Indici di posizione e di scala#
La visualizzazione grafica dei dati rappresenta il pilastro fondamentale di ogni analisi quantitativa. Grazie alle rappresentazioni grafiche adeguate, è possibile individuare importanti caratteristiche di una distribuzione, quali la simmetria o l’asimmetria, nonché la presenza di una o più mode. Successivamente, al fine di descrivere sinteticamente le principali caratteristiche dei dati, si rende necessario l’utilizzo di specifici indici numerici. In questo capitolo, verranno presentati i principali indicatori della statistica descrittiva.
:::{admonition} Obiettivi di apprendimento :class: tip
Dopo la lettura di questo capitolo gli studenti sapranno
calcolare e interpretare i principali indici di tendenza centrale e di variabilità. :::
Preparazione del Notebook#
import pandas as pd
import numpy as np
import seaborn as sns
from matplotlib import pyplot as plt
from scipy import stats
import arviz as az
# set seed to make the results fully reproducible
seed: int = sum(map(ord, "location_scale"))
rng: np.random.Generator = np.random.default_rng(seed=seed)
az.style.use("arviz-darkgrid")
plt.rcParams["figure.dpi"] = 100
plt.rcParams["figure.facecolor"] = "white"
%config InlineBackend.figure_format = "retina"
Indici di tendenza centrale#
Gli indici di tendenza centrale sono misure statistiche che cercano di rappresentare un valore tipico o centrale all’interno di un insieme di dati. Sono utilizzati per ottenere una comprensione immediata della distribuzione dei dati senza dover analizzare l’intero insieme. Gli indici di tendenza centrale sono fondamentali nell’analisi statistica, in quanto forniscono una sintesi semplice e comprensibile delle caratteristiche principali di un insieme di dati. I principali indici di tendenza centrale sono:
Media: La media è la somma di tutti i valori divisa per il numero totale di valori. È spesso utilizzata come misura generale di tendenza centrale, ma è sensibile agli estremi (valori molto alti o molto bassi).
Mediana: La mediana è il valore che divide l’insieme di dati in due parti uguali. A differenza della media, non è influenzata da valori estremi ed è quindi più robusta in presenza di outlier.
Moda: La moda è il valore che appare più frequentemente in un insieme di dati. In alcuni casi, può non essere presente o esserci più di una moda.
La scelta dell’indice di tendenza centrale appropriato dipende dalla natura dei dati e dall’obiettivo dell’analisi. Ad esempio, la mediana potrebbe essere preferita alla media se l’insieme di dati contiene valori anomali che potrebbero distorcere la rappresentazione centrale. La conoscenza e l’applicazione corretta di questi indici possono fornire una preziosa intuizione sulle caratteristiche centrali di una distribuzione di dati.
Media#
La media aritmetica di un insieme di valori rappresenta il punto centrale o il baricentro della distribuzione dei dati. È calcolata come la somma di tutti i valori divisa per il numero totale di valori, ed è espressa dalla formula:
dove \(x_i\) rappresenta i valori nell’insieme, \(n\) è il numero totale di valori, e \(\sum\) indica la sommatoria.
Proprietà della media#
Una proprietà fondamentale della media è che la somma degli scarti di ciascun valore dalla media è zero:
Infatti,
Questa proprietà implica che i dati sono equamente distribuiti intorno alla media.
La media come centro di gravità dell’istogramma#
La media aritmetica può essere interpretata come il centro di gravità o il punto di equilibrio della distribuzione dei dati. In termini fisici, il centro di gravità è il punto in cui la massa di un sistema è equilibrata o concentrata.
In termini statistici, possiamo considerare la media come il punto in cui la distribuzione dei dati è in equilibrio. Ogni valore dell’insieme di dati può essere visto come un punto materiale con una massa proporzionale al suo valore. Se immaginiamo questi punti disposti su una linea, con valori più grandi a destra e più piccoli a sinistra, la media corrisponderà esattamente al punto in cui la distribuzione sarebbe in equilibrio.
Principio dei minimi quadrati#
La posizione della media minimizza la somma delle distanze quadrate dai dati, un principio noto come «metodo dei minimi quadrati». Matematicamente, questo si traduce nel fatto che la somma dei quadrati degli scarti tra ciascun valore e la media è minima. Questo principio è alla base dell’analisi statistica dei modelli di regressione e conferma l’interpretazione della media come centro di gravità dell’istogramma.
Calcolo della media con NumPy#
Per calcolare la media di un piccolo numero di valori in Python, possiamo utilizzare la somma di questi valori e dividerla per il numero totale di elementi. Consideriamo ad esempio i valori 12, 44, 21, 62, 24:
(12 + 44 + 21 + 62 + 24) / 5
32.6
ovvero
x = np.array([12, 44, 21, 62, 24])
np.mean(x)
32.6
np.average(x)
32.6
Le proporzioni sono medie#
Se una collezione consiste solo di uni e zeri, allora la somma della collezione è il numero di uni in essa, e la media della collezione è la proporzione di uni.
zero_one = np.array([1, 1, 1, 0])
result = sum(zero_one)
print(result)
3
np.mean(zero_one)
0.75
È possibile sostituire 1 con il valore booleano True e 0 con False:
np.mean(np.array([(True, True, True, False)]))
0.75
Limiti della media aritmetica#
La media aritmetica, tuttavia, ha alcune limitazioni: non sempre è l’indice più adeguato per descrivere accuratamente la tendenza centrale della distribuzione, specialmente quando si verificano asimmetrie o valori anomali (outlier). In queste situazioni, è più indicato utilizzare la mediana o la media spuntata (come spiegheremo successivamente).
