here::here("code", "_common.R") |>
source()
# Load packages
if (!requireNamespace("pacman")) install.packages("pacman")
pacman::p_load(
corrplot, lavaan, semPlot, blavaan, ggdist, distributional, patchwork,
fancycut, psych
)62 Prior Predictive Model Checking
Prerequisiti
- Leggere l’articolo Good fit is weak evidence of replication: increasing rigor through prior predictive similarity checking di Bonifay et al. (2024).
Concetti e Competenze Chiave
Preparazione del Notebook
62.1 Introduzione
In questo capitolo verrà discusso l’approccio del Bayesian prior predictive similarity checking proposto da Bonifay et al. (2024).
62.2 Replicabilità e GOF
Il progresso scientifico empirico si basa sulla replicabilità, ossia la capacità di riprodurre i risultati di uno studio precedente seguendo le stesse procedure con nuovi dati (Bollen et al., 2015). Le ricerche sulla replicabilità in psicologia si sono spesso concentrate sugli effetti sperimentali (e.g., Klein, 2014; Open Science Collaboration, 2015; Youyou et al., 2023), ma molti ambiti della disciplina si fondano sull’uso di modelli statistici piuttosto che su un disegno sperimentale. Anche in questi contesti, è essenziale verificare il grado di replicabilità dei modelli statistici utilizzati.
Un modo per quantificare la replicabilità dei modelli (sia nell’analisi di regressione, nei modelli a equazioni strutturali (SEM), nella teoria della risposta al item, nei modelli di rete o in altri contesti di modellizzazione) è valutare la bontà di adattamento (GOF, goodness of fit) del modello ai dati osservati. Storicamente, molti ricercatori in psicologia hanno considerato la replicabilità di un modello principalmente come la capacità di riprodurre la bontà di adattamento di uno studio precedente: «[il] miglior adattamento del modello… ha replicato i risultati» di ricerche precedenti (Whiteman et al., 2022, p. 132), «il miglior adattamento… ha replicato i risultati precedenti» (Giuntoli et al., 2021, p. 1668), «un adattamento sostanzialmente migliore… ha replicato l’approccio classico» (Fernández de la Cruz et al., 2018, p. 608). Tuttavia, Bonifay et al. (2024) fanno notare come questa pratica meriti un’attenta considerazione, in quanto la mera replicazione di una buona bontà di adattamento non è sufficiente per confermare la validità del modello statistico originale e della teoria sottostante.
Bonifay et al. (2024) propongono il seguente esempio. Si considerino le matrici di covarianza simulate mostrate nella riga superiore della Figura 1. La matrice a sinistra (Pannello B) rappresenta le covarianze tra le variabili di uno studio originale, mentre le altre due (Pannelli C e D) rappresentano le covarianze delle stesse variabili in due dataset di replicazione. Questo scenario illustra il tipico caso di replicazione del modello, in cui la stessa struttura viene adattata a dataset differenti, lasciando liberi i parametri. Sebbene le differenze nei dati siano evidenti, un modello con due fattori correlati si adatta bene a ciascuna matrice di covarianza (indice di adattamento comparativo [CFI] elevato, i.e., ≥ 0.95). Una bontà di adattamento elevata indica che il modello rappresenta adeguatamente le covarianze all’interno del dataset originale e delle repliche, ma non informa sul fatto che il modello rifletta le stesse relazioni tra le variabili. Come mostrato in Figura 1, affidarsi esclusivamente alla bontà di adattamento può portare a ignorare differenze significative nei pattern di dati.
