![]()
Modello di Poisson#
In questo capitolo, esamineremo la stima del parametro “rate” di un modello di Poisson utilizzando PyMC. Il modello di Poisson è uno strumento impiegato per modellare il conteggio di eventi rari in un intervallo di tempo o spazio. Il parametro “rate” in questo contesto rappresenta il tasso di incidenza medio degli eventi nel sistema considerato, ovvero il numero medio di eventi che si verificano nell’unità di tempo o spazio.
Attraverso l’utilizzo di PyMC, otterremo la distribuzione a posteriori del parametro “rate” che tiene conto dell’incertezza nella stima. Ciò ci permetterà di ottenere stime puntuali e intervalli di credibilità per il parametro “rate”, fornendo una migliore comprensione dell’andamento degli eventi nel sistema considerato e una misura dell’incertezza associata alla nostra stima.
Il vantaggio principale di utilizzare la stima MCMC con PyMC è la sua capacità di gestire casi in cui i dati possono essere scarsi o non soddisfare gli assunti delle tecniche di stima tradizionali. Inoltre, attraverso questo approccio, potremo esplorare il comportamento del modello di Poisson e valutarne la capacità di descrivere correttamente il fenomeno oggetto di studio, consentendoci di ottenere una migliore comprensione e interpretazione dei dati osservati.
Preparazione del Notebook#
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import scipy.stats as stats
import pymc as pm
import pymc.sampling_jax
import arviz as az
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", category=Warning)
/Users/corrado/opt/anaconda3/envs/pymc_env/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
%config InlineBackend.figure_format = 'retina'
RANDOM_SEED = 42
rng = np.random.default_rng(RANDOM_SEED)
az.style.use("arviz-darkgrid")
sns.set_theme(palette="colorblind")
Domanda della ricerca#
Come spiegato qui, i dati che esamineremo sono raccolti dal Washington Post con lo scopo di registrare ogni sparatoria mortale negli Stati Uniti ad opera di agenti di polizia, a partire dal 1° gennaio 2015. Il Washington Post ha adottato un approccio sistematico e accurato nella raccolta di queste informazioni, fornendo dati che possono essere utili per valutare i problemi legati alla violenza delle forze di polizia negli Stati Uniti.
Lo scopo della presente analisi dei dati è determinare il tasso di sparatorie fatali da parte della polizia negli Stati Uniti per ogni anno, e fornire una stima dell’incertezza associata a questo valore.
Importazione e pre-processing dei dati#
url = "https://raw.githubusercontent.com/washingtonpost/data-police-shootings/master/v2/fatal-police-shootings-data.csv"
fps_dat = pd.read_csv(url)
fps_dat.head()
Show code cell output
