here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(brms, cmdstanr, posterior, brms, bayestestR, insight)70 Confronto tra due proporzioni indipendenti
70.1 Introduzione
Supponiamo di voler capire se due gruppi di persone hanno la stessa probabilità di “successo” in una certa attività. Per esempio, vogliamo sapere se due trattamenti diversi portano alla stessa percentuale di guarigione, oppure se studenti che seguono due metodi di studio differenti superano un esame con la stessa frequenza.
Quando il risultato per ogni persona è un valore binario — successo o insuccesso, sì o no, guarito o non guarito — possiamo usare un modello statistico chiamato regressione logistica.
In particolare, se i due gruppi sono indipendenti e distinti (cioè ogni persona appartiene a uno solo dei due gruppi), possiamo usare una versione semplice della regressione logistica con una sola variabile esplicativa binaria (una “dummy”).
Adottando un approccio bayesiano, possiamo:
- rendere esplicita l’incertezza sulle nostre ipotesi iniziali tramite le distribuzioni a priori;
- descrivere l’intera gamma di risultati plausibili, ottenendo una distribuzione a posteriori dei parametri invece di un singolo valore “stimato”.
70.2 La struttura dei dati
Consideriamo i dati che raccogliamo:
ogni partecipante è identificato da un indice \(i = 1, 2, \dots, N\);
-
per ciascuno osserviamo un esito binario:
\[ y_i = \begin{cases} 1 & \text{se c’è un successo},\\ 0 & \text{se c’è un insuccesso}. \end{cases} \]
ogni partecipante appartiene a uno e un solo gruppo. Chiamiamo gruppo 0 il primo gruppo (ad esempio, il gruppo di controllo) e gruppo 1 il secondo gruppo (ad esempio, il gruppo che riceve un trattamento sperimentale).
Per rappresentare questa appartenenza al gruppo, definiamo una variabile indicatrice:
\[ D_i = \begin{cases} 0 & \text{se il partecipante è nel gruppo 0},\\ 1 & \text{se il partecipante è nel gruppo 1}. \end{cases} \]
Questa variabile ci permette di costruire un modello che distingue i due gruppi.
70.3 Un modello statistico per dati binari
Poiché il risultato \(y\_i\) può essere solo 0 o 1, possiamo descriverlo con una distribuzione di Bernoulli, che rappresenta proprio questo tipo di variabili:
\[ y_i \sim \text{Bernoulli}(p_i), \]
dove \(p\_i\) è la probabilità che il partecipante \(i\) ottenga un successo (cioè che \(y_i = 1\)).
A questo punto potremmo pensare di modellare direttamente \(p_i\) come una funzione di \(D_i\). Ma c’è un problema tecnico importante.
70.3.1 Perché non modelliamo direttamente la probabilità \(p_i\)?
Le probabilità devono sempre stare tra 0 e 1. Ma se usassimo un modello lineare classico (come \(p\_i = \alpha + \gamma D_i\)), potremmo ottenere dei valori fuori da questo intervallo — ad esempio, una “probabilità” negativa o maggiore di 1, che non ha senso.
Per evitare questo, si usa una trasformazione matematica chiamata logit, che ha due proprietà molto utili:
- accetta in ingresso solo valori tra 0 e 1 (cioè le probabilità),
- restituisce un numero reale qualsiasi, da \(-\infty\) a \(+\infty\).
La trasformazione logit è definita così:
\[ \text{logit}(p_i) = \log\left(\frac{p_i}{1 - p_i}\right) . \]
Questa quantità si chiama log-odds e rappresenta il logaritmo del rapporto tra la probabilità di successo e quella di insuccesso.
Esempio:
- se \(p_i = 0.5\), allora \(\text{logit}(p_i) = \log(1) = 0\);
- se \(p_i = 0.8\), allora \(\text{logit}(p_i) = \log(4) \approx 1.39\);
- se \(p_i = 0.2\), allora \(\text{logit}(p_i) = \log(0.25) \approx -1.39\).
Grazie a questa trasformazione, possiamo costruire un modello lineare senza rischiare di ottenere valori fuori dall’intervallo [0,1].
70.4 Il modello di regressione logistica
Mettiamo insieme tutti i pezzi. Il nostro modello diventa:
\[ \begin{aligned} y_i &\sim \text{Bernoulli}(p_i), \\ \text{logit}(p_i) &= \alpha + \gamma D_i. \end{aligned} \]
Vediamo cosa significano i due parametri del modello:
-
\(\alpha\) è il log-odds di successo per il gruppo 0 (quando \(D_i = 0\)).
-
La probabilità di successo corrispondente si ottiene con la funzione logistica:
\[ p_0 = \frac{e^{\alpha}}{1 + e^{\alpha}} = \text{logistic}(\alpha) . \]
-
-
\(\gamma\) rappresenta la differenza nei log-odds tra il gruppo 1 e il gruppo 0.
-
Il log-odds nel gruppo 1 è quindi $+ $, e la probabilità è:
\[ p_1 = \frac{e^{\alpha + \gamma}}{1 + e^{\alpha + \gamma}} = \text{logistic}(\alpha + \gamma) . \]
-
70.4.1 Interpretazione pratica
- Se \(\gamma > 0\), il gruppo 1 ha una probabilità di successo più alta rispetto al gruppo 0.