# Load Correlation Matrices ----
cor_mats <- readRDS(
here::here("data", "Bonifay", "figure1_cormat.RDS")
)
# Create and Save Correlation Plots ----
corrplot(cor_mats[[1]],
method = "circle", type = "full",
tl.col = "black", tl.cex = 2.5, cl.pos = "n"
)
corrplot(cor_mats[[2]],
method = "circle", type = "full",
tl.col = "black", tl.cex = 2.5, cl.pos = "n"
)
corrplot(cor_mats[[3]],
method = "circle", type = "full",
tl.col = "black", tl.cex = 2.5, cl.pos = "n"
)


cor_mats- $original
-
A matrix: 6 x 6 of type dbl y1 y2 y3 y4 y5 y6 y1 1.000 0.682 0.638 0.185 0.507 0.571 y2 0.682 1.000 0.644 0.275 0.661 0.705 y3 0.638 0.644 1.000 0.189 0.473 0.532 y4 0.185 0.275 0.189 1.000 0.468 0.477 y5 0.507 0.661 0.473 0.468 1.000 0.730 y6 0.571 0.705 0.532 0.477 0.730 1.000 - $replication1
-
A matrix: 6 x 6 of type dbl y1 y2 y3 y4 y5 y6 y1 1.000 0.389 0.503 0.527 0.501 0.391 y2 0.389 1.000 0.536 0.432 0.420 0.423 y3 0.503 0.536 1.000 0.782 0.707 0.493 y4 0.527 0.432 0.782 1.000 0.766 0.452 y5 0.501 0.420 0.707 0.766 1.000 0.380 y6 0.391 0.423 0.493 0.452 0.380 1.000 - $replication2
-
A matrix: 6 x 6 of type dbl y1 y2 y3 y4 y5 y6 y1 1.0000 -0.2736 -0.3580 0.0224 0.1361 0.0264 y2 -0.2736 1.0000 0.5371 0.0917 0.0198 -0.0611 y3 -0.3580 0.5371 1.0000 -0.0743 -0.0419 -0.0680 y4 0.0224 0.0917 -0.0743 1.0000 0.3464 0.4743 y5 0.1361 0.0198 -0.0419 0.3464 1.0000 0.3296 y6 0.0264 -0.0611 -0.0680 0.4743 0.3296 1.0000
M <- '
F1 =~ NA*y1 + y2 + y3
F2 =~ NA*y4 + y5 + y6
F1 ~~ 1*F1
F2 ~~ 1 * F2
'
fit_original <- cfa(model = M, sample.cov = cor_mats$original, sample.nobs = 1000)
parameterEstimates(fit_original)| lhs | op | rhs | est | se | z | pvalue | ci.lower | ci.upper |
|---|---|---|---|---|---|---|---|---|
| <chr> | <chr> | <chr> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> |
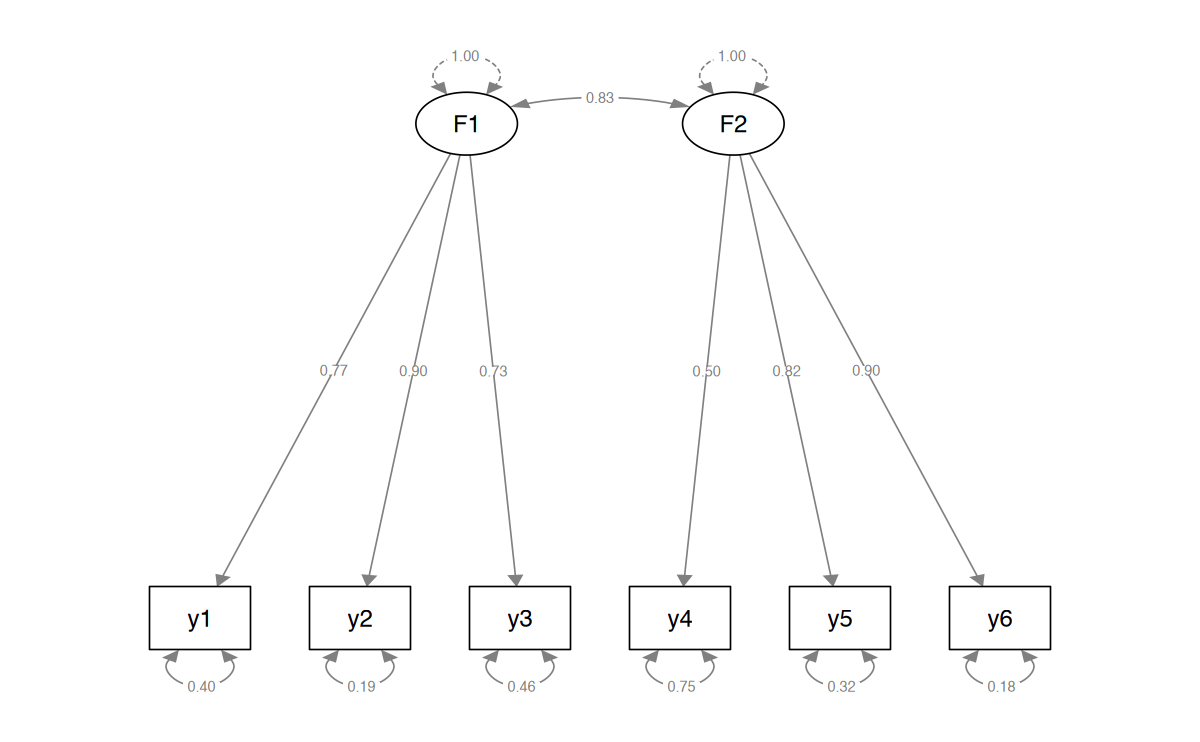
| F1 | =~ | y1 | 0.772 | 0.0278 | 27.73 | 0 | 0.718 | 0.827 |
| F1 | =~ | y2 | 0.899 | 0.0260 | 34.56 | 0 | 0.848 | 0.949 |
| F1 | =~ | y3 | 0.732 | 0.0284 | 25.77 | 0 | 0.677 | 0.788 |