| id | date | threat_type | flee_status | armed_with | city | county | state | latitude | longitude | location_precision | name | age | gender | race | race_source | was_mental_illness_related | body_camera | agency_ids | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 2015-01-02 | point | not | gun | Shelton | Mason | WA | 47.246826 | -123.121592 | not_available | Tim Elliot | 53.0 | male | A | not_available | True | False | 73 |
| 1 | 4 | 2015-01-02 | point | not | gun | Aloha | Washington | OR | 45.487421 | -122.891696 | not_available | Lewis Lee Lembke | 47.0 | male | W | not_available | False | False | 70 |
| 2 | 5 | 2015-01-03 | move | not | unarmed | Wichita | Sedgwick | KS | 37.694766 | -97.280554 | not_available | John Paul Quintero | 23.0 | male | H | not_available | False | False | 238 |
| 3 | 8 | 2015-01-04 | point | not | replica | San Francisco | San Francisco | CA | 37.762910 | -122.422001 | not_available | Matthew Hoffman | 32.0 | male | W | not_available | True | False | 196 |
| 4 | 9 | 2015-01-04 | point | not | other | Evans | Weld | CO | 40.383937 | -104.692261 | not_available | Michael Rodriguez | 39.0 | male | H | not_available | False | False | 473 |
# Convert date
fps_dat["date"] = pd.to_datetime(fps_dat["date"])
# Create a new column 'year' to store the year information from the 'date' column
fps_dat["year"] = fps_dat["date"].dt.year
fps_dat.columns
Index(['id', 'date', 'threat_type', 'flee_status', 'armed_with', 'city',
'county', 'state', 'latitude', 'longitude', 'location_precision',
'name', 'age', 'gender', 'race', 'race_source',
'was_mental_illness_related', 'body_camera', 'agency_ids', 'year'],
dtype='object')
# Filter out rows with year equal to 2023
fps = fps_dat[fps_dat["year"] != 2023]
# Count occurrences of each year in fps
year_counts = fps["year"].value_counts()
print(year_counts)
year
2022 1096
2021 1048
2020 1019
2019 997
2015 995
2018 992
2017 983
2016 958
2024 60
Name: count, dtype: int64
# Define the data
data = {
"year": [2022, 2021, 2020, 2019, 2015, 2018, 2017, 2016],
"events": [1096, 1048, 1019, 997, 995, 992, 983, 958],
}
# Convert the data to a DataFrame
df = pd.DataFrame(data)
print(df)
year events
0 2022 1096
1 2021 1048
2 2020 1019
3 2019 997
4 2015 995
5 2018 992
6 2017 983
7 2016 958
Modello di Poisson#
Il nostro interesse riguarda il tasso di occorrenza di sparatorie fatali da parte della polizia per anno. Indicheremo questo tasso come \(\theta\), e il suo intervallo di valori possibili è \([0, \infty)\). Un modello di Poisson rappresenta tipicamente il punto di partenza per l’analisi di dati relativi alle frequenze assolute di un evento in un intervallo di tempo fissato. Il modello presuppone che i dati seguano una distribuzione di Poisson con un parametro di tasso \(\theta\):
dove i dati \(y\) possono assumere solo valori interi non negativi.
Distribuzione a priori#
