Incorporare dati storici di controllo in una RCT#
Questo capitolo fornisce una trattazione semplificata di un importante problema affrontato da Frank Harrell in un suo intervento intitolato Incorporating Historical Control Data Into an RCT.
Preparazione del Notebook#
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import scipy.stats as stats
import arviz as az
import warnings
from cmdstanpy import cmdstan_path, CmdStanModel
# set seed to make the results fully reproducible
seed: int = sum(map(ord, "stan_rct"))
rng: np.random.Generator = np.random.default_rng(seed=seed)
az.style.use("arviz-darkgrid")
plt.rcParams["figure.dpi"] = 100
plt.rcParams["figure.facecolor"] = "white"
%config InlineBackend.figure_format = "retina"
Nella ricerca psicologica, ci troviamo di fronte a notevoli ostacoli nel reclutare un numero sufficiente di partecipanti per condurre studi controllati randomizzati (RCT), un problema che si acuisce quando si prevede l’assegnazione dei partecipanti a gruppi di controllo che ricevono trattamenti standard. Un’altra difficoltà sorge quando i potenziali partecipanti sono riluttanti a iscriversi agli studi a causa della possibilità di non ricevere il trattamento sperimentale. In questo contesto, l’utilizzo di Dati Storici (HD) per informare su possibili esiti nei gruppi di controllo assume un’importanza vitale. Tuttavia, l’integrazione di tali dati richiede strategie sofisticate per adeguare i bias e le disparità tra i diversi disegni di studio.
Stuart Pocock ha proposto un metodo nel quadro frequentista che valorizza la dimensione campionaria degli HD, pur ammettendo che questi possano riflettere realtà diverse rispetto agli esiti attesi nei gruppi di controllo degli RCT prospettici. La discrepanza include sia la vera performance sconosciuta del gruppo di controllo sia il bias inerente agli HD.
Björn Holzhauer ha ampliato questa visione attraverso lo sviluppo di approcci Bayesiani per l’appropriazione di dati, in particolare riguardo ai tassi di pericolo esponenziali, mediante l’utilizzo di simulazioni MCMC Bayesiane. Queste metodologie consentono l’elaborazione parallela di più modelli e l’inclusione diretta dei dati grezzi degli HD nell’analisi di nuovi dati sperimentali, affrontando direttamente le possibili discrepanze negli oggetti di stima tra HD e RCT.
Una caratteristica fondamentale di queste tecniche è l’aggregazione di dati grezzi da diverse fonti, facilitando un’analisi più precisa che considera l’intero spettro delle incertezze. Questo si contrappone agli approcci tradizionali, che spesso si basano su statistiche riassuntive e tendono a trascurare importanti variabilità, conferendo una fiducia ingiustificata nei dati storici. È, inoltre, cruciale l’ajustamento per covariate al fine di gestire l’eterogeneità degli esiti tra i trattamenti, aumentando così l’affidabilità e l’accuratezza delle stime dell’effetto del trattamento.
Procedendo senza dati diretti per valutare il bias, ci affidiamo a una distribuzione a priori gaussiana con media zero e deviazione standard sigma per descriverlo. Un valore di sigma nullo implica l’assenza di bias, permettendo di integrare gli HD nell’analisi allo stesso livello dei dati di controllo dello studio. Al contrario, un sigma infinito indica una completa ignoranza riguardo al bias, rendendo gli HD non informativi e pertanto trascurabili.
Il focus principale, l’effetto del trattamento delta, viene esaminato più efficacemente attraverso l’analisi di sigma. Un sigma inferiore a 2 rende lo studio informativo su delta, mentre un sigma superiore a 2 può portare a conclusioni errate, specialmente quando gli HD hanno una media artificiosamente gonfiata. Questo sottolinea l’importanza di una scelta accurata dei parametri analitici, in particolare nell’integrazione dei dati storici con quelli dei nuovi studi clinici, per fornire una rappresentazione equilibrata e critica dell’integrazione di tali dati nell’analisi statistica contemporanea.
