20 Flusso di lavoro bayesiano
“Bayesian data analysis is not a set of methods but a way of thinking: building models, checking them, and learning from the misfits.”
— Andrew Gelman, Bayesian Data Analysis (2013)
Introduzione
Abbiamo ormai gli strumenti fondamentali per affrontare l’inferenza bayesiana in contesti realistici. Abbiamo visto che, nei casi semplici, l’aggiornamento può essere calcolato analiticamente, ma che già con pochi parametri questo diventa impraticabile. Abbiamo introdotto l’algoritmo di Metropolis, che ci ha mostrato come sia sempre possibile campionare dalla distribuzione a posteriori, e poi abbiamo visto come i linguaggi probabilistici – e in particolare Stan – rendano questa possibilità accessibile e utilizzabile nella ricerca psicologica.
Ora, però, dobbiamo fare un passo ulteriore. Avere strumenti di calcolo non basta: serve un metodo di lavoro. L’inferenza bayesiana non è soltanto una formula o un algoritmo, ma un processo che accompagna il ricercatore dall’ideazione del modello fino alla comunicazione dei risultati. Questo processo prende il nome di workflow bayesiano.
20.1 Un processo iterativo
Il workflow bayesiano non è lineare, ma iterativo. Inizia con la formulazione di un modello, procede con l’analisi dei dati e la valutazione dei risultati, ma spesso richiede di tornare indietro, rivedere le ipotesi e migliorare le specifiche. A differenza dell’approccio frequentista tradizionale, che tende a concentrarsi solo sull’output numerico finale (ad esempio un p-value), l’approccio bayesiano incoraggia una riflessione costante sul legame tra teoria, modello e dati.
L’idea centrale è che ogni modello è un’ipotesi sul processo generativo che ha prodotto i dati. Il compito del ricercatore non è solo stimare parametri, ma verificare se il modello che li definisce è coerente con ciò che sappiamo e con ciò che osserviamo.
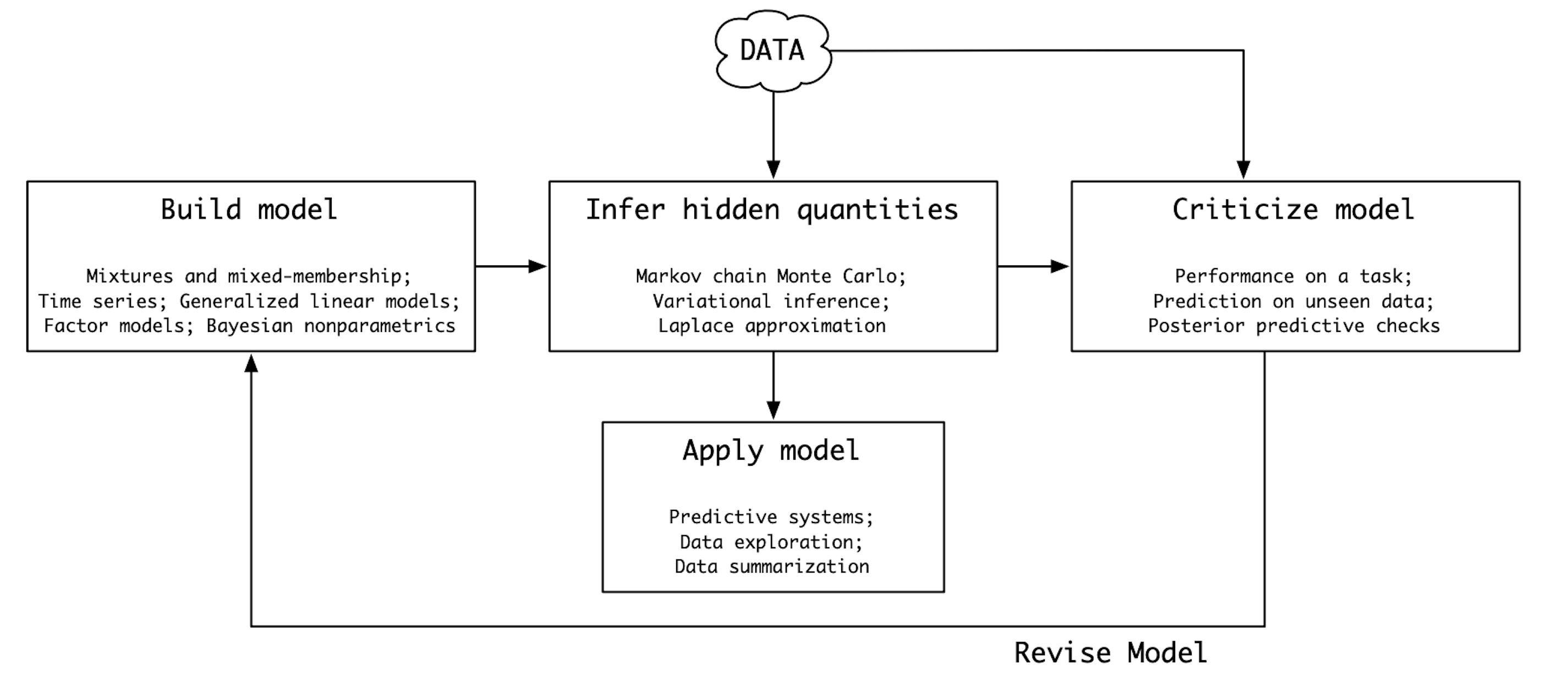
20.2 Le fasi del workflow
Il workflow può essere schematizzato in tre momenti principali, che però nella pratica si intrecciano continuamente.
1. Definizione del modello Il punto di partenza è sempre la teoria o l’ipotesi psicologica che vogliamo testare. In questa fase traduciamo le nostre idee in un modello probabilistico: definiamo i parametri, scegliamo i priori, specifichiamo la verosimiglianza. È il momento in cui ci chiediamo: quale processo potrebbe aver generato i dati che osserviamo?
