![]()
Modello gerarchico beta-binomiale#
In questo capitolo, introdurremo il concetto di modello gerarchico bayesiano. L’intuizione alla base della modellazione gerarchica può essere spiegata come segue. Prendiamo in considerazione un classico problema statistico: abbiamo un’urna che contiene palline blu e rosse. Estraendo un campione di 10 palline, possiamo stimare la proporzione delle palline blu. Questo rappresenta un esempio standard utilizzato per introdurre i concetti di stima statistica.
Ora, immaginiamo una situazione più complessa: abbiamo un’urna grande che al suo interno contiene 10 urne più piccole, ognuna delle quali ha le sue palline blu e rosse. Se selezioniamo 7 di queste urne minori ed estraemo 10 palline da ognuna, come dovremmo procedere nell’analizzare questi dati?
Una prima opzione è considerare ogni urna piccola come un’entità indipendente, il che equivarrebbe a ripetere 7 volte il medesimo problema statistico. Questo approccio è subottimale perché presuppone un’indipendenza assoluta tra le urne minori, ignorando che tutte derivano da un’urna più grande e, quindi, potrebbero avere alcune caratteristiche in comune.
Una seconda opzione è quella di ignorare il fatto che le palline sono raggruppate nelle urne più piccole e focalizzarsi esclusivamente sulla stima della proporzione delle palline blu nell’urna grande. Questo approccio è problematico perché trascura la struttura gerarchica intrinseca dei dati, ovvero il fatto che le palline sono organizzate in urne distinte.
L’approccio più adeguato è la modellazione gerarchica. In questo caso, tentiamo di stimare simultaneamente sia la proporzione di palline blu in ogni urna minore sia il grado di correlazione tra le urne. L’urna grande rappresenta una distribuzione sottostante che genera le urne minori. Comprendere questa distribuzione ci permetterà di effettuare stime più precise riguardo alla proporzione di palline blu che ci aspettiamo di trovare in ciascuna delle urne più piccole.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import pymc as pm
import pymc.sampling_jax
import scipy.stats as stats
import arviz as az
import requests
from io import StringIO
from scipy.stats import gaussian_kde
import warnings
plt.rcParams["figure.constrained_layout.use"] = True
warnings.filterwarnings("ignore", category=UserWarning)
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", category=Warning)
/Users/corrado/opt/anaconda3/envs/pymc9_env/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
%config InlineBackend.figure_format = 'retina'
RANDOM_SEED = 42
rng = np.random.default_rng(RANDOM_SEED)
az.style.use("arviz-darkgrid")
Nella discussione che segue, esamineremo il modello gerarchico bayesiano facendo ricorso al modello beta-binomiale. Tradizionalmente, i dati binomiali sono rappresentati attraverso la distribuzione binomiale, che quantifica il numero di “successi” in un numero fisso di tentativi indipendenti, ciascuno con una probabilità \( p \) di successo. Tuttavia, quando ci si trova di fronte a dati stratificati o raggruppati, l’assunzione di una singola probabilità \( p \) potrebbe non essere adeguata. In questi casi, entra in gioco il modello gerarchico beta-binomiale, che introduce un livello gerarchico superiore.
Nel modello gerarchico beta-binomiale, ogni gruppo (analogamente a una “urna piccola” nell’esempio precedente) ha una propria probabilità \( p \) di successo. Queste probabilità sono, a loro volta, generate da una distribuzione beta con parametri \( \alpha \) e \( \beta \). Ciò permette di modellare la variabilità sia all’interno dei gruppi che tra di essi, mentre si condividono le informazioni per ottenere stime più robuste.
Matematicamente, il modello può essere espresso come segue:
In questo contesto, \( y_i \) rappresenta il numero di successi nel gruppo \( i \), \( n_i \) è il numero di tentativi nel gruppo \( i \), e \( k \) è il numero totale di gruppi. I parametri \( \alpha \) e \( \beta \) della distribuzione beta sono spesso oggetto di inferenza bayesiana e possono avere distribuzioni a priori associate.
L’approccio gerarchico aumenta l’efficienza statistica dell’inferenza, consentendo una stima più accurata dei parametri del modello sia a livello di gruppo che di popolazione. Inoltre, fornisce un quadro teorico per comprendere la variabilità sia all’interno dei gruppi che tra di essi, in termini di una struttura di parametri comuni e specifici per ciascun gruppo.
In questo capitolo, applicheremo il modello gerarchico beta-binomiale a un set di dati reali e discuteremo le metodologie per l’inferenza bayesiana e l’interpretazione dei risultati.
Analisi bayesiana della “terapia tattile”#
Esaminiamo un problema presentato nel lavoro di Kruschke [Kru14] riguardante la “terapia tattile” (Therapeutic Touch), una pratica infermieristica incentrata sulla manipolazione del presunto “campo energetico” di un paziente. Nonostante la sua prevalenza nelle scuole di infermieristica e negli ospedali negli Stati Uniti, come riportato da Rosa et al. [RRSB98], evidenze empiriche a supporto della sua efficacia sono scarse o assenti.
Il focus dell’indagine di Rosa et al. [RRSB98] è una delle asserzioni cardine degli operatori di terapia tattile: la presunta capacità di percepire i campi energetici senza contatto visivo. Per testare questa affermazione, è stato progettato un esperimento in cui gli operatori ponevano le loro mani attraverso un pannello che bloccava la visione. In ciascuna prova, un esaminatore, seguendo l’esito di un lancio di moneta, posizionava la sua mano sopra una delle mani dell’operatore. L’operatore doveva quindi identificare quale delle sue mani era stata “selezionata” dall’esaminatore. Ogni tentativo è stato classificato come “corretto” o “errato”.
L’unità di osservazione in questo esperimento è costituita da un set di 10 prove per operatore. In totale, lo studio ha coinvolto 21 operatori, con sette di loro sottoposti a retest dopo circa un anno. I dati di retest sono stati trattati come entità indipendenti, portando a un campione effettivo di 28 osservazioni. La metrica di interesse è la proporzione di risposte corrette per ciascun operatore, con una proporzione attesa di 0.50 sotto l’ipotesi nulla di performance casuale.
La domanda della ricerca centrale è se il campione nel suo complesso è in grado di ottenere una prestazione superiore a quella attesa in base al caso soltanto e, inoltre, se vi sono variazioni nelle prestazioni individuali.
Inizieremo importando i dati forniti da Kruschke [Kru14].
# Define the URL of the CSV file on GitHub
url = "https://raw.githubusercontent.com/boboppie/kruschke-doing_bayesian_data_analysis/master/2e/TherapeuticTouchData.csv"
# Download the content of the CSV file
response = requests.get(url)
tt_dat = pd.read_csv(StringIO(response.text))
print(tt_dat.head())
y s
0 1 S01
1 0 S01
2 0 S01
3 0 S01
4 0 S01
tt_dat.shape
(280, 2)
Nella colonna y, il valore 1 indica una risposta corretta, mentre 0 indica una risposta errata. La seconda colonna contiene il codice identificativo di ciascun operatore.