- Se \(\gamma < 0\), il gruppo 1 ha una probabilità più bassa.
- Se \(\gamma = 0\), i due gruppi hanno la stessa probabilità di successo.
70.4.2 Vantaggi dell’approccio bayesiano
In un’analisi bayesiana, non ci limitiamo a stimare un singolo valore per \(\gamma\). Invece, otteniamo una distribuzione completa che rappresenta tutte le ipotesi plausibili sui valori di \(\gamma\), tenendo conto:
- della variabilità nei dati,
- delle nostre ipotesi iniziali (le distribuzioni a priori),
- e delle informazioni che emergono dai dati osservati.
Questo ci permette di rispondere a domande come:
- Quanto è probabile che \(\gamma\) sia maggiore di 0?
- Qual è l’intervallo più credibile in cui può trovarsi \(\gamma\) con il 95% di probabilità?
- Qual è la probabilità che la differenza tra i gruppi sia sostanziale, non solo presente?
70.4.3 Dai Logit alle Probabilità
Una volta stimati i coefficienti del modello di regressione logistica — in particolare, l’intercetta \(\beta\_0\) e uno o più coefficienti \(\beta_j\) associati ai predittori — questi si trovano sulla scala dei log-odds (cioè su scala logit). Per ottenere le probabilità previste per ciascuna combinazione di valori dei predittori, è sufficiente applicare la funzione logistica inversa, definita come:
\[ p = \text{logistic}(\eta) = \frac{1}{1 + e^{-\eta}}, \]
dove \(\eta = \beta_0 + \beta_1 x_1 + \dots + \beta_k x_k\) è il valore del predittore lineare per una certa combinazione dei predittori. Ad esempio, se si ha solo una variabile binaria \(x\) che vale 0 (gruppo di riferimento) o 1 (gruppo trattato), allora le probabilità nei due gruppi sono:
- gruppo di riferimento: \(p_0 = \frac{1}{1 + e^{-\beta_0}}\)
- gruppo trattamento: \(p_1 = \frac{1}{1 + e^{-(\beta\_0 + \beta_1)}}\)
In questo modo, si può interpretare il modello non solo in termini di log-odds, ma anche come probabilità di successo, rendendo più intuitivo il significato pratico dei risultati.
70.4.4 Inferenza bayesiana
-
Scelta delle prior
- Un’opzione comune è usare prior debolmente informative, ad esempio \(\alpha\sim\mathcal N(0,\,2.5)\) e \(\gamma\sim\mathcal N(0,\,2.5)\). Queste varianze larghe lasciano che i dati “parlino”, ma impediscono che le probabilità si avvicinino troppo a 0 o 1 senza evidenza.
-
Calcolo della distribuzione a posteriori
- Si usa normalmente l’algoritmo MCMC (per es. No‑U‑Turn Sampler di Stan).
- Otteniamo campioni \(\{\alpha^{(s)},\gamma^{(s)}\}_{s=1}^S\).
-
Quantità derivate di interesse
- Probabilità nei due gruppi: \(p_0^{(s)}=\operatorname{logistic}(\alpha^{(s)})\), \(p_1^{(s)}=\operatorname{logistic}(\alpha^{(s)}+\gamma^{(s)})\).
- Differenza di probabilità: \(\Delta^{(s)} = p_1^{(s)}-p_0^{(s)}\). Mostra quanto, in media, il gruppo 1 supera (o non supera) il gruppo 0 in termini di proporzione.
- Rapporto di odds: \(\text{OR}^{(s)} = e^{\gamma^{(s)}}\). Se \(\text{OR}=2\) significa che gli odds di successo nel gruppo 1 sono il doppio di quelli nel gruppo 0.
-
Sintesi dei risultati
- Media (o mediana) a posteriori per \(p_0, p_1, \Delta, \text{OR}\).
- Intervalli di credibilità al 95 %: tagliamo il 2.5 % di campioni in ciascuna coda.
- Probabilità che \(\Delta>0\) o che \(\text{OR}>1\): basta contare la frazione di campioni corrispondenti.
70.4.5 Perché tutto questo funziona?
Il logit “apre” l’intervallo (0, 1) rendendo possibile usare un modello lineare.
-
La regressione logistica con una dummy è l’esatto equivalente, in termini di parametri, al test bayesiano sulle due proporzioni, ma:
- consente estensioni (più covariate, effetti casuali, interazioni);
- permette di riportare risultati direttamente interpretabili (differenza di probabilità, OR, predicted probabilities).
L’approccio bayesiano produce output che si leggono come “date le nostre ipotesi preliminari e i dati, la plausibilità che la vera differenza di probabilità stia in questo intervallo è 95 %”, concetto spesso più intuitivo del valore‑p.
70.5 Inferenza sulle proporzioni
Il confronto tra le proporzioni di due gruppi indipendenti può essere affrontato sia con un approccio frequentista, basato sulla distribuzione campionaria, sia con un approccio bayesiano. Vediamo i due approcci in dettaglio.
