![]()
Modello di Poisson: derivazione analitica e MCMC#
In questo capitolo, spiegheremo la derivazione analitica della distribuzione a posteriori utilizzando una funzione di verosimiglianza di Poisson e una distribuzione a priori gamma. Inoltre, dimostreremo l’equivalenza tra la soluzione ottenuta analiticamente e quella ricavata attraverso l’utilizzo di PyMC.
Preparazione del Notebook#
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import scipy.stats as stats
import scipy.special as sp
from math import factorial
import pymc as pm
import pymc.sampling_jax
from scipy.integrate import quad
import arviz as az
import warnings
warnings.filterwarnings("ignore", category=UserWarning)
warnings.filterwarnings("ignore", category=FutureWarning)
warnings.filterwarnings("ignore", category=Warning)
/Users/corrado/opt/anaconda3/envs/pymc_env/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
%config InlineBackend.figure_format = 'retina'
RANDOM_SEED = 42
rng = np.random.default_rng(RANDOM_SEED)
az.style.use("arviz-darkgrid")
sns.set_theme(palette="colorblind")
Distribuzione di Poisson#
Ricordiamo che la distribuzione di Poisson è data da:
dove \(\lambda>0\). Risulta inoltre che \(E(Y)=\lambda\) e \(Var(Y)=\lambda\).
Simuliamo 100 osservazioni dalla distribuzione di Poisson con un parametro \(\lambda\) pari a 2.
n = 100
lam_true = 2
y = rng.poisson(lam=lam_true, size=n)
print(y)
