invece di intersect_AB
category = c("A", "B"),
fill = c("orange", "blue"),
alpha = 0.5,
cat.col = c("orange", "blue") # Corretto: allineato con i colori di fill
)
# Visualizza il diagramma
grid.draw(venn.plot)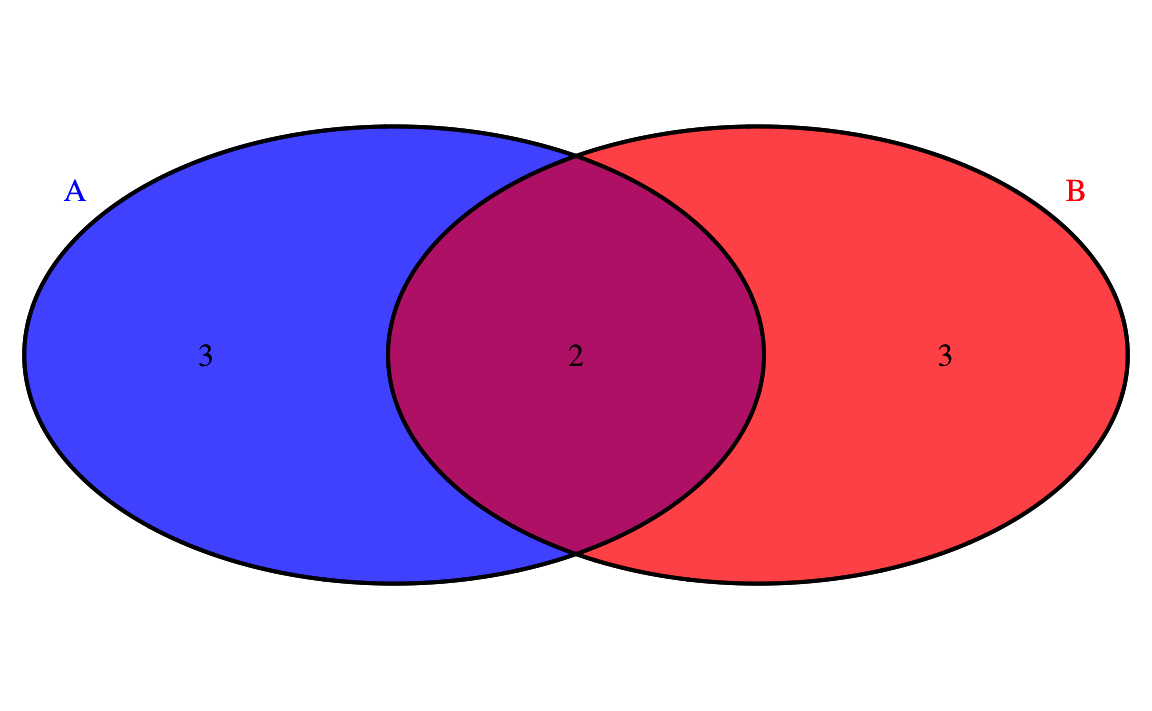
24.4.1 Proprietà fondamentali delle operazioni su eventi
Idempotenza: \[ A \cup A = A, \quad A \cap A = A. \]
Leggi di De Morgan: \[ (A \cup B)^c = A^c \cap B^c, \quad (A \cap B)^c = A^c \cup B^c. \]
Unione e Intersezione con l’insieme vuoto: \[ A \cup \emptyset = A, \quad A \cap \emptyset = \emptyset. \]
Unione e Intersezione con lo spazio campionario: \[ A \cup \Omega = \Omega, \quad A \cap \Omega = A. \]
Queste operazioni forniscono la base per costruire e manipolare eventi in contesti probabilistici, permettendo di calcolare probabilità e prendere decisioni basate sull’analisi degli esiti possibili.
24.5 Probabilità
Il terzo elemento fondamentale del modello probabilistico è la funzione di probabilità, che quantifica numericamente la possibilità di occorrenza degli eventi.
Definizione 24.3 Una probabilità \(P\) è una funzione \(P: \mathcal{F} \to [0,1]\) definita su una \(\sigma\)-algebra \(\mathcal{F}\) di sottoinsiemi di \(\Omega\). A ogni evento \(A \in \mathcal{F}\), la funzione assegna un valore reale compreso tra 0 e 1, rispettando i seguenti assiomi di Kolmogorov:
Non-negatività. Per ogni \(A \subseteq \Omega\), si richiede che \(0 \leq P(A) \leq 1\).