| F2 | =~ | y4 | 0.502 | 0.0311 | 16.11 | 0 | 0.441 | 0.563 |
| F2 | =~ | y5 | 0.823 | 0.0272 | 30.22 | 0 | 0.770 | 0.876 |
| F2 | =~ | y6 | 0.903 | 0.0262 | 34.53 | 0 | 0.852 | 0.954 |
| F1 | ~~ | F1 | 1.000 | 0.0000 | NA | NA | 1.000 | 1.000 |
| F2 | ~~ | F2 | 1.000 | 0.0000 | NA | NA | 1.000 | 1.000 |
| y1 | ~~ | y1 | 0.403 | 0.0224 | 18.00 | 0 | 0.359 | 0.447 |
| y2 | ~~ | y2 | 0.192 | 0.0183 | 10.49 | 0 | 0.156 | 0.227 |
| y3 | ~~ | y3 | 0.463 | 0.0243 | 19.03 | 0 | 0.415 | 0.511 |
| y4 | ~~ | y4 | 0.747 | 0.0348 | 21.45 | 0 | 0.679 | 0.816 |
| y5 | ~~ | y5 | 0.322 | 0.0206 | 15.59 | 0 | 0.281 | 0.362 |
| y6 | ~~ | y6 | 0.183 | 0.0192 | 9.53 | 0 | 0.146 | 0.221 |
| F1 | ~~ | F2 | 0.835 | 0.0156 | 53.59 | 0 | 0.804 | 0.865 |
fitMeasures(fit_original, "cfi") |> round(2)
cfi: 0.96
semPaths(fit_original,
whatLabels = "std",
sizeMan = 8,
edge.label.cex = 0.7,
style = "mx",
nCharNodes = 0, nCharEdges = 0
)
fit_rep1 <- cfa(model = M, sample.cov = cor_mats$replication1, sample.nobs = 1000)
parameterEstimates(fit_rep1)| lhs | op | rhs | est | se | z | pvalue | ci.lower | ci.upper |
|---|---|---|---|---|---|---|---|---|
| <chr> | <chr> | <chr> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> |
| F1 | =~ | y1 | 0.596 | 0.0300 | 19.88 | 0 | 0.537 | 0.655 |
| F1 | =~ | y2 | 0.566 | 0.0303 | 18.69 | 0 | 0.507 | 0.626 |
| F1 | =~ | y3 | 0.899 | 0.0265 | 33.95 | 0 | 0.847 | 0.951 |
| F2 | =~ | y4 | 0.904 | 0.0254 | 35.67 | 0 | 0.855 | 0.954 |
| F2 | =~ | y5 | 0.830 | 0.0265 | 31.34 | 0 | 0.778 | 0.882 |
| F2 | =~ | y6 | 0.524 | 0.0306 | 17.14 | 0 | 0.464 | 0.584 |
| F1 | ~~ | F1 | 1.000 | 0.0000 | NA | NA | 1.000 | 1.000 |
| F2 | ~~ | F2 | 1.000 | 0.0000 | NA | NA | 1.000 | 1.000 |
| y1 | ~~ | y1 | 0.644 | 0.0306 | 21.02 | 0 | 0.584 | 0.704 |
| y2 | ~~ | y2 | 0.678 | 0.0320 | 21.21 | 0 | 0.616 | 0.741 |
| y3 | ~~ | y3 | 0.191 | 0.0203 | 9.41 | 0 | 0.151 | 0.231 |
| y4 | ~~ | y4 | 0.181 | 0.0154 | 11.73 | 0 | 0.151 | 0.211 |
| y5 | ~~ | y5 | 0.310 | 0.0180 | 17.23 | 0 | 0.274 | 0.345 |