[4 3 3 2 1 5 2 0 1 3 1 0 1 4 3 1 1 4 1 0 4 2 0 1 2 0 1 4 2 0 2 1 2 2 0 0 5
2 0 2 2 4 2 1 2 0 1 3 0 3 3 1 2 0 2 1 2 2 2 4 3 2 6 3 0 3 0 1 1 2 3 0 1 1
3 3 0 2 3 1 2 1 6 0 3 3 2 2 3 0 1 2 2 1 0 0 1 3 3 1]
Esaminiamo la distribuzione dei 100 valori così ottenuti.
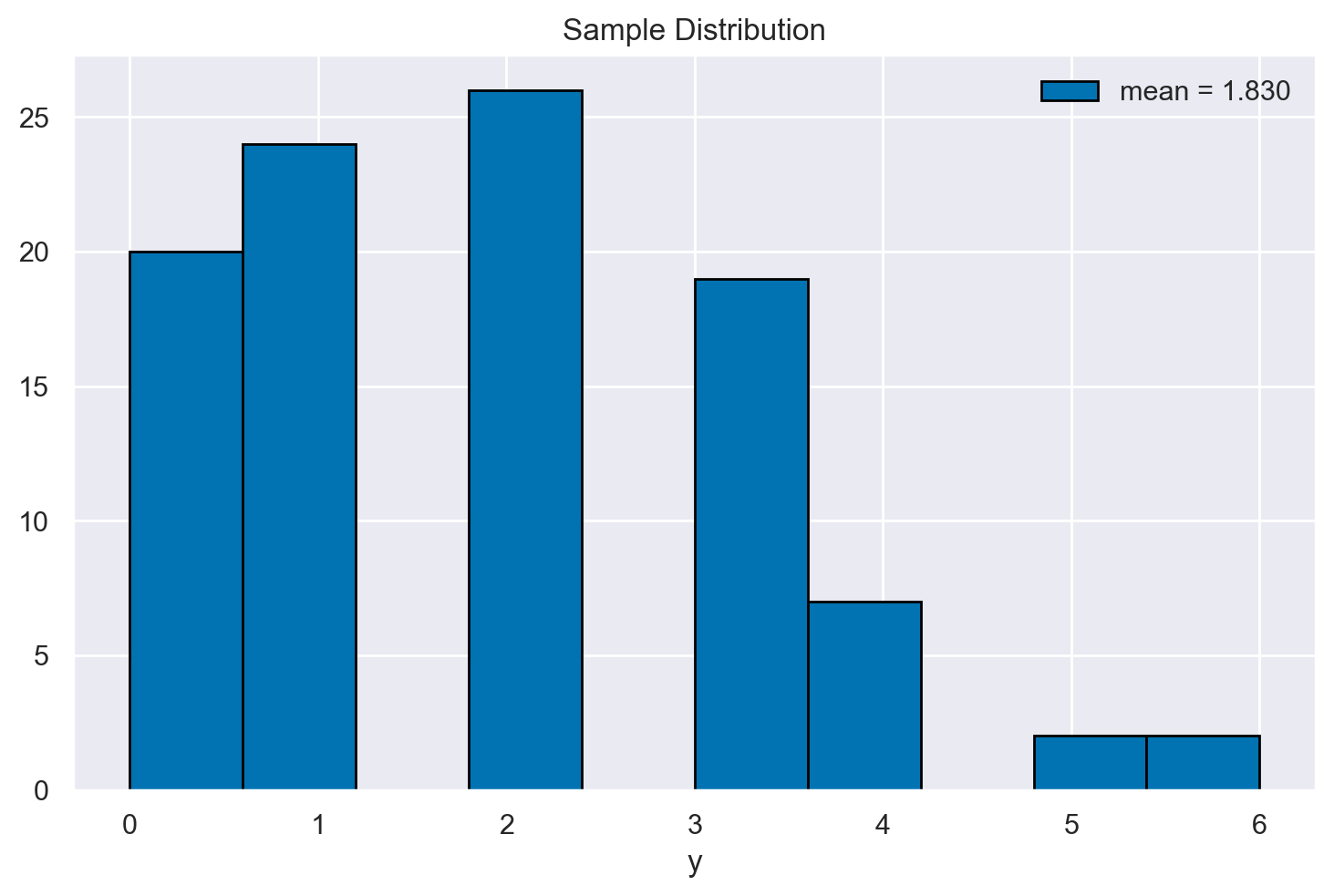
plt.hist(y, edgecolor="black", bins=10) # You can change the number of bins if desired
mean_y = y.mean()
plt.legend([f"mean = {mean_y:0.3f}"], loc="upper right")
plt.title("Sample Distribution")
plt.xlabel("y")
plt.show()
Distribuzione a priori Gamma#
Consideriamo una distribuzione a priori gamma per il parametro \(\lambda \sim \Gamma(a,b)\). Ricordiamo che la funzione di densità della distribuzione gamma è data da
dove \(a > 0\) rappresenta il parametro di forma e \(b > 0\) è il parametro di scala, spesso chiamato anche parametro di tasso.
Il valore atteso e la varianza della distribuzione gamma sono
Nella presente simulazione useremo una distribuzione a priori Gamma con i seguenti parametri.
a = 3 # shape
b = 1 # rate = 1/scale
Visualizziamo la distribuzione Gamma prescelta.
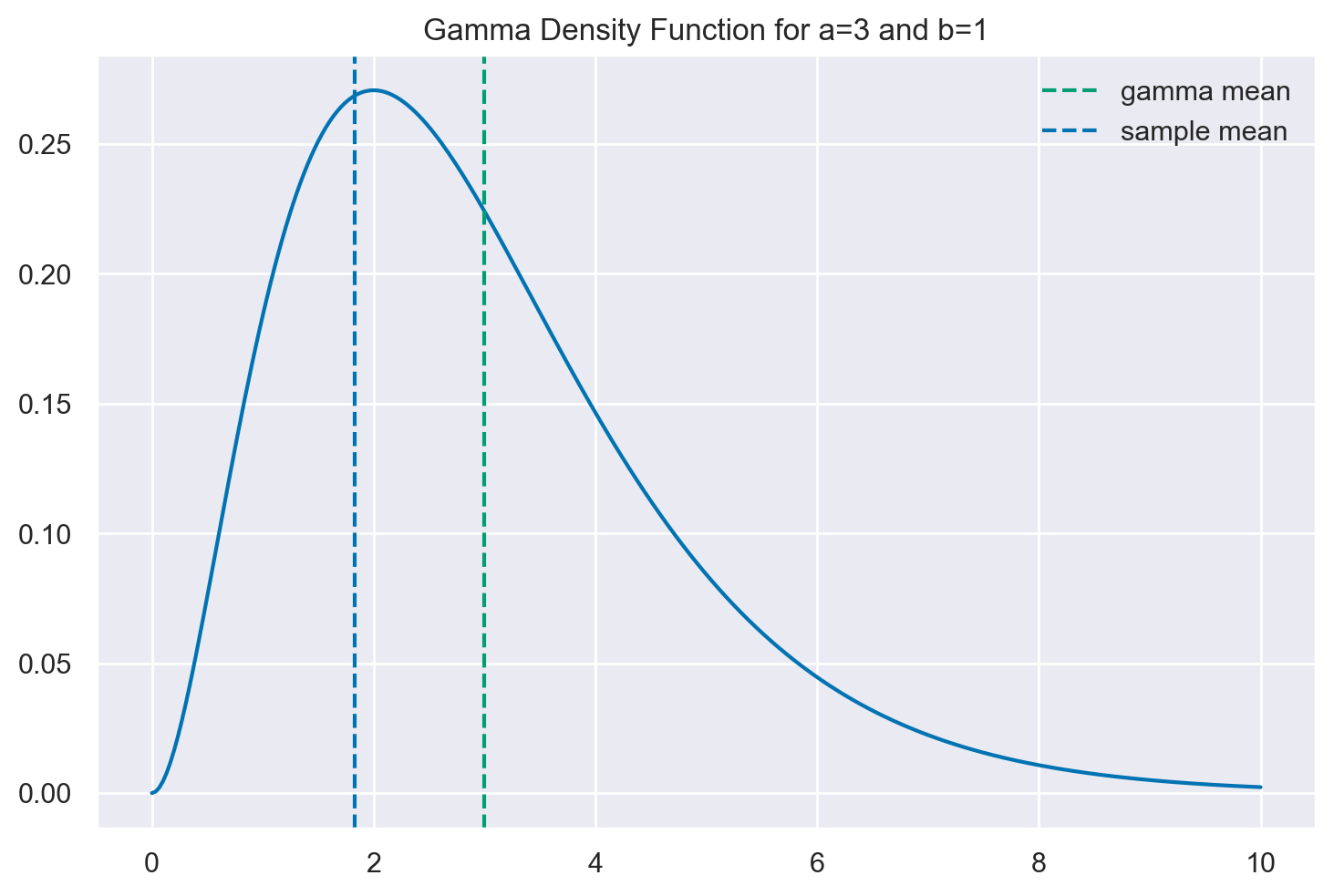
x = np.linspace(start=0, stop=10, num=300)
plt.plot(x, stats.gamma.pdf(x, a=a, scale=1 / b))
plt.axvline(x=a / b, linestyle="--", color="C2", label="gamma mean")
plt.axvline(x=y.mean(), linestyle="--", label="sample mean")
plt.legend()
plt.title(f"Gamma Density Function for a={a} and b={b}")
plt.show()