Normalizzazione (evento certo). \(P(\Omega) = 1\).
-
Additività numerabile. Se \(A_1, A_2, \dots\) sono eventi mutuamente esclusivi (cioè \(A_i \cap A_j = \emptyset\) per \(i \neq j\)), allora:
\[ P\!\Bigl(\bigcup_{i=1}^{\infty} A_i\Bigr) \;=\; \sum_{i=1}^{\infty} P(A_i). \]
In altre parole, una misura di probabilità non solo assegna numeri nell’intervallo \([0,1]\) a ogni evento, ma richiede che l’evento “certo” \(\Omega\) abbia probabilità 1 e che la probabilità di un’unione numerabile di eventi disgiunti sia la somma delle loro probabilità. Queste condizioni garantiscono la coerenza formale e l’interpretazione intuitiva del concetto di probabilità.
24.5.1 Interpretazione degli assiomi di Kolmogorov
Assioma 1 (Non-negatività e limiti 0–1)
La probabilità di un evento è sempre un numero reale compreso tra 0 e 1. Se la probabilità è 0, l’evento può considerarsi impossibile; se è 1, l’evento è certo.
Esempio: Nel lancio di un dado a sei facce, l’evento “Esce 7” non può verificarsi e ha probabilità 0, mentre l’evento “Esce un numero tra 1 e 6” ha probabilità 1.Assioma 2 (Evento certo)
Lo spazio campionario \(\Omega\) è l’insieme di tutti i possibili esiti dell’esperimento. Poiché in ogni prova deve accadere almeno uno degli esiti contenuti in \(\Omega\), la probabilità di \(\Omega\) è necessariamente 1.
Esempio: Nel lancio di un dado, lo spazio campionario \(\Omega\) è \(\{1,2,3,4,5,6\}\). L’evento “esce un numero tra 1 e 6” coincide con l’intero spazio campionario, quindi \(P(\Omega) = 1\).-
Assioma 3 (Additività per eventi incompatibili)
Se due o più eventi sono mutuamente esclusivi (o incompatibili) — cioè non possono verificarsi contemporaneamente — la probabilità della loro unione è la somma delle probabilità di ciascuno.
Esempio: Con un dado, l’evento “esce un numero pari” e l’evento “esce un numero dispari” non possono verificarsi nello stesso lancio. Di conseguenza,\[ P(\text{“pari”} \cup \text{“dispari”}) \;=\; P(\text{“pari”}) + P(\text{“dispari”})\,. \]
Questi assiomi assicurano che la probabilità, intesa come funzione che assegna valori tra 0 e 1 a ogni evento, rispetti la coerenza matematica e l’interpretazione intuitiva: non esistono eventi “negativi” o “più che certi”, e la probabilità totale dell’intero spazio dei possibili risultati deve sempre essere uguale a 1.
24.5.2 Proprietà fondamentali
Dagli assiomi di Kolmogorov discendono alcune proprietà fondamentali che descrivono come la probabilità si comporti in varie situazioni. Le principali sono elencate di seguito.
Teorema 24.1 Siano \(A\) e \(B\) eventi qualsiasi nello spazio campionario \(\Omega\). Allora valgono le seguenti relazioni:
Probabilità dell’evento impossibile
\[ P(\emptyset) = 0. \] Poiché l’insieme vuoto non include alcun esito sperimentale, non può mai verificarsi.Monotonicità
\[ A \subseteq B \quad \Longrightarrow \quad P(A) \le P(B). \] Se un evento è interamente contenuto in un altro, non può avere probabilità maggiore dell’evento che lo comprende.Probabilità del complementare
\[ P(A^c) = 1 - P(A). \] Poiché \(A\) e il suo complementare \(A^c\) coprono l’intero spazio \(\Omega\), la probabilità di \(A^c\) è la parte “rimanente” fino a 1.Regola dell’inclusione–esclusione
\[ P(A \cup B) \;=\; P(A) + P(B) \;-\; P(A \cap B). \] Per calcolare la probabilità dell’unione di due eventi qualsiasi, si sommano le probabilità di ciascun evento e si sottrae la probabilità della loro intersezione (altrimenti verrebbe conteggiata due volte).
