![]()
Paradosso di Simpson#
Nel presente capitolo approfondiremo il paradosso di Simpson, fenomeno che mette in risalto una significativa sfida epistemologica nel campo della psicologia. Tale paradosso prende forma quando una relazione negativa tra due variabili, chiaramente riconoscibile all’interno di un gruppo isolato, si altera, scompare o, sorprendentemente, si inverte una volta che i dati di più gruppi vengono uniti ed esaminati congiuntamente.
Questo fenomeno riveste un’importanza cruciale in psicologia, poiché apre un dibattito fondamentale sull’applicabilità dei risultati della ricerca psicologica all’individuo. In particolare, ci costringe a riflettere sulla legittimità dell’estrapolare conclusioni destinate all’individuo a partire da dati analizzati a livello aggregato, ovvero di popolazione.
La questione centrale della discussione diviene, dunque: è davvero possibile che i risultati ottenuti dalla ricerca psicologica, che si basa in larga parte sull’analisi di dati aggregati, siano applicabili a livello individuale, o trovano corrispondenza solo in un contesto più ampio, vale a dire quello della popolazione?
Nel corso del capitolo, illustreremo come l’interpretazione di analisi condotte su dati aggregati possa generare una visione distorta delle reali dinamiche a livello individuale. Esploreremo inoltre le potenzialità offerte dall’impiego di modelli gerarchici, che permettono di tener conto delle differenze individuali, garantendo risultati validi sia sul piano della collettività che su quello dell’individuo singolo.
Durante l’analisi, procederemo con una progressione di modelli di regressione lineare, cominciando dalla forma più semplice per arrivare alla variante gerarchica.
Nel corso del capitolo, ci addentreremo in diverse tematiche chiave, tra cui:
L’impiego dei contenitori
pm.Dataper semplificare le predizioni a posteriori relative a differenti valori di \(x\) utilizzando lo stesso modello;L’attribuzione di dimensioni specifiche agli array nei modelli mediante l’opzione
coords, una pratica che prevede l’utilizzo dixarrayed è particolarmente vantaggiosa nei modelli gerarchici o a più livelli.
Precisiamo che il codice usato in questo capitolo è tratto del tutorial sul paradosso di Simpson disponibile sul sito ufficiale di PyMC.
Preparazione del Notebook#
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import pymc as pm
import pymc.sampling_jax
import scipy.stats as stats
import seaborn as sns
import arviz as az
import xarray as xr
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", category=Warning)
/Users/corrado/opt/anaconda3/envs/pymc_env/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
%config InlineBackend.figure_format = 'retina'
RANDOM_SEED = 42
rng = np.random.default_rng(RANDOM_SEED)
az.style.use("arviz-darkgrid")
sns.set_theme(palette="colorblind")
Capire il Paradosso di Simpson#
Nel 1899, Karl Pearson e collaboratori illustrarono un paradosso statistico nelle associazioni marginali e parziali tra variabili continue. Successivamente, nel 1903, Udny Yule delineò “la teoria dell’associazione degli attributi in statistica”, svelando l’esistenza di un paradosso associativo con variabili categoriche. In un articolo pubblicato nel 1951, Edward H. Simpson descrisse il fenomeno dell’inversione dei risultati. Nel 1972 Colin R. Blyth coniò il termine “Paradosso di Simpson”.
Il paradosso di Simpson può manifestarsi in qualsiasi insieme di dati, indipendentemente dalle dimensioni dei dati e dalla tipologia di variabili contenute, evidenziando come l’analisi di dati aggregati possa talvolta offrire una visione distorta delle relazioni effettive presenti nel dataset.
Nella tabella successiva è presentato un esempio originale del Paradosso di Simpson mediante una tavola di contingenza 2×2 [Sim51]: il tipo di associazione per l’intera popolazione (𝑁=52) si inverte al livello delle sottopopolazioni di uomini e donne.
Popolazione 𝑁=52 |
Uomini (M) = 20 |
Donne (F) = 32 |
|
|---|---|---|---|
Successo (S) |
Successo |
Successo |
|
Insucceso (¬𝑆) |
Insucceso |
Insucceso |
|
Tasso di successo % |
Tasso di successo % |
Tasso di successo % |
|
T |
20 |
8 |
12 |
20 |
5 |
15 |
|
50% |
≈61% |
≈44% |
|
¬𝑇 |
6 |
4 |
2 |
6 |
3 |
3 |
|
50% |
≈57% |
≈40% |
Nella tabella sopra, “T” e “¬T” rappresentano due differenti condizioni o gruppi, mentre “Successo” e “Insucceso” rappresentano due possibili esiti. I valori numerici indicano il numero di individui che hanno ottenuto ciascun esito in ciascun gruppo, e i tassi di successo sono calcolati come la percentuale di successi rispetto al totale degli esiti per ciascun gruppo.
Il dataset delle ammissioni all’UC Berkeley è un esempio classico del paradosso di Simpson [BHOConnell75]. Questo dataset includeva 12763 candidati alla laurea (maschi e femmine) all’UC Berkeley nell’autunno del 1973. Il dataset è stato fornito dai ricercatori dell’UC Berkeley per indagare su possibili casi di pregiudizio di genere nelle ammissioni. Nel dataset, la percentuale di ammissione per le femmine è inferiore rispetto a quella per i maschi quando i dati sono aggregati; tuttavia, considerando separatamente ogni corso di laurea, le percentuali di ammissione delle femmine superano quelle dei maschi nella maggior parte dei sottogruppi.
Tabella 2. Presenza del Paradosso di Simpson: un caso di studio basato sul dataset delle ammissioni all’UC-Berkeley (autunno 1973).
Domande di ammissione |
Ammessi |
Rifiutati |
Percentuale di ammissione |
|
|---|---|---|---|---|
Uomini |
8442 |
3738 |
4704 |
44% |
Donne |
4321 |
1494 |
2827 |
35% |
Per comprendere appieno la situazione e le dinamiche sottostanti, è fondamentale non solo considerare i dati aggregati, ma anche esaminare i dati a livello di dipartimento, così come illustrato nella Tabella 3.
Tabella 3. Dataset delle ammissioni all’UC-Berkeley (autunno 1973): Percentuale del tasso di accettazione di uomini e donne in diversi dipartimenti.
Genere |
Dipartimento A |
Dipartimento B |
Dipartimento C |
Dipartimento D |
Dipartimento E |
Dipartimento F |
|---|---|---|---|---|---|---|
Uomini |
62.06% |
63.04% |
36.92% |
33.09% |
27.75% |
5.90% |
Donne |
82.41% |
68.00% |
34.06% |
34.93% |
23.92% |
7.04% |
I dati aggregati presentati nella Tabella 2 mostrano un significativo bias a favore dei candidati maschi; tuttavia, i dati relativi a ciascun dipartimento, forniti nella Tabella 3, rivelano una situazione opposta, con un bias a favore delle candidate femmine.
Un secondo esempio famoso è fornito da uno studio di Radelet and Pierce [RP91]. In tale studio è stata esaminata l’influenza della razza dell’accusato e della vittima sulle decisioni relative all’applicazione della pena di morte in Florida dal 1976 al 1987. Consideriamo inizialmente solo la razza dell’accusato. Dai dati raccolti su 674 individui accusati di omicidio plurimo, emerge che la propensione verso l’applicazione della pena di morte sembra essere più elevata per gli accusati bianchi rispetto a quelli afro-americani. Infatti, calcolando il rapporto delle quote (odds ratio, OR) a partire dai dati forniti:
risulta che gli accusati bianchi hanno una propensione all’applicazione della pena di morte 1.45 volte superiore rispetto agli afro-americani.
Tuttavia, l’analisi fornisce la conclusione opposta quando si incorpora anche la razza della vittima come ulteriore variabile. Introducendo questo elemento, troviamo che l’odds ratio relativo alla razza dell’accusato cambia notevolmente: \(\widehat{OR}_{\text{accusato}} = 0.42\). Questo significa che, controllando per la razza della vittima, la propensione all’applicazione della pena di morte è in realtà minore per gli accusati bianchi rispetto a quelli afro-americani. In termini più espliciti, la probabilità di ricevere la pena di morte è 2.38 volte maggiore per gli accusati afro-americani rispetto agli accusati bianchi.
L’analisi di questi dati mette in luce un altro chiaro esempio del paradosso di Simpson, dove l’associazione tra due variabili può cambiare direzione o addirittura scomparire quando si tiene conto di una terza variabile, in questo caso, la razza della vittima. Inizialmente, osservando solo l’associazione tra la razza dell’accusato e l’applicazione della pena di morte, sembrava che gli accusati bianchi avessero una maggiore propensione ad essere condannati a morte, con un rapporto delle quote (OR) di 1.4462. Tuttavia, questo risultato è stato capovolto quando abbiamo introdotto una variabile aggiuntiva, la razza della vittima, nel modello. Controllando per questa variabile, abbiamo trovato che la propensione all’applicazione della pena di morte era in realtà 2.38 volte maggiore per gli accusati afro-americani rispetto a quelli bianchi.
Questo ci porta a concludere che la razza dell’accusato da sola non è un indicatore sufficiente per prevedere l’applicazione della pena di morte; piuttosto, è l’interazione tra la razza dell’accusato e quella della vittima a determinare l’esito. Anche questo esempio sottolinea dunque l’importanza critica di esaminare attentamente tutte le variabili rilevanti in un’analisi statistica per evitare conclusioni errate.
Psicologia: una scienza individuale o di popolazione?#
Il Paradosso di Simpson rappresenta un nodo cruciale nella comprensione e nell’interpretazione delle analisi dei dati condotte frequentemente dagli psicologi durante la valutazione dei risultati sperimentali. Tradizionalmente, i corsi introduttivi di psicologia pongono l’individuo al centro dell’analisi, delineandolo come l’unità di analisi primaria. Nonostante ciò, sia gli strumenti didattici sia le metodologie di ricerca applicate nella pratica tendono a focalizzarsi maggiormente sulle medie di gruppo piuttosto che sull’individuo singolo.
Questo orientamento verso l’analisi aggregata introduce una sfida significativa, specialmente alla luce del Paradosso di Simpson. Infatti, abbiamo osservato come il paradosso si manifesti quando l’associazione tra due variabili, evidente a livello di popolazione, subisca un’inversione o persino scompaia quando la popolazione è divisa in sottogruppi diversi.
La ricerca psicologica, quindi, si trova a fronteggiare un dilemma metodologico: una relazione identificata a livello di popolazione non assicura la persistenza di tale relazione all’interno di tutti i sottogruppi presenti, soprattutto quando questi sottogruppi rappresentano gli individui. Sebbene esista una consapevolezza diffusa dell’unicità degli individui, nella prassi, le differenze individuali vengono frequentemente ridotte a semplici varianze o errori, venendo percepite come interferenze indesiderate all’analisi.
Di qui emerge una questione di fondo: può la psicologia ancora definirsi una scienza centrata sull’individuo o, piuttosto, dovrebbe essere vista come una scienza della popolazione, più vicina all’epidemiologia nella sua approccio?
Per navigare efficacemente attraverso le complessità portate dal Paradosso di Simpson e questioni correlate, diventa imprescindibile adottare modelli analitici che rispettino la strutturazione stratificata dei dati, evitando di appiattire le individualità in un aggregato di medie non rappresentative. Nonostante la tendenza attuale sia quella di focalizzarsi sulle medie del gruppo, è vitale accogliere e superare le sfide proposte dal Paradosso di Simpson, per preservare l’integrità delle inferenze sia a livello di popolazione che individuale.
Alla luce di tale complessità, è emera la necessità di rivedere l’approccio all’analisi dei dati in psicologia, assegnando un rilievo preminente alle differenze individuali. Questo non solo in omaggio all’unicità di ciascun individuo ma anche per affinare la validità e la pertinenza delle deduzioni tratte dalla ricerca psicologica.
Nel proseguo di questo capitolo, ci dedicheremo all’esplorazione di come i modelli gerarchici siano in grado di incorporare le differenze individuali, prevenendo le distorsioni interpretative scaturite dal paradosso di Simpson. Tale approccio permette di delineare un quadro analitico più preciso ed affidabile, che presti la dovuta attenzione alle singole peculiarità individuali.
Generare i dati#
Genereremo i dati seguendo le indicazioni fornite nel codice disponibile in questa pagina web, dove è presentato un tutorial dedicato al paradosso di Simpson. Mentre nelle sezioni precedenti ci siamo concentrati sul paradosso di Simpson in contesti che coinvolgono variabili qualitative, nella prossima parte della discussione ci focalizzeremo su un caso in cui il paradosso riguarda la relazione lineare tra due variabili continue, (x) e (y), in una situazione in cui i dati sono stratificati in diversi gruppi.
