Il modello lineare gerarchico#
In questo capitolo, esploreremo in dettaglio la metodologia della regressione lineare gerarchica Bayesiana, facendo uso delle API della libreria Bambi. Il nostro obiettivo principale è quello di applicare questo metodo statistico a un dataset multilivello. Nello specifico, ci concentreremo su un dataset che comprende diverse unità di osservazione, rappresentate dai soggetti, ciascuna delle quali è associata a più misurazioni. Per avere una comprensione visiva più chiara dei modelli gerarchici, possiamo consultare il demo di Michael Freeman disponibile su questo sito.
Preparazione del Notebook#
import warnings
import arviz as az
import bambi as bmb
import matplotlib.pyplot as plt
import numpy as np
import pingouin as pg
warnings.filterwarnings("ignore")
# set seed to make the results fully reproducible
seed: int = sum(map(ord, "stan_linreg_1"))
rng: np.random.Generator = np.random.default_rng(seed=seed)
az.style.use("arviz-darkgrid")
plt.rcParams["figure.dpi"] = 100
plt.rcParams["figure.facecolor"] = "white"
%config InlineBackend.figure_format = "retina"
Nei vari ambiti disciplinari, come la sociologia, l’economia, la demografia e l’epidemiologia, si osserva sempre più frequentemente l’analisi di fenomeni con una struttura informativa gerarchica. In questi casi, i dati si riferiscono a più livelli di osservazione o appartenenza, quali quello individuale, familiare, territoriale e sociale. In psicologia, questa struttura gerarchica si evidenzia nei disegni a misure ripetute, dove un singolo soggetto esegue un numero ( n ) di prove per ciascun compito. Specificatamente, lo studio delle interazioni tra l’individuo e il suo contesto è tipicamente analizzato attraverso fenomeni a struttura gerarchica. I modelli più adatti per l’elaborazione di dati con questa complessità sono i cosiddetti modelli multilivello.
I modelli gerarchici, conosciuti anche come modelli multilivello, modelli ad effetti misti, modelli ad effetti casuali o modelli nidificati, rappresentano un approccio efficace per l’analisi di dati organizzati in gruppi o livelli. Tali modelli possono applicarsi a dati geograficamente nidificati (ad esempio, dati di città all’interno di province, province all’interno di stati), dati organizzati gerarchicamente (come studenti all’interno di scuole o pazienti in ospedali), o dati che implicano misurazioni ripetute sugli stessi individui. Questi modelli sono particolarmente utili per gestire le complessità intrinseche a tali dati, consentendo di tenere conto delle variazioni sia condivise che uniche tra i gruppi.
I modelli gerarchici facilitano la condivisione di informazioni tra i gruppi mediante l’impiego di distribuzioni priori per i parametri, che a loro volta sono influenzate da distribuzioni priori di livello superiore, comunemente chiamate iperpriori. Il prefisso «iper» deriva dal termine greco per «sopra», indicando che queste distribuzioni priori operano a un livello superiore rispetto alle distribuzioni priori standard. Le distribuzioni degli iperparametri permettono al modello di equilibrare la descrizione delle caratteristiche specifiche dei gruppi con una descrizione delle tendenze comuni tra i gruppi. In definitiva, i parametri delle distribuzioni priori sono trattati come facenti parte di una popolazione di parametri più ampia. Questo principio è rappresentato graficamente nella figura di riferimento Fig. 6, che contrappone gli approcci dei modelli aggregati (dove i dati sono trattati come se provenissero da un unico gruppo), dei modelli non aggregati (dove ogni gruppo è trattato separatamente) e dei modelli gerarchici (o parzialmente aggregati), dove le informazioni sono condivise tra i gruppi.
Fig. 6 Le differenze tra un modello aggregato (pooled), un modello non aggregato (unpooled) e un modello gerarchico. (Figura tratta da Martin [Mar24]).#
Nei capitoli precedenti, abbiamo introdotto il concetto di modellazione gerarchica bayesiana, focalizzandoci sulla stima dei parametri di distribuzioni di probabilità. Per ulteriori dettagli, si rimanda al capitolo hier_beta_binom_model. In questo capitolo, estenderemo tale concetto alla stima dei parametri in un modello di regressione lineare, prendendo in esame dati suddivisi in vari gruppi.
Affrontando l’analisi di dati provenienti da gruppi eterogenei, potrebbe emergere la tentazione di ignorare le differenze intergruppo, applicando un modello unico che non distingua i vari gruppi. Un tale approccio, pur potenziando la precisione delle stime aggregando tutti i dati, potrebbe comportare la perdita di informazioni preziose specifiche per ciascun gruppo. Al contrario, analizzando i gruppi separatamente, si otterrebbe una panoramica dettagliata ma potenzialmente meno accurata per carenza di dati condivisi.
L’analisi gerarchica offre un compromesso tra questi due estremi, sintetizzando i benefici di entrambe le metodologie. Nel dettaglio, confronteremo tre diversi approcci di modellazione nei paragrafi seguenti:
Complete Pooling: Questo modello ignora la struttura gerarchica dei dati, trattando tutte le unità osservative come se appartenessero a una singola popolazione. Questo approccio può essere eccessivamente generalizzante e rischia di mascherare le variazioni intergruppo.
No Pooling: In netto contrasto, questo modello tratta ogni gruppo come indipendente dagli altri, senza riconoscere alcuna struttura gerarchica. Sebbene questo metodo possa mettere in luce le specificità di ciascun gruppo, può portare a conclusioni meno robuste per mancanza di un contesto più ampio.
Partial Pooling (o Modello Multi-Livello): Questo approccio è il più equilibrato tra i tre, presumendo che pendenze e intercette di ogni gruppo siano realizzazioni di variabili casuali, distribuite normalmente con parametri di media e varianza condivisi tra tutti i gruppi.
Il modello di «partial pooling» si distingue per la sua capacità di bilanciare l’indipendenza dei gruppi con la necessità di un’analisi aggregata. Facilita un adeguato «shrinkage» dei parametri, mitigando l’effetto di valori anomali o di gruppi con campioni limitati, e permettendo alle stime parametriche di ogni gruppo di essere influenzate sia dai dati specifici che dalla tendenza generale osservata nei dati aggregati.
EDA#
Iniziamo importando i dati e ispezionando la struttura delle osservazioni suddivise nei diversi cluster.
data = bmb.load_data("sleepstudy")
data.head()
| Reaction | Days | Subject | |
|---|---|---|---|
| 0 | 249.5600 | 0 | 308 |
| 1 | 258.7047 | 1 | 308 |
| 2 | 250.8006 | 2 | 308 |
| 3 | 321.4398 | 3 | 308 |
| 4 | 356.8519 | 4 | 308 |
Eliminiamo le righe in cui la colonna «Days» ha valore 0 o 1 dal dataset «sleepstudy» utilizzando il seguente codice:
data = data[data['Days'].isin([0, 1]) == False]
data.head()
| Reaction | Days | Subject | |
|---|---|---|---|
| 2 | 250.8006 | 2 | 308 |
| 3 | 321.4398 | 3 | 308 |
| 4 | 356.8519 | 4 | 308 |
| 5 | 414.6901 | 5 | 308 |
| 6 | 382.2038 | 6 | 308 |
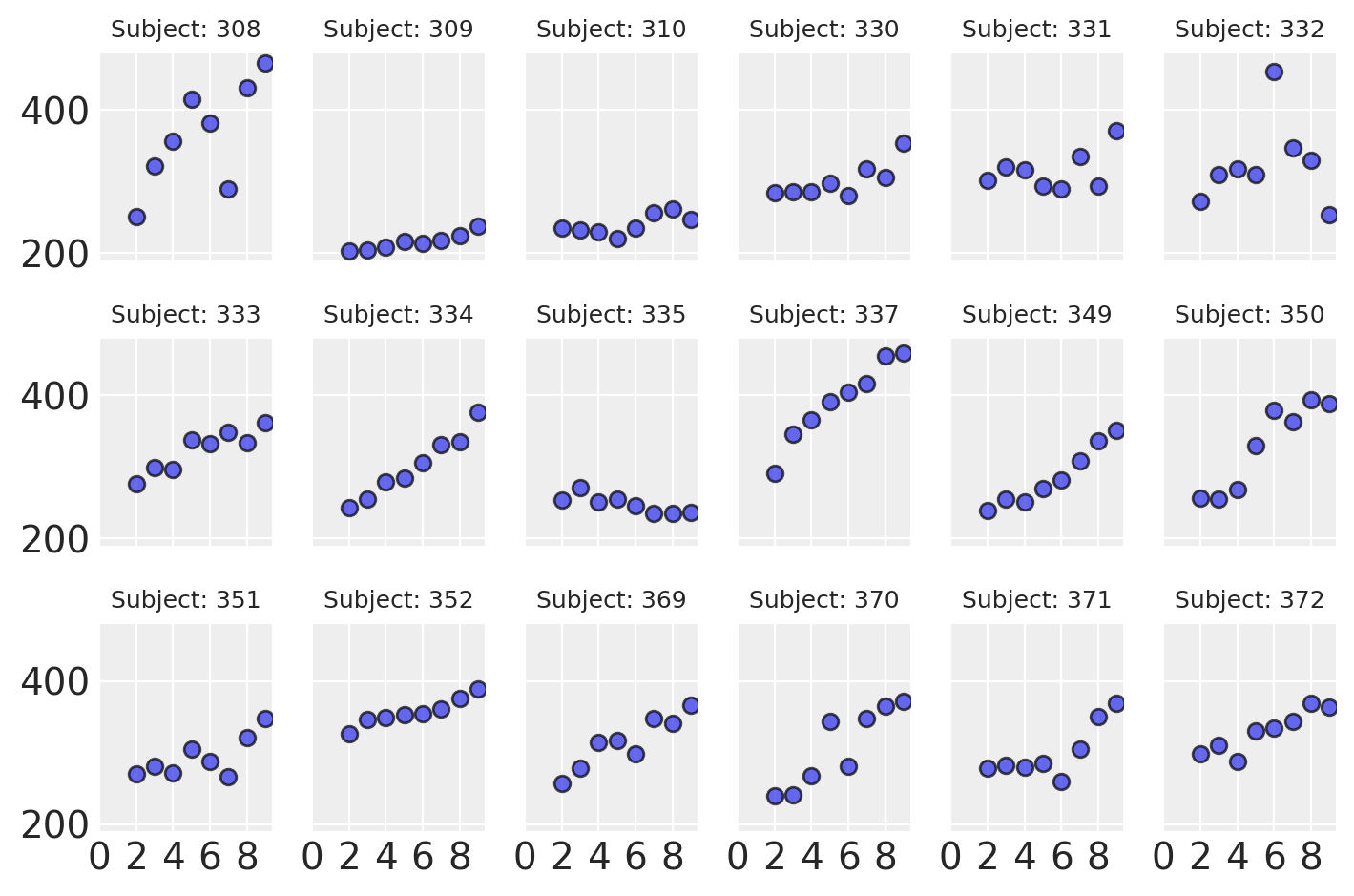
Analizziamo il tempo di reazione medio in relazione ai giorni di deprivazione del sonno, osservando come questo varia per ciascun soggetto coinvolto nello studio.
