Il teorema di Bayes#
Obiettivi di apprendimento
Dopo aver completato questo capitolo, acquisirete le competenze per:
Capire in profondità il teorema di Bayes e la sua importanza.
Utilizzare il teorema di Bayes per analizzare e interpretare i test diagnostici, tenendo in considerazione la prevalenza della malattia in questione.
Affrontare e risolvere problemi di probabilità discreta che necessitano dell’applicazione del teorema di Bayes.
In questo capitolo esploreremo il teorema di Bayes, un fondamentale risultato della teoria delle probabilità che ci permette di calcolare le probabilità a posteriori di eventi ipotetici, dati i loro valori a priori e nuove informazioni. In altre parole, ci consente di aggiornare razionalmente le nostre conoscenze alla luce di nuove evidenze. Prima di procedere con il presente capitolo, è essenziale leggere l’appendice Per liberarvi dai terrori preliminari.
Preparazione del Notebook#
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import arviz as az
import seaborn as sns
# set seed to make the results fully reproducible
seed: int = sum(map(ord, "bayes_theorem"))
rng: np.random.Generator = np.random.default_rng(seed=seed)
az.style.use("arviz-darkgrid")
plt.rcParams["figure.dpi"] = 100
plt.rcParams["figure.facecolor"] = "white"
%config InlineBackend.figure_format = "retina"
Storia#
Il teorema di Bayes, così denominato in onore del Reverendo Thomas Bayes, un matematico e filosofo del XVIII secolo, rappresenta uno dei concetti fondamentali nel campo della statistica e del calcolo delle probabilità. Sebbene Bayes non abbia pubblicato il suo lavoro durante la sua vita, ritenendolo non abbastanza significativo, fu il suo amico Richard Price a riconoscere il valore delle sue scoperte. Price non solo editò il manoscritto inedito di Bayes ma lo arricchì significativamente prima di sottometterlo per la pubblicazione nelle «Philosophical Transactions» nel 1763. Questa pubblicazione non solo introdusse il teorema di Bayes al mondo scientifico ma fornì anche una base filosofica per quello che sarebbe poi diventato noto come l’approccio bayesiano alla statistica.
Parallelamente e indipendentemente dai lavori di Bayes, Pierre-Simon Laplace, un eminente matematico e astronomo francese, formulò concetti simili. Nel 1774, e più dettagliatamente nella sua opera «Théorie analytique des probabilités» del 1812, Laplace esplorò l’uso della probabilità condizionale per aggiornare le conoscenze precedenti (probabilità a priori) sulla base di nuove evidenze (probabilità a posteriori). Sebbene Laplace abbia sviluppato questi principi senza conoscere il lavoro di Bayes, i suoi contributi hanno notevolmente esteso l’applicazione e l’interpretazione delle statistiche bayesiane.
Il teorema di Bayes, nella sua essenza, fornisce un meccanismo matematico per aggiornare le probabilità iniziali di un’ipotesi in base all’osservazione di nuove evidenze. Questo processo di revisione continua della probabilità si basa sulla combinazione di conoscenze preesistenti (il prior) con informazioni appena acquisite (la likelihood), per produrre una nuova comprensione (il posterior). Tale meccanismo riflette un approccio olistico alla conoscenza, che considera la comprensione come un processo dinamico e iterativo.
Nel contesto contemporaneo, l’importanza e l’applicabilità del teorema di Bayes vanno ben oltre la teoria della probabilità e la statistica, influenzando vari campi come l’intelligenza artificiale, l’apprendimento automatico, la psicologia, la medicina e persino la presa di decisioni nella vita quotidiana. La capacità di aggiornare costantemente le nostre convinzioni in base a nuove informazioni è fondamentale in un’era caratterizzata da un flusso incessante di dati. In modo emblematico, potremmo affermare che rilevanza universale del teorema di Bayes nella comprensione dei fenomeni e nella previsione degli eventi è enfatizzata nel titolo del libro di Tom Chivers pubblicato nel 2024: «Everything is predictable: how bayesian statistics explain our world».