Creazione di un Braccio di Controllo con HD#
Nel contesto di uno studio RCT condotto con un unico braccio sperimentale, dove i dati di controllo derivano unicamente da controlli storici non contemporanei, la sfida si amplifica. In queste circostanze, il bias intrinseco negli HD non può essere quantificato direttamente. Invece, ci si affida completamente alla distribuzione di incertezza prescelta per il bias. Questo approccio offre un’analisi che, pur essendo paragonabile a una verifica di sensibilità, si avvale del rigoroso quadro analitico Bayesiano. Quest’ultimo, per sua natura flessibile, permette un’estensione naturale a include la meta-analisi di dati individuali dei pazienti e l’adeguamento per covariate, arricchendo così la robustezza e l’affidabilità delle inferenze tratte dallo studio.
stan_file = os.path.join('stan', 'rct.stan')
with open(stan_file, 'r') as f:
print(f.read())
data {
int<lower=0> Nb; // # obs in RCT treatment B
int<lower=0> Nh; // # obs in historical control data
vector[Nb] yb; // vector of tx=B data
vector[Nh] yh; // vector of historical data
real<lower=0> sigma; // standard deviation of prior for bias
}
parameters {
real mua; // unknown mean for tx=A
real mub; // unknown mean for tx=B
real bias; // unknown bias
}
transformed parameters {
real delta;
delta = mua - mub;
}
model {
yb ~ normal(mub, 1.0);
yh ~ normal(mua + bias, 1.0);
bias ~ normal(0., sigma);
}
Compiliamo il modello.
model = CmdStanModel(stan_file=stan_file)
Na = 20
Nb = 40
Nh = 500
ya = rng.normal(loc=10, scale=1, size=Na)
yb = rng.normal(loc=5, scale=1, size=Nb)
yh = rng.normal(loc=20, scale=1, size=Nh)
Creiamo il dizionario che contiene i dati richiesti dal modello.
stan_data = {
"Nb" : Nb,
"Nh" : Nh,
"yb" : yb,
"yh" : yh,
"sigma" : 1.0
}
Eseguiamo il campionamento MCMC.
fit = model.sample(data=stan_data)
Show code cell output
09:49:56 - cmdstanpy - INFO - CmdStan start processing
09:49:56 - cmdstanpy - INFO - CmdStan done processing.
Esaminiamo i risultati ottenuti.
print(fit.summary())
Mean MCSE StdDev 5% 50% 95% \
lp__ -264.44900 0.035496 1.194000 -266.85100 -264.153000 -263.12400
mua 19.96750 0.031945 0.987698 18.30840 19.977100 21.57230
mub 5.20393 0.003939 0.161558 4.93481 5.205210 5.47048
bias -0.01375 0.031937 0.986492 -1.62647 -0.022246 1.65250
delta 14.76350 0.032078 1.001740 13.08890 14.775300 16.39420
N_Eff N_Eff/s R_hat
lp__ 1131.500 3025.41 1.00148
mua 955.960 2556.04 1.00570
mub 1682.640 4499.03 1.00196
bias 954.092 2551.05 1.00575
delta 975.225 2607.55 1.00521
az.summary(fit, var_names=(["bias", "delta"]), hdi_prob=0.95)