24.6 Spazi discreti e continui
La natura dello spazio campionario determina come definiamo e calcoliamo le probabilità. Distinguiamo i due casi fondamentali: lo spazio campionario discreto
\[ \Omega = \{a_1, a_2, \dots, a_n\} \quad \text{oppure} \quad \Omega = \{a_1, a_2, \dots\} \]
e lo spazio campionario continuo
\[ \Omega = \mathbb{R} . \]
24.6.1 Spazi campionari discreti
Caratteristiche:
- Gli esiti sono numerabili (finiti o infiniti ma separabili).
- Esempi:
- Lancio di un dado: \(\Omega = \{1, 2, 3, 4, 5, 6\}\).
- Numero di clienti in un negozio in un’ora: \(\Omega = \{0, 1, 2, \dots\}\).
- Lancio di un dado: \(\Omega = \{1, 2, 3, 4, 5, 6\}\).
Definizione di Probabilità:
-
Assegniamo una probabilità puntuale \(p_i \geq 0\) a ogni esito \(\omega_i\), con:
\[ \sum_{\text{tutti gli } i} p_i = 1 \quad \text{(normalizzazione)}. \]
-
La probabilità di un evento \(A\) si ottiene sommando le probabilità degli esiti in \(A\):
\[ P(A) = \sum_{\omega_i \in A} p_i. \]
24.6.2 Spazi campionari continui
Caratteristiche:
- Gli esiti sono non numerabili (infiniti e “densi”).
- Esempi:
- tempo di attesa all’autobus: \(\Omega = [0, \infty)\);
- altezza di una persona: \(\Omega = [50\, \text{cm}, 250\, \text{cm}]\).
- tempo di attesa all’autobus: \(\Omega = [0, \infty)\);
Definizione di Probabilità:
- Usiamo una funzione di densità di probabilità (PDF) \(f(x) \geq 0\), con:
\[ \int_{-\infty}^{\infty} f(x)\, dx = 1 \quad \text{(normalizzazione)}. \]
- La probabilità di un evento \(A\) si ottiene integrando la PDF su \(A\):
\[ P(A) = \int_{A} f(x)\, dx. \]
24.6.3 Confronto chiave
| Caratteristica | Spazio Discreto | Spazio Continuo |
|---|---|---|
| Esiti | Numerabili (es: 1, 2, 3) | Non numerabili (es: intervalli) |
| Probabilità di un singolo punto | \(P(\{\omega_i\}) = p_i\) (\(\geq\) 0) | \(P(\{x\}) = 0\) (sempre zero) |
| Strumento matematico | Somma \(\sum\) | Integrale \(\int\) |
| Esempi comuni | Dadi, monete, conteggi | Misure fisiche, tempi, temperature |
24.6.4 Dai concetti base alle proprietà fondamentali della probabilità
Abbiamo visto come un esperimento casuale possa essere formalizzato matematicamente attraverso tre elementi chiave:
- Spazio campionario (\(\Omega\)): l’insieme di tutti i possibili esiti dell’esperimento.
- Eventi: sottoinsiemi di \(\Omega\) che rappresentano combinazioni di esiti di interesse.
- Probabilità: una funzione \(P\) che assegna a ogni evento un valore numerico compreso tra 0 e 1, misurandone il grado di verosimiglianza.
Partendo da queste definizioni, è possibile derivare proprietà essenziali per il calcolo e l’analisi probabilistica. Queste proprietà consentono di determinare la probabilità di eventi complessi a partire da eventi elementari e di stabilire relazioni logiche tra di essi.
In questo corso, approfondiremo quattro teoremi fondamentali:
- teorema della somma;
- teorema del prodotto;
- teorema della probabilità totale;
- teorema di Bayes.
L’introduzione di operazioni sugli eventi (unione, intersezione, complemento) e delle proprietà della probabilità (teorema della somma, probabilità condizionata, teorema della probabilità totale, …) ci consente di costruire modelli probabilistici più complessi e applicabili a problemi reali.
Qui di seguito, approfondiamo il teorema della somma.