Calcoliamo la proporzione di risposte corrette per ciascun operatore.
tt_agg = tt_dat.groupby("s").agg(proportion_correct=("y", "mean")).reset_index()
tt_agg
| s | proportion_correct | |
|---|---|---|
| 0 | S01 | 0.1 |
| 1 | S02 | 0.2 |
| 2 | S03 | 0.3 |
| 3 | S04 | 0.3 |
| 4 | S05 | 0.3 |
| 5 | S06 | 0.3 |
| 6 | S07 | 0.3 |
| 7 | S08 | 0.3 |
| 8 | S09 | 0.3 |
| 9 | S10 | 0.3 |
| 10 | S11 | 0.4 |
| 11 | S12 | 0.4 |
| 12 | S13 | 0.4 |
| 13 | S14 | 0.4 |
| 14 | S15 | 0.4 |
| 15 | S16 | 0.5 |
| 16 | S17 | 0.5 |
| 17 | S18 | 0.5 |
| 18 | S19 | 0.5 |
| 19 | S20 | 0.5 |
| 20 | S21 | 0.5 |
| 21 | S22 | 0.5 |
| 22 | S23 | 0.6 |
| 23 | S24 | 0.6 |
| 24 | S25 | 0.7 |
| 25 | S26 | 0.7 |
| 26 | S27 | 0.7 |
| 27 | S28 | 0.8 |
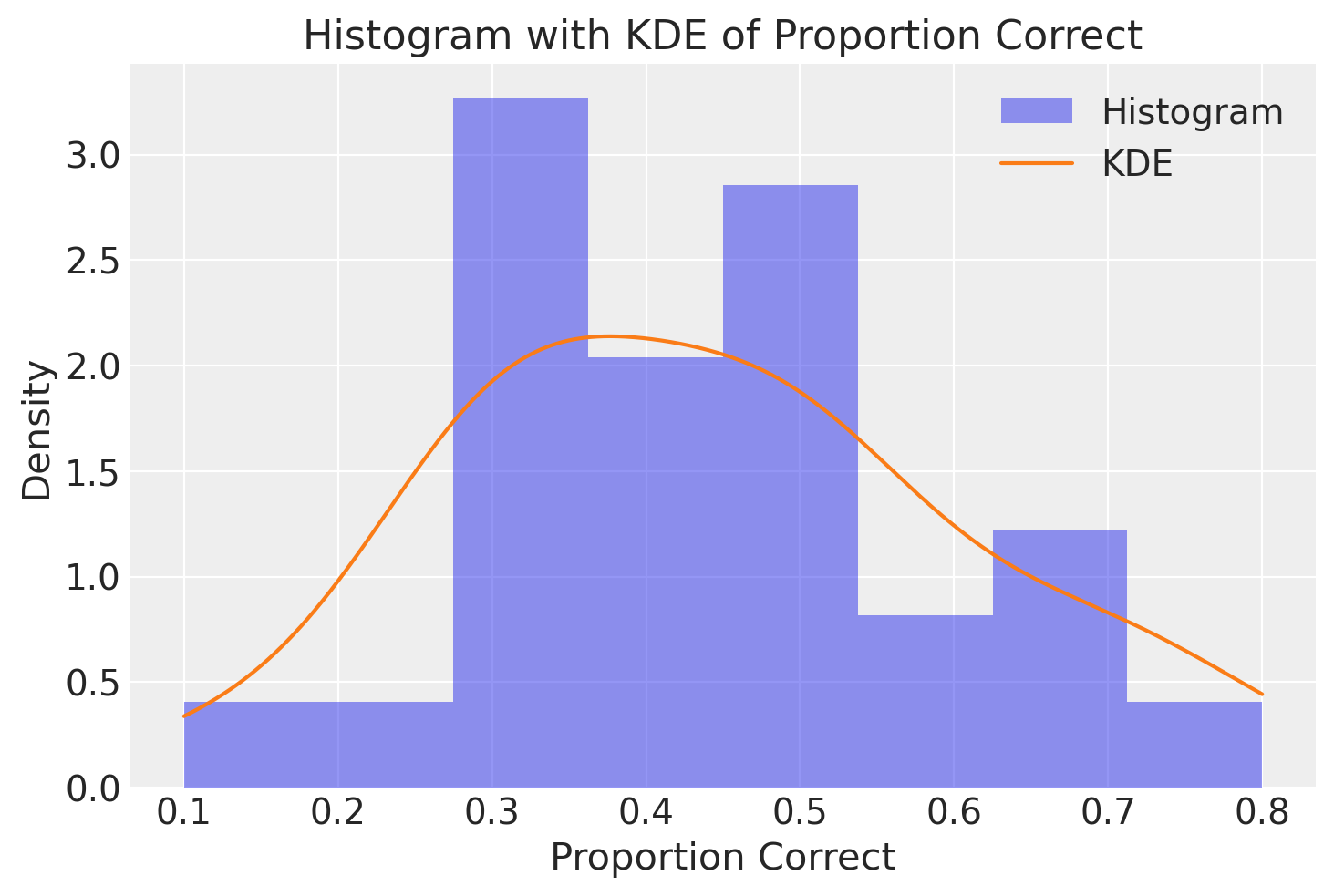
Creiamo ora un istogramma che rappresenti le proporzioni di risposte corrette. Valori superiori a 0.5 indicano la capacità di discriminare correttamente la posizione della mano dell’esaminatore, anche senza vederla. Valori inferiori a 0.5 indicano invece che, sebbene si riesca a distinguere la posizione della mano dell’esaminatore, le risposte sbagliate sono più frequenti rispetto al caso.
La distribuzione è unimodale, con un intervallo di valori tra 0 e 1, quindi può essere adeguatamente descritta dalla densità Beta.
# Create the histogram
plt.hist(tt_agg.proportion_correct, bins=8, density=True, alpha=0.5, label="Histogram")
# KDE plot
kde = gaussian_kde(tt_agg.proportion_correct)
x_range = np.linspace(
min(tt_agg.proportion_correct), max(tt_agg.proportion_correct), 1000
)
plt.plot(x_range, kde(x_range), label="KDE")
plt.xlabel("Proportion Correct")
plt.ylabel("Density")
plt.title("Histogram with KDE of Proportion Correct")
plt.legend()
plt.show()
Se consideriamo il numero di risposte corrette come “successi”, il modello di campionamento binomiale risulta essere una scelta naturale per questi dati. Osservando le proporzioni di risposte corrette, notiamo che alcuni operatori hanno tassi di risposte corrette molto più elevati rispetto ad altri. Ad esempio, la proporzione più alta di risposte corrette è 0.8 e la più bassa è 0.1. Se si assumesse una probabilità comune \(p\) di risposte corrette per tutti i 28 operatori, tale modello non renderebbe conto dei dati in maniera adeguata. D’altra parte, se si creassero 28 modelli di campionamento binomiale separati, uno per ciascun operatore, e si effettuassero inferenze separate, si perderebbe la possibilità di utilizzare informazioni potenziali sul tasso di risposte corrette dell’operatore \(j\) quando si conducono inferenze riguardanti un altro operatore \(i\).
Il modello gerarchico rappresenta una via di mezzo tra l’approccio combinato e quello separato nella modellazione. Costruiamo il modello gerarchico partendo dall’assunzione che il numero di risposte corrette per ciascun operatore sia una variabile casuale Binomiale. Per ciascuno dei ventotto operatori possiamo dunque scrivere:
con \(i = 0, \dots, 27\).
Quale distribuzione a priori per il parametro sconosciuto \(p_i\) possiamo fissare una distribuzione Beta di parametri \(a\) e \(b\):
Va notato che, in questo modo, gli iperparametri \(a\) e \(b\) sono condivisi tra tutti gli operatori. Se \(a\) e \(b\) sono noti, allora la distribuzione a posteriori per il parametro \(p\) è una distribuzione Beta:
Nel caso generale in cui gli iperparametri \(a\) e \(b\) sono incogniti, è necessario fissare una distribuzione a priori per ciascuno di essi.
