29 Variabili casuali
“A random variable is a real valued function on the measure space X.”
— Paul R. Halmos, Measure Theory.
Introduzione
Fino ad ora abbiamo studiato le probabilità associate a eventi, come la possibilità di vincere il gioco di Monty Hall o di avere una rara condizione medica in seguito a un test positivo. Tuttavia, in molte situazioni pratiche vogliamo conoscere aspetti più dettagliati. Ad esempio, potremmo chiederci:
- quanti tentativi occorrono affinché, in un gioco simile a Monty Hall, un concorrente vinca?
- quanto durerà un determinato evento o condizione?
- qual è la perdita attesa giocando d’azzardo con un dado sbilanciato per molte ore?
Per rispondere a tali domande è necessario lavorare con le variabili casuali. In questo capitolo introdurremo il concetto di variabile casuale e ne analizzeremo le proprietà fondamentali.
Panoramica del capitolo
- Le definizioni e le caratteristiche delle variabili casuali discrete e continue, e le relative distribuzioni di probabilità;
- Come calcolare e interpretare il valore atteso di variabili casuali, sia discrete che continue.
- Determinare e comprendere la varianza e la deviazione standard di variabili casuali.
29.1 Definizione di variabile casuale
Una variabile casuale è una funzione che associa ogni elemento di uno spazio campionario a un valore numerico. Questo strumento permette di trasformare esiti qualitativi (ad esempio, il risultato di un lancio di carte, come cuori, quadri, fiori, picche) in valori numerici, facilitando così l’analisi matematica.
Definizione 29.1 Sia \(S\) lo spazio campionario di un esperimento aleatorio. Una variabile casuale \(X\) è una funzione
\[
X: S \longrightarrow \mathbb{R},
\] che associa ad ogni esito \(s \in S\) un numero reale \(X(s)\).
Lanciamo due dadi equilibrati e annotiamo la somma dei valori delle loro facce. Ogni lancio genera una coppia di valori \((i,j)\), dove \(i\) è il risultato del primo dado e \(j\) il risultato del secondo dado. Lo spazio campionario completo dei possibili esiti è:
\[ \Omega = \{(1,1), (1,2), \dots, (6,5), (6,6)\}. \]
Definiamo una variabile casuale \(X\) che associa ciascun esito \((i,j)\) alla somma dei valori ottenuti dai due dadi, cioè:
\[ X(i,j) = i + j. \]
Ad esempio, se il primo dado mostra 4 e il secondo dado mostra 4, allora l’esito è \((4,4)\) e la variabile casuale \(X\) assume il valore 8.
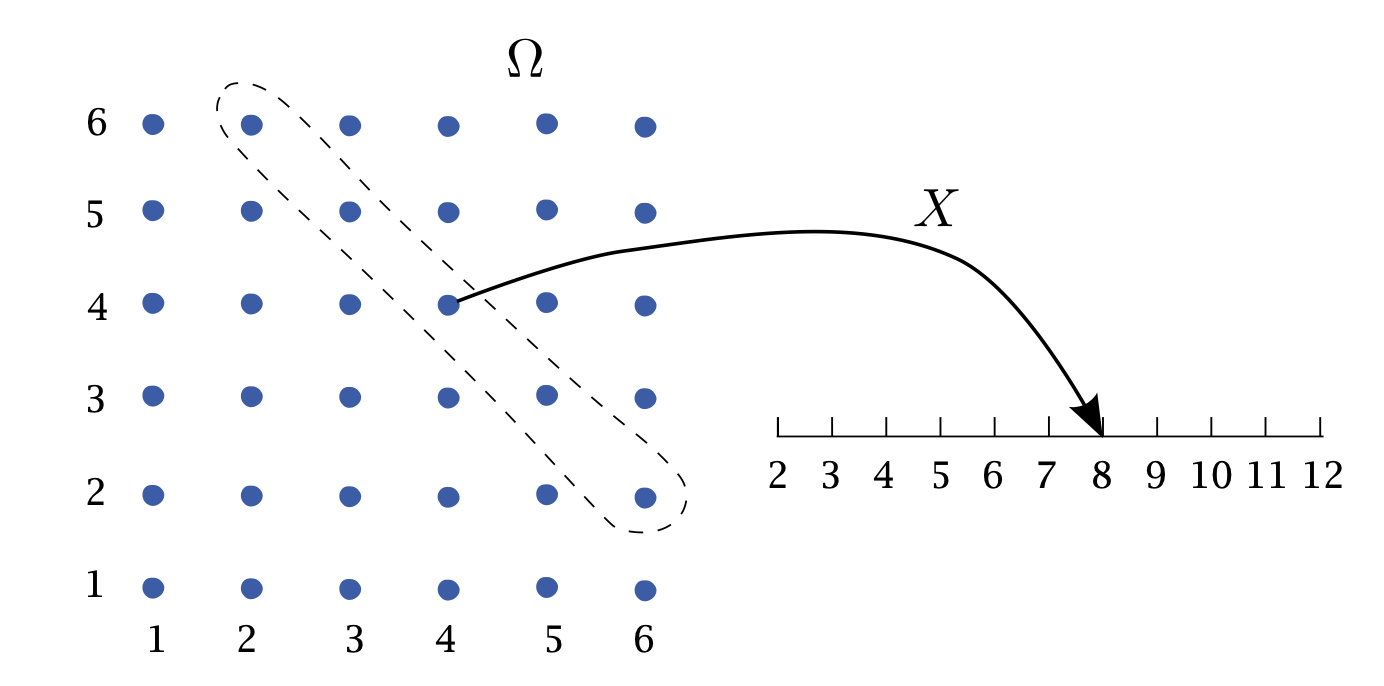
Consideriamo il valore specifico \(X=8\): questo valore può essere ottenuto attraverso cinque diversi esiti dello spazio campionario: \((2,6), (3,5), (4,4), (5,3), (6,2)\). Indichiamo con \(\{X=8\}\) l’insieme di questi esiti. Poiché tutti gli esiti in \(\Omega\) sono equiprobabili, possiamo calcolare la probabilità di ottenere una somma pari a 8 come:
\[ P(X=8) = \frac{5}{36}. \]
