![]()
Analisi di simulazione per la stima dei parametri nel modello di regressione#
In questo capitolo, esploreremo alcune funzionalità di PyMC che sono particolarmente utili per condurre analisi di simulazione. In questi studi, definiremo un modello generativo dei dati, stabiliremo i “valori veri” dei parametri del modello, genereremo campioni di dati dal modello e, infine, effettueremo inferenze sui parametri a partire dai dati osservati. Considerando l’ampiezza del set di dati e il livello di rumore introdotto nel processo di generazione dei dati, ci interrogheremo sulla capacità di recuperare accuratamente i veri valori dei parametri attraverso l’inferenza basata sui dati.
Preparazione del Notebook#
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import pymc as pm
from pymc import do, observe
import pymc.sampling_jax
import scipy.stats as stats
import seaborn as sns
import arviz as az
import networkx as nx
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", category=Warning)
/Users/corrado/opt/anaconda3/envs/pymc_env/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
%config InlineBackend.figure_format = 'retina'
RANDOM_SEED = 42
rng = np.random.default_rng(RANDOM_SEED)
az.style.use("arviz-darkgrid")
sns.set_theme(palette="colorblind")
Modello generativo dei dati#
Iniziamo definendo un modello “vuoto”, che serve come pura descrizione del nostro processo di generazione dei dati, senza essere condizionato su dati reali. Questo modello astratto verrà in seguito istanziato con dati effettivi per l’inferenza.
Specificazione di variabili casuali vettorizzate#
Per indicare che le variabili casuali \( x \) e \( y \) nel modello sono vettorizzate (ovvero, array di lunghezza \( N \) dove \( N \) non è ancora specificato), utilizziamo l’argomento coords_mutable in pm.Model.
Consideriamo l’istruzione coords_mutable={"i": [0]}:
“i”: Questo crea una dimensione chiamata \( i \) nel modello.
[0]: Inizializza questa dimensione con un singolo elemento, etichettato come 0.
Quest’impostazione funge da segnaposto, permettendoci di adattare facilmente il modello a dati di diverse dimensioni in seguito. Informa PyMC che nel modello esiste una dimensione mutabile chiamata \( i \), che attualmente ha un solo elemento ma può essere espansa o ridotta come necessario.
Priori#
beta_y0 = pm.Normal("beta_y0"): Specifica una distribuzione a priori per il termine noto (\( \beta_{y0} \)) nel modello di \( y \). Si presume che segua una distribuzione normale con media predefinita 0 e deviazione standard 1.beta_xy = pm.Normal("beta_xy"): Specifica una distribuzione a priori per il coefficiente (\( \beta_{xy} \)) di \( x \) nel modello di \( y \). Anche questo è presupposto essere distribuito normalmente.sigma_y = pm.HalfNormal("sigma_y"): Specifica una distribuzione a priori per il rumore osservativo (\( \sigma_y \)) in \( y \). Viene utilizzata una distribuzione HalfNormal, il che significa che può assumere solo valori non negativi.
Verosimiglianza e nodo deterministico#
x = pm.Normal("x", mu=0, sigma=1, dims="i"): Questa riga definisce \( x \) come una variabile casuale che segue una distribuzione normale con media 0 e deviazione standard 1. L’argomentodims="i"indica che \( x \) è un array di lunghezza \( N \), in accordo con la dimensione mutabile \( i \).y_mu = pm.Deterministic("y_mu", beta_y0 + (beta_xy * x), dims="i"): Questo è un nodo deterministico che calcola la media attesa (\( y_{\mu} \)) di \( y \) in base ai valori correnti di \( \beta_{y0} \), \( \beta_{xy} \) e \( x \).y = pm.Normal("y", mu=y_mu, sigma=sigma_y, dims="i"): Infine, la verosimiglianza di osservare \( y \) è modellata come una distribuzione normale con media \( y_{\mu} \) e deviazione standard \( \sigma_y \). Anche qui, l’argomentodims="i"specifica che \( y \) è un array di lunghezza \( N \), e si allinea con la dimensione \( i \) impostata in precedenza.