Show code cell content
def generate():
group_list = ["one", "two", "three", "four", "five"]
trials_per_group = 20
group_intercepts = rng.normal(0, 1, len(group_list))
group_slopes = np.ones(len(group_list)) * -0.5
group_mx = group_intercepts * 2
group = np.repeat(group_list, trials_per_group)
subject = np.concatenate(
[np.ones(trials_per_group) * i for i in np.arange(len(group_list))]
).astype(int)
intercept = np.repeat(group_intercepts, trials_per_group)
slope = np.repeat(group_slopes, trials_per_group)
mx = np.repeat(group_mx, trials_per_group)
x = rng.normal(mx, 1)
y = rng.normal(intercept + (x - mx) * slope, 1)
data = pd.DataFrame({"group": group, "group_idx": subject, "x": x, "y": y})
return data, group_list
Generiamo i dati insieme ad una lista che contiene i nomi dei cinque gruppi.
data, group_list = generate()
print(group_list)
['one', 'two', 'three', 'four', 'five']
display(data)
| group | group_idx | x | y | |
|---|---|---|---|---|
| 0 | one | 0 | -0.692745 | 0.750369 |
| 1 | one | 0 | 0.737275 | -0.709225 |
| 2 | one | 0 | 0.293192 | 0.123805 |
| 3 | one | 0 | 0.592633 | 1.153426 |
| 4 | one | 0 | -0.243610 | -0.996081 |
| ... | ... | ... | ... | ... |
| 95 | five | 4 | -4.280233 | -1.424379 |
| 96 | five | 4 | -2.602842 | -1.193167 |
| 97 | five | 4 | -4.258334 | -1.682318 |
| 98 | five | 4 | -3.164555 | -1.675854 |
| 99 | five | 4 | -4.835688 | -3.534398 |
100 rows × 4 columns
Creiamo uno scatterplot con i 5 gruppi di dati.
for i, group in enumerate(group_list):
plt.scatter(
data.x[data.group_idx == i],
data.y[data.group_idx == i],
color=f"C{i}",
label=f"{group}",
)
plt.legend(title="group");
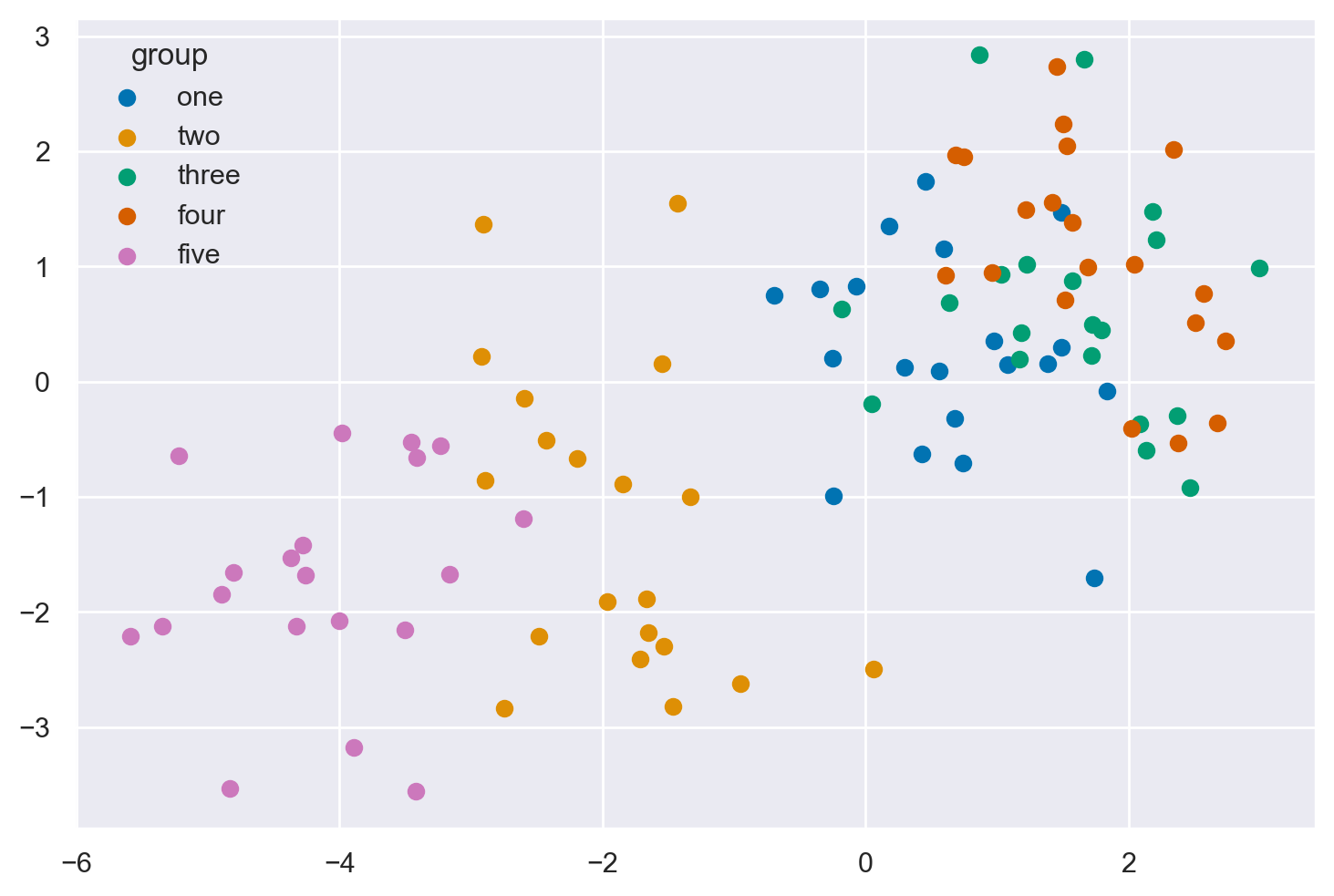
for i, group in enumerate(group_list):In questa linea, stiamo iniziando un ciclo for che itera attraverso ogni elemento in
group_list. La funzioneenumerateè utilizzata per ottenere sia l’indice (i) che il valore (group) per ogni iterazione.plt.scatter(...)Dentro il ciclo for, chiamiamo la funzione
scatterdaplt(che è una abbreviazione comune permatplotlib.pyplot) per creare un grafico a dispersione. Vediamo i dettagli di ciascun parametro che abbiamo passato alla funzionescatter:data.x[data.group_idx == i]Qui stiamo selezionando tutti i valori dalla colonna
'x'del DataFramedatadove i valori nella colonna'group_idx'sono uguali ai. Questo è fatto utilizzando il filtraggio booleano.data.y[data.group_idx == i]Simile al parametro x, qui stiamo selezionando tutti i valori dalla colonna
'y'del DataFramedatadove i valori nella colonna'group_idx'sono uguali ai.color=f"C{i}"Qui stiamo assegnando un colore unico a ciascun gruppo di punti nel grafico a dispersione.
f"C{i}"è una stringa f che inserisce il valore dii(l’indice corrente nel ciclo) nella stringa, creando stringhe come'C0','C1', …, che vengono utilizzate per specificare i colori in matplotlib.label=f"{group}"Qui stiamo assegnando un’etichetta a ciascun gruppo di punti, che verrà utilizzata nella legenda del grafico. Stiamo usando il valore corrente di
group(il nome del gruppo corrente) come etichetta.
plt.legend(title="group");Dopo la fine del ciclo for, chiamiamo la funzione
legenddapltper aggiungere una legenda al grafico. La legenda utilizzerà le etichette e i colori che abbiamo specificato nelle chiamate precedenti ascatterper creare una legenda che mostra quale colore corrisponde a quale gruppo. Abbiamo anche specificato un titolo per la legenda, che è"group".
Modello 1: regressione lineare bivariata#
Iniziamo con il modello più semplice - la regressione lineare semplice, che raggruppa tutti i dati e non ha alcuna conoscenza della struttura di gruppo/multilivello dei dati.
Definizione del modello#
with pm.Model() as linear_regression:
sigma = pm.HalfCauchy("sigma", beta=2)
β0 = pm.Normal("β0", 0, sigma=5)
β1 = pm.Normal("β1", 0, sigma=5)
x = pm.MutableData("x", data.x, dims="obs_id")
μ = pm.Deterministic("μ", β0 + β1 * x, dims="obs_id")
pm.Normal("y", mu=μ, sigma=sigma, observed=data.y, dims="obs_id")
with pm.Model() as linear_regression:
Qui iniziamo a definire il nostro modello PyMC3, creando un contesto per il nostro modello chiamato linear_regression.
sigma = pm.HalfCauchy("sigma", beta=2)
In questa linea, stiamo definendo una variabile casuale sigma che seguirà una distribuzione Half-Cauchy con un parametro beta impostato a 2. Questa variabile rappresenta la deviazione standard dei residui del modello.
β0 = pm.Normal("β0", 0, sigma=5)
β1 = pm.Normal("β1", 0, sigma=5)
Qui stiamo definendo due variabili casuali, β0 e β1, che rappresentano rispettivamente l’intercetta e la pendenza della linea di regressione. Entrambe sono assunte seguire una distribuzione normale con media 0 e deviazione standard 5.
x = pm.MutableData("x", data.x, dims="obs_id")
In questa linea, stiamo definendo un contenitore di dati mutabile per le variabili indipendenti (o predittori) del nostro modello, basato sul vettore data.x.
μ = pm.Deterministic("μ", β0 + β1 * x, dims="obs_id")
Qui, definiamo una variabile deterministica μ che rappresenta il valore atteso della variabile dipendente in funzione delle variabili indipendenti e dei parametri della regressione.
pm.Normal("y", mu=μ, sigma=sigma, observed=data.y, dims="obs_id")
Infine, definiamo la distribuzione delle variabili dipendenti (o risposte) assumendo che seguano una distribuzione normale con media μ e deviazione standard sigma. Impostiamo i dati osservati a data.y.
In sintesi, questo codice sta impostando un modello di regressione lineare semplice con PyMC, in cui si cerca di prevedere la variabile dipendente y in base alla variabile indipendente x, con parametri di regressione β0 e β1, e una deviazione standard dei residui sigma.
pm.model_to_graphviz(linear_regression)

Campionamento#
Una volta definito il modello, è possibile usare il sampling MCMC per ottenere stime dei parametri del modello.
with linear_regression:
idata = pm.sampling_jax.sample_numpyro_nuts()
Show code cell output
Compiling...
Compilation time = 0:00:01.564034
Sampling...
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
Running chain 0: 0%| | 0/2000 [00:02<?, ?it/s]
Running chain 1: 0%| | 0/2000 [00:02<?, ?it/s]
Running chain 2: 0%| | 0/2000 [00:02<?, ?it/s]
Running chain 3: 0%| | 0/2000 [00:02<?, ?it/s]
Running chain 0: 100%|█████████████████████████████████████████████████████| 2000/2000 [00:02<00:00, 869.67it/s]
Running chain 1: 100%|█████████████████████████████████████████████████████| 2000/2000 [00:02<00:00, 870.08it/s]
Running chain 2: 100%|█████████████████████████████████████████████████████| 2000/2000 [00:02<00:00, 870.79it/s]
Running chain 3: 100%|█████████████████████████████████████████████████████| 2000/2000 [00:02<00:00, 871.48it/s]
Sampling time = 0:00:02.672838
Transforming variables...
