3 La quantificazione dell’incertezza
Introduzione
Nel capitolo precedente abbiamo visto perché l’incertezza non è un problema da eliminare, ma una componente essenziale della ricerca psicologica. Abbiamo anche discusso come l’approccio bayesiano, a differenza di quello frequentista, permetta di trattare questa incertezza in modo più coerente e trasparente.
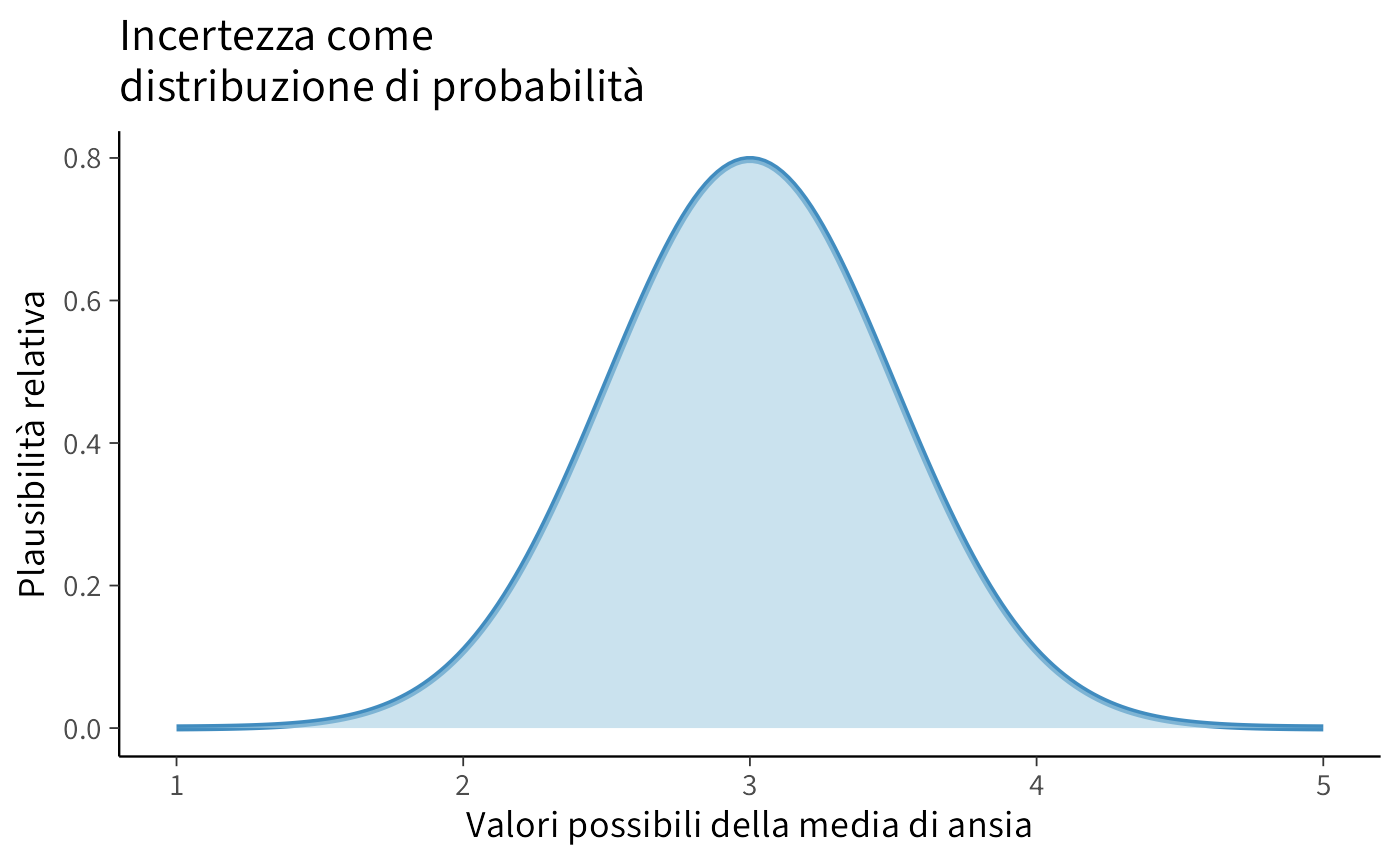
In questo capitolo facciamo un passo avanti: ci chiediamo come l’incertezza possa essere rappresentata e quantificata in pratica. Lo strumento fondamentale per farlo è la distribuzione di probabilità. Una distribuzione non restituisce un numero unico, ma un intero ventaglio di valori possibili, ciascuno associato a un grado di plausibilità. È questo che ci permette di descrivere in modo formale quanto siamo incerti riguardo a un parametro o a un’ipotesi.