Medie per gruppi#
Molto spesso però i nostri dati sono contenuti in file e inserire i dati manualmente non è fattibile. Per fare un esempio, considereremo i dati del Progetto STAR, contenuti nel file STAR.csv, che rappresentano un’importante indagine sulle prestazioni degli studenti in relazione alla dimensione delle classi. Negli anni “80, i legislatori del Tennessee considerarono la possibilità di ridurre le dimensioni delle classi per migliorare il rendimento degli studenti. Al fine di prendere decisioni informate, commissionarono lo studio multimilionario «Progetto Student-Teacher Achievement Ratio» (Project STAR). Lo studio coinvolgeva bambini della scuola materna assegnati casualmente a classi piccole, con 13-17 studenti, o classi di dimensioni regolari, con 22-25 studenti, fino alla fine della terza elementare. I ricercatori hanno seguito il progresso degli studenti nel tempo, concentrandosi su variabili di risultato, come i punteggi dei test standardizzati di lettura (reading) e matematica (math) alla terza elementare, oltre ai tassi di diploma di scuola superiore (graduated, con valore 1 per sì e 0 per no).
Poniamoci il problema di calcolare la media dei punteggi math calcolata separatamente per i due gruppi di studenti: coloro che hanno completato la scuola superiore e coloro che non l’hanno completata.
Procediamo all’importazione dei dati per iniziare l’analisi.
df = pd.read_csv("../data/STAR.csv")
df.head()
| classtype | reading | math | graduated | |
|---|---|---|---|---|
| 0 | small | 578 | 610 | 1 |
| 1 | regular | 612 | 612 | 1 |
| 2 | regular | 583 | 606 | 1 |
| 3 | small | 661 | 648 | 1 |
| 4 | small | 614 | 636 | 1 |
Esaminiamo la numerosità di ciascun gruppo.
df.groupby("graduated").size()
graduated
0 166
1 1108
dtype: int64
Ora procediamo al calcolo delle medie dei punteggi math all’interno dei due gruppi. Per rendere la risposta più concisa, useremo la funzione round() per stampare solo 2 valori decimali.
df.groupby("graduated")["math"].mean().round(2)
graduated
0 606.64
1 635.33
Name: math, dtype: float64
In alternativa, possiamo usare il metodo .describe():
df.groupby("graduated")["math"].describe().round(1)
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| graduated | ||||||||
| 0 | 166.0 | 606.6 | 34.1 | 526.0 | 580.5 | 606.0 | 629.0 | 711.0 |
| 1 | 1108.0 | 635.3 | 38.1 | 515.0 | 609.5 | 634.0 | 659.0 | 774.0 |
Media spuntata#
La media spuntata, indicata come \(\bar{x}_t\) o trimmed mean, è un metodo di calcolo della media che prevede l’eliminazione di una determinata percentuale di dati estremi prima di effettuare la media aritmetica. Solitamente, viene eliminato il 10% dei dati, ovvero il 5% all’inizio e alla fine della distribuzione. Per ottenere la media spuntata, i dati vengono ordinati in modo crescente, \(x_1 \leq x_2 \leq x_3 \leq \dots \leq x_n\), e quindi viene eliminato il primo 5% e l’ultimo 5% dei dati nella sequenza ordinata. Infine, la media spuntata è calcolata come la media aritmetica dei dati rimanenti. Questo approccio è utile quando ci sono valori anomali o quando la distribuzione è asimmetrica e la media aritmetica non rappresenta adeguatamente la tendenza centrale dei dati.
A titolo di esempio, procediamo al calcolo della media spuntata dei valori math per i due gruppi definiti dalla variabile graduated, escludendo il 10% dei valori più estremi.
not_graduated = df[df["graduated"] == 0].math
stats.trim_mean(not_graduated, 0.10)
605.6492537313433
graduated = df[df["graduated"] == 1].math
stats.trim_mean(graduated, 0.10)
634.4403153153153
Quantili#
Il quantile non interpolato di ordine \(p\) \((0 < p < 1)\) rappresenta il valore che divide la distribuzione dei dati in modo tale che una frazione \(p\) dei dati si trovi al di sotto di esso.
La formula per calcolare il quantile non interpolato è la seguente:
dove \(x_{(k)}\) è l’elemento \(k\)-esimo nell’insieme di dati ordinato in modo crescente, e \(k\) è calcolato come:
dove \(n\) è il numero totale di dati nel campione, e \(\lceil \cdot \rceil\) rappresenta la funzione di arrotondamento all’intero successivo. In questa definizione, il quantile non interpolato corrisponde al valore effettivo nell’insieme di dati, senza effettuare alcuna interpolazione tra i valori circostanti.
Ad esempio, consideriamo il seguente insieme di dati: \(\{ 15, 20, 23, 25, 28, 30, 35, 40, 45, 50 \}\). Supponiamo di voler calcolare il quantile non interpolato di ordine \(p = 0.3\) (cioè il 30° percentile).
Ordiniamo i dati in modo crescente: \(\{ 15, 20, 23, 25, 28, 30, 35, 40, 45, 50 \}.\) Calcoliamo \(k\) utilizzando la formula \(k = \lceil p \cdot n \rceil\), dove \(n\) è il numero totale di dati nel campione. Nel nostro caso, \(n = 10\) e \(p = 0.3\):
Il quantile non interpolato corrisponde al valore \(x_{(k)}\), ovvero l’elemento \(k\)-esimo nell’insieme ordinato: \(q_{0.3} = x_{(3)} = 23.\)
Oltre al quantile non interpolato, esiste anche il concetto di quantile interpolato. A differenza del quantile non interpolato, il quantile interpolato può essere calcolato anche per percentili che non corrispondono esattamente a valori presenti nell’insieme di dati. Per ottenere il valore del quantile interpolato, viene utilizzato un procedimento di interpolazione lineare tra i valori adiacenti. In genere, il calcolo del quantile interpolato viene eseguito mediante l’uso di software dedicati.