24.7 Teorema della somma
Il teorema della somma (o regola additiva) permette di determinare la probabilità che si verifichi almeno uno tra due eventi \(A\) e \(B\). La sua formulazione dipende dalla relazione tra i due eventi:
Caso 1: Eventi Mutuamente Esclusivi. Se \(A\) e \(B\) non possono verificarsi insieme (ossia \(A \cap B = \emptyset\)), la probabilità dell’unione è la somma delle singole probabilità:
\[ P(A \cup B) = P(A) + P(B). \tag{24.1}\]
Caso 2: Eventi Non Esclusivi. Se \(A\) e \(B\) possono coesistere, è necessario evitare di contare due volte la loro intersezione:
\[ P(A \cup B) = P(A) + P(B) - P(A \cap B). \tag{24.2}\]
Perché questa differenza?
La probabilità è una funzione d’insieme coerente con le operazioni insiemistiche. L’addizione diretta \(P(A) + P(B)\) conteggia due volte gli esiti comuni a \(A\) e \(B\) (rappresentati da \(A \cap B\)). La sottrazione di \(P(A \cap B)\) garantisce che ogni esito sia considerato una sola volta.
Il teorema della somma sottolinea come le operazioni logiche tra eventi (unione, intersezione) si riflettano in relazioni algebriche tra le loro probabilità, fornendo uno strumento operativo per modellare scenari reali.
24.8 Probabilità, calcolo combinatorio e simulazioni
In molti problemi di probabilità, soprattutto quelli di taglio scolastico o introduttivo, si assume che ogni evento elementare abbia la stessa probabilità di verificarsi (equiprobabilità). In queste situazioni, il calcolo combinatorio risulta particolarmente utile per determinare la probabilità di un evento, poiché basta:
-
Definire gli eventi di successo: identificare tutte le configurazioni compatibili con l’evento di interesse.
- Contare le possibilità: calcolare il numero di eventi di successo e rapportarlo al numero totale di eventi nello spazio campionario.
Nelle applicazioni più complesse, come il calcolo della probabilità di ottenere una determinata combinazione di carte o il formare gruppi specifici partendo da una popolazione, utilizzeremo tecniche combinatorie più avanzate — ad esempio permutazioni e combinazioni (si veda la Sezione Appendice H) — che consentono di contare in modo sistematico gli eventi possibili e quelli di successo.
24.8.1 Simulazioni Monte Carlo
Uno degli aspetti più impegnativi della probabilità è che molti problemi non si prestano a soluzioni immediate o intuitive. Per affrontarli, si possono adottare due approcci principali. Il primo consiste nell’applicare i teoremi della teoria della probabilità, un metodo rigoroso ma spesso controintuitivo. Il secondo approccio è quello della simulazione Monte Carlo, che permette di ottenere una soluzione approssimata, ma molto vicina al valore reale, seguendo una procedura più accessibile e intuitiva. Questo metodo prende il nome dal famoso Casinò di Monte Carlo a Monaco, anche se può essere semplicemente definito come “metodo di simulazione.”
La simulazione Monte Carlo appartiene a una classe generale di metodi stocastici che si contrappongono ai metodi deterministici. Questi metodi consentono di risolvere approssimativamente problemi analitici attraverso la generazione casuale delle quantità di interesse. Tra le tecniche comunemente utilizzate troviamo il campionamento con reinserimento, in cui la stessa unità può essere selezionata più volte, e il campionamento senza reinserimento, dove ogni unità può essere selezionata una sola volta. Questi strumenti rappresentano un mezzo potente e pratico per affrontare problemi complessi.
Il problema dei complenni
Un esempio classico di applicazione del metodo Monte Carlo è il calcolo delle probabilità relative a vari eventi definiti attraverso il modello dell’urna. Tra questi, abbiamo il celebre problema dei compleanni.
Il problema dei compleanni esplora la probabilità che, in un gruppo di \(n\) persone, almeno due persone condividano la stessa data di nascita. Supponendo che i compleanni siano distribuiti uniformemente su 365 giorni (ignorando anni bisestili), il problema sorprende molte persone per il fatto che già con 23 persone la probabilità di una coincidenza è superiore al 50%.
24.8.1.1 Soluzione analitica
Questo problema può essere risolto utilizzando il concetto di probabilità complementari. Infatti, il problema può essere visto da due prospettive complementari:
- Caso 1: tutti i compleanni sono diversi (nessuna persona condivide il compleanno con un’altra);
- Caso 2: almeno due persone condividono lo stesso compleanno.