Creiamo una funzione che calcola e ritorna il valore della funzione di densità della distribuzione gamma per un dato valore di ascissa.
def prior(lam):
return stats.gamma.pdf(lam, a=a, scale=1/b)
Verosimiglianza#
Poiché le osservazioni sono indipendenti, la funzione di verosimiglianza è
Nella parte sinistra dell’equazione, viene moltiplicata la probabilità della distribuzione di Poisson per ogni singola osservazione \(y_i\):
Nella parte destra dell’equazione, viene semplificata l’espressione:
\( e^{-\lambda} \) viene moltiplicato \( n \) volte, il che diventa \( e^{-n\lambda} \)
\( \lambda \) viene elevato alla potenza di ogni \( y_i \), il che diventa \( \lambda^{\sum_{i=1}^n y_i} \)
Il denominatore rimane come prodotto dei fattoriali delle osservazioni \( y_i \), cioè \( \prod_{i=1}^{n}y_i! \)
def log_likelihood(lam, y):
log_factorials = [np.log(factorial(i)) for i in y]
log_numerator = (-lam * y.size) + (y.sum() * np.log(lam))
log_denominator = np.sum(log_factorials)
return np.exp(log_numerator - log_denominator)
Distribuzione a posteriori per \(\lambda\) (a meno di una costante di proporzionalità)#
Poiché ci interessa solamente la struttura della distribuzione a posteriori, senza tener conto della costante di normalizzazione), abbiamo:
Scriviamo una funzione Python che ritorna la funzione a posteriori per \(\lambda\) a meno di una costante di proporzionalità – ovvero la funzione a posteriori non normalizzata.