2. Inferenza e stima Una volta definito il modello, utilizziamo strumenti come Stan per ottenere campioni dalla distribuzione a posteriori. Questa fase include la verifica tecnica del campionamento (convergenza delle catene, numero effettivo di campioni indipendenti, diagnosi di autocorrelazione). È qui che la potenza degli algoritmi MCMC diventa essenziale, perché ci permette di trattare modelli complessi senza dover ricorrere a semplificazioni eccessive.
3. Valutazione del modello Il passo successivo è chiederci se il modello “funziona”. Ciò significa, da un lato, confrontare le predizioni del modello con i dati osservati (posterior predictive checks) e, dall’altro, valutare la capacità del modello di generalizzare a nuovi dati (ad esempio tramite LOO-CV ed ELPD). La valutazione non è mai l’ultima parola, ma una guida per decidere se mantenere, modificare o sostituire il modello.
20.3 Una prospettiva cumulativa
Il workflow bayesiano ci ricorda che la scienza non procede per verità definitive, ma per modelli progressivamente migliori. Ogni modello è un passo in un percorso cumulativo, in cui le ipotesi vengono testate, confrontate e, se necessario, abbandonate.
Dal punto di vista della psicologia, questo approccio rappresenta una risposta concreta alla crisi di replicazione. Non ci limitiamo a verificare associazioni statistiche, ma costruiamo modelli espliciti dei processi psicologici, li testiamo sui dati e li confrontiamo in termini di capacità predittiva. È un metodo che promuove trasparenza, apertura alla revisione e cumulatività, tutti elementi essenziali per rafforzare le basi empiriche della disciplina.
Riflessioni conclusive
Con il workflow bayesiano abbiamo completato il nostro percorso introduttivo all’inferenza bayesiana. Abbiamo visto che non si tratta solo di imparare un nuovo insieme di tecniche, ma di adottare una prospettiva diversa sul rapporto tra teoria, dati e analisi statistica.
Il valore di questo approccio non sta soltanto nei dettagli tecnici, ma nel modo in cui ci spinge a pensare: ogni modello è un’ipotesi esplicita, ogni analisi è trasparente e riproducibile, ogni risultato è accompagnato da una valutazione critica della sua incertezza e della sua plausibilità.
Nei capitoli successivi vedremo come applicare questi principi a casi specifici e a modelli più articolati. Il workflow bayesiano rimarrà il filo conduttore: un metodo iterativo e riflessivo che ci guida nel costruire conoscenza scientifica solida, cumulativa e capace di rispondere alle sfide della psicologia contemporanea.