✏️ Esercizi#
Stiamo studiando la relazione tra la grandezza del cervello e il Quoziente d’Intelligenza (Full Scale Intelligence Quotient, FSIQ) in un gruppo di studenti universitari. I dati provengono da uno studio che ha utilizzato scansioni MRI per misurare la grandezza del cervello.
Riporto qui sotto la descrizione del set di dati.
The data are based on a study by Willerman et al. (1991) of the relationships between brain size, gender, and intelligence. The research participants consisted of 40 right-handed introductory psychology students with no history of alcoholism, unconsciousness, brain damage, epilepsy, or heart disease who were selected from a larger pool of introductory psychology students with total Scholastic Aptitude Test Scores higher than 1350 or lower than 940. The students in the study took four subtests (Vocabulary, Similarities, Block Design, and Picture Completion) of the Wechsler (1981) Adult Intelligence Scale-Revised. Among the students with Wechsler full-scale IQ’s less than 103, 10 males and 10 females were randomly selected. Similarly, among the students with Wechsler full-scale IQ’s greater than 130, 10 males and 10 females were randomly selected, yielding a randomized blocks design. MRI scans were performed at the same facility for all 40 research participants to measure brain size. The scans consisted of 18 horizontal MRI images. The computer counted all pixels with non-zero gray scale in each of the 18 images, and the total count served as an index for brain size. The dataset and description are adapted from the Data and Story Library (DASL) website.
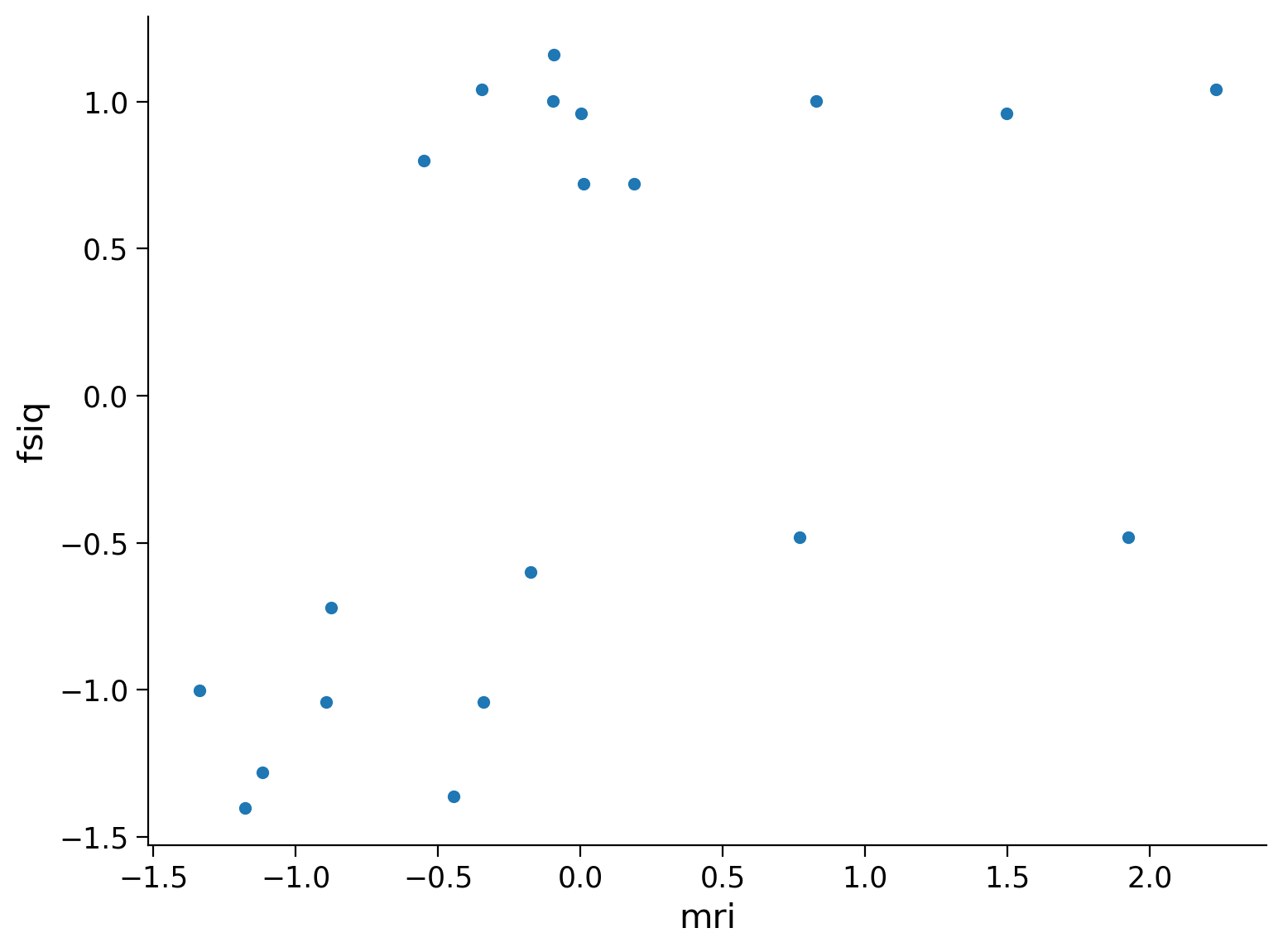
In questa analisi, ci concentreremo sui dati relativi ai maschi, cercando di capire se vi è una associazione positiva tra la grandezza del cervello (MRI) e il FSIQ. Si usi un’analisi di regressione con FSIQ come variabile dipendente e MRI come predittore.
Si trovi la distribuzione a posteriori del parametro \(\beta\). (a) Si trovi l’intervallo di credibilità a posteriodi HDI al 95% per \(\beta\). (b) Si trovi la probabilità a posteriori che \(\beta\) sia positivo. (c) Si interpretino i risultati.
Prima di eseguire l’analisi di regressione, si standardizzino i dati.
Soluzione#
import pymc as pm
import pandas as pd
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