Strutturando il modello in questo modo, si ottiene una grande flessibilità. È possibile adattare questo modello a diversi set di dati semplicemente aggiornando la dimensione \( i \) per farla corrispondere ai nuovi dati.
with pm.Model(coords_mutable={"i": [0]}) as model_generative:
# priors on Y <- X
beta_y0 = pm.Normal("beta_y0")
beta_xy = pm.Normal("beta_xy")
# observation noise on Y
sigma_y = pm.HalfNormal("sigma_y")
# core node and causal relationship
x = pm.Normal("x", mu=0, sigma=1, dims="i")
y_mu = pm.Deterministic("y_mu", beta_y0 + (beta_xy * x), dims="i")
y = pm.Normal("y", mu=y_mu, sigma=sigma_y, dims="i")
Creiamo il DAG per il modello che abbiamo specificato.
pm.model_to_graphviz(model_generative)

Simulazione dei dati#
Dopo aver definito l’intera distribuzione congiunta, useremo quest’ultima per generare dati simulati a partire dal modello, utilizzando parametri noti. Successivamente, testeremo se siamo in grado di recuperare questi parametri. Per farlo, indicheremo alcuni valori “veri” per i parametri che governano le relazioni causali tra i nodi.
Ovviamente, in scenari reali, non conosceremo i valori effettivi di questi parametri. Qui li conosciamo solo perché stiamo generando dati simulati e quindi siamo a conoscenza della verità di base. Il nostro obiettivo è di testare quanto bene possiamo inferire i parametri noti utilizzando solamente i dati, in un esercizio chiamato “Recupero dei Parametri”. Se non riusciamo a recuperare i parametri in un semplice scenario simulato, allora non dovremmo avere molta fiducia nella nostra capacità di stimare gli effetti reali in set di dati del mondo reale più complessi.
Sebbene ci siano altri metodi per raggiungere questo obiettivo, in questo caso useremo il nuovo operatore do per generare un nuovo modello con i parametri impostati su certi valori predefiniti.
true_values = {
"beta_y0": 0.25,
"beta_xy": 1.0,
"sigma_y": 0.75
}
model_simulate = do(model_generative, true_values)
La funzione do in PyMC serve per creare una versione “fissata” di un modello generativo esistente. Questo processo di “fissare” il modello è essenziale quando si desidera generare dati simulati che seguono una determinata struttura, ovvero quando si conoscono i “veri” parametri che si desidera simulare. Ecco come funziona.
Input: La funzione
doaccetta due elementi principali:Un modello generativo esistente, definito come un oggetto
pymc.Model.Un dizionario (
true_values) che specifica i valori a cui fissare le variabili casuali del modello.
Output: Restituisce un nuovo modello, in cui le variabili casuali originali sono sostituite da nodi costanti con i valori forniti nel dizionario.
Nel modello originale: Le variabili come
sigma_y,beta_y0, ebeta_xysono variabili aleatorie. Queste rappresentano l’incertezza sui parametri del modello e sono descritte da distribuzioni a priori.Nel nuovo modello: Queste variabili aleatorie diventano nodi costanti. Per esempio,
beta_y0diventa una costante con valore 0.25,beta_xydiventa 1.0, esigma_ydiventa 0.75.
Una volta ottenuto questo nuovo modello, possiamo usarlo per generare dati simulati. In questo contesto, usiamo la funzione pm.sample_prior_predictive per ottenere 100 campioni dalla distribuzione \( P(X, Y \mid \theta) \). Si noti che utilizziamo pm.sample_prior_predictive invece di pm.sample perché il nostro obiettivo è generare dati piuttosto che fare inferenza.
In sintesi, la funzione do ci permette di passare da un modello di incertezza a un modello più “deterministico”, utile per la simulazione di dati sotto condizioni controllate.