| y6 | ~~ | y6 | 0.724 | 0.0336 | 21.54 | 0 | 0.658 | 0.790 |
| F1 | ~~ | F2 | 0.959 | 0.0127 | 75.76 | 0 | 0.934 | 0.984 |
fitMeasures(fit_rep1, "cfi") |> round(2)
cfi: 0.96
fit_rep2 <- cfa(model = M, sample.cov = cor_mats$replication2, sample.nobs = 1000)
parameterEstimates(fit_rep2)| lhs | op | rhs | est | se | z | pvalue | ci.lower | ci.upper |
|---|---|---|---|---|---|---|---|---|
| <chr> | <chr> | <chr> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> | <dbl> |
| F1 | =~ | y1 | 0.422 | 0.0363 | 11.62 | 0.000000 | 0.35098 | 0.493 |
| F1 | =~ | y2 | -0.627 | 0.0412 | -15.23 | 0.000000 | -0.70783 | -0.546 |
| F1 | =~ | y3 | -0.855 | 0.0479 | -17.86 | 0.000000 | -0.94899 | -0.761 |
| F2 | =~ | y4 | 0.701 | 0.0418 | 16.78 | 0.000000 | 0.61899 | 0.783 |
| F2 | =~ | y5 | 0.491 | 0.0370 | 13.26 | 0.000000 | 0.41836 | 0.563 |
| F2 | =~ | y6 | 0.676 | 0.0411 | 16.43 | 0.000000 | 0.59526 | 0.757 |
| F1 | ~~ | F1 | 1.000 | 0.0000 | NA | NA | 1.00000 | 1.000 |
| F2 | ~~ | F2 | 1.000 | 0.0000 | NA | NA | 1.00000 | 1.000 |
| y1 | ~~ | y1 | 0.821 | 0.0405 | 20.27 | 0.000000 | 0.74139 | 0.900 |
| y2 | ~~ | y2 | 0.606 | 0.0463 | 13.09 | 0.000000 | 0.51506 | 0.696 |
| y3 | ~~ | y3 | 0.268 | 0.0707 | 3.79 | 0.000152 | 0.12918 | 0.406 |
| y4 | ~~ | y4 | 0.508 | 0.0496 | 10.23 | 0.000000 | 0.41057 | 0.605 |
| y5 | ~~ | y5 | 0.758 | 0.0403 | 18.81 | 0.000000 | 0.67902 | 0.837 |
| y6 | ~~ | y6 | 0.542 | 0.0477 | 11.37 | 0.000000 | 0.44876 | 0.636 |
| F1 | ~~ | F2 | 0.091 | 0.0432 | 2.11 | 0.035024 | 0.00639 | 0.176 |
fitMeasures(fit_rep2, "cfi") |> round(2)
cfi: 0.94
A complicare ulteriormente le cose, l’adattamento dello stesso modello a ciascuna matrice di dati produce stime dei parametri molto variabili. Ad esempio, il fattore di carico standardizzato l21 (secondo indicatore sul primo fattore) è stimato a 0.90, 0.57 e -2.63 nelle tre matrici, mentre la correlazione tra i fattori (c21) varia da quasi indipendenza (0.09) a una sovrapposizione quasi totale (0.96).