# Define the posterior distribution (up to a constant)
def posterior_up_to_constant(lam, y):
return log_likelihood(lam=lam, y=y) * prior(lam)
Distribuzione a posteriori per \(\lambda\)#
Per trovare la distribuzione a posteriori, è necessario normalizzare la funzione non normalizzata che abbiamo definito precedentemente, in modo che l’area totale sotto la curva sia unitaria. Questo significa che dobbiamo trovare una costante di normalizzazione, che è ottenuta calcolando l’integrale della funzione non normalizzata su tutto il dominio di λ.
lower_bound = 0
upper_bound = 10
def integrand(lam, y):
return posterior_up_to_constant(lam, y)
normalizing_constant, _ = quad(integrand, lower_bound, upper_bound, args=(y,))
Ora possiamo definire la funzione normalizzata a posteriori.
def posterior(lam, y):
return posterior_up_to_constant(lam, y) / normalizing_constant
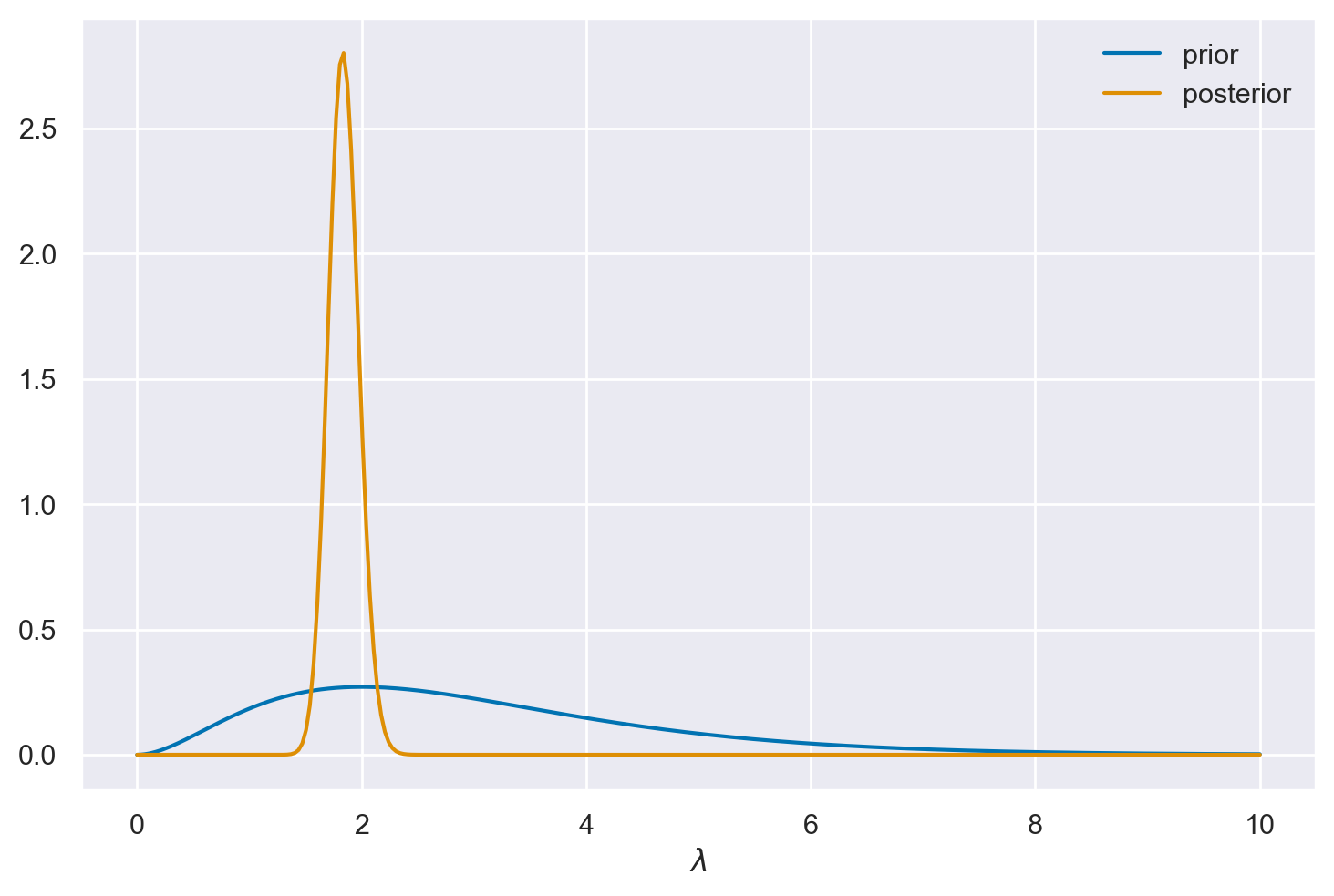
Esaminiamo graficamente la soluzione ottenuta.
x = np.linspace(start=0, stop=10, num=300)
plt.plot(x, prior(x), label="prior")
plt.plot(x, posterior(x, y), label="posterior")
plt.legend()
plt.xlabel("$\lambda$")
plt.show()
Soluzione analitica#
La distribuzione a priori per \( \lambda \) è una gamma con parametri \( a \) e \( b \), e la verosimiglianza è proporzionale a \( \lambda^{\left(\sum_{i=1}^n y_i\right)-1} e^{-(n\lambda)} \). I dati \( y \) seguono una distribuzione di Poisson.