70.6 Approccio Frequentista
Quando vogliamo confrontare le probabilità di successo in due gruppi distinti, possiamo analizzare la differenza tra le proporzioni di successo osservate. L’approccio frequentista affronta il problema studiando la distribuzione campionaria di questa differenza.
70.6.1 Modello di riferimento
Supponiamo di avere due gruppi indipendenti. In ciascun gruppo osserviamo esiti binari, come “successo” (1) o “insuccesso” (0), per ogni partecipante. Formalmente:
\[ Y_1 \sim \text{Bernoulli}(p_1), \quad Y_2 \sim \text{Bernoulli}(p_2), \]
dove \(p_1\) e \(p_2\) sono le probabilità di successo nella popolazione del primo e del secondo gruppo, rispettivamente.
70.6.2 Obiettivo dell’inferenza
Siamo interessati a stimare e fare inferenza sulla differenza tra le due proporzioni:
\[ \Delta = p_1 - p_2. \]
Poiché non conosciamo \(p_1\) e \(p_2\), li stimiamo usando le proporzioni campionarie:
\[ \hat{p}_1 = \frac{X_1}{n_1}, \quad \hat{p}_2 = \frac{X_2}{n_2}, \quad \text{e dunque} \quad \hat{\Delta} = \hat{p}_1 - \hat{p}_2. \]
70.6.3 Proprietà della distribuzione campionaria
Per capire se la differenza osservata tra \(\hat{p}_1\) e \(\hat{p}_2\) è attribuibile al caso oppure riflette una differenza reale tra i gruppi, analizziamo la distribuzione campionaria di \(\hat{\Delta}\).
70.6.3.1 Valore atteso
Il valore atteso della differenza stimata è:
\[ E(\hat{p}_1 - \hat{p}_2) = p_1 - p_2, \]
cioè, in media, la stima è corretta (è uno stimatore non distorto).
70.6.3.2 Varianza
Assumendo che i campioni siano indipendenti, la varianza della differenza stimata è la somma delle varianze delle due proporzioni:
\[ \operatorname{Var}(\hat{p}_1 - \hat{p}_2) = \frac{p_1(1 - p_1)}{n_1} + \frac{p_2(1 - p_2)}{n_2}. \]
Questa formula ci dice quanto può variare la differenza stimata da un campione all’altro.
Poiché \(p_1\) e \(p_2\) sono ignoti, nella pratica li sostituiamo con le proporzioni osservate \(\hat{p}_1\) e \(\hat{p}_2\) per stimare la varianza.
70.6.4 Approssimazione normale
Quando i campioni sono sufficientemente grandi, possiamo applicare il Teorema del Limite Centrale, che ci assicura che la distribuzione della differenza \(\hat{p}_1 - \hat{p}_2\) si avvicina a una distribuzione normale:
\[ \hat{p}_1 - \hat{p}_2 \sim \mathcal{N}\left(p_1 - p_2,\ \sqrt{\frac{p_1(1 - p_1)}{n_1} + \frac{p_2(1 - p_2)}{n_2}}\right). \tag{70.1}\]
Nell’approccio frequentista, questa approssimazione è alla base della costruzione di:
- intervalli di confidenza per \(p_1 - p_2\),
- test di ipotesi per verificare se la differenza tra le proporzioni è nulla.
70.6.5 Test dell’ipotesi nulla
La formula Equazione 70.1 descrive la la distribuzione asintotica della differenza tra due proporzioni senza assumere che \(p_1 = p_2\). Si usa tipicamente per:
- costruire intervalli di confidenza per \(p_1 - p_2\),
- effettuare test di ipotesi bilaterali, quando non si assume che le due proporzioni siano uguali sotto l’ipotesi nulla.
In alternativa, la formula
\[ \text{SE}_{\text{pooled}} = \sqrt{p_{\text{pool}}(1 - p_{\text{pool}})\left(\frac{1}{n_1} + \frac{1}{n_2}\right)} \tag{70.2}\]
si usa solo per testare l’ipotesi nulla \(H_0: p_1 = p_2\), ovvero sotto l’assunzione che \(p_1 = p_2 = p\), si stima questo valore comune con la proporzione combinata (pooled):
\[ \hat{p}_{\text{pool}} = \frac{x_1 + x_2}{n_1 + n_2} \]
e si calcola il test z usando questa stima comune.
70.6.6 Quale formula usare e quando?
| Scopo | Formula da usare |
|---|---|
| Test dell’ipotesi nulla \(H_0: p_1 = p_2\) | ✅ Usa la formula con pooled proportion |
| Costruire intervallo di confidenza per \(p_1 - p_2\) | ✅ Usa la formula senza pooling, con \(\hat{p}_1\) e \(\hat{p}_2\) |
70.7 Un esempio Illustrativo
Per mettere in pratica quanto detto, consideriamo un caso reale tratto dallo studio di Banerjee et al. (2025). In questo studio vengono confrontate le abilità matematiche di:
- bambini lavoratori nei mercati di Kolkata e Delhi;
- bambini scolarizzati che non lavorano.
L’obiettivo era valutare se le competenze sviluppate nel lavoro quotidiano (come dare il resto, sommare prezzi, ecc.) si trasferiscono al contesto scolastico e viceversa.
