here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(mice)5 Distribuzioni coniugate
“Conjugate families are not chosen because they are realistic, but because they allow us to see the Bayesian machinery at work in its simplest form.”
– Morris H. DeGrootx, Optimal Statistical Decisions (1970)
Introduzione
Nei capitoli precedenti abbiamo visto in azione l’aggiornamento bayesiano in un caso concreto: la stima della proporzione di successi con il modello Beta-Binomiale. Lì abbiamo osservato come la distribuzione a priori (Beta) e la verosimiglianza (Binomiale) si combinino attraverso il teorema di Bayes per produrre una distribuzione a posteriori che appartiene alla stessa famiglia della prior. Questo ci ha permesso di seguire passo dopo passo l’evoluzione delle nostre credenze in modo intuitivo e matematicamente elegante.
In questo capitolo generalizziamo questa idea e introduciamo il concetto di distribuzioni coniugate. Due distribuzioni sono dette coniugate quando, combinando una prior con la corrispondente verosimiglianza, otteniamo un posterior che appartiene alla stessa famiglia della prior. In altre parole, la forma della distribuzione rimane stabile, e a cambiare sono soltanto i parametri.
Questa proprietà, apparentemente tecnica, ha in realtà un grande valore didattico e pratico. Dal punto di vista concettuale, ci aiuta a visualizzare con chiarezza come i dati modifichino le nostre credenze: i parametri della distribuzione si aggiornano in modo diretto e cumulativo. Dal punto di vista operativo, rende il calcolo immediato, senza dover ricorrere a metodi di approssimazione numerica.
Naturalmente, sappiamo già dai capitoli precedenti che il mondo reale è spesso più complesso: non sempre abbiamo a disposizione una coppia coniugata, e per modelli più articolati ricorriamo a metodi computazionali come il campionamento MCMC. Ma prima di affrontare quei casi, è utile familiarizzare con le famiglie coniugate, che costituiscono il laboratorio ideale per comprendere a fondo la logica dell’aggiornamento bayesiano.
Panoramica del capitolo
- Introduzione del modello beta-binomiale.
- Analisi della distribuzione Beta e del suo ruolo come distribuzione a priori.
- Aescrizione del processo di aggiornamento bayesiano e dei vantaggi derivanti dall’uso di distribuzioni coniugate.
5.1 Il modello Beta-Binomiale
Il modello beta-binomiale è un esempio classico per analizzare una proporzione \(\theta\), ossia la probabilità di successo in una sequenza di prove binarie (ad esempio, successo/fallimento). Supponiamo di osservare \(y\) successi su \(n\) prove, dove ogni prova è indipendente e con la stessa probabilità di successo \(\theta\), che appartiene all’intervallo \([0,1]\).
La funzione di verosimiglianza, basata sulla distribuzione binomiale, è espressa come:
\[ \mathcal{Binomial}(y \mid n, \theta) = \binom{n}{y} \theta^y (1 - \theta)^{n - y}, \] dove \(\binom{n}{y}\) è il coefficiente binomiale che conta il numero di modi in cui \(y\) successi possono verificarsi in \(n\) prove.
Per modellare la nostra conoscenza preliminare su \(\theta\), scegliamo una distribuzione a priori Beta, che rappresenta un’ampia gamma di credenze iniziali con parametri flessibili.
5.2 La distribuzione Beta
La distribuzione Beta è definita come:
\[ \mathcal{Beta}(\theta \mid \alpha, \beta) = \frac{1}{B(\alpha, \beta)} \theta^{\alpha - 1} (1 - \theta)^{\beta - 1}, \quad \text{con } \theta \in (0, 1), \] dove:
\(\alpha > 0\) e \(\beta > 0\) sono i parametri che determinano la forma della distribuzione,
-
\(B(\alpha, \beta)\) è la funzione Beta di Eulero, calcolata come:
\[ B(\alpha, \beta) = \frac{\Gamma(\alpha)\Gamma(\beta)}{\Gamma(\alpha + \beta)}, \]
dove \(\Gamma(x)\) è la funzione Gamma, una generalizzazione del fattoriale.
In termini bayesiani, possiamo pensare a questi parametri nel modo seguente:
- \(\alpha -1\) rappresenta il numero ipotetico di “successi” a priori,
- \(\beta -1\) rappresenta il numero ipotetico di “fallimenti” a priori.
Ad esempio:
- una distribuzione Beta(1, 1) è uniforme (0 successi a priori e 0 fallimenti), indicando totale incertezza iniziale (assenza di credenze informate);
- una distribuzione Beta(10, 20) rappresenta una conoscenza a priori basata su 9 successi e 19 fallimenti ipotizzati, indicando una convinzione iniziale relativamente solida, poiché deriva da un totale di 28 osservazioni virtuali che riflettono le nostre credenze precedenti.
Questa interpretazione consente di calibrare le credenze a priori in base all’evidenza disponibile o alla fiducia nella stima.
La distribuzione Beta è estremamente versatile:
- valori diversi di \(\alpha\) e \(\beta\) producono distribuzioni simmetriche, asimmetriche o uniformi;
- valori elevati di \(\alpha\) e \(\beta\) riducono la varianza, riflettendo credenze più forti.
Questa flessibilità rende la distribuzione Beta una scelta ideale per rappresentare credenze iniziali sulle proporzioni.
5.3 Aggiornamento bayesiano
L’aggiornamento bayesiano combina le informazioni iniziali (distribuzione a priori) con i dati osservati (verosimiglianza) per produrre una nuova distribuzione delle nostre credenze (distribuzione a posteriori). Nel caso del modello beta-binomiale, questo processo è particolarmente semplice grazie alla “coniugazione”: il prior Beta e la verosimiglianza Binomiale producono una distribuzione a posteriori che appartiene ancora alla famiglia Beta.
Teorema 5.1 Sia \(Y\sim\mathrm{Binomial}(n,\theta)\) il numero di successi \(y\) in \(n\) prove indipendenti con probabilità di successo \(\theta\), e sia la nostra distribuzione a priori su \(\theta\) una Beta\(\bigl(\alpha,\beta\bigr).\) Allora la distribuzione a posteriori di \(\theta\) dato l’osservazione \(Y=y\) è
\[ \theta \mid Y=y \;\sim\; \mathrm{Beta}\bigl(\alpha + y,\;\beta + (n - y)\bigr), \tag{5.1}\] ovvero i parametri si aggiornano come
\[ \alpha' = \alpha + y, \quad \beta' = \beta + n - y. \tag{5.2}\]
5.3.1 Vantaggi del modello Beta-Binomiale
- Semplicità analitica: la coniugatezza della distribuzione Beta-Binomiale semplifica i calcoli, rendendo immediato l’aggiornamento dei parametri.
- Interpretazione intuitiva: l’aggiornamento dei parametri \(\alpha\) e \(\beta\) mostra in modo trasparente come i dati influenzino le credenze.
In sintesi, il modello Beta-Binomiale è un esempio didattico fondamentale per comprendere l’inferenza bayesiana e rappresenta un punto di partenza ideale per approcci più avanzati.
NotaEsercizio 1.
Nel Capitolo 4 abbiamo utilizzato il metodo basato su griglia per determinare la distribuzione a posteriori nel caso di \(y = 6\) successi su \(n = 9\) prove (vedi anche McElreath, 2020 per una discussione dettagliata). Ora esploriamo un approccio alternativo, sfruttando le proprietà delle famiglie coniugate.
La verosimiglianza binomiale per questo esperimento è espressa dalla seguente funzione:
\[ \mathcal{L}(\theta) \propto \theta^y (1-\theta)^{n-y}, \] dove \(y = 6\) rappresenta il numero di successi e \(n = 9\) il numero totale di prove.