Applichiamo dunque il modello gerarchico descritto sopra ai dati del therapeutic touch. Iniziamo a calcolare il numero di risposte corrette di ciascun operatore.
result = tt_dat.groupby("s")["y"].sum().reset_index()
y = result["y"]
print(*y)
1 2 3 3 3 3 3 3 3 3 4 4 4 4 4 5 5 5 5 5 5 5 6 6 7 7 7 8
In media, gli operatori rispondono correttamente 4.39 volte su 10.
y.mean()
4.392857142857143
Creiamo inoltre il vettore N che fornisce il numero di prove per ciascun operatore.
N = tt_dat.groupby("s")["y"].count()
N
s
S01 10
S02 10
S03 10
S04 10
S05 10
S06 10
S07 10
S08 10
S09 10
S10 10
S11 10
S12 10
S13 10
S14 10
S15 10
S16 10
S17 10
S18 10
S19 10
S20 10
S21 10
S22 10
S23 10
S24 10
S25 10
S26 10
S27 10
S28 10
Name: y, dtype: int64
Esaminiamo dunque i dati a disposizione.
print(*N)
10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10 10
print(*y)
1 2 3 3 3 3 3 3 3 3 4 4 4 4 4 5 5 5 5 5 5 5 6 6 7 7 7 8
Definiamo le coordinate necessarie per specificare la forma delle diverse distribuzioni di densità.
# The data has one dimension: operators_idx
# The "coordinates" are the unique values that this dimension can take
COORDS = {
"operators_idx": np.arange(len(y)),
}
print(COORDS)
{'operators_idx': array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27])}
Scriviamo ora il modello gerarchico Beta-Binomiale con la sintassi PyMC.
with pm.Model(coords=COORDS) as model:
y_data = pm.ConstantData("y_data", y)
n_trials = pm.ConstantData("n_trials", N)
alpha = pm.Gamma("alpha", 8, 2)
beta = pm.Gamma("beta", 27, 5)
p = pm.Beta("p", alpha, beta, dims="operators_idx")
Y_obs = pm.Binomial("Y_obs", n=n_trials, p=p, observed=y_data, dims="operators_idx")
Il modello Bayesiano definito sopra è progettato per analizzare i dati provenienti da diversi operatori nel contesto di un esperimento binomiale. Il termine “binomiale” implica che ci sono solo due possibili esiti per ciascun tentativo: successo o insuccesso. Il modello utilizza una struttura gerarchica, dove la distribuzione Beta viene utilizzata per modellare la probabilità di successo degli operatori, e la distribuzione Gamma serve come distribuzione a priori per i parametri di forma della distribuzione Beta.
Alpha e beta (parametri di forma della distribuzione Beta):
Questi sono i parametri che governano la forma della distribuzione Beta per la variabile latente
p.Sono modellati come variabili casuali che seguono una distribuzione Gamma. In questo specifico modello,
alphasegue una distribuzione Gamma con parametri 8 e 2, mentrebetasegue una distribuzione Gamma con parametri 27 e 5.
p (probabilità di successo):
Questa è la variabile latente di interesse e rappresenta la probabilità di successo in un esperimento binomiale.
Segue una distribuzione Beta parametrizzata da
alphaebeta.
Y_obs (variabile osservata):
Rappresenta il numero di successi ottenuti in
Ntentativi per ciascun operatore.Segue una distribuzione binomiale con
Ncome numero di tentativi epcome probabilità di successo.
Il modello utilizza la chiave
dimsper specificare che sia la variabile latentepche la variabile osservataY_obshanno una dimensione etichettata comeoperators_idx.Questa etichetta di dimensione è associata a un dizionario Python
COORDSche contiene 28 valori distinti, rappresentando così 28 operatori differenti.
Il modello stima probabilità di successo separate (p) per ciascun operatore, permettendo così di catturare l’eterogeneità tra diverse unità di osservazione.
Le distribuzioni a priori per alpha e beta sono scelte sulla base di informazioni empiriche. Ad esempio, se la probabilità di successo media è 0.44, i parametri della distribuzione Beta che producono questa media sono approssimativamente \(\alpha = 4\) e \(\beta = 5.4\).
I parametri delle distribuzioni Gamma per alpha e beta sono quindi scelti in modo da centrarsi attorno a queste stime empiriche, dando così una priorità informativa ai parametri.
pm.model_to_graphviz(model)

a = 8
b = 2
x = np.linspace(0, 10, 1000) # Valori x da 0 a 10
yy = stats.gamma.pdf(x, a, scale=1/b) # Funzione di densità di probabilità Gamma
plt.plot(x, yy)
plt.xlabel('x')
plt.ylabel('Densità di probabilità')
plt.title('Distribuzione Gamma(9, 2)');
plt.show()
Eseguiamo ora il campionamento.
with model:
trace = pm.sampling_jax.sample_numpyro_nuts(2000, tune=1000)
Show code cell output
Compiling...
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1699560195.830084 1 tfrt_cpu_pjrt_client.cc:349] TfrtCpuClient created.
Compilation time = 0:00:26.509886
Sampling...
0%| | 0/3000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/3000 [00:00<?, ?it/s]
0%| | 0/3000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/3000 [00:00<?, ?it/s]
0%| | 0/3000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/3000 [00:00<?, ?it/s]
0%| | 0/3000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/3000 [00:00<?, ?it/s]
Running chain 2: 0%| | 0/3000 [00:01<?, ?it/s]
Running chain 0: 0%| | 0/3000 [00:01<?, ?it/s]
Running chain 3: 0%| | 0/3000 [00:01<?, ?it/s]
Running chain 1: 0%| | 0/3000 [00:01<?, ?it/s]
Running chain 0: 100%|██████████████████████████████████████████████████████████████████| 3000/3000 [00:02<00:00, 1465.62it/s]
Running chain 1: 100%|██████████████████████████████████████████████████████████████████| 3000/3000 [00:02<00:00, 1467.28it/s]
Running chain 2: 100%|██████████████████████████████████████████████████████████████████| 3000/3000 [00:02<00:00, 1468.51it/s]
Running chain 3: 100%|██████████████████████████████████████████████████████████████████| 3000/3000 [00:02<00:00, 1469.24it/s]
Sampling time = 0:00:02.338413
Transforming variables...