In sintesi, la bontà di adattamento non ci fornisce alcuna indicazione sul grado di somiglianza tra il dataset di replicazione, i parametri del modello e quelli dello studio originale, mentre una forte somiglianza tra questi elementi è cruciale per valutare il successo della replicazione.
62.3 Bontà di Adattamento e Replicazione
Nel loro approfondimento critico sull’uso della bontà di adattamento come strumento per testare le teorie, Roberts & Pashler (2000) hanno sostenuto che «dimostrare che una teoria si adatta ai dati… è quasi privo di significato» (p. 361; vedi anche Vanpaemel, 2020). In particolare, hanno individuato tre limiti del GOF che ne impediscono l’uso come supporto teorico solido:
- Non chiarisce cosa predice una teoria.
- Non spiega la variabilità dei dati.
- Non considera la probabilità a priori che la teoria possa adattarsi a qualsiasi insieme di dati plausibili.
Di conseguenza, Roberts & Pashler (2000) hanno concluso che il GOF fornisce un supporto convincente a una teoria solo quando sia i dati che la teoria sono ben vincolati, ovvero quando i dati non sono troppo variabili e la teoria non è troppo flessibile. Tuttavia, in un singolo studio, tali vincoli possono essere difficili da definire e applicare, anche per la mancanza di criteri di riferimento (ad esempio, cosa significa dire che i dati «non sono troppo variabili»? Variabili rispetto a cosa? E in che misura?).
Nel contesto delle repliche, però, il confronto con lo studio originale offre un chiaro riferimento per caratterizzare la variabilità dei dati e delle stime dei parametri del modello. Questo consente di estendere naturalmente le tre critiche di Roberts & Pashler (2000) al tema della replicazione:
Previsione limitata del risultato della replica
La bontà di adattamento dello studio originale non fornisce alcuna informazione sostanziale sull’esito della replica. Il fatto che un modello si sia adattato bene nello studio originale non implica che si replichino aspetti inferenziali più importanti, come i pattern dei dati o le stime dei parametri.Assenza di indicazioni sulla somiglianza tra i dati originali e quelli della replica
Due set di dati possono presentare pattern nettamente distinti, potenzialmente derivanti da meccanismi di generazione diversi. Tuttavia, il modello potrebbe mascherare queste differenze, compromettendo l’accuratezza delle inferenze.Tendenza intrinseca del modello ad adattarsi bene
Se un modello possiede una forte predisposizione ad adattarsi bene ai dati (Bonifay & Cai, 2017; Falk & Muthukrishna, 2023), una buona bontà di adattamento per i dati originali e di replica non rappresenta una sorpresa né un valore scientifico. In tali casi, il GOF può replicarsi indipendentemente dai pattern specifici dei dati che il modello intende rappresentare.
Idealmente, i ricercatori possono essere fiduciosi che i loro risultati offrano un supporto alla teoria alla base del modello statistico solo se dimostrano che i dati della replica non sono più variabili rispetto ai dati originali, e che le stime dei parametri nella replica non riflettono una maggiore flessibilità rispetto a quelle originali.
62.4 Definire l’Obiettivo della Replica
In psicologia, ottenere una somiglianza perfetta tra studi è poco pratico e probabilmente non necessario, anche a causa dell’eterogeneità intrinseca della popolazione (McShane et al., 2019). Piuttosto, i ricercatori dovrebbero focalizzarsi sugli aspetti specifici dello studio originale che intendono replicare. A tal proposito, la Figura 2 illustra un approccio più ragionevole per definire obiettivi di replicazione.
Cerchio esterno del bersaglio: rappresenta la pratica attuale nelle scienze sociali, spesso limitata a verificare che il modello originale abbia una buona bontà di adattamento ai dati della replica, senza considerare le caratteristiche empiriche dello studio originale. Questa pratica offre il supporto più debole alla teoria originale.