Vedremo quindi come funziona l’aggiornamento bayesiano: partiremo da ciò che sappiamo prima dei dati (prior), incorporeremo l’evidenza empirica (verosimiglianza) e otterremo una nuova rappresentazione delle nostre credenze (posterior). Questo processo è dinamico e mai concluso: ogni nuovo dato modifica la distribuzione, permettendoci di accumulare conoscenza in modo coerente.
Il nostro obiettivo in questo capitolo è duplice:
- introdurre i concetti di distribuzione e aggiornamento bayesiano in forma semplice e intuitiva;
- mostrarne il funzionamento con un esempio classico e intuitivo (il globo terrestre), arricchito da riflessioni su cosa questo significhi per la ricerca psicologica.
In questo modo, passeremo dal piano concettuale a quello operativo, ponendo le basi per i capitoli successivi, dove useremo questi strumenti in contesti più complessi.
Panoramica del capitolo
- Come quantificare e rappresentare matematicamente l’incertezza attraverso le distribuzioni di densità.
- Il processo di integrazione delle nuove evidenze con le conoscenze preesistenti.
- Come i parametri sconosciuti determinano i dati osservati attraverso processi probabilistici.
3.1 Distribuzioni di probabilità
Per rappresentare l’incertezza in modo quantitativo ci serve uno strumento che mostri non solo un valore “tipico”, ma anche tutti i valori alternativi che consideriamo possibili. Questo strumento è la distribuzione di probabilità.
Una distribuzione ci dice due cose fondamentali:
- quali valori sono possibili per un certo fenomeno;
- quanto ciascun valore è plausibile alla luce delle nostre conoscenze.
3.1.1 Un esempio psicologico
Supponiamo di misurare il livello di ansia in un gruppo di studenti prima di un esame. I punteggi non saranno tutti uguali: alcuni studenti avranno valori bassi, altri molto alti, la maggior parte sarà in una zona intermedia. Invece di limitarsi a dire “il livello medio è 20”, una distribuzione ci permette di descrivere l’intero profilo di variabilità: quali valori sono più frequenti, quali sono rari e quali estremi sono comunque possibili.
In psicologia, quasi tutti i fenomeni che studiamo — dall’autostima alle prestazioni cognitive — possono essere rappresentati meglio con una distribuzione piuttosto che con un singolo numero.
E già qui si intravede la logica bayesiana: se, ad esempio, stiamo stimando l’efficacia di una terapia cognitivo-comportamentale, non ci basta sapere che l’effetto medio stimato è 0.3. Ci interessa sapere quali altri valori dell’effetto rimangono plausibili e con quale grado di fiducia.
3.1.2 Distribuzioni discrete e continue
Esistono due grandi famiglie di distribuzioni:
-
Discrete, quando i valori possibili sono separati e contabili.
- Esempio classico: il lancio di una moneta (testa o croce) o di un dado (sei possibili esiti).
- In psicologia: il numero di risposte corrette in un test a scelta multipla.
- Esempio classico: il lancio di una moneta (testa o croce) o di un dado (sei possibili esiti).
-
Continue, quando i valori possibili formano un intervallo continuo.
- Esempio classico: l’altezza di una persona o il tempo di reazione in millisecondi.