Transformation time = 0:00:00.170641
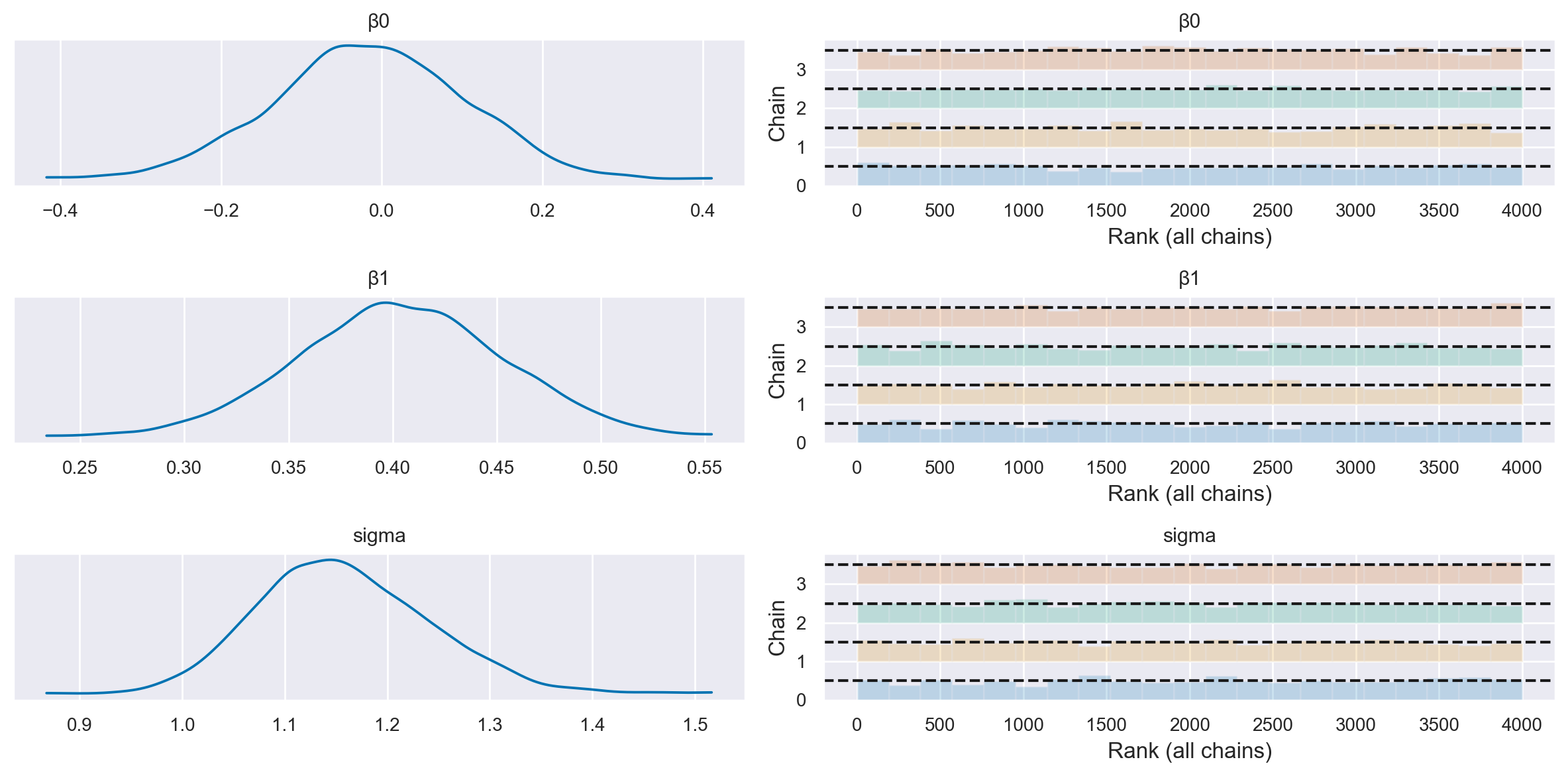
Esaminiamo le distribuzioni a posteriori dei parametri del modello.
az.plot_trace(
idata,
filter_vars="regex",
var_names=["~μ"],
kind="rank_bars",
combined=True,
divergences="bottom",
)
plt.tight_layout()
Visualizzazione#
Per ottenere una comprensione più profonda del nostro modello, decidiamo di eseguire una predizione a posteriori utilizzando un set di valori x che copre l’intervallo osservato dei nostri dati. Creiamo un array xi contenente 20 punti che spaziano linearmente dal minimo al massimo valore osservato di x.
Entrando nel contesto del nostro modello di regressione lineare, aggiorniamo il dataset del modello con questo nuovo array xi utilizzando pm.set_data. Successivamente, eseguiamo l’inferenza predittiva a posteriori utilizzando pm.sample_posterior_predictive, specificando che desideriamo ottenere campioni a posteriori per le variabili y e μ. Questo processo ci permette di ottenere una distribuzione di valori predetti y e μ, riflettendo non solo le incertezze nei parametri del modello ma anche la variabilità intrinseca nei dati.
Estendiamo il nostro contenitore di dati a posteriori idata con queste nuove predizioni, consentendoci così di analizzare e visualizzare la distribuzione a posteriori dei valori predetti in un secondo momento, fornendo una visione ricca dell’incertezza predittiva del nostro modello.
# posterior prediction for these x values
xi = np.linspace(data.x.min(), data.x.max(), 20)
# do posterior predictive inference
with linear_regression:
pm.set_data({"x": xi})
idata.extend(pm.sample_posterior_predictive(idata, var_names=["y", "μ"]))
Sampling: [y]
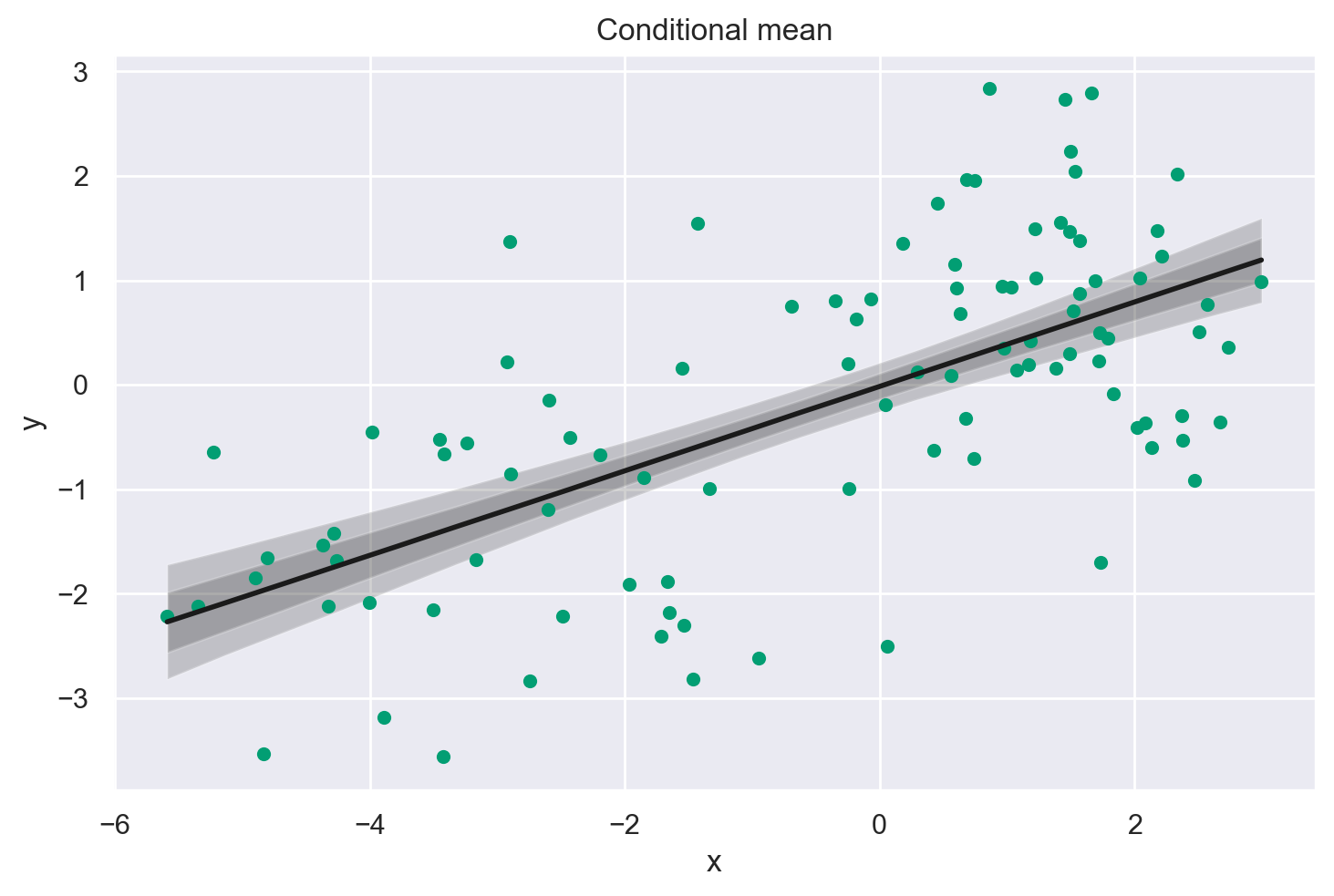
Una volta ottenuto l’oggetto idata con le caratteristiche descritte sopra, visualizziamo la soluzoine del modello che abbiamo definito usando il codice fornito nella pagina web.
post = az.extract(idata)
xi = xr.DataArray(np.linspace(np.min(data['x']), np.max(data['x']), 20), dims=["x_plot"])
y = post.β0 + post.β1 * xi
region = y.quantile([0.025, 0.15, 0.5, 0.85, 0.975], dim="sample")
fig, ax = plt.subplots(1, 1)
ax.fill_between(
xi, region.sel(quantile=0.025), region.sel(quantile=0.975), alpha=0.2, color="k", edgecolor="w"
)
ax.fill_between(
xi, region.sel(quantile=0.15), region.sel(quantile=0.85), alpha=0.2, color="k", edgecolor="w"
)
# Plotting the conditional mean
ax.plot(xi, region.sel(quantile=0.5), "k", linewidth=2)
# Plotting the data points
ax.scatter(data['x'], data['y'], color='C2', s=20, label='Data points')
# Formatting
ax.set(xlabel="x", ylabel="y", title="Conditional mean")
plt.show() # Add this line to actually show the plot
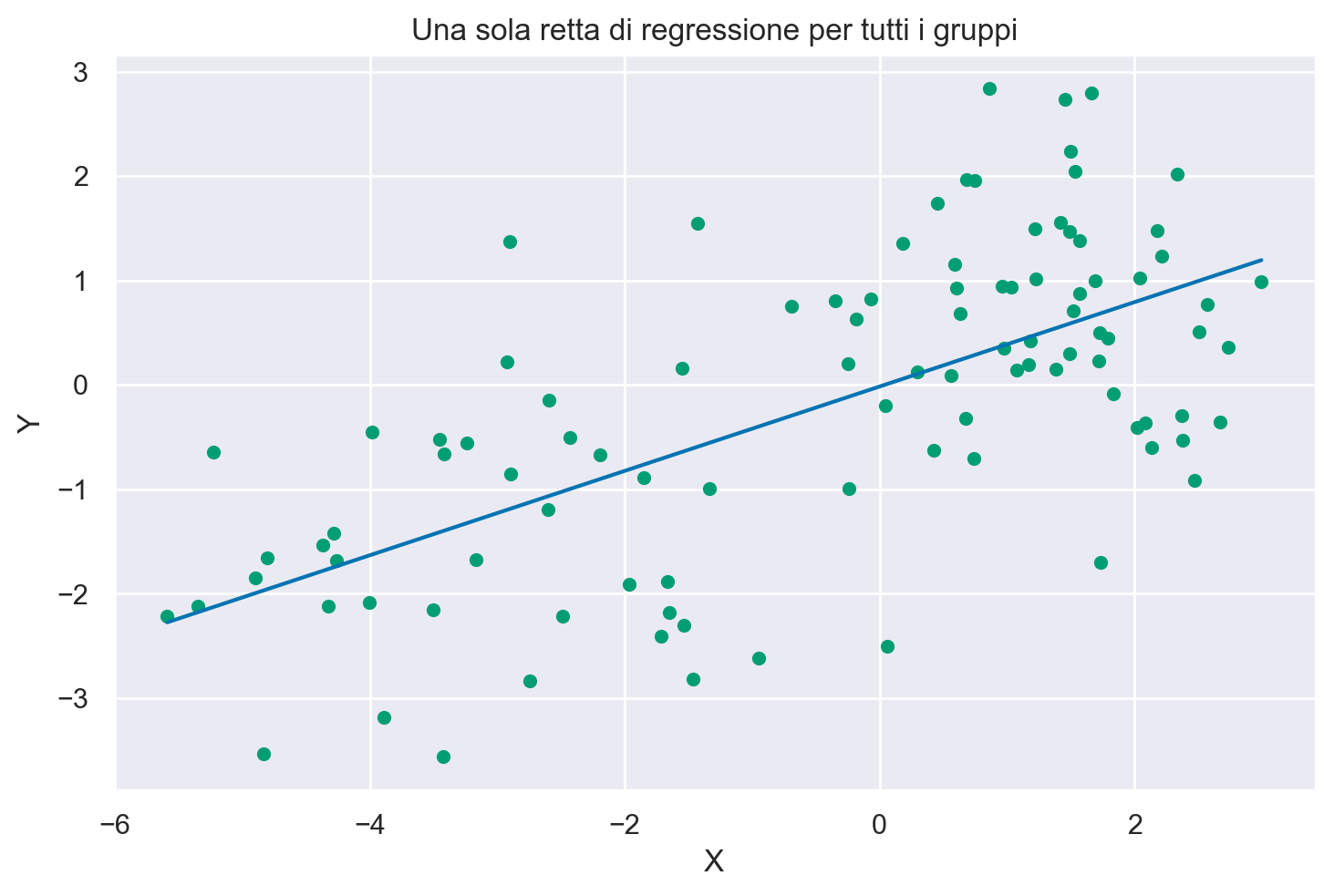
Per approfondire la comprensione del codice precedente, analizziamo la seguente versione semplificata.
beta_0 = idata.posterior.β0.mean().values
print(beta_0)
-0.01663299231684704
beta_1 = idata.posterior.β1.mean().values
print(beta_1)
0.4040968623679126
xi = np.linspace(np.min(data["x"]), np.max(data["x"]), 20)
xi
array([-5.58940481, -5.13754963, -4.68569444, -4.23383926, -3.78198407,
-3.33012889, -2.8782737 , -2.42641852, -1.97456333, -1.52270815,
-1.07085296, -0.61899778, -0.16714259, 0.28471259, 0.73656778,
1.18842296, 1.64027815, 2.09213333, 2.54398852, 2.9958437 ])
# Genera la linea di regressione utilizzando l'equazione della retta
y_pred = beta_0 + beta_1 * xi
# Visualizza la linea di regressione
plt.plot(xi, y_pred)
plt.scatter(data['x'], data['y'], color='C2', s=20)
plt.xlabel('X')
plt.ylabel('Y')
plt.title('Una sola retta di regressione per tutti i gruppi')
plt.show()
az.summary(idata, var_names="β1")
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| β1 | 0.404 | 0.049 | 0.312 | 0.496 | 0.001 | 0.001 | 3145.0 | 2722.0 | 1.0 |
L’analisi dei dati aggregati mostra la presenza di un’associazione positiva tra le variabili: β1 = 0.236, 94% CI [0.126, 0.351].