| mean | sd | hdi_2.5% | hdi_97.5% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| bias | -0.014 | 0.986 | -1.822 | 1.950 | 0.032 | 0.023 | 965.0 | 1031.0 | 1.01 |
| delta | 14.764 | 1.002 | 12.767 | 16.603 | 0.032 | 0.023 | 989.0 | 1118.0 | 1.01 |
_ = az.plot_trace(fit, var_names=(["bias", "delta"]))
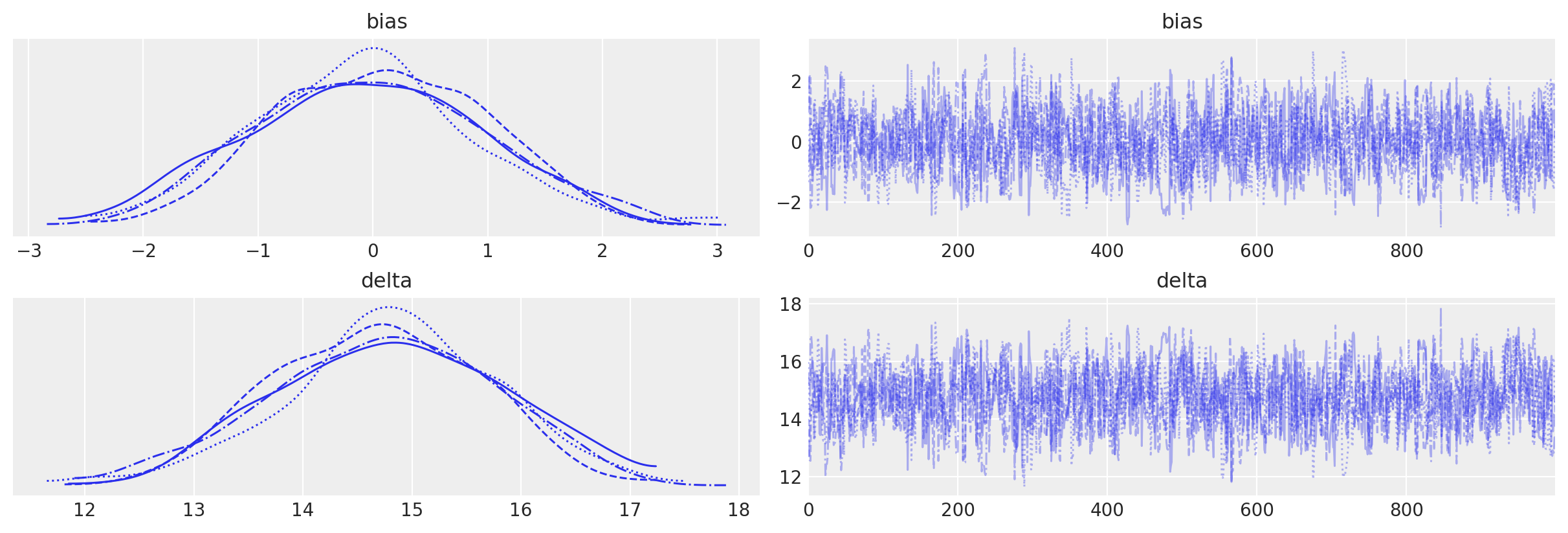
Si noti l’utilità dei dati storici nella riduzione dell’incertezza associata a delta. Quando diminuisce sigma, diminuisce anche l’incertezza associata all’effetto del trattamento.
stan_data = {
"Nb" : Nb,
"Nh" : Nh,
"yb" : yb,
"yh" : yh,
"sigma" : 0.25
}
fit1 = model.sample(data=stan_data)
Show code cell output
09:49:57 - cmdstanpy - INFO - CmdStan start processing
09:49:57 - cmdstanpy - INFO - CmdStan done processing.
az.summary(fit1, var_names=(["bias", "delta"]), hdi_prob=0.95)
| mean | sd | hdi_2.5% | hdi_97.5% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| bias | -0.005 | 0.252 | -0.503 | 0.501 | 0.007 | 0.005 | 1279.0 | 1397.0 | 1.0 |
| delta | 14.760 | 0.300 | 14.217 | 15.361 | 0.008 | 0.006 | 1387.0 | 1525.0 | 1.0 |
Conclusioni#
Per stabilire la distribuzione a priori del bias, è fondamentale considerare le informazioni disponibili riguardanti l’evoluzione delle pratiche terapeutiche, il bias di selezione dei pazienti e l’andamento della patologia di interesse. L’approccio Bayesiano ci libera dalla necessità di conoscere con precisione l’entità del bias, indirizzandoci invece a definire la sua distribuzione di incertezza. In caso questa distribuzione sia modellata come gaussiana, ci si avvale dell’ipotesi di simmetria per focalizzarsi sulla deviazione standard, sigma. Un metodo efficace per determinare sigma consiste nel fissarlo in modo che, per esempio, la probabilità che il bias si collochi entro un intervallo di \([-c, c]\) sia del 95%, per poi calcolare retrospettivamente il valore di sigma necessario a soddisfare questa condizione. Questo approccio garantisce una gestione più mirata e scientificamente fondata dell’incertezza legata al bias, fondamentale per l’integrazione ottimale dei dati storici nelle analisi statistiche avanzate.
Informazioni sull’Ambiente di Sviluppo#
%load_ext watermark
%watermark -n -u -v -iv -w -m -p cmdstanpy
Last updated: Sun Jun 16 2024
Python implementation: CPython
Python version : 3.12.3
IPython version : 8.25.0
cmdstanpy: 1.2.3
Compiler : Clang 16.0.6
OS : Darwin
Release : 23.4.0
Machine : arm64
Processor : arm
CPU cores : 8
Architecture: 64bit
scipy : 1.13.1
seaborn : 0.13.2
matplotlib: 3.8.4
numpy : 1.26.4
arviz : 0.18.0
pandas : 2.2.2
Watermark: 2.4.3