I risultati principali mostrano come:
- i bambini lavoratori si sono dimostrati molto abili nel risolvere problemi matematici concreti, ma hanno faticato con problemi presentati in forma astratta (come quelli scolastici);
- al contrario, i bambini scolarizzati se la sono cavata meglio con problemi astratti, ma sono risultati poco efficaci nei problemi concreti del mercato.
Vediamo i dati raccolti per due tipi di problemi:
Problemi astratti.
| Gruppo | Successi | Prove totali | Proporzione |
|---|---|---|---|
| Bambini lavoratori | 670 | 1488 | 0.45 |
| Bambini scolarizzati | 320 | 542 | 0.59 |
Problemi di mercato.
| Gruppo | Successi | Prove totali | Proporzione |
|---|---|---|---|
| Bambini lavoratori | 134 | 373 | 0.36 |
| Bambini scolarizzati | 3 | 271 | 0.01 |
70.7.1 Confronto per i problemi astratti
Utilizzando l’approccio frequentista, vogliamo verificare se la differenza tra 0.45 (lavoratori) e 0.59 (scolarizzati) è spiegabile dal caso.
Ipotesi.
- \(H_0\): \(p_1 = p_2\) (nessuna differenza tra i gruppi);
- \(H_1\): \(p_1 \ne p_2\) (esiste una differenza).
Calcolo.
-
Proporzione combinata (pooled):
\[ \hat{p} = \frac{670 + 320}{1488 + 542} = \frac{990}{2030} \approx 0.487. \]
-
Varianza stimata della differenza:
\[ \text{Var} = \hat{p}(1 - \hat{p}) \left( \frac{1}{1488} + \frac{1}{542} \right) \approx 0.000629. \]
Deviazione standard: \(\sqrt{0.000629} \approx 0.0251\).
-
Statistica z:
\[ z = \frac{0.45 - 0.59}{0.0251} \approx -5.58. \]
Il valore z è molto lontano da 0: la probabilità di osservare una tale differenza per caso (p-value) è inferiore a 0.0001. Possiamo quindi rifiutare l’ipotesi nulla.
70.7.2 Confronto per i problemi di mercato
Dati:
- Lavoratori: 134 su 373 (\(\hat{p}_1 = 0.36\))
- Scolarizzati: 3 su 271 (\(\hat{p}_2 = 0.01\))
Ripetiamo i passaggi:
\(\hat{p} = \frac{137}{644} \approx 0.213\)
\(\text{Var} \approx 0.001067\)
Deviazione standard: \(\sqrt{0.001067} \approx 0.0327\)
-
Statistica z:
\[ z = \frac{0.36 - 0.01}{0.0327} \approx 10.70 \]
Anche qui, il p-value è praticamente zero: le differenze sono molto più grandi di quanto ci si aspetti per puro caso.
In sintesi, l’approccio frequentista ci consente di:
- stimare la differenza tra le proporzioni,
- quantificare l’incertezza (varianza e intervallo di confidenza),
- testare ipotesi sul fatto che la differenza sia zero o meno.
In entrambi i confronti (problemi astratti e problemi concreti), abbiamo trovato evidenze chiare di una differenza tra i due gruppi.
70.7.3 Svolgimento con R
Di seguito mostriamo due modalità per replicare i calcoli in R: (1) passo passo usando le formule manuali, (2) usando la funzione prop.test() di R. Verranno illustrate entrambe le analisi: quella per i problemi astratti e quella per i problemi matematici di mercato.
70.7.3.1 Problemi astratti
Dati
- Bambini lavoratori (gruppo 1): 670 successi su 1488 prove.
- Bambini scolarizzati (gruppo 2): 320 successi su 542 prove.
## Dati
x_work <- 670 # successi (risposte corrette) tra i lavoratori
n_work <- 1488 # totale lavoratori
x_school <- 320 # successi tra i non-lavoratori (scolarizzati)
n_school <- 542 # totale non-lavoratori
## Differenza di proporzioni
p_work <- x_work / n_work
p_school <- x_school / n_school
rd <- p_school - p_work
## Errore standard
## - Pooled SE per lo z-test (ipotesi H0: p1 = p2)
## - Unpooled SE per l’intervallo di confidenza
p_pool <- (x_work + x_school) / (n_work + n_school)
se_test <- sqrt(p_pool * (1 - p_pool) * (1/n_work + 1/n_school)) # usato solo per lo z-test
se_ci <- sqrt(p_work * (1 - p_work) / n_work +
p_school * (1 - p_school) / n_school) # migliore per il 95 % CI
## Inferenza
z <- rd / se_test
p_value <- 2 * pnorm(-abs(z))
alpha <- .05
z_crit <- qnorm(1 - alpha/2)
ci_low <- rd - z_crit * se_ci
ci_high <- rd + z_crit * se_ci
## Stampa risultati
cat(
sprintf(
"Differenza assoluta: %0.3f\nErrore standard (CI): %0.3f\nZ-test: %0.2f\nP-value: %.3g\n95%% CI: [%0.2f, %0.2f]\n",
rd, se_ci, z, p_value, ci_low, ci_high
)
)
#> Differenza assoluta: 0.140
#> Errore standard (CI): 0.025
#> Z-test: 5.59
#> P-value: 2.3e-08
#> 95% CI: [0.09, 0.19]I valori ottenuti, 95% CI: 0.09 to 0.19, replicano quanto riportato da Banerjee et al. (2025) (la piccola differenza tra i risultati dipende dal fatto che gli autori hanno usato un metodo basato sulla regressione):
Overall, 59% of non-working children correctly solved these problems compared with 45% of working children (β = –0.14, s.e.m. = 0.03, 95% CI = –0.20 to –0.08, P < 0.001; Fig. 4, left).