Questi due casi sono mutuamente esclusivi (non possono verificarsi contemporaneamente) ed esaustivi (coprono tutte le possibilità). Pertanto, la somma delle loro probabilità deve essere uguale a 1:
\[ P(\text{almeno un compleanno in comune}) = 1 - P(\text{nessun compleanno in comune}). \]
In altre parole, per calcolare la probabilità che almeno due persone abbiano lo stesso compleanno, possiamo prima calcolare la probabilità che tutti i compleanni siano diversi e poi sottrarre questo valore da 1.
Caso 1: probabilità che tutti i compleanni siano diversi.
Per calcolare \(P(\text{nessun compleanno in comune})\), seguiamo questo ragionamento:
Prima persona: Può scegliere liberamente un giorno del calendario. Ci sono 365 possibilità (ignoriamo gli anni bisestili per semplicità).
Seconda persona: Deve avere un compleanno diverso dalla prima persona. Quindi, ci sono 364 giorni disponibili.
Terza persona: Deve avere un compleanno diverso dai primi due. Ci sono 363 giorni disponibili.
Questo processo continua fino alla \(n\)-esima persona, che avrà \(365 - n + 1\) giorni disponibili.
La probabilità che tutti i compleanni siano diversi si ottiene moltiplicando le probabilità individuali di ogni persona di avere un compleanno diverso dai precedenti. Poiché ogni scelta è indipendente, possiamo scrivere:
\[ P(\text{nessun compleanno in comune}) = \frac{365}{365} \cdot \frac{364}{365} \cdot \frac{363}{365} \cdot \ldots \cdot \frac{365-n+1}{365}. \]
Questo prodotto può essere espresso in forma compatta utilizzando il fattoriale:
\[ P(\text{nessun compleanno in comune}) = \frac{365!}{(365-n)! \cdot 365^n} , \]
dove:
- \(365!\) è il fattoriale di 365 (il prodotto di tutti i numeri interi da 1 a 365).
- \((365-n)!\) è il fattoriale di \(365 - n\).
- \(365^n\) rappresenta tutte le possibili combinazioni di compleanni per \(n\) persone.
Caso 2. Probabilità di almeno un compleanno in comune.
Ora che abbiamo calcolato la probabilità che tutti i compleanni siano diversi, possiamo trovare la probabilità che almeno due persone abbiano lo stesso compleanno come il complemento:
\[ P(\text{almeno un compleanno in comune}) = 1 - P(\text{nessun compleanno in comune}). \]
Sostituendo l’espressione precedente, otteniamo:
\[ P(\text{almeno un compleanno in comune}) = 1 - \frac{365!}{(365-n)! \cdot 365^n}. \]
Ora che abbiamo le formule per i due eventi complementari, come funzione di \(n\), applichiamole al caso specifico in cui \(n\) = 23. Questo è un valore interessante perché, come vedremo, la probabilità che almeno due persone su 23 condividano lo stesso compleanno supera il 50%.
La formula per la probabilità che tutti i compleanni siano diversi è:
\[ P(\text{nessun compleanno in comune}) = \frac{365!}{(365-n)! \cdot 365^n}. \]
Per \(n = 23\), sostituiamo il valore nella formula:
\[ P(\text{nessun compleanno in comune}) = \frac{365!}{(365-23)! \cdot 365^{23}}. \]
Semplifichiamo:
\[ P(\text{nessun compleanno in comune}) = \frac{365!}{342! \cdot 365^{23}}. \]
Utilizzando R, troviamo:
# Numero di persone
n <- 23
# Calcolo della probabilità che tutti abbiano compleanni diversi
numeratore <- prod(365:(365 - n + 1))
denominatore <- 365^n
P_diversi <- numeratore / denominatore
P_diversi # stampa la probabilità
#> [1] 0.493\[ P(\text{nessun compleanno in comune}) \approx 0{,}4927. \]
Ciò implica che la probabilità che 23 persone abbiano compleanni distinti sia approssimativamente 0.4927 (pari al 49.27%).
La probabilità che almeno due persone (su 23) condividano lo stesso compleanno corrisponde al complemento della probabilità appena calcolata:
\[ P(\text{almeno un compleanno in comune}) = 1 - P(\text{nessun compleanno in comune}). \]
Sostituendo il valore ottenuto:
\[ P(\text{almeno un compleanno in comune}) = 1 - 0{.}4927 = 0{.}5073. \]
Risultato finale:
Con \(n = 23\), la probabilità che almeno una coppia condivida il compleanno supera il 50%, attestandosi intorno a 0.5073 (50.73%). Questo esito è spesso sorprendente, poiché intuitivamente si tende a sottostimare l’effetto della combinatoria: sebbene 23 possano sembrare poche, le \(\binom{23}{2} = 253\) possibili coppie rendono statisticamente probabile una corrispondenza.