N = 100
with model_simulate:
simulate = pm.sample_prior_predictive(samples=N, random_seed=rng)
Sampling: [x, y]
Creiamo il DataFrame df usando i dati simulati.
observed = {
"y": simulate.prior["y"].values.flatten(),
"x": simulate.prior["x"].values.flatten(),
}
df = pd.DataFrame(observed).sort_values("x", ascending=False)
df.shape
(100, 2)
df.head()
| y | x | |
|---|---|---|
| 30 | 2.522725 | 2.414043 |
| 92 | 2.783802 | 1.791996 |
| 87 | 1.013874 | 1.746753 |
| 91 | 1.397997 | 1.571990 |
| 61 | 1.050603 | 1.317880 |
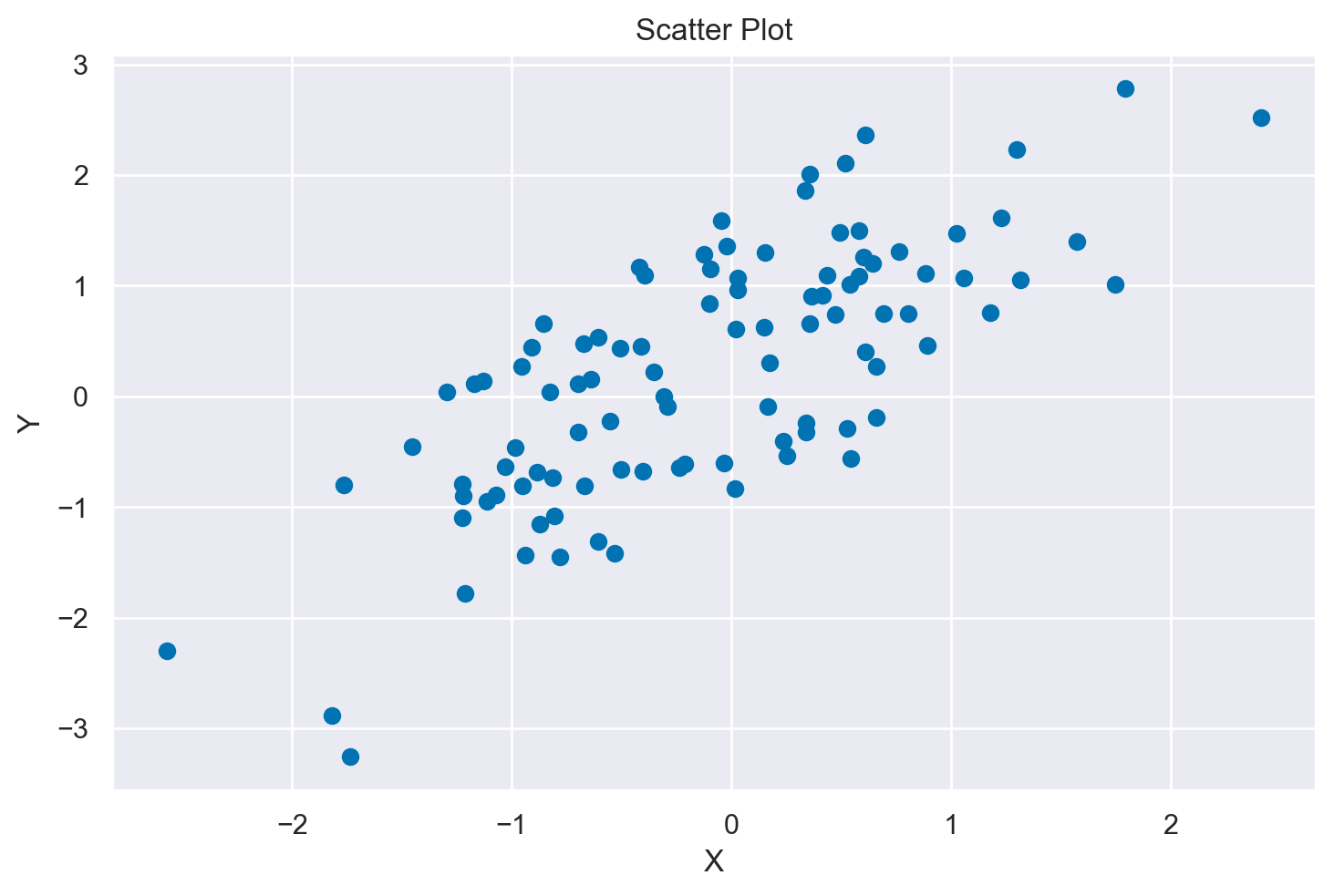
Creiamo un diagramma a dispersione.
plt.scatter(df["x"], df["y"])
plt.xlabel("X")
plt.ylabel("Y")
plt.title("Scatter Plot")
plt.show()
Inferenza#
Passiamo ora all’inferenza. Per farlo, potremmo semplicemente ridefinire il modello sopra indicato e utilizzare l’argomento observed, come è comune fare in PyMC.