def plot_data(data):
fig, axes = plt.subplots(3, 6, sharey=True, sharex=True, dpi=100, constrained_layout=True)
fig.subplots_adjust(left=0.075, right=0.975, bottom=0.075, top=0.925, wspace=0.03)
axes_flat = axes.ravel()
for i, subject in enumerate(data["Subject"].unique()):
ax = axes_flat[i]
idx = data.index[data["Subject"] == subject].tolist()
days = data.loc[idx, "Days"].values
reaction = data.loc[idx, "Reaction"].values
# Plot observed data points
ax.scatter(days, reaction, color="C0", ec="black", alpha=0.7)
# Add a title
ax.set_title(f"Subject: {subject}", fontsize=9)
# Remove axis labels for individual plots
for ax in axes_flat:
ax.set_xlabel('')
ax.set_ylabel('')
# Set x-axis ticks for the last row
for ax in axes[-1]:
ax.xaxis.set_ticks([0, 2, 4, 6, 8])
return axes
plot_data(data)
plt.tight_layout()
Modello complete pooling#
Il modello complete pooling tratta tutte le osservazioni come se fossero indipendenti, aggregandole in un unico gruppo. In questo modello, le rette di regressione lineare per tutti i soggetti hanno la stessa pendenza e la stessa intercetta. Il modello può essere descritto esplicitamente come segue:
Se disponiamo di \( m \) soggetti e ciascun soggetto \( i \) ha \( n_i \) osservazioni, il modello può essere definito da:
dove:
\(\text{Reaction}_{ij}\) è il tempo di reazione per il soggetto \( i \) al giorno \( j \).
\(\text{Days}_{ij}\) è il numero di giorni per il soggetto \( i \) all’osservazione \( j \).
\(\alpha\) è l’intercetta comune a tutti i soggetti.
\(\beta\) è la pendenza comune a tutti i soggetti.
\(\epsilon_{ij}\) è il termine di errore casuale per il soggetto \( i \) all’osservazione \( j \), che si suppone sia distribuito normalmente con media 0 e varianza costante \( \sigma^2 \).
Questo modello non distingue tra i gruppi di osservazoni che appartengono a soggetti diversi e stima un’unica pendenza e un’unica intercetta dai dati di tutti i soggetti. In Bambi, questo modello può essere specificato utilizzando solo la variabile Days come predittore, senza includere il Subject come fattore.
model_pooling = bmb.Model("Reaction ~ 1 + Days", data)
Procediamo con l’esecuzione del campionamento MCMC, utilizzando il metodo NUTS specifico per il campionatore JAX. Questo può essere fatto semplicemente passando l’opzione method="nuts_numpyro" durante la chiamata al campionamento. In questo modo, stiamo invocando direttamente il campionatore JAX, sfruttando le sue caratteristiche avanzate.
results_pooling = model_pooling.fit(nuts_sampler="numpyro", idata_kwargs={"log_likelihood": True})
Show code cell output
model_pooling.build()
model_pooling.graph()

Un sommario numerico delle distribuzioni a posteriori dei parametri si ottiene con az.summary.
az.summary(results_pooling, round_to=2)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| Days | 11.45 | 1.86 | 7.94 | 14.79 | 0.03 | 0.02 | 4038.37 | 2838.87 | 1.0 |
| Intercept | 244.89 | 11.03 | 223.95 | 264.80 | 0.18 | 0.12 | 3907.94 | 2915.86 | 1.0 |
| Reaction_sigma | 51.19 | 3.06 | 45.35 | 56.68 | 0.05 | 0.04 | 3582.99 | 2853.44 | 1.0 |
Modello no-pooling#
Il modello no-pooling tratta ogni soggetto come indipendente e adatta una retta di regressione separata per ciascun soggetto. Se disponiamo di \( m \) soggetti e ciascun soggetto \( i \) ha \( n_i \) osservazioni, il modello può essere definito da:
dove:
\(\text{Reaction}_{ij}\) è il tempo di reazione per il soggetto \( i \) al giorno \( j \).
\(\text{Days}_{ij}\) è il numero di giorni per il soggetto \( i \) all’osservazione \( j \).
\(\alpha_i\) è l’intercetta per il soggetto \( i \).
\(\beta_i\) è la pendenza per il soggetto \( i \).
\(\epsilon_{ij}\) è il termine di errore casuale per il soggetto \( i \) all’osservazione \( j \), che si suppone sia distribuito normalmente con media 0 e varianza costante \( \sigma^2 \).
Questo modello non fa alcuna ipotesi sulle relazioni tra diversi soggetti e stima la pendenza e l’intercetta di ciascun soggetto indipendentemente dagli altri soggetti. In Bambi, questo modello viene specificato con l’interazione tra Days e Subject, come descritto in seguito.
model_no_pooling = bmb.Model("Reaction ~ Days * C(Subject)", data=data)
results_no_pooling = model_no_pooling.fit(nuts_sampler="numpyro", idata_kwargs={"log_likelihood": True})
Show code cell output
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
model_no_pooling.build()
model_no_pooling.graph()

az.summary(results_no_pooling, round_to=2)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| C(Subject)[309] | -53.93 | 32.95 | -114.91 | 8.00 | 1.39 | 1.01 | 559.52 | 1090.14 | 1.01 |
| C(Subject)[310] | -26.85 | 32.86 | -84.27 | 38.46 | 1.38 | 0.99 | 562.50 | 1487.87 | 1.00 |
| C(Subject)[330] | 11.65 | 32.32 | -52.18 | 71.64 | 1.41 | 1.00 | 526.81 | 786.88 | 1.01 |
| C(Subject)[331] | 43.24 | 33.18 | -18.74 | 106.98 | 1.33 | 0.94 | 616.51 | 1509.45 | 1.00 |
| C(Subject)[332] | 66.11 | 33.17 | 1.69 | 124.92 | 1.47 | 1.04 | 513.40 | 1410.24 | 1.01 |
| C(Subject)[333] | 18.55 | 32.49 | -42.24 | 77.98 | 1.36 | 0.96 | 574.51 | 1186.35 | 1.01 |
| C(Subject)[334] | -43.34 | 33.46 | -108.05 | 16.63 | 1.35 | 0.96 | 607.54 | 1153.28 | 1.00 |
| C(Subject)[335] | 25.78 | 33.07 | -36.09 | 88.35 | 1.34 | 0.95 | 614.43 | 1357.84 | 1.01 |
| C(Subject)[337] | 22.51 | 32.95 | -41.23 | 83.47 | 1.37 | 0.97 | 583.85 | 1119.92 | 1.01 |
| C(Subject)[349] | -48.82 | 33.25 | -108.84 | 15.98 | 1.30 | 0.92 | 657.73 | 1237.12 | 1.00 |
| C(Subject)[350] | -44.14 | 33.94 | -107.23 | 19.95 | 1.44 | 1.02 | 553.25 | 1173.04 | 1.00 |
| C(Subject)[351] | 1.45 | 32.96 | -61.16 | 62.61 | 1.41 | 1.00 | 543.26 | 976.39 | 1.00 |
| C(Subject)[352] | 71.13 | 32.72 | 9.77 | 133.08 | 1.40 | 0.99 | 550.39 | 1341.33 | 1.00 |
| C(Subject)[369] | -6.05 | 32.71 | -69.11 | 51.76 | 1.35 | 0.96 | 583.61 | 928.91 | 1.01 |
| C(Subject)[370] | -51.56 | 32.39 | -109.38 | 12.96 | 1.34 | 0.97 | 588.35 | 1138.02 | 1.00 |
| C(Subject)[371] | -11.74 | 32.60 | -76.90 | 45.01 | 1.37 | 0.97 | 570.79 | 1487.86 | 1.01 |
| C(Subject)[372] | 22.88 | 33.00 | -37.93 | 83.18 | 1.40 | 0.99 | 555.22 | 1413.14 | 1.01 |
| Days | 21.56 | 3.87 | 14.20 | 28.71 | 0.22 | 0.15 | 322.04 | 442.38 | 1.01 |
| Days:C(Subject)[309] | -17.22 | 5.60 | -27.35 | -6.24 | 0.24 | 0.17 | 541.01 | 1236.42 | 1.01 |