Cerchi interni: rappresentano obiettivi progressivamente più ambiziosi.
62.4.1 Obiettivi di replica:
Replicazione informata dalla teoria: un ricercatore interessato alle implicazioni teoriche più ampie dello studio originale può puntare alla teoria sottostante, formulando ipotesi specifiche sui dati o sulle stime dei parametri (es. “Per supportare l’associazione positiva tra x e y, il coefficiente di replica b deve avere un valore positivo”). Questo approccio supera la semplice verifica del GOF e merita studi dedicati.
Replicazione empirica approssimativa: un ricercatore che desidera replicare direttamente i risultati empirici può puntare allo studio originale, testando la somiglianza approssimativa tra i dati e il modello della replica rispetto a quelli originali. Ad esempio, si può verificare se le covarianze tra i dati di replica riflettono quelle dello studio originale o se le stime dei parametri sono simili (es. “Per una replica approssimativa, b1 deve essere tra 0.4 e 0.7”).
Replicazione empirica ravvicinata: è il test più rigoroso, in cui le stime devono essere estremamente simili a quelle originali (es. “Per una replica ravvicinata, b1 deve essere tra 0.52 e 0.58”). Riuscire a soddisfare tali criteri fornisce prove solide che il modello cattura lo stesso segnale in entrambi gli studi.
62.4.2 Test progressivi e rischiosi
La struttura a cerchi concentrici del bersaglio rappresenta una sequenza di test sempre più stringenti. Come osservato da Roberts & Pashler (2000), i test di bontà di adattamento sono spesso troppo facili da superare, rendendoli deboli come prova di replica. La replicazione basata sul GOF è l’obiettivo più facile (e per alcuni modelli può comportare un rischio di fallimento praticamente nullo), offrendo il supporto più debole ai risultati originali.
- Cerchi interni del bersaglio: man mano che ci si avvicina al centro, il rischio di fallimento aumenta, ma aumenta anche la forza delle prove a favore della replica. La replicazione informata dalla teoria è più rigorosa rispetto al GOF, offrendo supporto alla teoria sottostante. La replicazione empirica approssimativa è ancora più rischiosa, ma fornisce prove solide di somiglianza tra dati e parametri. Infine, la replicazione empirica ravvicinata è il test più rischioso, ma il suo successo rappresenta una prova molto forte della replica dei risultati originali.
Come sottolineato da Waller & Meehl (2002), «i test rischiosi sono i mezzi più efficienti per valutare la solidità di una teoria».
Nella seconda parte dell’articolo, Bonifay et al. (2024) presentano un metodo statistico per quantificare la somiglianza tra i dati originali e replicati, oltre che tra le stime dei parametri. Discutono un esempio concreto nel contesto della modellizzazione della struttura latente della psicopatologia e forniscono raccomandazioni per futuri studi di replicazione.
62.5 Verifica Predittiva a Priori dei Modelli
Per indagare formalmente la somiglianza tra dati originali e di replica, nonché tra le stime dei parametri, Bonifay et al. (2024) propongono di utilizzare la verifica predittiva a priori bayesiana (Prior Predictive Model Checking, PrPMC; Box, 1980; Evans & Moshonov, 2006; Gelman et al., 2017). Questa tecnica sfrutta le distribuzioni a priori per valutare le implicazioni del modello prima di includere i dati osservati nell’analisi.
In un’analisi bayesiana, l’obiettivo principale è calcolare la distribuzione a posteriori \(p(\theta \mid y)\), combinando le informazioni sui dati osservati \(y\) e sul parametro sconosciuto \(\theta\) tramite il teorema di Bayes:
\[ p(\theta \mid y) \propto p(y \mid \theta)p(\theta), \]
dove:
- \(p(\theta)\) è la distribuzione a priori dei parametri.
- \(p(y \mid \theta)\) è la funzione di verosimiglianza dei dati dato il modello.
La PrPMC consiste nel generare campioni predittivi ipotetici per ciascuna variabile osservata, utilizzando esclusivamente le distribuzioni a priori definite sui parametri del modello. Questi campioni rappresentano scenari plausibili in base alle aspettative incorporate nei priori, permettendo una valutazione preliminare del modello.