Scegliendo una distribuzione a priori Beta con parametri \(\alpha = 2\) e \(\beta = 5\), possiamo applicare il teorema di Bayes per calcolare i parametri aggiornati della distribuzione a posteriori. In base alla regola di aggiornamento per distribuzioni coniugate, otteniamo:
\[ \alpha' = \alpha + y = 2 + 6 = 8. \] \[ \beta' = \beta + n - y = 5 + 9 - 6 = 8. \] La distribuzione a posteriori risultante è quindi una distribuzione Beta con parametri \(\mathcal{Beta}(8, 8)\).
Procediamo ora a visualizzare le tre distribuzioni rilevanti:
- Distribuzione a priori: \(\mathcal{Beta}(2, 2)\),
- Verosimiglianza binomiale: per \(y = 6\) e \(n = 9\),
- Distribuzione a posteriori: \(\text{Beta}(8, 5)\).
Ecco il codice R per generare il grafico comparativo:
# Definizione dei parametri
alpha_prior <- 2
beta_prior <- 5
y <- 6
n <- 9
# Parametri della distribuzione a posteriori
alpha_post <- alpha_prior + y
beta_post <- beta_prior + n - y
# Sequenza di valori di theta
theta <- seq(0, 1, length.out = 1000)
# Calcolo delle PDF
prior_pdf <- dbeta(theta, shape1 = alpha_prior, shape2 = beta_prior)
likelihood <- theta^y * (1 - theta)^(n - y)
# Normalizzazione della verosimiglianza
likelihood_integral <- sum(likelihood) * (theta[2] - theta[1])
normalized_likelihood <- likelihood / likelihood_integral
posterior_pdf <- dbeta(theta, shape1 = alpha_post, shape2 = beta_post)
# Creare un dataframe contenente i dati per il grafico
df <- data.frame(
theta = rep(theta, 3),
densita = c(prior_pdf, normalized_likelihood, posterior_pdf),
distribuzione = rep(c("Prior", "Likelihood", "Posterior"), each = length(theta))
)
# Creare il grafico
ggplot(df, aes(x = theta, y = densita, color = distribuzione)) +
geom_line(size = 1) + # Aggiungere le linee per le distribuzioni
scale_color_manual(values = c("Prior" = "blue", "Likelihood" = "green", "Posterior" = "red")) + # Assegnare i colori
labs(title = "Distribuzioni Prior, Likelihood e Posterior",
x = expression(theta),
y = "Densità",
color = "Distribuzione") + # Aggiungere titoli e label
theme(legend.position = "top") # Posizionare la legenda in alto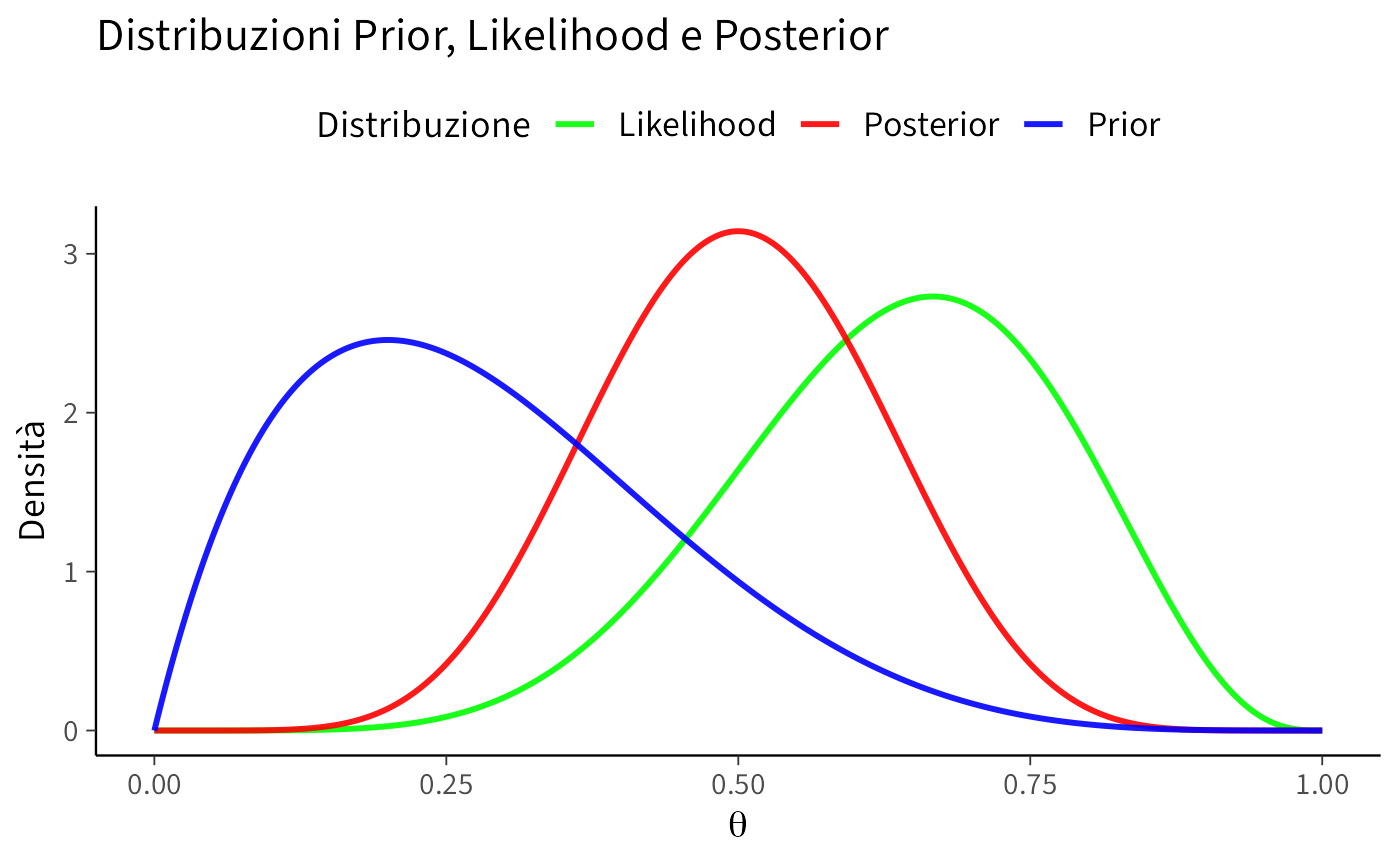
-
Curva blu: Prior \(\mathcal{Beta}(2, 5)\), che riflette le credenze iniziali prima dell’osservazione dei dati.
-
Curva verde: Likelihood (normalizzata), rappresenta l’evidenza fornita dai dati osservati.
- Curva rossa: Posterior \(\mathcal{Beta}(8, 8)\), risultato dell’aggiornamento bayesiano che combina prior e likelihood.
Nota sulla normalizzazione della verosimiglianza. La verosimiglianza binomiale non è una distribuzione di probabilità (il suo integrale non è pari a 1). Per rappresentarla visivamente accanto alla distribuzione a priori e a quella a posteriori, è necessario normalizzarla. Questo è fatto calcolando il suo integrale su \(\theta \in [0, 1]\) e dividendo la funzione per il risultato. La normalizzazione serve solo per la visualizzazione e non influisce sui calcoli analitici.
NotaEsercizio 2.