29.2 Tipologie di variabili casuali
Le variabili casuali si dividono in due categorie principali:
29.2.1 Variabili casuali discrete
Una variabile casuale discreta assume un insieme finito o numerabile di valori. Gli esempi includono il numero di teste ottenute in lanci di moneta o la somma dei risultati di due dadi. Per queste variabili, la funzione di massa di probabilità (PMF) assegna a ciascun valore \(x\) la probabilità \(P(X = x)\).
Esempio 29.1 Nel lancio di due dadi, la variabile \(X\) (somma dei punti) può assumere valori interi da 2 a 12. La distribuzione di \(X\) si ottiene contando i casi favorevoli per ciascun valore e dividendo per il numero totale di esiti (36).
29.2.2 Variabili casuali continue
Una variabile casuale continua può assumere infiniti valori in un intervallo (ad esempio, l’altezza di una persona). In questo caso non si assegna una probabilità a un singolo valore (che risulterebbe essere zero), ma si definisce una funzione di densità di probabilità (PDF), tale che l’integrale della funzione su un intervallo fornisce la probabilità che la variabile cada in quell’intervallo.
Esempio 29.2 Considera una variabile \(X\) che rappresenta l’altezza in centimetri. Invece di \(P(X = 170)\), calcoliamo probabilità come \(P(170 \leq X \leq 180)\) mediante l’integrale della PDF in quell’intervallo.
29.3 Notazione convenzionale
Nella teoria della probabilità si adotta una convenzione chiara per distinguere una variabile casuale dal suo valore osservato o realizzato:
- la variabile casuale viene indicata con lettere maiuscole (es. \(X\));
- il valore specifico assunto dalla variabile casuale viene indicato con lettere minuscole (es. \(x\)).
Questa convenzione aiuta a evitare ambiguità, soprattutto quando si definiscono:
- probabilità cumulative: \(P(X \leq x)\);
- valore atteso: \(E[X]\);
- funzioni di densità o massa di probabilità: \(f_X(x)\).
29.4 Variabili casuali multiple
In molti esperimenti, è utile considerare contemporaneamente più variabili casuali. Ad esempio, supponiamo di lanciare una moneta equilibrata tre volte. Definiamo tre variabili casuali indipendenti \(X_1\), \(X_2\) e \(X_3\), ciascuna associata all’esito di un lancio:
\[ P(X_n = 1) = 0.5 \quad (\text{testa}), \qquad P(X_n = 0) = 0.5 \quad (\text{croce}), \quad n = 1, 2, 3. \]
Possiamo poi definire una nuova variabile casuale derivata, ad esempio:
\[ Z = X_1 + X_2 + X_3, \]
che rappresenta il numero totale di teste ottenute nei tre lanci. In questo scenario, \(Z\) è una variabile casuale discreta che può assumere esclusivamente i valori 0, 1, 2 o 3.
29.5 Distribuzione di probabilità
Definizione 29.2 La distribuzione di probabilità di una variabile casuale descrive come le probabilità sono assegnate ai possibili valori (o intervalli di valori) della variabile.