# Numero di osservazioni nei dati
N = len(df)
# Valori osservati
obs_x = df["x"].values
obs_y = df["y"].values
with pm.Model(coords={"i": np.arange(N)}) as model_inference:
# Priori debolmente informativi su Y <- X
beta_y0 = pm.Normal("beta_y0", mu=0, sigma=1)
beta_xy = pm.Normal("beta_xy", mu=0, sigma=1)
# Rumore delle osservazioni Y
sigma_y = pm.HalfNormal("sigma_y", sigma=1)
# Nodo principale e relazione causale (qui usiamo i dati osservati)
x = pm.Data("x", obs_x, dims="i")
# Nodo deterministico per la media di Y
y_mu = pm.Deterministic("y_mu", beta_y0 + (beta_xy * x), dims="i")
# Verosimiglianza di Y (qui usiamo i dati osservati)
y = pm.Normal("y", mu=y_mu, sigma=sigma_y, observed=obs_y, dims="i")
Eseguiamo il campionamento.
with model_inference:
idata1 = pm.sampling_jax.sample_numpyro_nuts()
Show code cell output
Compiling...
Compilation time = 0:00:01.554648
Sampling...
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
Running chain 1: 0%| | 0/2000 [00:02<?, ?it/s]
Running chain 0: 0%| | 0/2000 [00:02<?, ?it/s]
Running chain 2: 0%| | 0/2000 [00:02<?, ?it/s]
Running chain 3: 0%| | 0/2000 [00:02<?, ?it/s]
Running chain 0: 100%|█████████████████████████████████████████████████████| 2000/2000 [00:02<00:00, 905.91it/s]
Running chain 1: 100%|█████████████████████████████████████████████████████| 2000/2000 [00:02<00:00, 906.54it/s]
Running chain 2: 100%|█████████████████████████████████████████████████████| 2000/2000 [00:02<00:00, 907.31it/s]
Running chain 3: 100%|█████████████████████████████████████████████████████| 2000/2000 [00:02<00:00, 907.99it/s]
Sampling time = 0:00:02.639111
Transforming variables...
Transformation time = 0:00:00.157031
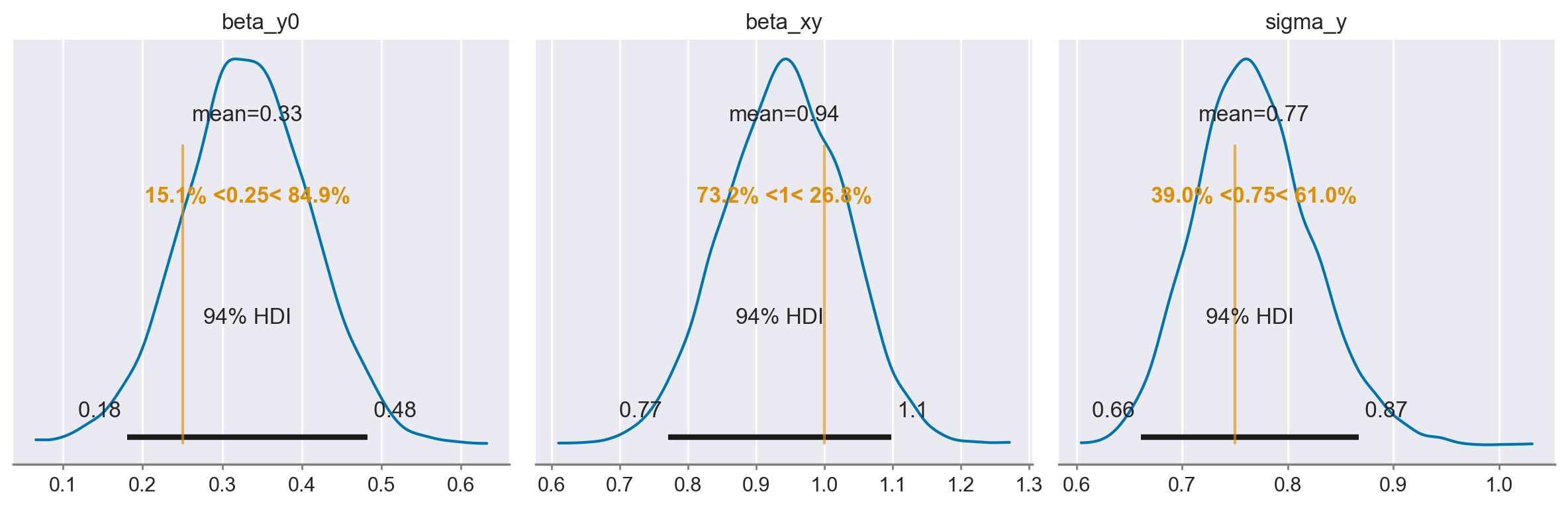
Esaminiamo le distribuzioni a posteriori dei parametri.