Esaminiamo ora un esempio discuso da Johnson et al. (2022). In uno studio molto famoso, Stanley Milgram ha studiato la propensione delle persone a obbedire agli ordini delle figure di autorità, anche quando tali ordini potrebbero danneggiare altre persone (Milgram 1963). Nell’articolo, Milgram descrive lo studio come
consistente nell’ordinare a un soggetto ingenuo di somministrare una scossa elettrica a una vittima. Viene utilizzato un generatore di scosse simulato, con 30 livelli di tensione chiaramente contrassegnati che vanno da IS a 450 volt. Lo strumento porta delle designazioni verbali che vanno da Scossa Lieve a Pericolo: Scossa Grave. Le risposte della vittima, che è un complice addestrato dell’esperimentatore, sono standardizzate. Gli ordini di somministrare scosse vengono dati al soggetto ingenuo nel contesto di un ‘esperimento di apprendimento’ apparentemente organizzato per studiare gli effetti della punizione sulla memoria. Man mano che l’esperimento procede, al soggetto ingenuo viene ordinato di somministrare scosse sempre più intense alla vittima, fino al punto di raggiungere il livello contrassegnato Pericolo: Scossa Grave.
In altre parole, ai partecipanti allo studio veniva dato il compito di testare un altro partecipante (che in realtà era un attore addestrato) sulla loro capacità di memorizzare una serie di item. Se l’attore non ricordava un item, al partecipante veniva ordinato di somministrare una scossa all’attore e di aumentare il livello della scossa con ogni fallimento successivo. I partecipanti non erano consapevoli del fatto che le scosse fossero finte e che l’attore stesse solo fingendo di provare dolore dalla scossa.
Nello studio di Milgram, 26 partecipanti su 40 hanno somministrato scosse al livello “Pericolo: Scossa Grave”. Il problema richiede di costruire la distribuzione a posteriori della probabilità \(\theta\) di infliggere una scossa a l livello “Pericolo: Scossa Grave”, ipotizzando che uno studio precedente aveva stabilito che \(\theta\) segue una distribuzione Beta(1, 10).
Iniziamo a fornire una rappresentazione grafica della distribuzione a priori.
# Impostazione dei parametri della distribuzione Beta
alpha <- 1
beta_val <- 10