Come distribuzione a priori per il parametro \(\theta\) nel modello di Poisson possiamo usare la distribuzione Gamma, poiché è una scelta coniugata. Ciò significa che, quando viene combinata con la distribuzione di Poisson come verosimiglianza dei dati, la distribuzione Gamma produce una distribuzione a posteriori con una forma analitica semplice. Questa caratteristica semplifica il processo di inferenza bayesiana.
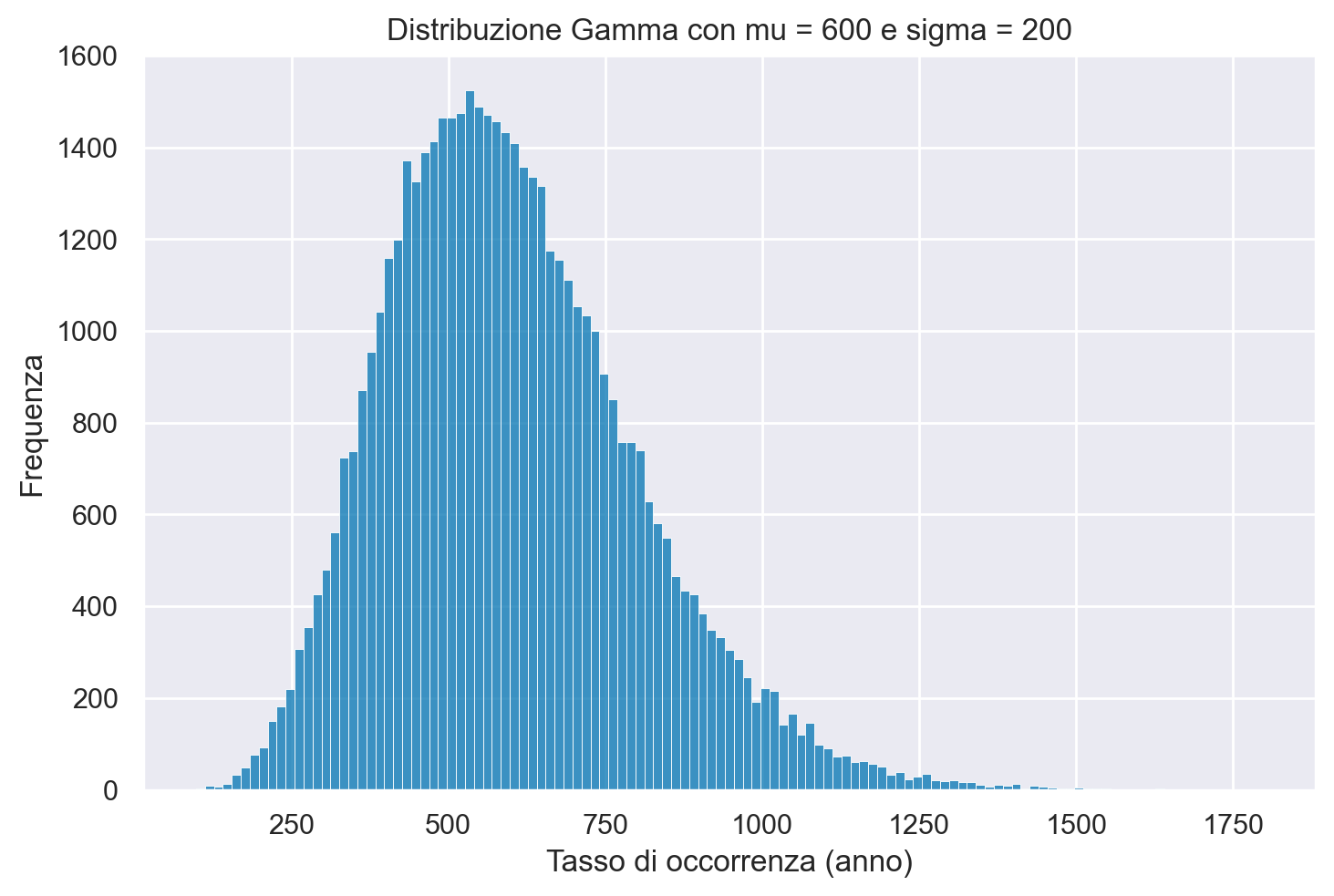
Nel nostro caso, il parametro \(\theta\) rappresenta il tasso di occorrenza di sparatorie fatali per anno negli Stati Uniti. Prima di osservare i dati effettivi riportati dal Washington Post, abbiamo una conoscenza limitata su tale fenomeno. Pertanto, dobbiamo specificare una distribuzione a priori per \(\theta\) che rifletta la nostra incertezza iniziale. As esempio, possiamo ipotizzare che ci sia, in media, una sparatoria mortale per stato al mese, quindi 12 sparatorie all’anno per stato. Questo ci porta a una stima iniziale di 600 sparatorie fatali negli Stati Uniti ogni anno. Dato che non siamo molto sicuri di questa ipotesi, vogliamo specificare una distribuzione a priori con un certo grado di incertezza. Imponiamo dunque una deviazione standard pari a 200.
Creiamo un istogramma della distribuzione Gamma con i parametri specificati sopra usando PyMC.
mu = 600 # mu hyperparameter for the Gamma prior
sigma = 200 # sigma hyperparameter for the Gamma prior
x = pm.Gamma.dist(mu=mu, sigma=sigma)
x_draws = pm.draw(x, draws=50000, random_seed=2)
sns.histplot(x_draws)
plt.xlabel("Tasso di occorrenza (anno)")
plt.ylabel("Frequenza")
plt.title("Distribuzione Gamma con mu = 600 e sigma = 200")
plt.show()
Modello di Poisson con PyMC#
In PyMC, la distribuzione Gamma è parametrizzata con alpha = shape e beta = 1/scale. Nel nostro caso, shape = 3 e scale = 200. Pertanto, nella parametrizzazione PyMC, la distribuzione Gamma avrà parametri alpha = 3 e beta = 1 / 200. Formuliamo dunque il modello di Poisson usando questi iper-parametri per la distribuzione a priori del parametro \(\lambda\) (rate) della distribuzione di Poisson.
with pm.Model() as poisson_model:
rate = pm.Gamma("rate", mu=mu, sigma=sigma)
# Likelihood (Poisson) using the observed data
y = df["events"].values
events = pm.Poisson("events", mu=rate, observed=y)
Eseguiamo il prior predictive check per verificare che l’instanziazione del modello sia corretta per quel che riguarda la distribuzione a priori.
# Use your model to sample from the prior
with poisson_model:
idata_prior = pm.sample_prior_predictive()
Show code cell output
Sampling: [events, rate]
az.plot_trace(idata_prior.prior);

La distribuzione predittiva a priori suggerisce che la distribuzione a priori per il parametro rate è adeguata per i dati a disposizione. Eseguiamo dunque il campionamento.
with poisson_model:
idata = pm.sampling_jax.sample_numpyro_nuts()
Show code cell output
Compiling...
Compilation time = 0:00:01.096445
Sampling...