24.8.1.2 Soluzione con simulazione in R
Per risolvere il problema tramite simulazione, possiamo generare gruppi casuali di \(n\) persone, assegnando loro un compleanno casuale tra 1 e 365. Per ogni gruppo, verifichiamo se almeno due persone condividono lo stesso compleanno.
Ecco il codice R:
# Numero di simulazioni
num_simulazioni <- 10000
# Funzione per simulare il problema del compleanno
simula_compleanno <- function(n) {
# Conta il numero di successi (almeno un compleanno in comune)
successi <- 0
# Loop per il numero di simulazioni
for (i in 1:num_simulazioni) {
# Genera n compleanni casuali
compleanni <- sample(1:365, n, replace = TRUE)
# Verifica se ci sono duplicati
if (any(duplicated(compleanni))) {
successi <- successi + 1
}
}
# Calcola la probabilità stimata
return(successi / num_simulazioni)
}Proviamo con diversi valori di n.
set.seed(123) # Fissiamo il seme per la riproducibilità
risultati <- sapply(1:50, simula_compleanno)
# Creiamo un data frame con i risultati
df <- data.frame(
n = 1:50,
prob = risultati
)
# Creiamo il grafico
ggplot(df, aes(x = n, y = prob)) +
geom_line(color = "blue") +
geom_point(color = "blue") +
geom_hline(yintercept = 0.5, color = "red", linetype = "dashed") +
labs(
x = "Numero di persone (n)",
y = "Probabilità stimata",
title = "Problema del Compleanno (Simulazione)"
)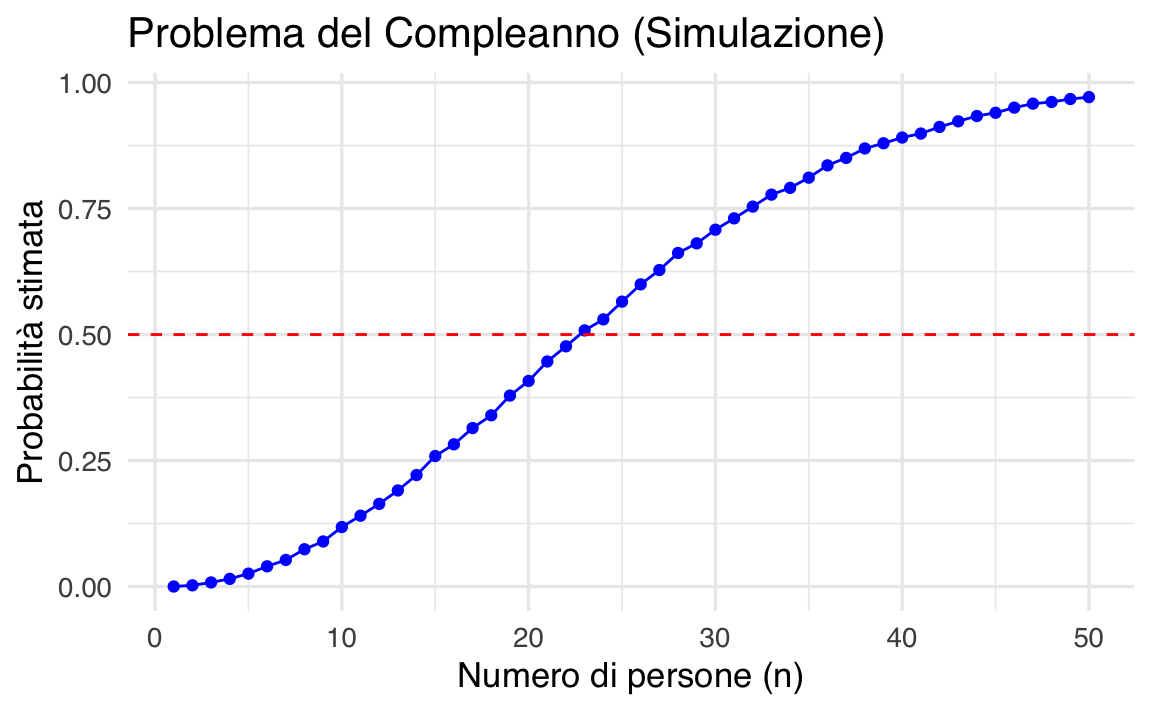
- Simulazioni: Per ogni gruppo di \(n\), si eseguono 10000 simulazioni, in cui si generano \(n\) compleanni casuali tra 1 e 365.