Ora, procediamo al calcolo dei quantili di ordine 0.10 e 0.90 per i valori math all’interno dei due gruppi. I quantili sono dei valori che dividono la distribuzione dei dati in parti specifiche. Ad esempio, il quantile di ordine 0.10 corrisponde al valore al di sotto del quale si trova il 10% dei dati, mentre il quantile di ordine 0.90 rappresenta il valore al di sotto del quale si trova il 90% dei dati.
Calcoliamo i quantili di ordine 0.1 e 0.9 della distribuzione dei punteggi math nei due gruppi definiti dalla variabile graduated.
# Quantili di ordine 0.1 e 0.9 per il gruppo di studenti che hanno completato la scuola superiore
[
df[df["graduated"] == 1]["math"].quantile(0.1),
df[df["graduated"] == 1]["math"].quantile(0.9)
]
[588.0, 684.0]
# Quantili di ordine 0.1 e 0.9 per il gruppo di studenti che non hanno completato la scuola superiore
[
df[df["graduated"] == 0]["math"].quantile(0.1),
df[df["graduated"] == 0]["math"].quantile(0.9),
]
[564.5, 651.0]
Moda e mediana#
In precedenza abbiamo già incontrato altri due popolari indici di tendenza centrale: la moda (Mo), che rappresenta il valore centrale della classe con la frequenza massima (in alcune distribuzioni può esserci più di una moda, rendendola multimodale e facendo perdere a questo indice il suo significato di indicatore di tendenza centrale); e la mediana (\(\tilde{x}\)), che rappresenta il valore corrispondente al quantile di ordine 0.5 della distribuzione.
Quando usare media, moda, mediana#
La moda può essere utilizzata per dati a livello nominale o ordinale ed è l’unica tra le tre statistiche che può essere calcolata in questi casi.
La media, d’altra parte, è una buona misura di tendenza centrale solo se la distribuzione dei dati è simmetrica, ossia se i valori sono distribuiti uniformemente a sinistra e a destra della media. Tuttavia, se ci sono valori anomali o se la distribuzione è asimmetrica, la media può essere influenzata in modo significativo e, pertanto, potrebbe non essere la scelta migliore come misura di tendenza centrale.
In queste situazioni, la mediana può fornire una misura migliore di tendenza centrale rispetto alla media poiché è meno influenzata dai valori anomali e si basa esclusivamente sul valore centrale dell’insieme di dati. Di conseguenza, la scelta tra media e mediana dipende dal tipo di distribuzione dei dati e dagli obiettivi dell’analisi.
Indici di dispersione#
Le misure di posizione descritte in precedenza, come le medie e gli indici di posizione, offrono una sintesi dei dati mettendo in evidenza la tendenza centrale delle osservazioni. Tuttavia, trascurano un aspetto importante della distribuzione dei dati: la variabilità dei valori numerici della variabile statistica. Pertanto, è essenziale completare la descrizione della distribuzione di una variabile statistica utilizzando anche indicatori che valutino la dispersione delle unità statistiche. In questo modo, otterremo una visione più completa e approfondita delle caratteristiche del campione analizzato.
Indici basati sull’ordinamento dei dati#
Per valutare la variabilità dei dati, è possibile utilizzare indici basati sull’ordinamento dei dati. L’indice più semplice è l’intervallo di variazione, che corrisponde alla differenza tra il valore massimo e il valore minimo di una distribuzione di dati. Tuttavia, questo indice ha il limite di essere calcolato basandosi solo su due valori della distribuzione, e non tiene conto di tutte le informazioni disponibili. Inoltre, l’intervallo di variazione può essere fortemente influenzato dalla presenza di valori anomali.
Un altro indice basato sull’ordinamento dei dati è la differenza interquartile, già incontrata in precedenza. Anche se questo indice utilizza più informazioni rispetto all’intervallo di variazione, presenta comunque il limite di essere calcolato basandosi solo su due valori della distribuzione, ossia il primo quartile \(Q_1\) e il terzo quartile \(Q_3\).
Per valutare la variabilità in modo più completo, è necessario utilizzare altri indici di variabilità che tengano conto di tutti i dati disponibili. In questo modo, si otterrà una valutazione più accurata della dispersione dei valori nella distribuzione e si potranno individuare eventuali pattern o tendenze nascoste.
Varianza#
Date le limitazioni delle statistiche descritte in precedenza, è più comune utilizzare una misura di variabilità che tenga conto della dispersione dei dati rispetto a un indice di tendenza centrale. La varianza è la misura di variabilità più utilizzata per valutare la variabilità di una variabile statistica. Essa è definita come la media dei quadrati degli scarti \(x_i - \bar{x}\) tra ogni valore e la media della distribuzione, come segue:
La varianza è una misura di dispersione più completa rispetto a quelle descritte in precedenza. Tuttavia, è appropriata solo nel caso di distribuzioni simmetriche ed è fortemente influenzata dai valori anomali, come altre misure di dispersione. Inoltre, la varianza è espressa in un’unità di misura che è il quadrato dell’unità di misura dei dati originali, pertanto, potrebbe non essere facilmente interpretata in modo intuitivo.