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
Running chain 1: 0%| | 0/2000 [00:01<?, ?it/s]
Running chain 3: 0%| | 0/2000 [00:01<?, ?it/s]
Running chain 0: 0%| | 0/2000 [00:01<?, ?it/s]
Running chain 2: 0%| | 0/2000 [00:01<?, ?it/s]
Running chain 0: 100%|████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1932.50it/s]
Running chain 1: 100%|████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1934.62it/s]
Running chain 2: 100%|████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1937.39it/s]
Running chain 3: 100%|████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1940.15it/s]
Sampling time = 0:00:01.274469
Transforming variables...
Transformation time = 0:00:00.066985
Esaminiamo la distribuzione a posteriori di rate.
az.plot_trace(idata, combined=True, kind="rank_bars");

Il modello converge rapidamente e i grafici delle tracce sembrano ben mescolati.
Generiamo un sommario numerico della distribuzione a posteriori.
pm.summary(idata)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| rate | 1010.358 | 10.908 | 989.279 | 1030.241 | 0.276 | 0.196 | 1555.0 | 2085.0 | 1.0 |
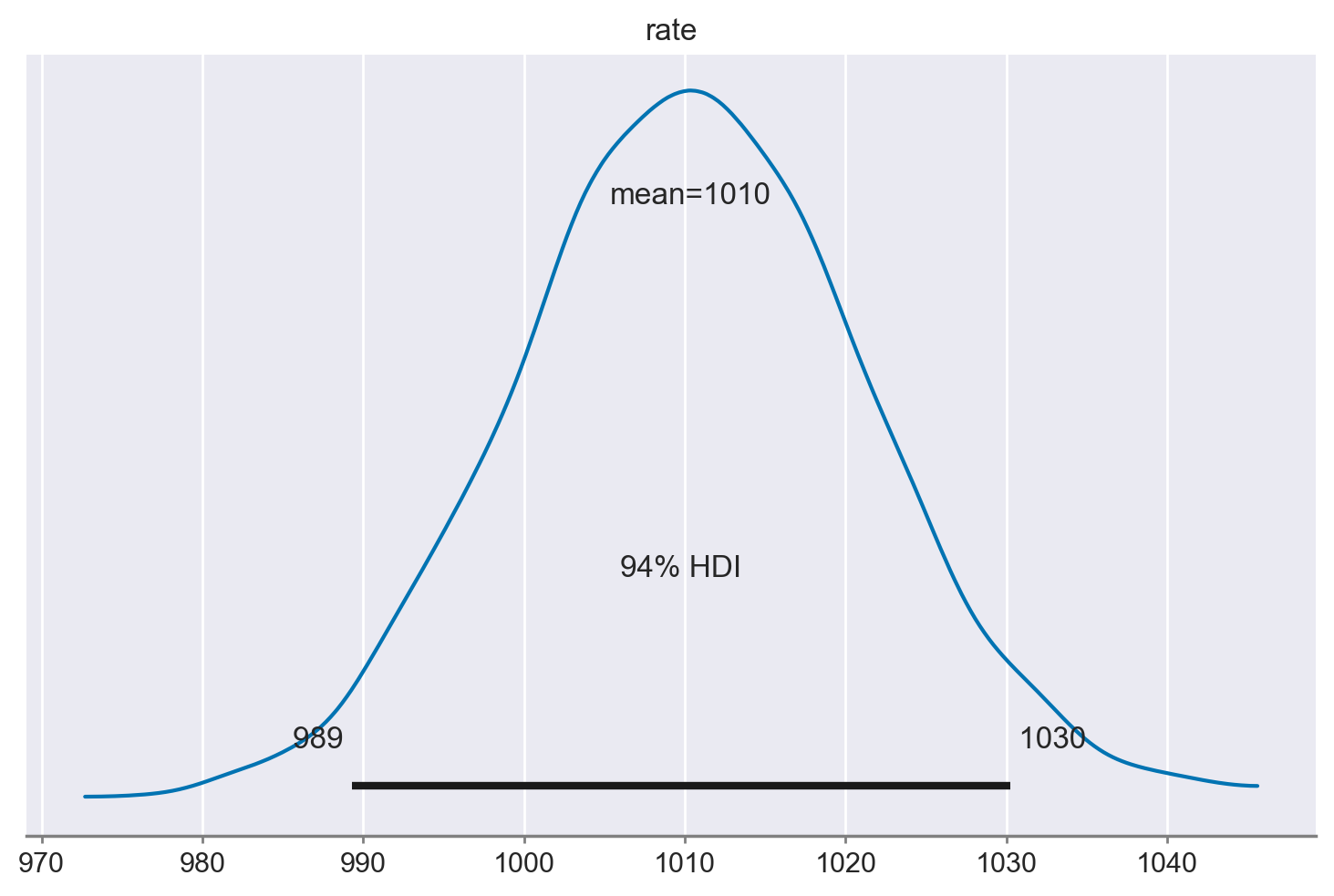
Usiamo ArviZ per generare l’intervallo di credibilità al 94% per la distribuzione a posteriori del parametro rate.