Supponiamo di voler stimare l’altezza media degli scalatori negli Stati Uniti, ipotizzando che sia vicina alla media nazionale di 168 cm (Fryar et al., 2021). Possiamo rappresentare questa aspettativa con una distribuzione normale \(N(\mu = 168, \sigma = 10)\). Generando campioni predittivi da questa distribuzione, otteniamo valori che variano plausibilmente attorno a questa media. Se la conoscenza sugli scalatori suggerisse un valore maggiore o minore, potremmo affinare i priori (ad esempio, aumentando \(\mu\) o riducendo \(\sigma\)) prima di raccogliere i dati.
La PrPMC può essere estesa per confrontare i dati osservati con i campioni predittivi. Questo confronto utilizza una statistica di test o una quantità di test per valutare la somiglianza tra i dati osservati e le aspettative predittive.
- Statistica di test: una proprietà statistica dei dati (es. mediana, range).
- Quantità di test: una proprietà dipendente dai dati e dal modello (es. stime dei parametri o indici di bontà di adattamento).
Ad esempio, per gli scalatori, potremmo confrontare la media delle altezze osservate con le medie dei campioni predittivi. Se la media osservata si trovasse agli estremi della distribuzione predittiva (ad esempio, \(prpp \leq 0.05\) o \(prpp \geq 0.95\)), ciò indicherebbe una discrepanza sistematica tra i dati osservati e le aspettative a priori.
Bonifay et al. (2024) propongono l’uso della PrPMC per verificare la somiglianza tra dati originali e di replica, così come tra le stime dei parametri del modello. Questo approccio, chiamato verifica di similarità predittiva a priori, consente di valutare:
- Somiglianza dei dati: confrontando la distribuzione dei dati replicati con le aspettative dei dati originali (es. intercorrelazioni tra item).
- Somiglianza dei parametri: confrontando le stime dei parametri derivanti dai dati di replica con quelle predette dal modello originale. Ad esempio, i caricamenti fattoriali stimati dal modello originale possono essere confrontati con quelli derivati da campioni predittivi a priori.
Come illustrato nella Figura 62.1, i cerchi concentrici rappresentano diversi livelli di rischio e severità nei test di replica:
- Cerchio esterno: distribuzioni a priori diffuse, che riflettono una bassa restrizione sui dati e sui parametri, portando a test meno rigorosi e meno significativi.
- Centro del bersaglio: distribuzioni a priori altamente informative, con restrizioni strette sui dati e sui parametri, producendo test più rigorosi e significativi.
Se il valore \(prpp\) risultante si trova tra \(0.05\) e \(0.95\), possiamo concludere che i dati e/o i parametri replicati sono coerenti con le aspettative a priori. Questo approccio consente di condurre test progressivamente più stringenti e di acquisire prove più solide del successo della replica.
62.6 Riflessioni Conclusive
In conclusione, la verifica predittiva a priori offre un metodo formale per quantificare la somiglianza tra studi originali e repliche, sia a livello di dati che di parametri. Implementando questa metodologia, i ricercatori possono definire obiettivi chiari e condurre analisi rigorose per valutare il successo della replicazione, migliorando così la robustezza delle conclusioni dello studio.