Calcoliamo la varianza dei valori math per i dati del progetto STAR. Applicando l’equazione della varianza, otteniamo:
sum((df["math"] - np.mean(df["math"])) ** 2) / len(df["math"])
1507.2328523125225
Più semplicemente, possiamo usare la funzione np.var():
np.var(df["math"])
1507.2328523125225
Stima della varianza della popolazione#
Si noti il denominatore della formula della varianza. Nell’equazione (3), ho utilizzato \(n\) come denominatore (l’ampiezza campionaria, ovvero il numero di osservazioni nel campione). In questo modo, otteniamo la varianza come statistica descrittiva del campione. Tuttavia, è possibile utilizzare \(n-1\) come denominatore alternativo:
In questo secondo caso, otteniamo la varianza come stimatore della varianza della popolazione. Si può dimostrare che l’equazione (4) fornisce una stima corretta (ovvero, non distorta) della varianza della popolazione da cui abbiamo ottenuto il campione, mentre l’equazione (3) fornisce (in media) una stima troppo piccola della varianza della popolazione. Si presti attenzione alla notazione: \(S^2\) rappresenta la varianza come statistica descrittiva, mentre \(s^2\) rappresenta la varianza come stimatore.
Per illustrare questo punto, svolgiamo una simulazione. Consideriamo la distribuzione dei punteggi del quoziente di intelligenza (QI). I valori del QI seguono una particolare distribuzione chiamata distribuzione normale, con media 100 e deviazione standard 15. La forma di questa distribuzione è illustrata nella figura seguente.
x = np.arange(100 - 4 * 15, 100 + 4 * 15, 0.001)
mu = 100
sigma = 15
pdf = stats.norm.pdf(x, mu, sigma)
plt.plot(x, pdf)
plt.xlabel("x")
plt.ylabel("f(x)")
plt.show()

Supponiamo di estrarre un campione casuale di 4 osservazioni dalla popolazione del quoziente di intelligenza – in altre parole, supponiamo di misurare il quoziente di intelligenza di 4 persone prese a caso dalla popolazione.
x = rng.normal(loc=100, scale=15, size=4)
print(x)
[133.75543403 101.43900843 94.59994101 92.23138768]
Calcoliamo la varianza usando \(n\) al denominatore. Si noti che la vera varianza del quoziente di intelligenza è \(15^2\) = 225.
np.var(x)
277.4320993427046
Consideriamo ora 10 campioni casuali del QI, ciascuno di ampiezza 4.
mu = 100
sigma = 15
size = 4
niter = 10
random_samples = []
for i in range(niter):
one_sample = rng.normal(loc=mu, scale=sigma, size=size)
random_samples.append(one_sample)
Il primo campione è
random_samples[0]
array([105.84924945, 124.12259109, 95.58010071, 76.35634967])
Il decimo campione è
random_samples[9]
array([ 89.29531757, 106.32615516, 91.6023182 , 90.68549989])
Stampiamo i valori di tutti i 10 campioni.
rs = np.array(random_samples)
rs
array([[105.84924945, 124.12259109, 95.58010071, 76.35634967],
[ 80.23586783, 114.3021062 , 98.54492676, 91.47149307],
[114.26794026, 86.66403178, 79.74954446, 102.23174837],
[110.22926012, 80.75554712, 100.93634803, 83.44336602],
[ 80.68461566, 122.39378237, 115.0707391 , 85.53365763],
[ 82.42398628, 99.06628072, 95.40790879, 95.03682044],
[ 86.56471564, 97.82411638, 98.28650923, 99.23388255],
[120.24780337, 94.92211176, 87.6421954 , 89.48037814],
[ 89.06126415, 109.72357033, 119.31191461, 125.38475089],
[ 89.29531757, 106.32615516, 91.6023182 , 90.68549989]])
Per ciascun campione (ovvero, per ciascuna riga della matrice precedente), calcoliamo la varianza usando la formula con \(n\) al denominatore. Otteniamo così 10 stime della varianza della popolazione del QI.
x_var = np.var(rs, axis=1) # applichiamo la funzione su ciascuna riga
print(x_var)
[298.44010918 152.5955359 180.87367224 149.56472568 326.89426388
39.64935846 26.73631903 171.07120901 189.71979388 47.47289476]
Notiamo due cose:
le stime sono molto diverse tra loro; questo fenomeno è noto con il nome di variabilità campionaria;
in media le stime sembrano troppo piccole.
Per aumentare la sicurezza riguardo al secondo punto menzionato in precedenza, ripeteremo la simulazione utilizzando un numero di iterazioni maggiore.
mu = 100
sigma = 15
size = 4
niter = 10000
random_samples = []
for i in range(niter):
one_sample = rng.normal(loc=mu, scale=sigma, size=size)
random_samples.append(one_sample)
rs = np.array(random_samples)
x_var = np.var(rs, ddof=0, axis=1)
Esaminiamo la distribuzione dei valori ottenuti.