Transformation time = 0:00:00.090672
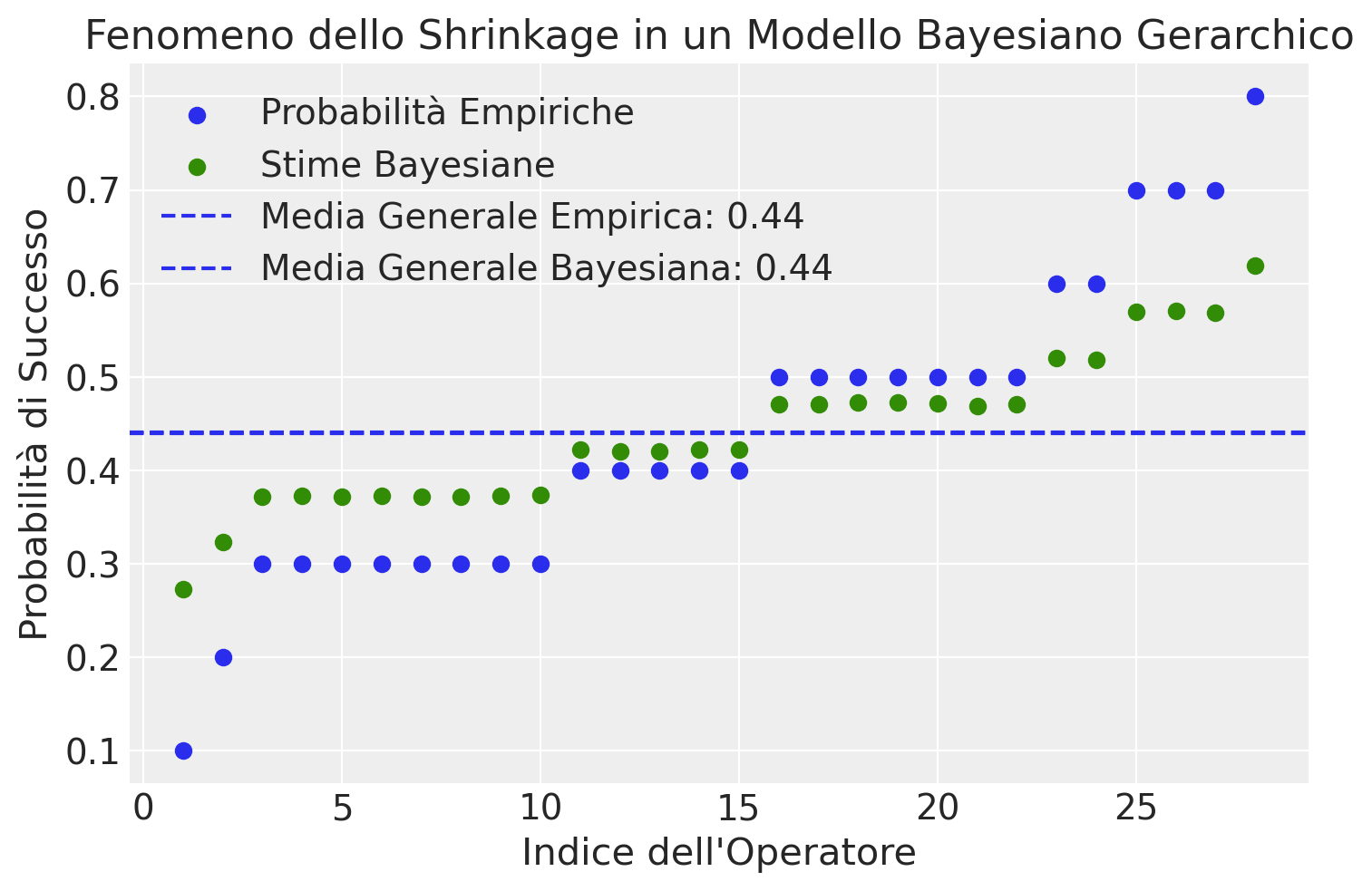
Nel modello beta-binomiale gerarchico, tutte le probabilità di successo dei diversi operatori vengono modellate utilizzando la stessa distribuzione a priori. Questo significa che si assume che le probabilità di successo di ciascun operatore derivino da una distribuzione comune. Di conseguenza, le stime individuali delle probabilità di successo per ogni operatore saranno “shrunk” o “ritratte” verso il valore medio della distribuzione comune. Questo fenomeno è noto come “shrinkage”. In altre parole, le stime tendono ad avvicinarsi alla media del gruppo, piuttosto che essere stime completamente indipendenti. Questo effetto di “shrinkage” permette di ottenere stime più stabili e generalizzabili, soprattutto quando i campioni per alcuni operatori sono limitati o poco informativi.
Questo effetto di shrinkage ha un importante vantaggio: migliora la precisione delle stime individuali. Le stime aggregate attraverso l’informazione del gruppo possono essere più affidabili e robuste rispetto alle stime basate su un numero limitato di dati. Di conseguenza, il modello beta-binomiale gerarchico permette di ottenere stime più accurate e stabili per le probabilità di successo degli operatori, tenendo conto sia delle informazioni specifiche di ogni operatore che delle informazioni comuni a tutto il gruppo – si confrontino le stime a posteriori della probabilità di successo xs con le stime della probabilità di successo calcolate separatamente per ciascun operatore (si veda la tabella precedente).
Esaminiamo dunque le stime a posteriori della probabilità di successo di ciascun operatore.
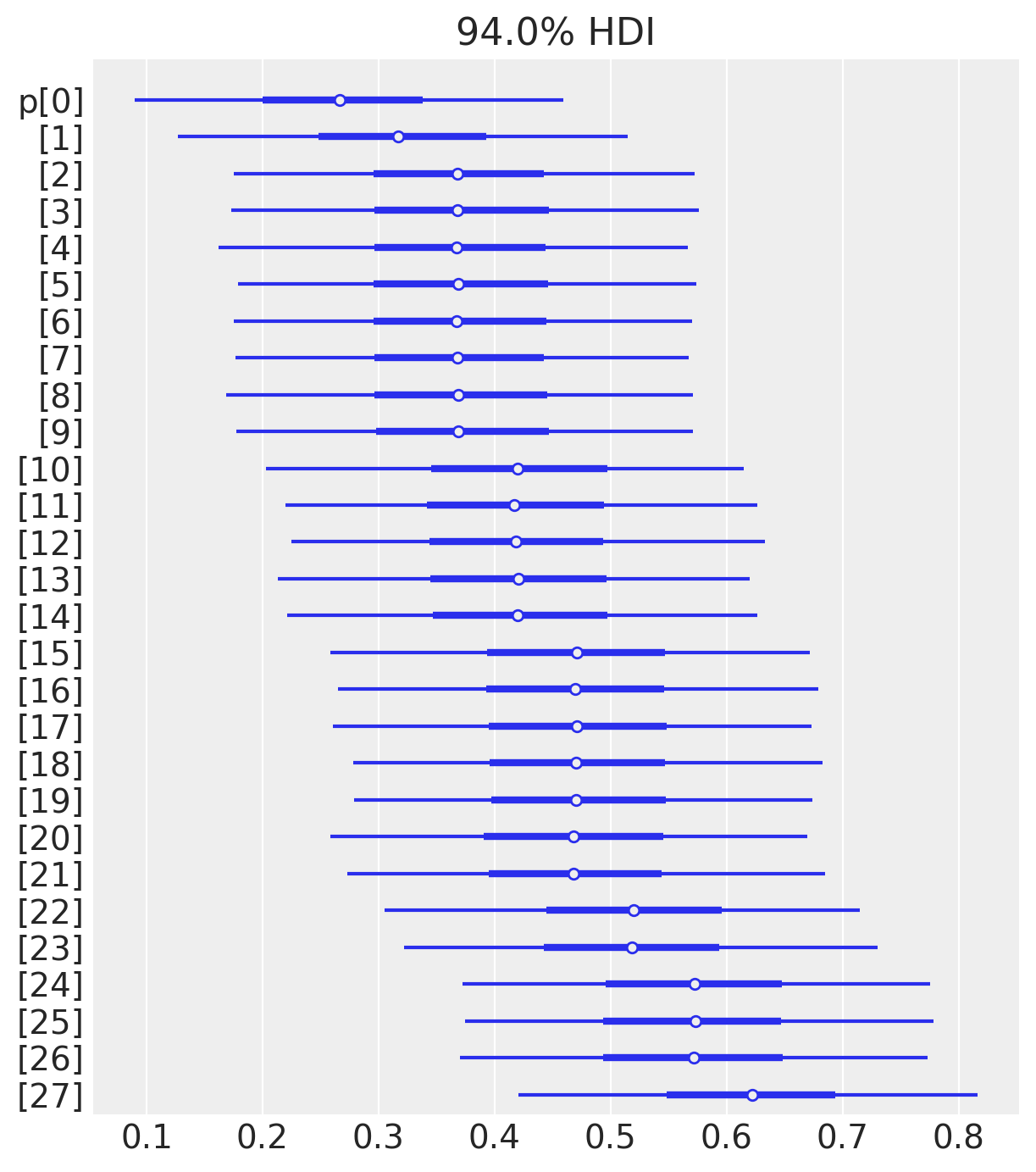
az.summary(trace, round_to=2)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
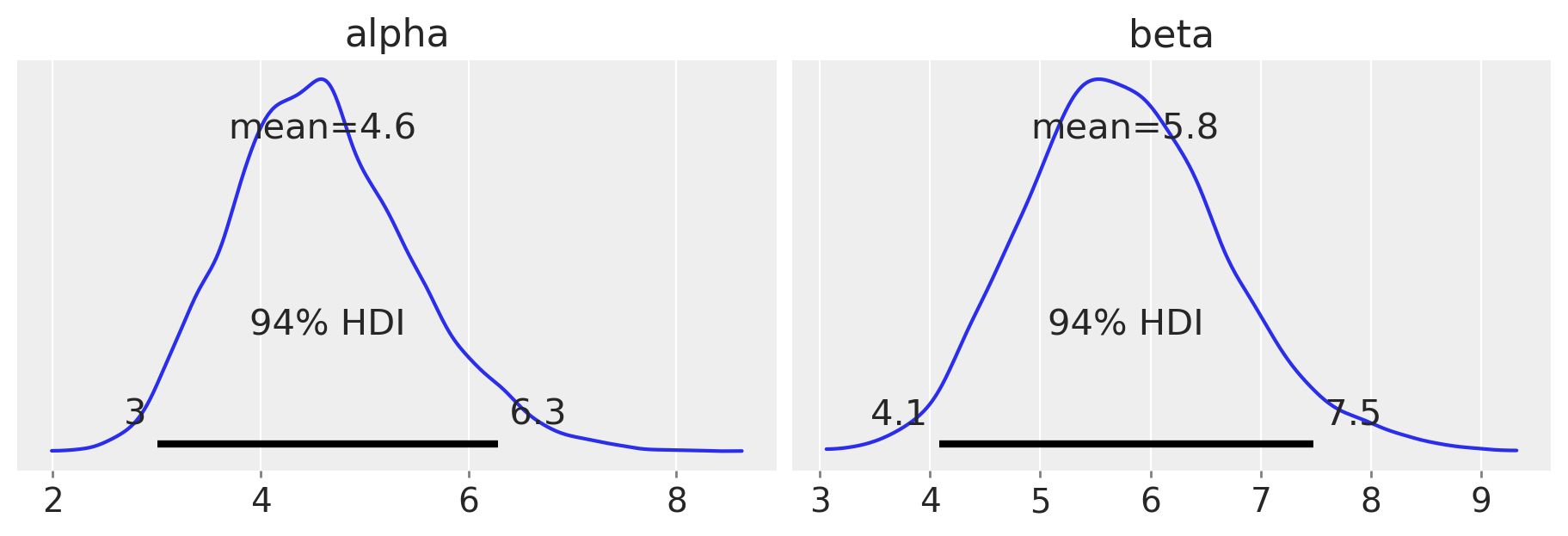
| alpha | 4.60 | 0.89 | 3.01 | 6.28 | 0.01 | 0.01 | 5383.58 | 5627.26 | 1.0 |
| beta | 5.77 | 0.91 | 4.08 | 7.48 | 0.01 | 0.01 | 6860.73 | 6073.01 | 1.0 |
| p[0] | 0.27 | 0.10 | 0.09 | 0.46 | 0.00 | 0.00 | 8980.99 | 5324.55 | 1.0 |
| p[1] | 0.32 | 0.10 | 0.13 | 0.51 | 0.00 | 0.00 | 11152.91 | 5690.98 | 1.0 |
| p[2] | 0.37 | 0.11 | 0.18 | 0.57 | 0.00 | 0.00 | 10750.21 | 5665.11 | 1.0 |