29.5.1 Funzione di massa di probabilità (PMF) per variabili discrete
Per una variabile casuale discreta \(X\), la distribuzione è definita tramite la funzione di massa di probabilità (PMF), indicata con \(f(x)\), dove:
\[ f(x) = P(X = x). \]
Nota la PMF, è possibile calcolare la probabilità di qualsiasi evento associato a \(X\). Ad esempio, per un insieme \(B\) di valori:
\[ P(X \in B) = \sum_{x \in B} f(x). \]
29.5.2 Funzione di distribuzione cumulativa (CDF)
Definizione 29.3 La funzione di distribuzione cumulativa (CDF) di una variabile casuale \(X\) è definita come: \[ F(x) = P(X \leq x). \] La CDF indica la probabilità che \(X\) assuma valori minori o uguali a un valore specifico \(x\).
29.5.3 Proprietà della CDF (funzione di ripartizione)
La CDF descrive la probabilità che una variabile casuale \(X\) assuma un valore minore o uguale a \(x\). Per capirla in psicologia (ad esempio, per analizzare dati di test, questionari, o esperimenti), bastano tre idee chiave:
-
Non diminuisce mai:
Se consideriamo valori \(x\) sempre più grandi, la probabilità cumulata non può diminuire.-
Esempio: Se la CDF a \(x = 50\) in un test è \(0.7\), a \(x = 60\) sarà almeno \(0.7\) (potrebbe salire, ma non scendere).
- Perché? Aggiungendo nuovi risultati (es.: punteggi più alti), la probabilità totale può solo aumentare o restare uguale.
-
Esempio: Se la CDF a \(x = 50\) in un test è \(0.7\), a \(x = 60\) sarà almeno \(0.7\) (potrebbe salire, ma non scendere).
-
Estremi prevedibili:
- Per valori molto bassi (es.: \(x \to -\infty\)), la probabilità cumulata è 0: non esistono punteggi infinitamente bassi.
- Per valori molto alti (es.: \(x \to +\infty\)), la probabilità cumulata è 1: tutti i possibili risultati sono inclusi.
- Esempio: In una scala Likert da 1 a 5, la CDF a \(x = 0\) è 0, e a \(x = 10\) è 1.
- Per valori molto bassi (es.: \(x \to -\infty\)), la probabilità cumulata è 0: non esistono punteggi infinitamente bassi.
-
Niente salti “a sorpresa” verso destra:
La CDF è costruita in modo che, se ci spostiamo di pochissimo a destra di un punto \(x\), la probabilità cumulata non crolla improvvisamente.-
Esempio:
Supponiamo che in un questionario, il punteggio \(x = 10\) corrisponda a una certa probabilità cumulata (es.: \(0.8\)). Se ci spostiamo di un millesimo a destra (es.: \(x = 10.001\)), la probabilità rimane \(0.8\), a meno che \(10.001\) non sia un punteggio valido.
- A cosa serve? Garantisce coerenza: se un punteggio \(x\) ha una certa probabilità, questa non viene “persa” spostandosi di poco a destra.
-
Esempio:
29.5.4 CDF per variabili discrete
In psicologia, spesso lavoriamo con dati discreti (es.: risposte a item di un test, come “1 = Mai” a “5 = Sempre”). In questi casi:
- La CDF si calcola sommando le probabilità di tutti i valori \(\leq x\).
-
Esempio: Se in una scala da 1 a 5, il 30% degli studenti risponde 1 o 2, allora \(F(2) = 0.3\).
- Graficamente: La CDF avrà “gradini” nei punti corrispondenti ai valori possibili (es.: 1, 2, 3, 4, 5).
29.5.4.1 Perché serve saperlo?
Queste proprietà aiutano a:
- Interpretare grafici cumulativi (es.: quanto è probabile che un partecipante abbia un punteggio \(\leq\) 20?).
- Evitare errori logici (es.: non ha senso aspettarsi un calo della probabilità cumulata all’aumentare di \(x\)).
- Leggere correttamente salti nei dati discreti (es.: un gradino in \(x = 4\) indica un accumulo di probabilità in quel punto).
29.5.5 Simulazione della distribuzione di probabilità
Spesso, anche se è possibile calcolare analiticamente la distribuzione di probabilità (come nel caso dei due dadi), può essere utile ottenere una stima empirica attraverso la simulazione. Questo approccio prevede di ripetere l’esperimento molte volte e di analizzare le frequenze relative dei risultati ottenuti.