| Days:C(Subject)[310] | -17.73 | 5.54 | -28.52 | -7.94 | 0.23 | 0.16 | 606.27 | 1170.99 | 1.00 |
| Days:C(Subject)[330] | -13.51 | 5.43 | -23.79 | -3.24 | 0.24 | 0.17 | 509.35 | 918.65 | 1.01 |
| Days:C(Subject)[331] | -16.71 | 5.60 | -27.26 | -6.26 | 0.23 | 0.16 | 590.12 | 1352.48 | 1.00 |
| Days:C(Subject)[332] | -19.22 | 5.55 | -29.66 | -8.63 | 0.25 | 0.17 | 512.20 | 1568.05 | 1.01 |
| Days:C(Subject)[333] | -10.75 | 5.49 | -21.05 | -0.70 | 0.23 | 0.16 | 570.50 | 1203.11 | 1.01 |
| Days:C(Subject)[334] | -3.49 | 5.64 | -14.22 | 7.11 | 0.23 | 0.16 | 593.73 | 1585.16 | 1.00 |
| Days:C(Subject)[335] | -25.71 | 5.55 | -35.96 | -15.01 | 0.22 | 0.16 | 610.90 | 1375.50 | 1.01 |
| Days:C(Subject)[337] | 0.90 | 5.50 | -9.02 | 11.65 | 0.23 | 0.16 | 579.39 | 1175.12 | 1.01 |
| Days:C(Subject)[349] | -5.16 | 5.57 | -15.66 | 5.63 | 0.21 | 0.15 | 691.39 | 1160.87 | 1.00 |
| Days:C(Subject)[350] | 1.74 | 5.68 | -8.47 | 12.58 | 0.24 | 0.17 | 564.64 | 912.42 | 1.00 |
| Days:C(Subject)[351] | -13.01 | 5.59 | -23.48 | -2.42 | 0.24 | 0.17 | 560.05 | 1111.86 | 1.01 |
| Days:C(Subject)[352] | -14.25 | 5.53 | -24.17 | -3.52 | 0.23 | 0.17 | 555.52 | 1300.96 | 1.00 |
| Days:C(Subject)[369] | -7.84 | 5.54 | -17.97 | 2.33 | 0.23 | 0.16 | 598.57 | 1138.88 | 1.01 |
| Days:C(Subject)[370] | -0.95 | 5.49 | -11.45 | 9.15 | 0.23 | 0.16 | 559.43 | 1207.04 | 1.00 |
| Days:C(Subject)[371] | -9.28 | 5.57 | -19.96 | 1.05 | 0.23 | 0.17 | 567.21 | 1246.60 | 1.01 |
| Days:C(Subject)[372] | -10.40 | 5.58 | -20.77 | -0.26 | 0.24 | 0.17 | 537.46 | 1020.16 | 1.00 |
| Intercept | 245.37 | 23.08 | 202.15 | 288.57 | 1.27 | 0.91 | 330.24 | 551.39 | 1.01 |
| Reaction_sigma | 25.79 | 1.77 | 22.60 | 29.18 | 0.03 | 0.02 | 3338.24 | 2720.44 | 1.00 |
Per ricavare i coefficienti \(\alpha\) delle regressioni individuali, dobbiamo sommare Intercept al valore del singolo soggetto. Per esempio, per il soggetto 309 abbiamo
246.98 + -55.29
191.69
Facciamo lo stesso per la pendenza individuale delle rette di regressione. Per il soggetto 309 otteniamo
21.30 + -16.97
4.330000000000002
Questi valori sono identici a quelli che si otterrebbero se adattassimo il modello di regressione separatamente per ciascun soggetto. In effetti, abbiamo fatto proprio questo, utilizzando un modello unico. Per esempio, esaminiamo i singoli dati del soggetto 309.
data_subject_309 = data[data["Subject"] == 309]
data_subject_309.shape
(8, 3)
Stimiamo l’intercetta e la pendenza della retta di regressione usando l’approccio frequentista mediante la funzione linear_regression del pacchetto pingouin.
result = pg.linear_regression(data_subject_309["Days"], data_subject_309["Reaction"])
print(result)
names coef se T pval r2 \
0 Intercept 191.576970 3.723259 51.454104 3.615788e-09 0.890144
1 Days 4.357144 0.624898 6.972569 4.325982e-04 0.890144
adj_r2 CI[2.5%] CI[97.5%]
0 0.871834 182.466483 200.687458
1 0.871834 2.828074 5.886214
Si noti che i risultati ottenuti sono sostanzialmente gli stessi, con solo qualche minima differenza numerica. Questa discrepanza deriva dalla diversità degli approcci utilizzati: in un caso abbiamo applicato un metodo bayesiano, mentre nell’altro abbiamo adottato una tecnica di stima frequentista.
Modello partial pooling#
Il modello gerarchico, conosciuto anche come modello di «partial pooling», consente di gestire la complessità presente nei dati raggruppati o clusterizzati, come nel caso presente. La regressione lineare classica presume che ogni osservazione sia indipendente dalle altre, ma questa ipotesi viene meno quando i dati sono organizzati in gruppi. Le osservazioni all’interno dello stesso gruppo tendono ad essere più correlate tra loro rispetto a quelle in gruppi diversi. Trascurare questa struttura gerarchica potrebbe portare a stime errate e conclusioni fuorvianti.
Il modello gerarchico affronta questo problema introducendo la nozione di effetti casuali, in contrapposizione agli effetti fissi del modello classico. Gli effetti fissi rappresentano l’effetto medio di una variabile predittiva su tutti gli individui o gruppi, mentre gli effetti casuali considerano come l’effetto di una variabile possa variare da un gruppo all’altro. Mentre gli effetti fissi sono comuni a tutto il dataset, gli effetti casuali tengono conto delle differenze tra i gruppi.
Questo modello gerarchico unisce effetti fissi e casuali per fornire una rappresentazione più accurata dei dati, quando questi mostrano relazioni gerarchiche o raggruppate. Il modello gerarchico di «partial pooling» considera le somiglianze tra i soggetti stimando un’intercetta e una pendenza comuni, ma consente anche variazioni individuali attorno a questi valori medi.
Possiamo rappresentare matematicamente il modello come segue:
dove:
\(\text{Reaction}_{ij}\) è il tempo di reazione del soggetto \(i\) al giorno \(j\).
\(\text{Days}_{ij}\) è il numero di giorni per il soggetto \(i\) all’osservazione \(j\).
\(\alpha_i\) è l’intercetta per il soggetto \(i\), che segue la distribuzione \(\alpha_i \sim \mathcal{N}(\alpha, \tau_\alpha^2)\).
\(\beta_i\) è la pendenza per il soggetto \(i\), che segue la distribuzione \(\beta_i \sim \mathcal{N}(\beta, \tau_\beta^2)\).
\(\epsilon_{ij}\) è l’errore casuale per il soggetto \(i\) all’osservazione \(j\), distribuito normalmente con media 0 e varianza costante \(\sigma^2\).
I parametri \(\alpha\) e \(\beta\) rappresentano l’intercetta e la pendenza medie per tutti i soggetti, e le varianze \(\tau_\alpha^2\) e \(\tau_\beta^2\) quantificano le differenze tra gli individui.
In questo modo, il modello gerarchico riesce a rappresentare sia le informazioni comuni a tutti i soggetti, sia le differenze individuali, considerando sia gli effetti fissi che quelli casuali. Può quindi offrire una visione più completa e realistica dei dati, tenendo conto della loro struttura gerarchica. In Bambi, questo modello può essere specificato utilizzando la variabile Days come predittore e includendo Subject come effetto casuale.
model_partial_pooling = bmb.Model(
"Reaction ~ 1 + Days + (Days | Subject)", data, categorical="Subject"
)
Eseguiamo il campionamento.
results_partial_pooling = model_partial_pooling.fit(
nuts_sampler="numpyro", idata_kwargs={"log_likelihood": True}
)
Show code cell output
model_partial_pooling.build()
model_partial_pooling.graph()

Esaminiamo i risultati.