- In psicologia: il livello di ansia misurato con una scala continua, la durata dell’attenzione in un compito sperimentale.
- Esempio classico: l’altezza di una persona o il tempo di reazione in millisecondi.
3.1.3 Perché le distribuzioni sono fondamentali
La potenza delle distribuzioni sta nel fatto che non riducono la realtà a un singolo numero, ma ci mostrano tutta la gamma di possibilità insieme al grado di plausibilità di ciascuna. In questo modo, l’incertezza diventa parte integrante della descrizione del fenomeno.
Nei prossimi paragrafi vedremo come le distribuzioni non siano solo uno strumento descrittivo, ma diventino il cuore dell’aggiornamento bayesiano: collegano ciò che sappiamo prima dei dati (prior), le nuove osservazioni (verosimiglianza) e le credenze aggiornate (posterior).
Rappresentare l’incertezza come distribuzione di probabilità significa passare da una visione rigida (“il valore è uno solo”) a una prospettiva più realistica e informativa (“alcuni valori sono più plausibili di altri”).
3.2 L’aggiornamento bayesiano
Il cuore dell’approccio bayesiano è il teorema di Bayes, che descrive come aggiornare in modo coerente le nostre convinzioni alla luce dei dati. L’idea è semplice: partiamo da ciò che sappiamo prima dei dati (prior), osserviamo nuove evidenze (verosimiglianza) e otteniamo credenze aggiornate (posterior).
Formalmente:
\[ P(\text{ipotesi | dati}) \;=\; \frac{P(\text{dati | ipotesi}) \; P(\text{ipotesi})}{P(\text{dati})}, \]
-
Posterior, \(P(\text{ipotesi | dati})\): la probabilità aggiornata dell’ipotesi, dopo aver visto i dati.
-
Likelihood (verosimiglianza), \(P(\text{dati | ipotesi})\): quanto i dati sono compatibili con l’ipotesi.
-
Prior, \(P(\text{ipotesi})\): le nostre convinzioni prima di osservare i dati.
- Evidenza, \(P(\text{dati})\): una costante di normalizzazione che assicura che le probabilità sommino a 1.
3.2.1 Perché l’aggiornamento è dinamico
Una delle intuizioni più potenti dell’approccio bayesiano è che l’aggiornamento delle nostre conoscenze non è mai definitivo: ogni nuovo dato contribuisce a ridefinire la distribuzione delle nostre credenze. La conoscenza scientifica non si “chiude” mai una volta per tutte, ma rimane sempre aperta a revisioni.
3.2.1.1 Messaggio chiave
L’aggiornamento bayesiano è cumulativo e dinamico: non produce verdetti, ma posterior sempre più informative man mano che i dati aumentano.
3.3 L’esempio del globo terrestre
Per capire in modo concreto come funziona l’aggiornamento bayesiano, consideriamo l’esempio del globo terrestre discusso da Richard McElreath nel suo Statistical Rethinking (McElreath, 2020). Immaginiamo di avere un globo coperto da due colori: blu per il mare, marrone per la terra. Senza guardare, lo giriamo e puntiamo un dito su una posizione casuale. Vogliamo stimare la proporzione di superficie terrestre che è blu (cioè la proporzione del globo ricoperta dall’acqua).