import arviz as az
# Impostazione del seme per la riproducibilità
np.random.seed(84735)
%config InlineBackend.figure_format = 'retina'
%load_ext watermark
RANDOM_SEED = 42
rng = np.random.default_rng(RANDOM_SEED)
plt.style.use("https://raw.githubusercontent.com/NeuromatchAcademy/course-content/main/nma.mplstyle")
brain_data = pd.read_csv("../data/brain_data.csv")
brain_data.head()
| ID | GENDER | FSIQ | VIQ | PIQ | MRI | IQDI | |
|---|---|---|---|---|---|---|---|
| 0 | 2 | Male | 140 | 150 | 124 | 1001121 | Higher IQ |
| 1 | 3 | Male | 139 | 123 | 150 | 1038437 | Higher IQ |
| 2 | 4 | Male | 133 | 129 | 128 | 965353 | Higher IQ |
| 3 | 9 | Male | 89 | 93 | 84 | 904858 | Lower IQ |
| 4 | 10 | Male | 133 | 114 | 147 | 955466 | Higher IQ |
# Filtraggio dei dati per i maschi
males = brain_data[brain_data['GENDER'] == 'Male']
males.shape
(20, 7)
# Standardizzazione di MRI e FSIQ
males['fsiq'] = (males['FSIQ'] - males['FSIQ'].mean()) / males['FSIQ'].std()
males['mri'] = (males['MRI'] - males['MRI'].mean()) / males['MRI'].std()
/var/folders/s7/z86r4t9j6yx376cm120nln6w0000gn/T/ipykernel_33970/2956472145.py:2: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
males['fsiq'] = (males['FSIQ'] - males['FSIQ'].mean()) / males['FSIQ'].std()
/var/folders/s7/z86r4t9j6yx376cm120nln6w0000gn/T/ipykernel_33970/2956472145.py:3: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
males['mri'] = (males['MRI'] - males['MRI'].mean()) / males['MRI'].std()
# Diagramma a dispersione
sns.scatterplot(data=males, x='mri', y='fsiq')
<Axes: xlabel='mri', ylabel='fsiq'>
# Dati per il modello
data = {
'N': len(males['fsiq']),
'x': males['mri'].values,
'y': males['fsiq'].values
}
df = pd.DataFrame(data)
df.head()
| N | x | y | |
|---|---|---|---|
| 0 | 20 | 0.827481 | 1.000548 |
| 1 | 20 | 1.494895 | 0.960526 |
| 2 | 20 | 0.187754 | 0.720394 |
| 3 | 20 | -0.894226 | -1.040570 |
| 4 | 20 | 0.010921 | 0.720394 |
# Definizione del modello
with pm.Model() as model:
alpha = pm.Normal("alpha", 0, 2.5)
beta = pm.Normal("beta", 0, 2.5)
sigma = pm.HalfNormal("sigma", 10)
mu = alpha + beta * data["x"]
y_obs = pm.Normal("y_obs", mu, sigma, observed=data["y"])
with model:
idata = pm.sample()
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [alpha, beta, sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.