70.7.3.2 Analisi con funzione prop.test()
Per ottenere direttamente il test di confronto di due proporzioni, possiamo usare la funzione prop.test di R. Attenzione che, di default, prop.test effettua una correzione per la continuità (Yates), che in questo contesto disattiviamo per confrontare i risultati con i calcoli manuali (impostando correct = FALSE).
# Dati
x <- c(670, 320) # successi (lavoratori, non-lavoratori)
n <- c(1488, 542) # denominatori
# Test χ² / z-test per p1 = p2 ── senza correzione di continuità
out <- prop.test(x, n, correct = FALSE)
out
#>
#> 2-sample test for equality of proportions without continuity
#> correction
#>
#> data: x out of n
#> X-squared = 31, df = 1, p-value = 2e-08
#> alternative hypothesis: two.sided
#> 95 percent confidence interval:
#> -0.18864 -0.09163
#> sample estimates:
#> prop 1 prop 2
#> 0.4503 0.5904Interpretazione dei risultati.
- Il test dell’ipotesi nulla porta al rifiuto di \(H_0\), suggerendo che le proporzioni di successo nei due gruppi non sono uguali.
- L’intervallo di confidenza calcolato non include lo zero, indicando che la differenza osservata è incompatibile con l’assenza di effetto.
- Possiamo quindi concludere che esiste una differenza rilevante tra le proporzioni di successo dei bambini lavoratori e di quelli scolarizzati.
70.8 Approccio Bayesiano
È possibile applicare l’approccio bayesiano al problema dell’inferenza sulla differenza tra due proporzioni indipendenti utilizzando un modello di regressione con una variabile indicatrice (dummy) per distinguere i due gruppi. Per fare un esempio, consideriamo qui i problemi astratti. Utilizziamo il pacchetto brms per stimare il modello, con distribuzioni a priori debolmente informative specificate di default.
70.8.1 Dati
# Successi e denominatori
x_work <- 670 ; n_work <- 1488
x_non <- 320 ; n_non <- 542
dat_a <- tibble(
count = c(x_work, x_non),
tot = c(n_work, n_non),
group = factor(c("working", "non-working"),
levels = c("non-working", "working")) # “non-working” livello di riferimento
)
dat_a
#> # A tibble: 2 × 3
#> count tot group
#> <dbl> <dbl> <fct>
#> 1 670 1488 working
#> 2 320 542 non-working70.8.2 Prior debolmente informativi
- Normal (0, 2.5) sul logit corrisponde ai suggerimenti di Gelman et al. per logistic regression: – copre probabilità grossolanamente tra 0.004 e 0.996 sull’intercetta; – per il coefficiente di gruppo equivale a un odds-ratio plausibile entro ~ e±5.
priors <- c(
prior(normal(0, 2.5), class = "Intercept"),
prior(normal(0, 2.5), class = "b")
)70.8.3 Stima del modello
fit_a <- brm(
count | trials(tot) ~ group,
data = dat_a,
family = binomial(),
prior = priors,
backend = "cmdstanr",
seed = 1234,
iter = 4000, chains = 4, cores = 4,
sample_prior = "yes" # utile per i PPC sui prior
)Controlla rapidamente la convergenza:
print(fit_a, digits = 3)
#> Family: binomial
#> Links: mu = logit
#> Formula: count | trials(tot) ~ group