| p[3] | 0.37 | 0.11 | 0.17 | 0.58 | 0.00 | 0.00 | 9501.70 | 5873.51 | 1.0 |
| p[4] | 0.37 | 0.11 | 0.16 | 0.57 | 0.00 | 0.00 | 10343.89 | 5794.76 | 1.0 |
| p[5] | 0.37 | 0.11 | 0.18 | 0.57 | 0.00 | 0.00 | 10807.54 | 5916.45 | 1.0 |
| p[6] | 0.37 | 0.11 | 0.18 | 0.57 | 0.00 | 0.00 | 11120.55 | 6069.07 | 1.0 |
| p[7] | 0.37 | 0.11 | 0.18 | 0.57 | 0.00 | 0.00 | 10107.58 | 6060.34 | 1.0 |
| p[8] | 0.37 | 0.11 | 0.17 | 0.57 | 0.00 | 0.00 | 11188.83 | 5866.04 | 1.0 |
| p[9] | 0.37 | 0.11 | 0.18 | 0.57 | 0.00 | 0.00 | 9880.54 | 5371.76 | 1.0 |
| p[10] | 0.42 | 0.11 | 0.20 | 0.61 | 0.00 | 0.00 | 10626.82 | 5818.44 | 1.0 |
| p[11] | 0.42 | 0.11 | 0.22 | 0.63 | 0.00 | 0.00 | 11687.72 | 5642.63 | 1.0 |
| p[12] | 0.42 | 0.11 | 0.22 | 0.63 | 0.00 | 0.00 | 10749.91 | 5784.65 | 1.0 |
| p[13] | 0.42 | 0.11 | 0.21 | 0.62 | 0.00 | 0.00 | 11241.34 | 5965.97 | 1.0 |
| p[14] | 0.42 | 0.11 | 0.22 | 0.63 | 0.00 | 0.00 | 10817.99 | 6032.37 | 1.0 |
| p[15] | 0.47 | 0.11 | 0.26 | 0.67 | 0.00 | 0.00 | 11498.43 | 6178.71 | 1.0 |
| p[16] | 0.47 | 0.11 | 0.27 | 0.68 | 0.00 | 0.00 | 10874.21 | 5443.33 | 1.0 |
| p[17] | 0.47 | 0.11 | 0.26 | 0.67 | 0.00 | 0.00 | 11210.34 | 6103.73 | 1.0 |
| p[18] | 0.47 | 0.11 | 0.28 | 0.68 | 0.00 | 0.00 | 11088.14 | 6198.76 | 1.0 |
| p[19] | 0.47 | 0.11 | 0.28 | 0.67 | 0.00 | 0.00 | 10092.98 | 6155.87 | 1.0 |
| p[20] | 0.47 | 0.11 | 0.26 | 0.67 | 0.00 | 0.00 | 10991.31 | 5982.08 | 1.0 |
| p[21] | 0.47 | 0.11 | 0.27 | 0.68 | 0.00 | 0.00 | 11505.00 | 5639.59 | 1.0 |
| p[22] | 0.52 | 0.11 | 0.31 | 0.71 | 0.00 | 0.00 | 10374.21 | 6199.09 | 1.0 |
| p[23] | 0.52 | 0.11 | 0.32 | 0.73 | 0.00 | 0.00 | 10783.80 | 6171.58 | 1.0 |
| p[24] | 0.57 | 0.11 | 0.37 | 0.78 | 0.00 | 0.00 | 10901.84 | 6004.54 | 1.0 |
| p[25] | 0.57 | 0.11 | 0.37 | 0.78 | 0.00 | 0.00 | 11597.80 | 6067.52 | 1.0 |
| p[26] | 0.57 | 0.11 | 0.37 | 0.77 | 0.00 | 0.00 | 11102.57 | 6146.34 | 1.0 |
| p[27] | 0.62 | 0.11 | 0.42 | 0.82 | 0.00 | 0.00 | 10563.20 | 5736.58 | 1.0 |
Creiamo un array che contiene le stime bayesiane della probabilità di successo di ciascun operatore fornite sopra dalla funzione summary di ArviZ. Per fare questo usiamo le funzionalità di xarray.