# Diagnostica
az.plot_trace(idata);
az.summary(idata, round_to=2)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
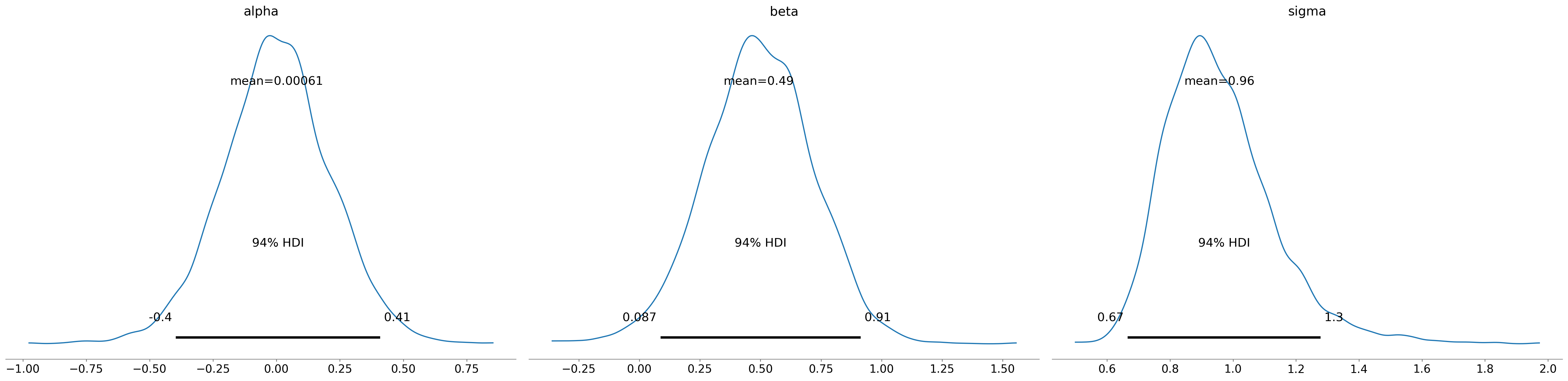
| alpha | 0.00 | 0.21 | -0.40 | 0.41 | 0.0 | 0.0 | 4767.07 | 2894.58 | 1.0 |
| beta | 0.49 | 0.22 | 0.09 | 0.91 | 0.0 | 0.0 | 3861.09 | 2541.83 | 1.0 |
| sigma | 0.96 | 0.17 | 0.67 | 1.28 | 0.0 | 0.0 | 3251.77 | 2650.32 | 1.0 |
az.hdi(idata, hdi_prob=0.95)
<xarray.Dataset> Size: 96B
Dimensions: (hdi: 2)
Coordinates:
* hdi (hdi) <U6 48B 'lower' 'higher'
Data variables:
alpha (hdi) float64 16B -0.4249 0.4154
beta (hdi) float64 16B 0.05738 0.9191
sigma (hdi) float64 16B 0.639 1.29idata
-
<xarray.Dataset> Size: 104kB Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999 Data variables: alpha (chain, draw) float64 32kB -0.5744 -0.1751 ... 0.1976 0.1622 beta (chain, draw) float64 32kB 0.7587 1.11 0.8543 ... 0.7331 0.8266 sigma (chain, draw) float64 32kB 1.433 1.422 1.152 ... 0.9225 1.249 Attributes: created_at: 2024-06-16T07:50:55.207637+00:00 arviz_version: 0.18.0 inference_library: pymc inference_library_version: 5.15.1 sampling_time: 0.8866710662841797 tuning_steps: 1000 -
<xarray.Dataset> Size: 496kB Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 32B 0 1 2 3 * draw (draw) int64 8kB 0 1 2 3 4 5 ... 995 996 997 998 999 Data variables: (12/17) acceptance_rate (chain, draw) float64 32kB 0.9794 0.95 ... 1.0 0.8463 diverging (chain, draw) bool 4kB False False ... False False energy (chain, draw) float64 32kB 38.29 39.02 ... 35.23 energy_error (chain, draw) float64 32kB -0.06341 ... 0.2091 index_in_trajectory (chain, draw) int64 32kB 2 2 -1 -2 3 ... 1 1 -2 -3 1 largest_eigval (chain, draw) float64 32kB nan nan nan ... nan nan ... ... process_time_diff (chain, draw) float64 32kB 0.000197 ... 0.000189 reached_max_treedepth (chain, draw) bool 4kB False False ... False False smallest_eigval (chain, draw) float64 32kB nan nan nan ... nan nan step_size (chain, draw) float64 32kB 0.9673 0.9673 ... 1.101 step_size_bar (chain, draw) float64 32kB 0.9066 0.9066 ... 0.9223 tree_depth (chain, draw) int64 32kB 2 2 2 2 3 1 ... 3 2 2 2 2 2 Attributes: created_at: 2024-06-16T07:50:55.215117+00:00 arviz_version: 0.18.0 inference_library: pymc inference_library_version: 5.15.1 sampling_time: 0.8866710662841797 tuning_steps: 1000 -