plt.hist(x_var, bins=10, color="skyblue", edgecolor="black")
plt.xlabel("Varianza")
plt.ylabel("Frequenza")
plt.title("Varianza del QI in campioni di n = 4")
plt.show()
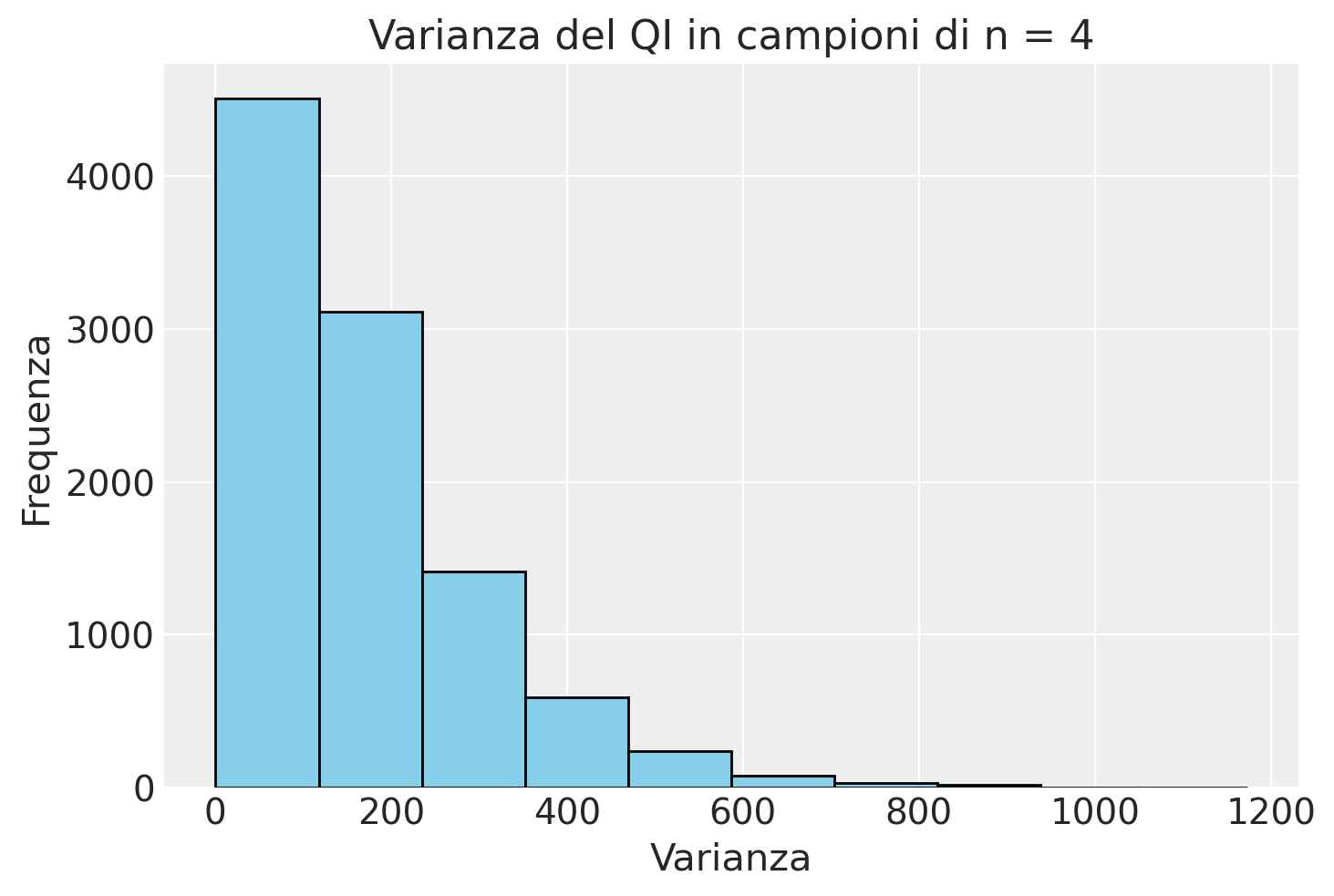
La stima più verosimile della varianza del QI è dato dalla media di questa distribuzione.
np.mean(x_var)
166.4352384309161
Si noti che il nostro spospetto è stato confermato: il valore medio della stima della varianza ottenuta con l’eq.(3) è troppo piccolo rispetto al valore corretto di \(15^2 = 225\).
Ripetiamo ora la simulazione usando la formula della varianza con \(n-1\) al denominatore.
mu = 100
sigma = 15
size = 4
niter = 10000
random_samples = []
for i in range(niter):
one_sample = rng.normal(loc=mu, scale=sigma, size=size)
random_samples.append(one_sample)
rs = np.array(random_samples)
x_var = np.var(rs, ddof=1, axis=1)
np.mean(x_var)
226.57333153886847
Nel secondo caso, se utilizziamo \(n-1\) come denominatore per calcolare la stima della varianza, il valore atteso di questa stima è molto vicino al valore corretto di 225. Se il numero di campioni fosse infinito, i due valori sarebbero identici.
In conclusione, le due formule della varianza hanno scopi diversi. La formula della varianza con \(n\) al denominatore viene utilizzata come statistica descrittiva per descrivere la variabilità di un particolare campione di osservazioni. D’altro canto, la formula della varianza con \(n-1\) al denominatore viene utilizzata come stimatore per ottenere la migliore stima della varianza della popolazione da cui quel campione è stato estratto.
Deviazione standard#
Per interpretare la varianza in modo più intuitivo, si può calcolare la deviazione standard (o scarto quadratico medio o scarto tipo) prendendo la radice quadrata della varianza. La deviazione standard è espressa nell’unità di misura originaria dei dati, a differenza della varianza che è espressa nel quadrato dell’unità di misura dei dati. La deviazione standard fornisce una misura della dispersione dei dati attorno alla media, rendendo più facile la comprensione della variabilità dei dati.
La deviazione standard (o scarto quadratico medio, o scarto tipo) è definita come:
Quando tutte le osservazioni sono uguali, \(s = 0\), altrimenti \(s > 0\).