# Bayesian estimates
# Calcola la media lungo le dimensioni 'chain' e 'draw'
bayesian_estimates = trace.posterior["p"].mean(dim=("chain", "draw"))
print(bayesian_estimates.values)
[0.2731482 0.32278283 0.37140286 0.37302738 0.37202906 0.37303144
0.37215181 0.37215784 0.37302342 0.37322351 0.42247895 0.41979045
0.41988967 0.42242386 0.42224729 0.47090629 0.47051333 0.47239054
0.47214868 0.47141132 0.46879507 0.47038446 0.5203012 0.51813907
0.56980907 0.57005627 0.56886998 0.61880784]
Generiamo un array con le probabilità empiriche.
# Empirical probabilities
empirical_probs = y.values / N.values
print(empirical_probs)
[0.1 0.2 0.3 0.3 0.3 0.3 0.3 0.3 0.3 0.3 0.4 0.4 0.4 0.4 0.4 0.5 0.5 0.5
0.5 0.5 0.5 0.5 0.6 0.6 0.7 0.7 0.7 0.8]
Il grafico seguente confronta le probabilità empiriche con le stime Bayesiane per la probabilità di successo associata a ciascun operatore. Questa rappresentazione evidenzia il fenomeno di “shrinkage” intrinseco ai modelli Bayesiani gerarchici. In particolare, il grafico illustra come le stime Bayesiane delle probabilità di successo per gli operatori tendano a convergere verso la media generale, in confronto alle probabilità empiriche.
# Calcola la media generale delle probabilità empiriche
mean_empirical_prob = np.mean(empirical_probs)
# Calcola la media generale delle stime Bayesiane
mean_bayesian_estimate = np.mean(bayesian_estimates)
# Crea il grafico
plt.figure()
# Traccia le probabilità empiriche
plt.scatter(range(1, 29), empirical_probs, label='Probabilità Empiriche')
# Traccia le stime Bayesiane
plt.scatter(range(1, 29), bayesian_estimates, color="C2", label='Stime Bayesiane')
# Aggiungi linee orizzontali per indicare le medie generali
plt.axhline(y=mean_empirical_prob, linestyle='--', label=f'Media Generale Empirica: {mean_empirical_prob:.2f}')
plt.axhline(y=mean_bayesian_estimate, linestyle='--', label=f'Media Generale Bayesiana: {mean_bayesian_estimate:.2f}')
# Etichette e titolo
plt.xlabel('Indice dell\'Operatore')
plt.ylabel('Probabilità di Successo')
plt.title('Fenomeno dello Shrinkage in un Modello Bayesiano Gerarchico')
plt.legend()
plt.show()
Nella figura seguente, le stime bayesiane sono rappresentate mediante un “forest plot” del parametro p, insieme all’intervallo di credibilità Highest Density Interval (HDI) al 94%.
samples_p = trace.posterior["p"]
az.plot_forest(samples_p, combined=True, hdi_prob=0.94)
plt.show()
Esaminiamo la distribuzione a posteriori dei parametri alpha e beta.
az.plot_posterior(trace, var_names=["alpha", "beta"], figsize=(9, 3))
plt.show()
az.plot_trace(trace, combined=True, figsize=(9, 6), kind="rank_bars")
plt.tight_layout()
plt.show();
Le distribuzioni posteriori degli iperparametri, prese da sole, non hanno un significato chiaro. Tuttavia, possiamo utilizzarle per calcolare la distribuzione a posteriori della probabilità di una risposta corretta per tutto il gruppo.
Iniziamo a recuperare le stime a posteriori di alpha e beta.
alphas = trace.posterior["alpha"]
betas = trace.posterior["beta"]
print(alphas)
<xarray.DataArray 'alpha' (chain: 4, draw: 2000)>
array([[4.31373833, 4.35001097, 5.2376626 , ..., 4.58164904, 5.23796169,
5.57763641],
[4.31465093, 5.07282001, 4.19369655, ..., 4.00186608, 4.64458498,
4.45079329],
[4.19247453, 5.74604455, 4.7577267 , ..., 3.9707988 , 5.63415419,
4.42416735],
[5.89348064, 6.41876393, 4.14790228, ..., 5.46629198, 4.12457368,
5.52468562]])
Coordinates:
* chain (chain) int64 0 1 2 3
* draw (draw) int64 0 1 2 3 4 5 6 7 ... 1993 1994 1995 1996 1997 1998 1999
Dato che ciascuna coppia di parametri alpha e beta definisce la distribuzione a posteriori Beta, calcoliamo la media della distribuzione Beta definita da ciascuna coppia di valori alpha e beta.
# Function to calculate the mean of a Beta distribution
def beta_mean(alpha, beta):
return alpha / (alpha + beta)
# Calculate the means for each pair of alpha and beta
sample_posterior_x_means = np.array([beta_mean(a, b) for a, b in zip(alphas, betas)])
Ci sono 8000 di queste medie.
sample_posterior_x_means.shape
(4, 2000)
sample_posterior_x_means
array([[0.41887073, 0.42504592, 0.47043047, ..., 0.39215345, 0.46730827,
0.46907438],
[0.43981986, 0.50448883, 0.42508267, ..., 0.43523326, 0.44302559,
0.44234802],
[0.48080226, 0.45766271, 0.46643822, ..., 0.43278012, 0.45133823,
0.44826289],
[0.49296599, 0.44270916, 0.45777915, ..., 0.47989613, 0.44280735,
0.48374652]])
print(sample_posterior_x_means.mean())
0.4422742402499882
Con questi 8000 valori a posteriori della media della distribuzione Beta che rappresenta il “meccanismo generatore” da cui i valori p di ciascun operatore vengono tratti, generiamo una densità empirica da cui è anche possibile calcolare l’intervallo che contiene il 94% dei valori della distribuzione.