<xarray.Dataset> Size: 320B Dimensions: (y_obs_dim_0: 20) Coordinates: * y_obs_dim_0 (y_obs_dim_0) int64 160B 0 1 2 3 4 5 6 ... 13 14 15 16 17 18 19 Data variables: y_obs (y_obs_dim_0) float64 160B 1.001 0.9605 ... -1.361 -1.041 Attributes: created_at: 2024-06-16T07:50:55.217372+00:00 arviz_version: 0.18.0 inference_library: pymc inference_library_version: 5.15.1
# Probabilità che beta sia maggiore di 0
prob_beta_positive = (idata.posterior["beta"] > 0).mean()
print("Probabilità che beta sia maggiore di 0:", prob_beta_positive)
Probabilità che beta sia maggiore di 0: <xarray.DataArray 'beta' ()> Size: 8B
array(0.9835)
# Grafico della distribuzione a posteriori dei parametri
az.plot_posterior(idata, round_to=2)
array([<Axes: title={'center': 'alpha'}>,
<Axes: title={'center': 'beta'}>,
<Axes: title={'center': 'sigma'}>], dtype=object)
Conclusioni#
Analizzando i dati, troviamo evidenze che, nei maschi, la grandezza del cervello, così come indicizzata dagli scan MRI, è positivamente associata al FSIQ. In particolare, un aumento di una deviazione standard nella grandezza del cervello, così com’è stata misurata nel presente studio, corrisponde a un aumento medio nel FSIQ di un valore proporzionale alla stima del parametro \(\beta\). Gli intervalli di credibilità possono essere utilizzati per quantificare l’incertezza associata a questa stima.
Questi risultati supportano l’idea che vi sia una relazione positiva tra la grandezza del cervello e l’intelligenza, almeno in questo specifico campione di maschi. Tuttavia, è importante notare che questi risultati non dimostrano una relazione causale, e ulteriori ricerche potrebbero essere necessarie per comprendere pienamente la natura di questa associazione.