# Creazione di valori x per il plot
x_values <- seq(0, 1, length.out = 1000)
# Calcolo della densità di probabilità per ogni valore di x
beta_pdf <- dbeta(x_values, shape1 = alpha, shape2 = beta_val)
# Creare un dataframe contenente i dati per il grafico
df <- data.frame(
x = x_values,
densita = beta_pdf
)
# Creare il grafico
ggplot(df, aes(x = x, y = densita)) +
geom_line(color = "#b97c7c", size = 1) + # Aggiungere la linea per la densità
labs(title = "Distribuzione Beta(1, 10)", # Aggiungere il titolo
x = "x", # Label dell'asse x
y = "Densità di probabilità") + # Label dell'asse y
theme(plot.title = element_text(hjust = 0.5)) + # Centrare il titolo
geom_vline(xintercept = 0, color = "black", linetype = "dashed", size = 0.5) + # Linea verticale opzionale
geom_vline(xintercept = 1, color = "black", linetype = "dashed", size = 0.5) + # Linea verticale opzionale
annotate("text", x = 0.8, y = max(beta_pdf) * 0.9, label = "Beta(1, 10)", color = "#b97c7c", size = 5) # Aggiungere una legenda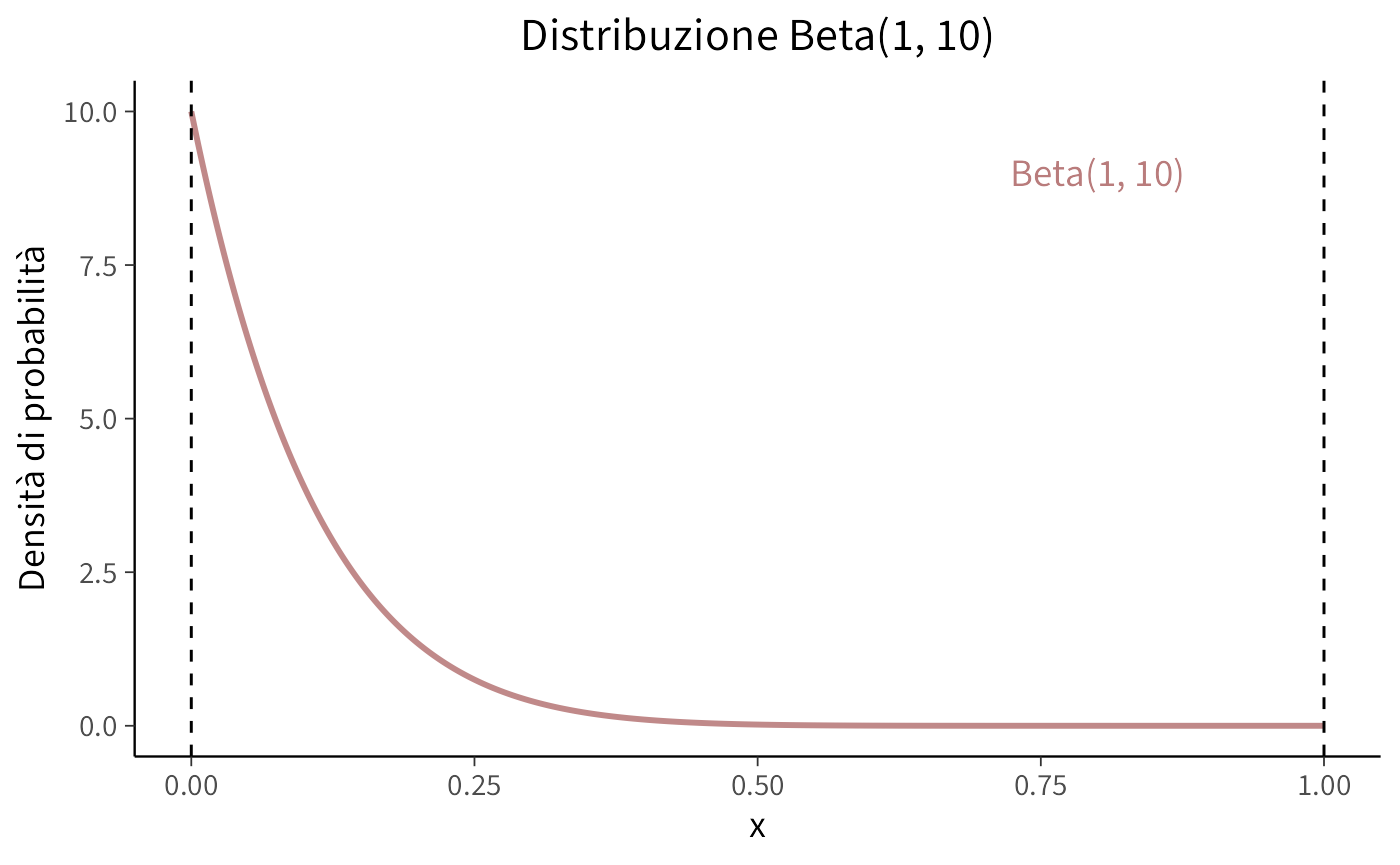
La distribuzione a posteriori segue una distribuzione Beta con parametri aggiornati:
y <- 26
n <- 40
alpha_prior <- 1
beta_prior <- 10
alpha_post <- alpha_prior + y
beta_post <- beta_prior + n - y
alpha_post
#> [1] 27
beta_post
#> [1] 24Creazione di un grafico per la distribuzione a posteriori:
# Creazione di valori x per il plot
x_values <- seq(0, 1, length.out = 1000)
# Calcolo della densità di probabilità per ogni valore di x
beta_pdf <- dbeta(x_values, alpha_post, beta_post)
# Creare un dataframe contenente i dati per il grafico
df <- data.frame(
theta = x_values,
densita = beta_pdf
)
# Creare il grafico con ggplot2
ggplot(df, aes(x = theta, y = densita)) +
geom_line(color = "blue", size = 1) + # Aggiungere la linea per la densità
labs(title = "Distribuzione Beta(27, 24)", # Aggiungere il titolo
x = expression(theta), # Label dell'asse x usando espressioni matematiche
y = "Densità di probabilità") + # Label dell'asse y
theme(plot.title = element_text(hjust = 0.5)) + # Centrare il titolo
annotate("text", x = 0.8, y = max(beta_pdf) * 0.9, label = "Beta(27, 24)", color = "blue", size = 5) 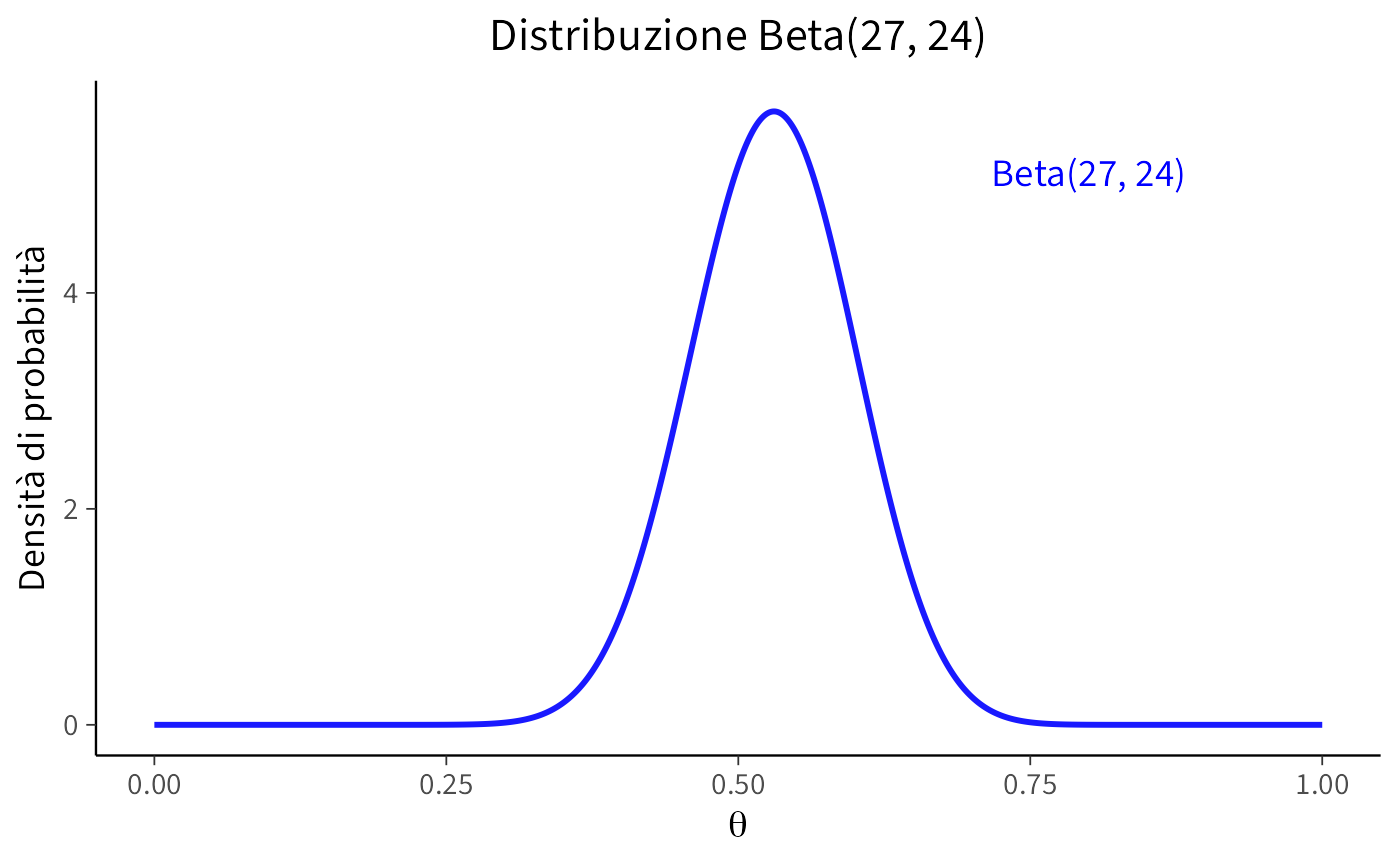
Calcolo della media a posteriori di \(\theta\):