az.summary(results_partial_pooling, round_to=2)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| 1|Subject[308] | 10.30 | 18.63 | -23.72 | 46.68 | 0.30 | 0.25 | 4016.12 | 3084.96 | 1.0 |
| 1|Subject[309] | -42.90 | 20.64 | -81.98 | -5.13 | 0.36 | 0.27 | 3309.63 | 2812.67 | 1.0 |
| 1|Subject[310] | -25.73 | 19.27 | -64.25 | 7.08 | 0.34 | 0.27 | 3277.97 | 3119.89 | 1.0 |
| 1|Subject[330] | 5.10 | 18.18 | -27.73 | 39.94 | 0.29 | 0.26 | 3953.31 | 3043.03 | 1.0 |
| 1|Subject[331] | 22.56 | 19.30 | -12.79 | 59.05 | 0.34 | 0.27 | 3343.98 | 2792.03 | 1.0 |
| 1|Subject[332] | 35.62 | 20.03 | 0.17 | 75.28 | 0.38 | 0.27 | 2801.47 | 2863.21 | 1.0 |
| 1|Subject[333] | 12.30 | 18.21 | -20.57 | 47.58 | 0.29 | 0.24 | 4036.79 | 3094.61 | 1.0 |
| 1|Subject[334] | -21.90 | 18.51 | -56.91 | 11.82 | 0.33 | 0.25 | 3145.55 | 3114.19 | 1.0 |
| 1|Subject[335] | 1.44 | 19.22 | -36.03 | 35.95 | 0.33 | 0.30 | 3330.64 | 2449.93 | 1.0 |
| 1|Subject[337] | 26.46 | 19.68 | -8.70 | 62.96 | 0.31 | 0.25 | 3941.04 | 3080.95 | 1.0 |
| 1|Subject[349] | -27.63 | 19.58 | -63.89 | 8.48 | 0.33 | 0.26 | 3449.44 | 2721.36 | 1.0 |
| 1|Subject[350] | -16.95 | 19.49 | -54.03 | 18.93 | 0.31 | 0.28 | 3884.45 | 3122.27 | 1.0 |
| 1|Subject[351] | -1.39 | 18.33 | -36.45 | 32.68 | 0.31 | 0.28 | 3548.57 | 2987.46 | 1.0 |
| 1|Subject[352] | 43.86 | 20.01 | 7.53 | 82.54 | 0.35 | 0.26 | 3215.03 | 3169.69 | 1.0 |
| 1|Subject[369] | -1.36 | 18.58 | -37.58 | 31.75 | 0.31 | 0.27 | 3551.01 | 2964.76 | 1.0 |
| 1|Subject[370] | -25.03 | 19.39 | -62.50 | 9.99 | 0.35 | 0.28 | 3054.48 | 2930.81 | 1.0 |
| 1|Subject[371] | -6.67 | 18.32 | -39.25 | 28.81 | 0.30 | 0.27 | 3757.77 | 2967.50 | 1.0 |
| 1|Subject[372] | 15.53 | 18.88 | -21.85 | 48.98 | 0.30 | 0.26 | 3998.95 | 3043.40 | 1.0 |
| 1|Subject_sigma | 31.82 | 9.31 | 15.19 | 49.71 | 0.25 | 0.18 | 1386.68 | 2123.39 | 1.0 |
| Days | 11.41 | 1.90 | 7.74 | 14.73 | 0.04 | 0.03 | 1855.73 | 2064.91 | 1.0 |
| Days|Subject[308] | 8.18 | 3.33 | 2.39 | 14.74 | 0.06 | 0.04 | 3208.46 | 3063.26 | 1.0 |
| Days|Subject[309] | -8.21 | 3.51 | -14.62 | -1.50 | 0.06 | 0.04 | 3459.45 | 3002.64 | 1.0 |
| Days|Subject[310] | -7.28 | 3.38 | -13.90 | -1.31 | 0.06 | 0.04 | 3152.68 | 2659.15 | 1.0 |
| Days|Subject[330] | -2.14 | 3.24 | -8.30 | 3.91 | 0.06 | 0.04 | 3349.69 | 2767.40 | 1.0 |
| Days|Subject[331] | -3.11 | 3.38 | -9.43 | 3.05 | 0.06 | 0.05 | 3187.03 | 2905.11 | 1.0 |
| Days|Subject[332] | -4.05 | 3.48 | -11.05 | 2.18 | 0.07 | 0.05 | 2649.87 | 2957.90 | 1.0 |
| Days|Subject[333] | 0.45 | 3.24 | -5.83 | 6.31 | 0.05 | 0.05 | 3510.96 | 3396.88 | 1.0 |
| Days|Subject[334] | 3.24 | 3.28 | -2.90 | 9.27 | 0.06 | 0.04 | 3208.08 | 3032.20 | 1.0 |
| Days|Subject[335] | -11.15 | 3.43 | -17.43 | -4.55 | 0.06 | 0.04 | 3212.90 | 2746.22 | 1.0 |
| Days|Subject[337] | 9.96 | 3.53 | 3.11 | 16.32 | 0.06 | 0.05 | 3083.53 | 2784.46 | 1.0 |
| Days|Subject[349] | 1.62 | 3.38 | -4.57 | 8.06 | 0.06 | 0.05 | 3141.56 | 2932.37 | 1.0 |
| Days|Subject[350] | 7.30 | 3.42 | 0.72 | 13.57 | 0.06 | 0.05 | 3139.15 | 2624.58 | 1.0 |
| Days|Subject[351] | -2.26 | 3.30 | -8.41 | 3.90 | 0.06 | 0.05 | 3285.66 | 2851.41 | 1.0 |
| Days|Subject[352] | 0.21 | 3.52 | -6.72 | 6.58 | 0.07 | 0.05 | 2873.35 | 2989.23 | 1.0 |
| Days|Subject[369] | 1.56 | 3.26 | -4.47 | 7.86 | 0.06 | 0.04 | 3374.40 | 3097.69 | 1.0 |
| Days|Subject[370] | 4.85 | 3.38 | -1.42 | 10.93 | 0.06 | 0.05 | 2753.32 | 3058.96 | 1.0 |
| Days|Subject[371] | 0.12 | 3.27 | -6.05 | 6.29 | 0.05 | 0.04 | 3703.48 | 3272.65 | 1.0 |
| Days|Subject[372] | 0.86 | 3.38 | -5.50 | 7.16 | 0.06 | 0.05 | 3388.00 | 2852.79 | 1.0 |
| Days|Subject_sigma | 6.88 | 1.68 | 4.10 | 10.05 | 0.04 | 0.03 | 1701.98 | 2052.19 | 1.0 |
| Intercept | 244.99 | 10.05 | 225.22 | 262.58 | 0.23 | 0.16 | 2034.41 | 2703.14 | 1.0 |
| Reaction_sigma | 26.02 | 1.77 | 22.71 | 29.36 | 0.03 | 0.02 | 2754.50 | 2580.64 | 1.0 |
Consideriamo il soggetto 309. Per questo soggetto l’intercetta è
245.24 + -42.22
203.02
e la pendenza della retta di regressione è
11.34 + -8.27
3.0700000000000003
Si noti che questi valori sono diversi da quelli ottenuti con la procedura di no-pooling. Entrambi i modelli di no pooling e il modello gerarchico di partial pooling riconoscono che ci possono essere differenze tra i diversi gruppi (o soggetti) nel dataset, ma gestiscono queste differenze in modi diversi.
Nel modello di no pooling, ogni gruppo viene trattato in modo completamente indipendente dagli altri. Ogni intercetta e pendenza viene stimata separatamente per ogni gruppo, senza fare riferimento agli altri gruppi. In altre parole, si adatta una regressione lineare separata per ciascun gruppo. Ciò significa che se si hanno molti gruppi, ci saranno molti parametri da stimare.
Questo approccio può catturare le differenze tra i gruppi molto accuratamente se ci sono molte osservazioni in ogni gruppo, ma può essere problematico se ci sono poche osservazioni per gruppo. Inoltre, non sfrutta le informazioni comuni tra i gruppi e può portare a stime molto variabili.
Il modello gerarchico di partial pooling, invece, riconosce che, anche se ci sono differenze tra i gruppi, questi potrebbero condividere alcune caratteristiche comuni. Invece di stimare le intercette e pendenze completamente separatamente per ogni gruppo, il modello gerarchico stima una media comune e una varianza comune per l’intercetta e la pendenza, e poi consente a ciascun gruppo di variare attorno a questi valori comuni.
Questo porta al concetto di «shrinkage». Le stime delle intercette e pendenze per ciascun gruppo tendono a essere «compresse» verso i valori medi. Se un gruppo ha poche osservazioni, la sua stima sarà più fortemente influenzata dalla media comune. Se ha molte osservazioni, la sua stima sarà meno influenzata dalla media comune. In questo modo, il modello riesce a bilanciare tra due tendenze opposte: rendere conto delle differenze tra i gruppi e sfruttare le informazioni comuni.
In sintesi, la differenza principale tra il modello no-pooling e il modello gerarchico partial-pooling sta nel modo in cui gestiscono le intercette e pendenze individuali:
Il modello no-pooling tratta ogni gruppo separatamente, stimando le intercette e pendenze individuali senza considerare gli altri gruppi.
Il modello gerarchico partial-pooling stima le intercette e pendenze comuni e consente a ciascun gruppo di variare attorno a questi valori comuni, dando luogo al fenomeno dello shrinkage.
Il modello di no pooling può essere più adatto se i gruppi sono veramente indipendenti e molto diversi tra loro, mentre il modello gerarchico è maggiormente appropriato quando ci sono somiglianze tra i gruppi che possono essere sfruttate per ottenere stime più precise e robuste.
Modello Gerarchico e Distribuzione dei Coefficienti#
In un contesto di modello gerarchico con partial pooling, gli effetti casuali, inclusi intercette e pendenze specifiche per ciascun gruppo o individuo, vengono trattati come esiti di variabili aleatorie. Questo approccio si distingue nettamente da quello adottato nei modelli di no pooling, nei quali ciascun coefficiente viene considerato come un parametro statico e indipendente.
All’interno di un modello gerarchico, l’assunzione di base è che questi effetti casuali siano distribuiti normalmente. Ciò implica che ogni coefficiente specifico di un gruppo o individuo (come l’intercetta per un dato soggetto) è visto come una manifestazione di una variabile aleatoria che segue una distribuzione normale. La distribuzione di queste variabili aleatorie, che rappresenta la popolazione degli effetti casuali, è caratterizzata da una media e una varianza condivise tra tutti i gruppi o soggetti, le quali vengono inferite direttamente dai dati raccolti. Questo permette di modellare la variabilità intra-gruppo e inter-gruppo in modo più flessibile e informato, offrendo una rappresentazione più accurata della struttura dei dati e delle relazioni sottostanti.
Ad esempio, le intercette individuali \(\alpha_i\) possono essere modellate come:
dove \(\alpha\) è l’intercetta media per tutti i soggetti e \(\tau_\alpha^2\) è la varianza delle intercette tra i soggetti. Analogamente, le pendenze individuali \(\beta_i\) possono essere modellate come:
dove \(\beta\) è la pendenza media e \(\tau_\beta^2\) è la varianza delle pendenze.