az.plot_posterior(idata, var_names="rate");
Eseguiamo il posterior predictive check.
with poisson_model:
pm.sample_posterior_predictive(idata, extend_inferencedata=True)
Sampling: [events]
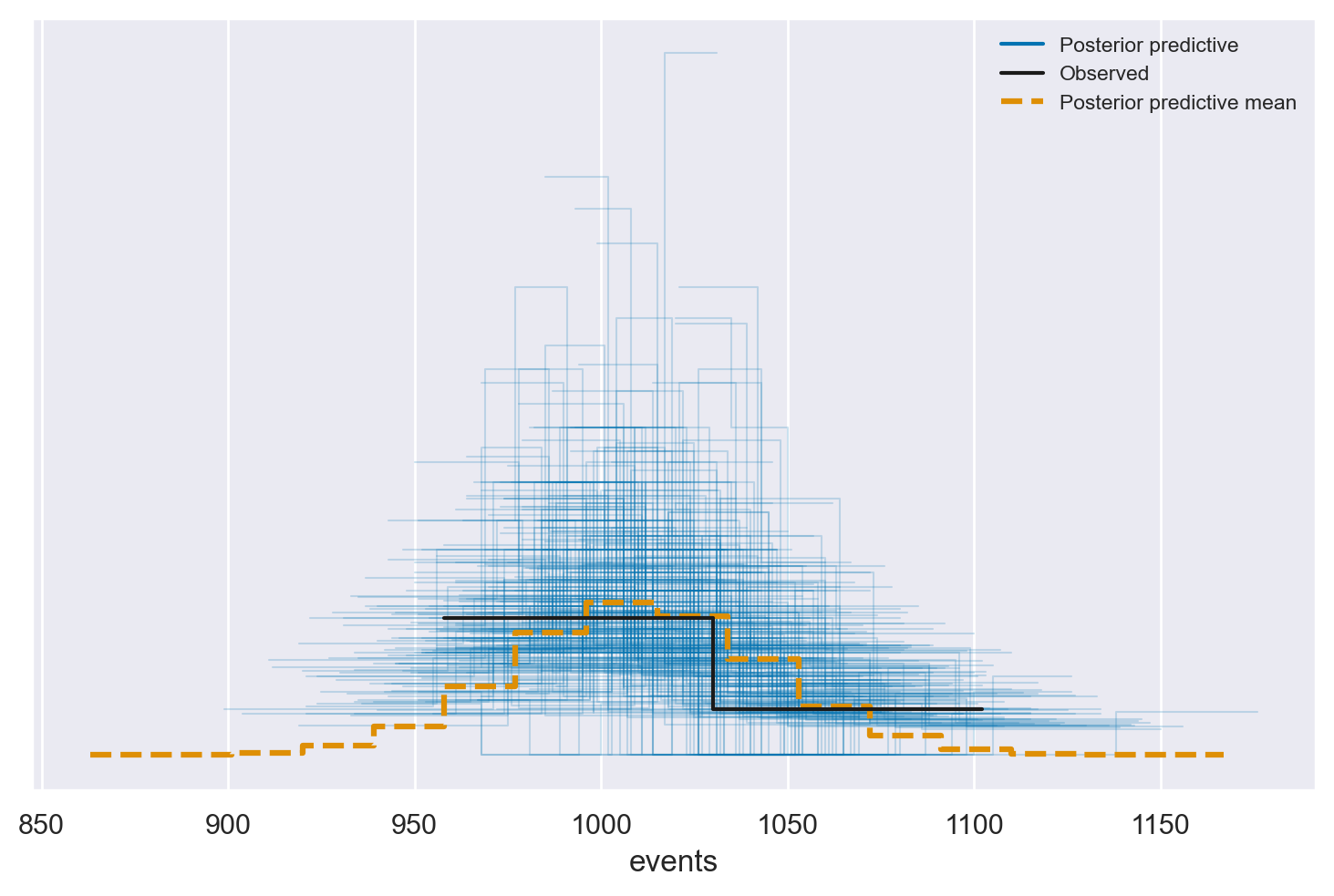
Possiamo utilizzare az.plot_ppc() per verificare che i campioni predittivi a posteriori siano simili ai dati osservati.
az.plot_ppc(idata, num_pp_samples=300);
In conclusione, possiamo affermare che il tasso stimato di sparatorie fatali da parte della polizia negli Stati Uniti è di 1011 casi all’anno, con un intervallo di credibilità del 94% di [988.53, 1031.41].