3.3.1 L’accumulo dell’evidenza
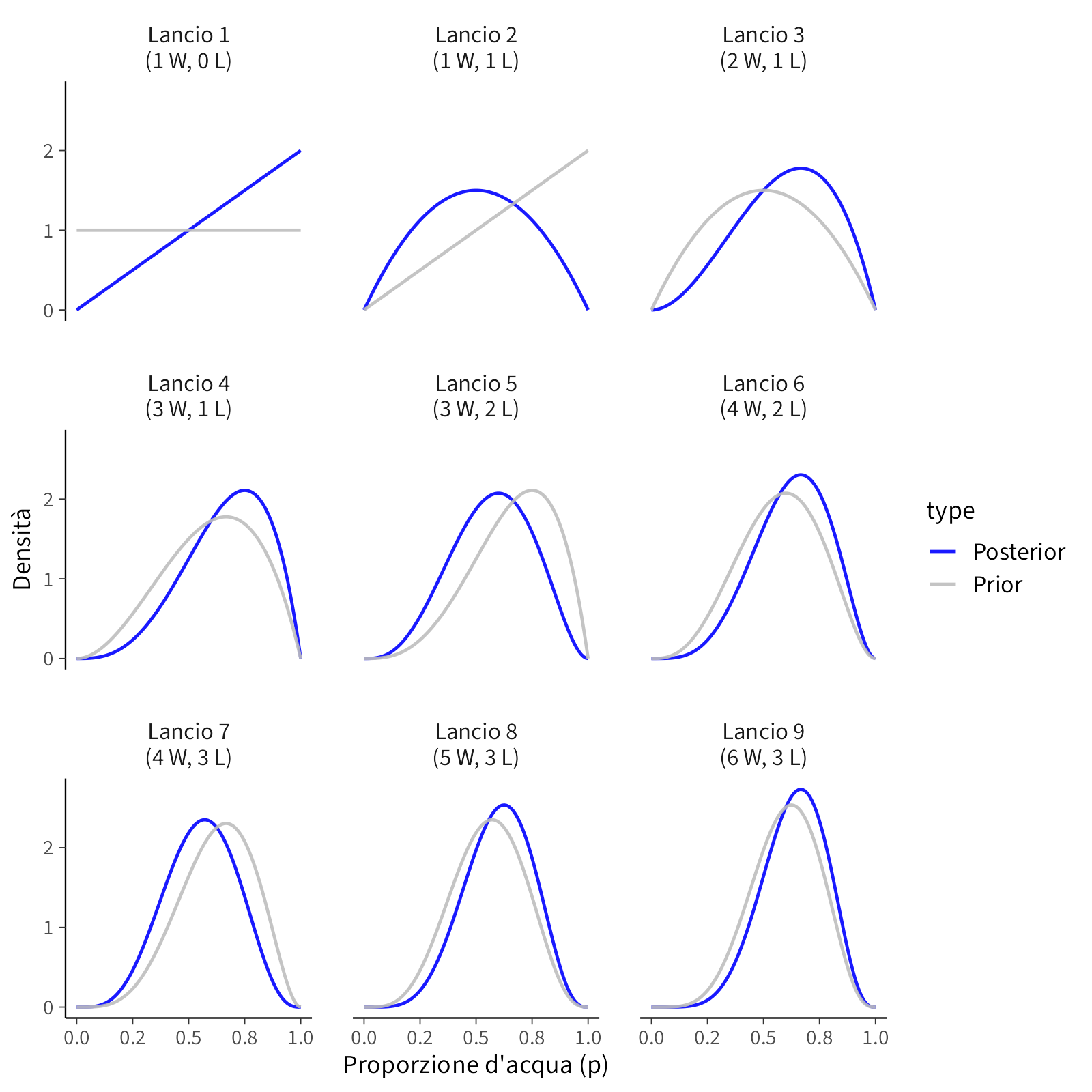
Consideriamo la sequenza: W, L, W, W, L, W, L, W, W, dove W indica acqua (water) e L terra (land). Dopo ogni nuova osservazione, la distribuzione delle plausibilità sui valori di \(p\) — la proporzione di oceano sulla superficie del globo — viene aggiornata.
Prima della prima osservazione. Non abbiamo alcuna informazione. Tutti i valori di \(p\), da 0 a 1, sono considerati ugualmente plausibili. La distribuzione iniziale (prior) è piatta: ogni ipotesi ha lo stesso peso. È come dire: qualsiasi proporzione di oceano è per ora concepibile.