Nota
Il termine standard deviation è stato introdotto in statistica da Pearson nel 1894 assieme alla lettera greca \(\sigma\) che lo rappresenta. Il termine italiano «deviazione standard» ne è la traduzione più utilizzata nel linguaggio comune; il termine dell’Ente Nazionale Italiano di Unificazione è tuttavia “scarto tipo”, definito come la radice quadrata positiva della varianza.
La deviazione standard \(s\) dovrebbe essere utilizzata solo quando la media è una misura appropriata per descrivere il centro della distribuzione, ad esempio nel caso di distribuzioni simmetriche. Tuttavia, è importante tener conto che, come la media \(\bar{x}\), anche la deviazione standard è fortemente influenzata dalla presenza di dati anomali, ovvero pochi valori che si discostano notevolmente dalla media rispetto agli altri dati della distribuzione. In presenza di dati anomali, la deviazione standard può risultare ingannevole e non rappresentare accuratamente la variabilità complessiva della distribuzione. Pertanto, è fondamentale considerare attentamente il contesto e le caratteristiche dei dati prima di utilizzare la deviazione standard come misura di dispersione. In alcune situazioni, potrebbe essere più appropriato ricorrere a misure di dispersione robuste o ad altre statistiche descrittive per caratterizzare la variabilità dei dati in modo più accurato e affidabile.
Per fare un esempio, calcoliamo la deviazione standard per i valori math del campione di dati del progetto STAR. Applicando l’eq. (5), per tutto il campione abbiamo
np.std(df.math)
38.82309689234648
Per ciascun gruppo, abbiamo:
df.groupby("graduated")["math"].std()
graduated
0 34.105746
1 38.130136
Name: math, dtype: float64
Interpretazione#
La deviazione standard può essere interpretata in modo semplice: essa rappresenta la dispersione dei dati rispetto alla media aritmetica. È simile allo scarto semplice medio campionario, cioè alla media aritmetica dei valori assoluti degli scarti tra ciascuna osservazione e la media, anche se non è identica. La deviazione standard ci fornisce un’indicazione di quanto, in media, le singole osservazioni si discostino dal centro della distribuzione.
Per verificare l’interpretazione della deviazione standard, utilizziamo i valori math del campione di dati del progetto STAR.
np.std(df["math"])
38.82309689234648
La deviazione standard calcolata per questi dati è \(\approx 38.8\). Questo valore ci indica che, in media, ogni osservazione si discosta di circa 38.8 punti dalla media aritmetica dei punteggi math. Maggiore è il valore della deviazione standard, maggiore è la dispersione dei dati attorno alla media, mentre un valore più piccolo indica che i dati sono più concentrati vicino alla media. La deviazione standard ci offre quindi una misura quantitativa della variabilità dei dati nella distribuzione.
Per questi dati, lo scarto semplice medio campionario è
np.mean(np.abs(df.math - np.mean(df.math)))
30.9682664274501
Si noti che i due valori sono simili, ma non identici.
Deviazione mediana assoluta#
Una misura robusta della dispersione statistica di un campione è la deviazione mediana assoluta (Median Absolute Deviation, MAD) definita come la mediana del valore assoluto delle deviazioni dei dati dalla mediana. Matematicamente, la formula per calcolare la MAD è:
La deviazione mediana assoluta è particolarmente utile quando si affrontano distribuzioni con presenza di dati anomali o asimmetrie, poiché è meno influenzata da questi valori estremi rispetto alla deviazione standard.
Quando i dati seguono una distribuzione gaussiana (normale), esiste una relazione specifica tra MAD e la deviazione standard (si veda il Capitolo Distribuzioni di v.c. continue). In una distribuzione normale, la MAD è proporzionale alla deviazione standard. La costante di proporzionalità dipende dalla forma esatta della distribuzione normale, ma in generale, la relazione è data da:
dove:
\( \sigma \) è la deviazione standard.
MAD è la Mediana della Deviazione Assoluta.
\( k \) è una costante che, per una distribuzione normale, è tipicamente presa come circa 1.4826.
Questa costante di 1.4826 è derivata dal fatto che, in una distribuzione normale, circa il 50% dei valori si trova entro 0.6745 deviazioni standard dalla media. Quindi, per convertire la MAD (basata sulla mediana) nella deviazione standard (basata sulla media), si usa il reciproco di 0.6745, che è approssimativamente 1.4826.
La formula completa per convertire la MAD in una stima della deviazione standard in una distribuzione normale è:
Questa relazione è utile per stimare la deviazione standard in modo più robusto, specialmente quando si sospetta la presenza di outlier o si ha a che fare con campioni piccoli. Di conseguenza, molti software restituiscono il valore MAD moltiplicato per questa costante per fornire un’indicazione più intuitiva della variabilità dei dati. Tuttavia, è importante notare che questa relazione si mantiene accurata solo per le distribuzioni che sono effettivamente normali. In presenza di distribuzioni fortemente asimmetriche o con elevati outlier, la deviazione standard e la MAD possono fornire indicazioni molto diverse sulla variabilità dei dati.
Per verificare questo principio, calcoliamo la deviazione mediana assoluta dei valori math del campione di dati del progetto STAR.