Derivazione analitica#
In realtà, il problema precedente poteva essere risolto in maniera analitica, senza ricorrere al campionamento MCMC. Infatti, la distribuzione coniugata al modello di Poisson è una densità di tipo gamma e dunque la distribuzione a posteriori è ancora una distribuzione gamma.
Consideriamo un modello di Poisson con verosimiglianza:
dove \(Y\) è il numero di eventi osservati e \(\theta\) è il parametro che rappresenta il tasso di incidenza degli eventi. Supponiamo di avere una distribuzione a priori gamma con i parametri \(a\) e \(b\):
dove \(a\) e \(b\) sono i parametri della distribuzione gamma. Per trovare la distribuzione a posteriori, dobbiamo moltiplicare la verosimiglianza e la distribuzione a priori, e normalizzare il risultato in modo che la distribuzione risultante sia una distribuzione di probabilità valida. La distribuzione a posteriori è quindi data da:
Per ottenere la distribuzione a posteriori normalizzata, dobbiamo dividere il risultato ottenuto per l’integrale di questa espressione su tutto l’intervallo dei valori di \(\theta\). Semplificando e normalizzando questa espressione, otteniamo la distribuzione a posteriori per \(\theta\) uguale ad una distribuzione gamma con parametri aggiornati, ovvero:
dove i parametri aggiornati sono dati da
In conclusione, la distribuzione a posteriori per \(\theta\), data una verosimiglianza di Poisson e una distribuzione a priori gamma, è ancora una distribuzione gamma con parametri aggiornati.
Risolviamo dunque il problema precedente utilizzando la formula della distribuzione a posteriori riportata sopra. Se la distribuzione a priori è una distribuzione gamma di parametri α e β, la distribuzione a posteriori è ancora una gamma con parametri aggiornati. Possiamo calcolare i parametri della distribuzione a posteriori nel modo seguente:
Parametro di forma a posteriori (α_post) = α_prior + Σ(y_i), dove Σ(y_i) rappresenta la somma dei dati osservati.
Parametro di tasso a posteriori (β_post) = β_prior + n, dove n è il numero di punti dati.
Con questi parametri aggiornati, possiamo poi calcolare la media a posteriori della distribuzione gamma e l’intervallo di credibilità.
data = [1096, 1048, 1019, 997, 995, 992, 983, 958]
# Prior hyperparameters
alpha_prior = 3
beta_prior = 1 / 200
# Data summary
n = len(data)
sum_y = np.sum(data)
# Posterior hyperparameters
alpha_post = alpha_prior + sum_y
beta_post = beta_prior + n
# Posterior distribution (Gamma)
posterior_gamma = stats.gamma(alpha_post, scale=1 / beta_post)
# Calculate the mean and credibility interval (94%)
posterior_mean = posterior_gamma.mean()
credible_interval = posterior_gamma.interval(0.94)
print("Estimated Rate (Posterior Mean):", posterior_mean)
print("Credibility Interval (94%):", credible_interval)
Estimated Rate (Posterior Mean): 1010.7432854465958
Credibility Interval (94%): (989.7152329772036, 1031.9826527942685)
L’output delle istruzioni precedenti fornisce il tasso stimato a posteriori e l’intervallo di credibilità al 94%. A causa di approssimazioni numeriche, i valori non coincidono esattamente con i risultati ottenuti con PyMC, ma sono molto simili.
Un altro esempio di applicazione del modello di Poisson è presentato in appendice.
%run ../wm.py
Watermark:
----------
Last updated: 2024-01-26T18:58:51.293717+01:00
Python implementation: CPython
Python version : 3.11.7
IPython version : 8.19.0
Compiler : Clang 16.0.6
OS : Darwin
Release : 23.3.0
Machine : x86_64
Processor : i386
CPU cores : 8
Architecture: 64bit