Teorema#
Consideriamo una situazione in cui lo spazio degli eventi possibili, \(\Omega\), è diviso in due eventi distinti e mutualmente esclusivi, denominati ipotesi \(H_1\) e \(H_2\). Supponiamo di avere già una certa comprensione di questi eventi, espressa attraverso le loro probabilità a priori \(P(H_1)\) e \(P(H_2)\). A questo punto, introduciamo un nuovo evento \(E\), la cui occorrenza è accompagnata da una probabilità non nulla e per il quale conosciamo le probabilità condizionate \(P(E \mid H_1)\) e \(P(E \mid H_2)\), che indicano quanto sia probabile osservare \(E\) assumendo che una delle due ipotesi sia vera. Se \(E\) si verifica, siamo interessati a determinare le probabilità a posteriori \(P(H_1 \mid E)\) e \(P(H_2 \mid E)\) delle nostre ipotesi alla luce di questa nuova evidenza.
La seguente illustrazione rappresenta come lo spazio totale degli eventi si suddivide tra le ipotesi \(H_1\) e \(H_2\), con l’evidenza \(E\) posizionata all’interno di questo contesto.
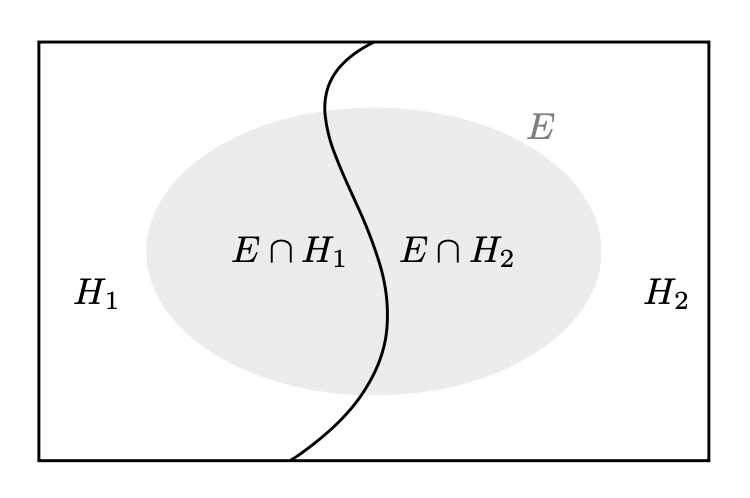
Per calcolare la probabilità a posteriori dell’ipotesi 1 data l’osservazione di \(E\), utilizziamo la formula:
Questo calcolo può essere semplificato sfruttando la definizione di probabilità condizionata, che ci permette di sostituire \(P(E \cap H_1)\) con \(P(E \mid H_1)P(H_1)\). Applicando questa sostituzione, otteniamo:
Dato che \(H_1\) e \(H_2\) si escludono a vicenda, la probabilità totale di \(E\) può essere espressa come la somma delle probabilità di \(E\) occorrente in concomitanza con ciascuna ipotesi, utilizzando il teorema della probabilità totale:
Incorporando questi valori nella formula di Bayes, giungiamo a:
Questa espressione costituisce l’essenza della formula di Bayes per il caso semplificato in cui le ipotesi si limitano a due eventi mutualmente esclusivi, \(H_1\) e \(H_2\).
Nel quadro delle probabilità discrete, questa formula può essere generalizzata per accogliere un insieme più ampio di ipotesi che formano una partizione completa dello spazio degli eventi \(\Omega\), dove ogni \(E\) rappresenta un evento con probabilità maggiore di zero. Per ogni ipotesi \(H_i\) all’interno di un insieme numerabile, la formula di Bayes si estende come segue:
Qui, il denominatore agisce come un fattore di normalizzazione che integra i prodotti delle probabilità a priori e delle verosimiglianze associate a ogni ipotesi considerata.
Per variabili continue, la formula di Bayes assume una forma integrale, adattandosi a situazioni in cui le ipotesi \(H_i\) rappresentano valori in un continuum. In questo contesto, la formula diventa:
offrendo un framework potente per aggiornare le probabilità a posteriori di ipotesi continue basate su nuove evidenze, sottolineando l’importanza della formula di Bayes non solo come strumento matematico, ma anche come filosofia di apprendimento continuo e adattamento alle nuove informazioni.
Interpretazione della Formula di Bayes#
La formula di Bayes si articola in tre elementi fondamentali che ne facilitano la comprensione e l’applicazione in diversi campi di studio:
Probabilità a Priori, \(P(H)\): Questa componente riflette la nostra valutazione preliminare riguardo la verosimiglianza dell’ipotesi \(H\) prima di prendere in esame nuove evidenze \(E\). Essa incarna il livello di credibilità o fiducia attribuita all’ipotesi, basandosi su conoscenze preesistenti o su deduzioni logiche. In sostanza, la probabilità a priori quantifica le nostre convinzioni pregresse o le aspettative iniziali su quanto sia probabile che l’ipotesi sia vera.