1.4826 * np.median(np.abs(df["math"] - np.median(df["math"])))
41.5128
In questo caso, la MAD per i punteggi di matematica è simile alla deviazione standard.
np.std(df["math"])
38.82309689234648
Infatti, la distribuzione dei punteggi math è approssimativamente gaussiana.
plt.hist(df["math"], bins=10, color="skyblue", edgecolor = "black")
plt.xlabel("math")
plt.ylabel("Frequenza")
plt.title("Distribuzione dei Punteggi di Matematica")
plt.show()
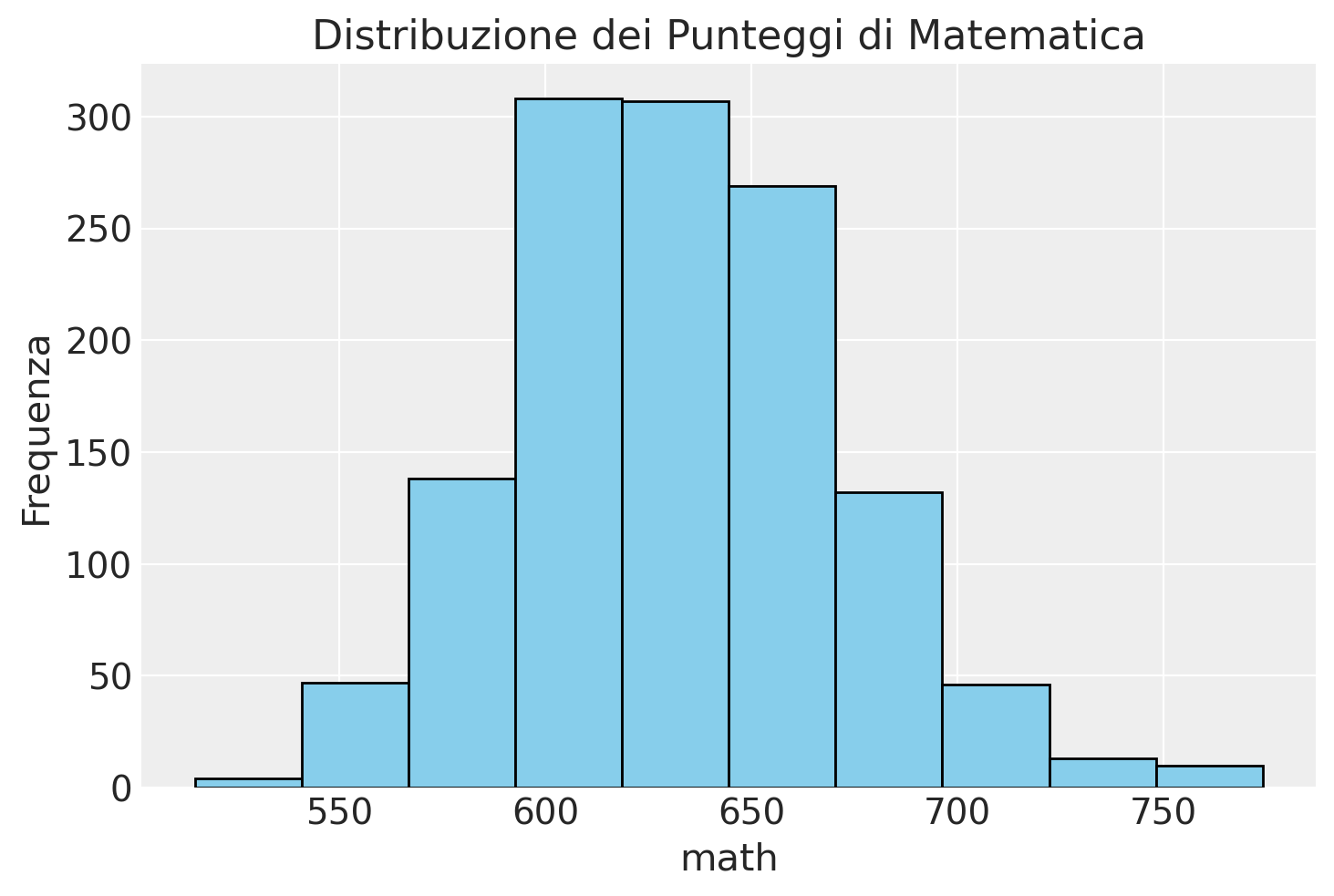
Verifichiamo nuovamente il principio usando un campione di dati estratto da una popolazione normale. Usiamo, ad esempio, la distribuzione \(\mathcal{N}(100, 15)\):
x = np.random.normal(loc=100, scale=15, size=10000)
1.4826 * np.median(np.abs(x - np.median(x)))
14.694076406131302
Quando usare la deviazione standard e MAD#
La deviazione standard e la MAD sono entrambe misure di dispersione che forniscono informazioni su quanto i dati in un insieme si discostano dalla tendenza centrale. Tuttavia, ci sono alcune differenze tra le due misure e situazioni in cui può essere più appropriato utilizzare una rispetto all’altra.
Deviazione standard: Questa misura è particolarmente utile per descrivere la dispersione dei dati in una distribuzione normale. La deviazione standard è una scelta appropriata se si vuole sapere quanto i dati sono distribuiti intorno alla media, o se si vuole confrontare la dispersione di due o più set di dati. Tuttavia, la deviazione standard è fortemente influenzata dalla presenza di dati anomali, e questo può rappresentare una limitazione in casi in cui sono presenti valori estremi nell’insieme di dati.
Deviazione mediana assoluta (MAD): La MAD è meno sensibile ai valori anomali rispetto alla deviazione standard, il che la rende una scelta migliore quando ci sono valori anomali nell’insieme di dati. Inoltre, la MAD può essere una buona scelta quando si lavora con dati non normalmente distribuiti, poiché non assume una distribuzione specifica dei dati. La MAD è calcolata utilizzando la mediana e i valori assoluti delle deviazioni dei dati dalla mediana, il che la rende una misura robusta di dispersione.