Dopo la prima osservazione (W). Puntiamo il dito e tocchiamo acqua. A questo punto sappiamo che \(p = 0\) è impossibile: il globo non può essere interamente terra, perché abbiamo osservato almeno una goccia d’acqua. La plausibilità dei valori alti di \(p\) (vicini a 1) cresce. La linea continua nel primo pannello mostra questa nuova distribuzione (posterior), mentre la linea tratteggiata rappresenta la distribuzione precedente (prior). In altre parole: le ipotesi che prevedono “tutto terra” sono escluse, quelle che prevedono “quasi tutto oceano” diventano più plausibili.
Dopo la seconda osservazione (L). Tocchiamo terra. Ora sappiamo che anche \(p = 1\) è impossibile: non può trattarsi di un globo interamente coperto d’acqua. La plausibilità si concentra quindi su valori intermedi, perché ora abbiamo evidenza sia di oceano che di terra. Nel grafico, la linea continua riflette questa nuova credenza aggiornata. Rispetto alla prima osservazione, la distribuzione si è riallineata: non privilegia più solo i valori alti di \(p\), ma si sposta verso ipotesi che tengano conto di entrambe le evidenze.
Dopo la terza osservazione (W). Tocchiamo di nuovo acqua. Questo spinge la curva nuovamente verso destra, in direzione di valori più alti di \(p\). Notiamo un aspetto importante: non stiamo semplicemente “contando” acqua e terra, ma traducendo queste osservazioni in un profilo di plausibilità che tiene insieme tutte le informazioni disponibili. Ogni osservazione contribuisce, ma nessuna singola osservazione domina: il modello “pesa” coerentemente l’insieme dei dati raccolti fino a quel momento.
Proseguendo con le osservazioni. Ogni nuovo dato modifica le plausibilità: un’osservazione di acqua spinge la curva verso destra (valori alti di \(p\)), un’osservazione di terra la spinge verso sinistra (valori bassi). Con l’accumularsi delle evidenze, la curva diventa più alta e più stretta: meno valori di \(p\) rimangono compatibili con i dati, e la nostra conoscenza si affina. Ciò che prima era “ampiamente possibile” diventa ora “altamente improbabile”.
3.3.2 Il significato
Ogni nuova osservazione raffina la credenza: la posterior si restringe progressivamente (senza mai annullare del tutto l’incertezza). La distribuzione evolve non solo in posizione (quali valori di \(p\) sono più plausibili), ma anche in forma (quanto stretta o larga è l’incertezza intorno a quei valori).
- Con pochi dati, la distribuzione è larga e riflette molta incertezza.
- Con più osservazioni, la distribuzione diventa più stretta: la conoscenza si affina.
- La velocità del restringimento dipende dai dati: sequenze molto coerenti riducono rapidamente l’incertezza, mentre sequenze contrastanti la riducono più lentamente.
In altre parole: l’incertezza non viene eliminata, ma organizzata e ridotta progressivamente grazie all’accumulo dell’evidenza.
3.3.3 Come leggere il grafico (e perché ci deve interessare in psicologia)
In ogni pannello, la linea tratteggiata rappresenta ciò che ritenevamo plausibile prima del nuovo dato (prior), mentre la linea continua rappresenta la distribuzione aggiornata (posterior). Il punto non è “indovinare un numero”, ma ridistribuire la plausibilità sui valori coerenti con i dati. Due aspetti chiave:
- Direzione: un “W” sposta massa di plausibilità verso valori più alti, un “L” verso valori più bassi.
- Forma (ampiezza): con l’aumentare dei dati, la curva si stringe, ovvero diminuisce il numero di valori compatibili e l’incertezza si riduce.
La stessa logica viene utilizzata in psicologia quando si passa da ipotesi teoriche generali a stime più circoscritte, man mano che si accumulano studi, repliche e dati di migliore qualità.
3.3.3.1 Dalla sfera terrestre ai problemi psicologici (tre mappe mentali)
Prevalenza/parametri di popolazione. Stimare la prevalenza di un comportamento a rischio tra gli studenti è analogo a stimare \(p\) sul globo: ogni nuova rilevazione (studente che presenta/non presenta il comportamento) aggiorna la distribuzione della prevalenza effettiva. Con pochi questionari, la distribuzione è larga; con campioni più grandi o campioni stratificati, invece, si stringe.