Modello 2: Modello con pendenze e intercette indipendenti#
Useremo gli stessi dati in questa seconda analisi, ma questa volta utilizzeremo la nostra conoscenza che i dati provengono da gruppi diversi. Più specificatamente, adatteremo regressioni indipendenti ai dati all’interno di ogni gruppo.
coords = {"group": group_list}
with pm.Model(coords=coords) as ind_slope_intercept:
# Define priors
sigma = pm.HalfCauchy("sigma", beta=2, dims="group")
β0 = pm.Normal("β0", 0, sigma=5, dims="group")
β1 = pm.Normal("β1", 0, sigma=5, dims="group")
# Data
x = pm.MutableData("x", data.x, dims="obs_id")
g = pm.MutableData("g", data.group_idx, dims="obs_id")
# Linear model
μ = pm.Deterministic("μ", β0[g] + β1[g] * x, dims="obs_id")
# Define likelihood
pm.Normal("y", mu=μ, sigma=sigma[g], observed=data.y, dims="obs_id")
Definizione delle coordinate
coords = {"group": group_list}
Qui, viene creato un dizionario che associa un nome (“group”) a una lista di gruppi (group_list). Questo verrà usato per specificare le dimensioni del modello.
Creazione del modello con PyMC3
with pm.Model(coords=coords) as ind_slope_intercept:
Inizia la definizione del modello PyMC3, dove coords=coords specifica le coordinate che verranno usate nel modello.
Definizione dei prior
sigma = pm.HalfCauchy("sigma", beta=2, dims="group")
β0 = pm.Normal("β0", 0, sigma=5, dims="group")
β1 = pm.Normal("β1", 0, sigma=5, dims="group")
In questa sezione, vengono definiti i prior per i parametri del modello. Sia β0 che β1 sono definiti come distribuzioni normali con una media di 0 e una deviazione standard di 5. La sigma, che rappresenta l’errore standard delle osservazioni, segue una distribuzione HalfCauchy con un parametro beta di 2. Questi prior sono definiti separatamente per ogni gruppo, come indicato da dims="group".
Specificazione dei dati
x = pm.MutableData("x", data.x, dims="obs_id")
g = pm.MutableData("g", data.group_idx, dims="obs_id")
I dati vengono inseriti nel modello tramite oggetti MutableData, che permettono di cambiare i dati in seguito senza dover definire un nuovo modello. Qui, data.x rappresenta la variabile indipendente e data.group_idx rappresenta gli indici dei gruppi.
Definizione del modello lineare
μ = pm.Deterministic("μ", β0[g] + β1[g] * x, dims="obs_id")
Qui, viene definito il modello lineare. La media (μ) viene calcolata come la somma dell’intercetta (β0) e la pendenza (β1) moltiplicata per la variabile indipendente (x). Questo viene fatto separatamente per ogni gruppo, come indicato dall’indexing con g.
Definizione della likelihood
pm.Normal("y", mu=μ, sigma=sigma[g], observed=data.y, dims="obs_id")
Infine, viene definita la funzione di likelihood, che è una distribuzione normale con una media (mu) definita dal modello lineare e una deviazione standard (sigma) specifica per ogni gruppo. Il parametro observed=data.y indica che stiamo adattando il modello ai dati osservati data.y. La specifica dims="obs_id" indica che questa parte del modello opera su una dimensione che rappresenta ciascuna osservazione individuale nel nostro set di dati.
pm.model_to_graphviz(ind_slope_intercept)

Campionamento#
with ind_slope_intercept:
idata = pm.sampling_jax.sample_numpyro_nuts()
Show code cell output
Compiling...
Compilation time = 0:00:01.231752
Sampling...
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
Running chain 2: 0%| | 0/2000 [00:02<?, ?it/s]
Running chain 1: 0%| | 0/2000 [00:02<?, ?it/s]
Running chain 3: 0%| | 0/2000 [00:02<?, ?it/s]
Running chain 0: 0%| | 0/2000 [00:02<?, ?it/s]
Running chain 1: 30%|███████████████▉ | 600/2000 [00:02<00:00, 5956.80it/s]
Running chain 2: 30%|███████████████▉ | 600/2000 [00:02<00:00, 5910.93it/s]
Running chain 0: 30%|███████████████▉ | 600/2000 [00:02<00:00, 5518.55it/s]
Running chain 3: 35%|██████████████████▌ | 700/2000 [00:02<00:00, 6259.67it/s]
Running chain 2: 70%|████████████████████████████████████▍ | 1400/2000 [00:02<00:00, 6960.57it/s]
Running chain 1: 70%|████████████████████████████████████▍ | 1400/2000 [00:02<00:00, 6839.19it/s]
Running chain 3: 75%|███████████████████████████████████████ | 1500/2000 [00:02<00:00, 7029.25it/s]
Running chain 0: 75%|███████████████████████████████████████ | 1500/2000 [00:02<00:00, 7019.05it/s]
Running chain 0: 100%|█████████████████████████████████████████████████████| 2000/2000 [00:02<00:00, 677.32it/s]
Running chain 1: 100%|█████████████████████████████████████████████████████| 2000/2000 [00:02<00:00, 677.61it/s]
Running chain 2: 100%|█████████████████████████████████████████████████████| 2000/2000 [00:02<00:00, 678.01it/s]
Running chain 3: 100%|█████████████████████████████████████████████████████| 2000/2000 [00:02<00:00, 678.37it/s]
Sampling time = 0:00:03.111960
Transforming variables...
Transformation time = 0:00:00.153296
az.plot_trace(
idata,
combined=True,
filter_vars="regex",
var_names=["~μ"],
kind="rank_bars",
divergences="bottom",
)
plt.tight_layout()
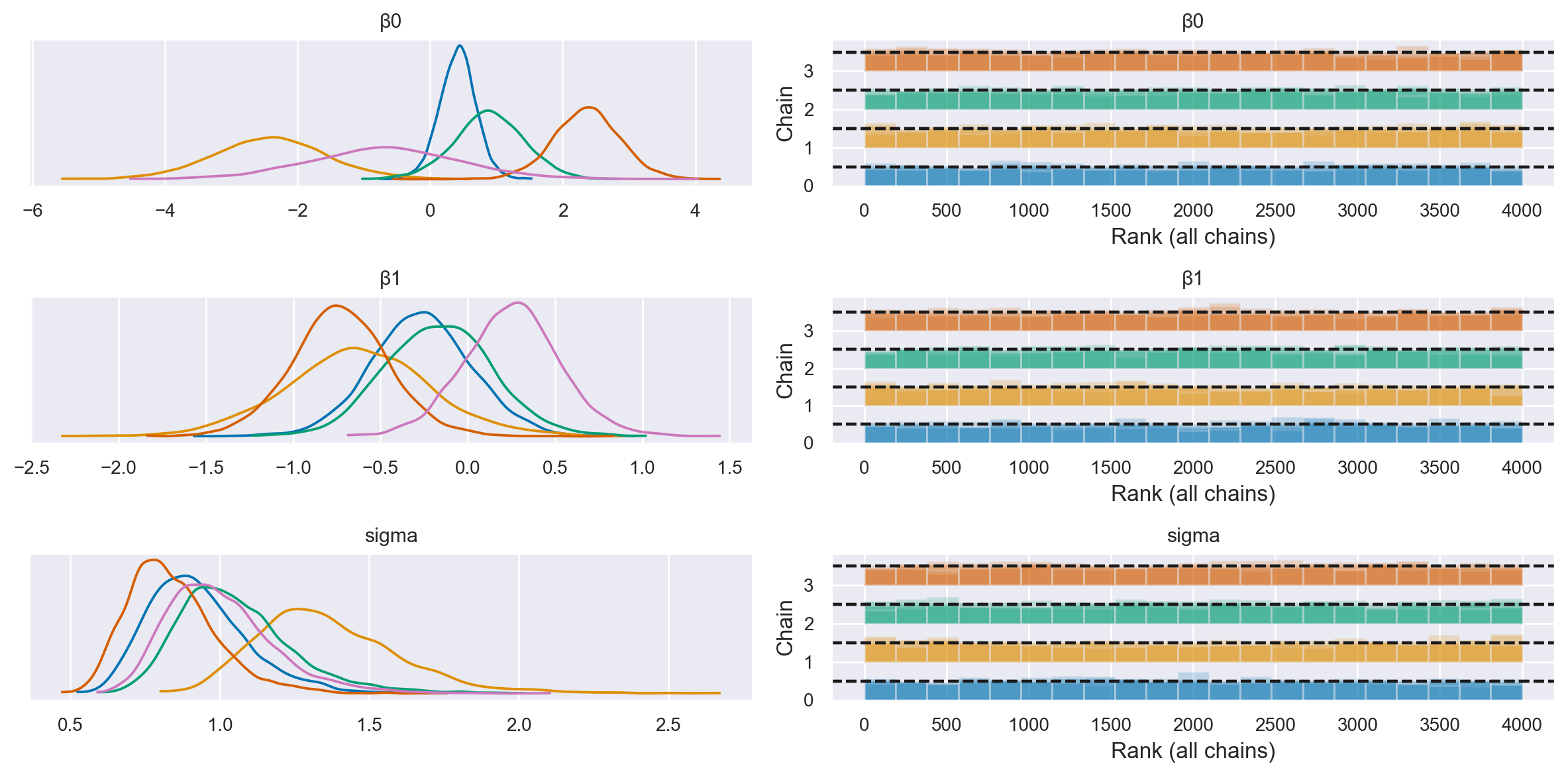
Visualizzazione#
# Create values of x and g to use for posterior prediction
xi = [
np.linspace(data.query(f"group_idx=={i}").x.min(), data.query(f"group_idx=={i}").x.max(), 10)
for i, _ in enumerate(group_list)
]
g = [np.ones(10) * i for i, _ in enumerate(group_list)]
xi, g = np.concatenate(xi), np.concatenate(g)
# Do the posterior prediction
with ind_slope_intercept:
pm.set_data({"x": xi, "g": g.astype(int)})
idata.extend(pm.sample_posterior_predictive(idata, var_names=["μ", "y"]))
Sampling: [y]
def get_ppy_for_group(group_list, group):
"""Get posterior predictive outcomes for observations from a given group"""
return idata.posterior_predictive.y.data[:, :, group_list == group]
fig, ax = plt.subplots(1, 1)
# conditional mean plot ---------------------------------------------
for i, groupname in enumerate(group_list):
# data
ax.scatter(data.x[data.group_idx == i], data.y[data.group_idx == i], color=f"C{i}")
# conditional mean credible intervals
post = az.extract(idata)
_xi = xr.DataArray(
np.linspace(np.min(data.x[data.group_idx == i]), np.max(data.x[data.group_idx == i]), 20),
dims=["x_plot"],
)
y = post.β0.sel(group=groupname) + post.β1.sel(group=groupname) * _xi
region = y.quantile([0.025, 0.15, 0.5, 0.85, 0.975], dim="sample")
ax.fill_between(
_xi,
region.sel(quantile=0.025),
region.sel(quantile=0.975),
alpha=0.2,
color=f"C{i}",
edgecolor="w",
)
ax.fill_between(
_xi,
region.sel(quantile=0.15),
region.sel(quantile=0.85),
alpha=0.2,
color=f"C{i}",
edgecolor="w",
)
# conditional mean
ax.plot(_xi, region.sel(quantile=0.5), color=f"C{i}", linewidth=2)
# formatting
ax.set(xlabel="x", ylabel="y", title="Conditional mean")
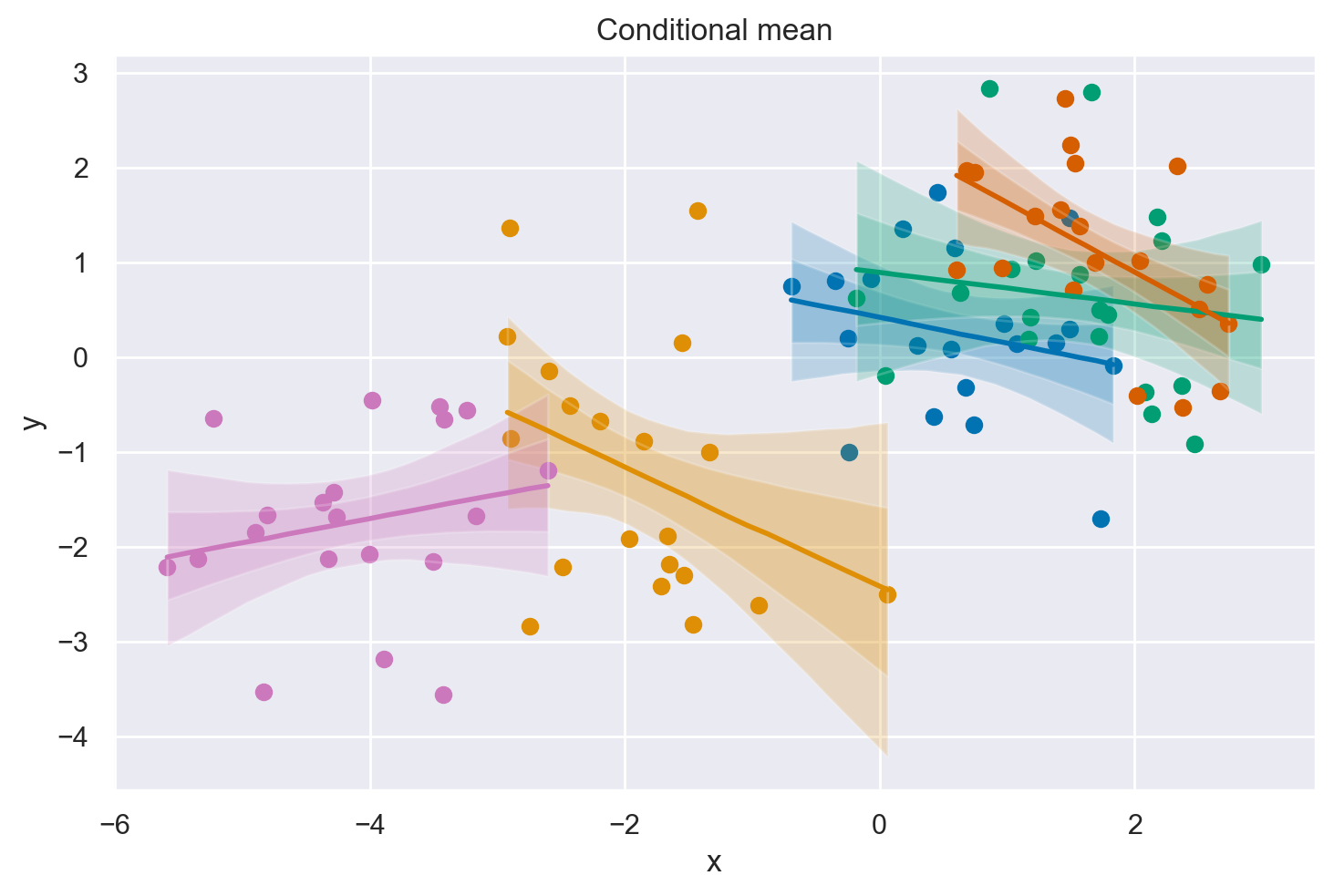
A differenza del semplice modello di regressione (Modello 1), quando modelliamo a livello di gruppo possiamo vedere che ora le prove indicano una relazione negativa tra \(x\) e \(y\).