az.plot_posterior(sample_posterior_x_means)
plt.show()
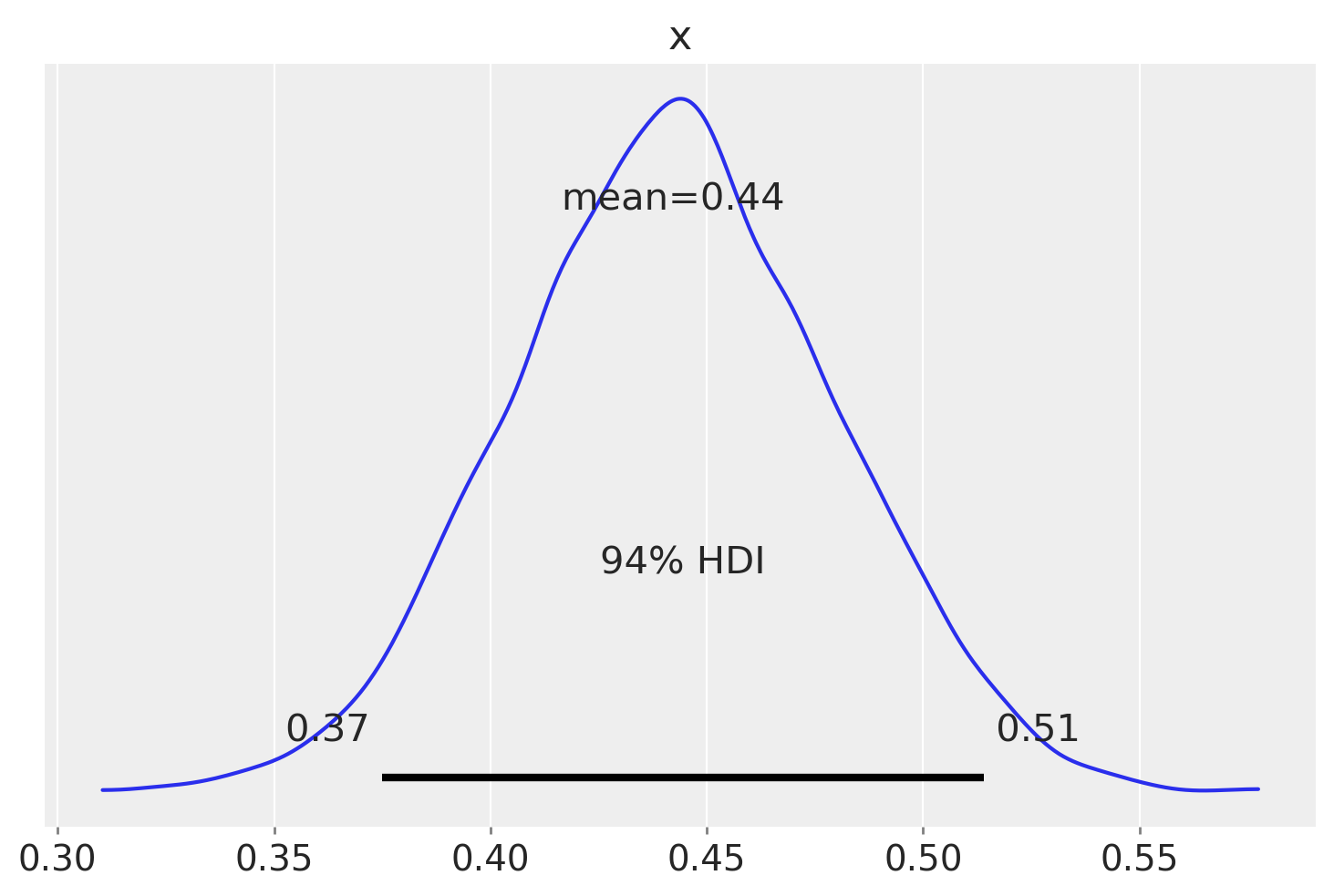
L’intervallo [0.37, 0.51] rappresenta l’intervallo di credibilità al 94% per la probabilità di risposta corretta p, considerando l’insieme del gruppo degli operatori. Questo intervallo ci fornisce un’indicazione sulla variabilità delle probabilità di successo tra gli operatori, considerando sia le differenze tra di loro che le somiglianze all’interno del gruppo.
Poiché l’intervallo di credibilità include il valore 0.5, possiamo concludere che non ci sono evidenze credibili che gli operatori, considerati nel loro insieme, siano in grado di “percepire il campo energetico di una persona senza vedere le mani” ad un livello diverso rispetto a quello che ci si potrebbe aspettare dal caso soltanto.
La ricerca sulla conformità sociale#
L’articolo “Studies of Independence and Conformity: I. A Minority of One Against a Unanimous Majority” di Solomon E. Asch è un lavoro pionieristico nel campo della psicologia sociale e si concentra sul fenomeno della conformità. Pubblicato nel 1951, questo studio ha esaminato fino a che punto la pressione sociale da parte di un gruppo può influenzare le scelte e i giudizi di un individuo. L’obiettivo era di esplorare le condizioni sotto le quali le persone conformano le loro opinioni e comportamenti a quelli del gruppo, anche quando queste opinioni sono manifestamente errate.
Il campione era composto principalmente da studenti universitari maschi.
Gli esperimenti erano progettati come test di percezione visiva. I partecipanti dovevano confrontare la lunghezza di una linea standard con quella di tre linee di confronto e indicare quale delle tre linee avesse la stessa lunghezza della linea standard.
In ogni sessione di test, c’era un solo partecipante reale. Gli altri membri del gruppo erano “confederati” istruiti dall’esperimentatore. Gli era stato detto di fornire risposte errate in modo unanime in alcune delle prove.
Durante l’esperimento, ogni partecipante (inclusi i confederati) doveva dichiarare ad alta voce quale delle tre linee di confronto avesse la stessa lunghezza della linea standard. Il partecipante reale era sempre l’ultimo o il penultimo a rispondere, consentendo la pressione del gruppo di manifestarsi pienamente.
Si misurava la frequenza con cui il partecipante reale conformava la sua risposta a quella del gruppo di confidenti.
Asch ha scoperto che una percentuale significativa di partecipanti ha scelto la risposta errata, seguendo l’opinione della maggioranza, anche quando la risposta corretta era ovvia.
Nel contesto della psicologia e delle scienze sociali, questo studio è ancora oggi una pietra miliare per la comprensione del comportamento umano in contesti sociali.
Ash (1951) riporta i risultati di vari studi. Leggiamo qui i dati della condizione sperimentale di un esperimento a cui hanno partecipato 25 soggetti.
df = pd.read_csv("../data/ash_25.csv")
df.head()
| subject_id | is_error | |
|---|---|---|
| 0 | Subject_1 | 0 |
| 1 | Subject_1 | 0 |
| 2 | Subject_1 | 0 |
| 3 | Subject_1 | 0 |
| 4 | Subject_1 | 0 |
La proporzione di errori replica il valore riportato da Ash (1951) per questo esperimento.
df["is_error"].mean()
0.43
Per fornire un punto di riferimento, Ash (1951) presenta i seguenti dati relativi alla condizione di controllo, che coinvolgeva 37 partecipanti: un solo individuo ha commesso un errore, un altro ha fatto due errori, mentre i restanti 35 partecipanti non hanno commesso alcun errore. In questo gruppo, la proporzione totale di errori è stata estremamente bassa, pari allo 0.007%.
Creaiamo un nuovo DataFrame con una versione aggregata dei dati per potere poi applicare ai dati una verosimiglianza binomiale.
# Group the data by 'subject_id' and sum the 'is_error' to get the number of errors for each subject
df_grouped = df.groupby('subject_id')['is_error'].sum().reset_index()
# Rename the column for clarity
df_grouped.rename(columns={'is_error': 'num_errors'}, inplace=True)
df_grouped
| subject_id | num_errors | |
|---|---|---|
| 0 | Subject_1 | 0 |
| 1 | Subject_10 | 4 |
| 2 | Subject_11 | 5 |
| 3 | Subject_12 | 5 |
| 4 | Subject_13 | 6 |
| 5 | Subject_14 | 6 |
| 6 | Subject_15 | 6 |
| 7 | Subject_16 | 6 |
| 8 | Subject_17 | 8 |
| 9 | Subject_18 | 8 |
| 10 | Subject_19 | 8 |
| 11 | Subject_2 | 0 |
| 12 | Subject_20 | 8 |
| 13 | Subject_21 | 9 |
| 14 | Subject_22 | 9 |
| 15 | Subject_23 | 10 |
| 16 | Subject_24 | 12 |
| 17 | Subject_25 | 12 |
| 18 | Subject_3 | 0 |
| 19 | Subject_4 | 0 |
| 20 | Subject_5 | 0 |
| 21 | Subject_6 | 1 |
| 22 | Subject_7 | 1 |
| 23 | Subject_8 | 2 |
| 24 | Subject_9 | 3 |
Definiamo ora le coordinate da passare a pm.Model.