alpha_post / (alpha_post + beta_post)
#> [1] 0.529Calcolo della moda a posteriori:
(alpha_post - 1) / (alpha_post + beta_post - 2)
#> [1] 0.531Calcolo della probabilità che \(\theta > 0.6\):
pbeta(0.6, alpha_post, beta_post, lower.tail = FALSE)
#> [1] 0.156Ovvero:
1 - pbeta(0.6, alpha_post, beta_post)
#> [1] 0.156Eseguiamo il problema utilizzando il metodo basato su griglia. Definiamo la griglia di interesse:
theta <- seq(0, 1, length.out = 100)Creiamo la distribuzione a priori:
prior <- dbeta(theta, alpha_prior, beta_prior)
# Normalizzazione della densità per ottenere una somma pari a 1
prior_normalized <- prior / sum(prior)
# Creare un dataframe contenente i dati per il grafico
df <- data.frame(
theta = theta,
probabilita = prior_normalized
)
# Creare il grafico con ggplot2
ggplot(df, aes(x = theta, y = probabilita)) +
geom_segment(aes(x = theta, xend = theta, y = 0, yend = probabilita),
color = "blue", size = 1) + # Linee verticali per rappresentare le probabilità
labs(title = "Distribuzione a priori", # Aggiungere il titolo
x = expression(theta), # Label dell'asse x usando espressioni matematiche
y = "Probabilità") + # Label dell'asse y
theme(plot.title = element_text(hjust = 0.5)) # Centrare il titolo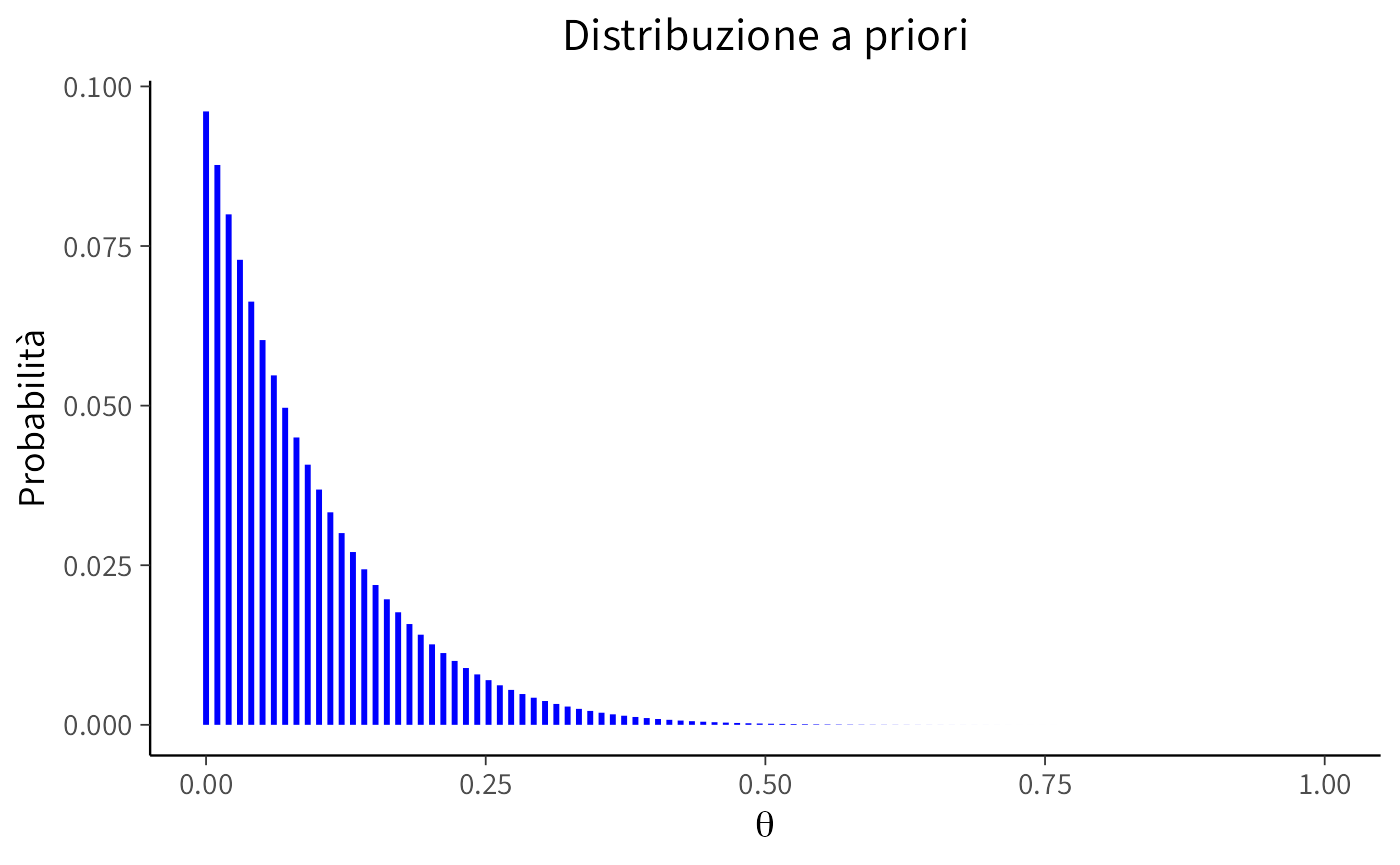
Creiamo la verosimiglianza:
lk <- dbinom(y, n, theta)
# Normalizzazione della verosimiglianza per ottenere una somma pari a 1
lk_normalized <- lk / sum(lk)
# Creare un dataframe contenente i dati per il grafico
df <- data.frame(
theta = theta,
probabilita = lk_normalized
)
# Creare il grafico con ggplot2
ggplot(df, aes(x = theta, y = probabilita)) +
geom_segment(aes(x = theta, xend = theta, y = 0, yend = probabilita),
color = "red", size = 1) + # Linee verticali per rappresentare la verosimiglianza
labs(title = "Verosimiglianza", # Aggiungere il titolo
x = expression(theta), # Label dell'asse x usando espressioni matematiche
y = "Probabilità") + # Label dell'asse y
theme(plot.title = element_text(hjust = 0.5)) # Centrare il titolo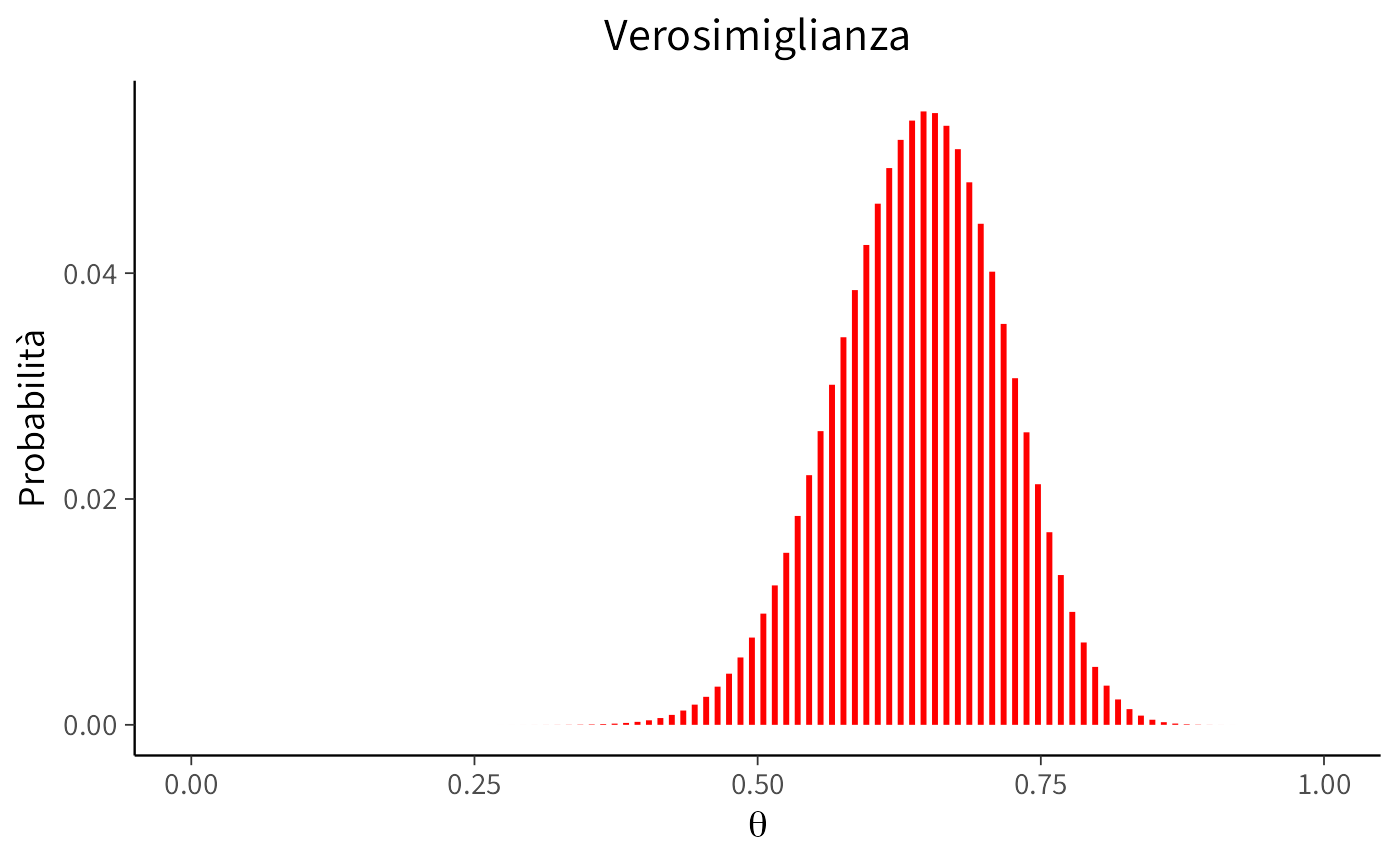
Calcoliamo la distribuzione a posteriori:
post <- (prior * lk) / sum(prior * lk)
# Normalizzazione della verosimiglianza per ottenere una somma pari a 1
lk_normalized <- lk / sum(lk)