Modello 3: Regressione gerarchica#
Possiamo andare oltre il Modello 2 e incorporare ancora più conoscenze riguardo alla struttura dei nostri dati. Invece di trattare ogni gruppo come completamente indipendente, possiamo utilizzare la nostra conoscenza che questi gruppi provengono da una distribuzione a livello di popolazione. Questi sono talvolta chiamati iperparametri.
In un certo senso, questo passaggio dal Modello 2 al Modello 3 può essere visto come l’aggiunta di parametri, e quindi l’aumento della complessità del modello. Tuttavia, in un altro senso, aggiungendo questa conoscenza sulla struttura nidificata dei dati fornisce effettivamente un vincolo sullo spazio dei parametri.
Note
Questo modello produce dei campioni divergenti, quindi è stato modificato mediante la tecnica della reparametrizzazione. Per maggiori informazioni su questo, si veda il post Why hierarchical models are awesome, tricky, and Bayesian sul blog di Thomas Wiecki.
non_centered = False
with pm.Model(coords=coords) as hierarchical:
# Hyperpriors
intercept_mu = pm.Normal("intercept_mu", 0, sigma=1)
intercept_sigma = pm.HalfNormal("intercept_sigma", sigma=2)
slope_mu = pm.Normal("slope_mu", 0, sigma=1)
slope_sigma = pm.HalfNormal("slope_sigma", sigma=2)
sigma_hyperprior = pm.HalfNormal("sigma_hyperprior", sigma=0.5)
# Define priors
sigma = pm.HalfNormal("sigma", sigma=sigma_hyperprior, dims="group")
if non_centered:
β0_offset = pm.Normal("β0_offset", 0, sigma=1, dims="group")
β0 = pm.Deterministic("β0", intercept_mu + β0_offset * intercept_sigma, dims="group")
β1_offset = pm.Normal("β1_offset", 0, sigma=1, dims="group")
β1 = pm.Deterministic("β1", slope_mu + β1_offset * slope_sigma, dims="group")
else:
β0 = pm.Normal("β0", intercept_mu, sigma=intercept_sigma, dims="group")
β1 = pm.Normal("β1", slope_mu, sigma=slope_sigma, dims="group")
# Data
x = pm.MutableData("x", data.x, dims="obs_id")
g = pm.MutableData("g", data.group_idx, dims="obs_id")
# Linear model
μ = pm.Deterministic("μ", β0[g] + β1[g] * x, dims="obs_id")
# Define likelihood
pm.Normal("y", mu=μ, sigma=sigma[g], observed=data.y, dims="obs_id")
pm.model_to_graphviz(hierarchical)

Campionamento (senza riparametrizzazione)#
with hierarchical:
idata = pm.sampling_jax.sample_numpyro_nuts(tune=5000, target_accept=0.99)
Show code cell output
Compiling...
Compilation time = 0:00:01.780467
Sampling...
0%| | 0/6000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/6000 [00:00<?, ?it/s]
0%| | 0/6000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/6000 [00:00<?, ?it/s]
0%| | 0/6000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/6000 [00:00<?, ?it/s]
0%| | 0/6000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/6000 [00:00<?, ?it/s]
Running chain 3: 0%| | 0/6000 [00:03<?, ?it/s]
Running chain 1: 0%| | 0/6000 [00:03<?, ?it/s]
Running chain 2: 0%| | 0/6000 [00:03<?, ?it/s]
Running chain 0: 0%| | 0/6000 [00:03<?, ?it/s]
Running chain 3: 5%|██▋ | 300/6000 [00:03<00:03, 1858.26it/s]
Running chain 1: 5%|██▋ | 300/6000 [00:03<00:03, 1729.40it/s]
Running chain 2: 5%|██▋ | 300/6000 [00:03<00:03, 1604.30it/s]
Running chain 0: 5%|██▋ | 300/6000 [00:03<00:03, 1560.87it/s]
Running chain 2: 10%|█████▎ | 600/6000 [00:03<00:02, 2126.84it/s]
Running chain 0: 10%|█████▎ | 600/6000 [00:03<00:02, 2132.96it/s]
Running chain 1: 10%|█████▎ | 600/6000 [00:03<00:02, 2024.51it/s]
Running chain 3: 10%|█████▎ | 600/6000 [00:03<00:03, 1785.80it/s]
Running chain 2: 15%|███████▉ | 900/6000 [00:03<00:02, 2288.82it/s]
Running chain 0: 15%|███████▉ | 900/6000 [00:03<00:02, 2276.98it/s]
Running chain 3: 15%|███████▉ | 900/6000 [00:03<00:02, 2124.57it/s]
Running chain 1: 15%|███████▉ | 900/6000 [00:03<00:02, 1952.04it/s]
Running chain 2: 20%|██████████▍ | 1200/6000 [00:04<00:01, 2503.72it/s]
Running chain 0: 20%|██████████▍ | 1200/6000 [00:04<00:01, 2458.33it/s]
Running chain 2: 25%|█████████████ | 1500/6000 [00:04<00:01, 2627.16it/s]
Running chain 3: 25%|█████████████ | 1500/6000 [00:04<00:01, 2541.54it/s]
Running chain 1: 20%|██████████▍ | 1200/6000 [00:04<00:03, 1489.10it/s]
Running chain 2: 30%|███████████████▌ | 1800/6000 [00:04<00:01, 2525.59it/s]
Running chain 3: 30%|███████████████▌ | 1800/6000 [00:04<00:01, 2562.76it/s]
Running chain 1: 25%|█████████████ | 1500/6000 [00:04<00:02, 1725.16it/s]
Running chain 0: 30%|███████████████▌ | 1800/6000 [00:04<00:02, 1868.97it/s]
Running chain 2: 40%|████████████████████▊ | 2400/6000 [00:04<00:01, 2817.66it/s]
Running chain 3: 40%|████████████████████▊ | 2400/6000 [00:04<00:01, 2833.33it/s]
Running chain 1: 30%|███████████████▌ | 1800/6000 [00:04<00:02, 1868.22it/s]
Running chain 0: 35%|██████████████████▏ | 2100/6000 [00:04<00:01, 2038.50it/s]
Running chain 2: 45%|███████████████████████▍ | 2700/6000 [00:04<00:01, 2645.69it/s]
Running chain 0: 40%|████████████████████▊ | 2400/6000 [00:04<00:01, 2237.58it/s]
Running chain 1: 35%|██████████████████▏ | 2100/6000 [00:04<00:02, 1846.56it/s]
Running chain 3: 50%|██████████████████████████ | 3000/6000 [00:04<00:01, 2672.98it/s]
Running chain 2: 50%|██████████████████████████ | 3000/6000 [00:04<00:01, 2599.99it/s]
Running chain 0: 45%|███████████████████████▍ | 2700/6000 [00:04<00:01, 2325.87it/s]
Running chain 1: 40%|████████████████████▊ | 2400/6000 [00:04<00:01, 2037.44it/s]
Running chain 2: 55%|████████████████████████████▌ | 3300/6000 [00:04<00:01, 2476.32it/s]
Running chain 3: 55%|████████████████████████████▌ | 3300/6000 [00:04<00:01, 2441.10it/s]
Running chain 0: 50%|██████████████████████████ | 3000/6000 [00:04<00:01, 2403.98it/s]
Running chain 1: 45%|███████████████████████▍ | 2700/6000 [00:04<00:01, 2193.69it/s]
Running chain 2: 60%|███████████████████████████████▏ | 3600/6000 [00:04<00:00, 2504.90it/s]
Running chain 3: 60%|███████████████████████████████▏ | 3600/6000 [00:05<00:01, 2377.19it/s]
Running chain 0: 55%|████████████████████████████▌ | 3300/6000 [00:05<00:01, 2309.65it/s]
Running chain 2: 65%|█████████████████████████████████▊ | 3900/6000 [00:05<00:00, 2630.26it/s]
Running chain 1: 50%|██████████████████████████ | 3000/6000 [00:05<00:01, 2085.46it/s]
Running chain 3: 65%|█████████████████████████████████▊ | 3900/6000 [00:05<00:00, 2478.24it/s]
Running chain 0: 60%|███████████████████████████████▏ | 3600/6000 [00:05<00:01, 2322.01it/s]
Running chain 2: 70%|████████████████████████████████████▍ | 4200/6000 [00:05<00:00, 2625.89it/s]
Running chain 1: 55%|████████████████████████████▌ | 3300/6000 [00:05<00:01, 2051.93it/s]
Running chain 0: 65%|█████████████████████████████████▊ | 3900/6000 [00:05<00:00, 2376.16it/s]
Running chain 2: 75%|███████████████████████████████████████ | 4500/6000 [00:05<00:00, 2332.67it/s]
Running chain 3: 75%|███████████████████████████████████████ | 4500/6000 [00:05<00:00, 2389.78it/s]
Running chain 0: 70%|████████████████████████████████████▍ | 4200/6000 [00:05<00:00, 2381.33it/s]
Running chain 1: 65%|█████████████████████████████████▊ | 3900/6000 [00:05<00:00, 2323.90it/s]
Running chain 2: 80%|█████████████████████████████████████████▌ | 4800/6000 [00:05<00:00, 2423.43it/s]
Running chain 3: 80%|█████████████████████████████████████████▌ | 4800/6000 [00:05<00:00, 2379.96it/s]
Running chain 0: 75%|███████████████████████████████████████ | 4500/6000 [00:05<00:00, 2381.28it/s]
Running chain 1: 70%|████████████████████████████████████▍ | 4200/6000 [00:05<00:00, 2393.39it/s]
Running chain 3: 85%|████████████████████████████████████████████▏ | 5100/6000 [00:05<00:00, 2418.08it/s]
Running chain 2: 85%|████████████████████████████████████████████▏ | 5100/6000 [00:05<00:00, 2087.25it/s]
Running chain 0: 80%|█████████████████████████████████████████▌ | 4800/6000 [00:05<00:00, 2315.08it/s]
Running chain 1: 75%|███████████████████████████████████████ | 4500/6000 [00:05<00:00, 2496.11it/s]
Running chain 3: 90%|██████████████████████████████████████████████▊ | 5400/6000 [00:05<00:00, 2495.06it/s]
Running chain 1: 80%|█████████████████████████████████████████▌ | 4800/6000 [00:05<00:00, 2556.83it/s]
Running chain 0: 85%|████████████████████████████████████████████▏ | 5100/6000 [00:05<00:00, 2310.17it/s]
Running chain 3: 95%|█████████████████████████████████████████████████▍ | 5700/6000 [00:05<00:00, 2572.25it/s]
Running chain 2: 90%|██████████████████████████████████████████████▊ | 5400/6000 [00:05<00:00, 1671.24it/s]
Running chain 1: 85%|████████████████████████████████████████████▏ | 5100/6000 [00:05<00:00, 2413.29it/s]
Running chain 3: 100%|████████████████████████████████████████████████████| 6000/6000 [00:05<00:00, 2592.35it/s]
Running chain 0: 95%|█████████████████████████████████████████████████▍ | 5700/6000 [00:05<00:00, 2631.03it/s]
Running chain 1: 90%|██████████████████████████████████████████████▊ | 5400/6000 [00:06<00:00, 2422.49it/s]
Running chain 1: 95%|█████████████████████████████████████████████████▍ | 5700/6000 [00:06<00:00, 2426.85it/s]
Running chain 2: 95%|█████████████████████████████████████████████████▍ | 5700/6000 [00:06<00:00, 1454.74it/s]
Running chain 1: 100%|████████████████████████████████████████████████████| 6000/6000 [00:06<00:00, 2445.40it/s]
Running chain 2: 100%|████████████████████████████████████████████████████| 6000/6000 [00:06<00:00, 1360.97it/s]
Running chain 0: 100%|█████████████████████████████████████████████████████| 6000/6000 [00:06<00:00, 932.58it/s]
Running chain 1: 100%|█████████████████████████████████████████████████████| 6000/6000 [00:06<00:00, 932.75it/s]
Running chain 2: 100%|█████████████████████████████████████████████████████| 6000/6000 [00:06<00:00, 932.98it/s]
Running chain 3: 100%|█████████████████████████████████████████████████████| 6000/6000 [00:06<00:00, 933.18it/s]
Sampling time = 0:00:06.629069
Transforming variables...