Probabilità a Posteriori, \(P(H \mid E)\): Questo valore aggiorna la nostra fiducia nell’ipotesi \(H\) in seguito all’osservazione dell’evidenza \(E\). In termini più intuitivi, rappresenta il livello di convinzione ricalibrato in \(H\) dopo aver considerato l’evidenza. La formula di Bayes ci offre un meccanismo matematicamente rigoroso per modulare questa probabilità alla luce delle nuove informazioni ricevute.
Verosimiglianza, \(P(E \mid H)\): La verosimiglianza esprime la probabilità di rilevare l’evidenza \(E\) dato che l’ipotesi \(H\) sia vera. È un indice di quanto l’evidenza supporti o confermi l’ipotesi. Un valore elevato di verosimiglianza indica che l’evidenza è fortemente in linea o prevista dalla veridicità dell’ipotesi.
Grazie alla formula di Bayes, possiamo adottare un processo di aggiornamento continuo delle nostre credenze in base a nuove informazioni, promuovendo un metodo dinamico per navigare tra conoscenza e incertezza. Questa metodologia ci fornisce un approccio strutturato per rivedere e adattare le nostre convinzioni riguardo l’ipotesi \(H\) di fronte a nuovi dati o evidenze \(E\). La capacità di rielaborare costantemente le nostre aspettative in funzione di informazioni aggiuntive si rivela essenziale in una vasta gamma di ambiti, inclusi l’intelligenza artificiale, la ricerca statistica, le discipline scientifiche e umanistiche. Tale prassi ci consente di prendere decisioni più informate, di interpretare con maggiore precisione i dati disponibili e di affinare significativamente le nostre previsioni e comprensioni del mondo circostante.
Alcuni esempi#
Esamineremo alcuni esempi basilari per illustrare in maniera più chiara il modo in cui il teorema di Bayes viene applicato e funziona.
Exercise 98
Consideriamo il caso in cui osserviamo una persona con i capelli lunghi e desideriamo valutare la probabilità che questa persona sia femminile. In termini formali, definiamo \(H = \text{"donna"}\) e \(E = \text{"capelli lunghi"}\), e miriamo a stimare \(P(H \mid E)\).
Le nostre conoscenze preliminari includono:
La probabilità a priori che la persona osservata sia una donna, \(P(H) = 0.5\),
La probabilità generale di osservare qualcuno con i capelli lunghi, \(P(E) = 0.4\),
La probabilità di avere i capelli lunghi dato che la persona è una donna, \(P(E \mid H) = 0.7\).
Applicando la formula di Bayes, possiamo determinare:
Questo risultato ci mostra che, alla luce delle informazioni a nostra disposizione, la probabilità che una persona con i capelli lunghi sia una donna è dell’0.875. In altre parole, prima di osservare l’evidenza (i capelli lunghi), partivamo da una conoscenza di base secondo cui c’era una chance su due (50%) che la persona fosse una donna. Dopo aver considerato l’evidenza dei capelli lunghi, abbiamo aggiornato la nostra stima alla probabilità «a posteriori» di 0.875, riflettendo così un incremento della nostra convinzione che la persona sia una donna basandoci su quest’ultima osservazione.
Exercise 99
Un esempio pratico che illustra efficacemente l’uso del teorema di Bayes è l’analisi del rapporto tra la mammografia e la diagnosi del cancro al seno, già considerato in precedenza. In questo contesto, si considerano due ipotesi: la presenza della malattia, indicata con \(M^+\), e l’assenza della malattia, denotata con \(M^-\). L’evidenza in questo caso è rappresentata dal risultato positivo di un test di mammografia, che indicheremo con \(T^+\). Applicando la formula di Bayes, possiamo esprimere la probabilità di avere il cancro al seno dato un risultato positivo al test come segue:
dove:
\(P(M^+ \mid T^+)\) è la probabilità di avere il cancro (\(M^+\)) dato un risultato positivo al test (\(T^+\)),
\(P(T^+ \mid M^+)\) rappresenta la probabilità che il test di mammografia risulti positivo (\(T^+\)) in presenza effettiva del cancro (\(M^+\)),
\(P(M^+)\) denota la probabilità a priori che una persona abbia il cancro prima di sottoporsi al test,
\(P(T^+ \mid M^-)\) indica la probabilità che il test risulti positivo (\(T^+\)) nonostante l’assenza del cancro (\(M^-\)); dal momento che la specificità è data e uguale a 0.9, possiamo calcolare la probabilità di un falso positivo come segue:
\[ P(T^+ \mid M^-) = 1 - \text{Specificità} = 1 - 0.9 = 0.1. \]Quindi, in questo contesto, \(P(T^+ \mid M^-) = 0.1\) significa che c’è un 10% di probabilità che il test diagnostichi erroneamente la presenza del cancro in una persona sana.