Implicazioni#
Questa struttura ha diverse implicazioni importanti:
Shrinkage: Come discusso in precedenza, le stime dei coefficienti individuali tendono a essere «compresse» verso i valori medi. Questo aiuta a stabilizzare le stime, specialmente quando ci sono poche osservazioni per gruppo.
Scambio di informazioni tra i gruppi: Poiché i coefficienti individuali sono considerati come estratti dalla stessa distribuzione, ciò permette uno scambio di informazioni tra i gruppi. Se un gruppo ha molte osservazioni, può aiutare a informare le stime per un gruppo con poche osservazioni.
Interpretazione gerarchica: Il modello riconosce una struttura gerarchica nei dati, con osservazioni raggruppate all’interno di gruppi, e gruppi che condividono caratteristiche comuni. Questa struttura può riflettere una realtà sottostante nella quale gli individui o i gruppi non sono completamente indipendenti l’uno dall’altro.
In conclusione, il modello gerarchico di partial-pooling offre un quadro flessibile e potente per analizzare dati raggruppati o clusterizzati, riconoscendo sia le somiglianze che le differenze tra i gruppi e utilizzando una struttura probabilistica per modellare le relazioni tra di loro.
Interpretazione#
Iniziamo considerando le stime a posteriori degli effetti fissi.
az.summary(results_partial_pooling, var_names=["Intercept", "Days"], round_to=2)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| Intercept | 244.99 | 10.05 | 225.22 | 262.58 | 0.23 | 0.16 | 2034.41 | 2703.14 | 1.0 |
| Days | 11.41 | 1.90 | 7.74 | 14.73 | 0.04 | 0.03 | 1855.73 | 2064.91 | 1.0 |
In media, il tempo di reazione medio delle persone all’inizio dello studio è compreso tra 227 e 264 millisecondi. Con ogni giorno aggiuntivo di privazione del sonno, i tempi di reazione medi aumentano, in media, tra 7.9 e 15.1 millisecondi.
L’interpretazione degli effetti fissi è semplice. Ma quest’analisi sarebbe incompleta e fuorviante se non valutiamo i termini specifici per i singoli soggetti che abbiamo aggiunto al modello. Questi termini ci dicono quanto i soggetti differiscono l’uno dall’altro in termini di tempo di reazione iniziale e dell’associazione tra giorni di privazione del sonno e tempi di reazione.
Di seguito, utilizziamo ArviZ per ottenere un traceplot delle intercetti specifiche per i soggetti 1|Subject e delle pendenze Days|Subject. Questo traceplot contiene due colonne. A sinistra, abbiamo le distribuzioni posteriori e a destra abbiamo i trace-plots. L’aspetto casuale stazionario, o l’apparenza di rumore bianco, ci dice che il campionatore ha raggiunto la convergenza e le catene sono ben mescolate.
az.plot_trace(
results_partial_pooling, combined=True, var_names=["1|Subject", "Days|Subject"]
)
plt.tight_layout()
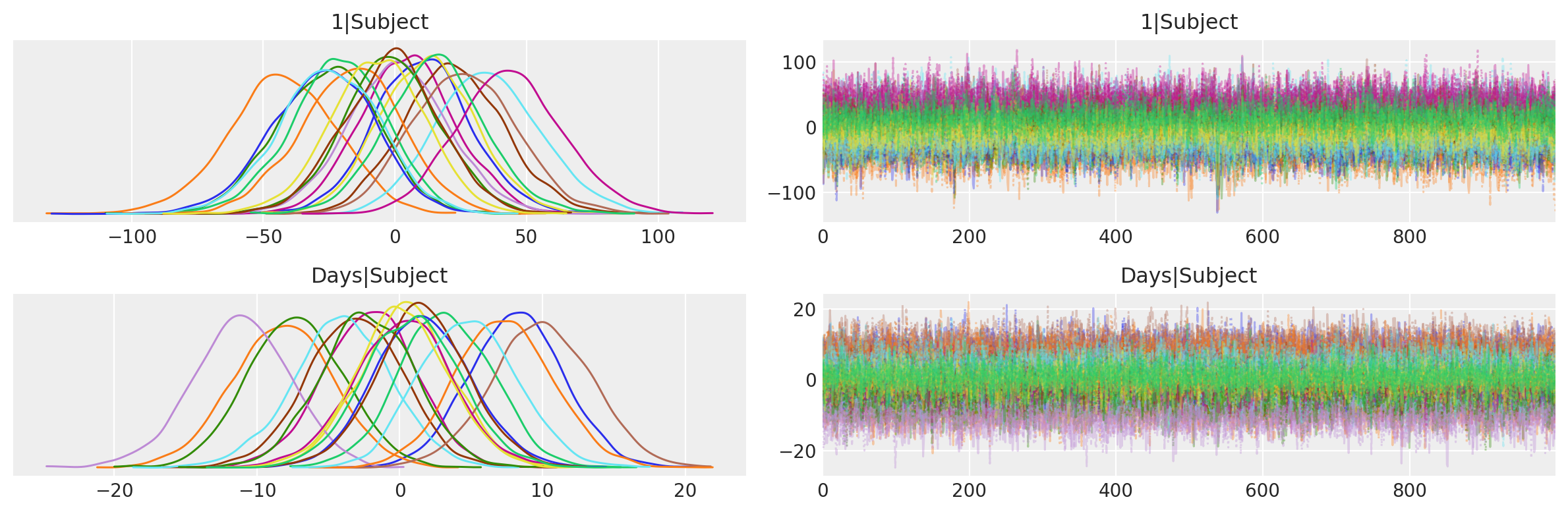
Dall’ampiezza delle distribuzioni a posteriori delle intercette per i singoli soggetti possiamo vedere che il tempo di reazione medio iniziale per un determinato soggetto può differire notevolmente dalla media generale che abbiamo visto nella tabella precedente. C’è anche una grande differenza nelle pendenze. Alcuni soggetti vedono aumentare rapidamente i loro tempi di reazione quando vengono deprivati del sonno, mentre altri hanno una tolleranza migliore e peggiorano più lentamente.
Una rappresentazione grafica della stima a posteriore dei parametri e dei dati si ottiene con az.plot_forest().
az.plot_forest(data=results_partial_pooling, r_hat=False, combined=True, textsize=8);
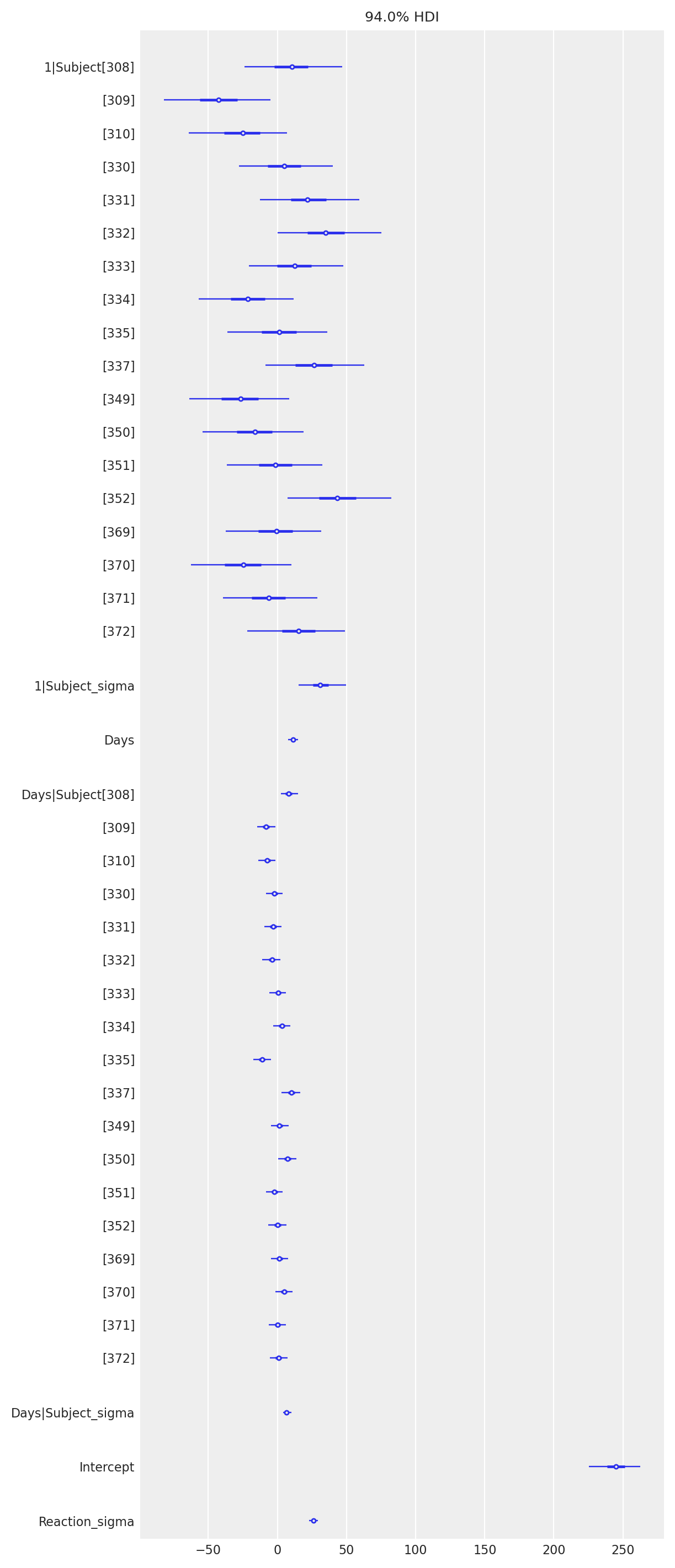
In sintesi, il modello gerarchico cattura il comportamento che abbiamo visto nella fase di esplorazione dei dati. Le persone differiscono sia nei tempi di reazione iniziali che nel modo in cui questi tempi di reazione sono influenzati dai giorni di deprivazione del sonno. Possiamo dunque giungere alle seguenti conclusioni:
Il tempo di reazione medio delle persone aumenta quando sono deprivate del sonno.