# Creare un dataframe contenente i dati per il grafico
df <- data.frame(
theta = theta,
probabilita = lk_normalized
)
# Creare il grafico con ggplot2
ggplot(df, aes(x = theta, y = probabilita)) +
geom_segment(aes(x = theta, xend = theta, y = 0, yend = probabilita),
color = "green", size = 1) + # Linee verticali per rappresentare la verosimiglianza
labs(title = "Distribuzione a posteriori", # Aggiungere il titolo
x = expression(theta), # Label dell'asse x usando espressioni matematiche
y = "Probabilità") + # Label dell'asse y
theme(plot.title = element_text(hjust = 0.5)) # Centrare il titolo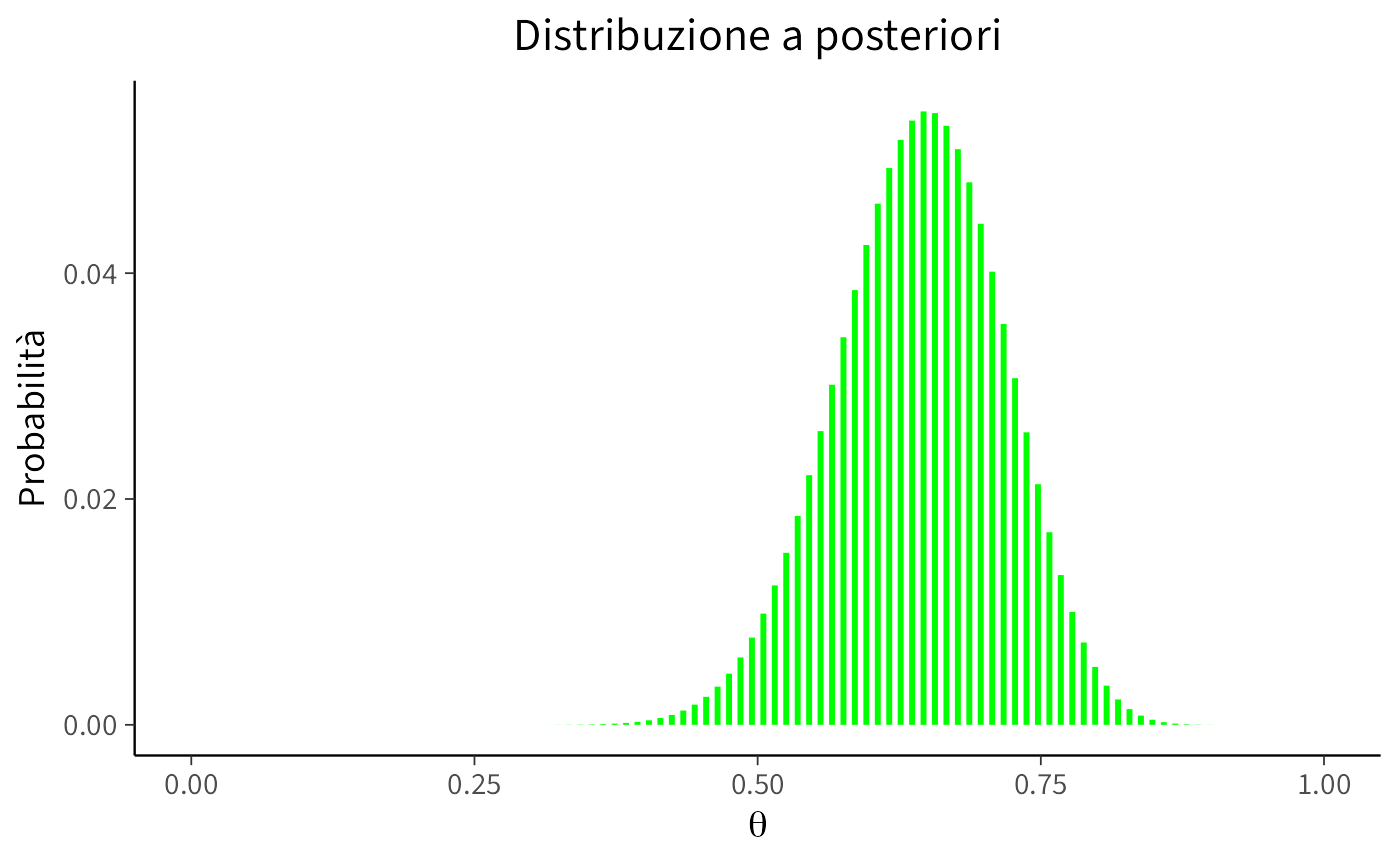
Estrazione di un campione dalla distribuzione a posteriori:
samples <- sample(theta, size = 1e6, replace = TRUE, prob = post)Troviamo la media a posteriori:
mean(samples)
#> [1] 0.529Calcoliamo la probabilità che \(\theta > 0.6\):
mean(samples > 0.6)
#> [1] 0.153Questo codice mantiene la struttura logica del problema e produce risultati equivalenti utilizzando R.
NotaEsercizio 3.
Consideriamo un esempio discusso da Nalborczyk (2018) nel quale, oltre all’applicazione del teorema beta-binimiale, viene anche introdotto il concetto di posterior-predictive check.
Supponiamo di reclutare partecipanti per uno studio di mezza ora:
- Possiamo farlo fra le 9:00 e le 18:00, con sessioni ogni 30 minuti.
- In una settimana lavorativa (lun–ven) otteniamo \(n = 90\) time slot.
- Ad ogni slot, il partecipante o si presenta (\(1\)) o manca (\(0\)).
Vogliamo stimare la probabilità media di presenza, che chiameremo \(\theta\).
Modello:
\[ \begin{cases} Y \mid \theta \;\sim\;\mathrm{Binomial}(n,\theta),\\[6pt] \theta \;\sim\;\mathrm{Beta}(\alpha,\beta). \end{cases} \]
Scelta del prior:
- conoscenze pregresse suggeriscono che \(\theta\) sia intorno a 0.5;
- scegliamo quindi un prior \(\;\mathrm{Beta}(2,2)\), che ha media \(0.5\) e riflette incertezza moderata.
Dati osservati:
# vettore di 0/1 con n = 90 osservazioni
y <- c(
0,0,0,1,1,1,0,0,0,1,1,1,1,1,1,1,0,0,
0,1,0,1,1,1,0,0,1,1,1,1,1,1,1,0,0,1,
1,0,0,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,
1,0,0,1,1,1,0,1,1,1,1,1,1,0,0,0,0,1,
0,1,0,1,1,1,0,0,0,0,0,1,1,1,1,1,1,0
)Calcoliamo
Posterior Beta–Binomiale.