Transformation time = 0:00:00.157495
az.plot_trace(
idata,
combined=True,
filter_vars="regex",
var_names=["~μ"],
kind="rank_bars",
divergences="bottom",
)
plt.tight_layout()
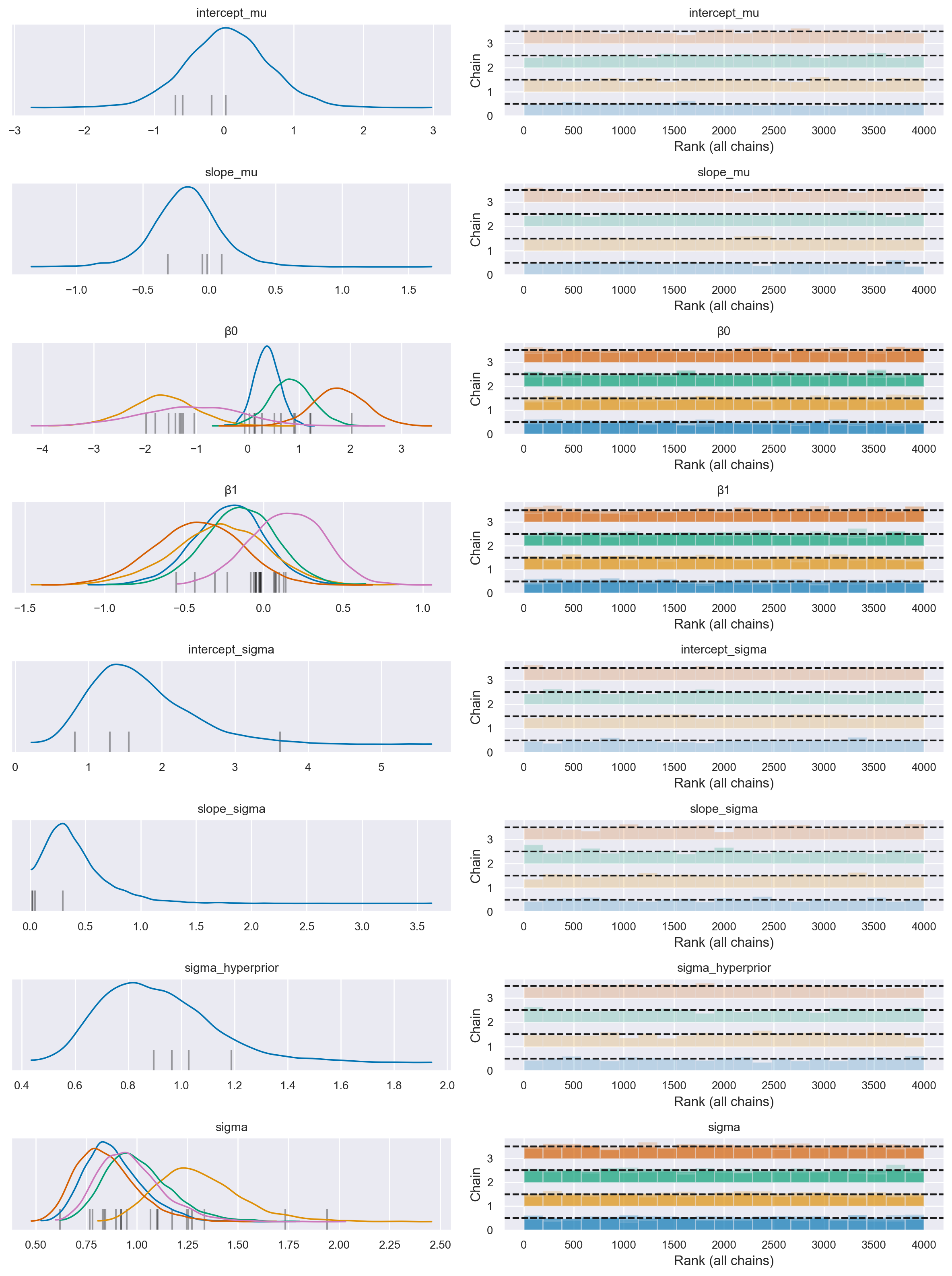
Si noti la presenza di transizioni divergenti.
Campionamento (con riparametrizzazione)#
non_centered = True
with pm.Model(coords=coords) as hierarchical:
# Hyperpriors
intercept_mu = pm.Normal("intercept_mu", 0, sigma=1)
intercept_sigma = pm.HalfNormal("intercept_sigma", sigma=2)
slope_mu = pm.Normal("slope_mu", 0, sigma=1)
slope_sigma = pm.HalfNormal("slope_sigma", sigma=2)
sigma_hyperprior = pm.HalfNormal("sigma_hyperprior", sigma=0.5)
# Define priors
sigma = pm.HalfNormal("sigma", sigma=sigma_hyperprior, dims="group")
if non_centered:
β0_offset = pm.Normal("β0_offset", 0, sigma=1, dims="group")
β0 = pm.Deterministic("β0", intercept_mu + β0_offset * intercept_sigma, dims="group")
β1_offset = pm.Normal("β1_offset", 0, sigma=1, dims="group")
β1 = pm.Deterministic("β1", slope_mu + β1_offset * slope_sigma, dims="group")
else:
β0 = pm.Normal("β0", intercept_mu, sigma=intercept_sigma, dims="group")
β1 = pm.Normal("β1", slope_mu, sigma=slope_sigma, dims="group")
# Data
x = pm.MutableData("x", data.x, dims="obs_id")
g = pm.MutableData("g", data.group_idx, dims="obs_id")
# Linear model
μ = pm.Deterministic("μ", β0[g] + β1[g] * x, dims="obs_id")
# Define likelihood
pm.Normal("y", mu=μ, sigma=sigma[g], observed=data.y, dims="obs_id")
with hierarchical:
idata = pm.sampling_jax.sample_numpyro_nuts(tune=5000, target_accept=0.99)
Show code cell output
Compiling...
Compilation time = 0:00:01.494932
Sampling...
0%| | 0/6000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/6000 [00:00<?, ?it/s]
0%| | 0/6000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/6000 [00:00<?, ?it/s]
0%| | 0/6000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/6000 [00:00<?, ?it/s]
0%| | 0/6000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/6000 [00:00<?, ?it/s]
Running chain 0: 0%| | 0/6000 [00:03<?, ?it/s]
Running chain 2: 0%| | 0/6000 [00:03<?, ?it/s]
Running chain 3: 0%| | 0/6000 [00:03<?, ?it/s]
Running chain 1: 0%| | 0/6000 [00:03<?, ?it/s]
Running chain 0: 5%|██▋ | 300/6000 [00:03<00:05, 984.53it/s]
Running chain 1: 5%|██▋ | 300/6000 [00:03<00:05, 951.05it/s]
Running chain 3: 5%|██▋ | 300/6000 [00:03<00:06, 940.66it/s]
Running chain 2: 5%|██▋ | 300/6000 [00:03<00:06, 881.26it/s]
Running chain 3: 10%|█████▎ | 600/6000 [00:04<00:04, 1241.30it/s]
Running chain 0: 10%|█████▎ | 600/6000 [00:04<00:04, 1218.61it/s]
Running chain 1: 10%|█████▎ | 600/6000 [00:04<00:04, 1206.80it/s]
Running chain 2: 10%|█████▎ | 600/6000 [00:04<00:04, 1175.81it/s]
Running chain 1: 15%|███████▉ | 900/6000 [00:04<00:03, 1364.77it/s]
Running chain 3: 15%|███████▉ | 900/6000 [00:04<00:03, 1340.45it/s]
Running chain 0: 15%|███████▉ | 900/6000 [00:04<00:04, 1272.60it/s]
Running chain 2: 15%|███████▉ | 900/6000 [00:04<00:03, 1311.96it/s]
Running chain 1: 20%|██████████▍ | 1200/6000 [00:04<00:03, 1411.07it/s]
Running chain 2: 20%|██████████▍ | 1200/6000 [00:04<00:03, 1414.07it/s]
Running chain 0: 20%|██████████▍ | 1200/6000 [00:04<00:03, 1325.09it/s]
Running chain 3: 20%|██████████▍ | 1200/6000 [00:04<00:03, 1301.35it/s]
Running chain 1: 25%|█████████████ | 1500/6000 [00:04<00:03, 1418.48it/s]
Running chain 2: 25%|█████████████ | 1500/6000 [00:04<00:03, 1416.38it/s]
Running chain 3: 25%|█████████████ | 1500/6000 [00:04<00:03, 1324.74it/s]
Running chain 0: 25%|█████████████ | 1500/6000 [00:04<00:03, 1316.36it/s]
Running chain 1: 30%|███████████████▌ | 1800/6000 [00:04<00:02, 1471.52it/s]
Running chain 2: 30%|███████████████▌ | 1800/6000 [00:04<00:03, 1358.92it/s]
Running chain 0: 30%|███████████████▌ | 1800/6000 [00:04<00:03, 1323.97it/s]
Running chain 3: 30%|███████████████▌ | 1800/6000 [00:04<00:03, 1270.19it/s]
Running chain 1: 35%|██████████████████▏ | 2100/6000 [00:05<00:02, 1466.41it/s]
Running chain 2: 35%|██████████████████▏ | 2100/6000 [00:05<00:02, 1379.92it/s]
Running chain 0: 35%|██████████████████▏ | 2100/6000 [00:05<00:02, 1356.13it/s]
Running chain 3: 35%|██████████████████▏ | 2100/6000 [00:05<00:02, 1317.13it/s]
Running chain 1: 40%|████████████████████▊ | 2400/6000 [00:05<00:02, 1511.80it/s]
Running chain 2: 40%|████████████████████▊ | 2400/6000 [00:05<00:02, 1362.58it/s]
Running chain 0: 40%|████████████████████▊ | 2400/6000 [00:05<00:02, 1341.41it/s]
Running chain 3: 40%|████████████████████▊ | 2400/6000 [00:05<00:02, 1305.07it/s]
Running chain 1: 45%|███████████████████████▍ | 2700/6000 [00:05<00:02, 1541.78it/s]
Running chain 2: 45%|███████████████████████▍ | 2700/6000 [00:05<00:02, 1420.67it/s]
Running chain 0: 45%|███████████████████████▍ | 2700/6000 [00:05<00:02, 1326.71it/s]
Running chain 3: 45%|███████████████████████▍ | 2700/6000 [00:05<00:02, 1353.97it/s]
Running chain 1: 50%|██████████████████████████ | 3000/6000 [00:05<00:01, 1505.53it/s]
Running chain 2: 50%|██████████████████████████ | 3000/6000 [00:05<00:02, 1425.76it/s]
Running chain 0: 50%|██████████████████████████ | 3000/6000 [00:05<00:02, 1381.82it/s]
Running chain 3: 50%|██████████████████████████ | 3000/6000 [00:05<00:02, 1385.74it/s]
Running chain 1: 55%|████████████████████████████▌ | 3300/6000 [00:05<00:01, 1497.63it/s]
Running chain 2: 55%|████████████████████████████▌ | 3300/6000 [00:05<00:01, 1436.71it/s]
Running chain 1: 60%|███████████████████████████████▏ | 3600/6000 [00:05<00:01, 1551.42it/s]
Running chain 0: 55%|████████████████████████████▌ | 3300/6000 [00:06<00:01, 1388.87it/s]
Running chain 3: 55%|████████████████████████████▌ | 3300/6000 [00:06<00:01, 1363.78it/s]
Running chain 2: 60%|███████████████████████████████▏ | 3600/6000 [00:06<00:01, 1430.44it/s]
Running chain 1: 65%|█████████████████████████████████▊ | 3900/6000 [00:06<00:01, 1545.23it/s]
Running chain 0: 60%|███████████████████████████████▏ | 3600/6000 [00:06<00:01, 1431.40it/s]