I soggetti hanno tempi di reazione diversi all’inizio dello studio.
Alcuni soggetti sono più colpiti dalla privazione del sonno rispetto ad altri.
Ma c’è un’altra domanda a cui non abbiamo ancora risposto: I tempi di reazione iniziali sono associati a quanto la deprivazione del sonno influisce sull’evoluzione dei tempi di reazione?
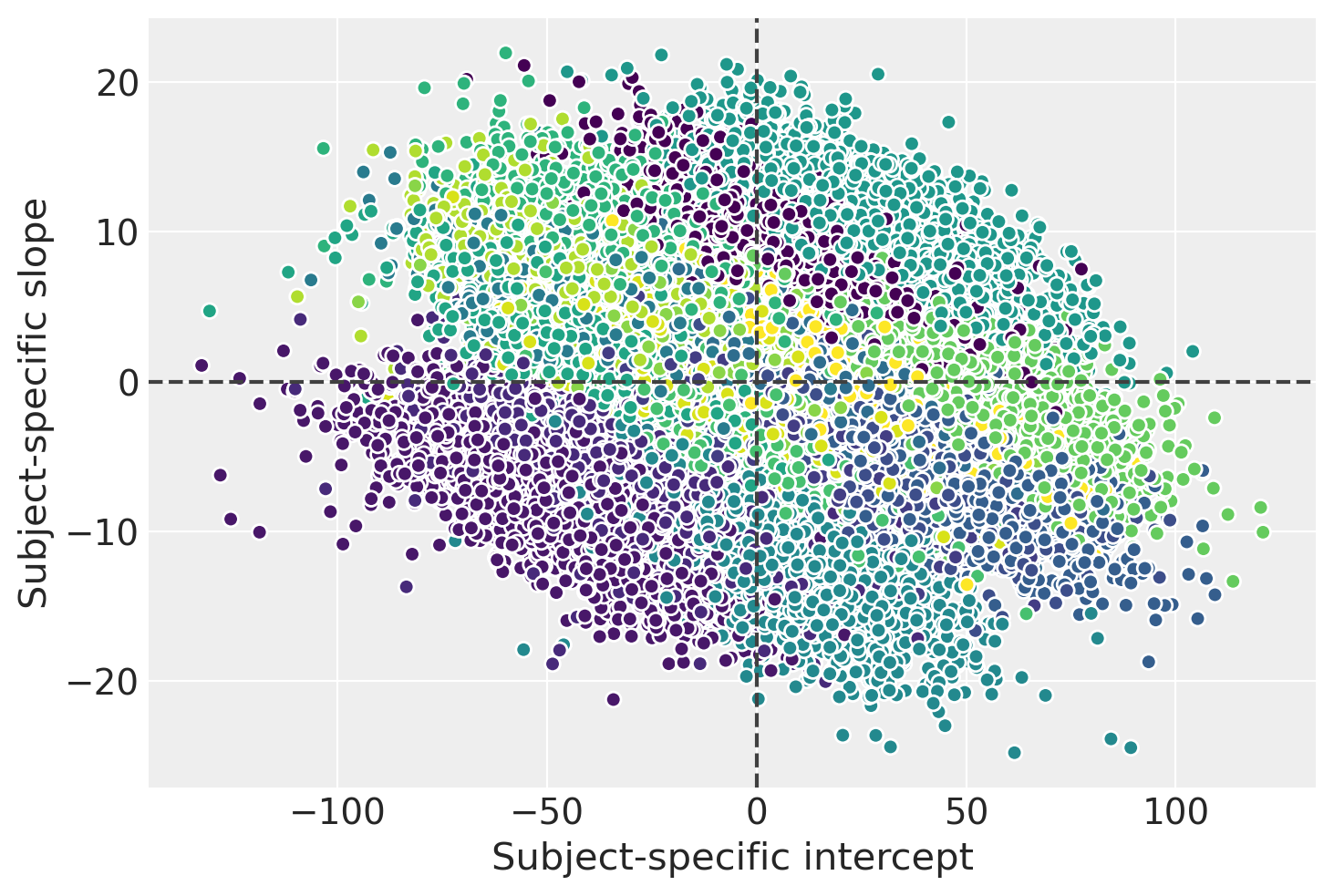
Creiamo un diagramma a dispersione per visualizzare le stime a posteriori congiunte delle intercette e delle pendenze specifiche per i soggetti. Questo grafico usa colori diversi per i soggetti. Se guardiamo il quadro generale, cioè trascurando i ragruppamenti dei dati in base ai soggetti, possiamo concludere che non c’è associazione tra l’intercetta e la pendenza. In altre parole, avere tempi di reazione iniziali più bassi o più alti non dice nulla su quanto la deprivazione del sonno influisca sul tempo di reazione medio di un determinato soggetto.
D’altra parte, se guardiamo la distribuzione a posteriori congiunta per un determinato individuo, possiamo vedere una correlazione negativa tra l’intercetta e la pendenza. Questo indica che, condizionalmente a un determinato soggetto, le stime a posteriori dell’intercetta e della pendenza non sono indipendenti.
# extract a subsample from the posterior and stack the chain and draw dims
posterior = az.extract(results_partial_pooling, num_samples=500)
_, ax = plt.subplots()
results_partial_pooling.posterior.plot.scatter(
x="1|Subject", y="Days|Subject",
hue="Subject__factor_dim",
add_colorbar=False,
add_legend=False,
edgecolors=None,
)
ax.axhline(c="0.25", ls="--")
ax.axvline(c="0.25", ls="--")
ax.set_xlabel("Subject-specific intercept")
ax.set_ylabel("Subject-specific slope");
Confronto dei modelli#
Un aspetto finale e cruciale del nostro studio riguarda il confronto tra i diversi modelli che abbiamo esaminato. La nostra intenzione è determinare quale modello fornisce una rappresentazione migliore dei dati, trovando un equilibrio appropriato tra l’accuratezza del modello e la sua complessità, cioè la parsimonia.
Per raggiungere questo scopo, faremo uso della metrica ELPD (Expected Log Predictive Density), che abbiamo introdotto in precedenza. ELPD ci consente di valutare un modello in termini di adattamento ai dati, considerando sia l’accuratezza delle previsioni che la complessità del modello.
Utilizzo di az.compare()#
In Python, possiamo sfruttare la funzione az.compare() per confrontare direttamente modelli bayesiani. Questa funzione accetta un dizionario contenente gli oggetti InferenceData, risultanti dalla funzione Model.fit(), e restituisce un dataframe. I modelli vengono ordinati dal migliore al peggiore in base ai criteri selezionati, e di default, ArviZ usa il criterio di convalida incrociata «leave one out» (LOO).
Convalida Incrociata «Leave One Out» (LOO)#
LOO è una tecnica di convalida che addestra il modello su tutti i dati disponibili tranne uno, utilizzando il singolo punto escluso come dati di test. Questo processo viene ripetuto per ogni punto dati nel set, e la media delle misure di errore fornisce una stima accurata dell’errore di generalizzazione del modello. Anche se computazionalmente impegnativa, LOO fornisce una valutazione affidabile delle prestazioni del modello. In ArviZ, la funzione loo implementa questo metodo seguendo un approccio bayesiano.
Widely Applicable Information Criterion (WAIC)#
Oltre a LOO, possiamo anche utilizzare il criterio WAIC (Widely Applicable Information Criterion). Il WAIC è uno strumento per la selezione del modello che mira a trovare il modello ottimale in un insieme di candidati, equilibrando l’adattamento ai dati e la complessità del modello, evitando così il sovradattamento. WAIC è particolarmente utile nel contesto bayesiano, poiché tiene conto dell’incertezza associata ai parametri del modello.
Sia LOO che WAIC possono essere visti come stime empiriche dell’ELPD, fornendo un quadro comprensivo delle prestazioni dei modelli.
Conclusione#
Utilizzando la funzione az.compare(), siamo in grado di effettuare una comparazione rapida ed efficace tra i diversi modelli, valutandoli secondo i criteri LOO e WAIC. Nel nostro caso specifico, il modello di «partial pooling» emerge come il migliore, presentando il valore ELPD stimato più alto. Questo risultato conferma la validità del modello nel rappresentare la struttura dei dati, tenendo conto delle differenze individuali all’interno dei cluster, e fornendo una stima coerente e informativa dell’effetto della deprivazione del sonno sul tempo di reazione.
models_dict = {
"pooling": results_pooling,
"no_pooling": results_no_pooling,
"partial_pooling": results_partial_pooling
}
df_compare = az.compare(models_dict)
df_compare
| rank | elpd_loo | p_loo | elpd_diff | weight | se | dse | warning | scale | |
|---|---|---|---|---|---|---|---|---|---|
| partial_pooling | 0 | -691.547706 | 30.299753 | 0.000000 | 9.503878e-01 | 21.319956 | 0.000000 | True | log |
| no_pooling | 1 | -694.855376 | 36.372203 | 3.307670 | 6.001324e-17 | 21.827659 | 3.169396 | True | log |
| pooling | 2 | -772.190908 | 3.062238 | 80.643201 | 4.961224e-02 | 9.011391 | 19.982860 | False | log |
È importante sottolineare che, per ottenere una stima dell’ELPD (Expected Log Predictive Density), è necessario includere l’opzione idata_kwargs={"log_likelihood": True} all’interno della funzione responsabile dell’esecuzione del campionamento MCMC.