\(P(M^-)\) rappresenta la probabilità a priori che una persona non sia affetta da cancro prima di effettuare il test.
Inserendo i valori specifici del contesto analizzato otteniamo:
Questo calcolo dimostra che, considerando una mammografia con risultato positivo ottenuta tramite un test con una sensibilità del 90% e una specificità del 90%, la probabilità che il paziente sia effettivamente affetto da cancro al seno è approssimativamente dell’8.3%.
Il Valore Predittivo di un Test di Laboratorio#
L’applicazione del teorema di Bayes nell’interpretazione dei risultati dei test di laboratorio è cruciale nella pratica clinica. Questo teorema consente di calcolare la probabilità che un individuo sia affetto da una specifica malattia dopo un risultato positivo al test, nonché la probabilità di non essere malati in caso di esito negativo. La comprensione di tre elementi è fondamentale per questo calcolo: la prevalenza della malattia, la sensibilità e la specificità del test.
Prevalenza: Si riferisce alla percentuale di individui in una popolazione che sono affetti da una certa malattia in un determinato momento. Viene espressa come percentuale o frazione della popolazione. Per esempio, una prevalenza del 0.5% indica che su mille persone, cinque sono affette dalla malattia.
Sensibilità: Indica la capacità del test di identificare correttamente la malattia negli individui malati. Viene calcolata come la frazione di veri positivi (individui malati correttamente identificati) sul totale degli individui malati. La formula della sensibilità (\(Sens\)) è la seguente:
\[ Sens = \frac{TP}{TP + FN}, \]dove \(TP\) rappresenta i veri positivi e \(FN\) i falsi negativi. Pertanto, la sensibilità misura la probabilità che il test risulti positivo se la malattia è effettivamente presente.
Specificità: Misura la capacità del test di riconoscere gli individui sani, producendo un risultato negativo per chi non è affetto dalla malattia. Si calcola come la frazione di veri negativi (individui sani correttamente identificati) sul totale degli individui sani. La specificità (\(Spec\)) si definisce come:
\[ Spec = \frac{TN}{TN + FP}, \]dove \(TN\) sono i veri negativi e \(FP\) i falsi positivi. Così, la specificità rappresenta la probabilità che il test risulti negativo in assenza della malattia.
Questa tabella riassume la terminologia:
\(T^+\) |
\(T^-\) |
Totale |
|
|---|---|---|---|
\(M^+\) |
\(P(T^+ \cap M^+)\) |
\(P(T^- \cap M^+)\) |
\(P(M^+)\) |
\(M^-\) |
\(P(T^+ \cap M^-)\) |
\(P(T^- \cap M^-)\) |
\(P(M^-)\) |
Totale |
\(P(T^+)\) |
\(P(T^-)\) |
1 |
dove \(T^+\) e \(T^-\) indicano rispettivamente un risultato positivo o negativo del test, mentre \(M^+\) e \(M^-\) la presenza o assenza effettiva della malattia. In questa tabella, i totali marginali rappresentano:
Totale per \(M^+\) e \(M^-\) (ultima colonna): La probabilità totale di avere la malattia (\(P(M^+)\)) e la probabilità totale di non avere la malattia (\(P(M^-)\)), rispettivamente. Questi valori sono calcolati sommando le probabilità all’interno di ciascuna riga.
Totale per \(T^+\) e \(T^-\) (ultima riga): La probabilità totale di un risultato positivo al test (\(P(T^+)\)) e la probabilità totale di un risultato negativo al test (\(P(T^-)\)), rispettivamente. Questi valori sono calcolati sommando le probabilità all’interno di ciascuna colonna.
Totale generale (angolo in basso a destra): La somma di tutte le probabilità, che per definizione è 1, rappresentando l’intera popolazione o il set di casi considerati.