Informazioni sull’Ambiente di Sviluppo
sessionInfo()R version 4.4.2 (2024-10-31)
Platform: aarch64-apple-darwin20
Running under: macOS Sequoia 15.1
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.4-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.12.0
Random number generation:
RNG: L'Ecuyer-CMRG
Normal: Inversion
Sample: Rejection
locale:
[1] C
time zone: Europe/Rome
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] quantreg_5.99 compute.es_0.2-5 simsem_0.5-16 kableExtra_1.4.0
[5] MASS_7.3-61 viridis_0.6.5 viridisLite_0.4.2 ggpubr_0.6.0
[9] ggExtra_0.10.1 gridExtra_2.3 patchwork_1.3.0 bayesplot_1.11.1
[13] semTools_0.5-6 semPlot_1.1.6 lavaan_0.6-19 psych_2.4.6.26
[17] scales_1.3.0 markdown_1.13 knitr_1.49 lubridate_1.9.3
[21] forcats_1.0.0 stringr_1.5.1 dplyr_1.1.4 purrr_1.0.2
[25] readr_2.1.5 tidyr_1.3.1 tibble_3.2.1 ggplot2_3.5.1
[29] tidyverse_2.0.0 here_1.0.1
loaded via a namespace (and not attached):
[1] splines_4.4.2 later_1.3.2 pbdZMQ_0.3-13
[4] R.oo_1.27.0 XML_3.99-0.17 rpart_4.1.23
[7] lifecycle_1.0.4 rstatix_0.7.2 rprojroot_2.0.4
[10] lattice_0.22-6 rockchalk_1.8.157 backports_1.5.0
[13] magrittr_2.0.3 openxlsx_4.2.7.1 Hmisc_5.2-0
[16] rmarkdown_2.29 httpuv_1.6.15 qgraph_1.9.8
[19] zip_2.3.1 pbapply_1.7-2 minqa_1.2.8
[22] multcomp_1.4-26 abind_1.4-8 quadprog_1.5-8
[25] R.utils_2.12.3 nnet_7.3-19 TH.data_1.1-2
[28] sandwich_3.1-1 openintro_2.5.0 arm_1.14-4
[31] MatrixModels_0.5-3 airports_0.1.0 svglite_2.1.3
[34] codetools_0.2-20 xml2_1.3.6 tidyselect_1.2.1
[37] farver_2.1.2 lme4_1.1-35.5 stats4_4.4.2
[40] base64enc_0.1-3 jsonlite_1.8.9 Formula_1.2-5
[43] survival_3.7-0 emmeans_1.10.5 systemfonts_1.1.0
[46] tools_4.4.2 rio_1.2.3 Rcpp_1.0.13-1
[49] glue_1.8.0 mnormt_2.1.1 xfun_0.49
[52] IRdisplay_1.1 withr_3.0.2 fastmap_1.2.0
[55] boot_1.3-31 fansi_1.0.6 SparseM_1.84-2
[58] digest_0.6.37 mi_1.1 timechange_0.3.0
[61] R6_2.5.1 mime_0.12 estimability_1.5.1
[64] colorspace_2.1-1 Cairo_1.6-2 gtools_3.9.5
[67] jpeg_0.1-10 R.methodsS3_1.8.2 utf8_1.2.4
[70] generics_0.1.3 data.table_1.16.2 corpcor_1.6.10
[73] usdata_0.3.1 htmlwidgets_1.6.4 pkgconfig_2.0.3
[76] sem_3.1-16 gtable_0.3.6 htmltools_0.5.8.1
[79] carData_3.0-5 png_0.1-8 rstudioapi_0.17.1
[82] tzdb_0.4.0 reshape2_1.4.4 uuid_1.2-1
[85] coda_0.19-4.1 checkmate_2.3.2 nlme_3.1-166
[88] nloptr_2.1.1 repr_1.1.7 zoo_1.8-12
[91] parallel_4.4.2 miniUI_0.1.1.1 foreign_0.8-87
[94] pillar_1.9.0 grid_4.4.2 vctrs_0.6.5
[97] promises_1.3.0 car_3.1-3 OpenMx_2.21.13
[100] xtable_1.8-4 cluster_2.1.6 htmlTable_2.4.3
[103] evaluate_1.0.1 pbivnorm_0.6.0 mvtnorm_1.3-2
[106] cli_3.6.3 kutils_1.73 compiler_4.4.2
[109] rlang_1.1.4 crayon_1.5.3 ggsignif_0.6.4
[112] fdrtool_1.2.18 plyr_1.8.9 stringi_1.8.4
[115] munsell_0.5.1 lisrelToR_0.3 pacman_0.5.1
[118] Matrix_1.7-1 IRkernel_1.3.2 hms_1.1.3
[121] glasso_1.11 shiny_1.9.1 igraph_2.1.1
[124] broom_1.0.7 RcppParallel_5.1.9 cherryblossom_0.1.0