La figura che segue illustra visivamente le informazioni rilevanti per il confronto tra i diversi modelli. In grigio è indicata l’incertezza nella stima della differenza tra i valori ELPD dei diversi modelli.
az.plot_compare(df_compare, insample_dev=False);
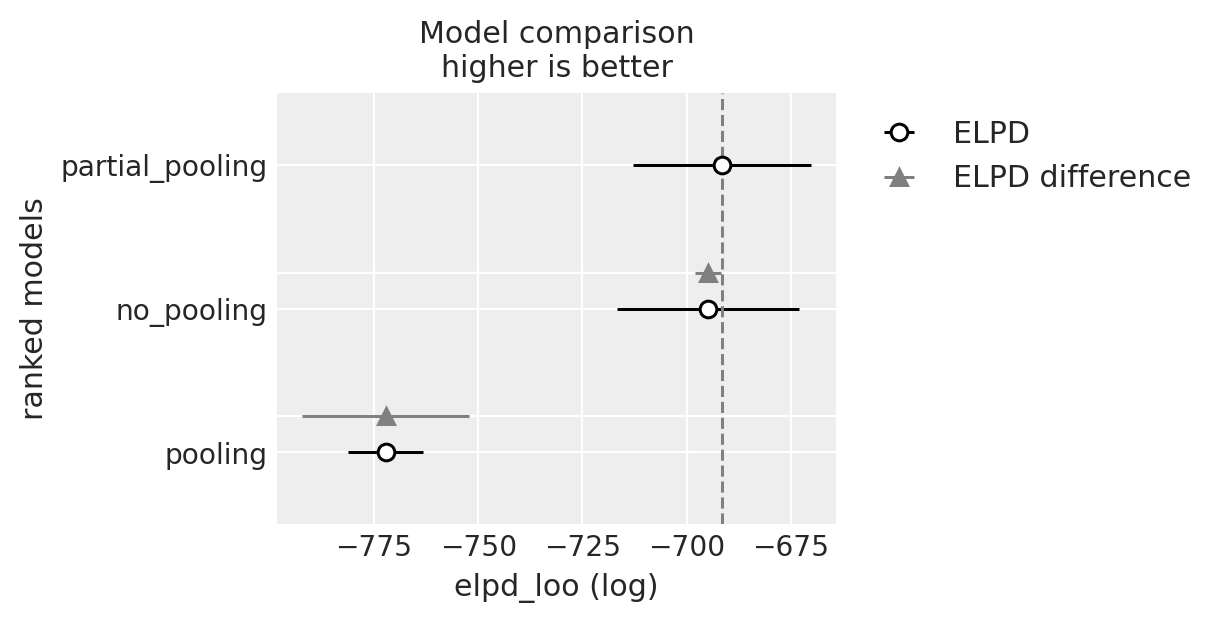
Il confronto tra i modelli guida il processo di selezione. In particolare, la comparazione tra il modello di partial-pooling e il modello completo di pooling è resa chiara dall”elpd_diff di 80.17 e dal suo errore standard di 19.97. Questi valori indicano inequivocabilmente che il modello di partial-pooling è superiore.
La situazione diventa più sfumata quando confrontiamo il modello di partial-pooling con il modello di no-pooling. In questo caso, le stime dell’ELPD mostrano una grande sovrapposizione, suggerendo che non c’è una differenza netta tra i due modelli in termini di adattamento ai dati.
Tuttavia, nonostante la vicinanza dei valori di ELPD, il modello di partial-pooling è da preferire. La ragione risiede nelle sue proprietà: esso fornisce stime più robuste e conservative delle differenze individuali. A differenza del modello di no-pooling, che può essere troppo sensibile alle variazioni all’interno dei cluster, il modello di partial-pooling incorpora un equilibrio tra la condivisione delle informazioni all’interno del gruppo e il riconoscimento delle differenze tra i gruppi. Questo lo rende più resistente alle fluttuazioni nei dati e offre una rappresentazione più affidabile delle relazioni sottostanti, rendendolo la scelta preferibile in questo contesto.
PPC plots#
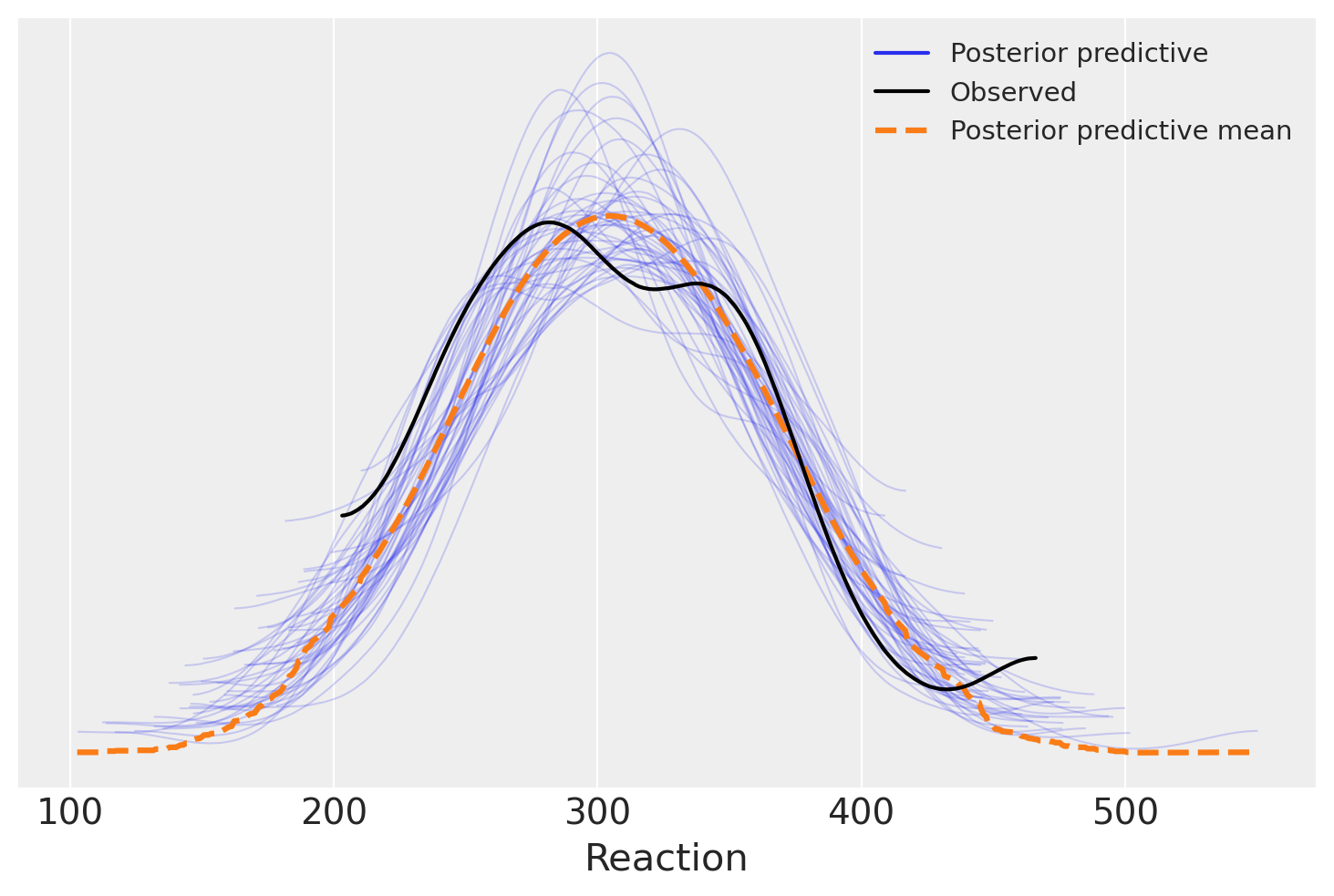
Per affrontare il tema della selezione di modelli, usano anche il metodo dei posterior predictive checks. Creiamo dunque i PPC plots per i tre modelli.
model_pooling_fitted = model_pooling.fit(idata_kwargs={"log_likelihood": True})
model_pooling.predict(model_pooling_fitted, kind="pps")
Show code cell output
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [Reaction_sigma, Intercept, Days]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.