29.6 Distribuzioni per variabili continue
Definizione 29.4 Una variabile casuale continua è una variabile aleatoria \(X\) caratterizzata da una distribuzione di probabilità continua. Formalmente, \(X\) si definisce continua se soddisfa le seguenti proprietà:
-
Esistenza della funzione di densità (pdf):
Esiste una funzione non negativa \(f(x)\), detta funzione di densità di probabilità (pdf, dall’inglese probability density function), tale che:-
\(f(x) \geq 0\) per ogni \(x \in \mathbb{R}\);
- L’area totale sotto la curva di \(f(x)\) è pari a 1:
\[ \int_{-\infty}^{+\infty} f(x) \, dx = 1. \]
-
\(f(x) \geq 0\) per ogni \(x \in \mathbb{R}\);
-
Calcolo delle probabilità tramite integrazione:
Per ogni intervallo \((a, b] \subseteq \mathbb{R}\) (con \(a < b\)), la probabilità che \(X\) assuma valori in \((a, b]\) è data dall’integrale della pdf su tale intervallo:\[ P(a < X \leq b) = \int_{a}^{b} f(x) \, dx. \]
Questa probabilità coincide anche con la differenza della funzione di ripartizione (CDF, cumulative distribution function) \(F(x) = P(X \leq x)\) agli estremi dell’intervallo:
\[ P(a < X \leq b) = F(b) - F(a). \]
29.6.1 Proprietà chiave delle variabili continue
-
Probabilità in un punto nulla:
A differenza delle variabili discrete, per una variabile continua la probabilità di assumere un valore esatto \(x_0\) è sempre zero:\[ P(X = x_0) = 0. \]
Questo avviene perché la probabilità è legata all’area sotto la curva \(f(x)\), e un singolo punto ha “larghezza zero”, risultando in un’area nulla. Di conseguenza, per variabili continue:
\[ P(a \leq X \leq b) = P(a < X \leq b) = P(a \leq X < b) = P(a < X < b). \]
Interpretazione della densità:
La funzione \(f(x)\) non rappresenta direttamente una probabilità, ma descrive come la probabilità si distribuisce nello spazio campionario. Valori maggiori di \(f(x)\) indicano regioni in cui è più probabile che \(X\) assuma valori (densità di probabilità).Modellizzazione di fenomeni continui:
Le distribuzioni continue sono utilizzate per rappresentare grandezze misurabili con precisione arbitraria, come tempo, lunghezze, o temperature. Esempi comuni includono la distribuzione normale, esponenziale e uniforme continua.
Riflessioni conclusive
In questo capitolo abbiamo introdotto e approfondito il concetto fondamentale di variabile casuale, illustrando come questo strumento permetta di formalizzare e analizzare matematicamente fenomeni casuali complessi. Attraverso esempi intuitivi, come il lancio di dadi o la simulazione di situazioni reali, abbiamo osservato come le variabili casuali consentano di tradurre domande astratte in analisi concrete e interpretabili.
Abbiamo esaminato le due principali tipologie di variabili casuali—discrete e continue—e discusso le relative distribuzioni di probabilità. Le distribuzioni discrete, caratterizzate da una funzione di massa di probabilità (PMF), si prestano particolarmente bene a modellare situazioni in cui gli eventi possono essere enumerati (come punteggi in test psicologici o risultati di giochi). Al contrario, le distribuzioni continue, descritte dalla funzione di densità di probabilità (PDF), sono essenziali per modellare misure precise, come l’altezza o il tempo, dove il numero di possibili valori è teoricamente infinito.
Un aspetto importante trattato è la funzione di distribuzione cumulativa (CDF), che fornisce una descrizione completa della distribuzione di una variabile casuale, facilitando la comprensione intuitiva della probabilità che un evento accada entro certi limiti. Conoscere le proprietà della CDF aiuta a prevenire errori comuni nella sua interpretazione e a trarre conclusioni più affidabili dai dati empirici.
Infine, attraverso l’utilizzo della simulazione, abbiamo mostrato come sia possibile avvicinarsi empiricamente a una distribuzione teorica, confermando e visualizzando in modo pratico e immediato concetti astratti. Questa capacità di simulare e verificare empiricamente le distribuzioni è estremamente utile, soprattutto quando i modelli teorici diventano troppo complessi da risolvere analiticamente.
Nei prossimi capitoli approfondiremo ulteriormente questi concetti, esaminando alcune distribuzioni di probabilità specifiche che sono comunemente usate nella ricerca psicologica e nelle applicazioni pratiche. Questo ci permetterà di passare da una conoscenza teorica delle variabili casuali a una competenza concreta nel loro utilizzo e nella loro interpretazione, sviluppando strumenti che miglioreranno le nostre capacità di analisi e di decisione in ambito psicologico e statistico.