- Duplicati: La funzione duplicated() verifica se ci sono compleanni ripetuti.
- Calcolo della probabilità: La proporzione di simulazioni in cui si verifica almeno un compleanno condiviso rappresenta la probabilità stimata.
- Visualizzazione: Si tracciano le probabilità per diversi valori di \(n\), evidenziando il punto in cui la probabilità supera il 50%.
Risultati attesi:
- con circa 23 persone, la probabilità stimata sarà superiore a 0.5;
- il grafico mostra una curva crescente con un rapido aumento della probabilità per \(n\) piccoli e un asintoto vicino a 1 per \(n\) grandi.
Questo approccio permette di comprendere intuitivamente il problema e di verificare i risultati teorici con la simulazione.
24.8.1.3 Assunzioni
Il problema dei compleanni evidenzia non solo l’efficacia dell’approccio simulativo nel semplificare la soluzione rispetto all’analisi formale, ma anche l’importanza delle assunzioni che entrambi i metodi condividono. In questo caso, l’assunzione è che la probabilità di nascita sia uniformemente distribuita nei 365 giorni dell’anno — un’ipotesi semplificativa che non rispecchia la realtà.
Questo esempio sottolinea un principio fondamentale dei modelli probabilistici (e scientifici in generale): ogni modello si basa su un insieme di assunzioni che ne delimitano la validità e l’applicabilità. Valutare criticamente la plausibilità di tali assunzioni è dunque essenziale per garantire che il modello fornisca una rappresentazione utile del fenomeno studiato.
Riflessioni conclusive
La teoria della probabilità fornisce un quadro rigoroso per descrivere e analizzare fenomeni caratterizzati dall’incertezza. In questo capitolo abbiamo introdotto i concetti fondamentali del calcolo delle probabilità, evidenziando come la modellazione matematica degli esperimenti casuali consenta di quantificare e prevedere eventi incerti. Abbiamo esplorato strumenti essenziali come la definizione di spazio campionario, la nozione di evento e le regole della probabilità, illustrando il loro utilizzo sia attraverso esempi teorici sia mediante simulazioni computazionali.
Un aspetto cruciale della modellazione probabilistica è il ruolo delle assunzioni su cui si basano i modelli. Ogni modello probabilistico si fonda su ipotesi specifiche riguardanti la natura del fenomeno studiato e il modo in cui gli esiti vengono generati. Queste ipotesi determinano non solo la validità del modello, ma anche il tipo di risposte che esso può fornire. Ad esempio, nel problema del compleanno, abbiamo ipotizzato che i compleanni siano distribuiti in modo uniforme nei 365 giorni dell’anno. Sebbene questa assunzione semplifichi notevolmente i calcoli, sappiamo che nella realtà esistono fluttuazioni stagionali nelle nascite che possono influenzare le probabilità effettive.
Questo ci porta a una considerazione più ampia: la probabilità non è solo un insieme di formule, ma uno strumento per rappresentare l’incertezza e prendere decisioni informate. Tuttavia, l’accuratezza di qualsiasi modello probabilistico dipende strettamente dalla plausibilità delle ipotesi adottate. Modelli diversi, basati su ipotesi differenti, possono portare a risultati diversi, e l’interpretazione dei risultati deve sempre tenere conto di queste assunzioni.
In definitiva, lo studio della probabilità non si limita alla manipolazione di formule, ma richiede un’attenta riflessione sulla relazione tra modelli teorici e fenomeni reali. Una comprensione critica delle assunzioni alla base di un modello è essenziale per applicare correttamente i concetti probabilistici in contesti pratici, sia in ambito scientifico che nelle decisioni quotidiane.
Esercizi
Bibliografia
Chan, J. C. C., & Kroese, D. P. (2025). Statistical Modeling and Computation (2ª ed.). Springer.