Effetto di un intervento. Valutare l’effetto medio di un training DBT sulle scale di disregolazione emotiva funziona allo stesso modo: il prior può incorporare l’evidenza pregressa (ad esempio, una meta-analisi), la verosimiglianza deriva dal modello di misura (affidabilità, errori, missing), e la posterior concentra plausibilità intorno agli effetti compatibili con i dati dello studio. Ogni nuova coorte/studio aggiorna ulteriormente la stima.
Modelli meccanicistici (es. apprendimento). Nei compiti di reinforcement learning, il parametro di interesse (es. tasso di apprendimento \(\alpha\)) si aggiorna man mano che si osservano scelte e feedback. Sequenze coerenti (feedback consistenti) “spingono” la plausibilità verso regioni più strette, mentre sequenze rumorose mantengono la distribuzione più larga. Si tratta della stessa dinamica vista con \(p\), solo applicata a un parametro psicologico.
In sintesi, leggere i pannelli dell’esempio del globo significa allenarsi a leggere qualsiasi grafico bayesiano in psicologia. Il punto cruciale non è individuare “il numero giusto”, ma comprendere “come si ridistribuisce la plausibilità quando le evidenze cambiano, date le nostre assunzioni sulla misurazione e il modello”.
Riflessioni conclusive
In questo capitolo abbiamo compiuto il primo ingresso operativo nel pensiero bayesiano. Abbiamo visto come l’incertezza possa essere rappresentata da distribuzioni di probabilità e come il teorema di Bayes colleghi in modo coerente convinzioni iniziali, dati osservati e convinzioni aggiornate. L’esempio del globo terrestre ha reso tangibile questa dinamica: ogni osservazione sposta o restringe la distribuzione su \(p\), mostrando che l’apprendimento è progressivo e cumulativo.
Per la ricerca psicologica, ciò significa tre cose fondamentali:
- i dati non producono certezze, ma affinano gradualmente le ipotesi;
- ogni studio è un contributo a un processo cumulativo;
- l’incertezza diventa una risorsa esplicita, non un problema da nascondere.
Come ogni osservazione restringe le ipotesi plausibili sulla proporzione di oceano sulla superficie terrestre, così in psicologia ogni nuovo dato restringe l’incertezza sulle nostre teorie e modelli, senza però azzerarla.
Da qui discendono alcune conseguenze pratiche. Il lavoro dell’analista non si esaurisce nel “trovare un numero”, ma consiste nel modellare con cura il problema, rendere esplicite le assunzioni e valutarne l’impatto. Scelta dei prior, oneri computazionali, interpretazione dei risultati e qualità del modello sono aspetti che accompagnano inevitabilmente l’applicazione concreta dei metodi bayesiani.
Il messaggio centrale è chiaro: l’approccio bayesiano non elimina l’incertezza, ma invece la organizza. Invece di nasconderla dietro esiti dicotomici, la rende visibile e misurabile, permettendo di comunicare quali valori dei parametri siano plausibili e con quale grado di fiducia.
Nei capitoli successivi tradurremo queste idee in pratica, costruendo modelli bayesiani via via più ricchi e applicandoli a contesti psicologici reali. L’obiettivo non è cercare una “certezza definitiva”, ma sviluppare l’abitudine a ragionare in termini di plausibilità e apprendimento continuo dai dati.
Bibliografia
Il tema delle analisi di sensibilità verrà trattato in seguito, quando discuteremo come valutare l’influenza del prior sui risultati.↩︎
L’assunzione di scambiabilità implica che la distribuzione dei dati sia invariante rispetto all’ordine in cui vengono osservati.↩︎
Più avanti introdurremo strumenti come gli intervalli credibili e la distribuzione predittiva a posteriori, che aiutano a interpretare la forma della distribuzione.↩︎