Running chain 3: 60%|███████████████████████████████▏ | 3600/6000 [00:06<00:01, 1426.98it/s]
Running chain 2: 65%|█████████████████████████████████▊ | 3900/6000 [00:06<00:01, 1455.88it/s]
Running chain 0: 65%|█████████████████████████████████▊ | 3900/6000 [00:06<00:01, 1431.98it/s]
Running chain 1: 70%|████████████████████████████████████▍ | 4200/6000 [00:06<00:01, 1420.34it/s]
Running chain 3: 65%|█████████████████████████████████▊ | 3900/6000 [00:06<00:01, 1396.37it/s]
Running chain 2: 70%|████████████████████████████████████▍ | 4200/6000 [00:06<00:01, 1445.21it/s]
Running chain 0: 70%|████████████████████████████████████▍ | 4200/6000 [00:06<00:01, 1410.75it/s]
Running chain 1: 75%|███████████████████████████████████████ | 4500/6000 [00:06<00:01, 1448.35it/s]
Running chain 3: 70%|████████████████████████████████████▍ | 4200/6000 [00:06<00:01, 1386.85it/s]
Running chain 2: 75%|███████████████████████████████████████ | 4500/6000 [00:06<00:01, 1474.47it/s]
Running chain 1: 80%|█████████████████████████████████████████▌ | 4800/6000 [00:06<00:00, 1476.40it/s]
Running chain 0: 75%|███████████████████████████████████████ | 4500/6000 [00:06<00:01, 1394.66it/s]
Running chain 3: 75%|███████████████████████████████████████ | 4500/6000 [00:06<00:01, 1368.22it/s]
Running chain 2: 80%|█████████████████████████████████████████▌ | 4800/6000 [00:06<00:00, 1458.79it/s]
Running chain 0: 80%|█████████████████████████████████████████▌ | 4800/6000 [00:07<00:00, 1419.56it/s]
Running chain 1: 85%|████████████████████████████████████████████▏ | 5100/6000 [00:07<00:00, 1429.93it/s]
Running chain 3: 80%|█████████████████████████████████████████▌ | 4800/6000 [00:07<00:00, 1369.56it/s]
Running chain 2: 85%|████████████████████████████████████████████▏ | 5100/6000 [00:07<00:00, 1434.71it/s]
Running chain 0: 85%|████████████████████████████████████████████▏ | 5100/6000 [00:07<00:00, 1458.87it/s]
Running chain 1: 90%|██████████████████████████████████████████████▊ | 5400/6000 [00:07<00:00, 1369.66it/s]
Running chain 3: 85%|████████████████████████████████████████████▏ | 5100/6000 [00:07<00:00, 1399.40it/s]
Running chain 2: 90%|██████████████████████████████████████████████▊ | 5400/6000 [00:07<00:00, 1435.31it/s]
Running chain 0: 90%|██████████████████████████████████████████████▊ | 5400/6000 [00:07<00:00, 1524.05it/s]
Running chain 3: 90%|██████████████████████████████████████████████▊ | 5400/6000 [00:07<00:00, 1477.23it/s]
Running chain 1: 95%|█████████████████████████████████████████████████▍ | 5700/6000 [00:07<00:00, 1332.56it/s]
Running chain 0: 95%|█████████████████████████████████████████████████▍ | 5700/6000 [00:07<00:00, 1573.75it/s]
Running chain 2: 95%|█████████████████████████████████████████████████▍ | 5700/6000 [00:07<00:00, 1417.87it/s]
Running chain 3: 95%|█████████████████████████████████████████████████▍ | 5700/6000 [00:07<00:00, 1535.18it/s]
Running chain 0: 100%|████████████████████████████████████████████████████| 6000/6000 [00:07<00:00, 1602.63it/s]
Running chain 1: 100%|████████████████████████████████████████████████████| 6000/6000 [00:07<00:00, 1294.33it/s]
Running chain 2: 100%|████████████████████████████████████████████████████| 6000/6000 [00:07<00:00, 1436.03it/s]
Running chain 3: 100%|████████████████████████████████████████████████████| 6000/6000 [00:07<00:00, 1562.65it/s]
Running chain 0: 100%|█████████████████████████████████████████████████████| 6000/6000 [00:07<00:00, 764.62it/s]
Running chain 1: 100%|█████████████████████████████████████████████████████| 6000/6000 [00:07<00:00, 764.74it/s]
Running chain 2: 100%|█████████████████████████████████████████████████████| 6000/6000 [00:07<00:00, 764.89it/s]
Running chain 3: 100%|█████████████████████████████████████████████████████| 6000/6000 [00:07<00:00, 765.03it/s]
Sampling time = 0:00:08.034354
Transforming variables...
Transformation time = 0:00:00.189316
az.plot_trace(
idata,
combined=True,
filter_vars="regex",
var_names=["~μ"],
kind="rank_bars",
divergences="bottom",
)
plt.tight_layout()
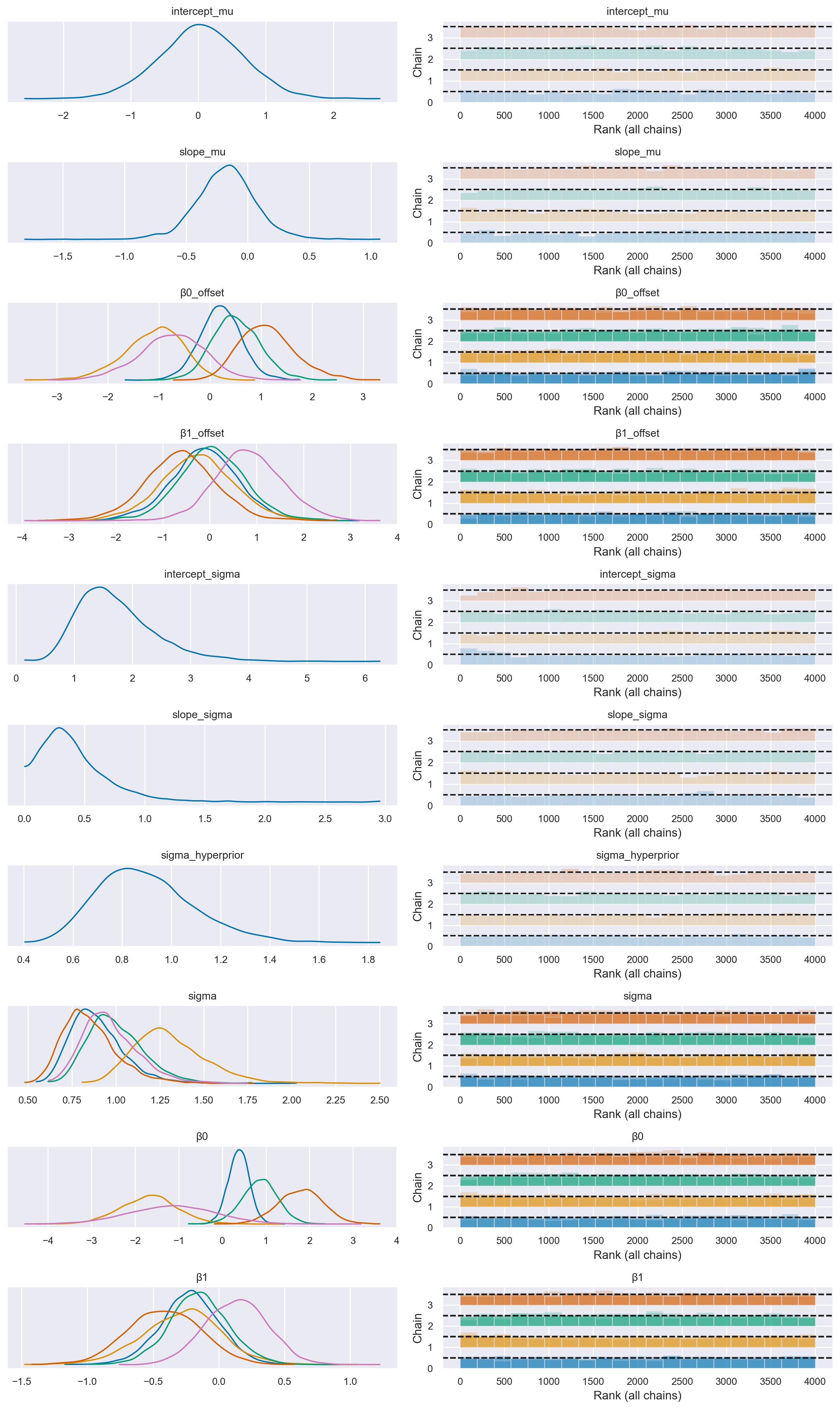
Si noti che non vi sono più transizioni divergenti.
Visualizzazione#
# Create values of x and g to use for posterior prediction
xi = [
np.linspace(data.query(f"group_idx=={i}").x.min(), data.query(f"group_idx=={i}").x.max(), 10)
for i, _ in enumerate(group_list)
]
g = [np.ones(10) * i for i, _ in enumerate(group_list)]
xi, g = np.concatenate(xi), np.concatenate(g)
# Do the posterior prediction
with hierarchical:
pm.set_data({"x": xi, "g": g.astype(int)})
idata.extend(pm.sample_posterior_predictive(idata, var_names=["μ", "y"]))
Sampling: [y]
fig, ax = plt.subplots(1, 1)
# conditional mean plot ---------------------------------------------
for i, groupname in enumerate(group_list):
# data
ax.scatter(data.x[data.group_idx == i], data.y[data.group_idx == i], color=f"C{i}")
# conditional mean credible intervals
post = az.extract(idata)
_xi = xr.DataArray(
np.linspace(np.min(data.x[data.group_idx == i]), np.max(data.x[data.group_idx == i]), 20),
dims=["x_plot"],
)
y = post.β0.sel(group=groupname) + post.β1.sel(group=groupname) * _xi
region = y.quantile([0.025, 0.15, 0.5, 0.85, 0.975], dim="sample")
ax.fill_between(
_xi,
region.sel(quantile=0.025),
region.sel(quantile=0.975),
alpha=0.2,
color=f"C{i}",
edgecolor="w",
)
ax.fill_between(
_xi,
region.sel(quantile=0.15),
region.sel(quantile=0.85),
alpha=0.2,
color=f"C{i}",
edgecolor="w",
)
# conditional mean
ax.plot(_xi, region.sel(quantile=0.5), color=f"C{i}", linewidth=2)
# formatting
ax.set(xlabel="x", ylabel="y", title="Conditional mean")
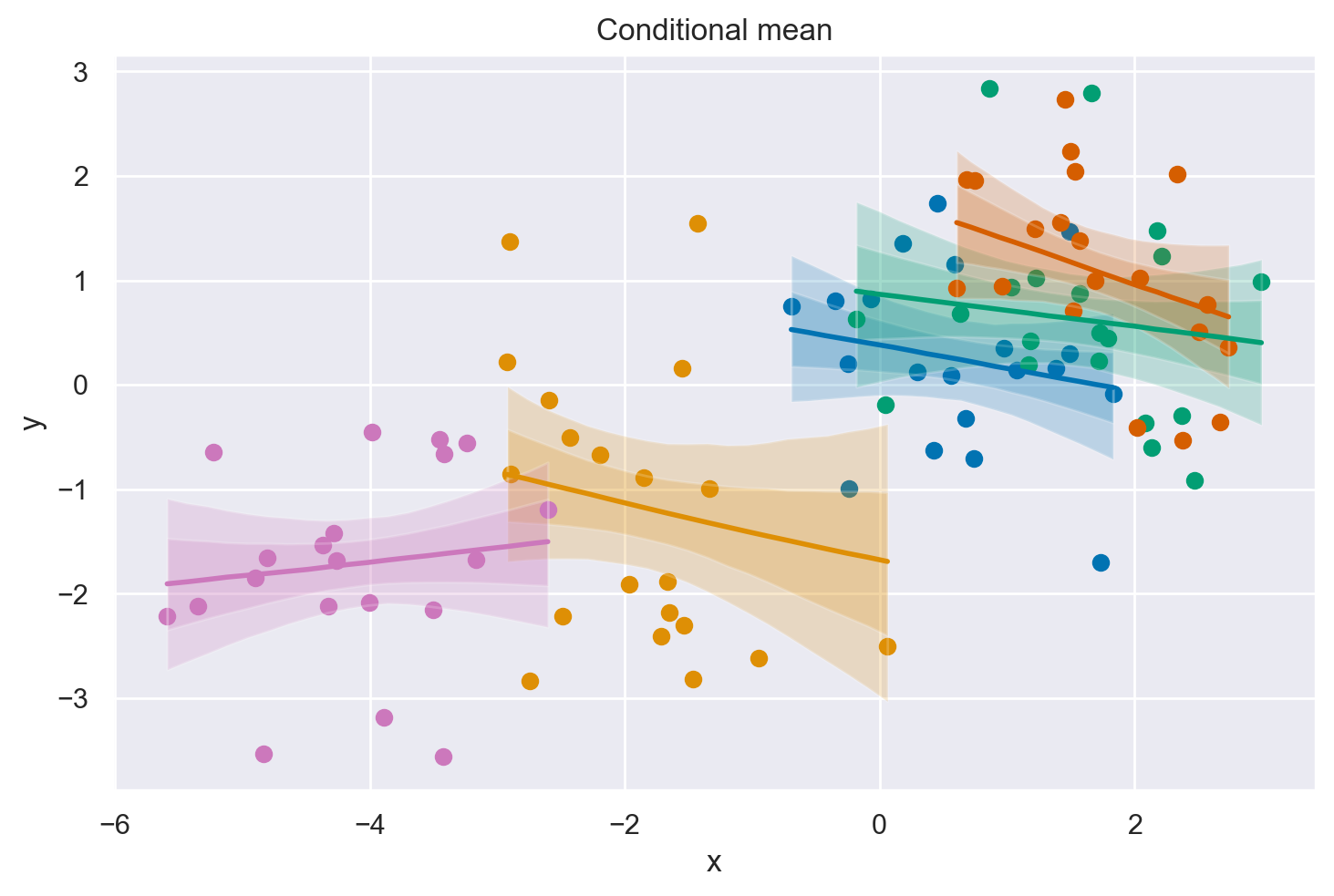
La figura mostra la distribuzione a posteriori di gruppo dei parametri di pendenza e intercetta. Tuttavia, questa particolare visualizzazione risulta poco chiara, quindi possiamo semplicemente tracciare la distribuzione marginale della pendenza a livello di popolazione per vedere quanto sia fondata la credenza che tale pendenza sia minore di zero.