# Definizione delle coordinate
coords = {
"subject": pd.Categorical(df_grouped['subject_id']).categories.tolist()
}
print(coords)
{'subject': ['Subject_1', 'Subject_10', 'Subject_11', 'Subject_12', 'Subject_13', 'Subject_14', 'Subject_15', 'Subject_16', 'Subject_17', 'Subject_18', 'Subject_19', 'Subject_2', 'Subject_20', 'Subject_21', 'Subject_22', 'Subject_23', 'Subject_24', 'Subject_25', 'Subject_3', 'Subject_4', 'Subject_5', 'Subject_6', 'Subject_7', 'Subject_8', 'Subject_9']}
Nell’esperimento condotto da Ash, ciascun partecipante ha effettuato un totale di 12 prove cruciali. La frequenza degli errori è stata determinata in relazione a questo numero complessivo di prove.
ntrials = 12 # Numero di prove per ciascun soggetto
Nel modello PyMC che definiamo qui sotto, abbiamo adottato un approccio gerarchico per stimare la probabilità \( p \) di commettere un errore per ciascun soggetto. Gli iperparametri \( \alpha \) e \( \beta \), estratti da una distribuzione Gamma, parametrizzano una distribuzione Beta da cui vengono estratte le probabilità specifiche per ogni soggetto (\( p \)).
Oltre a ciò, abbiamo incluso una variabile deterministica, denominata overall_p, per calcolare la probabilità media di commettere un errore a livello di gruppo. Questa probabilità media viene calcolata come il rapporto \( \frac{\alpha}{\alpha + \beta} \), che è la media di una distribuzione Beta con parametri \( \alpha \) e \( \beta \).
In questo modo, il modello non solo fornisce stime delle probabilità di errore per ciascun soggetto, ma anche una stima globale della probabilità di errore a livello di gruppo. Quest’ultima è particolarmente utile per avere una visione d’insieme del fenomeno che stiamo studiando.
with pm.Model(coords=coords) as model_2:
y_data = pm.ConstantData("y_data", df_grouped["num_errors"])
n_trials = pm.ConstantData("n_trials", ntrials)
# Iperparametri per la distribuzione a livello di gruppo
alpha = pm.Gamma("alpha", 2, 0.5)
beta = pm.Gamma("beta", 2, 0.5)
# Probabilità specifiche per ciascun soggetto
p = pm.Beta("p", alpha, beta, dims="subject")
# Calcolo della probabilità media a livello di gruppo
overall_p = pm.Deterministic("overall_p", alpha / (alpha + beta))
# Verosimiglianza del modello
Y_obs = pm.Binomial("Y_obs", n=n_trials, p=p, observed=y_data, dims="subject")
Eseguiamo il campionamento.
with model_2:
idata_2 = pm.sampling_jax.sample_numpyro_nuts()
Show code cell output
Compiling...
Compilation time = 0:00:09.803439
Sampling...
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
Running chain 1: 0%| | 0/2000 [00:01<?, ?it/s]
Running chain 0: 0%| | 0/2000 [00:01<?, ?it/s]
Running chain 3: 0%| | 0/2000 [00:01<?, ?it/s]
Running chain 2: 0%| | 0/2000 [00:01<?, ?it/s]
Running chain 0: 100%|██████████████████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1051.89it/s]
Running chain 1: 100%|██████████████████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1052.43it/s]
Running chain 2: 100%|██████████████████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1053.15it/s]
Running chain 3: 100%|██████████████████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1053.75it/s]
Sampling time = 0:00:02.056859
Transforming variables...
Transformation time = 0:00:00.101312
Esaminiamo la distribuzione a posteriori della variabile di interesse.
var_names = ["overall_p"]
az.plot_trace(
idata_2, combined=True, var_names=var_names, kind="rank_bars", figsize=(9, 3)
)
plt.tight_layout()
plt.show();
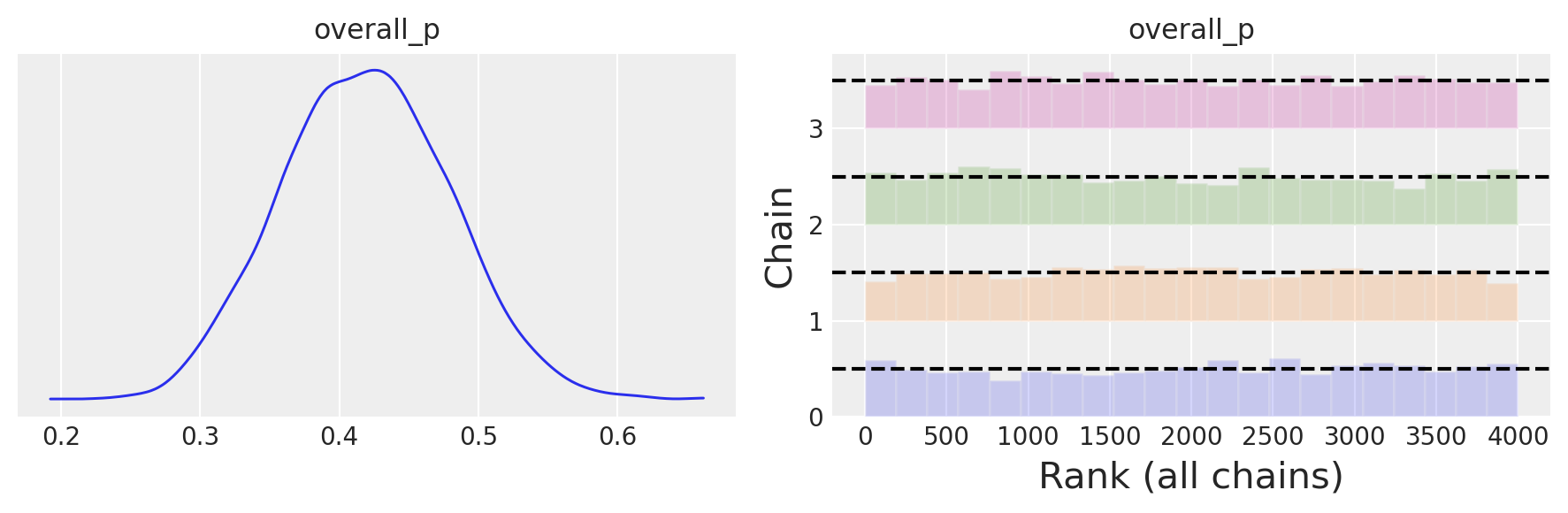
Generiamo un sommario numerico.
az.summary(idata_2, "overall_p")
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| overall_p | 0.419 | 0.061 | 0.299 | 0.525 | 0.001 | 0.001 | 4137.0 | 3156.0 | 1.0 |
Dai risultati ottenuti, possiamo affermare che la probabilità a posteriori di commettere un errore nel contesto sperimentale esaminato da Ash (1951) è di circa 0.42. Questa stima è accompagnata da un intervallo di credibilità al 94% che va da 0.31 a 0.53. Nonostante la dimensione ridotta del campione studiato da Ash (1951), ed esaminato qui, l’incertezza associata alla nostra stima a posteriori è sufficientemente bassa da differenziare in modo credibile la condizione sperimentale in questione dalla relativa condizione di controllo.
Considerazioni conclusive#
Il modello gerarchico beta-binomiale rappresenta uno strumento fondamentale per l’analisi di dati binomiali provenienti da gruppi o categorie diverse, consentendo di trattare dati complessi in modo integrato. Questo modello ci permette di studiare le probabilità di successo in modo unificato, considerando sia le caratteristiche specifiche di ogni gruppo che le somiglianze tra di essi. L’approccio gerarchico aumenta la precisione delle stime e ci aiuta a comprendere meglio le differenze tra i gruppi e le tendenze comuni a tutti. Questo rende il modello gerarchico beta-binomiale uno strumento importante per la valutazione e l’interpretazione di dati binomiali raggruppati.
Watermark#
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor
Last updated: Thu Nov 09 2023
Python implementation: CPython
Python version : 3.11.6
IPython version : 8.16.1
pytensor: 2.13.1
pymc : 5.9.1
scipy : 1.11.3
arviz : 0.16.1
matplotlib: 3.8.0
numpy : 1.25.2
requests : 2.31.0
pandas : 2.1.1
Watermark: 2.4.3