In sintesi, se si sta lavorando con dati normalmente distribuiti, la deviazione standard è la misura di dispersione più appropriata. Se si lavora con dati non normalmente distribuiti o si hanno valori anomali nell’insieme di dati, la MAD può essere una scelta migliore. In ogni caso, la scelta tra le due misure dipende dal tipo di dati che si sta analizzando e dall’obiettivo dell’analisi.
Indici di variabilità relativi#
A volte può essere necessario confrontare la variabilità di grandezze incommensurabili, ovvero di caratteri misurati con differenti unità di misura. In queste situazioni, le misure di variabilità descritte in precedenza diventano inadeguate poiché dipendono dall’unità di misura utilizzata. Per superare questo problema, si ricorre a specifici numeri adimensionali chiamati indici relativi di variabilità.
Il più importante di questi indici è il coefficiente di variazione (\(C_v\)), definito come il rapporto tra la deviazione standard (\(\sigma\)) e la media dei dati (\(\bar{x}\)):
Il coefficiente di variazione è un numero puro e permette di confrontare la variabilità di distribuzioni con unità di misura diverse.
Un altro indice relativo di variabilità è la differenza interquartile rapportata a uno dei tre quartili (primo quartile, terzo quartile o mediana). Questo indice è definito come:
Questi indici relativi di variabilità forniscono una misura adimensionale della dispersione dei dati, rendendo possibile il confronto tra grandezze con diverse unità di misura e facilitando l’analisi delle differenze di variabilità tra i dati.
La fallacia ergodica
Sebbene il concetto di «media» possa sembrare chiaro, ciò non implica che il suo utilizzo non presenti delle problematiche nell’ambito della pratica psicologica. Un aspetto su cui vale la pena soffermarsi è ciò che viene definito «fallacia ergodica».
Il concetto di «fallacia ergodica» [SPRM24] si riferisce all’errore compiuto dai ricercatori quando assumono che le caratteristiche medie di un gruppo di individui possano essere applicate a ciascun individuo all’interno di quel gruppo, senza considerare le differenze individuali o le variazioni nel tempo. Questa fallacia emerge dalla pratica comune nella ricerca psicologica di raccogliere dati aggregati da gruppi di persone per stimare parametri della popolazione, al fine di confrontare comportamenti in condizioni diverse o esplorare associazioni tra diverse misurazioni della stessa persona.
Il problema di questo approccio è che l’uso dei risultati basati sul gruppo per caratterizzare le caratteristiche degli individui o per estrapolare a persone simili a quelle del gruppo è ingiustificato, poiché le medie di gruppo possono fornire informazioni solo sui risultati collettivi, come la performance media del gruppo, e non consentono di fare affermazioni accurate sugli individui che compongono quel gruppo. La fallacia ergodica si basa sull’assunzione che per utilizzare legittimamente una statistica aggregata (ad esempio, la media) derivata da un gruppo per descrivere un individuo di quel gruppo, due condizioni devono essere soddisfatte: gli individui devono essere così simili da essere praticamente interscambiabili, e le caratteristiche degli individui devono essere temporalmente stabili.
Tuttavia, i fenomeni e i processi psicologici di interesse per i ricercatori sono per natura non uniformi tra gli individui e variabili nel tempo, sia all’interno degli individui che tra di loro. Di conseguenza, i risultati ottenuti dalla media di misure di comportamenti, cognizioni o stati emotivi di più individui non descrivono accuratamente nessuno di quegli individui in un dato momento, né possono tenere conto dei cambiamenti in quelle variabili per un individuo nel tempo.
Speelman et al. [SPRM24] osservano che la stragrande maggioranza degli articoli che hanno analizzato include conclusioni nelle sezioni degli Abstract e/o delle Discussioni che implicano che i risultati trovati con dati aggregati di gruppo si applichino anche agli individui in quei gruppi e/o si applichino agli individui nella popolazione. Questa pratica riflette la fallacia ergodica, che consiste nell’assumere che i campioni siano sistemi ergodici quando non lo sono.
Commenti e considerazioni finali#
Le statistiche descrittive ci permettono di ottenere indicatori sintetici che riassumono i dati di una popolazione o di un campione estratto da essa. Questi indicatori includono misure di tendenza centrale, come la media, la mediana e la moda, che ci forniscono informazioni sulla posizione centrale dei dati rispetto alla distribuzione. Inoltre, ci sono gli indici di dispersione, come la deviazione standard e la varianza, che ci indicano quanto i dati si disperdono attorno alla tendenza centrale. Questi indici ci aiutano a comprendere quanto i valori si discostano dalla media, e quindi ci forniscono un’idea della variabilità dei dati. In sintesi, le statistiche descrittive ci offrono un quadro chiaro e sintetico delle caratteristiche principali dei dati, consentendoci di comprendere meglio la loro distribuzione e variabilità.
Informazioni sull’Ambiente di Sviluppo#
%load_ext watermark
%watermark -n -u -v -iv -w -m
Last updated: Sun Jun 16 2024
Python implementation: CPython
Python version : 3.12.3
IPython version : 8.25.0
Compiler : Clang 16.0.6
OS : Darwin
Release : 23.4.0
Machine : arm64
Processor : arm
CPU cores : 8
Architecture: 64bit
matplotlib: 3.8.4
pandas : 2.2.2
numpy : 1.26.4
arviz : 0.18.0
scipy : 1.13.1
seaborn : 0.13.2
Watermark: 2.4.3