I parametri aggiornati sono
\[ \alpha_{post} = \alpha + z, \quad \beta_{post} = \beta + (n - z). \]
In particolare, con \(\alpha=\beta=2\):
a <- b <- 2
a_post <- a + z
b_post <- b + (n - z)Il posterior è quindi
\[ \theta\mid y \;\sim\;\mathrm{Beta}(a+z,\;b+n-z). \]
Visualizzazione:
# griglia per theta
grid <- seq(0, 1, length.out = 1000)
# densità
prior <- dbeta(grid, a, b)
posterior <- dbeta(grid, a_post, b_post)
df <- data.frame(theta = grid,
prior = prior,
posterior = posterior)
ggplot(df) +
geom_area(aes(x = theta, y = prior,
fill = "Prior", colour = "Prior"),
alpha = 0.5, size = 1) +
geom_area(aes(x = theta, y = posterior,
fill = "Posterior", colour = "Posterior"),
alpha = 0.5, size = 1) +
scale_fill_grey(name = "") +
scale_colour_grey(name = "") +
theme_bw(base_size = 12) +
xlab(expression(theta)) +
ylab("") +
ggtitle("Densità Prior e Posterior\nmodello Beta–Binomiale")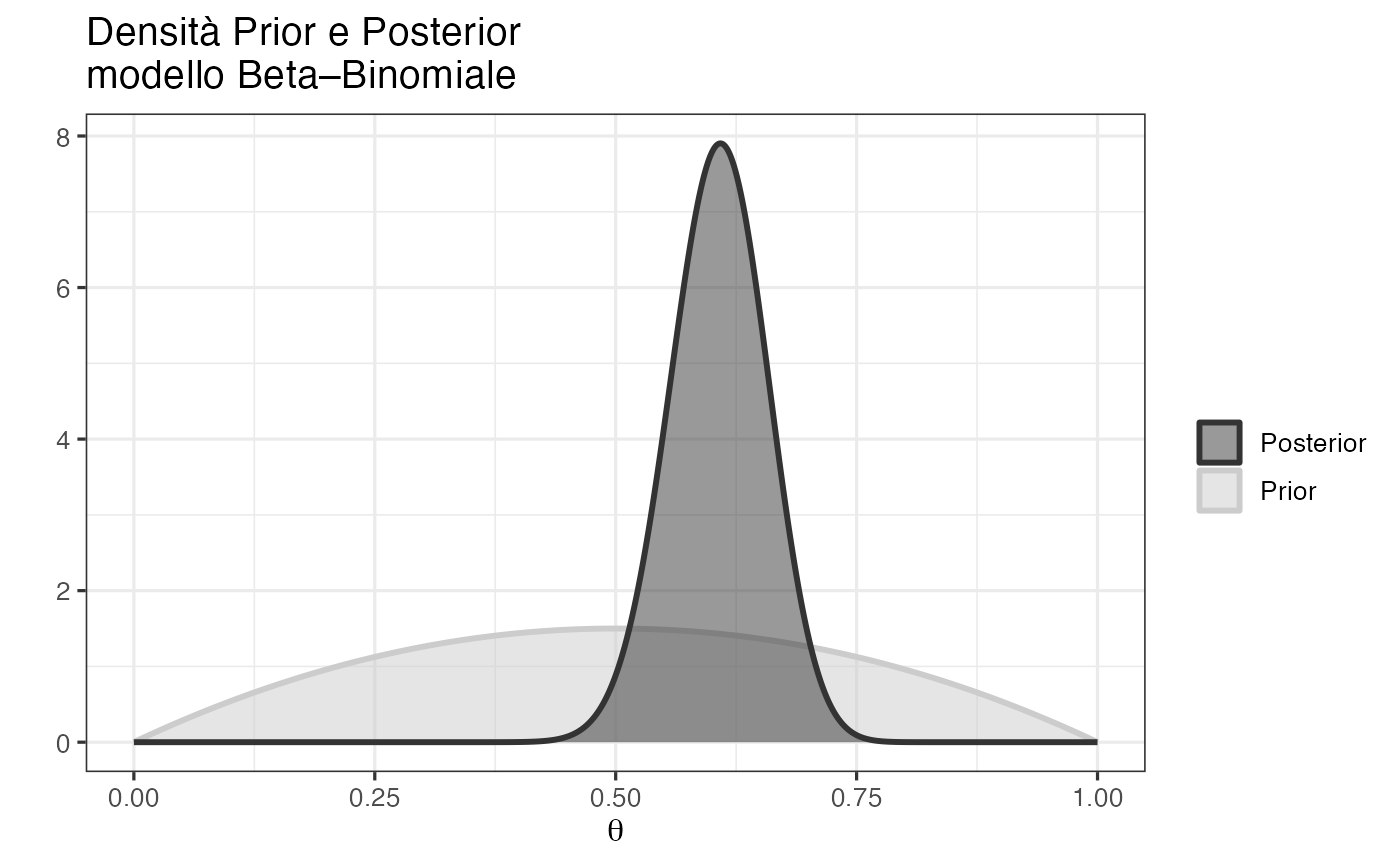
Introduzione ai posterior predictive checks.
Il modello assume indipendenza fra i time slot. Se questa assunzione è violata (ad es. presenza autocorrelata nel tempo), le nostre stime potrebbero essere fuorvianti.
Idea:
- Simulare \(\theta\) dal posterior.
- Dato ciascun \(\theta\), generare una nuova serie \(y^{rep}\) da
\(\mathrm{Binomial}(n,\theta)\).
- Calcolare su ogni \(y^{rep}\) una test-quantità \(T(y^{rep})\).
- Confrontare la distribuzione di \(T(y^{rep})\) con il valore osservato \(T(y)\).
Se \(T(y)\) è un outlier rispetto ai \(T(y^{rep})\), l’assunzione di indipendenza è sospetta.
Test‐quantità: numero di “switch”.
Definiamo una funzione che conta quante volte la serie passa da 0→1 o da 1→0:
Simulazione e istogramma.
set.seed(123) # per riproducibilità
nsims <- 10000 # numero di repliche
sim_switches <- replicate(nsims, {
# 1) estrai un theta dal posterior
theta_sim <- rbeta(1, a_post, b_post)
# 2) genera y^rep ~ Bernoulli(theta_sim)
y_sim <- rbinom(n, size = 1, prob = theta_sim)
# 3) conta gli switch
count_switches(y_sim)
})
# Istogramma
hist(sim_switches,
breaks = 30,
col = "lightgrey",
main = "Distribuzione Posterior Predictive\ndel numero di switch",
xlab = "Numero di switch",
ylab = "Frequenza")
abline(v = Ty, col = "darkgreen", lty = 2, lwd = 2)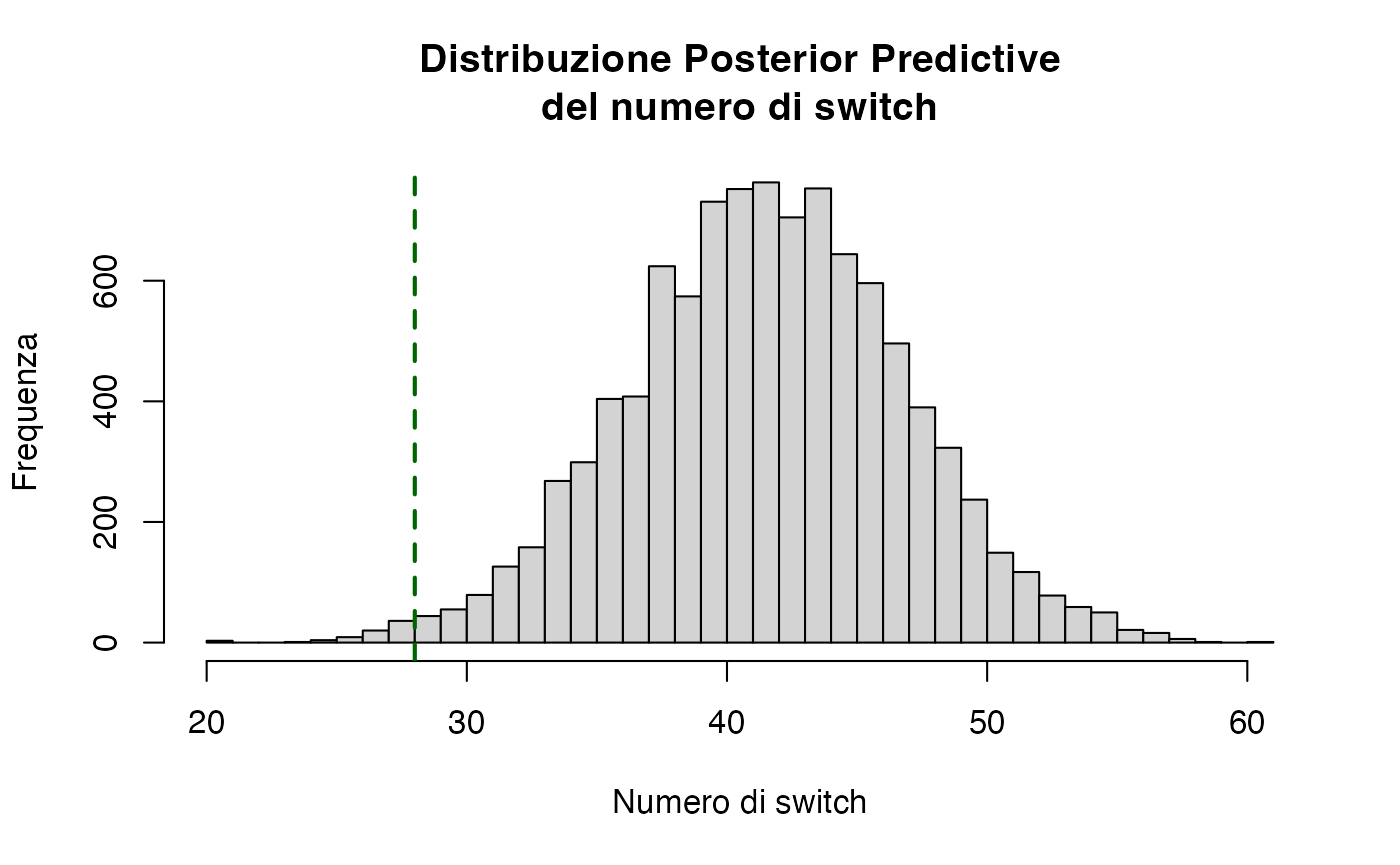
Bayesian p‐value.