az.plot_posterior(
idata1,
var_names=list(true_values.keys()),
ref_val=list(true_values.values()),
figsize=(12, 4),
)
_ = plt.tight_layout()
Tuttavia, possiamo fare qualcosa di un po’ più interessante utilizzando un’altra nuova funzione chiamata observe(). Questa funzione prende un modello e dei dati, e restituisce un nuovo modello in cui i dati sono impostati come osservati sulla nostra variabile casuale di interesse, in modo simile alla funzione do().
È importante notare che vogliamo derivare questo modello osservato dal nostro modello “vuoto” originale model_generative menzionato sopra, in cui nessun parametro era fissato.
model_inference2 = observe(model_generative, {"x": df["x"], "y": df["y"]})
model_inference2.set_dim("i", N, coord_values=np.arange(N))
Eseguiamo il campionamento.
with model_inference2:
idata2 = pm.sampling_jax.sample_numpyro_nuts(random_seed=rng)
Show code cell output
Compiling...
Compilation time = 0:00:00.871031
Sampling...
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
Running chain 2: 0%| | 0/2000 [00:02<?, ?it/s]
Running chain 3: 0%| | 0/2000 [00:02<?, ?it/s]
Running chain 1: 0%| | 0/2000 [00:02<?, ?it/s]
Running chain 0: 0%| | 0/2000 [00:02<?, ?it/s]
Running chain 0: 100%|█████████████████████████████████████████████████████| 2000/2000 [00:02<00:00, 963.52it/s]
Running chain 1: 100%|█████████████████████████████████████████████████████| 2000/2000 [00:02<00:00, 964.07it/s]
Running chain 2: 100%|█████████████████████████████████████████████████████| 2000/2000 [00:02<00:00, 964.90it/s]
Running chain 3: 100%|█████████████████████████████████████████████████████| 2000/2000 [00:02<00:00, 965.60it/s]
Sampling time = 0:00:02.173935
Transforming variables...