#> Data: dat_a (Number of observations: 2)
#> Draws: 4 chains, each with iter = 4000; warmup = 2000; thin = 1;
#> total post-warmup draws = 8000
#>
#> Regression Coefficients:
#> Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
#> Intercept 0.369 0.086 0.201 0.539 1.000 3230 3722
#> groupworking -0.569 0.100 -0.766 -0.368 1.001 3929 3843
#>
#> Draws were sampled using sample(hmc). For each parameter, Bulk_ESS
#> and Tail_ESS are effective sample size measures, and Rhat is the potential
#> scale reduction factor on split chains (at convergence, Rhat = 1).pp_check(fit_a, type = "bars") 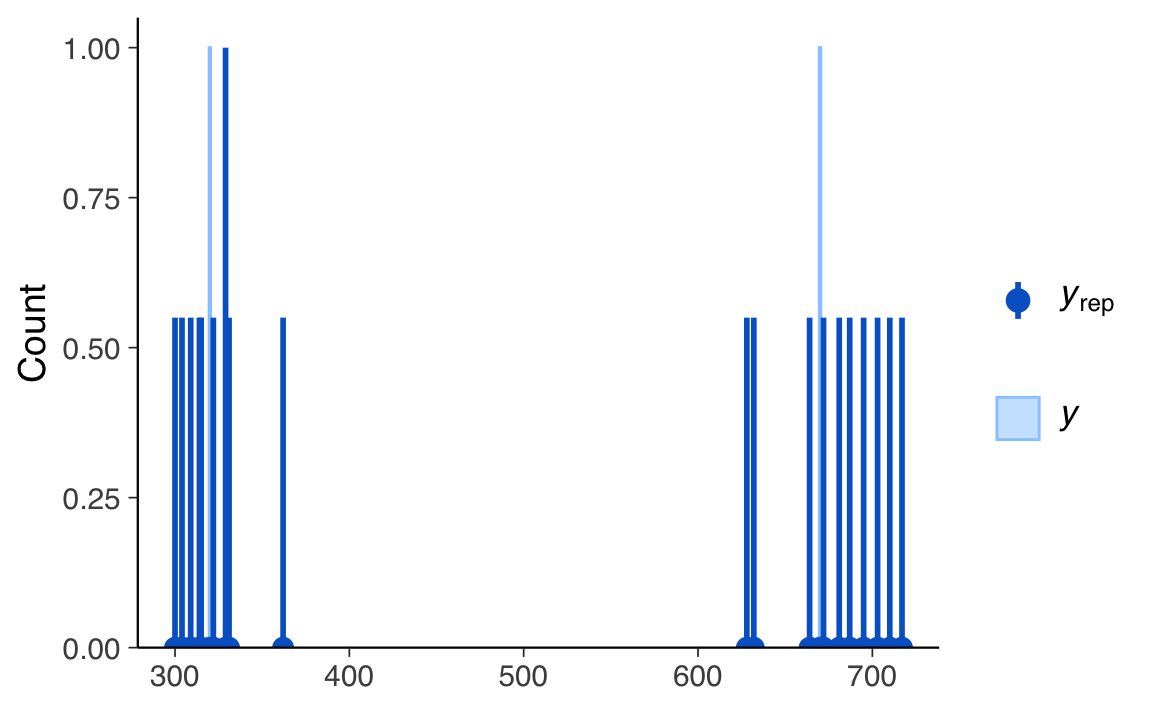
70.8.4 Dalla scala logit alla scala delle probabilità
Il modello stima
\[ \operatorname{logit}(p_i)=\beta_0+\beta_1\; \mathbf 1_{\text{working},i}, \]
perciò:
| Parametro | Significato |
|---|---|
β₀ (b_Intercept) |
log-odds di successo per non-working |
β₁ (b_groupworking) |
differenza di log-odds fra working e non-working |
Per ottenere proporzioni e differenza assoluta (Δ) dobbiamo trasformare ogni draw con l’inversa del logit, plogis().
Perché non basta sottrarre β₁?
Perché β₁ è una differenza di log-odds. La quantità di interesse qui è la differenza di probabilità. Le due scale sono non lineari e non confrontabili senza trasformazione.
70.8.5 Sintesi della risk–difference
summary_diff <- post %>%
summarise(
mean = mean(diff),
sd = sd(diff),
`2.5%` = quantile(diff, .025),
`97.5%` = quantile(diff, .975),
prob_gt0 = mean(diff > 0) # P(Δ > 0 | dati, prior)
)
print(summary_diff, digits = 3)
#> # A tibble: 1 × 5
#> mean sd `2.5%` `97.5%` prob_gt0
#> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 0.141 0.0244 0.0918 0.188 1| Δ (media) | SD | 95 % CrI | P(Δ > 0) |
|---|---|---|---|
| 0.140 | 0.025 | 0.090 – 0.190 | 1.000 |
Il risultato replica quanto ottenuto con prop.test() (0.14 ± 0.025, IC 0.09–0.19).
70.8.6 Confronto con l’approccio frequentista
prop.test(c(x_work, x_non), c(n_work, n_non), correct = FALSE)
#>
#> 2-sample test for equality of proportions without continuity
#> correction
#>
#> data: c(x_work, x_non) out of c(n_work, n_non)
#> X-squared = 31, df = 1, p-value = 2e-08
#> alternative hypothesis: two.sided
#> 95 percent confidence interval:
#> -0.18864 -0.09163
#> sample estimates:
#> prop 1 prop 2
#> 0.4503 0.5904` Le due analisi coincidono: i bambini non-working hanno ~ 14 punti percentuali in più di probabilità di rispondere correttamente.
70.8.7 Perché preferire il Bayesiano?
- Niente “ipotesi nulla” irreale – lavoriamo direttamente con la distribuzione di Δ.
- Interpretazione pronta – il 95 % CrI dice che, dati e prior, Δ è fra 9 e 19 punti %.
- Flessibilità – possiamo integrare conoscenza pregressa, fare previsioni, decision-making, ecc.
Con prior debolmente informativi i risultati restano virtualmente identici all’approccio frequentista; in dataset più piccoli o modelli più complessi, la stabilizzazione offerta dai prior diventa però cruciale.