Mediante il teorema di Bayes, possiamo usare queste informazioni per stimare la probabilità post-test di avere o non avere la malattia basandoci sul risultato del test, fornendo così una base razionale per decisioni diagnostiche e terapeutiche.
La probabilità post-test che un individuo sia malato dato un risultato positivo del test è calcolata come:
Questa formula rappresenta il valore predittivo positivo, indicando la probabilità che un individuo sia realmente malato se il test è positivo. Analogamente, il valore predittivo negativo, che è la probabilità che un individuo non sia malato dato un risultato negativo del test, si calcola come:
Questi valori predittivi sono essenziali per valutare l’efficacia di un test diagnostico, aiutando a determinare quanto sia affidabile un risultato positivo o negativo nel contesto di una specifica popolazione e malattia.

Exercise 100
Calcoliamo ora il valore predittivo del test positivo e il valore predittivo del test negativo per i dati dell’esempio sulla mammografia e cancro al seno.
def positive_predictive_value_of_diagnostic_test(sens, spec, prev):
return (sens * prev) / (sens * prev + (1 - spec) * (1 - prev))
Valore Predittivo Positivo (Positive Predictive Value, PPV): Questa misura indica la probabilità che un individuo sia effettivamente malato se ha ricevuto un risultato positivo al test. La formula che hai fornito per il PPV è:
Qui, sens rappresenta la sensibilità del test, spec la specificità, e prev la prevalenza della malattia nella popolazione. La formula riflette il calcolo del PPV basato sul teorema di Bayes.
def negative_predictive_value_of_diagnostic_test(sens, spec, prev):
return (spec * (1 - prev)) / (spec * (1 - prev) + (1 - sens) * prev)
Valore Predittivo Negativo (Negative Predictive Value, NPV): Questa misura indica la probabilità che un individuo non sia malato se ha ricevuto un risultato negativo al test. La formula per il NPV è:
Anche in questo caso, sens, spec, e prev hanno gli stessi significati menzionati sopra. Questa formula calcola il NPV basandosi sul teorema di Bayes.
Inseriamo i dati del problema.
sens = 0.9 # sensibilità
spec = 0.9 # specificità
prev = 0.01 # prevalenza
Il valore predittivo del test positivo è:
res_pos = positive_predictive_value_of_diagnostic_test(sens, spec, prev)
print(f"P(M+ | T+) = {round(res_pos, 3)}")
P(M+ | T+) = 0.083
Il valore predittivo del test negativo è:
res_neg = negative_predictive_value_of_diagnostic_test(sens, spec, prev)
print(f"P(M- | T-) = {round(res_neg, 3)}")
P(M- | T-) = 0.999
Exercise 101
Consideriamo ora un altro esempio relativo al test antigenico rapido per il virus SARS-CoV-2, che può essere eseguito mediante tampone nasale, tampone naso-orofaringeo o campione di saliva. L’Istituto Superiore di Sanità ha pubblicato un documento il 5 novembre 2020, nel quale viene sottolineato che, fino a quel momento, i dati disponibili sui vari test sono quelli forniti dai produttori: la sensibilità varia tra il 70% e l’86%, mentre la specificità si attesta tra il 95% e il 97%.
Per fare un esempio, consideriamo i dati di un certo momento temporale. Nella settimana tra il 17 e il 23 marzo 2023, in Italia, il numero di individui positivi al virus è stato stimato essere di 138.599 (fonte: Il Sole 24 Ore). Questo dato corrisponde a una prevalenza di circa 0.2% su una popolazione totale di circa 59 milioni di persone.
prev = 138599 / 59000000
prev
0.002349135593220339
L’obiettivo è determinare la probabilità di essere effettivamente affetti da Covid-19, dato un risultato positivo al test antigenico rapido, ossia \(P(M^+ \mid T^+)\). Per raggiungere questo scopo, useremo la formula relativa al valore predittivo positivo del test.
sens = (0.7 + 0.86) / 2 # sensibilità
spec = (0.95 + 0.97) / 2 # specificità
res_pos = positive_predictive_value_of_diagnostic_test(sens, spec, prev)
print(f"P(M+ | T+) = {round(res_pos, 3)}")
P(M+ | T+) = 0.044
Pertanto, se il risultato del tampone è positivo, la probabilità di essere effettivamente affetti da Covid-19 è solo del 4.4%, approssimativamente.