Calcoliamo la probabilità di ottenere un numero di switch ≤ di quello osservato:
- Un valore molto basso (es. \(<0.05\)) indica che \(T(y)\) è sorprendente rispetto alle predizioni del modello.
- Qui: se \(p\approx 0.01\), la bassa variabilità di switch suggerisce dipendenza fra le osservazioni.
Interpretazione.
-
Un modello non è “giusto” o “sbagliato”, ma deve descrivere bene il processo che genera i dati.
- Il nostro check mostra che il numero di switch osservato è molto minore di quanto ci aspetteremmo sotto l’ipotesi di indipendenza.
- Con tutta probabilità c’è autocorrelazione temporale (le presenze dipendono dall’ora del giorno).
- Per tenerne conto, si potrebbero usare modelli più avanzati (es. processi gaussiani).
In sintesi, il posterior predictive checking ci offre un modo flessibile per diagnosticare diverse violazioni del modello, scegliendo test‐quantities adatte (media, varianza, max, autocorrelazione, …). Come scrivono Gelman et al. (2013), “i p-valori posteriori … possono essere calcolati per varie test-quantities per valutare più modi in cui un modello può fallire”.
5.4 Principali distribuzioni coniugate
Esistono altre combinazioni di verosimiglianza e distribuzione a priori che producono una distribuzione a posteriori con la stessa forma della distribuzione a priori. Ecco alcune delle più note coniugazioni tra modelli statistici e distribuzioni a priori:
Nel modello Normale-Normale \(\mathcal{N}(\mu, \sigma^2_0)\), la distribuzione a priori è \(\mathcal{N}(\mu_0, \tau^2)\) e la distribuzione a posteriori è \(\mathcal{N}\left(\frac{\mu_0\sigma^2 + \bar{y}n\tau^2}{\sigma^2 + n\tau^2}, \frac{\sigma^2\tau^2}{\sigma^2 + n\tau^2} \right)\).
Nel modello Poisson-gamma \(\text{Po}(\theta)\), la distribuzione a priori è \(\Gamma(\lambda, \delta)\) e la distribuzione a posteriori è \(\Gamma(\lambda + n \bar{y}, \delta +n)\).
Nel modello Esponenziale \(\text{Exp}(\theta)\), la distribuzione a priori è \(\Gamma(\lambda, \delta)\) e la distribuzione a posteriori è \(\Gamma(\lambda + n, \delta +n\bar{y})\).
Nel modello Uniforme-Pareto \(\text{U}(0, \theta)\), la distribuzione a priori è \(\text{Pa}(\alpha, \varepsilon)\) e la distribuzione a posteriori è \(\text{Pa}(\alpha + n, \max(y_{(n)}, \varepsilon))\).
Riflessioni conclusive
In questo capitolo abbiamo approfondito l’idea di famiglia coniugata, mostrando come, in certi casi, il teorema di Bayes mantenga invariata la forma della distribuzione a priori. L’esempio del modello Beta-Binomiale, già incontrato in precedenza, ci ha offerto l’occasione di vedere con chiarezza come i dati modifichino le nostre credenze in modo semplice e cumulativo: basta aggiornare i parametri della distribuzione, senza cambiare la sua struttura.
Questa proprietà, apparentemente tecnica, riveste una grande importanza concettuale. Le distribuzioni coniugate costituiscono il laboratorio ideale per comprendere a fondo la logica dell’inferenza bayesiana: permettono di seguire con trasparenza il passaggio da prior a posterior, di vedere come ogni nuova osservazione si traduca in un aggiornamento dei parametri e di cogliere in maniera intuitiva la natura dinamica del processo.
Naturalmente, sappiamo che la coniugazione è un caso speciale. Nella maggior parte dei problemi reali, soprattutto quando i modelli diventano complessi e includono più parametri o strutture gerarchiche, non esiste una coppia prior–verosimiglianza coniugata che semplifichi i calcoli. È in questi casi che entrano in gioco metodi computazionali più generali, come il campionamento MCMC, che ci permettono di affrontare situazioni realistiche senza rinunciare alla coerenza dell’approccio bayesiano (Johnson et al., 2022).
In questo senso, le famiglie coniugate non rappresentano un punto di arrivo, ma un passaggio fondamentale: ci insegnano i principi dell’aggiornamento bayesiano in un contesto semplice, che prepara la strada verso strumenti più potenti e flessibili.
Bibliografia
Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., & Rubin, D. B. (2013). Bayesian Data Analysis (3rd ed.). Chapman; Hall/CRC.
Gori, B., Grippo, A., Focardi, M., & Lolli, F. (2024). The Italian version of Edinburgh Handedness Inventory: Translation, transcultural adaptation, and validation in healthy subjects. Laterality, 29(2), 151–168.
Johnson, A. A., Ott, M., & Dogucu, M. (2022). Bayes Rules! An Introduction to Bayesian Modeling with R. CRC Press.
McElreath, R. (2020). Statistical rethinking: A Bayesian course with examples in R and Stan (2nd Edition). CRC Press.
Nalborczyk, L. (2018, gennaio 23). Checking the Asumption of Independence in Binomial Trials Using Posterior Predictive Checking. https://lnalborczyk.github.io/blog/2018-01-23-ppc
Papadatou-Pastou, M., Ntolka, E., Schmitz, J., Martin, M., Munafò, M. R., Ocklenburg, S., & Paracchini, S. (2020). Human handedness: A meta-analysis. Psychological bulletin, 146(6), 481–524.
Scheel, A. M., Schijen, M. R., & Lakens, D. (2021). An excess of positive results: Comparing the standard psychology literature with registered reports. Advances in Methods and Practices in Psychological Science, 4(2), 25152459211007467.