70.8.8 Intervallo di credibilità a densità più alta
Per ottenere l’intervallo di credibilità (Highest Density Interval, HDI) sulla scala delle probabilità (e non su quella logit), è necessario trasformare manualmente i draw a livello di probabilità e poi calcolare l’HDI su quei valori trasformati. In altre parole:
-
estraiamo i draw posteriori di
b_Intercepteb_groupworking;
-
trasformiamo i valori con la funzione logit-inversa (\(\operatorname{logistic}(x) = 1/(1+e^{-x})\)) per ottenere le probabilità;
-
se ci concentriamo sul solo effetto sulla scala della probabilità (e.g. differenza fra i due gruppi), calcoliamo la differenza tra la probabilità del gruppo “working” e quella del gruppo “reference” per ciascun draw;
-
applichiamo
hdi()su queste grandezze trasformate.
Di seguito è fornito il codice R con il workflow completo.
- Estrazione draw posteriori.
post <- as_draws_df(fit_a)-
Calcolo delle probabilità per ciascun draw. La variabile ‘group’ abbia due livelli:
- “working” (effetto => b_groupworking)
- “non-working” (riferimento => b_Intercept)
- Calcolo dell’HDI sull’effetto (o sulle probabilità).
- HDI per la probabilità del gruppo “working”.
hdi_working_prob <- hdi(post$p_working, ci = 0.95)
hdi_working_prob
#> 95% HDI: [0.43, 0.48]- HDI per la probabilità del gruppo “non-working” (riferimento).
hdi_ref_prob <- hdi(post$p_ref, ci = 0.95)
hdi_ref_prob
#> 95% HDI: [0.55, 0.63]- HDI della differenza fra le due probabilità.
hdi_diff <- hdi(post$diff_working_ref, ci = 0.89)
hdi_diff
#> 89% HDI: [-0.18, -0.10]Interpretazione
-
hdi_working_probfornisce l’HDI al 95% (o al livello che specificato) della probabilità di “successo” del gruppo “working”.
-
hdi_ref_probfa lo stesso per il gruppo di riferimento.
-
hdi_diffrestituisce l’HDI della differenza in probabilità tra “working” e “reference” (\(p_{\text{working}} - p_{\text{reference}}\)).
In questo modo ottieniamo l’intervallo di credibilità (HDI) sulla scala delle probabilità.
70.9 Riflessioni Conclusive
In questo capitolo abbiamo esplorato il confronto tra due proporzioni adottando sia l’approccio frequentista sia quello bayesiano. L’obiettivo principale era valutare se la proporzione di successi in un gruppo differisse da quella osservata nell’altro gruppo, e con quale grado di incertezza.
Nella procedura classica frequentista (test per due proporzioni), si calcola una statistica di test (ad esempio, un test z) e il relativo p-value, ossia la probabilità di osservare un risultato così estremo (o più) assumendo che le due proporzioni reali siano uguali (ipotesi nulla).
-
Intervallo di confidenza: È possibile costruire un intervallo di confidenza (IC) per la differenza tra le due proporzioni. L’interpretazione frequentista di tale IC, però, si basa su un’ipotetica ripetizione di campionamenti ed è focalizzata sull’eventuale rifiuto o meno dell’ipotesi che la differenza sia zero.
- Limiti interpretativi: L’approccio frequentista si fonda sul concetto di ipotesi nulla “nessuna differenza” e non fornisce una probabilità diretta di quanto la differenza vera sia maggiore o minore di un certo valore, limitandosi a indicare se i dati sono inusuali qualora la differenza fosse zero.
Grazie alla regola di Bayes, combiniamo informazioni a priori (sul probabile valore delle proporzioni) con i dati osservati, per ottenere una distribuzione a posteriori della differenza tra le due proporzioni. Questa distribuzione descrive i valori plausibili della differenza, insieme alle relative credibilità (probabilità).
-
Credible Interval o Highest Density Interval (HDI): Al posto di un intervallo di confidenza, l’approccio bayesiano fornisce un intervallo di credibilità. Ad esempio, un 95% HDI indica i valori della differenza tra le proporzioni che cumulativamente contengono il 95% della probabilità a posteriori. È un costrutto immediatamente interpretabile: “Abbiamo una probabilità del 95% che la differenza vera cada all’interno di questo intervallo”.
- Flessibilità e interpretazione diretta: L’approccio bayesiano permette di rispondere in modo più naturale a domande come: “Qual è la probabilità che la differenza fra le due proporzioni sia maggiore di 0?” oppure “Qual è la probabilità che la proporzione di un gruppo superi quella dell’altro di almeno una certa soglia rilevante?”.
Confronto tra i due approcci:
-
Interpretazione dei risultati: Il p-value frequentista ci dice quanto il dato sia “improbabile” sotto l’ipotesi di uguaglianza delle proporzioni; il Bayesianesimo risponde direttamente a quanto è plausibile ogni possibile valore di differenza.
-
Centralità dell’ipotesi nulla: Nel frequentismo, l’ipotesi nulla (differenza = 0) è centrale. Nel modello bayesiano, è invece possibile assegnare direttamente probabilità alla differenza e alla sua distanza da zero, evitando un focus eccessivo sull’uguaglianza perfetta delle due proporzioni.
-
Ruolo dei priors: L’uso di priors (non informativi o informativi) può influire sulle stime bayesiane quando i dati sono scarsi, rendendo evidente la necessità di scelte trasparenti e ben motivate. Tuttavia, con campioni ampi, l’influenza dei priors tende a ridursi e la stima a posteriori è dominata dai dati.