Quando moltiplichiamo la distribuzione a priori gamma per questa verosimiglianza, otteniamo la distribuzione a posteriori non normalizzata:
Questa espressione ha esattamente la forma della funzione di densità di probabilità di una distribuzione gamma, ma con parametri aggiornati:
il parametro di forma è \( \sum_{i=1}^n y_i + a \),
il parametro di scala è \( n + b \).
Quindi, possiamo scrivere la distribuzione a posteriori normalizzata come:
Questo è un esempio di coppia coniugata, dove la scelta della distribuzione a priori consente di ottenere una distribuzione a posteriori dello stesso tipo della distribuzione a priori. In questo caso, una distribuzione gamma a priori con una verosimiglianza di Poisson porta a una distribuzione gamma a posteriori.
Riscriviamo dunque in Python la funzione per la distribuzione a posteriori.
def posterior_an(lam, y):
shape = a + y.sum()
rate = b + y.size
return stats.gamma.pdf(lam, shape, scale=1 / rate)
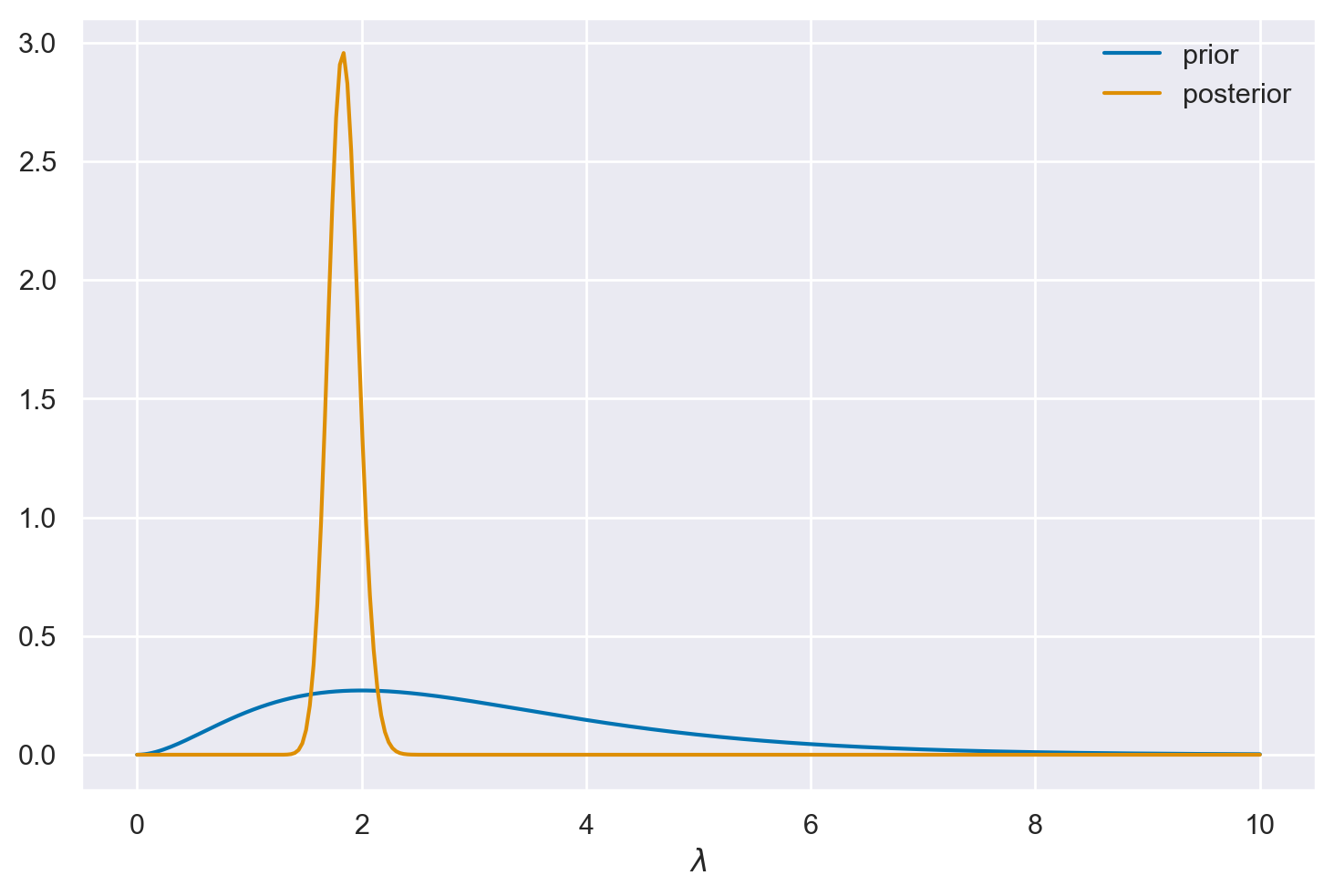
Con la funzione posterior_an possiamo ottenere lo stesso grafico creato in precedenza.