Transformation time = 0:00:00.084212
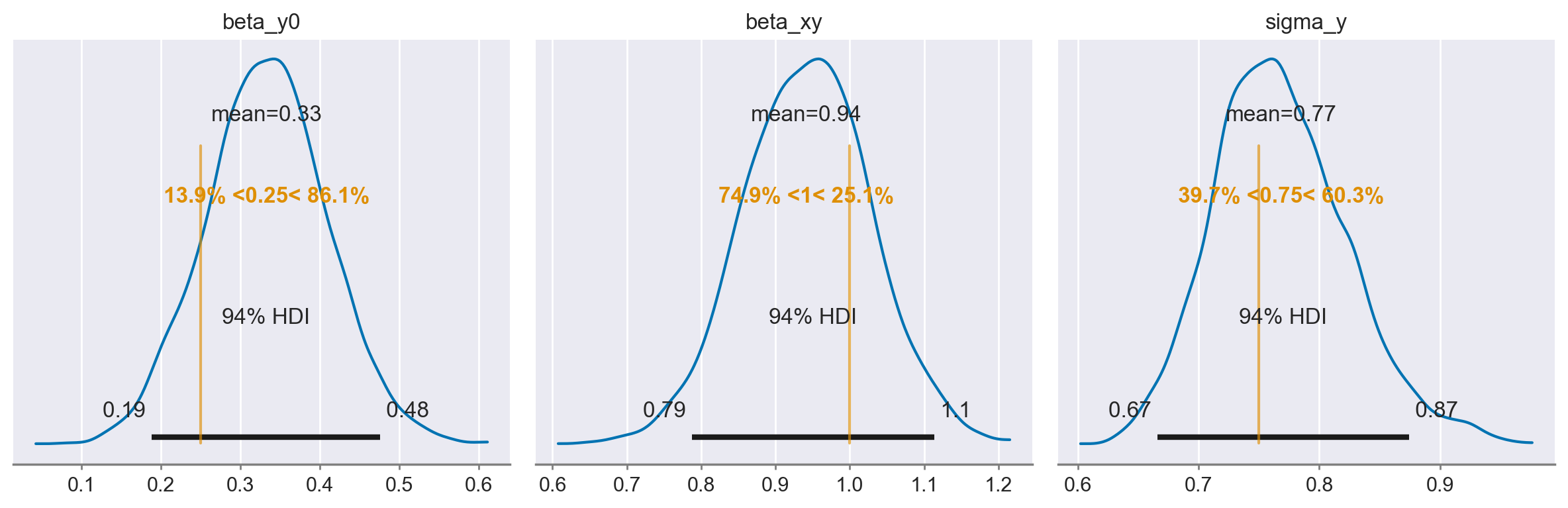
Esaminiamo le distribuzioni a posteriori dei parametri.
az.plot_posterior(
idata2,
var_names=list(true_values.keys()),
ref_val=list(true_values.values()),
figsize=(12, 4),
)
_ = plt.tight_layout()
Commenti e considerazioni conclusive#
In questo capitolo, abbiamo esaminato come utilizzare PyMC per definire un modello generativo dei dati, specificamente per un modello di regressione lineare bivariato. Nel contesto bayesiano, questo modello generativo è rappresentato come una rete bayesiana, in cui ogni variabile casuale diventa un nodo all’interno della rete.
Una rete bayesiana è una struttura grafica che rappresenta le relazioni causali e di dipendenza probabilistica tra variabili casuali. Ogni nodo nella rete rappresenta una variabile casuale, mentre gli archi tra i nodi indicano relazioni dirette o causali. La rete fornisce un quadro per incorporare sia le informazioni strutturali che le incertezze, permettendo una rappresentazione visuale e concettuale del modello generativo dei dati.
Le reti bayesiane non solo mappano le relazioni causali, ma forniscono anche una struttura per quantificare l’incertezza associata a ciascuna variabile. Questa incertezza è modellata attraverso distribuzioni di probabilità. In un modello di regressione lineare, per esempio, i coefficienti della regressione e il termine di errore sono rappresentati come variabili casuali con distribuzioni a priori.
Abbiamo inoltre discusso come effettuare inferenza bayesiana sui dati generati dal modello. In particolare, abbiamo introdotto la funzione observe, che prende come argomenti il modello generativo e i dati osservati. Questa funzione modifica il modello originale, impostando le variabili osservate come ‘conosciute’ e lasciando le altre come ‘sconosciute’, preparando il terreno per l’inferenza bayesiana. Questo processo ci permette di aggiornare le nostre credenze sulle variabili sconosciute (parametri, in questo caso) alla luce dei dati osservati.
In sintesi, le reti bayesiane offrono un quadro robusto e flessibile per modellare le relazioni causali e le incertezze in un’ampia varietà di contesti, e PyMC fornisce gli strumenti per eseguire inferenze bayesiane su tali modelli.
%load_ext watermark
%watermark -n -u -v -iv -w
Last updated: Fri Jan 26 2024
Python implementation: CPython
Python version : 3.11.7
IPython version : 8.19.0
matplotlib: 3.8.2
scipy : 1.11.4
seaborn : 0.13.0
networkx : 3.2.1
pymc : 5.10.3
arviz : 0.17.0
pandas : 2.1.4
numpy : 1.26.2
Watermark: 2.4.3