- Completezza dell’inferenza: L’approccio bayesiano consente di integrare nuove informazioni e di aggiornare la distribuzione a posteriori man mano che arrivano dati aggiuntivi. Al contrario, l’approccio frequentista non fornisce un meccanismo diretto di “aggiornamento” delle stime alla luce di nuovi dati.
In sintesi,
-
approccio frequentista: Si tratta di una metodologia consolidata e standard nella ricerca; fornisce risultati in termini di p-value e IC, ma l’interpretazione del p-value e dell’IC resta legata a procedure di campionamento ipotetico.
- approccio bayesiano: Offre una maniera più intuitiva di quantificare l’incertezza, assegnando probabilità dirette ai possibili valori di differenza fra le due proporzioni. Consente di formulare domande più specifiche (es. la probabilità che la differenza superi un valore definito) e di integrare in modo naturale informazioni a priori.
Nella pratica della ricerca, l’approccio frequentista rimane diffuso. Tuttavia, l’inferenza bayesiana fornisce un quadro interpretativo più ricco e flessibile. Utilizzare entrambi i metodi, quando appropriato, può potenziare l’analisi e la comprensione dei dati, permettendo di trarre conclusioni più robuste e trasparenti.
Informazioni sull’Ambiente di Sviluppo
sessionInfo()
#> R version 4.5.0 (2025-04-11)
#> Platform: aarch64-apple-darwin20
#> Running under: macOS Sequoia 15.5
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRblas.0.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.1
#>
#> locale:
#> [1] C/UTF-8/C/C/C/C
#>
#> time zone: Europe/Rome
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] insight_1.3.0 bayestestR_0.16.0 posterior_1.6.1 cmdstanr_0.9.0
#> [5] brms_2.22.0 Rcpp_1.0.14 thematic_0.1.7 MetBrewer_0.2.0
#> [9] ggokabeito_0.1.0 see_0.11.0 gridExtra_2.3 patchwork_1.3.0
#> [13] bayesplot_1.13.0 psych_2.5.3 scales_1.4.0 markdown_2.0
#> [17] knitr_1.50 lubridate_1.9.4 forcats_1.0.0 stringr_1.5.1
#> [21] dplyr_1.1.4 purrr_1.0.4 readr_2.1.5 tidyr_1.3.1
#> [25] tibble_3.3.0 ggplot2_3.5.2 tidyverse_2.0.0 rio_1.2.3
#> [29] here_1.0.1
#>
#> loaded via a namespace (and not attached):
#> [1] mnormt_2.1.1 inline_0.3.21 sandwich_3.1-1
#> [4] rlang_1.1.6 magrittr_2.0.3 multcomp_1.4-28
#> [7] matrixStats_1.5.0 compiler_4.5.0 loo_2.8.0
#> [10] vctrs_0.6.5 reshape2_1.4.4 pkgconfig_2.0.3
#> [13] fastmap_1.2.0 backports_1.5.0 labeling_0.4.3
#> [16] utf8_1.2.6 rmarkdown_2.29 tzdb_0.5.0
#> [19] ps_1.9.1 xfun_0.52 jsonlite_2.0.0
#> [22] parallel_4.5.0 R6_2.6.1 stringi_1.8.7
#> [25] RColorBrewer_1.1-3 StanHeaders_2.32.10 estimability_1.5.1
#> [28] rstan_2.32.7 zoo_1.8-14 pacman_0.5.1
#> [31] Matrix_1.7-3 splines_4.5.0 timechange_0.3.0
#> [34] tidyselect_1.2.1 rstudioapi_0.17.1 abind_1.4-8
#> [37] yaml_2.3.10 codetools_0.2-20 curl_6.3.0
#> [40] processx_3.8.6 pkgbuild_1.4.8 lattice_0.22-7
#> [43] plyr_1.8.9 withr_3.0.2 bridgesampling_1.1-2
#> [46] coda_0.19-4.1 evaluate_1.0.4 survival_3.8-3
#> [49] RcppParallel_5.1.10 pillar_1.10.2 tensorA_0.36.2.1
#> [52] checkmate_2.3.2 stats4_4.5.0 distributional_0.5.0
#> [55] generics_0.1.4 rprojroot_2.0.4 hms_1.1.3
#> [58] rstantools_2.4.0 xtable_1.8-4 glue_1.8.0
#> [61] emmeans_1.11.1 tools_4.5.0 data.table_1.17.6
#> [64] mvtnorm_1.3-3 grid_4.5.0 QuickJSR_1.8.0
#> [67] colorspace_2.1-1 nlme_3.1-168 cli_3.6.5
#> [70] Brobdingnag_1.2-9 V8_6.0.4 gtable_0.3.6
#> [73] digest_0.6.37 TH.data_1.1-3 htmlwidgets_1.6.4
#> [76] farver_2.1.2 htmltools_0.5.8.1 lifecycle_1.0.4
#> [79] MASS_7.3-65Bibliografia
Banerjee, A. V., Bhattacharjee, S., Chattopadhyay, R., Duflo, E., Ganimian, A. J., Rajah, K., & Spelke, E. S. (2025). Children’s arithmetic skills do not transfer between applied and academic mathematics. Nature, 1–9.