Se la prevalenza fosse 100 volte superiore (cioè, pari al 23.5%), la probabilità di avere il Covid-19, dato un risultato positivo del tampone, aumenterebbe notevolmente e sarebbe pari a circa l’86%.
prev = 138599 / 59000000 * 100
res_pos = positive_predictive_value_of_diagnostic_test(sens, spec, prev)
print(f"P(M+ | T+) = {round(res_pos, 3)}")
P(M+ | T+) = 0.857
Se il risultato del test fosse negativo, considerando la prevalenza stimata del Covid-19 nella settimana dal 17 al 23 marzo 2023, la probabilità di non essere infetto sarebbe del 99.9%, approssimativamente.
sens = (0.7 + 0.86) / 2 # sensibilità
spec = (0.95 + 0.97) / 2 # specificità
prev = 138599 / 59000000 # prevalenza
res_neg = negative_predictive_value_of_diagnostic_test(sens, spec, prev)
print(f"P(M- | T-) = {round(res_neg, 3)}")
P(M- | T-) = 0.999
Tuttavia, un’esito del genere non dovrebbe sorprenderci, considerando che la prevalenza della malattia è molto bassa; in altre parole, il risultato negativo conferma una situazione già presunta prima di sottoporsi al test. Il vero ostacolo, specialmente nel caso di malattie rare come il Covid-19 in quel periodo specifico, non risiede tanto nell’asserire l’assenza della malattia quanto piuttosto nel confermarne la presenza.
Commenti e considerazioni finali#
La riflessione epistemologica contemporanea ha ribadito che la conoscenza non può essere vista come una certezza inconfutabile o una garanzia razionale di verità. Invece, essa emerge come una serie di decisioni prese all’interno di un contesto di incertezza. Questa comprensione è particolarmente pertinente nel campo della ricerca scientifica, dove né la logica deduttiva né le rigorose dimostrazioni matematiche sono sufficienti. Di conseguenza, la scienza necessita di una «logica dell’incertezza,» che è efficacemente fornita dalla teoria delle probabilità, e più specificamente, dal teorema di Bayes.
Il teorema di Bayes ci offre un framework per interpretare la probabilità come una valutazione soggettiva influenzata da diversi fattori condizionanti. In pratica, il teorema esprime la probabilità a posteriori \( P(H_i \mid E) \) come un risultato derivato dalla combinazione della probabilità a priori \( P(H_i) \) e della verosimiglianza \( P(E \mid H_i) \). Questa formulazione sottolinea che la nostra valutazione probabilistica di una data ipotesi \( H_i \) è modulata sia dall’evidenza empirica \( E \) che dalle nostre credenze a priori \( P(H_i) \).
Poiché la probabilità è una valutazione intrinsecamente soggettiva, è possibile che diversi osservatori arrivino a conclusioni differenti. Tuttavia, il teorema di Bayes fornisce un meccanismo razionale—conosciuto come «aggiornamento bayesiano»—per ricalibrare queste credenze in risposta a nuove informazioni o evidenze.
L’approccio bayesiano offre strumenti per valutare l’efficacia di diverse strategie di trattamento o interventi in psicologia clinica. Per esempio, se si afferma che la meditazione mattutina è efficace nel trattamento della depressione, è essenziale valutare questa affermazione nel contesto di tutte le evidenze disponibili, compresi i casi in cui la meditazione non ha portato a miglioramenti.
In sintesi, la metodologia bayesiana fornisce una cornice robusta per l’aggiornamento delle probabilità in presenza di nuove informazioni, offrendo spunti importanti sia per la ricerca che per la pratica clinica in psicologia.
Nel contesto di questo capitolo, abbiamo focalizzato la nostra discussione sul teorema di Bayes nel caso delle variabili casuali discrete. Tuttavia, nel prossimo capitolo, esploreremo come il teorema può essere applicato in modo più intuitivo alle variabili casuali continue. Per ulteriori dettagli, si rimanda al notebook Modellazione bayesiana.
Informazioni sull’Ambiente di Sviluppo#
%load_ext watermark
%watermark -n -u -v -iv -w -m
Last updated: Sun Jun 16 2024
Python implementation: CPython
Python version : 3.12.3
IPython version : 8.25.0
Compiler : Clang 16.0.6
OS : Darwin
Release : 23.4.0
Machine : arm64
Processor : arm
CPU cores : 8
Architecture: 64bit
numpy : 1.26.4
seaborn : 0.13.2
arviz : 0.18.0
matplotlib: 3.8.4
pandas : 2.2.2
Watermark: 2.4.3