az.plot_ppc(model_pooling_fitted, num_pp_samples=50);
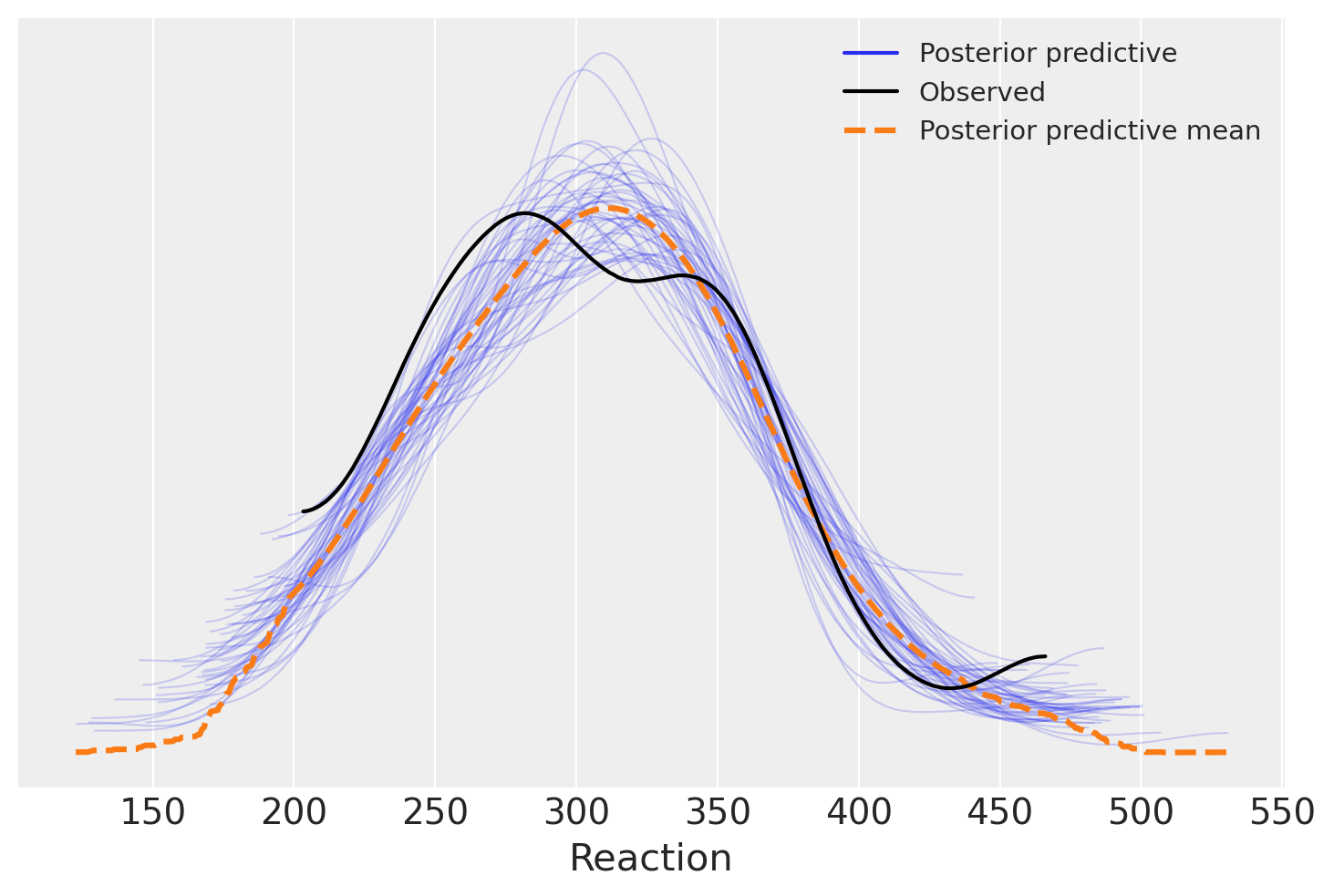
model_no_pooling_fitted = model_no_pooling.fit(idata_kwargs={"log_likelihood": True})
model_no_pooling.predict(model_no_pooling_fitted, kind="pps");
Show code cell output
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [Reaction_sigma, Intercept, Days, C(Subject), Days:C(Subject)]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 6 seconds.
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details
az.plot_ppc(model_no_pooling_fitted, num_pp_samples=50);
model_partial_pooling_fitted = model_partial_pooling.fit(idata_kwargs={"log_likelihood": True})
model_partial_pooling.predict(model_partial_pooling_fitted, kind="pps");
Show code cell output
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [Reaction_sigma, Intercept, Days, 1|Subject_sigma, 1|Subject_offset, Days|Subject_sigma, Days|Subject_offset]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 7 seconds.
az.plot_ppc(model_partial_pooling_fitted, num_pp_samples=50);
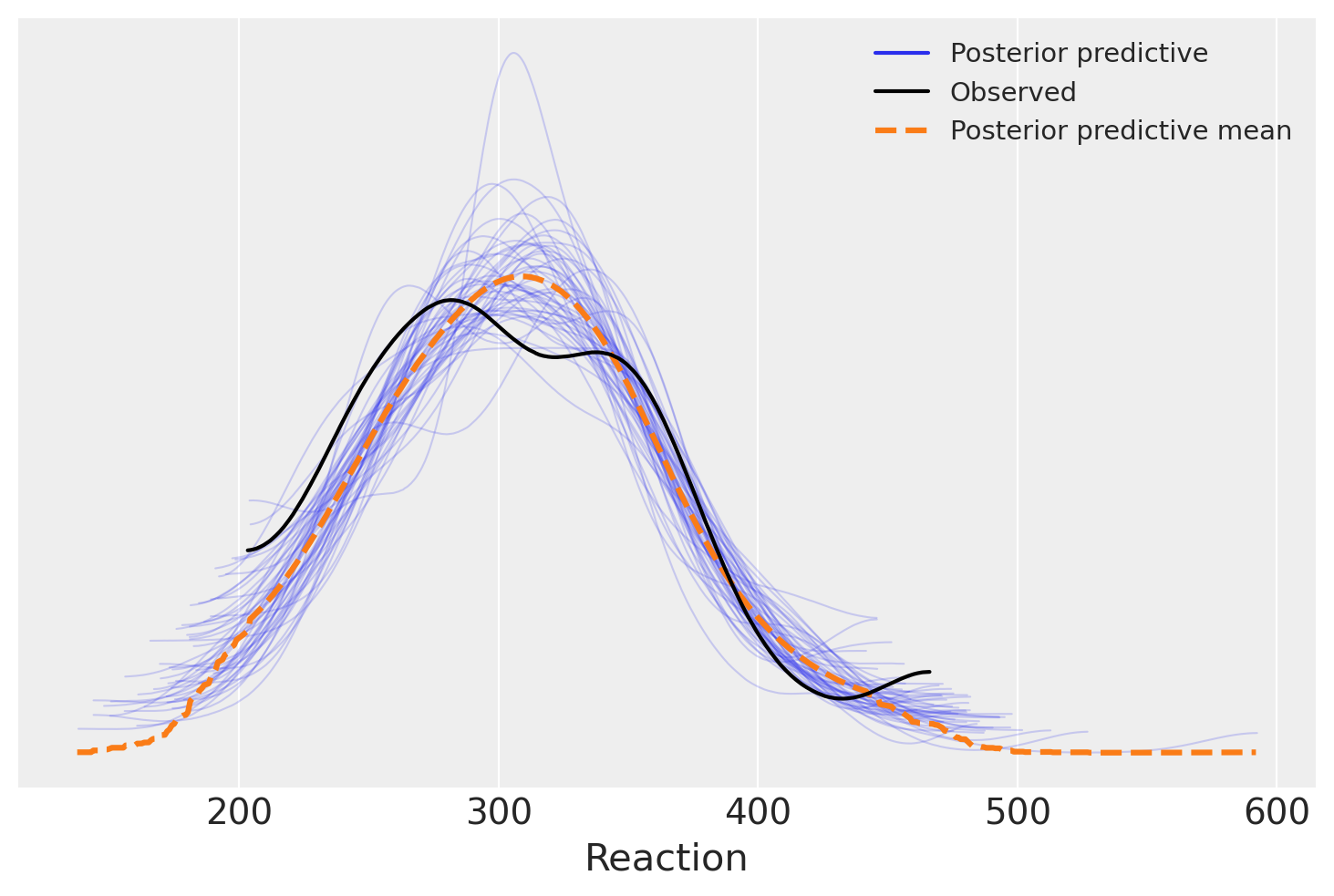
In questo contesto specifico, l’analisi tramite i PPC (Posterior Predictive Checks) plots non rivela differenze evidenti tra i tre modelli in esame: tutti sembrano egualmente adeguati nell’adattarsi ai dati. Di conseguenza, i PPC plots non forniscono ulteriori chiarimenti o conferme alle conclusioni già raggiunte attraverso il confronto tra modelli basato sulla differenza ELPD (Expected Log Predictive Density). In altre parole, l’analisi visiva tramite i PPC plots non aggiunge valore o informazioni supplementari a quanto già dedotto dalle metriche di confronto.
Conclusioni#
In questo capitolo, abbiamo esaminato e confrontato i modelli di pooling, no pooling e partial pooling utilizzando i dati provenienti dallo studio sul sonno di Belenky et al. [BWT+03] («sleepstudy»). Ciascun modello presenta caratteristiche distintive: il pooling per la sua struttura comune, il no pooling per la sua indipendenza tra i gruppi e il partial pooling come un compromesso equilibrato tra i due.
L’analisi basata sulla differenza della densità predittiva logaritmica attesa (ELPD) è stata cruciale per selezionare il modello più appropriato. Nonostante ciascun modello abbia vantaggi specifici, valutare l’ELPD ha fornito una misura obiettiva della qualità di adattamento, facilitando la scelta del modello che meglio rispecchia la struttura sottostante dei dati.
In conclusione, l’approccio combinato di comprensione delle caratteristiche dei modelli e l’applicazione di metodi quantitativi come l’ELPD ha permesso una selezione dei modelli informata ed efficace.
Informazioni sull’Ambiente di Sviluppo#
Show code cell source
%load_ext watermark
%watermark -n -u -v -iv -w -m
Last updated: Sun Jun 16 2024
Python implementation: CPython
Python version : 3.12.3
IPython version : 8.25.0
Compiler : Clang 16.0.6
OS : Darwin
Release : 23.4.0
Machine : arm64
Processor : arm
CPU cores : 8
Architecture: 64bit
bambi : 0.13.0
arviz : 0.18.0
matplotlib: 3.8.4
numpy : 1.26.4
pingouin : 0.5.4
Watermark: 2.4.3