plt.plot(x, prior(x), label="prior")
plt.plot(x, posterior_an(x, y), label="posterior")
plt.legend()
plt.xlabel("$\lambda$")
plt.show()
Procediamo ora con il calcolo della soluzione analitica per la media della distribuzione a posteriori del parametro \(\lambda\).
# Posterior gamma parameters.
shape = a + y.sum()
rate = b + y.size
# Posterior mean.
print(f"Posterior Mean = {shape / rate: 0.3f}")
Posterior Mean = 1.842
Soluzione con PyMC#
Poniamoci il problema di replicare i risulati precedenti usando PyMC. Specifichiamo il modello.
df = pd.DataFrame()
df["y"] = y
with pm.Model() as model:
data = pm.ConstantData("data", df["y"])
# Define the prior of the parameter lambda.
lam = pm.Gamma("lambda", alpha=a, beta=b)
# Define the likelihood function.
pm.Poisson("y", mu=lam, observed=data)
pm.model_to_graphviz(model)

Eseguiamo il campionamento.
with model:
idata = pm.sampling_jax.sample_numpyro_nuts()
Show code cell output
Compiling...
Compilation time = 0:00:00.582920
Sampling...
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
0%| | 0/2000 [00:00<?, ?it/s]
Compiling.. : 0%| | 0/2000 [00:00<?, ?it/s]
Running chain 3: 0%| | 0/2000 [00:01<?, ?it/s]
Running chain 2: 0%| | 0/2000 [00:01<?, ?it/s]
Running chain 1: 0%| | 0/2000 [00:01<?, ?it/s]
Running chain 0: 0%| | 0/2000 [00:01<?, ?it/s]
Running chain 0: 100%|████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1841.69it/s]
Running chain 1: 100%|████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1843.45it/s]
Running chain 2: 100%|████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1845.31it/s]
Running chain 3: 100%|████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1847.65it/s]
Sampling time = 0:00:01.280893
Transforming variables...
Transformation time = 0:00:00.053224
Utilizziamo la libreria ArviZ per creare un grafico che rappresenti la distribuzione a posteriori e per mostrare la traccia corrispondente.
az.plot_trace(data=idata, combined=True)
plt.show()

az.plot_rank(idata, kind="vlines")
<Axes: title={'center': 'lambda'}, xlabel='Rank (all chains)'>
Troviamo la media della distribuzione a posteriori di \(\lambda\).
az.summary(idata)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| lambda | 1.837 | 0.134 | 1.581 | 2.086 | 0.004 | 0.003 | 1384.0 | 2015.0 | 1.0 |
Si noti che, mediante l’impiego del campionamento MCMC, abbiamo ottenuto una stima precisa del parametro \(\lambda\), facendo ricorso a un campione contenente soltanto 100 osservazioni.
Watermark#
%load_ext watermark
%watermark -n -u -v -iv -w
Last updated: Tue Jan 23 2024
Python implementation: CPython
Python version : 3.11.7
IPython version : 8.19.0
seaborn : 0.13.0
scipy : 1.11.4
numpy : 1.26.2
arviz : 0.17.0
pandas : 2.1.4
pymc : 5.10.3
matplotlib: 3.8.2
Watermark: 2.4.3