idata
-
<xarray.Dataset> Dimensions: (chain: 4, draw: 1000, group: 5, obs_id: 100) Coordinates: * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 3 4 5 6 ... 993 994 995 996 997 998 999 * group (group) <U5 'one' 'two' 'three' 'four' 'five' * obs_id (obs_id) int64 0 1 2 3 4 5 6 7 ... 92 93 94 95 96 97 98 99 Data variables: intercept_mu (chain, draw) float64 0.3922 0.4374 ... 1.429 0.8488 slope_mu (chain, draw) float64 -0.01342 -0.3831 ... -0.1482 -0.1965 β0_offset (chain, draw, group) float64 0.06959 -0.8703 ... -1.459 β1_offset (chain, draw, group) float64 -0.5162 -0.1451 ... 0.07584 intercept_sigma (chain, draw) float64 2.053 2.474 3.74 ... 3.041 2.228 slope_sigma (chain, draw) float64 0.6434 0.1755 ... 0.4488 0.518 sigma_hyperprior (chain, draw) float64 0.9299 0.9727 ... 0.9198 0.9865 sigma (chain, draw, group) float64 0.9658 1.154 ... 1.043 1.049 β0 (chain, draw, group) float64 0.5351 -1.395 ... -2.402 β1 (chain, draw, group) float64 -0.3455 -0.1068 ... -0.1572 μ (chain, draw, obs_id) float64 0.7744 0.2803 ... -1.642 Attributes: created_at: 2024-01-26T21:48:21.760629 arviz_version: 0.17.0 -
<xarray.Dataset> Dimensions: (chain: 4, draw: 1000, obs_id: 50) Coordinates: * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 3 4 5 6 7 8 ... 992 993 994 995 996 997 998 999 * obs_id (obs_id) int64 0 1 2 3 4 5 6 7 8 9 ... 41 42 43 44 45 46 47 48 49 Data variables: μ (chain, draw, obs_id) float64 0.7744 0.6775 ... -1.941 -1.993 y (chain, draw, obs_id) float64 0.8251 1.123 ... -0.5599 -1.993 Attributes: created_at: 2024-01-26T21:48:26.785660 arviz_version: 0.17.0 inference_library: pymc inference_library_version: 5.10.3 -
<xarray.Dataset> Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 3 4 5 6 ... 993 994 995 996 997 998 999 Data variables: acceptance_rate (chain, draw) float64 0.9794 0.9978 ... 0.9916 0.9737 step_size (chain, draw) float64 0.02943 0.02943 ... 0.02946 0.02946 diverging (chain, draw) bool False False False ... False False False energy (chain, draw) float64 172.7 169.5 180.9 ... 174.7 178.4 n_steps (chain, draw) int64 127 127 63 127 127 ... 127 127 127 127 tree_depth (chain, draw) int64 7 7 6 7 7 7 7 7 7 ... 7 7 7 7 7 7 7 7 7 lp (chain, draw) float64 160.2 161.9 172.2 ... 163.8 167.6 Attributes: created_at: 2024-01-26T21:48:21.766543 arviz_version: 0.17.0 -
<xarray.Dataset> Dimensions: (obs_id: 100) Coordinates: * obs_id (obs_id) int64 0 1 2 3 4 5 6 7 8 9 ... 91 92 93 94 95 96 97 98 99 Data variables: y (obs_id) float64 0.7504 -0.7092 0.1238 ... -1.682 -1.676 -3.534 Attributes: created_at: 2024-01-26T21:48:21.768382 arviz_version: 0.17.0 inference_library: numpyro inference_library_version: 0.13.2 sampling_time: 8.034354 -
<xarray.Dataset> Dimensions: (obs_id: 100) Coordinates: * obs_id (obs_id) int64 0 1 2 3 4 5 6 7 8 9 ... 91 92 93 94 95 96 97 98 99 Data variables: x (obs_id) float64 -0.6927 0.7373 0.2932 ... -4.258 -3.165 -4.836 g (obs_id) int32 0 0 0 0 0 0 0 0 0 0 0 0 ... 4 4 4 4 4 4 4 4 4 4 4 4 Attributes: created_at: 2024-01-26T21:48:21.768952 arviz_version: 0.17.0 inference_library: numpyro inference_library_version: 0.13.2 sampling_time: 8.034354
# plot posterior for population level slope
slope = rng.normal(az.extract(idata.posterior, var_names="slope_mu"))
az.plot_posterior(slope, ref_val=0)
_ = plt.title("Population level slope parameter")
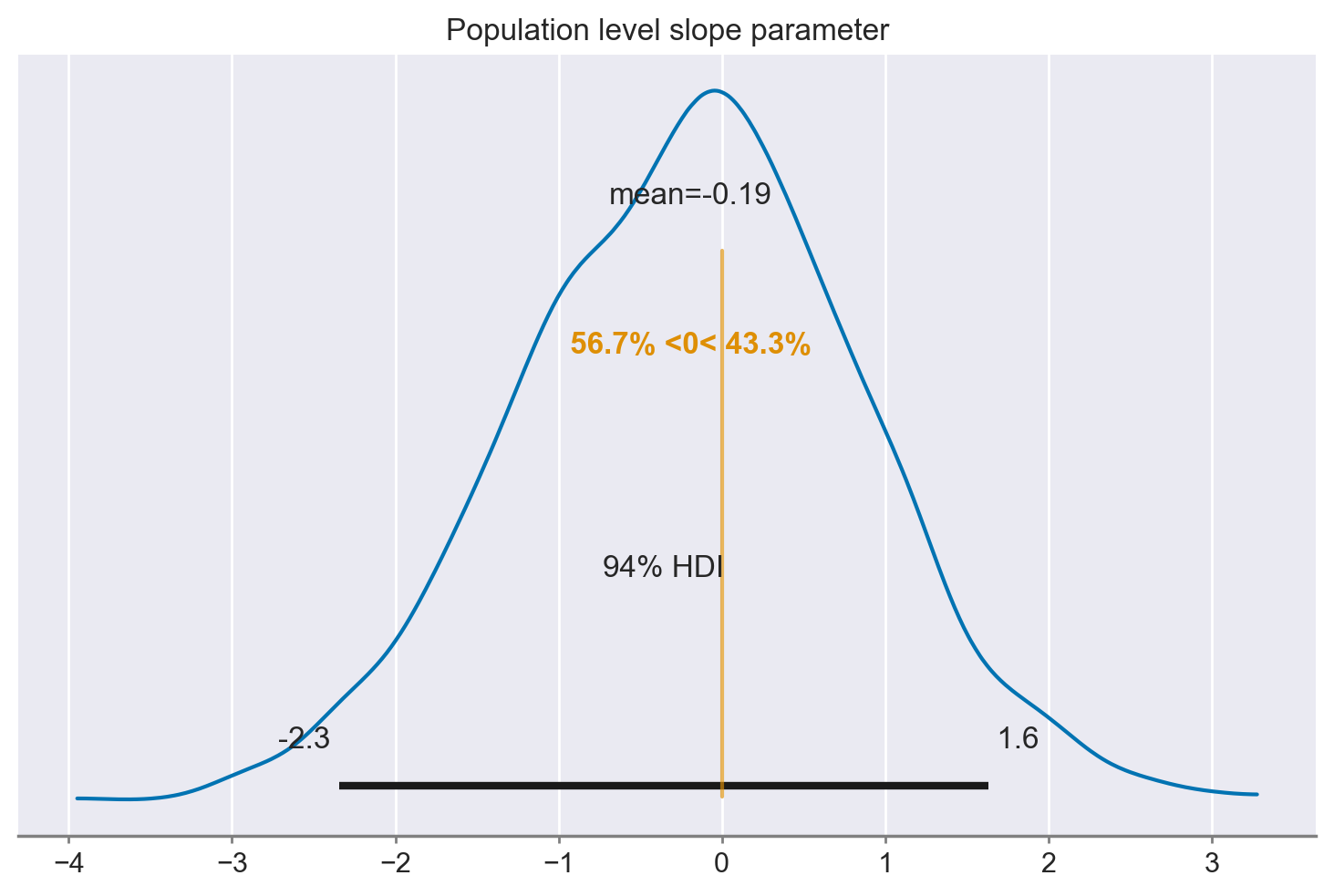
Si osserva che, analizzando i dati a livello di popolazione attraverso un approccio che tiene in considerazione la struttura gerarchica dei dati, non emerge alcuna evidenza di una associazione lineare tra le due variabili in questione; il coefficiente \(\beta_1\) è pari a -0.44 con un intervallo di credibilità al 94% che va da -2.6 a 1.4. Questo risultato contraddice le conclusioni tratte dall’analisi condotta sui dati aggregati, indicando l’assenza di una relazione tra le variabili a livello di popolazione.
Commenti e considerazioni finali#
Utilizzando il paradosso di Simpson, abbiamo esaminato tre modelli differenti. Il primo è una semplice regressione lineare che tratta tutti i dati come provenienti da un unico gruppo. Abbiamo visto che ciò ci ha portato a credere che la pendenza della regressione fosse positiva.
Sebbene ciò non sia necessariamente sbagliato, è paradossale quando osserviamo che le pendenze delle regressioni per i dati all’interno di un gruppo sono negative. Nel secondo modello, abbiamo visto come applicare regressioni separate per i dati in ogni gruppo.
Il terzo e ultimo modello ha aggiunto un ulteriore livello alla gerarchia, catturando la nostra consapevolezza che ciascuno di questi gruppi è campionato da una popolazione generale. Questo ha aggiunto la capacità di fare inferenze non solo riguardo i parametri di regressione a livello di gruppo, ma anche a livello di popolazione. L’ultimo grafico mostra la nostra distribuzione a posteriori su questo parametro di pendenza a livello di popolazione, da cui crediamo che i gruppi siano campionati.
%load_ext watermark
%watermark -n -u -v -iv -w
Last updated: Fri Jan 26 2024
Python implementation: CPython
Python version : 3.11.7
IPython version : 8.19.0
numpy : 1.26.2
seaborn : 0.13.0
xarray : 2023.12.0
matplotlib: 3.8.2
scipy : 1.11.4
pandas : 2.1.4
pymc : 5.10.3
arviz : 0.17.0
Watermark: 2.4.3